
D:\comfyUI\ComfyUI_windows_portable\ComfyUI把这里面的extra_model_paths.yaml.example后的.example删除掉就可以正式生效的配置文件了
a111:
base_path: path/to/stable-diffusion-webui/
checkpoints: models/Stable-diffusion
configs: models/Stable-diffusion
vae: models/VAE
loras: |
models/Lora
models/LyCORIS
upscale_models: |
models/ESRGAN
models/RealESRGAN
models/SwinIR
embeddings: embeddings
hypernetworks: models/hypernetworks
controlnet: models/ControlNet
这里要注意修改 把base_path: path/to/stable-diffusion-webui/改成自己的大模型路径
这里的controlnet: models/ControlNet也是需要修改成controlnet: extensions\sd-webui-controlnet\models
2026年1月秋叶大佬最新Comfyui整合包:ComfyUI-aki-V3.7和V2.7-史诗级更新 - ComfyUI资源网
- 在设置中可以设置
Comfy的信息 双击空白位置可以直接搜索对应的节点- 左侧的
节点库不但可以手动搜索节点,还可以一级一级查找 - 右键
添加组可以同时对组内的所有节点进行统一管理出现一个框 - 点击
运行箭头时有更改时运行、实时运行 - 从latent接口长按鼠标左按拖出一条线 会弹出系统推荐的几个适合这个接口的节点
- 在
工作流(w)可以选择某个工作流右键添加到画布中 Comfy的开发者模式:如果要通过comfyui对接外部程序开发一些app之类的应用- 节点连线中间会多出一个
Add Reroute点击后会多出一个大的转接点;之后移动这个Reroute点就可以调整连线的路径了;现在就可以通过调整Reroute节点的位置实现远程连接加规整连线的效果了;也可以在Reroute节点上按住shift,这样就可以在这个Reroute点上新建出一个分支出来了,在空白位置松手就会弹出一个搜索框,添加额外的节点进来;也可以按住shift键在Reroute点创建分支连接到已有的其他接口去 - 按住Ctrl+左键框选后再按
Ctrl + G即可创建一个组(可以移动组内款选的所有节点);删除组时要右键点击编辑框的Edit Group → 删除即可删除这个组;现在也可以左键点击组后按退格键即可删除这个组;如果想把这个组固定不动按P就可以固定这个组了;也可以给新建的Reroute点进行Ctrl + G打组 - 组与组之间可以进行嵌套使用;可以在大的组里面进行右键
Edit Group进行更改颜色 - 键盘的
.可以将工作流快速定位到界面的中心;选中某个节点按下键盘的.就会直接放大界面到这个节点中去 - 右键某个节点有个
折叠,点击后当前节点就会最小化显示了;节点左上方也有个小圆点也可以直接最小化,再点击一下即可自动复原 正面提示词一般可以把节点改成红色,负面提示词一般可以把节点改成绿色- 按住
Ctrl不放,点击节点即可对多个节点选择;长按Ctrl + 左键不放也可以进行多个节点选择;这里比如框了两个节点然后我需要移动这两个,此时需要按住Shift不放即可拖动选中的两个节点 - 选中其中一个节点
Ctrl + C后Ctrl + V就可以复制这个节点了;或者选中某个节点长按Alt不放再进行鼠标拖动即可复制节点 - 如果需要复制的节点携带连线则需要
Ctrl + C复制节点后再Ctrl + Shift + V进行复制携带连线的节点(保留连线关系的节点)
插件安装
在这里E:\ComfyUI-AI_DeskTop\ComfyUI-aki-v3\ComfyUI\custom_nodes
安装方式
①:确保\custom_nodes路径 然后用Git从GitHub上复制git clone xxxx地址后进行安装
②:点击UI界面的Manager→Custom Nodes Manager 里面集成ComfyUI的各种节点
workspace-manager是左上角文件夹图标管理工作流的插件ComfyUI-Custom-Scripts很多小功能和节点;如果最后一个节点是保存节点,那么工作流生成的图片都可以在E:\ComfyUI-AI_DeskTop\ComfyUI-aki-v3\ComfyUI\output里面获取到;也可以在图片右键通过保存图片来保存;instant一直执行change当改变节点状态后就会立刻执行
ComfyUI的Manager管理器
★ 点击Manager 左上角的DB是数据库
- 数据库:频道(1天缓存):comfyUI管理器里面的数据库每天更新一次
- 数据库:本地:仅仅为你本地的上一次更新为准
- 数据库:频道(远程):远程实时更新
★ 下面Channel指ComfyUI针对性的给你推送对应频道的插件和节点内容
★ 目前没有找到可以调出小狐狸的图标 以及每个节点右上角的ID号和所对应的父类
★ Component是工作流节点的使用情况
Use workflow version:使用作者分享工作流本身的节点版本Use higher version:使用最高版本Use my version:使用当前节点的版本来替代作者工作流的节点版本
★ SnapshotManager快照管理器 可以给当前的comfyui添加一个快照;随时可以恢复到之前的快照了
★ Install PIP packages安装pip包
★ Install via Git URL通过复制GitHub的连接来安装插件
★ Upadte All更新ComfyUI全部和节点本身
★ Community Gallery社区手册
秋叶启动器
秋叶启动器的高级选项
选择有CUDA的生成引擎
疑难解答
可以检测扫描包的问题
版本管理
可以插件、扩展、内核的管理
工作流的保存和使用
尽量去用.json去保存或导入
工作流分享平台:(https://comfyworkflows.com/) 和 https://openart.ai/workflows/
[ComfyUI工作流下载渠道整理 - 设计经验 - 素材集市](https://www.sucaijishi.com/articles-51-571-1.html#:~:text=国外老牌工作流网站%2C需科学上网访问,提供免费下载和付费在线生成服务。 包含国外大神的ComfyUI基础教学视频,资源全面,学习ComfyUI的绝佳去处。 https%3A%2F%2Fopenart.ai%2Fworkflows%2Fhome,无需科学上网,功能类似OpenArt Flow%2C可直接下载使用工作流,工作流资源丰富。 https%3A%2F%2Fcomfyworkflows.com%2F)
