数据类型
基本数据类型
- 整数 int
- 浮点数 float
- 复数 complex
- 布尔 bool
字符串
容器类型
- 列表 list
- 元组 tuple
- 集合 set
- 字典 dict
特殊类型
上述类型中
- 不可变的有:数值、字符串、元组
- 可变的类型有:列表、集合、字典
如果数字比较大,可使用下划线将其中的数字分组,使其更清晰易读。
num1 = 1_000_000_000_000_000
print(num1) # 1000000000000000
type 与 isinstance 类型判断
可以使用 type() 来查看变量类型,使用 isinstance() 来判断变量类型。
type() 和 isinstance() 的区别在于 type() 不会认为子类是一种父类类型,isinstance() 会认为子类是一种父类类型。
num1 = True
num2 = 10
print(type(num1)) # <class 'bool'>
print(type(num2)) # <class 'int'>
print(type(num1) == type(num2)) # False
print(isinstance(num1, bool)) # True
print(isinstance(num1, int)) # True,Python3中,bool是int的子类
print(isinstance(num2, int)) # True
小整数池
Python将 [-5, 256] 的整数维护在小整数对象池中。这些整数提前创建好且不会被垃圾回收,避免了为整数频繁申请和销毁内存空间。不管在程序的什么位置,使用的位于这个范围内的整数都是同一个对象。
大整数池
一开始大整数池为空,每创建一个大整数就会向池中存储一个。
不同的 Python 实现:小整数池的范围和实现细节可能因 Python 的不同实现(如 CPython、Jython、IronPython 等)而有所不同。上述提到的[-5, 256]范围是 CPython 的默认实现。
有时连续赋值的相同大整数也可能指向同一对象,这是因为Python环境的优化机制,但是这个优化不是绝对的,也取决于解释器以及交互式以及脚本环境。
float浮点型
Python将所有带小数点的数称为浮点数。要注意在使用浮点数进行计算时可能会存在微小误差,可以通过导入decimal解决
num1 = 0.1
num2 = 0.2
print(num1 + num2) # 0.30000000000000004
from decimal import Decimal
num3 = Decimal('1.0')
num4 = Decimal('0.9')
print(num3-num4)
也可以使用科学计数法表示浮点数。
num1 = 1.3e7
print(num1) # 13000000.0
在Python中,能够解释为假的值不只有False,还有:
- None、0、0.0、False、所有的空容器(空列表、空元组、空字典、空集合、空字符串)
为了解决浮点数丢失精度情况,可以借助py其他模块提供的功能
from decimal import Decimal
bool是int的子类型,可以和整数进行运算
num1 = True print(num1 + 10)
| *转义字符* |
*说明* |
| \ |
在行尾作为续行符 |
| \ \ |
反斜杠符号 |
| \ ‘ |
单引号 |
| \ “ |
双引号 |
| *\b* |
退格 |
| *\n* |
换行 |
| *\t* |
横向制表符 |
| *\r* |
回车,回到行首 |
| *函数* |
*说明* |
| *int(x [,base])* |
将x转换为一个整数,x若为字符串可用base指定进制 |
| *float(x)* |
将x转换为一个浮点数 |
| *complex(real[,imag])* |
创建一个实部为real,虚部为imag的复数 |
| *str(x)* |
将对象x转换为一个字符串 |
| repr(x) |
将对象x转换为一个字符串,可以转义字符串中的特殊字符 |
| *eval(x)* |
执行x字符串表达式,并返回表达式的值 |
| *bin(x)* |
将一个整数转换为一个二进制字符串 |
| *oct(x)* |
将一个整数转换为一个八进制字符串 |
| *hex(x)* |
将一个整数转换为一个十六进制字符串 |
| *ord(x)* |
将一个字符转换为它的ASCII整数值 |
| *chr(x)* |
将一个整数转换为一个Unicode字符 |
| *tuple(s)* |
将序列s转换为一个元组 |
| *list(s)* |
将序列s转换为一个列表 |
| set(s) |
转换s为可变集合 |
num_int = 123
num_str = "456"
print("num_int 数据类型为:",type(num_int))
print("类型转换前,num_str 数据类型为:",type(num_str))
num_str = int(num_str) # 强制转换为整型
print("类型转换后,num_str 数据类型为:",type(num_str))
num_sum = num_int + num_str
print("num_int 与 num_str 相加结果为:",num_sum)
print("sum 数据类型为:",type(num_sum))
输出:
num_int 数据类型为: <class 'int'>
类型转换前,num_str 数据类型为: <class 'str'>
类型转换后,num_str 数据类型为: <class 'int'>
num_int 与 num_str 相加结果为: 579
sum 数据类型为: <class 'int'>
输入
# Python开始等待你的输入。这时,你可以输入任意字符,然后按回车后完成输入。
input_str = input("请输入:")
# 输入完成后,不会有任何提示,刚才输入的内容存放到input_str变量里了
print("input_str数据类型为:",type(input_str))
# 输出input_str查看变量内容
print(input_str)
输出
使用 print() 可将内容打印。
print("Hello Python")
多个内容之间可以使用逗号隔开。
print("Hello", " Python")
可以使用 end= 来控制 print() 以什么结尾。
print("使用\\n结尾", end="\n") # 用\n结尾,等同于print("使用\\n结尾")
print('使用""结尾', end="") # 用空字符串结尾
print("Hello")
格式化输出
(1)字符串中使用 % 占位
int1 = 10
float1 = 3.14159
str1 = "int1 = %d, float1 = %f" % (int1, float1)
print(str1) # int1 = 10, float1 = 3.141590
方式1:不设置指定位置,按默认顺序
int1 = 10
float1 = 3.14159
bool1 = True
str2 = "int1 = {}, float1 = {}, bool1 = {}".format(int1, float1, bool1)
print(str2) # int1 = 10, float1 = 3.14159, bool1 = True
方式2:设置指定位置,不能和方式1混合使用
int1 = 10
float1 = 3.14159
bool1 = True
str2 = "int1 = {0}, float1 = {1}, bool1 = {2}".format(int1, float1, bool1)
print(str2) # int1 = 10, float1 = 3.14159, bool1 = True
方式3:设置参数
int1 = 10
float1 = 3.14159
bool1 = True
str2 = "int1 = {i1}, float1 = {f1}, bool1 = {b1}".format(i1=int1, f1=float1, b1=bool1)
print(str2) # int1 = 10, float1 = 3.14159, bool1 = True
f-字符串
字符串前加上一个 f ,字符串中的{}内写入变量名。
int1 = 10
float1 = 3.14159
str3 = f"int1 = {int1}, float1 = {float1}"
print(str3) # int1 = 10, float1 = 3.14159
{}内变量名后可以加上 = ,打印时会在变量值前加上 变量名=
int1 = 10
float1 = 3.14159
str3 = f"{int1 = }, {float1 = }"
print(str3) # int1 = 10, float1 = 3.14159
num1 = 10
num2 = 20
num3 = 30
print(f"num1 = {num1}, num2 = {num2}, num3 = {num3}")
print(f"{num1=}, {num2=}, {num3=}")
{}外再套一层{},即{ { } },会转义
int1 = 10
float1 = 3.14159
str3 = f"{{int1 = }}, {{float1 = }}"
print(str3) # {int1 = }, {float1 = }
成员运算符
| 运算符 |
说明 |
实例 |
| in |
在指定的序列中找到值返回 True,否则返回 False |
a in [‘a’, ‘b’, ‘c’] |
| not in |
在指定的序列中没有找到值返回 True,否则返回 False |
a not in [‘a’, ‘b’, ‘c’] |
# -------------成员运算符---------------
num6 = 1
num7 = 20
test_list = [1,2,3,4,5]
print(test_list)
print(num6 in test_list) # True 判断1是不是列表中的的成员
print(num7 not in test_list) # True
身份运算符
| 运算符 |
说明 |
实例 |
| is |
判断两个标识符是不是引用自相同对象 |
a is b,类似id(a) == id(b)。如果引用的是同一个对象则返回True,否则返回False |
| not is |
判断两个标识符是不是引用自不同对象 |
a is not b,类似id(a) != id(b)。如果引用的不是同一个对象则返回True,否则返回False |
# -------------身份运算符---------------
m = 20
n = 20
q = 30
print(m is n) # True 判断m和n在内存中是否指向同一个地址 都在小整数池里
print(n is q) # False
print(n is not q) # True
# id() 用于获取对象在内存中的地址
print(id(m) == id(n)) # True
print("-" * 30)
# -------------is和==的区别---------------
a = [1,2,3]
b = a
print(b is a) # True
print(b == a) # True
b = a[:] # 快速复刻一个新的列表并给b
print(b)
print(b is a) # False
print(b == a) # True
单分支
语法:
if 表达式:
语句
双分支
语法:
if 表达式:
语句1
else:
语句2
双分支
语法:
if 表达式1:
语句1
elif 表达式2:
语句2
elif 表达式3:
语句3
else: # else如不需要可以省略
语句4
嵌套分支
语法:
if 表达式1:
if 表达式2:
语句1
else:
语句2
else:
if 表达式3:
语句3
else:
语句4
match case语句
语法:
match x:
case a:
语句1
case b:
语句2
case _:
语句3
match month := 3:
case 1 | 3 | 5 | 7 | 8 | 10 | 12:
print(f"{month}月有31天")
case 4 | 6 | 9 | 11:
print(f"{month}月有30天")
case 2:
print(f"{month}月可能有28天")
case _:
print(f"{month}月有?天")
三目运算符
num1 = 2
num2 = 3
max_num = num1 if num1 > num2 else num2
print(max_num)
循环
while
while 表达式:
语句-循环体
import time
num = 1
while num < 100:
print("\r" + "=" * num, end="")
num += 1
time.sleep(0.05)
while else
while 后可以加上 else,当 while 表达式结果为 False 时会执行 else 中的语句。
rabbit = 2
week = 1
while week < 10:
rabbit = rabbit + rabbit * 2
week += 1
else:
print(f"第{week}周有{rabbit}只兔子")
for循环
语法
for 循环可以用来遍历可迭代对象,如列表或字符串
for 临时变量 in 可迭代对象:
语句
for 循环后也可以加上 else,循环结束后会执行 else 中语句
for 临时变量 in 可迭代对象:
语句1
else:
语句2
(1)遍历列表
for i in [2, 3, 5, 7, 11, 13, 17, 19]:
print(i)
(2)遍历字符串
for i in "hello world":
print(i)
(3)遍历range数列
for i in range(10):
print(i)
range()
range([start,] stop[, step]) 函数可以生成数列,它返回一个可迭代对象。
指定生成到stop(不包含stop)的数列,默认从0开始
for i in range(10):
print(i)
指定生成数列的范围,从start到stop(不包含stop),可设定步长,默认步长为1,步长可正可负。
or i in range(-10, 10):
print(i)
for i in range(10, -10, -3):
print(i)
continue
跳过当前循环块中的剩余语句,继续进行下一轮循环。一般写在if判断中。
案例,打印0-9,跳过偶数
for i in range(10):
if i % 2 == 0:
continue
print(i)
break
跳出当前for或while的循环体,一般写在if判断中。
如果for 或while循环通过break终止,循环对应的else 将不执行。
案例:求0-9每个数自己幂自己的加和,如果大于10000000则循环终止。
sum = 0
for i in range(10):
sum = sum + i**i
if sum > 10000000:
break
print(i, sum)
else:
print("循环完成,sum = ", sum)
pass【循环体或函数写的时候思考的占位】
pass是空语句,是为了保持程序结构 的完整性。
pass不做任何事情,一般用做占位语句。
例如:在一个循环中,如果循环体为空,语法会提示报错,
这个时候我们就可以使用pass占位
for i in range(10):
pass
while True:
pass
循环相关的关键字:::::
continue
跳出当前正在进行的循环,继续下次循环
break
跳出整个循环
pass
循环体的占位
容器数据类型
list 列表
tuple 元组
set 集合
dict 字典
不可变类型:数组、字符串、元组
可变类型:列表、集合、字典
按ctrl+p可以看某个函数所需要填的元素
序列
序列(Sequence)是一种基本且核心的数据结构,它允许我们以有序的方式存储和操作数据。序列可以包含不同类型的元素,并且支持通过索引来访问和修改这些元素。常见的序列类型包括:列表(List)、元组(Tuple)、字符串(String)
序列的操作
Ø 索引:sequence[0]
Ø 切片:sequence[1:3]
Ø 相加:sequence1 + sequence2
Ø 乘法:sequence * 3
Ø 检查成员:x in sequence
Ø 计算长度:len(sequence)
Ø 计算最大值、最小值:max(sequence)、min(sequence)
列表List
Ø 列表是一个可变的、有序的元素集合
Ø 列表使用 [] 定义,数据之间使用 , 分隔。
Ø 列表中每个元素都有对应的位置值,称为索引或下标,索引从起始从0开始向后逐个递增,并且从末尾从-1开始逐个向前递减。
Ø 列表中元素可以是不同的类型。
创建列表
list1 = [100, 200, 300, 400, 500]
访问列表
通过索引获取列表中元素
list1 = [100, 200, 300, 400, 500]
print(list1[1]) # 200
print(list1[-2]) # 400
列表切片
list1 = [100, 200, 300, 400, 500]
print(list1) # 取全部元素
print(list1[:]) # 复制整个列表
print(list1[2:4]) # 取索引从2开始到4(不包含)的元素
print(list1[2:]) # 取索引从2开始到末尾的元素
print(list1[:2]) # 取索引从0开始到2(不包含)的元素
print(list1[2:-1]) # 取索引从2开始到-1(不包含)的元素
print(list1[::-1]) # 倒序取元素
向列表中添加元素【append】
list1 = [100, 200, 300, 400, 500]
list1.append(600) # 在列表末尾追加元素
list1.insert(2,700) # 在列表指定的位置追加元素
print(list1)
列表相加
list1 = [100, 200, 300]
list2 = ["a", "b", "c"]
print(list1 + list2) # [100, 200, 300, 'a', 'b', 'c']
列表乘法
list1 = [100, 200, 300]
print(list1 * 2) # [100, 200, 300, 100, 200, 300]
修改列表中元素
通过下标修改
list1 = [100, 200, 300, 400, 500]
list1[0] = -1
print(list1)
通过切片修改
list1 = [100, 200, 300, 400, 500]
list1[2:4] = ["a", "b", "c"]
print(list1)
检查成员是否为列表中元素
list1 = [100, 200, 300]
print(100 in list1) # True
获取列表长度
list1 = [100, 200, 300]
print(len(list1)) # 3
5.2.9 求列表中元素的最大值、最小值、加和
list1 = [100, 200, 300, 400, 500]
print(max(list1)) # 500
print(min(list1)) # 100
print(sum(list1)) # 1500
5.2.10 遍历列表
1)直接遍历列表元素
list1 = [100, 200, 300, 400, 500]
for i in list1:
print(i)
2)通过下标遍历列表
list1 = [100, 200, 300, 400, 500]
for i in range(len(list1)):
print(i, list1[i])
3)使用enumerate()同时获取列表的下标和元素
list1 = [100, 200, 300, 400, 500]
for i, val in enumerate(list1):
print(i, val)
——-——————————————————————————
0 100
1 200
2 300
3 400
4 500
5.2.11 删除列表指定位置元素或者切片
list1 = [100, 200, 300, 400, 500]
del list1[2]
print(list1)
5.2.12 嵌套列表
列表中元素可以为列表。
list1 = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
for inner_list in list1:
print(inner_list)
list2 = [100,200,300,400,500]
list2.insert(3,300)
# 删除第一次出现的x
list2.remove(300)
print(list2)
列表推导式
列表推导式是 Python 中一种简洁创建列表的方式,它将一个可迭代对象(如列表、元组、集合、字符串等)的元素通过某种运算或条件筛选后生成一个新的列表。
(1)基础的列表推导式
squares = [x**2 for x in range(5)]
print(squares) # [0, 1, 4, 9, 16]
(2)带条件的列表推导式
squares = [x**2 for x in range(10) if x % 2 == 0]
print(squares) # [0, 4, 16, 36, 64]
(3)使用现有列表的列表推导式
list1 = [1, 2, 3, 4, 5]
squares = [x**2 for x in list1]
print(squares) # [1, 4, 9, 16, 25]
(4)包含多个循环的列表推导式
list1 = [1, 2, 3, 4, 5]
list2 = ["a", "b", "c", "d", "e"]
tuple_list = [(i, j) for i in list1 for j in list2]
print(tuple_list)
# i,j 为元素 组合成了(i,j)元组
# i在list1中 j在list2中
zip()函数
zip() 函数可将多个可迭代对象中对应元素打包为一个个元组。
list1 = [1, 2, 3, 4, 5]
list2 = ["a", "b", "c", "d", "e"]
zipped = zip(list1, list2)
print(list(zipped))
# [(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd'), (5, 'e')]
列表常用方法
# 在指定位置插入x
list.insert(index,x)
# 在列表末尾追加x
list.append(x)
# 在列表1的末尾追加列表2的数据
list1.extend(list2)
# 删除指定位置的数据或切片
del list[index]
# 删除第一次出现的x
list.remove(x)
# 删除指定位置的数据,默认为末尾数据
list.pop([index])
# 清空列表中元素
list.clear()
# 修改指定位置的数据
list[index] = x
# 修改列表切片的数据
list1[start:end] = list2
# 返回排序后的新列表,可选降序
sorted(list[,reverse=True])
# 对列表就地排序,可选降序
list.sort([reverse=True])
# 反转列表中的元素
list.reverse()
# 返回x在列表中首次出现的位置,可指定起始和结束范围
list.index(x[,start,[,end]])
# 返回x的数量
list.count(x)
# 返回列表元素个数
len(list)
# 返回列表中最大值
max(list)
# 返回列表中最小值
min(list)
# 返回列表中所有元素和
sum(list)
# 拷贝列表
list.copy()
# 将序列转换为列表
list(x)
列表元素遍历
list1 = [100, 200, 300, 400, 500]
for i in range(0,len(list1)):
print(i, list1[i])
0 100
1 200
2 300
3 400
4 500
列表 list
- list是可变的,可以对list中的元素进行修改
- list是有序的,每个元素都有对应的下标(索引),可以通过索引获取元素以及对list进行切片操作
- list中可以存放不同类型的元素
- 使用[]定义list
字符串 String(是不可变的)
