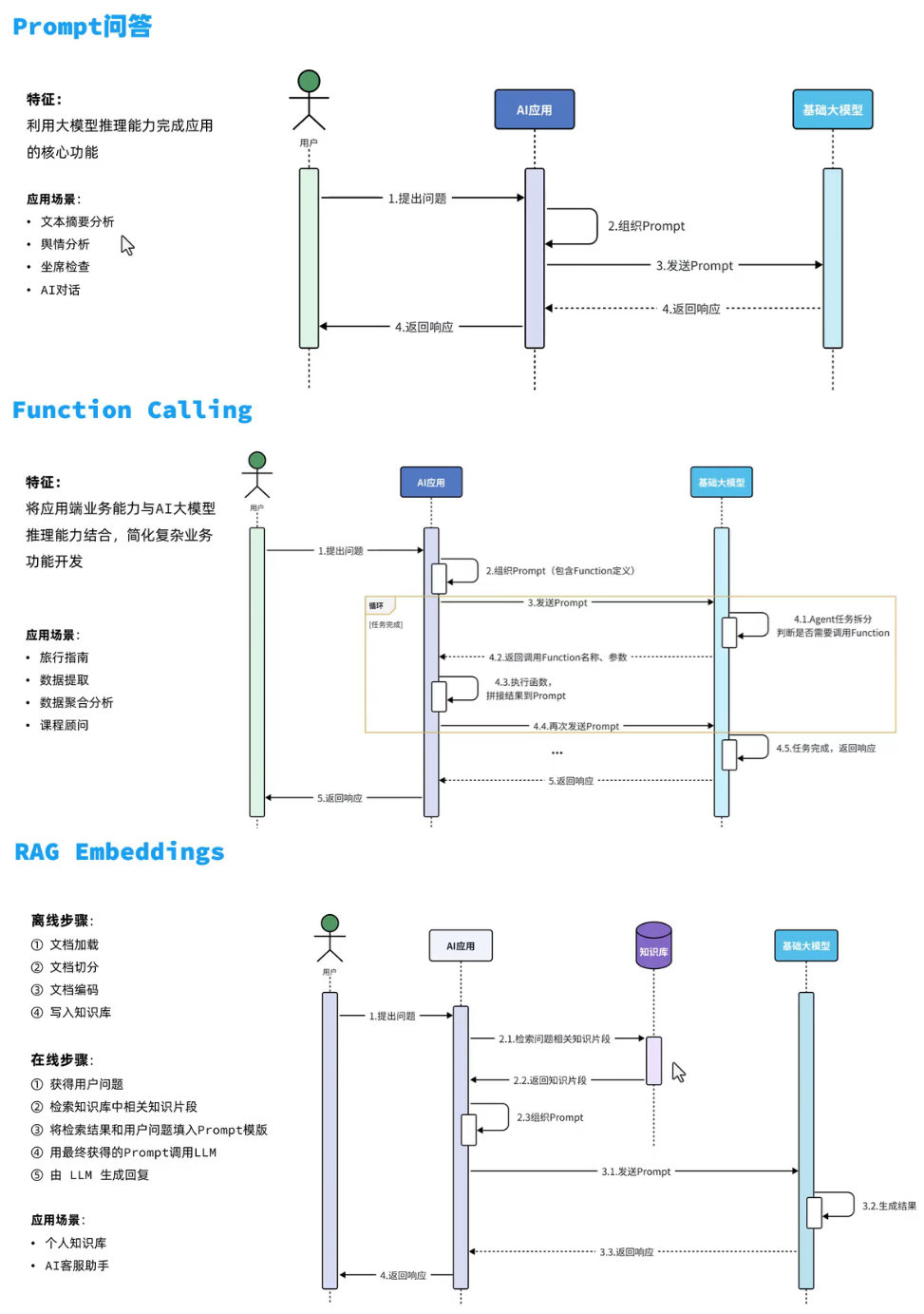
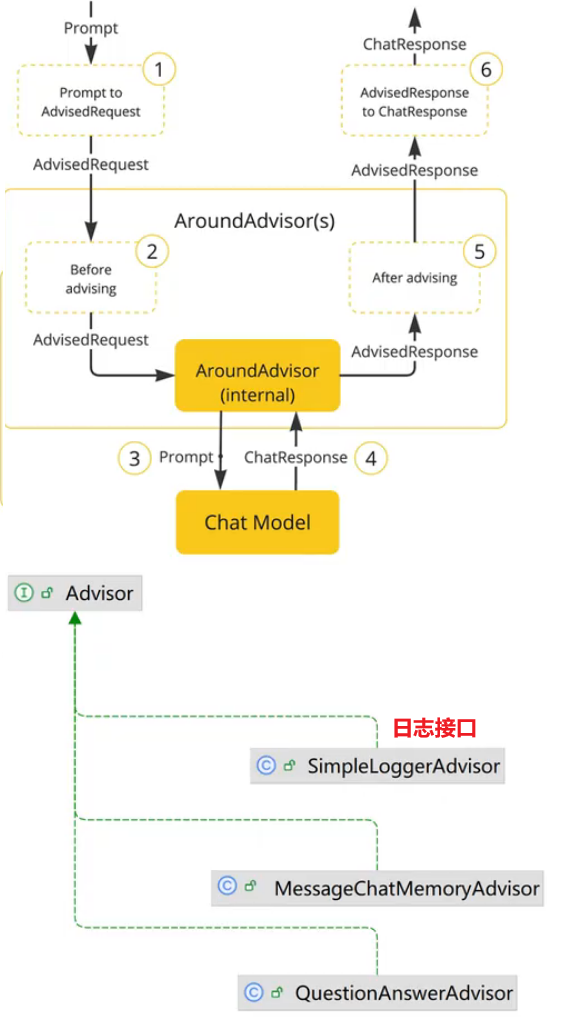
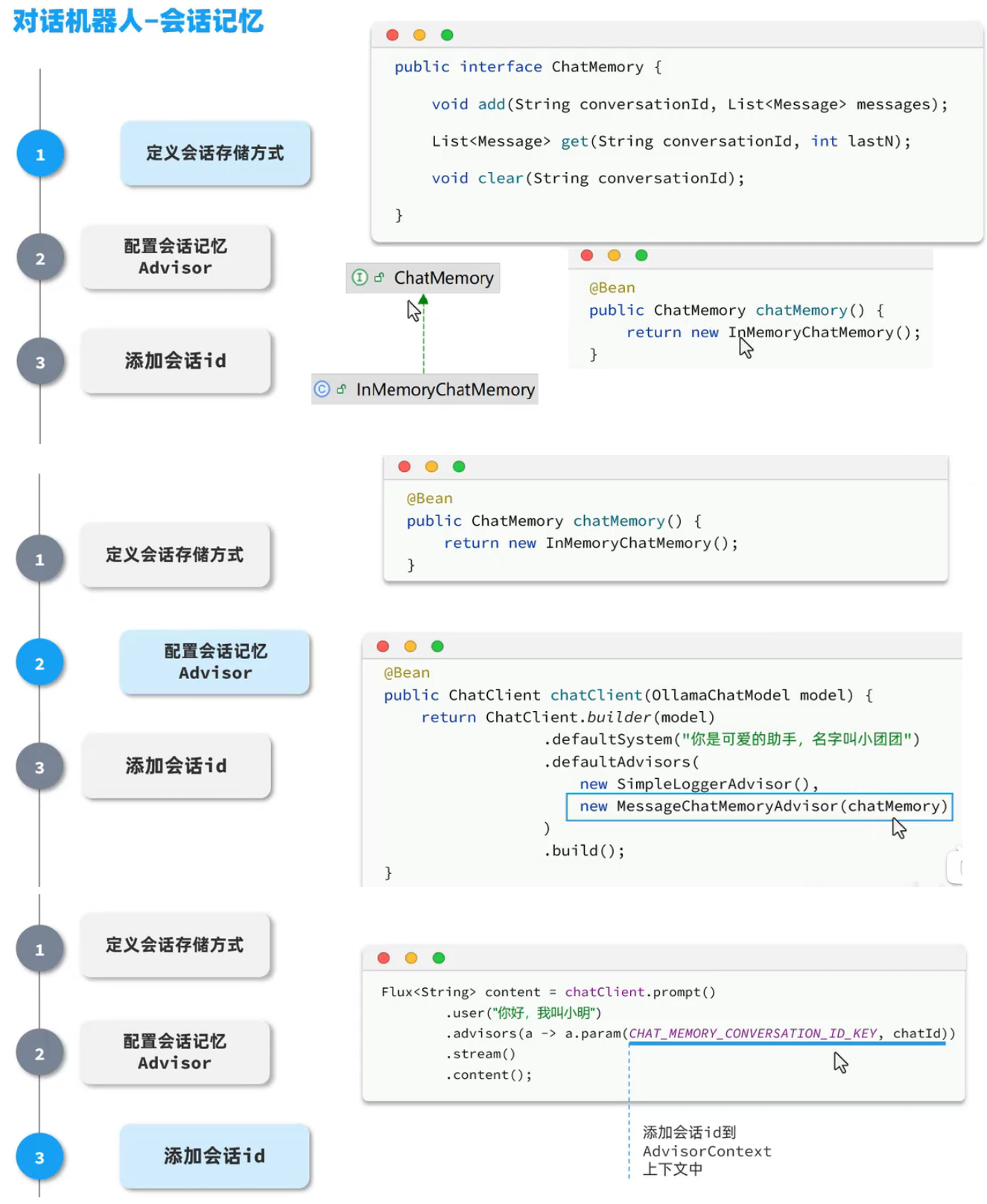
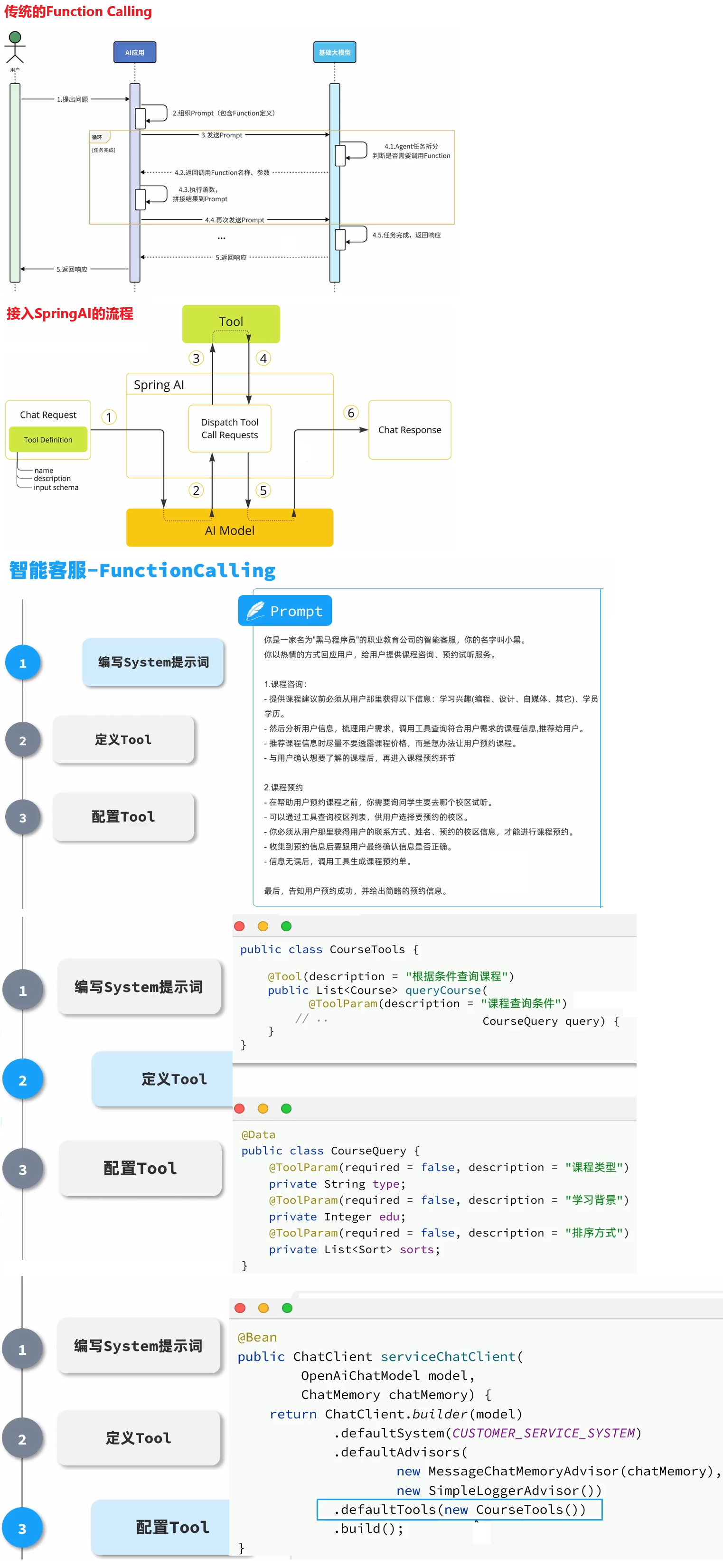
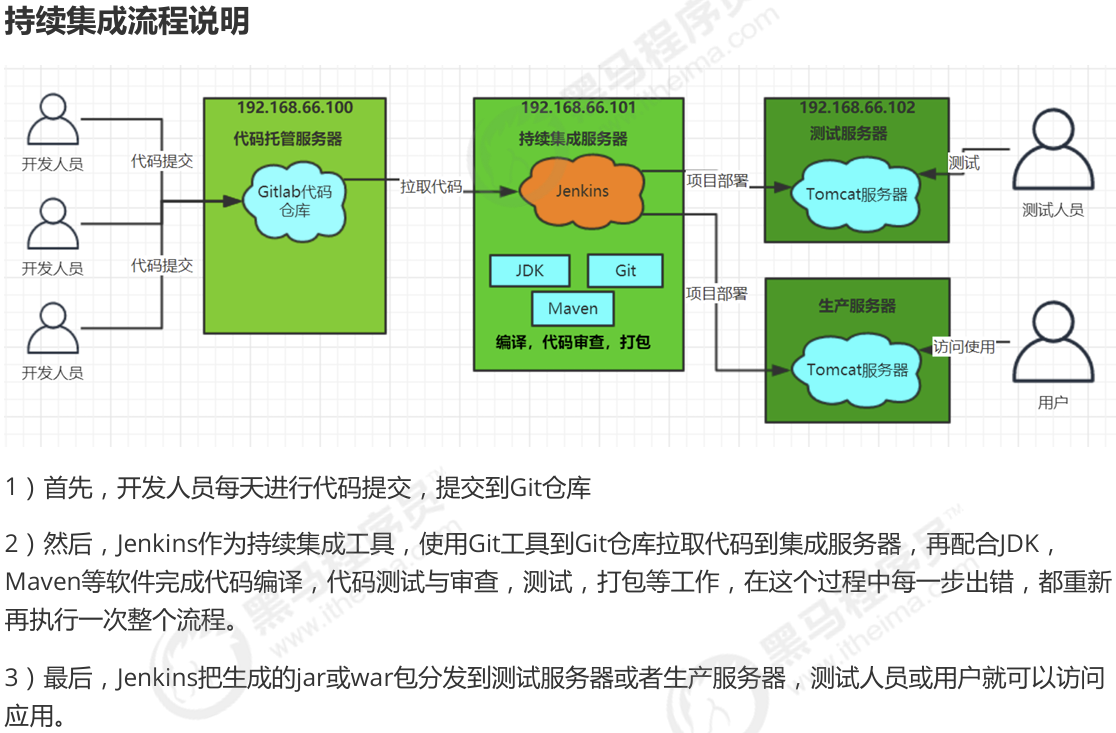
持续集成及JenKins介绍
配套原版资料:Jenkins持续集成从入门到精通.pdf
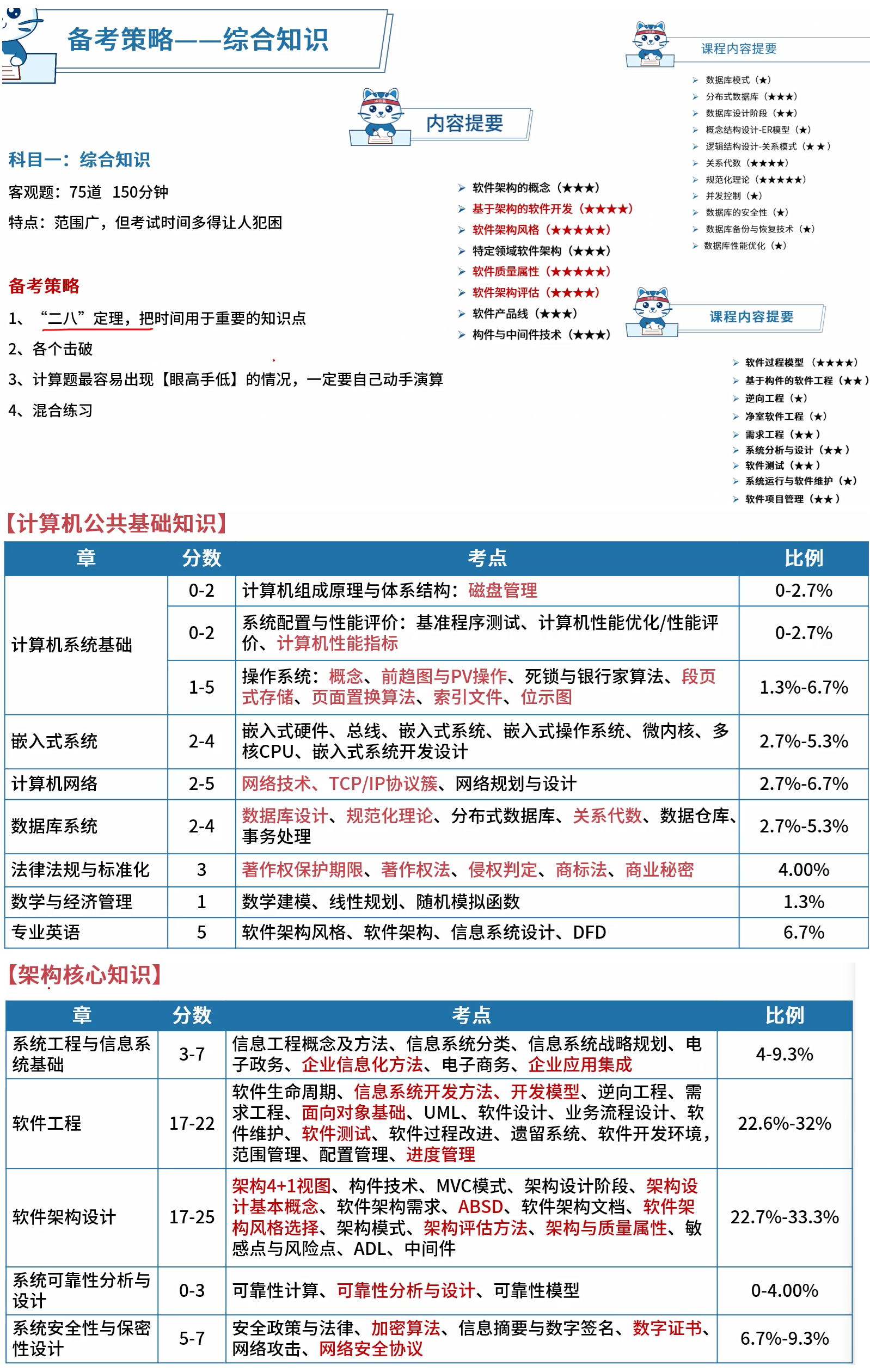
软件开发生命周期【需求分析、设计、实现、测试、进化】
软件开发瀑布模型
瀑布模型是最著名和最常使用的软件开发模型。瀑布模型就是一系列的软件开发过程。它是由制造业繁 衍出来的。一个高度化的结构流程在一个方向上流动,有点像生产线一样。在瀑布模型创建之初,没有 其它开发的模型,有很多东西全靠开发人员去猜测,去开发。这样的模型仅适用于那些简单的软件开 发, 但是已经不适合现在的开发了。
| 优势 |
劣势 |
| 简单易用和理解 |
各个阶段的划分完全固定,阶段之间产生大量的文档,极大地 增加了工作量。 |
| 当前一阶段完成后,您只需要 去关注后续阶段 |
由于开发模型是线性的,用户只有等到整个过程的末期才能见 到开发成果,从而增加了开发风险 |
| 为项目提供了按阶段划分的检 查节点 |
瀑布模型的突出缺点是不适应用户需求的变化 |
软件开发敏捷开发模型
敏捷开发(Agile Development) 的核心是迭代开发(Iterative Development) 与 增量开发 (Incremental Development) 。
==何为迭代开发?== 对于大型软件项目,传统的开发方式是采用一个大周期(比如一年)进行开发,整个过程就是一次”大 开发”;迭代开发的方式则不一样,它将开发过程拆分成多个小周期,即一次”大开发”变成多次”小开 发”,每次小开发都是同样的流程,所以看上去就好像重复在做同样的步骤。 举例来说,SpaceX 公司想造一个大推力火箭,将人类送到火星。但是,它不是一开始就造大火箭,而 是先造一个最简陋的小火箭 Falcon 1。结果,第一次发射就爆炸了,直到第四次发射,才成功进入轨 道。然后,开发了中型火箭 Falcon 9,九年中发射了70次。最后,才开发 Falcon 重型火箭。如果 SpaceX 不采用迭代开发,它可能直到现在还无法上天。
==何为增量开发?== 软件的每个版本,都会新增一个用户可以感知的完整功能。也就是说,按照新增功能来划分迭代。 举例来说,房产公司开发一个10栋楼的小区。如果采用增量开发的模式,该公司第一个迭代就是交付一 号楼,第二个迭代交付二号楼……每个迭代都是完成一栋完整的楼。而不是第一个迭代挖好10栋楼的地 基,第二个迭代建好每栋楼的骨架,第三个迭代架设屋顶…..
敏捷开发如何迭代?
虽然敏捷开发将软件开发分成多个迭代,但是也要求,每次迭代都是一个完整的软件开发周期,必须按 照软件工程的方法论,进行正规的流程管理。
敏捷开发有什么好处?
==早期交付== 敏捷开发的第一个好处,就是早期交付,从而大大降低成本。 还是以上一节的房产公司为例,如果按照 传统的”瀑布开发模式”,先挖10栋楼的地基、再盖骨架、然后架设屋顶,每个阶段都等到前一个阶段完 成后开始,可能需要两年才能一次性交付10栋楼。也就是说,如果不考虑预售,该项目必须等到两年后 才能回款。 敏捷开发是六个月后交付一号楼,后面每两个月交付一栋楼。因此,半年就能回款10%,后 面每个月都会有现金流,资金压力就大大减轻了。
==降低风险== 敏捷开发的第二个好处是,及时了解市场需求,降低产品不适用的风险。 请想一想,哪一种情况损失比 较小:10栋楼都造好以后,才发现卖不出去,还是造好第一栋楼,就发现卖不出去,从而改进或停建后面9栋楼
持续集成
持续集成( Continuous integration , 简称 CI )指的是,频繁地(一天多次)将代码集成到主干。 持续集成的目的,就是让产品可以快速迭代,同时还能保持高质量。它的核心措施是,代码集成到主干 之前,必须通过自动化测试。只要有一个测试用例失败,就不能集成。 通过持续集成, 团队可以快速的从一个功能到另一个功能,简而言之,敏捷软件开发很大一部分都要归 功于持续集成
持续集成的流程
提交
流程的第一步,是开发者向代码仓库提交代码。所有后面的步骤都始于本地代码的一次提交 (commit)。
测试(第一轮)
代码仓库对commit操作配置了钩子(hook),只要提交代码或者合并进主干,就会跑自动化测试。
构建
通过第一轮测试,代码就可以合并进主干,就算可以交付了。 交付后,就先进行构建(build),再进入第二轮测试。所谓构建,指的是将源码转换为可以运行的实 际代码,比如安装依赖,配置各种资源(样式表、JS脚本、图片)等等。
测试(第二轮)
构建完成,就要进行第二轮测试。如果第一轮已经涵盖了所有测试内容,第二轮可以省略,当然,这时 构建步骤也要移到第一轮测试前面。
部署
过了第二轮测试,当前代码就是一个可以直接部署的版本(artifact)。将这个版本的所有文件打包( tar filename.tar * )存档,发到生产服务器。
回滚
一旦当前版本发生问题,就要回滚到上一个版本的构建结果。最简单的做法就是修改一下符号链接,指 向上一个版本的目录
持续集成的组成要素
- 一个自动构建过程, 从检出代码、 编译构建、 运行测试、 结果记录、 测试统计等都是自动完成 的,无需人工干预。
- 一个代码存储库,即需要版本控制软件来保障代码的可维护性,同时作为构建过程的素材库,一般使用SVN或Git。
- 一个持续集成服务器,Jenkins 就是一个配置简单和使用方便的持续集成服务器
持续集成的好处
1、降低风险,由于持续集成不断去构建,编译和测试,可以很早期发现问题,所以修复的代价就少;
2、对系统健康持续检查,减少发布风险带来的问题;
3、减少重复性工作;
4、持续部署,提供可部署单元包;
5、持续交付可供使用的版本;
6、增强团队信心
JenKins介绍
Jenkins 是一款流行的开源持续集成(Continuous Integration)工具,广泛用于项目开发,具有自动化构建、测试和部署等功能。官网: http://jenkins-ci.org/
CI:持续集成(Continuous Integration)
CD:持续部署(Continuous ????)
Jenkins的特征:
- 开源的 Java语言开发持续集成工具,支持持续集成,持续部署。
- 易于安装部署配置:可通过 方便web界面配置管理。
- 消息通知及测试报告:集成 yum安装,或下载war包以及通过docker容器等快速实现安装部署,可 RSS/E-mail通过RSS发布构建结果或当构建完成时通过e-mail通知,生成JUnit/TestNG测试报告。 Jenkins能够让多台计算机一起构建/测试。
- 分布式构建:支持
- 文件识别: Jenkins能够跟踪哪次构建生成哪些jar,哪次构建使用哪个版本的jar等。
- 丰富的插件支持:支持扩展插件,你可以开发适合自己团队使用的工具,如 docker等
服务器列表[统一使用CentOS7]
| 名称 |
IP地址 |
安装的软件 |
| 代码托管服务器 |
192.168.200.128 |
Gitlab-12.4.2 |
| 持续集成服务器 |
192.168.200.129 |
Jenkins-2.190.3,JDK1.8,Maven3.6.2,Git, SonarQube |
| 应用测试服务器 |
192.168.66.102 |
JDK1.8,Tomcat8.5 |
Gitlab[团队个人版github]代码托管服务器安装
[lanyun_group / web_demo · GitLab] (http://192.168.200.128:82/lanyun_group/web_demo)
官网: https://about.gitlab.com/
GitLab 是一个用于仓库管理系统的开源项目,使用Git作为代码管理工具,并在此基础上搭建起来的 web服务。
GitLab和GitHub一样属于第三方基于Git开发的作品,免费且开源(基于MIT协议),与Github类似, 可以注册用户,任意提交你的代码,添加SSHKey等等。不同的是,GitLab是可以部署到自己的服务器 上,数据库等一切信息都掌握在自己手上,适合团队内部协作开发,你总不可能把团队内部的智慧总放 在别人的服务器上吧?简单来说可把GitLab看作个人版的GitHub
安装相关依赖
yum -y install policycoreutils openssh-server openssh-clients postfix
启动ssh服务&设置为开机启动
systemctl enable sshd && sudo systemctl start sshd
设置postfix开机自启,并启动,postfix支持gitlab发信功能
systemctl enable postfix && systemctl start postfix
开放ssh以及http服务,然后重新加载防火墙列表
firewall-cmd –add-service=ssh –permanent
firewall-cmd –add-service=http –permanent
firewall-cmd –reload
如果关闭防火墙就不需要做以上配置
下载gitlab包,并且安装
在线下载安装包:
wget https://mirrors.tuna.tsinghua.edu.cn/gitlab-ce/yum/el6/gitlab-ce-12.4.2-ce.0.el6.x 86_64.rpm 安装:
rpm -i gitlab-ce-12.4.2-ce.0.el6.x86_64.rpm
修改gitlab配置
vi /etc/gitlab/gitlab.rb
修改gitlab访问地址和端口,默认为80,我们改为82
external_url ‘ http://192.168.200.132:82'
nginx[‘listen_port’] = 82
重载配置及启动gitlab
gitlab-ctl reconfigure
gitlab-ctl restart ★★
把端口添加到防火墙
firewall-cmd –zone=public –add-port=82/tcp –permanent
firewall-cmd –reload
启动成功后,看到以下修改管理员root密码的页面,修改密码后,然后登录即可
账号:root
密码:panchunyao123
Gitlab用户在组里面有5种不同权限:
Guest:可以创建issue、发表评论,不能读写版本库
Reporter:可以克隆代码,不能提交,QA、PM 可以赋予这个权限
Developer:可以克隆代码、开发、提交、push,普通开发可以赋予这个权限
Maintainer:可以创建项目、添加tag、保护分支、添加项目成员、编辑项目,核心开发可以赋予这个 权限 Owner:可以设置项目访问权限 - Visibility Level、删除项目、迁移项目、管理组成员,开发组组 长可以赋予这个权限
如果张三被管理员添加了Owner权限,那么张三就可以在idea里面通过gitlab里面的仓库地址 上传项目到这个web_demo了。
持续集成环境—Jenkins安装【我用了最新的Jenkins 2.440.1】
[Setup Wizard [Jenkins]] (http://192.168.200.129:8888/)
安装目录为:/usr/lib/jvm
下载页面: https://jenkins.io/zh/download/
安装文件:jenkins-2.190.3-1.1.noarch.rpm
修改内容如下:
JENKINS_USER=”root”
JENKINS_PORT=”8888”
综上操作
[root@localhost ~]# java -version
java version “21.0.1” 2023-10-17 LTS
Java(TM) SE Runtime Environment (build 21.0.1+12-LTS-29)
Java HotSpot(TM) 64-Bit Server VM (build 21.0.1+12-LTS-29, mixed mode, sharing)
[root@localhost ~]# cd /usr/lib/jvm
[root@localhost jvm]# ll
总用量 0
lrwxrwxrwx. 1 root root 26 6月 15 16:27 java -> /etc/alternatives/java_sdk
lrwxrwxrwx. 1 root root 32 6月 15 16:27 java-1.8.0 -> /etc/alternatives/java_sdk_1.8.0
lrwxrwxrwx. 1 root root 40 6月 15 16:27 java-1.8.0-openjdk -> /etc/alternatives/java_sdk_1.8.0_openjdk
drwxr-xr-x. 9 root root 109 6月 15 16:27 java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64
lrwxrwxrwx. 1 root root 34 6月 15 16:27 java-openjdk -> /etc/alternatives/java_sdk_openjdk
lrwxrwxrwx. 1 root root 21 6月 15 16:27 jre -> /etc/alternatives/jre
lrwxrwxrwx. 1 root root 27 6月 15 16:27 jre-1.8.0 -> /etc/alternatives/jre_1.8.0
lrwxrwxrwx. 1 root root 35 6月 15 16:27 jre-1.8.0-openjdk -> /etc/alternatives/jre_1.8.0_openjdk
lrwxrwxrwx. 1 root root 49 6月 15 16:27 jre-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64 -> java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64/jre
lrwxrwxrwx. 1 root root 29 6月 15 16:27 jre-openjdk -> /etc/alternatives/jre_openjdk
[root@localhost jvm]# cd java-1.8.0-openjdk
[root@localhost java-1.8.0-openjdk]#
下一步:你只需要执行 升级Jenkins的升级流程
以下是你的专属升级操作指令合集(CentOS 7 专用):
🔧 1. 备份 Jenkins 数据(可选但强烈推荐)
sudo systemctl stop jenkins
sudo cp -r /var/lib/jenkins /var/lib/jenkins_backup_$(date +%F)
sudo cp /etc/sysconfig/jenkins /etc/sysconfig/jenkins.bak
🔧 2. 添加 Jenkins 官方 LTS Yum 源
sudo curl --silent --location https://pkg.jenkins.io/redhat-stable/jenkins.repo | sudo tee /etc/yum.repos.d/jenkins.repo > /dev/null
sudo rpm --import https://pkg.jenkins.io/redhat-stable/jenkins.io-2023.key
🔧 3. 升级 Jenkins
sudo yum clean all
sudo yum makecache
sudo yum upgrade jenkins -y
如果提示没有可升级的版本,执行以下命令强制重新安装最新版 Jenkins:
sudo yum remove jenkins -y
sudo yum install jenkins -y
⚠️ 不会丢失数据,因为 Jenkins 配置、任务、插件都在 /var/lib/jenkins 中,你已经备份过。
🔧 4. 启动 Jenkins 并查看状态
sudo systemctl daemon-reexec
sudo systemctl start jenkins
sudo systemctl status jenkins
🔧 5. 访问 Jenkins 页面
访问地址:
http://<你的服务器IP>:8888
🔧 6. 查看 Jenkins 新版本号
jenkins --version
或者登录网页右下角查看,应该是类似:
Jenkins ver. 2.440.1
查看 Jenkins 服务状态
请运行以下命令获取具体错误:
sudo systemctl status jenkins -l
步骤 3:重启 Jenkins 服务
sudo systemctl daemon-reexec
sudo systemctl restart jenkins
sudo systemctl status jenkins -l
🔗 插件下载地址与命令
以下命令会下载所有缺失依赖:
bash复制编辑# 进入 Jenkins 插件目录
cd /var/lib/jenkins/plugins
# 下载缺失的依赖插件
wget https://updates.jenkins.io/download/plugins/commons-lang3-api/3.13.0-62.v7d18e55f51e2/commons-lang3-api.hpi
wget https://updates.jenkins.io/download/plugins/ionicons-api/56.v1b_1c8c49374e/ionicons-api.hpi
wget https://updates.jenkins.io/download/plugins/caffeine-api/3.1.8-133.v17b_1ff2e0599/caffeine-api.hpi
持续集成环境—Jenkins插件管理【Manage Jenkins】
Jenkins本身不提供很多功能,我们可以通过使用插件来满足我们的使用。例如从Gitlab拉取代码,使用 Maven构建项目等功能需要依靠插件完成。接下来演示如何下载插件。
修改Jenkins插件下载地址
Jenkins国外官方插件地址下载速度非常慢,所以可以修改为国内插件地址:
Jenkins->Manage Jenkins->Manage Plugins,点击Available
新版本:Jenkins → Manage Jenkins → Plugins → Avaliable plugins
去Jenkins默认的开发目录
这样做是为了把 Jenkins官方的插件列表下载到本地,接着修改地址文件,替换为国内插件地址
[root@localhost sysconfig]# cd /var/lib/jenkins/
[root@localhost jenkins]# cd updates/
[root@localhost updates]# ll
总用量 3064
-rw-r–r–. 1 root root 3125621 6月 15 16:38 default.json
-rw-r–r–. 1 root root 7976 6月 15 16:38 hudson.tasks.Maven.MavenInstaller
sed -i ‘s/http://updates.jenkins ci.org/download/https://mirrors.tuna.tsinghua.edu.cn/jenkins/g’ default.json && sed -i ‘s/http:// www.google.com/https:\/\/ www.baidu.com/g' default.json
最后,Manage Plugins点击Advanced,把Update Site改为国内插件下载地址
https://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json
http://192.168.200.129:8888/restart 重启Jenkins
下载中文汉化插件
http://192.168.66.101:8888/restart ,重启Jenkins。 Jenkins->Manage Jenkins->Manage Plugins,点击Available,搜索”Chinese”
开启权限全局安全配置
在Security中的授权策略切换为 “Role-Based Strategy”,保存
【从插件市场上下载下来的 可以直接通过MobaXterm 放在/var/lib/jenkins/plugins/ 然后重启Jenkins】
创建角色
在系统管理页面进入 Manage and Assign Roles;点击”Manage Roles”
里面的Global roles(全局角色):管理员等高级用户可以创建基于全局的角色 Project roles(项目角色): 针对某个或者某些项目的角色 Slave roles(奴隶角色):节点相关的权限
我们添加以下三个角色:【一个基础角色 两个项目角色】
- baseRole :该角色为全局角色。这个角色需要绑定Overall下面的Read权限,是为了给所有用户绑 定最基本的Jenkins访问权限。注意:如果不给后续用户绑定这个角色,会报错误:用户名 is missing the Overall/Read permission
- role1 :该角色为项目角色(下面的Item roles)。使用正则表达式绑定” itcast.* “,意思是只能操作itcast开头的项目。
- role2 :该角色也为项目角色。绑定”itheima.*”,意思是只能操作itheima开头的项目。
创建用户
在系统管理页面进入 Manage Users
用户一:用户名:eric 密码:123456
用户二:用户名:JacK 密码:123456
给用户分配角色
系统管理页面进入Manage and Assign Roles,点击Assign Roles
绑定规则如下:
- eric 用户分别绑定baseRole和role1角色
- jack 用户分别绑定baseRole和role2角色
创建项目测试权限
以itcast管理员账户创建两个项目,分别为itcast01和itheima01
结果为:
- eric 用户登录,只能看到itcast01项目
- jack 用户登录,只能看到itheima01项目
持续集成环境—Jenkins凭证管理
凭据可以用来存储需要密文保护的数据库密码、Gitlab密码信息、Docker私有仓库密码等,以便 Jenkins可以和这些第三方的应用进行交互。
安装Credentials Binding插件
要在Jenkins使用凭证管理功能,需要安装Credentials Binding插件
安装插件后,左边多了”凭证“菜单,在这里管理所有凭证 [新版是在Security栏有凭证管理]
进入凭据后点击Stores scoped to Jenkins下 域的**全局**
可以添加的凭证有 5种:
- Username with password :用户名和密码
- SSH Username with private key: 使用SSH用户和密钥
- Secret file:需要保密的文本文件,使用时Jenkins会将文件复制到一个临时目录中,再将文件路径 设置到一个变量中,等构建结束后,所复制的Secret file就会被删除。
- Secret text :需要保存的一个加密的文本串,如钉钉机器人或Github的api token【k8s也会用】
- Certificate :通过上传证书文件的方式
常用的凭证类型有:Username with password(用户密码)和SSH Username with private key(SSH 密钥)
接下来以使用Git工具到Gitlab拉取项目源码为例,演示Jenkins的如何管理Gitlab的凭证
★ 在Jenkins里面安装git插件
★ 要先在Jenkins的服务里面安装git插件
CentOS7上安装Git工具:
yum install git -y 安装
git --version 安装后查看版本
用户密码类型
**全局添加凭证**:Dashboard → Manage Jenkins → Credentials → System → Global credentials (unrestricted) → New credentials
-
Jenkins->凭证->系统->全局凭证->添加凭证
测试凭证是否可用
创建一个FreeStyle项目:新建Item->FreeStyle Project->确定
找到 “源码管理”->”Git”,在Repository URL复制Gitlab中的项目URL
新搞个item然后点击进去 左侧的配置→General→源码管理→选择Git →↓
Repository URL:http://192.168.200.128:82/lanyun_group/web_demo.git
Credentials:【选择刚刚给张三创建的凭证】
保存配置后,点击构建 ”Build Now“ 开始构建项目
可以在左下方的Builds里找到刚刚构建的项目 可以查看控制台输出
Started by user root
Running as SYSTEM
Building in workspace /var/lib/jenkins/workspace/test02
The recommended git tool is: NONE
using credential ca22e56f-0ecc-4fdc-965d-01e329a0b68a
Cloning the remote Git repository
Cloning repository http://192.168.200.128:82/lanyun_group/web_demo.git
> git init /var/lib/jenkins/workspace/test02 # timeout=10
Fetching upstream changes from http://192.168.200.128:82/lanyun_group/web_demo.git
> git --version # timeout=10
> git --version # 'git version 1.8.3.1'
using GIT_ASKPASS to set credentials gitlab-auth-password
> git fetch --tags --progress http://192.168.200.128:82/lanyun_group/web_demo.git +refs/heads/*:refs/remotes/origin/* # timeout=10
> git config remote.origin.url http://192.168.200.128:82/lanyun_group/web_demo.git # timeout=10
> git config --add remote.origin.fetch +refs/heads/*:refs/remotes/origin/* # timeout=10
Avoid second fetch
> git rev-parse refs/remotes/origin/master^{commit} # timeout=10
Checking out Revision 2f41cd33af519a5c55df8d78ba59032d9069f0b8 (refs/remotes/origin/master)
> git config core.sparsecheckout # timeout=10
> git checkout -f 2f41cd33af519a5c55df8d78ba59032d9069f0b8 # timeout=10
Commit message: "初始化项目提交"
First time build. Skipping changelog.
