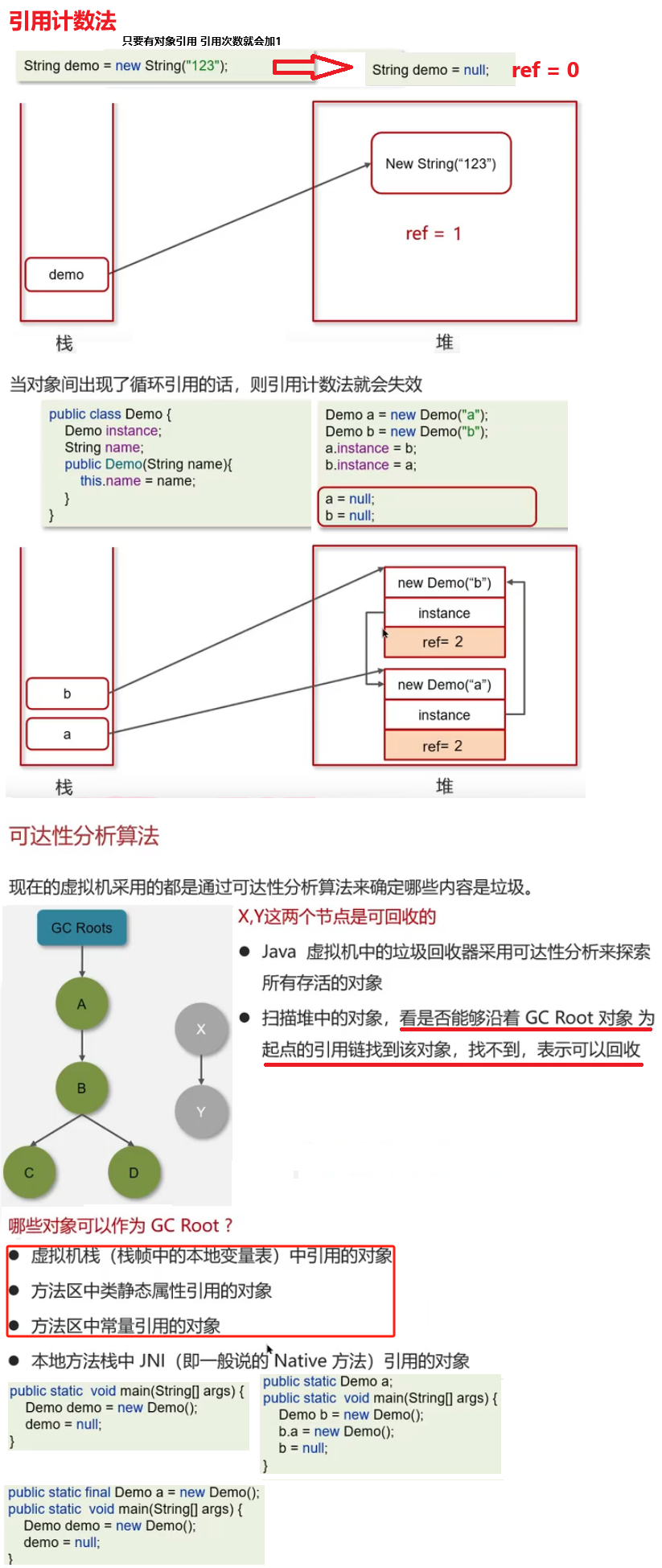
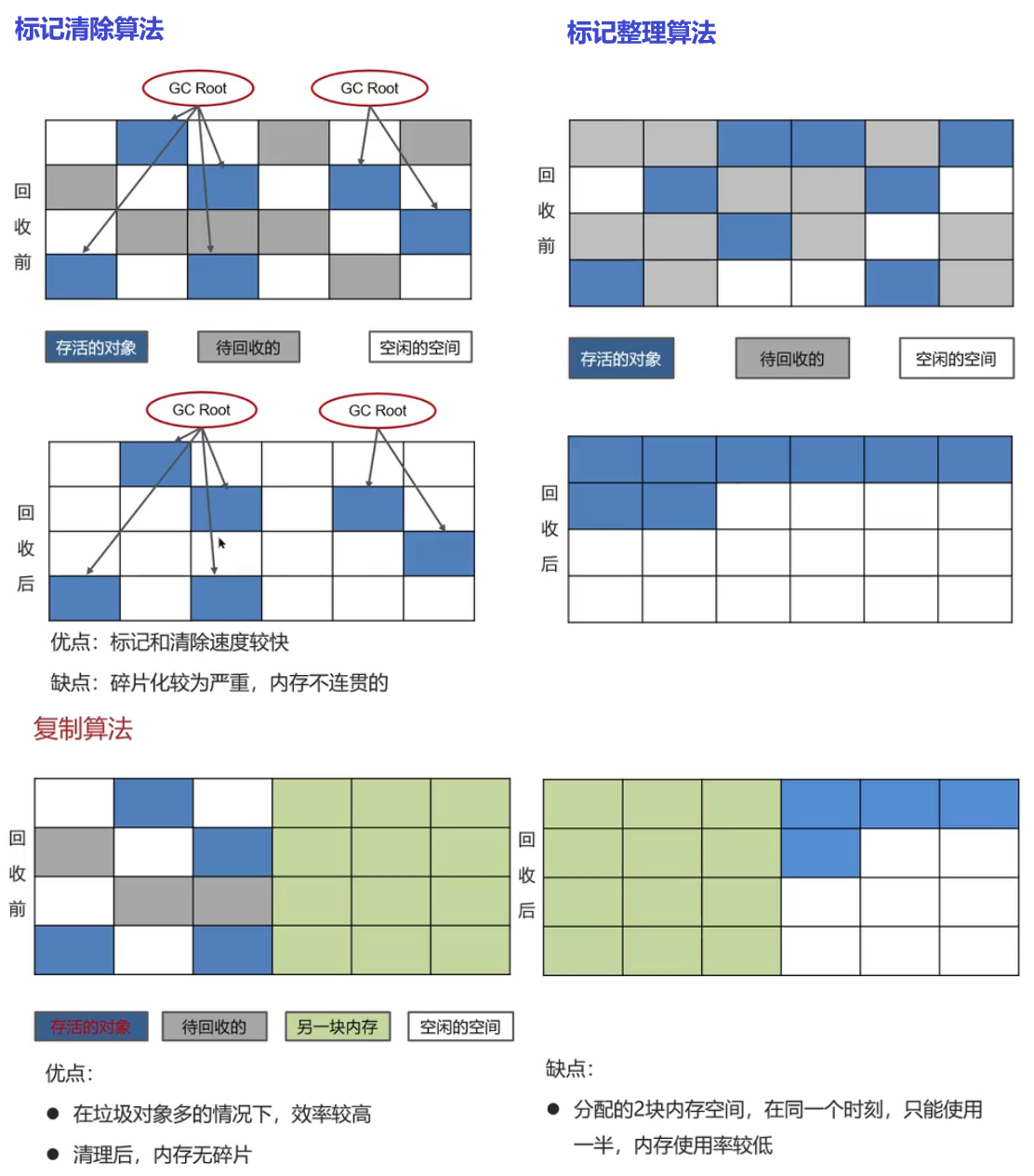
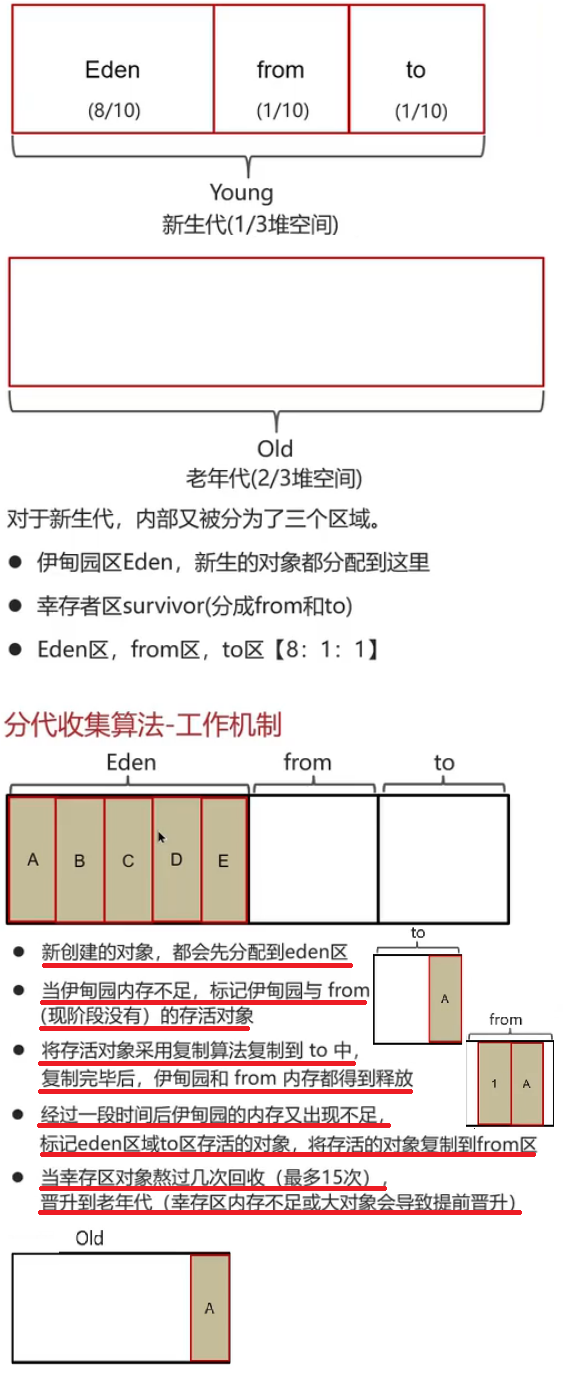
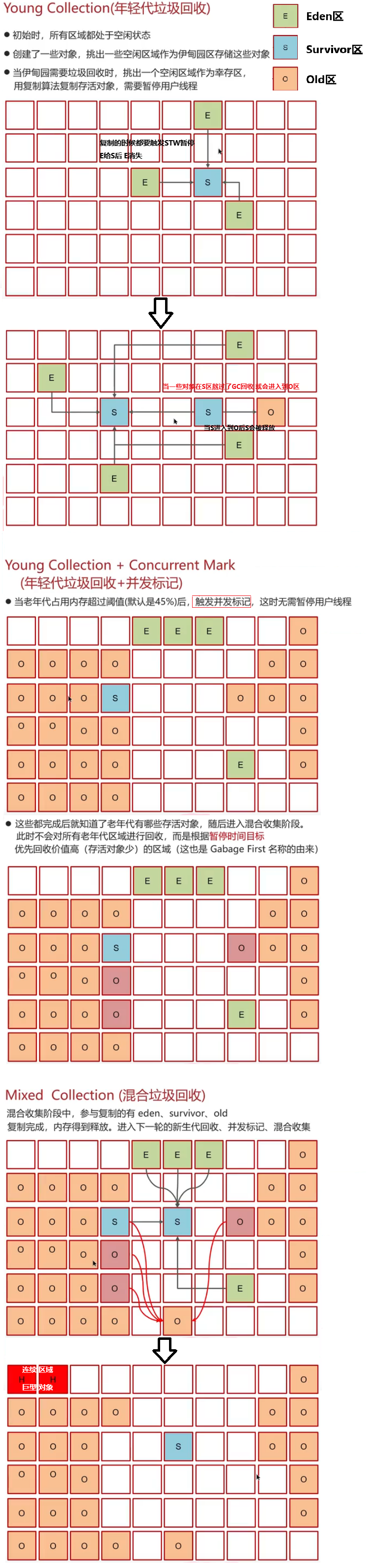
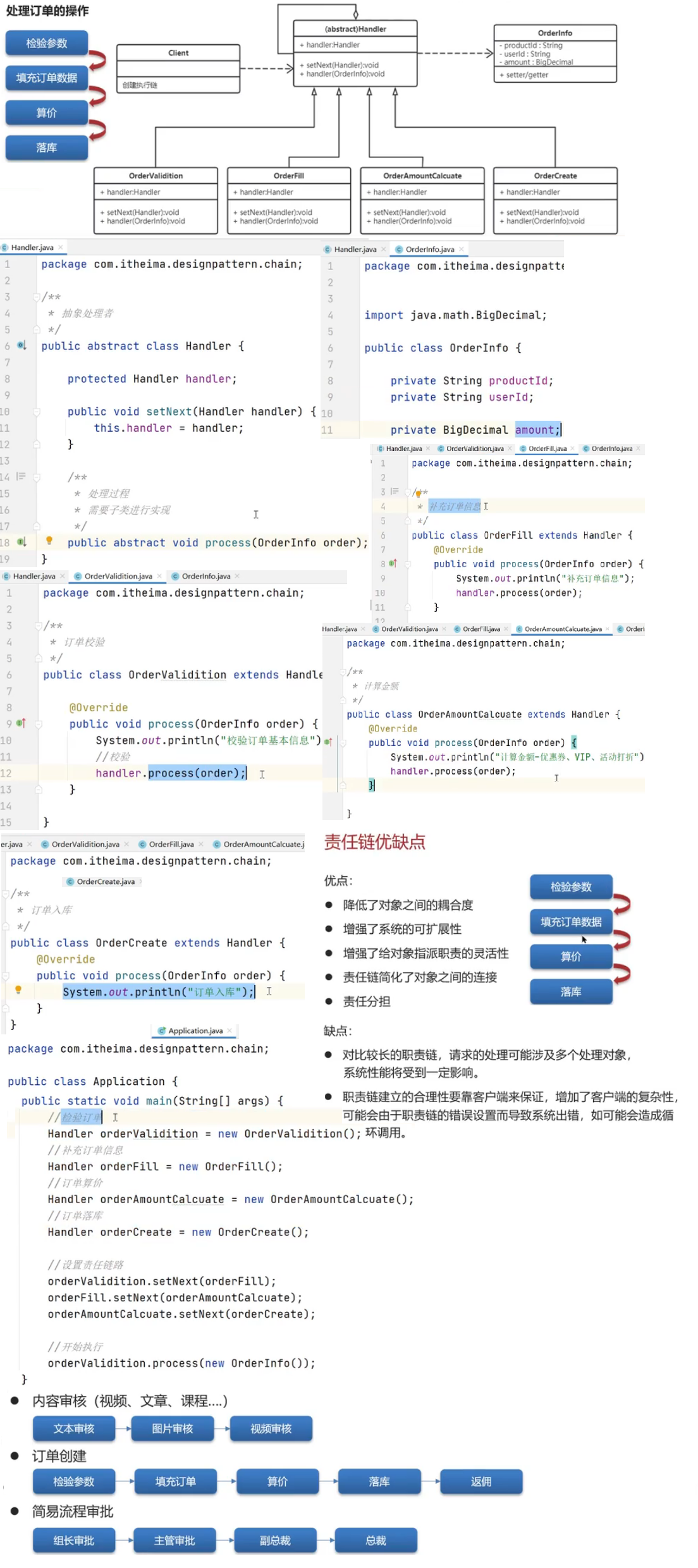
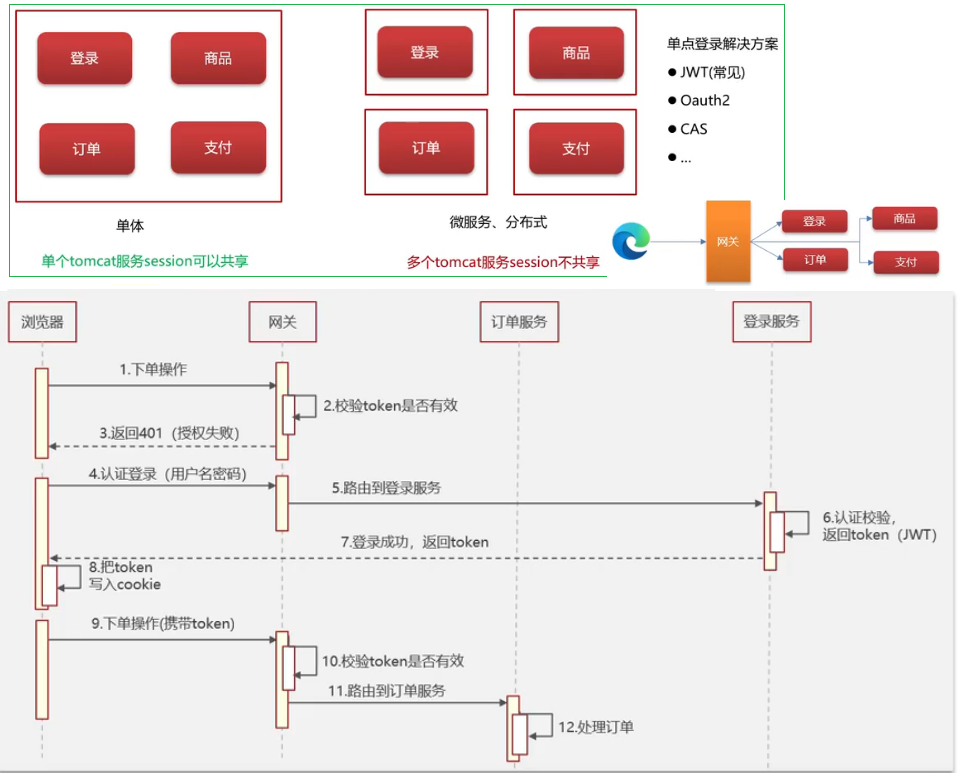
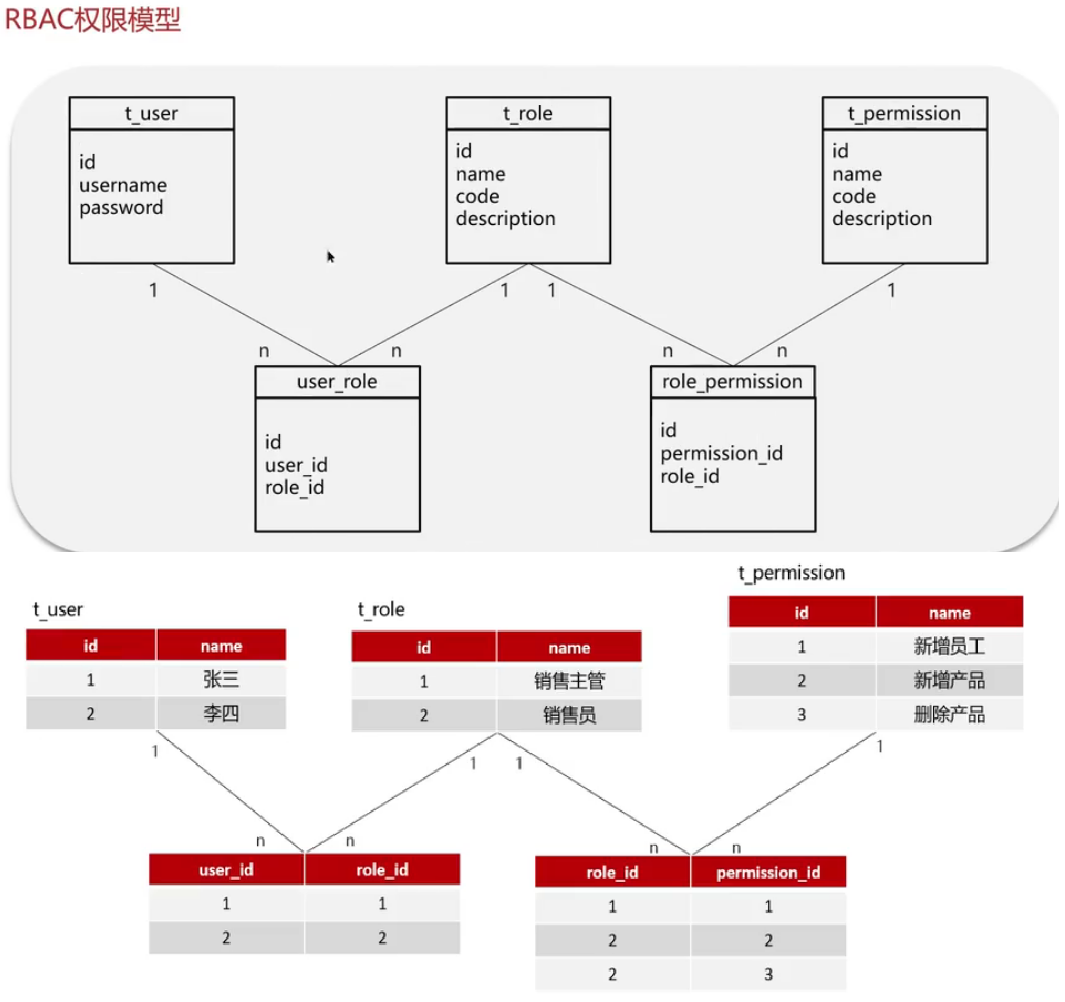
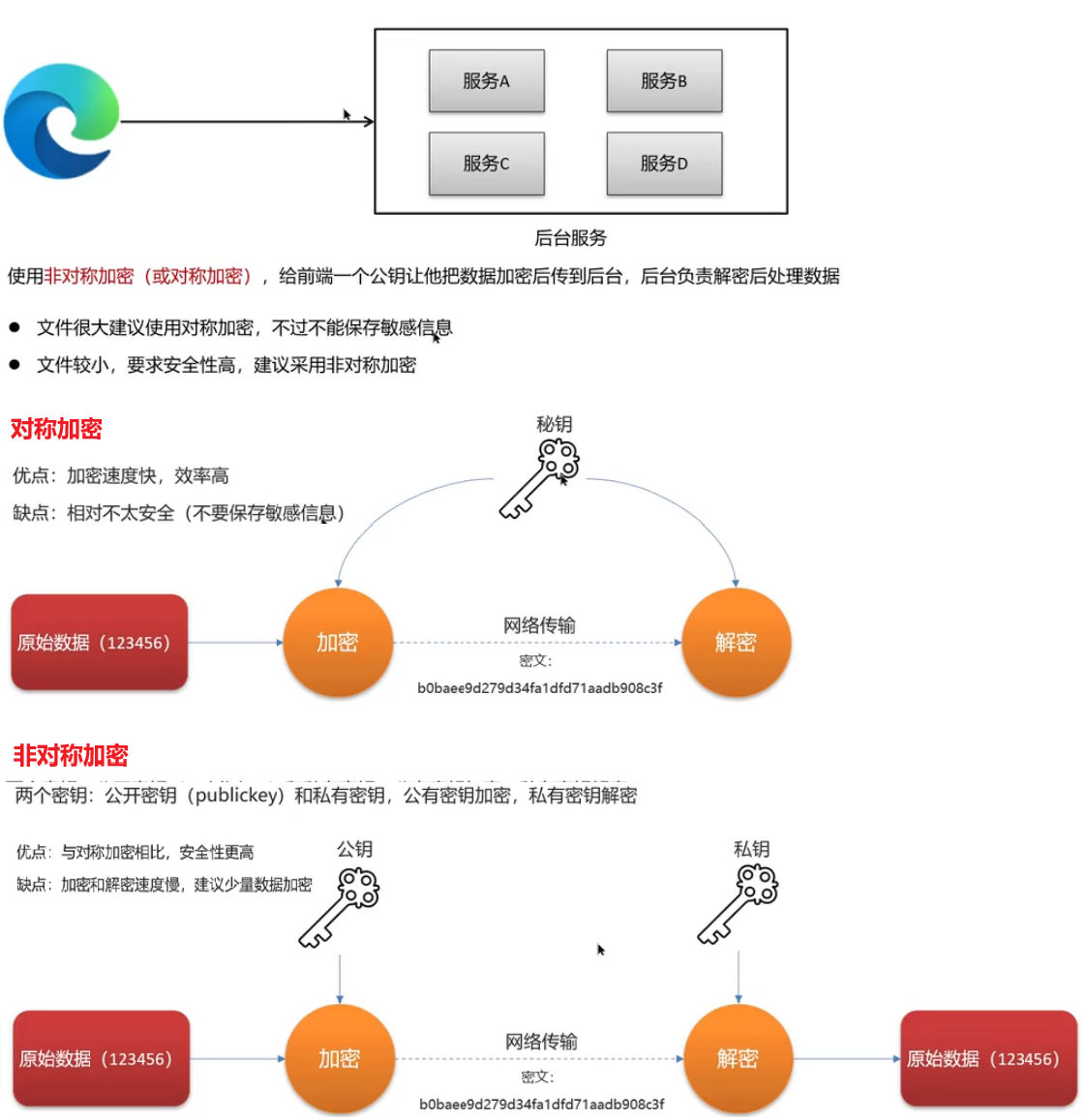
苍穹外卖
软件开发整体介绍
软件开发流程
需求分析
设计
编码
测试
上线运维
角色分工
- 项目经理:对整个项目负责,任务分配、把控进度
- 产品经理:进行需求调研,输出需求调研文档、产品原型等
- UI设计师:根据产品原型输出界面效果图
- 架构师:项目整体架构设计、技术选型等
- 开发工程师:代码实现
- 测试工程师:编写测试用例,输出测试报告
- 运维工程师:软件环境搭建、项目上线
软件环境
开发环境:开发人员在开发阶段使用的环境
测试环境:专门给测试人员使用的环境,用于项目测试
生产环境:线上环境
第二轮补充知识点复习 会以橙色标注
苍穹外卖项目介绍
项目介绍
- 定位:专门为餐饮制定的一款软件产品[管理端 与 用户端]
功能架构 (体现项目中的业务功能模块)
- 管理端:员工、分类、菜品、套餐、订单管理、工作台、数据统计、来单提醒
- 用户端:微信登录、商品浏览、购物车、用户下单、微信支付、历史订单、地址管理、用户催单
产品原型“在文件里有用户端和管理端” (用于展示项目的业务功能 一般由产品经理进行设计)
技术选型 (展示项目中使用到的技术框架和中间件)
用户层:node.js、VUE.js、ElementUI、微信小程序、apache echarts
网关层:Nginx
应用层:SpringBoot、SpringMVC、SpringTask、httpclient、SpringCache、JWT、阿里云OSS、Swagger、POI(操作excel表格)、WebSocket(网络协议<催单…>)
数据层:MySQL、Redis、MyBatis、PageHelper、Spring Data Redis
工具:Git、Maven、Junit、PostMan
开发环境搭建
前端:管理端(Web基于Nginx)、用户端(小程序)
前端环境位置:
E:\Java实例项目1-20套\第24套【项目实战】Java外卖项目实战《苍穹外卖》SpringBoot+SpringMVC+Vue+Swagger+Lombok+Mybatis+SpringSession+Redis+Nginx+小程序\0-0 源码资料\资料\day01\前端运行环境\nginx-1.20.2\html\sky
D:\nginx-1.20.2 [放在英文目录下 双击 nginx.exe] 默认端口号80
[苍穹外卖] (http://localhost/#/login) 如果被其他占用(比如RAGFlow)就把 localhost 换成 127.0.0.1
后端:后端服务(Java)
后端环境位置:
E:\Java实例项目1-20套\第24套【项目实战】Java外卖项目实战《苍穹外卖》SpringBoot+SpringMVC+Vue+Swagger+Lombok+Mybatis+SpringSession+Redis+Nginx+小程序\0-0 源码资料\资料\day01\后端初始工程\sky-take-out
把sky-take-out导入到idea
- sky-take-out [maven父工程,统一管理依赖版本,聚合其他子模块]
- sky-common [子模块,存放公共类(工具类、常量类、异常类)]
- sky-pojo [子模块,存放实体类、VO、DTO等]
- sky-server [子模块,后端服务,存放配置文件、Controller、Service、Mapper等]
| 名称 |
说明 |
| Entity |
实体,通常和数据库中的表对应 |
| DTO |
数据传输对象,通常用程序中各层之间传递数据 |
| VO |
视图对象,为前端展示数据提供的对象 |
| POJO |
普通Java对象,只有属性和对应的Getter和Setter |
深刻理解POJO
POJO的内在含义是指:那些没有继承任何类、也没有实现任何接口[可以实现],更没有被其它框架侵入的java对象。
POJO是一个简单的、普通Java对象,它包含业务逻辑处理或持久化逻辑等,但不是JavaBean、EntityBean等不具有任何特殊角色,不继承或不实现任何其它Java框架的类或接口。 可以包含类似与JavaBean属性和对属性访问的setter和getter方法的
一般在web应用程序中建立一个数据库的映射对象时,我们只能称它为POJO。
- POJO持久化之后==〉PO(在运行期,由Hibernate中的cglib动态把POJO转换为PO,PO相对于POJO会增加一些用来管理数据库entity状态的属性和方法。PO对于programmer来说完全透明,由于是运行期生成PO,所以可以支持增量编译,增量调试。)
- POJO传输过程中==> DTO
- POJO用作表示层==> VO
深刻理解PO、DTO、VO
PO(persistent object):就是将对象与关系数据库绑定,用对象来表示关系数据,
最简单的PO就是对应数据库中某个表中的一条记录,多个记录可以用PO的集合。PO中应该不包含任何对数据库的操作。
- 有时也被称为Data对象,对应数据库的entity,简单认为一个PO对应数据库中的一条记录
- PO中不应该包含任何对数据库的操作
- PO的属性是跟数据表的字段一一对应的
- PO对象需要实现序列化接口
DTO(Data Transfer Object): → 数据传输对象
主要用于远程调用需要大量传输对象的地方
我们可以将PO中的部分属性抽取出来,就形成了DTO
举例说明:
比如我们有一张表有100个字段,那么对应的PO就有100个属性
但是我们界面上需要显示10个字段,客户端用WEB service来获取数据,没必要把整个PO对象传递到客户端,这时我们就可以用只有这10个属性的DTO来传递结果到客户端,这样就不会暴露服务端表结构,到达客户端后,如果用这个对象来对应界面显示,那么此时它的身份就转为了VO(View Object)
VO
VO(value object) 是值对象,精确点讲它是业务对象,是存活在业务层的,是业务逻辑使用的,它存活的目的就是为数据提供一个生存的地方。VO的属性是根据当前业务的不同而不同的,也就是说,它的每一个属性都一一对应当前业务逻辑所需要的数据的名称。 VO是什么?它是值对象,准确地讲,它是业务对象,是生活在业务层的,是业务逻辑需要了解,需要使用的,再简单地讲,它是概念模型转换得到的。
重点:
一个VO可以只是PO的一部分,也可以是多个PO构成,同样也等同于一个PO(指的是属性)。正因为这样,PO独立出来,数据持久层也就独立出来了,它不会受到任何业务的影响和干涉。又因为这样,业务逻辑层也独立开来,它不会受到数据持久层的影响,业务层只关心业务逻辑的处理,怎么存和读都交给别人。
深刻理解什么是DAO
DAO(Data Access Object):数据访问对象
主要用来封装对数据库的访问。通过它可以把POJO持久化为PO,用PO组装出来VO、DTO。
是一个sun的一个标准j2ee设计模式,这个模式中有个接口就是DAO,它负持久层的操作。为业务层提供接口。此对象用于访问数据库。通常和PO结合使用,DAO中包含了各种数据库的操作方法。通过它的方法,结合PO对数据库进行相关的操作。夹在业务逻辑与数据库资源中间。配合VO,提供数据库的CRUD操作…
深刻理解JavaBean
JavaBean是一个遵循特定写法的Java类,是一种Java语言编写的可重用组件,它的方法命名,构造及行为必须符合特定的约定:
1、这个类必须具有一个公共的(public)无参构造函数;
2、所有属性私有化(private);
3、私有化的属性必须通过public类型的方法(getter和setter)暴露给其他程序,并且方法的命名也必须遵循一定的命名规范。
4、这个类应是可序列化的。(比如可以实现Serializable 接口,用于实现bean的持久性)
JavaBean在JavaEE开发中,通常用于封装数据
许多开发者会把JavaBean看作村从特定命名约定的POJOPOJO按照JavaBean的规则来就可以变成JavaBean
当一个POJO可序列化,有一个无参的构造函数,使用getter和setter方法来访问属性时,他就是一个JavaBean
JavaBean是一种组件技术,就好像你做了一个扳手,而这个扳手会在很多地方被拿去用,这个扳子也提供多种功能(你可以拿这个扳手扳、锤、撬等等),而这个扳手就是一个组件。
common里的constant、context、properties代表什么意思
constant:
用于存放常量类。这些常量可能是项目中频繁使用的固定值,如状态码、错误码、系统配置项等。
常量类中的变量一般使用public static final修饰,确保其不可变性。
context:
用于存放上下文类。上下文类通常用来保存和传递运行时环境信息或状态。
在Spring框架中,ApplicationContext就是一个典型的上下文对象,它提供了对Bean的访问以及配置信息的管理。
properties:
用于存放属性文件。这些文件通常以.properties为扩展名,用于存储配置信息,如数据库连接字符串、系统参数等。
属性文件可以通过Properties类来读取和写入,方便在运行时动态调整系统行为。
Final的巩固
问:对于引用类型(如String、Object等),final变量的引用不能被改变,但引用的对象内部状态可以改变。 这句话是什么意思?
答:当一个引用类型的变量被声明为final时,这个变量的引用(即指向的对象)不能被改变,但该对象的内部状态是可以改变的。我们可以通过具体的例子来理解这一点。
public class Example {
public static final String EMP_ID = "empId";
public static void main(String[] args){
// 下面这行代码会编译失败,因为EMP_ID是final的
// EMP_ID = "newEmpId"; // 编译错误
// 但是可以创建一个新的String对象并使用EMP_ID内容
String anotherId = EMP_ID + "123";
sout(anotherId) => empId123;
}
}
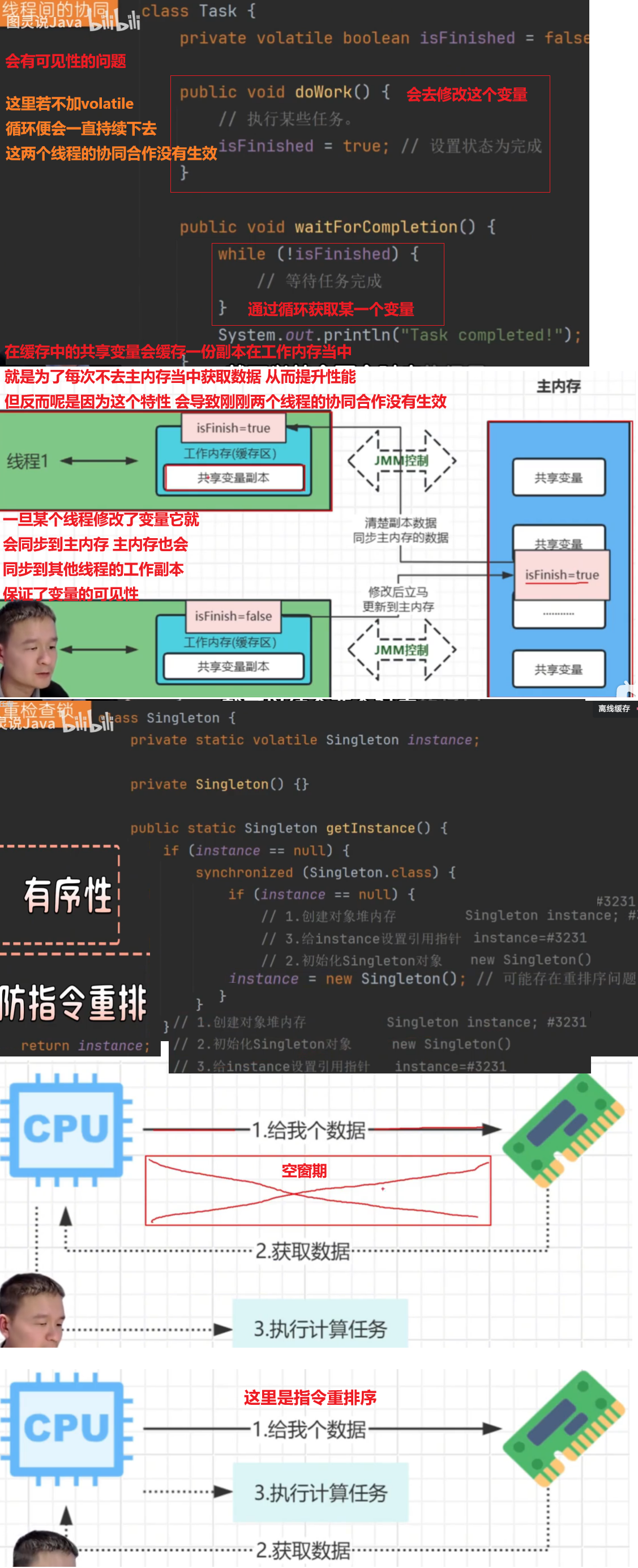
解析context (实现上下类的逻辑原理) 内的代码
package com.sky.context;
public class BaseContext {
public static ThreadLocal<Long> threadLocal = new ThreadLocal<>();
//ThreadLocal 是一个线程局部变量,每个线程都有自己的独立副本。这意味着不同线程之间不会共享同一个 ThreadLocal实例的数据,从而避免了多线程环境下的数据竞争问题。
public static void setCurrentId(Long id) {
threadLocal.set(id);
}
public static Long getCurrentId() {
return threadLocal.get();
}
public static void removeCurrentId() {
threadLocal.remove();
}
}
/*
这个类通常用于需要在多线程环境中传递和管理线程上下文信息的场景。例如:
Web应用:在处理HTTP请求时,可能需要将用户ID或其他上下文信息绑定到当前线程,以便在整个请求处理过程中都能访问到这些信息。
日志记录:在日志记录中,可能需要记录每个操作的执行者ID,通过 ThreadLocal 可以方便地在日志记录器中获取当前操作者的ID。
事务管理:在分布式事务中,可能需要将事务ID绑定到当前线程,以便在事务的各个阶段都能访问到这个ID。
内存泄漏:如果 ThreadLocal 中存储的对象没有及时释放,可能会导致内存泄漏。因此,建议在不再需要 ThreadLocal 中的数据时,调用 remove 方法将其移除。
线程池:在使用线程池时,特别需要注意 ThreadLocal 的管理。线程池中的线程是复用的,如果不及时清理 ThreadLocal 中的数据,可能会导致数据混淆或内存泄漏。
*/
静态变量解析
//静态变量 (static)
静态变量:在 Java 中,静态变量属于类而不是类的实例。这意味着无论创建多少个类的实例,静态变量都只有一份拷贝,并且所有实例共享这份拷贝。
作用域:静态变量在类加载时初始化,并且在类卸载时销毁。它们存在于类的生命周期内,而不是实例的生命周期内。
//结合 static 和 ThreadLocal
在 BaseContext 类中,threadLocal 被声明为 static,这意味着所有 BaseContext 实例共享同一个 ThreadLocal 实例。但这并不意味着所有线程共享同一个 ThreadLocal 实例的数据。相反,每个线程都有自己独立的 ThreadLocal 数据副本。
静态变量:
public static ThreadLocal<Long> threadLocal = new ThreadLocal<>();
这行代码声明了一个静态的 ThreadLocal 变量 threadLocal,所有 BaseContext 实例共享这个 ThreadLocal 实例。
使用Git进行版本控制
- 创建Git本地仓库
- 创建Git远程仓库[GitHub、Gitee]
- 将本地文件推送到Git远程仓库
.gitignore[文件设置]
//忽略git管理的文件
**/target/
.idea
*.iml
*.class
*Test.java
**/test/
创建远程仓库流程:【提交到本地】
VCS → Create Git Repository → sky-take-out → √ → Unversinoed Files(All) → Commit
去创建一个仓库:[Pluminary/sky-take-out (gitee.com)] (https://gitee.com/Pluminary/sky-take-out)
推送代码到Gitee远程仓库:Idea右上角的↗ → 定义一下本地和远程仓库关联 点击Define remote → Name: origin
URL: https://gitee.com/Pluminary/sky-take-out.git (这个是在Gitee上创建仓库后复制的代码)
推送成功:[Pluminary/sky-take-out (gitee.com)] (https://gitee.com/Pluminary/sky-take-out)
后端环境搭建
数据库环境搭建
Unknown collation: ‘utf8mb4_0900_ai_ci‘的解决方法_unknown collation utf8mb4-CSDN博客
前后端联调
浏览器
↓
Controller:
1.接收并封装参数
2.调用service方法查询数据库
3.封装结果并相应
↓
Service:
1.调用mapper查询数据库
2.密码对比
3.返回结果
↓
Mapper:
1.select * from employee where username = ?
↓
数据库
IDEA中导入多module的Maven项目无法识别module的解决办法_idea modules太多 mvn clean 对某个module不起作用-CSDN博客
Maven → compile(编译聚合模块 )
[INFO] ————————————————————————
[INFO] Reactor Summary for sky-take-out 1.0-SNAPSHOT:
[INFO]
[INFO] sky-take-out ………………………………… SUCCESS [ 0.003 s]
[INFO] sky-common ………………………………….. SUCCESS [ 2.761 s]
[INFO] sky-pojo ……………………………………. SUCCESS [ 2.227 s]
[INFO] sky-server ………………………………….. SUCCESS [ 1.294 s]
[INFO] ————————————————————————
[INFO] BUILD SUCCESS
在数据库中 新建查询 → SELECT VERSION(); → 引擎是8.0.33的是正规操作mysql此时对应的任务管理器服务里搜索mysql(名称:MySQL80)开启这个 → 如果开启了服务里的MySQL那SELECT VERSION()查询就是11.0.5-MariaDB
handler:全局异常处理器
右侧Maven的具体用途
clean
功能:清除项目构建过程中生成的所有文件,通常包括 target 目录下的内容。
命令:mvn clean
使用场景:
在每次构建之前,确保没有旧的构建产物干扰新构建。
清理项目目录,准备进行新的构建。
validate
功能:验证项目的正确性,确保所有必要的信息都已就绪。
命令:mvn validate
使用场景:
在构建过程的早期阶段,检查项目配置是否正确。
**确保所有依赖项和资源都可用**。
compile
功能:编译项目的源代码。
命令:mvn compile
使用场景:
编译项目源代码,生成 .class 文件。
通常在开发过程中频繁使用,确保代码可以成功编译。
test
功能:运行项目的单元测试。
命令:mvn test
使用场景:
在代码提交前,确保所有单元测试通过。
持续集成(CI)过程中,自动运行测试以确保代码质量。
package
功能:将编译后的代码打包成可分发的格式,如 JAR、WAR 等。
命令:mvn package
使用场景:
构建项目并生成可部署的包。
通常在开发和部署过程中使用,生成最终的可发布版本。
verify
功能:运行任何检查以验证包的完整性和有效性。
命令:mvn verify
使用场景:
在发布前,进行更严格的验证,确保包的质量。
运行集成测试、性能测试等。
install
功能:将包安装到本地 Maven 仓库,供其他项目使用。
命令:mvn install
使用场景:
将项目依赖安装到本地仓库,以便其他项目可以引用。
通常在开发和测试环境中使用,确保依赖项可用。
site
功能:生成项目的站点文档,包括项目报告、测试覆盖率等。
命令:mvn site
使用场景:
生成项目文档,供团队成员和外部用户查阅。
文档生成和发布,提高项目的透明度和可维护性。
deploy
功能:将最终的包部署到远程仓库,如 Nexus、Artifactory 等。
命令:mvn deploy
使用场景:
将项目发布到远程仓库,供其他团队或项目使用。
通常在持续集成和持续部署(CI/CD)流程中使用,确保发布的版本可用。
总结
clean:清理构建产物。
validate:验证项目配置。
compile:编译源代码。
test:运行单元测试。
package:打包项目。
verify:验证包的完整性和有效性。
install:安装到本地仓库。
site:生成项目文档。
deploy:部署到远程仓库。
思考:前端发送的请求,是如何请求到后端服务的?
前端请求地址:http://localhost/api/employee/login
后端接口地址:http://localhost:8080/admin/employee/login
nginx 反向代理的配置方式
nginx.conf
server{
listen 80;
server_name localhost;
location /api/{
proxy_pass http://localhost:8080/admin/; #反向代理
}
}
nginx 负载均衡的配置方法(平均转发到多台后端服务器)
nginx.conf
upstream webservers{
server 192.168.100.128:8080;
server 192.168.100.129:8080;
}
server{
listen 80;
server_name localhost;
location /api/{
proxy_pass http://webservers/admin/; #反向代理
}
}
nginx 负载均衡策略:
| 名称 |
说明 |
| 轮询 |
默认方式 |
| weight |
权重方式,默认为1,权重越高,被分配的客户端请求就越多 |
| ip_hash |
依据ip分配方式,这样每个访客可以固定访问一个后端服务 |
| least_conn |
依据最少连接方式,把请求优先分配给连接数少的后端服务 |
| url_hash |
依据url分配方式,这样相同的url会被分配到同一个后端服务 |
| fair |
依据相应时间方式,响应时间短的服务将会被优先分配 |
完善登录功能
问题:员工表中的密码是明文存储,安全性太低
在Idea中有 “//TODO” 这代表着标记处 此处还未完成一些操作 标记后可以在idea的下面快速定位到TODO
MD5密码加密后 也区分大小写 如果相同的密文但是大小写不同 结果还是不同的
修改密码
com/sky/controller/admin/EmployeeController.java
@PutMapping("/editPassword")
@ApiOperation("修改密码")
public Result editPassword(@RequestBody PasswordEditDTO passwordEditDTO) {
log.info("修改密码:{}", passwordEditDTO);
employeeService.updatePassword(passwordEditDTO);
return Result.success();
}
com/sky/service/EmployeeService.java
/**
* 更改密码
* @param passwordEditDTO
*/
void updatePassword(PasswordEditDTO passwordEditDTO);
com/sky/service/impl/EmployeeServiceImpl.java
/**
* 更改密码
* @param passwordEditDTO
*/
@Override
public void updatePassword(PasswordEditDTO passwordEditDTO) {
//getCurrentId 方法:public static Long getCurrentId() 方法用于获取当前线程的用户ID。
Long empId = BaseContext.getCurrentId();
//select * from employee where id = #{id} 根据id查员工的所有
Employee employee = employeeMapper.getById(empId);
//用md根据从前端传来的oldpassword 去判断employee的原始代码是否相同
if (!employee.getPassword().equals(DigestUtils.md5DigestAsHex(passwordEditDTO.getOldPassword().getBytes()))) {
throw new PasswordErrorException(MessageConstant.PASSWORD_ERROR);
}
String newPassword = DigestUtils.md5DigestAsHex(passwordEditDTO.getNewPassword().getBytes());
employee.setPassword(newPassword);
employeeMapper.update(employee);
}
导入接口文档
前后端分离开发流程
- 定制接口(定义规范) → 前端开发(mock数据) + 后端开发(后端自测) → 连调(校验格式) → 提测(自动化测试)
将课程资料中提供的项目接口导入YApi
苍穹外卖-管理端接口.json
苍穹外卖-用户端接口.json
苍穹外卖-管理端+用户端接口 → 数据管理 → 数据导入(json 随后把json文件拖入) → 点击接口可查看
Swagger介绍和使用方式
Knife4j是为Java MVC框架集成Swagger生成Api文档的增强解决方案
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
<version>3.0.2</version>
</dependency>
使用方式
- 导入knife4j的maven坐标
- 在配置类中加入knife4j相关配置
sky-server com/sky/config/WebMvcConfiguration.java
/**
* 通过knife4j生成接口文档
* @return
*/
@Bean
public Docket docket() {
ApiInfo apiInfo = new ApiInfoBuilder()
.title("苍穹外卖项目接口文档")
.version("2.0")
.description("苍穹外卖项目接口文档")
.build();
Docket docket = new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo)
.select()
//指定生成接口需要扫描的包
.apis(RequestHandlerSelectors.basePackage("com.sky.controller"))
.paths(PathSelectors.any())
.build();
return docket;
}
/**
* 设置静态资源映射
* @param registry
*/
protected void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("/doc.html").addResourceLocations("classpath:/META-INF/resources/");
registry.addResourceHandler("/webjars/**").addResourceLocations("classpath:/META-INF/resources/webjars/");
}
[苍穹外卖项目接口文档] (http://localhost:8080/doc.html#/home) 这个文档是解析EmployeeController来的
通过Swagger就可以生成接口文档,那么我们不需要Yapi了?
- Yapi是设计阶段使用的工具,管理和维护接口
- Swagger在开发阶段使用的框架,帮助后端开发人员做后端的接口测试
编写接口文档 在企业中需要注意:
测试:
为每个API编写单元测试和集成测试,确保API的正确性和稳定性。
使用自动化测试工具(如Postman, JUnit等)来定期验证API的行为。
Swagger常用注解
| 注解 |
说明 |
| @Api |
用在类上,例如Controller,表明对类的说明 |
| @ApiModel |
用在类上,例如entity、DTO、VO |
| @ApiModelProperty |
用在属性上,描述属性信息 |
| @ApiOperation |
用在方法上,例如Controller的方法,说明方法的用途、作用 |
sky-server com/sky/controller/admin/EmployeeController.java
package com.sky.controller.admin;
import com.sky.constant.JwtClaimsConstant;
import com.sky.dto.EmployeeLoginDTO;
import com.sky.entity.Employee;
import com.sky.properties.JwtProperties;
import com.sky.result.Result;
import com.sky.service.EmployeeService;
import com.sky.utils.JwtUtil;
import com.sky.vo.EmployeeLoginVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.Map;
/**
* 员工管理
*/
@RestController
@RequestMapping("/admin/employee")
@Slf4j
@Api(tags = "员工相关接口")
public class EmployeeController {
@Autowired
private EmployeeService employeeService;
@Autowired
private JwtProperties jwtProperties;
/**
* 登录
*
* @param employeeLoginDTO
* @return
*/
@PostMapping("/login")
@ApiOperation(value = "员工登录")
public Result<EmployeeLoginVO> login(@RequestBody EmployeeLoginDTO employeeLoginDTO) {
log.info("员工登录:{}", employeeLoginDTO);
Employee employee = employeeService.login(employeeLoginDTO);
//登录成功后,生成jwt令牌
Map<String, Object> claims = new HashMap<>();
claims.put(JwtClaimsConstant.EMP_ID, employee.getId());
String token = JwtUtil.createJWT(
jwtProperties.getAdminSecretKey(),
jwtProperties.getAdminTtl(),
claims);
EmployeeLoginVO employeeLoginVO = EmployeeLoginVO.builder()
.id(employee.getId())
.userName(employee.getUsername())
.name(employee.getName())
.token(token)
.build();
return Result.success(employeeLoginVO);
}
/**
* 退出
*
* @return
*/
@PostMapping("/logout")
@ApiOperation(value = "员工退出")
public Result<String> logout() {
return Result.success();
}
}
sky-pojo com/sky/vo/EmployeeLoginVO.java
// 这里是最后返回的数据vo [已经经历过由po→DTO→vo的过程] 这里的po应该就是Employee
package com.sky.vo;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@ApiModel(description = "员工登录返回的数据格式")
public class EmployeeLoginVO implements Serializable {
@ApiModelProperty("主键值")
private Long id;
@ApiModelProperty("用户名")
private String userName;
@ApiModelProperty("姓名")
private String name;
@ApiModelProperty("jwt令牌")
private String token;
}
sky-pojo com/sky/dto/EmployeeLoginDTO.java
// 这里的DTO是传输中的数据
package com.sky.dto;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.io.Serializable;
@Data
@ApiModel(description = "员工登录时传递的数据模型")
public class EmployeeLoginDTO implements Serializable {
@ApiModelProperty("用户名")
private String username;
@ApiModelProperty("密码")
private String password;
}
Getter与Setter无中生有?? 以及快速创建对象builder
在上述VO和DTO代码中很显然没有看到常见的Getter和Setter
这是因为代码使用了 Lombok 注解,Lombok 是一个 Java 库,可以通过注解自动生成常见的样板代码,如 getter、setter、toString、equals 和 hashCode 等方法。
Lombok 注解解释:
@Data:
作用:这是一个组合注解,包含了 @ToString、@EqualsAndHashCode、@Getter、@Setter 和 @RequiredArgsConstructor。
效果:自动生成所有字段的 getter 和 setter 方法,toString 方法,equals 和 hashCode 方法,以及一个包含所有 final 字段和 @NonNull 字段的构造函数。
@Builder:
作用:生成一个构建器模式的类,使得对象的创建更加灵活和可读。
效果:自动生成一个静态内部类 EmployeeLoginVO.EmployeeLoginVOBuilder,并提供构建方法。
生成的构建器类包含所有字段的设置方法,并提供一个 build 方法来最终构建对象
使用构建器模式可以让你在创建对象时更清晰地指定各个字段的值,特别是在对象有很多字段时。
构建器模式允许你按需设置字段,而不需要为每个字段组合创建多个构造函数。
生成的构建器类:
Lombok 会自动生成一个静态内部类 EmployeeLoginVOBuilder,包含所有字段的设置方法和一个 build 方法。
- 设置字段:
你可以按需调用构建器的设置方法来设置字段值,例如 id(1L)、userName(“john_doe”) 等。
- 构建对象:
最后调用 build 方法来创建 EmployeeLoginVO 对象。
// 使用构建器创建 EmployeeLoginVO 对象
EmployeeLoginVO employeeLoginVO = EmployeeLoginVO.builder()
.id(1L)
.userName("john_doe")
.name("John Doe")
.token("eyJhbGciOiJIUzI1NiJ9...")
.build();
System.out.println(employeeLoginVO);
@NoArgsConstructor:
作用:生成一个无参构造函数。
效果:自动生成一个不带任何参数的构造函数。
@AllArgsConstructor:
作用:生成一个全参构造函数。
效果:自动生成一个包含所有字段的构造函数。
详细解析@GetMapping 与 @PostMapping
选择使用 @GetMapping 还是 @PostMapping 主要取决于Http请求的性质和用途
@GetMapping
作用:
特点:
- 请求参数通常附加在URL中
@GetMapping("/xxx/{id}") 底下会跟 @PathVariable
- 请求是安全的不会修改服务器状态
适用场景:
- 查询数据:获取用户列表、搜索结果
- 获取静态资源:图片、css文件
- 获取单个资源:获取某个用户的详细信息
@PostMapping
作用:
- @PostMapping专门用于处理HTTP POST请求
- POST请求通常用于向服务器发送数据,可能会对服务器上的数据进行修改
特点:
- 请求参数放在请求体中,不会显示在URL这种
@PostMapping("/users")底下会跟@RequestBody
- 请求体的大小没有固定限制,可以发送大量数据
- 多次相同的POST请求可能会产生不同的结果,可能会修改服务器状态
- 请求是不安全的,可能会修改服务器状态
适用场景:
- 创建新资源:注册新用户、添加新订单
- 更新现有资源:修改用户信息、更新订单状态
- 发送表单数据:登录、提交评论
- 上传文件:图片、文档
以下是一些可能的原因,解释了为什么您看到的前端项目代码不是“正经的网页代码”:
- 构建过程:现代前端项目通常有一个构建过程,使用工具如Webpack、Rollup或Parcel等将源代码转换和打包。原始的代码可能在
src目录中,而您看到的是构建后的dist目录,其中包含了转换和压缩后的文件。
- 模块化和组件化:前端框架和库鼓励开发者将UI拆分成可复用的模块和组件。这意味着不再有传统的HTML、CSS和JavaScript混合在一起的代码,而是分别在不同的文件中定义。
- 框架和库的使用:现代前端开发往往依赖于各种框架和库,这些框架和库有自己的文件结构和编写方式,可能和您熟悉的传统网页代码写法有很大不同。
根据@PutMapping(“/{Id}”)提问
我为什么@PutMapping(“/{id}”)是id呢 是不是因为我后面需要数据库where id = #{id} 查询才这样传输 如果 我想以name去查询呢
在RESTful API设计中,资源通常通过其唯一标识符(如ID)来访问和操作。@PutMapping("/{id}")使用{id}作为路径变量是因为ID是数据库中记录的唯一标识,这使得通过ID查找和更新特定的记录变得直接和高效。
如果你想要通过name来查询和更新记录,这在理论上是可行的,但需要注意以下几点:
name字段可能不是唯一的,这意味着可能有多条记录具有相同的名称。- 使用非唯一字段作为更新依据可能会导致数据不一致或错误更新。
更新员工 前后端联调原理
★ 在前端使用Ajax与后端URL对应时,你需要确保Ajax请求的URL与后端控制器中定义的映射相匹配。在你提供的例子中,后端使用@PutMapping("/{id}")来定义更新员工信息的端点,因此前端的Ajax URL应该包含员工的ID
// 绑定更新按钮的点击事件
$('#updateBtn').click(function() {
var employee = {
id: $('#id').val(), // 假设这是员工的唯一标识符
name: $('#name').val(),
email: $('#email').val(),
department: $('#department').val()
};
// 发起Ajax PUT请求,URL中包含员工的ID
$.ajax({
url: `/api/employees/${employee.id}`, // 注意这里的URL与后端的@PutMapping("/{id}")对应
type: 'PUT',
contentType: 'application/json', // 指定发送给服务器的数据类型
data: JSON.stringify(employee), // 将JavaScript对象转换为JSON字符串
success: function(response) {
// 请求成功,可以在这里处理响应数据
alert('Employee information updated successfully!');
// 如果需要,可以在这里更新页面上的表单数据
},
error: function(xhr, status, error) {
// 请求失败,可以在这里处理错误信息
alert('Error updating employee information: ' + xhr.responseText);
}
});
});
//在这个例子中,employee.id是从表单中获取的员工ID,它被拼接到URL字符串中,以形成完整的请求URL。这个URL应该与后端控制器中定义的@PutMapping("/{id}")相对应。当点击更新按钮时,Ajax请求会被发送到后端,后端会根据提供的ID找到对应的员工记录并进行更新。
@PutMapping("/{id}")
public ResponseEntity<Employee> updateEmployee(@PathVariable Long id, @RequestBody Employee employeeDetails) {
Employee employee = employeeService.getEmployeeById(id);
if (employee != null) {
employee.setName(employeeDetails.getName());
employee.setEmail(employeeDetails.getEmail());
employee.setDepartment(employeeDetails.getDepartment());
Employee updatedEmployee = employeeService.updateEmployee(employee);
return ResponseEntity.ok(updatedEmployee);
} else {
return ResponseEntity.notFound().build();
}
}
}
//这里{id}是路径变量,它会匹配Ajax请求URL中的employee.id。这样,前后端的URL就正确对应起来了。
新增员工(Post+Json提交格式)
需求分析和设计
账号必须是唯一的、手机号校验合法11位、性别单选男女、身份证合法18位号码、新增密码默认为123456
本项目约定:
- 管理端发出的请求,统一使用 /admin 作为前缀
- 用户端发出的请求,统一使用 /user 作为前缀
代码开发
根据新增员工接口设计对应的DTO
注意:当前提交的数据和实体类中对应的属性差别比较大时,建议使用DTO(数据传输)来封装数据
sky-pojo com/sky/dto/EmployeeDTO.java
package com.sky.dto;
import lombok.Data;
import java.io.Serializable;
@Data
public class EmployeeDTO implements Serializable {
private Long id;
private String username;
private String name;
private String phone;
private String sex;
private String idNumber;
}
sky-server com/sky/controller/admin/EmployeeController.java
/**
* 新增员工
* @param employeeDTO
* @return
*/
@PostMapping
@ApiOperation("新增员工")
public Result save(@RequestBody EmployeeDTO employeeDTO){
// 因为是JSON格式 要加@RequestBody
log.info("新增员工:{}",employeeDTO);
employeeService.save(employeeDTO);
return Result.success();
}
sky-server com/sky/service/EmployeeService.java
package com.sky.service;
import com.sky.dto.EmployeeDTO;
import com.sky.dto.EmployeeLoginDTO;
import com.sky.entity.Employee;
public interface EmployeeService {
/**
* 员工登录
* @param employeeLoginDTO
* @return
*/
Employee login(EmployeeLoginDTO employeeLoginDTO);
/**
* 新增员工
* @param employeeDTO
*/
void save(EmployeeDTO employeeDTO);
}
sky-server com/sky/service/impl/EmployeeServiceImpl.java
/**
* 新增员工
* @param employeeDTO
*/
@Override
public void save(EmployeeDTO employeeDTO) {
Employee employee = new Employee();
//employee.setName(employeeDTO.getName()); 太多了 用对象属性拷贝
BeanUtils.copyProperties(employeeDTO,employee); //其余的要手动设置
//设置账号状态,默认正常状态 1正常 0锁定 规范封装
employee.setStatus(StatusConstant.ENABLE);
//设置密码,默认密码123456
employee.setPassword(DigestUtils.md5DigestAsHex(PasswordConstant.DEFAULT_PASSWORD.getBytes()));
//设置当前记录的创建时间和修改时间
employee.setCreateTime(LocalDateTime.now());
employee.setUpdateTime(LocalDateTime.now());
//设置当前记录创建人id和修改人id
//TODO 后期需要改为当前登录用户的id
employee.setCreateUser(10L);
employee.setUpdateUser(10L);
employeeMapper.insert(employee);
}
sky-pojo com/sky/entity/Employee.java
package com.sky.entity;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.time.LocalDateTime;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Employee implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private String username;
private String name;
private String password;
private String phone;
private String sex;
private String idNumber;
private Integer status;
//@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime createTime;
//@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime updateTime;
private Long createUser;
private Long updateUser;
}
sky-server com/sky/mapper/EmployeeMapper.java
/**
* 插入员工数据
*/
@Insert("insert into employee (name,username,password,phone,sex,id_number,create_time,update_time,create_user,update_user))" +
"values" +
"(#{name},#{username},#{password},#{phone},#{sex},#{idNumber},#{createTime},#{updateTime},#{createUser},#{updateUser},#{status})")
void insert(Employee employee);
@Builder 和 @JsonFormat
@Builder 是 Lombok 提供的一个注解,用于自动生成构建器模式的代码。
它会在编译时生成一个静态的 Builder 类和相关的方法,使得对象的创建更加灵活和可读。
需要创建不可变对象时,可以使用 @Builder 结合 @Value 注解。
需要创建复杂的对象时,可以通过构建器模式逐步设置属性,提高代码的可读性和可维护性
@JsonFormat 是 Jackson 库提供的注解,用于指定日期时间字段在 JSON 序列化和反序列化时的格式。
通过设置 pattern 属性,可以控制日期时间字段的格式化方式。
当需要将 LocalDateTime、Date 等日期时间类型的字段转换为特定格式的字符串时。
在 RESTful API 中,返回的 JSON 数据需要符合特定的日期时间格式要求。
使用 @Builder 的场景
public class Main {
public static void main(String[] args) {
// 使用 @Builder 创建 Employee 对象
Employee employee = Employee.builder()
.id(1L)
.username("user123")
.name("张三")
.password("password123")
.phone("12345678901")
.sex("男")
.idNumber("123456789012345678")
.status(1)
.createTime(LocalDateTime.now())
.updateTime(LocalDateTime.now())
.createUser(1L)
.updateUser(1L)
.build();
System.out.println(employee);
}
}
//创建 RESTful API
Employee里面的pojo就不详细写了
//@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime createTime;
//@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime updateTime;
==========================================================================
@RestController
public class EmployeeController {
@GetMapping("/employee")
public ResponseEntity<String> getEmployee() throws Exception {
// 创建 Employee 对象
Employee employee = Employee.builder()
.id(1L)
.username("user123")
.name("张三")
.password("password123")
.phone("12345678901")
.sex("男")
.idNumber("123456789012345678")
.status(1)
.createTime(LocalDateTime.now())
.updateTime(LocalDateTime.now())
.createUser(1L)
.updateUser(1L)
.build();
// 使用 ObjectMapper 将 Employee 对象转换为 JSON 字符串
ObjectMapper objectMapper = new ObjectMapper();
String json = objectMapper.writeValueAsString(employee);
return ResponseEntity.ok(json);
}
}
===========================================================================
// 除了 @JsonFormat 注解,还有其他方式可以指定日期时间格式,具体取决于你的需求和使用的库。
public static void main(String[] args) {
LocalDateTime now = LocalDateTime.now();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
String formattedDateTime = now.format(formatter);
Employee employee = Employee.builder()
.id(1L)
.username("user123")
.name("张三")
.password("password123")
.phone("12345678901")
.sex("男")
.idNumber("123456789012345678")
.status(1)
.createTime(now)
.updateTime(now)
.createUser(1L)
.updateUser(1L)
.build();
System.out.println("Formatted Create Time: " + formattedDateTime);
System.out.println("Formatted Update Time: " + formattedDateTime);
}
@Builder:
通过 Employee.builder() 创建了一个构建器对象。
使用链式调用设置各个属性,最后调用 build() 方法生成 Employee 实例。
这种方式使得创建对象的代码更加简洁和易读,特别是当对象属性较多时。
@JsonFormat:
在 createTime 和 updateTime 字段上使用了 @JsonFormat 注解,指定了日期时间的格式为 “yyyy-MM-dd HH:mm:ss”。
当 Employee 对象被转换为 JSON 字符串时,这两个字段会被格式化为指定的日期时间格式。
这样可以确保返回的 JSON 数据符合预期的格式要求。
RESTful风
可缓存性:
RESTful API 可以利用 HTTP 缓存机制,减少网络请求,提高性能。
客户端可以缓存响应,减少服务器的负载。
易于集成:
RESTful API 使用标准的 HTTP 协议,几乎所有的编程语言和框架都支持 HTTP 请求。
这使得不同系统之间的集成变得更加容易。
可读性强:
RESTful API 的 URL 设计通常非常直观,易于理解和记忆。
例如,/users/123 表示用户 ID 为 123 的资源,/users/123/orders 表示该用户的订单资源。
灵活性:
RESTful API 支持多种数据格式(如 JSON、XML 等),可以根据需要选择合适的格式。
客户端和服务器可以通过协商确定数据格式,提高了灵活性。
GET /users
GET /users/{id}
POST /users
PUT /users/{id}
功能测试
功能测试方式:
注意:由于开发阶段前后端是并行开发的,后端完成某个功能后,此时前端对应的功能可能还没有开发完成,导致无法进行前后端联调测试。所以在开发阶段,后端测试主要以接口文档测试为主
[苍穹外卖项目接口文档] (http://localhost:8080/doc.html#/documentManager/GlobalParameters-default)
首先要拿到JWT令牌(去接口进行一次登录测试后会有) → 全局参数设置 → 添加参数
注意:这个jwt→json是有有效期的(2小时=7200000秒)
sky:
jwt:
# 设置jwt签名加密时使用的秘钥
admin-secret-key: itcast
# 设置jwt过期时间
admin-ttl: 7200000
# 设置前端传递过来的令牌名称
admin-token-name: token
{
“code”: 1,
“msg”: null,
“data”: {
“id”: 1,
“userName”: “admin”,
“name”: “管理员”,
“token”: “eyJhbGciOiJIUzI1NiJ9.eyJlbXBJZCI6MSwiZXhwIjoxNzI3NjAxMTAxfQ.rnxaRc7fjPzMYwGHk3VzKA4EOxRFrYkKzesxEQsCQUc”
}
}
新增参数:
参数名称:token
参数值:eyJhbGciOiJIUzI1NiJ9.eyJlbXBJZCI6MSwiZXhwIjoxNzI3NjAxMTAxfQ.rnxaRc7fjPzMYwGHk3VzKA4EOxRFrYkKzesxEQsCQUc
参数类型:header
新增员工接口
{
“idNumber”: “1321321312”,
“name”: “张三”,
“phone”: “11111111111”,
“sex”: “1”,
“username”: “zhangsan”
}
响应内容:
{
“code”: 1,
“msg”: null,
“data”: null
}
sky-server com/sky/interceptor/JwtTokenAdminInterceptor.java
package com.sky.interceptor;
import com.sky.constant.JwtClaimsConstant;
import com.sky.properties.JwtProperties;
import com.sky.utils.JwtUtil;
import io.jsonwebtoken.Claims;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.web.method.HandlerMethod;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* jwt令牌校验的拦截器
*/
@Component //将该类注册为 Spring 管理的 Bean。
@Slf4j //使用 Lombok 自动生成日志记录器
public class JwtTokenAdminInterceptor implements HandlerInterceptor {
// 包含 JWT 相关的配置属性,如令牌名称和密钥
@Autowired
private JwtProperties jwtProperties;
/**
* 校验jwt
*
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//判断当前拦截到的是Controller的方法还是其他资源
//检查当前拦截到的是否是 Controller 的方法。如果不是,直接放行
if (!(handler instanceof HandlerMethod)) {
//当前拦截到的不是动态方法,直接放行
return true;
}
//1、从请求头中获取令牌
String token = request.getHeader(jwtProperties.getAdminTokenName());
//2、校验令牌
try {
log.info("jwt校验:{}", token);
Claims claims = JwtUtil.parseJWT(jwtProperties.getAdminSecretKey(), token);
Long empId = Long.valueOf(claims.get(JwtClaimsConstant.EMP_ID).toString());
log.info("当前员工id:", empId);
//3、通过,放行
return true;
} catch (Exception ex) {
//4、不通过,响应401状态码
response.setStatus(401);
return false;
}
}
}
com/sky/properties/JwtProperties.java
package com.sky.properties;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Component
@ConfigurationProperties(prefix = "sky.jwt")
@Data
public class JwtProperties {
/**
* 管理端员工生成jwt令牌相关配置
*/
private String adminSecretKey;
private long adminTtl;
private String adminTokenName;
/**
* 用户端微信用户生成jwt令牌相关配置
*/
private String userSecretKey;
private long userTtl;
private String userTokenName;
}
代码完善
程序存在的问题:
- 录入的用户名已存在,抛出异常后没有处理
- 新增员工时,创建人id和修改人id设置了固定值
当你在 Maven 中执行 compile 命令时,它会强制 Maven 重新编译整个项目,包括所有的类和资源。这一过程会清除任何旧的编译结果,确保所有的依赖和代码都是最新的。这可能导致以下几种情况,从而解决了你的问题:
**重新编译:**Maven 会重新编译所有的源代码,包括你修改或新增的类,这样就能解决因为旧的编译缓存而引起的引用问题。
**更新依赖:**如果你在项目中添加或修改了依赖,执行 compile 可以确保这些依赖被正确加载和引用。
清理旧缓存:在编译过程中,Maven 会清理旧的缓存和临时文件,避免由于这些文件造成的潜在冲突。
**IDE 同步:**有时候,IDE 的状态可能与 Maven 项目状态不一致,执行 Maven 命令可以帮助 IDE 重新同步项目的状态。
问题①
sky-server com/sky/handler/GlobalExceptionHandler.java
package com.sky.handler;
import com.sky.constant.MessageConstant;
import com.sky.exception.BaseException;
import com.sky.result.Result;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import java.sql.SQLIntegrityConstraintViolationException;
/**
* 全局异常处理器,处理项目中抛出的业务异常
*/
@RestControllerAdvice
@Slf4j
public class GlobalExceptionHandler {
/**
* 捕获业务异常
* @param ex
* @return
*/
@ExceptionHandler
public Result exceptionHandler(BaseException ex){
log.error("异常信息:{}", ex.getMessage());
return Result.error(ex.getMessage());
}
@ExceptionHandler
public Result exceptionHandler(SQLIntegrityConstraintViolationException ex) {
String message = ex.getMessage();
if (message.contains("Duplicate entry")) {
// Duplicate entry 'zhangsan' for key 'employee.idx_username'
// 在这里,我们使用 split("'") 将字符串分割为多个部分。这样,parts[1] 将得到 zhangsan,因为它位于单引号之间。这种方式可以正确提取用户名。
String[] split = message.split("'");
String username = split[1];
// String msg = username + "已存在";
String msg = username + MessageConstant.ALREADY_EXISTS;
return Result.error(msg);
}else {
return Result.error(MessageConstant.UNKNOWN_ERROR);
}
}
}
Split的深入学习
split 方法接受一个正则表达式作为参数,因此分隔符可以是复杂的模式,而不仅仅是单个字符。
例如,split(“\s+”) 可以用来按一个或多个空白字符(包括空格、制表符、换行符等)进行分割。
split 方法还有一个重载版本 split(String regex, int limit),可以限制分割的次数。
例如,split(“‘“, 3) 只会进行两次分割,结果数组最多包含三个元素。
问题② 解析出员工登录id后,如何转递给Service的save方法?→ ThreadLocal
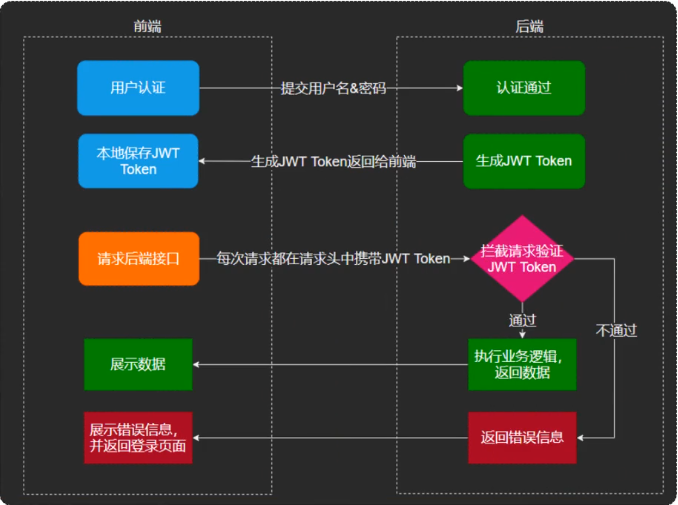
前端会携带JWT令牌,通过JWT令牌可以解析出当前登录员工id:
//1、从请求头中获取令牌
String token = request.getHeader(jwtProperties.getAdminTokenName());
//2、校验令牌
try {
log.info("jwt校验:{}", token);
Claims claims = JwtUtil.parseJWT(jwtProperties.getAdminSecretKey(), token);
Long empId = Long.valueOf(claims.get(JwtClaimsConstant.EMP_ID).toString());
log.info("当前员工id:", empId);
//3、通过,放行
return true;
} catch (Exception ex) {
//4、不通过,响应401状态码
response.setStatus(401);
return false;
}
ThreadLocal
ThreadLocal并不是一个Thread,Thread的局部变量
ThreadLocal为每个线程提供单独一份存储空间,具有线程隔离的效果,只有在线程内才能获得到对应的值,线程外则不能访问
sky-common com/sky/context/BaseContext.java
package com.sky.context;
public class BaseContext {
public static ThreadLocal<Long> threadLocal = new ThreadLocal<>();
public static void setCurrentId(Long id) {
threadLocal.set(id);
}
public static Long getCurrentId() {
return threadLocal.get();
}
public static void removeCurrentId() {
threadLocal.remove();
}
}
sky-server com/sky/interceptor/JwtTokenAdminInterceptor.java
package com.sky.interceptor;
import com.sky.constant.JwtClaimsConstant;
import com.sky.context.BaseContext;
import com.sky.properties.JwtProperties;
import com.sky.utils.JwtUtil;
import io.jsonwebtoken.Claims;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.web.method.HandlerMethod;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* jwt令牌校验的拦截器
*/
@Component
@Slf4j
public class JwtTokenAdminInterceptor implements HandlerInterceptor {
@Autowired
private JwtProperties jwtProperties;
/**
* 校验jwt
*
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//判断当前拦截到的是Controller的方法还是其他资源
if (!(handler instanceof HandlerMethod)) {
//当前拦截到的不是动态方法,直接放行
return true;
}
//1、从请求头中获取令牌
String token = request.getHeader(jwtProperties.getAdminTokenName());
//2、校验令牌
try {
log.info("jwt校验:{}", token);
Claims claims = JwtUtil.parseJWT(jwtProperties.getAdminSecretKey(), token);
Long empId = Long.valueOf(claims.get(JwtClaimsConstant.EMP_ID).toString());
log.info("当前员工id:", empId);
// ★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★
BaseContext.setCurrentId(empId);
//3、通过,放行
return true;
} catch (Exception ex) {
//4、不通过,响应401状态码
response.setStatus(401);
return false;
}
}
}
sky-server com/sky/service/impl/EmployeeServiceImpl.java
/**
* 新增员工
* @param employeeDTO
*/
@Override
public void save(EmployeeDTO employeeDTO) {
Employee employee = new Employee();
// employee.setName(employeeDTO.getName()); 太多了 用对象属性拷贝
BeanUtils.copyProperties(employeeDTO,employee); //其余的要手动设置
//设置账号状态,默认正常状态 1正常 0锁定 规范封装
employee.setStatus(StatusConstant.ENABLE);
//设置密码,默认密码123456
employee.setPassword(DigestUtils.md5DigestAsHex(PasswordConstant.DEFAULT_PASSWORD.getBytes()));
//设置当前记录的创建时间和修改时间
employee.setCreateTime(LocalDateTime.now());
employee.setUpdateTime(LocalDateTime.now());
//设置当前记录创建人id和修改人id
//TODO 后期需要改为当前登录用户的id
// employee.setCreateUser(10L);
// ★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★
employee.setCreateUser(BaseContext.getCurrentId());
employee.setUpdateUser(BaseContext.getCurrentId());
employeeMapper.insert(employee);
}
// ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ 如果想单独针对22行代码 测试部分的值是多少 ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
// 左键选中'BaseContext.getCurrentId()' 右键Evaluate Expression单独计算即可
将员工登录ID放在 ThreadLocal 中的原因
在多线程环境中,使用 ThreadLocal 来存储和传递员工的完整信息是一个常见的做法。这样可以确保每个线程都有独立的变量副本,避免并发问题。以下是一些步骤和最佳实践,帮助你在 ThreadLocal 中安全地传递和存储员工的完整信息。
ThreadLocal 主要用于在同一个线程内传递和存储数据,确保每个线程都有独立的变量副本。在你的例子中,ThreadLocal 用于存储员工ID,确保在多线程环境下员工ID的安全传递。
- 线程隔离:ThreadLocal 确保每个线程都有独立的员工ID副本,避免了多线程环境下的并发问题。
防止篡改:只有当前线程可以访问和修改 ThreadLocal 中的员工ID,其他线程无法访问,确保了ID的安全性。
- 员工其他信息的安全性
数据库查询:员工的其他信息是从数据库中查询的,而不是从 ThreadLocal 中获取的。数据库查询本身是安全的,只要数据库连接和查询操作是安全的。
权限控制:确保只有经过认证的用户才能执行查询操作,防止未授权访问。
数据加密:敏感信息(如密码)在存储和传输过程中应进行加密,确保数据的安全性。
线程安全:
ThreadLocal 为每个线程提供独立的变量副本,避免了多线程环境下的并发问题。每个线程都可以安全地读取和修改自己的 ThreadLocal 变量,而不会影响其他线程。
简化代码:
在 Web 应用中,通常需要在多个方法或组件之间传递用户身份信息(如员工登录ID)。使用 ThreadLocal 可以避免在每个方法调用中显式传递这些信息,从而简化代码。
全局访问:
在同一个线程内,任何地方都可以访问 ThreadLocal 中存储的值,这使得在复杂的业务逻辑中传递和使用员工登录ID变得非常方便。
避免传递参数:
在多层调用中,如果需要传递员工登录ID,通常需要在每个方法签名中添加相应的参数。使用 ThreadLocal 可以避免这种繁琐的参数传递,提高代码的可读性和可维护性。
// 设置员工登录ID:
在用户登录成功后,将员工登录ID设置到 ThreadLocal 中。
@PostMapping("/login")
public ResponseEntity<?> login(@RequestBody LoginRequest loginRequest) {
// 验证用户名和密码
User user = userService.validateUser(loginRequest.getUsername(), loginRequest.getPassword());
if (user != null) {
// 设置当前线程的员工登录ID
BaseContext.setCurrentId(user.getId());
// 返回登录成功信息
return ResponseEntity.ok("Login successful");
} else {
return ResponseEntity.status(HttpStatus.UNAUTHORIZED).body("Invalid username or password");
}
}
// 获取员工登录ID
在需要使用员工登录ID的地方,直接从 ThreadLocal 中获取
@Service
public class OrderService {
public void createOrder(Order order) {
Long currentUserId = BaseContext.getCurrentId();
if (currentUserId != null) {
order.setCreatedBy(currentUserId);
orderRepository.save(order);
} else {
throw new RuntimeException("User ID not found in context");
}
}
}
将员工登录ID放在 ThreadLocal 中,可以确保每个线程都有独立的变量副本,避免多线程环境下的并发问题。同时,这种方式简化了代码,提供了全局访问的能力,避免了繁琐的参数传递,使得在复杂的业务逻辑中传递和使用员工登录ID变得非常方便。
员工分页查询
需求分析和设计
业务规则:(查询 → get)
- 根据页码展示员工信息
- 每页展示10条数据
- 分页查询时可以根据需要,输入员工姓名进行查询
代码开发
根据分页查询接口设计对应的DTO:
Query
| 参数名称 |
是否必须 |
示例 |
备注 |
| name |
否 |
张三 |
员工姓名 |
| page |
是 |
1 |
页码 |
| pageSize |
是 |
10 |
每页记录数 |
@Data
public class EmployeePageQueryDTO implements Serializable{
private String name;
private int page;
private int pageSize;
}
/*封装分页查询结果*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class PageResult implements Serializable{
private long total;
private List records;
}
sky-server com/sky/controller/admin/EmployeeController.java
/**
* 员工分页查询
* @param employeePageQueryDTO
* @return
*/
@GetMapping("/page")
public Result<PageResult> page(EmployeePageQueryDTO employeePageQueryDTO){
//格式不是JSON不用加 @RequestBody
log.info("员工分页查询,参数为:{}", employeePageQueryDTO);
PageResult pageResult = employeeService.pageQuery(employeePageQueryDTO);
return Result.success(pageResult);
}
sky-server com/sky/service/EmployeeService.java
/**
* 分页查询
* @param employeePageQueryDTO
* @return
*/
PageResult pageQuery(EmployeePageQueryDTO employeePageQueryDTO);
sky-server com/sky/service/impl/EmployeeServiceImpl.java
/**
* 分页查询
* @param employeePageQueryDTO
* @return
*/
@Override
public PageResult pageQuery(EmployeePageQueryDTO employeePageQueryDTO) {
// select * from employee limit 0,10
// 开始分页查询 动态拼接
PageHelper.startPage(employeePageQueryDTO.getPage(), employeePageQueryDTO.getPageSize());
Page<Employee> page = employeeMapper.pageQuery(employeePageQueryDTO);
long total = page.getTotal();
List<Employee> records = page.getResult();
return new PageResult(total, records);
}
逐行研究分页查询
PageHelper.startPage 是 MyBatis 分页插件提供的方法,用于开启分页功能
employeePageQueryDTO.getPage() 获取当前页码。
employeePageQueryDTO.getPageSize() 获取每页显示的记录数
这一行代码的作用是告诉 MyBatis 在接下来的查询中启用分页,并设置分页参数
employeeMapper.pageQuery(employeePageQueryDTO) 是调用 MyBatis 的 Mapper 接口方法,执行分页查询。
- employeePageQueryDTO 包含了查询条件,如关键字、排序字段等。
- 查询结果会被封装成 Page 对象,其中包含了分页数据和分页元数据。
page.getTotal() 获取分页查询的总记录数。
List records = page.getResult();
- page.getResult() 获取分页查询的实际数据列表。
- 这个列表包含了当前页的员工记录
return new PageResult(total, records);
new PageResult(total, records) 创建一个新的 PageResult 对象,将总记录数和分页数据列表封装起来
PageResult 类通常包含 total 和 records 属性,用于返回给客户端
假设 employeePageQueryDTO.getPage() 返回 2,employeePageQueryDTO.getPageSize() 返回 10,那么 MyBatis 生成的 SQL 可能类似于:
SELECT * FROM employee
WHERE ... -- 根据 employeePageQueryDTO 中的查询条件
LIMIT 10 OFFSET 10;
LIMIT 10:表示每页显示 10 条记录。
OFFSET 10:表示从第 11 条记录开始(因为页码从 1 开始,所以第 2 页的偏移量是 10)。
PageResult 类:用于封装分页查询的结果,包括总记录数和当前页的数据集合。
使用场景:在分页查询服务中,将查询结果封装为 PageResult 对象,通过控制器返回给客户端。
Serializable 接口:是 Java 中的一个标记接口,没有定义任何方法。实现 Serializable 接口的类的对象可以被序列化,即将对象的状态转换为字节流,以便在网络上传输或持久化存储。反序列化则是将字节流恢复为对象的过程。
对象状态转换:将对象的状态(即对象的字段值)转换为字节流。
默认序列化机制:Java 提供了默认的序列化机制,通过 ObjectOutputStream 类的 writeObject 方法实现。
自定义序列化:可以通过实现 writeObject 和 readObject 方法来自定义序列化和反序列化过程。
持久化:序列化的主要目的是将对象的状态保存到存储介质中,或者通过网络传输对象。
查询结果会被封装到 PageResult 对象中,其中 total 表示总记录数,records 表示当前页的数据集合。
sky-server com/sky/mapper/EmployeeMapper.java
/**
* 分页查询 [动态sql 不用注解了 写道 EmployeeMapper.xml]
* @param employeePageQueryDTO
* @return
*/
Page<Employee> pageQuery(EmployeePageQueryDTO employeePageQueryDTO);
sky-server mapper/EmployeeMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.EmployeeMapper">
<select id="pageQuery" resultType="com.sky.entity.Employee">
select * from employee
<where>
<if test="name != null and name != ''">
and name like concat('%',#{name},'%')
</if>
</where>
order by create_time desc
</select>
</mapper>
<!--
and name like concat('%',#{name},'%'):
如果条件成立,生成的 SQL 条件为 AND name LIKE '%${name}%',实现名称的模糊匹配
-->
[员工管理] (http://localhost/#/employee)
代码完善
问题:创建/更新时间那边传入的数据不是想要的
// 2024929214237
"createTime": [
2024,
9,
29,
22,
10,
37
],
"updateTime": [
2024,
9,
29,
22,
10,
37
],
解决方式:
方法一:在属性上加注解,对日期进行格式化(只能处理单独一个属性)
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime updateTime;
------------------------------------------------------------------------
"createTime": "2024-09-29 22:10:37",
方法二:在WebMvcConfiguration中扩展Spring MVC的消息转换器,统一对日期类型进行格式化处理
重写父类方法 去扩展 消息转换器
sky-server com/sky/config/WebMvcConfiguration.java
/**
* 扩展Spring MVC框架的消息转化器
* @param converters
*/
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
log.info("扩展消息转换器...");
//创建一个消息转换器对象
MappingJackson2HttpMessageConverter converter = new MappingJackson2HttpMessageConverter();
//需要为消息转换器设置一个对象转换器,对象转换器可以将Java对象序列化为json数据
converter.setObjectMapper(new JacksonObjectMapper());
//将自己的消息转化器加入容器中
converters.add(0,converter);
}
package com.sky.json;
import com.fasterxml.jackson.databind.DeserializationFeature;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.module.SimpleModule;
import com.fasterxml.jackson.datatype.jsr310.deser.LocalDateDeserializer;
import com.fasterxml.jackson.datatype.jsr310.deser.LocalDateTimeDeserializer;
import com.fasterxml.jackson.datatype.jsr310.deser.LocalTimeDeserializer;
import com.fasterxml.jackson.datatype.jsr310.ser.LocalDateSerializer;
import com.fasterxml.jackson.datatype.jsr310.ser.LocalDateTimeSerializer;
import com.fasterxml.jackson.datatype.jsr310.ser.LocalTimeSerializer;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.LocalTime;
import java.time.format.DateTimeFormatter;
import static com.fasterxml.jackson.databind.DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES;
/**
* 对象映射器:基于jackson将Java对象转为json,或者将json转为Java对象
* 将JSON解析为Java对象的过程称为 [从JSON反序列化Java对象]
* 从Java对象生成JSON的过程称为 [序列化Java对象到JSON]
*/
public class JacksonObjectMapper extends ObjectMapper {
public static final String DEFAULT_DATE_FORMAT = "yyyy-MM-dd";
//public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm:ss";
public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm";
public static final String DEFAULT_TIME_FORMAT = "HH:mm:ss";
public JacksonObjectMapper() {
super();
//收到未知属性时不报异常
this.configure(FAIL_ON_UNKNOWN_PROPERTIES, false);
//反序列化时,属性不存在的兼容处理
this.getDeserializationConfig().withoutFeatures(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES);
SimpleModule simpleModule = new SimpleModule()
.addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addDeserializer(LocalDate.class, new LocalDateDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addDeserializer(LocalTime.class, new LocalTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)))
.addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addSerializer(LocalDate.class, new LocalDateSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addSerializer(LocalTime.class, new LocalTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)));
//注册功能模块 例如,可以添加自定义序列化器和反序列化器
this.registerModule(simpleModule);
}
}
启用禁用员工账号
需求分析和设计
业务规则:
- 可以对状态为 “启用” 的员工账号进行 “禁用” 操作
- 可以对状态为 “禁用” 的员工账号进行 “启用” 操作
- 状态为 “禁用” 的员工账号不能登录系统
sky-server
/**
* 启用禁用员工账号
* @param status
* @param id
* @return
*/
@PostMapping("/status/{status}")
@ApiOperation("启用禁用员工账号")
//因为上面的和下面的参数都是一致 不然需要@PathVariable("status")解释一下
public Result startOrStop(@PathVariable("status") Integer status, Long id) {
log.info("启用禁用员工账号: {},{}",status,id);
employeeService.startOrStop(status, id);
return Result.success();
}
sky-server com/sky/service/EmployeeService.java
/**
* 启用禁用员工账号
* @param status
* @param id
* @return
*/
void startOrStop(Integer status, Long id);
sky-server com/sky/service/impl/EmployeeServiceImpl.java
/**
* 启用禁用员工账号
* @param status
* @param id
* @return
*/
@Override
public void startOrStop(Integer status, Long id) {
// update employee set status = ? where id = ?
Employee employee = new Employee();
employee.setStatus(status);
employee.setId(id);
/** 要在Employee.java中添加@Builder 才能使用这种风格
* Employee employee = Employee.builder()
* .status(status)
* .id(id)
* .build();
*/
employeeMapper.update(employee);
}
sky-server com/sky/mapper/EmployeeMapper.java
/**
* 根据主键动态修改属性
* @param employee
*/
void update(Employee employee);
sky-server mapper/EmployeeMapper.xml
<update id="update" parameterType="Employee">
update employee
<set>
<if test="name != null">name = #{name},</if>
<if test="username != null">username = #{username},</if>
<if test="password != null">password = #{password},</if>
<if test="phone != null">phone = #{phone},</if>
<if test="sex != null">sex = #{sex},</if>
<if test="idNumber != null">id_Number = #{idNumber},</if>
<if test="updateTime != null">update_Time = #{updateTime},</if>
<if test="updateUser != null">update_User = #{updateUser},</if>
<if test="status != null">status = #{status},</if>
</set>
where id = #{id}
</update>
编辑员工
需求分析和设计[回写数据]
编辑员工功能涉及到两个接口:
代码开发
sky-server com/sky/controller/admin/EmployeeController.java
/**
* 根据id查询员工信息
* @param id
* @return
*/
@GetMapping("/{id}")
@ApiOperation("根据id查询员工信息")
public Result<Employee> getById(@PathVariable Long id){
Employee employee = employeeService.getById(id);
return Result.success(employee);
}
/**
* 编辑员工信息
* @param employeeDTO
* @return
*/
@PutMapping
@ApiOperation("编辑员工信息")
public Result update(@RequestBody EmployeeDTO employeeDTO){
log.info("编辑员工信息:{}", employeeDTO);
employeeService.update(employeeDTO);
return Result.success();
}
sky-server com/sky/service/EmployeeService.java
/**
* 根据id查询员工
* @param id
* @return
*/
Employee getById(Long id);
/**
* 编辑员工信息
* @param employeeDTO
*/
void update(EmployeeDTO employeeDTO);
sky-server com/sky/service/impl/EmployeeServiceImpl.java
/**
* 根据id查询员工
* @param id
* @return
*/
public Employee getById(Long id) {
Employee employee = employeeMapper.getById(id);
employee.setPassword("****");
return employee;
}
/**
* 编辑员工信息
* @param employeeDTO
*/
public void update(EmployeeDTO employeeDTO) {
Employee employee = new Employee();
BeanUtils.copyProperties(employeeDTO, employee);
//employee.setUpdateTime(LocalDateTime.now());
//employee.setUpdateUser(BaseContext.getCurrentId());
employeeMapper.update(employee);
}
sky-server com/sky/mapper/EmployeeMapper.java
/**
* 根据主键动态修改属性
* @param employee
*/
void update(Employee employee);
/**
* 根据id查询员工信息
* @param id
* @return
*/
@Select("select * from employee where id = #{id}")
Employee getById(Long id);
- 前端提交表单:
用户在前端页面编辑员工信息并提交表单。
表单数据被序列化为 JSON 格式,通过 HTTP PUT 请求发送到后端。
- 后端接收数据:
控制器方法 update 接收到 EmployeeDTO 对象。
记录日志,输出接收到的员工信息。
调用服务层的 update 方法,处理员工信息的更新。
- 服务层处理:
创建一个新的 Employee 对象。
使用 BeanUtils.copyProperties 将 EmployeeDTO 的属性复制到 Employee 对象中。
调用 MyBatis 的 employeeMapper,执行更新操作。
- MyBatis 更新操作:
生成动态 SQL 语句,只更新传入的非 null 属性。
例如,如果 name 和 phone 不为 null,生成的 SQL 语句如下:
数据回写的具体过程
- 前端请求获取员工信息 // 根据id查询员工信息
当你点击编辑按钮时,前端会发起一个 HTTP GET 请求,从后端获取员工的详细信息。这些信息将被用来填充表单字段。
- 后端处理 GET 请求
后端需要提供一个接口来处理这个 GET 请求,并返回员工的详细信息。
- 前端处理响应并填充表单
前端接收到后端返回的员工信息后,将其填充到表单字段中
/**
* 根据id查询员工信息
* @param id
* @return
*/
@GetMapping("{/id}")
@ApiOperation("根据id查询员工信息")
public Result<Employee> getById(@PathVariable Long id) {
log.info("根据id查询员工信息:{}", id);
Employee employee = employeeService.getById(id);
return Result.success(employee);
}
<script>export default {
data() {
return {
employee: {
id: null,
name: '',
username: '',
password: '',
phone: '',
sex: '',
idNumber: ''
}
};
},
methods: {
async fetchEmployee(id) {
try {
const response = await this.$axios.get(`/employees/${id}`);
this.employee = response.data.data;
} catch (error) {
console.error('获取员工信息失败', error);
}
},
async updateEmployee() {
try {
await this.$axios.put('/employees', this.employee);
alert('员工信息更新成功');
} catch (error) {
console.error('更新员工信息失败', error);
}
}
},
mounted() {
const id = this.$route.params.id; // 假设通过路由参数传递员工ID
this.fetchEmployee(id);
}
};
</script>
- 提交表单
当用户编辑完表单并点击保存按钮时,前端会发起一个 HTTP PUT 请求,将更新后的员工信息发送到后端进行处理
总结
前端请求获取员工信息:点击编辑按钮时,前端发起 GET 请求获取员工的详细信息。
后端处理 GET 请求:后端提供一个接口处理 GET 请求,返回员工的详细信息。
前端处理响应并填充表单:前端接收到员工信息后,将其填充到表单字段中。
提交表单:用户编辑完表单并点击保存按钮,前端发起 PUT 请求,将更新后的员工信息发送到后端进行处理。
[苍穹外卖项目接口文档] (http://localhost:8080/doc.html#/default/员工相关接口/updateUsingPUT)
导入分类管理功能代码
业务规则:
- 分类名称必须是唯一的
- 分类按章类型可分为菜品分类和套餐分类
- 新添加的分类状态默认认为 “禁用“
接口设计:
- 新增分类
- 分类分页查询
- 根据id删除分类
- 修改分类
- 启用禁止分类
- 根据类型调查分类
数据库设计(category表)
sky-server com/sky/controller/admin/CategoryController.java
package com.sky.controller.admin;
import com.sky.dto.CategoryDTO;
import com.sky.dto.CategoryPageQueryDTO;
import com.sky.entity.Category;
import com.sky.result.PageResult;
import com.sky.result.Result;
import com.sky.service.CategoryService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
/**
* 分类管理
*/
@RestController
@RequestMapping("/admin/category")
@Api(tags = "分类相关接口")
@Slf4j
public class CategoryController {
@Autowired
private CategoryService categoryService;
/**
* 新增分类
* @param categoryDTO
* @return
*/
@PostMapping
@ApiOperation("新增分类")
public Result<String> save(@RequestBody CategoryDTO categoryDTO){
log.info("新增分类:{}", categoryDTO);
categoryService.save(categoryDTO);
return Result.success();
}
/**
* 分类分页查询
* @param categoryPageQueryDTO
* @return
*/
@GetMapping("/page")
@ApiOperation("分类分页查询")
public Result<PageResult> page(CategoryPageQueryDTO categoryPageQueryDTO){
log.info("分页查询:{}", categoryPageQueryDTO);
PageResult pageResult = categoryService.pageQuery(categoryPageQueryDTO);
return Result.success(pageResult);
}
/**
* 删除分类
* @param id
* @return
*/
@DeleteMapping
@ApiOperation("删除分类")
public Result<String> deleteById(Long id){
log.info("删除分类:{}", id);
categoryService.deleteById(id);
return Result.success();
}
/**
* 修改分类
* @param categoryDTO
* @return
*/
@PutMapping
@ApiOperation("修改分类")
public Result<String> update(@RequestBody CategoryDTO categoryDTO){
categoryService.update(categoryDTO);
return Result.success();
}
/**
* 启用、禁用分类
* @param status
* @param id
* @return
*/
@PostMapping("/status/{status}")
@ApiOperation("启用禁用分类")
public Result<String> startOrStop(@PathVariable("status") Integer status, Long id){
categoryService.startOrStop(status,id);
return Result.success();
}
/**
* 根据类型查询分类
* @param type
* @return
*/
@GetMapping("/list")
@ApiOperation("根据类型查询分类")
public Result<List<Category>> list(Integer type){
List<Category> list = categoryService.list(type);
return Result.success(list);
}
}
sky-server com/sky/service/CategoryService.java
package com.sky.service;
import com.sky.dto.CategoryDTO;
import com.sky.dto.CategoryPageQueryDTO;
import com.sky.entity.Category;
import com.sky.result.PageResult;
import java.util.List;
public interface CategoryService {
/**
* 新增分类
* @param categoryDTO
*/
void save(CategoryDTO categoryDTO);
/**
* 分页查询
* @param categoryPageQueryDTO
* @return
*/
PageResult pageQuery(CategoryPageQueryDTO categoryPageQueryDTO);
/**
* 根据id删除分类
* @param id
*/
void deleteById(Long id);
/**
* 修改分类
* @param categoryDTO
*/
void update(CategoryDTO categoryDTO);
/**
* 启用、禁用分类
* @param status
* @param id
*/
void startOrStop(Integer status, Long id);
/**
* 根据类型查询分类
* @param type
* @return
*/
List<Category> list(Integer type);
}
sky-server com/sky/service/impl/CategoryServiceImpl.java
package com.sky.service.impl;
import com.github.pagehelper.Page;
import com.github.pagehelper.PageHelper;
import com.sky.constant.MessageConstant;
import com.sky.constant.StatusConstant;
import com.sky.context.BaseContext;
import com.sky.dto.CategoryDTO;
import com.sky.dto.CategoryPageQueryDTO;
import com.sky.entity.Category;
import com.sky.exception.DeletionNotAllowedException;
import com.sky.mapper.CategoryMapper;
import com.sky.mapper.DishMapper;
import com.sky.mapper.SetmealMapper;
import com.sky.result.PageResult;
import com.sky.service.CategoryService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.time.LocalDateTime;
import java.util.List;
/**
* 分类业务层
*/
@Service
@Slf4j
public class CategoryServiceImpl implements CategoryService {
@Autowired
private CategoryMapper categoryMapper;
@Autowired
private DishMapper dishMapper;
@Autowired
private SetmealMapper setmealMapper;
/**
* 新增分类
* @param categoryDTO
*/
public void save(CategoryDTO categoryDTO) {
Category category = new Category();
//属性拷贝
BeanUtils.copyProperties(categoryDTO, category);
//分类状态默认为禁用状态0
category.setStatus(StatusConstant.DISABLE);
//设置创建时间、修改时间、创建人、修改人
category.setCreateTime(LocalDateTime.now());
category.setUpdateTime(LocalDateTime.now());
category.setCreateUser(BaseContext.getCurrentId());
category.setUpdateUser(BaseContext.getCurrentId());
categoryMapper.insert(category);
}
/**
* 分页查询
* @param categoryPageQueryDTO
* @return
*/
public PageResult pageQuery(CategoryPageQueryDTO categoryPageQueryDTO) {
PageHelper.startPage(categoryPageQueryDTO.getPage(),categoryPageQueryDTO.getPageSize());
//下一条sql进行分页,自动加入limit关键字分页
Page<Category> page = categoryMapper.pageQuery(categoryPageQueryDTO);
return new PageResult(page.getTotal(), page.getResult());
}
/**
* 根据id删除分类
* @param id
*/
public void deleteById(Long id) {
//查询当前分类是否关联了菜品,如果关联了就抛出业务异常
Integer count = dishMapper.countByCategoryId(id);
if(count > 0){
//当前分类下有菜品,不能删除
throw new DeletionNotAllowedException(MessageConstant.CATEGORY_BE_RELATED_BY_DISH);
}
//查询当前分类是否关联了套餐,如果关联了就抛出业务异常
count = setmealMapper.countByCategoryId(id);
if(count > 0){
//当前分类下有菜品,不能删除
throw new DeletionNotAllowedException(MessageConstant.CATEGORY_BE_RELATED_BY_SETMEAL);
}
//删除分类数据
categoryMapper.deleteById(id);
}
/**
* 修改分类
* @param categoryDTO
*/
public void update(CategoryDTO categoryDTO) {
Category category = new Category();
BeanUtils.copyProperties(categoryDTO,category);
//设置修改时间、修改人
category.setUpdateTime(LocalDateTime.now());
category.setUpdateUser(BaseContext.getCurrentId());
categoryMapper.update(category);
}
/**
* 启用、禁用分类
* @param status
* @param id
*/
public void startOrStop(Integer status, Long id) {
Category category = Category.builder()
.id(id)
.status(status)
.updateTime(LocalDateTime.now())
.updateUser(BaseContext.getCurrentId())
.build();
categoryMapper.update(category);
}
/**
* 根据类型查询分类
* @param type
* @return
*/
public List<Category> list(Integer type) {
return categoryMapper.list(type);
}
}
sky-server com/sky/mapper/CategoryMapper.java
package com.sky.mapper;
import com.github.pagehelper.Page;
import com.sky.enumeration.OperationType;
import com.sky.dto.CategoryPageQueryDTO;
import com.sky.entity.Category;
import org.apache.ibatis.annotations.Delete;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface CategoryMapper {
/**
* 插入数据
* @param category
*/
@Insert("insert into category(type, name, sort, status, create_time, update_time, create_user, update_user)" +
" VALUES" +
" (#{type}, #{name}, #{sort}, #{status}, #{createTime}, #{updateTime}, #{createUser}, #{updateUser})")
void insert(Category category);
/**
* 分页查询
* @param categoryPageQueryDTO
* @return
*/
Page<Category> pageQuery(CategoryPageQueryDTO categoryPageQueryDTO);
/**
* 根据id删除分类
* @param id
*/
@Delete("delete from category where id = #{id}")
void deleteById(Long id);
/**
* 根据id修改分类
* @param category
*/
void update(Category category);
/**
* 根据类型查询分类
* @param type
* @return
*/
List<Category> list(Integer type);
}
sky-server mapper/CategoryMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.CategoryMapper">
<select id="pageQuery" resultType="com.sky.entity.Category">
select * from category
<where>
<if test="name != null and name != ''">
and name like concat('%',#{name},'%')
</if>
<if test="type != null">
and type = #{type}
</if>
</where>
order by sort asc , create_time desc
</select>
<update id="update" parameterType="Category">
update category
<set>
<if test="type != null">
type = #{type},
</if>
<if test="name != null">
name = #{name},
</if>
<if test="sort != null">
sort = #{sort},
</if>
<if test="status != null">
status = #{status},
</if>
<if test="updateTime != null">
update_time = #{updateTime},
</if>
<if test="updateUser != null">
update_user = #{updateUser}
</if>
</set>
where id = #{id}
</update>
<select id="list" resultType="Category">
select * from category
where status = 1
<if test="type != null">
and type = #{type}
</if>
order by sort asc,create_time desc
</select>
</mapper>
sky-server com/sky/mapper/DishMapper.java
package com.sky.mapper;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
@Mapper
public interface DishMapper {
/**
* 根据分类id查询菜品数量
* @param categoryId
* @return
*/
@Select("select count(id) from dish where category_id = #{categoryId}")
Integer countByCategoryId(Long categoryId);
}
sky-server com/sky/mapper/SetmealMapper.java
package com.sky.mapper;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
@Mapper
public interface SetmealMapper {
/**
* 根据分类id查询套餐的数量
* @param id
* @return
*/
@Select("select count(id) from setmeal where category_id = #{categoryId}")
Integer countByCategoryId(Long id);
}
菜品管理
公共字段自动填充
业务表中的公共字段:(后期会很多[菜品/套餐管理])
问题:代码冗余不利于后期维护
| 序号 |
字段名 |
含义 |
数据类型 |
| 1 |
create_time |
创建时间 |
datetime |
| 2 |
create_user |
创建人id |
bigint |
| 3 |
update_time |
修改时间 |
datetime |
| 4 |
update_user |
修改人id |
bigint |
解决:技术点 → 枚举、注解、AOP、反射
| 序号 |
字段名 |
含义 |
数据类型 |
操作类型 |
| 1 |
create_time |
创建时间 |
datetime |
insert |
| 2 |
create_user |
创建人id |
bigint |
insert |
| 3 |
update_time |
修改时间 |
datetime |
insert、update |
| 4 |
update_user |
修改人id |
bigint |
insert、update |
- 自定义注解 AutoFill,用于标识需要进行公共字段自动填充的方法
- 自定义切面 AutoFillAspect,统一拦截加入了 AutoFill 注解的方法,通过反射为公共字段赋值
- 在 Mapper 的方法上加入 AutoFill 注解
代码开发1
sky-server com/sky/annotation/AutoFill.java
package com.sky.annotation;
import com.sky.enumeration.OperationType;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* 自定义注解,用于标识某个方法需要进行功能字段自动填充处理
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface AutoFill {
// 枚举数据库操作类型:UPDATE INSERT [只要在这情况才有必要设置]
OperationType value();
}
sky-server com/sky/aspect/AutoFillAspect.java
package com.sky.aspect;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
/**
* 自定义切面,实现公共字段自动填充处理逻辑
*/
@Aspect
@Component
@Slf4j
public class AutoFillAspect {
/**
* 切入点
*/
// 拦截类 + 注解的东西
@Pointcut("execution(* com.sky.mapper.*.*(..)) && @annotation(com.sky.annotation.AutoFill)")
public void autoFillPointCut(){}
// 前置通知,在通知中进行公共字段的赋值
@Before("autoFillPointCut()")
public void autoFill(JoinPoint joinPoint) {
log.info("开始公共字段自动填充...");
}
}
sky-server com/sky/mapper/EmployeeMapper.java
//只在update和insert里加
@Mapper
public interface EmployeeMapper {
/**
* 插入员工数据
* @param employee
*/
@Insert("insert into employee (name, username, password, phone, sex, id_number, create_time, update_time, create_user, update_user,status) " +
"values " +
"(#{name},#{username},#{password},#{phone},#{sex},#{idNumber},#{createTime},#{updateTime},#{createUser},#{updateUser},#{status})")
@AutoFill(value = OperationType.INSERT)
void insert(Employee employee);
/**
* 分页查询 [动态sql 不用注解了 写道 EmployeeMapper.xml]
* @param employeePageQueryDTO
* @return
*/
Page<Employee> pageQuery(EmployeePageQueryDTO employeePageQueryDTO);
@AutoFill(value = OperationType.UPDATE)
}
sky-server com/sky/mapper/CategoryMapper.java
package com.sky.mapper;
import com.github.pagehelper.Page;
import com.sky.annotation.AutoFill;
import com.sky.enumeration.OperationType;
import com.sky.dto.CategoryPageQueryDTO;
import com.sky.entity.Category;
import org.apache.ibatis.annotations.Delete;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface CategoryMapper {
/**
* 插入数据
* @param category
*/
@Insert("insert into category(type, name, sort, status, create_time, update_time, create_user, update_user)" +
" VALUES" +
" (#{type}, #{name}, #{sort}, #{status}, #{createTime}, #{updateTime}, #{createUser}, #{updateUser})")
void insert(Category category);
/**
* 根据id修改分类
* @param category
*/
void update(Category category);
}
详细讲解@AutoFill
@Target(ElementType.METHOD)
使用@Target注解指定自定义注解@AutoFill可以应用的目标元素类,这里指定了ElementType.METHOD,表示@AutoFill**只能应用于方法上**
@Retention(RetentionPolicy.RUNTIME)
使用 @Retention 注解指定自定义注解 @AutoFill 的保留策略。这里指定了 RetentionPolicy.RUNTIME,表示 @AutoFill 注解会在运行时保留,可以通过反射获取到。
public @interface AutoFill {…}
@interface:关键字,用于定义一个新的注解类型。
AutoFill:注解的名称,表示这个注解就叫做AutoFill
区分普通接口:@interface 与普通的 interface 不同,普通的interface用于定义接口,而@interface用于定义注解,@符号帮助编译器区分这两者
package com.sky.enumeration;
/**
* 数据库操作类型
*/
public enum OperationType {
/**
* 更新操作
*/
UPDATE,
/**
* 插入操作
*/
INSERT
}
@Aspect
使用@Aspect注解将这个类标记为一个切面,切面是AOP(面向切面编程),用于定义切面关注点(日志记录、事务管理)
@Component
使用@Component注解将这个类标记为Spring管理的Bean,这样Spring容器会自动扫描并管理这个类的实例
@Slf4j
使用 @Slf4j 注解生成一个日志记录器(Logger)实例。这个注解来自 Lombok 库,可以简化日志记录器的创建
@Pointcut("execution(* com.sky.mapper.*.*(..)) && @annotation(com.sky.annotation.AutoFill)")
public void autoFillPointCut(){}
使用@Pointcut注解定义一个切入点autoFillPointCut
execution(* com.sky.mapper.*.*(..)):匹配com.sky.mapper包下所有类的所有方法&& @annotation(com.sky.annotation.AutoFill):并且这些方法必须带有@AutoFill注解- public void autoFillPointCut():定义一个空的方法,用于标识这个切入点
/**
* 自定义切面,实现公共字段自动填充处理逻辑
*/
@Aspect
@Component
@Slf4j
public class AutoFillAspect {
/**
* 切入点
*/
// 拦截类 + 注解的东西
@Pointcut("execution(* com.sky.mapper.*.*(..)) && @annotation(com.sky.annotation.AutoFill)")
public void autoFillPointCut(){}
// 前置通知,在通知中进行公共字段的赋值
@Before("autoFillPointCut()")
public void autoFill(JoinPoint joinPoint) {
log.info("开始公共字段自动填充...");
}
}
使用@Before注解定义一个前置通知autoFill,这个通知会在切入点方法执行前被调用
@Before("autoFillPointCut()"):指定这个通知应用于autoFillPointCut切入点public void autoFill(JoinPoint joinPoint):定义通知方法,接收一个JoinPoint参数,JoinPoint包含了连接点的信息,如被拦截的方法、参数等
代码开发2
公共属性赋值后 Service里的 save(Employee employee) → employee.setCreateUser(BaseContext.getCurrentId())就不用再去赋值了
这个写完后 就可以把Service里的一些employee.setXXX的删除了 因为公共属性只需要加@AutoFill
sky-server com/sky/annotation/AutoFill.java 不变
sky-server com/sky/aspect/AutoFillAspect.java
package com.sky.aspect;
import com.sky.annotation.AutoFill;
import com.sky.constant.AutoFillConstant;
import com.sky.context.BaseContext;
import com.sky.enumeration.OperationType;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.Signature;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.stereotype.Component;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.time.LocalDateTime;
/**
* 自定义切面,实现公共字段自动填充处理逻辑
*/
@Aspect
@Component
@Slf4j
public class AutoFillAspect {
/**
* 切入点
*/
// 拦截类 + 注解的东西
@Pointcut("execution(* com.sky.mapper.*.*(..)) && @annotation(com.sky.annotation.AutoFill)")
public void autoFillPointCut(){}
// 前置通知,在通知中进行公共字段的赋值
@Before("autoFillPointCut()")
public void autoFill(JoinPoint joinPoint) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
log.info("开始公共字段自动填充...");
// 获取当前被拦截的方法上的数据库操作类型(Update/Insert)
MethodSignature signature = (MethodSignature)joinPoint.getSignature(); //方法签名对象
AutoFill autoFill = signature.getMethod().getAnnotation(AutoFill.class); //获得方法上的注解对象
OperationType operationType = autoFill.value();//获得数据库操作类型
// 获取当当前被拦截的方法的参数--实体对象 (Employee employee)
Object[] args = joinPoint.getArgs();
if (args == null || args.length == 0) { //没有参数不执行
return;
}
Object entity = args[0]; //获得第一个
// 准备赋值数据
LocalDateTime now = LocalDateTime.now();
Long currentId = BaseContext.getCurrentId();
// 根据当前不同的操作类型,对对应的属性通过反射来赋值
if (operationType == OperationType.INSERT) {
// 为4个公共字段赋值
Method setCreateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_CREATE_TIME, LocalDateTime.class);
Method setCreateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_CREATE_USER, Long.class);
Method setUpdateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_TIME, LocalDateTime.class);
Method setUpdateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_USER, Long.class);
//通过反射对对象赋值属性
setCreateTime.invoke(entity,now);
setCreateUser.invoke(entity,currentId);
setUpdateTime.invoke(entity,now);
setUpdateUser.invoke(entity,currentId);
} else if (operationType == OperationType.UPDATE) {
// 为2个公共字段赋值
Method setUpdateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_TIME, LocalDateTime.class);
Method setUpdateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_USER, Long.class);
//通过反射对对象赋值属性
setUpdateTime.invoke(entity,now);
setUpdateUser.invoke(entity,currentId);
}
}
}
新增菜品
业务规则:
- 菜品名称必须是唯一的
- 菜品必须属于某个分类下,不能单独存在
- 新增菜品时可以根据选择情况菜品的口味
- 每个菜品必须对应一张图片
接口设计:
数据库设计:
- dish菜品表 [一个菜品对应着多种口味]
- dish_flavour口味表
开发文件上传接口:
浏览器 → 后端服务 → 阿里云OSS
sky-common com/sky/utils/AliOssUtil.java
package com.sky.utils;
import com.aliyun.oss.ClientException;
import com.aliyun.oss.OSS;
import com.aliyun.oss.OSSClientBuilder;
import com.aliyun.oss.OSSException;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import java.io.ByteArrayInputStream;
@Data
@AllArgsConstructor
@Slf4j
public class AliOssUtil {
// 通过配置类初始化这些数据
private String endpoint;
private String accessKeyId;
private String accessKeySecret;
private String bucketName;
/**
* 文件上传
*
* @param bytes
* @param objectName
* @return
*/
public String upload(byte[] bytes, String objectName) {
// 创建OSSClient实例。 将字节数组转换为输入流,并将其上传到指定的bucket和objectName
OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret);
try {
// 创建PutObject请求。
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(bytes));
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message:" + ce.getMessage());
} finally {
if (ossClient != null) {
ossClient.shutdown();
}
}
//文件访问路径规则 https://BucketName.Endpoint/ObjectName
StringBuilder stringBuilder = new StringBuilder("https://");
stringBuilder
.append(bucketName)
.append(".")
.append(endpoint)
.append("/")
.append(objectName);
log.info("文件上传成功,访问路径:{}", stringBuilder);
return stringBuilder.toString();
}
}
sky-common com/sky/constant/AutoFillConstant.java
package com.sky.constant;
/**
* 公共字段自动填充相关常量
*/
public class AutoFillConstant {
/**
* 实体类中的方法名称
*/
public static final String SET_CREATE_TIME = "setCreateTime";
public static final String SET_UPDATE_TIME = "setUpdateTime";
public static final String SET_CREATE_USER = "setCreateUser";
public static final String SET_UPDATE_USER = "setUpdateUser";
}
application-dev.yml
sky:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
host: localhost
port: 3306
database: sky_take_out
username: root
password: root
alioss:
endpoint: XXXXXXXXX
access-key-id: XXXXXXXXXXXX
access-key-secret: XXXXXXXXXXX
bucketName: XXXXXXXXX
sky-server com/sky/controller/admin/CommonController.java
package com.sky.controller.admin;
import com.sky.result.Result;
import com.sky.utils.AliOssUtil;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.util.UUID;
/**
* 通用接口
*/
@RestController
@RequestMapping("/admin/common")
@Api(tags = "通用接口")
@Slf4j
public class CommonController {
@Autowired
private AliOssUtil aliOssUtil;
@PostMapping("/upload")
@ApiOperation("文件上传")
// 如果要测试文件上传 只能用postman或者前后端联调
public Result<String> upload(MultipartFile file) {
log.info("文件上传:{}", file);
// 防止重名覆盖
try {
// 原始文件名
String filename = file.getOriginalFilename();
// 截取原始文件名的后缀
String extension = filename.substring(filename.lastIndexOf("."));
// 构造新文件名UUID
String objectName = UUID.randomUUID().toString() + extension;
// 文件的请求路径
String filepath = aliOssUtil.upload(file.getBytes(), objectName);
log.info("文件上传成功,访问路径:{}", filepath);
return Result.success(filepath);
} catch (IOException e) {
log.error("文件上传失败:{}", e);
}
return Result.error(MessageConstant.UPLOAD_FAILED);
}
}
如何让application.yml识别到我在application-dev.yml里设置的值呢?
server:
port: 8080
spring:
profiles:
active: dev
你已经在 application.yml 中指定了 spring.profiles.active: dev,这样在启动应用程序时,Spring Boot 会自动加载 application-dev.yml 中的配置
如果你使用的是 IDE(如 IntelliJ IDEA 或 Eclipse),你可以在运行配置中指定激活的环境配置文件。例如,在 IntelliJ IDEA 中:
打开 Run -> Edit Configurations。
选择你的应用程序配置。
在 VM options 中添加 -Dspring.profiles.active=dev。
# 在 VM options 中配置的原理:
在 VM options 中添加 -Dspring.profiles.active=dev 的原理是通过 Java 虚拟机(JVM)的系统属性来设置 Spring Boot 应用程序的活动配置文件。以下是详细的解释:
原理
JVM 系统属性:
JVM 提供了一种机制,允许你在启动时通过命令行参数传递系统属性。这些系统属性可以在应用程序中通过 System.getProperty 方法访问。
-D 前缀用于设置系统属性。例如,-Dkey=value 会将 key 设置为 value。
Spring Boot 配置:
Spring Boot 会读取 spring.profiles.active 系统属性来确定当前激活的配置文件。
当你通过 -Dspring.profiles.active=dev 设置系统属性时,Spring Boot 会在启动时读取这个属性,并根据其值加载相应的配置文件(如 application-dev.yml)。
新增菜品重要代码
sky-pojo com/sky/dto/DishDTO.java
package com.sky.dto;
import com.sky.entity.DishFlavor;
import lombok.Data;
import java.io.Serializable;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
@Data
public class DishDTO implements Serializable {
//dish属性封装成dto
private Long id;
//菜品名称
private String name;
//菜品分类id
private Long categoryId;
//菜品价格
private BigDecimal price;
//图片
private String image;
//描述信息
private String description;
//0 停售 1 起售
private Integer status;
//口味[因为有多种口味要区分]
private List<DishFlavor> flavors = new ArrayList<>();
}
sky-pojo com/sky/entity/DishFlavor.java
package com.sky.entity;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
/**
* 菜品口味
*/
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class DishFlavor implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
//菜品id
private Long dishId;
//口味名称
private String name;
//口味数据list
private String value;
}
sky-server com/sky/controller/admin/DishController.java
package com.sky.controller.admin;
import com.sky.dto.DishDTO;
import com.sky.result.Result;
import com.sky.service.DishService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 菜品管理
*/
@RestController
@RequestMapping("/admin/dish")
@Api(tags = "菜品相关接口")
@Slf4j
public class DishController {
@Autowired
private DishService dishService;
@PostMapping
@ApiOperation("新增菜品")
//@RequestBody 封装JSON格式的数据
public Result save(@RequestBody DishDTO dishDTO) {
log.info("新增菜品:{}", dishDTO);
dishService.saveWithFlavour(dishDTO);
return Result.success();
}
}
com/sky/service/DishService.java
package com.sky.service;
import com.sky.dto.DishDTO;
public interface DishService {
/**
* 新增菜品和对应的口味
* @param dishDTO
*/
public void saveWithFlavour(DishDTO dishDTO);
}
com/sky/service/impl/DishServiceImpl.java
package com.sky.service.impl;
import com.sky.dto.DishDTO;
import com.sky.entity.Dish;
import com.sky.entity.DishFlavor;
import com.sky.mapper.DishFlavorMapper;
import com.sky.mapper.DishMapper;
import com.sky.service.DishService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
@Service
@Slf4j
public class DishServiceImpl implements DishService {
@Autowired
private DishMapper dishMapper;
@Autowired
private DishFlavorMapper dishFlavorMapper;
/**
* 新增菜品和对应的口味
* @param dishDTO
*/
@Override
@Transactional //保证事务一致性
public void saveWithFlavour(DishDTO dishDTO) {
Dish dish = new Dish();
//直接new出来是空的需要先赋值 属性拷贝[属性命名要一致]
BeanUtils.copyProperties(dishDTO,dish);
// 向菜品表插入1条数据
dishMapper.insert(dish);
// 前端无法传 要获取dishId
// <insert id="insertBatch" useGeneratedKeys="true" keyProperty="id"> 获取主键值
Long dishId = dish.getId();
List<DishFlavor> flavors = dishDTO.getFlavors();
if (flavors != null && flavors.size() > 0) {
flavors.forEach(dishFlavor -> {
dishFlavor.setDishId(dishId);
});
// 向口味表插入n条数据 集合对象批量传入不用集合
dishFlavorMapper.insertBatch(flavors);
}
}
}
sky-server com/sky/mapper/DishMapper.java
package com.sky.mapper;
import com.sky.annotation.AutoFill;
import com.sky.entity.Dish;
import com.sky.enumeration.OperationType;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
@Mapper
public interface DishMapper {
/**
* 根据分类id查询菜品数量
* @param categoryId
* @return
*/
@Select("select count(id) from dish where category_id = #{categoryId}")
Integer countByCategoryId(Long categoryId);
/**
* 插入菜品数据
*/
@AutoFill(value = OperationType.INSERT)
void insert(Dish dish);
}
sky-server mapper/DishMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.DishMapper">
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
insert into dish (name, category_id, price, image, description, create_time, update_time, create_user,
update_user, status)
values (#{name}, #{categoryId}, #{price}, #{image}, #{description}, #{createTime}, #{updateTime}, #{createUser},
#{updateUser}, #{status})
</insert>
</mapper>
sky-server com/sky/mapper/DishFlavorMapper.java
package com.sky.mapper;
import com.sky.entity.DishFlavor;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface DishFlavorMapper {
/**
* 批量插入口味数据
*/
void insertBatch(List<DishFlavor> flavors);
}
sky-server mapper/DishFlavorMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.DishFlavorMapper">
<insert id="insertBatch" useGeneratedKeys="true" keyProperty="id">
insert into dish_flavor (dish_id, name, value) values
<foreach collection="flavors" item="df" separator=",">
(#{df.dishId},#{df.name},#{df.value})
</foreach>
</insert>
</mapper>
菜品分页查询
菜品名称[ ] 菜品分类[ ] 售卖状态[ ] [搜索]
菜品名称、图片、菜品分类、售价、售卖状态、最后操作事件、操作[修改 删除 启售,停售]
右下角 分页操作
业务规则:
- 根据页码展示菜品信息
- 每页展示10条数据
- 分页查询时可以根据需要输入菜品名称、菜品分类、菜品状态进行查询
接口设计:
Path:/admin/dish/page
Method:GET
代码开发:
根据菜品分页查询接口定义设计对应的DTO
根据菜品分页查询接口定义设计对应的VO[转成Json数据给前端]
sky-server com/sky/controller/admin/DishController.java
@GetMapping("/page")
@ApiOperation("菜品分页查询")
public Result<PageResult> page(DishPageQueryDTO dishPageQueryDTO){
log.info("菜品分页查询:{}", dishPageQueryDTO);
PageResult pageResult = dishService.pageQuery(dishPageQueryDTO);
return Result.success(pageResult);
}
sky-server com/sky/service/DishService.java
package com.sky.service;
import com.sky.dto.DishDTO;
import com.sky.dto.DishPageQueryDTO;
import com.sky.result.PageResult;
public interface DishService {
/**
* 新增菜品和对应的口味
* @param dishDTO
*/
public void saveWithFlavour(DishDTO dishDTO);
/**
* 菜品分页查询
* @param dishPageQueryDTO
* @return
*/
PageResult pageQuery(DishPageQueryDTO dishPageQueryDTO);
}
sky-server com/sky/service/impl/DishServiceImpl.java
@Service
@Slf4j
public class DishServiceImpl implements DishService {
@Autowired
private DishMapper dishMapper;
@Autowired
private DishFlavorMapper dishFlavorMapper;
@Override
public PageResult pageQuery(DishPageQueryDTO dishPageQueryDTO) {
// 1. 开启分页功能,设置当前页和每页显示的数量
PageHelper.startPage(dishPageQueryDTO.getPage(), dishPageQueryDTO.getPageSize());
// 2. 调用 dishMapper 的 pageQuery 方法进行分页查询,返回一个 Page<DishVO> 对象
Page<DishVO> page = dishMapper.pageQuery(dishPageQueryDTO);
// 3. 创建并返回 PageResult 对象,包含总记录数和查询结果列表
return new PageResult(page.getTotal(), page.getResult());
}
}
sky-server com/sky/mapper/DishMapper.java
/**
* 菜品分页查询
* @param dishPageQueryDTO
* @return
*/
Page<DishVO> pageQuery(DishPageQueryDTO dishPageQueryDTO);
sky-server mapper/DishMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.DishMapper">
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
insert into dish (name, category_id, price, image, description, create_time, update_time, create_user,
update_user, status)
values (#{name}, #{categoryId}, #{price}, #{image}, #{description}, #{createTime}, #{updateTime}, #{createUser},
#{updateUser}, #{status})
</insert>
<select id="pageQuery" resultType="com.sky.vo.DishVO">
select d.*, c.name as categoryName
from dish d
left join category c
on d.category_id=c.id
<where>
<if test="name != null and name != ''">
and d.name like concat('%',#{name},'%')
</if>
<if test="categoryId != null">
and d.category_id = #{categoryId}
</if>
<if test="status != null">
and d.status = #{status}
</if>
</where>
order by d.update_time desc
</select>
</mapper>
分页查询SQL语句分析
<select id="pageQuery" resultType="com.sky.vo.DishVO">
select d.*, c.name as categoryName
from dish d
left join category c
on d.category_id=c.id
<where>
<if test="name != null and name != ''">
and d.name like concat('%',#{name},'%')
</if>
<if test="categoryId != null">
and d.category_id = #{categoryId}
</if>
<if test="status != null">
and d.status = #{status}
</if>
</where>
order by d.update_time desc
</select>
从 dish 表中选择所有列,并从 category 表中选择 name 列,别名为 categoryName。
使用左连接 (left join) 将 dish 表和 category 表连接起来,连接条件是 d.category_id = c.id。
动态生成WHERE子句,< where >标签会自动处理AND和OR关键字的添加,并且会忽略第一个条件前的ADN和OR
删除菜品
单个删除、批量删除、先停售后删除
业务规则:
Path: /admin/dish
Method: DELETE
数据库设计:
dish表 → id 【菜品】
dish_flavor表 → dish_id 【口味】
setmeal_dish表 → dish_id
- 起售中的菜品不能删除
- 被套餐关联的菜品不能删除
- 删除菜品后,关联的口味数据也需要删除
代码开发:
sky-server com/sky/controller/admin/DishController.java
/**
* 菜品的批量删除
* @param ids
* @return
*/
@DeleteMapping
@ApiOperation("批量删除菜品")
//@RequestParam MVC动态解析字符串 ids提取出来
public Result delete(@RequestParam List<Long> ids) { //ids
log.info("批量删除菜品:{}", ids);
dishService.deleteBatch(ids);
return Result.success();
}
sky-server com/sky/service/DishService.java
/**
* 菜品的批量删除
* @param ids
* @return
*/
void deleteBatch(List<Long> ids);
sky-server com/sky/service/impl/DishServiceImpl.java
/**
* 菜品的批量删除
* @param ids
* @return
*/
@Override
public void deleteBatch(List<Long> ids) {
// 判断当前菜品是否能够删除--是否存在起售中的菜品?? 取出id
for (Long id : ids) {
Dish dish = dishMapper.getById(id);
if (dish.getStatus() == StatusConstant.ENABLE) {
//当前菜品处于起售中,不能删除
throw new DeletionNotAllowedException(MessageConstant.DISH_ON_SALE);
}
}
// 判断当前菜品是否能够删除--是否被套餐关联了
List<Long> setMealIds = setmealDishMapper.getSetmealIdsByDishId(ids);
if (setMealIds != null && setMealIds.size() > 0) { //存在不允许删除
// 当前菜品被套餐关联了,不能删除
throw new DeletionNotAllowedException(MessageConstant.DISH_BE_RELATED_BY_SETMEAL);
}
// 删除菜品表中的菜品数据
for (Long id : ids) {
dishMapper.deleteById(id);
// 删除菜品关联的口味数据
dishFlavorMapper.deleteByDishId(id);
}
}
sky-server com/sky/mapper/DishMapper.java
/**
* 根据主键删除菜品数据
*/
@Delete("delete from dish where id = #{id}")
void deleteById(Long id);
sky-server com/sky/mapper/DishFlavorMapper.java
/**
* 根据菜品id删除对应的 口味数据
* @param id
*/
@Delete("delete from dish_flavor where dish_id = #{id}")
void deleteByDishId(Long id);
sky-server com/sky/mapper/SetmealDishMapper.java
package com.sky.mapper;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface SetmealDishMapper {
/**
* 根据菜品id查询对应的套餐id
* @param dishIds
* @return
*/
// select setmeal_id from setmeal_dish where dish_id in (1,2,3)
// 在mapper.xml中dishIds是形参 <foreach collection="dishIds">
List<Long> getSetmealIdsByDishId(List<Long> dishIds);
}
sky-server mapper/SetmealDishMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.SetmealDishMapper">
<select id="getSetmealIdsByDishId" resultType="java.lang.Long">
SELECT setmeal_id
FROM setmeal_dish
WHERE dish_id IN
<foreach collection="dishIds" item="dishId" open="(" separator="," close=")">
#{dishId}
</foreach>
</select>
</mapper>
<!--
★ foreach 标签用于遍历集合,并生成相应的 SQL 语句。
★ collection="dishIds":指定要遍历的集合名称,即传入的参数 dishIds。
★ item="dishId":指定集合中的每个元素的别名,即每次迭代时的变量名。
★ separator=",":指定每个元素之间的分隔符,这里是逗号 ,。
★ open="(" 和 close=")":指定生成的 SQL 语句的开始和结束符号,这里是括号 ( 和 )。
-->
@RequestParm详细分析
public Result delete(@RequestParam List<Long> ids)
@RequestParam:注解用于将请求参数绑定到方法参数上。具体来说,它可以从请求的查询参数中提取出指定的参数值,并将其转换为方法参数的类型;在这个例子中,@RequestParam List ids 表示从请求的查询参数中提取 ids 参数,并将其转换为 List 类型。
修改菜品
数据回显
接口设计:
口味也要回显
Path: /admin/dish/{id}
Method:GET
- 根据类型查询分类(已实现)
- 文件上传(已实现)
- 修改菜品
根据ID修改
Path:/admin/dish
Method:PUT
代码开发:
根据id查询菜品进行信息回显
sky-server com/sky/controller/admin/DishController.java
/**
* 根据id查询菜品和对应的口味数据
* @param id
* @return
*/
@GetMapping("/{id}")
@ApiOperation("根据id查询菜品")
// @PathVariable 注解用于从 URL 路径中的占位符参数中提取值,并将其绑定到方法参数上
public Result<DishVO> getById(@PathVariable long id) {
log.info("根据id查询菜品:{}", id);
DishVO dishVO = dishService.getByIdWithFlavor(id);
return Result.success(dishVO);
}
sky-server com/sky/service/DishService.java
/**
* 根据id查询菜品和对应的口味数据
* @param id
* @return
*/
DishVO getByIdWithFlavor(long id);
sky-server com/sky/service/impl/DishServiceImpl.java
/**
* 根据id查询菜品和对应的口味数据
* @param id
* @return
*/
@Override
public DishVO getByIdWithFlavor(long id) {
// 根据id查询菜品数据
Dish dish = dishMapper.getById(id);
// 根据菜品id查询口味数据
List<DishFlavor> dishFlavors = dishFlavorMapper.getByDishId(id);
// 将查询到的数据封装到VO
DishVO dishVO = new DishVO();
// 属性拷贝
BeanUtils.copyProperties(dish,dishVO);
dishVO.setFlavors(dishFlavors);
return dishVO;
}
sky-server com/sky/mapper/DishFlavorMapper.java
/**
* 根据菜品id查询对应的口味数据
* @param id
* @return
*/
@Select("select * from dish_flavor where dish_id = #{id}")
List<DishFlavor> getByDishId(long id);
修改菜品接口
sky-server com/sky/controller/admin/DishController.java
/**
* 根据id修改菜品和对应的口味数据
* @param dishDTO
* @return
*/
@PutMapping
@ApiOperation("修改菜品")
public Result update(@RequestBody DishDTO dishDTO) {
log.info("修改菜品:{}", dishDTO);
dishService.updateWithFlavor(dishDTO);
return Result.success();
}
sky-server com/sky/service/DishService.java
/**
* 根据id修改菜品和对应的口味数据
* @param dishDTO
* @return
*/
void updateWithFlavor(DishDTO dishDTO);
sky-server com/sky/service/impl/DishServiceImpl.java
/**
* 根据id修改菜品和对应的口味数据
* @param dishDTO
* @return
*/
@Override
public void updateWithFlavor(DishDTO dishDTO) {
Dish dish = new Dish();
BeanUtils.copyProperties(dishDTO,dish);
// 修改菜品表基本信息 只是基础信息噢
dishMapper.update(dish);
// 先删掉原先的
dishFlavorMapper.deleteByDishId(dishDTO.getId());
// 再重新插入新的
List<DishFlavor> flavors = dishDTO.getFlavors();
if (flavors != null && flavors.size() > 0) {
flavors.forEach(dishFlavor -> {
dishFlavor.setDishId(dishDTO.getId());
});
// 向口味表插入n条数据 集合对象批量传入不用集合
dishFlavorMapper.insertBatch(flavors);
}
}
/*
这段代码中,将 dishDTO 的属性复制到 dish 对象的主要原因有以下几点:
数据模型分离:
dishDTO 通常用于数据传输,包含前端传来的所有数据。
dish 是数据库实体类,只包含数据库表中的字段。
安全性:
使用 BeanUtils.copyProperties 可以避免将不必要的字段(如前端传来的额外属性)写入数据库。
确保只有预期的字段被更新。
数据校验:
dishDTO 可以包含更多的验证逻辑或额外的属性,而 dish 对象则严格遵循数据库模型。
通过这种方式,可以在更新前对数据进行进一步校验。
事务管理:
添加 @Transactional 注解确保整个更新过程在一个事务中完成。
如果任何一步出错,整个事务都会回滚,保证数据一致性。
*/
sky-server com/sky/mapper/DishMapper.java
/**
* 根据id修改菜品和对应的口味数据
* @param dish
*/
//有时间和修改人 不要忘记自动填充
@AutoFill(value = OperationType.UPDATE)
void update(Dish dish);
sky-server mapper/DishMapper.xml
<update id="update">
update dish
<set>
<if
test="name != null and name != ''">
name = #{name},
</if>
</set>
where id = #{id}
</update>
菜品起售停售
sky-server com/sky/controller/admin/DishController.java
/**
* 菜品起售停售
*
* @param status
* @param id
* @return
*/
@PostMapping("/status/{status}")
@ApiOperation("菜品起售停售")
public Result<String> startOrStop(@PathVariable Integer status, Long id) {
dishService.startOrStop(status, id);
return Result.success();
}
sky-server com/sky/service/DishService.java
/**
* 菜品起售停售
*
* @param status
* @param id
* @return
*/
void startOrStop(Integer status, Long id);
sky-server com/sky/service/impl/DishServiceImpl.java
/**
* 菜品起售停售
* @param status
* @param id
*/
@Override
public void startOrStop(Integer status, Long id) {
Dish dish = Dish.builder()
.id(id)
.status(status)
.build();
dishMapper.update(dish);
if (status == StatusConstant.DISABLE) {
// 如果是停售操作,还需要将包含当前菜品的套餐也停售
List<Long> dishIds = new ArrayList<>();
dishIds.add(id);
// select setmeal_id from setmeal_dish where dish_id in (?,?,?)
List<Long> setmealIds = setmealDishMapper.getSetmealIdsByDishIds(dishIds);
if (setmealIds != null && setmealIds.size() > 0) {
for (Long setmealId : setmealIds) {
Setmeal setmeal = Setmeal.builder()
.id(setmealId)
.status(StatusConstant.DISABLE)
.build();
setmealMapper.update(setmeal);
}
}
}
}
sky-server com/sky/mapper/SetmealMapper.java
/**
* 根据id修改套餐
*
* @param setmeal
*/
@AutoFill(OperationType.UPDATE)
void update(Setmeal setmeal);
sky-server com/sky/mapper/DishMapper.java
/**
* 根据套餐id查询菜品
* @param setmealId
* @return
*/
@Select("select a.* from dish a left join setmeal_dish b on a.id = b.dish_id where b.setmeal_id = #{setmealId}")
List<Dish> getBySetmealId(Long setmealId);
/*
在 SQL 查询中添加筛选条件。
确保返回的结果集中,setmeal_dish 表中的 setmeal_id 字段值与传入的 setmealId 参数值相匹配,从而获取与指定套餐 ID 相关的菜品列表。
*/
sky-server mapper/SetmealMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.SetmealMapper">
<resultMap id="setmealAndDishMap" type="com.sky.vo.SetmealVO" autoMapping="true">
<result column="id" property="id"/>
<collection property="setmealDishes" ofType="SetmealDish">
<result column="sd_id" property="id"/>
<result column="setmeal_id" property="setmealId"/>
<result column="dish_id" property="dishId"/>
<result column="sd_name" property="name"/>
<result column="sd_price" property="price"/>
<result column="copies" property="copies"/>
</collection>
</resultMap>
<update id="update" parameterType="Setmeal">
update setmeal
<set>
<if test="name != null">
name = #{name},
</if>
<if test="categoryId != null">
category_id = #{categoryId},
</if>
<if test="price != null">
price = #{price},
</if>
<if test="status != null">
status = #{status},
</if>
<if test="description != null">
description = #{description},
</if>
<if test="image != null">
image = #{image},
</if>
<if test="updateTime != null">
update_time = #{updateTime},
</if>
<if test="updateUser != null">
update_user = #{updateUser}
</if>
</set>
where id = #{id}
</update>
</mapper>
@Mapper
public interface SetmealDishMapper {
/**
* 根据菜品id查询对应的套餐id
* @param dishIds
* @return
*/
// select setmeal_id from setmeal_dish where dish_id in (1,2,3)
// 在mapper.xml中dishIds是形参 <foreach collection="dishIds">
List<Long> getSetmealIdsByDishIds(List<Long> dishIds);
SetmealDishMapper.xml
<select id="getSetmealIdsByDishIds" resultType="java.lang.Long">
select setmeal_id from setmeal_dish where dish_id in
<foreach collection="dishIds" item="dishId" separator="," open="(" close=")">
#{dishId}
</foreach>
</select>
修改套餐那些事
sky-server com/sky/controller/admin/SetmealController.java
package com.sky.controller.admin;
import com.sky.dto.SetmealDTO;
import com.sky.dto.SetmealPageQueryDTO;
import com.sky.result.PageResult;
import com.sky.result.Result;
import com.sky.service.SetmealService;
import com.sky.vo.SetmealVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.annotation.CacheEvict;
import org.springframework.web.bind.annotation.*;
import java.util.List;
/**
* 套餐管理
*/
@RestController
@RequestMapping("/admin/setmeal")
@Api(tags = "套餐相关接口")
@Slf4j
public class SetmealController {
@Autowired
private SetmealService setmealService;
/**
* 新增套餐
*
* @param setmealDTO
* @return
*/
@PostMapping
@ApiOperation("新增套餐")
@CacheEvict(cacheNames = "setmealCache",key = "#setmealDTO.categoryId")//key: setmealCache::100
public Result save(@RequestBody SetmealDTO setmealDTO) {
setmealService.saveWithDish(setmealDTO);
return Result.success();
}
/**
* 分页查询
*
* @param setmealPageQueryDTO
* @return
*/
@GetMapping("/page")
@ApiOperation("分页查询")
public Result<PageResult> page(SetmealPageQueryDTO setmealPageQueryDTO) {
PageResult pageResult = setmealService.pageQuery(setmealPageQueryDTO);
return Result.success(pageResult);
}
/**
* 批量删除套餐
*
* @param ids
* @return
*/
@DeleteMapping
@ApiOperation("批量删除套餐")
@CacheEvict(cacheNames = "setmealCache",allEntries = true)
public Result delete(@RequestParam List<Long> ids) {
setmealService.deleteBatch(ids);
return Result.success();
}
/**
* 根据id查询套餐,用于修改页面回显数据
*
* @param id
* @return
*/
@GetMapping("/{id}")
@ApiOperation("根据id查询套餐")
public Result<SetmealVO> getById(@PathVariable Long id) {
SetmealVO setmealVO = setmealService.getByIdWithDish(id);
return Result.success(setmealVO);
}
/**
* 修改套餐
*
* @param setmealDTO
* @return
*/
@PutMapping
@ApiOperation("修改套餐")
@CacheEvict(cacheNames = "setmealCache",allEntries = true)
public Result update(@RequestBody SetmealDTO setmealDTO) {
setmealService.update(setmealDTO);
return Result.success();
}
/**
* 套餐起售停售
*
* @param status
* @param id
* @return
*/
@PostMapping("/status/{status}")
@ApiOperation("套餐起售停售")
@CacheEvict(cacheNames = "setmealCache",allEntries = true)
public Result startOrStop(@PathVariable Integer status, Long id) {
setmealService.startOrStop(status, id);
return Result.success();
}
}
sky-server com/sky/service/SetmealService.java
package com.sky.service;
import com.sky.dto.SetmealDTO;
import com.sky.dto.SetmealPageQueryDTO;
import com.sky.entity.Setmeal;
import com.sky.result.PageResult;
import com.sky.vo.DishItemVO;
import com.sky.vo.SetmealVO;
import java.util.List;
public interface SetmealService {
/**
* 新增套餐,同时需要保存套餐和菜品的关联关系
*
* @param setmealDTO
*/
void saveWithDish(SetmealDTO setmealDTO);
/**
* 分页查询
*
* @param setmealPageQueryDTO
* @return
*/
PageResult pageQuery(SetmealPageQueryDTO setmealPageQueryDTO);
/**
* 批量删除套餐
*
* @param ids
*/
void deleteBatch(List<Long> ids);
/**
* 根据id查询套餐和关联的菜品数据
*
* @param id
* @return
*/
SetmealVO getByIdWithDish(Long id);
/**
* 修改套餐
*
* @param setmealDTO
*/
void update(SetmealDTO setmealDTO);
/**
* 套餐起售、停售
*
* @param status
* @param id
*/
void startOrStop(Integer status, Long id);
/**
* 条件查询
* @param setmeal
* @return
*/
List<Setmeal> list(Setmeal setmeal);
/**
* 根据id查询菜品选项
* @param id
* @return
*/
List<DishItemVO> getDishItemById(Long id);
}
sky-server com/sky/service/impl/SetmealServiceImpl.java
package com.sky.service.impl;
import com.github.pagehelper.Page;
import com.github.pagehelper.PageHelper;
import com.sky.constant.MessageConstant;
import com.sky.constant.StatusConstant;
import com.sky.dto.SetmealDTO;
import com.sky.dto.SetmealPageQueryDTO;
import com.sky.entity.Dish;
import com.sky.entity.Setmeal;
import com.sky.entity.SetmealDish;
import com.sky.exception.DeletionNotAllowedException;
import com.sky.exception.SetmealEnableFailedException;
import com.sky.mapper.DishMapper;
import com.sky.mapper.SetmealDishMapper;
import com.sky.mapper.SetmealMapper;
import com.sky.result.PageResult;
import com.sky.service.SetmealService;
import com.sky.vo.DishItemVO;
import com.sky.vo.SetmealVO;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
/**
* 套餐业务实现
*/
@Service
@Slf4j
public class SetmealServiceImpl implements SetmealService {
@Autowired
private SetmealMapper setmealMapper;
@Autowired
private SetmealDishMapper setmealDishMapper;
@Autowired
private DishMapper dishMapper;
/**
* 新增套餐,同时需要保存套餐和菜品的关联关系
*
* @param setmealDTO
*/
@Transactional
public void saveWithDish(SetmealDTO setmealDTO) {
Setmeal setmeal = new Setmeal();
BeanUtils.copyProperties(setmealDTO, setmeal);
//向套餐表插入数据
setmealMapper.insert(setmeal);
//获取生成的套餐id
Long setmealId = setmeal.getId();
List<SetmealDish> setmealDishes = setmealDTO.getSetmealDishes();
setmealDishes.forEach(setmealDish -> {
setmealDish.setSetmealId(setmealId);
});
//保存套餐和菜品的关联关系
setmealDishMapper.insertBatch(setmealDishes);
}
/**
* 分页查询
*
* @param setmealPageQueryDTO
* @return
*/
public PageResult pageQuery(SetmealPageQueryDTO setmealPageQueryDTO) {
int pageNum = setmealPageQueryDTO.getPage();
int pageSize = setmealPageQueryDTO.getPageSize();
PageHelper.startPage(pageNum, pageSize);
Page<SetmealVO> page = setmealMapper.pageQuery(setmealPageQueryDTO);
return new PageResult(page.getTotal(), page.getResult());
}
/**
* 批量删除套餐
*
* @param ids
*/
@Transactional
public void deleteBatch(List<Long> ids) {
ids.forEach(id -> {
Setmeal setmeal = setmealMapper.getById(id);
if (StatusConstant.ENABLE == setmeal.getStatus()) {
//起售中的套餐不能删除
throw new DeletionNotAllowedException(MessageConstant.SETMEAL_ON_SALE);
}
});
ids.forEach(setmealId -> {
//删除套餐表中的数据
setmealMapper.deleteById(setmealId);
//删除套餐菜品关系表中的数据
setmealDishMapper.deleteBySetmealId(setmealId);
});
}
/**
ids.forEach(id -> { ... }):对ids集合中的每个元素id执行大括号内的操作。
id -> { ... }:定义了一个接受单个参数id的函数,并执行大括号内的逻辑。
在大括号内,根据id查询数据库获取套餐信息,并检查其状态,若状态符合启用条件,则抛出异常。
**/
/**
* 根据id查询套餐和套餐菜品关系
*
* @param id
* @return
*/
public SetmealVO getByIdWithDish(Long id) {
SetmealVO setmealVO = setmealMapper.getByIdWithDish(id);
return setmealVO;
}
/**
* 修改套餐
*
* @param setmealDTO
*/
@Transactional
public void update(SetmealDTO setmealDTO) {
Setmeal setmeal = new Setmeal();
BeanUtils.copyProperties(setmealDTO, setmeal);
//1、修改套餐表,执行update
setmealMapper.update(setmeal);
//套餐id
Long setmealId = setmealDTO.getId();
//2、删除套餐和菜品的关联关系,操作setmeal_dish表,执行delete
setmealDishMapper.deleteBySetmealId(setmealId);
List<SetmealDish> setmealDishes = setmealDTO.getSetmealDishes();
setmealDishes.forEach(setmealDish -> {
setmealDish.setSetmealId(setmealId);
});
//3、重新插入套餐和菜品的关联关系,操作setmeal_dish表,执行insert
setmealDishMapper.insertBatch(setmealDishes);
}
/**
* 套餐起售、停售
*
* @param status
* @param id
*/
public void startOrStop(Integer status, Long id) {
//起售套餐时,判断套餐内是否有停售菜品,有停售菜品提示"套餐内包含未启售菜品,无法启售"
if (status == StatusConstant.ENABLE) {
//select a.* from dish a left join setmeal_dish b on a.id = b.dish_id where b.setmeal_id = ?
List<Dish> dishList = dishMapper.getBySetmealId(id);
if (dishList != null && dishList.size() > 0) {
dishList.forEach(dish -> {
if (StatusConstant.DISABLE == dish.getStatus()) {
throw new SetmealEnableFailedException(MessageConstant.SETMEAL_ENABLE_FAILED);
}
});
}
}
Setmeal setmeal = Setmeal.builder()
.id(id)
.status(status)
.build();
setmealMapper.update(setmeal);
}
/**
* 条件查询
* @param setmeal
* @return
*/
public List<Setmeal> list(Setmeal setmeal) {
List<Setmeal> list = setmealMapper.list(setmeal);
return list;
}
/**
* 根据id查询菜品选项
* @param id
* @return
*/
public List<DishItemVO> getDishItemById(Long id) {
return setmealMapper.getDishItemBySetmealId(id);
}
}
sky-server com/sky/mapper/SetmealMapper.java
package com.sky.mapper;
import com.github.pagehelper.Page;
import com.sky.annotation.AutoFill;
import com.sky.dto.SetmealPageQueryDTO;
import com.sky.entity.Setmeal;
import com.sky.enumeration.OperationType;
import com.sky.vo.DishItemVO;
import com.sky.vo.SetmealVO;
import org.apache.ibatis.annotations.Delete;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
import java.util.Map;
@Mapper
public interface SetmealMapper {
/**
* 根据分类id查询套餐的数量
*
* @param id
* @return
*/
@Select("select count(id) from setmeal where category_id = #{categoryId}")
Integer countByCategoryId(Long id);
/**
* 根据id修改套餐
*
* @param setmeal
*/
@AutoFill(OperationType.UPDATE)
void update(Setmeal setmeal);
/**
* 新增套餐
*
* @param setmeal
*/
@AutoFill(OperationType.INSERT)
void insert(Setmeal setmeal);
/**
* 分页查询
* @param setmealPageQueryDTO
* @return
*/
Page<SetmealVO> pageQuery(SetmealPageQueryDTO setmealPageQueryDTO);
/**
* 根据id查询套餐
* @param id
* @return
*/
@Select("select * from setmeal where id = #{id}")
Setmeal getById(Long id);
/**
* 根据id删除套餐
* @param setmealId
*/
@Delete("delete from setmeal where id = #{id}")
void deleteById(Long setmealId);
/**
* 根据id查询套餐和套餐菜品关系
* @param id
* @return
*/
SetmealVO getByIdWithDish(Long id);
/**
* 动态条件查询套餐
* @param setmeal
* @return
*/
List<Setmeal> list(Setmeal setmeal);
/**
* 根据套餐id查询菜品选项
* @param setmealId
* @return
*/
@Select("select sd.name, sd.copies, d.image, d.description " +
"from setmeal_dish sd left join dish d on sd.dish_id = d.id " +
"where sd.setmeal_id = #{setmealId}")
List<DishItemVO> getDishItemBySetmealId(Long setmealId);
/**
* 根据条件统计套餐数量
* @param map
* @return
*/
Integer countByMap(Map map);
}
sky-server mapper/SetmealMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.SetmealMapper">
<resultMap id="setmealAndDishMap" type="com.sky.vo.SetmealVO" autoMapping="true">
<result column="id" property="id"/>
<collection property="setmealDishes" ofType="SetmealDish">
<result column="sd_id" property="id"/>
<result column="setmeal_id" property="setmealId"/>
<result column="dish_id" property="dishId"/>
<result column="sd_name" property="name"/>
<result column="sd_price" property="price"/>
<result column="copies" property="copies"/>
</collection>
</resultMap>
<update id="update" parameterType="Setmeal">
update setmeal
<set>
<if test="name != null">
name = #{name},
</if>
<if test="categoryId != null">
category_id = #{categoryId},
</if>
<if test="price != null">
price = #{price},
</if>
<if test="status != null">
status = #{status},
</if>
<if test="description != null">
description = #{description},
</if>
<if test="image != null">
image = #{image},
</if>
<if test="updateTime != null">
update_time = #{updateTime},
</if>
<if test="updateUser != null">
update_user = #{updateUser}
</if>
</set>
where id = #{id}
</update>
<!--
<insert>:表示这是一个插入操作。
id="insert":指定这个 SQL 语句的唯一标识符,通常用于在 MyBatis 映射文件中引用此 SQL 语句。
parameterType="Setmeal":指定插入操作的参数类型为 Setmeal 类型。
useGeneratedKeys="true":指示 MyBatis 在执行插入操作后自动获取自动生成的主键。
keyProperty="id":指定将自动生成的主键值设置到对象的 id 属性上。
-->
<insert id="insert" parameterType="Setmeal" useGeneratedKeys="true" keyProperty="id">
insert into setmeal
(category_id, name, price, status, description, image, create_time, update_time, create_user, update_user)
values (#{categoryId}, #{name}, #{price}, #{status}, #{description}, #{image}, #{createTime}, #{updateTime},
#{createUser}, #{updateUser})
</insert>
<select id="pageQuery" resultType="com.sky.vo.SetmealVO">
select
s.*,c.name categoryName
from
setmeal s
left join
category c
on
s.category_id = c.id
<where>
<if test="name != null">
and s.name like concat('%',#{name},'%')
</if>
<if test="status != null">
and s.status = #{status}
</if>
<if test="categoryId != null">
and s.category_id = #{categoryId}
</if>
</where>
order by s.create_time desc
</select>
<select id="getByIdWithDish" parameterType="long" resultMap="setmealAndDishMap">
select a.*,
b.id sd_id,
b.setmeal_id,
b.dish_id,
b.name sd_name,
b.price sd_price,
b.copies
from setmeal a
left join
setmeal_dish b
on
a.id = b.setmeal_id
where a.id = #{id}
</select>
<select id="list" parameterType="Setmeal" resultType="Setmeal">
select * from setmeal
<where>
<if test="name != null">
and name like concat('%',#{name},'%')
</if>
<if test="categoryId != null">
and category_id = #{categoryId}
</if>
<if test="status != null">
and status = #{status}
</if>
</where>
</select>
<select id="countByMap" resultType="java.lang.Integer">
select count(id) from setmeal
<where>
<if test="status != null">
and status = #{status}
</if>
<if test="categoryId != null">
and category_id = #{categoryId}
</if>
</where>
</select>
</mapper>
Redis入门 [调整营业状态]
Redis是一个基于内存的 key-value 结构数据库
- 基于内存存储,读写性能高
- 适合存储热点数据 (热点商品、资讯、新闻) 访问量较大
- 企业应用广泛
Redis常用数据类型
Redis存储的是key-value结构的数据,其中key是字符串类型,value有5种常用的数据类型:
- 字符串 string:普通字符串
- 哈希 hash:散列,类似于java中的HashMap结构
- 列表 list:按照插入顺序排序,可以有重复元素,类似于java中的LinkedList
- 集合 set:无序集合,没有重复元素,类似于java中的HashSet
- 有序集合 sorted set / zset:集合中每个元素关联一个分数(score),根据分数升序排序,没有重复元素
Redis常用命令
字符串操作命令
ValueOperations valueOperations = redisTemplate.opsForValue();
- SET key value 设置指定key的值
- GET key 获取指定key的值
- SETEX key seconds value 设置指定key的值,并将key的过期时间设为 seconds秒
- SETNX key value 只有在key不存在时设置key的值
哈希操作命令 [key → value(field1 value1, field2 value2)]
HashOperations hashOperations = redisTemplate.opsForHash();
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象
- HSET key field value 将哈希表key中的字段field的值设为value
- HGET key field 获取存储在哈希表中指定字段的值
- HDEL key field 删除存储在哈希表中的指定字段
- HKEYS key 获取哈希表中所有字段
- HVALS key 获取哈希表中所有值
列表操作命令
ListOperations listOperations = redisTemplate.opsForList();
- LPUSH key value1 [value2] 将一个或多个值插入到列表头部
- LRANGE key start stop 获取列表指定范围内的元素
- RPOP key 移除并获取列表最后一个元素
- LLEN key 获取列表长度
集合操作命令
SetOperations setOperations = redisTemplate.opsForSet();
Redis set是string类型的无序集合。集合成员是唯一的,集合中不能出现重复的数据
- SADD key member1 [member2] 向集合添加一个或多个成员 [无序插入]
- SMEMBERS key 返回集合中的所有成员
- SCARD key 获取集合的成员数
- SINTER key1 [key2] 返回给定所有集合的交集
- SUNION key1 [key2] 返回所有给定集合的并集
- SREM key member1 [member2] 删除集合中一个或多个成员
有序列表操作命令
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
Redis有序集合是string类型元素的集合,且不允许重复成员。每个元素都会关联一个double类型的分数
- ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员
- ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合中指定区间内的成员
- ZINCRBY key increment member 有序集合中对指定成员的分数加上增量increment
- ZREM key member [member …] 移除有序集合中的一个或多个成员
通用命令
Redis的通用命令是不分数据类型的,都可以使用的命令
- KEYS pattern 查找所有符合给定模式(pattern)的key
- EXISTS key 检查给定key是否存在
- TYPE key 返回key所存储的值的类型
- DEL key 该命令用于在key存在是删除key
在java中操作Redis_SpringDataRedis
序列化器:redisTemplate.setKeySerializer(new StringRedisSerializer());
Redis的Java客户端很多
- Jedis
- Lettuce
- Spring Data Redis
Spring Data Redis 是 Spring 的一部分,对Redis底层开发包进行了高度封装
在Spring项目中,可以使用Spring Data Redis来简化操作
Spring Data Redis
导入Spring Data Redis的maven坐标
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.7.3</version>
</dependency>
配置Redis数据源
spring:
redis:
host: localhost
port: 6379
password:
编写配置类,创建RedisTemplate对象
package com.sky.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
@Slf4j
public class RedisConfiguration {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory){
log.info("开始创建redis模板对象...");
RedisTemplate redisTemplate = new RedisTemplate();
//设置redis的连接工厂对象
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置redis key的序列化器
redisTemplate.setKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
}
通过RedisTemplate对象操作Redis
测试连接
application.yml
redis:
host: ${sky.redis.host}
port: ${sky.redis.port}