https://civitai.com
导入工作流节点错误处理方法
在网上下载的工作流会出现节点爆红的情况:绝大部分原因就是当前工作流里用的插件在我们comfyUI中并没有安装 → 直接点击
Manager → Install Missing Custom Nodes直接安装缺失节点即可如果自动安装缺失节点也会有莫名其妙报错 那就直接卸载删除,手动搜索节点去安装
报错查找与解决方法
在秋叶管理器里面的疑难解答 右上角开始扫描寻找报错情况
所用插件报错 可以去该插件的GitHub官方的Issues中搜索核心报错关键词则同款问题的报错即可出现
从入门到进阶
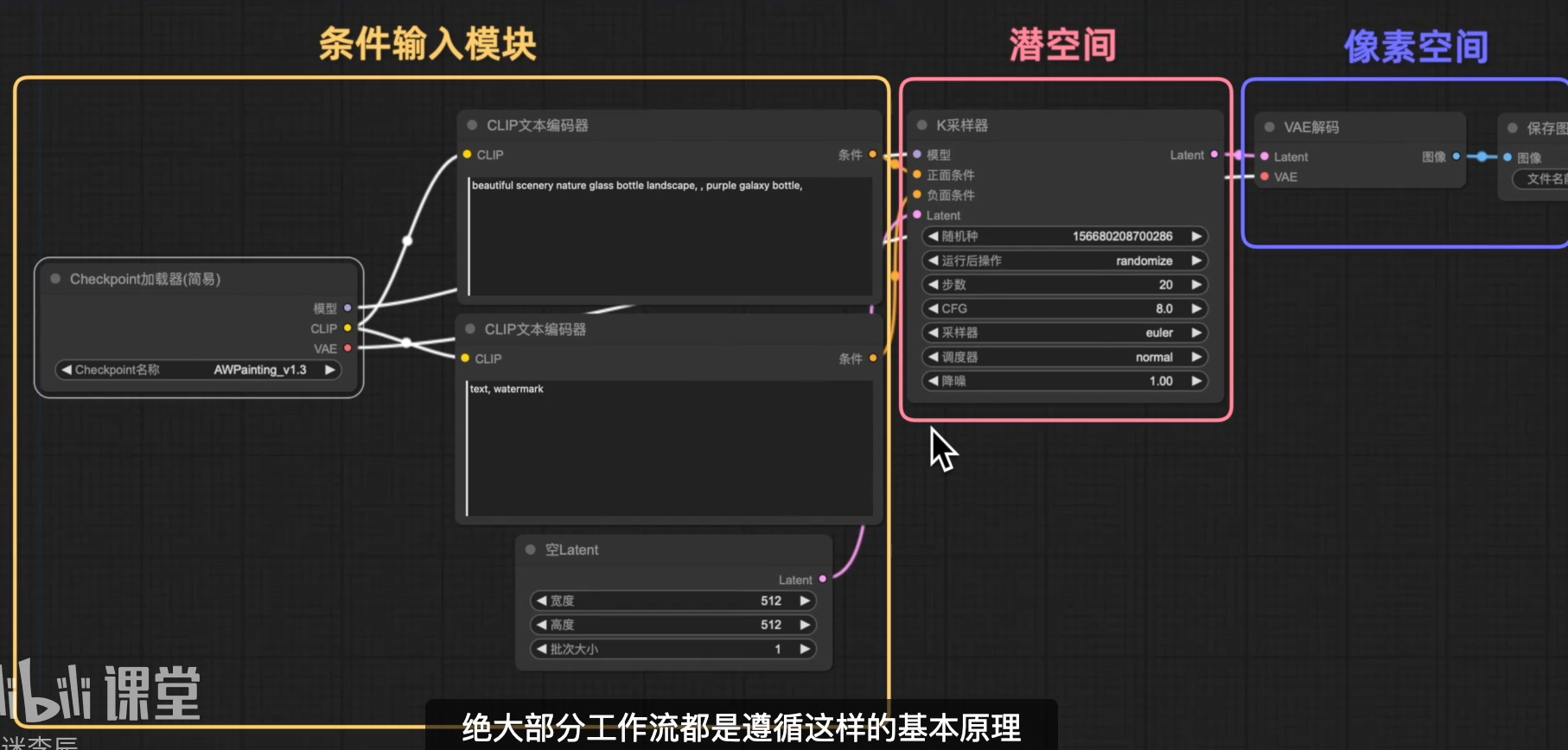
潜空间
潜空间(K采样器):所谓就是AI处理图像的空间,加噪去噪采样生成图片,但生成图片仅被AI识别;
但这个图片在潜空间里面经过加噪去噪处理后不能直接显现出来,要通过VAE解码这个节点,把潜空间的图像转变为最终像素空间图形,这个才是我们最终看到的结果。
Lora、Controlnet
LoRA 可以理解成 AI 绘画的「专属技能包 / 插件」,核心作用是:让 AI 快速学会特定风格、物体、人物或细节,不用重新训练整个大模型,是你做「产品替换 / 电商图」的超级利器。
如果要给工作流加Lora、Controlnet节点的话,首先要确定节点是加载哪个的模块里面;这两个模型都是属于限制最终生成图片的前置条件 → 是要在条件输入模块里添加的 [双击空白地方 添加lora加载器]
不同节点之间接口是有名称和颜色之分的,一般情况下不同颜色的接口是不能相互连接的,需要把相同颜色的接口对接一下;随后选择一个想要的lora风格
ControlNet = 给 AI 套上 “规矩”,让它严格按你的形状、线条、姿势、结构来画图。
- 普通生图:AI 自由发挥,产品容易变形、角度乱飞、透视不对。
- ControlNet:AI 必须遵守你给的轮廓 / 线条 / 深度图,想画歪都难
Controlnet的加载相对复杂一些。要安装controlnet_aux插件,下载Controlnet模型。
模型放置到comfyui安装目录\models\controlnet里面 不过都已经搞好了 只需要双击空白区域,搜索controlnet应用这个节点即可
comfyUI第四阶段难点:
- ComfyUI更新速度太快导致以往工作流报错
- 需要学习的插件太多 增加了学习成本
- 部分插件更新颠覆旧工作流
ComfyUI的原理是黑色代表0,白色代表1;后续需加图像反转进行01反转
降噪:相当于重绘幅度。数值越小,越忠于原图效果。数值越大,画面会改变增加AI想法
使用每个工作流时
理解一下当前工作流的运行逻辑
- 别人为什么要这样搭建
- 有没有可以删除、修改、优化的
- 多看、多想、多思考
Comfyui的原理
条件输入模块中的CLIP(Contrastive Language-lmage Pre-training)对比性语言—图像预训练用于提示词与图像之间进行转化的多模态部件;让我们输入的提示词直接转换到K采样器的潜空间中;通过加噪去噪的步骤来转换成图片,
潜空间(Latent Space):像素非常低,是AI的工作空间;仅需很低的像素就可以正确认识和处理图像 当处理完毕后,再通过像素空间,把潜空间的低像素图片转换成我们肉眼所看的最终像素图片[这个转换的过程就要用到VAE解码器]
Comfyui每个节点都有不同颜色的端口;右边的为输出端口,是用来连接到下一个节点的输入端口中去的;不过每一个节点之间的连线要相同颜色的接口才可以匹配上。
所有的节点输入接口都只能连接一个线路;输入接口只能1对1;输出接口可以1对多
工作流的顺序一般都是从左到右生成的,但核心的最好是从最中心开始也就是K采样器
Clip终止层与LORA的加载
在网站上下载元素时 Usage Tips:CLIP SKIP:2
Clip是一个先进的神经网络,他把我们输入的关键词转换成很多层数值来生成图片
Clip Skip默认值是1 也就是Clip神经网络从开始参与到结束 [计算层1……计算层20]
Clip Skip=2时 也就是 [计算层1……计算层19]
Clip Skip的值会对最终生成的效果有较大的影响
LORA是一种微调模型是依附在大模型身上的,可以在大模型的模型接口拖出一条线就可以看到lora加载器了
绕过:右键节点可以进行绕过,在工作流上就会选择跳过。该节点变淡
CLIP文本编码(SDXL)工作流 与 高级采样器
CLIP文本编码SDXL更加精细化的文本
在空白节点中 右键 → 添加节点 → 高级 → 条件 → CLIP文本编码(SDXL)
CLIP_G:是直接的文本 [有一只精致的猫宇航员穿着太空服在宇宙飞船里面]
CLIP_L:是一个个的关键词 [猫、宇航员、太空服、宇宙飞船]
上面的宽度和高度一般都是生成图片分辨率的两倍/四倍 比如1024 × 1024的图片 就可以设置为2048/4096
CLIP文本编码SDXL(Refiner)
在空白节点中 右键 → 添加节点 → 高级 → 条件 → CLIP文本编码(Refiner)
Refiner是在采样过程中将近结束的时候才起效的
美学分数:是用来设置细化强度的 [一般是4-6 细节增加最好]
K采样器(高级)
高级采样器比普通采样器多了添加噪波和下面的开始/结束降噪步数和返回噪波
关闭天机噪波(因为下面自己添加了) 步数30 开始降噪步数:0 结束降噪部步数:25 → 从一开始运行到25步的时候就转到refiner的采样器了(开启返回噪波 剩下的5步可以返回出去了)
提示词自动翻译与自定义风格预设
- 直接输入中文
- 提示词预设
- 自定义提示词
- 随机提示词
安装ComfyUI Easy Use可以提供一系列提示词预设
安装...alek...翻译功能
在空白区域右键 → 添加节点 → EasyUse → 提示词 → 风格提示词选择器;不过这个是字符串的接口 直接连是无法连接上的,需要把clip文本编码器的提示词右键转换文本为输入[新版本直接可以将正反面提示词连接到文本了]
在前面增加正面提示词和负面提示词
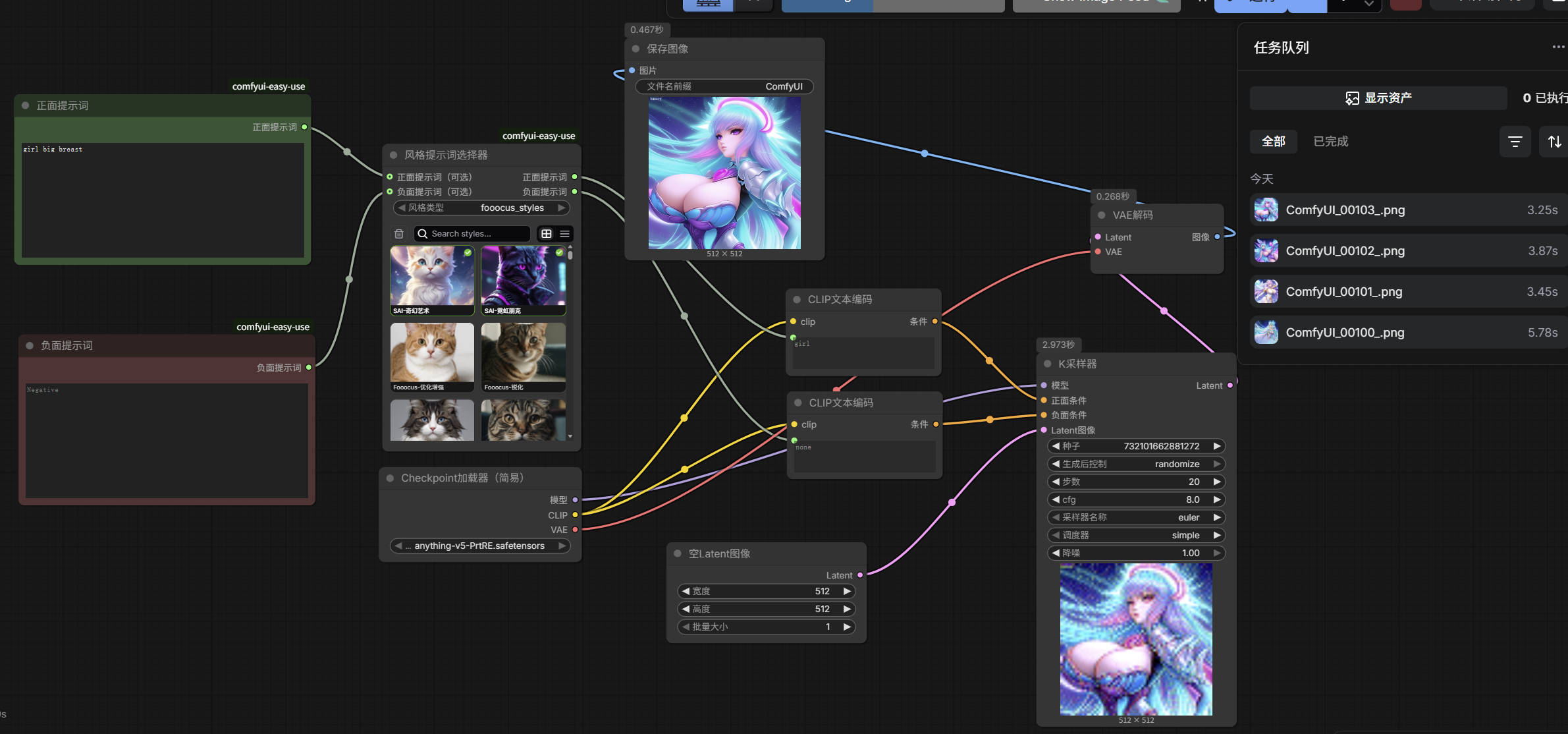
安装 https://github.com/thisjam/comfyui-sixgod_prompt.git **六神clip文本编码(自动翻译)**重启后按Alt + Q进入专门的提示词页面;这里双击才能给六神提示词设置快速选中写入!!
Alt+Q 点击自定义随机词库 在上方先输入prompt提示词后 在配置随机词库中选择 下方的任意标签 以及内部的标签;再随便起个标题 → 发送到提示框
在收藏夹内可以收藏自己的预设!!