- str是不可变的,不能直接对原字符串进行修改, 如果修改会创建新的对象
- str是有序的,字符串中的每个字符都有对应的下标(素引) ,可以通过索引获取字符以及队str进行切片操作
- str的定义方式:
单引号
双引号
# 三引号可以保留字符串的样式
三引号
str1 = """abc
def"""
# 获取字符以及字符串切片
print(str1[3])
print(str1[1:5])
print(str1[:5])
print(str1[:]) #原输出
print(str1[::-1]) #逆向获取
5.3.1创建字符串
str1 = "hello world"
5.3.2访问字符串
str1 = "hello world"
print(str1[0])
print(str1[-1])
print(str1[4:-3])
5.3.3字符串相加
str1 = "hello world"
str2 = "dlrow olleh"
print(str1 + str2) # hello worlddlrow olleh
5.3.4字符串乘法
str1 = "hello world"
print(str1 * 2) # hello worldhello world
5.3.5检查成员是否为字符串中元素
str1 = "hello world"
print("lo" in str1) # True
5.3.6原始字符串
所有的字符串按照字面意思处理,没有转义字符。需在字符串前加上r / R。
print("hello\nworld")
print(r"hello\nworld")
print(R"hello\t\tworld")
常用函数
| 函数 |
说明 |
| str.replace(old,new[,max]) |
把将字符串中的old替换成new,如果指定max,则替换不超过max次 |
| str.split([x][,n]) |
按x分隔字符串,默认按任何空白字符串分隔并在结果中丢弃空字符串。可指定最大分隔次数 |
| str.rsplit([x] [,n]) |
与split()类似,从右边开始分隔 |
| join(seq) |
以x作为分隔符,将序列中所有的字符串合并为一个新的字符串 |
| str.strip([x]) |
截掉字符串两边的空格或指定字符 |
| str.lstrip([x]) |
截掉字符串左边的空格或指定字符 |
| str.rstrip([x]) |
截掉字符串右边的空格或指定字符 |
list1 = ["a","b","c","d","e","f"]
str1 = "-".join(list1)
print(str1)
# a-b-c-d-e-f
list1 = "abcdefg"
str1 = list1.find("g")
print(str1)
# 6
str1 = list1.find("d",3,5)
print(str1)
# 3
元组 tuple
- tuple是不可变的,不能直接队元组中的元素进行修改
- tuple是有序的,每个元素都有对应的下标(索引),可以通过索引获取元组中以及队元组进行切片
- tuple中可以存放不同类型的数据
- 使用()定义tuple
# 创建元组对象
tup = (100,200,300,400,500)
# 如果元组中只有一个元组,那么在元素的后面也需要加','
tup1 = (100,)
# 使用元组推导式 创建元组
list1 = [i*2 for i in range(10)]
print(tup)
print(tup1, type(tup1))
# (100, 200, 300, 400, 500)
# (100,) <class 'tuple'>
# 访问元组
tuple1 = (100,200,300,400,500)
print(tuple1[-2])
# 400
#元组相加
tuple1 = (100, 200, 300)
tuple2 = ("a", "b", "c")
print(tuple1 + tuple2)
# (100, 200, 300, 'a', 'b', 'c')
#元组相乘
tuple1 = (100, 200, 300)
print(tuple1 * 2)
# (100, 200, 300, 100, 200, 300)
#检查成员是否为元组中元素
tuple1 = (100, 200, 300, 400, 500)
print(300 in tuple1)
# True
#获取元组长度
tuple1 = (100, 200, 300, 400, 500)
print(len(tuple1))
# 5
#求元组中元素的最大值、最小值、加和
tuple1 = (100, 200, 300, 400, 500)
print(max(tuple1)) # 500
print(min(tuple1)) # 100
print(sum(tuple1)) # 1500
#遍历元组
tuple1 = (100, 200, 300, 400, 500)
for i in tuple1:
print(i)
for i in range(len(tuple1)):
print(i, tuple1[i])
for i, val in enumerate(tuple1):
print(i, val)
元组的不可变
元组的不可变指的是元组所指向的内存中的内容不可变,但可以重新赋值
tuple1 = (100, 200, 300)
print(id(tuple1), tuple1)
tuple1 = tuple1 + (1, 2, 3)
print(id(tuple1), tuple1)
如果元组中元素是可变数据类型,其嵌套项可以被修改
tuple1 = (100, 200, 300, [1, 2, 3])
tuple1[3].append(4)
print(tuple1) # (100, 200, 300, [1, 2, 3, 4])
集合Set
- 集合是无序的,且不包含重复元素。
- 集合使用 {} 定义,数据之间使用 , 分隔,也可以使用set()定义。
- 集合没有索引,所以不能通过切片方式访问集合元素。
- 集合中元素可以是不同的类型。
- 集合可以进行数学上的集合操作,如并集、交集和差集。
- 集合适用于需要快速成员检查、消除重复项和集合运算的场景。
创建集合
可以通过{}或set()创建集合,但创建空集合需要使用set()而非{},因为{}会创建空字典。
set1 = {1, 2, 3}
set2 = set([1, 2, 3]) # 使用set()函数从列表创建集合
set3 = set()
print(set1, set2, set3)
也可以通过集合推导式创建集合。
set1 = {x for x in range(10) if x % 2 == 0}
print(set1) # {0, 2, 4, 6, 8}
向集合中添加元素
set1 = {1, 2, 3}
set1.add(4)
set1.add(5)
print(set1)
从集合中删除元素
set1 = {1, 2, 3}
set1.remove(2)
print(set1)
检查成员是否为集合中元素
set1 = {1, 2, 3, 4, 5}
print(2 in set1) # True
获取集合长度
set1 = {1, 2, 3, 4, 5}
print(len(set1)) # 5
求集合中元素的最大值、最小值、加和
set1 = {1, 2, 3, 4, 5}
print(max(set1)) # 5
print(min(set1)) # 1
print(sum(set1)) # 15
遍历集合
set1 = {1, 2, 3, 4, 5}
for item in set1:
print(item)
# 变量去掉 不需要
for _ in rang(len(set1))
print(set1.pop())
#添加元素
set.add(x)
#添加元素,x可以为列表、元组、字符串、字典等可迭代对象
set.update(x)
#添加元素后返回一个新的集合,x可以为列表、元组、字符串、字典等可迭代对象
set.union(x)
#从集合中移除x,x不存在则报错
set.remove(x)
#从集合中移除x,x不存在也不报错
set.discard(x)
#【随机取出】集合中的一个元素,如果集合为空则报错
set.pop()
#清空集合
set.clear()
#求set1和x1的差集,返回一个新的集合
set.difference(x1,...)
#求set1和x1的差集
set.difference_update(x1,...)
#求set1和x1的交集,返回一个新的集合
set.intersection(x1,...)
#求set1和x1的交集
set.intersection_update(x1,...)
#两集合求交集
set1 & set2
#两集合求并集
set1 | set2
#两集合求差集
set1 - set2
#判断两集合是否没有交集
set1.isdisjoint(set2)
#判断set1是否为set2的子集
set1.issubset(set2)
#判断set2是否为set1的子集
set1.issuperset(set2)
#求两集合中不重复的元素,返回一个新的集合
set1.symmetric_difference(set2)
#求两集合中不重复的元素
set1.symmetric_difference_update(set2)
#拷贝集合
set.copy()
#返回集合元素个数
len(set)
#求集合中元素的最大值
max(set)
#求集合中元素的最小值
min(set)
#求集合中元素的加和
sum(set)
字典Dictionary [k:v键值对形式]
- 一个无序的键值对集合,键是唯一的,而值可以重复。
- 字典使用 {} 定义,键(key)和值(value)使用 : 连接,每个键值对之间使用 , 分隔。如{key1 : value1**,** key2 : value2}
- 字典没有索引。
- 字典可以通过键来获取对应的值。
- 值可以取任何数据类型,但键必须是不可变的,如字符串、数字、元组。
空集合可以通过dict1={}或set=()去创建
可以通过{}或dict()创建字典
dict1 = {}
dict2 = dict()
dict3 = {"name": "Alice", "age": 18, "gender": "male"}
dict4 = dict(name="Bob", age=20, gender="female")
dict5 = dict([("name", "Tom"), ("age", 22), ("gender", "male")])
print(dict1)
print(dict2)
print(dict3)
print(dict4)
print(dict5)
也可以通过字典推导式创建字典
squares = {x: x**2 for x in range(4)}
print(squares) # {0: 0, 1: 1, 2: 4, 3: 9}
访问字典
可通过 [] 访问字典中的元素。key不存在时会报错
dict1 = {"name": "Alice", "age": 18, "gender": "male"}
print(dict1["name"]) # Alice
print(dict1["age"]) # 18
print(dict1["gender"]) # male
print(dict1["address"]) # 报错
也可以通过get()获取字典中的元素。key不存在时会返回None,也可以指定默认值。
dict1 = {"name": "Alice", "age": 18, "gender": "male"}
print(dict1.get("name")) # Alice
print(dict1.get("age")) # 18
print(dict1.get("gender")) # male
print(dict1.get("address")) # None
# 这里earth是默认值 如果找不到address的value就默认是earth
print(dict1.get("address", "earth")) # earth
向字典中添加元素
为字典指定的key赋值value,若key原本不存在则会被添加
dict1 = {"name": "Alice", "age": 18, "gender": "male"}
dict1["address"] = "earth"
print(dict1)
#{'name': 'Alice', 'age': 18, 'gender': 'male', 'address': 'earth'}
修改字典中元素
通过key修改对应的value
dict1 = {"name": "Alice", "age": 18, "gender": "male"}
dict1["name"] = "Bob"
print(dict1)
#{'name': 'Bob', 'age': 18, 'gender': 'male', 'address': 'earth'}
检查成员是否为字典中的key
dict1 = {"name": "Alice", "age": 81, "gender": "male"}
print("name" in dict1) # 检查key是否存在
print("Alice" in dict1) # 无法直接检查value是否存在
获取字典长度
dict1 = {"name": "Alice", "age": 81, "gender": "male"}
print(len(dict1)) # 3
遍历字典
dict1={"name":"tom","age":18}
#遍历所有k
allKeys = dict1.keys()
for i in allKeys:
print(i)
print("*********")
#遍历所有v
allValues = dict1.values()
for k in allValues:
print(k)
print("*********")
#遍历所有k-v
for i in allKeys:
print(i + "---" + str(dict1[i]))
或
print(f"{i}---{dict1[i]}")
print("*********")
------------------------------------
*********
tom
18
*********
name---tom
age---18
*********
方法2
item一般对容器来讲 是代表当前容器的元素项
对于字典来讲 是每个元素是配对键值对形式
items = dict1.items()
print(items)
print(type(items))
for item in items:
print(item)
----------------------
dict_items([('name', 'tom'), ('age', 18)])
<class 'dict_items'>
('name', 'tom')
('age', 18)
删除字典元素
my_dict = {'Name': 'Tom', 'Age': 17}
del my_dict['Name'] # 删除键 'Name'
# my_dict.clear() # 清空字典
# del my_dict # 删除字典
print (my_dict)
常用函数
#根据key删除键值对
del dict[key]
#获取key所对应的value,同时删除该键值对,可设置默认值
dict.pop(key[,default])
#取出字典中的最后插入的键值对,字典为空则报错
dict.popitem()
#清空字典
dict.clear()
#将dict2中的键值对更新到dict1中
dict1.update(dict2)
#获取字典中key对应value,可设置默认值
dict.get(key[,default])
#获取字典中key对应value,可设置默认值。若key不存在于字典中,将会添加key并将value设为默认值
dict.setdefault(key[,default])
#获取字典所有的key,返回一个视图对象。字典改变,视图也会跟着变化
dict.keys()
#获取字典所有的value,返回一个视图对象
dict.values()
#获取字典所有的(key,value),返回一个视图对象
dict.items()
#拷贝字典
dict.copy()
#以序列seq中元素做字典的key创建一个新字典,可设置value的默认值
dict.fromkeys(seq[,default])
列表、元组、字典和集合的区别
| 数据结构 |
是否可变 |
是否重复 |
是否有序 |
定义符号 |
| 列表【List】 |
可变 |
允许 |
有序 |
[]或list() |
| 元组【Tuple】 |
不可变 |
允许 |
有序 |
()或tuple() |
| 字典【Dictionary】 |
可变 |
键不允许,值允许 |
键无序(Python 3.7+版本中保持插入顺序) |
{}或dict() |
| 集合【Set】 |
可变 |
允许 |
无序 |
{}或set() |
函数
- 直观理解,带名字的代码块
- 将完成某一块功能的代码抽取出来,取一个名字,就是函数。如果以后再要完成这个功能的时候,就不需要再编写整体代码了,直接通过名字去调用函数即可。
案例:打印两次2x3的*
'''
该案例演示了函数的抽取以及调用
打印如下图形
***
***
-------
***
***
'''
# 定义一个函数,该函数完成打印输出2*3 "*"的功能
def printStar() :
'''
这是对函数功能的说明
'''
row = 2
while row > 0 :
print("*" * 3)
row -= 1
# 调用函数
printStar()
print("-" * 20)
printStar()
(1)注意:
- 函数必须先定义再调用
- 函数在定义的时候只是告诉解释器我定义了一个这样的函数,可以完成某些功能,但是这个时候函数还没有执行,需要调用函数后,才会执行。
函数的定义
语法:
def 函数名(参数列表)
函数体
[return]
说明:
"def" 是定义函数的关键字
# 函数名:程序员自己定义的,需要遵循标识符的命名规范
函数名后,跟着一对小括号,里面放的是参数列表
参数,函数执行的时候需要依赖的值
参数可以有多个,多个参数之间用逗号分隔
如果没有参数,小括号不能省略
用:结束函数的声明
函数具体完成的功能在函数体中实现,需要进行缩进
通过return关键字将函数执行的结果返回给调用者【可以不加,默认返回值是None】
--------------------------------------------------------------------
def print_star():
num = 2
while num > 0:
print("*" * 3)
num -= 1
print_star()
print("-" * 30)
print_star()
函数的形参和实参
在函数的提供者定义函数时候,声明的参数称之为形式参数
def print_star(rows,clos):
在函数的调用者调用函数的时候,传递的参数称之为实际参数
print_star(100,3)
注意:在函数声明的时候,并没有给形式参数分配内容空间,只是做了一个占位
在调用的时候,会将实参的地址引用赋值给形参
# 原始方法
def print_star_1():
num = 2
while num > 0:
print("*" * 3)
num -= 1
def print_star_2():
num = 1
while num > 0:
print("*" * 6)
num -= 1
print_star_1()
print("~" * 30)
print_star_2()
------------------------------
# 抽取函数(加参数)
def print_star(rows,clos):
while rows > 0:
print("*" * clos)
rows -= 1
print_star(2,3)
------------------------------
***
***
赋值操作情况说明
对于参数传递的是可变数据类型
var1 *= 2 使用了原地址
var1 = var1 * 2 开辟了新的空间
参数传递的形式【*a是要传元组(val1,val2)、**a是要传字典{key,val}】
必须参数【参数个数和顺序要一致 通过位置进行赋值】
关键字参数【传递实参的时候要带名称且一致,位置可以不一致】
默认值参数【在定义参数的时候,可以给参数指定默认值;形参数量可以和实参数量不一致,不传参则默认值】
不定长参数
【def 函数名([普通参数], *不定长参数名, [普通参数2])】调用时,普通参数1是按照位置进行匹配的;普通参数2按照关键字进行匹配;处理不定长参数时,使用元组进行处理
def func(num,*args,plu):
print(num)
print(args)
print(plu)
func(3, 2,1,1,1,1, plu = 666)
-------------------------
3
(2, 1, 1, 1, 1)
666
【def 函数名([普通参数], **不定长参数名)】调用时,普通参数1是按照位置进行匹配的;不定长参数后面不允许出现其他的参数;处理不定长参数时,使用字典{key:value}进行处理
def func(num,**args):
print(num)
print(args)
func(300, a = 1,b =2 ,c = 3,d = 4)
-------------------------
300
{'a': 1, 'b': 2, 'c': 3, 'd': 4}
def func(**args):
print(arg)
func(**{"name":"zs","age":18})
不定长参数可以在形参前面加”*”【定义的是元组】
def func(num,*args):
print(num)
print(args)
func(3, 2,1,1,1,1)
(1)注意:
Ø 加了星号 * 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数。
Ø 如果形参中出现了不定长参数,那么在调用函数的时候,先通过位置进行必须参数的匹配,然后不定长参数后面的参数必须通过关键字参数匹配
Ø 如果不定长的参数后面还有参数,必须通过关键字参数传参
def func(num,*args):
print(num)
print(args)
func(3, 2,1,1,1,1, num1 = 300)
Ø 还有一种就是参数带两个星号 **的可变长参数,基本语法如下:
def 函数名([普通参数,] **var_args_dict ):
函数体
加了两个星号 ** 的参数会以字典的形式导入,后面就不能再有其他参数了
'''
该案例演示了函数调用时的不定长参数
'''
def printInfo(num,**vardict):
print(num)
print(vardict)
# return
printInfo(10,key1 = 20,key2 = 30)
printInfo(10,a = 20,b = 30)
解包传参
若函数的形参是定长参数,可以通过 * 和 ** 对列表、元组、字典等解包传参。
def func(a, b, c):
return a + b + c
tuple11 = (1, 2, 3)
print(func(*tuple11))
# 字典中key的名称和参数名必须一致
dict1 = {"a": 1, "b": 2, "c": 3}
print(func(**dict1))
---------------------------------
6
6
#若是直接 print(a,b,c) => 1,2,3
强制使用位置传参或关键字参数
/ 前的参数必须使用位置传参,* 后的参数必须用关键字传参。
def f(a, b, /, c, d, *, e, f):
print(a, b, c, d, e, f)
f(1, 2, 3, d=4, e=5, f=6)
浅拷贝
"""
通过函数修改列表中元素的练习题
需求:要函数对列表进行处理,又不希望函数修改原列表
例如:
有一个列表,list[1,2,3,[100,200,300]]
定义一个函数,向列表中的子列表后追加一个新的元素400 => list[1,2,3,[100,200,300,400]]
"""
def change_list(m_list):
print(f"函数内修改列表前列表地址:{id(m_list)},列表中的元素:{m_list}")
m_list[3].append(400)
print(f"函数内修改列表前列表地址:{id(m_list)},列表中的元素:{m_list}")
list1 = [1,2,3,[100,200,300]]