database: ${sky.redis.database}
application-dev.yml
redis:
host: localhost
port: 6379
database: 1
sky-server com/sky/config/RedisConfiguration.java
package com.sky.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
@Slf4j
public class RedisConfiguration {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory){
log.info("开始创建redis模板对象...");
RedisTemplate redisTemplate = new RedisTemplate();
//设置redis的连接工厂对象
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置redis key的序列化器 在图形化界面不出现乱码
redisTemplate.setKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
}
sky-server【测试类】 com/sky/test/SpringDataRedisTest.java
package com.sky.test;
import com.mysql.cj.util.TimeUtil;
import net.sf.jsqlparser.statement.select.KSQLWindow;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.*;
import java.util.concurrent.TimeUnit;
@SpringBootTest //测试完记得注释 不然每次启动类就会运行这个测试类
public class SpringDataRedisTest {
@Autowired
private RedisTemplate redisTemplate;
@Test
public void testRedisTemplate(){
System.out.println(redisTemplate);
//创建根据字符串、哈希、列表、集合、有序列表、通用命令的代码
ValueOperations valueOperations = redisTemplate.opsForValue();
HashOperations hashOperations = redisTemplate.opsForHash();
ListOperations listOperations = redisTemplate.opsForList();
SetOperations setOperations = redisTemplate.opsForSet();
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
}
/**
* 操作字符串类型的数据
*/
@Test
public void testString(){
// set get setex setnx
redisTemplate.opsForValue().set("city","北京");
String city = (String) redisTemplate.opsForValue().get("city");
System.out.println(city); // 北京
redisTemplate.opsForValue().set("code", "1234", 3, TimeUnit.MINUTES);
// 第一次调用可以设置成功
redisTemplate.opsForValue().setIfAbsent("lock", "1");
// 第二次不可以成功
redisTemplate.opsForValue().setIfAbsent("lock", "2");
Object lock = redisTemplate.opsForValue().get("lock");
System.out.println(lock); // 1
Object lock2 = redisTemplate.opsForValue().get("locwwk");
System.out.println(lock2);// null
}
/**
* 操作哈希类型的数据
*/
@Test
public void testHash(){
//hset hget hdel hkeys havls
HashOperations hashOperations = redisTemplate.opsForHash();
hashOperations.put("100","name","tom");
hashOperations.put("100","age","20");
String name = (String) hashOperations.get("100","name");
System.out.println(name);
Set keys = hashOperations.keys("100");
System.out.println(keys);
List values = hashOperations.values("100");
System.out.println(values);
hashOperations.delete("100","age");
/**
* 操作列表类型的数据
*/
@Test
public void testList(){
//lpush lrange rpop llen
ListOperations listOperations = redisTemplate.opsForList();
listOperations.leftPushAll("mylist","a","b","c");
listOperations.leftPush("mylist","d");
List mylist = listOperations.range("mylist", 0, -1);
System.out.println(mylist);
listOperations.rightPop("mylist");
Long size = listOperations.size("mylist");
System.out.println(size);
}
/**
* 操作集合类型的数据
*/
@Test
public void testSet(){
//sadd smembers scard sinter sunion srem
SetOperations setOperations = redisTemplate.opsForSet();
setOperations.add("set1","a","b","c","d");
setOperations.add("set2","a","b","x","y");
Set members = setOperations.members("set1");
System.out.println(members);
Long size = setOperations.size("set1");
System.out.println(size);
Set intersect = setOperations.intersect("set1", "set2");
System.out.println(intersect);
Set union = setOperations.union("set1", "set2");
System.out.println(union);
setOperations.remove("set1","a","b");
}
/**
* 操作有序集合类型的数据
*/
@Test
public void testZset(){
//zadd zrange zincrby zrem
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
zSetOperations.add("zset1","a",10);
zSetOperations.add("zset1","b",12);
zSetOperations.add("zset1","c",9);
Set zset1 = zSetOperations.range("zset1", 0, -1);
System.out.println(zset1);
zSetOperations.incrementScore("zset1","c",10);
zSetOperations.remove("zset1","a","b");
}
/**
* 通用命令操作
*/
@Test
public void testCommon(){
//keys exists type del
Set keys = redisTemplate.keys("*");
System.out.println(keys);
Boolean name = redisTemplate.hasKey("name");
Boolean set1 = redisTemplate.hasKey("set1");
for (Object key : keys) {
DataType type = redisTemplate.type(key);
System.out.println(type.name());
}
redisTemplate.delete("mylist");
}
}
店铺营业状态设置 【存入Redis】
接口设计:
设置营业状态
Path:/admin/shop/{status}
Method:PUT
status 1 店铺营业状态:1为营业,0为打样
管理端查询营业状态
Path:/admin/shop/status
Method:GET
用户端查询营业状态
Path:/user/shop/status
Method:GET
★ ★ 本项目约定 ★ ★
- 管理端发出的请求,统一使用**/admin**作为前缀
- 用户端发出的请求,统一使用**/user**作为前缀
营业状态数据存储方式:基于Redis的字符串来进行存储
key: SHOP_STATUS value: 1 1为营业,0为打样
代码开发:
sky-server com/sky/controller/admin/ShopController.java
package com.sky.controller.admin;
import com.sky.result.Result;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.*;
@RestController("adminShopController")
@RequestMapping("/admin/shop")
@Api(tags = "店铺相关接口")
@Slf4j
public class ShopController {
public static final String KEY = "SHOP_STATUS";
@Autowired
private RedisTemplate redisTemplate;
/**
* 设置店铺营业状态
* @param status
* @return
*/
@PutMapping("/{status}") //动态取到status
@ApiOperation("设置店铺营业状态")
public Result setStatus(@PathVariable Integer status) {
log.info("设置店铺的营业状态为:{}", status == 1 ? "营业中" : "打样中");
redisTemplate.opsForValue().set(KEY, status);
return Result.success();
}
/**
* 获取店铺的营业状态
* @return
*/
@GetMapping("/status")
@ApiOperation("获取店铺的营业状态")
public Result<Integer> getStatus(){
Integer status = (Integer) redisTemplate.opsForValue().get(KEY);
log.info("获取到的店铺营业状态为:{}",status == 1 ? "营业中" : "打样中");
return Result.success(status);
}
}
sky-server com/sky/controller/user/ShopController.java
package com.sky.controller.user;
import com.sky.result.Result;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.*;
//@RestController("userShopController") 指定了这个控制器的名称为 userShopController
//这有助于在应用中唯一标识这个控制器,便于管理和调用
@RestController("userShopController")
@RequestMapping("/user/shop")
@Api(tags = "店铺相关接口")
@Slf4j
public class ShopController {
public static final String KEY = "SHOP_STATUS";
@Autowired
private RedisTemplate redisTemplate;
/**
* 获取店铺的营业状态
* @return
*/
@GetMapping("/status")
@ApiOperation("获取店铺的营业状态")
public Result<Integer> getStatus(){
Integer status = (Integer) redisTemplate.opsForValue().get(KEY);
log.info("获取到的店铺营业状态为:{}",status == 1 ? "营业中" : "打样中");
return Result.success(status);
}
}
sky-server com/sky/config/WebMvcConfiguration.java
// 设置两个接口文档方便在前端文档处调试【管理端+用户端】
package com.sky.config;
import com.sky.interceptor.JwtTokenAdminInterceptor;
import com.sky.interceptor.JwtTokenUserInterceptor;
import com.sky.json.JacksonObjectMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.http.converter.HttpMessageConverter;
import org.springframework.http.converter.json.MappingJackson2HttpMessageConverter;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.ResourceHandlerRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurationSupport;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import java.util.List;
/**
* 配置类,注册web层相关组件
*/
@Configuration
@Slf4j
public class WebMvcConfiguration extends WebMvcConfigurationSupport {
@Autowired
private JwtTokenAdminInterceptor jwtTokenAdminInterceptor;
@Autowired
private JwtTokenUserInterceptor jwtTokenUserInterceptor;
/**
* 注册自定义拦截器
* @param registry
*/
protected void addInterceptors(InterceptorRegistry registry) {
log.info("开始注册自定义拦截器...");
registry.addInterceptor(jwtTokenAdminInterceptor)
.addPathPatterns("/admin/**")
.excludePathPatterns("/admin/employee/login");
registry.addInterceptor(jwtTokenUserInterceptor)
.addPathPatterns("/user/**")
.excludePathPatterns("/user/user/login")
.excludePathPatterns("/user/shop/status");
}
@Bean
public Docket docket1(){
log.info("准备生成接口文档...");
ApiInfo apiInfo = new ApiInfoBuilder()
.title("苍穹外卖项目接口文档")
.version("2.0")
.description("苍穹外卖项目接口文档")
.build();
Docket docket = new Docket(DocumentationType.SWAGGER_2)
.groupName("管理端接口")
.apiInfo(apiInfo)
.select()
//指定生成接口需要扫描的包
.apis(RequestHandlerSelectors.basePackage("com.sky.controller.admin"))
.paths(PathSelectors.any())
.build();
return docket;
}
@Bean
public Docket docket2(){
log.info("准备生成接口文档...");
ApiInfo apiInfo = new ApiInfoBuilder()
.title("苍穹外卖项目接口文档")
.version("2.0")
.description("苍穹外卖项目接口文档")
.build();
Docket docket = new Docket(DocumentationType.SWAGGER_2)
.groupName("用户端接口")
.apiInfo(apiInfo)
.select()
//指定生成接口需要扫描的包
.apis(RequestHandlerSelectors.basePackage("com.sky.controller.user"))
.paths(PathSelectors.any())
.build();
return docket;
}
/**
* 设置静态资源映射,主要是访问接口文档(html、js、css)
* @param registry
*/
protected void addResourceHandlers(ResourceHandlerRegistry registry) {
log.info("开始设置静态资源映射...");
registry.addResourceHandler("/doc.html").addResourceLocations("classpath:/META-INF/resources/");
registry.addResourceHandler("/webjars/**").addResourceLocations("classpath:/META-INF/resources/webjars/");
}
/**
* 扩展Spring MVC框架的消息转化器
* @param converters
*/
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
log.info("扩展消息转换器...");
//创建一个消息转换器对象
MappingJackson2HttpMessageConverter converter = new MappingJackson2HttpMessageConverter();
//需要为消息转换器设置一个对象转换器,对象转换器可以将Java对象序列化为json数据
converter.setObjectMapper(new JacksonObjectMapper());
//将自己的消息转化器加入容器中
converters.add(0,converter);
}
}
回顾拦截器原理
HttpClient & 微信小程序开发
HttpClient
HttpClient 是 Apache Jakarta Common下的子项目,可以用来提供高效的、最新的、功能丰富的支持HTTP协议的客户端编程工具包,并且它支持HTTP协议最新的版本和建议
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>
核心API:
- HttpClient
- HttpClients
- CloseableHttpClient
- HttpGet
- HttpPost
发送请求步骤:
- 创建HttpClient对象
- 创建Http请求对象
- 调用HttpClient的execute方法发送请求
发送GET方式请求 [要先把项目跑起来]
sky-server com/sky/test/HttpClientTest.java
package com.sky.test;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest
public class HttpClientTest {
/**
* 测试通过httpclient发送GET方式的请求
*/
@Test
public void testGET() throws IOException {
// 创建httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建请求对象接口 (GET请求方式+请求地址)
HttpGet httpGet = new HttpGet("http://localhost:8080/user/shop/status");
// 发送请求,接受响应结果
CloseableHttpResponse response = httpClient.execute(httpGet);
// 获取服务端返回的状态码
int statusCode = response.getStatusLine().getStatusCode();
System.out.println("服务端返回的状态码为:" + statusCode);
HttpEntity entity = response.getEntity();// 获得请求体
String body = EntityUtils.toString(entity);
System.out.println("服务端返回的数据为:" + body);
// 关闭资源
response.close();
httpClient.close();
}
/**
* 测试通过httpclient发送POST方式的请求
*/
}
--------------------------------------------------------------------------------
服务端返回的状态码为:200
服务端返回的数据为:{"code":1,"msg":null,"data":0}
发送POST方式请求 [要先把项目跑起来]
sky-server com/sky/test/HttpClientTest.java
/**
* 测试通过httpclient发送POST方式的请求
*/
@Test
public void testPOST() throws Exception{
// 创建httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建请求对象
HttpPost httpPost = new HttpPost("http://localhost:8080/admin/employee/login");
// 以json方式请求提交参数
JSONObject jsonObject = new JSONObject();
jsonObject.put("username","admin");
jsonObject.put("password","123456");
StringEntity entity = new StringEntity(jsonObject.toString());
// 指定请求编码方式
entity.setContentEncoding("utf-8");
// 数据格式
entity.setContentType("application/json");
httpPost.setEntity(entity);
// 发送请求
CloseableHttpResponse response = httpClient.execute(httpPost);
// 解析返回结果
int statusCode = response.getStatusLine().getStatusCode();
System.out.println("响应码为:" + statusCode);
HttpEntity entity1 = response.getEntity();
String body = EntityUtils.toString(entity1);
System.out.println("响应数据为:" + body);
// 关闭资源
response.close();
httpClient.close();
}
--------------------------------------------------------------------------------
响应码为:200
响应数据为:{"code":1,"msg":null,"data":{"id":1,"userName":"admin","name":"管理员","token":"eyJhbGciOiJIUzI1NiJ9.eyJlbXBJZCI6MSwiZXhwIjoxNzI4MTMyMzczfQ.8M2nIkgtHx8wpORNfhKEWjbprBV6OwC82wgYjAMxe2I"}}
封装后的HttpClientUtil
package com.sky.utils;
import com.alibaba.fastjson.JSONObject;
import org.apache.http.NameValuePair;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.utils.URIBuilder;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.net.URI;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* Http工具类
*/
public class HttpClientUtil {
static final int TIMEOUT_MSEC = 5 * 1000;
/**
* 发送GET方式请求
* @param url
* @param paramMap
* @return
*/
public static String doGet(String url,Map<String,String> paramMap){
// 创建Httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
String result = "";
CloseableHttpResponse response = null;
try{
URIBuilder builder = new URIBuilder(url);
if(paramMap != null){
for (String key : paramMap.keySet()) {
builder.addParameter(key,paramMap.get(key));
}
}
URI uri = builder.build();
//创建GET请求
HttpGet httpGet = new HttpGet(uri);
//发送请求
response = httpClient.execute(httpGet);
//判断响应状态
if(response.getStatusLine().getStatusCode() == 200){
result = EntityUtils.toString(response.getEntity(),"UTF-8");
}
}catch (Exception e){
e.printStackTrace();
}finally {
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
/**
* 发送POST方式请求
* @param url
* @param paramMap
* @return
* @throws IOException
*/
public static String doPost(String url, Map<String, String> paramMap) throws IOException {
// 创建Httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
String resultString = "";
try {
// 创建Http Post请求
HttpPost httpPost = new HttpPost(url);
// 创建参数列表
if (paramMap != null) {
List<NameValuePair> paramList = new ArrayList();
for (Map.Entry<String, String> param : paramMap.entrySet()) {
paramList.add(new BasicNameValuePair(param.getKey(), param.getValue()));
}
// 模拟表单
UrlEncodedFormEntity entity = new UrlEncodedFormEntity(paramList);
httpPost.setEntity(entity);
}
httpPost.setConfig(builderRequestConfig());
// 执行http请求
response = httpClient.execute(httpPost);
resultString = EntityUtils.toString(response.getEntity(), "UTF-8");
} catch (Exception e) {
throw e;
} finally {
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return resultString;
}
/**
* 发送POST方式请求
* @param url
* @param paramMap
* @return
* @throws IOException
*/
public static String doPost4Json(String url, Map<String, String> paramMap) throws IOException {
// 创建Httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
String resultString = "";
try {
// 创建Http Post请求
HttpPost httpPost = new HttpPost(url);
if (paramMap != null) {
//构造json格式数据
JSONObject jsonObject = new JSONObject();
for (Map.Entry<String, String> param : paramMap.entrySet()) {
jsonObject.put(param.getKey(),param.getValue());
}
StringEntity entity = new StringEntity(jsonObject.toString(),"utf-8");
//设置请求编码
entity.setContentEncoding("utf-8");
//设置数据类型
entity.setContentType("application/json");
httpPost.setEntity(entity);
}
httpPost.setConfig(builderRequestConfig());
// 执行http请求
response = httpClient.execute(httpPost);
resultString = EntityUtils.toString(response.getEntity(), "UTF-8");
} catch (Exception e) {
throw e;
} finally {
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return resultString;
}
private static RequestConfig builderRequestConfig() {
return RequestConfig.custom()
.setConnectTimeout(TIMEOUT_MSEC)
.setConnectionRequestTimeout(TIMEOUT_MSEC)
.setSocketTimeout(TIMEOUT_MSEC).build();
}
}
微信小程序开发
小程序 (qq.com)
详情 → 本地设置 → [取消勾选]不校验合法域名…
操作步骤
了解小程序目录结构
小程序包含一个描述整体程序的app和多个和描述各自页面的page,一个小程序主体部分由三个文件组村,必须放在项目的根目录
| 文件 |
必需 |
作用 |
| app.js |
是 |
小程序逻辑 |
| app.json |
是 |
小程序公共配置 |
| app.wxss |
否 |
小程序公共样式表 |
一个小程序页面由四个文件组成 [pages → index → …]
| 文件类型 |
必需 |
作用 |
| js |
是 |
页面逻辑 |
| wxml |
是 |
页面结构 |
| json |
否 |
页面配置 |
| wxss |
否 |
页面样式表 |
编写测试小程序代码
微信getUserProfile不弹出授权框_wx.getuserprofile没有弹窗-CSDN博客
app.json 【外面一层】
{
"pages": [
"pages/index/index",
"pages/logs/logs"
],
"window": {
"navigationBarTextStyle": "black",
"navigationBarTitleText": "Sky-Delivery",
"navigationBarBackgroundColor": "#ffffff"
},
"style": "v2",
"componentFramework": "glass-easel",
"sitemapLocation": "sitemap.json",
"lazyCodeLoading": "requiredComponents"
}
pages/index/index.wxml
<view class="container">
<view>
{{msg}}
</view>
<view>
<button bindtap="getUserInfo" type="primary">获取用户信息</button>
昵称:{{nickName}}
<image src="{{url}}" style="width: 200px;height: 200px;"></image>
<button bindtap="wxLogin" type="warn">微信登录</button>
授权码:{{code}}
</view>
<view>
<button bindtap="sendRequest" type="default">发送请求</button>
</view>
</view>
pages/index/index.js
Page({
data: {
msg: 'hello world',
nickName: '',
url:'',
code:'',
},
// 获取微信用户的头像和昵称
getUserInfo(e){
wx.getUserProfile({
desc: '获取用户信息',
success: (res) => {
console.log(res.userInfo);
// 为数据赋值
this.setData({
nickName: res.userInfo.nickName,
url: res.userInfo.avatarUrl
})
},
fail:(err) => {
console.error('获取用户信息失败', err);
}
});
},
//微信登录,获取微信用户的授权码
//拿到后可以去请求微信服务器获得openId
//授权码提交到后端去调用服务器
wxLogin(){
wx.login({
success: (res) => {
console.log(res.code)
this.setData({
code: res.code
})
}
})
},
//发送请求
sendRequest(){
wx.request({
url: 'http://localhost:8080/user/shop/status',
method: 'GET',
success: (res)=>{
// data是后端响应回来的整个数据
console.log(res.data)
}
})
}
});
编译小程序
微信登录
导入小程序代码
E:\Java实例项目1-20套\第24套【项目实战】Java外卖项目实战《苍穹外卖》SpringBoot+SpringMVC+Vue+Swagger+Lombok+Mybatis+SpringSession+Redis+Nginx+小程序\0-0 源码资料\资料\day06\微信小程序代码\mp-weixin
【注意:导入后有很多包名错误common、components】
微信登录流程
开放能力 / 用户信息 / 小程序登录 (qq.com)
| 属性 |
类型 |
默认值 |
必填 |
说明 |
| appid |
string |
|
是 |
小程序 appId |
| secret |
string |
|
是 |
小程序 appSecret |
| js_code |
string |
|
是 |
登录时获取的 code |
| grant_type |
string |
|
是 |
授权类型,此处只需填写 authorization_code |
PostMan测试 →
GET:https://api.weixin.qq.com/sns/jscode2session?appid=wxa33b4bae9165c5a5&secret=c2d6fc237953d711146c4ad5db3ef947&js_code=0f1hdA200TsYYS1ghD100c3GZJ1hdA2w&grant_type=authorization_code
返回:
{“session_key”:”HsYD32ryqarcnrCXbEyWhg==”,”openid”:”obaex5N3w1_oAP6a4h-c-CkQBsZQ”}
需求分析和设计
数据库设计(user表)
代码开发
sky-server application.yml
sky:
jwt:
# 设置jwt签名加密时使用的秘钥
admin-secret-key: itcast
# 设置jwt过期时间
admin-ttl: 7200000
# 设置前端传递过来的令牌名称
admin-token-name: token
user-secret-key: itheima
user-ttl: 7200000
user-token-name: authentication
alioss:
endpoint: ${sky.alioss.endpoint}
access-key-id: ${sky.alioss.access-key-id}
access-key-secret: ${sky.alioss.access-key-secret}
bucket: ${sky.alioss.bucket}
wechat:
appid: ${sky.wechat.appid}
secret: ${sky.wechat.secret}
sky-server application-dev.yml
wechat:
appid: xxxxxxx
secret: xxxxxxx
sky-common com/sky/properties/WeChatProperties.java
package com.sky.properties;
import lombok.Data;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Component
@ConfigurationProperties(prefix = "sky.wechat")
@Data
public class WeChatProperties {
private String appid; //小程序的appid
private String secret; //小程序的秘钥
private String mchid; //商户号
private String mchSerialNo; //商户API证书的证书序列号
private String privateKeyFilePath; //商户私钥文件
private String apiV3Key; //证书解密的密钥
private String weChatPayCertFilePath; //平台证书
private String notifyUrl; //支付成功的回调地址
private String refundNotifyUrl; //退款成功的回调地址
}
sky-server com/sky/controller/user/UserController.java
package com.sky.controller.user;
import com.sky.constant.JwtClaimsConstant;
import com.sky.dto.UserLoginDTO;
import com.sky.entity.User;
import com.sky.properties.JwtProperties;
import com.sky.result.Result;
import com.sky.service.UserService;
import com.sky.utils.JwtUtil;
import com.sky.vo.UserLoginVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.Map;
@RestController
@RequestMapping("/user/user")
@Api(tags = "C端用户相关接口")
@Slf4j
public class UserController {
@Autowired
private UserService userService;
@Autowired
private JwtProperties jwtProperties;
/**
* 微信登录
* @param userLoginDTO
* @return
*/
@PostMapping("/login")
@ApiOperation("微信登录")
public Result<UserLoginVO> login(@RequestBody UserLoginDTO userLoginDTO) {
log.info("微信登录:{}", userLoginDTO.getCode());
//微信登录
User user = userService.wxLogin(userLoginDTO);
//为微信用户生成jwt令牌
Map<String, Object> claims = new HashMap<>();
claims.put(JwtClaimsConstant.USER_ID, user.getId());
String token = JwtUtil.createJWT(jwtProperties.getUserSecretKey(),jwtProperties.getUserTtl(),claims);
UserLoginVO userLoginVO = UserLoginVO.builder()
.id(user.getId())
.openid(user.getOpenid())
.token(token)
.build();
return Result.success(userLoginVO);
}
}
sky-server com/sky/service/UserService.java
package com.sky.service;
import com.sky.dto.UserLoginDTO;
import com.sky.entity.User;
public interface UserService {
/**
* 微信登录
* @return
*/
User wxLogin(UserLoginDTO userLoginDTO);
}
sky-server com/sky/service/impl/UserServiceImpl.java
package com.sky.service.impl;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.sky.constant.MessageConstant;
import com.sky.dto.UserLoginDTO;
import com.sky.entity.User;
import com.sky.exception.LoginFailedException;
import com.sky.mapper.UserMapper;
import com.sky.properties.WeChatProperties;
import com.sky.service.UserService;
import com.sky.utils.HttpClientUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.time.LocalDateTime;
import java.util.HashMap;
import java.util.Map;
@Service
@Slf4j
public class UserServiceImpl implements UserService {
// 微信服务接口地址
public static final String WX_LOGIN = "https://api.weixin.qq.com/sns/jscode2session";
@Autowired
private WeChatProperties weChatProperties;
@Autowired
private UserMapper userMapper;
/**
* 微信登录
* @param userLoginDTO
* @return
*/
@Override
public User wxLogin(UserLoginDTO userLoginDTO) {
String openid = getOpenid(userLoginDTO.getCode());
// 判断openId是否真的获取到 如果为空代表失败 业务异常
if (openid == null){
throw new LoginFailedException(MessageConstant.LOGIN_FAILED);
}
// openId是否在表里 可判断是否为新用户
User user = userMapper.getByOpenid(openid);
// 如果是新用户,自动完成注册
if (user == null) {
user = User.builder()
.openid(openid)
.createTime(LocalDateTime.now())
.build();
userMapper.insert(user);
}
// 返回这个用户对象
return user;
}
/**
* 调用微信接口服务,获取微信用户的openid
* @param code
* @return
*/
//只有当前类用到
private String getOpenid(String code) {
// 调用微信服务器接口 获得当前用户的openid
// 四个请求参数
Map<String, String> map = new HashMap<>();
map.put("appid", weChatProperties.getAppid());
map.put("secret", weChatProperties.getSecret());
map.put("js_code", code);
map.put("grant_type", "authorization_code");
String json = HttpClientUtil.doGet(WX_LOGIN, map);
// 获得json对象
JSONObject jsonObject = JSON.parseObject(json);
String openid = jsonObject.getString("openid");
return openid;
}
}
sky-server com/sky/mapper/UserMapper.java
package com.sky.mapper;
import com.sky.entity.User;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
@Mapper
public interface UserMapper {
/**
* 根据openid查询用户
* @param openid
* @return
*/
@Select("select * from user where openid = #{openid}")
User getByOpenid(String openid);
/**
* 新增用户
* @param user
*/
void insert(User user);
}
sky-server mapper/UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.UserMapper">
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
insert into user (openid, name, phone, sex, id_number, avatar, create_time)
values (#{openid}, #{name}, #{phone}, #{sex}, #{idNumber}, #{avatar}, #{createTime})
</insert>
</mapper>
【检测小程序用户是否登陆性】
sky-server com/sky/interceptor/JwtTokenUserInterceptor.java
package com.sky.interceptor;
import com.sky.constant.JwtClaimsConstant;
import com.sky.context.BaseContext;
import com.sky.properties.JwtProperties;
import com.sky.utils.JwtUtil;
import io.jsonwebtoken.Claims;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.web.method.HandlerMethod;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* jwt令牌校验的拦截器
*/
@Component
@Slf4j
public class JwtTokenUserInterceptor implements HandlerInterceptor {
@Autowired
private JwtProperties jwtProperties;
/**
* 校验jwt
*
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//判断当前拦截到的是Controller的方法还是其他资源
if (!(handler instanceof HandlerMethod)) {
//当前拦截到的不是动态方法,直接放行
return true;
}
//1、从请求头中获取令牌
String token = request.getHeader(jwtProperties.getUserTokenName());
//2、校验令牌
try {
log.info("jwt校验:{}", token);
Claims claims = JwtUtil.parseJWT(jwtProperties.getUserSecretKey(), token);
Long userId = Long.valueOf(claims.get(JwtClaimsConstant.USER_ID).toString());
log.info("当前用户的id:", userId);
BaseContext.setCurrentId(userId);
//3、通过,放行
return true;
} catch (Exception ex) {
//4、不通过,响应401状态码
response.setStatus(401);
return false;
}
}
}
sky-server com/sky/config/WebMvcConfiguration.java 【增加jwtTokenUserInterceptor】
/**
* 配置类,注册web层相关组件
*/
@Configuration
@Slf4j
public class WebMvcConfiguration extends WebMvcConfigurationSupport {
@Autowired
private JwtTokenAdminInterceptor jwtTokenAdminInterceptor;
@Autowired
private JwtTokenUserInterceptor jwtTokenUserInterceptor;
/**
* 注册自定义拦截器
* @param registry
*/
protected void addInterceptors(InterceptorRegistry registry) {
log.info("开始注册自定义拦截器...");
registry.addInterceptor(jwtTokenAdminInterceptor)
.addPathPatterns("/admin/**")
.excludePathPatterns("/admin/employee/login");
registry.addInterceptor(jwtTokenUserInterceptor)
.addPathPatterns("/user/**")
.excludePathPatterns("/user/user/login")
.excludePathPatterns("/user/shop/status");
}
}
导入商品浏览功能代码
接口设计
查询分类
Path: /user/category/list
Method:GET
请求参数
Type: 分类类型→1.菜品分类 2.套餐分类
根据分类id查询菜品
Path: /user/dish/list
Method:GET
请求参数
categoryId 分类id
根据分类id查询套餐
Path: /user/setmeal/list?category=111
Method:GET
请求参数
categoryId 分类id
根据套餐id查询包含的菜品
Path: /user/setmeal/dish/10
Method:GET
请求参数
id 套餐id
返回数据:
copies 份数
description 菜品描述
image 菜品图片
name 菜品名称
sky-server com/sky/controller/user/DishController.java
package com.sky.controller.user;
import com.sky.constant.StatusConstant;
import com.sky.entity.Dish;
import com.sky.result.Result;
import com.sky.service.DishService;
import com.sky.vo.DishVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController("userDishController")
@RequestMapping("/user/dish")
@Slf4j
@Api(tags = "C端-菜品浏览接口")
public class DishController {
@Autowired
private DishService dishService;
/**
* 根据分类id查询菜品
*
* @param categoryId
* @return
*/
@GetMapping("/list")
@ApiOperation("根据分类id查询菜品")
public Result<List<DishVO>> list(Long categoryId) {
Dish dish = new Dish();
dish.setCategoryId(categoryId);
dish.setStatus(StatusConstant.ENABLE);//查询起售中的菜品
List<DishVO> list = dishService.listWithFlavor(dish);
return Result.success(list);
}
}
sky-server com/sky/service/DishService.java
package com.sky.service;
import com.sky.dto.DishDTO;
import com.sky.dto.DishPageQueryDTO;
import com.sky.entity.Dish;
import com.sky.result.PageResult;
import com.sky.vo.DishVO;
import java.util.List;
public interface DishService {
/**
* 新增菜品和对应的口味
* @param dishDTO
*/
public void saveWithFlavour(DishDTO dishDTO);
/**
* 菜品分页查询
* @param dishPageQueryDTO
* @return
*/
PageResult pageQuery(DishPageQueryDTO dishPageQueryDTO);
/**
* 菜品的批量删除
* @param ids
* @return
*/
void deleteBatch(List<Long> ids);
/**
* 根据id查询菜品和对应的口味数据
* @param id
* @return
*/
DishVO getByIdWithFlavor(long id);
/**
* 修改菜品
* @param dishDTO
* @return
*/
void updateWithFlavor(DishDTO dishDTO);
/**
* 菜品起售停售
*
* @param status
* @param id
* @return
*/
void startOrStop(Integer status, Long id);
/**
* 根据分类id查询菜品
* @param categoryId
* @return
*/
List<Dish> list(Long categoryId);
/**
* 条件查询菜品和口味
* @param dish
* @return
*/
List<DishVO> listWithFlavor(Dish dish);
}
sky-server com/sky/service/impl/DishServiceImpl.java
package com.sky.service.impl;
import com.github.pagehelper.Page;
import com.github.pagehelper.PageHelper;
import com.sky.constant.MessageConstant;
import com.sky.constant.StatusConstant;
import com.sky.dto.DishDTO;
import com.sky.dto.DishPageQueryDTO;
import com.sky.entity.Dish;
import com.sky.entity.DishFlavor;
import com.sky.entity.Setmeal;
import com.sky.exception.DeletionNotAllowedException;
import com.sky.mapper.DishFlavorMapper;
import com.sky.mapper.DishMapper;
import com.sky.mapper.SetmealDishMapper;
import com.sky.mapper.SetmealMapper;
import com.sky.result.PageResult;
import com.sky.service.DishService;
import com.sky.vo.DishVO;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.ArrayList;
import java.util.List;
@Service
@Slf4j
public class DishServiceImpl implements DishService {
@Autowired
private DishMapper dishMapper;
@Autowired
private DishFlavorMapper dishFlavorMapper;
@Autowired
private SetmealDishMapper setmealDishMapper;
@Autowired
private SetmealMapper setmealMapper;
/**
* 新增菜品和对应的口味
* @param dishDTO
*/
@Override
@Transactional //保证事务一致性
public void saveWithFlavour(DishDTO dishDTO) {
Dish dish = new Dish();
//直接new出来是空的需要先赋值 属性拷贝[属性命名要一致]
BeanUtils.copyProperties(dishDTO,dish);
// 向菜品表插入1条数据
dishMapper.insert(dish);
// 前端无法传 要获取dishId
// <insert id="insertBatch" useGeneratedKeys="true" keyProperty="id"> 获取主键值
Long dishId = dish.getId();
List<DishFlavor> flavors = dishDTO.getFlavors();
if (flavors != null && flavors.size() > 0) {
flavors.forEach(dishFlavor -> {
dishFlavor.setDishId(dishId);
});
// 向口味表插入n条数据 集合对象批量传入不用集合
dishFlavorMapper.insertBatch(flavors);
}
}
/**
* 菜品分页查询
* @param dishPageQueryDTO
* @return
*/
@Override
public PageResult pageQuery(DishPageQueryDTO dishPageQueryDTO) {
PageHelper.startPage(dishPageQueryDTO.getPage(), dishPageQueryDTO.getPageSize());
Page<DishVO> page = dishMapper.pageQuery(dishPageQueryDTO);
return new PageResult(page.getTotal(), page.getResult());
}
/**
* 菜品的批量删除
* @param ids
* @return
*/
@Transactional
public void deleteBatch(List<Long> ids) {
// 判断当前菜品是否能够删除--是否存在起售中的菜品?? 取出id
for (Long id : ids) {
Dish dish = dishMapper.getById(id);
if (dish.getStatus() == StatusConstant.ENABLE) {
//当前菜品处于起售中,不能删除
throw new DeletionNotAllowedException(MessageConstant.DISH_ON_SALE);
}
}
// 判断当前菜品是否能够删除--是否被套餐关联了
List<Long> setMealIds = setmealDishMapper.getSetmealIdsByDishIds(ids);
if (setMealIds != null && setMealIds.size() > 0) { //存在不允许删除
// 当前菜品被套餐关联了,不能删除
throw new DeletionNotAllowedException(MessageConstant.DISH_BE_RELATED_BY_SETMEAL);
}
// 删除菜品表中的菜品数据
for (Long id : ids) {
dishMapper.deleteById(id);
// 删除菜品关联的口味数据
dishFlavorMapper.deleteByDishId(id);
}
}
/**
* 根据id查询菜品和对应的口味数据
* @param id
* @return
*/
@Override
public DishVO getByIdWithFlavor(long id) {
// 根据id查询菜品数据
Dish dish = dishMapper.getById(id);
// 根据菜品id查询口味数据
List<DishFlavor> dishFlavors = dishFlavorMapper.getByDishId(id);
// 将查询到的数据封装到VO
DishVO dishVO = new DishVO();
// 属性拷贝
BeanUtils.copyProperties(dish,dishVO);
dishVO.setFlavors(dishFlavors);
return dishVO;
}
/**
* 修改菜品
* @param dishDTO
* @return
*/
@Override
public void updateWithFlavor(DishDTO dishDTO) {
Dish dish = new Dish();
BeanUtils.copyProperties(dishDTO,dish);
// 修改菜品表基本信息 只是基础信息噢
dishMapper.update(dish);
// 先删掉原先的
dishFlavorMapper.deleteByDishId(dishDTO.getId());
// 再重新插入新的
List<DishFlavor> flavors = dishDTO.getFlavors();
if (flavors != null && flavors.size() > 0) {
flavors.forEach(dishFlavor -> {
dishFlavor.setDishId(dishDTO.getId());
});
// 向口味表插入n条数据 集合对象批量传入不用集合
dishFlavorMapper.insertBatch(flavors);
}
}
/**
* 菜品起售停售
* @param status
* @param id
*/
@Override
public void startOrStop(Integer status, Long id) {
Dish dish = Dish.builder()
.id(id)
.status(status)
.build();
dishMapper.update(dish);
if (status == StatusConstant.DISABLE) {
// 如果是停售操作,还需要将包含当前菜品的套餐也停售
List<Long> dishIds = new ArrayList<>();
dishIds.add(id);
// select setmeal_id from setmeal_dish where dish_id in (?,?,?)
List<Long> setmealIds = setmealDishMapper.getSetmealIdsByDishIds(dishIds);
if (setmealIds != null && setmealIds.size() > 0) {
for (Long setmealId : setmealIds) {
Setmeal setmeal = Setmeal.builder()
.id(setmealId)
.status(StatusConstant.DISABLE)
.build();
setmealMapper.update(setmeal);
}
}
}
}
/**
* 根据分类id查询菜品
* @param categoryId
* @return
*/
public List<Dish> list(Long categoryId) {
Dish dish = Dish.builder()
.categoryId(categoryId)
.status(StatusConstant.ENABLE)
.build();
return dishMapper.list(dish);
}
/**
* 条件查询菜品和口味
* @param dish
* @return
*/
public List<DishVO> listWithFlavor(Dish dish) {
List<Dish> dishList = dishMapper.list(dish);
List<DishVO> dishVOList = new ArrayList<>();
for (Dish d : dishList) {
DishVO dishVO = new DishVO();
BeanUtils.copyProperties(d,dishVO);
//根据菜品id查询对应的口味
List<DishFlavor> flavors = dishFlavorMapper.getByDishId(d.getId());
dishVO.setFlavors(flavors);
dishVOList.add(dishVO);
}
return dishVOList;
}
}
sky-server com/sky/controller/user/SetmealController.java
package com.sky.controller.user;
import com.sky.constant.StatusConstant;
import com.sky.entity.Setmeal;
import com.sky.result.Result;
import com.sky.service.SetmealService;
import com.sky.vo.DishItemVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController("userSetmealController")
@RequestMapping("/user/setmeal")
@Api(tags = "C端-套餐浏览接口")
public class SetmealController {
@Autowired
private SetmealService setmealService;
/**
* 条件查询
*
* @param categoryId
* @return
*/
@GetMapping("/list")
@ApiOperation("根据分类id查询套餐")
public Result<List<Setmeal>> list(Long categoryId) {
Setmeal setmeal = new Setmeal();
setmeal.setCategoryId(categoryId);
setmeal.setStatus(StatusConstant.ENABLE);
List<Setmeal> list = setmealService.list(setmeal);
return Result.success(list);
}
/**
* 根据套餐id查询包含的菜品列表
*
* @param id
* @return
*/
@GetMapping("/dish/{id}")
@ApiOperation("根据套餐id查询包含的菜品列表")
public Result<List<DishItemVO>> dishList(@PathVariable("id") Long id) {
List<DishItemVO> list = setmealService.getDishItemById(id);
return Result.success(list);
}
}
sky-server com/sky/service/SetmealService.java
package com.sky.service;
import com.sky.dto.SetmealDTO;
import com.sky.dto.SetmealPageQueryDTO;
import com.sky.entity.Setmeal;
import com.sky.result.PageResult;
import com.sky.vo.DishItemVO;
import com.sky.vo.SetmealVO;
import java.util.List;
public interface SetmealService {
/**
* 新增套餐,同时需要保存套餐和菜品的关联关系
*
* @param setmealDTO
*/
void saveWithDish(SetmealDTO setmealDTO);
/**
* 分页查询
*
* @param setmealPageQueryDTO
* @return
*/
PageResult pageQuery(SetmealPageQueryDTO setmealPageQueryDTO);
/**
* 批量删除套餐
*
* @param ids
*/
void deleteBatch(List<Long> ids);
/**
* 根据id查询套餐和关联的菜品数据
*
* @param id
* @return
*/
SetmealVO getByIdWithDish(Long id);
/**
* 修改套餐
*
* @param setmealDTO
*/
void update(SetmealDTO setmealDTO);
/**
* 套餐起售、停售
*
* @param status
* @param id
*/
void startOrStop(Integer status, Long id);
/**
* 条件查询
* @param setmeal
* @return
*/
List<Setmeal> list(Setmeal setmeal);
/**
* 根据id查询菜品选项
* @param id
* @return
*/
List<DishItemVO> getDishItemById(Long id);
}
sky-server com/sky/service/impl/SetmealServiceImpl.java
package com.sky.service.impl;
import com.github.pagehelper.Page;
import com.github.pagehelper.PageHelper;
import com.sky.constant.MessageConstant;
import com.sky.constant.StatusConstant;
import com.sky.dto.SetmealDTO;
import com.sky.dto.SetmealPageQueryDTO;
import com.sky.entity.Dish;
import com.sky.entity.Setmeal;
import com.sky.entity.SetmealDish;
import com.sky.exception.DeletionNotAllowedException;
import com.sky.exception.SetmealEnableFailedException;
import com.sky.mapper.DishMapper;
import com.sky.mapper.SetmealDishMapper;
import com.sky.mapper.SetmealMapper;
import com.sky.result.PageResult;
import com.sky.service.SetmealService;
import com.sky.vo.DishItemVO;
import com.sky.vo.SetmealVO;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
/**
* 套餐业务实现
*/
@Service
@Slf4j
public class SetmealServiceImpl implements SetmealService {
@Autowired
private SetmealMapper setmealMapper;
@Autowired
private SetmealDishMapper setmealDishMapper;
@Autowired
private DishMapper dishMapper;
/**
* 新增套餐,同时需要保存套餐和菜品的关联关系
*
* @param setmealDTO
*/
@Transactional
public void saveWithDish(SetmealDTO setmealDTO) {
Setmeal setmeal = new Setmeal();
BeanUtils.copyProperties(setmealDTO, setmeal);
//向套餐表插入数据
setmealMapper.insert(setmeal);
//获取生成的套餐id
Long setmealId = setmeal.getId();
List<SetmealDish> setmealDishes = setmealDTO.getSetmealDishes();
setmealDishes.forEach(setmealDish -> {
setmealDish.setSetmealId(setmealId);
});
//保存套餐和菜品的关联关系
setmealDishMapper.insertBatch(setmealDishes);
}
/**
* 分页查询
*
* @param setmealPageQueryDTO
* @return
*/
public PageResult pageQuery(SetmealPageQueryDTO setmealPageQueryDTO) {
int pageNum = setmealPageQueryDTO.getPage();
int pageSize = setmealPageQueryDTO.getPageSize();
PageHelper.startPage(pageNum, pageSize);
Page<SetmealVO> page = setmealMapper.pageQuery(setmealPageQueryDTO);
return new PageResult(page.getTotal(), page.getResult());
}
/**
* 批量删除套餐
*
* @param ids
*/
@Transactional
public void deleteBatch(List<Long> ids) {
ids.forEach(id -> {
Setmeal setmeal = setmealMapper.getById(id);
if (StatusConstant.ENABLE == setmeal.getStatus()) {
//起售中的套餐不能删除
throw new DeletionNotAllowedException(MessageConstant.SETMEAL_ON_SALE);
}
});
ids.forEach(setmealId -> {
//删除套餐表中的数据
setmealMapper.deleteById(setmealId);
//删除套餐菜品关系表中的数据
setmealDishMapper.deleteBySetmealId(setmealId);
});
}
/**
* 根据id查询套餐和套餐菜品关系
*
* @param id
* @return
*/
public SetmealVO getByIdWithDish(Long id) {
SetmealVO setmealVO = setmealMapper.getByIdWithDish(id);
return setmealVO;
}
/**
* 修改套餐
*
* @param setmealDTO
*/
@Transactional
public void update(SetmealDTO setmealDTO) {
Setmeal setmeal = new Setmeal();
BeanUtils.copyProperties(setmealDTO, setmeal);
//1、修改套餐表,执行update
setmealMapper.update(setmeal);
//套餐id
Long setmealId = setmealDTO.getId();
//2、删除套餐和菜品的关联关系,操作setmeal_dish表,执行delete
setmealDishMapper.deleteBySetmealId(setmealId);
List<SetmealDish> setmealDishes = setmealDTO.getSetmealDishes();
setmealDishes.forEach(setmealDish -> {
setmealDish.setSetmealId(setmealId);
});
//3、重新插入套餐和菜品的关联关系,操作setmeal_dish表,执行insert
setmealDishMapper.insertBatch(setmealDishes);
}
/**
* 套餐起售、停售
*
* @param status
* @param id
*/
public void startOrStop(Integer status, Long id) {
//起售套餐时,判断套餐内是否有停售菜品,有停售菜品提示"套餐内包含未启售菜品,无法启售"
if (status == StatusConstant.ENABLE) {
//select a.* from dish a left join setmeal_dish b on a.id = b.dish_id where b.setmeal_id = ?
List<Dish> dishList = dishMapper.getBySetmealId(id);
if (dishList != null && dishList.size() > 0) {
dishList.forEach(dish -> {
if (StatusConstant.DISABLE == dish.getStatus()) {
throw new SetmealEnableFailedException(MessageConstant.SETMEAL_ENABLE_FAILED);
}
});
}
}
Setmeal setmeal = Setmeal.builder()
.id(id)
.status(status)
.build();
setmealMapper.update(setmeal);
}
/**
* 条件查询
* @param setmeal
* @return
*/
public List<Setmeal> list(Setmeal setmeal) {
List<Setmeal> list = setmealMapper.list(setmeal);
return list;
}
/**
* 根据id查询菜品选项
* @param id
* @return
*/
public List<DishItemVO> getDishItemById(Long id) {
return setmealMapper.getDishItemBySetmealId(id);
}
}
sky-server com/sky/controller/user/CategoryController.java
package com.sky.controller.user;
import com.sky.entity.Category;
import com.sky.result.Result;
import com.sky.service.CategoryService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController("userCategoryController")
@RequestMapping("/user/category")
@Api(tags = "C端-分类接口")
public class CategoryController {
@Autowired
private CategoryService categoryService;
/**
* 查询分类
* @param type
* @return
*/
@GetMapping("/list")
@ApiOperation("查询分类")
public Result<List<Category>> list(Integer type) {
List<Category> list = categoryService.list(type);
return Result.success(list);
}
}
sky-server com/sky/service/CategoryService.java
package com.sky.service;
import com.sky.annotation.AutoFill;
import com.sky.dto.CategoryDTO;
import com.sky.dto.CategoryPageQueryDTO;
import com.sky.entity.Category;
import com.sky.result.PageResult;
import java.util.List;
public interface CategoryService {
/**
* 新增分类
* @param categoryDTO
*/
void save(CategoryDTO categoryDTO);
/**
* 分页查询
* @param categoryPageQueryDTO
* @return
*/
PageResult pageQuery(CategoryPageQueryDTO categoryPageQueryDTO);
/**
* 根据id删除分类
* @param id
*/
void deleteById(Long id);
/**
* 修改分类
* @param categoryDTO
*/
void update(CategoryDTO categoryDTO);
/**
* 启用、禁用分类
* @param status
* @param id
*/
void startOrStop(Integer status, Long id);
/**
* 根据类型查询分类
* @param type
* @return
*/
List<Category> list(Integer type);
}
sky-server com/sky/service/impl/CategoryServiceImpl.java
package com.sky.service.impl;
import com.github.pagehelper.Page;
import com.github.pagehelper.PageHelper;
import com.sky.constant.MessageConstant;
import com.sky.constant.StatusConstant;
import com.sky.context.BaseContext;
import com.sky.dto.CategoryDTO;
import com.sky.dto.CategoryPageQueryDTO;
import com.sky.entity.Category;
import com.sky.exception.DeletionNotAllowedException;
import com.sky.mapper.CategoryMapper;
import com.sky.mapper.DishMapper;
import com.sky.mapper.SetmealMapper;
import com.sky.result.PageResult;
import com.sky.service.CategoryService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.time.LocalDateTime;
import java.util.List;
/**
* 分类业务层
*/
@Service
@Slf4j
public class CategoryServiceImpl implements CategoryService {
@Autowired
private CategoryMapper categoryMapper;
@Autowired
private DishMapper dishMapper;
@Autowired
private SetmealMapper setmealMapper;
/**
* 新增分类
* @param categoryDTO
*/
public void save(CategoryDTO categoryDTO) {
Category category = new Category();
//属性拷贝
BeanUtils.copyProperties(categoryDTO, category);
//分类状态默认为禁用状态0
category.setStatus(StatusConstant.DISABLE);
/** 公共属性
//设置创建时间、修改时间、创建人、修改人
category.setCreateTime(LocalDateTime.now());
category.setUpdateTime(LocalDateTime.now());
category.setCreateUser(BaseContext.getCurrentId());
category.setUpdateUser(BaseContext.getCurrentId());
**/
categoryMapper.insert(category);
}
/**
* 分页查询
* @param categoryPageQueryDTO
* @return
*/
public PageResult pageQuery(CategoryPageQueryDTO categoryPageQueryDTO) {
PageHelper.startPage(categoryPageQueryDTO.getPage(),categoryPageQueryDTO.getPageSize());
//下一条sql进行分页,自动加入limit关键字分页
Page<Category> page = categoryMapper.pageQuery(categoryPageQueryDTO);
return new PageResult(page.getTotal(), page.getResult());
}
/**
* 根据id删除分类
* @param id
*/
public void deleteById(Long id) {
//查询当前分类是否关联了菜品,如果关联了就抛出业务异常
Integer count = dishMapper.countByCategoryId(id);
if(count > 0){
//当前分类下有菜品,不能删除
throw new DeletionNotAllowedException(MessageConstant.CATEGORY_BE_RELATED_BY_DISH);
}
//查询当前分类是否关联了套餐,如果关联了就抛出业务异常
count = setmealMapper.countByCategoryId(id);
if(count > 0){
//当前分类下有菜品,不能删除
throw new DeletionNotAllowedException(MessageConstant.CATEGORY_BE_RELATED_BY_SETMEAL);
}
//删除分类数据
categoryMapper.deleteById(id);
}
/**
* 修改分类
* @param categoryDTO
*/
public void update(CategoryDTO categoryDTO) {
Category category = new Category();
BeanUtils.copyProperties(categoryDTO,category);
//设置修改时间、修改人 (公共属性)
// category.setUpdateTime(LocalDateTime.now());
// category.setUpdateUser(BaseContext.getCurrentId());
categoryMapper.update(category);
}
/**
* 启用、禁用分类
* @param status
* @param id
*/
public void startOrStop(Integer status, Long id) {
Category category = Category.builder()
.id(id)
.status(status) // 下面注释是公共属性AOP有写
// .updateTime(LocalDateTime.now())
// .updateUser(BaseContext.getCurrentId())
.build();
categoryMapper.update(category);
}
/**
* 根据类型查询分类
* @param type
* @return
*/
public List<Category> list(Integer type) {
return categoryMapper.list(type);
}
}
缓存菜品 【redis】
问题说明:
用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大
实现思路:
通过Redis来缓存菜品数据,减少数据库查询操作
开始→(查询菜品)→后端服务→缓存是否存在→(是)→读取缓存
(否)→查询数据库→载入缓存
缓存逻辑分析:
sky-server com/sky/controller/user/DishController.java
package com.sky.controller.user;
import com.sky.constant.StatusConstant;
import com.sky.entity.Dish;
import com.sky.result.Result;
import com.sky.service.DishService;
import com.sky.vo.DishVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController("userDishController")
@RequestMapping("/user/dish")
@Slf4j
@Api(tags = "C端-菜品浏览接口")
public class DishController {
@Autowired
private DishService dishService;
@Autowired
private RedisTemplate redisTemplate;
/**
* 根据分类id查询菜品
*
* @param categoryId
* @return
*/
@GetMapping("/list")
@ApiOperation("根据分类id查询菜品")
public Result<List<DishVO>> list(Long categoryId) {
//构造redis中的key,规则:dish_分类id
String key = "dish_" + categoryId;
//查询redis中是否存在菜品数据
List<DishVO> list = (List<DishVO>) redisTemplate.opsForValue().get(key);
if(list != null && list.size() > 0){
//如果存在,直接返回,无须查询数据库
return Result.success(list);
}
Dish dish = new Dish();
dish.setCategoryId(categoryId);
dish.setStatus(StatusConstant.ENABLE);//查询起售中的菜品
//如果不存在,查询数据库,将查询到的数据放入redis中
list = dishService.listWithFlavor(dish);
redisTemplate.opsForValue().set(key, list);
return Result.success(list);
}
}
清理缓存数据
防止 新增/更改/删除/起售停售 后无法及时在用户手机端接收
修改管理端接口 DishController 加入清理缓存的逻辑 (新增菜品、修改菜品、批量删除菜品、起售停售菜品)
sky-server com/sky/controller/admin/DishController.java
/**
* 菜品管理
*/
@RestController
@RequestMapping("/admin/dish")
@Api(tags = "菜品相关接口")
@Slf4j
public class DishController {
@Autowired
private DishService dishService;
@Autowired
private RedisTemplate redisTemplate;
@PostMapping
@ApiOperation("新增菜品")
//@RequestBody 封装JSON格式的数据
public Result save(@RequestBody DishDTO dishDTO) {
log.info("新增菜品:{}", dishDTO);
dishService.saveWithFlavour(dishDTO);
//清理缓存数据(精确查询)
String key = "dish_" + dishDTO.getCategoryId();
cleanCache(key);
return Result.success();
}
/**
* 菜品的批量删除
* @param ids
* @return
*/
@DeleteMapping
@ApiOperation("批量删除菜品")
//@RequestParam MVC动态解析字符串 ids提取出来
public Result delete(@RequestParam List<Long> ids) { //ids
log.info("批量删除菜品:{}", ids);
dishService.deleteBatch(ids);
// 将所有的菜品缓存数据清理掉,所有的以dish_开头的key
cleanCache("dish_*");
return Result.success();
}
/**
* 修改菜品
* @param dishDTO
* @return
*/
@PutMapping
@ApiOperation("修改菜品")
public Result update(@RequestBody DishDTO dishDTO) {
log.info("修改菜品:{}", dishDTO);
dishService.updateWithFlavor(dishDTO);
// 将所有的菜品缓存数据清理掉,所有的以dish_开头的key
cleanCache("dish_*");;
return Result.success();
}
/**
* 菜品起售停售
*
* @param status
* @param id
* @return
*/
@PostMapping("/status/{status}")
@ApiOperation("菜品起售停售")
public Result<String> startOrStop(@PathVariable Integer status, Long id) {
dishService.startOrStop(status, id);
// 将所有的菜品缓存数据清理掉,所有的以dish_开头的key
cleanCache("dish_*");
return Result.success();
}
private void cleanCache(String pattern){
/** 因为单独清理每个菜品可能会有关联套餐 就直接清理全部
* 1. 先获取到所有的key
* 2. 遍历key,判断是否以pattern开头
* 3. 删除所有的key
*/
Set keys = redisTemplate.keys(pattern);
redisTemplate.delete(keys);
}
}
缓存套餐 【SpringCache】
Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能
Spring Cache 提供了一层抽象,底层可以切换不同的缓存实现
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
Spring Cache
| 注解 |
说明 |
| @EnableCaching |
开启缓存注解功能,通常加在启动类上 |
| @Cacheable |
在方法执行前先查询缓存中是否有数据,如果有数据,则直接返回缓存数据;如果没有缓存数据,调用方法并将方法返回值放到缓存中 |
| @CachePut |
将方法的返回值放到缓存中 |
| @CacheEvict |
将一条或多条数据从缓存中删除 |
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {
@CachePut(cacheNames = "userCache",key = "#user.id")
// 将方法的返回值放到缓存中
// 如果使用Spring Cache缓存数据,key的生成"#user.id"
public User save(@RequestBody User user){
userMapper.insert(user);
return user;
}
@DeleteMapping
@CacheEvict(cacheNames = "userCache",key = "#id")
public void deleteById(Long id){
userMapper.deleteById(id);
}
@DeleteMapping("/delAll")
@CacheEvict(cacheNames = "userCache",allEntries = true)
public void deleteAll(){
userMapper.deleteAll();
}
@GetMapping
@Cacheable(cacheNames = "userCache",key = "#id")
// 在方法执行前先查询缓存中是否有数据,如果有数据,则直接返回缓存数据;如果没有缓存数据,调用方法并将方法返回值放到缓存中
public User getById(Long id){
User user = userMapper.getById(id);
return user;
}
SpringCache入门案例
初始资源:
package com.itheima.controller;
import com.itheima.entity.User;
import com.itheima.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {
@Autowired
private UserMapper userMapper;
@PostMapping
public User save(@RequestBody User user){
userMapper.insert(user);
return user;
}
@DeleteMapping
public void deleteById(Long id){
userMapper.deleteById(id);
}
@DeleteMapping("/delAll")
public void deleteAll(){
userMapper.deleteAll();
}
@GetMapping
public User getById(Long id){
User user = userMapper.getById(id);
return user;
}
}
package com.itheima.mapper;
import com.itheima.entity.User;
import org.apache.ibatis.annotations.*;
@Mapper
public interface UserMapper{
@Insert("insert into user(name,age) values (#{name},#{age})")
@Options(useGeneratedKeys = true,keyProperty = "id")
void insert(User user);
@Delete("delete from user where id = #{id}")
void deleteById(Long id);
@Delete("delete from user")
void deleteAll();
@Select("select * from user where id = #{id}")
User getById(Long id);
}
package com.itheima.entity;
import lombok.Data;
import java.io.Serializable;
@Data
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private String name;
private int age;
}
package com.itheima.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.ResourceHandlerRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurationSupport;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
@Configuration
@Slf4j
public class WebMvcConfiguration extends WebMvcConfigurationSupport {
/**
* 生成接口文档配置
* @return
*/
@Bean
public Docket docket(){
log.info("准备生成接口文档...");
ApiInfo apiInfo = new ApiInfoBuilder()
.title("接口文档")
.version("2.0")
.description("接口文档")
.build();
Docket docket = new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo)
.select()
//指定生成接口需要扫描的包
.apis(RequestHandlerSelectors.basePackage("com.itheima.controller"))
.paths(PathSelectors.any())
.build();
return docket;
}
/**
* 设置静态资源映射
* @param registry
*/
protected void addResourceHandlers(ResourceHandlerRegistry registry) {
log.info("开始设置静态资源映射...");
registry.addResourceHandler("/doc.html").addResourceLocations("classpath:/META-INF/resources/");
registry.addResourceHandler("/webjars/**").addResourceLocations("classpath:/META-INF/resources/webjars/");
}
}
application.yml
server:
port: 8888
spring:
datasource:
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/spring_cache_demo?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
username: root
password: root
redis:
host: localhost
port: 6379
database: 1
logging:
level:
com:
itheima:
mapper: debug
service: info
controller: info
springcachedemo.sql
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
`age` int DEFAULT NULL,
PRIMARY KEY (`id`)
);
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.3</version>
<relativePath/>
</parent>
<groupId>com.itheima</groupId>
<artifactId>springcache-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
<version>3.0.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.7.3</version>
</plugin>
</plugins>
</build>
</project>
开始调试咯
com/itheima/CacheDemoApplication.java
package com.itheima;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cache.annotation.EnableCaching;
//@EnableCaching 放在 Application 类上,这样整个应用就启用了缓存支持
@Slf4j
@SpringBootApplication
@EnableCaching
public class CacheDemoApplication {
public static void main(String[] args) {
SpringApplication.run(CacheDemoApplication.class,args);
log.info("项目启动成功...");
}
}
com/itheima/controller/UserController.java
package com.itheima.controller;
import com.itheima.entity.User;
import com.itheima.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.annotation.CacheEvict;
import org.springframework.cache.annotation.CachePut;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {
/*
set a:b:c:d: itheima 这个就是树形结构在Redis里面 文件夹包着文件夹
*/
@Autowired
private UserMapper userMapper;
@PostMapping
// @CachePut(cacheNames = "userCache",key = "#result.id") 对象导航
// @CachePut(cacheNames = "userCache",key = "#p0.id")
// @CachePut(cacheNames = "userCache",key = "#root.args[0]")
@CachePut(cacheNames = "userCache",key = "#user.id")
// 将方法的返回值放到缓存中
// 如果使用Spring Cache缓存数据,key的生成"#user.id"
public User save(@RequestBody User user){
userMapper.insert(user);
return user;
}
@DeleteMapping
@CacheEvict(cacheNames = "userCache",key = "#id")
public void deleteById(Long id){
userMapper.deleteById(id);
}
@DeleteMapping("/delAll")
@CacheEvict(cacheNames = "userCache",allEntries = true)
public void deleteAll(){
userMapper.deleteAll();
}
@GetMapping
@Cacheable(cacheNames = "userCache",key = "#id")
// 在方法执行前先查询缓存中是否有数据,如果有数据,则直接返回缓存数据;如果没有缓存数据,调用方法并将方法返回值放到缓存中
public User getById(Long id){
User user = userMapper.getById(id);
return user;
}
}
缓存套餐_代码开发
实现思路
- 导入 Spring Cache 和 Redis 相关maven坐标
- 在启动类上加入 @EnableCaching 注解,开启缓存注解功能
- 在用户端接口 SetmealController 的 list 方法上加入 @Cacheable 注解
- 在管理端接口 SetmealController 的 save、delete、update、startOrStop 等方法上
加入**@CacheEvict** 注解保证数据一致性
com/sky/SkyApplication.java
package com.sky;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@SpringBootApplication
@EnableTransactionManagement //开启注解方式的事务管理
@Slf4j
@EnableCaching //开启缓存注解
public class SkyApplication {
public static void main(String[] args) {
SpringApplication.run(SkyApplication.class, args);
log.info("server started");
}
}
sky-server com/sky/controller/user/SetmealController.java
@RestController("userSetmealController")
@RequestMapping("/user/setmeal")
@Api(tags = "C端-套餐浏览接口")
public class SetmealController {
@Autowired
private SetmealService setmealService;
/**
* 条件查询
*
* @param categoryId
* @return
*/
@GetMapping("/list")
@ApiOperation("根据分类id查询套餐")
@Cacheable(cacheNames = "setmealCache",key = "#categoryId") //key: setmealCache::100
public Result<List<Setmeal>> list(Long categoryId) {
Setmeal setmeal = new Setmeal();
setmeal.setCategoryId(categoryId);
setmeal.setStatus(StatusConstant.ENABLE);
List<Setmeal> list = setmealService.list(setmeal);
return Result.success(list);
}
}
sky-server com/sky/controller/admin/SetmealController.java
/**
* 套餐管理
*/
@RestController
@RequestMapping("/admin/setmeal")
@Api(tags = "套餐相关接口")
@Slf4j
public class SetmealController {
@Autowired
private SetmealService setmealService;
/**
* 新增套餐
*
* @param setmealDTO
* @return
*/
@PostMapping
@ApiOperation("新增套餐")
@CacheEvict(cacheNames = "setmealCache",key = "#setmealDTO.categoryId")//key: setmealCache::100
public Result save(@RequestBody SetmealDTO setmealDTO) {
setmealService.saveWithDish(setmealDTO);
return Result.success();
}
/**
* 批量删除套餐
*
* @param ids
* @return
*/
@DeleteMapping
@ApiOperation("批量删除套餐")
@CacheEvict(cacheNames = "setmealCache",allEntries = true)
public Result delete(@RequestParam List<Long> ids) {
setmealService.deleteBatch(ids);
return Result.success();
}
/**
* 修改套餐
*
* @param setmealDTO
* @return
*/
@PutMapping
@ApiOperation("修改套餐")
@CacheEvict(cacheNames = "setmealCache",allEntries = true)
public Result update(@RequestBody SetmealDTO setmealDTO) {
setmealService.update(setmealDTO);
return Result.success();
}
/**
* 套餐起售停售
*
* @param status
* @param id
* @return
*/
@PostMapping("/status/{status}")
@ApiOperation("套餐起售停售")
@CacheEvict(cacheNames = "setmealCache",allEntries = true)
public Result startOrStop(@PathVariable Integer status, Long id) {
setmealService.startOrStop(status, id);
return Result.success();
}
}
添加购物车
套餐直接点击加号
菜品+ 或者有口味数据的选择后才可以加入购物车
接口设计:
- 请求方式:POST
- 请求路径:/user/shoppingCart/add
- 请求参数:菜品id(dish_id)、口味(dish_flavor) 或 套餐id(setmeal_id) (JSON请求体)
- 返回结果:code、data、msg
- 作用:暂时存放所选商品的地方
- 选的什么商品
- 每个商品都买了几个
- 不同用户的购物车需要区分开
sky-pojo com/sky/dto/ShoppingCartDTO.java
package com.sky.dto;
import lombok.Data;
import java.io.Serializable;
@Data
public class ShoppingCartDTO implements Serializable {
private Long dishId;
private Long setmealId;
private String dishFlavor;
}
sky-server com/sky/controller/user/ShoppingCartController.java
package com.sky.controller.user;
import com.sky.dto.ShoppingCartDTO;
import com.sky.result.Result;
import com.sky.service.ShoppingCartService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/user/shoppingCart")
@Slf4j
@Api(tags = "C端添加购物车接口")
public class ShoppingCartController {
@Autowired
private ShoppingCartService shoppingCartService;
/**
* 添加购物车
* @param shoppingCartDTO
* @return
*/
@PostMapping("/add")
@ApiOperation("添加购物车")
public Result add(@RequestBody ShoppingCartDTO shoppingCartDTO){
log.info("添加购物车,商品信息为:{}",shoppingCartDTO);
shoppingCartService.addShoppingCart(shoppingCartDTO);
return Result.success();
}
}
sky-server com/sky/service/ShoppingCartService.java
package com.sky.service;
import com.sky.dto.ShoppingCartDTO;
import org.springframework.stereotype.Service;
public interface ShoppingCartService {
/**
* 添加购物车
* @param shoppingCartDTO
*/
void addShoppingCart(ShoppingCartDTO shoppingCartDTO);
}
sky-server com/sky/service/impl/ShoppingCartServiceImpl.java
package com.sky.service.impl;
import com.sky.context.BaseContext;
import com.sky.dto.ShoppingCartDTO;
import com.sky.entity.Dish;
import com.sky.entity.Setmeal;
import com.sky.entity.ShoppingCart;
import com.sky.mapper.DishMapper;
import com.sky.mapper.SetmealMapper;
import com.sky.mapper.ShoppingCartMapper;
import com.sky.service.ShoppingCartService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.time.LocalDateTime;
import java.util.List;
@Service
@Slf4j
public class ShoppingCartServiceImpl implements ShoppingCartService {
/**
* 添加购物车
* @param shoppingCartDTO
*/
@Autowired
private ShoppingCartMapper shoppingCartMapper;
@Autowired
private DishMapper dishMapper;
@Autowired
private SetmealMapper setmealMapper;
@Override
public void addShoppingCart(ShoppingCartDTO shoppingCartDTO) {
// 判断当前加入购物车中的商品是否已经存在了 (user_id + setmeal_id)
ShoppingCart shoppingCart = new ShoppingCart();
BeanUtils.copyProperties(shoppingCartDTO, shoppingCart);
Long userId = BaseContext.getCurrentId();
shoppingCart.setUserId(userId);
List<ShoppingCart> list = shoppingCartMapper.list(shoppingCart);
// 如果已经存在了,只需要将数量+1
if (list != null && list.size() > 0) {
ShoppingCart cart = list.get(0);
cart.setNumber(cart.getNumber() + 1);
// update shopping_cart set number = ? where id = ?
shoppingCartMapper.updateNumberById(cart);
} else {
// 如果不存在,需要插入一条购物车数据
// [先确定套餐or菜品]
// 判断本次添加到购物车的是菜品还是套餐
Long dishId = shoppingCartDTO.getDishId();
if (dishId != null) {
//本次添加到购物车的是菜品
Dish dish = dishMapper.getById(dishId);
shoppingCart.setName(dish.getName());
shoppingCart.setImage(dish.getImage());
shoppingCart.setAmount(dish.getPrice());
} else {
//本次添加到购物车的是套餐 查菜品表
Long setmealId = shoppingCartDTO.getSetmealId();
Setmeal setmeal = setmealMapper.getById(setmealId);
shoppingCart.setName(setmeal.getName());
shoppingCart.setImage(setmeal.getImage());
shoppingCart.setAmount(setmeal.getPrice());
}
shoppingCart.setNumber(1);
shoppingCart.setCreateTime(LocalDateTime.now());
shoppingCartMapper.insert(shoppingCart);
}
}
}
sky-server com/sky/mapper/ShoppingCartMapper.java
package com.sky.mapper;
import com.sky.entity.ShoppingCart;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Update;
import java.util.List;
@Mapper
public interface ShoppingCartMapper {
List<ShoppingCart> list(ShoppingCart shoppingCart);
/**
* 根据id修改商品数量
* @param shoppingCart
*/
@Update("update shopping_cart set number = #{number} where id = #{id}")
void updateNumberById(ShoppingCart shoppingCart);
/**
* 插入购物车数据
* @param shoppingCart
*/
@Insert("insert into shopping_cart (name, user_id, dish_id, setmeal_id, dish_flavor, number, amount, image, create_time) " +
" values (#{name},#{userId},#{dishId},#{setmealId},#{dishFlavor},#{number},#{amount},#{image},#{createTime})")
void insert(ShoppingCart shoppingCart);
}
sky-server mapper/ShoppingCartMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.ShoppingCartMapper">
<select id="list" resultType="com.sky.entity.ShoppingCart">
select * from shopping_cart
<where>
<if test="userId != null">
and user_id = #{userId}
</if>
<if test="dishId != null">
and dish_id = #{dishId}
</if>
<if test="setmealId != null">
and setmeal_id = #{setmealId}
</if>
<if test="dishFlavor != null">
and dish_flavor = #{dishFlavor}
</if>
</where>
</select>
</mapper>
删除购物车
sky-server com/sky/controller/user/ShoppingCartController.java
/**
* 删除购物车
* @param shoppingCartDTO
* @return
*/
@PostMapping("/sub")
@ApiOperation("删除购物车")
public Result sub(@RequestBody ShoppingCartDTO shoppingCartDTO){
log.info("删除购物车,商品信息为:{}",shoppingCartDTO);
shoppingCartService.subShoppingCart(shoppingCartDTO);
return Result.success();
}
sky-server com/sky/service/ShoppingCartService.java
/**
* 删除购物车
* @param shoppingCartDTO
*/
void subShoppingCart(ShoppingCartDTO shoppingCartDTO);
sky-server com/sky/service/impl/ShoppingCartServiceImpl.java
/**
* 删除购物车中的商品
* @param shoppingCartDTO
*/
@Override
public void subShoppingCart(ShoppingCartDTO shoppingCartDTO) {
Long userId = BaseContext.getCurrentId();
ShoppingCart shoppingCart = new ShoppingCart();
BeanUtils.copyProperties(shoppingCartDTO, shoppingCart);
shoppingCart.setUserId(userId);
List<ShoppingCart> list = shoppingCartMapper.list(shoppingCart);
if (list != null && list.size() > 0) {
ShoppingCart cart = list.get(0);
if (cart.getNumber() > 1) {
// 如果 number >1, 则需要将 number - 1
cart.setNumber(cart.getNumber() - 1);
shoppingCartMapper.updateNumberById(cart);
} else {
// 如果 number <=1,则直接删除该购物车数据
shoppingCartMapper.deleteById(cart.getId());
}
}
}
sky-server com/sky/mapper/ShoppingCartMapper.java
/**
* 根据id删除购物车数据
* @param id
*/
@Delete("delete from shopping_cart where id = #{id}")
void deleteById(Long id);
查看购物车
名称、价格、商品、数量
Path:/user/shoppingCart/list
PUT
sky-server com/sky/controller/user/ShoppingCartController.java
/**
* 查看购物车
* @return
*/
@GetMapping("/list")
@ApiOperation("查看购物车")
public Result<List<ShoppingCart>> list(){
List<ShoppingCart> list = shoppingCartService.showShoppingCart();
return Result.success(list);
}
sky-server com/sky/service/ShoppingCartService.java
/**
* 查看购物车
* @return
*/
List<ShoppingCart> showShoppingCart();
sky-server com/sky/service/impl/ShoppingCartServiceImpl.java
/**
* 查看购物车
* @return
*/
@Override
public List<ShoppingCart> showShoppingCart() {
// 获取到当前微信用户的id
Long userId = BaseContext.getCurrentId();
ShoppingCart shoppingCart = ShoppingCart.builder()
.userId(userId)
.build();
List<ShoppingCart> list = shoppingCartMapper.list(shoppingCart);
return list;
}
清空购物车
Path:user/shoppingCart/clean
Method:DELETE
返回:code date msg
sky-server com/sky/controller/user/ShoppingCartController.java
/**
* 清空购物车
* @return
*/
@DeleteMapping("/clean")
@ApiOperation("清空购物车")
public Result clean() {
shoppingCartService.cleanShoppingCart();
return Result.success();
}
sky-server com/sky/service/ShoppingCartService.java
/**
* 清空购物车 删除自己的购物车
*/
void cleanShoppingCart();
sky-server com/sky/service/impl/ShoppingCartServiceImpl.java
/**
* 清空购物车
*/
@Override
public void cleanShoppingCart() {
//获取到当前用户的id
Long userId = BaseContext.getCurrentId();
shoppingCartMapper.deleteByUserId(userId);
}
sky-server com/sky/mapper/ShoppingCartMapper.java
/**
* 根据用户id清空购物车
* @param userId
*/
@Delete("delete from shopping_cart where user_id = #{userId}")
void deleteByUserId(Long userId);
支付接口
导入地址簿功能代码
业务功能:
查询地址列表
新增地址
修改地址
Path:/user/addressBook
Method:PUT
删除地址
设置默认地址
查询默认地址
接口设计:
新增地址
Path: /user/addressBook
Method: POST
查询当前登录用户的所有地址信息
Path: /user/addressBook/list
Method: GET
查询默认地址
根据id修改地址
根据id删除地址
Path:/user/addressBook
Method:DELETE
根据id查询地址
Path:/user/addressBook/{id}
Method:GET
设置默认地址
Path:/user/addressBook/default
Method:PUT
数据库设计(address_book表)
用户下单
在电商系统中,用户是通过下单的方式通知商家,用户已经购买了商品,需要商家进行备货和发货
用户下单后会产生订单相关数据,订单数据需要体现信息:
- 订单总金额是多少?
- 哪个用户下的单?
- 买的哪些商品?
- 每个商品数量是多少?
- 收货地址是哪?
- 用户手机号是多少?
餐盒费:用数量算
用户下单接口设计
请求方式:POST
请求路径:/user/order/submit
参数:
- 地址簿id
addressBookId
- 配送状态(立即送出、选择送出时间)
deliveryStatus
- 打包费
packAmount
- 总金额
amount
- 备注
remark
- 餐具数量
tablewareNumber
支付订单接口设计
返回数据:
数据库设计订单表orders、订单明细表order_detail
- 订单表 orders
- 谁的订单?
- 送哪去?
- 打哪个电话联系?
- 多少钱?
- 什么时间下的单?
- 什么时间支付的?
- 订单的状态?
- 订单号是多少?
- 订单明细表 order_detail
- 当前明细属于哪个订单?
- 具体点的是什么商品?
- 这个商品点了几份?
代码开发
用户下单1
根据用户下单接口的参数设计DTO:
sky-pojo com/sky/dto/OrdersSubmitDTO.java
package com.sky.dto;
import com.fasterxml.jackson.annotation.JsonFormat;
import lombok.Data;
import java.io.Serializable;
import java.math.BigDecimal;
import java.time.LocalDateTime;
@Data
public class OrdersSubmitDTO implements Serializable {
//地址簿id
private Long addressBookId;
//付款方式
private int payMethod;
//备注
private String remark;
//预计送达时间
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime estimatedDeliveryTime;
//配送状态 1立即送出 0选择具体时间
private Integer deliveryStatus;
//餐具数量
private Integer tablewareNumber;
//餐具数量状态 1按餐量提供 0选择具体数量
private Integer tablewareStatus;
//打包费
private Integer packAmount;
//总金额
private BigDecimal amount;
}
sky-pojo com/sky/vo/OrdersSubmitVO.java
package com.sky.vo;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.math.BigDecimal;
import java.time.LocalDateTime;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class OrderSubmitVO implements Serializable {
//订单id
private Long id;
//订单号
private String orderNumber;
//订单金额
private BigDecimal orderAmount;
//下单时间
private LocalDateTime orderTime;
}
sky-server com/sky/controller/user/OrderController.java
package com.sky.controller.user;
import com.sky.dto.OrdersSubmitDTO;
import com.sky.result.Result;
import com.sky.service.OrderService;
import com.sky.vo.OrderSubmitVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController("userOrderController")
@RequestMapping("/user/order")
@Api(tags = "用户订单相关接口")
@Slf4j
public class OrderController {
@Autowired
private OrderService orderService;
/**
* 用户下单
* @param ordersSubmitDTO
* @return
*/
@PostMapping("/submit")
@ApiOperation("用户下单")
public Result<OrderSubmitVO> submit(@RequestBody OrdersSubmitDTO ordersSubmitDTO) {
log.info("用户下单,参数为:{}", ordersSubmitDTO);
OrderSubmitVO orderSubmitVO = orderService.submitOrder(ordersSubmitDTO);
return Result.success(orderSubmitVO);
}
}
sky-server com/sky/service/OrderService.java
package com.sky.vo;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.math.BigDecimal;
import java.time.LocalDateTime;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class OrderSubmitVO implements Serializable {
//订单id
private Long id;
//订单号
private String orderNumber;
//订单金额
private BigDecimal orderAmount;
//下单时间
private LocalDateTime orderTime;
}
用户下单2
sky-pojo com/sky/entity/AddressBook.java
package com.sky.entity;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
/**
* 地址簿
*/
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class AddressBook implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
//用户id
private Long userId;
//收货人
private String consignee;
//手机号
private String phone;
//性别 0 女 1 男
private String sex;
//省级区划编号
private String provinceCode;
//省级名称
private String provinceName;
//市级区划编号
private String cityCode;
//市级名称
private String cityName;
//区级区划编号
private String districtCode;
//区级名称
private String districtName;
//详细地址
private String detail;
//标签
private String label;
//是否默认 0否 1是
private Integer isDefault;
}
sky-server com/sky/service/impl/OrderServiceImpl.java
package com.sky.service.impl;
import com.sky.constant.MessageConstant;
import com.sky.context.BaseContext;
import com.sky.dto.OrdersSubmitDTO;
import com.sky.entity.AddressBook;
import com.sky.entity.Orders;
import com.sky.entity.ShoppingCart;
import com.sky.exception.AddressBookBusinessException;
import com.sky.exception.ShoppingCartBusinessException;
import com.sky.mapper.AddressBookMapper;
import com.sky.mapper.OrderDetailMapper;
import com.sky.mapper.OrderMapper;
import com.sky.mapper.ShoppingCartMapper;
import com.sky.service.OrderService;
import com.sky.vo.OrderSubmitVO;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.time.LocalDateTime;
import java.util.List;
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private OrderDetailMapper orderDetailMapper;
@Autowired
private AddressBookMapper addressBookMapper;
@Autowired
private ShoppingCartMapper shoppingCartMapper;
/**
* 用户下单
* @param ordersSubmitDTO
* @return
*/
@Override
public OrderSubmitVO submitOrder(OrdersSubmitDTO ordersSubmitDTO) {
// 1.处理各种业务异常(地址簿为空,购物车数据为空)
AddressBook addressBook = addressBookMapper.getById(ordersSubmitDTO.getAddressBookId());
if (addressBook == null) {
// 抛出业务异常
throw new AddressBookBusinessException(MessageConstant.ADDRESS_BOOK_IS_NULL);
}
// 查询当前用户购物车信息
Long userId = BaseContext.getCurrentId();
ShoppingCart shoppingCart = new ShoppingCart();
shoppingCart.setUserId(userId);
List<ShoppingCart> shoppingCartList = shoppingCartMapper.list(shoppingCart);
if (shoppingCartList == null || shoppingCartList.size() == 0) {
// 抛出业务异常
throw new ShoppingCartBusinessException(MessageConstant.SHOPPING_CART_IS_NULL);
}
// 2.向订单表插入1条数据
Orders orders = new Orders();
BeanUtils.copyProperties(ordersSubmitDTO, orders);
orders.setOrderTime(LocalDateTime.now());
orders.setPayStatus(Orders.UN_PAID);
orders.setStatus(Orders.PENDING_PAYMENT);
orders.setNumber(String.valueOf(System.currentTimeMillis()));//订单号
orders.setPhone(addressBook.getPhone());
orders.setConsignee(addressBook.getConsignee());
orders.setUserId(userId);
orderMapper.insert(orders);
// 3.向订单明细表插入n条数据
// 4,清空当前用户的购物车数据
// 5.封装VO返回结果
return null;
}
}
sky-server com/sky/mapper/OrderMapper.java
package com.sky.mapper;
import com.sky.entity.Orders;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface OrderMapper {
/**
* 用户下单
* @param orders
*/
void insert(Orders orders);
}
代码开发3
sky-server com/sky/service/impl/OrderServiceImpl.java
package com.sky.service.impl;
import com.sky.constant.MessageConstant;
import com.sky.context.BaseContext;
import com.sky.dto.OrdersSubmitDTO;
import com.sky.entity.AddressBook;
import com.sky.entity.OrderDetail;
import com.sky.entity.Orders;
import com.sky.entity.ShoppingCart;
import com.sky.exception.AddressBookBusinessException;
import com.sky.exception.ShoppingCartBusinessException;
import com.sky.mapper.AddressBookMapper;
import com.sky.mapper.OrderDetailMapper;
import com.sky.mapper.OrderMapper;
import com.sky.mapper.ShoppingCartMapper;
import com.sky.service.OrderService;
import com.sky.vo.OrderSubmitVO;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private OrderDetailMapper orderDetailMapper;
@Autowired
private AddressBookMapper addressBookMapper;
@Autowired
private ShoppingCartMapper shoppingCartMapper;
/**
* 用户下单
* @param ordersSubmitDTO
* @return
*/
@Transactional
public OrderSubmitVO submitOrder(OrdersSubmitDTO ordersSubmitDTO) {
// 1.处理各种业务异常(地址簿为空,购物车数据为空)
AddressBook addressBook = addressBookMapper.getById(ordersSubmitDTO.getAddressBookId());
if (addressBook == null) {
// 抛出业务异常
throw new AddressBookBusinessException(MessageConstant.ADDRESS_BOOK_IS_NULL);
}
// 查询当前用户购物车信息
Long userId = BaseContext.getCurrentId();
ShoppingCart shoppingCart = new ShoppingCart();
shoppingCart.setUserId(userId);
List<ShoppingCart> shoppingCartList = shoppingCartMapper.list(shoppingCart);
if (shoppingCartList == null || shoppingCartList.size() == 0) {
// 抛出业务异常
throw new ShoppingCartBusinessException(MessageConstant.SHOPPING_CART_IS_NULL);
}
// 2.向订单表插入1条数据
Orders orders = new Orders();
BeanUtils.copyProperties(ordersSubmitDTO, orders);
orders.setOrderTime(LocalDateTime.now());
orders.setPayStatus(Orders.UN_PAID);
orders.setStatus(Orders.PENDING_PAYMENT);
orders.setNumber(String.valueOf(System.currentTimeMillis()));//订单号
orders.setPhone(addressBook.getPhone());
orders.setConsignee(addressBook.getConsignee());
orders.setUserId(userId);
orderMapper.insert(orders);
//批量插入订单明细数据
List<OrderDetail> orderDetailList = new ArrayList<>();
// 3.向订单明细表插入n条数据
for (ShoppingCart cart : shoppingCartList) {
OrderDetail orderDetail = new OrderDetail(); //订单明细
BeanUtils.copyProperties(cart, orderDetail);
orderDetail.setOrderId(orders.getId()); //设置当前订单明细关联的订单id
orderDetailList.add(orderDetail);
}
orderDetailMapper.insertBatch(orderDetailList);
// 4.清空当前用户的购物车数据
shoppingCartMapper.deleteByUserId(userId);
// 5.封装VO返回结果
OrderSubmitVO ordersubmitVO = OrderSubmitVO.builder()
.id(orders.getId())
.orderNumber(orders.getNumber())
.orderAmount(orders.getAmount())
.orderTime(orders.getOrderTime())
.build();
return ordersubmitVO;
}
}
sky-server com/sky/mapper/OrderDetailMapper.java
package com.sky.mapper;
import com.sky.entity.OrderDetail;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface OrderDetailMapper {
/**
* 批量插入订单明细数据
*/
void insertBatch(List<OrderDetail> orderDetailList);
}
sky-server mapper/OrderDetailMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.OrderDetailMapper">
<insert id="insertBatch">
insert into order_detail (name, image, order_id, dish_id, setmeal_id, dish_flavor, number, amount)
values
<foreach collection="orderDetailList" item="od" separator=",">
(#{od.name},#{od.image},#{od.orderId},#{od.dishId},#{od.setmealId},#{od.dishFlavor},#{od.number},#{od.amount})
</foreach>
</insert>
</mapper>
订单支付
微信支付产品 + 微信支付
参考:https://pay.weixin.qq.com/static/product/product_index.shtml
微信支付接入流程:
提交资料 → 签署协议 → 绑定场景
微信小程序支付时序图:
JSAPI下单:商户系统调用该接口在微信支付服务后台生成预支付交易单
请求URL:https://api.mch.weixin.qq.com/v3/pay/transactions/jsapi
获取微信支付平台证书、商户私钥文件:
内网穿透工具
E:\Java实例项目1-20套\第24套【项目实战】Java外卖项目实战《苍穹外卖》SpringBoot+SpringMVC+Vue+Swagger+Lombok+Mybatis+SpringSession+Redis+Nginx+小程序\0-0 源码资料\资料\day08\安装包cpolar_amd64.msi
cpolar - secure introspectable tunnels to localhost
验证
你的隧道
[复制token] → 在cpolar文件里/cmd[C:\Program Files\cpolar] → cpolar.exe authtoken xxxx[Authtoken:这个是在网站验证里复制的] → cpolar.exe http 8080
cpolar by @bestexpresser (Ctrl+C to quit)
Tunnel Status online
Account Pluminary (Plan: Free)
Version 2.86.16/3.18
Web Interface 127.0.0.1:4042
Forwarding http://22d34b67.r9.cpolar.top -> http://localhost:8080
Forwarding https://22d34b67.r9.cpolar.top -> http://localhost:8080
Conn 0
Avg Conn Time 0.00ms
启动穿透地址:[22d34b67.r9.cpolar.top/doc.html] (https://22d34b67.r9.cpolar.top/doc.html)
此时正在下载资源
HTTP Requests
GET /v2/api-docs 200
GET /swagger-resources 200
GET /webjars/js/chunk-3b888a6 200
GET /webjars/js/chunk-589faee 200
GET /webjars/js/chunk-2d0bd79 200
GET /webjars/js/chunk-0fd6771 200
GET /webjars/js/chunk-0c58d94 200
GET /webjars/css/chunk-62d2fe 200
GET /webjars/js/app.0f2f48b5. 200
随后就可以访问到接口文档了!!
原理:使用内网穿透工具临时获得一个域名
CPolar 和 SwitchHosts 是两种不同类型的软件,它们的功能和用途有所区别。
CPolar 是一款内网穿透软件,主要用于将本地运行的服务暴露到公网上,使得外网可以访问。它通过在本地和公网服务器之间建立一个安全的隧道,使得用户可以在任何地方通过互联网访问到本地的服务,比如网站、SSH、数据库等。
SwitchHosts 则是一款用于管理和切换本地hosts文件的软件。Hosts文件是操作系统用于将一些域名解析到特定的IP地址的一个文本文件。SwitchHosts 允许用户方便地添加、切换、备份不同的hosts规则,对于开发者来说,这在开发过程中进行域名映射和测试非常有用。
总结来说,CPolar主要用于内网穿透,而SwitchHosts用于hosts文件管理。两者解决的问题和适用场景不同,不是同一种软件。
内网、公网、外网和CPolar这几个概念在网络通信中扮演着不同的角色,以下是它们的定义和它们之间的联系:
- 内网(Local Network 或 Intranet): 内网是指一个私有网络,通常是在家庭、办公室或企业内部使用。内网中的设备通常通过路由器连接,并使用私有IP地址(如192.168.x.x或10.x.x.x)。内网中的设备一般不能直接从外部互联网访问,它们之间的通信受到防火墙和NAT(网络地址转换)的保护。
- 公网(Public Network 或 Internet): 公网是指全球范围内的开放网络,即互联网。公网上的设备使用公网IP地址,这些地址是全球唯一的,可以通过互联网被其他设备访问。网站、电子邮件服务器和其他在线服务都部署在公网上。
- 外网(External Network): 外网通常是指相对于内网而言的任何外部网络,特别是指互联网。当说“外网”时,通常是指从内网之外访问的资源或服务。
- CPolar: CPolar是一款内网穿透工具,它的主要作用是帮助内网中的设备暴露服务到公网上,使得这些服务可以被外网访问。以下是CPolar与内网、公网、外网之间的联系:
- 内网到公网:CPolar在本地设备上运行一个客户端,该客户端与CPolar的服务器建立连接。当外部网络(公网)尝试访问CPolar服务器上配置的特定端口时,CPolar服务器会将这些请求转发到运行CPolar客户端的内网设备上。
- 公网访问:通过CPolar,内网中的服务可以被赋予一个公网可访问的地址(通常是CPolar服务器的一个子域名或自定义域名),这样外网的任何用户都可以通过这个地址访问到内网的服务。
简而言之,CPolar是实现内网服务与公网之间通信的桥梁,它使得原本只能在局域网内部访问的服务能够被外网的用户访问。这对于远程工作、调试、以及需要在公网上提供服务的内网应用来说非常有用
导入功能代码【由于没有微信凭证 此接口未能正常开发 但代码均可学习】
sky-server application-dev.yml
wechat:
appid: wxffb3637a228223b8
secret: 84311df9199ecacdf4f12d27b6b9522d
mchid : 1561414331
mchSerialNo: 4B3B3DC35414AD50B1B755BAF8DE9CC7CF407606
privateKeyFilePath: D:\pay\apiclient_key.pem
apiV3Key: CZBK51236435wxpay435434323FFDuv3
weChatPayCertFilePath: D:\pay\wechatpay_166D96F876F45C7D07CE98952A96EC980368ACFC.pem
notifyUrl: https://58869fb.r2.cpolar.top/notify/paySuccess
refundNotifyUrl: https://58869fb.r2.cpolar.top/notify/refundSuccess
sky-server com/sky/controller/user/OrderController.java
/**
* 订单支付
*
* @param ordersPaymentDTO
* @return
*/
@PutMapping("/payment")
@ApiOperation("订单支付")
public Result<OrderPaymentVO> payment(@RequestBody OrdersPaymentDTO ordersPaymentDTO) throws Exception {
log.info("订单支付:{}", ordersPaymentDTO);
OrderPaymentVO orderPaymentVO = orderService.payment(ordersPaymentDTO);
log.info("生成预支付交易单:{}", orderPaymentVO);
return Result.success(orderPaymentVO);
}
sky-server com/sky/service/OrderService.java
/**
* 订单支付
* @param ordersPaymentDTO
* @return
*/
OrderPaymentVO payment(OrdersPaymentDTO ordersPaymentDTO) throws Exception;
/**
* 支付成功,修改订单状态
* @param outTradeNo
*/
void paySuccess(String outTradeNo);
sky-server com/sky/service/impl/OrderServiceImpl.java
@Autowired
private UserMapper userMapper;
@Autowired
private WeChatPayUtil weChatPayUtil;
/**
* 订单支付
*
* @param ordersPaymentDTO
* @return
*/
public OrderPaymentVO payment(OrdersPaymentDTO ordersPaymentDTO) throws Exception {
// 查询订单
Orders order = orderMapper.getByOrderNumber(ordersPaymentDTO.getOrderNumber());
if (order == null) {
throw new OrderBusinessException("订单不存在");
}
// 检查订单支付状态
if (order.getPayStatus() == 1) { // 1 表示已支付
throw new OrderBusinessException("该订单已支付");
}
order.setPayStatus(1);
// 更新订单支付状态为已支付
order.setPayStatus(Orders.PAID);
order.setCheckoutTime(LocalDateTime.now());
order.setPayMethod(ordersPaymentDTO.getPayMethod());
order.setStatus(Orders.CONFIRMED);
orderMapper.update(order);
// 构造并返回支付结果对象
OrderPaymentVO orderPaymentVO = new OrderPaymentVO();
orderPaymentVO.setOrderNumber(order.getNumber()); // 订单号
orderPaymentVO.setPaymentTime(new Date());
orderPaymentVO.setPaymentStatus("SUCCESS");
return orderPaymentVO;
}
/**
* 支付成功,修改订单状态
*
* @param outTradeNo
*/
public void paySuccess(String outTradeNo) {
// 当前登录用户id
Long userId = BaseContext.getCurrentId();
// 根据订单号查询当前用户的订单
Orders ordersDB = orderMapper.getByNumberAndUserId(outTradeNo, userId);
// 根据订单id更新订单的状态、支付方式、支付状态、结账时间
Orders orders = Orders.builder()
.id(ordersDB.getId())
.status(Orders.TO_BE_CONFIRMED)
.payStatus(Orders.PAID)
.checkoutTime(LocalDateTime.now())
.build();
orderMapper.update(orders);
}
}
sky-server com/sky/mapper/OrderMapper.java
package com.sky.mapper;
import com.github.pagehelper.Page;
import com.sky.dto.GoodsSalesDTO;
import com.sky.dto.OrdersPageQueryDTO;
import com.sky.entity.Orders;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.time.LocalDateTime;
import java.util.List;
import java.util.Map;
@Mapper
public interface OrderMapper {
/**
* 插入订单数据
* @param order
*/
void insert(Orders order);
/**
* 根据订单号和用户id查询订单
* @param orderNumber
* @param userId
*/
@Select("select * from orders where number = #{orderNumber} and user_id= #{userId}")
Orders getByNumberAndUserId(String orderNumber, Long userId);
/**
* 修改订单信息
* @param orders
*/
void update(Orders orders);
/**
* 根据id查询订单
* @param id
*/
@Select("select * from orders where id = #{id}}")
Orders getById(Long id);
}
resources/mapper/OrderMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.OrderMapper">
<insert id="insert" parameterType="Orders" useGeneratedKeys="true" keyProperty="id">
insert into orders
(number, status, user_id, address_book_id, order_time, checkout_time, pay_method, pay_status, amount, remark,
phone, address, consignee, estimated_delivery_time, delivery_status, pack_amount, tableware_number,
tableware_status)
values (#{number}, #{status}, #{userId}, #{addressBookId}, #{orderTime}, #{checkoutTime}, #{payMethod},
#{payStatus}, #{amount}, #{remark}, #{phone}, #{address}, #{consignee},
#{estimatedDeliveryTime}, #{deliveryStatus}, #{packAmount}, #{tablewareNumber}, #{tablewareStatus})
</insert>
<update id="update" parameterType="com.sky.entity.Orders">
update orders
<set>
<if test="cancelReason != null and cancelReason!='' ">
cancel_reason=#{cancelReason},
</if>
<if test="rejectionReason != null and rejectionReason!='' ">
rejection_reason=#{rejectionReason},
</if>
<if test="cancelTime != null">
cancel_time=#{cancelTime},
</if>
<if test="payStatus != null">
pay_status=#{payStatus},
</if>
<if test="payMethod != null">
pay_method=#{payMethod},
</if>
<if test="checkoutTime != null">
checkout_time=#{checkoutTime},
</if>
<if test="status != null">
status = #{status},
</if>
<if test="deliveryTime != null">
delivery_time = #{deliveryTime}
</if>
</set>
where id = #{id}
</update>
<!-- 根据订单号查询订单 -->
<select id="getByOrderNumber" parameterType="String" resultType="Orders">
select * from orders where number = #{orderNumber}
</select>
</mapper>
sky-server com/sky/mapper/UserMapper.java
@Select("select * from user where id = #{id}}")
User getById(Long userId);
sky-server com/sky/controller/notify/PayNotifyController.java
package com.sky.controller.notify;
import com.alibaba.druid.support.json.JSONUtils;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
//import com.sky.annotation.IgnoreToken;
import com.sky.properties.WeChatProperties;
import com.sky.service.OrderService;
import com.wechat.pay.contrib.apache.httpclient.util.AesUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.http.entity.ContentType;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.BufferedReader;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
/**
* 支付回调相关接口
*/
@RestController
@RequestMapping("/notify")
@Slf4j
public class PayNotifyController {
@Autowired
private OrderService orderService;
@Autowired
private WeChatProperties weChatProperties;
/**
* 支付成功回调
*
* @param request
*/
// @IgnoreToken
@RequestMapping("/paySuccess")
public void paySuccessNotify(HttpServletRequest request, HttpServletResponse response) throws Exception {
//读取数据
String body = readData(request);
log.info("支付成功回调:{}", body);
//数据解密
String plainText = decryptData(body);
log.info("解密后的文本:{}", plainText);
JSONObject jsonObject = JSON.parseObject(plainText);
String outTradeNo = jsonObject.getString("out_trade_no");//商户平台订单号
String transactionId = jsonObject.getString("transaction_id");//微信支付交易号
log.info("商户平台订单号:{}", outTradeNo);
log.info("微信支付交易号:{}", transactionId);
//业务处理,修改订单状态、来单提醒
orderService.paySuccess(outTradeNo);
//给微信响应
responseToWeixin(response);
}
/**
* 读取数据
*
* @param request
* @return
* @throws Exception
*/
private String readData(HttpServletRequest request) throws Exception {
BufferedReader reader = request.getReader();
StringBuilder result = new StringBuilder();
String line = null;
while ((line = reader.readLine()) != null) {
if (result.length() > 0) {
result.append("\n");
}
result.append(line);
}
return result.toString();
}
/**
* 数据解密
*
* @param body
* @return
* @throws Exception
*/
private String decryptData(String body) throws Exception {
JSONObject resultObject = JSON.parseObject(body);
JSONObject resource = resultObject.getJSONObject("resource");
String ciphertext = resource.getString("ciphertext");
String nonce = resource.getString("nonce");
String associatedData = resource.getString("associated_data");
AesUtil aesUtil = new AesUtil(weChatProperties.getApiV3Key().getBytes(StandardCharsets.UTF_8));
//密文解密
String plainText = aesUtil.decryptToString(associatedData.getBytes(StandardCharsets.UTF_8),
nonce.getBytes(StandardCharsets.UTF_8),
ciphertext);
return plainText;
}
/**
* 给微信响应
* @param response
*/
private void responseToWeixin(HttpServletResponse response) throws Exception{
response.setStatus(200);
HashMap<Object, Object> map = new HashMap<>();
map.put("code", "SUCCESS");
map.put("message", "SUCCESS");
response.setHeader("Content-type", ContentType.APPLICATION_JSON.toString());
response.getOutputStream().write(JSONUtils.toJSONString(map).getBytes(StandardCharsets.UTF_8));
response.flushBuffer();
}
}
查询历史订单
业务规则
- 分页查询历史订单
- 可以根据订单状态查询
- 展示订单数据时,需要展示的数据包括:下单时间、订单状态、订单金额、订单明细(商品名称、图片)
接口设计:参见接口文档
1.2 代码实现
1.2.1 user/OrderController
/**
* 历史订单查询
*
* @param page
* @param pageSize
* @param status 订单状态 1待付款 2待接单 3已接单 4派送中 5已完成 6已取消
* @return
*/
@GetMapping("/historyOrders")
@ApiOperation("历史订单查询")
public Result<PageResult> page(int page, int pageSize, Integer status) {
PageResult pageResult = orderService.pageQuery4User(page, pageSize, status);
return Result.success(pageResult);
}
1.2.2 OrderService
/**
* 用户端订单分页查询
* @param page
* @param pageSize
* @param status
* @return
*/
PageResult pageQuery4User(int page, int pageSize, Integer status);
1.2.3 OrderServiceImpl
/**
* 用户端订单分页查询
*
* @param pageNum
* @param pageSize
* @param status
* @return
*/
public PageResult pageQuery4User(int pageNum, int pageSize, Integer status) {
// 设置分页
PageHelper.startPage(pageNum, pageSize);
OrdersPageQueryDTO ordersPageQueryDTO = new OrdersPageQueryDTO();
ordersPageQueryDTO.setUserId(BaseContext.getCurrentId());
ordersPageQueryDTO.setStatus(status);
// 分页条件查询
Page<Orders> page = orderMapper.pageQuery(ordersPageQueryDTO);
List<OrderVO> list = new ArrayList();
// 查询出订单明细,并封装入OrderVO进行响应
if (page != null && page.getTotal() > 0) {
for (Orders orders : page) {
Long orderId = orders.getId();// 订单id
// 查询订单明细
List<OrderDetail> orderDetails = orderDetailMapper.getByOrderId(orderId);
OrderVO orderVO = new OrderVO();
BeanUtils.copyProperties(orders, orderVO);
orderVO.setOrderDetailList(orderDetails);
list.add(orderVO);
}
}
return new PageResult(page.getTotal(), list);
}
1.2.4 OrderMapper
/**
* 分页条件查询并按下单时间排序
* @param ordersPageQueryDTO
*/
Page<Orders> pageQuery(OrdersPageQueryDTO ordersPageQueryDTO);
1.2.5 OrderMapper.xml
<select id="pageQuery" resultType="Orders">
select * from orders
<where>
<if test="number != null and number!=''">
and number like concat('%',#{number},'%')
</if>
<if test="phone != null and phone!=''">
and phone like concat('%',#{phone},'%')
</if>
<if test="userId != null">
and user_id = #{userId}
</if>
<if test="status != null">
and status = #{status}
</if>
<if test="beginTime != null">
and order_time >= #{beginTime}
</if>
<if test="endTime != null">
and order_time <= #{endTime}
</if>
</where>
order by order_time desc
</select>
1.2.6 OrderDetailMapper
/**
* 根据订单id查询订单明细
* @param orderId
* @return
*/
@Select("select * from order_detail where order_id = #{orderId}")
List<OrderDetail> getByOrderId(Long orderId);
查询订单详情
2.2 代码实现
2.2.1 user/OrderController
/**
* 查询订单详情
*
* @param id
* @return
*/
@GetMapping("/orderDetail/{id}")
@ApiOperation("查询订单详情")
public Result<OrderVO> details(@PathVariable("id") Long id) {
OrderVO orderVO = orderService.details(id);
return Result.success(orderVO);
}
2.2.2 OrderService
/**
* 查询订单详情
* @param id
* @return
*/
OrderVO details(Long id);
2.2.3 OrderServiceImpl
/**
* 查询订单详情
*
* @param id
* @return
*/
public OrderVO details(Long id) {
// 根据id查询订单
Orders orders = orderMapper.getById(id);
// 查询该订单对应的菜品/套餐明细
List<OrderDetail> orderDetailList = orderDetailMapper.getByOrderId(orders.getId());
// 将该订单及其详情封装到OrderVO并返回
OrderVO orderVO = new OrderVO();
BeanUtils.copyProperties(orders, orderVO);
orderVO.setOrderDetailList(orderDetailList);
return orderVO;
}
2.2.4 OrderMapper
/**
* 根据id查询订单
* @param id
*/
@Select("select * from orders where id=#{id}")
Orders getById(Long id);
取消订单
业务规则:
- 待支付和待接单状态下,用户可直接取消订单
- 商家已接单状态下,用户取消订单需电话沟通商家
- 派送中状态下,用户取消订单需电话沟通商家
- 如果在待接单状态下取消订单,需要给用户退款
- 取消订单后需要将订单状态修改为“已取消”
3.2.1 user/OrderController
/**
* 用户取消订单
*
* @return
*/
@PutMapping("/cancel/{id}")
@ApiOperation("取消订单")
public Result cancel(@PathVariable("id") Long id) throws Exception {
orderService.userCancelById(id);
return Result.success();
}
3.2.2 OrderService
/**
* 用户取消订单
* @param id
*/
void userCancelById(Long id) throws Exception;
3.2.3 OrderServiceImpl
/**
* 用户取消订单
*
* @param id
*/
public void userCancelById(Long id) throws Exception {
// 根据id查询订单
Orders ordersDB = orderMapper.getById(id);
// 校验订单是否存在
if (ordersDB == null) {
throw new OrderBusinessException(MessageConstant.ORDER_NOT_FOUND);
}
//订单状态 1待付款 2待接单 3已接单 4派送中 5已完成 6已取消
if (ordersDB.getStatus() > 2) {
throw new OrderBusinessException(MessageConstant.ORDER_STATUS_ERROR);
}
Orders orders = new Orders();
orders.setId(ordersDB.getId());
// 订单处于待接单状态下取消,需要进行退款
if (ordersDB.getStatus().equals(Orders.TO_BE_CONFIRMED)) {
//调用微信支付退款接口
weChatPayUtil.refund(
ordersDB.getNumber(), //商户订单号
ordersDB.getNumber(), //商户退款单号
new BigDecimal(0.01),//退款金额,单位 元
new BigDecimal(0.01));//原订单金额
//支付状态修改为 退款
orders.setPayStatus(Orders.REFUND);
}
// 更新订单状态、取消原因、取消时间
orders.setStatus(Orders.CANCELLED);
orders.setCancelReason("用户取消");
orders.setCancelTime(LocalDateTime.now());
orderMapper.update(orders);
}
再来一单
4.2.1 user/OrderController
/**
* 再来一单
*
* @param id
* @return
*/
@PostMapping("/repetition/{id}")
@ApiOperation("再来一单")
public Result repetition(@PathVariable Long id) {
orderService.repetition(id);
return Result.success();
}
4.2.2 OrderService
/**
* 再来一单
*
* @param id
*/
void repetition(Long id);
4.2.3 OrderServiceImpl
/**
* 再来一单
*
* @param id
*/
@Override
public void repetition(Long id) {
//查询当前用户id
Long userId = BaseContext.getCurrentId();
//根据订单id查询当前订单详情
List<OrderDetail> orderDetailList = orderDetailMapper.getByOrderId(id);
// 将订单详情对象转换为购物车对象
// 这一行使用 map 方法对每个 OrderDetail 对象进行转换操作,x 是当前遍历的 OrderDetail 对象
List<ShoppingCart> shoppingCartList = orderDetailList.stream().map(x -> {
//表示一个函数,该函数接受一个参数 x 并返回一个新对象
ShoppingCart shoppingCart = new ShoppingCart();
// 将原订单详情里面的菜品信息重新复制到购物车对象中
BeanUtils.copyProperties(x, shoppingCart, "id");
shoppingCart.setUserId(userId);
shoppingCart.setCreateTime(LocalDateTime.now());
return shoppingCart;
}).collect(Collectors.toList());
// 使用 collect 方法将转换后的 ShoppingCart 对象收集到一个新的 List<ShoppingCart> 列表中
// 将购物车对象批量添加到数据库
shoppingCartMapper.insertBatch(shoppingCartList);
}
/**
* 批量插入购物车数据
*
* @param shoppingCartList
*/
void insertBatch(List<ShoppingCart> shoppingCartList);
<insert id="insertBatch" parameterType="list">
insert into shopping_cart
(name, image, user_id, dish_id, setmeal_id, dish_flavor, number, amount, create_time)
values
<foreach collection="shoppingCartList" item="sc" separator=",">
</foreach>
</insert>
订单搜索
1.2.1 admin/OrderController
在admin包下创建OrderController
/**
* 订单管理
*/
@RestController("adminOrderController")
@RequestMapping("/admin/order")
@Slf4j
@Api(tags = "订单管理接口")
public class OrderController {
@Autowired
private OrderService orderService;
/**
* 订单搜索
*
* @param ordersPageQueryDTO
* @return
*/
@GetMapping("/conditionSearch")
@ApiOperation("订单搜索")
public Result<PageResult> conditionSearch(OrdersPageQueryDTO ordersPageQueryDTO) {
PageResult pageResult = orderService.conditionSearch(ordersPageQueryDTO);
return Result.success(pageResult);
}
}
1.2.2 OrderService
/**
* 条件搜索订单
* @param ordersPageQueryDTO
* @return
*/
PageResult conditionSearch(OrdersPageQueryDTO ordersPageQueryDTO);
1.2.3 OrderServiceImpl
/**
* 订单搜索
*
* @param ordersPageQueryDTO
* @return
*/
public PageResult conditionSearch(OrdersPageQueryDTO ordersPageQueryDTO) {
PageHelper.startPage(ordersPageQueryDTO.getPage(), ordersPageQueryDTO.getPageSize());
Page<Orders> page = orderMapper.pageQuery(ordersPageQueryDTO);
// 部分订单状态,需要额外返回订单菜品信息,将Orders转化为OrderVO
List<OrderVO> orderVOList = getOrderVOList(page);
return new PageResult(page.getTotal(), orderVOList);
}
private List<OrderVO> getOrderVOList(Page<Orders> page) {
// 需要返回订单菜品信息,自定义OrderVO响应结果
List<OrderVO> orderVOList = new ArrayList<>();
List<Orders> ordersList = page.getResult();
if (!CollectionUtils.isEmpty(ordersList)) {
for (Orders orders : ordersList) {
// 将共同字段复制到OrderVO
OrderVO orderVO = new OrderVO();
BeanUtils.copyProperties(orders, orderVO);
String orderDishes = getOrderDishesStr(orders);
// 将订单菜品信息封装到orderVO中,并添加到orderVOList
orderVO.setOrderDishes(orderDishes);
orderVOList.add(orderVO);
}
}
return orderVOList;
}
/**
* 根据订单id获取菜品信息字符串
*
* @param orders
* @return
*/
private String getOrderDishesStr(Orders orders) {
// 查询订单菜品详情信息(订单中的菜品和数量)
List<OrderDetail> orderDetailList = orderDetailMapper.getByOrderId(orders.getId());
// 将每一条订单菜品信息拼接为字符串(格式:宫保鸡丁*3;)
List<String> orderDishList = orderDetailList.stream().map(x -> {
String orderDish = x.getName() + "*" + x.getNumber() + ";";
return orderDish;
}).collect(Collectors.toList());
// 将该订单对应的所有菜品信息拼接在一起
return String.join("", orderDishList);
}
各个状态的订单数量统计
2.2.1 admin/OrderController
/**
* 各个状态的订单数量统计
*
* @return
*/
@GetMapping("/statistics")
@ApiOperation("各个状态的订单数量统计")
public Result<OrderStatisticsVO> statistics() {
OrderStatisticsVO orderStatisticsVO = orderService.statistics();
return Result.success(orderStatisticsVO);
}
2.2.2 OrderService
/**
* 各个状态的订单数量统计
* @return
*/
OrderStatisticsVO statistics();
2.2.3 OrderServiceImpl
/**
* 各个状态的订单数量统计
*
* @return
*/
public OrderStatisticsVO statistics() {
// 根据状态,分别查询出待接单、待派送、派送中的订单数量
Integer toBeConfirmed = orderMapper.countStatus(Orders.TO_BE_CONFIRMED);
Integer confirmed = orderMapper.countStatus(Orders.CONFIRMED);
Integer deliveryInProgress = orderMapper.countStatus(Orders.DELIVERY_IN_PROGRESS);
// 将查询出的数据封装到orderStatisticsVO中响应
OrderStatisticsVO orderStatisticsVO = new OrderStatisticsVO();
orderStatisticsVO.setToBeConfirmed(toBeConfirmed);
orderStatisticsVO.setConfirmed(confirmed);
orderStatisticsVO.setDeliveryInProgress(deliveryInProgress);
return orderStatisticsVO;
}
2.2.4 OrderMapper
/**
* 根据状态统计订单数量
* @param status
*/
@Select("select count(id) from orders where status = #{status}")
Integer countStatus(Integer status);
查询订单详情
业务规则:
- 订单详情页面需要展示订单基本信息(状态、订单号、下单时间、收货人、电话、收货地址、金额等)
- 订单详情页面需要展示订单明细数据(商品名称、数量、单价)
3.2.1 admin/OrderController
/**
* 订单详情
*
* @param id
* @return
*/
@GetMapping("/details/{id}")
@ApiOperation("查询订单详情")
public Result<OrderVO> details(@PathVariable("id") Long id) {
OrderVO orderVO = orderService.details(id);
return Result.success(orderVO);
}
接单
业务规则:
4.2.1 admin/OrderController
/**
* 接单
*
* @return
*/
@PutMapping("/confirm")
@ApiOperation("接单")
public Result confirm(@RequestBody OrdersConfirmDTO ordersConfirmDTO) {
orderService.confirm(ordersConfirmDTO);
return Result.success();
}
4.2.2 OrderService
/**
* 接单
*
* @param ordersConfirmDTO
*/
void confirm(OrdersConfirmDTO ordersConfirmDTO);
4.2.3 OrderServiceImpl
/**
* 接单
*
* @param ordersConfirmDTO
*/
public void confirm(OrdersConfirmDTO ordersConfirmDTO) {
Orders orders = Orders.builder()
.id(ordersConfirmDTO.getId())
.status(Orders.CONFIRMED)
.build();
orderMapper.update(orders);
}
拒单
业务规则:
- 商家拒单其实就是将订单状态修改为“已取消”
- 只有订单处于“待接单”状态时可以执行拒单操作
- 商家拒单时需要指定拒单原因
- 商家拒单时,如果用户已经完成了支付,需要为用户退款
5.2.1 admin/OrderController
/**
* 拒单
*
* @return
*/
@PutMapping("/rejection")
@ApiOperation("拒单")
public Result rejection(@RequestBody OrdersRejectionDTO ordersRejectionDTO) throws Exception {
orderService.rejection(ordersRejectionDTO);
return Result.success();
}
5.2.2 OrderService
/**
* 拒单
*
* @param ordersRejectionDTO
*/
void rejection(OrdersRejectionDTO ordersRejectionDTO) throws Exception;
5.2.3 OrderServiceImpl
/**
* 拒单
*
* @param ordersRejectionDTO
*/
public void rejection(OrdersRejectionDTO ordersRejectionDTO) throws Exception {
// 根据id查询订单
Orders ordersDB = orderMapper.getById(ordersRejectionDTO.getId());
// 订单只有存在且状态为2(待接单)才可以拒单
if (ordersDB == null || !ordersDB.getStatus().equals(Orders.TO_BE_CONFIRMED)) {
throw new OrderBusinessException(MessageConstant.ORDER_STATUS_ERROR);
}
//支付状态
Integer payStatus = ordersDB.getPayStatus();
if (payStatus == Orders.PAID) {
//用户已支付,需要退款
String refund = weChatPayUtil.refund(
ordersDB.getNumber(),
ordersDB.getNumber(),
new BigDecimal(0.01),
new BigDecimal(0.01));
log.info("申请退款:{}", refund);
}
// 拒单需要退款,根据订单id更新订单状态、拒单原因、取消时间
Orders orders = new Orders();
orders.setId(ordersDB.getId());
orders.setStatus(Orders.CANCELLED);
orders.setRejectionReason(ordersRejectionDTO.getRejectionReason());
orders.setCancelTime(LocalDateTime.now());
orderMapper.update(orders);
}
取消订单
6.2 代码实现
6.2.1 admin/OrderController
/**
* 取消订单
*
* @return
*/
@PutMapping("/cancel")
@ApiOperation("取消订单")
public Result cancel(@RequestBody OrdersCancelDTO ordersCancelDTO) throws Exception {
orderService.cancel(ordersCancelDTO);
return Result.success();
}
6.2.2 OrderService
/**
* 商家取消订单
*
* @param ordersCancelDTO
*/
void cancel(OrdersCancelDTO ordersCancelDTO) throws Exception;
6.2.3 OrderServiceImpl
/**
* 取消订单
*
* @param ordersCancelDTO
*/
public void cancel(OrdersCancelDTO ordersCancelDTO) throws Exception {
// 根据id查询订单
Orders ordersDB = orderMapper.getById(ordersCancelDTO.getId());
//支付状态
Integer payStatus = ordersDB.getPayStatus();
if (payStatus == 1) {
//用户已支付,需要退款
String refund = weChatPayUtil.refund(
ordersDB.getNumber(),
ordersDB.getNumber(),
new BigDecimal(0.01),
new BigDecimal(0.01));
log.info("申请退款:{}", refund);
}
// 管理端取消订单需要退款,根据订单id更新订单状态、取消原因、取消时间
Orders orders = new Orders();
orders.setId(ordersCancelDTO.getId());
orders.setStatus(Orders.CANCELLED);
orders.setCancelReason(ordersCancelDTO.getCancelReason());
orders.setCancelTime(LocalDateTime.now());
orderMapper.update(orders);
}
派送订单
业务规则:
- 派送订单其实就是将订单状态修改为“派送中”
- 只有状态为“待派送”的订单可以执行派送订单操作
7.2.1 admin/OrderController
/**
* 派送订单
*
* @return
*/
@PutMapping("/delivery/{id}")
@ApiOperation("派送订单")
public Result delivery(@PathVariable("id") Long id) {
orderService.delivery(id);
return Result.success();
}
7.2.2 OrderService
/**
* 派送订单
*
* @param id
*/
void delivery(Long id);
7.2.3 OrderServiceImpl
/**
* 派送订单
*
* @param id
*/
public void delivery(Long id) {
// 根据id查询订单
Orders ordersDB = orderMapper.getById(id);
// 校验订单是否存在,并且状态为3
if (ordersDB == null || !ordersDB.getStatus().equals(Orders.CONFIRMED)) {
throw new OrderBusinessException(MessageConstant.ORDER_STATUS_ERROR);
}
Orders orders = new Orders();
orders.setId(ordersDB.getId());
// 更新订单状态,状态转为派送中
orders.setStatus(Orders.DELIVERY_IN_PROGRESS);
orderMapper.update(orders);
}
完成订单
业务规则:
- 完成订单其实就是将订单状态修改为“已完成”
- 只有状态为“派送中”的订单可以执行订单完成操作
8.2.1 admin/OrderController
/**
* 完成订单
*
* @return
*/
@PutMapping("/complete/{id}")
@ApiOperation("完成订单")
public Result complete(@PathVariable("id") Long id) {
orderService.complete(id);
return Result.success();
}
8.2.2 OrderService
/**
* 完成订单
*
* @param id
*/
void complete(Long id);
8.2.3 OrderServiceImpl
/**
* 完成订单
*
* @param id
*/
public void complete(Long id) {
// 根据id查询订单
Orders ordersDB = orderMapper.getById(id);
// 校验订单是否存在,并且状态为4
if (ordersDB == null || !ordersDB.getStatus().equals(Orders.DELIVERY_IN_PROGRESS)) {
throw new OrderBusinessException(MessageConstant.ORDER_STATUS_ERROR);
}
Orders orders = new Orders();
orders.setId(ordersDB.getId());
// 更新订单状态,状态转为完成
orders.setStatus(Orders.COMPLETED);
orders.setDeliveryTime(LocalDateTime.now());
orderMapper.update(orders);
}
校验收货地址是否超出配送范围
1. 环境准备
注册账号:https://passport.baidu.com/v2/?reg&tt=1671699340600&overseas=&gid=CF954C2-A3D2-417F-9FE6-B0F249ED7E33&tpl=pp&u=https%3A%2F%2Flbsyun.baidu.com%2Findex.php%3Ftitle%3D%E9%A6%96%E9%A1%B5
登录百度地图开放平台:https://lbsyun.baidu.com/
进入控制台,创建应用,获取AK:


相关接口:
https://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-geocoding
https://lbsyun.baidu.com/index.php?title=webapi/directionlite-v1
2. 代码开发
2.1 application.yml
配置外卖商家店铺地址和百度地图的AK:

2.2 OrderServiceImpl
改造OrderServiceImpl,注入上面的配置项:
com/sky/properties/BaiDuProperties.java
package com.sky.properties;
import lombok.Data;
import lombok.Value;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Component
// 多个prefix
@ConfigurationProperties(prefix = "sky.baidu")
@Data
public class BaiDuProperties {
private String shopAddress;
private String ak;
}
application.yml
baidu:
ak: ${sky.baidu.ak}
shopAddress: ${sky.baidu.shopAddress}
application-dev.yml
baidu:
ak: xxxxxxxxx
shopAddress: 河北省唐山市丰润区燕山路街道美景花园
在OrderServiceImpl中提供校验方法:
/**
* 检查客户的收货地址是否超出配送范围
* @param address
*/
private void checkOutOfRange(String address) {
Map<String, String> map = new HashMap<>();
map.put("address", baiDuProperties.getShopAddress());
map.put("output", "json");
map.put("ak", baiDuProperties.getAk());
//获取店铺的经纬度坐标
String shopCoordinate = HttpClientUtil.doGet("https://api.map.baidu.com/geocoding/v3", map);
JSONObject jsonObject = JSON.parseObject(shopCoordinate);
if(!jsonObject.getString("status").equals("0")){
throw new OrderBusinessException("店铺地址解析失败");
}
//数据解析
JSONObject location = jsonObject.getJSONObject("result").getJSONObject("location");
String lat = location.getString("lat");
String lng = location.getString("lng");
//店铺经纬度坐标
String shopLngLat = lat + "," + lng;
map.put("address",address);
//获取用户收货地址的经纬度坐标
String userCoordinate = HttpClientUtil.doGet("https://api.map.baidu.com/geocoding/v3", map);
jsonObject = JSON.parseObject(userCoordinate);
if(!jsonObject.getString("status").equals("0")){
throw new OrderBusinessException("收货地址解析失败");
}
//数据解析
location = jsonObject.getJSONObject("result").getJSONObject("location");
lat = location.getString("lat");
lng = location.getString("lng");
//用户收货地址经纬度坐标
String userLngLat = lat + "," + lng;
map.put("origin",shopLngLat);
map.put("destination",userLngLat);
map.put("steps_info","0");
//路线规划
String json = HttpClientUtil.doGet("https://api.map.baidu.com/directionlite/v1/driving", map);
jsonObject = JSON.parseObject(json);
if(!jsonObject.getString("status").equals("0")){
throw new OrderBusinessException("配送路线规划失败");
}
//数据解析
JSONObject result = jsonObject.getJSONObject("result");
JSONArray jsonArray = (JSONArray) result.get("routes");
Integer distance = (Integer) ((JSONObject) jsonArray.get(0)).get("distance");
if(distance > 5000){
//配送距离超过5000米
throw new OrderBusinessException("超出配送范围");
}
}
在OrderServiceImpl的submitOrder方法中调用上面的校验方法:
// 检查用户的收获地址是否超出配送范围
checkOutOfRange(addressBook.getCityName() + addressBook.getDistrictName() + addressBook.getDetail());