★ 很多时候我们输入提示词的时候是直接输入中文的 那么刚刚安装的新插件就可以派上用场了 右键 → 添加节点 → AlekPet Nodes →文本→Deep Translator Text Node(有代理的)
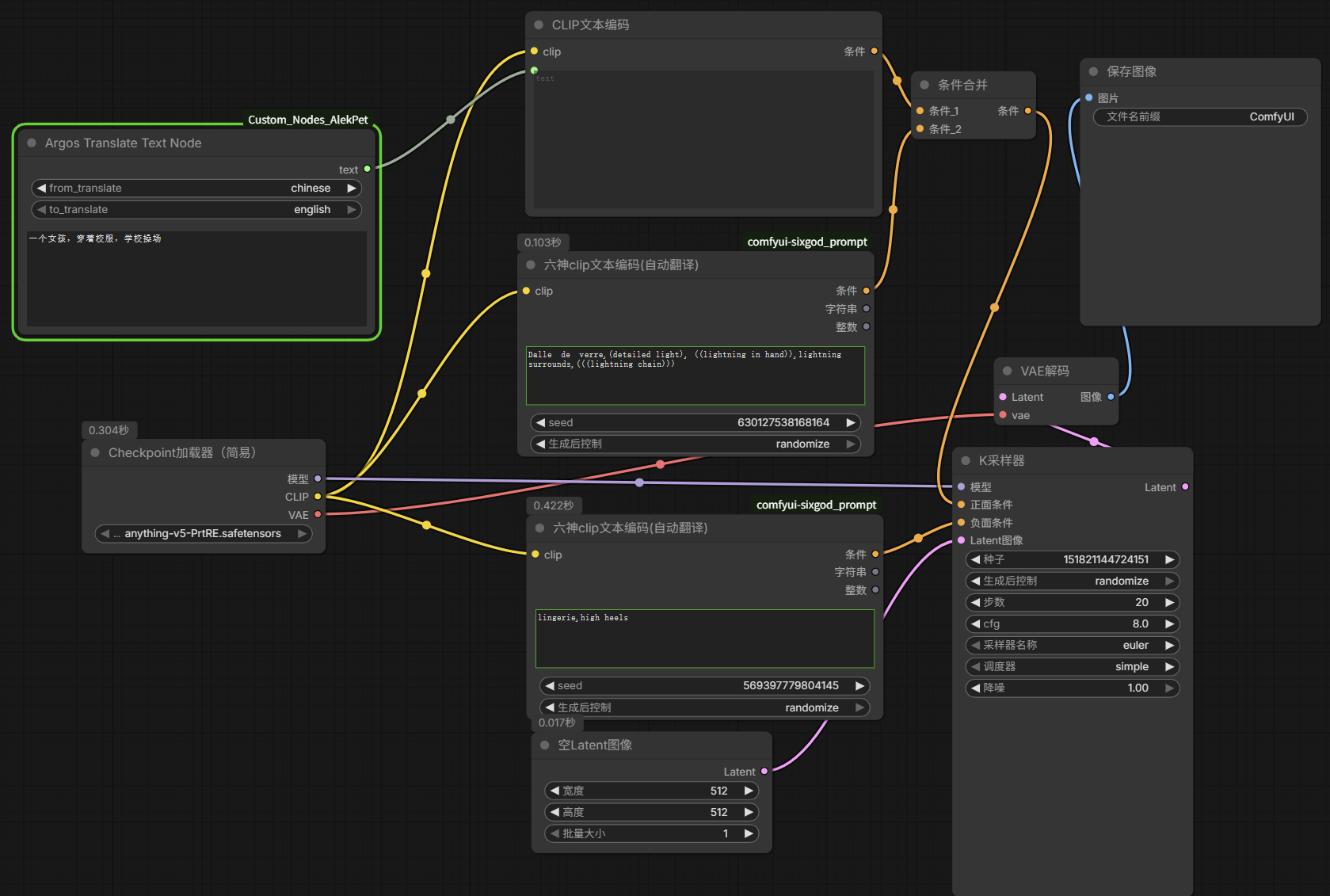
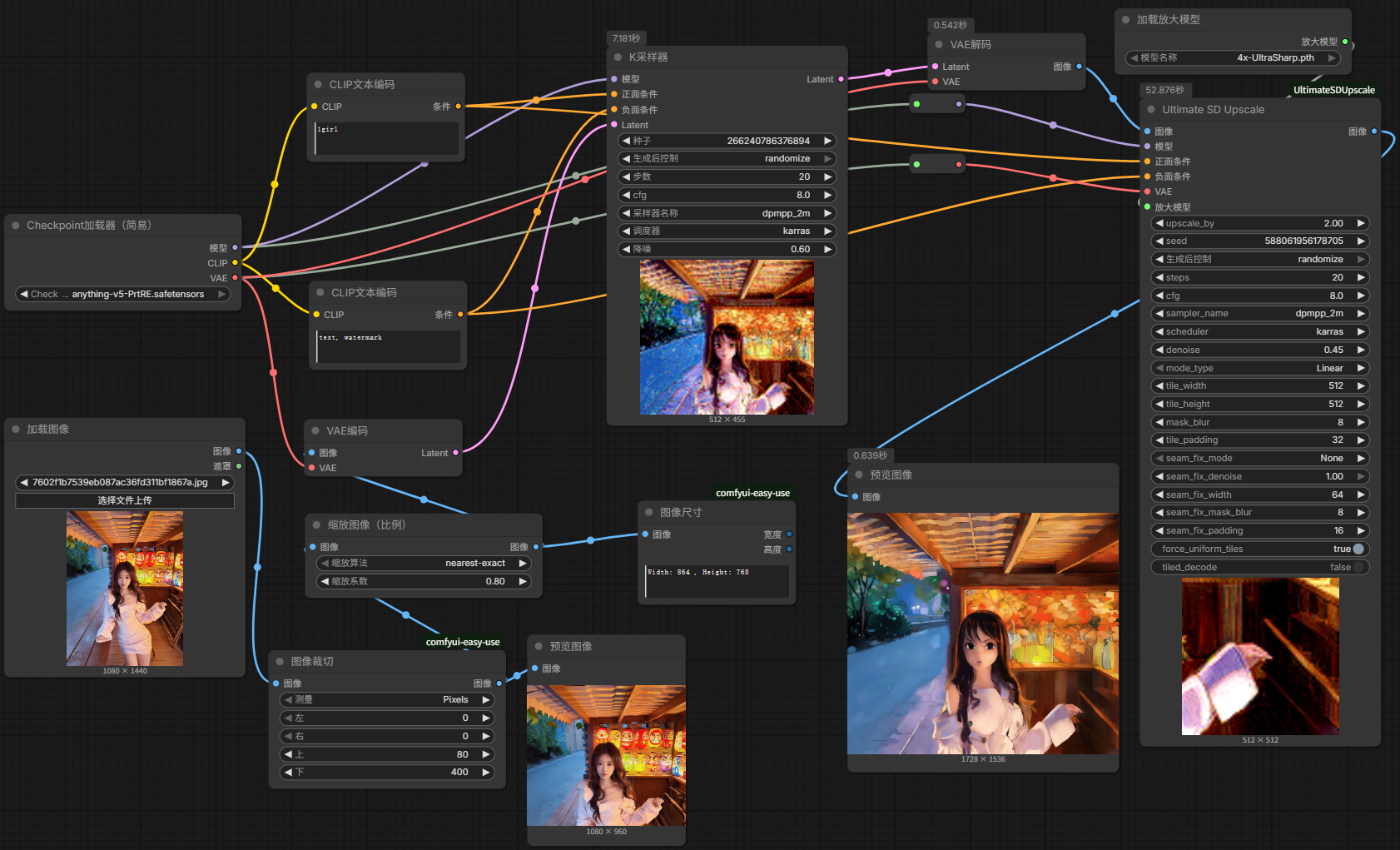
ComfyUI 四种放大方式
下载的模型可以放到ComfyUI目录/models/upscale_models里面
- 新建节点 → 图像 → 放大 → 使用模型放大图像;然后从该节点的放大模型拖出一条线到空白选择建立
加载放大模型→选择4x-UltraSharp.pth
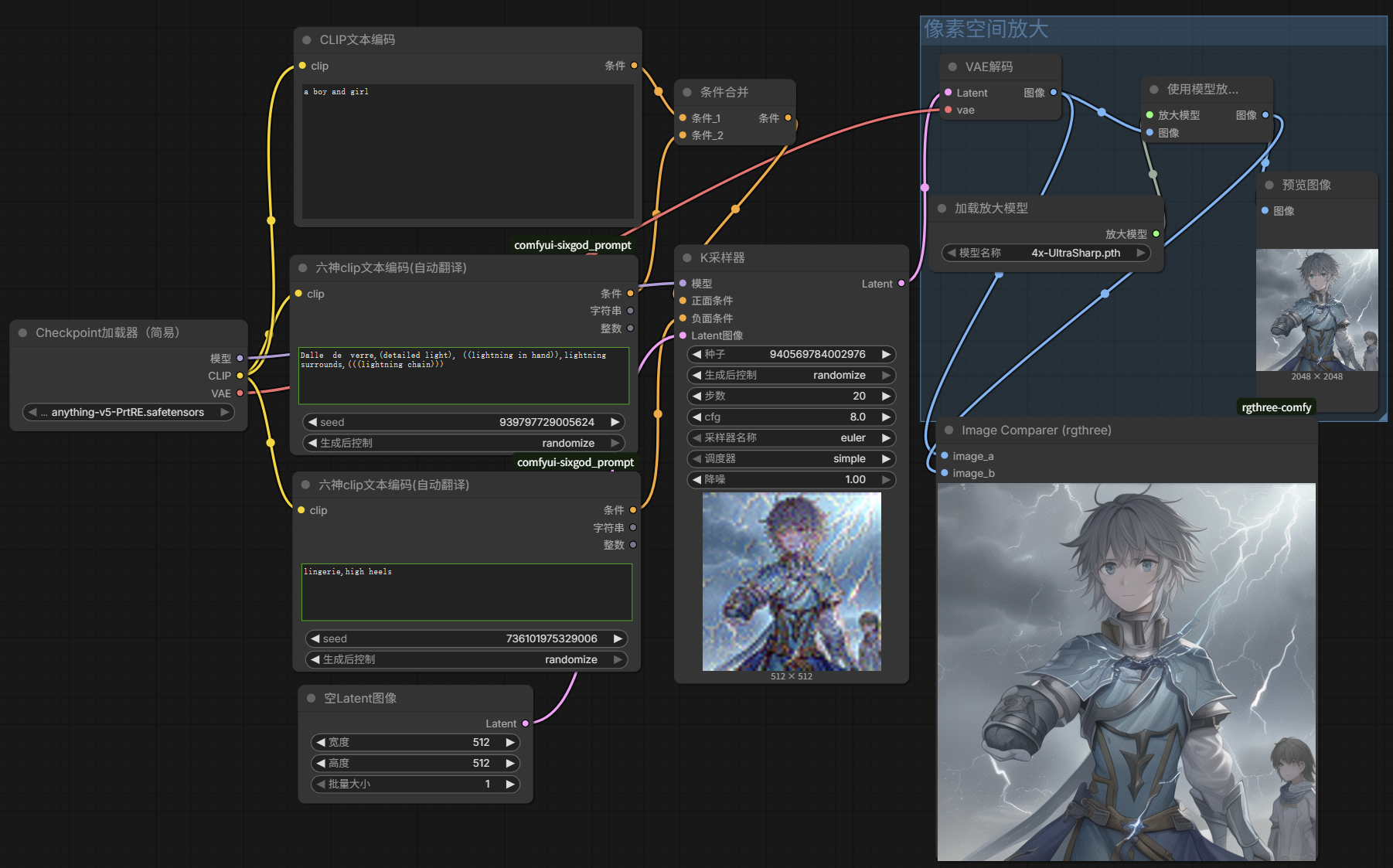
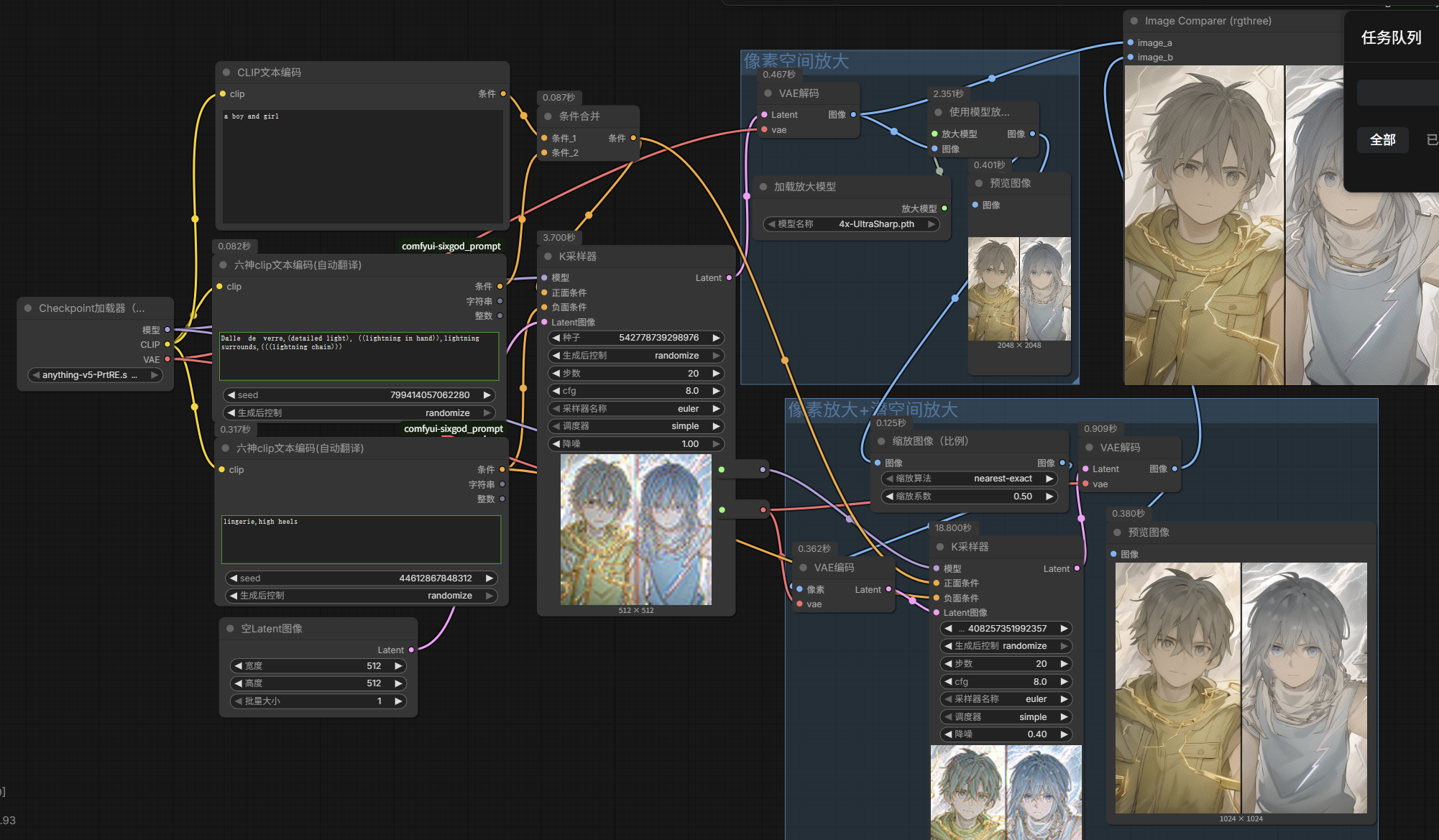
- 整个流程先进行一次采样,通过图像模型放大节点对第一次采样的像素空间图片放大4倍,把这个4倍的图片重新编码调入到潜空间进行二次采样[由于像素空间进行了四倍的放大,那么这个4倍放大的图片进入潜空间就会非常大了,非常容易导致爆显存和大幅增加渲染时间],所以要在放大的节点后面从图像拖出一个按系数缩放节点 系数0.5(画面缩小50%)。先放大4倍再缩小2倍=放大2倍
在VAE节点上点击鼠标中键即可快速新建一个转节点出来;由于二次采样,我不希望画质变化太多,所以第二个的k采样器的降噪要改小点