Finished: SUCCESS
查看**/var/lib/jenkins/workspace/**目录,发现已经从Gitlab成功拉取了代码到Jenkins中
SSH密钥类型
SSH免密登录示意图:
[GitLab服务器(存放公钥:id_rsa.pub)] ←←←ssh免密登录←←← [Jenkins服务器(存放私钥:id_rsa)]
ssh-keygen -t rsa
在 192.168.200.129_Jenkins 服务器里
[root@localhost ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:88fFvAS2e6i9c4+KXfmENWeu6NJNmOb1+CCsYLarYLc root@localhost.localdomain
The key's randomart image is:
+---[RSA 2048]----+
| |
| |
| o |
| . = |
| S .o=.+|
| o o+=oBo|
| o . + .+B+Boo|
| . o + o.B+=+*.|
| E.o.+oB=oo+|
+----[SHA256]-----+
[root@localhost ~]# cd /root/.ssh
[root@localhost .ssh]# ll
总用量 8
-rw-------. 1 root root 1679 6月 18 20:05 id_rsa 【私钥】
-rw-r--r--. 1 root root 408 6月 18 20:05 id_rsa.pub 【公钥】
以root账户登录->点击头像->Settings->SSH Keys→在Jenkins服务里面用
[root@localhost .ssh]# cat id_rsa.pub
打开公钥的文件得到信息。复制刚才id_rsa.pub文件的内容到这里,点击”Add Key”
在Jenkins添加一个全局新的凭证,类型为”SSH Username with private key“,在jenkins服务器里输入指令查看私钥
[root@localhost .ssh]# cat id_rsa
把刚才生成私钥文件内容复制过来塞进去
此时去gitlab项目中把ssh的复制过来git@192.168.200.128:lanyun_group/web_demo.git
同样尝试构建项目,如果代码可以正常拉取,代表凭证配置成功!
如果报错:
Command "git ls-remote -h git@192.168.200.128:lanyun_group/web_demo.git HEAD" returned status code 128
stderr: No ECDSA host key is known for 192.168.200.128 and you have requested strict checking.
Host key verification failed.
fatal: Could not read from remote repository.
报错原因:
SSH 主机指纹未验证(Host key verification failed)
Git 使用的是 SSH 协议访问远程仓库(git@192.168.200.128),但本地机器之前没有连接过该主机,或者 .ssh/known_hosts 文件中没有该 IP 的公钥信息。
而且启用了“严格检查”(Strict Host Key Checking),所以 Git 拒绝连接该服务器。
★★ 方法:手动信任主机(推荐)★★
ssh git@192.168.200.128
系统会提示你是否信任该主机,比如:
The authenticity of host '192.168.200.128 (192.168.200.128)' can't be established.
ECDSA key fingerprint is SHA256:xxx...
Are you sure you want to continue connecting (yes/no/[fingerprint])?
✅ 输入 yes 之后,主机公钥会加入 ~/.ssh/known_hosts 文件,后续连接将不再失败。
到这里已经完成了这份图的部分内容,要开始融入Maven
持续集成环境—Maven安装和配置
在Jenkins集成服务器上,我们需要安装Maven来编译和打包项目
把apache-maven-3.6.2-bin.tar.gz传到 /root 根目录中【Jenkins服务器】
tar -xzf apache-maven-3.6.2-bin.tar.gz 解压
mkdir -p /opt/maven 创建目录
mv apache-maven-3.6.2/* /opt/maven 移动文件
[root@localhost ~]# mkdir -p /opt/maven
[root@localhost ~]# mv apache-maven-3.6.2/* /opt/maven
[root@localhost ~]# cd /opt/maven/
[root@localhost maven]# ll
总用量 28
drwxr-xr-x. 2 root root 97 6月 18 21:37 bin
drwxr-xr-x. 2 root root 42 6月 18 21:37 boot
drwxrwxr-x. 3 1000 mysql 63 8月 27 2019 conf
drwxrwxr-x. 4 1000 mysql 4096 6月 18 21:37 lib
-rw-rw-r–. 1 1000 mysql 12846 8月 27 2019 LICENSE
-rw-rw-r–. 1 1000 mysql 182 8月 27 2019 NOTICE
-rw-rw-r–. 1 1000 mysql 2533 8月 27 2019 README.txt
[root@localhost maven]#
配置环境变量
vi /etc/profile
export JAVA_HOME=/usr/local/java/jdk-17.0.8+7
export MAVEN_HOME=/opt/maven
export PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin
source /etc/profile 配置生效
mvn -v 查找Maven版本
全局工具配置关联JDK和Maven
Jenkins->Manage Jenkins->Tools→ JDK安装 → 新增JDK →
【JDK】
别名:jdk-17.0.8+7
JAVA_HOME:/usr/local/java/jdk-17.0.8+7
下面的Maven安装→ 新增Maven →
【Maven】
Name:maven3.6.2
MAVEN_HOME:/opt/maven
点击应用 → 保存
添加Jenkins全局变量
Jenkins → Manage Jenkins → System → 下面找到全局属性 → Environment variables
以下是用键值对的形式显示:
JAVA_HOME /usr/local/java/jdk-17.0.8+7
M2_HOME /opt/maven
PATH+EXTRA $M2_HOME/bin
修改Maven的settings.xml
mkdir /root/repo 创建本地仓库目录
vi /opt/maven/conf/settings.xml
本地仓库改为:/root/repo
<!-- localRepository
| The path to the local repository maven will use to store artifacts.
|
| Default: ${user.home}/.m2/repository
-->
<localRepository>/root/repo</localRepository>
添加阿里云私服地址:
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
测试Maven是否配置成功
使用之前的gitlab密码测试项目,修改配置;
在某个项目中→Triggers中→Build Steps选择 Execute shell(执行shell脚本命令)
输入
mvn clean package
然后再去构建!!
🔧 步骤一:删除损坏的插件文件
执行以下命令彻底删除这个错误的插件缓存:
rm -rf /root/repo/org/apache/maven/plugins/maven-clean-plugin
🔧 步骤二:将 Maven 镜像源改为稳定的中央仓库
编辑 /root/.m2/settings.xml 或 /etc/maven/settings.xml(按你的系统配置)为以下内容:
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
http://maven.apache.org/xsd/settings-1.0.0.xsd">
<localRepository>/root/repo</localRepository>
<mirrors>
<mirror>
<id>central</id>
<mirrorOf>*</mirrorOf>
<name>Maven Central</name>
<url>https://repo.maven.apache.org/maven2</url>
</mirror>
</mirrors>
</settings>
持续集成环境—Tomcat安装和配置
安装Tomcat8.5 把Tomcat压缩包上传到192.168.200.131服务器
yum install java-1.8.0-openjdk* -y 安装JDK(已完成)
tar -xzf apache-tomcat-8.5.47.tar.gz 解压
mkdir -p /opt/tomcat 创建目录
mv /root/apache-tomcat-8.5.47/* /opt/tomcat 移动文件
启动tomcat
/opt/tomcat/bin/startup.sh ★★
[Apache Tomcat/8.5.47] (http://192.168.200.131:8090/) 【已改端口8090】
关闭已有 Tomcat(建议先关闭,避免冲突):
/opt/tomcat/bin/shutdown.sh
再启动:
/opt/tomcat/bin/startup.sh
不过现在访问这个地址是没有权限的[403 Access Denied] (http://192.168.200.131:8090/manager/) 现在要增加权限
配置 Tomcat用户角色权限
默认情况下Tomcat是没有配置用户角色权限的
403 Access Denied
You are not authorized to view this page.
By default the Manager is only accessible from a browser running on the same machine as Tomcat. If you wish to modify this restriction, you’ll need to edit the Manager’s context.xml file.
If you have already configured the Manager application to allow access and you have used your browsers back button, used a saved book-mark or similar then you may have triggered the cross-site request forgery (CSRF) protection that has been enabled for the HTML interface of the Manager application. You will need to reset this protection by returning to the main Manager page. Once you return to this page, you will be able to continue using the Manager application’s HTML interface normally. If you continue to see this access denied message, check that you have the necessary permissions to access this application.
If you have not changed any configuration files, please examine the file conf/tomcat-users.xml in your installation. That file must contain the credentials to let you use this webapp.
For example, to add the manager-gui role to a user named tomcat with a password of s3cret, add the following to the config file listed above.
<role rolename="manager-gui"/>
<user username="tomcat" password="s3cret" roles="manager-gui"/>
Note that for Tomcat 7 onwards, the roles required to use the manager application were changed from the single manager role to the following four roles. You will need to assign the role(s) required for the functionality you wish to access.
manager-gui - allows access to the HTML GUI and the status pagesmanager-script - allows access to the text interface and the status pagesmanager-jmx - allows access to the JMX proxy and the status pagesmanager-status - allows access to the status pages only
The HTML interface is protected against CSRF but the text and JMX interfaces are not. To maintain the CSRF protection:
- Users with the
manager-gui role should not be granted either the manager-script or manager-jmx roles.
- If the text or jmx interfaces are accessed through a browser (e.g. for testing since these interfaces are intended for tools not humans) then the browser must be closed afterwards to terminate the session.
For more information - please see the Manager App How-To.
但是,后续Jenkins部署项目到Tomcat服务器,需要用到Tomcat的用户,所以修改tomcat以下配置, 添加用户及权限
vi /opt/tomcat/conf/tomcat-users.xml
内容如下:
<tomcat-users>
<role rolename="tomcat"/>
<role rolename="role1"/>
<role rolename="manager-script"/>
<role rolename="manager-gui"/>
<role rolename="manager-status"/>
<role rolename="admin-gui"/>
<role rolename="admin-script"/>
<user username="tomcat" password="tomcat" roles="manager-gui,manager
script,tomcat,admin-gui,admin-script"/>
</tomcat-users>
用户和密码都是: tomcat
注意:为了能够刚才配置的用户登录到Tomcat,还需要修改以下配置
vi /opt/tomcat/webapps/manager/META-INF/context.xml
<!--
<Valve className="org.apache.catalina.valves.RemoteAddrValve"
allow="127\.\d+\.\d+\.\d+|::1|0:0:0:0:0:0:0:1" />
-->
注释掉这行就行!!
关闭已有 Tomcat(建议先关闭,避免冲突):
/opt/tomcat/bin/shutdown.sh
再启动:
/opt/tomcat/bin/startup.sh
[/manager] (http://192.168.200.131:8090/manager/html) 此时就可以访问了!!!
3、Jenkins构建Maven项目
Jenkins项目构建类型(1)-Jenkins构建的项目类型介绍
Jenkins中自动构建项目的类型有很多,常用的有以下三种:
- 自由风格软件项目( FreeStyle Project)
- Maven 项目(Maven Project)
- 流水线项目( Pipeline Project)
每种类型的构建其实都可以完成一样的构建过程与结果,只是在操作方式、灵活度等方面有所区别,在 实际开发中可以根据自己的需求和习惯来选择。(PS:个人推荐使用流水线类型,因为灵活度非常高)
Jenkins项目构建类型(2)-自由风格项目构建
下面演示创建一个自由风格项目来完成项目的集成过程:
拉取代码→编译→打包→部署
……
部署
把项目部署到远程的Tomcat里面
1)安装 Deploy to container插件
Jenkins本身无法实现远程部署到Tomcat的功能,需要在Jenkins里面安装Deploy to container插件实现
Jenkins持续集成从入门到精通.pdf 【39页】
①:Build Steps → Execute shell →↓
echo "开始进行编译构建"
mvn clean package
echo "编译构建结束"
②:在Jenkins的项目配置里 下面
构建后操作:【Deploy war/ear to a container】→ 选择 Tomcat 8.x Remote
WAR/EAR files:target/*.war
Containers:
新增一个凭证 用户名tomcat 密码tomcat
部署成功后,访问项目:[演示项目主页] (http://192.168.200.131:8090/web_demo-1.0-SNAPSHOT/)
如果看到此页面,代表项目部署成功啦!--这是master分支 添加用户
修改用户
删除用户 查询用户
演示改动代码后的持续集成
1)IDEA中源码修改并提交到gitlab
2)在Jenkins中项目重新构建
3)访问Tomcat
演示改动代码后的持续集成
1)IDEA中源码修改并提交到gitlab
2)在Jenkins中项目重新构建
3)访问Tomcat
Jenkins项目构建类型(3)-Maven项目构建
1)安装 Maven Integration 插件
2)创建 Maven 项目
3)配置项目
拉取代码和远程部署的过程和自由风格项目一样,只是”构建”部分不同
新建Item → 构建一个maven项目
其中Build的Root POM是要找到pom.xml的路径才行【默认执行maven命令】
所以只需要在Goals and options里面敲上clean package
Jenkins项目构建类型(4)-Pipeline流水线项目构建(*)
Pipeline简介
1)概念
Pipeline,简单来说,就是一套运行在 Jenkins 上的工作流框架,将原来独立运行于单个或者多个节点 的任务连接起来,实现单个任务难以完成的复杂流程编排和可视化的工作。
2)使用Pipeline有以下好处(来自翻译自官方文档):
代码:Pipeline以代码的形式实现,通常被检入源代码控制,使团队能够编辑,审查和迭代其传送流 程。 持久:无论是计划内的还是计划外的服务器重启,Pipeline都是可恢复的。 可停止:Pipeline可接 收交互式输入,以确定是否继续执行Pipeline。 多功能:Pipeline支持现实世界中复杂的持续交付要 求。它支持fork/join、循环执行,并行执行任务的功能。 可扩展:Pipeline插件支持其DSL的自定义扩 展 ,以及与其他插件集成的多个选项。
3)如何创建 Jenkins Pipeline呢?
- Pipeline 脚本是由 Groovy 语言实现的,但是我们没必要单独去学习 Groovy
- Pipeline 支持两种语法:Declarative(声明式) 和 Scripted Pipeline(脚本式)语法
- Pipeline 也有两种创建方法:可以直接在 Jenkins 的 Web UI 界面中输入脚本;也可以通过创建一 个 Jenkinsfile 脚本文件放入项目源码库中(一般我们都推荐在 Jenkins 中直接从源代码控制(SCM) 中直接载入 Jenkinsfile Pipeline 这种方法)
安装Pipeline插件如果一次安装失败,重启一次再安装[没视图就安装pipeline Stage View]
Manage Jenkins->Manage Plugins->可选插件
Pipeline语法快速入门
1)Declarative声明式-Pipeline
创建项目 [agent是代理、stage是阶段、steps是步骤]
- Node :节点,一个 Node 就是一个 Jenkins 节点,Master 或者 Agent,是执行 Step 的具体运行 环境,后续讲到Jenkins的Master-Slave架构的时候用到。
- Stage :阶段,一个 Pipeline 可以划分为若干个 Stage,每个 Stage 代表一组操作,比如: Build、Test、Deploy,Stage 是一个逻辑分组的概念。
- Step :步骤,Step 是最基本的操作单元,可以是打印一句话,也可以是构建一个 Docker 镜像, 由各类 Jenkins 插件提供,比如命令:sh ‘make’,就相当于我们平时 shell 终端中执行 make 命令 一样。
pipeline {
agent any
stages {
stage('pull code') {
steps {
echo 'pull code'
}
}
stage('build project') {
steps {
echo 'build project'
}
}
stage('publish project') {
steps {
echo 'publish project'
}
}
}
}
2)Scripted Pipeline脚本式-Pipeline
创建项目
流水线那里选择 “Scripted Pipeline“
node {
def mvnHome
stage('pull code'){
echo 'pull code'
}
stage('build project'){
echo 'build project'
}
stage('publish project'){
echo 'publish project'
}
}
流水线脚本:点击可以使用官方的脚本生成器
- 片段生成器:
示例步骤:checkout:Check out from version control [从版本控制里拉取代码]
选择git拉取代码 填写URL和凭证 → 生成流水线脚本
拉取代码
Pipeline script
pipeline{
agent any
stages{
stage('拉取代码'){
steps{
checkout scmGit(branches: [[name: '*/master']], extensions: [], userRemoteConfigs: [[credentialsId: 'ca22e56f-0ecc-4fdc-965d-01e329a0b68a', url: 'http://192.168.200.132:82/lanyun_group/web_demo.git']])
}
}
}
}
Console Output
Started by user root
[Pipeline] Start of Pipeline
[Pipeline] node
Running on Jenkins in /var/lib/jenkins/workspace/web_demo_pipeline
[Pipeline] {
[Pipeline] stage
[Pipeline] { (拉取代码)
[Pipeline] checkout
The recommended git tool is: NONE
using credential ca22e56f-0ecc-4fdc-965d-01e329a0b68a
Cloning the remote Git repository
Cloning repository http://192.168.200.132:82/lanyun_group/web_demo.git
> git init /var/lib/jenkins/workspace/web_demo_pipeline # timeout=10
Fetching upstream changes from http://192.168.200.132:82/lanyun_group/web_demo.git
> git --version # timeout=10
> git --version # 'git version 1.8.3.1'
using GIT_ASKPASS to set credentials gitlab-auth-password
> git fetch --tags --progress http://192.168.200.132:82/lanyun_group/web_demo.git +refs/heads/*:refs/remotes/origin/* # timeout=10
> git config remote.origin.url http://192.168.200.132:82/lanyun_group/web_demo.git # timeout=10
> git config --add remote.origin.fetch +refs/heads/*:refs/remotes/origin/* # timeout=10
Avoid second fetch
> git rev-parse refs/remotes/origin/master^{commit} # timeout=10
Checking out Revision 7ae1ec4086586fb471b0e9dee0a0d00d0b6d6f54 (refs/remotes/origin/master)
> git config core.sparsecheckout # timeout=10
> git checkout -f 7ae1ec4086586fb471b0e9dee0a0d00d0b6d6f54 # timeout=10
Commit message: "修改index.jsp加入细节(!)"
First time build. Skipping changelog.
[Pipeline] }
[Pipeline] // stage
[Pipeline] }
[Pipeline] // node
[Pipeline] End of Pipeline
Finished: SUCCESS
去Jenkins的服务器里寻找/var/lib/jenkins/workspace/web_demo_pipeline
编译打包
流水线脚本:点击可以使用官方的脚本生成器
- 片段生成器:
示例步骤:sh:Shell Script
Shell Script:里面需要打所需要的命令 mvn clean package
Pipeline script
pipeline{
agent any
stages{
stage('build project'){
steps{
sh 'mvn clean package'
}
}
}
}
--------------------------------------------
【总流水线代码】
pipeline {
agent any
stages {
stage('pull code') {
steps {
checkout scmGit(
branches: [[name: '*/master']],
extensions: [],
userRemoteConfigs: [[
credentialsId: 'ca22e56f-0ecc-4fdc-965d-01e329a0b68a',
url: 'http://192.168.200.132:82/lanyun_group/web_demo.git'
]]
)
}
}
stage('build project') {
steps {
sh 'mvn clean package'
}
}
}
}
Console Output
Started by user root
[Pipeline] Start of Pipeline
[Pipeline] node
Running on Jenkins in /var/lib/jenkins/workspace/web_demo_pipeline
[Pipeline] {
[Pipeline] stage
[Pipeline] { (pull code)
[Pipeline] checkout
The recommended git tool is: NONE
using credential ca22e56f-0ecc-4fdc-965d-01e329a0b68a
> git rev-parse --resolve-git-dir /var/lib/jenkins/workspace/web_demo_pipeline/.git # timeout=10
Fetching changes from the remote Git repository
> git config remote.origin.url http://192.168.200.132:82/lanyun_group/web_demo.git # timeout=10
Fetching upstream changes from http://192.168.200.132:82/lanyun_group/web_demo.git
> git --version # timeout=10
> git --version # 'git version 1.8.3.1'
using GIT_ASKPASS to set credentials gitlab-auth-password
> git fetch --tags --progress http://192.168.200.132:82/lanyun_group/web_demo.git +refs/heads/*:refs/remotes/origin/* # timeout=10
> git rev-parse refs/remotes/origin/master^{commit} # timeout=10
Checking out Revision 7ae1ec4086586fb471b0e9dee0a0d00d0b6d6f54 (refs/remotes/origin/master)
> git config core.sparsecheckout # timeout=10
> git checkout -f 7ae1ec4086586fb471b0e9dee0a0d00d0b6d6f54 # timeout=10
Commit message: "修改index.jsp加入细节(!)"
> git rev-list --no-walk 7ae1ec4086586fb471b0e9dee0a0d00d0b6d6f54 # timeout=10
[Pipeline] }
[Pipeline] // stage
[Pipeline] stage
[Pipeline] { (build project)
[Pipeline] sh
+ mvn clean package
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------< com.itheima:web_demo >------------------------
[INFO] Building web_demo 1.0-SNAPSHOT
[INFO] --------------------------------[ war ]---------------------------------
[INFO]
[INFO] --- maven-clean-plugin:2.5:clean (default-clean) @ web_demo ---
[INFO]
[INFO] --- maven-resources-plugin:2.6:resources (default-resources) @ web_demo ---
[WARNING] Using platform encoding (UTF-8 actually) to copy filtered resources, i.e. build is platform dependent!
[INFO] skip non existing resourceDirectory /var/lib/jenkins/workspace/web_demo_pipeline/src/main/resources
[INFO]
[INFO] --- maven-compiler-plugin:3.8.1:compile (default-compile) @ web_demo ---
[INFO] Changes detected - recompiling the module!
[INFO] Compiling 1 source file to /var/lib/jenkins/workspace/web_demo_pipeline/target/classes
[INFO]
[INFO] --- maven-resources-plugin:2.6:testResources (default-testResources) @ web_demo ---
[WARNING] Using platform encoding (UTF-8 actually) to copy filtered resources, i.e. build is platform dependent!
[INFO] skip non existing resourceDirectory /var/lib/jenkins/workspace/web_demo_pipeline/src/test/resources
[INFO]
[INFO] --- maven-compiler-plugin:3.8.1:testCompile (default-testCompile) @ web_demo ---
[INFO] No sources to compile
[INFO]
[INFO] --- maven-surefire-plugin:2.12.4:test (default-test) @ web_demo ---
[INFO] No tests to run.
[INFO]
[INFO] --- maven-war-plugin:3.3.2:war (default-war) @ web_demo ---
[INFO] Packaging webapp
[INFO] Assembling webapp [web_demo] in [/var/lib/jenkins/workspace/web_demo_pipeline/target/web_demo-1.0-SNAPSHOT]
[INFO] Processing war project
[INFO] Copying webapp resources [/var/lib/jenkins/workspace/web_demo_pipeline/src/main/webapp]
[INFO] Building war: /var/lib/jenkins/workspace/web_demo_pipeline/target/web_demo-1.0-SNAPSHOT.war
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 10.242 s
[INFO] Finished at: 2025-06-24T20:32:45+08:00
[INFO] ------------------------------------------------------------------------
[Pipeline] }
[Pipeline] // stage
[Pipeline] }
[Pipeline] // node
[Pipeline] End of Pipeline
Finished: SUCCESS
部署
流水线脚本:点击可以使用官方的脚本生成器
- 片段生成器:
示例步骤:deploy:Deploy war/ear to a container
WAR/EAR files:target/*.war
containers:Tomcat 8.x Remote 【容器可以增加多台】
credentials:添加tomcat凭证
Tomcat URL:http://192.168.200.131:8090/
Pipeline script
【总流水线代码】
pipeline {
agent any
stages {
stage('pull code') {
steps {
checkout scmGit(
branches: [[name: '*/master']],
extensions: [],
userRemoteConfigs: [[
credentialsId: 'ca22e56f-0ecc-4fdc-965d-01e329a0b68a',
url: 'http://192.168.200.132:82/lanyun_group/web_demo.git'
]]
)
}
}
stage('build project') {
steps {
sh 'mvn clean package'
}
}
stage('publish') {
steps {
deploy adapters: [tomcat8(alternativeDeploymentContext: '', credentialsId: 'e847a130-29c3-4d0b-bf35-db8d00de7950', path: '', url: 'http://192.168.200.131:8090/')], contextPath: null, war: 'target/*.war'
}
}
}
}
Console Output
Started by user root
[Pipeline] Start of Pipeline
[Pipeline] node
Running on Jenkins in /var/lib/jenkins/workspace/web_demo_pipeline
[Pipeline] {
[Pipeline] stage
[Pipeline] { (pull code)
[Pipeline] checkout
The recommended git tool is: NONE
using credential ca22e56f-0ecc-4fdc-965d-01e329a0b68a
> git rev-parse --resolve-git-dir /var/lib/jenkins/workspace/web_demo_pipeline/.git # timeout=10
Fetching changes from the remote Git repository
> git config remote.origin.url http://192.168.200.132:82/lanyun_group/web_demo.git # timeout=10
Fetching upstream changes from http://192.168.200.132:82/lanyun_group/web_demo.git
> git --version # timeout=10
> git --version # 'git version 1.8.3.1'
using GIT_ASKPASS to set credentials gitlab-auth-password
> git fetch --tags --progress http://192.168.200.132:82/lanyun_group/web_demo.git +refs/heads/*:refs/remotes/origin/* # timeout=10
> git rev-parse refs/remotes/origin/master^{commit} # timeout=10
Checking out Revision 7ae1ec4086586fb471b0e9dee0a0d00d0b6d6f54 (refs/remotes/origin/master)
> git config core.sparsecheckout # timeout=10
> git checkout -f 7ae1ec4086586fb471b0e9dee0a0d00d0b6d6f54 # timeout=10
Commit message: "修改index.jsp加入细节(!)"
> git rev-list --no-walk 7ae1ec4086586fb471b0e9dee0a0d00d0b6d6f54 # timeout=10
[Pipeline] }
[Pipeline] // stage
[Pipeline] stage
[Pipeline] { (build project)
[Pipeline] sh
+ mvn clean package
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------< com.itheima:web_demo >------------------------
[INFO] Building web_demo 1.0-SNAPSHOT
[INFO] --------------------------------[ war ]---------------------------------
[INFO]
[INFO] --- maven-clean-plugin:2.5:clean (default-clean) @ web_demo ---
[INFO] Deleting /var/lib/jenkins/workspace/web_demo_pipeline/target
[INFO]
[INFO] --- maven-resources-plugin:2.6:resources (default-resources) @ web_demo ---
[WARNING] Using platform encoding (UTF-8 actually) to copy filtered resources, i.e. build is platform dependent!
[INFO] skip non existing resourceDirectory /var/lib/jenkins/workspace/web_demo_pipeline/src/main/resources
[INFO]
[INFO] --- maven-compiler-plugin:3.8.1:compile (default-compile) @ web_demo ---
[INFO] Changes detected - recompiling the module!
[INFO] Compiling 1 source file to /var/lib/jenkins/workspace/web_demo_pipeline/target/classes
[INFO]
[INFO] --- maven-resources-plugin:2.6:testResources (default-testResources) @ web_demo ---
[WARNING] Using platform encoding (UTF-8 actually) to copy filtered resources, i.e. build is platform dependent!
[INFO] skip non existing resourceDirectory /var/lib/jenkins/workspace/web_demo_pipeline/src/test/resources
[INFO]
[INFO] --- maven-compiler-plugin:3.8.1:testCompile (default-testCompile) @ web_demo ---
[INFO] No sources to compile
[INFO]
[INFO] --- maven-surefire-plugin:2.12.4:test (default-test) @ web_demo ---
[INFO] No tests to run.
[INFO]
[INFO] --- maven-war-plugin:3.3.2:war (default-war) @ web_demo ---
[INFO] Packaging webapp
[INFO] Assembling webapp [web_demo] in [/var/lib/jenkins/workspace/web_demo_pipeline/target/web_demo-1.0-SNAPSHOT]
[INFO] Processing war project
[INFO] Copying webapp resources [/var/lib/jenkins/workspace/web_demo_pipeline/src/main/webapp]
[INFO] Building war: /var/lib/jenkins/workspace/web_demo_pipeline/target/web_demo-1.0-SNAPSHOT.war
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 7.472 s
[INFO] Finished at: 2025-06-24T20:39:46+08:00
[INFO] ------------------------------------------------------------------------
[Pipeline] }
[Pipeline] // stage
[Pipeline] stage
[Pipeline] { (publish)
[Pipeline] deploy
[DeployPublisher][INFO] Attempting to deploy 1 war file(s)
[DeployPublisher][INFO] Deploying /var/lib/jenkins/workspace/web_demo_pipeline/target/web_demo-1.0-SNAPSHOT.war to container Tomcat 8.x Remote with context null
Redeploying [/var/lib/jenkins/workspace/web_demo_pipeline/target/web_demo-1.0-SNAPSHOT.war]
Undeploying [/var/lib/jenkins/workspace/web_demo_pipeline/target/web_demo-1.0-SNAPSHOT.war]
Deploying [/var/lib/jenkins/workspace/web_demo_pipeline/target/web_demo-1.0-SNAPSHOT.war]
[Pipeline] }
[Pipeline] // stage
[Pipeline] }
[Pipeline] // node
[Pipeline] End of Pipeline
Finished: SUCCESS
Pipeline Script from SCM
刚才我们都是直接在Jenkins的UI界面编写Pipeline代码,这样不方便脚本维护,建议把Pipeline脚本放 在项目中(一起进行版本控制)
1)在项目根目录建立Jenkinsfile文件,把内容复制到该文件中。把Jenkinsfile上传到Gitlab
Jenkinsfile【在根目录下】
pipeline {
agent any
stages {
stage('pull code') {
steps {
checkout scmGit(
branches: [[name: '*/master']],
extensions: [],
userRemoteConfigs: [[
credentialsId: 'ca22e56f-0ecc-4fdc-965d-01e329a0b68a',
url: 'http://192.168.200.132:82/lanyun_group/web_demo.git'
]]
)
}
}
stage('build project') {
steps {
sh 'mvn clean package'
}
}
stage('publish') {
steps {
deploy adapters: [tomcat8(alternativeDeploymentContext: '', credentialsId: 'e847a130-29c3-4d0b-bf35-db8d00de7950', path: '', url: 'http://192.168.200.131:8090/')], contextPath: null, war: 'target/*.war'
}
}
}
}
2)在项目中引用该文件
在流水线上
定义Pipeline script from SCM → 选择git → 填写gitlab的url和凭证 → 脚本路径Jenkinsfile(这是我们上传的jenkinsfile里面包含着流水线代码的文件)
Jenkins项目构建细节(1)-常用的构建触发器
Jenkins内置4种构建触发器:
- 触发远程构建
- 其他工程构建后触发( Build after other projects are build)
- 定时构建( Build periodically)
- 轮询 SCM(Poll SCM)
触发远程构建
打开web_demo_pipeline的配置 里面的Triggers 选择触发远程构建 身份验证令牌(这个token最好是加密的) 下面有个触发地址:
Use the following URL to trigger build remotely: JENKINS_URL/job/web_demo_pipeline/build?token=TOKEN_NAME 或者 /buildWithParameters?token=TOKEN_NAME
Optionally append &cause=Cause+Text to provide text that will be included in the recorded build cause.
上面地址里面的:job/web_demo_pipeline/build?token=TOKEN_NAME
→ http://192.168.200.129:8888/job/web_demo_pipeline/build?token=6666
在浏览器输入上述地址 回车打开 你会发现已经远程触发了Jenkins的构建行为!!
其他工程构建后触发
1)创建pre_job流水线工程
2)配置需要触发的工程
打开web_demo_pipeline的配置 里面的Triggers 选择Build after other projects are built
新建item → 创建一个pre_job的自由风格的工程 → 构建Execute shell 执行一个简单的脚本
回到web_demo_pipeline工程 在Triggers里面选择前置工程pre_job
此时去构建pre_job你会发现 在构建完后 web_demo_pipeline也会进行自动构建
定时构建
定时字符串从左往右分别为: 分 时 日 月 周
一些定时表达式的例子:(H为0 就为整点)
每30分钟构建一次:H代表形参 H/30 * * * * 10:02 10:32
每2个小时构建一次: H H/2 * * *
每天的8点,12点,22点,一天构建3次: (多个时间点中间用逗号隔开) 0 8,12,22 * * *
每天中午12点定时构建一次 H 12 * * *
每天下午18点定时构建一次 H 18 * * *
在每个小时的前半个小时内的每10分钟 H(0-29)/10 * * * *
每两小时一次,每个工作日上午9点到下午5点(也许是上午10:38,下午12:38,下午2:38,下午
4:38) H H(9-16)/2 * * 1-5
打开web_demo_pipeline的配置 里面的Triggers 选择 Build periodically 然后可以写时间cron表达式即可
轮询SCM [版本控制] [企业级不推荐使用]
轮询SCM,是指定时扫描本地代码仓库的代码是否有变更,如果代码有变更就触发项目构建。
打开web_demo_pipeline的配置 里面的Triggers 选择Poll SCM
jenkins的轮询SCM的构建到底是远程仓库变动触发 还是 本地仓库变动触发?