SpringTask[定时任务]定时自动执行某段Java代码
SpringTask是Spring框架提供的任务调度工具,可以按照约定的时间自动执行某个代码逻辑
应用场景
- 信用卡每月还款提醒
- 银行贷款每月还款提醒
- 火车票售票系统处理未支付订单
- 入职纪念日为用户发送通知
cron表达式
cron表达式其实就是一个字符串,通过cron表达式可以定义任务触发时间
构成规则:分为6或7个域,由空格分隔开,每个域代表一个含义
每个域的含义分别为:秒、分钟、小时、日、月、周、年(可选)
2022年10月12日上午9点整 对应的cron表达式(日 和 周 不能同时定义)
0 0 9 12 10 ? 2022
https://cron.qqe2.com
| 秒 |
分钟 |
小时 |
日 |
月 |
周 |
| 0 |
0 |
9 |
12 |
10 |
? |
SpringTask使用步骤:
- 导入maven坐标 spring-context(已存在)
- 启动类添加注解
@EnableScheduling 开启任务调度
- 自定义定时任务类
sky-server com/sky/task/MyTask.java
package com.sky.task;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.util.Date;
/**
* 自定义定时任务类
*/
@Component
@Slf4j
public class MyTask {
/**
* 定时任务 每隔5秒触发一次
*/
@Scheduled(cron = "0/5 * * * * ?")
public void executeTask(){
log.info("定时任务开始执行:{}", new Date());
}
}
订单状态定时处理
用户下单后可能存在的情况:
- 下单后未支付,订单一直处于”待支付“状态
- 用户收获后管理端未点击完成按钮,订单一直处于“派送中”状态
- 通过定时任务每分钟检查一次是否存在支付超时订单(超过15min),如果存在则修改订单状态为”已取消”
- 通过定时任务每天凌晨1点检查一次是否存在”派送中”的订单,如果存在则修改订单状态为”已完成”
代码开发:
sky-server com/sky/task/OrderTask.java
package com.sky.task;
import com.sky.entity.Orders;
import com.sky.mapper.OrderMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.util.List;
@Component
@Slf4j
public class OrderTask {
@Autowired
private OrderMapper orderMapper;
/**
* 处理超时订单的方法
*/
@Scheduled(cron = "0 * * * * ?")//每分钟触发一次
public void processTimeoutOrder(){
log.info("定时处理超时订单");
// select * from orders where status = ? and order_time = (当前时间 - 15分钟)
LocalDateTime time = LocalDateTime.now().plusMinutes(-15);
List<Orders> ordersList = orderMapper.getByStatusAndOrderTimeLT(Orders.PENDING_PAYMENT, time);
if (ordersList != null && ordersList.size() > 0) {
for (Orders orders : ordersList) {
orders.setStatus(Orders.CANCELLED);
orders.setCancelReason("订单超时,自动取消");
orders.setCancelTime(LocalDateTime.now());
orderMapper.update(orders);
}
}
}
/**
* 处理一直处于派送中状态的订单
*/
@Scheduled(cron = "0 0 1 * * ?")//每天凌晨一点
public void processDeliveryOrder() {
log.info("定时处理处于派送中的订单");
LocalDateTime time = LocalDateTime.now().plusMinutes(-60);
List<Orders> ordersList = orderMapper.getByStatusAndOrderTimeLT(Orders.DELIVERY_IN_PROGRESS, time);
if (ordersList != null && ordersList.size() > 0) {
for (Orders orders : ordersList) {
orders.setStatus(Orders.COMPLETED);
orderMapper.update(orders);
}
}
}
}
sky-server com/sky/mapper/OrderMapper.java
/**
*
* 根据订单状态和下单时间查询订单
* @param status
* @param orderTime
* @return
*/
@Select("select * from orders where status = #{status} and order_time < #{orderTime}")
List<Orders> getByStatusAndOrderTimeLT(Integer status, LocalDateTime orderTime);
WebSocket
WebSocket是基于TCP的一种新的网络协议,它实现了浏览器与服务器全双工通信——浏览器和服务器只需要完成一次握手,两者之间就可以创建持续性连接,并进行双向数据传输