print(f"函数外列表地址:{id(list1)},列表中的元素:{list1}")
list2 = list1.copy()
print(id(list2))
print(id(list1))
change_list(list1)
print(f"函数外调用函数后列表地址:{id(list1)},列表中的元素:{list1}")
#浅拷贝
# list2 = list1.copy()
#深拷贝
# list2 = copy.deepcopy(list1)
-----------------------------------------------
函数外列表地址:2259355396224,列表中的元素:[1, 2, 3, [100, 200, 300]]
2259354860416
2259355396224
函数内修改列表前列表地址:2259355396224,列表中的元素:[1, 2, 3, [100, 200, 300]]
函数内修改列表前列表地址:2259355396224,列表中的元素:[1, 2, 3, [100, 200, 300, 400]]
函数外调用函数后列表地址:2259355396224,列表中的元素:[1, 2, 3, [100, 200, 300, 400]]
返回值
在程序开发中,有时候希望一个函数执行结束后,告诉调用者一个结果,以便调用者针对具体的结果做后续的处理。返回值就是函数完成工作后,给调用者的一个结果
Ø 在函数中使用 return 关键字可以返回结果 ,并结束正在执行的函数
Ø 如果return后面跟[表达式],在结束函数的同时向调用方返回一个表达式。
Ø 如果仅仅是return关键字,后面没有加内容,函数执行返回调用方None。
Ø 调用函数一方,可以使用变量来接收函数的返回结果
(1)不带表达式的 return 语句,返回 None。
def f(a, b, c):
pass
return
print(f(1, 2, 3)) # None
(2)函数中如果没有 return 语句,在函数运行结束后也会返回 None。
def f(a, b, c):
pass
print(f(1, 2, 3)) # None
(3)用变量接收返回结果
def add(num1,num2) :
'''求两个数的和'''
sum1 = num1 + num2
return sum1
res = add(10,20)
print("两个数的和为:" ,res)
(4)return 语句可以返回多个值,多个值会放在一个元组中。
def f(a, b, c):
return a, b, c, [a, b, c]
print(f(1, 2, 3)) # (1, 2, 3, [1, 2, 3])
什么是闭包【可以延长局部变量的生命周期 】
当调用的函数执行完毕后,函数内的变量就会被销毁。但有时希望在调用函数后函数内的数据能够保存下来重复使用,这时候可以用到闭包。闭包可以避免使用全局值,并提供某种形式的数据隐藏。
构建闭包的条件:
Ø 外部函数内定义一个内部函数。
Ø 内部函数用到外部函数中的变量。
Ø 外部函数将内部函数作为返回值。
# 构建闭包
def linear(a, b):
def inner(x):
return a * x + b
return inner
y1 = linear(1, 1)
print(y1) # <function linear.<locals>.inner at 0x00000291279D19E0>
print(y1(5)) # 6
将调用 linear() 后返回的函数对象赋值给 y1,虽然 linear() 函数已经执行完毕,但是我们调用 y1() 时,y1() 仍然记得 linear() 中 a 和 b 的值。
查看闭包中的值
所有函数对象都有一个 closure 属性,如果它是一个闭包函数,则该属性返回单元格对象的元组。
def linear(a, b):
def inner(x):
return a * x + b
return inner
y1 = linear(1, 2)
objects = y1.__closure__
print(objects)
print(objects[0].cell_contents) # 1
print(objects[1].cell_contents) # 2
全局变量和局部变量
全局变量-作用于整个模块
局部变量-作用于当前函数
在局部作用域内,如果给变量进行赋值操作,会将遍历当做局部变量进行处理
'''
该案例演示了全局变量和局部变量
'''
sum = 0 # 这是一个全局变量
def add(num1,num2) :
sum = num1 + num2 # 这是一个局部变量
print("函数内局部变量的值:",sum,id(sum))
return sum
add(10,20)
# print(num1) # num1访问不到
print("函数外全局变量:",sum,id(sum))
_global和nonlocal关键字
_global
在函数内使用 global 声明全局变量
函数内使用 global 声明全局变量后,可以修改全局变量。
var1 = 10
def func():
# 声明:当前在局部作用域中使用全局的变量 var1
global var1
var1 = 20
print(f"局部作用域中的var1={var1, id(var1)}")
func()
print(f"全局作用域中的var1={var1, id(var1)}")
----------------------------------------
局部作用域中的var1=(20, 2091892605776)
全局作用域中的var1=(20, 2091892605776)
list1 = [1,2,3]
def func():
# 声明:当前在局部作用域中使用全局的变量 var1
list1[0] = 100
print(f"局部作用域中的var1={list1, id(list1)}")
func()
print(f"全局作用域中的var1={list1, id(list1)}")
-----------------------------------------
局部作用域中的var1=([100, 2, 3], 1992346097088)
全局作用域中的var1=([100, 2, 3], 1992346097088)
nonlocal
nonlocal 也用作内部作用域修改外部作用域的变量的场景,不过此时外部作用域不是全局作用域而是嵌套作用域。
def outer():
var1 = 10
def inner():
nonlocal var1
var1 = 20
print(f"局部作用域中的var1={var1, id(var1)}")
inner()
print(f"嵌套作用域中的var1={var1, id(var1)}")
outer()
------------------------------------------
局部作用域中的var1=(20, 1769305604944)
嵌套作用域中的var1=(20, 1769305604944)
递归
递归是一种逻辑思想,将一个大工作分为逐渐减小的小工作,比如说一个和尚要搬50块石头,他想,只要先搬走49块,那剩下的一块就能搬完了,然后考虑那49块,只要先搬走48块,那剩下的一块就能搬完了……,递归是一种思想,只不过在程序中,就是依靠函数嵌套这个特性来实现了
本质:递归调用就是在函数体中又调用了函数本身
匿名函数的定义
匿名函数
语法
Python使用 lambda 来定义匿名函数,所谓匿名,指其不用 def 的标准形式定义函数。
lambda 参数列表: 表达式
Ø lambda 只是一个表达式,函数体比def简单很多。
Ø lambda的主体是一个表达式,而不是一个代码块,所以仅仅能在lambda表达式中封装有限的逻辑进去。
Ø lambda函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
普通函数传参
def operator(a, b):
return a + b
def function(a, b, operator):
return operator(a, b)
print(function(1, 2, operator))
匿名函数传参
def function(a, b, operator):
return operator(a, b)
print(function(1, 2, lambda x, y: x + y))
匿名函数作为内置函数的参数
可以将匿名函数与常用的内置参数搭配使用。
#有三名学生的姓名和年龄,按年龄排序。
student_list = [{"name": "zhang3", "age": 36}, {"name": "li4", "age": 14}, {"name": "wang5", "age": 27}]
print(sorted(student_list, key=lambda x: x["age"]))
-----------------------------------------------------
student_list.sort(key= lambda stu: stu["age"])
print(student_list)
-----------------------------------------------------
def getKey(std):
return std["age"]
student_list.sort(key=getKey)
print(student_list)
map() #函数对序列中元素逐一处理。
map_result = map(lambda x: x * x, [0, 1, 3, 7, 9])
print(list(map_result)) # [0, 1, 9, 49, 81]
----------------------------------------------------
list1 = [1,2,3,4,5,6,7,8,9,10]
print(list(map(lambda item: item * item, list1)))
filter() #函数对序列中元素过滤。
filter_result = filter(lambda x: x >= 0, [-0, -1, -3, 7, 9])
print(list(filter_result)) # [0, 7, 9]
reduce() #函数对序列中元素进行累积。
from functools import reduce
reduce_result = reduce(lambda x, y: x * y, [1, 2, 3, 4, 5])
print(reduce_result) # 120
文件操作
文件的基本概念
在计算机中,文件是存储在磁盘上的数据集合。文件可以包含各种类型的数据,如文本、图像、音频、视频或程序代码。
文件系统通过文件名和文件路径来定位和管理文件。文件名通常包含文件的名称和扩展名,扩展名用于表示文件的类型(例如 .txt 表示文本文件,**.jpg** 表示图像文件)。文件路径可以是绝对路径(从文件系统的根目录开始)或相对路径(相对于当前工作目录)。
在编写程序的时候,数据是以二进制的形式存储在内存的,将数据写到磁盘文件的过程称之为持久化。
文件的分类
1)纯文本文件
有统一的编码,可以被看做存储在磁盘上的长字符串。
纯文本文件编码格式常见的有ASCII、ISO-8859-1、GB2312、GBK、UTF-8、UTF-16等。
2)二进制文件
没有统一的字符编码,直接由0与1组成。
如图片文件(jpg、png),视频文件(avi)等。
文件的打开与关闭
1)打开文件
使用 open() 打开或创建文件,该方法执行完毕之后返回的是一个file对象。
常用形式
open(文件名, 模式)
f = open("test.txt", "w")
模式 说明
r 读写方式:只读,文件若不存在会报错。默认此模式
w 读写方式:写入,写入前清空原有数据。文件不存在会创建文件
a 读写方式:追加写入,在原有数据后追加,文件不存在会创建文件
x 读写方式:创建新文件并写入,文件若已存在会报错
b 编码方式:以二进制打开。一般用于非文本文件如图片等
t 编码方式:以文本模式打开,默认此模式
+ 能读能写
2)完整形式
open(
file, # 文件路径 ★★★★★★★★★
mode="r", # 文件打开模式
buffering=-1, # 缓冲
encoding=None, # 文本编码方式,一般用utf8 ★★★★★★★★★
errors=None, # 报错级别
newline=None, # 区分换行符
closefd=True, # 传入的file参数类型
opener=None, # 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符
)
3)关闭文件
f.close()
读写数据
"""
该案例演示了读写文件操作
"""
"""
# 向文件中写入数据
# 打开文件(建立程序和文件之间的通道)
f = open("test.txt","w")
# 向文件中写入数据
f.write("hello world\n")
f.write("nihao python\n")
# 关闭和文件之间的建立的通道
f.close()
"""
# 从文件中读取数据
# 打开文件(建立程序和文件之间的通道)
f = open("test.txt","r")
# 从文件中读取数据 read() 默认读取所有数据
# print(f.read())
# 从文件中读取指定的字节大小数据
# print(f.read(5))
# print(f.read(8))
# 读取一行数据
# print(f.readline())
# print(f.readline())
# 读取所有行
print(f.readlines())
# 关闭和文件之间的建立的通道
f.close()
1)read
read([size]) 可以从文件中读取数据,size 表示要从文件中读取的数据的长度(单位是字节),如果没有传入 size 则读取文件中所有的数据。
# 打开文件
f = open("test.txt", "rt")
# 读取文件所有数据
print(f.read())
# 关闭文件
f.close()
print("-"*20)
f = open("test.txt", "rt")
# 读取文件5个字节数据
print(f.read(5))
print(f.read(8))
f.close()
2)readline
readline([size]) 可以从文件中读取整行数据,也可以通过 size 设置读取数据的长度。
f = open("test.txt", "rt")
print(f.readline())
print(f.readline(1))
print(f.readline(1))
f.close()
3)readlines
readlines([size]) 读取所有行并返回列表,若给定 size>0,返回总和大约为 size 字节的行, 实际读取值可能比 size 大。
f = open("test.txt", "r", encoding="utf-8")
print(f.readlines())
f.close()
常用函数
函数 说明
# 移动偏移量并返回新的绝对位置
file.seek(offset[,from]) 。
offset:移动的字节数,如果是负数表示从倒数第几位开始。
from:从哪个位置开始移动;0为开头,1为当前位置,2为末尾。from不为0时需使用'b'二进制模式打开文件。
# 返回当前偏移量
file.tell()
# 从开头开始截断文件为size个字符,无size表示从当前位置截断。windows系统下的换行大小2个字符
file.truncate([size])
# 将序列中字符串写入文件,需要自己加入换行符
file.writelines(seq)
# 如果可以读取文件则返回True
file.readable()
# 如果可以写入文件则返回True
file.writeable()
# 如果文件支持随机访问则返回True
file.seekable()
# 重命名文件
os.rename(old,new)
# 删除文件
os.remove(file)
# 创建目录,不支持递归创建
os.mkdir(dir)
# 递归创建目录
os.makedirs(dir)
# 获取当前路径
os.getcwd()
# 进入指定目录
os.chdir(dir)
# 获取目录下文件和目录列表
os.listdir(dir)
# 删除空目录
os.rmdir(dir)
# 递归删除空目录
os.removedirs(dir)
# 将相对路径转换为绝对路径
os.path.abspath(path)
# 获取路径中的文件名部分
os.path.basename(path)
# 获取路径中的目录部分
os.path.dirname(path)
# 拼接多个路径,自动处理路径分隔符
os.path.join(*paths)
# 将路径分割为目录和文件名的元组
os.path.split(path)
# 将路径分割为文件名和扩展名的元组
os.path.splitext(path)
# 判断路径是否存在
os.path.exists(path)
# 判断路径是否为文件
os.path.isfile(path)
# 判断路径是否为目录
os.path.isdir(path)
# 获取文件的大小,以字节为单位
os.path.getsize(path)
# 获取文件的最后访问时间
os.path.getatime(path)
# 获取文件的最后修改时间
os.path.getmtime(path)
图片拷贝
def file_copy(source_file_path, dest_file_path):
# 打开源文件
source_file = open(source_file_path, 'rb')
# 从源文件中读取数据
content = source_file.read()
# 打开目标文件
dest_file = open(dest_file_path, 'wb')
# 将内容写到目标文件
dest_file.write(content)
# 关闭源文件
source_file.close()
# 关闭目标文件
dest_file.close()
file_copy("c:\\Users\\Pluminary\\Desktop\\HouDuan\\22.png","c:\\Users\\Pluminary\\Desktop\\HouDuan\\echos\\11.png")
图片拷贝优化[不要一次性读取完,要指定读取字节]
def file_copy(source_file_path, dest_file_path):
# 打开源文件
source_file = open(source_file_path, 'rb')
# 打开目标文件
dest_file = open(dest_file_path, 'wb')
# 从源文件中读取数据
content = source_file.read(1024)
# 将内容写到目标文件
while content:
dest_file.write(content)
content = source_file.read(1024)
# 关闭源文件
source_file.close()
# 关闭目标文件
dest_file.close()
file_copy("c:\\Users\\Pluminary\\Desktop\\HouDuan\\22.png","c:\\Users\\Pluminary\\Desktop\\HouDuan\\echos\\1.png")
面向对象之类和对象
面向过程编程(Procedural Programming)和面向对象编程(OOP)是两种不同的编程范式,它们在软件开发中都有广泛的应用。
Python是一种混合型的语言,既支持面向过程的编程,也支持面向对象的编程。
面向过程的编程是一种以过程为中心的编程方式,主要关注解决问题的步骤,并将这些步骤写成函数或方法。
面向对象的编程是一种以对象为中心的编程方式,主要关注在解决问题的过程中涉及哪些对象以及这些对象如何交互
"""
该案例对比面向过程变成、面向函数式编程、面向对象编程
准备做3道菜,通过程序描述出每道菜的做菜流程
东北大拉皮
东北大乱炖
锅包肉
*的意思是:可能要拌多种食物
"""
# 面向对象的编程
class 菜:
def __init__(self,name):
self.name = name
def 洗(self,clm):
print(f"{self.name}洗{clm}")
def 切(self,clm):
print(f"{self.name}切{clm}")
def 拌(self,*clm):
print(f"{self.name}拌{clm}")
def 炖(self,*clm):
print(f"{self.name}炖{clm}")
def 炸(self,clm):
print(f"{self.name}炸{clm}")
def 上菜(self):
print(f"{self.name}上菜")
# dlp是面向对象的对象
dlp = 菜("东北大拉皮")
dlp.洗("黄瓜")
dlp.洗("拉皮")
dlp.切("黄瓜")
dlp.拌("黄瓜","拉皮","调料")
dlp.上菜()
"""
面向函数的编程方式
def 东北大拉皮(func):
洗("黄瓜")
洗("拉皮")
切("黄瓜")
拌("黄瓜", "拉皮", "调料")
上菜("东北大拉皮")
def 东北大乱炖():
洗("白菜")
洗("豆角")
洗("土豆")
切("肉")
炖("白菜", "土豆", "豆角", "肉", "玉米", "粉条", "调料")
上菜("东北大乱炖")
def 小酥肉():
洗("肉")
切("肉")
拌("肉", "淀粉")
炸("肉")
上菜("小酥肉")
print("~" * 30)
东北大拉皮()
东北大乱炖()
小酥肉()
"""
"""
面向过程的编程方式
适合一些简单的流程和步骤,如果业务比较复杂,不太合适
# 东北大拉皮
洗("黄瓜")
洗("拉皮")
切("黄瓜")
拌("黄瓜","拉皮","调料")
上菜("东北大拉皮")
print("~"*30)
# 东北大乱炖
洗("白菜")
洗("豆角")
洗("土豆")
切("肉")
炖("白菜","土豆","豆角","肉","玉米","粉条","调料")
上菜("东北大乱炖")
print("~"*30)
# 小酥肉
洗("肉")
切("肉")
拌("肉","淀粉")
炸("肉")
上菜("小酥肉")
print("~"*30)
"""
类和对象的概念
类是大量对象共性的抽象
在程序中,类是创建对象的模板
类是客观事物在人脑中的主观反应
对象在自然界中,只要是客观存在事物都是(万物皆对象)
类是抽象的,对象是具体的
类的组成
定义类
1)语法
class 类名:
"""类说明文档"""
类体
类名一般使用大驼峰命名法。
类体中可以包含类属性(也叫类变量)、方法、实例属性(也叫实例变量)等。
"""
该案例演示了简单的类的定义以及对象的创建
"""
# 定义一个学生类
class Student:
'''这是一个学生类'''
# 类属性 所有类的实例共享的
school = "atguigu"
# 在创建学生对象(实例)的时候,会自动调用的方法
def __init__(self, name, age):
# 定义实例属性 每个实例属性是独立的,相互不影响
self.name = name
self.age = age
# 实例方法 方法第一个参数是self,表示当前实例对象
# 对象.方法() 调用当前方法的时候,会将当前对象自身作为参数传递给方法
def play_game(self):
print(f"{self.age}岁的{self.name}正在专注的玩着游戏")
def study(self):
print(f"{self.age}岁的{self.name}正在有一搭没一搭的学着")
def video(self):
print(f"{self.age}岁的{self.name}正在录着视频")
# 通过类这个模板创建当前类的实例(对象)
mzl = Student("mzl",23)
print(mzl.name)
print(mzl.age)
print(mzl.school)
mzl.video()
dgd = Student("dgd", 23)
print(dgd.name)
print(dgd.age)
print(mzl.school)
dgd.study()
类的定义以及类的操作
成员引用
类名.成员名
案例:
class Person:
"""人的类"""
home = "earth"
def __init__(self):
self.age = 0
def eat(self):
print("eating...")