Jenkins 的“轮询 SCM”是通过轮询远程 Git 仓库(如 GitLab、GitHub)判断是否有变更,从而决定是否触发构建。
注意:这次构建触发器, Jenkins会定时扫描整个项目的代码,增大系统的开销,不建议使用。
Jenkins项目构建细节(2)-Git hook自动触发构建(*)gitlab就用gitlab插件,github则是github插件
先在Jenkins市场安装gitlab插件
刚才我们看到在Jenkins的内置构建触发器中,轮询SCM可以实现Gitlab代码更新,项目自动构建,但是 该方案的性能不佳。那有没有更好的方案呢? 有的。就是利用Gitlab的webhook实现代码push到仓 库,立即触发项目自动构建。
轮询SCM原理:Jenkins →(发送定时请求)→ Gitlab代码变更
webhook原理:Gitlab代码变更 →(发送构建请求)→ Jenkins
打开web_demo_pipeline的配置 里面的Triggers 选择Build when a change is pushed to GitLab. GitLab webhook URL: http://192.168.200.129:8888/project/web_demo_pipeline
★ 要用root账号去GitLab开通一个webhook规则 → 点击上方的小齿轮 → 右侧Settings → Network → 展开Outbound requests → 勾选Allow requests to the local network from web hooks and services和Allow requests to the local network from system hooks保存 → 在web_demo项目中 → Settings → Integrations → 可以粘贴URL(这里就是在Jenkins里面的http://192.168.200.129:8888/project/web_demo_pipeline) [把代码push到项目里来就会触发这个url自动构建] → Add webhook → 下方可以进行测试test → push event →↓
若出现 则证明gitlab是成功 只是Jenkins需要认证请求 去Jenkins开放接收请求的功能
Hook executed successfully but returned HTTP 403 <html> <head> <meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1"/> <title>Error 403 anonymous is missing the Job/Build permission</title> </head> <body><h2>HTTP ERROR 403 anonymous is missing the Job/Build permission</h2> <table> <tr><th>URI:</th><td>/project/web_demo_pipeline</td></tr> <tr><th>STATUS:</th><td>403</td></tr> <tr><th>MESSAGE:</th><td>anonymous is missing the Job/Build permission</td></tr> <tr><th>SERVLET:</th><td>Stapler</td></tr> </table> <hr/><a href="https://jetty.org/">Powered by Jetty:// 12.0.19</a><hr/> </body> </html>
Jenkins开放接收请求 → 打开主页并跟随路径Dashboard → Manage Jenkins → System 找到 GitLab Enable authentication for ‘/project’ end-point【这个要反选 就是不能选钩 且里面的东西删除】 → 再去进行测试test → push event 即可成功Hook executed successfully: HTTP 200
Jenkins项目构建细节(3)-Jenkins的参数化构建
有时在项目构建的过程中,我们需要**根据用户的输入动态传入一些参数**,从而影响整个构建结果,这时 我们可以使用参数化构建。
Jenkins支持非常丰富的参数类型
大概意思就是 我在项目的jenkinsfile文件里面
steps {
checkout scmGit(
branches: [[name: ‘*/master’]],
extensions: [],
userRemoteConfigs: [[
credentialsId: ‘ca22e56f-0ecc-4fdc-965d-01e329a0b68a’,
url: ‘http://192.168.200.132:82/lanyun_group/web_demo.git'
]]
)
这个branches里面的 */master我要求是让用户动态输入值 而不是写死
首先要在项目里面增加一些参数 web_demo_pipeline 项目中 可以先把触发器的值取消掉 → 进入上面的General的配置 选择This project is parameterized → 可以添加参数 → 加入String Parameter参数 →
输入 名称:branch,默认值:master,描述:请输入一个分支的名称 → 此时在左侧就会出现一个 Build with Parameters →↓
pipeline {
agent any
stages {
stage(‘pull code’) {
steps {
checkout scmGit(
branches: [[name: ‘/${branch}}’]],
extensions: [],
userRemoteConfigs: [[
credentialsId: ‘ca22e56f-0ecc-4fdc-965d-01e329a0b68a’,
url: ‘http://192.168.200.132:82/lanyun_group/web_demo.git'
]]
)
}
}
stage(‘build project’) {
steps {
sh ‘mvn clean package’
}
}
stage(‘publish’) {
steps {
deploy adapters: [tomcat8(alternativeDeploymentContext: ‘’, credentialsId: ‘e847a130-29c3-4d0b-bf35-db8d00de7950’, path: ‘’, url: ‘http://192.168.200.131:8090/')], contextPath: null, war: ‘target/.war’
}
}
}
}
【这时你在Jenkins构建时输入的参数就可以对应着Jenkinsfile文件的动态参数进行构建 (动态值红色已标注)】→ 需要把jenkinsfile的代码push到仓库里去
Jenkins项目构建细节(4)-配置邮箱服务器发送构建结果
安装Email Extension Template插件
Jenkins设置邮箱相关参数
Dashboard → Manage Jenkins → System → Extended E-mail Notification → QQ邮箱【官网 账号安全设置】打开SMTP服务 找到 POP3/SMTP服务,点击「开启」→ 勾选“开启服务”旁边的复选框 → 生成SMTP/IMAP 授权码已生成 → jitgujalhqtecadc → 回到Jenkins → SMTP server填写:smtp.qq.com;端口是465 → Default user e-mail suffix:@qq.com 下面的用户名是发件人 密码是授权码 使用SSL协议的话SMTP端口就是465 → Jenkins Location 系统管理员邮件地址是发件人地址
准备邮件内容
在项目根目录编写email.html,并把文件推送到Gitlab,内容如下:【根目录下】
BUILD_NUMBER、BUILD_STATUS等 来自于Jenkins的全局变量
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>${ENV, var="JOB_NAME"}-第${BUILD_NUMBER}次构建日志</title>
</head>
<body leftmargin="8" marginwidth="0" topmargin="8" marginheight="4"
offset="0">
<table width="95%" cellpadding="0" cellspacing="0"
style="font-size: 11pt; font-family: Tahoma, Arial, Helvetica, sans-serif">
<tr>
<td>(本邮件是程序自动下发的,请勿回复!)</td>
</tr>
<tr>
<td><h2>
<font color="#0000FF">构建结果 - ${BUILD_STATUS}</font>
</h2></td>
</tr>
<tr>
<td><br />
<b><font color="#0B610B">构建信息</font></b>
<hr size="2" width="100%" align="center" /></td>
</tr>
<tr>
<td>
<ul>
<li>项目名称 : ${PROJECT_NAME}</li>
<li>构建编号 : 第${BUILD_NUMBER}次构建</li>
<li>触发原因: ${CAUSE}</li>
<li>构建日志: <a href="${BUILD_URL}console">${BUILD_URL}console</a></li>
<li>构建 Url : <a href="${BUILD_URL}">${BUILD_URL}</a></li>
<li>工作目录 : <a href="${PROJECT_URL}ws">${PROJECT_URL}ws</a></li>
<li>项目 Url : <a href="${PROJECT_URL}">${PROJECT_URL}</a></li>
</ul>
</td>
</tr>
<tr>
<td><b><font color="#0B610B">Changes Since Last
Successful Build:</font></b>
<hr size="2" width="100%" align="center" /></td>
</tr>
<tr>
<td>
<ul>
<li>历史变更记录 : <a href="${PROJECT_URL}changes">${PROJECT_URL}changes</a></li>
</ul> ${CHANGES_SINCE_LAST_SUCCESS,reverse=true, format="Changes for Build #%n:<br />%c<br />",showPaths=true,changesFormat="<pre>[%a]<br />%m</pre>",pathFormat=" %p"}
</td>
</tr>
<tr>
<td><b>Failed Test Results</b>
<hr size="2" width="100%" align="center" /></td>
</tr>
<tr>
<td><pre
style="font-size: 11pt; font-family: Tahoma, Arial, Helvetica, sans-serif">$FAILED_TESTS</pre>
<br /></td>
</tr>
<tr>
<td><b><font color="#0B610B">构建日志 (最后 100行):</font></b>
<hr size="2" width="100%" align="center" /></td>
</tr>
<tr>
<td><textarea cols="80" rows="30" readonly="readonly"
style="font-family: Courier New">${BUILD_LOG, maxLines=100}</textarea>
</td>
</tr>
</table>
</body>
</html>
post的内容可以用流水线语法生成 → 完成之后点击片段生成器 生成一个 emailext: Extended Email 的代码片段
pipeline {
agent any
stages {
stage('pull code') {
steps {
checkout scmGit(
branches: [[name: '*/${branch}']],
extensions: [],
userRemoteConfigs: [[
credentialsId: 'ca22e56f-0ecc-4fdc-965d-01e329a0b68a',
url: 'http://192.168.200.132:82/lanyun_group/web_demo.git'
]]
)
}
}
stage('build project') {
steps {
sh 'mvn clean package'
}
}
stage('publish') {
steps {
deploy adapters: [tomcat8(alternativeDeploymentContext: '', credentialsId: 'e847a130-29c3-4d0b-bf35-db8d00de7950', path: '', url: 'http://192.168.200.131:8090/')], contextPath: null, war: 'target/*.war'
}
}
}
post{
always{
emailext(
subject: '构建通知:${PROJECT_NAME} - Build # ${BUILD_NUMBER} - ${BUILD_STATUS}!',
body: '${FILE,path="email.html"}',
to: '2523419709@qq.com'
)
}
}
}
PS:邮件相关全局参数参考列表:
系统设置->Extended E-mail Notification->Content Token Reference,点击旁边的?号
Jenkins+SonarQube代码审查(1) - 安装SonarQube
SonaQube简介
SonarQube 是一个用于管理代码质量的开放平台,可以快速的定位代码中潜在的或者明显的错误。目前 支持java,C#,C/C++,Python,PL/SQL,Cobol,JavaScrip,Groovy等二十几种编程语言的代码质量管理与检 测。
官网: https://www.sonarqube.org/
环境要求
| 软件 |
服务器 |
版本 |
| JDK |
192.168.200.129 |
1.8 |
| MySQL |
192.168.200.129 |
5.7 |
| SonarQube |
192.168.200.129 |
6.7.4 |
安装SonarQube
1)安装MySQL(已完成)
2)安装SonarQube
使用5.7数据库
先删除以前的
建议操作:
- 先把多余或冲突的文件临时备份移动一下,避免yum混乱
bash复制编辑sudo mv /etc/yum.repos.d/mysql-community.repo.rpmsave /root/
sudo mv /etc/yum.repos.d/mysql57.repo /root/
- 只保留
mysql-community.repo 这个 repo 文件,确保它内容正确(你可以用cat看下内容)
cat /etc/yum.repos.d/mysql-community.repo
- 清理缓存,重新生成
sudo yum clean all
sudo yum makecache
- 尝试安装mysql 5.7
sudo yum install mysql-community-server
解决方案:用符合策略的密码先改,再降低策略
- 用一个符合复杂度的密码先改密码,例如:
sql
复制编辑
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Root@12345';
- 登录成功后降低密码策略:
sql复制编辑SET GLOBAL validate_password_policy=LOW;
SET GLOBAL validate_password_length=1;
- 再修改为你想要的简单密码(比如
root):
sql
复制编辑
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
- 刷新权限
FLUSH PRIVILEGES;
在mysql创建sonar数据库
启动 MySQL 服务(如果没启动)
systemctl start mysqld
启动后再次检查状态:
systemctl status mysqld
mysql -uroot -p
账号密码是:root
mysql> create database sonar;
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sonar |
| sys |
+--------------------+
5 rows in set (0.07 sec)
解压sonar,并设置权限
yum install unzip
unzip sonarqube-6.7.4.zip 解压
mkdir /opt/sonar 创建目录
mv sonarqube-6.7.4/* /opt/sonar 移动文件
useradd sonar 创建sonar用户,必须sonar用于启动,否则报错
chown -R sonar. /opt/sonar 更改sonar目录及文件权限
[root@localhost ~]# cd /opt/sonar
[root@localhost sonar]# ll
总用量 12
drwxr-xr-x. 8 sonar sonar 136 5月 30 2018 bin
drwxr-xr-x. 2 sonar sonar 50 5月 30 2018 conf
-rw-r–r–. 1 sonar sonar 7651 5月 30 2018 COPYING
drwxr-xr-x. 2 sonar sonar 24 5月 30 2018 data
drwxr-xr-x. 7 sonar sonar 150 5月 30 2018 elasticsearch
drwxr-xr-x. 4 sonar sonar 40 5月 30 2018 extensions
drwxr-xr-x. 9 sonar sonar 140 5月 30 2018 lib
drwxr-xr-x. 2 sonar sonar 6 5月 30 2018 logs
drwxr-xr-x. 2 sonar sonar 24 5月 30 2018 temp
drwxr-xr-x. 9 sonar sonar 4096 5月 30 2018 web
修改sonar配置文件数据库连接信息
[root@localhost opt]# cd sonar
[root@localhost sonar]# cd conf
[root@localhost conf]# vi sonar.properties
|| || || ||
......
sonar.jdbc.username=root
sonar.jdbc.password=root
......
sonar.jdbc.url=jdbc:mysql://127.0.0.1:3306/sonar?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true&useConfigs=maxPerformance&useSSL=false 【这里打开注释】
注意:sonar默认监听9000端口,如果9000端口被占用,需要更改
如果要改端口 在这里:
sonar.web.port=9999
启动sonar 129
[root@localhost bin]# pwd
/opt/sonar/bin
cd /opt/sonar/bin
修改配置文件:vi /opt/sonar/conf/sonar.properties
重启sonar:sudo -u sonar /opt/sonar/bin/linux-x86-64/sonar.sh restart ★★ [Jenkins服务]
实时跟踪最新日志输出(推荐用于调试启动或运行时状态)
tail -f /opt/sonar/logs/sonar.log
tail -f /opt/sonar/logs/web.log
tail -f /opt/sonar/logs/es.log
查看日志末尾100条内容(快速查看最近日志)
tail -n 100 /opt/sonar/logs/sonar.log
tail -n 100 /opt/sonar/logs/web.log
tail -n 100 /opt/sonar/logs/es.log
查看整个日志文件大小和权限
ls -lh /opt/sonar/logs/*.log
访问SonarQube
[192.168.200.129] (http://192.168.200.129:9999/)
账号密码:admin admin
生成了一个token:sonar: d30033c63973bd4183b6015995dbb513627c6f59
启动命令总结:
[192.168.200.132] GitLab:gitlab-ctl restart
lanyun_group / web_demo · GitLab
[192.168.200.131] Tomcat:/opt/tomcat/bin/startup.sh
演示项目主页
[192.168.200.129] Jenkins:systemctl start jenkins
登录 - Jenkins
[192.168.200.129] SonarQube:sudo -u sonar /opt/sonar/bin/linux-x86-64/sonar.sh restart
192.168.200.129
Jenkins+SonarQube代码审查(2) - 实现代码审查
审查流程:
Jenkins →(调用)→ Sonar-Scanner →(提交审查结果)→ SonarQube →(保存审查结果)→ MySQL数据库
安装SonarQube Scanner插件
打开Jenkins的全局配置 → SonarQube Servers → Add SonarQube → Name:sonarqube;Server URL:http://192.168.200.129:9999/ → 新建一个证书[Manage Jenkins → Credentials → System → 全局添加 → 类型选择Secret text ;Secret是之前复制到的token字符串 ;描述:sonarqube-auth] → Server authentication token选择刚刚创建的sonarqube-auth
SonarQube 关闭审查结果上传到SCM功能
[General Settings - Administration] (http://192.168.200.129:9999/admin/settings?category=scm) 上方的Administration → 左侧的SCM → 第一个打开SCN Sensor
回到Jenkins的web_demo_freestyle项目点击构建 下方的Build Steps下面的增加构建步骤 选择Execute SonarQube Scanner (这里要在去Tools里安装配置 SonarQube Scanner 安装 → Name:sonar-scanner;Install automatically:SonarQube Scanner 4.2.0.1873) → 这里的jdk是根据Jenkins的jdk配置的 → (Path to project properties这个可以在项目下搞 也可以用Analysis properties 属性放在前端ui界面里面) 这里选择Analysic properties→↓
# must be unique in a given SonarQube instance
sonar.projectKey=web_demo_freestyle
# this is the name and version displayed in the SonarQube UI. Was mandatory
prior to SonarQube 6.1.
sonar.projectName=web_demo_freestyle
sonar.projectVersion=1.0
# Path is relative to the sonar-project.properties file. Replace "\" by "/" on
Windows.
# This property is optional if sonar.modules is set.
sonar.sources=.
sonar.exclusions=**/test/**,**/target/**
sonar.java.source=1.8
sonar.java.target=1.8
# Encoding of the source code. Default is default system encoding
sonar.sourceEncoding=UTF-8
→ 应用保存 + 重新构建
现在有个问题就是我Jenkins是2.504.2 然后jdk是17 我不想换jdk的情况下就要去
Build Steps里面的执行脚本
echo "开始进行编译构建"
mvn clean package
echo "编译构建结束"
# 设置环境变量,给sonar-scanner的JVM传参数,解决Java17模块访问问题
export SONAR_SCANNER_OPTS="--add-opens=java.base/java.lang=ALL-UNNAMED \
--add-opens=java.base/java.lang.reflect=ALL-UNNAMED \
--add-opens=java.base/java.io=ALL-UNNAMED"
# 执行Sonar扫描
/var/lib/jenkins/tools/hudson.plugins.sonar.SonarRunnerInstallation/sonar-scanner/bin/sonar-scanner \
-Dsonar.projectKey=web_demo_freestyle \
-Dsonar.host.url=http://192.168.200.129:9999 \
-Dsonar.sources=. \
-Dsonar.exclusions=**/test/**,**/target/** \
-Dsonar.java.source=1.8 \
-Dsonar.java.target=1.8
echo "SonarQube扫描结束"
打开idea jenkinsfile文件
pipeline {
agent any
stages {
stage('pull code') {
steps {
checkout scmGit(
branches: [[name: "*/${branch}"]],
extensions: [],
userRemoteConfigs: [[
credentialsId: 'ca22e56f-0ecc-4fdc-965d-01e329a0b68a',
url: 'http://192.168.200.132:82/lanyun_group/web_demo.git'
]]
)
}
}
stage('build project') {
steps {
sh 'mvn clean package'
}
}
stage('sonarqube scan') {
environment {
// 传递给sonar-scanner JVM的启动参数,解决模块访问限制
SONAR_SCANNER_OPTS = '--add-opens=java.base/java.lang=ALL-UNNAMED ' +
'--add-opens=java.base/java.lang.reflect=ALL-UNNAMED ' +
'--add-opens=java.base/java.io=ALL-UNNAMED'
}
steps {
sh '''
/var/lib/jenkins/tools/hudson.plugins.sonar.SonarRunnerInstallation/sonar-scanner/bin/sonar-scanner \
-Dsonar.projectKey=web_demo_freestyle \
-Dsonar.host.url=http://192.168.200.129:9999 \
-Dsonar.sources=. \
-Dsonar.exclusions=**/test/**,**/target/** \
-Dsonar.java.source=1.8 \
-Dsonar.java.target=1.8
'''
}
}
stage('publish') {
steps {
deploy adapters: [tomcat8(
alternativeDeploymentContext: '',
credentialsId: 'e847a130-29c3-4d0b-bf35-db8d00de7950',
path: '',
url: 'http://192.168.200.131:8090/'
)], contextPath: null, war: 'target/*.war'
}
}
}
post {
always {
emailext(
subject: '构建通知:${PROJECT_NAME} - Build # ${BUILD_NUMBER} - ${BUILD_STATUS}!',
body: '${FILE,path="email.html"}',
to: '2523419709@qq.com'
)
}
}
}
✅ 方法一:编辑 SonarScanner 的配置文件(最可靠)
编辑 Jenkins 中自动下载的 sonar-scanner 的 JVM 启动参数配置文件:
sudo vi /var/lib/jenkins/tools/hudson.plugins.sonar.SonarRunnerInstallation/sonar-scanner/conf/sonar-scanner.properties
在文件最后 添加
# 开启JDK17对反射的兼容
sonar.scanner.jvmArgs=--add-opens java.base/java.lang=ALL-UNNAMED
整体的文件是这样的:
#Configure here general information about the environment, such as SonarQube server connection details for example
#No information about specific project should appear here
#----- Default SonarQube server
sonar.host.url=http://localhost:9999
#----- Default source code encoding
#sonar.sourceEncoding=UTF-8
# 开启JDK17对反射的兼容
sonar.scanner.jvmArgs=--add-opens java.base/java.lang=ALL-UNNAMED
★如果要使用sonarqube 一定要jdk是1.8★
首先需要去全局那里设置jdk(Manage jenkins → System)
键:
JAVA_HOME
值:
/usr/local/java/jdk-17.0.8+7
键:
JAVA_HOME
值:
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64
在构建项目配置的时候Build Steps → Execute SonarQube Scanner → jdk一定要选择1.8的!!!
流水线构建版本用的jdk17解决办法
要默认的1.8才支持 所以直接从根源上解决这个问题
你当前的系统默认 Java 是 JDK 1.8,路径在:
/usr/bin/java
你执行的:
java -version
输出是:
openjdk version "1.8.0_262"
说明现在 Jenkins 主机上默认使用的是 Java 8,这是符合 SonarQube 6.7.4 的推荐版本,很好!
✅ 接下来你要做的
为了确保 Jenkins 中的 SonarScanner 也用 Java 8 运行,你还需要修改如下:
✅ 方法一:修改 sonar-scanner 启动脚本(推荐)
vi /var/lib/jenkins/tools/hudson.plugins.sonar.SonarRunnerInstallation/sonar-scanner/bin/sonar-scanner
在顶部添加下面两行 👇:
export JAVA_HOME=/usr
export PATH=$JAVA_HOME/bin:$PATH
模拟SonaQube代码审查机制
C:\Users\Pluminary\Desktop\web_demo\src\main\java\com\itheima\HelloServlet.java
package com.itheima;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
*
*/
public class HelloServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
super.doPost(req,resp);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//模拟代码错误
int i = 100/0;
//模拟冗余代码
int a = 100;
a = 200;
resp.getWriter().write("hello Servlet!");
}
}
在项目添加SonaQube代码审查(流水线项目)不在Jenkins里面写配置,在项目的文件里面写!
sonar-project.properties
# must be unique in a given SonarQube instance
sonar.projectKey=web_demo_pipline
# this is the name and version displayed in the SonarQube UI. Was mandatory prior to SonarQube 6.1.
sonar.projectName=web_demo_pipline
sonar.projectVersion=1.0
# Path is relative to the sonar-project.properties file. Replace "\" by "/" on Windows.
# This property is optional if sonar.modules is set.
sonar.sources=.
sonar.exclusions=**/test/**,**/target/**
sonar.java.source=1.8
sonar.java.target=1.8
# Encoding of the source code. Default is default system encoding
sonar.sourceEncoding=UTF-8
pipeline {
agent any
tools {
// 使用 Jenkins 配置好的 JDK 1.8(别名需和你Jenkins中配置一致)
jdk 'jdk-1.8.0'
}
environment {
// Sonar Scanner JVM 启动参数,开启必要的module访问权限
SONAR_SCANNER_OPTS = '--add-opens=java.base/java.lang=ALL-UNNAMED ' +
'--add-opens=java.base/java.lang.reflect=ALL-UNNAMED ' +
'--add-opens=java.base/java.io=ALL-UNNAMED'
}
stages {
stage('Pull Code') {
steps {
checkout scmGit(
branches: [[name: "*/${branch}"]],
extensions: [],
userRemoteConfigs: [[
credentialsId: 'ca22e56f-0ecc-4fdc-965d-01e329a0b68a',
url: 'http://192.168.200.132:82/lanyun_group/web_demo.git'
]]
)
}
}
stage('Build Project') {
steps {
sh 'mvn clean package'
}
}
stage('SonarQube Scan') {
steps {
// 强制切换到 JDK8 环境,避免默认JDK17导致权限异常
withEnv([
'JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64',
'PATH=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64/bin:' + env.PATH
]) {
sh '''
/var/lib/jenkins/tools/hudson.plugins.sonar.SonarRunnerInstallation/sonar-scanner/bin/sonar-scanner \
-Dsonar.projectKey=web_demo_freestyle \
-Dsonar.host.url=http://192.168.200.129:9999 \
-Dsonar.sources=. \
-Dsonar.exclusions=**/test/**,**/target/** \
-Dsonar.java.source=1.8 \
-Dsonar.java.target=1.8
'''
}
}
}
stage('Publish') {
steps {
deploy adapters: [tomcat8(
alternativeDeploymentContext: '',
credentialsId: 'e847a130-29c3-4d0b-bf35-db8d00de7950',
path: '',
url: 'http://192.168.200.131:8090/'
)], contextPath: null, war: 'target/*.war'
}
}
}
post {
always {
emailext(
subject: '构建通知:${PROJECT_NAME} - Build # ${BUILD_NUMBER} - ${BUILD_STATUS}!',
body: '${FILE,path="email.html"}',
to: '2523419709@qq.com'
)
}
}
}
Jenkins+Docker+SpringCloud微服务持续集成(上)
Jenkins+Docker+SpringCloud持续集成流程说明
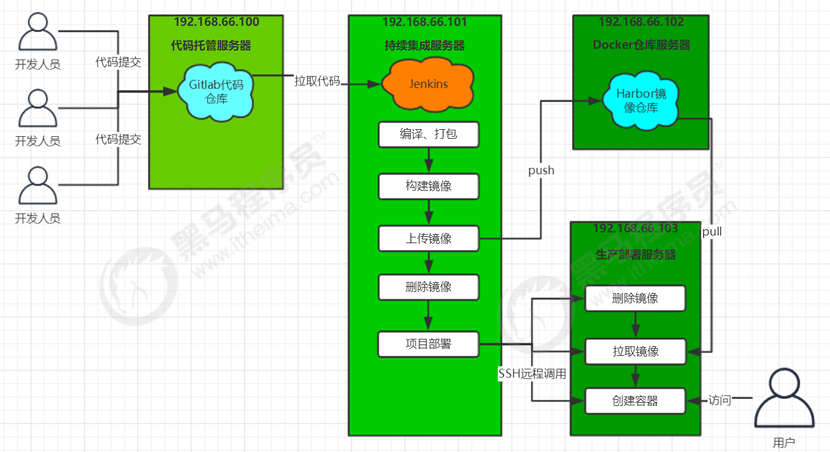
大致流程说明:
1)开发人员每天把代码提交到Gitlab代码仓库
2)Jenkins从Gitlab中拉取项目源码,编译并打成jar包,然后构建成Docker镜像,将镜像上传到 Harbor私有仓库。
3)Jenkins发送SSH远程命令,让生产部署服务器到Harbor私有仓库拉取镜像到本地,然后创建容器。
4)最后,用户可以访问到容器
服务列表(红色的软件为需要安装的软件,黑色代表已经安装)
| 服务器名称 |
IP地址 |
安装的软件 |
| 代码托管服务器 |
192.168.200.132 |
Gitlab |
| 持续集成服务器 |
192.168.200.129 |
Jenkins,Maven,Docker18.06.1-ce |
| Docker仓库服务器 |
|
Docker18.06.1-ce,Harbor1.9.2 |
| 生产部署服务器 |
|
Docker18.06.1-ce |
SpringCloud微服务源码概述
项目架构:前后端分离
后端技术栈:SpringBoot+SpringCloud+SpringDataJpa(Spring全家桶)
位置:C:\Users\Pluminary\Desktop\HouDuan\tensquare_parent
微服务项目结构:
- tensquare_parent :父工程,存放基础配置
- tensquare_common :通用工程,存放工具类
- tensquare_eureka_server:SpringCloud的Eureka注册中心
- tensquare_zuul :SpringCloud的网关服务
- tensquare_admin_service :基础权限认证中心,负责用户认证(使用JWT认证)
- tensquare_gathering : 一个简单的业务模块,活动微服务相关逻辑
数据库结构:
- tensquare_user :用户认证数据库,存放用户账户数据。对应tensquare_admin_service微服务
- tensquare_gathering :活动微服务数据库。对应tensquare_gathering微服务
微服务配置分析:
tensquare_eureka
tensquare_zuul
tensquare_admin_service
tensquare_gathering
查看效果
application.yaml
spring:
application:
name: EUREKA-HA
---
spring:
profiles: eureka-server1
server:
port: 10086
eureka:
instance:
hostname: localhost
client:
service-url:
defaultZone: http://localhost:10086/eureka/,http://localhost:10087/eureka/
---
spring:
profiles: eureka-server2
server:
port: 10087
eureka:
instance:
hostname: localhost
client:
service-url:
defaultZone: http://localhost:10086/eureka/,http://localhost:10087/eureka/
依次开启这些服务:tensquare_eureka_server → tensquare_zuul → tensquare_admin_service → tensquare_gathering
tensquare_eureka_server 要在配置的地方配置两个【复制出多一个】配置信息添加Program arguments
EurekaServerApplication-Server1:-spring.profiles.active=eureka-server1
EurekaServerApplication-Server2:–spring.profiles.active=eureka-server2
调用postman
测试gathering接口的时候一定要在请求头带token
测试获得token接口的时候一定是post请求 请求体是json形式
GET:http://localhost:10020/gathering/gathering
Headers:这里的token是去post请求获得
POST:http://localhost:10020/admin/admin/login
json:{
"loginname": "admin",
"password": "123456"
}
本地部署(1)-SpringCloud微服务部署
本地运行微服务
- 逐一启动微服务
- 使用postman测试功能是否可用
本地部署微服务
打开idea终端
PS C:\Users\Pluminary\Desktop\HouDuan\tensquare_parent>
托选想要打包的项目到终端
PS C:\Users\Pluminary\Desktop\HouDuan\tensquare_parent\tensquare_eureka_server> mvn clean package
此时就打好了jar包
C:\Users\Pluminary\Desktop\HouDuan\tensquare_parent\tensquare_eureka_server\target的tensquare_eureka_server-1.0-SNAPSHOT.jar
必须导入该插件
在根pom.xml中
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
★ 这个就可以对springcloud进行打包 微服务的jar可以独立部署 扔到任何一个服务就可以单独运行 而不需要借助单独的tomcat ★
打包后在 target下产生jar包
java -jar xxx.jar
C:\Users\Pluminary\Desktop>java -jar tensquare_eureka_server-1.0-SNAPSHOT.jar
2025-07-01 15:33:09.363 INFO 27172 --- [ main] o.s.core.annotation.AnnotationUtils : Failed to introspect annotations on class org.springframework.cloud.netflix.eureka.config.EurekaDiscoveryClientConfigServiceBootstrapConfiguration: java.lang.IllegalStateException: Could not obtain annotation attribute value for public abstract java.lang.Class[] org.springframework.boot.autoconfigure.condition.ConditionalOnClass.value()
2025-07-01 15:33:09.373 INFO 27172 --- [ main] s.c.a.AnnotationConfigApplicationContext : Refreshing org.springframework.context.annotation.AnnotationConfigApplicationContext@8f4ea7c: startup date [Tue Jul 01 15:33:09 CST 2025]; root of context hierarchy
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.springframework.cglib.core.ReflectUtils$1 (jar:file:/C:/Users/Pluminary/Desktop/tensquare_eureka_server-1.0-SNAPSHOT.jar!/BOOT-INF/lib/spring-core-5.0.5.RELEASE.jar!/) to method java.lang.ClassLoader.defineClass(java.lang.String,byte[],int,int,java.security.ProtectionDomain)
WARNING: Please consider reporting this to the maintainers of org.springframework.cglib.core.ReflectUtils$1
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
2025-07-01 15:33:09.531 INFO 27172 --- [ main] f.a.AutowiredAnnotationBeanPostProcessor : JSR-330 'javax.inject.Inject' annotation found and supported for autowiring
2025-07-01 15:33:09.554 INFO 27172 --- [ main] trationDelegate$BeanPostProcessorChecker : Bean 'configurationPropertiesRebinderAutoConfiguration' of type [org.springframework.cloud.autoconfigure.ConfigurationPropertiesRebinderAutoConfiguration$$EnhancerBySpringCGLIB$$83532275] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying)
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.0.1.RELEASE)
本地部署(2)-前端静态web网站
前端技术栈:NodeJS+VueJS+ElementUI
使用Visual Studio Code打开源码
位置:C:\Users\Pluminary\Desktop\QianDuan\tensquareAdmin
因为老版本无法继续用最新的nodejs
需要用nvm进行统一的nodejs管理 如果无法直接nvm下载的话
我们可以去官网下载安装包zip后解压进去 改名就行
✅ 1. 下载 Node.js v10.24.1 64位 zip 版本
你可以从官方链接下载:
📦 下载地址(Windows 64位):
bash
复制编辑
https://nodejs.org/dist/v10.24.1/node-v10.24.1-win-x64.zip
下载后,解压得到一个文件夹(比如叫 node-v10.24.1-win-x64)
✅ 2. 放入 NVM 的版本目录
将你解压得到的 node-v10.24.1-win-x64 文件夹重命名为:
10.24.1
然后放入这个目录下:
C:\Program Files\nvm\versions\10.24.1\
C:\Users\Pluminary\Desktop\QianDuan\tensquareAdmin>nvm list
- 20.12.0 (Currently using 64-bit executable)
10.24.1
C:\Users\Pluminary\Desktop\QianDuan\tensquareAdmin>nvm use 10.24.1
Now using node v10.24.1 (64-bit)
🚀 步骤 1:重新下载对应 binding.node
在项目目录下运行:
bash
复制编辑
npm rebuild node-sass
I Your application is running here: http://localhost:9528 前端即可启动!
name: admin password: 123456
[十次方社交平台-管理员后台] (http://localhost:9528/#/gathering/index)
环境准备(1)-Docker快速入门
Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流 行的 Linux 机器上,也可以实现虚拟化。 容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app),更重要的是容器性能开销 极低。 Docker容器技术 vs 传统虚拟机技术
|
虚拟机 |
容器 |
| 占用磁盘空间 |
非常大,GB级 |
小,MB甚至KB级 |
| 启动速度 |
慢。分钟级 |
快,秒级 |
| 运行状态 |
运行于Hypervisor上 |
直接运行在宿主机内核上 |
| 并发性 |
一台宿主机上十几个,最多几十个 |
上百个,甚至数百上千个 |
| 性能 |
逊于宿主机 |
接近宿主机本地进程 |
| 资源利用率 |
低 |
高 |
简单一句话总结:Docker技术就是让我们更加高效轻松地将任何应用在Linux服务器部署和使用。
Docker安装
1)卸载旧版本
yum list installed | grep docker 列出当前所有docker的包
yum -y remove docker的包名称 卸载docker包
rm -rf /var/lib/docker 删除docker的所有镜像和容器
2)安装必要的软件包
sudo yum install -y yum-utils \ device-mapper-persistent-data \ lvm2
3)设置下载的镜像仓库
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
4)列出需要安装的版本列表
yum list docker-ce --showduplicates | sort -r
docker-ce.x86_64 3:18.09.1-3.el7
docker-ce.x86_64 3:18.09.0-3.el7
docker-ce.x86_64 18.06.1.ce-3.el7
docker-ce.x86_64 18.06.0.ce-3.el7
……
5 )安装指定版本(这里使用18.0.1版本)
sudo yum install docker-ce-18.06.1.ce
6)查看版本
docker -v
7)启动Docker
sudo systemctl start docker 启动
sudo systemctl enable docker 设置开机启动
8)添加阿里云镜像下载地址
sudvi /etc/docker/daemon.json
{
“registry-mirrors”: [“https://zydiol88.mirror.aliyuncs.com"]
}
9 )重启Docker
sudo systemctl restart docker
第四步看这里:你现在的问题还是和之前一样:
❌ 无法访问 Docker 官方源(https://download.docker.com/...),报错 curl#35 - TCP connection reset by peer。
✅ 解决方法:使用国内镜像(如清华、阿里)
你需要 手动切换 Docker yum 源为国内镜像,否则无法继续安装。下面是最直接可行的解决方法。
🚀 一键换成清华源(CentOS 7 示例)
请复制以下命令到你的服务器执行:
bash复制编辑sudo tee /etc/yum.repos.d/docker-ce.repo <<-'EOF'
[docker-ce-stable]
name=Docker CE Stable - Tsinghua Mirror
baseurl=https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/7/x86_64/stable
enabled=1
gpgcheck=1
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/gpg
EOF
🔁 然后执行:
sudo yum clean all
sudo yum makecache fast
✅ 安装 Docker 指定版本(比如 18.06)
sudo yum install docker-ce-18.06.1.ce docker-ce-cli-18.06.1.ce containerd.io
或者查看所有可用版本:
yum list docker-ce --showduplicates
🟢 启动并设置开机启动:
sudo systemctl start docker
sudo systemctl enable docker
Docker基本命令快速入门
1)镜像命令
[docker配置镜像Docker pull时报错:https://registry-1.docker.io/v2/ - 知乎] (https://zhuanlan.zhihu.com/p/24228872523)
这个错误表明Docker客户端尝试访问Docker Hub或其他Docker注册中心时出现了问题。具体来说,是在尝试获取注册中心API的响应时遇到了错误。可能的原因包括网络问题、认证问题、注册中心URL不正确或者注册中心服务本身不可用。
2、解决方法
systemctl status docker
sudo mkdir -p /etc/docker
vim /etc/docker/daemon.json
添加:
{
"registry-mirrors" : ["https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc",
"https://do.nark.eu.org",
"https://dc.j8.work",
"https://dockerproxy.com",
"https://gst6rzl9.mirror.aliyuncs.com",
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"http://mirrors.ustc.edu.cn/",
"https://mirrors.tuna.tsinghua.edu.cn/",
"http://mirrors.sohu.com/"
],
"insecure-registries" : [
"registry.docker-cn.com",
"docker.mirrors.ustc.edu.cn"
],
"debug": true,
"experimental": false
}
重载和重启dockers服务
sudo systemctl daemon-reload
sudo systemctl restart docker
docker info
重新执行
docker run hello-world
镜像:相当于应用的安装包,在Docker部署的任何应用都需要先构建成为镜像
docker search 镜像名称 搜索镜像
docker pull 镜像名称 拉取镜像
docker images 查看本地所有镜像
docker rmi -f 镜像名称 删除镜像
docker pull openjdk:8-jdk-alpine
[root@localhost ~]# docker pull openjdk:8-jdk-alpine
8-jdk-alpine: Pulling from library/openjdk
e7c96db7181b: Pull complete
f910a506b6cb: Pull complete
c2274a1a0e27: Pull complete
Digest: sha256:94792824df2df33402f201713f932b58cb9de94a0cd524164a0f2283343547b3
Status: Downloaded newer image for openjdk:8-jdk-alpine
[root@localhost ~]#
2)容器命令
容器:容器是由镜像创建而来。容器是Docker运行应用的载体,每个应用都分别运行在Docker的每个 容器中。
docker run -i 镜像名称:标签 运行容器(默认是前台运行)
docker ps 查看运行的容器
docker ps -a 查询所有容器
常用的参数:
-i:运行容器
-d:后台守方式运行(守护式)
--name:给容器添加名称
-p:公开容器端口给当前宿主机
-v:挂载目录
docker exec -it 容器ID/容器名称 /bin/bash 进入容器内部
docker start/stop/restart 容器名称/ID 启动/停止/重启容器
docker rm -f 容器名称/ID 删除容器
docker run -i nginx 运行容器
docker run -di nginx 后台运行容器
运行的时候创建端口 把端口暴露给宿主机 这样宿主机就可以进行ip地址+端口的访问虚拟机的容器了
-p是公开端口 外部用90端口访问80端口
docker run -di -p 90:80 nginx
[root@localhost ~]# docker run -di -p 90:80 nginx
04726503f6ee2d053b54b6361d128827d5fb26b867c8fbd5439a370a4ac137d9
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
04726503f6ee nginx “/docker-entrypoint.…” 29 seconds ago Up 27 seconds 0.0.0.0:90->80/tcp relaxed_goldberg
此时用宿主机去访问:[Welcome to nginx!] (http://192.168.200.129:90/)
Welcome to nginx!