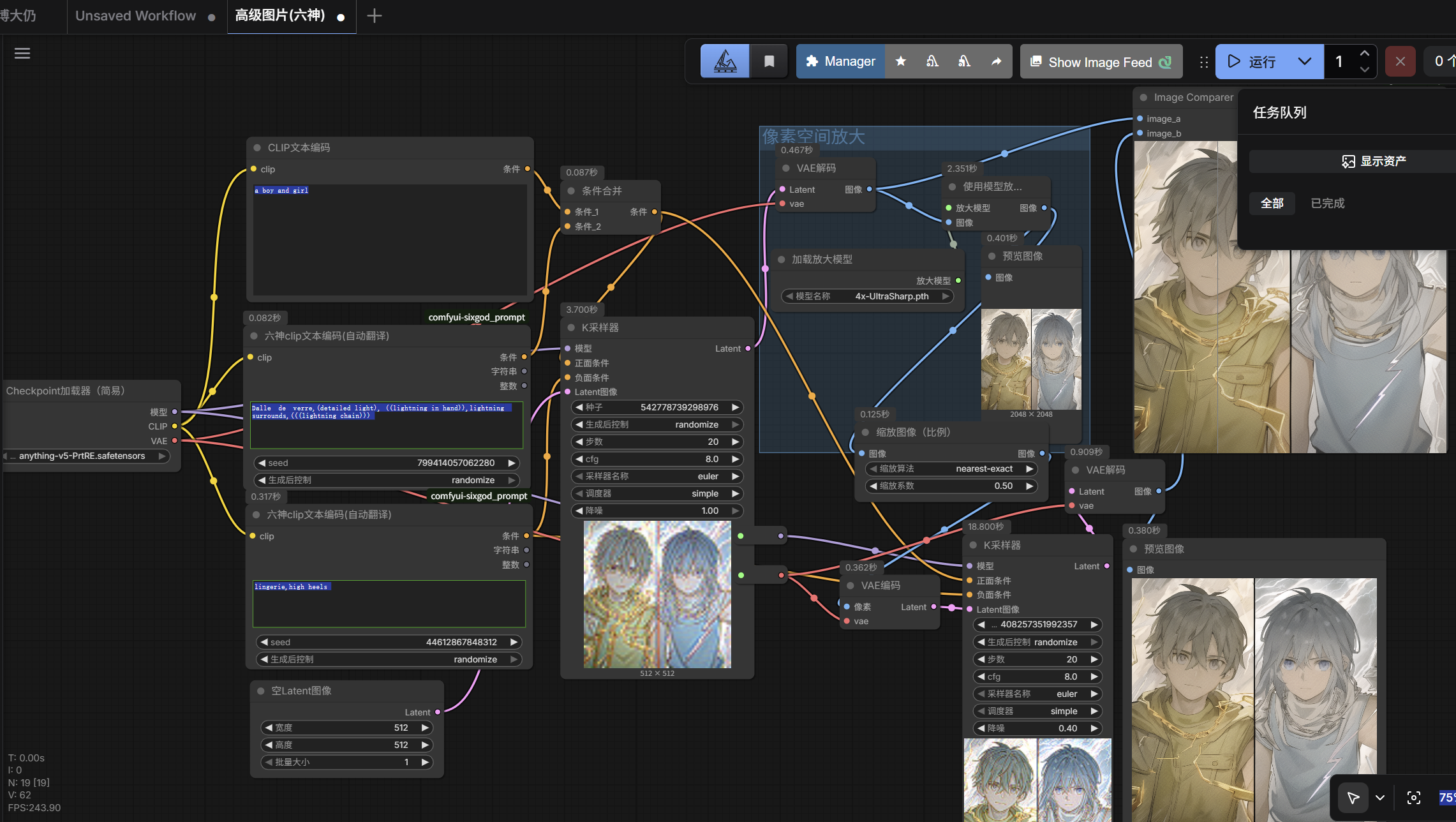
- 直接在第一层k采样器里拖出一个
Latent按系数缩放……
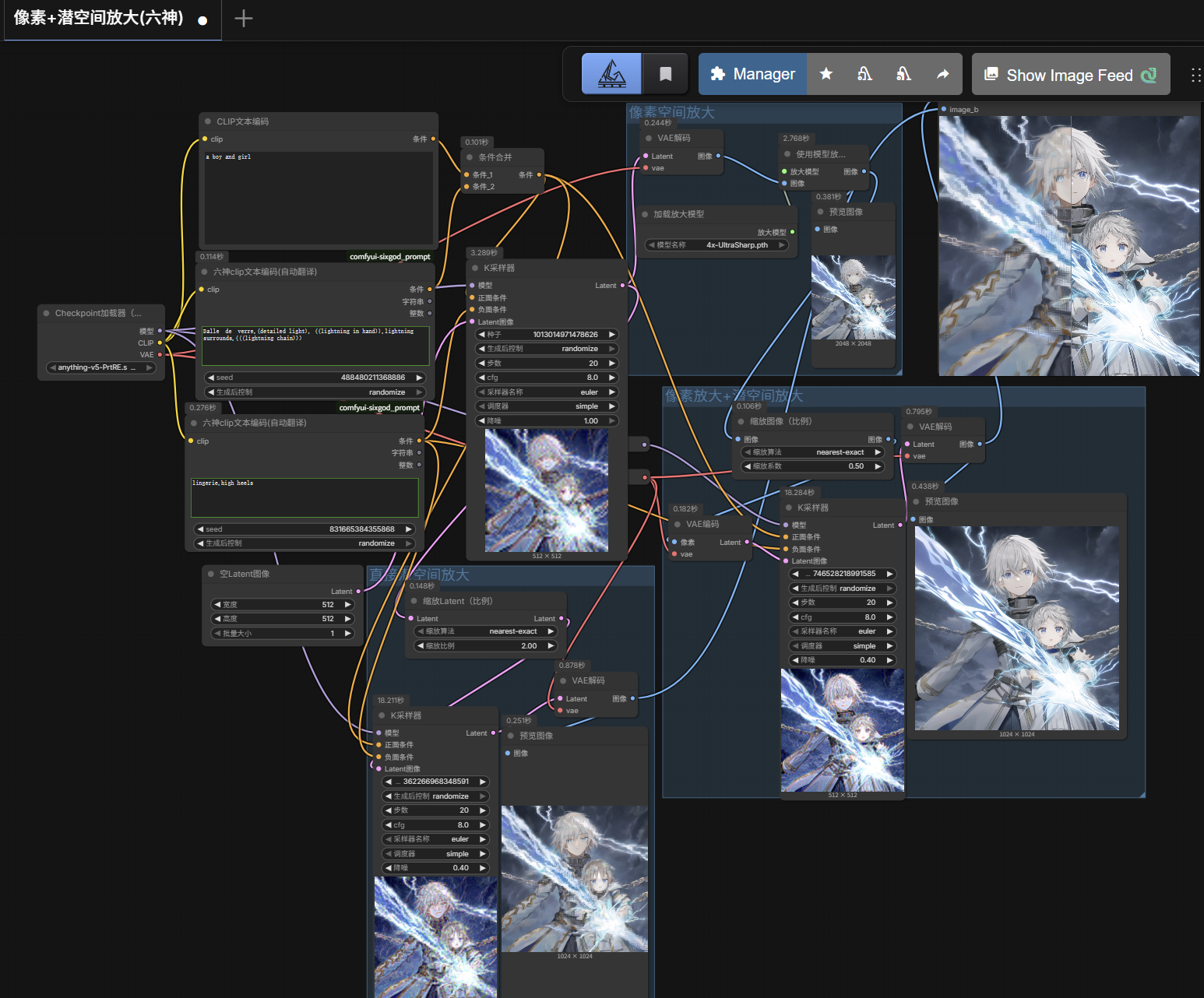
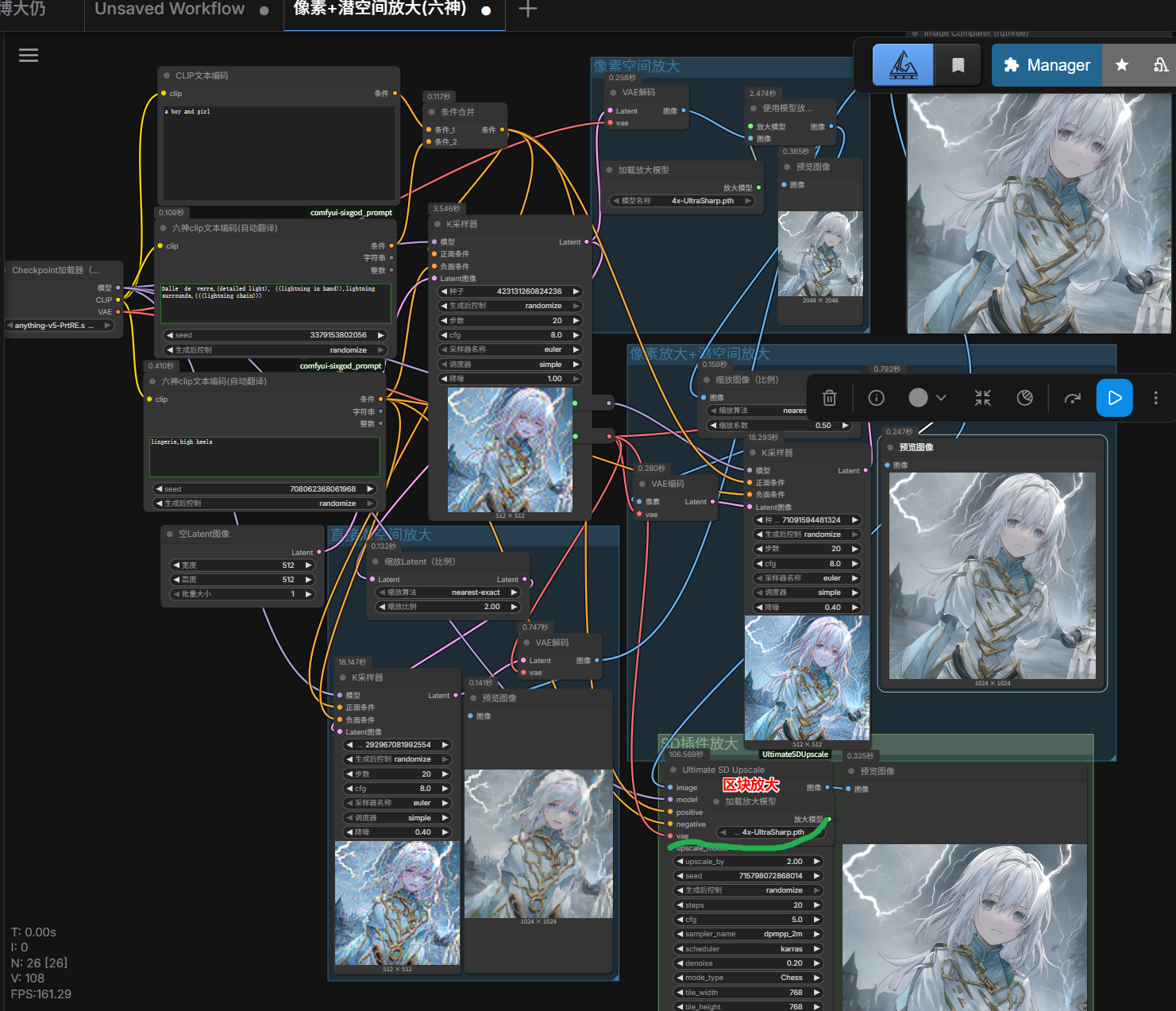
- 图片放大到4K甚至更高分辨率(若按之前方法就很容易爆显存):需要用到分块放大来节省系统资源;新增
Ultimate SD Upscale
精讲一下 CLIP、VAE、Latent
1. 三大核心模型:各自负责什么?
📝 CLIP:文本编码器(把文字变成模型能懂的向量)
- 本质:OpenAI 开发的多模态模型,负责把自然语言提示词转换成「文本嵌入向量」。
- 在 SD/SDXL 里的作用
- 把你的提示词(比如
a girl in school uniform)编码成高维向量,告诉模型「我想要画什么」。 - SDXL 是双编码器:
CLIP-G(全局语义)+CLIP-L(细节语义),所以用CLIPTextEncodeSDXL节点。
- 把你的提示词(比如
- 关键节点
CLIPTextEncode:SD 1.5 用,输入CLIP模型 + 提示词,输出CONDITIONING(条件向量)。CLIPTextEncodeSDXL:SDXL 专用,分别输入text_g和text_l提示词。