def drink(self):
print("drinking...")
---------------------------------------------------------------
home = Person.home # 获取一个字符串 这里是通过类
eat_function = Person.eat # 获取一个函数对象
doc = Person.__doc__ # 获取类的说明文档
print(home) # earth
print(eat_function) # <function Person.eat at 0x00000232C8230F40>
print(doc) # 人的类
-----------------------------或者-------------------------------
p = Person() # 创建一个对象
print(p.home) # earth 这里是通过对象
print(p.age) # 0
p.eat() # eating...
p.drink() # drinking...
_ _ init() _ _
__init__() 方法的调用时机在实例(通过 [__new__()](#object.__new__))被创建之后,返回调用者之前。一般用于初始化一些数据。当类定义了 __init__() 方法后,在类实例化的时候会自动调用 __init__() 方法。也可以向 __init__() 方法中传参。
class Person:
"""人的类"""
home = "earth"
def __init__(self, name):
self.name = name
p = Person("张三") # 创建一个对象
print(p.name) # 张三
self 作为实例传参
self代表类的实例自身。调用实例方法时,实例对象会作为第一个参数被传入。因此,我们调用p.eat()时就相当于调用了Person.eat(p)。
在__init__方法以及其他的实例方法中,第一个参数都是self
self是一个约定俗成的名字,一般不需要我们去关心,可以通过self去调用当前类中其他实例属性或方法;__init__不能又返回值只能是None
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def eat(self):
print("eating")
def study(self):
print("studying")
def study_eat(self):
self.eat()
self.study()
zsf = Student("zsf",18)
zsf.study_eat()
-------------------------------
eating
studying
类属性
类属性也叫类变量,在类中方法外面进行定义
类中所有的实例共享这个类属性
1)通过 类名.属性名 或 实例名.属性名 访问
class Person:
"""人的类"""
home = "earth" # 定义类属性
print(Person.home) # 通过类名访问类属性
p1 = Person() # 创建一个实例对象
print(p1.home) # 通过实例名访问类属性,(如果实例没有覆盖这个类属性的值)
2)通过 类名.属性名 添加与修改类属性
class Person:
"""人的类"""
Person.home = "earth" # 添加类属性
print(Person.home) # earth
Person.home = "mars" # 修改类属性
print(Person.home) # mars
若使用 实例名.属性名 则会创建或修改实例属性,因此不建议类属性和实例属性同名
class Person:
"""人的类"""
home = "earth"
p1 = Person()
p2 = Person()
print(Person.home) # earth
print(p1.home) # earth
print(p2.home) # earth
print("通过 类名.属性名 修改 类属性")
Person.home = "mars"
print(Person.home) # mars
print(p1.home) # mars
print(p2.home) # mars
print("通过 实例名.属性名 会创建 实例属性")
p1.home = "venus"
print(Person.home) # mars
print(p1.home) # venus
print(p2.home) # mars
3)所有该类的实例共享同一个类属性
class Person:
"""人的类"""
home = "earth" # 定义类属性,所有实例共享
p1 = Person() # 创建一个实例对象
p2 = Person() # 创建另一个实例对象
print(p1.home) # earth
print(p2.home) # earth
Person.home = "mars" # 修改类属性
print(p1.home) # mars
print(p2.home) # mars
实例属性
也叫实例变量。在类方法中定义的属性。通过 self.属性名定义。
1)通过实例名.属性名 访问
class Person:
"""人的类"""
def __init__(self, name, age):
self.name = name # 定义实例属性
self.age = age # 定义实例属性
p1 = Person("张三", 18) # 创建一个实例对象
print(p1.name, p1.age) # 张三 18
p2 = Person("李四", 81) # 创建一个实例对象
print(p2.name, p2.age) # 李四 81
print(Person.name) # 报错
2)通过 实例名.属性名 添加与修改实例属性
只是对当前的实例添加 对其他的没有影响
class Person:
"""人的类"""
pass
p1 = Person() # 创建一个实例对象
p1.name = "张三" # 添加实例属性
p1.age = 18 # 添加实例属性
print(p1.name, p1.age) # 张三 18
p1.age = 25 # 修改实例属性
print(p1.name, p1.age) # 张三 25
3)每个实例独有一份实例属性
class Person:
"""人的类"""
def __init__(self, name):
self.name = name # 定义实例属性
self.age = 0 # 定义实例属性
p1 = Person("张三") # 创建一个实例对象
print(p1.name, p1.age) # 张三 0
p1.age = 18 # 修改p1的age属性
print(p1.name, p1.age) # 张三 18
p2 = Person("李四") # 创建另一个实例对象
print(p2.name, p2.age) # 李四 0
方法
Python的类中有三种方法:实例方法、静态方法、类方法
实例方法
Ø 实例方法在类中定义,第一个参数为self,代表实例本身。
Ø 实例方法只能被实例对象调用。
Ø 可以访问实例属性、类属性、类方法。
class Person:
"""人的类"""
home = "earth"
def __init__(self, name):
self.name = name
def instance_method(self):
print(self.name, self.home, Person.home)
p = Person("张三")
p.instance_method() # 张三 earth earth,此时p中没有home实例属性,会去查找home类属性
Person.home = "venus" # 修改类属性
p.home = "mars" # 定义实例属性
p.instance_method() # 张三 mars venus
类方法
Ø 类方法在类中通过 @classmethod 定义,第一个参数为cls,代表类本身。
Ø 类方法可以被类和实例对象调用。
Ø 可以访问类属性。
在不创建实例的情况下调用,通过类名直接调用,非常方便,适合一些和类整体相关的操作。
静态方法
Ø 静态方法在类中通过 @staticmethod 定义
Ø 不访问实例属性或类属性,只依赖于传入的参数
Ø 可以通过类名或实例调用,但它不会访问类或实例的内部信息,更像是一个工具函数,只是为了方便组织代码,把它放在了类里面。
"""
该案例演示了方法
"""
import types
def drink(self):
print("drinking")
class Student:
"""这是一个学生类"""
school = "atguigu"
def __init__(self, name, age):
self.name = name
self.age = age
# 实例方法
def eat(self):
print(self.school)
print(self.name)
print(self.age)
# 类方法
@classmethod
def get_info(cls):
print(cls.school)
print(cls.__doc__)
zwj = Student("zwj",30)
# zwj.eat()
# zwj.get_info()
# Student.get_info()
# zwj.drink = drink
# zwj.drink()
# Student.drink = drink
# zwj.drink()
# Student.drink(zwj)
zcs = Student("zcs",50)
zcs.drink = types.MethodType(drink, zcs)
zcs.drink()
Student.get_info()
"""
class MathUtil:
@staticmethod # 不加是用不了的
def add(a, b):
return a + b
print(MathUtil.add(10, 20))
"""
-----------------------------------
drinking
atguigu
这是一个学生类
特殊方法
方法名中有两个前缀下划线和两个后缀下划线的方法为特殊方法,也叫魔法方法。上文提到的 __init__()就是一个特殊方法。这些方法会在进行特定的操作时自动被调用。
几个常见的特殊方法:
1)__new__()
对象实例化时第一个调用的方法。
2)__init__()
类的初始化方法。
3)__del__()
对象的销毁器,定义了当对象被垃圾回收时的行为。使用 del xxx 时不会主动调用 __del__() ,除非此时引用计数==0。
4)__str__()
定义了对类的实例调用 str() 时的行为。
5)__repr__()
定义对类的实例调用 repr() 时的行为。 str() 和 repr() 最主要的差别在于目标用户。 repr() 的作用是产生机器可读的输出(大部分情况下,其输出可以作为有效的Python代码),而 str() 则产生人类可读的输出。
6)__getattribute__()
属性访问拦截器,定义了属性被访问前的操作。
动态添加属性与方法
动态给对象添加属性
class Person:
def __init__(self, name=None):
self.name = name
p = Person("张三")
print(p.name) # 张三
p.age = 18
print(p.age) # 18
动态给类添加属性
class Person:
def __init__(self, name=None):
self.name = name
p = Person("张三")
print(p.name) # 张三
Person.age = 0
print(p.age) # 0
动态给对象添加方法
1)添加普通方法
class Person:
def __init__(self, name=None):
self.name = name
def eat():
print("吃饭")
p = Person("张三")
p.eat = eat
p.eat() # 吃饭
2)添加实例方法
给对象添加的实例方法只绑定在当前对象上,不对其他对象生效,而且需要传入 self 参数。需要使用 types.MethodType(方法名,实例对象) 来添加实例方法。
import types
class Person:
def __init__(self, name=None):
self.name = name
def eat(self):
print(f"{self.name}在吃饭")
p = Person("张三")
p.eat = types.MethodType(eat, p)
p.eat() # 张三在吃饭
动态给类添加方法
给类添加的方法对它的所有对象都生效,添加类方法需要传入 cls 参数,添加静态方法则不需要。
class Person:
home = "earth"
def __init__(self, name=None):
self.name = name
# 定义类方法
@classmethod
def come_from(cls):
print(f"来自{cls.home}")
# 定义静态方法
@staticmethod
def static_function():
print("static function")
Person.come_from = come_from
Person.come_from() # 来自earth
Person.static_function = static_function
Person.static_function() # static function
动态删除属性与方法
Ø del 对象**.**属性名
Ø delattr(对象,属性名)
__slots__限制实例属性与实例方法
Python允许在定义类的时候,定义一个特殊的 __slots__变量,来限制该类的实例能添加的属性。使用__slots__可以限制添加实例属性和实例方法,但类属性、类方法和静态方法还可以添加。__slots__仅对当前类生效,对其子类无效。
import types
class Person:
__slots__ = ("name", "age", "eat")
def __init__(self, name=None):
self.name = name
def eat(self):
print(f"{self.name}在吃饭")
def drink(self):
print(f"{self.name}在喝水")
p = Person("张三")
# 添加实例属性
p.age = 10
print(p.age) # 10
# 添加实例方法
p.eat = types.MethodType(eat, p)
p.eat() # 张三在吃饭
# 添加实例属性
p.weight = 100 # AttributeError: 'Person' object has no attribute 'weight'
# 添加实例方法
p.drink = type.MethodType(drink, p) # AttributeError: type object 'type' has no attribute 'MethodType'
面向对象的三大特征
封装
- 成员私有化
- 在类中定义的成员,只能在类中被访问,类的外部访问不到
- 有些类中的成员不想被子类继承,也可以进行私有化
继承
- 子类可以继承父类的非私有成员,当然子类也可以定义自己特有的方法,也可以对父类的方法进行重写
多态
私有化
有时为了限制属性和方法只能在类内访问,外部无法访问;或父类中某些属性和方法不希望被子类继承。可以将其私有化。
不想被访问的话 前面要加个下划线home = "earth" => _home = "earth"
1)单下划线:非公开API
大多数Python代码都遵循这样一个约定:有一个前缀下划线的变量或方法应被视为非公开的API,例如 _var1。这种约定不具有强制力。
class Person:
_home = "earth"
def __init__(self):
self.name = "John"
self.age = 25
def _eat(self):
print("I'm eating")
print(Person._home)
zsf = Person()
print(zsf.age)
2)双下划线:名称改写
有两个前缀下划线,并至多一个后缀下划线的标识符,例如 __x,会被改写为 _类名__x。只有在类内部可以通过 __x 访问,其他地方无法访问或只能通过 _类名__x 访问。
class Person:
__home = "earth"
# 修改构造函数接受name和age参数
def __init__(self, name="John", age=25):
self.name = name
self.age = age
# 将方法改为公共方法,去掉双下划线
def eat(self):
print(self.__home)
print("I'm eating")
def eat_1(self):
print(self.__home)
print("I'm \n")
self.eat()
zsf = Person("zsf", 18)
zsf.eat() # 可以正常调用
zsf.eat_1() # 可以正常调用
------------------------------
earth
I'm eating
earth
I'm
earth
I'm eating
成员私有化本质
如果成员以双下划线开头,名字会被改写,改为_类名__成员名
class Person:
__home = "earth"
# 修改构造函数接受name和age参数
def __init__(self, name="John", age=25):
self.__name = name
self.__age = age
# 将方法改为公共方法,去掉双下划线
def eat(self):
print(self.__home)
print("I'm eating")
def eat_1(self):
print(self.__home)
print("I'm \n")
self.eat()
zsf = Person("zsf", 18)
print(zsf._Person__name)
print(zsf._Person__age)
-----------------------------
zsf
18
@property用法
1)方法转换为属性
可通过@property装饰器将一个方法转换为属性来调用。转换后可直接使用 .方法名 来使用,而无需使用.方法名() 。
class Person:
def __init__(self, name):
self.name = name
@property
def eat(self):
print(f"{self.name} is eating...")
p = Person("张三")
p.eat # 张三 is eating...