If you see this page, the nginx web server is successfully installed and working. Further configuration is required.
For online documentation and support please refer to nginx.org.
Commercial support is available at nginx.com.
Thank you for using nginx.
进入某个容器内部查看其内容:
[root@localhost ~]# docker exec -it 04726503f6ee /bin/bash
root@04726503f6ee:/# ls
bin boot dev docker-entrypoint.d docker-entrypoint.sh etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
root@04726503f6ee:/#
删除容器
[root@localhost ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
04726503f6ee nginx “/docker-entrypoint.…” 4 minutes ago Up 4 minutes 0.0.0.0:90->80/tcp relaxed_goldberg
9b9b1ec3e7a1 nginx “/docker-entrypoint.…” 10 minutes ago Up 8 minutes 80/tcp gracious_knuth
4fb9d9e6858a hello-world “/hello” 29 minutes ago Exited (0) 29 minutes ago elated_bhaskara
[root@localhost ~]# docker rm -f 4fb9d9e6858a
4fb9d9e6858a
虚拟机变化ip 导致无法ping通 解决办法
cd /etc/sysconfig/network-scripts/
vi ifcfg-ens33
❗核心问题总结:
你的宿主机(Windows)的真实联网网卡是:
- 无线网卡 WLAN
- IP:
192.168.31.103
- 网关:
192.168.31.1
而你的 VMware 虚拟机设置的是:
- 静态 IP:192.168.200.132
- 网关:
192.168.200.1
- 网络模式:你设为桥接模式
❗问题本质:
你的虚拟机静态 IP 设置在 192.168.200.x 网段,但 宿主机是在 192.168.31.x 网段,说明你的桥接实际上根本没有生效,或者桥接到了错误的物理网卡。
✅ 最快修复方案(推荐,100% 可行):
🛠️ 步骤一:修改 VMware 桥接设置
- 关闭虚拟机
- 打开 VMware 主界面 → 选择你的虚拟机 → 设置(Settings)→ 网络适配器
- 选择:
- ✔️ 网络连接 → 桥接模式(Bridged)
- 点开旁边的 “桥接设置(Bridge Settings)”
- 手动选择你的 Wi-Fi 无线网卡(例如 Intel Wireless-AC 或 Realtek Wireless)
- 取消勾选“复制物理网络连接状态”这一项
- 保存设置
🛠️ 步骤二:修改虚拟机内 IP 设置
由于你真实网络是 192.168.31.x,所以虚拟机也应该设置为这个网段,例如:
编辑 vi /etc/sysconfig/network-scripts/ifcfg-ens33:
BOOTPROTO=static
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.31.150 # ← 随便取一个没被占用的
NETMASK=255.255.255.0
GATEWAY=192.168.31.1 # 这个是在宿主机网络下的环境网关 ipconfig
DNS1=8.8.8.8
然后执行:
sudo systemctl restart network
或者:
sudo ifdown ens33 && sudo ifup ens33
✅ 步骤三:在 Windows 上 ping 新的虚拟机 IP
ping 192.168.31.150
🧠 如果你担心 IP 冲突怎么办?
在 Windows 上运行:
ping 192.168.31.150
如果 ping 不通,就说明这个 IP 是空闲的,可以用。
✅ 替代方案(保留 NAT 模式)
如果你不想改桥接模式,可以继续用 VMware NAT 模式,那就让虚拟机保留原来的:
- IP:192.168.200.132
- 网关:192.168.200.1
- 然后通过端口转发(NAT 端口映射)来从主机访问虚拟机(需要手动配置)
但 桥接 + 静态 IP 更简单、稳定、兼容性好。
✅ 最终目标
你的宿主机和虚拟机 在同一个网段(如都在 192.168.31.x),并且虚拟机网卡状态为 UP,那 ping 肯定通!
🔚 结论
| 问题 |
解决方法 |
| 虚拟机 IP 设置错网段了 |
改为 192.168.31.x(和主机一样的网段) |
| 桥接失败 |
手动指定桥接物理网卡为你的 无线网卡,不能选自动 |
| 不能 ping 通 |
网卡 DOWN → 启动;IP 不通 → 改网段;防火墙 → 暂停 |
如果ip a show ens33没有ip地址怎么办 这样会导致moba连不上
应该是网卡状态为down说明网卡没启用
直接用ip命令把网卡打开sudo ip link set ens33 up
然后找一下有没有 ip a show ens33
重启网络服务:sudo systemctl restart network 再次查看
如果还是没有 就手动设置IP
sudo ip addr add 192.168.200.131/24 dev ens33
再次重启网络服务:sudo systemctl restart network
然后再次查看 ip a show ens33
我想了解一下 虚拟机的 net直连 桥接 仅主机模式 自定义虚拟网络 这些有什么区别啊
| 模式名称 |
虚拟机是否能访问外网 |
能否与主机通信 |
能否被局域网其它设备访问 |
场景用途 |
| NAT(网络地址转换) |
✅ 可以 |
✅ 可以 |
❌ 不能 |
默认模式,适合访问互联网但不被访问 |
| 桥接模式(Bridged) |
✅ 可以 |
✅ 可以 |
✅ 可以 |
适合开发、调试服务端程序 |
| 仅主机模式(Host-Only) |
❌ 不可以 |
✅ 可以 |
❌ 不能 |
适合测试虚拟机与主机通信,隔离网络 |
| 自定义虚拟网络(VMnetX) |
看配置情况 |
看配置情况 |
看配置情况 |
高级用途,如多机组网、模拟拓扑 |
✅ 判断网络模式
你需要检查虚拟机使用的网络连接方式,有几种常见模式:
| 网络模式 |
是否能上网 |
是否能被主机访问 |
说明 |
| NAT |
✅ |
❌ |
默认可以上网,不能被主机访问 |
| 桥接模式 |
✅ |
✅ |
与主机同网段,能上网、能互通 |
| Host-only |
❌ |
✅ |
不能上网,只能主机访问 |
| 内部网络(仅限虚拟机) |
❌ |
❌ |
用于多虚拟机内部通信 |
1️⃣ NAT 模式(默认)
虚拟机通过 VMware NAT 服务共享主机网络访问外网
特点:
- 虚拟机 IP 是
192.168.200.x 之类的 VMware 虚拟网段
- 宿主机充当“路由器”角色
- 适合需要上网,但不想暴露虚拟机到外部网络
优点:
- 无需特殊配置即可访问外网
- 安全,外部无法直接访问虚拟机
缺点:
- 外部机器(包括宿主机)无法直接 ping 通虚拟机
- 虚拟机 IP 不稳定
2️⃣ 桥接模式(Bridged)
虚拟机像真实电脑一样连接到局域网(通过宿主机的物理网卡桥接出去)
特点:
- 虚拟机 IP 和宿主机一样,都由路由器分配(比如
192.168.31.x)
- 可以直接与宿主机、局域网其他设备通信
优点:
- 和真实电脑一样,可以被 ping 通、远程访问、部署服务等
- 最贴近真实网络环境,适合服务器开发
缺点:
- 依赖物理网络(尤其 Wi-Fi 桥接时可能失败)
- 公司/学校网络可能屏蔽桥接
3️⃣ 仅主机模式(Host-Only)
虚拟机只能和宿主机通信,完全与外网隔离
特点:
- 虚拟机 IP 通常是
192.168.56.x 或 192.168.152.x
- 不能访问互联网
优点:
- 安全,完全离线隔离
- 虚拟机和主机之间能稳定通信(做测试非常好)
缺点:
4️⃣ 自定义虚拟网络(VMnet0~19)
高级用户使用,可自由配置网络结构
典型用途:
- 多台虚拟机组成专属局域网
- 配置 DHCP、NAT、Host-Only 混合网络
- 构建模拟数据中心、私有云、堡垒机环境等
🎯 总结建议(适合不同场景):
| 场景 |
建议使用模式 |
| 日常使用、能上网即可 |
NAT 模式(默认) |
| 开发服务端、需要固定 IP + 被访问 |
桥接模式 ✅ |
| 只在主机和虚拟机之间通信 |
Host-Only 模式 |
| 多虚拟机模拟复杂网络 |
自定义(VMnet) |
📌 一句话总结:
NAT 是“内网访问外网”,桥接是“虚拟机等于真电脑”,Host-Only 是“我只和主机说话”,自定义是“你说了算”。
环境准备(2)—Dockerfile镜像脚本快速入门
Dockerfile其实就是我们用来构建Docker镜像的源码,当然这不是所谓的编程源码,而是一些命令的组 合,只要理解它的逻辑和语法格式,就可以编写Dockerfile了。 简单点说,Dockerfile的作用:它可以让用户个性化定制Docker镜像。因为工作环境中的需求各式各 样,网络上的镜像很难满足实际的需求。
| 命令 |
作用 |
| FROM image_name:tag |
|
| MAINTAINER user_name |
声明镜像的作者 |
| ENV key value |
设置环境变量(可以写多条) |
| RUN command |
编译镜像时运行的脚本(可以写多条) |
| CMD |
设置容器的启动命令 |
| ENTRYPOINT |
设置容器的入口程序 |
| ADD source_dir/file dest_dir/file |
将宿主机的文件复制到容器内,如果是一个压缩文件。将会在复制后自动解压 |
| COPY source_dir/file dest_dir/file |
和ADD相似,但是如果又压缩文件并不能解压 |
| WORKDIR path_dir |
设置工作目录 |
| ARG |
设置编译镜像时加入的参数 |
| VOLUMN |
设置容器的挂载卷 |
新镜像是从基础镜像一层一层叠加生成的。每安装一个软件,就在现有镜像的基础上增加一 层
使用Dockerfile制作微服务镜像
我们利用Dockerfile制作一个Eureka注册中心的镜像
1)上传Eureka的微服务jar包到linux这里的jar包要和Dockerfile文件在同一目录下
2)编写Dockerfile vi Dockerfile
作用:📦 构建一个用于运行 Java 应用(Spring Boot 或其他 jar 应用)的 Docker 镜像。
这个 Dockerfile 是在用 Java 8 的轻量镜像里,运行你打包好的 jar 应用,并对外开放 10086 端口,非常适合部署 Spring Boot 项目。
FROM openjdk:8-jdk-alpine
ARG JAR_FILE
COPY ${JAR_FILE} app.jar
EXPOSE 10086
ENTRYPOINT ["java","-Djava.net.preferIPv4Stack=true","-jar","/app.jar"]
3 )构建镜像
docker build --build-arg JAR_FILE=tensquare_eureka_server-1.0-SNAPSHOT.jar -t eureka:v1 .
-t是定义名字 .是在当前目录
4)查看镜像是否创建成功
docker images
[root@localhost ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
eureka v1 36af14603456 15 seconds ago 150MB
nginx latest 9592f5595f2b 7 days ago 192MB
hello-world latest 74cc54e27dc4 5 months ago 10.1kB
openjdk 8-jdk-alpine a3562aa0b991 6 years ago 105MB
5)创建容器
docker run -i --name=eureka -p 10086:10086 eureka:v1
后台运行:docker run -d --name=eureka -p 10086:10086 eureka:v1
删除容器:docker rm -f eureka
查看容器是否启动docker ps
查看日志docker logs -f eureka
后面可以直接启动这个容器 docker start eureka
6)访问容器 http://192.168.200.129:10086
修改后重新构建镜像:
docker stop eureka
docker rm eureka
# 重新构建镜像(确保 Dockerfile 和配置文件都在当前目录)
docker build --build-arg JAR_FILE=tensquare_eureka_server-1.0-SNAPSHOT.jar -t eureka:v1 .
# 启动容器并映射端口
docker run -d --name=eureka -p 10086:10086 eureka:v1
进入容器(你已经会了):
docker exec -it eureka /bin/sh
- **容器内查找
application.yaml**:
find / -name application.yaml 2>/dev/null
2>/dev/null 是把权限不够或找不到文件时的报错信息过滤掉,方便看结果。
- 找到路径后,用
cat 查看内容:
假设查到文件在 /config/application.yaml,那么:
cat /config/application.yaml
你要删除 <none> 的镜像,也就是“悬空镜像(dangling image)”,可以使用以下命令:
🔍 查看所有悬空镜像
docker images -f "dangling=true"
🗑 删除所有悬空镜像
docker rmi $(docker images -f "dangling=true" -q)
root@localhost ~]# docker run -d –name=eureka -p 10086:10086 eureka:v1 docker: Error response from daemon: Conflict. The container name “/eureka” is already in use by container “9ea494448aeb1d99faecfe11e652f438938b87e1caaca890f9001199e1166dbc”. You have to remove (or rename) that container to be able to reuse that name. See ‘docker run –help’. 这个错误说明:虽然你已经 docker stop eureka 停止了容器,但它还没有被删除,所以容器名 /eureka 依然占用中,不能再用这个名字启动新的容器。
✅ 解决方案:删除旧容器
你需要先 删除已停止的 eureka 容器,再重新启动:
docker rm eureka
然后再重新运行新的容器:
docker run -d --name=eureka -p 10086:10086 eureka:v1
是桥接 能ping通 防火墙永久关闭了 本机打开了clash系统代理+全局
ChatGPT 说:
非常关键的点来了!
你说:
✅ 虚拟机是桥接模式
✅ 能 ping 通虚拟机 192.168.200.129
✅ 防火墙是永久关闭状态
❌ 本机打开了 Clash 并启用了系统代理 + 全局模式
✅ 你的 Eureka 服务配置和容器启动都是正确的,问题现在就出在:你本机开启了 Clash 的全局代理。
❗这会导致浏览器请求走代理,无法访问内网地址(例如 192.168.200.129:10086)。
删除镜像:docker rmi eureka:v1
删除所有悬挂镜像:< none >的 docker images | grep "<none>" | awk '{print $3}' | xargs -r docker rmi -f
ss -tlnp | grep 10086✅ 你看到的是:
LISTEN 0 1024 :::10086 :::* users:(("docker-proxy",pid=31831,fd=4))
📌 说明:
这是 宿主机上的 docker-proxy 在监听 10086 端口,它只是端口映射的外壳进程。
但我们没有看到你容器内部的 Spring Boot 应用是否在监听端口,也就是说:
✅ docker-proxy 映射是 OK 的
❗️容器里的 Spring Boot 可能绑定了 127.0.0.1:10086,不是 0.0.0.0:10086,导致 proxy 转发过去失败
✅ 解决方案 —— 修改配置,显式绑定 0.0.0.0
请 **修改你的 application.yml**,在 server 配置中添加这一行:
yaml复制编辑server:
port: 10086
address: 0.0.0.0 # <-- 显式监听所有网卡地址
[root@localhost ~]# netstat -tln
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 127.0.0.1:9100 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:9229 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:8080 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:9168 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:8082 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:82 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:9236 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:3000 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8060 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:9121 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:9090 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:9187 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:9093 0.0.0.0:* LISTEN
tcp6 0 0 :::3306 :::* LISTEN
tcp6 0 0 ::1:9168 :::* LISTEN
tcp6 0 0 :::22 :::* LISTEN
tcp6 0 0 :::10086 :::* LISTEN
tcp6 0 0 :::9094 :::* LISTEN
你贴的 netstat -tln 结果说明:
- 你的服务监听在
:::10086(IPv6的所有地址),没有监听任何IPv4地址(比如0.0.0.0:10086)
- 这意味着你的Spring Boot应用只监听了IPv6地址,IPv4访问就无法连接(所以你用
http://192.168.200.129:10086 访问会失败)
具体做法:
- 修改你的
Dockerfile 中 ENTRYPOINT:
FROM openjdk:8-jdk-alpine
ARG JAR_FILE
COPY ${JAR_FILE} app.jar
EXPOSE 10086
ENTRYPOINT ["java","-Djava.net.preferIPv4Stack=true","-jar","/app.jar"]
2. 构建新镜像(建议打新标签)
docker build --build-arg JAR_FILE=tensquare_eureka_server-1.0-SNAPSHOT.jar -t eureka:v2 .
3. 停止并删除旧容器(如果还在运行)
docker stop eureka
docker rm eureka
4. 运行新镜像容器
docker run -d -p 10086:10086 --name eureka eureka:v2
6. 测试访问
浏览器打开:
http://192.168.200.129:10086
现在可以访问成功了 为什么加上这句话就好了 ENTRYPOINT [“java”,”-Djava.net.preferIPv4Stack=true”,”-jar”,”/app.jar”] 为什么监听的时候还是ipv6 [root@localhost ~]# ss -tlnp | grep 10086 LISTEN 0 1024 :::10086 :::* users:((“docker-proxy”,pid=35209,fd=4)) 但是成功在主机访问地址了
为什么加上 -Djava.net.preferIPv4Stack=true 就好了?
- 这个参数告诉 JVM 优先使用 IPv4 网络栈,避免只监听 IPv6 导致外部 IPv4 地址访问不到的问题。
- Spring Boot 的内嵌 Tomcat 在默认情况下,Linux 可能优先监听 IPv6 地址(
:::port)。
- 加了这个参数后,Tomcat 会优先绑定 IPv4 地址,从而确保 Docker 的端口映射能正常被外部 IPv4 网络访问。
为什么监听时还是显示 IPv6 (:::10086)?
- Linux 上 IPv6 的监听套接字
::: 默认是包含 IPv4 地址 0.0.0.0 的(叫做 IPv4-mapped IPv6 地址)。
- 也就是说,监听
:::10086 实际上同时监听了所有 IPv6 和 IPv4 地址。
- 这是一种操作系统层面的机制,不是 Java 层面的问题。
总结
-Djava.net.preferIPv4Stack=true 让 JVM 侧优先用 IPv4,避免了纯 IPv6 监听带来的访问问题。ss 看到的 :::10086 其实也包括了 IPv4 地址,所以你才能用 IPv4 地址成功访问。- 访问成功说明网络和端口映射都正常工作了。
太好了,你现在已经非常接近成功了,我们来梳理一下现状和如何解决你“既能联网又能用 Mobaxterm 连上虚拟机”的问题。
✅ 当前状态分析
你目前有两张网卡:
| 网卡名 |
IP 地址 |
状态 |
说明 |
ens33 |
192.168.200.131 |
✅ UP,有 IP |
是你原来的桥接或 Host-Only 网卡,用于主机连虚拟机 |
ens36 |
无 IP |
❌ DOWN |
是你新加的 NAT 网卡,但 没有启动 / 没有获取 IP |
🧩 为什么还无法联网?
你 curl 下载失败,是因为 NAT 网卡 ens36 没启动,虚拟机依然没联网。
✅ 解决方案:启动 NAT 网卡并设置为默认出网口
第一步:激活 ens36(NAT 网卡)
执行:
dhclient ens36
⏳ 如果你没装 dhclient,可以试试:
nmcli device connect ens36
然后再次查看 IP:
ip addr
你应该能看到 ens36 分配到类似 192.168.226.x 的地址(NAT 网段)
总结一下视频里的服务器ip所对应的服务
192.168.66.100 GitLab
192.168.66.101 Jenkins
192.168.66.102 Harbor && Tomcat
192.168.66.103 生产部署服务器
环境准备(3)-Harbor镜像仓库安装及使用
Harbor简介
Harbor(港口,港湾)是一个用于存储和分发Docker镜像的企业级Registry服务器。 除了Harbor这个私有镜像仓库之外,还有Docker官方提供的Registry。相对Registry,Harbor具有很多优势:
- 提供分层传输机制,优化网络传输 Docker镜像是是分层的,而如果每次传输都使用全量文件(所以 用FTP的方式并不适合),显然不经济。必须提供识别分层传输的机制,以层的UUID为标识,确定 传输的对象。
- 提供WEB界面,优化用户体验 只用镜像的名字来进行上传下载显然很不方便,需要有一个用户界 面可以支持登陆、搜索功能,包括区分公有、私有镜像。
- 支持水平扩展集群 当有用户对镜像的上传下载操作集中在某服务器,需要对相应的访问压力作分解。
- 良好的安全机制 企业中的开发团队有很多不同的职位,对于不同的职位人员,分配不同的权限,具有更好的安全性。
Harbor安装
Harbor需要安装在192.168.200.131 Harbor && Tomcat上
你可以使用 离线安装 docker-compose 的方式,在主机上下载好二进制文件,再拷贝到虚拟机中使用,非常简单。
✅ 方法一:主机下载 → 拷贝到虚拟机
步骤 1️⃣:在主机(Windows)上用浏览器下载这个文件
访问地址如下(你这个版本是 1.21.2):
👉 https://github.com/docker/compose/releases/download/1.21.2/docker-compose-Linux-x86_64
下载后,重命名为:docker-compose
步骤 2️⃣:用 MobaXterm 拷贝到虚拟机
你在 Mobaxterm 中连接好虚拟机后:
- 左侧文件管理器中找到
/usr/local/bin(或 /root)
- 把你刚下载的
docker-compose 拖进去上传
或者用 scp 命令上传:
scp docker-compose root@192.168.200.131:/usr/local/bin/docker-compose
把 192.168.200.131 换成你虚拟机 IP,输入密码即可
步骤 3️⃣:在虚拟机中赋予执行权限
chmod +x /usr/local/bin/docker-compose
步骤 4️⃣:验证安装成功
docker-compose -v
输出类似:
docker-compose version 1.21.2, build ...
✅ 完成!
这里有个经典的超级牛逼的大bug
抛出问题:
这是我vi /etc/sysconfig/network-scripts/ifcfg-ens33
DEFROUTE=yes
NAME=ens33
UUID=a8ca17a4-0388-4b06-81b3-895e1a8180fe
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.200.131
NETMASK=255.255.255.0
GATEWAY=192.168.31.1
DNS1=8.8.8.8
这是我虚拟机的ip add
[root@localhost ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:7b:04:23 brd ff:ff:ff:ff:ff:ff
inet 192.168.200.131/24 brd 192.168.200.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe7b:423/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:94:7c:ad:4a brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
该虚拟机选择了桥接模式 且 勾选了复制到物理网络连接状态
其虚拟网络编辑器里面
VMnet0 桥接模式 自动桥接 主机连接无 DHCP无 子网地址无
VMnet1 仅主机 外部连接无 主机连接已连接 DHCP已启用 子网地址192.168.22.0
VMnet8 NAT模式 NAT模式 主机连接已连接 DHCP无 子网地址192.168.200.0
这是我主机ipconfig
C:\Users\Pluminary>ipconfig
Windows IP 配置
以太网适配器 以太网 4:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
无线局域网适配器 本地连接* 1:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
无线局域网适配器 本地连接* 2:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
以太网适配器 VMware Network Adapter VMnet1:
连接特定的 DNS 后缀 . . . . . . . :
本地链接 IPv6 地址. . . . . . . . : fe80::1ea6:88fa:c0e1:f1ca%22
IPv4 地址 . . . . . . . . . . . . : 192.168.22.1
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . :
以太网适配器 VMware Network Adapter VMnet8:
连接特定的 DNS 后缀 . . . . . . . :
本地链接 IPv6 地址. . . . . . . . : fe80::9e33:f9ac:4f64:9d71%3
IPv4 地址 . . . . . . . . . . . . : 192.168.200.2
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . : 192.168.200.1
无线局域网适配器 WLAN:
连接特定的 DNS 后缀 . . . . . . . :
本地链接 IPv6 地址. . . . . . . . : fe80::7df7:efe4:1d3b:e2d2%12
IPv4 地址 . . . . . . . . . . . . : 192.168.31.103
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . : 192.168.31.1
我现在的问题是 如果我改了GATEWAY=192.168.31.1 为别的 那么我MobaXterm就连不上该虚拟机 现在的问题是 虚拟机没有网 我镜像都下载不了[root@localhost harbor]# ./prepare
prepare base dir is set to /opt/harbor
Unable to find image ‘goharbor/prepare:v1.9.2’ locally
^C
[root@localhost harbor]# ^C
[root@localhost harbor]#
GitHub解决方案:
你目前的状态是:
✅ 虚拟机 IP 是 192.168.200.131(静态 IP,桥接模式下设置的)
✅ 宿主机 WLAN IP 是 192.168.31.103
❌ 虚拟机无法联网(不能拉取镜像)
✅ MobaXterm 可以连接虚拟机(192.168.200.131)
⚠️ 虚拟机网关设置为 192.168.31.1,其实这是 WLAN 的网关,不属于 192.168.200.x 子网
🔥 你现在的问题本质:
- 虽然 MobaXterm 能访问虚拟机
192.168.200.131,但虚拟机设置了一个不在本网段的网关:192.168.31.1
- 所以虚拟机根本无法出网(不能 ping 外网,也不能拉 harbor 镜像)
✅ 正确配置方式:
让虚拟机在桥接模式下能 联网 + 被访问
✅ 第一步:设置正确网关(匹配虚拟机 IP 网段)
你虚拟机静态 IP 是 192.168.200.131,所以网关必须也在 192.168.200.1~254 范围。
观察宿主机 VMnet8(NAT)是 192.168.200.2,它的网关是:
默认网关: 192.168.200.1
所以你应设置:
IPADDR=192.168.200.131
NETMASK=255.255.255.0
GATEWAY=192.168.200.1
DNS1=8.8.8.8
✅ 这个配置能让虚拟机出网(使用 VMware NAT 出口),也能让宿主机通过 192.168.200.131 访问虚拟机。
✅ 第二步:如果你用的是 NAT 模式,则使用上面的 GATEWAY 是对的
但你说你用了 桥接模式,那就要看桥接的是哪块网卡。
桥接模式下,正确做法是:
- 虚拟机 IP 要跟宿主机所连网络同一个网段
- 网关要设置为 宿主机 WLAN 的网关:
192.168.31.1
这样你才会在 MobaXterm 能访问、也能联网。
❗但你现在问题是:
你桥接了,但 IP 却在 192.168.200.x,这说明虚拟机并没有成功桥接到宿主机 WLAN 网卡,而是连到了 VMware 的 NAT 网络(即使你设置桥接,也可能没生效)
✅ 最建议方案
A. 用 NAT 模式 + 正确网关(推荐稳定,适合大多数人)
- 把虚拟机改为 NAT 模式
ifcfg-ens33 设置如下:
DEVICE=ens33
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.200.131
NETMASK=255.255.255.0
GATEWAY=192.168.200.1 # NAT 的默认网关
DNS1=8.8.8.8
- 重启网络:
systemctl restart network
- 测试网络:
ping -c 3 8.8.8.8
curl www.baidu.com
- 然后使用
MobaXterm 访问你设置的 192.168.200.131,或设置端口转发(如 127.0.0.1:2222 → 192.168.200.131:22)
B. 或者继续桥接,但设置静态 IP 为 192.168.31.x 网段
如果你要桥接到宿主机 WLAN:
- 修改
/etc/sysconfig/network-scripts/ifcfg-ens33:
DEVICE=ens33
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.31.130 # 自己定个没冲突的 IP
NETMASK=255.255.255.0
GATEWAY=192.168.31.1 # 你的无线网关
DNS1=8.8.8.8
- 重启网络:
systemctl restart network
- 检查 IP 和连通性:
ip addr
ping 8.8.8.8
✅ 结论
你现在 MobaXterm 能连接,是因为用了静态 IP 192.168.200.131,但由于网关不在同一网段,导致不能联网。
你只要根据你实际使用的网络模式(NAT 或桥接),把网关改成同网段的地址,问题就能解决。
如果你告诉我你最终想使用 NAT 还是桥接(是否希望虚拟机能被其它设备访问),我可以直接帮你生成完整配置文件。
继续延申问题:
我按照你说的改了 改成了nat模式 然后也改了配置 但是还是不行 [rooteloca1host ~]# ping -c 3 8.8.8.8PING 8.8.8.8(8.8.8.8) 56(84) bytes of data.From 192.168.200.131 icmp_seq=1 Destination Host UnreachableFrom 192.168.200.131 icmp_seq=2 Destination Host UnreachableFrom 192.168.200.131 icmp_seq=3 Destination Host Unreachable8.8.8.8 ping statistics3 packets transmitted,0 received, +3 errors, 100% packet loss,time 1999mspipe3 现在连MobaXterm都连不上了 Network error: Connection timed out ───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── Session stopped - Press to exit tab - Press R to restart session - Press S to save terminal output to file
✅ 你现在的问题是:
你切换到 NAT 模式了,配置也改了,但:
- ❌ 仍然无法联网(
ping 8.8.8.8 不通)
- ❌ MobaXterm 也连不上虚拟机(连接超时)
- ✅ 虚拟机 IP 是
192.168.200.131,网关你应该已改为 192.168.200.1(对吧?)
我们来一步步快速排查:
✅ 第一步:确认虚拟机网卡配置是否正确
在虚拟机里执行:
cat /etc/sysconfig/network-scripts/ifcfg-ens33
确认配置如下(静态 IP 模式 + NAT 网段的正确网关):
DEVICE=ens33
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.200.131
NETMASK=255.255.255.0
GATEWAY=192.168.200.1
DNS1=8.8.8.8
如果不是这样,请立刻修改。
然后执行:
systemctl restart network
✅ 第二步:确认 NAT 模式是否正确工作
打开 VMware 虚拟网络编辑器,确认:
- VMnet8 网络的 子网 IP 是
192.168.200.0
- 默认网关(Gateway)是
192.168.200.1
- 启用了 NAT 功能(有
NAT 设置 按钮,不是空的)
- 勾选了 “使用本地 DHCP 服务将 IP 地址分配给虚拟机”(建议开启)
✅ 第三步:确认虚拟机路由是否存在
在虚拟机中执行:
ip route
你应该看到类似:
default via 192.168.200.1 dev ens33
192.168.200.0/24 dev ens33 proto kernel scope link src 192.168.200.131
如果没有 default via 192.168.200.1,说明网关没生效,路由不通。
✅ 第四步:确认宿主机启用了 NAT 网络服务
- 打开 VMware 网络编辑器(以管理员身份运行)
- 点击
VMnet8,点右侧的 “NAT 设置”
- 看到:
网关 IP: 192.168.200.1
下面是端口转发之类设置,不用动。
- 确保 VMware NAT Service 是运行状态:
- 在宿主机按 Win+R → 输入
services.msc
- 找到
VMware NAT Service 和 VMware DHCP Service
- 状态必须是“正在运行”
✅ 第五步:测试连接
- 在虚拟机里执行:
ping 192.168.200.1
能 ping 通说明 NAT 网关 OK。
- 在虚拟机里执行:
ping 8.8.8.8
仍然不通,说明出网失败,可能是:
- 路由表错(
ip route 查看)
- NAT 服务没开(第 4 步)
- 没走正确网关(第 1 步)
按照你说的做了 [root@localhost harbor]# docker ps | grep nginx 1773679bace8 goharbor/nginx-photon:v1.9.2 “nginx -g ‘daemon of…” 9 seconds ago Up 7 seconds (health: starting) 0.0.0.0:85->8080/tcp nginx 7e41a5e0662b goharbor/harbor-portal:v1.9.2 “nginx -g ‘daemon of…” 14 seconds ago Up 10 seconds (health: starting) 8080/tcp harbor-portal [root@localhost harbor]#
ChatGPT 说:
非常好,你现在的操作都没错,但从这条日志来看:
0.0.0.0:85->8080/tcp nginx
说明 docker-compose.yml 里仍然是 85:8080 映射,而不是我们期望的:
85:80
✅ 解决方案:手动改一下 docker-compose.yml,然后重新启动 Harbor
✏️ 步骤 1:手动修改端口映射
打开 docker-compose.yml,找到 proxy: 下面这段:
ports:
- 85:8080
改成:
ports:
- 85:80
🔁 如果你在 Vim 里编辑,改完后按:
Esc → :wq
🔄 步骤 2:重启 Harbor 服务
docker-compose down
docker-compose up -d
🔍 步骤 3:确认端口映射是否正确
docker ps | grep nginx
应该看到:
0.0.0.0:85->80/tcp nginx
✅ 最后:浏览器访问 Harbor
打开浏览器访问:
http://192.168.200.131:85/
你应该能看到 Harbor 登录页面。
🔍 目前情况总结:
| 项 |
状态 |
nginx 容器健康 |
✅ healthy |
curl localhost:85 |
❌ 失败(提示:Connection reset by peer) |
ss -tnlp 显示监听 |
✅ docker-proxy 在监听 :::85 |
ping 192.168.200.131 |
✅ 通 |
浏览器访问 http://192.168.200.131:85 |
❌ 超时 |
✅ 正确的配置应为:
在 docker-compose.yml 里,把 proxy 服务的 ports 改为:
ports:
- 85:80
然后执行如下命令使配置生效:
# 停止并清理容器
docker-compose down
# 再启动
docker-compose up -d
再执行:
curl -I http://localhost:85
你应该能看到:
HTTP/1.1 200 OK
然后用浏览器访问:
http://192.168.200.131:85
✅ 成功进入 Harbor 页面!
我已经用了NAT模式 + 静态ip [root@localhost harbor]# curl -I http://localhost:85 curl: (56) Recv failure: Connection reset by peer [root@localhost harbor]# 嗯… 无法访问此页面 192.168.200.131 响应时间太长 请尝试: 在 Web 上搜索 192 168 200 131 检查连接 检查代理和防火墙 ERR_CONNECTION_TIMED_OUT
ChatGPT 说:
你现在的情况是:
- ✅ 已经使用了 NAT 模式;
- ✅
docker ps 显示 Harbor 的 nginx 容器 端口映射是正确的:0.0.0.0:85->80;
- ❌ 但
curl localhost:85 报错:Connection reset by peer,说明容器里的 nginx 拒绝了连接;
- ❌ 主机访问
http://192.168.200.131:85 报超时,NAT 本身不支持直接访问虚拟机的 IP;
- ✅ 你已给虚拟机设置静态 IP 为
192.168.200.131;
- ❗ 你没有配置端口转发!
🎯 结论:你现在这种做法是错误的
NAT 模式下,主机不能通过虚拟机的 IP(192.168.200.131)访问 Harbor 的端口。
应该通过端口转发实现!
✅ 正确做法:配置端口转发(NAT ➜ 主机映射)
🛠 步骤如下:
① 打开 VMware 虚拟网络编辑器
- 打开 VMware Workstation(非虚拟机内部)
- 菜单栏 ➜
编辑 ➜ 虚拟网络编辑器
- 找到
VMnet8(即 NAT 模式)
② 点击右下角的“NAT 设置”
- 在弹出的 NAT 设置窗口中 ➜ 点击“端口转发(Port Forwarding)”
③ 添加一条端口转发规则:
| 名称 |
协议 |
主机端口 |
虚拟机 IP |
虚拟机端口 |
| harbor |
TCP |
1085 |
192.168.200.131 |
85 |
主机端口你可以写 1085,避免冲突;虚拟机端口是 Harbor 的端口 85。
📌 说明:为什么 NAT 模式不能直接访问虚拟机 IP?