🎨 VAE:图像编码器 / 解码器(像素 ↔ 潜在空间)
- 本质:变分自编码器,负责在「像素图像」和「潜在空间(Latent)」之间互相转换。
- 核心功能
- 编码(Encode):把高清图片压缩成小尺寸的
Latent向量(比如 1024×1024 像素 → 128×128 潜在特征),大幅降低计算量。 - 解码(Decode):把生成好的
Latent向量还原成可预览的 PNG/JPG 像素图。
- 编码(Encode):把高清图片压缩成小尺寸的
- 关键节点
VAEEncode:输入图像 + VAE 模型 → 输出LATENT。VAEDecode:输入LATENT+ VAE 模型 → 输出图像。
- 注意:SDXL 有专门的 VAE,不能和 SD 1.5 的混用,否则会出噪点 / 颜色崩坏。
✨ Latent:潜在空间(模型真正「画图」的地方)
- 本质:高维特征空间,是 Stable Diffusion 模型实际操作的中间表示,不是肉眼可见的图片。
- 作用
- 比原始像素图小很多(比如 8× 压缩),让扩散模型能高效迭代生成。
- 承载了图像的「结构、风格、细节」等核心信息,是
KSampler迭代的对象。
- 关键节点
EmptyLatentImage:生成空白LATENT(决定画布尺寸)。LatentComposite:把多个LATENT合成。LatentUpscale:对LATENT做超分。
2. 文生图完整数据流:节点是怎么连起来的?