2)只读属性
将方法名设置为去掉双下划线的私有属性名,方法中返回私有属性。
class Person:
def __init__(self, name):
self.__name = name
@property
def name(self):
return self.__name
p = Person("张三")
print(p.name) # 张三
p.name = "李四" # 报错
3)读写属性
将方法名设置为去掉双下划线的私有属性名,使用 属性名.setter 装饰。
class Person:
def __init__(self, name):
self.__name = name
@property
def name(self):
return self.__name
@name.setter
def name(self, name):
self.__name = name
p = Person("张三")
print(p.name) # 张三
p.name = "李四"
print(p.name) # 李四
也可以在写方法中设置一些拦截条件来规范私有属性的写入。
class Person:
def __init__(self, name):
self.__name = name
@property
def name(self):
return self.__name
@name.setter
def name(self, name):
if name == "李四":
print("不许叫李四")
else:
self.__name = name
p = Person("张三")
print(p.name) # 张三
p.name = "李四" # 提示 “不许叫李四”
print(p.name) # 张三
p.name = "王五"
print(p.name) # 王五
‘信用卡’ 封装案例
"""
封装信用卡类设计案例
"""
class CreditCard:
def __init__(self, name):
self.name = name
self.__password = None
self.__balance = 0 # 初始化为0
@property
def password(self):
return self.__password
@password.setter
def password(self, password):
if password != "888888":
print("密码错误")
else:
print("密码正确")
self.__password = password
@property
def balance(self):
return self.__balance
@balance.setter
def balance(self, balance):
# 确保balance是数字类型
try:
balance = float(balance) # 转换为数字类型
if balance < 0:
print("余额不足")
else:
print(f"{self.name}存款成功") # 修改提示信息
self.__balance = balance
except (ValueError, TypeError):
print("余额必须是数字")
c1 = CreditCard("张三")
c1.password = "666666"
c1.balance = 888888 # 传入数字而不是字符串
print(f"当前余额: {c1.balance}")
----------------------------------------------------
密码错误
张三存款成功
当前余额: 888888.0
单继承
子类(派生类)继承父类(基类)中的属性和方法,实现代码重用。子类可以新增自己特有的方法,也可以重写父类的方法。子类不能继承父类的私有属性和私有方法,因为存在名称改写。
语法
class 父类:
pass
class 子类(父类):
pass
案例
class Person:
"""人的类"""
home = "earth" # 定义类属性
def __init__(self, name):
self.name = name # 定义实例属性
def eat(self):
print("eating...")
class YellowRace(Person):
"""黄种人"""
color = "yellow" # 定义类属性
class WhiteRace(Person):
"""白种人"""
color = "white" # 定义类属性
class BlackRace(Person):
"""黑种人"""
color = "black" # 定义类属性
y1 = YellowRace("张三")
print(y1.home) # earth
print(y1.color) # yellow
print(y1.name) # 张三
y1.eat() # eating...
w1 = WhiteRace("李四")
print(w1.home) # earth
print(w1.color) # white
print(w1.name) # 李四
w1.eat() # eating...
b1 = BlackRace("王五")
print(b1.home) # earth
print(b1.color) # black
print(b1.name) # 王五
b1.eat() # eating...
多继承
一个子类可以同时调多个父类;调用方法时先在子类中查找,若不存在则从左到右依次查找父类中是否包含方法。
1)语法
class 类名(父类1, 父类2, ...):
类体
2)案例
class Person:
"""人的类"""
home = "earth"
def __init__(self, name):
self.name = name
def eat(self):
print("eating...")
class YellowRace(Person):
"""黄种人"""
color = "yellow"
def run(self):
print("runing...")
class Student(Person):
"""学生"""
def __init__(self, name, grade):
self.name = name
self.grade = grade
def study(self):
print("studying...")
class ChineseStudent(Student, YellowRace): # 继承了Student和YellowRace
"""中国学生"""
country = "中国"
y1 = ChineseStudent("张三", "三年级")
print(y1.home, y1.color, y1.country, y1.name, y1.grade)
y1.eat()
y1.run()
y1.study()
复用父类方法
子类可以在类中使用 super().方法名() 或 父类名.方法名() 来调用父类的方法。
调用方法时先在子类中查找,若不存在则从左到右依次查找多个父类中是否包含方法
1)super().方法名()
这里要注意 方法1 和 方法2
class Person:
"""人的类"""
home = "earth"
def __init__(self, name):
self.name = name
def eat(self):
print("eating...")
class YellowRace(Person):
"""黄种人"""
color = "yellow"
def run(self):
print("runing...")
class Student(Person):
"""学生"""
def __init__(self, name, grade):
# 调用父类中的方法
# super().__init__(name) ### 方式1:通过super().父类方法调用
self.name = name
self.grade = grade
def study(self):
print("先吃再学")
# Person.eat(self) ### 方法2:通过父类名.父类方法名(self)
super().eat() # 子类中调用父类的方法
print("studying...")
class ChineseStudent(Student, YellowRace): # 继承了Student和YellowRace
"""中国学生"""
country = "中国"
y1 = ChineseStudent("张三", "三年级")
print(y1.home, y1.color, y1.country, y1.name, y1.grade)
y1.study()
方法解析顺序
方法解析顺序(mro—Method Resolution Order)。可使用 类名.mro 访问类的继承链来查看方法解析顺序。
class Person:
"""人的类"""
home = "earth"
def __init__(self, name):
self.name = name
def eat(self):
print("eating...")
class YellowRace(Person):
"""黄种人"""
color = "yellow"
def run(self):
print("runing...")
class Student(Person):
"""学生"""
def __init__(self, name, grade):
self.name = name
self.grade = grade
def study(self):
print("先吃再学")
Person.eat(self)
print("studying...")
class ChineseStudent(Student, YellowRace):
"""中国学生"""
country = "中国"
y1 = ChineseStudent("张三", "三年级")
print(
ChineseStudent.__mro__
)
-----------------------------------------------------------
# (<class '__main__.ChineseStudent'>, <class '__main__.Student'>, <class '__main__.YellowRace'>, <class '__main__.Person'>, <class 'object'>)
方法重写
在子类中定义与父类方法重名的方法,调用时会调用子类中重写的方法
class Person:
home = "earth"
def __init__(self, name):
self.name = name
def eat(self):
print("eating...")
class Chinese(Person):
color = "yellow"
# 重写父类方法
def eat(self):
print("用筷子吃")
y1 = Chinese("张三")
y1.eat()
注意:子类重写 __init__() 并调用时,不会执行父类的 __init__() 方法。如有必要,需在子类 __init__() 中使用 super().__init__() 来调用父类的 __init__() 方法。
class Person:
def __init__(self, name):
self.name = name
class Chinese(Person):
def __init__(self, name, area):
super().__init__(name) # 调用父类的__init__()
self.area = area
y1 = Chinese("张三", "北京")
print(y1.name, y1.area)
多态
同一事物在不同场景下呈现不同状态。
多态应用在方法的返回值上
class Animal:
def go(self):
pass
class Dog(Animal):
def go(self):
print("跑")
class Fish(Animal):
def go(self):
print("游")
class Bird(Animal):
def go(self):
print("飞")
def go(animal):
animal.go() # 将不同的实例传入,执行不同的方法
dog = Dog()
fish = Fish()
bird = Bird()
go(dog)
go(fish)
go(bird)
class Bird:
def __init__(self, name):
self.name = name
class Fish:
def __init__(self, name):
self.name = name
class Dog:
def __init__(self, name):
self.name = name
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def call(self, flag):
ani = None
# 将字符串转换为整数进行匹配
flag_int = int(flag) if isinstance(flag, str) else flag
match flag_int:
case 1:
ani = Bird('Bird')
case 2:
ani = Fish('Fish')
case 3:
ani = Dog('Dog')
return ani
wf = Person("wf", 20)
ani = wf.call('3') # 传入字符串 '3'
print(ani.name) # 输出: Dog
愤怒的小鸟案例说明
class 类{
属性
类属性
实例属性
方法
类方法
静态方法
实例方法
魔法方法
}
1.1 游戏背景
在这个模拟的愤怒的小鸟游戏世界里,绿色的小猪偷走了小鸟们的蛋,这引发了小鸟们的愤怒,它们决定展开反击。每只小鸟都具有独特的颜色,并且各自拥有不同的技能,玩家需要操控这些小鸟,利用它们的技能去攻击小猪们建造的各种障碍物,从而达成击败小猪、夺回鸟蛋的目标。
1.2 类的设计思路
1.2.1 Birds 基类
1)设计目的
作为所有小鸟类的基类,它定义了小鸟的通用属性和行为,为后续具体小鸟类的扩展提供基础框架,体现了面向对象编程中的抽象和封装思想。
2)属性设计
name:用于标识每只小鸟的名称,方便区分不同个体。
color:代表小鸟的颜色,这是小鸟的一个显著特征,在游戏中可以对应不同类型的小鸟。
skill_description:描述小鸟所具备的独特技能,让玩家了解每只小鸟的特殊能力。
3)方法设计
fly():描述小鸟飞行的基本动作,是小鸟在游戏中的常见行为,所有子类都可以重写该方法来展示不同的飞行特点。
call():模拟小鸟发出叫声的行为,同样可以被子类重写以体现不同小鸟的叫声差异。
use_skill():用于触发小鸟的特殊技能,展示小鸟使用技能的情况,子类可以根据自身技能特点进行相应实现。
1.1.1 具体小鸟子类(RedBirds、YellowBirds、BlueBirds)
1)设计目的
继承自 Birds 基类,每个子类代表一种特定颜色的小鸟,它们在继承基类属性和方法的基础上,重写部分方法以展示不同小鸟的独特行为和技能,体现了面向对象编程中的继承和多态思想。
2)属性设计
通过调用基类的 init 方法,初始化各自的 name、color 和 skill_description 属性,确保每只小鸟都有自己的独特标识和技能。
3)方法设计
fly():重写基类的 fly() 方法,展示不同小鸟的飞行特点,如红鸟以稳定速度飞行,黄鸟快速飞行,蓝鸟优雅飞行。
call():重写基类的 call() 方法,模拟不同小鸟的叫声,增加游戏的趣味性。
1.1.2 Obstacle 类
1)设计目的
代表游戏中的障碍物,如木头堡垒、石头塔楼等,负责处理障碍物被小鸟攻击的逻辑,与小鸟类进行交互,体现了面向对象编程中的对象交互和封装思想。
2)属性设计
name:标识障碍物的名称,方便区分不同类型的障碍物。
strength:表示障碍物的强度,即它能够承受的伤害值,当强度降为 0 时,障碍物被摧毁。
3)方法设计
be_attacked(bird):模拟障碍物被小鸟攻击的过程,根据小鸟的类型计算伤害,并更新障碍物的强度,同时输出攻击和受损信息,让玩家了解游戏进展。
1.1 方法设计思路
1.1.1 Birds 类的方法
1)fly()
作为通用的飞行方法,提供了小鸟飞行的基本描述,子类可以根据自身特点进行个性化实现,以体现不同小鸟的飞行风格。
2)call()
模拟小鸟发出叫声的行为,为游戏增加生动性,子类可以重写该方法来展示不同小鸟的叫声特点。
3)use_skill()
用于触发小鸟的特殊技能,通过输出技能描述,让玩家了解小鸟使用技能的情况,不同子类可以根据自身技能进行不同的实现。
1.1.2 具体小鸟子类的方法
fly() 和 call():重写基类的方法,根据不同小鸟的特点进行个性化实现,展示不同小鸟的飞行和叫声差异,体现了多态性。
1.1.3 Obstacle 类的方法
be_attacked(bird):接收一个小鸟对象作为参数,根据小鸟的类型计算伤害,并更新障碍物的强度。通过判断障碍物的强度是否小于等于 0,输出障碍物是否被摧毁的信息,实现了障碍物与小鸟之间的交互逻辑。
通过这样的类和方法设计,整个游戏模拟程序具有良好的扩展性和可维护性,方便后续添加更多类型的小鸟和障碍物,以及实现更复杂的游戏逻辑。
代码实现
# 定义鸟类基类
class Birds:
def __init__(self, name, color, skill_description):
self.name = name
self.color = color
self.skill_description = skill_description
def fly(self):
print(f"{self.name} 正在飞行...")
def call(self):
print(f"{self.name} 发出叫声...")
def use_skill(self):
print(f"{self.name} 使用了技能:{self.skill_description}")
# 定义红鸟子类
class RedBirds(Birds):
def __init__(self):
super().__init__("红火", "红色", "撞击前方障碍物,造成大量伤害")
def fly(self):
print("红火以稳定的速度向前飞行...")
def call(self):
print("红火发出 'wei呀....' 的叫声")
# 定义黄鸟子类
class YellowBirds(Birds):
def __init__(self):
super().__init__("小黄", "黄色", "瞬间加速,穿透薄障碍物")
def fly(self):
print("小黄快速向前飞行...")
def call(self):
print("小黄发出 '啾啾啾....' 的叫声")
# 定义蓝鸟子类
class BlueBirds(Birds):
def __init__(self):
super().__init__("小蓝", "蓝色", "分裂成三只小鸟,分散攻击")
def fly(self):
print("小蓝优雅地向前飞行...")
def call(self):
print("小蓝发出 '叽叽叽....' 的叫声")
# 定义障碍物类
class Obstacle:
def __init__(self, name, strength):
self.name = name
self.strength = strength
def be_attacked(self, bird):
print(f"{bird.name} 冲向了 {self.name}")
bird.use_skill()
# isinstance判断当前对象是否属于xx的类型
if isinstance(bird, RedBirds):
damage = 80
elif isinstance(bird, YellowBirds):
damage = 50
elif isinstance(bird, BlueBirds):
damage = 30 * 3 # 分裂成三只,每只造成 30 点伤害
self.strength -= damage
if self.strength <= 0:
print(f"{self.name} 被摧毁了!")
else:
print(f"{self.name} 还剩余 {self.strength} 点强度")
# 模拟游戏过程
if __name__ == "__main__":
# 创建不同颜色的小鸟
red_bird = RedBirds()
yellow_bird = YellowBirds()
blue_bird = BlueBirds()
# 创建障碍物
obstacle1 = Obstacle("木头堡垒", 100)
obstacle2 = Obstacle("石头塔楼", 200)
# 红鸟攻击木头堡垒
obstacle1.be_attacked(red_bird)
# 黄鸟攻击石头塔楼
obstacle2.be_attacked(yellow_bird)
# 蓝鸟攻击石头塔楼
obstacle2.be_attacked(blue_bird)
异常处理基础语法
1.1 异常介绍
Python是一门解释型语言,只有在程序运行后才会执行语法检查。所以,只有在运行或测试程序时,才会真正知道该程序能不能正常运行。
Python有两种错误很容易辨认:语法错误和异常。
1.1.1 语法错误
程序解析时遇到的错误。
例如以下程序,因缺少 : 而出现语法错误。
while True print(1)
# while True print(1)
# ^^^^^
# SyntaxError: invalid syntax
11.1.2 异常
Python 程序的语法是正确的,在运行它的时候,也有可能发生错误。运行期检测到的错误被称为异常。
例如以下程序,因变量名未找到而引发NameError。
print(var1)
# print(var1)
# ^^^^
# NameError: name 'var1' is not defined. Did you mean: 'vars'?
大多数的异常都不会被程序处理,都以错误信息的形式打印出来,错误信息的前面部分显示了异常发生的上下文,并以调用栈的形式显示具体信息。
11.2 异常处理
对异常进行处理并不是将错误规避了,而是当程序运行的时候,出现错误的时候提供解决方案,不终止程序,可以让程序继续执行。
11.2.1 try except
可以使用 try except 语句来捕获异常并处理。
语法
try:
可能发生异常的代码
except:
异常处理的代码
Ø 如果没有发生异常,程序会忽略except中的代码,继续向下执行。
Ø 如果发生了异常,会忽略try中剩余代码,执行except中的代码。
Ø 程序异常处理后的其他代码会正常执行
案例
try:
result = 3 / 1
print("没有发生异常")
except:
print("发生异常了")
print("End")
11.2.2 捕获指定类型的异常以及获取异常描述信息
在打印出来的异常信息中,冒号之前是异常类型,冒号之后是异常描述信息
# NameError: name 'a' is not defined
# NameError: 冒号之前是异常类型
# : name 'a' is not defined 冒号之后是异常描述信息
print(a)
如果出现的异常不是我们指定的类型中的其中一个,我们在程序中想对不同类型的异常进行不同的处理,并在处理异常的时候,要获取异常信息,我们可以通过如下方式。
语法【as是起别名】
try:
可能发生异常的代码
except 异常类型1 as 变量名1:
异常处理的代码
except 异常类型2 as 变量名2:
异常处理的代码
except(异常类型3, 异常类型4, 异常类型5) as 变量名3:
异常处理的代码
except:
异常处理的代码
Ø 如果没有发生异常,程序会忽略except中的代码,继续向下执行。
Ø 如果发生了异常,会忽略try中剩余代码,根据异常类型匹配到相应的 except 并执行其中的代码。
Ø 如果发生了异常,且异常类型无法和任何except匹配,异常将向外传递。
Ø 一个except可以同时处理多个异常,将这些异常放在一个元组中。
Ø 最后一个 except 可以忽略异常类型,它将被作为通配符使用。
案例
try:
result = 3 / 0
print("发生异常了")
except ZeroDivisionError as e:
print(e)
except (RuntimeError, TypeError, NameError) as e:
print(e)
except:
print("Unexpected error")
print("End")
else关键字
可选地将else放在所有except之后。如果try中代码没有发生异常,将执行 else 中的代码。
try:
可能发生异常的代码
except 异常类型1 as 变量名1:
异常处理的代码
except 异常类型2 as 变量名2:
异常处理的代码
else:
没有异常时执行的代码
说明
Ø 从执行效果上说,将代码放到else块和直接放到try块中是一样的。
Ø 将try正常执行完毕而没有引发任何异常后被执行的代码放到else中。提供了一种清晰的逻辑区分,将正常情况的代码与异常处理代码分开,使代码更易于理解和维护,有助于代码的可读性和可维护性。
Ø 例如,你希望在try块中有些操作执行成功后,再执行其它代码,那就可以把代码放到else语句块中。
案例
try:
result = x / y
except ZeroDivisionError:
print("除数不能为零!")