NAT 模式是虚拟机通过主机“共享网络”出去访问外部,但主机无法通过虚拟机的 NAT IP(如 192.168.200.131)访问回来,因为这个网段对主机来说是隔离的。
除非做端口转发,否则无法通信。
🧭 接下来的最后一步:
你当前的网络结构是:
Windows 浏览器访问 localhost:10085
↓
VMware NAT 端口转发:10085 → 192.168.200.131:85
↓
Harbor Docker:85 → nginx容器的 82
↓
nginx 正常监听 82
cd /opt/harbor/
搞了好久 估计是网络+配置的问题
这是docker-compose.yml的配置信息
version: '2.3'
services:
log:
image: goharbor/harbor-log:v1.9.2
container_name: harbor-log
restart: always
dns_search: .
cap_drop:
- ALL
cap_add:
- CHOWN
- DAC_OVERRIDE
- SETGID
- SETUID
volumes:
- /var/log/harbor/:/var/log/docker/:z
- ./common/config/log/logrotate.conf:/etc/logrotate.d/logrotate.conf:z
- ./common/config/log/rsyslog_docker.conf:/etc/rsyslog.d/rsyslog_docker.conf:z
ports:
- 127.0.0.1:1514:10514
networks:
- harbor
registry:
image: goharbor/registry-photon:v2.7.1-patch-2819-2553-v1.9.2
container_name: registry
restart: always
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
volumes:
- /data/registry:/storage:z
- ./common/config/registry/:/etc/registry/:z
- type: bind
source: /data/secret/registry/root.crt
target: /etc/registry/root.crt
networks:
- harbor
dns_search: .
depends_on:
- log
logging:
driver: "syslog"
options:
syslog-address: "tcp://127.0.0.1:1514"
tag: "registry"
registryctl:
image: goharbor/harbor-registryctl:v1.9.2
container_name: registryctl
env_file:
- ./common/config/registryctl/env
restart: always
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
volumes:
- /data/registry:/storage:z
- ./common/config/registry/:/etc/registry/:z
- type: bind
source: ./common/config/registryctl/config.yml
target: /etc/registryctl/config.yml
networks:
- harbor
dns_search: .
depends_on:
- log
logging:
driver: "syslog"
options:
syslog-address: "tcp://127.0.0.1:1514"
tag: "registryctl"
postgresql:
image: goharbor/harbor-db:v1.9.2
container_name: harbor-db
restart: always
cap_drop:
- ALL
cap_add:
- CHOWN
- DAC_OVERRIDE
- SETGID
- SETUID
volumes:
- /data/database:/var/lib/postgresql/data:z
networks:
harbor:
dns_search: .
env_file:
- ./common/config/db/env
depends_on:
- log
logging:
driver: "syslog"
options:
syslog-address: "tcp://127.0.0.1:1514"
tag: "postgresql"
core:
image: goharbor/harbor-core:v1.9.2
container_name: harbor-core
env_file:
- ./common/config/core/env
restart: always
cap_drop:
- ALL
cap_add:
- SETGID
- SETUID
volumes:
- /data/ca_download/:/etc/core/ca/:z
- /data/psc/:/etc/core/token/:z
- /data/:/data/:z
- ./common/config/core/certificates/:/etc/core/certificates/:z
- type: bind
source: ./common/config/core/app.conf
target: /etc/core/app.conf
- type: bind
source: /data/secret/core/private_key.pem
target: /etc/core/private_key.pem
- type: bind
source: /data/secret/keys/secretkey
target: /etc/core/key
networks:
harbor:
dns_search: .
depends_on:
- log
- registry
- redis
- postgresql
logging:
driver: "syslog"
options:
syslog-address: "tcp://127.0.0.1:1514"
tag: "core"
portal:
image: goharbor/harbor-portal:v1.9.2
container_name: harbor-portal
restart: always
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
- NET_BIND_SERVICE
networks:
- harbor
dns_search: .
depends_on:
- log
logging:
driver: "syslog"
options:
syslog-address: "tcp://127.0.0.1:1514"
tag: "portal"
jobservice:
image: goharbor/harbor-jobservice:v1.9.2
container_name: harbor-jobservice
env_file:
- ./common/config/jobservice/env
restart: always
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
volumes:
- /data/job_logs:/var/log/jobs:z
- type: bind
source: ./common/config/jobservice/config.yml
target: /etc/jobservice/config.yml
networks:
- harbor
dns_search: .
depends_on:
- core
logging:
driver: "syslog"
options:
syslog-address: "tcp://127.0.0.1:1514"
tag: "jobservice"
redis:
image: goharbor/redis-photon:v1.9.2
container_name: redis
restart: always
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
volumes:
- /data/redis:/var/lib/redis
networks:
harbor:
dns_search: .
depends_on:
- log
logging:
driver: "syslog"
options:
syslog-address: "tcp://127.0.0.1:1514"
tag: "redis"
proxy:
image: goharbor/nginx-photon:v1.9.2
container_name: nginx
restart: always
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
- NET_BIND_SERVICE
volumes:
- ./common/config/nginx:/etc/nginx:z
networks:
- harbor
dns_search: .
ports:
- 85:8080
depends_on:
- registry
- core
- portal
- log
logging:
driver: "syslog"
options:
syslog-address: "tcp://127.0.0.1:1514"
tag: "proxy"
networks:
harbor:
external: false
这是harbor里的nginx的配置
[root@localhost nginx]# cat nginx.conf
worker_processes auto;
pid /tmp/nginx.pid;
events {
worker_connections 1024;
use epoll;
multi_accept on;
}
http {
client_body_temp_path /tmp/client_body_temp;
proxy_temp_path /tmp/proxy_temp;
fastcgi_temp_path /tmp/fastcgi_temp;
uwsgi_temp_path /tmp/uwsgi_temp;
scgi_temp_path /tmp/scgi_temp;
tcp_nodelay on;
# this is necessary for us to be able to disable request buffering in all cases
proxy_http_version 1.1;
upstream core {
server core:8080;
}
upstream portal {
server portal:8080;
}
log_format timed_combined '$remote_addr - '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" '
'$request_time $upstream_response_time $pipe';
access_log /dev/stdout timed_combined;
server {
listen 8080;
server_tokens off;
# disable any limits to avoid HTTP 413 for large image uploads
client_max_body_size 0;
# Add extra headers
add_header X-Frame-Options DENY;
add_header Content-Security-Policy "frame-ancestors 'none'";
# costumized location config file can place to /etc/nginx/etc with prefix harbor.http. and suffix .conf
include /etc/nginx/conf.d/harbor.http.*.conf;
location / {
proxy_pass http://portal/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# When setting up Harbor behind other proxy, such as an Nginx instance, remove the below line if the proxy already has similar settings.
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering off;
proxy_request_buffering off;
}
location /c/ {
proxy_pass http://core/c/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# When setting up Harbor behind other proxy, such as an Nginx instance, remove the below line if the proxy already has similar settings.
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering off;
proxy_request_buffering off;
}
location /api/ {
proxy_pass http://core/api/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# When setting up Harbor behind other proxy, such as an Nginx instance, remove the below line if the proxy already has similar settings.
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering off;
proxy_request_buffering off;
}
location /chartrepo/ {
proxy_pass http://core/chartrepo/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# When setting up Harbor behind other proxy, such as an Nginx instance, remove the below line if the proxy already has similar settings.
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering off;
proxy_request_buffering off;
}
location /v1/ {
return 404;
}
location /v2/ {
proxy_pass http://core/v2/;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# When setting up Harbor behind other proxy, such as an Nginx instance, remove the below line if the proxy already has similar settings.
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering off;
proxy_request_buffering off;
}
location /service/ {
proxy_pass http://core/service/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# When setting up Harbor behind other proxy, such as an Nginx instance, remove the below line if the proxy already has similar settings.
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering off;
proxy_request_buffering off;
}
location /service/notifications {
return 404;
}
}
}
这里附带重大BUG排查思路
当然可以!我帮你把这整个过程的错误、涉及的宿主机、虚拟机、nginx(宿主机与容器里Harbor的nginx),以及排查思路,综合讲清楚,方便你理解整体流程。
1. 相关环境和组件说明
- 宿主机:你的真实物理机或主机系统(Windows),负责运行虚拟机软件(比如VMware)。
- 虚拟机:运行 Harbor 的 Linux 虚拟机(192.168.200.131),是 Harbor 的部署环境。
- Docker 容器内的 nginx:Harbor 里内置的 nginx 作为反向代理服务器,监听容器内部的端口(如 82 或 8080),将请求转发给 Harbor 应用组件。
- 宿主机与虚拟机的网络:
- 虚拟机配置桥接或NAT网络,宿主机通过 IP 和端口转发访问虚拟机。
- 端口转发需确保宿主机防火墙、虚拟机防火墙和 Docker 端口映射正确。
2. 你遇到的主要错误和症状总结
| 错误/症状 |
可能原因 |
备注 |
Test-NetConnection 提示 TCP 连接失败(比如端口1085失败,10085成功但浏览器连接拒绝) |
端口未开放或服务未监听,防火墙或网络配置问题 |
端口映射或容器服务没启动好 |
Docker 启动 nginx 容器时报错:unknown log opt 'syslog-address' for json-file log driver |
logging 配置不兼容,json-file 驱动不支持 syslog-address 参数 |
需要调整日志驱动配置 |
curl http://localhost:85 返回 302 或 200,但浏览器访问虚拟机IP时超时或重置连接 |
虚拟机防火墙、宿主机端口转发配置错误,或者nginx监听端口配置不一致 |
宿主机访问虚拟机端口不通 |
虚拟机上 ss -tnlp 看到 nginx 监听的是 82 端口,而 Docker 映射是 85:82 |
端口映射正确,但宿主机访问端口和内部监听端口不一致需要确认 |
访问时端口错位会导致访问失败 |
3. 排查思路和步骤详解
Step 1:确认容器服务启动及端口监听情况
docker-compose up -d 启动 Harbor 相关服务,包括 nginx 代理容器。docker ps 看 nginx 容器是否在运行。docker logs nginx 查看 nginx 容器日志,看是否报错。ss -tnlp(或 netstat -tnlp)确认 nginx 容器内部监听端口,例如82或8080。
Step 2:确认端口映射和宿主机网络
- 确认 docker-compose 端口映射,比如
- 85:82 说明宿主机85端口映射到容器82端口。
- 确认虚拟机的网络IP(192.168.200.131)可访问,虚拟机是否允许访问85端口。
- 通过宿主机(Windows)
Test-NetConnection 192.168.200.131 85 测试连通性。
- 如果端口连接失败,检查:
- 虚拟机防火墙状态(如
firewall-cmd),确认85端口开放。
- 虚拟机网络配置是否正确。
- 宿主机是否正确做了端口转发(NAT配置等)。
Step 3:确认宿主机与虚拟机间端口转发与防火墙设置
- 你之前做的 VMware NAT 端口转发配置,确认宿主机的10085端口转发到虚拟机的85端口。
- 虚拟机防火墙是否禁用或开放该端口(你确认了
firewalld 未运行)。
- SELinux 状态(你确认是
Permissive,不阻止)。
Step 4:确认容器内部 nginx 与 Harbor 应用运行状态
- 容器内 nginx 配置监听82端口,但外部映射成85端口,确认两者一致。
- 容器内 curl localhost:82 返回200,说明 nginx 服务正常。
- nginx 返回的网页中包含 Harbor 前端静态资源,但前端一直转圈,可能是后端 API 没响应。
- 可能是 Harbor 核心服务(core)未正常工作或访问不到数据库/redis,导致页面没加载完成。
Step 5:重启虚拟机后问题消失
- 重启虚拟机后,网络重新初始化,Docker网络也重建,端口转发生效,nginx和Harbor服务正常,浏览器访问成功。
- 说明之前网络环境(端口转发、Docker网络或nginx监听)存在缓存或未正常启动的问题。
4. 你看到的“宿主机与虚拟机”和“nginx内部/外部”的关系
| 层级 |
作用 |
备注 |
| 宿主机 (Windows) |
你直接操作的机器,运行 VMware,提供 NAT/桥接网络,做端口转发 |
访问虚拟机IP和端口 |
| 虚拟机 (Linux Harbor 环境) |
Harbor 部署环境,运行 Docker 和 Harbor 服务容器 |
虚拟机防火墙和网络设置必须正确 |
| Docker 容器内 nginx |
Harbor 的反向代理,监听容器内部端口(如82),转发给 Harbor 应用服务 |
Docker端口映射:宿主机85端口映射到容器82端口 |
| Harbor 应用组件 |
Core、Portal、Registry 等,负责业务逻辑和数据 |
需要数据库和redis支持,服务正常才能正常访问 |
5. 综合总结
- 你先遇到的端口连接失败,是虚拟机内服务监听、端口映射、虚拟机防火墙或宿主机端口转发配置的问题。
- Docker 容器日志中的
unknown log opt 'syslog-address' 是日志驱动配置错误,需要统一用 json-file 或兼容的驱动。
- 宿主机访问端口和容器监听端口要对应,nginx监听82端口,宿主机映射85端口,访问时要用宿主机的85端口。
- 访问 Harbor 首页看到 nginx 返回 200,说明 nginx 正常,前端页面开始加载,但若页面卡住,可能是后端服务未完全启动或网络访问不到其他 Harbor 服务。
- 重启虚拟机会刷新网络环境和容器服务,解决了之前隐藏的网络端口转发、Docker网络或者服务启动顺序的问题。
- 最后确认服务正常,可以访问页面。
如果总结起来,整个排查流程是:
- 确认服务启动和端口监听(
docker-compose up、ss -tnlp、docker logs)。
- 检查端口映射和虚拟机网络配置(NAT端口转发、虚拟机IP、防火墙)。
- 宿主机访问测试(PowerShell的Test-NetConnection)。
- 确认容器内服务状态(容器内curl)。
- 调整配置并重启验证。
- 最终确认页面访问正常。
Harbor 访问故障排查文档
一、背景说明
你在虚拟机上用 Docker Compose 部署 Harbor,遇到宿主机访问 Harbor Web UI 端口无法连接的问题。本文档总结了排查和解决过程,覆盖容器服务状态、端口映射、虚拟机网络、防火墙配置等关键点。
二、排查准备
- 宿主机环境:Windows(通过 VMware 运行虚拟机)
- 虚拟机环境:Linux,Harbor 服务部署环境,IP 如
192.168.200.131
- Docker Harbor 版本:v1.9.2
- 访问端口映射:宿主机端口 85 映射到容器内 nginx 监听端口 82
三、排查步骤
Step 1. 容器服务启动状态检查
使用命令:
bash复制编辑docker-compose up -d
docker ps
docker logs nginx --tail 50
确认 nginx 容器及其他 Harbor 服务容器是否运行正常,没有报错。
使用命令查看容器内部端口监听:
bash
ss -tnlp | grep nginx
确认 nginx 是否监听正确的端口(一般是 82 或 8080)。
Step 2. Docker 端口映射与虚拟机端口监听确认
ports:
- 85:82
表示宿主机(虚拟机)85端口映射到容器82端口。
- 在虚拟机上确认端口监听:
ss -tnlp | grep :85
```
通常 docker-proxy 会监听对应端口。
Step 3. 虚拟机网络配置和防火墙检查
firewall-cmd --state
确保防火墙关闭或已开放对应端口。
建议设置为 `Permissive` 或 `Disabled`。
- 检查虚拟机的 IP 配置,确认使用的是正确的 IP。
- 在宿主机(Windows)上使用 PowerShell 测试端口连通:
powershell
复制编辑
Test-NetConnection -ComputerName 192.168.200.131 -Port 85
------
### Step 4. 宿主机与虚拟机端口转发设置(NAT模式)
- 如果使用 VMware NAT,需要在 VMware NAT 设置中配置端口转发:
- 主机端口(宿主机)设为 `10085`(或你需要的端口)
- 转发到虚拟机 IP(如 `192.168.200.131`)的 85 端口
- 通过宿主机访问 `localhost:10085`,实际访问虚拟机的 Harbor 服务。
------
### Step 5. 使用 curl 命令测试服务
- 在虚拟机内部测试:
curl -I http://localhost:82
- 在虚拟机外部测试(宿主机):
curl -I http://192.168.200.131:85
```
- 观察返回结果,确认 HTTP 状态码是否正常(200/302 等)。
Step 6. 遇到问题的典型症状及对应处理
| 症状 |
可能原因 |
解决办法 |
| 宿主机无法连接端口,连接超时 |
防火墙阻止、端口未开放 |
关闭防火墙或放行端口 |
| curl 返回连接重置或拒绝 |
服务未启动或监听端口错误 |
检查 nginx 配置和容器启动 |
| curl 返回200但页面加载不出 |
后端服务未就绪或网络不通 |
检查 Harbor core 服务状态 |
| 日志中报错日志驱动不支持 |
docker-compose 日志配置错误 |
统一使用 json-file 驱动 |
| 端口映射配置错误 |
端口映射写错 |
纠正 docker-compose.yml 中端口映射 |
Step 7. 重启生效验证
- 重启虚拟机,有时可以修复网络绑定、端口冲突等隐患问题。
- 重启后再次测试端口连通性和页面访问。
四、示例核心配置(端口映射部分)
services:
proxy:
image: goharbor/nginx-photon:v1.9.2
container_name: nginx
ports:
- 85:82 # 宿主机端口 85 映射到容器内 nginx 监听的 82 端口
volumes:
- ./common/config/nginx:/etc/nginx:z
depends_on:
- core
- portal
- registry
五、常用命令汇总
| 作用 |
命令示例 |
| 查看容器状态 |
docker ps |
| 查看容器日志 |
docker logs nginx --tail 50 |
| 查看端口监听 |
`ss -tnlp |
| 测试端口连通(宿主机) |
Test-NetConnection -ComputerName 192.168.200.131 -Port 85 (PowerShell) |
| 虚拟机防火墙状态 |
firewall-cmd --state |
| SELinux 状态 |
getenforce |
| 虚拟机内访问本地端口 |
curl -I http://localhost:82 |
访问故障排查简易步骤清单
- 确认 Docker 容器和服务状态
docker-compose up -ddocker psdocker logs nginx
- 确认端口监听和映射
- 容器内部
ss -tnlp | grep nginx
- 虚拟机
ss -tnlp | grep :85
docker-compose.yml 中端口映射是否正确
- 检查虚拟机网络和防火墙
- 宿主机端口转发(NAT 模式)配置正确
- 测试端口连通性
- 宿主机 PowerShell 测试端口连通
- 虚拟机内 curl 测试端口访问
- 浏览器访问测试
- 用正确端口访问 Harbor 页面
- 观察是否能正常加载
- 重启虚拟机和服务
在Harbor创建用户和项目
Harbor的项目分为公开和私有的:
公开项目:所有用户都可以访问,通常存放公共的镜像,默认有一个library公开项目。 私有项目:只有授权用户才可以访问,通常存放项目本身的镜像。
我们可以为微服务项目创建一个新的项目
| 角色 |
权限说明 |
| 访客 |
对于指定项目拥有只读权限 |
| 开发人员 |
对于指定项目拥有读写权限 |
| 维护人员 |
对于指定项目拥有读写权限,创建Webhooks |
| 项目管理员 |
除了读写权限,同时拥有用户管理/镜像扫描等管理权限 |
把镜像上传到Harbor
需要重启Docker
systemctl restart docker
再次执行推送命令,会显示权限不足
docker push 192.168.200.131:85/tensquare/eureka:v1
denied: requested access to the resource is denied
需要先登录 Harbor,再推送镜像
登录Harbor
docker login -u eric -p Eric123456 192.168.200.131:85
再次push
docker push 192.168.200.131:85/tensquare/eureka:v1
从Harbor下载镜像
需求:在192.168.200.130服务器完成从Harbor下载镜像
安装并启动Docker
修改Docker配置
vi /etc/docker/daemon.json
{
"registry-mirrors": ["https://zydiol88.mirror.aliyuncs.com"],
"insecure-registries": ["192.168.66.102:85"]
}
重启docker:systemctl restart docker
先登录,再从Harbor下载镜像
docker login -u eric -p Eric123456 192.168.200.131:85
docker pull 192.168.200.131:85/tensquare/eureka:v1
微服务持续集成(1)-项目代码上传到Gitlab
在IDEA操作即可,参考之前的步骤。包括后台微服务(tensquare_back)和前端web网站(tensquare_front)代码
[lanyun_group · GitLab] (http://192.168.200.132:82/lanyun_group)
微服务持续集成(2)-从Gitlab拉取项目源码后台微服务的持续集成
先去Jenkins里面创建一个tensquare_back的流水线 → 流水线定义选择Pipeline script form SCM脚本文件放在项目根目录下 → SCM选择Git拉取脚本文件 → 在根目录下创建一个Jenkinsfile → 用流水线语法写’拉取代码’的语法 → ↓
stage('拉取代码') {
checkout scmGit(branches: [[name: '*/master']], extensions: [], userRemoteConfigs: [[credentialsId: 'ca22e56f-0ecc-4fdc-965d-01e329a0b68a', url: 'http://192.168.200.132:82/lanyun_group/tensquare_back.git']])
}
→ 修改语法代码里的 name: ‘*/master’ 为可变参数 → 去流水线的配置里 勾选This project is parameterized → 添加参数选择String Parameter → 名称:branch 默认值:master 描述:请输入一个分支名称 → 修改里面的参数为动态的 →↓
stage('拉取代码') {
checkout scmGit(branches: [[name: "*/${branch}"]], extensions: [], userRemoteConfigs: [[credentialsId: 'ca22e56f-0ecc-4fdc-965d-01e329a0b68a', url: 'http://192.168.200.132:82/lanyun_group/tensquare_back.git']])
}
→ 将后面的credentialsId和url可以定义为脚本参数全局引用 → ↓
//git凭证ID
def git_auth = "ca22e56f-0ecc-4fdc-965d-01e329a0b68a"
//git的url地址
def git_url = "http://192.168.200.132:82/lanyun_group/tensquare_back.git"
node {
stage('拉取代码') {
checkout scmGit(branches: [[name: "*/${branch}"]], extensions: [], userRemoteConfigs: [[credentialsId: "${git_auth}", url: "${git_url}"]])
}
}
构建即可成功!! 可以去Moba的/var/lib/jenkins/workspace/查看是否有tensquare_back
微服务持续集成(3)-提交到SonarQube代码审查
创建tensquare_back项目,添加两个参数 → 在流水线上设置里选择choice Parameter → 名称:project_name;选项:tensquare_eureka_server、tensquare_zuul、tensquare_admin_service、tensquare_gathering;描述:请选择一个构建的项目
每个项目的根目录下添加sonar-project.properties
eureka_server gathering admin_service zuul
只需要改里面的projectName和projectKey即可
# must be unique in a given SonarQube instance
sonar.projectKey=tensquare_eureka_server
# this is the name and version displayed in the SonarQube UI. Was mandatory prior to SonarQube 6.1.
sonar.projectName=tensquare_eureka_server
sonar.projectVersion=1.0
# Path is relative to the sonar-project.properties file. Replace "\" by "/" on Windows.
# This property is optional if sonar.modules is set.
sonar.sources=.
sonar.exclusions=**/test/**,**/target/**
sonar.java.binaries=.
sonar.java.source=1.8
sonar.java.target=1.8
#sonar.java.libraries=**/target/classes/**
# Encoding of the source code. Default is default system encoding
sonar.sourceEncoding=UTF-8
要在Jenkins的全局Tools管理里面 有SonarQube Scanner安装
Jenkins全局的system里面有定义sonarqube的url
//git凭证ID
def git_auth = "ca22e56f-0ecc-4fdc-965d-01e329a0b68a"
//git的url地址
def git_url = "http://192.168.200.132:82/lanyun_group/tensquare_back.git"
node {
stage('拉取代码') {
checkout scmGit(branches: [[name: "*/${branch}"]], extensions: [], userRemoteConfigs: [[credentialsId: "${git_auth}", url: "${git_url}"]])
}
stage('代码审查') {
//定义当前的Jenkins的sonarqubeScanner工具 Jenkins的全局Tools里
def scannerHome = tool 'sonar-scanner'
//引用当前JenkinsSonarQube环境 Jenkins的System里
withSonarQubeEnv('sonarqube'){
// 需要进入某个项目 在Jenkins选择什么项目就cd什么项目
sh """
cd ${project_name}
${scannerHome}/bin/sonar-scanner
"""
}
}
}
微服务持续集成(4)-使用Dockerfile编译、生成镜像
利用dockerfile-maven-plugin插件构建Docker镜像
- 在每个微服务项目的pom.xml加入dockerfile-maven-plugin插件
<plugin>
<groupId>com.spotify</groupId>
<artifactId>dockerfile-maven-plugin</artifactId>
<version>1.3.6</version>
<configuration>
<repository>${project.artifactId}</repository>
<buildArgs>
<JAR_FILE>target/${project.build.finalName}.jar</JAR_FILE>
</buildArgs>
</configuration>
</plugin>
- 修改Jenkinsfile让他根据参数打包微服务工程
//git凭证ID
def git_auth = "ca22e56f-0ecc-4fdc-965d-01e329a0b68a"
//git的url地址
def git_url = "http://192.168.200.132:82/lanyun_group/tensquare_back.git"
node {
stage('拉取代码') {
checkout scmGit(branches: [[name: "*/${branch}"]], extensions: [], userRemoteConfigs: [[credentialsId: "${git_auth}", url: "${git_url}"]])
}
stage('代码审查') {
//定义当前的Jenkins的sonarqubeScanner工具 Jenkins的全局Tools里
def scannerHome = tool 'sonar-scanner'
//引用当前JenkinsSonarQube环境 Jenkins的System里
withSonarQubeEnv('sonarqube'){
// 需要进入某个项目 在Jenkins选择什么项目就cd什么项目
sh """
cd ${project_name}
${scannerHome}/bin/sonar-scanner
"""
}
}
stage('编译,安装公共子工程'){
sh "mvn -f tensquare_common clean install"
}
stage('编译,打包微服务工程'){
sh "mvn -f ${project_name} clean package"
}
}
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tensquare</groupId>
<artifactId>tensquare_parent</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>tensquare_common</module>
<module>tensquare_eureka_server</module>
<module>tensquare_zuul</module>
<module>tensquare_admin_service</module>
<module>tensquare_gathering</module>
</modules>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.1.RELEASE</version>
<relativePath />
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<!-- ✅ 推荐使用正式版本 Finchley.SR4 -->
<spring-cloud.version>Finchley.SR4</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<!-- 可选:保留 spring-milestones -->
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
</project>
- 通过MoBa把
E:\Java实例项目1-20套\资料-Jenkins教程\Jenkins资料\资料\资料\03.资料\tensquare_parent的tensquare_parent项目保存到/root/repo/com/tensquare/里
- 随后通过步骤二,构建所有的工程 → 打包所有微服务的工程 → 在Jenkins虚拟机的
/var/lib/jenkins/workspace/tensquare_back/这里面的各个项目的target里面打包了刚刚微服务的所有构建东西
微服务持续集成(4)-使用Dockerfile编译、生成镜像
利用dockerfile-maven-plugin插件构建Docker镜像
- 在每个微服务项目的pom.xml加入dockerfile-maven-plugin插件
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>com.spotify</groupId>
<artifactId>dockerfile-maven-plugin</artifactId>
<version>1.3.6</version>
<configuration>
<repository>${project.artifactId}</repository>
<buildArgs>
<JAR_FILE>target/${project.build.finalName}.jar</JAR_FILE>
</buildArgs>
</configuration>
</plugin>
</plugins>
</build>
- 在dockerfile父目录文件中增加一个
...dockerfile:build去触发每个微服务项目的dockerfile执行【用流水线进行镜像构建】
stage('编译,安装公共子工程'){
sh "mvn -f tensquare_common clean install"
}
stage('编译,打包微服务工程'){
sh "mvn -f ${project_name} clean package dockerfile:build"
}
全部构建完成后就大功告成!!!
[root@localhost docker]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
tensquare_gathering latest a62362e8dc2f 8 minutes ago 155MB
tensquare_admin_service latest ee2a85292e98 9 minutes ago 156MB
tensquare_eureka_server latest 2a78c4a12fc4 11 minutes ago 148MB
tensquare_zuul latest 33bf136ee3cb 12 minutes ago 146MB
eureka v2 2c9a3610123d 24 hours ago 150MB
192.168.200.131:85/tensquare/eureka v1 e85b5d3d9090 25 hours ago 150MB
eureka v1 e85b5d3d9090 25 hours ago 150MB
nginx latest 9592f5595f2b 8 days ago 192MB
hello-world latest 74cc54e27dc4 5 months ago 10.1kB
openjdk 8-jdk-alpine a3562aa0b991 6 years ago 105MB
微服务持续集成(5)-上传到Harbor镜像仓库
//git凭证ID
def git_auth = "ca22e56f-0ecc-4fdc-965d-01e329a0b68a"
//git的url地址
def git_url = "http://192.168.200.132:82/lanyun_group/tensquare_back.git"
//镜像的版本号
def tag = "latest"
//Harbor的url地址
def harbor_url = "192.168.200.131:85"
//镜像库项目名称
def harbor_project = "tensquare"
node {
stage('拉取代码') {
checkout scmGit(branches: [[name: "*/${branch}"]], extensions: [], userRemoteConfigs: [[credentialsId: "${git_auth}", url: "${git_url}"]])
}
stage('代码审查') {
//定义当前的Jenkins的sonarqubeScanner工具 Jenkins的全局Tools里
def scannerHome = tool 'sonar-scanner'
//引用当前JenkinsSonarQube环境 Jenkins的System里
withSonarQubeEnv('sonarqube'){
// 需要进入某个项目 在Jenkins选择什么项目就cd什么项目
sh """
cd ${project_name}
${scannerHome}/bin/sonar-scanner
"""
}
}
stage('编译,安装公共子工程'){
sh "mvn -f tensquare_common clean install"
}
stage('编译,打包微服务工程'){
sh "mvn -f ${project_name} clean package dockerfile:build"
// 定义镜像名称
def imageName = "${project_name}:${tag}"
// 对镜像打上标签
sh "docker tag ${imageName} ${harbor_url}/${harbor_project}/${imageName}"
}
}
此时再去构建一个项目在Jenkins虚拟机服务的镜像里就会出现按照规则打好tag的镜像
[root@localhost ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
192.168.200.131:85/tensquare/tensquare_eureka_server latest e19b4ba07d54 About a minute ago 148MB
把镜像推送到Harbor(要登录 输入账号密码 不要写在脚本文件 把harbor账号密码用jenkins全局凭证)
去Jenkins申请一个全局的凭证,ID:f83725d3-d5fc-4faf-8ac1-1a56487dfc7b
怎么在jenkinsfile里面使用呢?要用流水线语法的片段生成器 withCredentials:Bind credentials to variables[借助凭证进行脚本处理] (如果没有显示绑定 就刷新一下界面);选择绑定→用户名变量:username 密码变量:password 这个是引用的刚刚创立的eric_harbor-auth凭证
//git凭证ID
def git_auth = "ca22e56f-0ecc-4fdc-965d-01e329a0b68a"
//git的url地址
def git_url = "http://192.168.200.132:82/lanyun_group/tensquare_back.git"
//镜像的版本号
def tag = "latest"
//Harbor的url地址
def harbor_url = "192.168.200.131:85"
//镜像库项目名称
def harbor_project = "tensquare"
//harbor的登录凭证ID
def harbor_auth = "f83725d3-d5fc-4faf-8ac1-1a56487dfc7b"
node {
stage('拉取代码') {
checkout scmGit(branches: [[name: "*/${branch}"]], extensions: [], userRemoteConfigs: [[credentialsId: "${git_auth}", url: "${git_url}"]])
}
stage('代码审查') {
//定义当前的Jenkins的sonarqubeScanner工具 Jenkins的全局Tools里
def scannerHome = tool 'sonar-scanner'
//引用当前JenkinsSonarQube环境 Jenkins的System里
withSonarQubeEnv('sonarqube'){
// 需要进入某个项目 在Jenkins选择什么项目就cd什么项目
sh """
cd ${project_name}
${scannerHome}/bin/sonar-scanner
"""
}
}
stage('编译,安装公共子工程'){
sh "mvn -f tensquare_common clean install"
}
stage('编译,打包微服务工程'){
sh "mvn -f ${project_name} clean package dockerfile:build"
// 定义镜像名称
def imageName = "${project_name}:${tag}"
// 对镜像打上标签
sh "docker tag ${imageName} ${harbor_url}/${harbor_project}/${imageName}"
// 把镜像推送到Harbor(要登录 输入账号密码 不要写在脚本文件 把harbor账号密码用jenkins全局凭证)
withCredentials([usernamePassword(credentialsId: "${harbor_auth}", passwordVariable: 'password', usernameVariable: 'username')]) {
// 登录到Harbor
sh "docker login -u ${username} -p ${password} ${harbor_url}"
//镜像上传
sh "docker push ${harbor_url}/${harbor_project}/${imageName}"
sh "echo '🔥🔥镜像上传成功✅✅'"
}
}
}
此时harbor的tensquare中镜像仓库就有了tensquare/tensquare_eureka_server
微服务持续集成(6)-拉取镜像和发布应用
安装 Publish Over SSH 插件目的是想把129Jenkins和130product进行连通
安装此插件可以实现远程发送Shell命令
随后去全局system寻找Publish over SSH
在product虚拟机:id_rsa是私钥,id_rsa.pub是公钥
[root@localhost ~]# cd /root/.ssh
[root@localhost .ssh]# ll
总用量 12
-rw-------. 1 root root 1679 6月 18 20:05 id_rsa
-rw-r--r--. 1 root root 408 6月 18 20:05 id_rsa.pub
-rw-r--r--. 1 root root 177 6月 18 21:00 known_hosts
[root@localhost .ssh]#
输入[root@localhost .ssh]# ssh-keygen -y -f /root/.ssh/id_rsa会显示私钥
如果直接输出 ssh-rsa AAAA... 这样的公钥内容 → 说明没有加密,Jenkins 中可以把 Passphrase 留空
下面添加一台远程服务器SSH Servers
Name:master_server
Hostname:192.168.200.130
Username:root
Remote Directory:/
配置远程部署服务器
是的,你遇到的错误:
Failed to connect session for config [master_server]. Message [Auth fail for methods 'publickey,gssapi-keyex,gssapi-with-mic,password']
说明 Jenkins 使用你提供的私钥连接远程服务器失败。这个问题一般由以下几种原因导致:
✅【推荐方案】重新生成兼容格式的私钥(PEM)
你看到的建议:
ssh-keygen -m PEM -t rsa -b 4096
是完全正确的,因为:
- Jenkins 使用的 Java SSH 实现(JSch 或 Trilead)不支持 OpenSSH 的新私钥格式(RFC4716);
-m PEM 表示使用旧版兼容格式(Jenkins 能识别);-t rsa -b 4096 表示生成 RSA 4096 位密钥。
✅ 重新生成 SSH 密钥步骤如下
- 在 Jenkins 所在机器上执行(推荐使用
jenkins 用户身份,不要用 root):
ssh-keygen -m PEM -t rsa -b 4096 -C "jenkins@tensquare" -f ~/.ssh/id_rsa_jenkins
过程中会问你是否设置密码(passphrase),你可以 直接回车留空。
生成后会有两个文件:
~/.ssh/id_rsa_jenkins ← 私钥(复制给 Jenkins)
~/.ssh/id_rsa_jenkins.pub ← 公钥(配置到目标服务器)
- 把公钥内容添加到远程主机的 authorized_keys 中
cat ~/.ssh/id_rsa_jenkins.pub | ssh root@192.168.200.130 "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys && chmod 600 ~/.ssh/authorized_keys"
或者你手动将 id_rsa_jenkins.pub 内容添加到 /root/.ssh/authorized_keys 中。
- Jenkins 中配置 SSH 连接
在 Jenkins → Manage Jenkins → Configure System → Publish over SSH:
- Path to Key:填入
/root/.ssh/id_rsa_jenkins(或你放的实际路径)
- Key:可留空(有 Path 即可)
- Passphrase:如果你上面生成时留空,这里也留空
- Name:master_server
- Hostname:192.168.200.130
- Username:root(或其他你授权了公钥的用户)
- Remote Directory:比如
/home/jenkins-deploy 或 /root/或/
✔ 点击 Test Configuration 测试成功为止
里面的$port需要搞成可变参数 去Jenkins里面添加一个参数
名称:port
默认值:10086
描述:请输入一个对应服务的端口
在生产虚拟机先[root@localhost ~]# mkdir /opt/jenkins_shell然后把E:\Java实例项目1-20套\资料-Jenkins教程\Jenkins资料\资料\资料\03.资料\部署脚本的deploy.sh传入 之后添加执行权限[root@localhost jenkins_shell]# chmod +x deploy.sh
成功!!!