我们用最经典的「文生图」工作流来串一遍,你就能理解每个节点的角色:
1. 文本输入 → CLIPTextEncode → CONDITIONING(告诉模型画什么)
2. EmptyLatentImage → LATENT(空白画布,决定尺寸)
3. CheckpointLoader → 模型本体 + CLIP + VAE
4. CONDITIONING + LATENT + 模型 → KSampler(核心生成步骤)
5. 生成后的 LATENT → VAEDecode → 最终图像
🔄 分步拆解原理
- 提示词编码阶段
Text节点输入中文 / 英文提示词 → 连接到CLIPTextEncode的text端口。CheckpointLoader输出的CLIP模型 → 连接到CLIPTextEncode的clip端口。- 输出
CONDITIONING:这是「文本条件」,告诉扩散模型「我要生成符合这个描述的图」。
- 潜在空间初始化
EmptyLatentImage节点设置宽高(比如 1024×1024)→ 输出空白LATENT。- 这相当于给模型一张「隐形画布」,所有生成操作都在这上面进行。
- 扩散生成阶段(KSampler)
- 这是 ComfyUI 的「心脏」,负责迭代去噪生成图像:
- 输入:
LATENT(画布)、positive CONDITIONING(正向提示词)、negative CONDITIONING(反向提示词)、model(扩散模型本体)。 - 原理:从随机噪声开始,一步步根据文本条件「擦掉」噪声,逐步逼近目标图像。
- 输出:生成完成的
LATENT(还不是图片,是特征向量)。
- 输入:
- 这是 ComfyUI 的「心脏」,负责迭代去噪生成图像:
- 图像解码阶段
KSampler输出的LATENT→ 连接到VAEDecode的samples端口。CheckpointLoader输出的VAE模型 → 连接到VAEDecode的vae端口。- 输出:最终的像素图像(
IMAGE类型),可以用PreviewImage或SaveImage节点查看 / 保存。
4. 一句话总结
- CLIP:把文字变成模型能懂的「指令向量」。
- KSampler:拿着 CLIP 的指令,在 Latent 画布上迭代生成,最后用 VAE 翻译成图片。
- VAE:在「像素图」和「潜在特征」之间做翻译。
- Latent:模型真正画图的「隐形画布」。
Controlnet核心节点串联
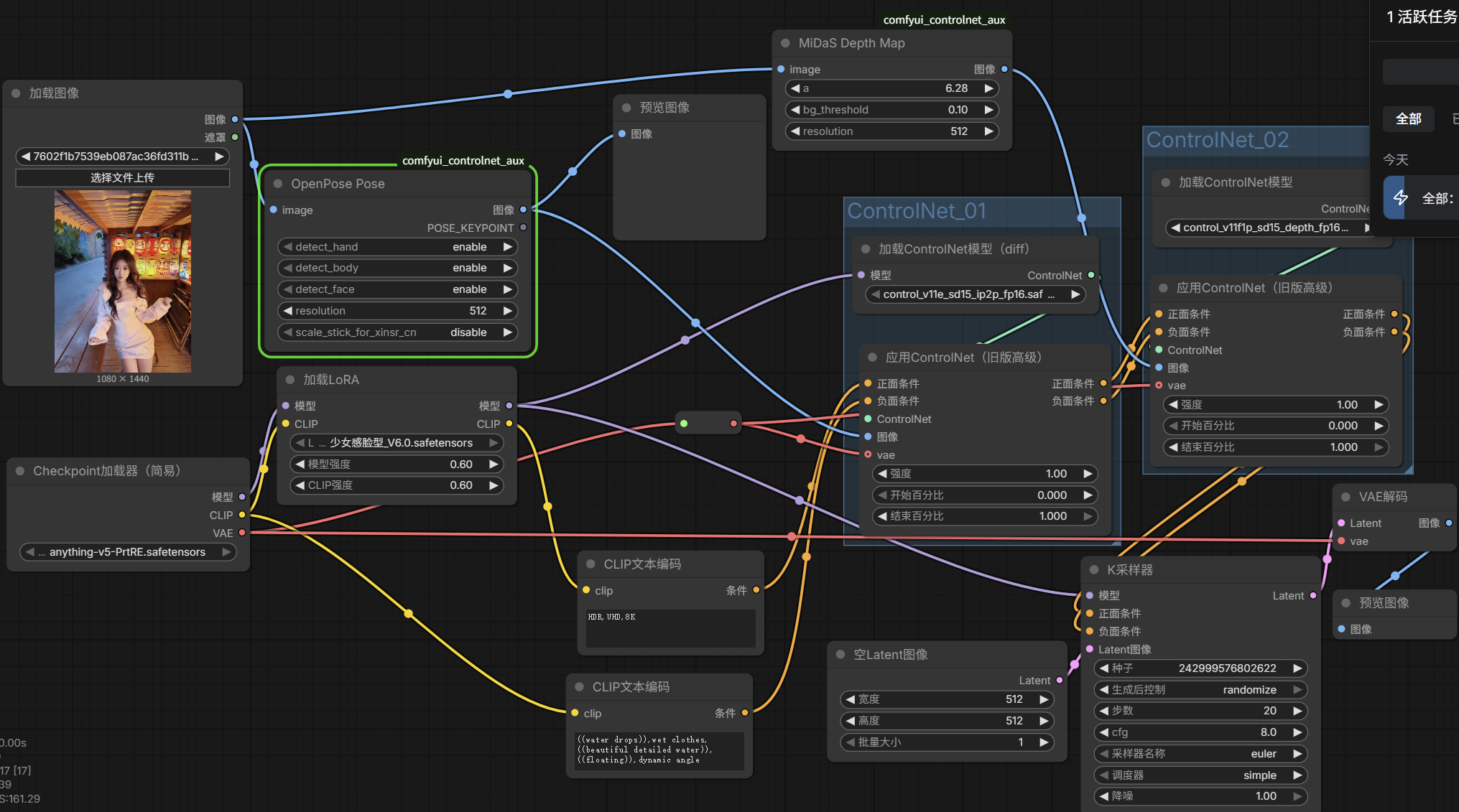
知识点讲解
你现在学的是 ComfyUI 最核心、最强大的功能,搞懂这个,你就入门高阶 AI 画图了。
- ControlNet 加载器 = 拿工具
- ControlNet 应用 = 用工具
- 串一起 = 让 AI 严格按你的要求画图,不乱来
二、ControlNet 加载器 是干啥的?
作用:加载 ControlNet 模型
你可以把它理解成:
给 AI 配一个 “专用规则老师”
比如:
- OpenPose 模型 → 管姿势
- Canny 边缘模型 → 管线条结构
- Depth 模型 → 管景深、立体
- Lineart 模型 → 管线稿
加载器干的事:
- 从你的硬盘里读取
.safetensors模型 - 告诉系统:我现在要用这个规则
它不处理图片,只负责把模型准备好。
增加一个OpenPose Pose姿态预处理器、再加一个应用controlnet(高级)
在ControlNet拉出一条线 → DiffControlNet加载器(向下兼容controlnet加载器)
三、ControlNet 应用(Apply ControlNet)是干啥的?
作用:把规则强行灌给主模型,让它听话
主模型(SD/SDXL)本来是自由发挥的。
ControlNet 就是强制约束。
Apply 节点干两件事:
- 接收 预处理好的图(OpenPose 骨架、Canny 线条、深度图…)
- 把 约束规则 注入到生成过程中
简单说:
AI 必须按这个结构 / 姿势 / 线条来画,不能乱变。
四、它俩为什么必须串联?
因为:
光有模型不行,光有指令也不行,必须结合。
正确逻辑链:
ControlNetLoader
→ 加载姿势 / 边缘 / 深度模型
ControlNetApply
→ 把这个约束应用到画图过程
串联后效果:
主模型(画内容) + ControlNet(定结构)= 精准可控的画面
没有加载器 → 没有规则
没有应用 → 规则不生效
五、controlnet有哪些场景?
ControlNet 的本质:
强行控制画面的结构、姿势、线条、空间、视角,让 AI 不乱画。
1. 控制人物姿势(最常用)
用 OpenPose
- 固定人物动作:站、坐、跳、躺、比心、跳舞
- 不让手崩、不让姿势乱飞
- 想画什么动作,先摆好骨架,AI 照着画
用途:
角色插画、COS 图、动态人物、二次元姿势
2. 控制画面线条 / 轮廓
用 Canny / LineArt
- 你给一张线稿 → AI 帮你上色、细化
- 你给一张草图 → AI 帮你精修
- 强制保留物体轮廓,不改变构图
用途:
线稿上色、草图转插画、漫画上色
3. 控制画面深度 / 空间
用 Depth
- 控制:谁在前、谁在后
- 控制:近大远小、立体感、透视
- 画场景、建筑、室内特别稳
用途:
场景画、建筑、室内设计、写实风景
4. 控制人体结构 / 姿态更精准
用 DensePose / OpenPose
- 人体结构不崩
- 动作更自然
- 多人物不乱叠
5. 控制画面构图 / 边缘结构
用 SoftEdge / HED / Canny
- 你定好:人物在哪、物体在哪
- AI 只负责画内容,不改变布局
- 做分镜、故事板超好用
6. 控制人脸角度、五官位置
用 FaceLandmark
- 正脸、侧脸、45° 想定就定
- 不歪脸、不崩五官
- 做头像、证件照、角色脸
7. 控制画面风格、边缘、质感
用 Shuffle / Tile / Style
- 强化细节
- 高清修复
- 保持风格统一
8. 控制画面 “语义”:什么东西在哪
用 Seg(语义分割)
- 天空、地面、人物、建筑
- 强制分区,AI 不能画错区域
- 做场景、建筑、环境设计最稳
9. 控制画面 “正常姿势” 不崩坏
用 OpenPose + Depth
- 手不崩
- 身体不扭曲
- 多人不乱跑
- 视角不乱飞
这是画人物必开组合。
10. 做 “同一动作、不同画风” 批量出图
一个姿势骨架
→ 换模型、换风格、换衣服
→ 动作完全不变
做表情包、角色设定、系列图神器。
🧠 最简单记忆法
- OpenPose = 管人动作
- Canny = 管线条轮廓
- Depth = 管空间立体
- LineArt = 管线稿
- Seg = 管物体位置
- Face = 管脸
🔥 最实用的 3 个组合(你必学)
OpenPose + 主模型
画人物不崩姿势
Canny + 主模型
线稿上色、结构不变
Depth + 主模型
场景、建筑、透视超准
调整人物骨骼编辑&控制
安装插件ComfyUI-Openpose-Editor-Plus这个插件只能调整大骨骼
所以再通过Git URL安装一个https://github.com/yanlang0123/ComfyUI_Lam.git
修复 ComfyUI Manager 安全级别错误
当通过 Git URL 安装 ComfyUI 插件时遇到
This action is not allowed with this security level configuration报错,本质是ComfyUI Manager的安全策略限制了外部代码执行。本教程提供了方案,覆盖 Windows/macOS/Linux 全平台操作。其实在 ComfyUI Manager 的仓库中已经有说明如何解决这个问题,
E:\ComfyUI-AI_DeskTop\ComfyUI-aki-v3\ComfyUI\user__manager
通过修改config.ini文件来修改安全级为weak即可解决。
安装完毕后双击寻找openpose→姿态编辑器ref可以给当前节点添加一个参考图进来,并且可以改变图片的宽度和高度,点击显/隐画板就可以调出画板出来
把人体、脸部、手部骨骼文件下载并导入到E:\ComfyUI-AI_DeskTop\ComfyUI-aki-v3\ComfyUI\custom_nodes\comfyui_controlnet_aux\cache\lllyasviel\Annotators
人体:body_pose_model.pth
手部:hand_pose_model.pth
脸部:facenet.pth
如果插件冲突或者版本不对直接在missing里面找一下上面的IMPORT FAILED报错,然后问豆包 安装缺少的东西
PS E:\ComfyUI-AI_DeskTop\ComfyUI-aki-v3>
完美!我看到真正的问题了!你的系统装了 Python3.13,和 ComfyUI 自带的 Python 打架了,所以命令直接报错!
我给你最终、最简单、100% 能成功的方案,不用管任何复杂路径,直接复制运行!