应用场景:
- 视频弹幕
- 网页聊天
- 体育实况更新
- 股票基金报价实时更新
入门案例
实现步骤:
- 直接使用websocket.html页面坐位WebSocket客户端
- 导入WebSocket的maven坐标
- 导入WebSocket服务端组件WebSocketServer,用于和客户端通信
- 导入配置类WebSocketConfiguration,注册WebSocket的服务端组件
- 导入定时人物类WebSocketTask,定时向客户端推送数据
websocket.html
<!DOCTYPE HTML>
<html>
<head>
<meta charset="UTF-8">
<title>WebSocket Demo</title>
</head>
<body>
<input id="text" type="text" />
<button onclick="send()">发送消息</button>
<button onclick="closeWebSocket()">关闭连接</button>
<div id="message">
</div>
</body>
<script type="text/javascript">
var websocket = null;
var clientId = Math.random().toString(36).substr(2);
//判断当前浏览器是否支持WebSocket
if('WebSocket' in window){
//连接WebSocket节点
websocket = new WebSocket("ws://localhost:8080/ws/"+clientId);
}
else{
alert('Not support websocket')
}
//连接发生错误的回调方法
websocket.onerror = function(){
setMessageInnerHTML("error");
};
//连接成功建立的回调方法
websocket.onopen = function(){
setMessageInnerHTML("连接成功");
}
//接收到消息的回调方法
websocket.onmessage = function(event){
setMessageInnerHTML(event.data);
}
//连接关闭的回调方法
websocket.onclose = function(){
setMessageInnerHTML("close");
}
//监听窗口关闭事件,当窗口关闭时,主动去关闭websocket连接,防止连接还没断开就关闭窗口,server端会抛异常。
window.onbeforeunload = function(){
websocket.close();
}
//将消息显示在网页上
function setMessageInnerHTML(innerHTML){
document.getElementById('message').innerHTML += innerHTML + '<br/>';
}
//发送消息
function send(){
var message = document.getElementById('text').value;
websocket.send(message);
}
//关闭连接
function closeWebSocket() {
websocket.close();
}
</script>
</html>
com/sky/websocket/WebSocketServer.java
package com.sky.websocket;
import org.springframework.stereotype.Component;
import javax.websocket.OnClose;
import javax.websocket.OnMessage;
import javax.websocket.OnOpen;
import javax.websocket.Session;
import javax.websocket.server.PathParam;
import javax.websocket.server.ServerEndpoint;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
/**
* WebSocket服务
*/
@Component //交给spring容器管理
@ServerEndpoint("/ws/{sid}")
public class WebSocketServer {
//存放会话对象
private static Map<String, Session> sessionMap = new HashMap();
/**
* 连接建立成功调用的方法
*/
@OnOpen
public void onOpen(Session session, @PathParam("sid") String sid) {
System.out.println("客户端:" + sid + "建立连接");
sessionMap.put(sid, session);
}
/**
* 收到客户端消息后调用的方法
*
* @param message 客户端发送过来的消息
*/
@OnMessage
public void onMessage(String message, @PathParam("sid") String sid) {
System.out.println("收到来自客户端:" + sid + "的信息:" + message);
}
/**
* 连接关闭调用的方法
*
* @param sid
*/
@OnClose
public void onClose(@PathParam("sid") String sid) {
System.out.println("连接断开:" + sid);
sessionMap.remove(sid);
}
/**
* 群发
*
* @param message
*/
public void sendToAllClient(String message) {
Collection<Session> sessions = sessionMap.values();
for (Session session : sessions) {
try {
//服务器向客户端发送消息
session.getBasicRemote().sendText(message);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
com/sky/config/WebSocketConfiguration.java
package com.sky.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.socket.server.standard.ServerEndpointExporter;
/**
* WebSocket配置类,用于注册WebSocket的Bean
*/
@Configuration
public class WebSocketConfiguration {
@Bean
public ServerEndpointExporter serverEndpointExporter() {
return new ServerEndpointExporter();
}
}
com/sky/task/WebSocketTask.java
package com.sky.task;
import com.sky.websocket.WebSocketServer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
@Component
public class WebSocketTask {
@Autowired
private WebSocketServer webSocketServer;
/**
* 通过WebSocket每隔5秒向客户端发送消息
*/
@Scheduled(cron = "0/5 * * * * ?")
public void sendMessageToClient() {
webSocketServer.sendToAllClient("这是来自服务端的消息:" + DateTimeFormatter.ofPattern("HH:mm:ss").format(LocalDateTime.now()));
}
}
来单提醒
用户下单并且支付成功后,需要第一时间通知外卖商家
设计:
- 通过WebSocket实现管理端页面和服务端保持长连接状态
- 当客户支付后,调用WebSocket的相关API实现服务端向客户端推送消息
- 客户端浏览器解析服务端推送的消息,判断是来单提醒还是客户催单,进行相应的消息提示和语音播报
- 约定服务器发送给客户端浏览器的数据格式为JSON,字段包括:type,orderId,content
- type 为消息类型,1为来单提醒 2为客户催单
- orderId 为订单id
- content 为消息内容
sky-server com/sky/service/impl/OrderServiceImpl.java
/**
* 订单支付
*
* @param ordersPaymentDTO
* @return
*/
public OrderPaymentVO payment(OrdersPaymentDTO ordersPaymentDTO) throws Exception {
// 查询订单
Orders order = orderMapper.getByOrderNumber(ordersPaymentDTO.getOrderNumber());
if (order == null) {
throw new OrderBusinessException("订单不存在");
}
// 检查订单支付状态
if (order.getPayStatus() == 1) { // 1 表示已支付
throw new OrderBusinessException("该订单已支付");
}
order.setPayStatus(1);
// 更新订单支付状态为已支付
order.setPayStatus(Orders.PAID);
order.setCheckoutTime(LocalDateTime.now());
order.setPayMethod(ordersPaymentDTO.getPayMethod());
order.setStatus(Orders.TO_BE_CONFIRMED);
// 支付成功后通过 WebSocket 向客户端推送消息
Map<String, Object> map = new HashMap<>();
map.put("type", 1); // 1 表示来单提醒
map.put("orderId", order.getId());
map.put("content", "订单号:" + ordersPaymentDTO.getOrderNumber());
webSocketServer.sendToAllClient(JSON.toJSONString(map));
orderMapper.update(order);
// 构造并返回支付结果对象
OrderPaymentVO orderPaymentVO = new OrderPaymentVO();
orderPaymentVO.setOrderNumber(order.getNumber()); // 订单号
orderPaymentVO.setPaymentTime(new Date());
orderPaymentVO.setPaymentStatus("SUCCESS");
return orderPaymentVO;
}
用户催单
com/sky/controller/user/OrderController.java
/**
* 客户催单
* @param id
* @return
*/
@GetMapping("/reminder/{id}")
@ApiOperation("客户催单")
public Result reminder(@PathVariable("id") Long id){
orderService.reminder(id);
return Result.success();
}
com/sky/service/OrderService.java
/**
* 用户催单
* @param id
*/
void reminder(Long id);
com/sky/service/impl/OrderServiceImpl.java
/**
* 客户催单
* @param id
*/
public void reminder(Long id) {
// 根据id查询订单
Orders ordersDB = orderMapper.getById(id);
// 校验订单是否存在
if (ordersDB == null) {
throw new OrderBusinessException(MessageConstant.ORDER_STATUS_ERROR);
}
Map map = new HashMap();
map.put("type",2); //1表示来单提醒 2表示客户催单
map.put("orderId",id);
map.put("content","订单号:" + ordersDB.getNumber());
//通过websocket向客户端浏览器推送消息
webSocketServer.sendToAllClient(JSON.toJSONString(map));
}
ApacheECharts
http://echarts.apache.org/zh/index.html
使用Echarts,重点在于研究当前图标所需数据格式,通常是需要后端提供符合格式要求的动态数据,然后相应给前端来展示图表
营业额统计
业务规则
- 营业额指订单状态为已完成的订单金额合计
- 基于可视化报表的折线图展示营业额数据,x轴为日期,y轴为营业额
- 根据时间选择区间,展示每天的营业额数据
根据接口定义设计对应的vo:
sky-pojo com/sky/vo/TurnoverReportVO.java
package com.sky.vo;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class TurnoverReportVO implements Serializable {
//日期,以逗号分隔,例如:2022-10-01,2022-10-02,2022-10-03 [开始到结束的每一天]
private String dateList;
//营业额,以逗号分隔,例如:406.0,1520.0,75.0 [营业额一一对应]
private String turnoverList;
}
sky-server com/sky/controller/admin/ReportController.java
package com.sky.controller.admin;
import com.sky.result.Result;
import com.sky.service.ReportService;
import com.sky.vo.TurnoverReportVO;
import io.swagger.annotations.Api;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.format.annotation.DateTimeFormat;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.time.LocalDate;
/**
* 数据统计相关接口
*/
@RestController
@RequestMapping("/admin/report")
@Api(tags = "数据统计接口")
@Slf4j
public class ReportController {
@Autowired
private ReportService reportService;
/**
* 统计指定时间区间内的营业额数据
* @param begin
* @param end
* @return
*/
@GetMapping("/turnoverStatistics")
public Result<TurnoverReportVO> turnoverStatistics(
@DateTimeFormat(pattern = "yyyy-MM-dd")LocalDate begin,
@DateTimeFormat(pattern = "yyyy-MM-dd")LocalDate end) {
log.info("营业额统计:{},{}",begin,end);
return Result.success(reportService.getTurnoverStatistics(begin,end));
}
}
sky-server com/sky/service/ReportService.java
package com.sky.service;
import com.sky.vo.TurnoverReportVO;
import java.time.LocalDate;
public interface ReportService {
/**
* 统计指定时间区间内的营业额数据
* @param begin
* @param end
* @return
*/
TurnoverReportVO getTurnoverStatistics(LocalDate begin, LocalDate end);
}
sky-server com/sky/service/impl/ReportServiceImpl.java
package com.sky.service.impl;
import com.sky.entity.Orders;
import com.sky.mapper.OrderMapper;
import com.sky.service.ReportService;
import com.sky.vo.TurnoverReportVO;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.LocalTime;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Service
@Slf4j
public class ReportServiceImpl implements ReportService {
@Autowired
private OrderMapper orderMapper;
/**
* 统计指定时间区间内的营业额数据
* @param begin
* @param end
* @return
*/
@Override
public TurnoverReportVO getTurnoverStatistics(LocalDate begin, LocalDate end) {
// 当前集合用于存放从begin到end范围内的每天的日期
List<LocalDate> dateList = new ArrayList<>();
dateList.add(begin);
while (!begin.equals(end)) {
//日期计算,计算指定日期的后一天对应的日期
begin = begin.plusDays(1);
dateList.add(begin);
}
// 存放每天的营业额
List<Double> turnoverList = new ArrayList<>();
for (LocalDate date : dateList) { //LocalDate只是年月日 而下单的Order有时分秒
// 查询Date日期对应的营业额数据,数据额是指:订单状态为“已完成”的订单金额合计
LocalDateTime beginTime = LocalDateTime.of(date, LocalTime.MIN);
LocalDateTime endTime = LocalDateTime.of(date, LocalTime.MAX);
// select sum(count) from orders where order_time > ? and order_time < ? and status = 5
Map map = new HashMap<>();
map.put("begin", beginTime);
map.put("end", endTime);
map.put("status", Orders.COMPLETED);
Double turnover = orderMapper.sumByMap(map);
turnover = turnover == null ? 0.0 : turnover;//没有营业额则默认为0
turnoverList.add(turnover);
}
return TurnoverReportVO.builder()
.dateList(StringUtils.join(dateList, ","))
.turnoverList(StringUtils.join(turnoverList, ","))
.build();
}
}
sky-server com/sky/mapper/OrderMapper.java
/**
* 根据动态条件统计营业额数据
* @param map
* @return
*/
Double sumByMap(Map map);
sky-server mapper/OrderMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.OrderMapper">
<insert id="insert" parameterType="Orders" useGeneratedKeys="true" keyProperty="id">
insert into orders
(number, status, user_id, address_book_id, order_time, checkout_time, pay_method, pay_status, amount, remark,
phone, address, consignee, estimated_delivery_time, delivery_status, pack_amount, tableware_number,
tableware_status)
values (#{number}, #{status}, #{userId}, #{addressBookId}, #{orderTime}, #{checkoutTime}, #{payMethod},
#{payStatus}, #{amount}, #{remark}, #{phone}, #{address}, #{consignee},
#{estimatedDeliveryTime}, #{deliveryStatus}, #{packAmount}, #{tablewareNumber}, #{tablewareStatus})
</insert>
<update id="update" parameterType="com.sky.entity.Orders">
update orders
<set>
<if test="cancelReason != null and cancelReason!='' ">
cancel_reason=#{cancelReason},
</if>
<if test="rejectionReason != null and rejectionReason!='' ">
rejection_reason=#{rejectionReason},
</if>
<if test="cancelTime != null">
cancel_time=#{cancelTime},
</if>
<if test="payStatus != null">
pay_status=#{payStatus},
</if>
<if test="payMethod != null">
pay_method=#{payMethod},
</if>
<if test="checkoutTime != null">
checkout_time=#{checkoutTime},
</if>
<if test="status != null">
status = #{status},
</if>
<if test="deliveryTime != null">
delivery_time = #{deliveryTime}
</if>
</set>
where id = #{id}
</update>
<select id="pageQuery" resultType="Orders">
select * from orders
<where>
<if test="number != null and number!=''">
and number like concat('%',#{number},'%')
</if>
<if test="phone != null and phone!=''">
and phone like concat('%',#{phone},'%')
</if>
<if test="userId != null">
and user_id = #{userId}
</if>
<if test="status != null">
and status = #{status}
</if>
<if test="beginTime != null">
and order_time >= #{beginTime}
</if>
<if test="endTime != null">
and order_time <= #{endTime}
</if>
</where>
order by order_time desc
</select>
<!-- 根据订单号查询订单 -->
<select id="getByOrderNumber" parameterType="String" resultType="Orders">
select * from orders where number = #{orderNumber}
</select>
<select id="sumByMap" resultType="java.lang.Double">
select sum(amount) from orders
<where>
<if test="begin != null">
and order_time > #{begin}
</if>
<if test="end != null">
and order_time < #{end}
</if>
<if test="status != null">
and status = #{status}
</if>
</where>
</select>
</mapper>
用户统计
业务规则:
- 根据时间选择区间,展示每天的用户总量和新增用户量数据
据接口定义设计对应的vo:
sky-pojo com/sky/vo/UserReportVO.java
package com.sky.vo;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class UserReportVO implements Serializable {
//日期,以逗号分隔,例如:2022-10-01,2022-10-02,2022-10-03
private String dateList;
//用户总量,以逗号分隔,例如:200,210,220
private String totalUserList;
//新增用户,以逗号分隔,例如:20,21,10
private String newUserList;
}
sky-server com/sky/controller/admin/ReportController.java
package com.sky.controller.admin;
import com.sky.result.Result;
import com.sky.service.ReportService;
import com.sky.vo.TurnoverReportVO;
import io.swagger.annotations.Api;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.format.annotation.DateTimeFormat;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.time.LocalDate;
/**
* 用户统计
* @param begin
* @param end
* @return
*/
@GetMapping("/userStatistics")
@ApiOperation("用户统计")
public Result<UserReportVO> userStatistics(
@DateTimeFormat(pattern = "yyyy-MM-dd")LocalDate begin,
@DateTimeFormat(pattern = "yyyy-MM-dd")LocalDate end){
log.info("用户数据统计:{},{}",begin,end);
return Result.success(reportService.getUserStatistics(begin,end));
}
sky-server com/sky/service/ReportService.java
package com.sky.service;
import com.sky.vo.TurnoverReportVO;
import java.time.LocalDate;
public interface ReportService {
/**
* 用户统计
* @param begin
* @param end
* @return
*/
UserReportVO getUserStatistics(LocalDate begin, LocalDate end);
}
sky-server com/sky/service/impl/ReportServiceImpl.java
package com.sky.service.impl;
import com.sky.entity.Orders;
import com.sky.mapper.OrderMapper;
import com.sky.service.ReportService;
import com.sky.vo.TurnoverReportVO;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.LocalTime;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Service
@Slf4j
public class ReportServiceImpl implements ReportService {
/**
* 统计指定时间区间内的用户数据
* @param begin
* @param end
* @return
*/
@Override
public UserReportVO getUserStatistics(LocalDate begin, LocalDate end) {
// 存放从begin 到 end之间的日期
List<LocalDate> dateList = new ArrayList<>();
dateList.add(begin);
while (!begin.equals(end)) {
//日期计算,计算指定日期的后一天的日期
begin = begin.plusDays(1);
dateList.add(begin);
}
// 存放每天新增用户数量 select count(id) from user where create_time > ? and create_time < ?
List<Integer> newUserList = new ArrayList<>();
// 存放每天的总用户数量 select count(id) from user where create_time <= ?
List<Integer> totalUserList = new ArrayList<>();
for (LocalDate date : dateList) {
// 遍历每一天的用户总量和数量
LocalDateTime beginTime = LocalDateTime.of(date, LocalTime.MIN);
LocalDateTime endTime = LocalDateTime.of(date, LocalTime.MAX);
Map map = new HashMap<>();
map.put("end", endTime);
// 总用户数量
Integer integer = userMapper.countByMap(map);
map.put("begin", beginTime);
//新增用户数量
Integer newUser = userMapper.countByMap(map);
totalUserList.add(integer);
newUserList.add(newUser);
}
return UserReportVO.builder()
.dateList(StringUtils.join(dateList, ","))
.totalUserList(StringUtils.join(totalUserList, ","))
.newUserList(StringUtils.join(newUserList, ","))
.build();
}
}
sky-server com/sky/mapper/UserMapper.java
/**
* 根据动态条件统计用户数量
* @param map
* @return
*/
Integer countByMap(Map map);
sky-server mapper/UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.OrderMapper">
<select id="countByMap" resultType="java.lang.Integer">
select count(id) from orders
<where>
<if test="begin != null">
and order_time > #{begin}
</if>
<if test="end != null">
and order_time < #{end}
</if>
</where>
</select>
</mapper>
订单统计
业务规则
- 根据时间选择区间,展示每天的订单总数和有效订单数
- 展示所选时间区间内的有效订单数、总订单数、订单完成率
- 订单完成率 = 有效订单数 / 总订单数 * 100%
返回数据
- dataList 日期列表以逗号分隔
- orderCompletionRate 订单完成率
- orderCountList 订单数列表以逗号分隔
- totalOrderCount 订单总数
- validOrderCount 有效订单数
- validOrderCountList 有效订单数列表以逗号分隔
据接口定义设计对应的vo:
sky-pojo com/sky/vo/OrderReportVO.java
package com.sky.vo;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class OrderReportVO implements Serializable {
//日期,以逗号分隔,例如:2022-10-01,2022-10-02,2022-10-03
private String dateList;
//每日订单数,以逗号分隔,例如:260,210,215
private String orderCountList;
//每日有效订单数,以逗号分隔,例如:20,21,10
private String validOrderCountList;
//订单总数
private Integer totalOrderCount;
//有效订单数
private Integer validOrderCount;
//订单完成率
private Double orderCompletionRate;
}
sky-server com/sky/controller/admin/ReportController.java
package com.sky.controller.admin;
import com.sky.result.Result;
import com.sky.service.ReportService;
import com.sky.vo.TurnoverReportVO;
import io.swagger.annotations.Api;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.format.annotation.DateTimeFormat;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.time.LocalDate;
/**
* 订单统计
* @param begin
* @param end
* @return
*/
@GetMapping("/ordersStatistics")
@ApiOperation("订单统计")
public Result<OrderReportVO> ordersStatistics(
@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin,
@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate end){
log.info("订单数据统计:{},{}",begin,end);
return Result.success(reportService.getOrderStatistics(begin,end));
}
sky-server com/sky/service/ReportService.java
package com.sky.service;
import com.sky.vo.TurnoverReportVO;
import java.time.LocalDate;
public interface ReportService {
/**
* 统计指定时间区间内的订单数据
* @param begin
* @param end
* @return
*/
OrderReportVO getOrderStatistics(LocalDate begin, LocalDate end);
}
sky-server com/sky/service/impl/ReportServiceImpl.java
package com.sky.service.impl;
import com.sky.entity.Orders;
import com.sky.mapper.OrderMapper;
import com.sky.service.ReportService;
import com.sky.vo.TurnoverReportVO;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.LocalTime;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 统计指定时间区间内的订单数据
* @param begin
* @param end
* @return
*/
public OrderReportVO getOrderStatistics(LocalDate begin, LocalDate end) {
//存放从begin到end之间的每天对应的日期
List<LocalDate> dateList = new ArrayList<>();
dateList.add(begin);
while (!begin.equals(end)) {
begin = begin.plusDays(1);
dateList.add(begin);
}
//存放每天的订单总数
List<Integer> orderCountList = new ArrayList<>();
//存放每天的有效订单数
List<Integer> validOrderCountList = new ArrayList<>();
//遍历dateList集合,查询每天的有效订单数和订单总数
for (LocalDate date : dateList) {
//查询每天的订单总数 select count(id) from orders where order_time > ? and order_time < ?
LocalDateTime beginTime = LocalDateTime.of(date, LocalTime.MIN);
LocalDateTime endTime = LocalDateTime.of(date, LocalTime.MAX);
Integer orderCount = getOrderCount(beginTime, endTime, null);
//查询每天的有效订单数 select count(id) from orders where order_time > ? and order_time < ? and status = 5
Integer validOrderCount = getOrderCount(beginTime, endTime, Orders.COMPLETED);
orderCountList.add(orderCount);
validOrderCountList.add(validOrderCount);
}
//计算时间区间内的订单总数量
Integer totalOrderCount = orderCountList.stream().reduce(Integer::sum).get();
//计算时间区间内的有效订单数量
Integer validOrderCount = validOrderCountList.stream().reduce(Integer::sum).get();
Double orderCompletionRate = 0.0;
if(totalOrderCount != 0){
//计算订单完成率
orderCompletionRate = validOrderCount.doubleValue() / totalOrderCount;
}
return OrderReportVO.builder()
.dateList(StringUtils.join(dateList,","))
.orderCountList(StringUtils.join(orderCountList,","))
.validOrderCountList(StringUtils.join(validOrderCountList,","))
.totalOrderCount(totalOrderCount)
.validOrderCount(validOrderCount)
.orderCompletionRate(orderCompletionRate)
.build();
}
/**
* 根据条件统计订单数量
* @param begin
* @param end
* @param status
* @return
*/
private Integer getOrderCount(LocalDateTime begin, LocalDateTime end, Integer status){
Map map = new HashMap();
map.put("begin",begin);
map.put("end",end);
map.put("status",status);
return orderMapper.countByMap(map);
}
sky-server com/sky/mapper/OrderMapper.java
/**
* 根据动态条件统计用户数量
* @param map
* @return
*/
Integer countByMap(Map map);
sky-server mapper/OrderMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.sky.mapper.OrderMapper">
<select id="countByMap" resultType="java.lang.Integer">
select count(id) from orders
<where>
<if test="begin != null">
and order_time > #{begin}
</if>
<if test="end != null">
and order_time < #{end}
</if>
<if test="status != null">
and status = #{status}
</if>
</where>
</select>
</mapper>
销量排名Top10
产品原型 (查已完成的数据)
sky-server com/sky/controller/admin/ReportController.java
/**
* 销量排名统计
* @param begin
* @param end
* @return
*/
@GetMapping("/top10")
@ApiOperation("销量排名top10")
public Result<SalesTop10ReportVO> top10(
@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin,
@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate end){
log.info("销量排名top10:{},{}",begin,end);
return Result.success(reportService.getSalesTop10(begin,end));
}
sky-server com/sky/service/ReportService.java
/**
* 销量排名统计
* @param begin
* @param end
* @return
*/
SalesTop10ReportVO getSalesTop10(LocalDate begin, LocalDate end);
sky-server com/sky/service/impl/ReportServiceImpl.java
/**
* 统计指定时间区间内的销量排名前10
* @param begin
* @param end
* @return
*/
@Override
public SalesTop10ReportVO getSalesTop10(LocalDate begin, LocalDate end) {
LocalDateTime beginTime = LocalDateTime.of(begin, LocalTime.MIN);
LocalDateTime endTime = LocalDateTime.of(end, LocalTime.MAX);
List<GoodsSalesDTO> salesTop10 = orderMapper.getSalesTop10(beginTime, endTime);
List<String> names = salesTop10.stream().map(GoodsSalesDTO::getName).collect(Collectors.toList());
String nameList = StringUtils.join(names, ",");
List<Integer> numbers = salesTop10.stream().map(GoodsSalesDTO::getNumber).collect(Collectors.toList());
String numberList = StringUtils.join(numbers, ",");
//封装返回结果数据
return SalesTop10ReportVO
.builder()
.nameList(nameList)
.numberList(numberList)
.build();
}
sky-server com/sky/mapper/OrderMapper.java
/**
* 统计指定时间内的销量排名
* @return
*/
List<GoodsSalesDTO> getSalesTop10(LocalDateTime begin,LocalDateTime end);
sky-server mapper/OrderMapper.xml
<select id="getSalesTop10" resultType="com.sky.dto.GoodsSalesDTO">
select od.name, sum(od.number) number
from order_detail od,orders o
where od.order_id = o.id and o.status = 5
<if test="begin != null">
and o.order_time > #{begin}
</if>
<if test="end != null">
and o.order_time < #{end}
</if>
group by od.name
order by number desc
limit 0,10
</select>
重装数据库
C:\Windows\System32>cd D:\MySQL\MySQL Server 8.0\bin
C:\Windows\System32>mysqld --install MySQL80
Service successfully installed.
C:\Windows\System32>sc query | findstr MySQL
C:\Windows\System32>net start MySQL80
MySQL80 服务正在启动 .
MySQL80 服务已经启动成功。
服务里的MySQL80是Mysql服务
-----------------------------------------------------------------------------------------
C:\Windows\System32>cd D:\MariaDB 11.0\bin
C:\Windows\System32>mysqld --install MariaDB
Service successfully installed.
C:\Windows\System32>net start MariaDB
MariaDB 服务正在启动 .
MariaDB 服务无法启动。
服务里的MariaDB是MariaDB服务
工作台
工作台是系统运营的数据看板,并提供快捷操作入口,可以有效提高商家的工作效率
功能工作台展示的数据:
名词解释:
- 营业额:已完成订单的总金额
- 有效订单:已完成订单的数量
- 订单完成率:有效订单数 / 总订单数 * 100%
- 平均客单价:营业额 / 有效订单数
- 新增用户:新增用户的数量
接口设计:
今日数据接口
Path: /admin/workspace/businessData
Method: Get
订单管理接口
Path: /admin/workspace/overviewOrders
Method: Get
菜品总览接口
Path: /admin/workspace/overviewDishes
Method: Get
套餐总览接口
Path: /admin/workspace/overviewSetmeals
Method: Get
订单搜索(已完成)
sky-server com/sky/controller/admin/WorkSpaceController.java
package com.sky.controller.admin;
import com.sky.result.Result;
import com.sky.service.WorkspaceService;
import com.sky.vo.BusinessDataVO;
import com.sky.vo.DishOverViewVO;
import com.sky.vo.OrderOverViewVO;
import com.sky.vo.SetmealOverViewVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.time.LocalDateTime;
import java.time.LocalTime;
/**
* 工作台
*/
@RestController
@RequestMapping("/admin/workspace")
@Slf4j
@Api(tags = "工作台相关接口")
public class WorkSpaceController {
@Autowired
private WorkspaceService workspaceService;
/**
* 工作台今日数据查询
* @return
*/
@GetMapping("/businessData")
@ApiOperation("工作台今日数据查询")
public Result<BusinessDataVO> businessData(){
//获得当天的开始时间
LocalDateTime begin = LocalDateTime.now().with(LocalTime.MIN);
//获得当天的结束时间
LocalDateTime end = LocalDateTime.now().with(LocalTime.MAX);
BusinessDataVO businessDataVO = workspaceService.getBusinessData(begin, end);
return Result.success(businessDataVO);
}
/**
* 查询订单管理数据
* @return
*/
@GetMapping("/overviewOrders")
@ApiOperation("查询订单管理数据")
public Result<OrderOverViewVO> orderOverView(){
return Result.success(workspaceService.getOrderOverView());
}
/**
* 查询菜品总览
* @return
*/
@GetMapping("/overviewDishes")
@ApiOperation("查询菜品总览")
public Result<DishOverViewVO> dishOverView(){
return Result.success(workspaceService.getDishOverView());
}
/**
* 查询套餐总览
* @return
*/
@GetMapping("/overviewSetmeals")
@ApiOperation("查询套餐总览")
public Result<SetmealOverViewVO> setmealOverView(){
return Result.success(workspaceService.getSetmealOverView());
}
}
sky-server com/sky/service/WorkspaceService.java
package com.sky.service;
import com.sky.vo.BusinessDataVO;
import com.sky.vo.DishOverViewVO;
import com.sky.vo.OrderOverViewVO;
import com.sky.vo.SetmealOverViewVO;
import java.time.LocalDateTime;
public interface WorkspaceService {
/**
* 根据时间段统计营业数据
* @param begin
* @param end
* @return
*/
BusinessDataVO getBusinessData(LocalDateTime begin, LocalDateTime end);
/**
* 查询订单管理数据
* @return
*/
OrderOverViewVO getOrderOverView();
/**
* 查询菜品总览
* @return
*/
DishOverViewVO getDishOverView();
/**
* 查询套餐总览
* @return
*/
SetmealOverViewVO getSetmealOverView();
}
sky-server com/sky/service/impl/WorkspaceServiceImpl.java
package com.sky.service.impl;
import com.sky.constant.StatusConstant;
import com.sky.entity.Orders;
import com.sky.mapper.DishMapper;
import com.sky.mapper.OrderMapper;
import com.sky.mapper.SetmealMapper;
import com.sky.mapper.UserMapper;
import com.sky.service.WorkspaceService;
import com.sky.vo.BusinessDataVO;
import com.sky.vo.DishOverViewVO;
import com.sky.vo.OrderOverViewVO;
import com.sky.vo.SetmealOverViewVO;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.time.LocalDateTime;
import java.time.LocalTime;
import java.util.HashMap;
import java.util.Map;
@Service
@Slf4j
public class WorkspaceServiceImpl implements WorkspaceService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private UserMapper userMapper;
@Autowired
private DishMapper dishMapper;
@Autowired
private SetmealMapper setmealMapper;
/**
* 根据时间段统计营业数据
* @param begin
* @param end
* @return
*/
public BusinessDataVO getBusinessData(LocalDateTime begin, LocalDateTime end) {
/**
* 营业额:当日已完成订单的总金额
* 有效订单:当日已完成订单的数量
* 订单完成率:有效订单数 / 总订单数
* 平均客单价:营业额 / 有效订单数
* 新增用户:当日新增用户的数量
*/
Map map = new HashMap();
map.put("begin",begin);
map.put("end",end);
//查询总订单数
Integer totalOrderCount = orderMapper.countByMap(map);
map.put("status", Orders.COMPLETED);
//营业额
Double turnover = orderMapper.sumByMap(map);
turnover = turnover == null? 0.0 : turnover;
//有效订单数
Integer validOrderCount = orderMapper.countByMap(map);
Double unitPrice = 0.0;
Double orderCompletionRate = 0.0;
if(totalOrderCount != 0 && validOrderCount != 0){
//订单完成率
orderCompletionRate = validOrderCount.doubleValue() / totalOrderCount;
//平均客单价
unitPrice = turnover / validOrderCount;
}
//新增用户数
Integer newUsers = userMapper.countByMap(map);
return BusinessDataVO.builder()
.turnover(turnover)
.validOrderCount(validOrderCount)
.orderCompletionRate(orderCompletionRate)
.unitPrice(unitPrice)
.newUsers(newUsers)
.build();
}
/**
* 查询订单管理数据
*
* @return
*/
public OrderOverViewVO getOrderOverView() {
Map map = new HashMap();
map.put("begin", LocalDateTime.now().with(LocalTime.MIN));
map.put("status", Orders.TO_BE_CONFIRMED);
//待接单
Integer waitingOrders = orderMapper.countByMap(map);
//待派送
map.put("status", Orders.CONFIRMED);
Integer deliveredOrders = orderMapper.countByMap(map);
//已完成
map.put("status", Orders.COMPLETED);
Integer completedOrders = orderMapper.countByMap(map);
//已取消
map.put("status", Orders.CANCELLED);
Integer cancelledOrders = orderMapper.countByMap(map);
//全部订单
map.put("status", null);
Integer allOrders = orderMapper.countByMap(map);
return OrderOverViewVO.builder()
.waitingOrders(waitingOrders)
.deliveredOrders(deliveredOrders)
.completedOrders(completedOrders)
.cancelledOrders(cancelledOrders)
.allOrders(allOrders)
.build();
}
/**
* 查询菜品总览
*
* @return
*/
public DishOverViewVO getDishOverView() {
Map map = new HashMap();
map.put("status", StatusConstant.ENABLE);
Integer sold = dishMapper.countByMap(map);
map.put("status", StatusConstant.DISABLE);
Integer discontinued = dishMapper.countByMap(map);
return DishOverViewVO.builder()
.sold(sold)
.discontinued(discontinued)
.build();
}
/**
* 查询套餐总览
*
* @return
*/
public SetmealOverViewVO getSetmealOverView() {
Map map = new HashMap();
map.put("status", StatusConstant.ENABLE);
Integer sold = setmealMapper.countByMap(map);
map.put("status", StatusConstant.DISABLE);
Integer discontinued = setmealMapper.countByMap(map);
return SetmealOverViewVO.builder()
.sold(sold)
.discontinued(discontinued)
.build();
}
}
sky-server com/sky/mapper/DishMapper.java
/**
* 根据条件统计菜品数量
* @param map
* @return
*/
Integer countByMap(Map map);
sky-server mapper/DishMapper.xml
<select id="countByMap" resultType="java.lang.Integer">
select count(id) from dish
<where>
<if test="status != null">
and status = #{status}
</if>
<if test="categoryId != null">
and category_id = #{categoryId}
</if>
</where>
</select>
sky-server com/sky/mapper/SetmealMapper.java
/**
* 根据条件统计套餐数量
* @param map
* @return
*/
Integer countByMap(Map map);
sky-server mapper/SetmealMapper.xml
<select id="countByMap" resultType="java.lang.Integer">
select count(id) from setmeal
<where>
<if test="status != null">
and status = #{status}
</if>
<if test="categoryId != null">
and category_id = #{categoryId}
</if>
</where>
</select>
Apache POI
在Java中操控Excel文件 [读写操作]
Apache POI 是一个处理Miscrosoft Office各种文件格式的开源项目,POI都是用于操作Excel文件
Apache POI应用场景:
- 银行网银系统导出交易明细
- 各种业务系统到出Excel报表
- 批量导入业务数据
sky-server com/sky/test/POITest.java
package com.sky.test;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
public class POITest {
/**
* 通过POI创建Excel文件并且写入文件内容
*/
public static void write() throws Exception {
// 在内存中创建一个Excel文件
XSSFWorkbook excel = new XSSFWorkbook();
// 在Excel文件中创建一个sheet页
XSSFSheet sheet = excel.createSheet("info");
// 在Sheet中创建行对象, rownum编号从0开始
XSSFRow row = sheet.createRow(1);
// 创建单元格并写入文件内容
row.createCell(1).setCellValue("姓名");
row.createCell(2).setCellValue("城市");
// 创建一个新行
row = sheet.createRow(2);
row.createCell(1).setCellValue("张三");
row.createCell(2).setCellValue("北京");
row = sheet.createRow(3);
row.createCell(1).setCellValue("李四");
row.createCell(2).setCellValue("南京");
// 通过输出流将内存中的Excel文件写入到磁盘
FileOutputStream out = new FileOutputStream(new File("C:\\Users\\Pluminary\\Desktop\\itcast.xlsx"));
excel.write(out);
// 关闭资源
out.close();
excel.close();
}
public static void main(String[] args) throws Exception {
write();
}
}
导出运营数据Excel报表
实现步骤:
- 设计Excel模板文件
- 查询近30天的运营数据
- 将查询到的运营数据写入模板文件
- 通过输出流将Excel文件下载到客户端浏览器
sky-pojo com/sky/vo/BusinessDataVO.java
package com.sky.vo;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
/**
* 数据概览
*/
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class BusinessDataVO implements Serializable {
private Double turnover;//营业额
private Integer validOrderCount;//有效订单数
private Double orderCompletionRate;//订单完成率
private Double unitPrice;//平均客单价
private Integer newUsers;//新增用户数
}
sky-server com/sky/controller/admin/ReportController.java
/**
* 导出运营数据报表
* @param response
*/
@GetMapping("/export")
@ApiOperation("导出运营数据报表")
public void export(HttpServletResponse response) {
reportService.exportBusinessData(response);
}
sky-server com/sky/service/ReportService.java
/**
* 导出运营数据报表
* @param response
*/
void exportBusinessData(HttpServletResponse response);
sky-server com/sky/service/impl/ReportServiceImpl.java
/**
* 导出运营数据报表
* @param response
*/
@Override
public void exportBusinessData(HttpServletResponse response) {
// 查询数据库 获取营业数据 -- 查询最近30天的营业数据
LocalDate dateBegin = LocalDate.now().minusDays(30);
LocalDate dateEnd = LocalDate.now().minusDays(1);
// 查询概览数据
BusinessDataVO businessDataVO = workspaceService.getBusinessData(LocalDateTime.of(dateBegin, LocalTime.MIN),LocalDateTime.of(dateEnd, LocalTime.MAX));
// 查询的数据通过POI写入Excel文件中 (获得对象 获得类加载器 类加载器读取资源)
InputStream in = this.getClass().getClassLoader().getResourceAsStream("template/运营数据报表模板.xlsx");
try {
// 基于模板文件创建一个新的Excel文件
XSSFWorkbook excel = new XSSFWorkbook();
// 填充数据 [获取标签页]
XSSFSheet sheet = excel.getSheet("Sheet1");
// 获取第二行[索引是从0开始]
sheet.getRow(1).createCell(1).setCellValue("时间:" + dateBegin + "至" + dateEnd);
// 获得第四行
XSSFRow row = sheet.getRow(3);
row.getCell(2).setCellValue(businessDataVO.getTurnover());//营业额
row.getCell(4).setCellValue(businessDataVO.getOrderCompletionRate());//订单完成率
row.getCell(6).setCellValue(businessDataVO.getNewUsers());//新增用户数
// 获得第五行
row = sheet.getRow(4);
row.getCell(2).setCellValue(businessDataVO.getValidOrderCount());//有效订单数
row.getCell(4).setCellValue(businessDataVO.getUnitPrice());//平均单品价格
// 填充明细数据
for (int i = 0; i < 30; i++) {
LocalDate date = dateBegin.plusDays(i);
// 查询某一天的营业数据
workspaceService.getBusinessData(LocalDateTime.of(date, LocalTime.MIN), LocalDateTime.of(date, LocalTime.MAX));
// 获得某一行
row = sheet.getRow(7 + i);// 利用循环 超越循环
row.getCell(1).setCellValue(date.toString());
row.getCell(2).setCellValue(businessDataVO.getTurnover());
row.getCell(3).setCellValue(businessDataVO.getValidOrderCount());
row.getCell(6).setCellValue(businessDataVO.getOrderCompletionRate());
row.getCell(4).setCellValue(businessDataVO.getUnitPrice());
row.getCell(5).setCellValue(businessDataVO.getNewUsers());
}
// 通过输出流将Excel文件下载到客户端浏览器
ServletOutputStream out = response.getOutputStream();
excel.write(out);
// 关闭资源
out.close();
excel.close();
} catch (Exception e) {
throw new RuntimeException(e);
}
}