[root@localhost jenkins_shell]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
192.168.200.131:85/tensquare/eureka v1 e85b5d3d9090 44 hours ago 150MB
[root@localhost jenkins_shell]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@localhost jenkins_shell]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
192.168.200.131:85/tensquare/tensquare_eureka_server latest 60d020191110 35 seconds ago 148MB
192.168.200.131:85/tensquare/eureka v1 e85b5d3d9090 44 hours ago 150MB
[root@localhost jenkins_shell]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b934523c60da 192.168.200.131:85/tensquare/tensquare_eureka_server:latest “java -jar /app.jar” 33 seconds ago Up 30 seconds 0.0.0.0:10086->10086/tcp focused_boyd
成功访问:[Eureka] (http://192.168.200.130:10086/)
如果要下载其他镜像 需要把每个服务的application.yml更改连接地址
更改所有服务的application.yml地址
sonarqube的是129里面有mysql
eureka的是130用的生产虚拟服务器
那我微服务里的application.yml server: port: 9001 spring: application: name: tensquare-admin-service #指定服务名 datasource: driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://192.168.200.129/tensquare_user?characterEncoding=UTF8 username: root password: root jpa: database: mysql show-sql: true 这样写可以吗
那个192.168.200.129:3306/回答:
- 如果你的微服务运行环境和 MySQL 在同一局域网内,且 192.168.200.129 是 MySQL 服务所在虚拟机的有效IP,且网络是通的,端口 3306 没被防火墙拦截,NAT或者桥接配置无误,使用这个 IP 和端口是完全没问题的。
- 也就是说,如果你从微服务所在的机器能 ping 通
192.168.200.129 并且 telnet 192.168.200.129 3306 可以连通,就可以这么写。
你需要确认的:
- 你的微服务运行在哪台机器?
- 如果微服务也在虚拟机里(同一台虚拟机或同一内网),用虚拟机的IP写就对。
- 如果微服务在宿主机,且虚拟机用的是 NAT 模式,你必须确认端口映射存在,否则宿主机连这个 IP 3306 不通(原因是 NAT 隔离)。这时用虚拟机私有 IP 直接连接是不行的。
- 网络连通性
- 微服务所在机器能
ping 通该 IP。
- 能
telnet IP 3306 连通。
总结
- 只要网络通,端口放通,
jdbc:mysql://192.168.200.129:3306/数据库名 写法就是标准且正确的。
- 如果网络不通,就要调整网络配置(比如桥接、端口映射),或者改用
localhost、127.0.0.1 访问本机MySQL。
分别构建其余的几个微服务项目 记住port端口是要跟application.yml里面一致的
[root@localhost ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
192.168.200.131:85/tensquare/tensquare_gathering latest c700a6359fce 33 seconds ago 155MB
192.168.200.131:85/tensquare/tensquare_admin_service latest 92453ab6e765 2 minutes ago 156MB
192.168.200.131:85/tensquare/tensquare_zuul latest 122afd78d6ef 3 minutes ago 146MB
192.168.200.131:85/tensquare/tensquare_eureka_server latest 60d020191110 4 hours ago 148MB
192.168.200.131:85/tensquare/eureka v1 e85b5d3d9090 2 days ago 150MB
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
aa2178c7dd0d 192.168.200.131:85/tensquare/tensquare_gathering:latest “java -Djava.net.pre…” About a minute ago Up 59 seconds 0.0.0.0:9002->9002/tcp nostalgic_lichterman
14e040066165 192.168.200.131:85/tensquare/tensquare_admin_service:latest “java -Djava.net.pre…” 2 minutes ago Up 2 minutes 0.0.0.0:9001->9001/tcp dreamy_montalcini
8143d8ccbeee 192.168.200.131:85/tensquare/tensquare_zuul:latest “java -Djava.net.pre…” 3 minutes ago Up 3 minutes 0.0.0.0:10020->10020/tcp gracious_kalam
b934523c60da 192.168.200.131:85/tensquare/tensquare_eureka_server:latest “java -jar /app.jar” 4 hours ago Up 4 hours 0.0.0.0:10086->10086/tcp focused_boyd
你这个情况是镜像有了,但是没有运行的容器,所以要启动镜像,创建并运行容器。
启动镜像★★的基本命令是:[Jenkins 129服务器]
docker run -d -p <宿主机端口>:<容器端口> --name <容器名字> <镜像名>
直接启动无需重新创建容器:
先查看所有容器(包括已停止的):docker ps -a
docker start tensquare_admin_service
docker start tensquare_gathering
docker start tensquare_zuul
docker start tensquare_eureka_server
若需要删除再重新启动
举个例子:
先删除之前的容器:
docker rm tensquare_admin_service
docker rm tensquare_gathering
docker rm tensquare_zuul
docker rm tensquare_eureka_server
docker run -d -p 9001:9101 --name tensquare_admin_service 192.168.200.131:85/tensquare/tensquare_admin_service:latest
docker run -d -p 9002:9002 --name tensquare_gathering 192.168.200.131:85/tensquare/tensquare_gathering:latest
docker run -d -p 10020:10020 --name tensquare_zuul 192.168.200.131:85/tensquare/tensquare_zuul:latest
docker run -d -p 10086:10086 --name tensquare_eureka_server 192.168.200.131:85/tensquare/tensquare_eureka_server:latest
[root@localhost ~]# docker rm -f tensquare_admin_service
tensquare_admin_service
[root@localhost ~]# docker run -d -p 9101:9001 –name tensquare_admin_service 192.168.200.131:85/tensquare/tensquare_admin_service:latest
634a31582dc81acf34b101d468d84b1c3f92b75477b6ad469abe00dc09821d4b
[root@localhost ~]#
端口映射要根据你的程序监听端口设定,否则外部访问不到容器服务。
此时也要在生产130服务器上去重新启动那些容器
✅ 1. 重启 130 上的容器
可以用 docker start 容器ID或容器名 重启:
bash复制编辑docker start e55957d0a79e # gathering
docker start 3c8592621ab7 # admin_service
docker start 43a7ca513e37 # zuul
docker start 831aeb331519 # eureka
或者统一启动:
bash
复制编辑
docker start $(docker ps -a -q)
删除镜像
停止容器:
docker stop 容器ID或容器名
删除容器:
docker rm 容器ID或容器名
3. 删除镜像
删除有标签的镜像:
docker rmi 192.168.200.131:85/tensquare/tensquare_gathering
docker rmi tensquare_gathering
删除无标签的悬空镜像:
docker rmi 08b0a9196df2
4. 如果有多个无标签镜像,删除所有悬空镜像
docker image prune
[生产]:[Eureka] (http://192.168.200.130:10086/)
Instances currently registered with Eureka
Jenkinsfile
//git凭证ID
def git_auth = "ca22e56f-0ecc-4fdc-965d-01e329a0b68a"
//git的url地址
def git_url = "http://192.168.200.132:82/lanyun_group/tensquare_back.git"
//镜像的版本号
def tag = "latest"
//Harbor的url地址
def harbor_url = "192.168.200.131:85"
//镜像库项目名称
def harbor_project = "tensquare"
//harbor的登录凭证ID
def harbor_auth = "f83725d3-d5fc-4faf-8ac1-1a56487dfc7b"
node {
stage('拉取代码') {
checkout scmGit(branches: [[name: "*/${branch}"]], extensions: [], userRemoteConfigs: [[credentialsId: "${git_auth}", url: "${git_url}"]])
}
stage('代码审查') {
//定义当前的Jenkins的sonarqubeScanner工具 Jenkins的全局Tools里
def scannerHome = tool 'sonar-scanner'
//引用当前JenkinsSonarQube环境 Jenkins的System里
withSonarQubeEnv('sonarqube'){
// 需要进入某个项目 在Jenkins选择什么项目就cd什么项目
sh """
cd ${project_name}
${scannerHome}/bin/sonar-scanner
"""
}
}
stage('编译,安装公共子工程'){
sh "mvn -f tensquare_common clean install"
}
stage('编译,打包微服务工程'){
sh "mvn -f ${project_name} clean package dockerfile:build"
// 定义镜像名称
def imageName = "${project_name}:${tag}"
// 对镜像打上标签
sh "docker tag ${imageName} ${harbor_url}/${harbor_project}/${imageName}"
// 把镜像推送到Harbor(要登录 输入账号密码 不要写在脚本文件 把harbor账号密码用jenkins全局凭证)
withCredentials([usernamePassword(credentialsId: "${harbor_auth}", passwordVariable: 'password', usernameVariable: 'username')]) {
// 登录到Harbor
sh "docker login -u ${username} -p ${password} ${harbor_url}"
//镜像上传
sh "docker push ${harbor_url}/${harbor_project}/${imageName}"
sh "echo '🔥🔥镜像上传成功✅✅'"
}
// 部署应用 发送命令调用生产服务器的shell脚本文件 完成所有的微服务项目部署行为
// deploy.sh 是触发远程脚本文件(镜像拉取和容器创建的行为)
sshPublisher(publishers: [sshPublisherDesc(configName: 'master_server', transfers: [sshTransfer(cleanRemote: false, excludes: '', execCommand: "/opt/jenkins_shell/deploy.sh $harbor_url $harbor_project $project_name $tag $port", execTimeout: 120000, flatten: false, makeEmptyDirs: false, noDefaultExcludes: false, patternSeparator: '[, ]+', remoteDirectory: '', remoteDirectorySDF: false, removePrefix: '', sourceFiles: '')], usePromotionTimestamp: false, useWorkspaceInPromotion: false, verbose: false)])
}
}
deploy.sh
#! /bin/sh
#接收外部参数
harbor_url=$1
harbor_project_name=$2
project_name=$3
tag=$4
port=$5
imageName=$harbor_url/$harbor_project_name/$project_name:$tag
echo "$imageName"
#查询容器是否存在,存在则删除
containerId=`docker ps -a | grep -w ${project_name}:${tag} | awk '{print $1}'`
if [ "$containerId" != "" ] ; then
#停掉容器
docker stop $containerId
#删除容器
docker rm $containerId
echo "成功删除容器"
fi
#查询镜像是否存在,存在则删除
imageId=`docker images | grep -w $project_name | awk '{print $3}'`
if [ "$imageId" != "" ] ; then
#删除镜像
docker rmi -f $imageId
echo "成功删除镜像"
fi
# 登录Harbor
docker login -u eric -p Eric123456 $harbor_url
# 下载镜像
docker pull $imageName
# 启动容器
docker run -di -p $port:$port $imageName
echo "容器启动成功"
连接数据库的时候有问题
[root@localhost ~]# /usr/local/mysql/bin/mysqld –initialize –user=mysql –datadir=/var/lib/mysql 2025-07-04T10:46:28.109697Z 0 [Warning] [MY-011070] [Server] ‘Disabling symbolic links using –skip-symbolic-links (or equivalent) is the default. Consider not using this option as it’ is deprecated and will be removed in a future release. 2025-07-04T10:46:28.110588Z 0 [System] [MY-013169] [Server] /usr/local/mysql/bin/mysqld (mysqld 8.0.30) initializing of server in progress as process 31821 2025-07-04T10:46:28.115123Z 0 [ERROR] [MY-010457] [Server] –initialize specified but the data directory has files in it. Aborting. 2025-07-04T10:46:28.115149Z 0 [ERROR] [MY-013236] [Server] The designated data directory /var/lib/mysql/ is unusable. You can remove all files that the server added to it. 2025-07-04T10:46:28.115231Z 0 [ERROR] [MY-010119] [Server] Aborting 2025-07-04T10:46:28.115717Z 0 [System] [MY-010910] [Server] /usr/local/mysql/bin/mysqld: Shutdown complete (mysqld 8.0.30) MySQL Community Server - GPL. [root@localhost ~]#
ChatGPT 说:
报错很明确:
--initialize specified but the data directory has files in it. Aborting.
意思是:你指定的 /var/lib/mysql 目录 里面已经有文件了,所以初始化被拒绝了。
解决方案
1. 备份或清空 /var/lib/mysql 目录
如果你确认目录里面的数据可以删除(或者你已经备份了重要数据),执行:
rm -rf /var/lib/mysql/*
确保目录下文件都删干净。
2. 再次执行初始化
/usr/local/mysql/bin/mysqld --initialize --user=mysql --datadir=/var/lib/mysql
这次应该会成功。
3. 启动 MySQL 服务
systemctl start mysql
4. 查看状态和日志,确保启动成功
systemctl status mysql
tail -n 50 /var/log/mariadb/mariadb.log
如果你担心误删数据,可以先备份目录:
mv /var/lib/mysql /var/lib/mysql_backup_$(date +%F_%T)
mkdir /var/lib/mysql
chown mysql:mysql /var/lib/mysql
然后再初始化。
这样启动mysql -uroot -p --socket=/var/lib/mysql/mysql.sock
宿主机(Windows)通过 NAT 模式连接虚拟机的正确姿势不是直接用虚拟机IP,而是用映射到宿主机的端口。
你当前用的:
mysql -uroot -proot -h192.168.200.129 -P3306
这是虚拟机的私有IP,NAT模式下外部访问是被隔离的,直接连这个IP不通。
正确做法:
- 在 VMware 的 NAT 设置里添加端口转发规则,把宿主机的某个端口(比如3306)转发到虚拟机的3306端口。
- 宿主机连接时,用
127.0.0.1(或者 localhost)加端口访问。
例如:
mysql -uroot -proot -h127.0.0.1 -P3306
如果你想用虚拟机的私有IP直接连接,建议改成桥接网卡。
总结:
- 你的 MySQL 配置没问题了
- NAT模式下宿主机访问虚拟机MySQL必须用端口转发+127.0.0.1
- 或切换桥接,直接用虚拟机IP访问
✅ 查看容器日志命令:
docker logs -f dreamy_montalcini
-f 表示 实时追踪日志,相当于 tail -f 的效果- 如果你只想看最近的日志行数,比如 100 行:
docker logs --tail 100 dreamy_montalcini
✅ 还可以用容器 ID:
docker logs -f 14e040066165
如果mysql忘记密码了怎么办
✅ 第一步:找出 mysqld_safe 路径
所以系统找不到 mysqld_safe 命令。请执行下面命令找出它在哪:
sudo find / -name mysqld_safe
它一般可能在 /usr/bin/mysqld_safe 或 /usr/local/mysql/bin/mysqld_safe
找到后,比如它在 /usr/local/mysql/bin/mysqld_safe,那你这样启动 MySQL 跳过权限:
sudo /usr/local/mysql/bin/mysqld_safe --skip-grant-tables --skip-networking &
然后 等待几秒钟(5-10s) 再执行:
mysql -uroot
[root@localhost ~]# sudo /usr/local/mysql/bin/mysqld_safe –pid-file=/var/run/mysqld/mysqld.pid &
[1] 56721
[root@localhost ~]# 2025-07-04T13:53:36.378946Z mysqld_safe Logging to ‘/var/log/mariadb/mariadb.log’.
2025-07-04T13:53:36.468224Z mysqld_safe Starting mysqld daemon with databases from /var/lib/mysql
[root@localhost ~]# sudo /usr/local/mysql/bin/mysqld_safe –pid-file=/var/run/mysqld/mysqld.pid &
[2] 56935
[root@localhost ~]# 2025-07-04T13:53:48.624877Z mysqld_safe Logging to ‘/var/log/mariadb/mariadb.log’.
2025-07-04T13:53:48.718002Z mysqld_safe A mysqld process already exists
[2]+ 退出 1 sudo /usr/local/mysql/bin/mysqld_safe –pid-file=/var/run/mysqld/mysqld.pid
[root@localhost ~]# ps aux | grep mysqld
root 56721 0.0 0.0 241292 632 pts/1 S 21:53 0:00 sudo /usr/local/mysql/bin/mysqld_safe –pid-file=/var/run/mysqld/mysqld.pid
root 56723 0.1 0.0 113412 452 pts/1 S 21:53 0:00 /bin/sh /usr/local/mysql/bin/mysqld_safe –pid-file=/var/run/mysqld/mysqld.pid
mysql 56861 22.2 18.1 1774388 339036 pts/1 Sl 21:53 0:03 /usr/local/mysql/bin/mysqld –basedir=/usr/local/mysql –datadir=/var/lib/mysql –plugin-dir=/usr/local/mysql/lib/plugin –user=mysql –log-error=/var/log/mariadb/mariadb.log –pid-file=/var/run/mysqld/mysqld.pid –socket=/var/lib/mysql/mysql.sock
root 57071 0.0 0.0 112828 988 pts/1 S+ 21:53 0:00 grep –color=auto mysqld
[root@localhost ~]#
数据库修改策略权限以及让远程宿主机连接
mysql -uroot -p
SET GLOBAL validate_password_policy = LOW;
SET GLOBAL validate_password_length = 4;
mysql> GRANT ALL PRIVILEGES ON . TO ‘root‘@’%’ IDENTIFIED BY ‘root’ WITH GRANT OPTION;
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.01 sec)
mysql> select user, host from mysql.user where user=’root’;
+——+————+
| user | host |
+——+————+
| root | % |
| root | 172.17.0.5 |
| root | localhost |
+——+————+
3 rows in set (0.00 sec)
你给的 Spring Boot 配置文件(application.yml)大致结构是对的,不过结合你之前报错信息(MySQL 连接时出现 CommunicationsException,SSL握手失败)和你的配置,有几点需要确认和调整:
1. MySQL 连接 URL 推荐加上参数,关闭 SSL
默认情况下 MySQL Connector 可能会尝试用 SSL 连接,而你的报错就是 SSL 握手失败:
Caused by: javax.net.ssl.SSLException: Received fatal alert: internal_error
解决办法是在 URL 中明确关闭 SSL,改成:
spring:
datasource:
url: jdbc:mysql://192.168.200.129:3306/tensquare_user?characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghai
useSSL=false 关闭 SSL 连接serverTimezone=Asia/Shanghai 解决时区警告(可选)characterEncoding=UTF-8 保持编码一致(注意大小写)
微服务持续集成(7)-部署前端静态web网站
129机器进行npm命令打包 → 远程传输文件 →(SSH远程调用)→ 130生产服务器Nginx
为什么用 Nginx 而不是直接用 Docker?
① Nginx 是专业的高性能静态文件服务器
- 速度快、资源占用低,响应迅速
- 支持缓存、压缩、访问控制、日志、反向代理等丰富功能
- 易于配置访问路径、rewrite规则等
② Docker 是“容器化”技术,适合运行应用程序
- Docker 让你把应用和运行环境打包,适合部署动态应用(比如后端服务)
- 纯静态文件没运行时依赖,没必要额外用容器包裹
- 如果直接用 Docker 部署静态网站,往往是把 Nginx 或 Apache 装在容器里,再由容器提供静态服务 — 这就和单纯用 Nginx 差不多,只是多了容器层
安装Nginx服务器
yum install epel-release
yum -y install nginx 安装
修改nginx的端口,默认80,改为9090:
vi /etc/nginx/nginx.conf
server {
listen 9099 default_server;
listen [::]:9099 default_server;
server_name _;
root /usr/share/nginx/html;
还需要关闭 selinux,将SELINUX=disabled
setenforce 0 先临时关闭
vi /etc/selinux/config 编辑文件,永久关闭 SELINUX=disabled
启动Nginx ★★
systemctl enable nginx 设置开机启动
systemctl start nginx 启动
systemctl stop nginx 停止
systemctl restart nginx 重启
systemctl status nginx.service 查看运行状态
[Welcome to CentOS] (http://192.168.200.130:9099/)
在Jenkins的服务器里 安装NodeJS插件
前端在本机的位置:C:\Users\Pluminary\Desktop\QianDuan\tensquareAdmin
Jenkins配置Nginx服务器
Dashboard → Manage Jenkins → Tools → NodeJS新增
别名:nodejs12
版本:NodeJS 12.3.1
创建前端流水线项目 tensquare_front
添加一个参数This project is parameterized → 名称branch 默认值master
在Jenkins里找一个凭证点击右侧zhangsan → 更新 → 就会显示有ID 复制后变成git_auth
流水线Pipeline script
//gitlab凭证
def git_auth = "ca22e56f-0ecc-4fdc-965d-01e329a0b68a"
node{
stage('拉取代码'){
checkout scmGit(branches: [[name: '*/${branch}']], extensions: [], userRemoteConfigs: [[credentialsId: "${git_auth}", url: 'http://192.168.200.132:82/lanyun_group/tensquare_front.git']])
}
stage('打包,部署网站') {
//使用NodeJS的npm进行打包
nodejs('nodejs12'){
sh '''
npm install
npm run build
'''
}
}
//=====以下为远程调用进行项目部署========
sshPublisher(publishers: [sshPublisherDesc(configName: 'master_server', transfers: [sshTransfer(cleanRemote: false, excludes: '', execCommand: '', execTimeout: 120000, flatten: false, makeEmptyDirs: false, noDefaultExcludes: false, patternSeparator: '[, ]+', remoteDirectory: '/usr/share/nginx/html', remoteDirectorySDF: false, removePrefix: 'dist', sourceFiles: 'dist/**')], usePromotionTimestamp: false, useWorkspaceInPromotion: false, verbose: false)])
}
去gitlab里面修改tensquare_front里面的config→prod.env.js
'use strict'
module.exports = {
NODE_ENV: '"production"',
// BASE_API: '"http://192.168.207.131:7300/mock/5c0b42c85b4c7508d4dc568c/1024"'
BASE_API: '"http://192.168.200.130:10020"' // 管理员网关[生产]
}
去构建一下!
然后去生产服务器寻找
[root@localhost html]# cd /usr/share/nginx/html
[root@localhost html]# ll
总用量 80
-rw-r–r–. 1 root root 3650 11月 11 2022 404.html
-rw-r–r–. 1 root root 3693 11月 11 2022 50x.html
lrwxrwxrwx. 1 root root 20 7月 5 19:30 en-US -> ../../doc/HTML/en-US
-rw-r–r–. 1 root root 67646 7月 5 20:12 favicon.ico
drwxr-xr-x. 2 root root 27 7月 5 19:30 icons
lrwxrwxrwx. 1 root root 18 7月 5 19:30 img -> ../../doc/HTML/img
lrwxrwxrwx. 1 root root 25 7月 5 19:30 index.html -> ../../doc/HTML/index.html
-rw-r–r–. 1 root root 368 11月 11 2022 nginx-logo.png
lrwxrwxrwx. 1 root root 14 7月 5 19:30 poweredby.png -> nginx-logo.png
drwxr-xr-x. 6 root root 51 7月 5 20:12 static
[root@localhost html]#
回头再去访问:http://192.168.200.130:9099/ 已经成功
admin 123456
登录进去查看是否能连通之前在镜像部署的微服务后端!!![一次成功 完美!!]
Jenkins+Docker+SpringCloud微服务持续集成(下)之前是单机版
上面部署方案存在的问题:
1)一次只能选择一个微服务部署
2)只有一台生产者部署服务器
3)每个微服务只有一个实例,容错率低
初级版已完成接下来是中级版本!!
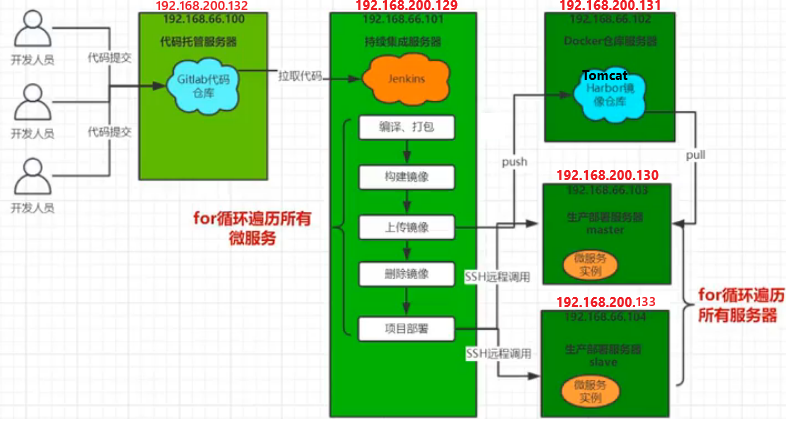
在idea项目中增加一台新的机器作为eureka注册的地方
tensquare_gathering/src/main/resources/application.yml
server:
port: 9002
spring:
application:
name: tensquare-gathering #指定服务名
datasource:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.200.129:3306/tensquare_gathering?characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: root
jpa:
database: mysql
show-sql: true
#Eureka客户端配置
eureka:
client:
service-url:
defaultZone: http://192.168.200.130:10086/eureka,http://192.168.200.133:10086/eureka
instance:
lease-renewal-interval-in-seconds: 5 # 每隔5秒发送一次心跳
lease-expiration-duration-in-seconds: 10 # 10秒不发送就过期
prefer-ip-address: true
tensquare_admin_service/src/main/resources/application.yml
server:
port: 9001
spring:
application:
name: tensquare-admin-service #指定服务名
datasource:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.200.129:3306/tensquare_user?characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: root
jpa:
database: mysql
show-sql: true
#Eureka配置
eureka:
client:
service-url:
defaultZone: http://192.168.200.130:10086/eureka,http://192.168.200.133:10086/eureka
instance:
lease-renewal-interval-in-seconds: 5 # 每隔5秒发送一次心跳
lease-expiration-duration-in-seconds: 10 # 10秒不发送就过期
prefer-ip-address: true
# jwt参数
jwt:
config:
key: itcast
ttl: 1800000
tensquare_zuul/src/main/resources/application.yml
server:
port: 10020 # 端口
# 基本服务信息
spring:
application:
name: tensquare-zuul # 服务ID
# Eureka配置
eureka:
client:
service-url:
defaultZone: http://192.168.200.130:10086/eureka,http://192.168.200.133:10086/eureka
instance:
prefer-ip-address: true
# 修改ribbon的超时时间
ribbon:
ConnectTimeout: 1500 # 连接超时时间,默认500ms
ReadTimeout: 3000 # 请求超时时间,默认1000ms
# 修改hystrix的熔断超时时间
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMillisecond: 2000 # 熔断超时时长,默认1000ms
# 网关路由配置
zuul:
routes:
admin:
path: /admin/**
serviceId: tensquare-admin-service
gathering:
path: /gathering/**
serviceId: tensquare-gathering
# jwt参数
jwt:
config:
key: itcast
ttl: 1800000
C:\Users\Pluminary\Desktop\HouDuan\tensquare_parent\tensquare_eureka_server\src\main\resources\application.yml
# 集群版
spring:
application:
name: EUREKA-HA
---
server:
port: 10086
spring:
# 指定profile=eureka-server1
profiles: eureka-server1
eureka:
instance:
# 指定当profile=eureka-server1时,主机名是eureka-server1
hostname: 192.168.66.130
client:
service-url:
# 将自己注册到eureka-server1、eureka-server2这个Eureka上面去
defaultZone: http://192.168.66.130:10086/eureka/,http://192.168.66.133:10086/eureka/
---
server:
port: 10086
spring:
profiles: eureka-server2
eureka:
instance:
hostname: 192.168.66.132
client:
service-url:
defaultZone: http://192.168.66.130:10086/eureka/,http://192.168.66.133:10086/eureka/
然后更改提交push到gitlab
设计Jenkins集群项目的构建参数
安装Extended Choice Parameter插件支持多选框
新建一个tensquare_back_cluster的item
流水线选择piplin…SCM;git的url填gitlab里的后端地址
第一步安装好插件后 就可以在This project... 中看到Choice Parameter
先添加一个String Parameter:名称branch 默认值master 描述请输入分支名称
再添加参数选择多选Extended Choice Parameter:名称project_name 描述:请选择需要部署的微服务;勾选Basic Parameter Types → Check Boxes → Number of Visble Items:4 → Delimiter,(用逗号去隔开) → 点击下面的Choose Source for Value → Value为tensquare_eureka_server@10086,tensquare_zuul@10020,tensquare_admin_service@9001,tensquare_gathering@9002 → 点击Choose Source for Default Value(选择默认值):tensquare_eureka_server@10086 → 点击ChooseSourceforValueDescription(描述备注) Description:注册中心,服务网关,认证中心,活动微服务 👉 应用保存 → 构建就可以看到
★★ 请注意 配置多选的时候 Jenkins那里一定不要多加空格什么的!
更新Jenkinsfile代码
//git凭证ID
def git_auth = "ca22e56f-0ecc-4fdc-965d-01e329a0b68a"
//git的url地址
def git_url = "http://192.168.200.132:82/lanyun_group/tensquare_back.git"
//镜像的版本号
def tag = "latest"
//Harbor的url地址
def harbor_url = "192.168.200.131:85"
//镜像库项目名称
def harbor_project = "tensquare"
//harbor的登录凭证ID
def harbor_auth = "f83725d3-d5fc-4faf-8ac1-1a56487dfc7b"
node {
// 获取当前选择的项目名称 要用逗号去切割
def selectedProjectNames = "${project_name}".split(",")
stage('拉取代码') {
checkout scmGit(branches: [[name: "*/${branch}"]], extensions: [], userRemoteConfigs: [[credentialsId: "${git_auth}", url: "${git_url}"]])
}
stage('代码审查') {
for(int i = 0; i < selectedProjectNames.length; i++){
// tensquare_eureka_server@10086
def projectInfo = selectedProjectNames[i];
// 当前遍历的项目名称
def currentProjectName = "${projectInfo}".split("@")[0]
// 当前遍历的项目端口
def currentProjectPort = "${projectInfo}".split("@")[1]
//定义当前的Jenkins的sonarqubeScanner工具 Jenkins的全局Tools里
def scannerHome = tool 'sonar-scanner'
//引用当前JenkinsSonarQube环境 Jenkins的System里
withSonarQubeEnv('sonarqube'){
// 需要进入某个项目 在Jenkins选择什么项目就cd什么项目
sh """
cd ${currentProjectName}
${scannerHome}/bin/sonar-scanner
"""
}
}
}
stage('编译,安装公共子工程'){
sh "mvn -f tensquare_common clean install"
}
stage('编译,打包微服务工程'){
sh "mvn -f ${project_name} clean package dockerfile:build"
// 定义镜像名称
def imageName = "${project_name}:${tag}"
// 对镜像打上标签
sh "docker tag ${imageName} ${harbor_url}/${harbor_project}/${imageName}"
// 把镜像推送到Harbor(要登录 输入账号密码 不要写在脚本文件 把harbor账号密码用jenkins全局凭证)
withCredentials([usernamePassword(credentialsId: "${harbor_auth}", passwordVariable: 'password', usernameVariable: 'username')]) {
// 登录到Harbor
sh "docker login -u ${username} -p ${password} ${harbor_url}"
//镜像上传
sh "docker push ${harbor_url}/${harbor_project}/${imageName}"
sh "echo '🔥🔥镜像上传成功✅✅'"
}
// 部署应用 发送命令调用生产服务器的shell脚本文件 完成所有的微服务项目部署行为
// deploy.sh 是触发远程脚本文件(镜像拉取和容器创建的行为)
sshPublisher(publishers: [sshPublisherDesc(configName: 'master_server', transfers: [sshTransfer(cleanRemote: false, excludes: '', execCommand: "/opt/jenkins_shell/deploy.sh $harbor_url $harbor_project $project_name $tag $port", execTimeout: 120000, flatten: false, makeEmptyDirs: false, noDefaultExcludes: false, patternSeparator: '[, ]+', remoteDirectory: '', remoteDirectorySDF: false, removePrefix: '', sourceFiles: '')], usePromotionTimestamp: false, useWorkspaceInPromotion: false, verbose: false)])
}
}
多个项目打包及构建上传镜像
//git凭证ID
def git_auth = "ca22e56f-0ecc-4fdc-965d-01e329a0b68a"
//git的url地址
def git_url = "http://192.168.200.132:82/lanyun_group/tensquare_back.git"
//镜像的版本号
def tag = "latest"
//Harbor的url地址
def harbor_url = "192.168.200.131:85"
//镜像库项目名称
def harbor_project = "tensquare"
//harbor的登录凭证ID
def harbor_auth = "f83725d3-d5fc-4faf-8ac1-1a56487dfc7b"
node {
// 获取当前选择的项目名称 要用逗号去切割
def selectedProjectNames = "${project_name}".split(",")
stage('拉取代码') {
checkout scmGit(branches: [[name: "*/${branch}"]], extensions: [], userRemoteConfigs: [[credentialsId: "${git_auth}", url: "${git_url}"]])
}
stage('代码审查') {
for(int i=0;i<selectedProjectNames.length;i++){
// tensquare_eureka_server@10086
def projectInfo = selectedProjectNames[i];
// 当前遍历的项目名称
def currentProjectName = "${projectInfo}".split("@")[0]
// 当前遍历的项目端口
def currentProjectPort = "${projectInfo}".split("@")[1]
//定义当前的Jenkins的sonarqubeScanner工具 Jenkins的全局Tools里
def scannerHome = tool 'sonar-scanner'
//引用当前JenkinsSonarQube环境 Jenkins的System里
withSonarQubeEnv('sonarqube'){
// 需要进入某个项目 在Jenkins选择什么项目就cd什么项目
sh """
cd ${currentProjectName}
${scannerHome}/bin/sonar-scanner
"""
}
}
}
stage('编译,安装公共子工程'){
sh "mvn -f tensquare_common clean install"
}
stage('编译,打包微服务工程,上传镜像') {
for (int i = 0; i < selectedProjectNames.length; i++) {
//tensquare_eureka_server@10086
def projectInfo = selectedProjectNames[i];
//当前遍历的项目名称
def currentProjectName = "${projectInfo}".split("@")[0]
//当前遍历的项目端口
def currentProjectPort = "${projectInfo}".split("@")[1]
sh "mvn -f ${currentProjectName} clean package dockerfile:build"
//定义镜像名称
def imageName = "${currentProjectName}:${tag}"
// 对镜像打上标签
sh "docker tag ${imageName} ${harbor_url}/${harbor_project}/${imageName}"
// 把镜像推送到Harbor(要登录 输入账号密码 不要写在脚本文件 把harbor账号密码用jenkins全局凭证)
withCredentials([usernamePassword(credentialsId: "${harbor_auth}", passwordVariable: 'password', usernameVariable: 'username')]) {
// 登录到Harbor
sh "docker login -u ${username} -p ${password} ${harbor_url}"
//镜像上传
sh "docker push ${harbor_url}/${harbor_project}/${imageName}"
sh "echo '🔥🔥镜像上传成功✅✅'"
}
// 部署应用 发送命令调用生产服务器的shell脚本文件 完成所有的微服务项目部署行为
// deploy.sh 是触发远程脚本文件(镜像拉取和容器创建的行为)
sshPublisher(publishers: [sshPublisherDesc(configName: 'master_server', transfers: [sshTransfer(cleanRemote: false, excludes: '', execCommand: "/opt/jenkins_shell/deploy.sh $harbor_url $harbor_project $project_name $tag $port", execTimeout: 120000, flatten: false, makeEmptyDirs: false, noDefaultExcludes: false, patternSeparator: '[, ]+', remoteDirectory: '', remoteDirectorySDF: false, removePrefix: '', sourceFiles: '')], usePromotionTimestamp: false, useWorkspaceInPromotion: false, verbose: false)])
}
}
}
把Eureka注册中心集群部署到多台服务器
Dashboard → Manage Jenkins → 下面的SSH Server → 增加一台133的机器
测试之前需要把Jenkins服务的公钥拷贝到133上面
在Jenkins的129机器
[root@localhost ~]# ssh-copy-id 192.168.200.133 [Product_slave]
SSH Server→【应用+Save】
Name:slave_server
Hostname:192.168.200.133
Username:root
Remote Directory:/
继续在Jenkins的tensquare_back_cluster中的Configure的Extended Choice Parameter的下面添加参数 → 继续添加Extended Choice Parameter → 在里面继续添加Name:publish_server;Description:请选择需要部署的服务器 → 勾选Basic Parameter Types, Parameter Type:Check Boxes → Number of Visible Items:2, Delimiter:, 下面的Choose Source for Value → Value:master_server,slave_server → 下面的Default Value:master_server → 下面的Description:主节点,从节点 → 应用+Save
//git凭证ID
def git_auth = "ca22e56f-0ecc-4fdc-965d-01e329a0b68a"
//git的url地址
def git_url = "http://192.168.200.132:82/lanyun_group/tensquare_back.git"
//镜像的版本号
def tag = "latest"
//Harbor的url地址
def harbor_url = "192.168.200.131:85"
//镜像库项目名称
def harbor_project = "tensquare"
//harbor的登录凭证ID
def harbor_auth = "f83725d3-d5fc-4faf-8ac1-1a56487dfc7b"
node {
// 获取当前选择的项目名称 要用逗号去切割
def selectedProjectNames = "${project_name}".split(",")
// 获取当前选择的服务器名称
def selectedServers = "${publish_server}".split(",")
stage('拉取代码') {
checkout scmGit(branches: [[name: "*/${branch}"]], extensions: [], userRemoteConfigs: [[credentialsId: "${git_auth}", url: "${git_url}"]])
}
stage('代码审查') {
for(int i=0;i<selectedProjectNames.length;i++){
// tensquare_eureka_server@10086
def projectInfo = selectedProjectNames[i];
// 当前遍历的项目名称
def currentProjectName = "${projectInfo}".split("@")[0]
// 当前遍历的项目端口
def currentProjectPort = "${projectInfo}".split("@")[1]
//定义当前的Jenkins的sonarqubeScanner工具 Jenkins的全局Tools里
def scannerHome = tool 'sonar-scanner'
//引用当前JenkinsSonarQube环境 Jenkins的System里
withSonarQubeEnv('sonarqube'){
// 需要进入某个项目 在Jenkins选择什么项目就cd什么项目
sh """
cd ${currentProjectName}
${scannerHome}/bin/sonar-scanner
"""
}
}
}
stage('编译,安装公共子工程'){
sh "mvn -f tensquare_common clean install"
}
stage('编译,打包微服务工程,上传镜像') {
for (int i = 0; i < selectedProjectNames.length; i++) {
//tensquare_eureka_server@10086
def projectInfo = selectedProjectNames[i];
//当前遍历的项目名称
def currentProjectName = "${projectInfo}".split("@")[0]
//当前遍历的项目端口
def currentProjectPort = "${projectInfo}".split("@")[1]
sh "mvn -f ${currentProjectName} clean package dockerfile:build"
//定义镜像名称
def imageName = "${currentProjectName}:${tag}"
// 对镜像打上标签
sh "docker tag ${imageName} ${harbor_url}/${harbor_project}/${imageName}"
// 把镜像推送到Harbor(要登录 输入账号密码 不要写在脚本文件 把harbor账号密码用jenkins全局凭证)
withCredentials([usernamePassword(credentialsId: "${harbor_auth}", passwordVariable: 'password', usernameVariable: 'username')]) {
// 登录到Harbor
sh "docker login -u ${username} -p ${password} ${harbor_url}"
//镜像上传
sh "docker push ${harbor_url}/${harbor_project}/${imageName}"
sh "echo '🔥🔥镜像上传成功✅✅'"
}
//遍历所有服务器,分别部署
for (int j = 0; j < selectedServers.length; j++) {
//获取当前遍历的服务器名称
def currentServerName = selectedServers[j]
//加上的参数格式:--spring.profiles.active=eureka-server1/eureka-server2
def activeProfile = "--spring.profiles.active="
//根据不同的服务名称来读取不同的Eureka配置信息
if (currentServerName == "master_server") {
activeProfile = activeProfile + "eureka-server1"
} else if (currentServerName == "slave_server") {
activeProfile = activeProfile + "eureka-server2"
}
// 部署应用 发送命令调用生产服务器的shell脚本文件 完成所有的微服务项目部署行为
// deploy.sh 是触发远程脚本文件(镜像拉取和容器创建的行为)
sshPublisher(publishers: [sshPublisherDesc(configName: "${currentServerName}", transfers: [sshTransfer(cleanRemote: false, excludes: '', execCommand: "/opt/jenkins_shell/deployCluster.sh $harbor_url $harbor_project $currentProjectName $tag $currentProjectPort $activeProfile", execTimeout: 120000, flatten: false, makeEmptyDirs: false, noDefaultExcludes: false, patternSeparator: '[, ]+', remoteDirectory: '', remoteDirectorySDF: false, removePrefix: '', sourceFiles: '')], usePromotionTimestamp: false, useWorkspaceInPromotion: false, verbose: false)])
}
}
}
}
- 将之前的
deploy.sh换成了deployCluster.sh
#! /bin/sh
#接收外部参数
harbor_url=$1
harbor_project_name=$2
project_name=$3
tag=$4
port=$5
profile=$6
imageName=$harbor_url/$harbor_project_name/$project_name:$tag
echo "$imageName"
#查询容器是否存在,存在则删除
containerId=`docker ps -a | grep -w ${project_name}:${tag} | awk '{print $1}'`
if [ "$containerId" != "" ] ; then
#停掉容器
docker stop $containerId
#删除容器
docker rm $containerId
echo "成功删除容器"
fi
#查询镜像是否存在,存在则删除
imageId=`docker images | grep -w $project_name | awk '{print $3}'`
if [ "$imageId" != "" ] ; then
#删除镜像
docker rmi -f $imageId
echo "成功删除镜像"
fi
# 登录Harbor
docker login -u eric -p Eric123456 $harbor_url
# 下载镜像
docker pull $imageName
# 启动容器
docker run -di -p $port:$port $imageName $profile
echo "容器启动成功"
master_server,slave_server将130生产的机器master机器里 放入deployCluster.sh 是在这个目录/opt/jenkins_shell/里面
然后加上权限
[root@localhost ~]# cd /opt/jenkins_shell/
[root@localhost jenkins_shell]# chmod +x deployCluster.sh
然后在133机器上slave机器 按照上一步的操作拖进去 然后加入权限
[root@localhost ~]# cd /opt/jenkins_shell/
[root@localhost jenkins_shell]# chmod +x deployCluster.sh
[Eureka] (http://192.168.200.130:10086/) + [Eureka] (http://192.168.200.133:10086/)
然后再去把剩下的都构建了
project_name
请选择需要部署的微服务
publish_server
请选择需要部署的服务器
Nginx + Zuul集群实现高可用网关
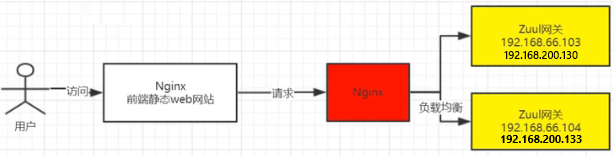
更改133的nginx配置
vi /etc/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 4096;
include /etc/nginx/mime.types;
default_type application/octet-stream;
include /etc/nginx/conf.d/*.conf;
### 新增负载均衡配置
upstream zuulServer {
server 192.168.200.130:10020 weight=1;
server 192.168.200.133:10020 weight=1;
}
server {
listen 85 default_server;
listen [::]:85 default_server;
server_name _;·
root /usr/share/nginx/html;
include /etc/nginx/default.d/*.conf;
location / {
proxy_pass http://zuulServer/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
error_page 404 /404.html;
location = /404.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
}
重启Nginx:systemctl restart nginx
修改前端Nginx的访问地址tensquare_front → config → prod.env.js
'use strict'
module.exports = {
NODE_ENV: '"production"',
// BASE_API: '"http://192.168.207.131:7300/mock/5c0b42c85b4c7508d4dc568c/1024"'
BASE_API: '"http://192.168.200.133:85"' // 管理员网关
}
基于Kubernetes/K8S构建Jenkins持续集成平台(上)
Jenkins的Master-Slave分布式构建
什么是Master-Slave分布式构建
Jenkins的Master-Slave分布式构建,就是通过将构建过程分配到从属Slave节点上,从而减轻Master节 点的压力,而且可以同时构建多个,有点类似负载均衡的概念。
如何实现Master-Slave分布式构建
开启代理程序的TCP端口Dashboard → Manage Jenkins → Security → 代理:随机选取
新建节点 Dashboard → Manage Jenkins → Nodes → New node → 节点名称: slave1 勾选Permanent Agent → create → 我的Jenkins主节点在101机器,从节点就放在102机器吧 → 去102机器cd /root; mkdir jenkins → 远程工作目录:/root/jenkins → 用法;启动方式;可用性都是默认第一个 → 点进去刚刚创建的slave →↓
Run from agent command line: (Unix)
# 下载agent.jar
curl -sO http://192.168.200.133:8888/jnlpJars/agent.jar
java -jar agent.jar -url http://192.168.200.129:8888/ -secret 85f68f679a60139d7867571d577299c3c7d10f913acfca589bb0b9018b86e14d -name slave1 -webSocket -workDir "/root/jenkins"
想要这个 需要下载个agent.jar包传到102的/root机器中
✅ 最简单解决方案(推荐)
✅ 方案一:从 Jenkins 主机上下载,再用 SCP 复制到 agent 机器
在 Jenkins 主机(192.168.200.129)上执行:
curl -sO http://localhost:8888/jnlpJars/agent.jar
然后从主机 scp 到 192.168.200.133:
scp agent.jar root@192.168.200.133:/root/
登录密码或配置了免密都行。
Kubernetes实现Master-Slave分布式构建方案
传统Jenkins的Master-Slave方案的缺陷
- Master 每个 节点发生单点故障时,整个流程都不可用了
- Slave节点的配置环境不一样,来完成不同语言的编译打包等操作,但是这些差异化的配置致管理起来非常不方便,维护起来也是比较费劲
- 资源分配不均衡,有的 Slave节点要运行的job出现排队等待,而有的Slave节点处于空闲状态
- 资源浪费,每台 掉资源 Slave节点可能是实体机或者VM,当Slave节点处于空闲状态时,也不会完全释放
以上种种问题,我们可以引入Kubernates来解决!