终极一键修复(复制这 3 行,直接运行)
E:\ComfyUI-AI_DeskTop\ComfyUI-aki-v3\python在你现在这个 蓝色 PowerShell 窗口里,直接复制粘贴这 3 条命令,一条一条运行:
.\python\python.exe -m pip uninstall tensorflow -y.\python\python.exe -m pip uninstall protobuf -y.\python\python.exe -m pip install protobuf==4.25.3
..\..\..\python_embeded\python -m pip install -r requirements.txt 来手动安装各种python
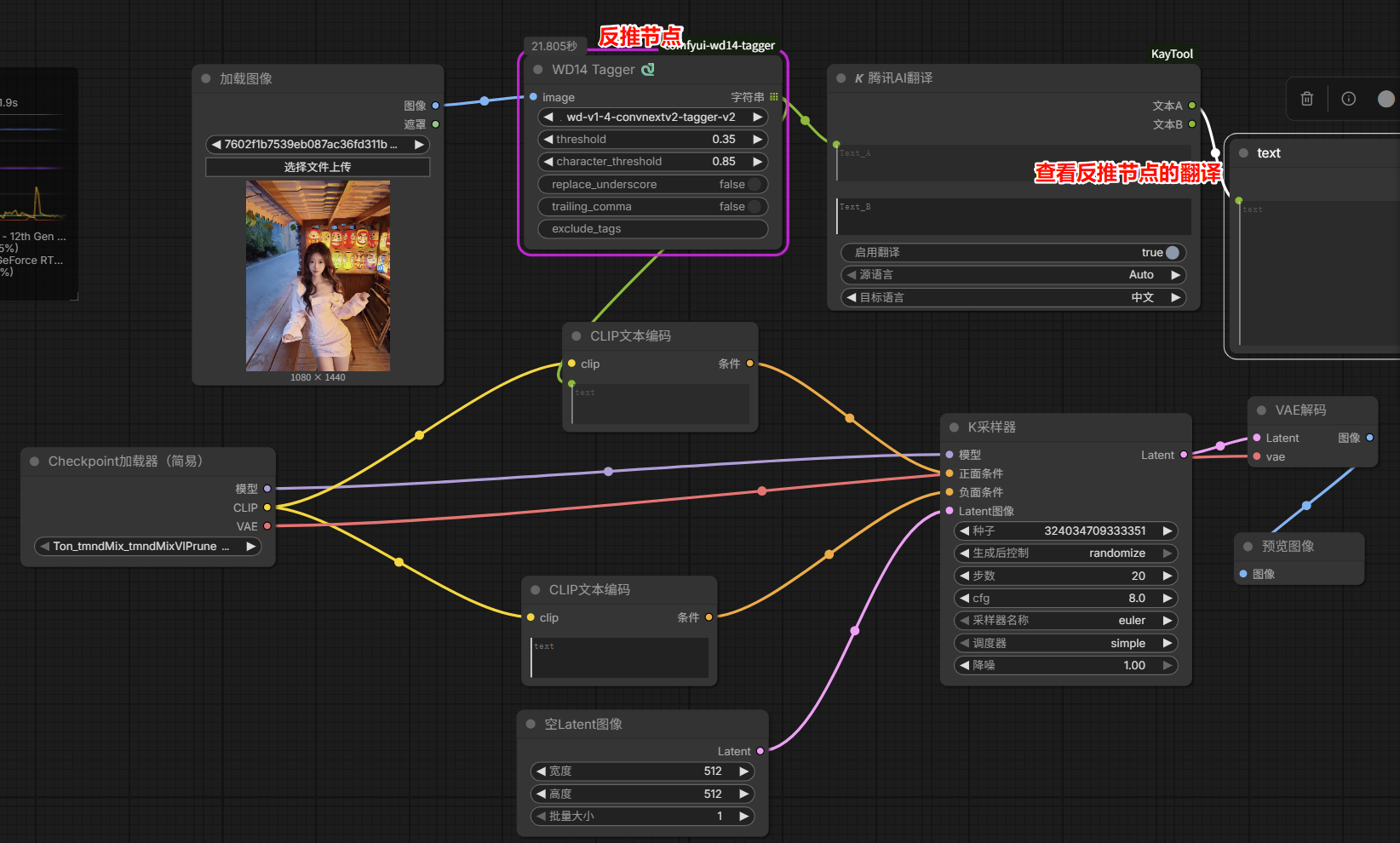
ComfyUI反推提示词WD
WD14 Tagger
- threshold(阈值):数值越高,抓取的提示词越少;
- character_tthreshold(人物特征特提示词):比上方阈值效果低
- exclude_tags(排除元素):cat可以排除
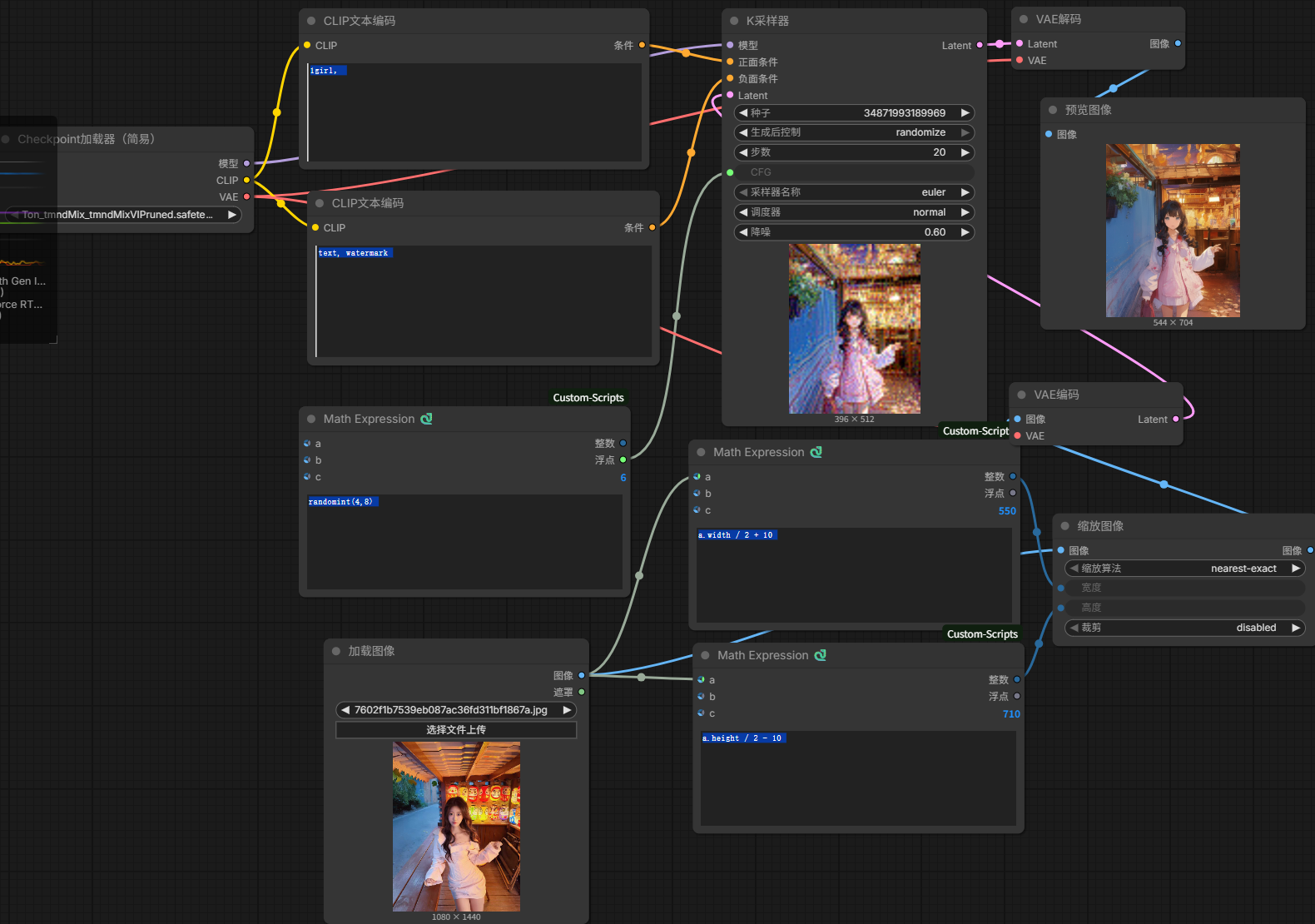
图像尺寸 图像缩放 裁剪节点
尺寸太大会直接变形、畸变SD1.5大模型基础出图分辨率最多只能去到768分辨率
大尺寸等比缩小再传到k采样器中
数学表达式节点
可以通过数学运算逻辑去进行图像缩放及适 合运算的节点
K采样器可以进化成输入的 带有CFG的随机数种子 然后将数学表达式拖入CFG 是「提示词引导强度」,核心作用是:控制 AI 生成的图片有多 “听” 你的提示词指令,是 K 采样器里最影响生成效果的参数之一。
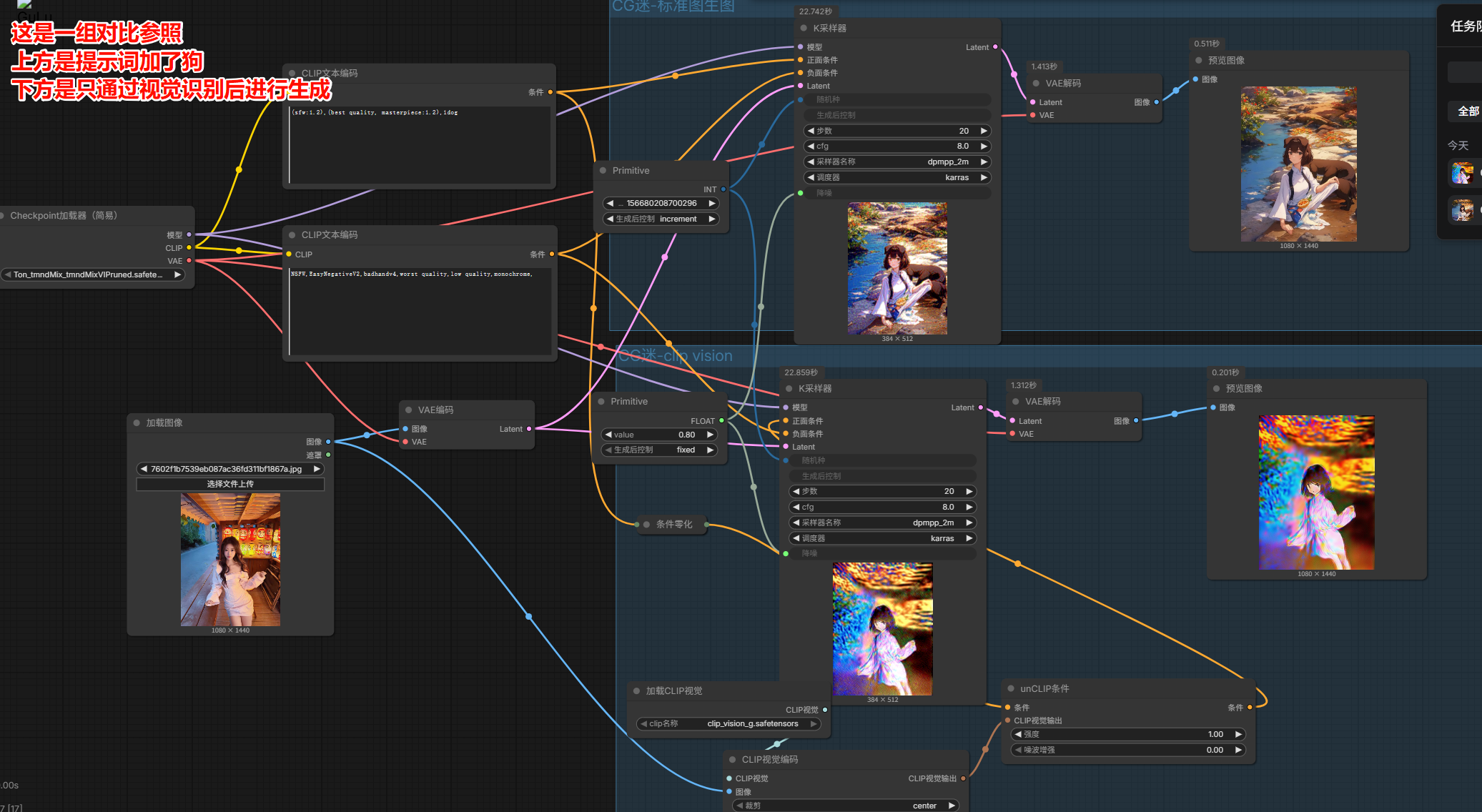
Clip Vision视觉编码节点
是能够通过对应的视觉模型实实在在的对上传的图片进行分析和学习【其实跟图生图类似 但大有区别】
能够获取和分析我们上传的图片,从而编码成对应的条件作为输出传输给K采样器来生成图片
要想效果更好 要把大模型切换到SDX大模型
这里的大模型都要放到:E:\ComfyUI-AI_DeskTop\ComfyUI-aki-v3\ComfyUI\models\clip_vision 中
下载clip_vsion_g.safetensors
unCLIP条件节点可以读取CLIP视觉编码节点的数据,并经过模型进行学习,从而转换成条件传给K采样器;这个条件节点还可以配合正向提示词一起起到双重叠加的效果
条件零化:可以让正向提示词传输过来的数据归零,正向提示词的效果不会发生作用!