else:
print(f"结果是: {result}")
finally关键字
可选地,放在最后。无论是否发生异常都会执行的代码,通常用于执行一些必须要进行的清理操作,例如关闭文件、释放资源(如网络连接、数据库连接、锁等),即使在执行 try 块中的代码时出现了异常,也能保证这些操作得以完成。
语法
try:
可能发生异常的代码
except 异常类型1 as 变量名1:
异常处理的代码
except 异常类型2 as 变量名2:
异常处理的代码
else:
没有异常时执行的代码
finally:
无论是否发生异常都会执行的代码
说明
Ø 如果从执行效果上说,大部分场景,将代码放到finally语句和放到try-except块外效果是一样的。
Ø finally 语句块是 try-except 结构的一部分,它确保了无论 try 块中是否发生异常,也无论 except 块是否被执行,其中的代码都会被执行
Ø 直接放在try-except结构外面的代码只会在try-except结构正常执行完毕后才会执行,如果在try块中出现异常且没有被except块捕获,或者在except块中出现了新的异常导致程序终止,那么这部分代码将不会被执行。
案例
# try:
# result = 3 / 0
# except ZeroDivisionError as e:
# print(e)
# else:
# print(result)
# finally:
# print("finally")
# print("End")
#输出结果:
# division by zero
# finally
# End
try:
result = 3 / 0
except NameError as e:
print(e)
else:
print(result)
finally:
print("finally")
raise
当你想要在代码中明确表示发生了错误或异常情况时,可以使用 raise 来抛出异常。这可以帮助你在满足某些条件时停止程序的正常执行,并将控制权转移到异常处理部分。
语法
raise 异常类型("异常描述")
案例
def int_add(x, y):
if isinstance(x, int) and isinstance(y, int):
return x + y
else:
raise TypeError("参数类型错误")
print(int_add(1, 2)) # 3
print(int_add("1", "2")) # TypeError: 参数类型错误
assert断言
assert用于判断一个表达式,在表达式条件为False的时候触发异常,常用于调试程序。
语法
assert 表达式 [,异常描述]
#等价于
if not 表达式:
raise AssertionError([异常描述])
案例
def int_add(x, y):
assert isinstance(x, int) and isinstance(y, int), "参数类型错误"
return x + y
print(int_add(1, 2)) # 3
print(int_add("1", "2")) # AssertionError: 参数类型错误
自定义异常
通过直接或者间接继承Exception类来创建自己的异常。例如:
class MyError(Exception):
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value)
try:
raise MyError(1)
except MyError as e:
print("触发自定义异常:", e.value)
异常的传递
当存在 try 嵌套或函数嵌套时,若内层出现了异常且在内层无法处理,会将异常一层一层向外传递,直到异常被处理或程序报错。
try:
try:
try:
print(1 / 0)
except NameError as e:
print("第三层", e)
except TypeError as e:
print("第二层", e)
except Exception as e:
print("第一层", type(e), e)
# 第一层 <class 'ZeroDivisionError'> division by zero
with关键字
Python中的with语句用于异常处理,封装了try except finally编码范式,提供了一种简洁的方式来确保资源的正确获取和释放,同时处理可能发生的异常,提高了易用性。使代码更清晰、更具可读性,简化了文件流等公共资源的管理。
语法:
with expression as variable:
# 代码块
说明:
expression:通常是一个对象或函数调用,该对象需要是一个上下文管理器,即实现了__enter__和__exit__方法variable:是可选的,用于存储expression的__enter__方法的返回值
工作原理:
Ø 使用 with 关键字系统会自动调用 f.close() 方法, with 的作用等效于 try finally 语句。
Ø 当执行with语句时,会调用expression对象的__enter__方法。
Ø enter 方法的返回值可以被存储在 variable 中(如果有),以供 with 代码块中使用。
Ø 然后执行 with 语句内部的代码块。
Ø 无论在代码块中是否发生异常,都会调用 expression 对象的__exit__ 方法,以确保资源的释放或清理工作,这类似于 try-except-finally 中的 finally 子句。
案例:打开一个文件并向其中写入内容,验证出现异常后文件是否正常关闭
1)常规方式
try:
file = open("test.txt", "w")
file.write(a)
file.close()
finally:
print("文件是否关闭:", file.closed) # 文件是否关闭: False
2)使用 try finally
try:
file = open("test.txt", "w")
try:
file.write(a)
finally:
file.close()
finally:
print("文件是否关闭:", file.closed) # 文件是否关闭: True
3)使用 with # file是取的别名
try:
with open("test.txt", "w") as file:
file.write(a)
finally:
print("文件是否关闭:", file.closed) # 文件是否关闭: True
Python常见异常
异常基类
具体异常
| *异常* |
*说明* |
| *AssertionError* |
当 assert 语句失败时将被引发。 |
| *AttributeError* |
当属性引用或赋值失败时将被引发。 |
| *IndexError* |
当序列抽取超出范围时将被引发。 |
| *KeyError* |
当在现有键集合中找不到指定的映射(字典)键时将被引发。 |
| *KeyboardInterrupt* |
当用户按下中断键 (通常为 Control-C 或 Delete) 时将被引发。 |
| *MemoryError* |
当一个操作耗尽内存但情况仍可(通过删除一些对象)进行挽救时将被引发。 |
| *NameError* |
当某个局部或全局名称未找到时将被引发。 |
| *OSError* |
此异常在一个系统函数返回系统相关的错误时将被引发,此类错误包括 I/O 操作失败例如 文件未找到 或 磁盘已满 等。 |
| *SyntaxError* |
当解析器遇到语法错误时引发。 |
| *TypeError* |
当一个操作或函数被应用于类型不适当的对象时将被引发。 |
模块与包
模块描述
Python中一个以.py结尾的源文件即为一个模块(Module)。其中可以包含变量、函数和类等。通常情况下,我们把能够实现某一特定功能的代码放置在一个文件中作为一个模块。
使用模块提高了代码的可维护性,也提高了代码的复用性。即编写好一个模块后,只要是实现该功能的程序,都可以导入这个模块实现。另外,使用模块也可以避免名称冲突,相同名字的函数或变量可以分别存在与不同的模块中。
创建模块
模块名区分大小写,且不能与Python自带的标准模块重名。
创建一个模块my_add.py
num =100
def add(a, b):
"""求两个数的和"""
return a + b
导入模块
全部导入import
导入模块的所有成员,通过模块名.成员名的方式访问。即使多次使用 import导入同一模块,模块也只会被导入一次。
语法
import 模块名 [as 别名]
案例
在同一目录下创建一个main.py文件,在其中导入 my_add.py 模块并使用
# 导入模块
import my_add
# 使用模块
print(my_add.add(1, 2))
print(my_add.num)
也可以在导入模块时给模块起别名。
# 导入模块
import my_add as a1
# 使用模块
print(a1.add(1, 2))
print(a1.num)
局部导入 from import
指定导入模块的部分成员,直接通过成员名的方式访问。只能使用其导入的成员,未导入的成员不能使用。如果多个模块中存在重名成员,后一次导入会覆盖前一次导入。
语法
from 模块名 import 成员名1[as 别名], 成员名2[as 别名],…
案例
Ø 创建新的模块my_multi.py
num =200
_str1="abc"
def multi(a, b):
"""求两个数的积"""
return a * b
Ø 只能使用导入的成员
from my_add import add
print(add(1, 2))
print(num) # NameError: name 'num' is not defined
Ø 重名变量,后一次导入会覆盖前一次导入
# 导入模块
from my_add import add,num
from my_multi import num
# 使用模块
print(add(1, 2))
print(num)
Ø 通过别名区分不同模块的变量
# 导入模块
from my_add import add,num as a1
from my_multi import num as m1
# 使用模块
print(add(1, 2))
print(a1)
print(m1)
局部导入 from import
导入模块中所有不以单下划线开头的成员,直接通过成员名的方式访问。
语法
from 模块名 import *
案例
# 导入模块
from my_add import *
# 使用模块
print(add(1, 2))
print(num)
print(_str1)
模块搜索顺序
当导入一个模块时,会按照以下顺序进行查找:
(1)当前目录。
(2)PYTHONPATH环境变量中的目录。
(3)包含标准 Python 模块以及这些模块所依赖的任何 extension module 的目录。
可以使用以下方式查看模块搜索顺序:
import sys
print(sys.path)
也可以通过 sys.path.append(路径) 向 sys.path 中临时添加路径。
import sys
print(sys.path)
sys.path.append("./..")
print(sys.path)
__all__ [在被导入模块中进行限制]
使用from import *导入模块时,可以在被导入的模块中使用 all设置哪些内容可以被导入。all 的设置只针对使用 from import * 导入模块时有效。
在my_add.py 中向__all__添加部分元素:
__all__ = ["num","add"] # 内容必须要用引号引起来
num = 100
num1 = 200
_str1="abc"
def add(a, b):
"""求两个数的和"""
return a + b
在main.py中使用 from my_add import *导入模块中的内容。没在 __all__ 中的变量在使用时会报错:
from my_add import *
print(add(1, 2))
print(num)
print(num1) # NameError: name 'num1' is not defined
而使用import my_add全局导入模块后可以正常使用所有元素:
import my_add
print(my_add.add(1, 2))
print(my_add.num)
print(my_add.num1) # NameError: name 'num1' is not defined
__name__
在 Python 中,name 是一个特殊的内置变量
Ø 当一个Python文件被直接运行时,该文件的__name__属性值为”main“。
Ø 当一个Python文件作为模块被导入时,__name__属性会被设置为该模块的名称(即文件名,不包含 .py 后缀)。
1)导入模块时测试代码被执行
有时我们会在模块中写一些测试代码,当模块被其他文件导入时这些测试代码会被执行。
在 my_add.py 中写一些测试代码:
"""my_add.py"""
__all__ = ["num","add"]
num = 100
num1 = 200
_str1="abc"
def add(a, b):
"""求两个数的和"""
return a + b
print(add(10,20))
在 main.py 中导入模块,发现 my_add.py 中的测试代码被执行了:
"""main.py"""
import my_add
2)使用__name__ == "__main__"避免测试代码被执行
为了避免模块被导入时测试代码被执行,我们可以在被导入模块中添加对 name 属性的检查:
"""my_add.py"""
__all__ = ["num","add"]
num = 100
num1 = 200
_str1="abc"
def add(a, b):
"""求两个数的和"""
return a + b
print(__name__)
if __name__ == "__main__":
print(add(10,20))
## 这里print(__name__)输出的结果其实是 "my_add"
## 我要忽略输出其他的 我要用 if __name__ == "__main__": 就可以忽略
此时再在 main.py 中导入模块,测试代码不会被执行:
"""main.py"""
import my_add
dir()
dir() 是一个内置函数,主要用于列出对象的属性和方法,或者列出当前作用域中定义的名称,并以一个字符串列表的形式返回。
Ø 当你将一个模块作为 dir() 的参数时,它会返回该模块中定义的名称列表,包括函数、类、变量等
import math
# 查看math模块下的
print(dir(math))
Ø 当你将一个对象作为 dir() 的参数时,它会返回该对象的属性和方法列表
class MyClass:
def __init__(self):
self.x = 1
self.y = 2
def method1(self):
pass
obj = MyClass()
print(dir(obj))
Ø 当你不传递任何参数调用 dir() 时,它会列出当前作用域中定义的名称,包括变量、函数、类等
def my_function():
pass
variable = 10
print(dir())
包概述
包是一种管理 Python 模块命名空间的形式.
通过使用.模块名来构造Python模块命名空间的一种方式。例如,模块名A.B表示名为A的包中名为B的子模块。通常我们将多个有联系的模块放入一个包中。包与文件夹相似,不过该文件夹下必须有一个__init__.py文件。
假设要为统一处理声音文件与声音数据设计一个模块集(包)。声音文件的格式很多(通常以扩展名来识别,例如:.wav,.aiff,.au),因此,为了不同文件格式之间的转换,需要创建和维护一个不断增长的模块集合。为了实现对声音数据的不同处理(例如:混声、添加回声、均衡器功能、创造人工立体声效果),还要编写无穷无尽的模块流。下面这个分级文件树展示了这个包的架构:
sound/ 最高层级的包
__init__.py 初始化 sound 包
formats/ 用于文件格式转换的子包
__init__.py
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py
...
effects/ 用于音效的子包
__init__.py
echo.py
surround.py
reverse.py
...
filters/ 用于过滤器的子包
__init__.py
equalizer.py
vocoder.py
karaoke.py
...
创建包(Python Package) 和 创建文件夹(Directory)不一样 包里面是有__init__的
创建包
__init__.py 可以只是一个空文件,也可以执行包的初始化代码或设置 __all__ 变量。
在PyCharm创建一个graphic文件夹,并在其中创建circle.py、rectangle.py 文件。其中__init__.py文件暂时为空。 circle.py 和 rectangle.py 文件写入代码。
导入包
全局导入import
从包中导入模块
语法
import 包名.模块名 [as 别名]
调用方式:包名.模块名[别名].成员名
import graphic.circle
print(graphic.circle.area(10)) # 314.15926
使用 import 时,除最后一项外都必须是包。最后一项可以是模块或包,但不能是类、函数或变量。
局部导入包下的模块 from import
从包中导入模块
语法
from 包名 import 模块名 [as 别名]
调用方式:模块名.成员名
from graphic import circle
print(circle.area(10)) # 314.15926
局部导入包下模块的成员 from import
从包中模块导入功能
语法
from 包名.模块名 import 成员名 [as 别名]
调用方式:成员名
from graphic.circle import area
print(area(10)) # 314.15926
局部导入 from import * 从包中导入模块
当我们使用 from import * 时,Python并不会查找并导入包的所有子模块,因为这将花费很长的时间,并且可能会产生我们不想要的副作用。
唯一的解决办法是提供包的显式索引。如果包的 __init__.py 中定义了 **all**,运行 from import * 时,它就是被导入的模块名列表。
语法
from 包名.模块名 import *
调用方式:功能名
在 __init__.py 中添加如下内容:
__all__ = ["circle"]
注意:如果不加会无法导包
在 main.py 中使用 from import * 导入模块:
from graphic import *
print(circle.area(10)) # 314.15926
print(rectangle.area(10)) # 报错
常用标准库(包)
标准库指的是在安装Python时就一同被安装的库。这些库经过精心挑选和开发,旨在为Python开发者提供通用且强大的工具集,涵盖各种不同的应用领域。
| *名称* |
*说明* |
| *o**s* |
多种操作系统接口。 |
| *sys* |
系统相关的形参和函数。 |
| *time* |
时间的访问和转换。 |
| *datetime* |
提供了用于操作日期和时间的类。 |
| *math* |
数学函数。 |
| *random* |
生成伪随机数。 |
| *re* |
正则表达式匹配操作。 |
| *json* |
JSON 编码器和解码器。 |
| *collections* |
实现了一些专门化的容器,提供了对 Python 的通用内建容器 dict、list、set 和 tuple 的补充。 |
| *functools* |
高阶函数,以及可调用对象上的操作 |
| *hashlib* |
安全哈希与消息摘要。 |
| *urllib* |
URL 处理模块。 |
| *smtplib* |
SMTP 协议客户端,邮件处理。 |
| *zlib* |
与 gzip 兼容的压缩。 |
| *gzip* |
对 gzip 文件的支持。 |
| *bz2* |
对 bzip2 压缩算法的支持。 |
| *multiprocessing* |
基于进程的并行。 |
| *threading* |
基于线程的并行。 |
| *copy* |
浅层及深层拷贝操作。 |
| *socket* |
低层级的网络接口。 |
| *shutil* |
提供了一系列对文件和文件集合的高阶操作,特别是提供了一些支持文件拷贝和删除的函数。 |
| *glob* |
Unix 风格的路径名模式扩展。 |
更多标准库可参考https://docs.python.org/zh-cn/3/library/index.html。
引入第三方库
当需要使用Python中没有内置的库时,可以通过以下方式安装第三方库pip install
pip是Python包管理工具,该工具提供了对 Python 包的查找、下载、安装、卸载的功能。pip 默认的源是 Python Package Index(PyPI),其地址为 https://pypi.org/simple/,如果下载比较慢,还可以指定其它的源
Ø 阿里云:http://mirrors.aliyun.com/pypi/simple/
Ø 豆瓣:http://pypi.douban.com/simple/
Ø 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
1)pip常用命令
Ø 查看我们已经安装的软件包
pip list
Ø 安装软件包-具体包名就什么可以到PyPI上查找
pip install 包名
Ø 卸载软件包
pip uninstall 包名
Ø 临时使用其他源
pip install -i http://mirrors.aliyun.com/pypi/simple/ 包名
Ø 永久修改源
pip config set global.index-url http://mirrors.aliyun.com/pypi/simple/
2) 通过命令行的方式安装,是将第三方包安装在本地python下
例如:D:\dev\software\Python3.12.8\Lib\site-packages
3) 在pycharm中引入
右下角的编译器设置 → Interpreter Settings... → 在python Interprete中点”+”号 → 搜素要添加的包
通过Pycharm安装,我们选择的解释器类型每个项目独立的,所以是将第三方包安装在当前项目环境下,例如:D:\dev\workspace\python-2025.venv\Lib\site-packages
打包自己的库并安装
如果不安装setuptools库,后续打包时可能会遇到报错 ModuleNotFoundError: No module named ‘distutils’,所以可以提前安装 setuptools 库。在命令提示符中执行如下命令:pip install setuptools
- 在包外创建一个
setup.py文件
setup.py 中添加如下内容
from distutils.core import setup
setup(
name="graphic", # 需要打包的名字
version="1.0", # 版本
py_modules=["graphic.circle", "graphic.rectangle"], # 需要打包的模块
)
pip install path_to_your_package/dist/your_package_name-0.1.tar.gz
右下角的编译器设置 → Interpreter Settings... → 点击蓝色的Go to tool window → 点击⚙ → Install From Disk...