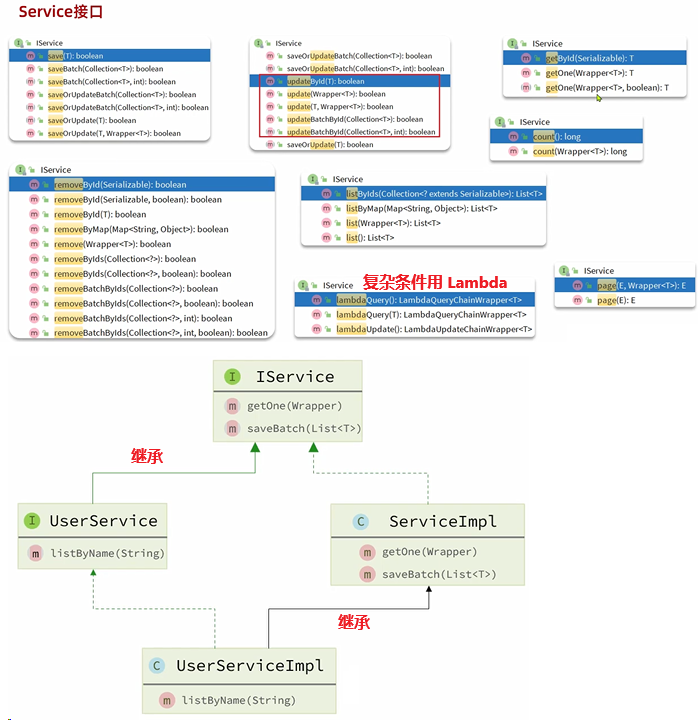

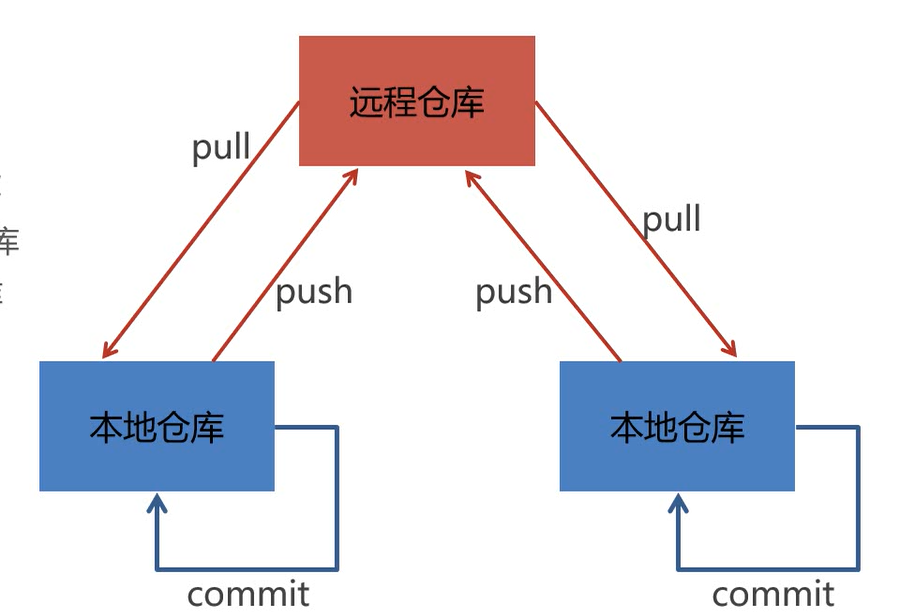
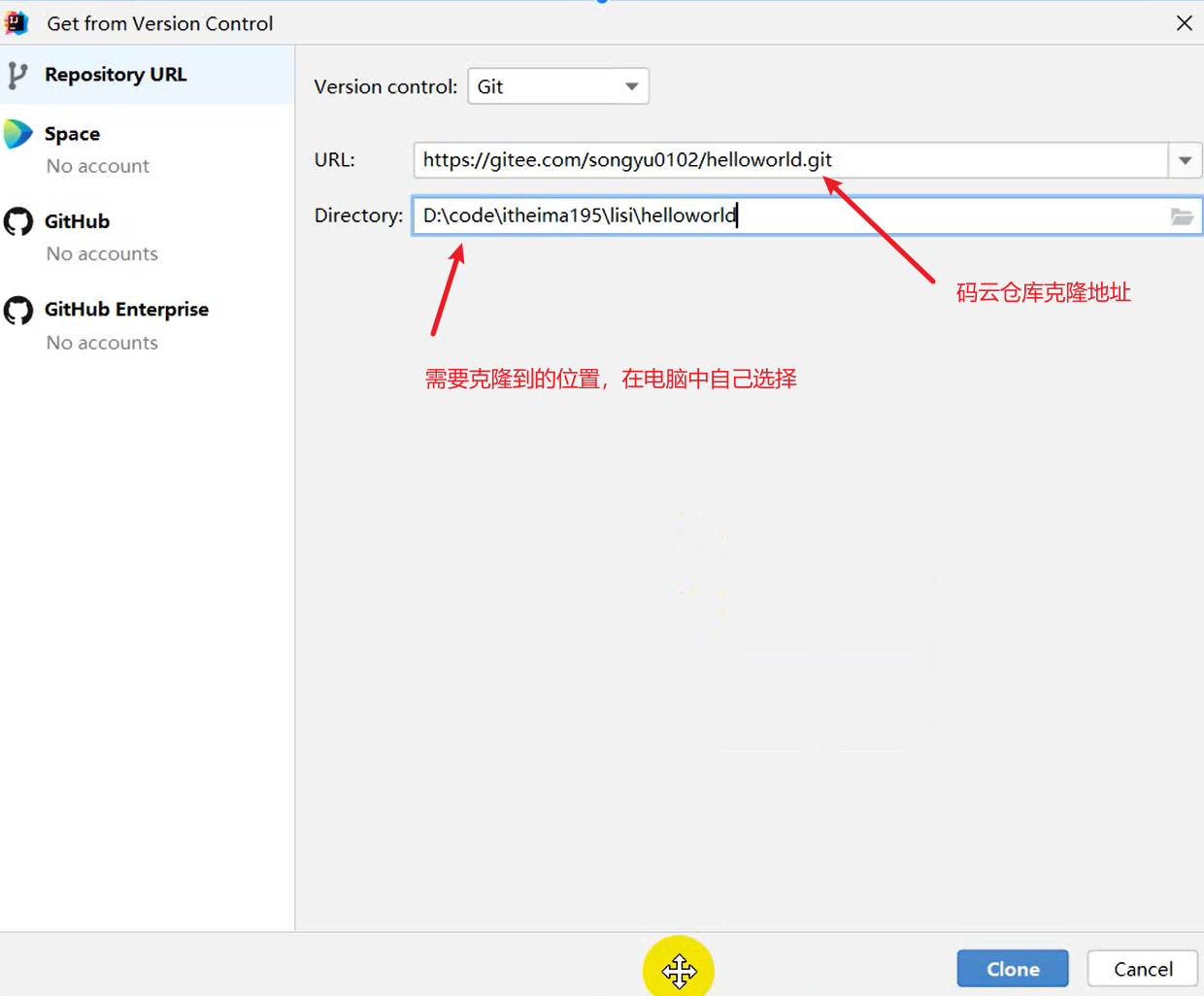
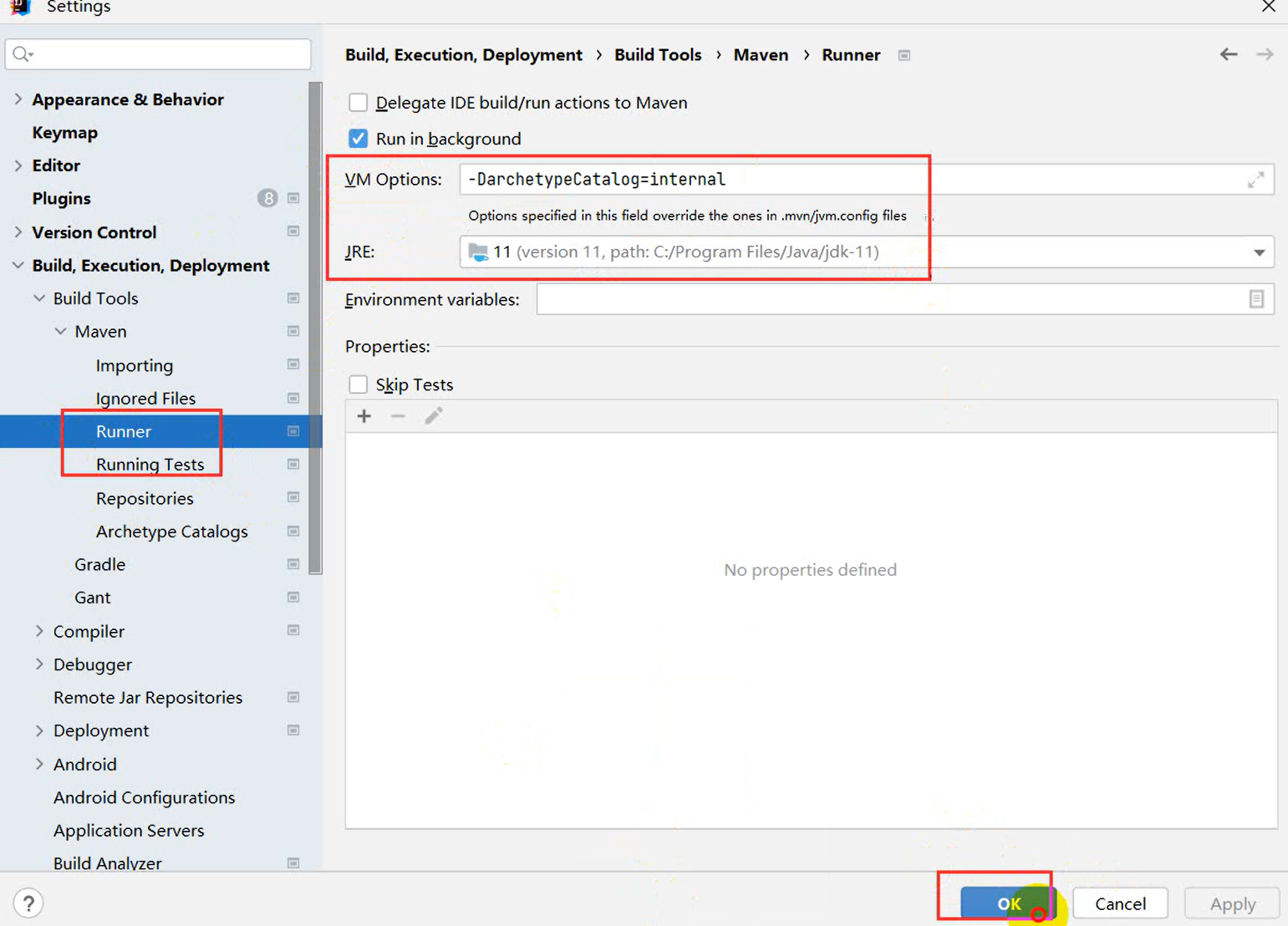
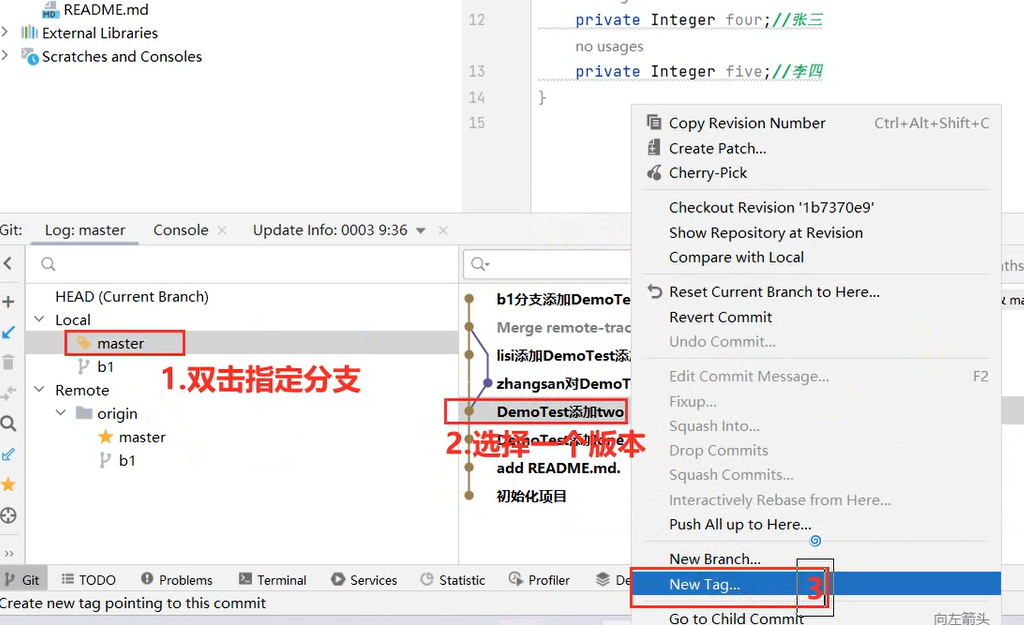
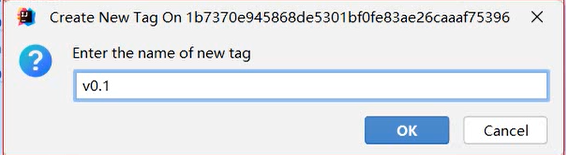