K8S是对主从分布式架构的优化!!!
Kubernates简介
Kubernetes(简称,K8S)是Google开源的容器集群管理系统,在Docker技术的基础上,为容器化的 应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模容器集群管理的 便捷性。 其主要功能如下:
- 使用 Docker对应用程序包装(package)、实例化(instantiate)、运行(run)。
- 以集群的方式运行、管理跨机器的容器。以集群的方式运行、管理跨机器的容器。
- 解决 Docker跨机器容器之间的通讯问题。解决Docker跨机器容器之间的通讯问题。
- Kubernetes 的自我修复机制使得容器集群总是运行在用户期望的状态。
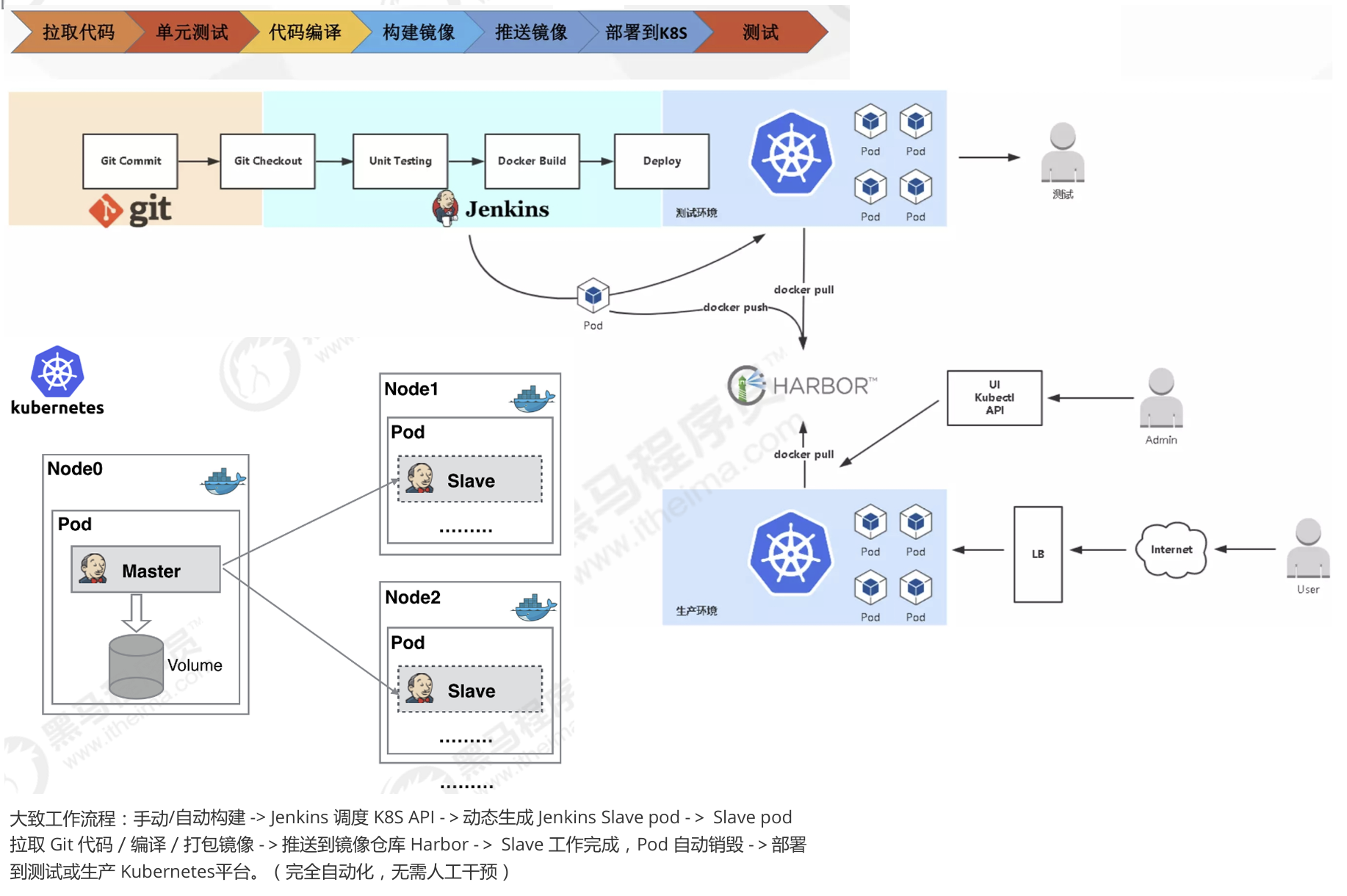
Kubernates+Docker+Jenkins持续集成方案好处
- 服务高可用:当 Jenkins Master 出现故障时,Kubernetes 会自动创建一个新的 Jenkins Master 容器,并且将 Volume 分配给新创建的容器,保证数据不丢失,从而达到集群服务高可用。
- 动态伸缩,合理使用资源:每次运行 Job 时,会自动创建一个 Jenkins Slave,Job 完成后,Slave 自动注销并删除容器,资源自动释放,而且 Kubernetes 会根据每个资源的使用情况,动态分配 Slave 到空闲的节点上创建,降低出现因某节点资源利用率高,还排队等待在该节点的情况。
- 扩展性好 :当 Kubernetes 集群的资源严重不足而导致 Job 排队等待时,可以很容易的添加一个 Kubernetes Node 到集群中,从而实现扩展。
Kubeadm安装Kubernetes
Kubernetes的架构
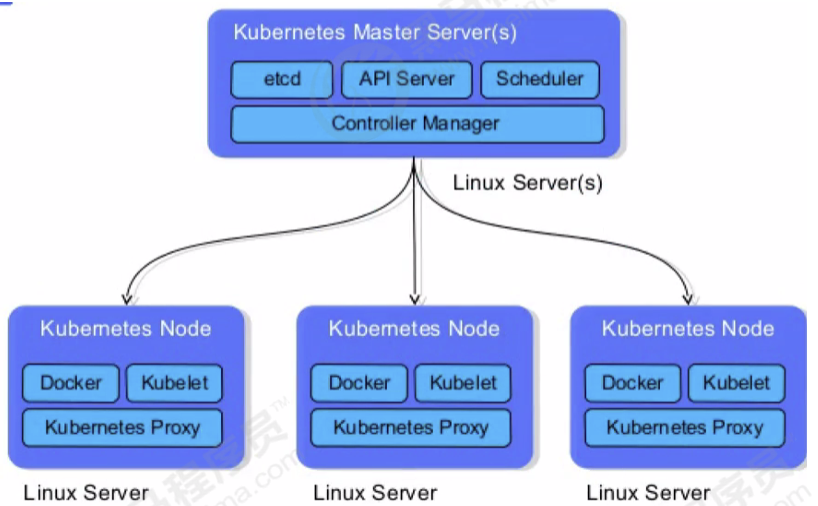
- API Server :用于暴露Kubernetes API,任何资源的请求的调用操作都是通过kube-apiserver提供的接 口进行的。
- Etcd:是Kubernetes提供默认的存储系统,保存所有集群数据,使用时需要为etcd数据提供备份计 划。
- Controller-Manager:作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点 (Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额 (ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化 修复流程,确保集群始终处于预期的工作状态。
- Scheduler:监视新创建没有分配到Node的Pod,为Pod选择一个Node。
- Kubelet:负责维护容器的生命周期,同时负责Volume和网络的管理
- Kube proxy:是Kubernetes的核心组件,部署在每个Node节点上,它是实现Kubernetes Service的通 信与负载均衡机制的重要组件。
| 主机名称 |
IP地址 |
安装的软件 |
| 代码托管服务器 |
192.168.200.132 |
Gitlab-12.4.2 |
| Docker仓库服务器 |
192.168.200.131 |
Harbor1.9.2 |
| k8s-master |
192.168.200.129 |
kube-apiserver、kube-controller-manager、kube scheduler、docker、etcd、calico,NFS |
| k8s-node1 |
192.168.200.130 |
kubelet、kubeproxy、Docker18.06.1-ce |
| k8s-node2 |
192.168.200.133 |
kubelet、kubeproxy、Docker18.06.1-ce |
三台机器都需要完成(结束我会提示)
修改三台机器的hostname及hosts文件
【输入hostname即可查看是否改成功】
hostnamectl set-hostname k8s-master 【129】
hostnamectl set-hostname k8s-node1 【130】
hostnamectl set-hostname k8s-node2 【133】
【将id映射的hostname进行关联】
[输入 cat /etc/hosts 查看是否成功]
cat >>/etc/hosts<<EOF
192.168.200.129 k8s-master
192.168.200.130 k8s-node1
192.168.200.133 k8s-node2
EOF
效果图
[root@localhost ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.200.129 k8s-master
192.168.200.130 k8s-node1
192.168.200.133 k8s-node2
关闭防火墙和关闭SELinux
systemctl stop firewalld
systemctl disable firewalld
setenforce 0 临时关闭
vi /etc/sysconfig/selinux 永久关闭
改为SELINUX=disabled
关闭 SELinux 可以避免一些服务(如 Jenkins、SonarQube、Docker)因为权限问题无法访问网络或文件,但不是永久推荐的安全实践。
设置系统参数
设置允许路由转发,不对bridge的数据进行处理
创建文件
vi /etc/sysctl.d/k8s.conf
内容如下:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
vm.swappiness = 0
执行文件
sysctl -p /etc/sysctl.d/k8s.conf
kube-proxy开启ipvs的前置条件
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash ☆☆
/etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
所有节点关闭swap
swapoff -a 临时关闭
vi /etc/fstab 永久关闭
注释掉以下字段
/dev/mapper/cl-swap swap swap defaults 0 0
安装kubelet、kubeadm、kubectl
- kubeadm:用来初始化集群的指令。
- kubelet:在集群中的每个节点上用来启动 pod 和 container 等。
- kubectl: 清空yum缓存 用来与集群通信的命令行工具。
清空yum缓存
yum clean all
设置yum安装源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
安装:yum install -y kubelet kubeadm kubectl
kubelt 设置开机启动(注意:先不启动,现在启动的话会报错)
systemctl start kubelet 启动 ★★
systemctl enable kubelet 开机启动
查看版本
kubelet --version → Kubernetes v1.28.2
结束!
Master节点需要完成 [129主节点]
kubeadm init --kubernetes-version=1.28.2 \
--apiserver-advertise-address=192.168.200.129 \
--image-repository registry.aliyuncs.com/google_containers \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16
如何重新初始化?
解决步骤
1. 清理旧集群残留
先执行 kubeadm reset 清理当前节点的 Kubernetes 配置和状态:
kubeadm reset -f
kubeadm reset
这个命令会清理 kubelet 配置文件、证书、容器网络和所有 Kubernetes 相关状态。
2. 清理网络相关残留
清理 CNI 网络配置和容器残留:
rm -rf /etc/cni/net.d
rm -rf /var/lib/cni/
rm -rf /var/lib/kubelet/*
3. 确认 containerd 服务启动
确保 containerd 运行:
systemctl restart containerd
systemctl status containerd
4. 重新初始化 Kubernetes
执行你之前的初始化命令:
kubeadm init --kubernetes-version=1.28.2 \
--apiserver-advertise-address=192.168.200.129 \
--image-repository registry.aliyuncs.com/google_containers \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16
5. 配置 kubeconfig
初始化完成后,按照提示将配置文件复制到用户目录:
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
6. 部署网络插件
根据你使用的网络插件(比如 Flannel、Calico),按照官方文档部署。以 Flannel 为例:
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
7. 验证
查看节点和 Pod 状态:
kubectl get nodes
kubectl get pods -n kube-system
kubeadm join 192.168.200.129:6443 --token q54yl3.xgho0e6o5080hnnf \
--discovery-token-ca-cert-hash sha256:b8f6a58b65ad6bcfec65e5ed6ab5efac95f3a4ee82b2c388a87b20c3e813079b
总结
你之前的配置文件和状态未清理,导致不能重新初始化。先用 kubeadm reset 清理,再重新初始化。这样会自动生成 kubelet 配置文件和 kubelet.conf,解决你遇到的启动失败问题。
问题: [ERROR CRI]: container runtime is not running: output: E0706 21:24:43.293740 26106 remote_runtime.go:616] “Status from runtime service failed” err=”rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial unix /var/run/containerd/containerd.sock: connect: no such file or directory"“ time=”2025-07-06T21:24:43+08:00” level=fatal msg=”getting status of runtime: rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial unix /var/run/containerd/containerd.sock: connect: no such file or directory"“ , error: exit status 1 [preflight] If you know what you are doing, you can make a check non-fatal with --ignore-preflight-errors=... To see the stack trace of this error execute with –v=5 or higher [root@k8s-master ~]#
✅ 立即解决步骤(推荐直接复制粘贴执行)
1️⃣ 安装 containerd
yum install -y containerd
你这里显示的是一个非标准的 containerd 配置模板(很可能来自旧版本或 docker 提供的 containerd),缺失了完整配置结构和 SystemdCgroup 字段,所以这不是我们需要的配置。
✅ 正确做法是:用标准 containerd 命令生成完整配置
请执行以下命令替换掉旧配置:
🔁 步骤 1:重新生成 containerd 的标准配置文件
rm -f /etc/containerd/config.toml # 删除旧文件
containerd config default > /etc/containerd/config.toml
🔧 步骤 2:编辑配置文件,修改 SystemdCgroup = true
vi /etc/containerd/config.toml
在文件中搜索这一行(用 /SystemdCgroup):
SystemdCgroup = false
将它修改为:
SystemdCgroup = true
🔁 步骤 3:重启 containerd
systemctl daemon-reexec
systemctl restart containerd
systemctl enable containerd
✅ 步骤 4:验证是否运行中
systemctl status containerd
确保输出中看到:Active: active (running)
然后你就可以继续 kubeadm init 了。如果你愿意,我可以一步步带你确认配置生效。现在请先执行
一、清理旧的集群数据
你可以执行下面命令,清理之前的 kubeadm 初始化信息:
kubeadm reset
你这边的核心问题是:
❌ containerd 没有启动,导致 kubeadm 报错
"connect: no such file or directory" → /var/run/containerd/containerd.sock
这说明 containerd 根本没跑起来,Kubernetes 无法连接它。
✅ 解决思路:修复 containerd 的配置 + 启动 containerd
我们手把手来操作👇
🧹 第一步:清空 containerd 的配置文件并重新生成
rm -f /etc/containerd/config.toml
containerd config default > /etc/containerd/config.toml
✅ 这一步会恢复官方默认配置。
✏️ 第二步:使用 vi(所有 Linux 通用)
vi /etc/containerd/config.toml
查找这一段:
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.k8s.io/pause:3.6"
把它改成:
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"
✅ 保存并退出🔄 第三步:重启 containerd
systemctl daemon-reexec
systemctl restart containerd
✅ 第四步:确认 containerd 已成功启动
systemctl status containerd
看输出里有 Active: active (running),说明启动成功。🧪 第五步:验证 socket 文件是否存在
ls -l /var/run/containerd/containerd.sock
应该能看到类似:
srw-rw---- 1 root root 0 Jul 6 22:06 /var/run/containerd/containerd.sock
如果没看到,说明 containerd 没真正运行成功。
🧱 第六步:重新执行 kubeadm init
kubeadm init --kubernetes-version=1.28.2 \
--apiserver-advertise-address=192.168.200.129 \
--image-repository registry.aliyuncs.com/google_containers \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16
若是token忘记了 可以执行直接生成一个新的
kubeadm token create --print-join-command
[root@k8s-master calico]# kubeadm token create --print-join-command
kubeadm join 192.168.200.129:6443 --token jn3083.g1lz52mo680wiic9 --discovery-token-ca-cert-hash sha256:d03d798679d90f348b1cf7a1c12d5d1bfcbe2bd18e4a1aec97055b60c0f042ca
此时去从节点生成可能会有报错你这个错误说明当前节点(k8s-node1)
之前已经执行过 kubeadm join 或者其他 kubeadm 相关操作,留下了配置文件或端口被占用,不能直接再次执行 kubeadm join。
❗报错详情分析:
[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
这些错误说明:
/etc/kubernetes/kubelet.conf 文件存在 —— 说明 kubelet 被配置过。10250 端口已被占用 —— kubelet 服务正在运行。/etc/kubernetes/pki/ca.crt 文件存在 —— 集群证书存在,可能是之前加入过失败或残留文件。
✅ 解决方法(清理残留再重新 join):
你可以先在 node 节点执行 重置操作:
kubeadm reset -f
然后再清理一下配置和 iptables 规则(可选但推荐):
rm -rf /etc/kubernetes/pki
rm -rf /etc/kubernetes/kubelet.conf
rm -rf /var/lib/kubelet/*
iptables -F
systemctl restart kubelet
然后重新执行你之前的 kubeadm join 命令:
kubeadm join 192.168.200.129:6443 --token eoxdev.8tkpz5csc7x1mqgc \
--discovery-token-ca-cert-hash sha256:6acf9c7e6c11bb973bd57404f9ec28b93ab5b48f8a50f0213bc389bbfb4bf68f
一切顺利的话,k8s 就能初始化成功了!
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run “kubectl apply -f [podnetwork].yaml” with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.200.129:6443 –token zjoxjc.f58nh7lixocvjpgj
–discovery-token-ca-cert-hash sha256:3cbdd81868c4470767b5c82af37fb63c2240c98e5f00eb0458df99350cabb7b3
[root@k8s-master ~]#
kubeadm join 192.168.200.129:6443 --token zjoxjc.f58nh7lixocvjpgj \
--discovery-token-ca-cert-hash sha256:3cbdd81868c4470767b5c82af37fb63c2240c98e5f00eb0458df99350cabb7b3
- 按照它的提示逐步修改k8s配置文件 配置
kubectl 工具
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
mkdir k8s
cd k8s
wget https://docs.projectcalico.org/v3.10/getting-started/kubernetes/installation/hosted/kubernetes-datastore/calico-networking/1.7/calico.yaml
// 上面的别用了 用这个新的
wget https://jiangstudy.online:8081/sources/calico.yaml
sed -i 's/192.168.0.0/10.244.0.0/g' calico.yaml 【改地址 分给prod的虚拟地址】
kubectl apply -f calico.yaml
或者ai说的
# 1. 创建工作目录
mkdir -p ~/k8s && cd ~/k8s
# 2. 下载 Calico 清单文件(推荐使用最新版本,而非 v3.10)
wget https://docs.projectcalico.org/manifests/calico.yaml -O calico.yaml
# 3. 修改 POD CIDR(根据您的集群规划)
# 注意:必须与 kubeadm init 时指定的 --pod-network-cidr 一致
sed -i 's|192.168.0.0/16|10.244.0.0/16|g' calico.yaml
# 4. 部署 Calico
kubectl apply -f calico.yaml
# 5. 验证安装
kubectl get pods -n kube-system -w
- 等待几分钟,查看所有Pod的状态,确保所有Pod都是Running状态
kubectl get pod --all-namespaces -o wide
你这个 calico.yaml 是 很老的版本 v3.10,其中用的是 apiextensions.k8s.io/v1beta1,早在 Kubernetes v1.22 中就被移除了,你现在用的是 Kubernetes 1.28,自然就出错了。
✅ 正确做法:使用 Calico 官方支持 Kubernetes v1.28 的最新 YAML
https://docs.projectcalico.org/manifests/calico.yaml浏览器访问然后去/root/k8s里面进行全部替换成新版本
一键下载安装推荐版本:
curl https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/calico.yaml -O
Calico v3.26 支持 Kubernetes v1.28,放心使用
然后再修改 Pod CIDR:
sed -i 's/192.168.0.0/10.244.0.0/g' calico.yaml
- 建议修改镜像源为阿里云(国内可拉取):
例如将以下几行(在 calico.yaml 中):
image: calico/cni:v3.26.1
替换为:
image: registry.cn-hangzhou.aliyuncs.com/chenby/calico_cni:v3.26.1
最后重新部署:
kubectl apply -f calico.yaml
✅ 检查 Calico 状态
部署完大约 10~30 秒后执行:
kubectl get pods -n kube-system
正常会看到 calico-node 和 calico-kube-controllers 都处于 Running 状态。
傻卵ai和scdn 查半天都没用 还不如B站up的方法[一遍通]
【kubernetes】Calico组件的安装-云途运维
以下步骤只在master01执行:相关的yaml已上传文件资源服务器,需要下载下来使用:
mkdir /root/calico && cd /root/calico/
wget https://jiangstudy.online:8081/sources/calico.yaml
修改POD网段 说明:pod网段即为主机规划时的网段。
POD_SUBNET=`cat /etc/kubernetes/manifests/kube-controller-manager.yaml | grep cluster-cidr= | awk -F= '{print $NF}'`
sed -i "s#POD_CIDR#${POD_SUBNET}#g" calico.yaml
部署calico
kubectl apply -f calico.yaml
查看状态
kubectl get node
kubectl get pods -n kube-system -w
Slave节点需要完成
让所有节点让集群环境
使用之前Master节点产生的命令加入集群
kubeadm join 192.168.200.129:6443 --token eoxdev.8tkpz5csc7x1mqgc \
--discovery-token-ca-cert-hash sha256:6acf9c7e6c11bb973bd57404f9ec28b93ab5b48f8a50f0213bc389bbfb4bf68f
启动kubelet
systemctl start kubelet 启动
systemctl status kubelet 查看状态
回到Master节点查看,如果Status全部为Ready,代表集群环境搭建成功!!!
kubectl get nodes
你的这个报错:
validate service connection: CRI v1 runtime API is not implemented for endpoint "unix:///var/run/containerd/containerd.sock"
说明 containerd 的 CRI 接口没启用,这是因为你的 /etc/containerd/config.toml 配置不完整或者缺少必要字段。
✅ 立即修复步骤如下:
🔧 第一步:重新生成 config.toml 配置文件
rm -f /etc/containerd/config.toml
containerd config default > /etc/containerd/config.toml
🛠️ 第二步:修改配置启用 CRI + systemd 驱动
vim /etc/containerd/config.toml
找到这段:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = false
把 false 改成 true:
SystemdCgroup = true
或者直接用命令修改:
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
🚀 第三步:重启 containerd
systemctl daemon-reexec
systemctl restart containerd
systemctl status containerd
确认运行正常后:
ls /var/run/containerd/containerd.sock
如果有输出说明 socket 正常,containerd 工作 OK。
🔁 第四步:再次执行 kubeadm join
kubeadm join 192.168.200.129:6443 --token zjoxjc.f58nh7lixocvjpgj \
--discovery-token-ca-cert-hash sha256:3cbdd81868c4470767b5c82af37fb63c2240c98e5f00eb0458df99350cabb7b3
如果重复导入节点报error
你这个问题是由于 kubeadm join 重复执行导致节点上已有残留的配置文件和端口占用,所以报错。
✅ 正确处理方式:重置 node 节点后重新 join
执行以下命令即可:
1. 重置 node 节点配置
kubeadm reset -f
2. 清理 CNI 网络配置
rm -rf /etc/cni/net.d
3. 重启相关服务
systemctl restart kubelet
systemctl restart containerd
4. 重新 join
然后再执行你原来的 join 生成的命令即可:
kubeadm join 192.168.200.129:6443 --token zjoxjc.f58nh7lixocvjpgj \
--discovery-token-ca-cert-hash sha256:3cbdd81868c4470767b5c82af37fb63c2240c98e5f00eb0458df99350cabb7b3
[root@k8s-master k8s]# docker pull docker.io/calico/node:v3.26.1
v3.26.1: Pulling from calico/node
c998069b4a7c: Downloading [===============================================> ] 81.5MB/86.58MB
6cf92fa5251d: Download complete
[root@k8s-master k8s]# docker save docker.io/calico/node:v3.26.1 -o calico-node-v3.26.1.tar
[root@k8s-master k8s]# ctr images import –all-platforms calico-node-v3.26.1.tar
unpacking docker.io/calico/node:v3.26.1 (sha256:568fb25384d6460176b5528381a2d6fef36d110cfaddda5ae286afbf8fe15d5b)…done
[root@k8s-master k8s]# ctr images ls | grep calico/node
docker.io/calico/node:v3.26.1 application/vnd.docker.distribution.manifest.v2+json sha256:568fb25384d6460176b5528381a2d6fef36d110cfaddda5ae286afbf8fe15d5b 247.7 MiB linux/arm64 -
[root@k8s-master k8s]# kubectl -n kube-system delete pod -l k8s-app=calico-node
(你刚才就是 calico_cni 拉失败)
你可以用如下命令一口气替换:
sed -i 's@docker.io/calico/cni@registry.cn-hangzhou.aliyuncs.com/chenby/calico_cni@g' calico.yaml
sed -i 's@docker.io/calico/pod2daemon-flexvol@registry.cn-hangzhou.aliyuncs.com/chenby/calico_pod2daemon-flexvol@g' calico.yaml
sed -i 's@docker.io/calico/node@registry.cn-hangzhou.aliyuncs.com/chenby/calico_node@g' calico.yaml
sed -i 's@docker.io/calico/kube-controllers@registry.cn-hangzhou.aliyuncs.com/chenby/calico_kube-controllers@g' calico.yaml
🔧 步骤四:重新部署
kubectl apply -f calico.yaml
sudo tee /etc/docker/daemon.json <<-‘EOF’
{
“registry-mirrors”: [“https://docker.m.daocloud.io","https://p5lmkba8.mirror.aliyuncs.com","https://registry.docker-cn.com"]
}
EOF
————————————————
大坑:子节点的calico一直处于初始化无法启动解决方案
虽然都在,但关键是containerd配置是否默认用的是 registry.k8s.io/pause:3.6 ,导致kubelet拉这个镜像时出错。
请你检查并修改 containerd配置,明确指定 sandbox_image 用阿里云镜像:
cat /etc/containerd/config.toml | grep sandbox_image
如果没设置,执行:
containerd config default > /etc/containerd/config.toml.backup
containerd config default > /etc/containerd/config.toml
然后编辑 /etc/containerd/config.toml,找到 [plugins."io.containerd.grpc.v1.cri".containerd] 部分,加入或修改为:
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.6"
保存后,重启containerd:
systemctl restart containerd
然后重启 kubelet:
systemctl restart kubelet
确认 containerRuntimeEndpoint 在 kubelet 配置文件或启动参数中有正确指向:
containerRuntimeEndpoint: unix:///run/containerd/containerd.sock
最后删除calico-node和kube-proxy pod,触发重新调度:
kubectl -n kube-system delete pod -l k8s-app=calico-node
kubectl -n kube-system delete pod -l k8s-app=kube-proxy
然后观察节点状态和Pod状态。
kubectl get nodes 查看节点状态
kubectl get pods -n kube-system -o wide 查看pod状态
总结:
确保 containerd 配置里的 sandbox_image 指向阿里云镜像,避免kubelet拉不到官方registry.k8s.io的镜像导致网络插件初始化失败,从而使节点一直NotReady。
报错:
calico-node-xb2js 0/1 CrashLoopBackOff 9 (4m12s ago) 25m 192.168.200.130 k8s-node1
❗你的 k8s-node1 上 端口 9099 被 Nginx 占用了,而这个端口正是 Calico 默认用于健康检查的端口。
导致结果就是:
calico-node 启动失败并反复报错 listen tcp 127.0.0.1:9099: bind: address already in use,Pod 状态进入 CrashLoopBackOff。
✅ 解决方案
你可以选 其中一个方法:
✅ 方案一:改 Nginx 的端口(推荐)
找到你的 nginx 配置文件(通常在 vi /etc/nginx/nginx.conf 或 /etc/nginx/conf.d/xxx.conf)
修改 listen 9877; 为其他端口,比如 listen 8081;
重启 nginx:
systemctl restart nginx
删除重启 calico-node Pod:
kubectl delete pod -n kube-system -l k8s-app=calico-node --field-selector spec.nodeName=k8s-node1
等待 Pod 变成 Running 状态。
基于Kubernetes/K8S构建Jenkins持续集成平台(下)
安装和配置NFS文件共享服务器
安装和配置 NFS
NFS(Network File System),它最大的功能就是可以通过网络,让不同的机器、不同的操作系统可以共享彼此的文件。我们可以利用NFS共享Jenkins运行的配置文件、Maven的仓库依赖文件等
我们把NFS服务器安装在192.168.200.129机器上
安装NFS服务(在所有K8S的节点都需要安装)
yum install -y nfs-utils 【仅此这个都要运行】
创建共享目录
mkdir -p /opt/nfs/jenkins
编写NFS的共享配置:
vi /etc/exports
内容如下: 代表对所有IP都开放此目录,rw是读写
【no_root_suqash root用户生成的数据不做身份转换,也就原来是root,归root用户管理。权限太大实际需要评估】
/opt/nfs/jenkins *(rw,no_root_squash)
启动服务
systemctl enable nfs 开机启动
systemctl start nfs 启动
查看NFS共享目录
showmount -e 192.168.200.129
在这之前也要安装nfs服务:yum install -y nfs-utils
[root@k8s-node1 ~]# showmount -e 192.168.200.129
Export list for 192.168.200.129:
/opt/nfs/jenkins *
在Kubernetes安装Jenkins-Master
创建NFS client provisioner
nfs-client-provisioner 是一个Kubernetes的简易NFS的外部provisioner,本身不提供NFS,需要现有 的NFS服务器提供存储。
上传nfs-client-provisioner构建文件
把E:\Java实例项目1-20套\资料-Jenkins教程\Jenkins资料\资料\资料\03.资料\k8s-jenkins的jenkins-master和nfs-client上传到129Jenkins虚拟机上面
[root@k8s-master ~]# cd jenkins-master/
[root@k8s-master jenkins-master]# ll
总用量 16
-rw-r–r– 1 root root 1874 7月 7 15:59 rbac.yaml
-rw-r–r– 1 root root 87 7月 7 15:59 ServiceaAcount.yaml
-rw-r–r– 1 root root 284 7月 7 15:59 Service.yaml 【对外暴露信息】
-rw-r–r– 1 root root 2116 7月 7 15:59 StatefulSet.yaml 【有状态应用】
[root@k8s-master ~]# cd nfs-client/
[root@k8s-master nfs-client]# ll
总用量 12
-rw-r–r– 1 root root 225 7月 7 16:03 class.yaml
-rw-r–r– 1 root root 985 7月 7 16:03 deployment.yaml
-rw-r–r– 1 root root 1526 7月 7 16:03 rbac.yaml
[root@k8s-master nfs-client]# vi deployment.yaml
修改里面的地址为主节点Jenkins的
构建nfs-client-provisioner的pod资源
cd nfs-client
kubectl create -f .