迭代器
迭代是遍历容器中元素的一种 方式,而迭代器是一个可以记住遍历的位置的对象。迭代器对象从容器的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不能后退,字符串。列或元组对象都可以用于创建迭代器
可迭代对象
我们发现大多数容器对象都可以使用 for 语句:
import os
for element in [1, 2, 3]:
print(element)
for element in (1, 2, 3):
print(element)
for key in {"one": 1, "two": 2}:
print(key)
for char in "123":
print(char)
with open("myfile.txt", "w") as f:
f.write("H\ne\nl\nl\no\n \nW\no\nr\nl\nd\n")
for line in open("myfile.txt"):
print(line, end="")
os.remove("myfile.txt")
可以直接作用于 for 循环的数据类型有以下几种:
Ø 容器,如 list 、 tuple 、 dict 、 set 、 str 等。
Ø generator ,包括生成器和带 yield 的generator function。
这些可以直接作用于 for 循环的对象统称为可迭代对象:Iterable。
使用迭代器
迭代器有两个基本的方法:iter() 和 **next()**。
在容器对象上使用 for 语句时,在幕后,for 语句会在容器对象上调用 iter()。该函数返回一个定义了 next() 方法的迭代器对象,此方法将逐一访问容器中的元素。当元素用尽时,next() 将引发 StopIteration 异常来通知终止 for 循环。 你可以使用 next() 内置函数来调用 next() 方法。
我们可以使用 iter() 获取一个可迭代对象的迭代器,并使用 next() 遍历迭代器:
list = [1, 2, 3]
it = iter(list) # 创建迭代器对象
print(next(it)) # 输出迭代器的下一个元素,1
print(next(it)) # 2
print(next(it)) # 3
print(next(it)) # StopIteration
也可以使用 for 来遍历迭代器:
list = [1, 2, 3]
it = iter(list) # 创建迭代器对象
for i in it:
print(i)
创建迭代器