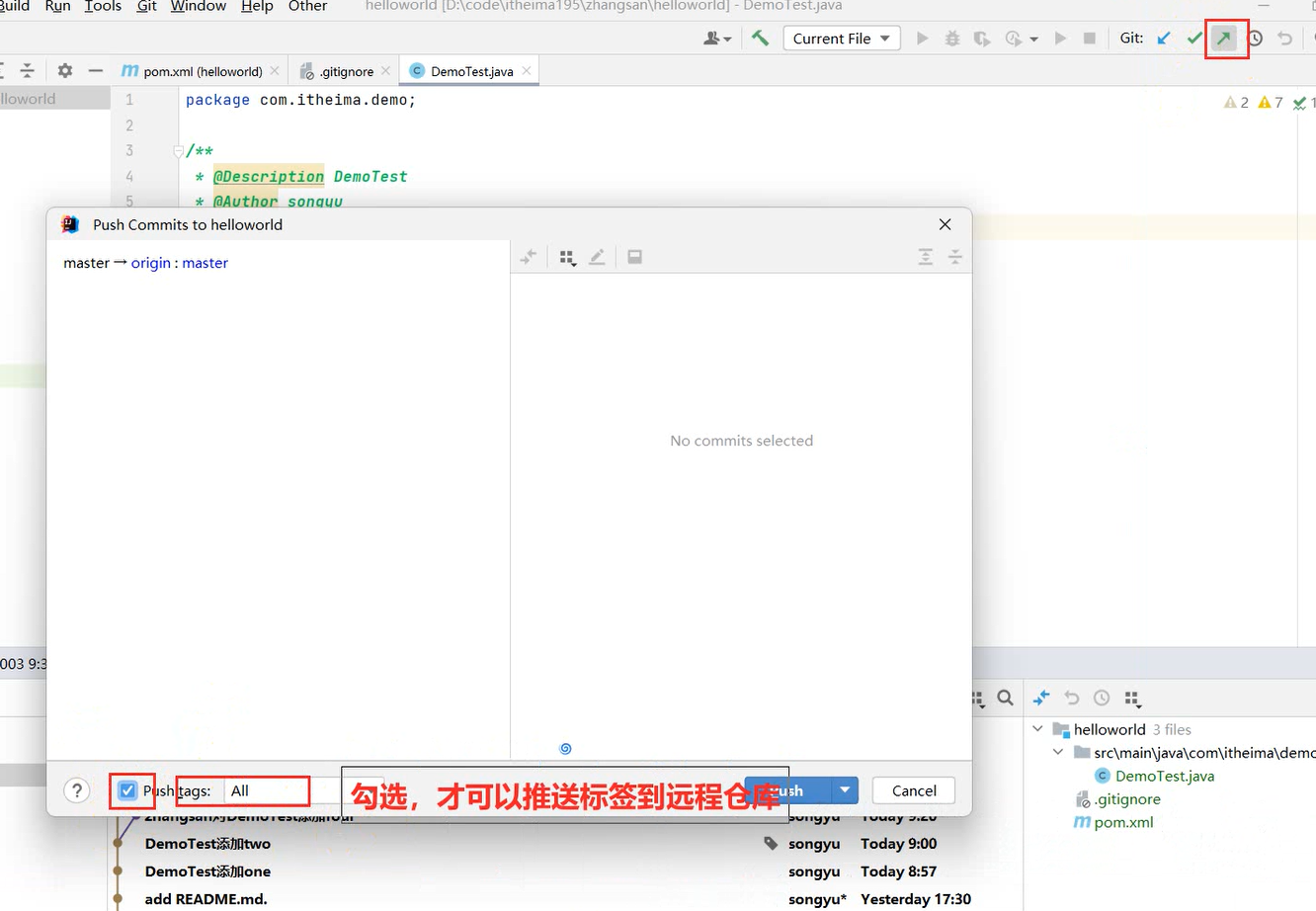
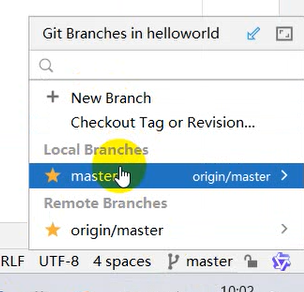
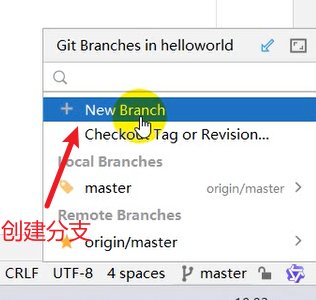
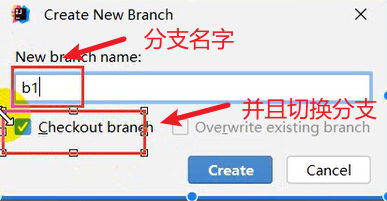
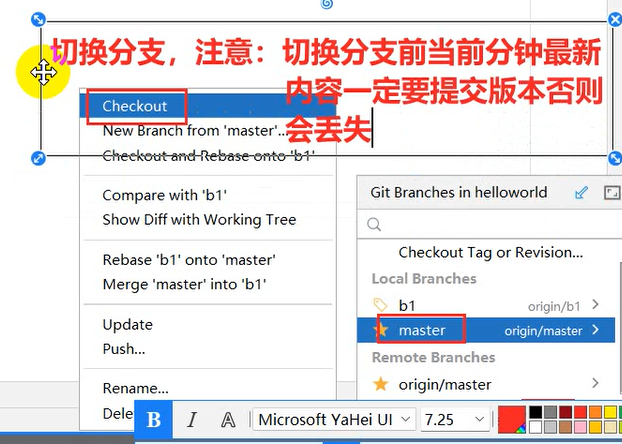
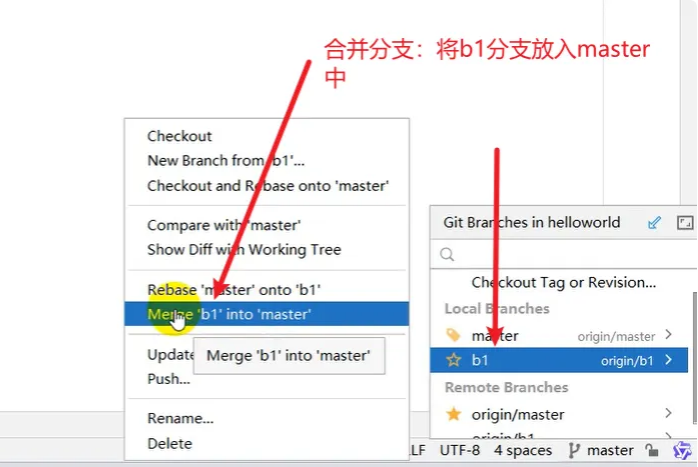
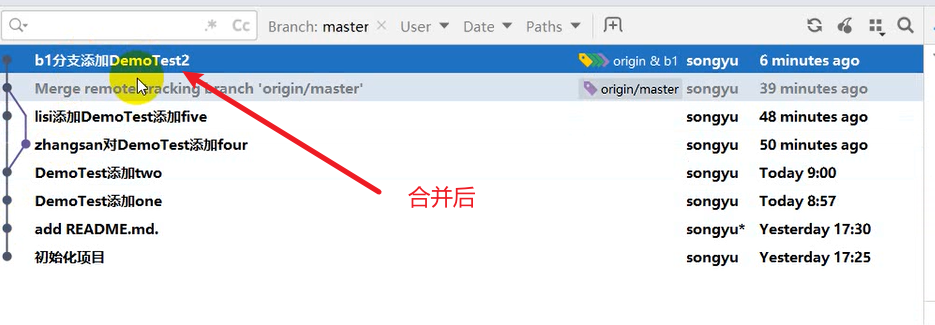
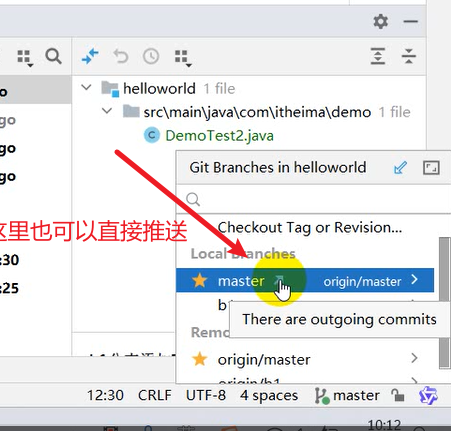
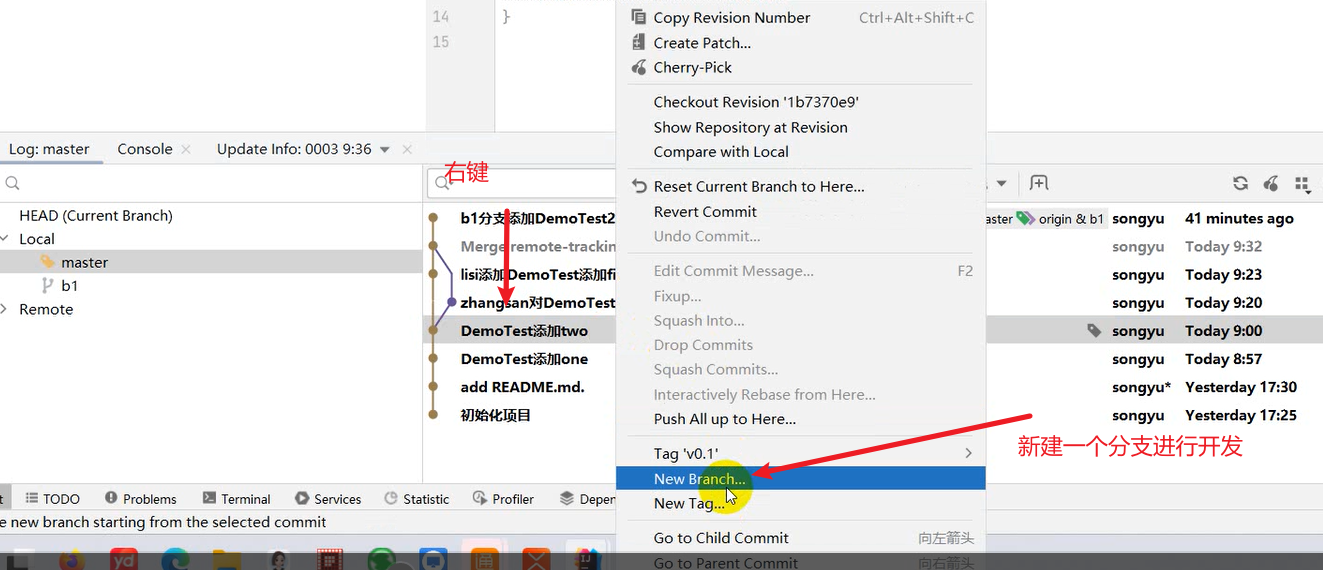
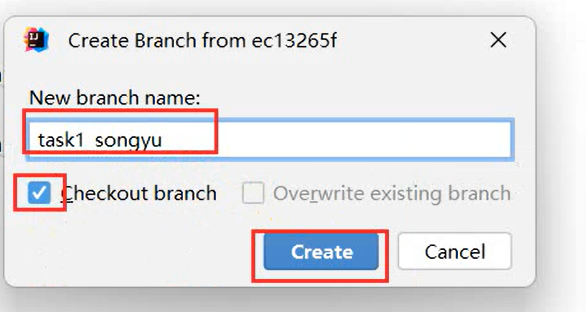
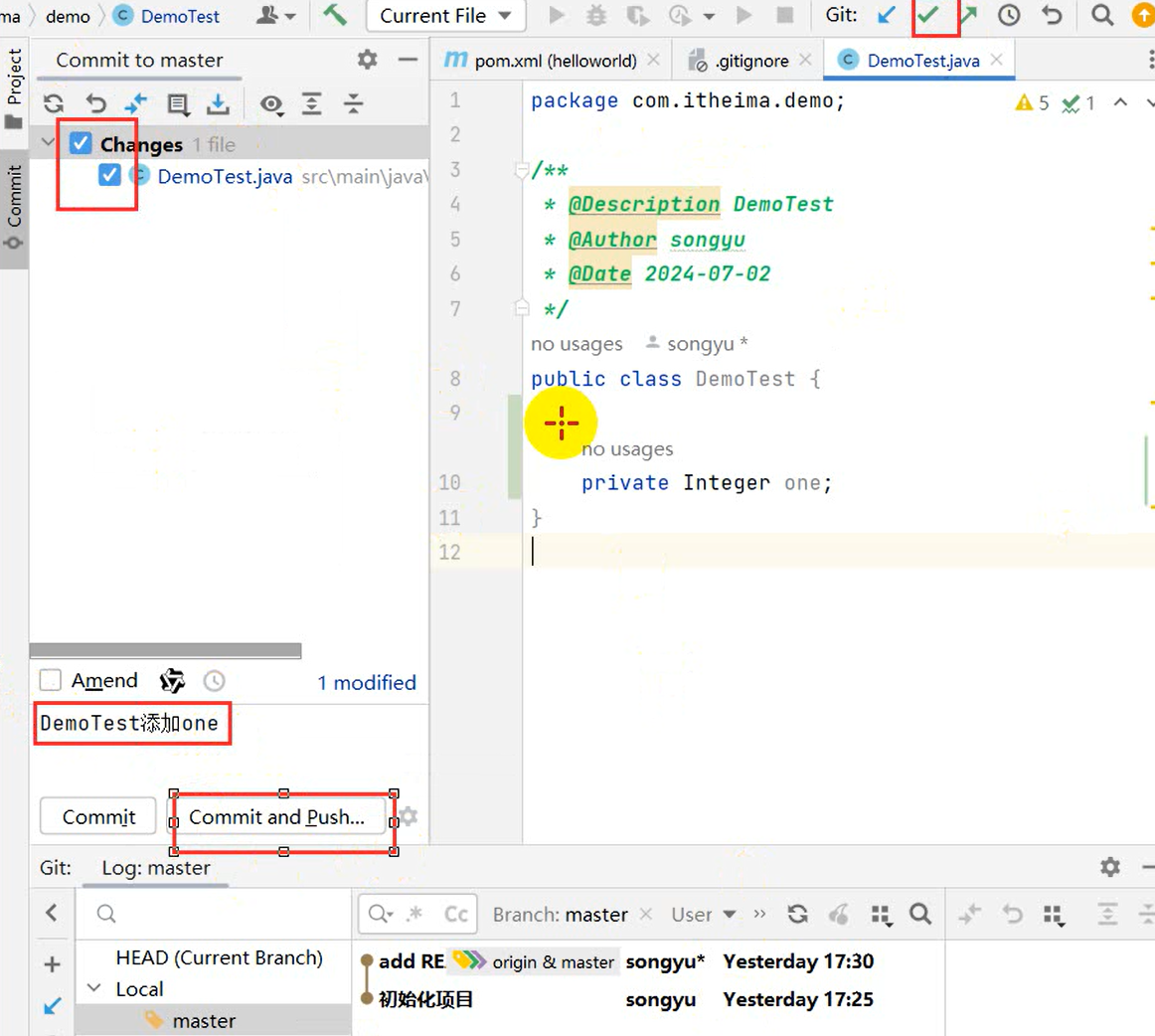
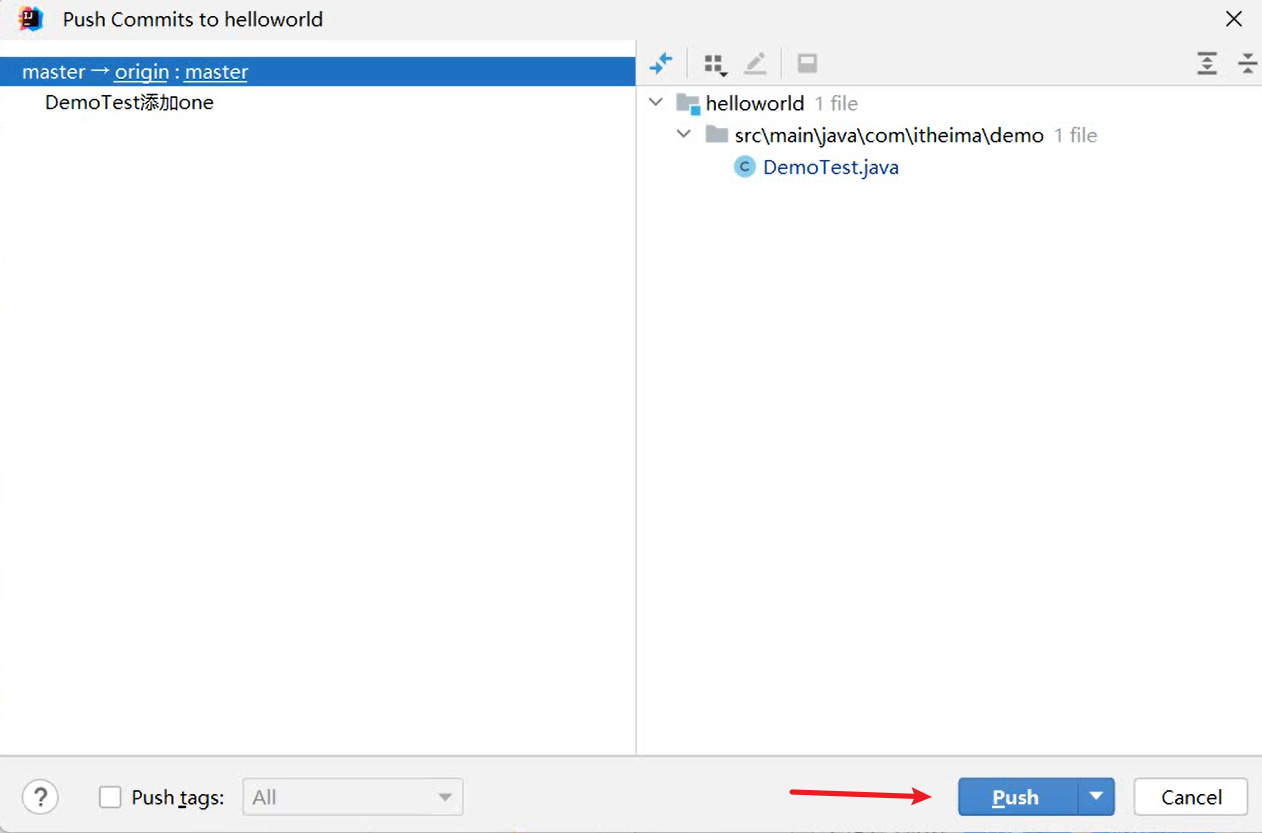
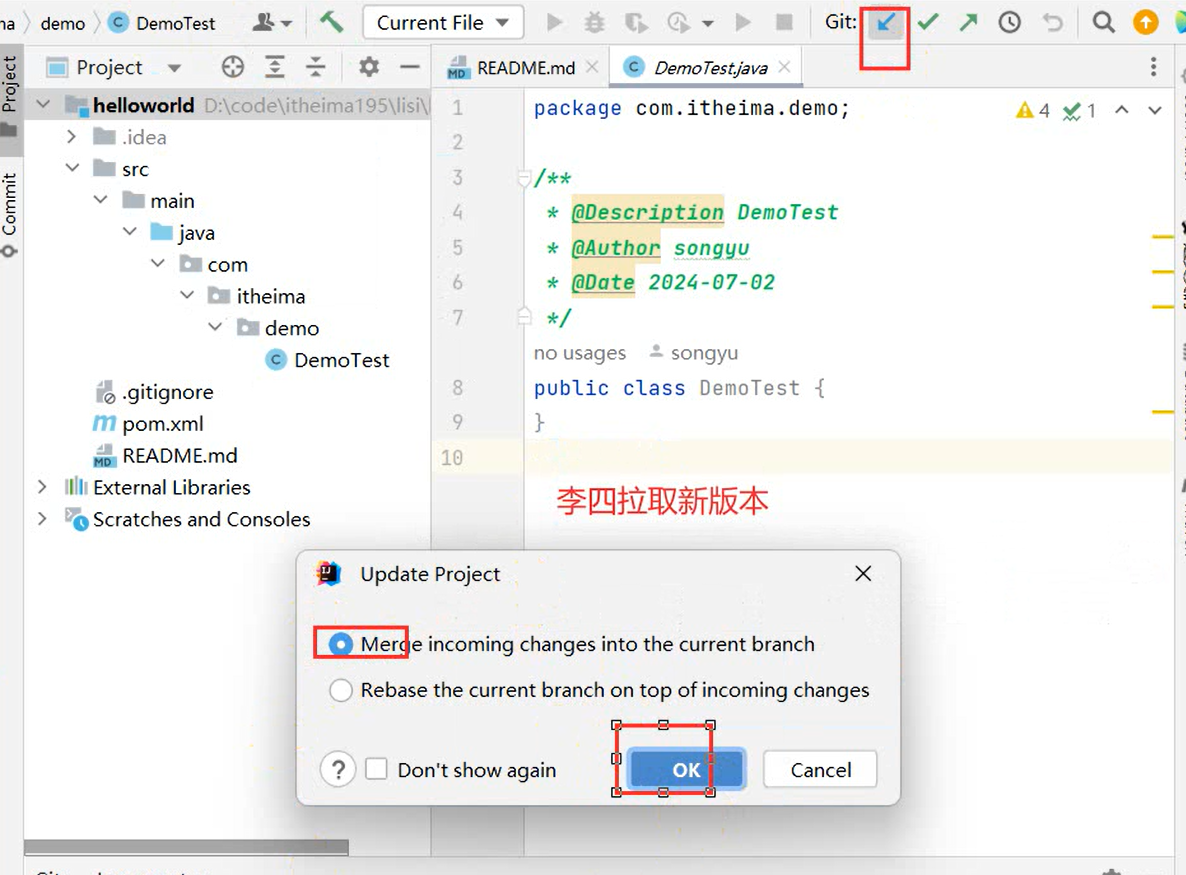
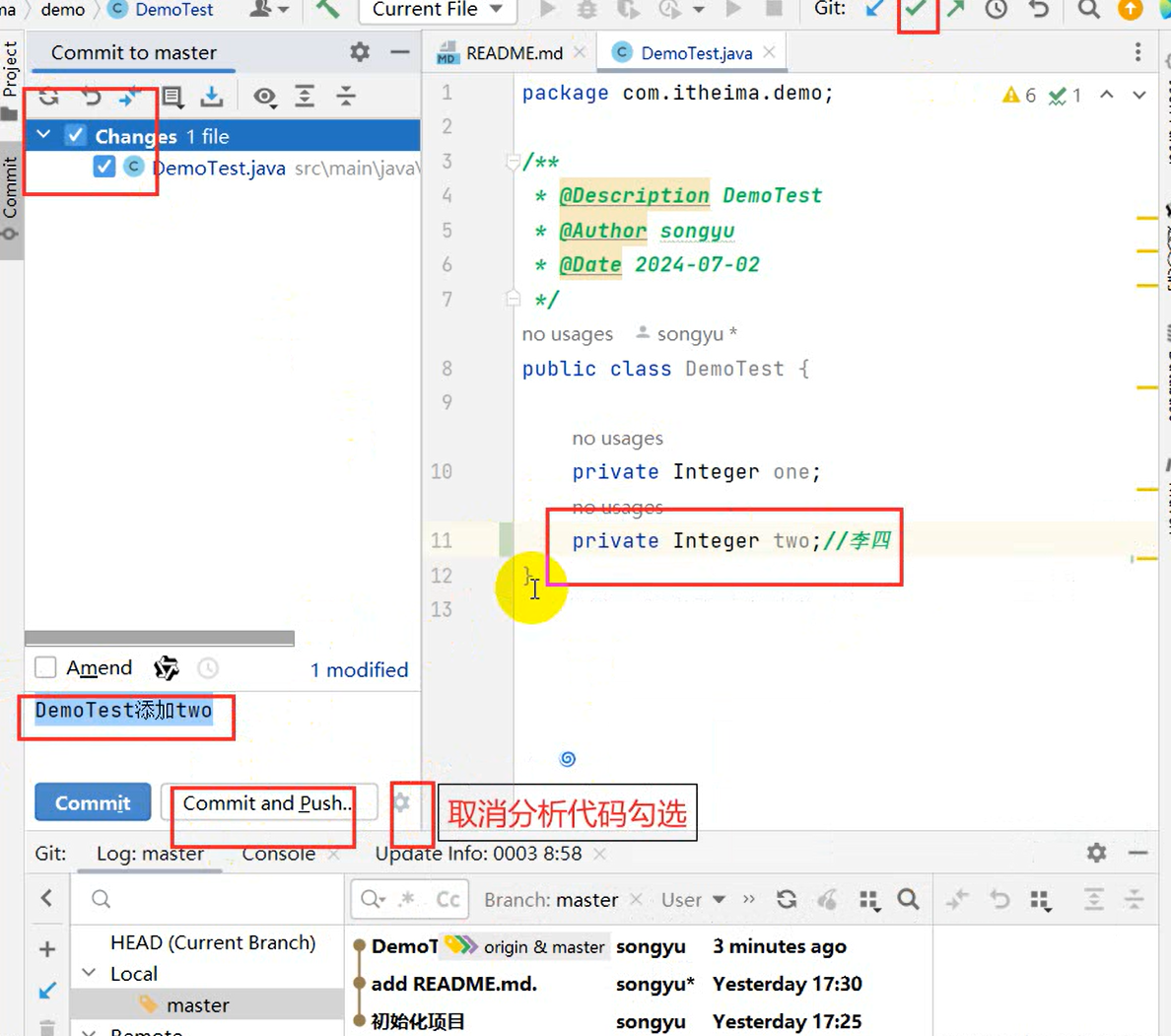
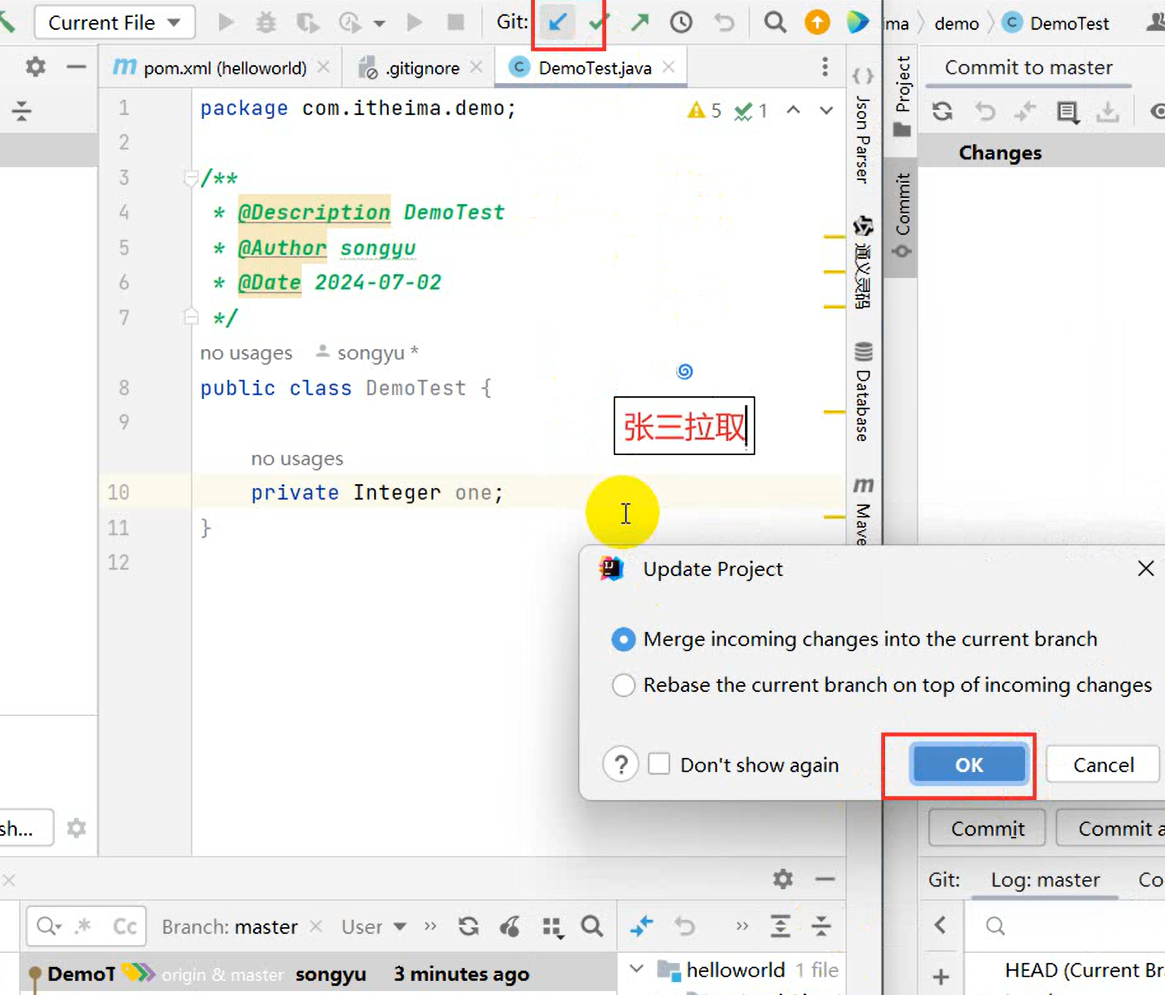
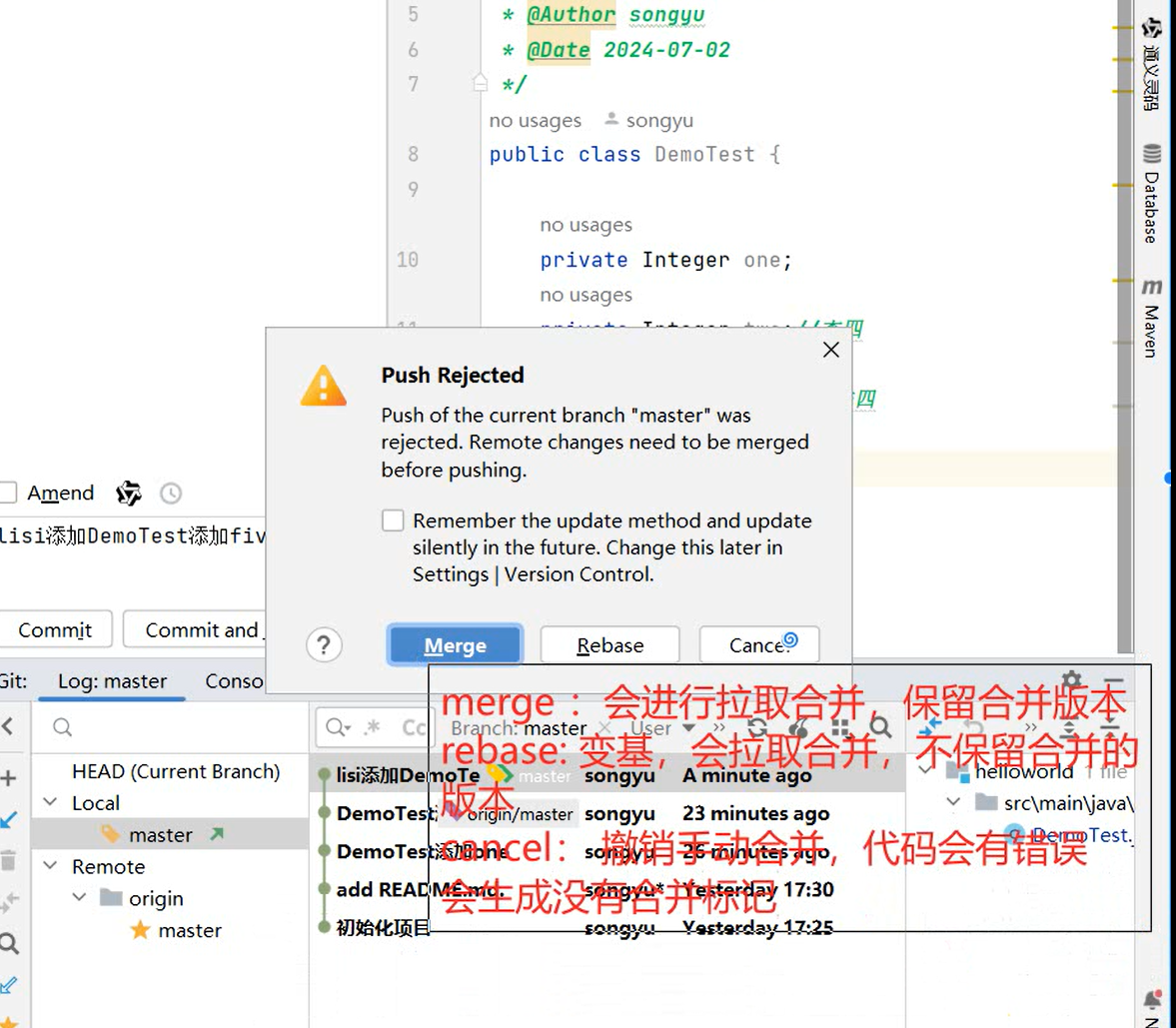
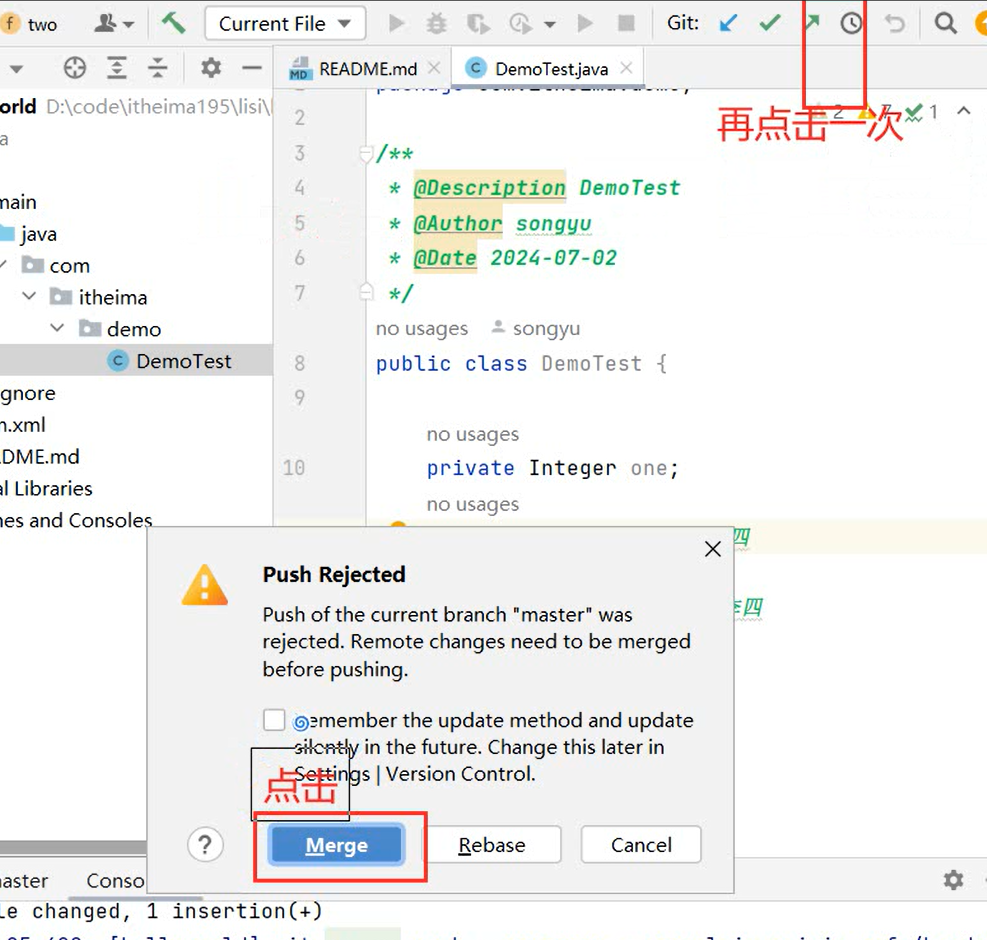
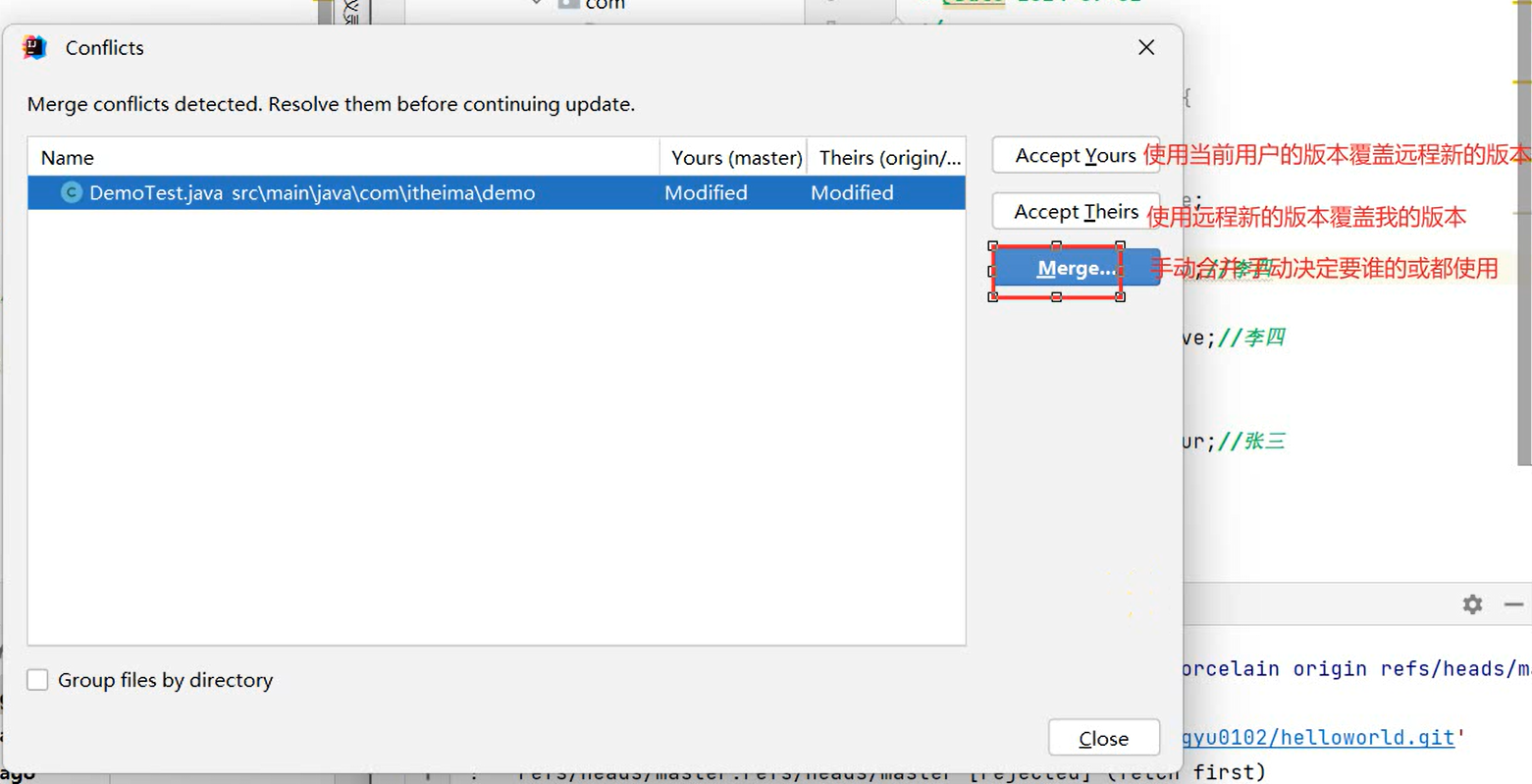
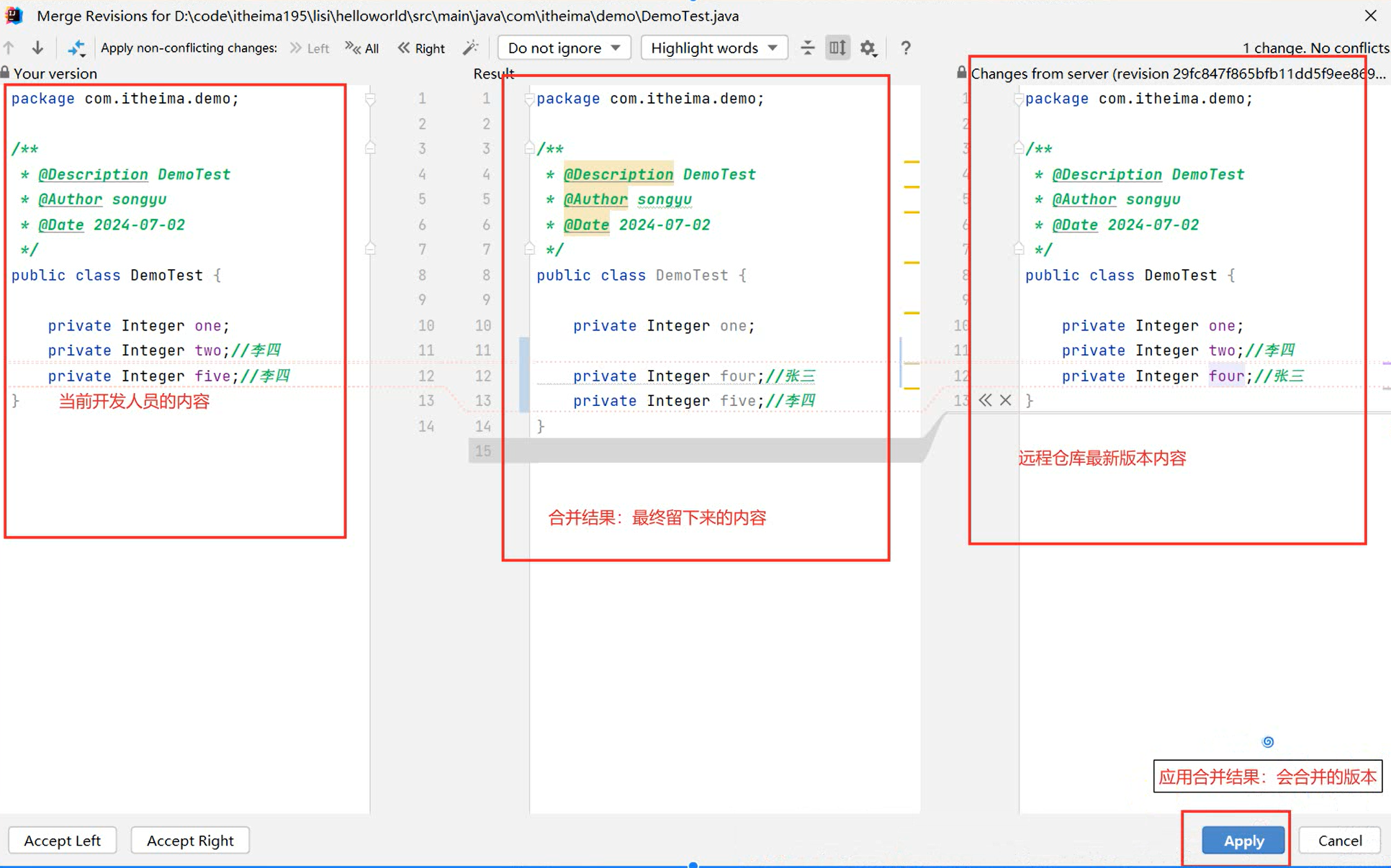

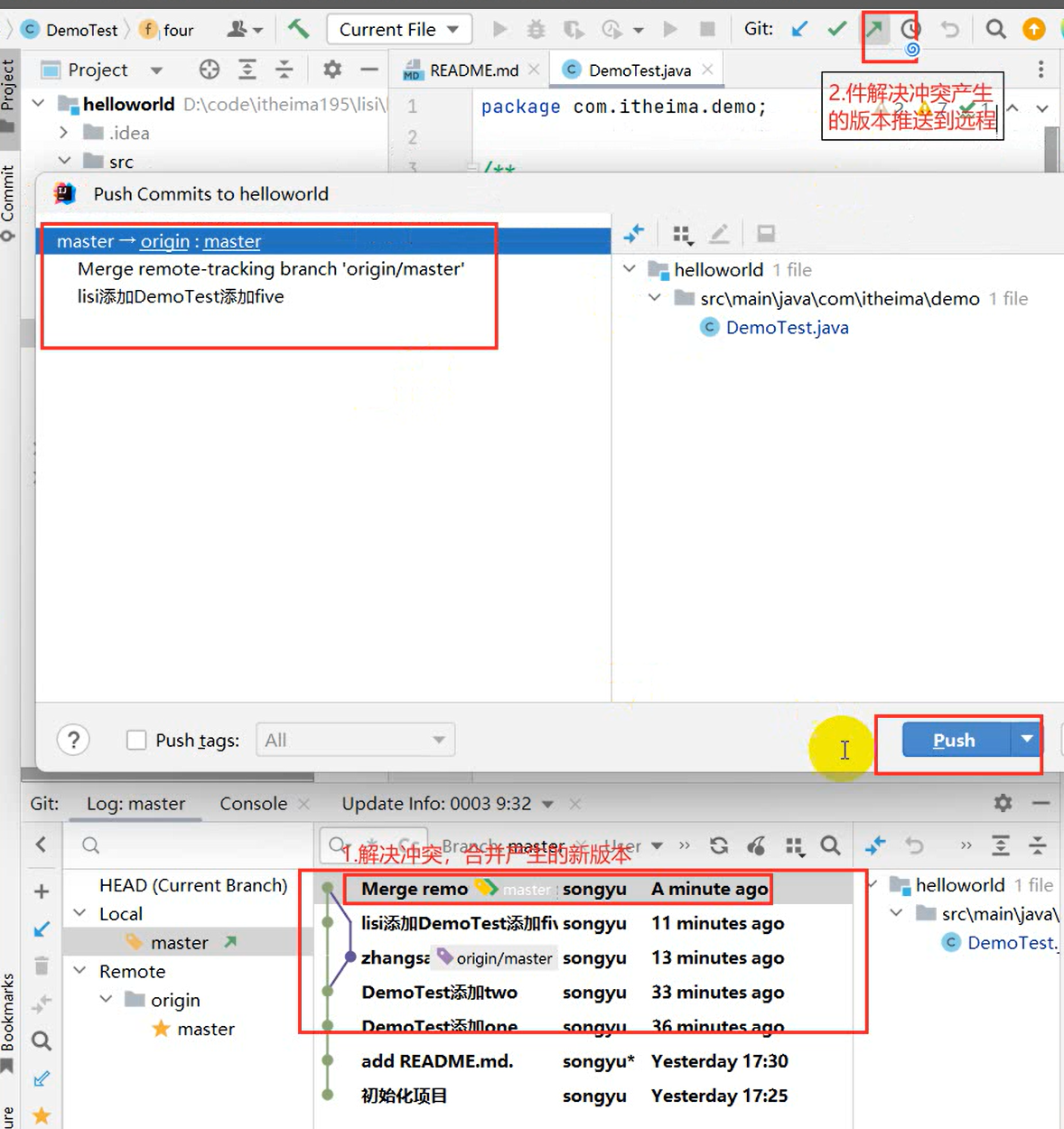
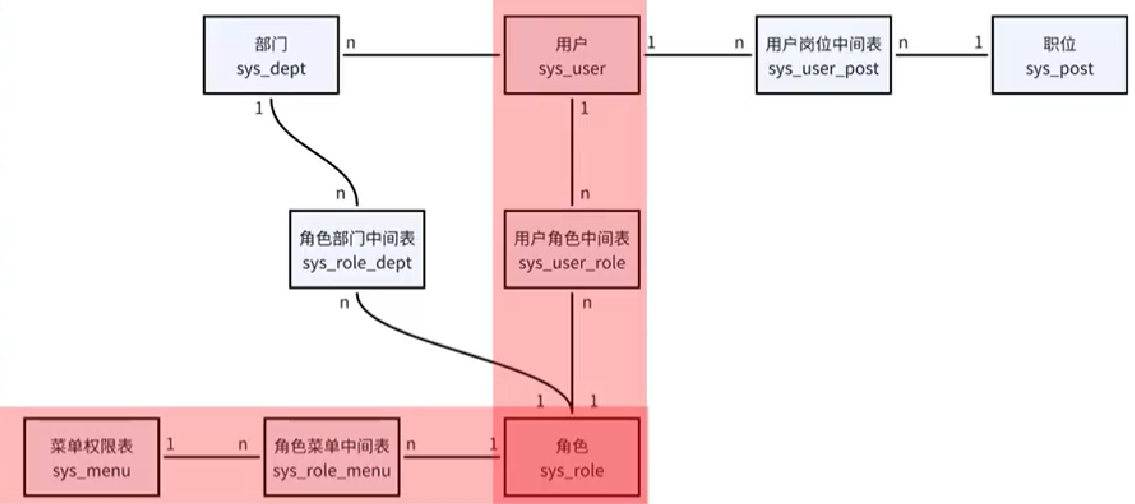

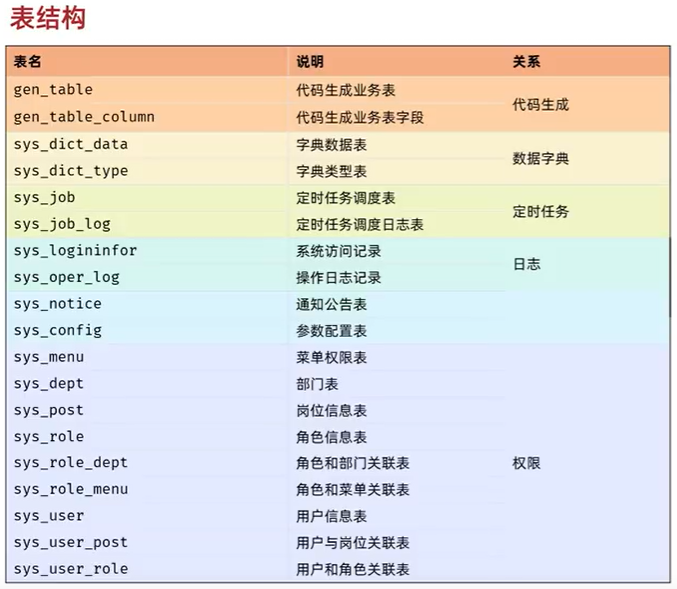


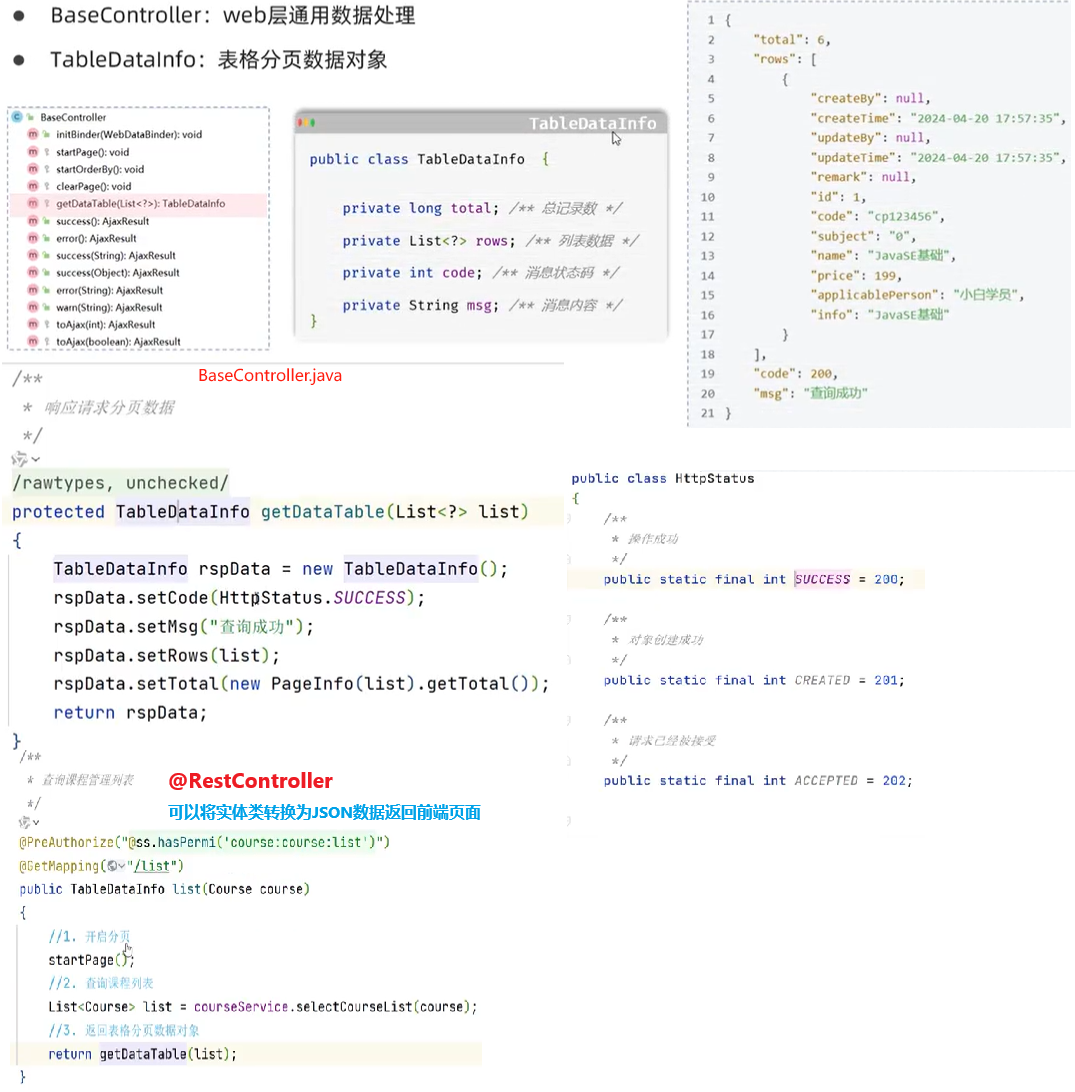
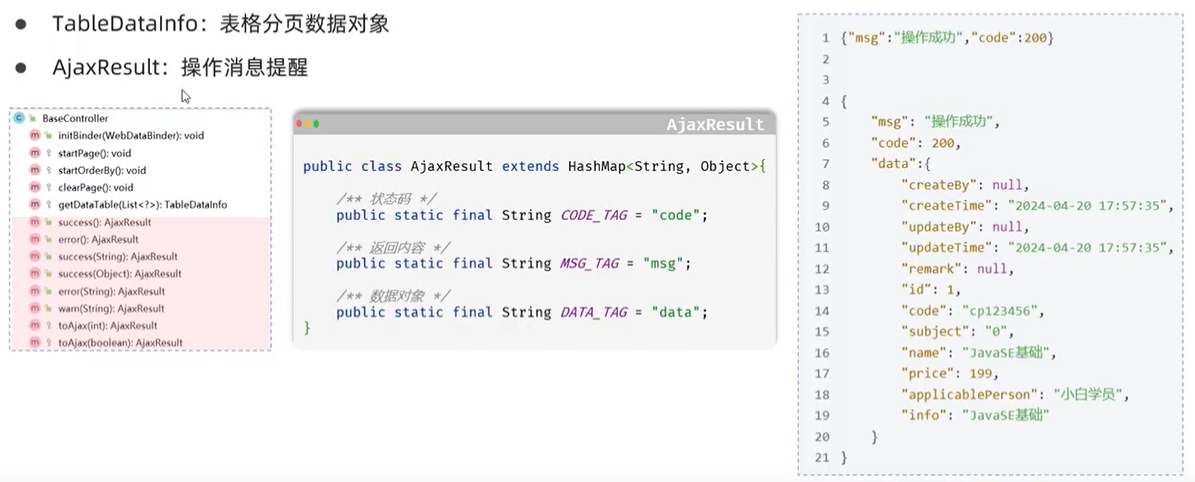
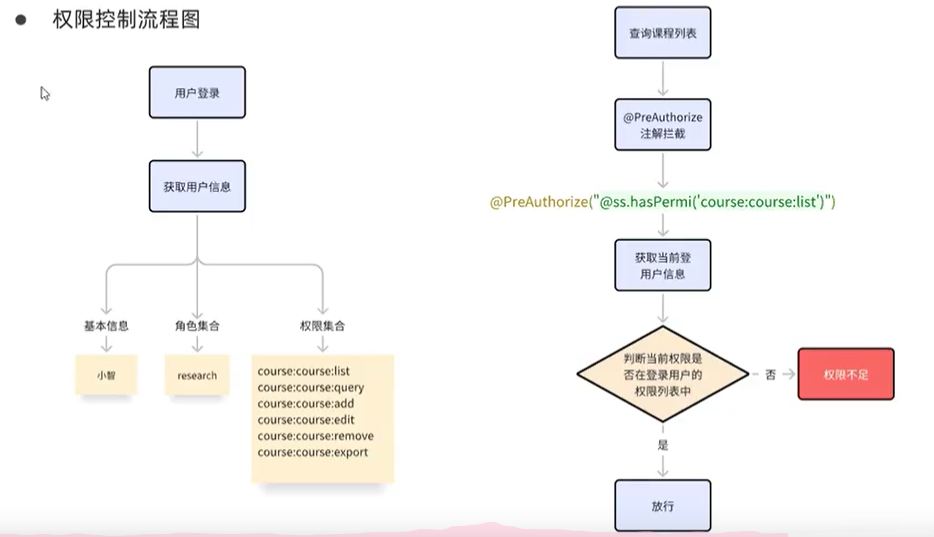
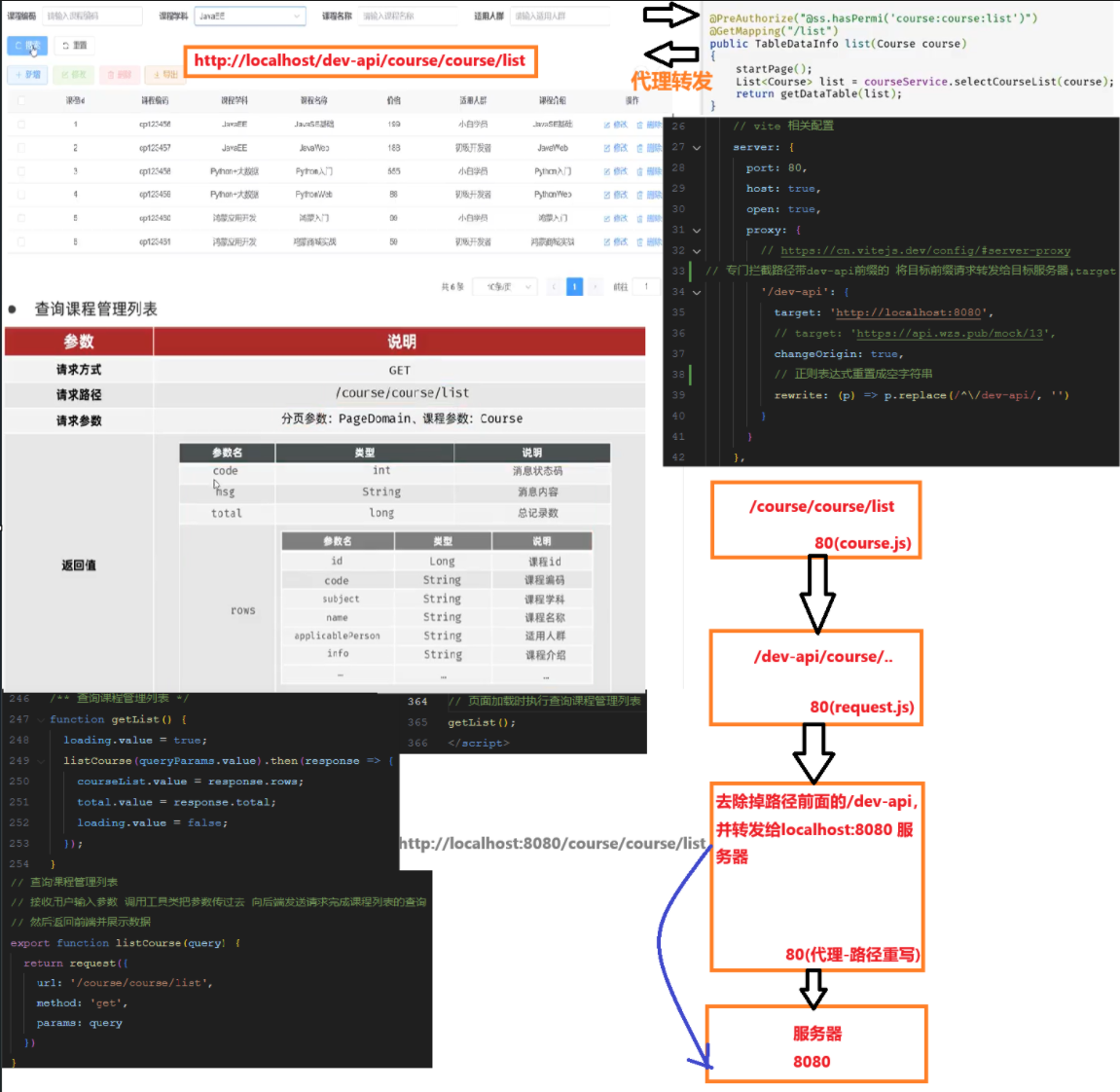
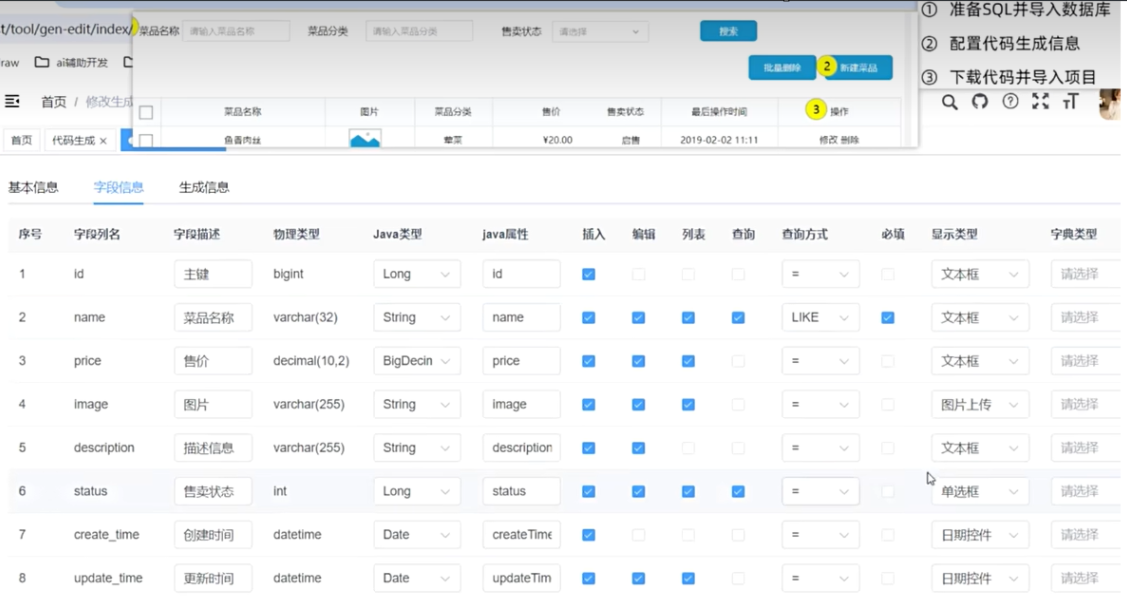
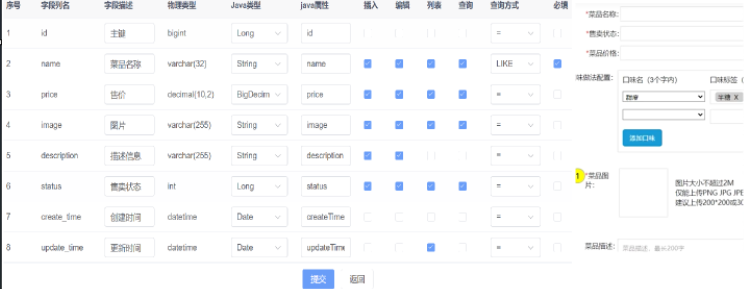
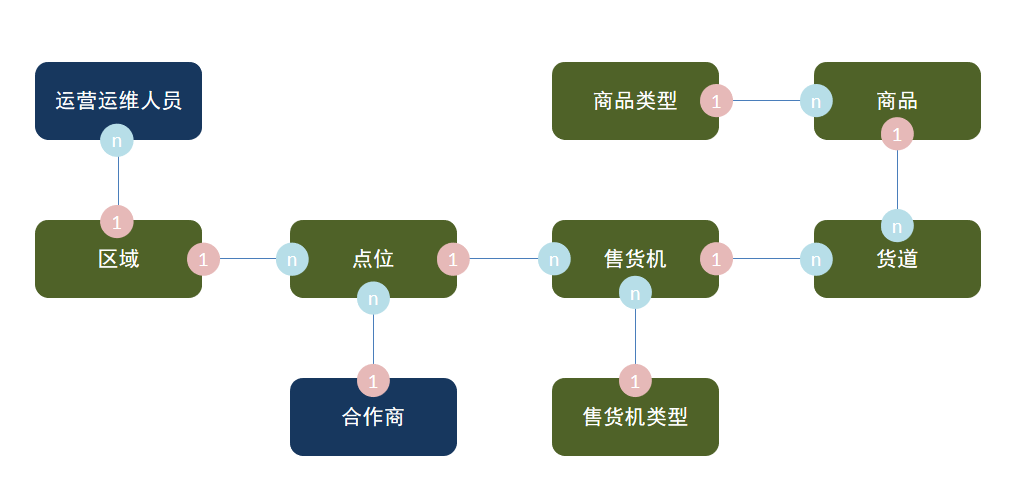
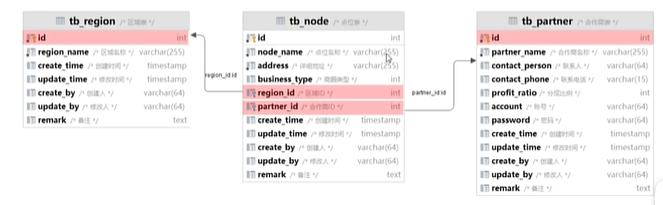
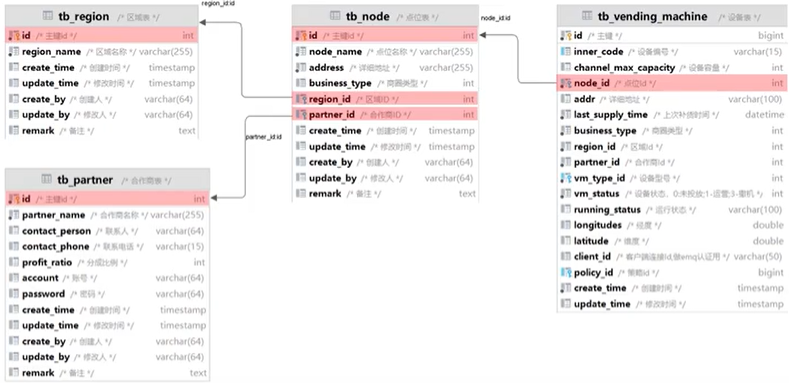
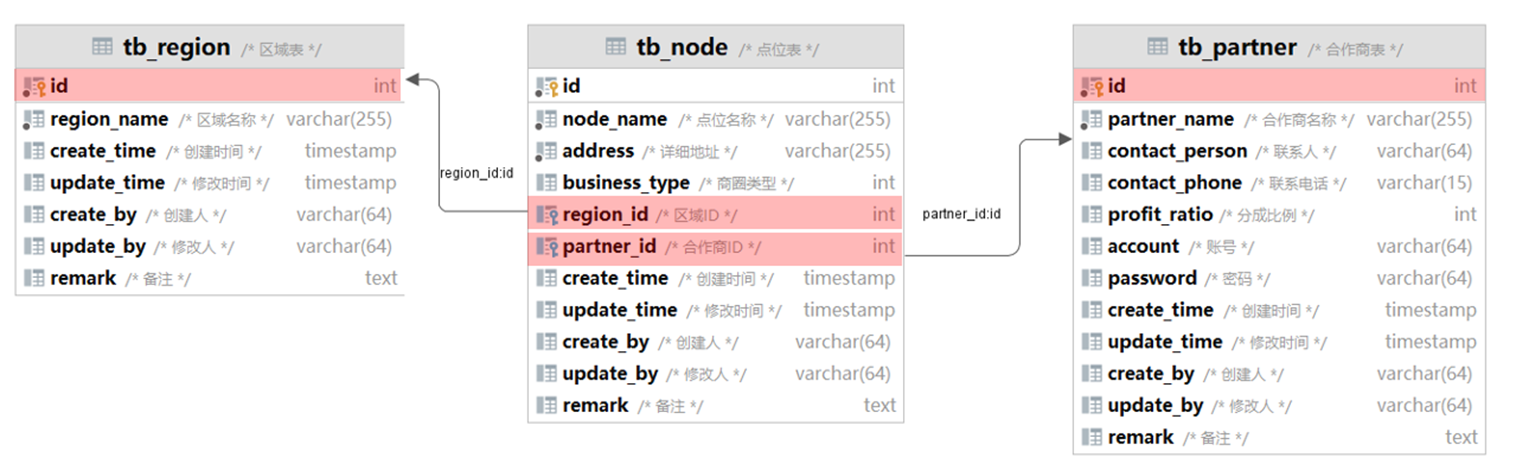

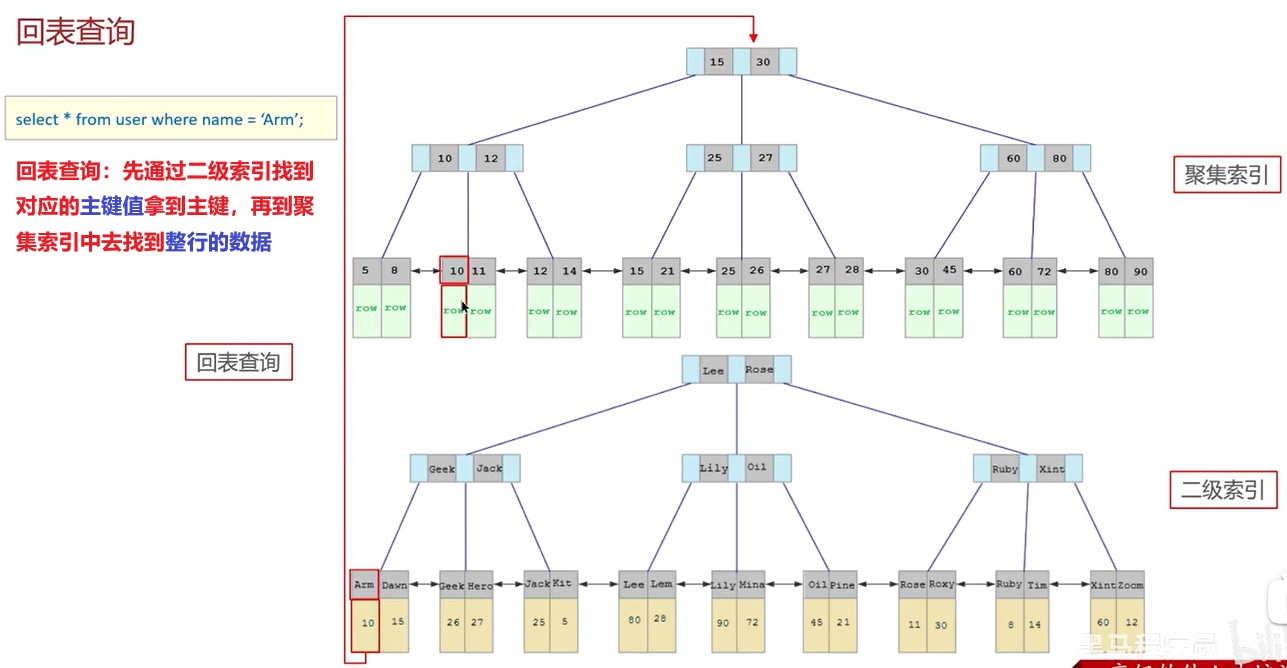
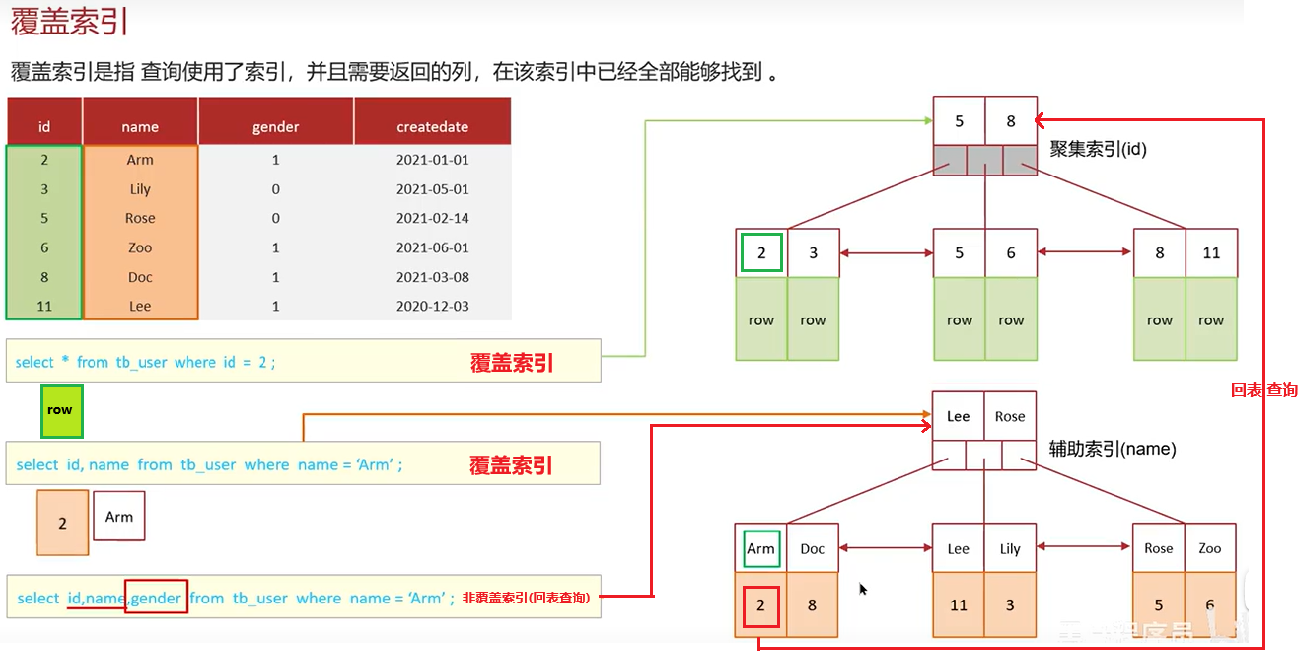

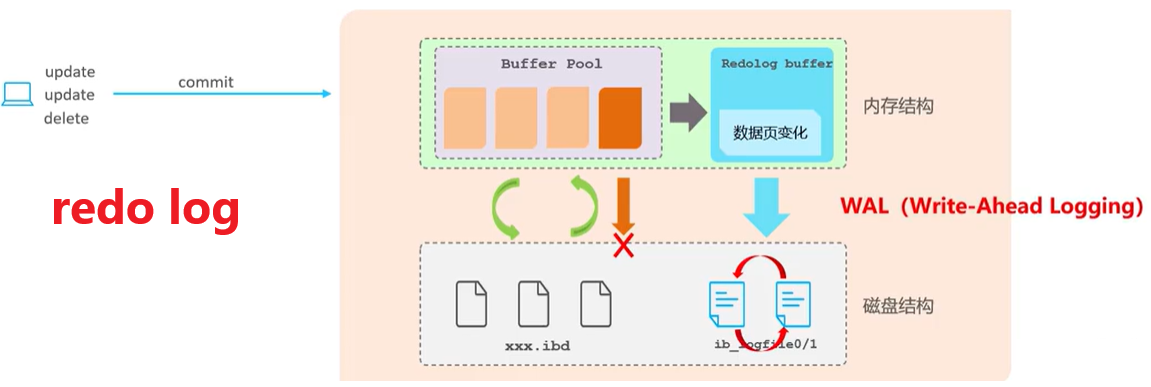
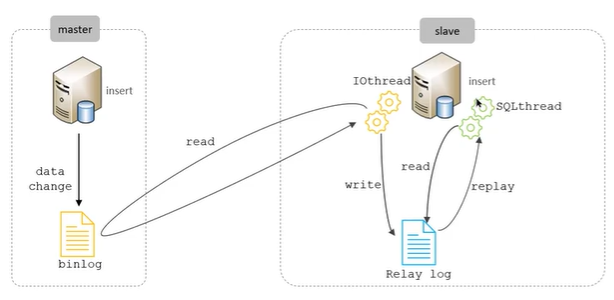