查看pod是否创建成功
kubectl get pods
[root@k8s-master nfs-client]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-68cd5845b6-dqqm2 0/1 ContainerCreating 0 15s
这里也有个拉镜像的问题 deployment.yaml的lizhenliang/nfs-client-provisioner:latest
接下来操作步骤:
1. 修改你的 deployment.yaml 中的镜像字段,改成刚拉取的镜像:
containers:
- name: nfs-client-provisioner
image: quay.io/external_storage/nfs-client-provisioner:v3.1.0-k8s1.11
# 其他配置保持不变
确保 env 和 volumes 中 NFS 服务器地址及路径正确,和你之前确认的一致。
2. 应用更新后的 Deployment 配置:
kubectl apply -f deployment.yaml
3. 查看 Pod 状态:
kubectl get pods -w
等待 Pod 状态变成 Running 和 READY 1/1。
[root@k8s-master nfs-client]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-7d79bcf5d4-tddhl 1/1 Running 0 3m33s
可用的deployment.yaml 位置在129机器的/root/nfs-client
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-client-provisioner
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: quay.io/external_storage/nfs-client-provisioner:v3.1.0-k8s1.11
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: fuseim.pri/ifs
- name: NFS_SERVER
value: 192.168.200.129
- name: NFS_PATH
value: /opt/nfs/jenkins/
volumes:
- name: nfs-client-root
nfs:
server: 192.168.200.129
path: /opt/nfs/jenkins/
返回jenkins-master目录
[root@k8s-master ~]# cd jenkins-master/
[root@k8s-master jenkins-master]#
[root@k8s-master jenkins-master]# kubectl create namespace kube-ops
namespace/kube-ops created
[root@k8s-master jenkins-master]# kubectl create -f .
✅ 如果你只是想重新部署,可以改用 kubectl apply -f . (推荐,用于更新已有资源)
❌ 如果你要重新初始化,先删除旧资源:
kubectl delete -f . && kubectl create -f .
这里报错因为有一些过时了的 需要更改 注意是在/root/jenkins-master中的rbac.yaml
你这个问题根源就是 apiVersion 使用了 rbac.authorization.k8s.io/v1beta1,新版 Kubernetes 不再支持这个版本了,必须改成 rbac.authorization.k8s.io/v1。
另外,你 ClusterRole 不应该带 namespace 字段,因为 ClusterRole 是集群级别的资源,不属于某个命名空间。
我帮你改成符合最新标准的版本,注意几点:
- 所有
rbac.authorization.k8s.io/v1beta1 改为 rbac.authorization.k8s.io/v1
- 删除
ClusterRole 中的 namespace
- Role 和 RoleBinding 保留
namespace: kube-ops
- RoleBinding 和 ClusterRoleBinding 中的
subjects namespace 保持和 ServiceAccount 一致
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: jenkins
namespace: kube-ops
rules:
- apiGroups: ["extensions", "apps"]
resources: ["deployments"]
verbs: ["create", "delete", "get", "list", "watch", "patch", "update"]
- apiGroups: [""]
resources: ["services"]
verbs: ["create", "delete", "get", "list", "watch", "patch", "update"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/exec"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get","list","watch"]
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: jenkins
namespace: kube-ops
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: jenkins
subjects:
- kind: ServiceAccount
name: jenkins
namespace: kube-ops
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: jenkinsClusterRole
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/exec"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get","list","watch"]
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: jenkinsClusterRoleBinding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: jenkinsClusterRole
subjects:
- kind: ServiceAccount
name: jenkins
namespace: kube-ops
保存后,用:
kubectl apply -f rbac.yaml
应该就不会再报找不到资源类型的错误了。
成功!!
service/jenkins created
serviceaccount/jenkins created
statefulset.apps/jenkins created
role.rbac.authorization.k8s.io/jenkins created
rolebinding.rbac.authorization.k8s.io/jenkins created
clusterrole.rbac.authorization.k8s.io/jenkinsClusterRole created
clusterrolebinding.rbac.authorization.k8s.io/jenkinsClusterRoleBinding created
输入kubectl get pod --namespace kube-ops
[root@k8s-master jenkins-master]# kubectl get pod --namespace kube-ops
NAME READY STATUS RESTARTS AGE
[root@k8s-master jenkins-master]# kubectl get service --namespace kube-ops
更详细的查看:kubectl get service --namespace kube-ops -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
jenkins NodePort 10.1.85.222 8080:30742/TCP,50000:31261/TCP 8m1s
如果不能running看这里!
你应该把 Deployment 里的镜像改成 quay.io/external_storage/nfs-client-provisioner:v3.1.0-k8s1.11,这样 Pod 就能正常拉镜像启动了。
正确示例片段改成:
containers:
- name: nfs-client-provisioner
image: quay.io/external_storage/nfs-client-provisioner:v3.1.0-k8s1.11
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: fuseim.pri/ifs
- name: NFS_SERVER
value: 192.168.200.129
- name: NFS_PATH
value: /opt/nfs/jenkins/
volumes:
- name: nfs-client-root
nfs:
server: 192.168.200.129
path: /opt/nfs/jenkins/
改完后执行:
、kubectl apply -f deployment.yaml
kubectl delete pod -n default -l app=nfs-client-provisioner
kubectl get pods -n default -w
确认 Pod 快速启动且状态为 Running。
这样 PVC 才能被正确绑定,jenkins 的 PVC Pending 状态才会解决。
你这边已经非常接近解决了,目前的 唯一问题是 Provisioner 报了 selfLink was empty, can't make reference 的错误,这在 Kubernetes v1.20+ 中是常见兼容性问题,因为 selfLink 字段已经被弃用并默认禁用了。
✅ 当前现状确认:
| 项目 |
状态 |
| NFS 服务 |
正常可挂载 ✅ |
| Jenkins PVC |
一直 Pending ❌ |
| Provisioner Pod 状态 |
Running ✅ |
| Provisioner 日志报错 |
selfLink ❌ |
| StorageClass/Provisioner 名 |
一致 ✅ |
🚨 问题根因
nfs-client-provisioner 的老版本依赖了 selfLink 字段,但你用的是 Kubernetes v1.28,从 v1.20 起 selfLink 默认禁用,导致:
unexpected error getting claim reference: selfLink was empty, can't make reference
✅ 解决方案:用国内镜像源代替
我推荐你使用 阿里云加速镜像 或 [DockerHub 镜像代理]。下面我给你一份修改好的 deployment.yaml,使用了国内可访问的镜像仓库地址。
✅ 修改后的 deployment.yaml(适配国内镜像源)
yaml复制编辑apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-client-provisioner
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: registry.cn-hangzhou.aliyuncs.com/zhangshijie/nfs-subdir-external-provisioner:v4.0.2
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: fuseim.pri/ifs
- name: NFS_SERVER
value: 192.168.200.129
- name: NFS_PATH
value: /opt/nfs/jenkins/
volumes:
- name: nfs-client-root
nfs:
server: 192.168.200.129
path: /opt/nfs/jenkins/
📌 操作步骤
- 把上面内容保存为
deployment.yaml
- 应用并重建:
kubectl apply -f deployment.yaml
kubectl delete pod -n default -l app=nfs-client-provisioner
- 然后检查 PVC 状态是否变成
Bound:
kubectl get pvc -n kube-ops
这里是第二种方法[已尝试可行]!
/root/jenkins-master/
你贴出来的 StatefulSet.yaml 文件已经包含了镜像配置的位置!
🎯 问题就在这一段:
yaml复制编辑containers:
- name: jenkins
image: jenkins/jenkins:lts-alpine 👈 就是这行!!!
这个 image: 指定的镜像目前拉不下来(你刚才试图用的是阿里云镜像,结果不存在),所以你现在只需要 改成可用的镜像地址。
✅ 推荐改法如下:
yaml复制编辑containers:
- name: jenkins
image: jenkins/jenkins:lts-jdk17 # ✅ 推荐:可拉取的官方 Jenkins 镜像
imagePullPolicy: IfNotPresent
💡这是 Jenkins 官方最新稳定版本(带 JDK 17)的镜像,在 Docker Hub 可用,国内访问可能慢一点,但比你原来的阿里云镜像靠谱。
🛠 修改步骤:
打开 StatefulSet.yaml:
vim StatefulSet.yaml
找到:
image: jenkins/jenkins:lts-alpine
改成:
image: jenkins/jenkins:lts-jdk17
保存退出(按 Esc 然后输入 :wq)
🔁 然后重新部署:
kubectl apply -f StatefulSet.yaml
kubectl delete pod jenkins-0 -n kube-ops
第二条命令是为了立刻让 Pod 使用新镜像重建。
[root@k8s-master jenkins-master]# kubectl apply -f StatefulSet.yaml statefulset.apps/jenkins configured [root@k8s-master jenkins-master]# kubectl delete pod jenkins-0 -n kube-ops pod “jenkins-0” deleted [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 4s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 8s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 9s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 10s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 11s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 11s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 19s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ErrImagePull 0 24s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ErrImagePull 0 27s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ErrImagePull 0 27s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ErrImagePull 0 31s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ErrImagePull 0 32s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ImagePullBackOff 0 47s [root@k8s-master jenkins-master]#
很好,你的 Jenkins Pod 现在变成了:
STATUS: ImagePullBackOff
✅ 这说明你已经修改成功了,但节点还是拉不到镜像。
我们确认下你用了哪个镜像,执行:
kubectl get pod jenkins-0 -n kube-ops -o=jsonpath='{.spec.containers[0].image}'
你应该看到输出类似于:
jenkins/jenkins:lts-jdk17
然后我们来排查下一步。
🧭 下一步:去节点上测试能否手动拉取镜像
进入 k8s-node1 节点(Pod 分配在哪个节点,看 kubectl describe pod 可以看到):
ssh root@k8s-node1
在节点上运行:
docker pull jenkins/jenkins:lts-jdk17
或者如果你用的是 containerd 作为容器运行时:
ctr images pull docker.io/jenkins/jenkins:lts-jdk17
[root@k8s-master jenkins-master]# kubectl apply -f StatefulSet.yaml statefulset.apps/jenkins configured [root@k8s-master jenkins-master]# kubectl delete pod jenkins-0 -n kube-ops pod “jenkins-0” deleted [root@k8s-master jenkins-master]# clear [root@k8s-master jenkins-master]# ll 总用量 16 -rw-r–r– 1 root root 1863 7月 7 16:39 rbac.yaml -rw-r–r– 1 root root 87 7月 7 15:59 ServiceaAcount.yaml -rw-r–r– 1 root root 284 7月 7 15:59 Service.yaml -rw-r–r– 1 root root 2117 7月 7 18:37 StatefulSet.yaml [root@k8s-master jenkins-master]# kubectl apply -f StatefulSet.yaml statefulset.apps/jenkins configured [root@k8s-master jenkins-master]# kubectl delete pod jenkins-0 -n kube-ops pod “jenkins-0” deleted [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 4s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 8s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 9s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 10s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 11s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 11s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ContainerCreating 0 19s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ErrImagePull 0 24s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ErrImagePull 0 27s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ErrImagePull 0 27s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ErrImagePull 0 31s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ErrImagePull 0 32s [root@k8s-master jenkins-master]# kubectl get pod -n kube-ops NAME READY STATUS RESTARTS AGE jenkins-0 0/1 ImagePullBackOff 0 47s [root@k8s-master jenkins-master]# ^C [root@k8s-master jenkins-master]# kubectl get pod jenkins-0 -n kube-ops -o=jsonpath=’{.spec.containers[0].image}’ jenkins/jenkins:lts-jdk17[root@k8s-master jenkins-master]# ssh root@k8s-node1 The authenticity of host ‘k8s-node1 (192.168.200.130)’ can’t be established. ECDSA key fingerprint is SHA256:LMkCxwuWrKBih+Iy+lnayVkAyKdVG7JpVVR3TctpMuk. ECDSA key fingerprint is MD5:c1:76:72:fb:65:64:f8:d5:71:5b:38:a8:9b:07:a6:e6. Are you sure you want to continue connecting (yes/no)? docker pull jenkins/jenkins:lts-jdk17 Please type ‘yes’ or ‘no’: yes Warning: Permanently added ‘k8s-node1’ (ECDSA) to the list of known hosts. root@k8s-node1’s password: Permission denied, please try again. root@k8s-node1’s password: Last failed login: Mon Jul 7 18:39:33 CST 2025 from k8s-master on ssh:notty There was 1 failed login attempt since the last successful login. Last login: Mon Jul 7 17:36:26 2025 from 192.168.200.2 [root@k8s-node1 ~]# docker pull jenkins/jenkins:lts-jdk17 lts-jdk17: Pulling from jenkins/jenkins 0c01110621e0: Pull complete 2315362e4443: Pull complete 4185f63a4bf1: Pull complete 51c9d25ed578: Pull complete 10709260192c: Pull complete 474c0ab7c65d: Pull complete 62d5bb186774: Pull complete f1c4b8ee4b6f: Pull complete 065b78ceb30c: Pull complete b99138e4f420: Pull complete e05a8359c72d: Pull complete 981fa0afce25: Pull complete Digest: sha256:dd570585c3adadefcfbeba915e27bf7feca1815a0ea8a659d46b51f54fc7ea06 Status: Downloaded newer image for jenkins/jenkins:lts-jdk17 [root@k8s-node1 ~]#
太好了!你已经在 k8s-node1 节点上 成功拉下来了 Jenkins 的镜像:
bash
复制编辑
✅ jenkins/jenkins:lts-jdk17 拉取成功!
❓但为什么 Pod 还是拉不到?
Kubernetes 默认不会自动使用你用 docker pull 拉下来的镜像,除非你的 K8s 用的容器运行时 就是 Docker。
现在我们确认一下你的容器运行时是不是 Docker,执行下面的命令:
bash
复制编辑
ps -ef | grep kubelet | grep -v grep
看结果里面有没有:
--container-runtime=docker ✅(说明用的是 Docker)- 或者有
containerd 或 cri-o ❌(说明用的是 containerd,不会用 docker 拉的镜像)
✅ 如果你看到用的是 containerd(大概率是)
那你就需要把 Docker 拉下来的镜像导入给 containerd 用!
🔄 导入镜像到 containerd 的方法如下:
- 在
k8s-node1 节点上保存镜像为 tar 包:
docker save jenkins/jenkins:lts-jdk17 -o jenkins.tar
- 用
ctr 命令导入给 containerd 使用:
ctr -n k8s.io images import jenkins.tar
- 验证 containerd 已经识别:
ctr -n k8s.io images ls | grep jenkins
你应该看到 docker.io/jenkins/jenkins:lts-jdk17 这一行。
🔁 然后重启 Pod:
kubectl delete pod jenkins-0 -n kube-ops
过一会再执行:
kubectl get pod -n kube-ops
你现在在 master 节点(192.168.200.129),但 Jenkins Pod 被调度到 node1 节点(192.168.200.130),所以镜像必须在 node1 上可用。而你刚才是手动在 node1 上 docker pull 了 Jenkins 镜像,这一步做得 ✅没问题。
✅ 问题核心确认
你当前用的是 Kubernetes,但默认的容器运行时 不是 Docker,而是 containerd,所以:
❗ 你用 docker pull 拉下的镜像 containerd 用不到
✅ 解决方案:把 docker 镜像导入到 containerd 里
在 node1 上(192.168.200.130)执行以下命令:
- 把镜像导出为 tar 包
docker save jenkins/jenkins:lts-jdk17 -o jenkins.tar
- 导入到 containerd:
ctr -n k8s.io images import jenkins.tar
- 检查 containerd 是否导入成功:
ctr -n k8s.io images ls | grep jenkins
你应该看到输出类似:
docker.io/jenkins/jenkins:lts-jdk17 ...
🔄 然后,在 master 节点(192.168.200.129)上执行:
kubectl delete pod jenkins-0 -n kube-ops
等 10~20 秒后看 Pod 是否启动成功:
kubectl get pod -n kube-ops
看到状态变为:
jenkins-0 1/1 Running
就说明一切 OK ✅!
你现在遇到的问题是:
⚠️ 在 node1(130) 节点上运行 kubectl 命令时,K8s API server 无法正常访问,提示 the server could not find the requested resource。
这是因为:
👉 kubectl 命令只能在 已配置好 K8s 集群访问权限的节点上使用,通常是 master 节点(192.168.200.129)。
✅ 正确操作流程如下:
🔁 你刚才在 node1 上导入 containerd 镜像已经成功了,现在:
- 返回到 master 节点(192.168.200.129)
- 执行删除 pod 的命令(由 master 控制):
kubectl delete pod jenkins-0 -n kube-ops
- 查看 pod 状态:
kubectl get pod -n kube-ops
你应该看到 jenkins-0 在 node1 上重新启动,并变成 Running 状态。
你现在正登录在 node1 节点(192.168.200.130),而你的 kubectl 应该在 master 节点(192.168.200.129) 上执行。
✅ 回到 master 节点的方法:
只要你是通过 SSH 登录进来的,直接输入 exit 或按 Ctrl+D 即可退出当前 SSH 会话,返回 master 节点:
[root@k8s-node1 ~]# exit
或
[root@k8s-node1 ~]# logout
然后你就会看到:
[root@k8s-master ~]#
这时候你就在 master 节点上了!
🧠 提醒:kubectl 只能在 master 上执行
比如这些命令:
kubectl delete pod jenkins-0 -n kube-ops
kubectl get pods -n kube-ops
kubectl logs jenkins-0 -n kube-ops
都需要在 master 节点(192.168.200.129) 上执行,其他 node 节点默认是没有权限或 kubeconfig 配置的。
现在你可以:
✅ 先退出 node1:
exit
✅ 然后在 master 上执行:
kubectl delete pod jenkins-0 -n kube-ops
kubectl get pod -n kube-ops -w
成功!!!!
[root@k8s-master jenkins-master]# kubectl get pod -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins-0 1/1 Running 0 7m39s
[root@k8s-master jenkins-master]#
承接上文!!
kubectl get service --namespace kube-ops 得到端口号
[root@k8s-master jenkins-master]# kubectl get service –namespace kube-ops
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
jenkins NodePort 10.1.85.222 8080:30742/TCP,50000:31261/TCP 3h3m
访问即可:http://192.168.200.130:30742/
如何查密码?
解锁 Jenkins
为了确保管理员安全地安装 Jenkins,密码已写入到日志中(不知道在哪里?)该文件在服务器上:
/var/jenkins_home/secrets/initialAdminPassword
请从本地复制密码并粘贴到下面。
管理员密码:
cd /opt/nfs/jenkins
ll
cd kube-ops-jenkins-home-jenkins-0-pvc-18f7c50d-f5e6-443d-ab24-2ebd09b88a2e
cd secrets
cat initialAdminPassword
[root@k8s-master jenkins-master]# cd /opt/nfs
[root@k8s-master nfs]# ll
总用量 0
drwxr-xr-x 3 root root 86 7月 7 17:13 jenkins
[root@k8s-master nfs]# cd jenkins/
[root@k8s-master jenkins]# ll
总用量 4
drwxrwxrwx 11 root root 4096 7月 7 19:10 kube-ops-jenkins-home-jenkins-0-pvc-18f7c50d-f5e6-443d-ab24-2ebd09b88a2e
[root@k8s-master kube-ops-jenkins-home-jenkins-0-pvc-18f7c50d-f5e6-443d-ab24-2ebd09b88a2e]# ll
总用量 28
-rw-r–r– 1 sonar 1000 1663 7月 7 18:58 config.xml
-rw-r–r– 1 sonar 1000 216 7月 7 18:57 copy_reference_file.log
-rw-r–r– 1 sonar 1000 156 7月 7 18:58 hudson.model.UpdateCenter.xml
-rw-r–r– 1 sonar 1000 171 7月 7 18:55 jenkins.telemetry.Correlator.xml
drwxr-xr-x 2 sonar 1000 6 7月 7 18:55 jobs
-rw-r–r– 1 sonar 1000 1037 7月 7 18:58 nodeMonitors.xml
drwxr-xr-x 2 sonar 1000 6 7月 7 18:55 plugins
-rw-r–r– 1 sonar 1000 258 7月 7 18:57 queue.xml.bak
-rw-r–r– 1 sonar 1000 64 7月 7 18:55 secret.key
-rw-r–r– 1 sonar 1000 0 7月 7 18:55 secret.key.not-so-secret
drwx—— 2 sonar 1000 91 7月 7 18:55 secrets
drwxr-xr-x 2 sonar 1000 67 7月 7 18:58 updates
drwxr-xr-x 2 sonar 1000 24 7月 7 18:55 userContent
drwxr-xr-x 3 sonar 1000 56 7月 7 18:55 users
drwxr-xr-x 10 sonar 1000 247 7月 7 18:55 war
[root@k8s-master kube-ops-jenkins-home-jenkins-0-pvc-18f7c50d-f5e6-443d-ab24-2ebd09b88a2e]# ^C
[root@k8s-master kube-ops-jenkins-home-jenkins-0-pvc-18f7c50d-f5e6-443d-ab24-2ebd09b88a2e]# cd secrets
[root@k8s-master secrets]# ll
总用量 12
-rw-r—– 1 sonar 1000 33 7月 7 18:55 initialAdminPassword
-rw-r–r– 1 sonar 1000 32 7月 7 18:55 jenkins.model.Jenkins.crumbSalt
-rw-r–r– 1 sonar 1000 256 7月 7 18:55 master.key
[root@k8s-master secrets]# cat initialAdminPassword
7a2c40f15a564286aac63f61b9f20b95 【复制它去上面管理员密码解锁!!】
创建管理员用户前选自选安装 → 无 → 账号:root 密码:panchunyao123
Jenkins URL:http://192.168.200.130:30742/
这里面的插件和配置延续之前129机器上的
cd /opt/nfs/jenkins/kube-ops-jenkins-home-jenkins-0-pvc-18f7c50d-f5e6-443d-ab24-2ebd09b88a2e/updates
输入[替换国内地址]:sed -i 's/http:\/\/updates.jenkins ci.org\/download/https:\/\/mirrors.tuna.tsinghua.edu.cn\/jenkins/g' default.json && sed -i 's/http:\/\/ www.google.com/https:\/\/ www.baidu.com/g' default.json
最后,Manage Plugins点击Advanced,把Update Site改为国内插件下载地址
https://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json
上面这个不行就按照老的来吧
https://updates.jenkins.io/update-center.json
http://192.168.200.129:8888/restart 重启Jenkins
先安装基本的插件
- Localization:Chinese
- Git
- Pipeline
- Extended Choice Parameter
Jenkins与Kubernetes整合
安装Kubernetes插件
安装后 依次点击Dashboard -> 系统管理 -> 云 -> 新建云 -> Kubernetes
new cloud → cloud name:kubernetes Type:kubernetes → create →
Kubernetes 地址:https://kubernetes.default.svc.cluster.local
命名空间:kube-ops
→ 连接测试 → Connected to Kubernetes v1.28.2
→ Jenkins URL地址: http://jenkins.kube-ops.svc.cluster.local:8080
→ 应用 + 保存
构建Jenkins-Slave自定义镜像
- Jenkins-Master在构建Job的时候,Kubernetes会创建Jenkins-Slave的Pod来完成Job的构建。我们选择 运行Jenkins-Slave的镜像为官方推荐镜像:jenkins/jnlp-slave:latest,但是这个镜像里面并没有Maven 环境,为了方便使用,我们需要自定义一个新的镜像:
先把E:\Java实例项目1-20套\资料-Jenkins教程\Jenkins资料\资料\资料\03.资料\k8s-jenkins的jenkins-slave塞进129的/root/下
[root@k8s-master jenkins-slave]# ll
总用量 8948
-rw-r–r– 1 root root 9142315 7月 7 20:47 apache-maven-3.6.2-bin.tar.gz
-rw-r–r– 1 root root 556 7月 7 20:47 Dockerfile
-rw-r–r– 1 root root 10475 7月 7 20:47 settings.xml
# Dockerfile
FROM jenkins/jnlp-slave:latest
MAINTAINER itcast
# 切换到 root 账户进行操作
USER root
# 安装 maven
COPY apache-maven-3.6.2-bin.tar.gz .
RUN tar -zxf apache-maven-3.6.2-bin.tar.gz && \
mv apache-maven-3.6.2 /usr/local && \
rm -f apache-maven-3.6.2-bin.tar.gz && \
ln -s /usr/local/apache-maven-3.6.2/bin/mvn /usr/bin/mvn && \
ln -s /usr/local/apache-maven-3.6.2 /usr/local/apache-maven && \
mkdir -p /usr/local/apache-maven/repo
COPY settings.xml /usr/local/apache-maven/conf/settings.xml
USER jenkins
构建出一个新镜像:jenkins-slave-maven:latest
docker build -t jenkins-slave-maven:latest
然把镜像上传到Harbor的公共库library中
先打标签!
docker tag jenkins-slave-maven:latest 192.168.200.131:85/library/jenkins-slave-maven:latest
然后登录!
docker login -u admin -p Harbor12345 192.168.200.131:85
WARNING! Using –password via the CLI is insecure. Use –password-stdin. Error response from daemon: Get https://192.168.200.131:85/v2/: http: server gave HTTP response to HTTPS client [root@k8s-master jenkins-slave]# docker login -u admin -p Harbor12345 192.168.200.131:85 WARNING! Using –password via the CLI is insecure. Use –password-stdin. Error response from daemon: Get https://192.168.200.131:85/v2/: http: server gave HTTP response to HTTPS client [root@k8s-master jenkins-slave]#
你这个错误的根本原因是:Harbor 使用的是 HTTP 协议,而 Docker 默认使用 HTTPS,所以报错:
http: server gave HTTP response to HTTPS client
✅ 解决方案(分两步):
🔧 第一步:允许 Docker 使用 HTTP 连接 Harbor(非安全模式)
1️⃣ 修改 Docker 配置文件 /etc/docker/daemon.json
vi /etc/docker/daemon.json
添加(或修改)以下内容:
{
"insecure-registries": ["192.168.200.131:85"]
}
如果已有其他配置,比如 registry-mirrors,合并在一个 JSON 对象内:
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://wy1u1ijg.mirror.aliyuncs.com",
"https://p5lmkba8.mirror.aliyuncs.com",
"https://registry.docker-cn.com"
],
"insecure-registries": [
"192.168.200.131:85"
]
}
2️⃣ 重启 Docker 服务
systemctl daemon-reexec
systemctl restart docker
🧪 第二步:重新登录 Harbor
docker login 192.168.200.131:85 -u admin -p Harbor12345
这时你不会再看到 HTTPS 报错了。
测试Jenkins-Slave是否可以创建
去子节点的Jenkins创建一个item:test_jenkins_slave 是流水线项目
一定要在流水线上告诉Jenkins是放在从节点上的!
Pipeline scipt
// git 的 URL 和 凭证ID
def git_address = "http://192.168.200.132:82/lanyun_group/tensquare_back.git"
def git_auth = "630eed58-d62f-4c1b-bf96-1cf9c92a7f36"
// 正确使用 podTemplate 包裹 node
podTemplate(label: 'jenkins-slave', cloud: 'kubernetes', containers: [
containerTemplate(
name: 'jnlp',
image: "192.168.200.131:85/library/jenkins-slave-maven:latest",
ttyEnabled: true,
command: '/bin/sh'
)
]) {
node("jenkins-slave") {
stage('拉取代码') {
checkout scmGit(
branches: [[name: "master"]],
extensions: [],
userRemoteConfigs: [[
credentialsId: "${git_auth}",
url: "${git_address}"
]]
)
}
}
}
然后点击构建 就会在从节点进行创建 此时去看Dashboard → 系统管理 → 节点和云管理的时候就会多一个刚刚自主创建的节点 快速创建 并快速回收!!
Jenkins+Kubernetes+Docker完成微服务持续集成
拉取代码,构建镜像
创建NFS共享目录
让所有Jenkins-Slave构建指向NFS的Maven的共享仓库目录
vi /etc/exports
添加内容:
/opt/nfs/jenkins *(rw,no_root_squash)
/opt/nfs/maven *(rw,no_root_squash)
systemctl restart nfs 重启NFS
[root@k8s-node1 ~]# showmount -e 192.168.200.129
Export list for 192.168.200.129:
/opt/nfs/maven * 【maven仓库实现共享】
/opt/nfs/jenkins *
[root@k8s-node1 ~]#
创建项目,编写构建Pipeline
// git 的 URL 和 凭证ID
def git_address = "http://192.168.200.132:82/lanyun_group/tensquare_back.git"
def git_auth = "630eed58-d62f-4c1b-bf96-1cf9c92a7f36"
//构建版本的名称
def tag = "latest"
//Harbor私服地址
def harbor_url = "192.168.200.131:85"
//Harbor的项目名称
def harbor_project_name = "tensquare"
//Harbor的凭证
def harbor_auth = "f82340a4-5173-40e3-bc76-602db3a5acf5"
podTemplate(
label: 'jenkins-slave',
cloud: 'kubernetes',
containers: [
containerTemplate(
name: 'jnlp',
image: "192.168.200.131:85/library/jenkins-slave-maven:latest"
),
containerTemplate(
name: 'docker',
image: "docker:stable",
ttyEnabled: true,
command: 'cat'
)
],
volumes: [
hostPathVolume(
mountPath: '/var/run/docker.sock',
hostPath: '/var/run/docker.sock'
),
nfsVolume(
mountPath: '/usr/local/apache-maven/repo',
serverAddress: '192.168.200.129',
serverPath: '/opt/nfs/maven'
)
]
) {
node("jenkins-slave") {
stage('拉取代码') {
checkout scmGit(
branches: [[name: "master"]],
extensions: [],
userRemoteConfigs: [[
credentialsId: "${git_auth}",
url: "${git_address}"
]]
)
}
stage('编译,安装公共子工程') {
sh "mvn -f tensquare_common clean install"
}
stage('构建镜像,部署项目') {
// 把选择的项目信息转为数组
def selectedProjects = "${project_name}".split(',')
for (int i = 0; i < selectedProjects.size(); i++) {
// 取出每个项目的名称和端口
def currentProject = selectedProjects[i]
def currentProjectName = currentProject.split('@')[0]
def currentProjectPort = currentProject.split('@')[1]
def imageName = "${currentProjectName}:${tag}"
// 编译,构建本地镜像
sh "mvn -f ${currentProjectName} clean package dockerfile:build"
container('docker') {
// 给镜像打标签
sh "docker tag ${imageName} ${harbor_url}/${harbor_project_name}/${imageName}"
// 登录 Harbor,并上传镜像
withCredentials([usernamePassword(
credentialsId: "${harbor_auth}",
passwordVariable: 'password',
usernameVariable: 'username'
)]) {
sh "docker login -u ${username} -p ${password} ${harbor_url}"
sh "docker push ${harbor_url}/${harbor_project_name}/${imageName}"
}
// 删除本地镜像
sh "docker rmi -f ${imageName}"
sh "docker rmi -f ${harbor_url}/${harbor_project_name}/${imageName}"
}
}
}
}
}
勾选参数化构建过程 → Extended Choice Parameter和之前的一样 可回看tensquare_eureka_server@10086,tensquare_zuul@10020,tensquare_admin_service@9001,tensquare_gathering@9002
安装Kubernetes Continuous Deploy插件 || Kubernetes CLI插件 || Kubernetes Credentials Provider
修改后的流水线脚本
// 这里是在全局凭证添加后点进去可以查看ID
dsf k8s_auth = "xxxxxxxxx"
// 定义k8s-harbor的凭证
def secret_name = "registry-auth-secret"
...
...
def deploy_image_name = "${harbor_url}/${harbor_project_name}/${imageName}"
//部署到K8S
sh """
sed -i 's#\$IMAGE_NAME#${deploy_image_name}#'
${currentProjectName}/deploy.yml
sed -i 's#\$SECRET_NAME#${secret_name}#'
${currentProjectName}/deploy.yml
"""
kubernetesDeploy configs: "${currentProjectName}/deploy.yml",
kubeconfigId: "${k8s_auth}"
去Jenkins的凭证里加k8s凭证
❗Credentials from Kubernetes Secrets will not be available
🧠 说明:
- 这个警告说明 Jenkins 无法通过 Kubernetes 插件从
Secret 里加载凭证。
- 通常是以下原因之一:
- Pod 没有挂载正确的 ServiceAccount / RBAC 不够
- 缺少
Kubernetes Credentials Provider Plugin
- 没有开启 K8s secret credential provider 功能
✅ 解决方案:
确保你安装了插件:
KubernetesKubernetes Credentials Provider
配置 Jenkins Deployment 的 ServiceAccount 具备权限,绑定如下 ClusterRole:
你可以给 Jenkins 的 ServiceAccount 绑定一个 ClusterRole 来读取 secrets:
/root/jenkins-master/的ServiceaAcount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: jenkins
namespace: kube-ops
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: jenkins-read-secrets
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: view
subjects:
- kind: ServiceAccount
name: jenkins
namespace: kube-ops
👆这会给 jenkins 账户授予读取所有 namespace 的 secret 权限。
将上面内容保存为 jenkins-rbac.yaml,然后执行:
kubectl apply -f jenkins-rbac.yaml
添加凭证 → 类型Kubernetes configuration(kubeconfig);范围全局;描述k8s-auth;Kubeconfig选择Enter directly这里面的密钥要去 129Jenkins机器上拿
cd /root/.kube → cat config 显示的内容全部原封不动的复制到那里面
在每个项目下建立deploy.xml
Eureka的deply.yml
---
apiVersion: v1
kind: Service
metadata:
name: eureka
labels:
app: eureka
spec:
type: NodePort
ports:
- port: 10086
name: eureka
targetPort: 10086
selector:
app: eureka
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: eureka
spec:
serviceName: "eureka"
replicas: 2
selector:
matchLabels:
app: eureka
template:
metadata:
labels:
app: eureka
spec:
imagePullSecrets:
- name: $SECRET_NAME
containers:
- name: eureka
image: $IMAGE_NAME
ports:
- containerPort: 10086
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: EUREKA_SERVER
value: "http://eureka-0.eureka:10086/eureka/,http://eureka-1.eureka:10086/eureka/"
- name: EUREKA_INSTANCE_HOSTNAME
value: ${MY_POD_NAME}.eureka
podManagementPolicy: "Parallel"
其他项目的deploy.yml主要把名字和端口修改:
zuul的deploy.yml
---
apiVersion: v1
kind: Service
metadata:
name: zuul
labels:
app: zuul
spec:
type: NodePort
ports:
- port: 10020
name: zuul
targetPort: 10020
selector:
app: zuul
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zuul
spec:
serviceName: "zuul"
replicas: 2
selector:
matchLabels:
app: zuul
template:
metadata:
labels:
app: zuul
spec:
imagePullSecrets:
- name: $SECRET_NAME
containers:
- name: zuul
image: $IMAGE_NAME
ports:
- containerPort: 10020
podManagementPolicy: "Parallel"
还要在流水线定义k8s-harbor的凭证
生成Docker凭证 Docker凭证,用于Kubernetes到Docker私服拉取镜像
docker login -u itcast -p Itcast123 192.168.66.102:85 登录Harbor
kubectl create secret docker-registry registry-auth-secret –docker server=192.168.200.131:85 –docker-username=itcast –docker-password=Itcast123 – docker-email=itcast@itcast.cn 生成
kubectl get secret 查看密钥
项目构建后,查看服务创建情况
kubectl get pods -owide
kubectl get service
启动命令总结
[192.168.200.132]GitLab:gitlab-ctl restart
[192.168.200.131]Tomcat:/opt/tomcat/bin/startup.sh
[192.168.200.129]Jenkins:/systemctl start jenkins
[192.168.200.129]SonarQube:sudo -u sonarqube /opt/sonar/bin/linux-x86-64/sonar.sh restart
2025.7.8 0:02 完结撒花★,°:.☆( ̄▽ ̄)/$:.°★ 。