了解了迭代器协议背后的机制后,就可以为类添加迭代器行为了。定义 iter() 方法用于返回一个带有 next() 方法的对象。如果类已定义了 **next()**,那么 iter() 可以简单地返回 self。
class Reverse:
"""对一个序列执行反向循环的迭代器。"""
def __init__(self, data):
self.data = data
self.index = len(data)
def __iter__(self):
return self
def __next__(self):
if self.index == 0:
raise StopIteration
self.index = self.index - 1
return self.data[self.index]
rev = Reverse([2, 3, 5, 7, 11, 13, 17, 19])
iter(rev)
for char in rev:
print(char)
生成器
生成器(generator)是一个用于创建迭代器的简单而强大的工具。它的写法类似于标准的函数,但当它要返回数据时会使用 yield 语句。当在生成器函数中使用 yield 语句时,函数的执行将会暂停,并将 yield 后的表达式作为当前迭代的值返回。
每次调用生成器的 next() 方法或使用 for 循环进行迭代时,函数会从上次暂停的地方继续执行(它会记住上次执行语句时的所有数据值),直到再次遇到 yield 语句。这样,生成器函数可以逐步产生值,而不需要一次性计算并返回所有结果。
生成器函数的优势是它们可以按需生成值,避免一次性生成大量数据并占用大量内存。此外,生成器还可以与其他迭代工具(如for循环)无缝配合使用,提供简洁和高效的迭代方式。
send()
向生成器fa’song

.png)
.json.png)
.png)
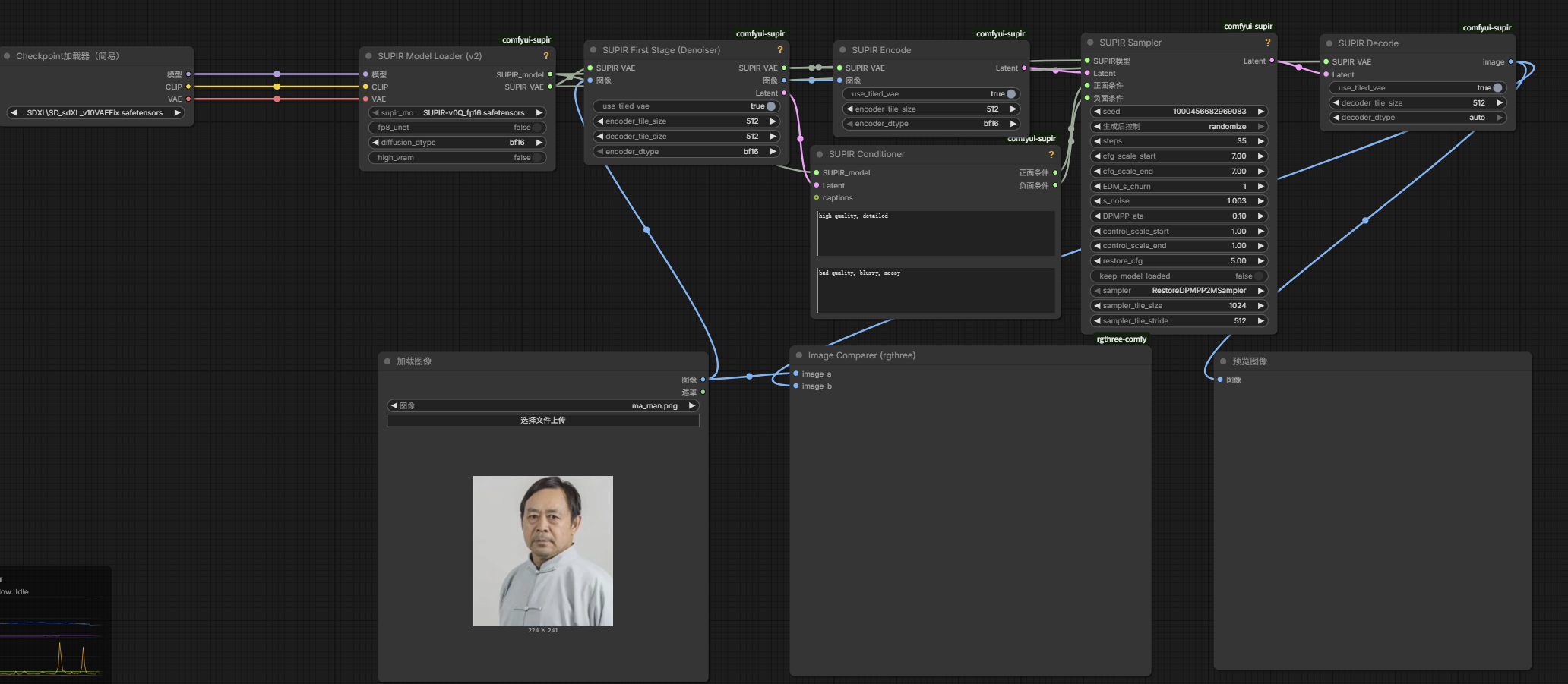
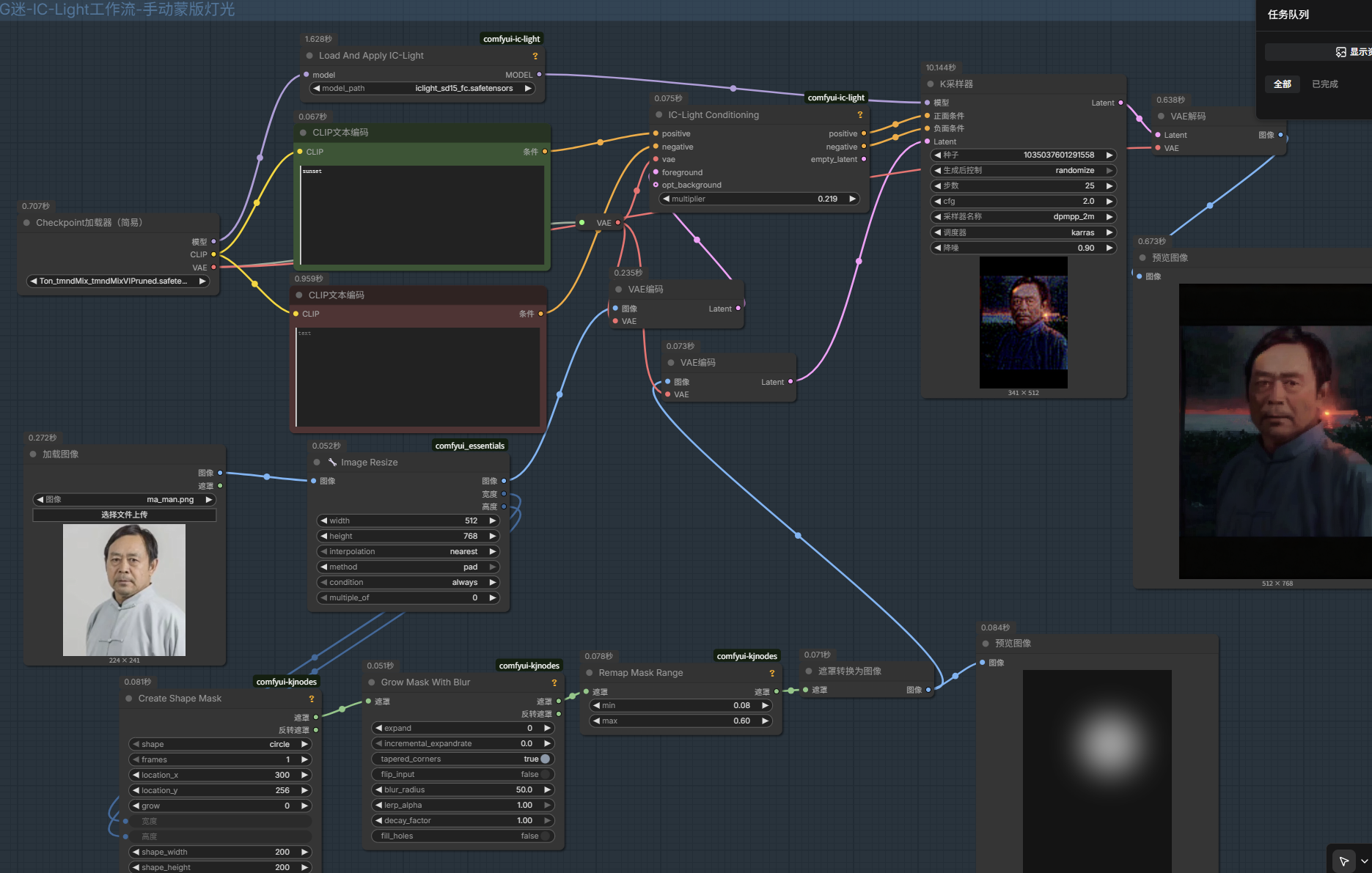
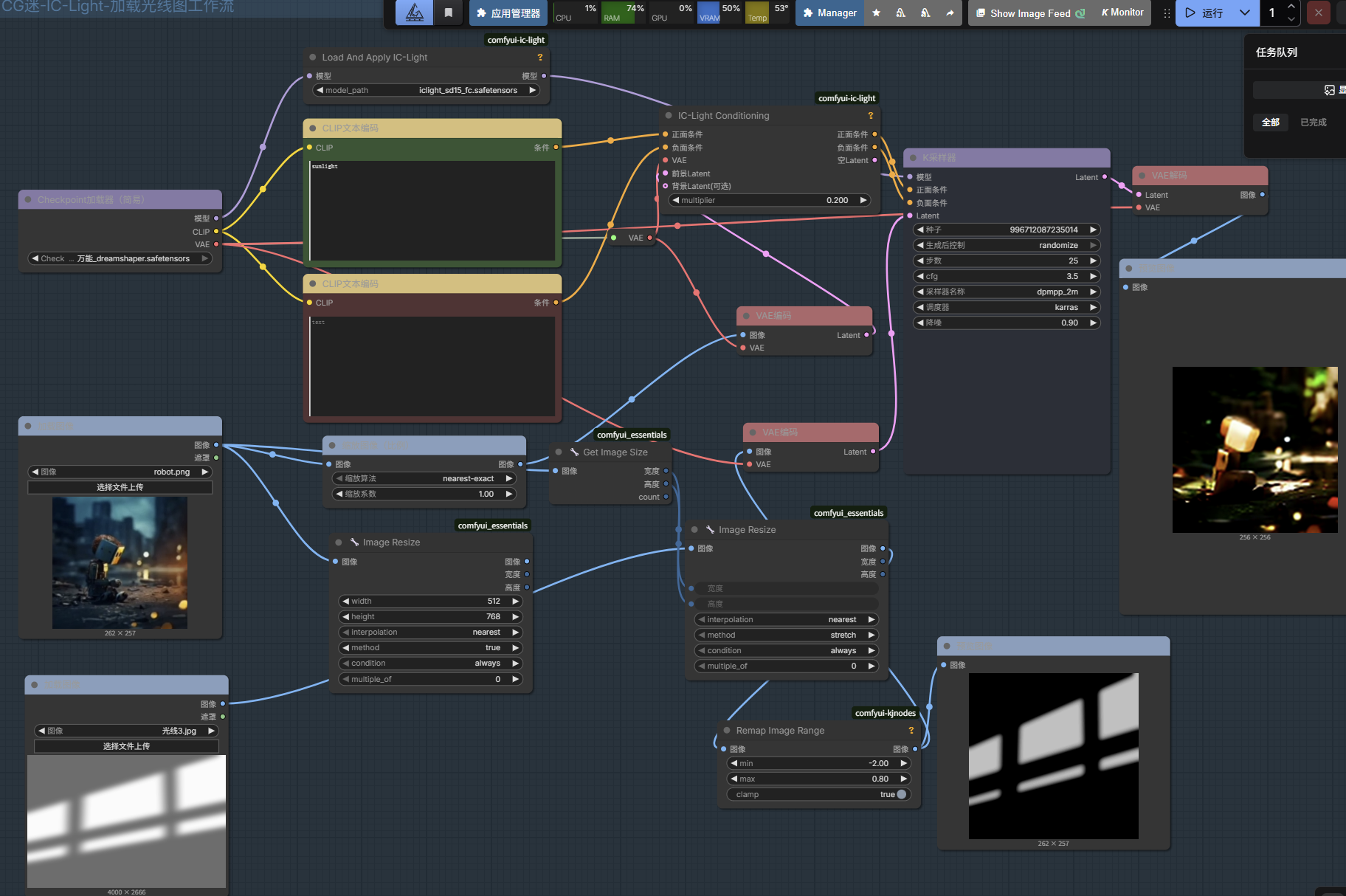
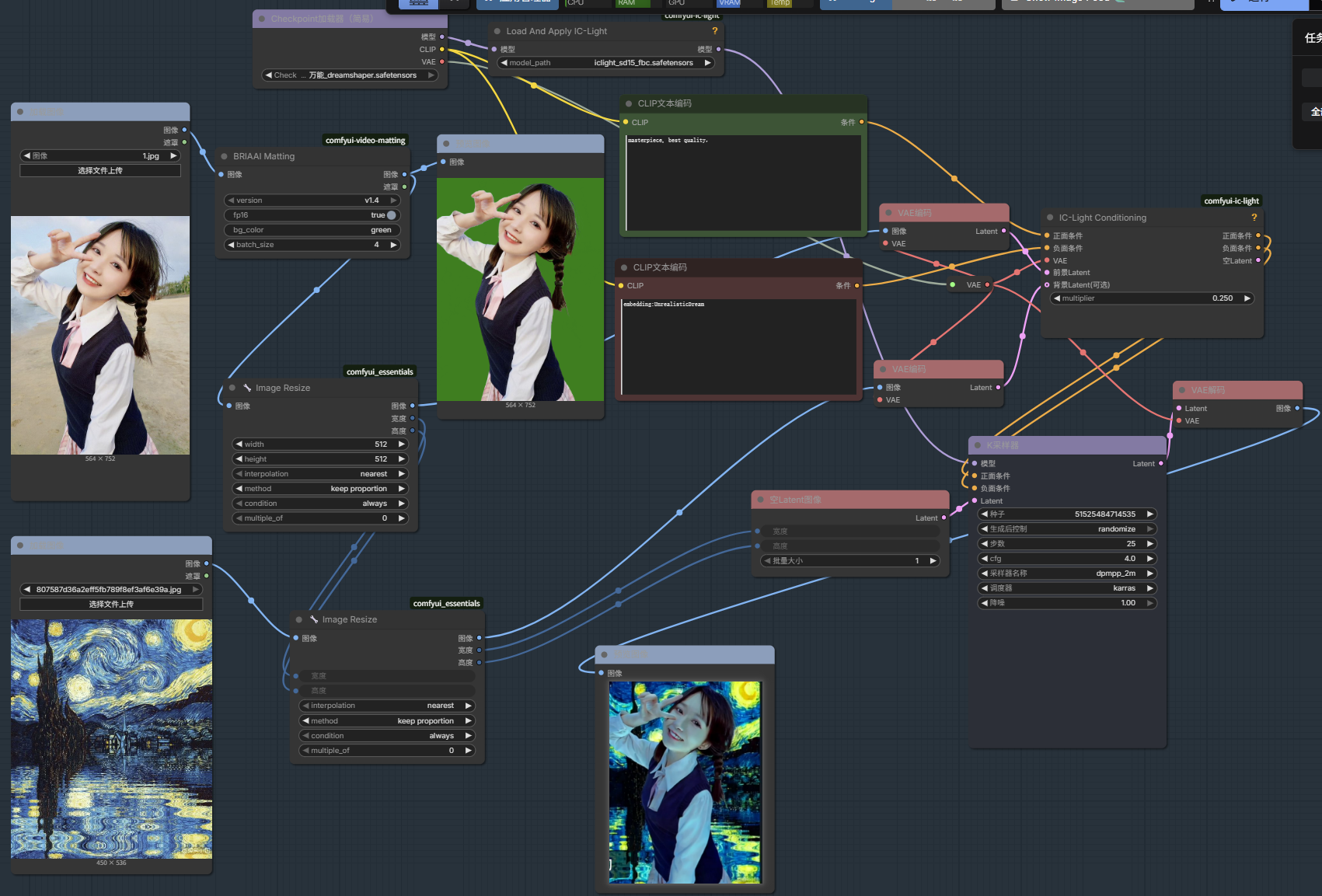
.png)
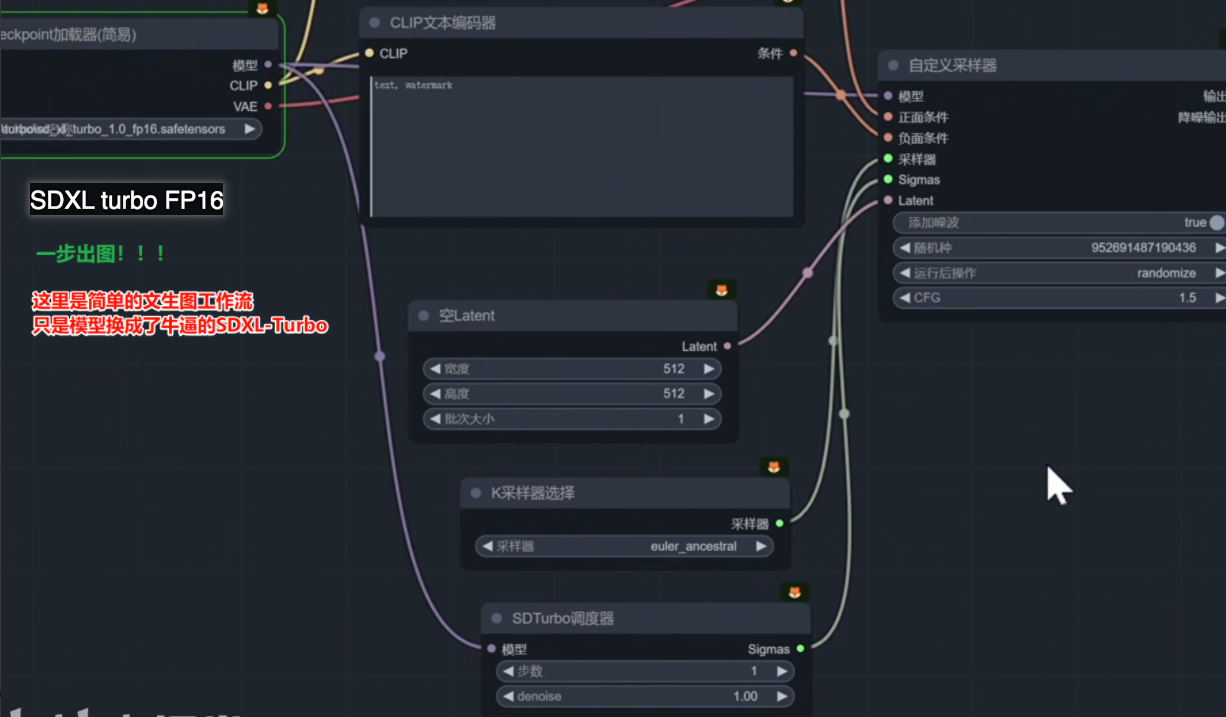
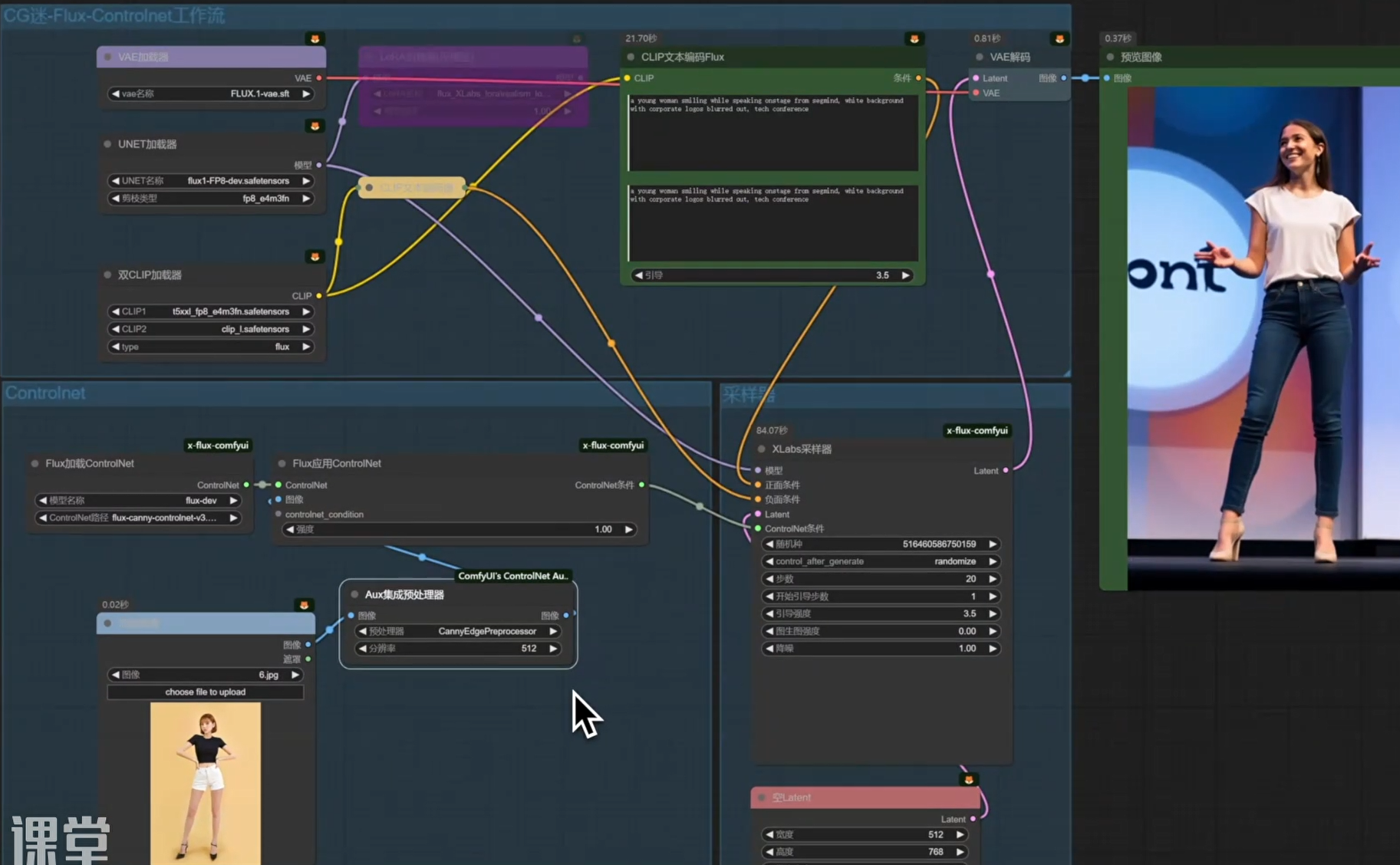
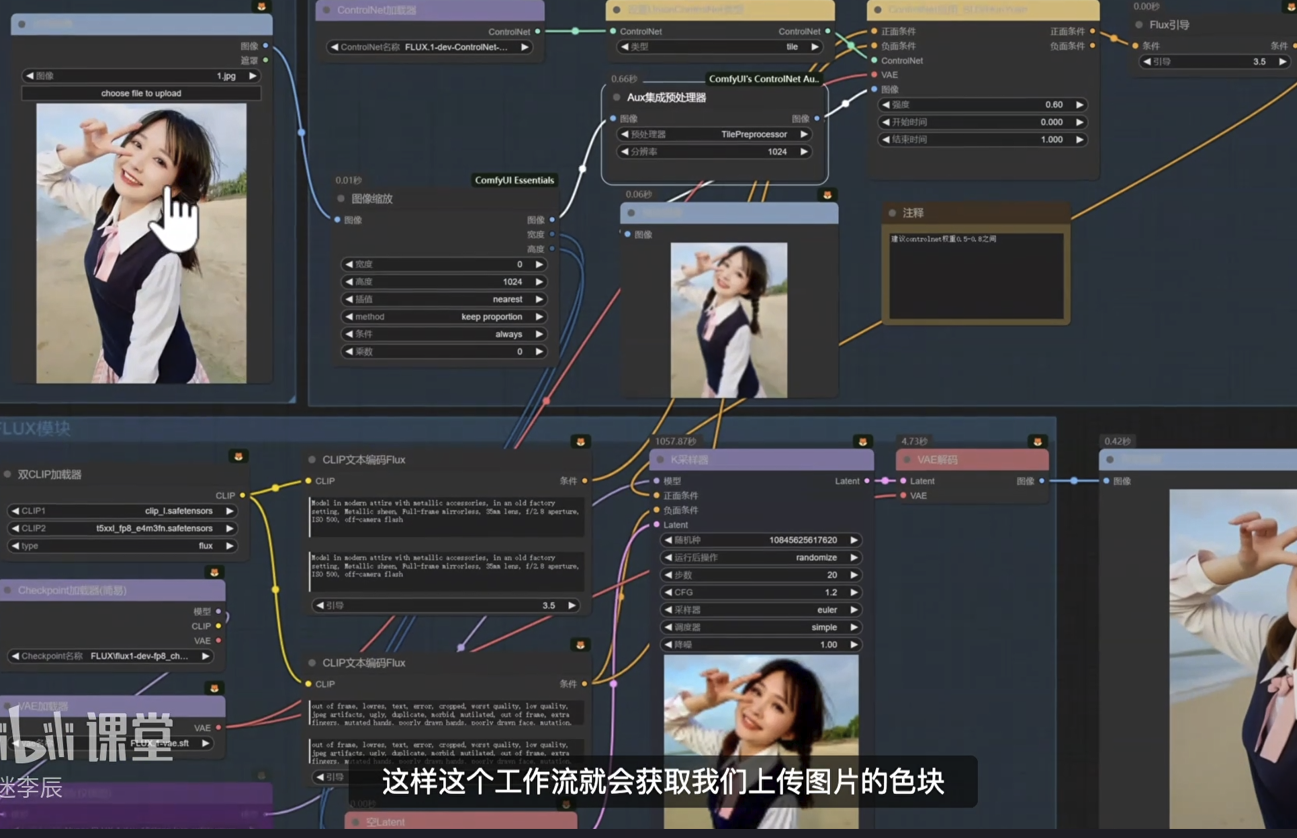
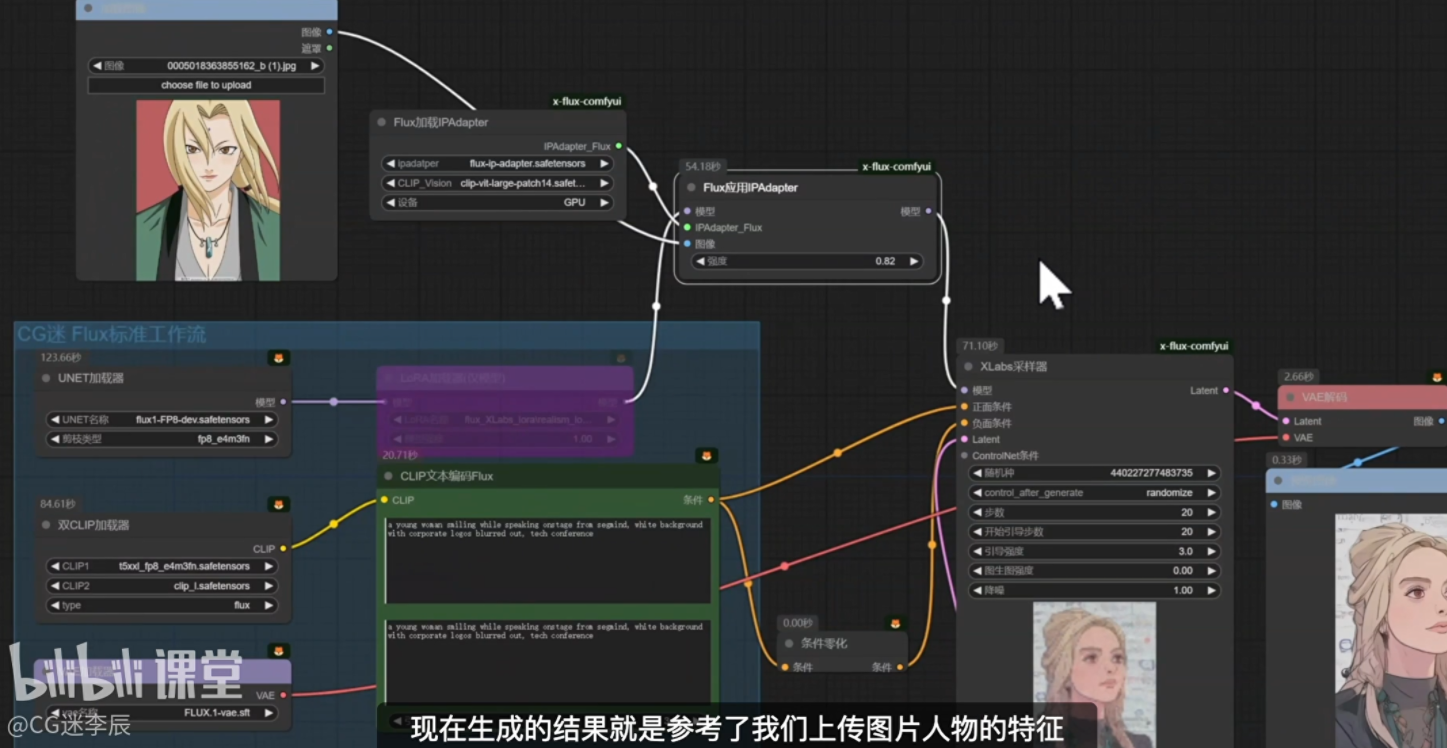
.png)
.png)

.png)