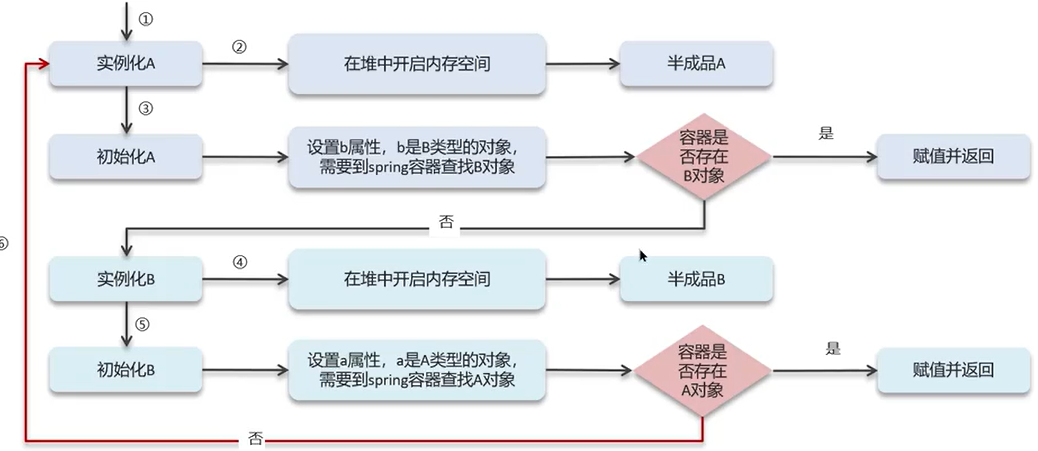




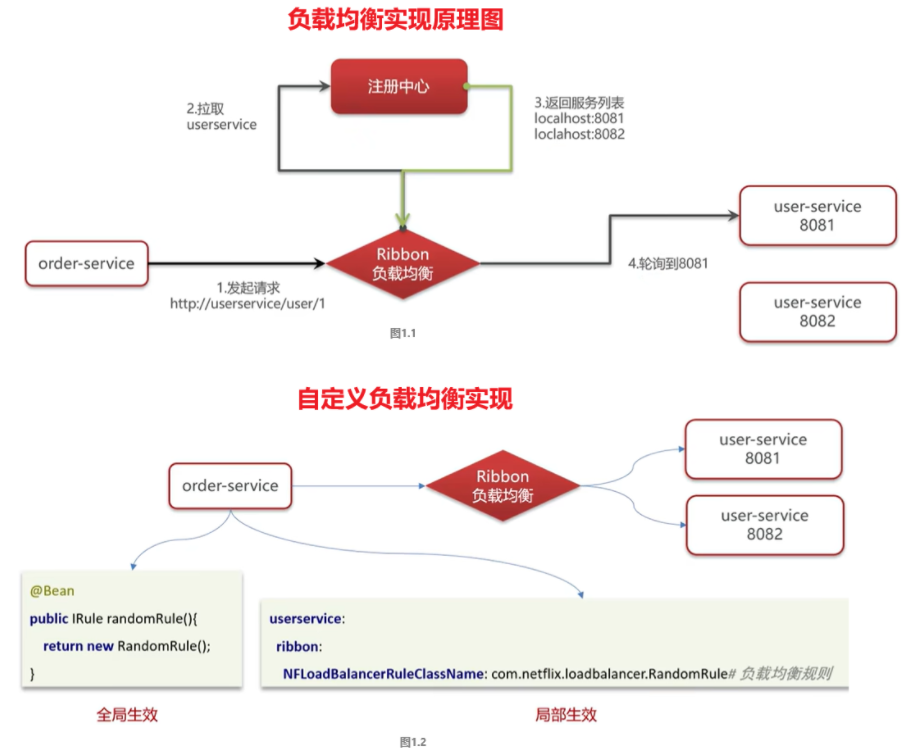



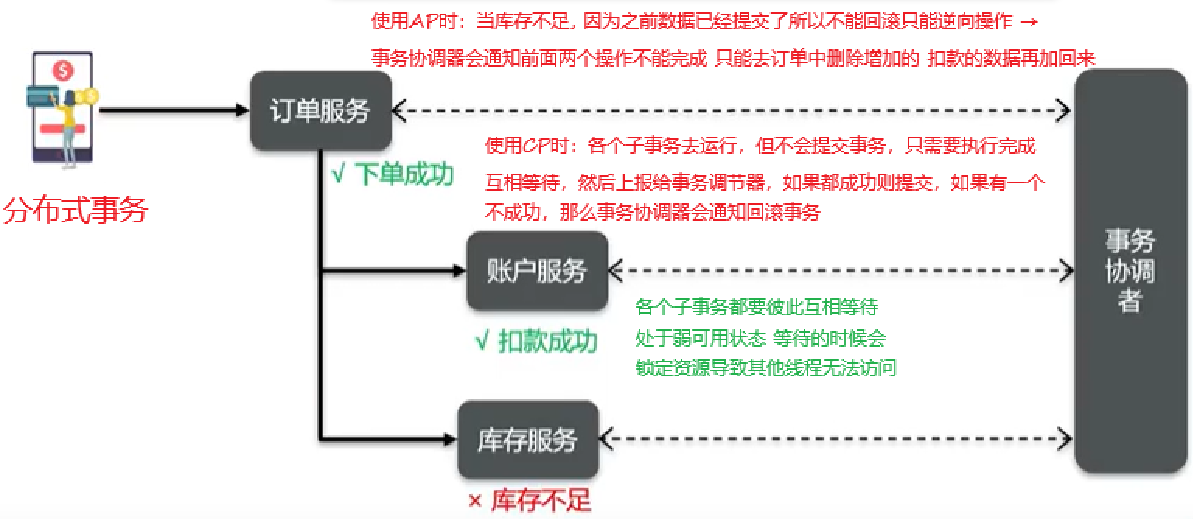



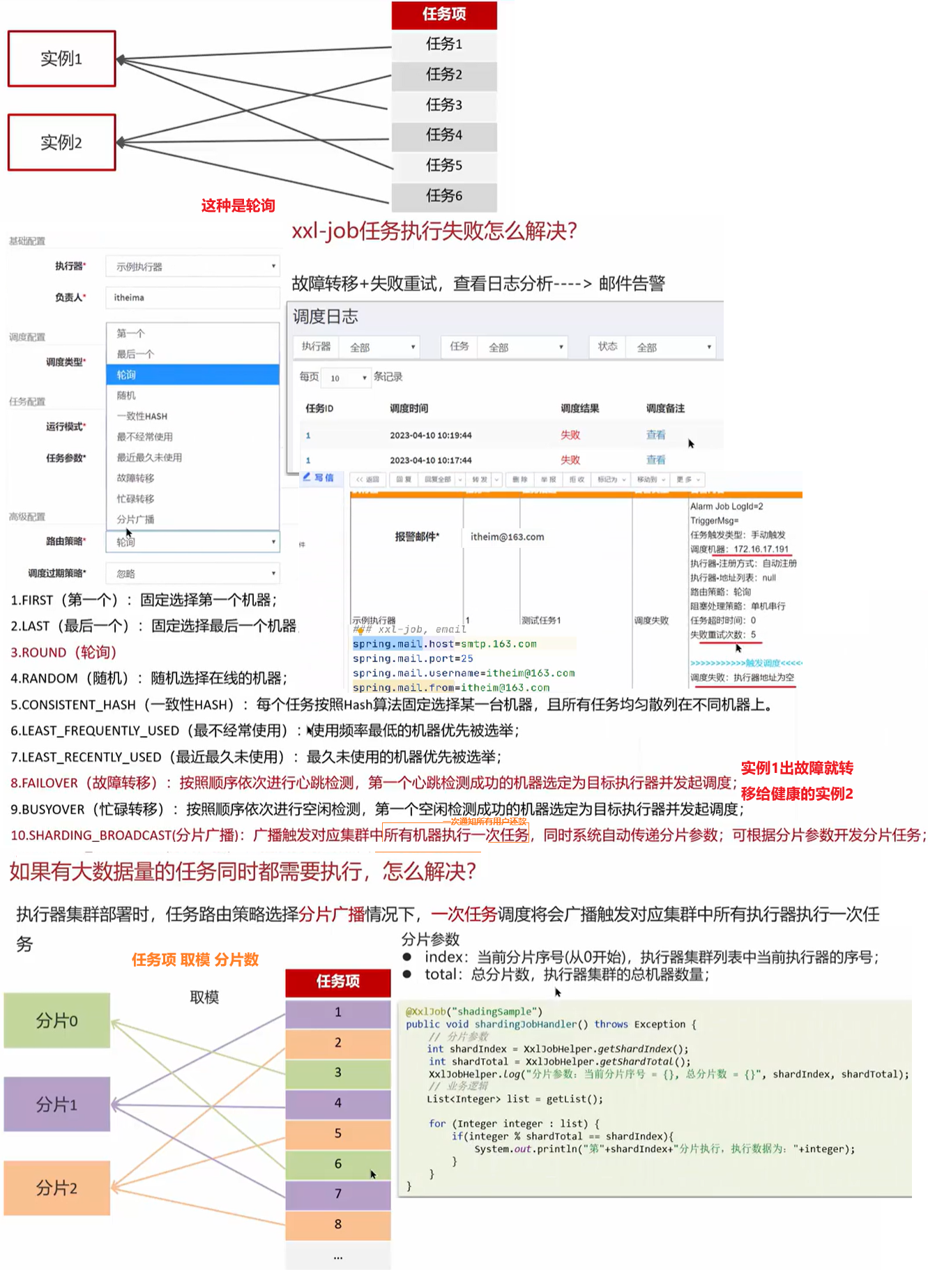

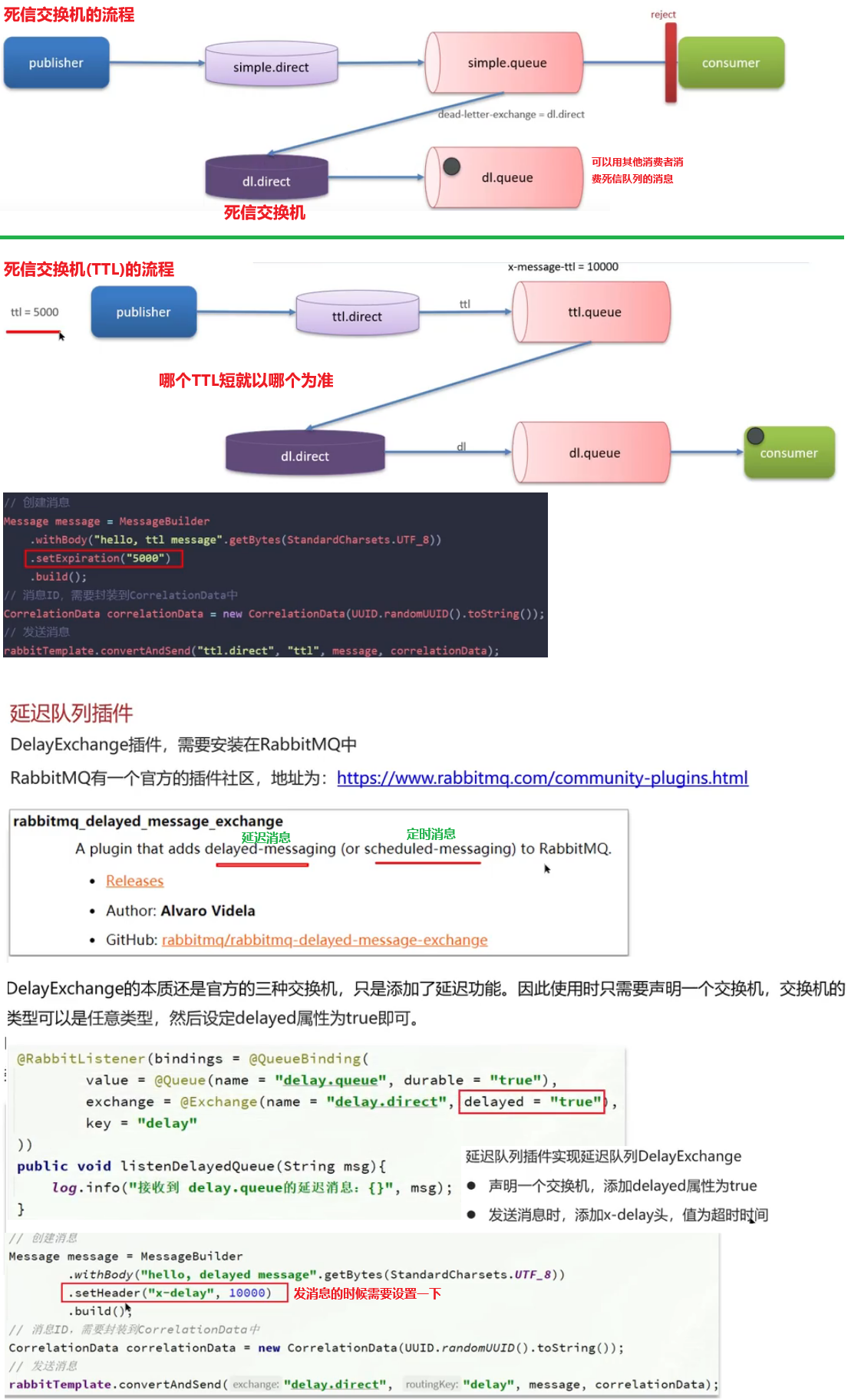
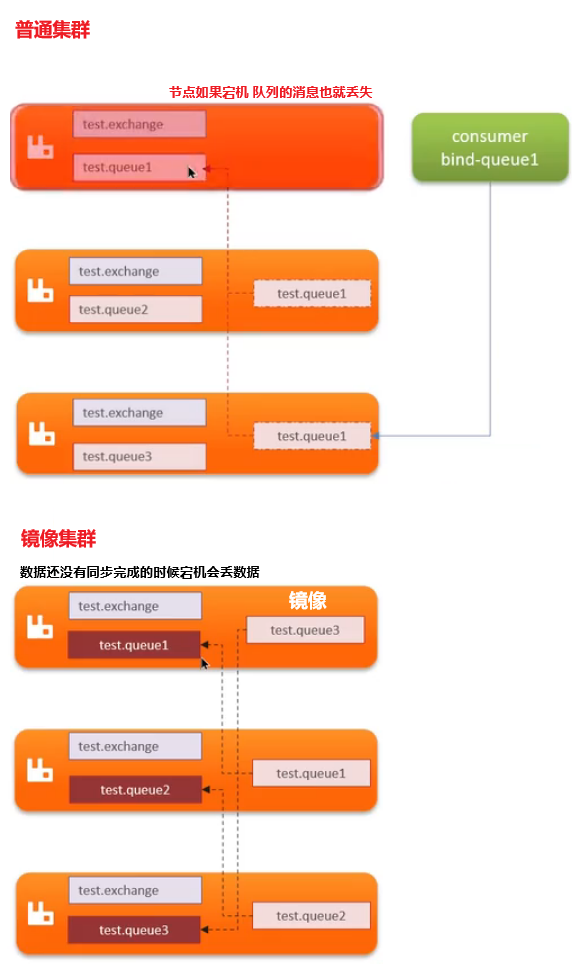
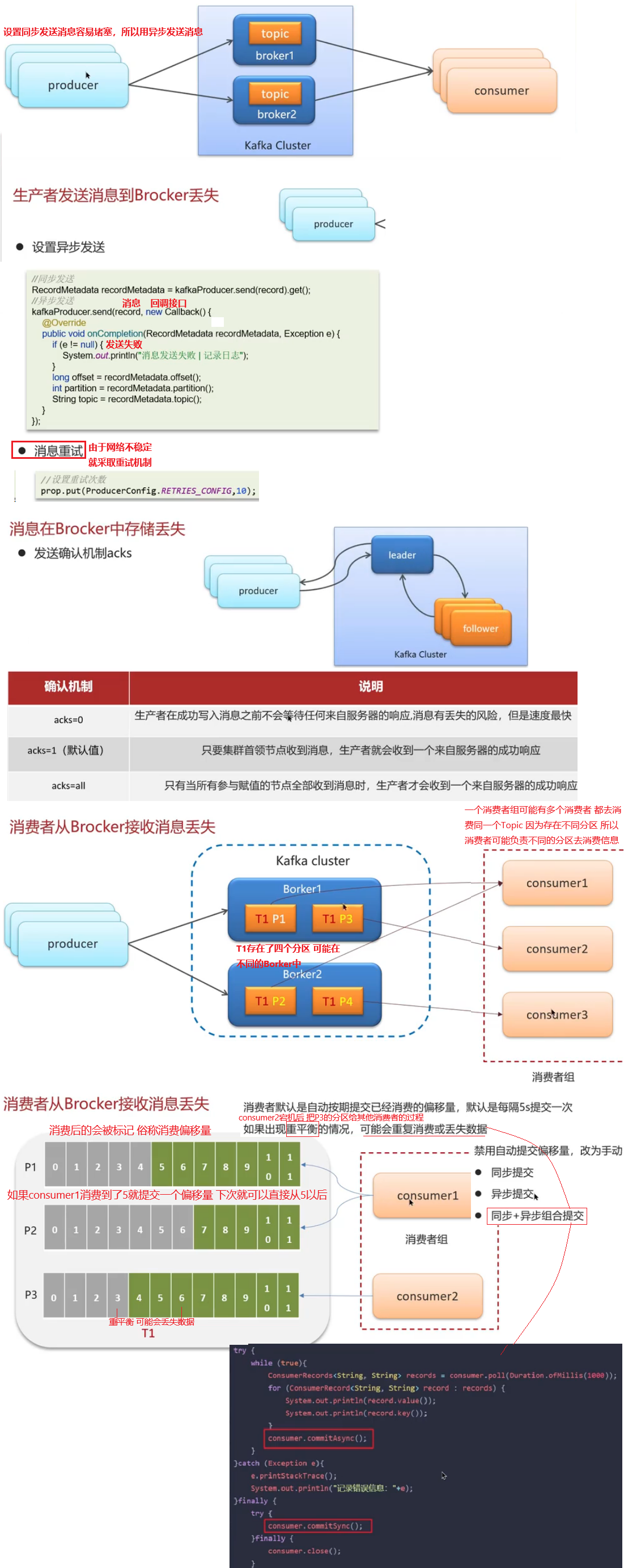
.png)
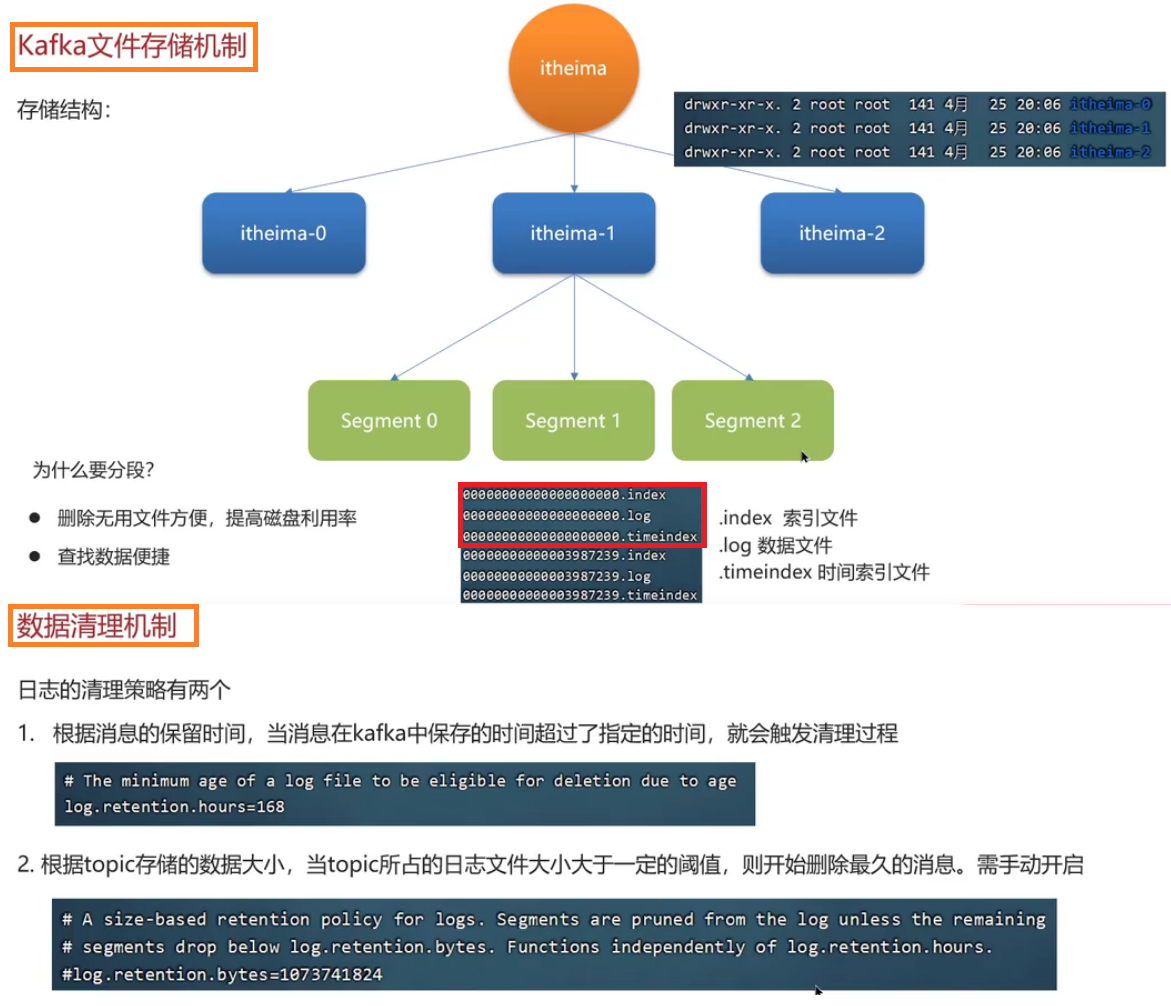
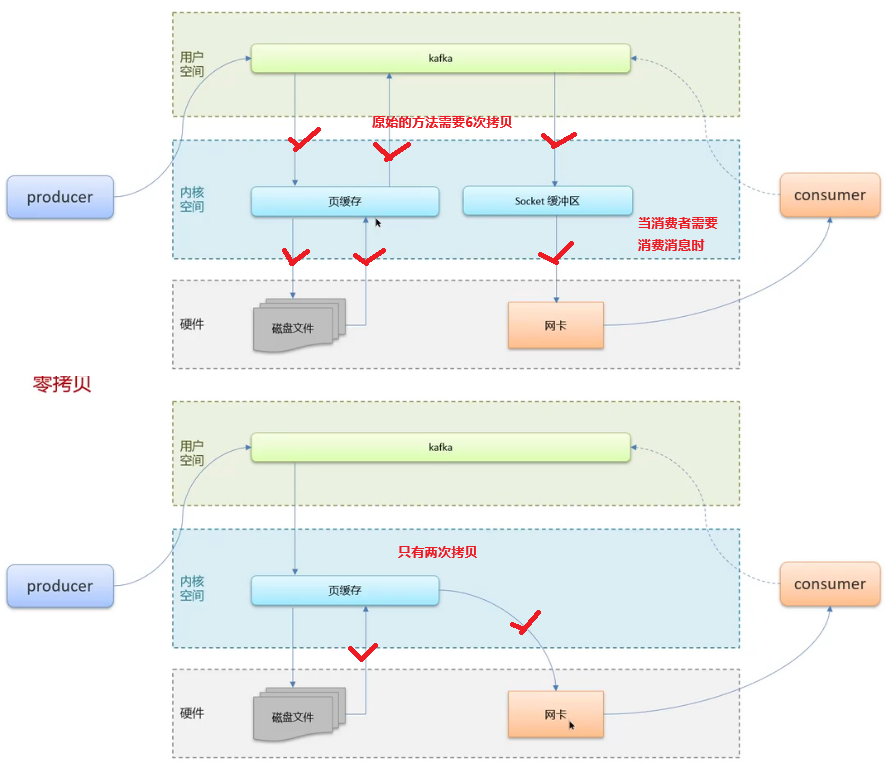
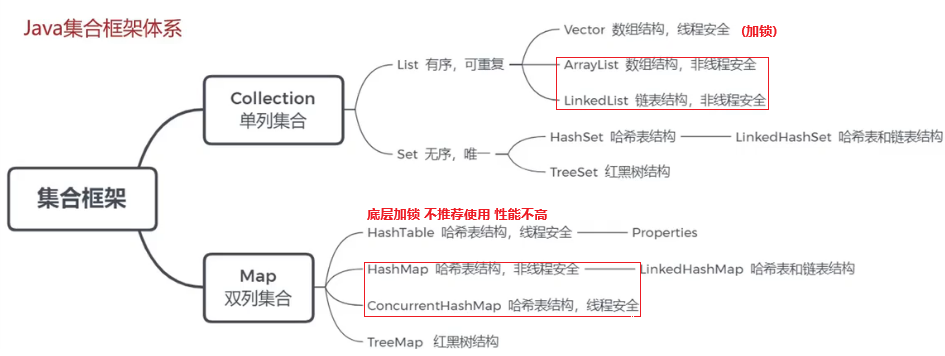




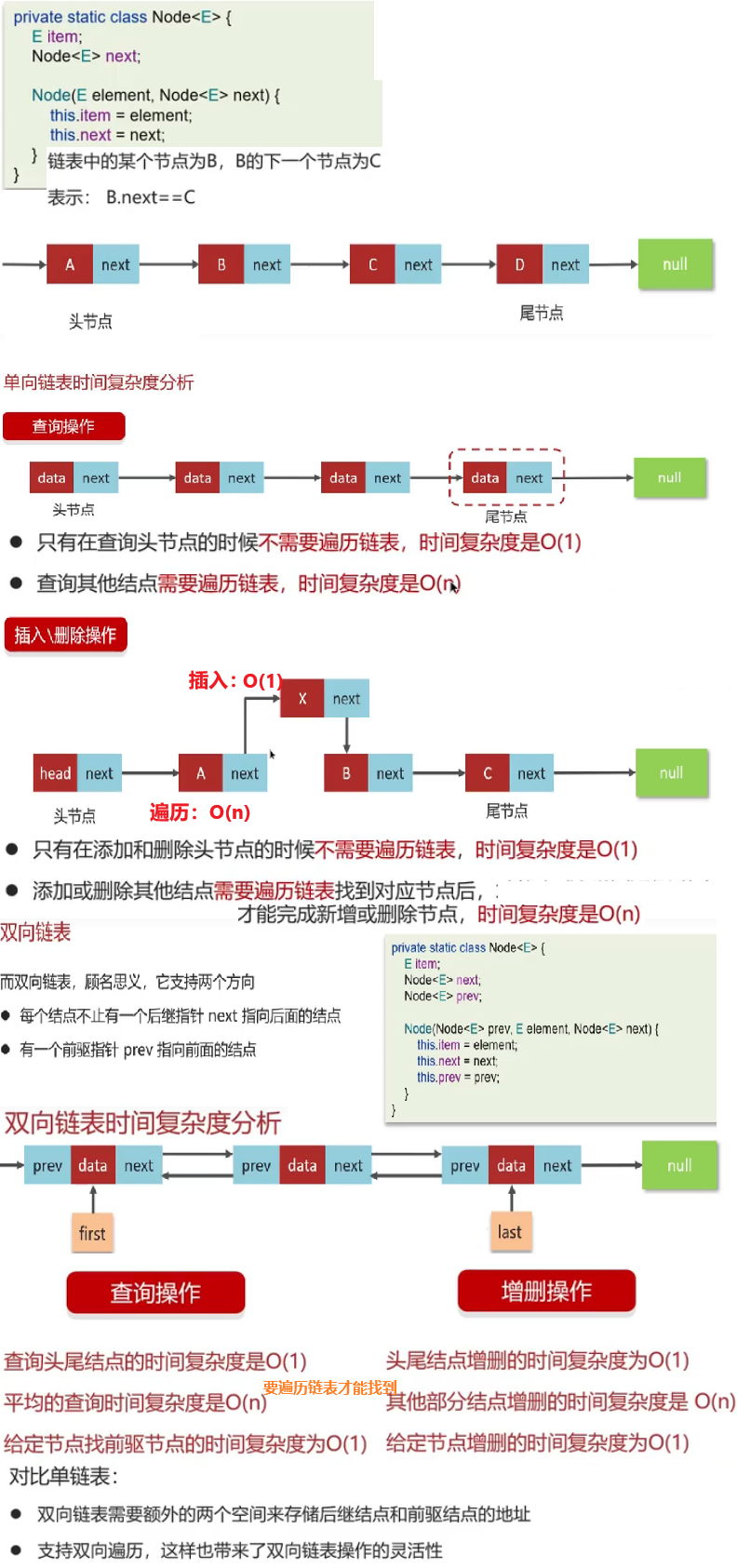
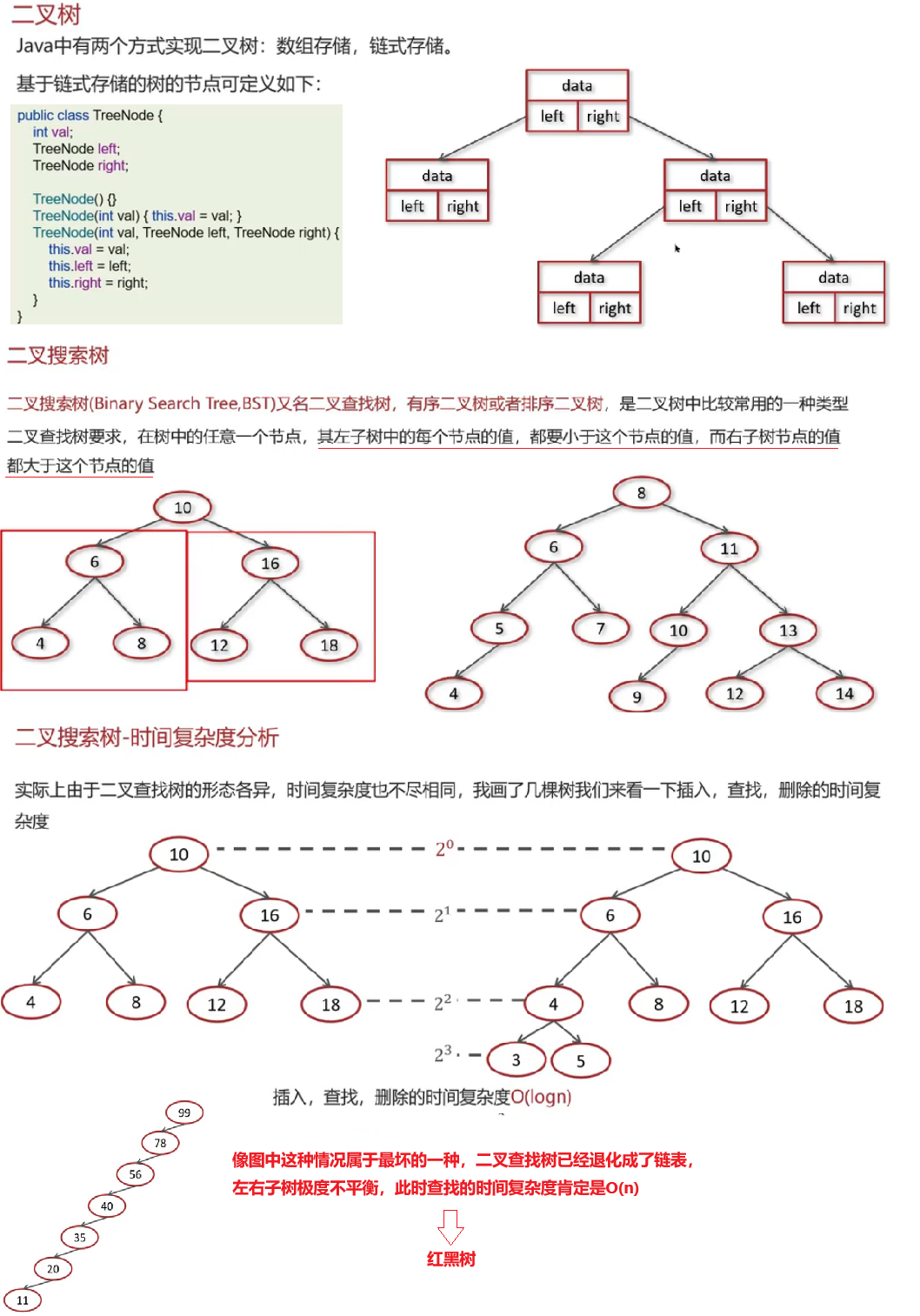
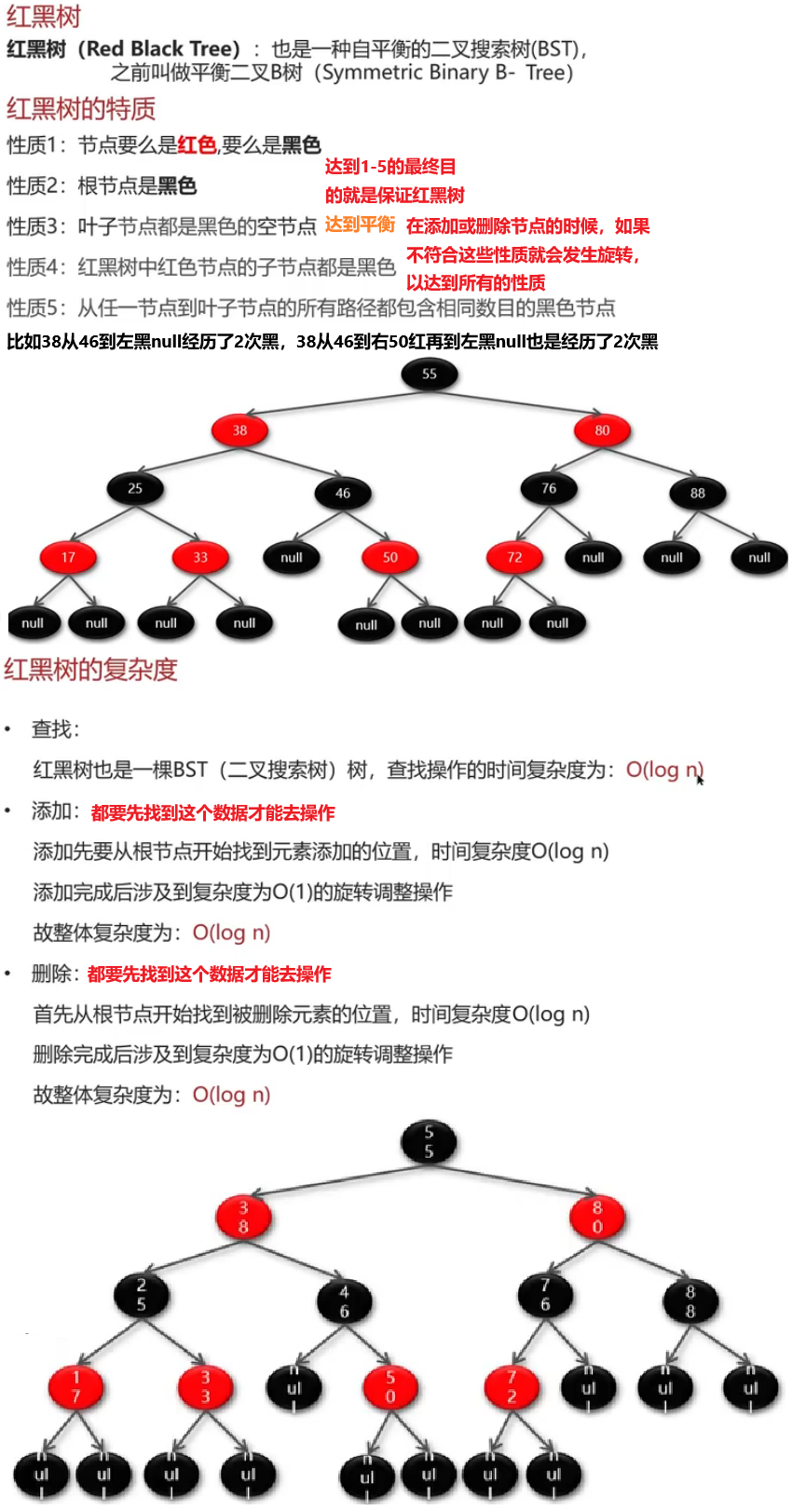
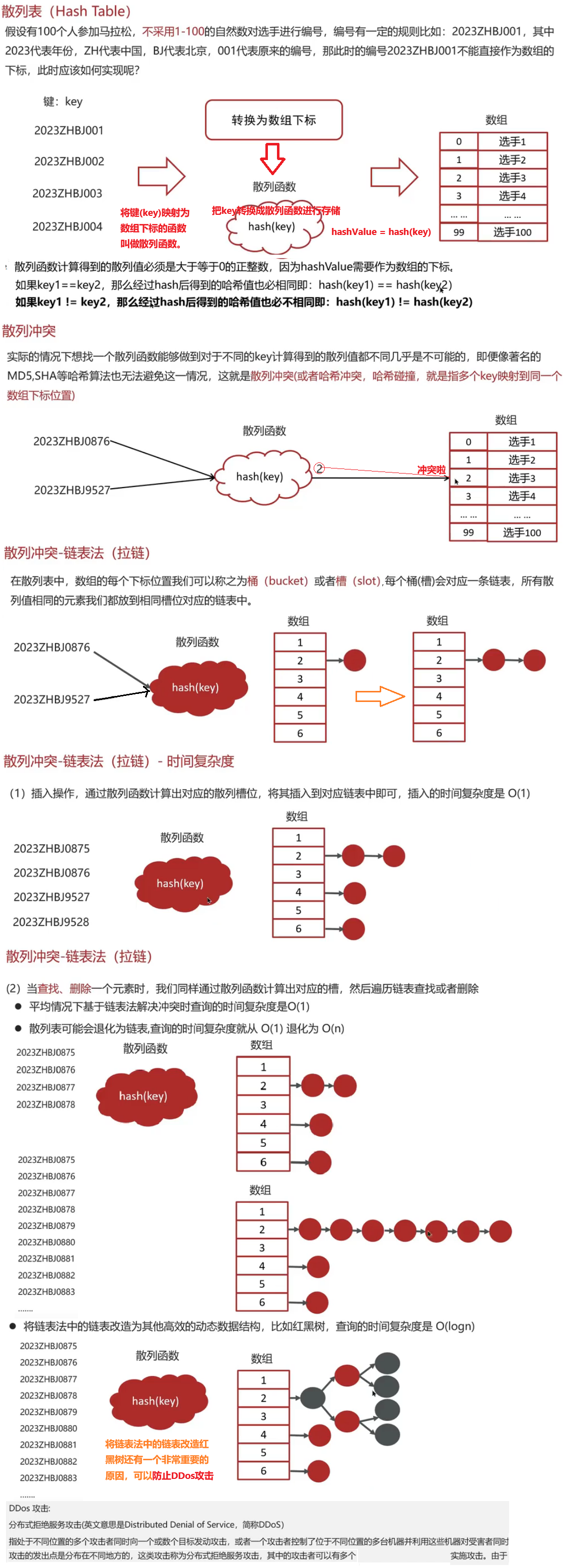
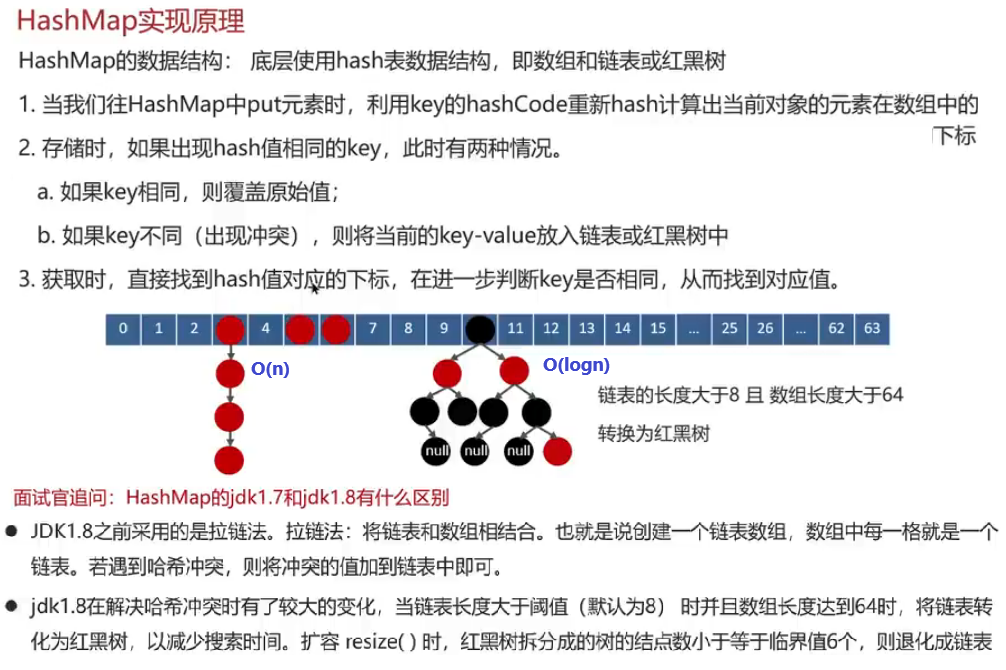
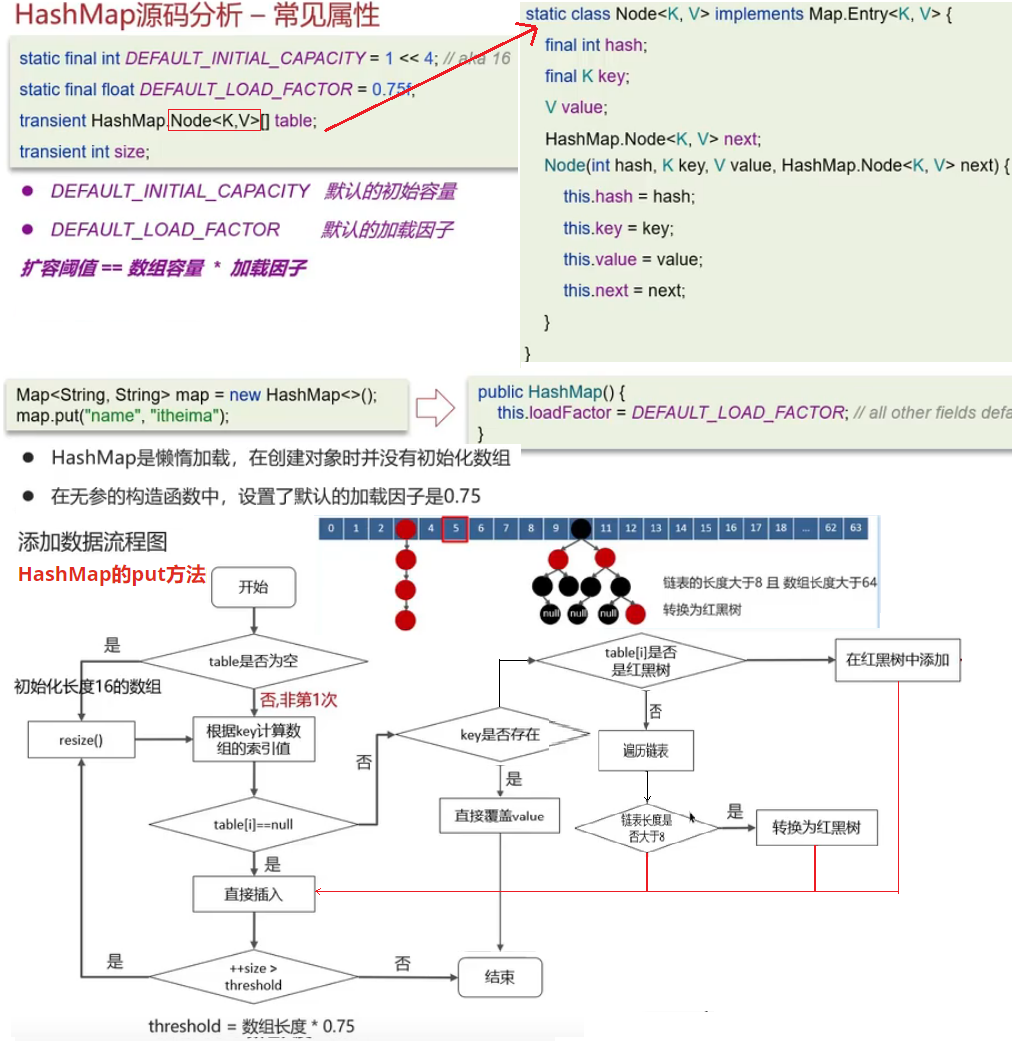
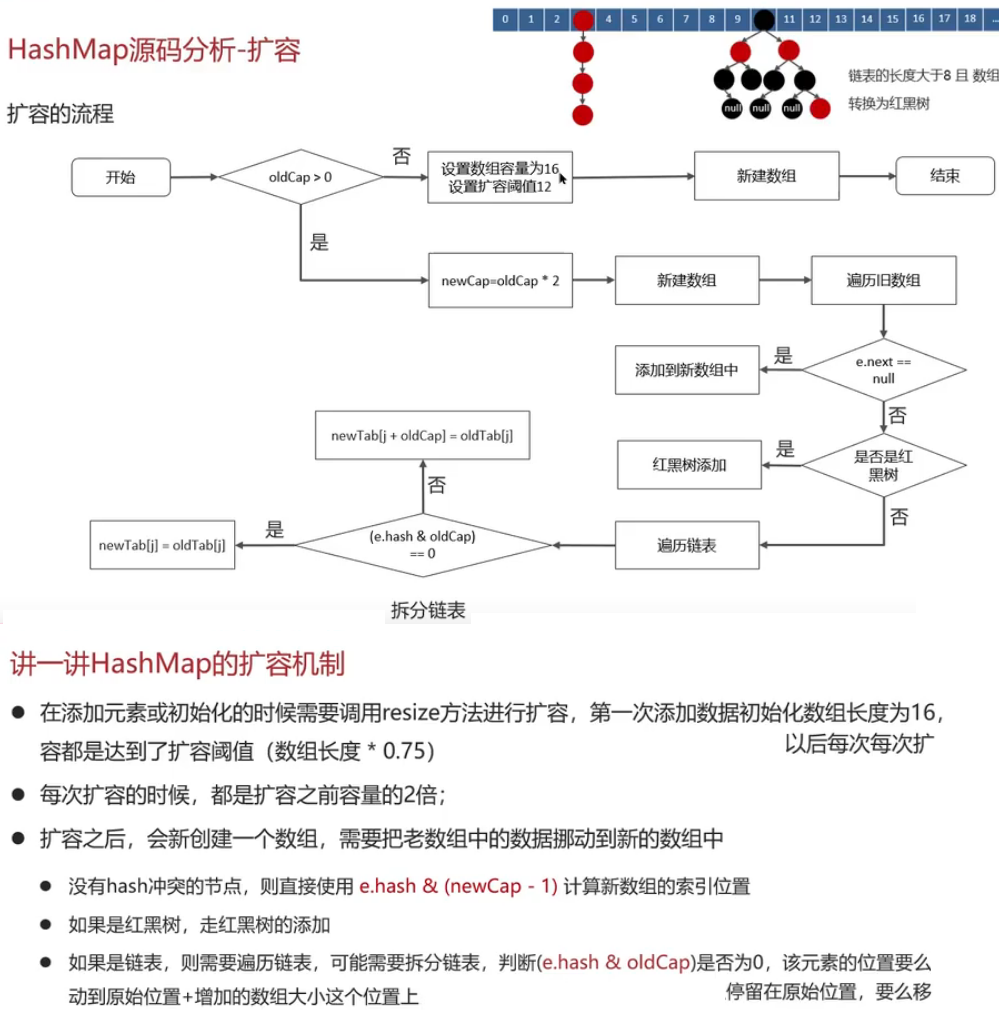
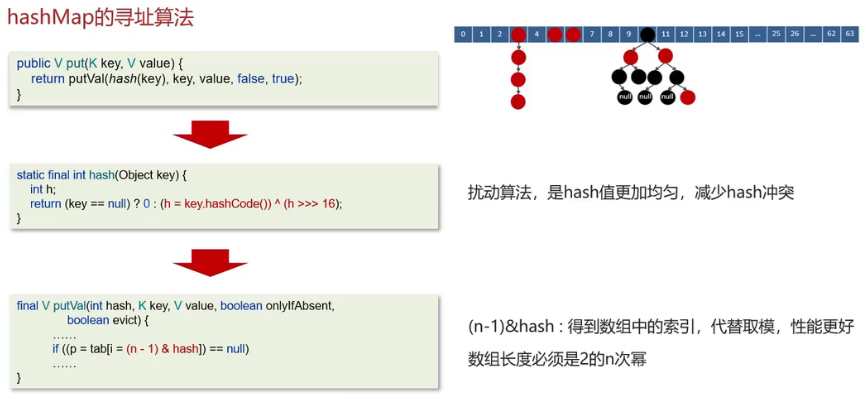
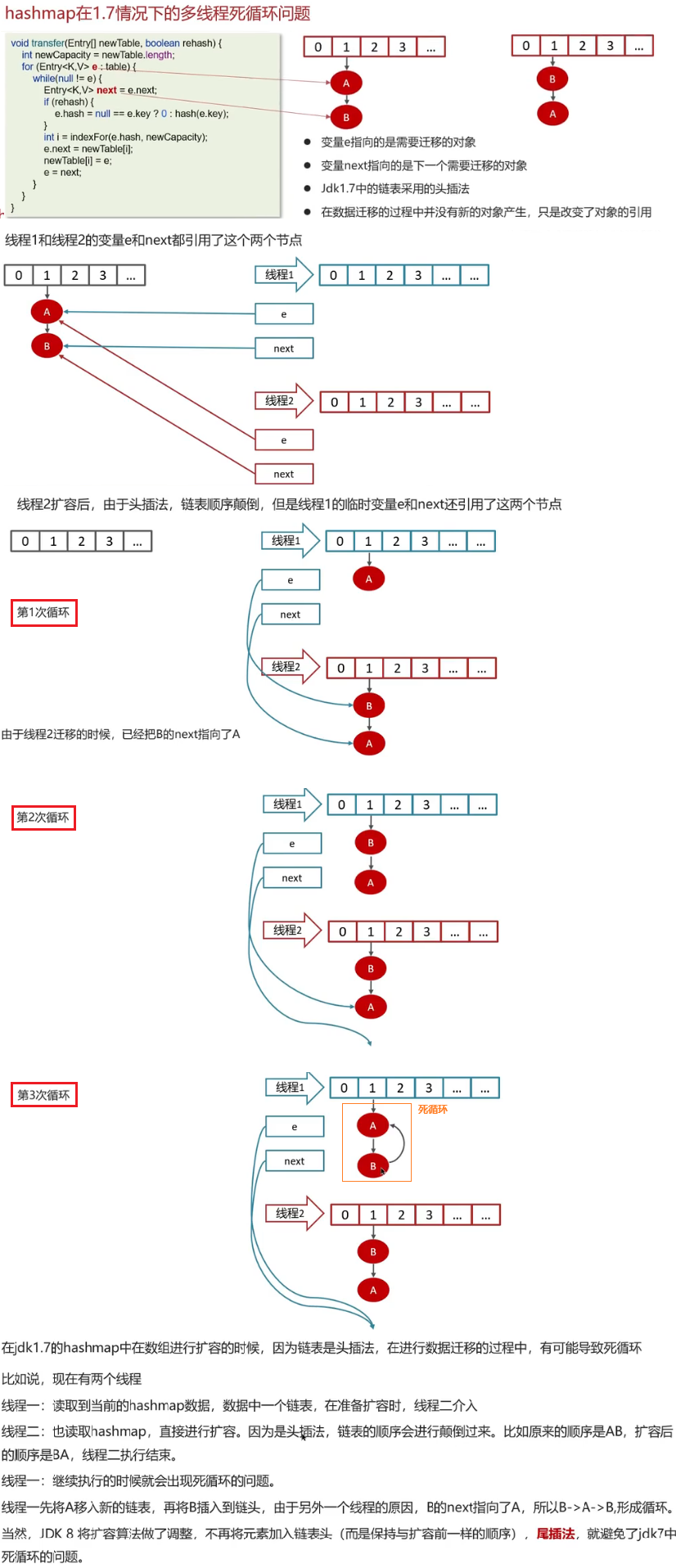
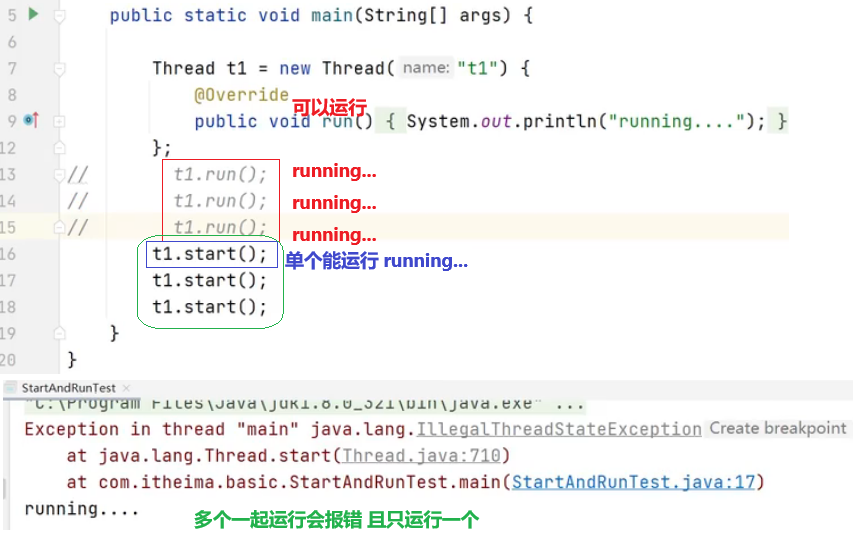
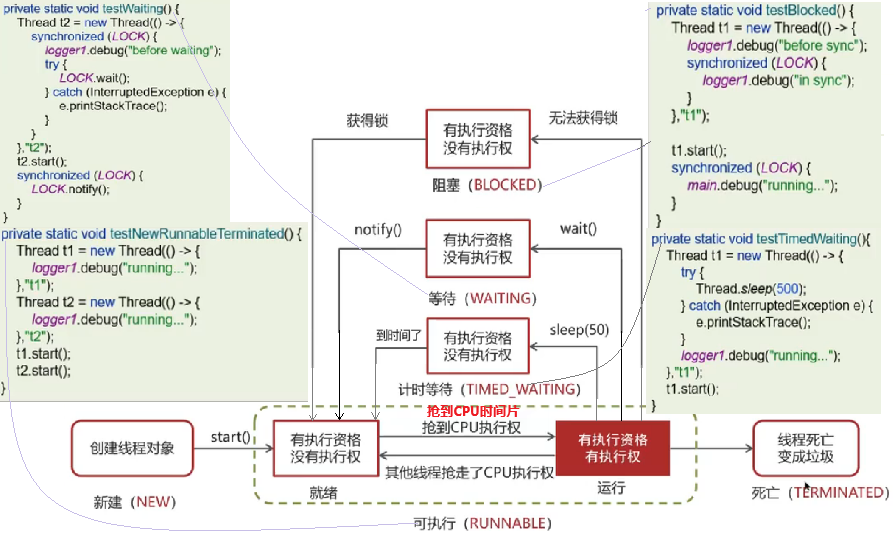

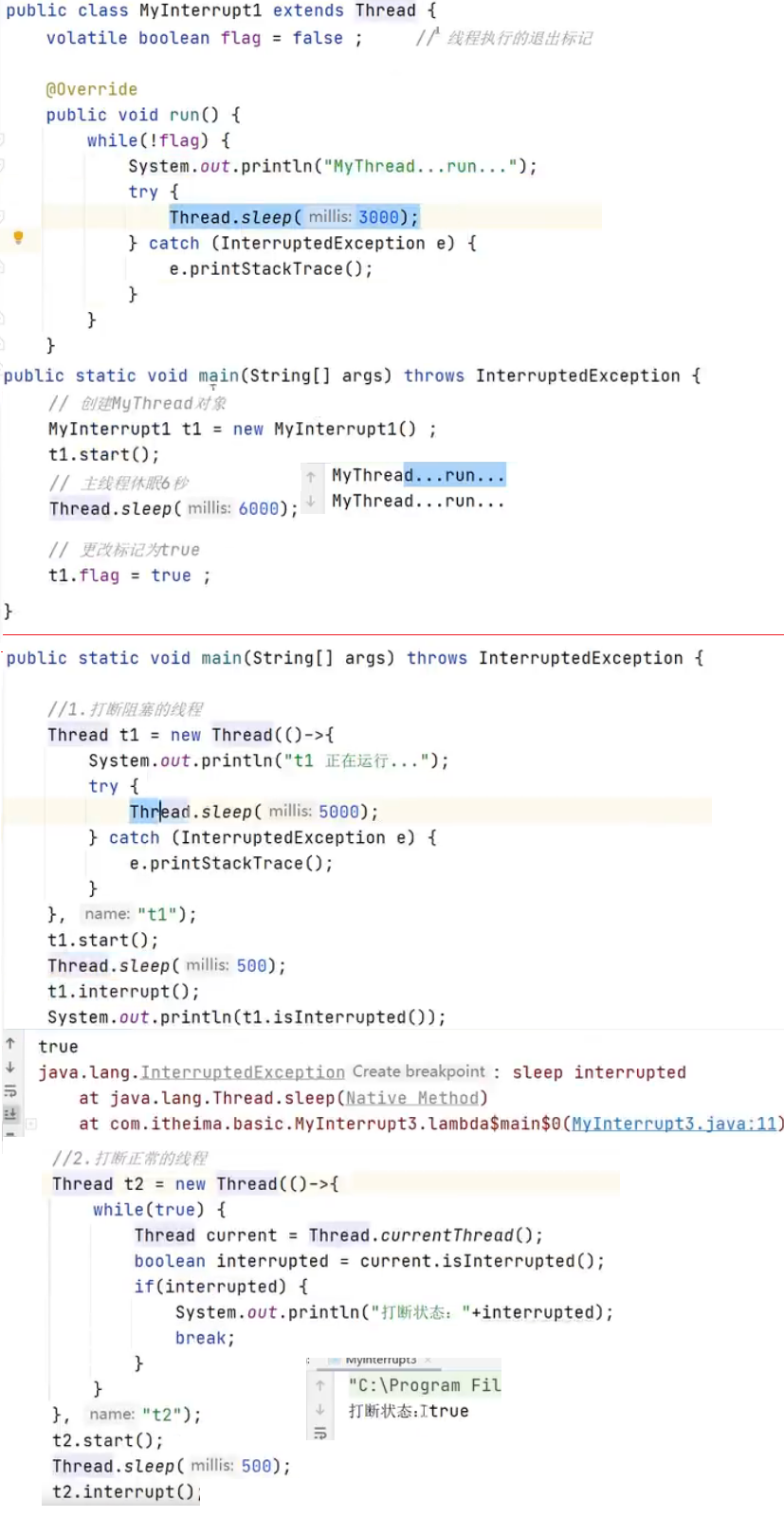
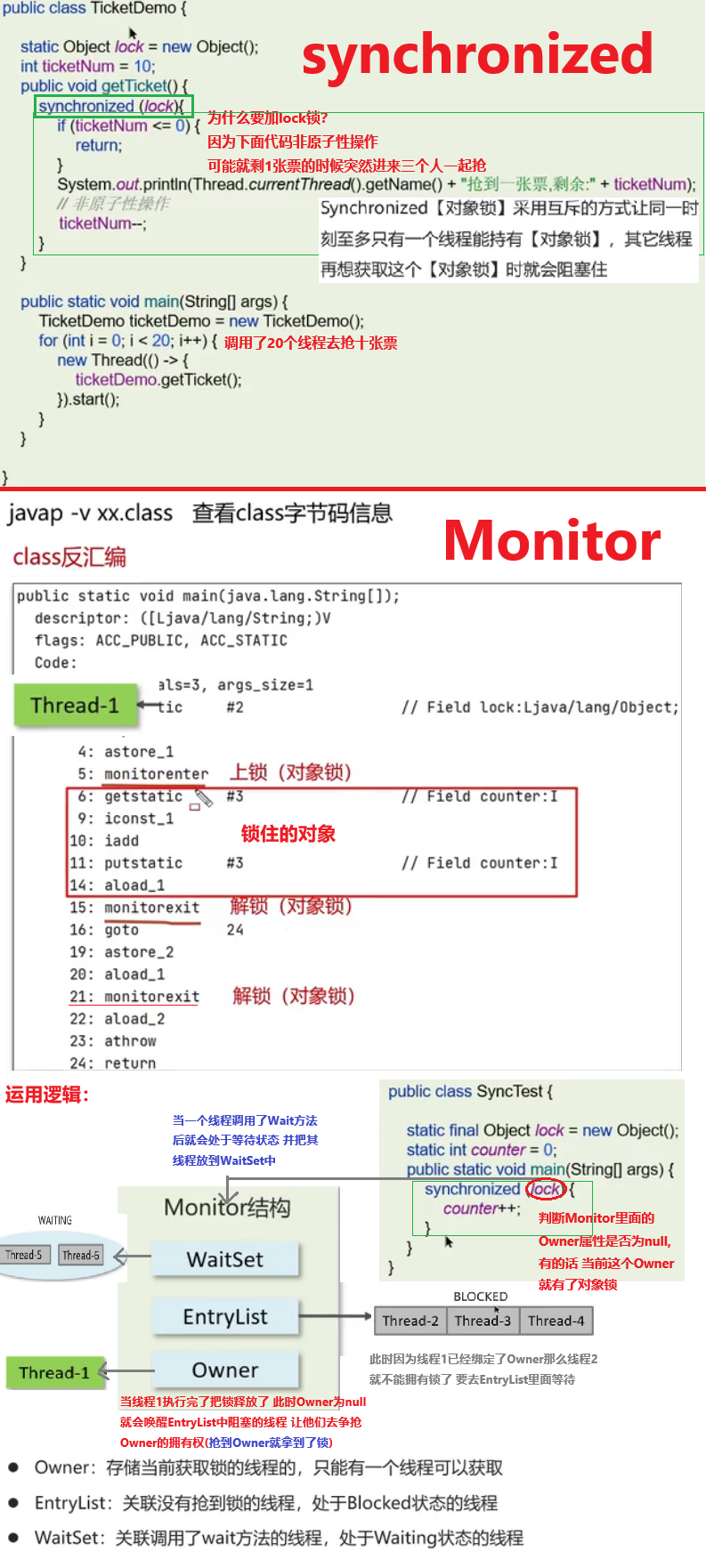

+CAS.png)