高效的集成节点,管道,元组,堆栈
集成节点:一个节点顶替多个节点【类似于SD放大节点】是众多节点的融合体
pipe管道节点(ToBasicPipe + KSampler SDXF(Eff.) ):到基础束【整合到了很多在一起】→ 可以创建一个**k采样器(节点束)**【减少线路的长途跋涉连线】
【到基础束】
- 模型 ⚪ 基础节点束
- CLIP
- VAE
- 正面条件
- 负面条件
元组TUPLE(Eff. Loader SDXL + KSampler SDXF(Eff.) ):集成了CLIP Skip跳过、VAE、正向提示词、负向提示词
堆栈 + 效率节点:
效率工具缺点:由于集成度过高,会失去一些自定义、定制化的功能;需要配到插件使用,所以兼容性和工作流迁移方面没有原始节点好;稳定性和速度方面欠缺(引入网上的工作流会出现)
embeddings加载与webui参数复用
embeddings:体积很小的标签模型,相当于输入一系列的优化提示词
可以直接从LibLibAI的地方点击图片右下角的感叹号信息,可以获取提示词Prompt;但直接复制到自己的里面会发现生成的效果很差,这里面的原因是复制的提示词可能缺失了对应的lora模型,而且对方在负面提示词里经常会加入(embeddings);只需要加入到负面提示词里就相当于输入了一串十多二十多个优化人物体态的负面提示词;需要手动在后面加入embedding:xxxx,xxx是所对应的模型名称
NSFW,(worst quality:2),(low quality:2),normal quality,(lowres),bad anatomy,bad proportions,wrong fluoroscopy,limb dislocation,malformed limbs,extra limbs,bad facial,bad face,unnatural face proportions,swollen or deformed face,embedding:xxxx
默认ComfyUI是通过CPU来生成噪波的,WebUI是通过GPU(显卡)生成噪波的;
在 ComfyUI / AI 画图里,噪波(Noise) 你就记一句最简单的:
噪波 = AI 画图的 “起点”
AI 不是凭空画,而是从一堆随机杂色点开始,慢慢擦除、细化,变成清晰图片。这堆随机杂色,就叫 噪波。
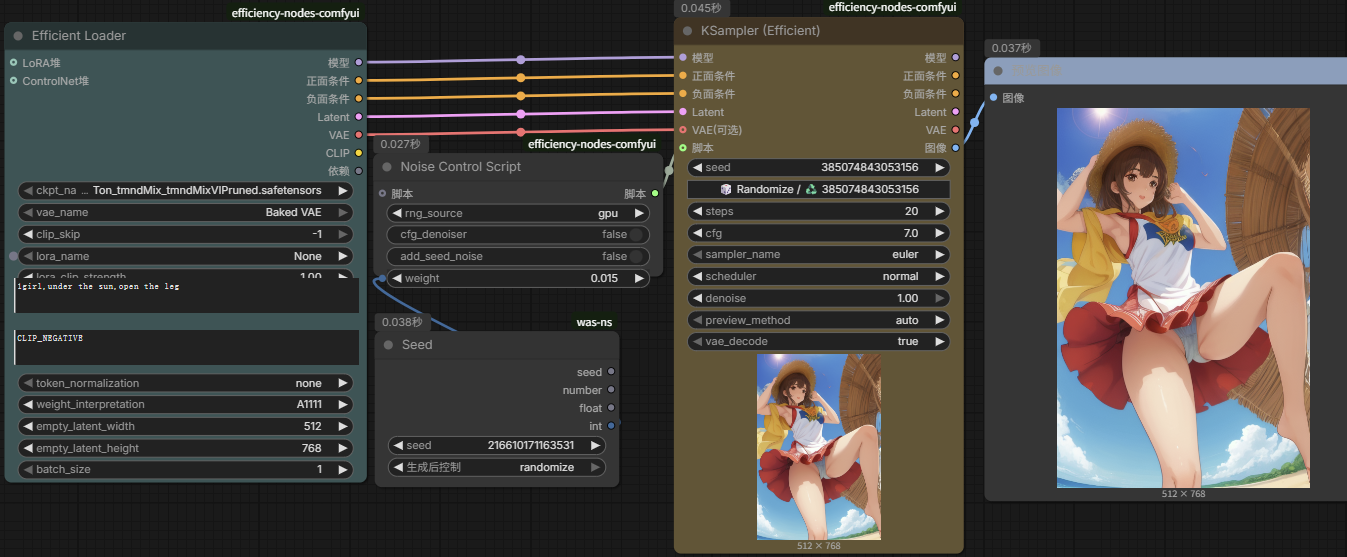
集成预处理器 + Controlnet-union全能控制
AIO Aux Preprocessor:集成的预处理器节点(包含非常多常用的预处理器节点)
万能controlnet模型:controlnet-union-sdxl-1.0 仅支持SDXL大模型使用;controlnet_union_sdxl.safetensors; controlnet_union_sdxl_promax.safetensors
下载后放在E:\ComfyUI-AI_DeskTop\ComfyUI-aki-v3\ComfyUI\models\controlnet中
就可以新建节点 → 条件 → ControlNet → 设置UnionControlNet类型
这样一个模型就内置了13款常用的controlnet模型了!
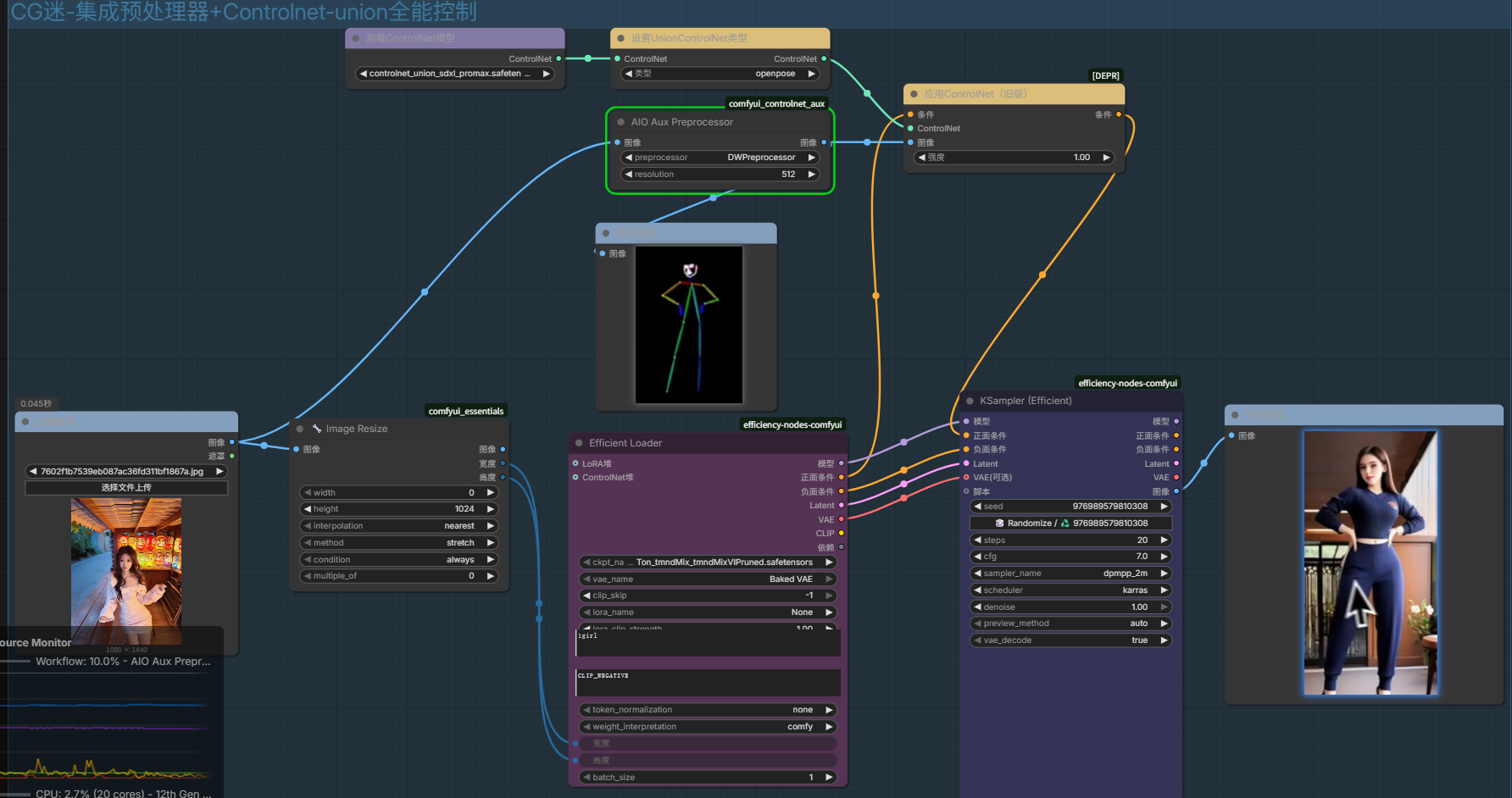
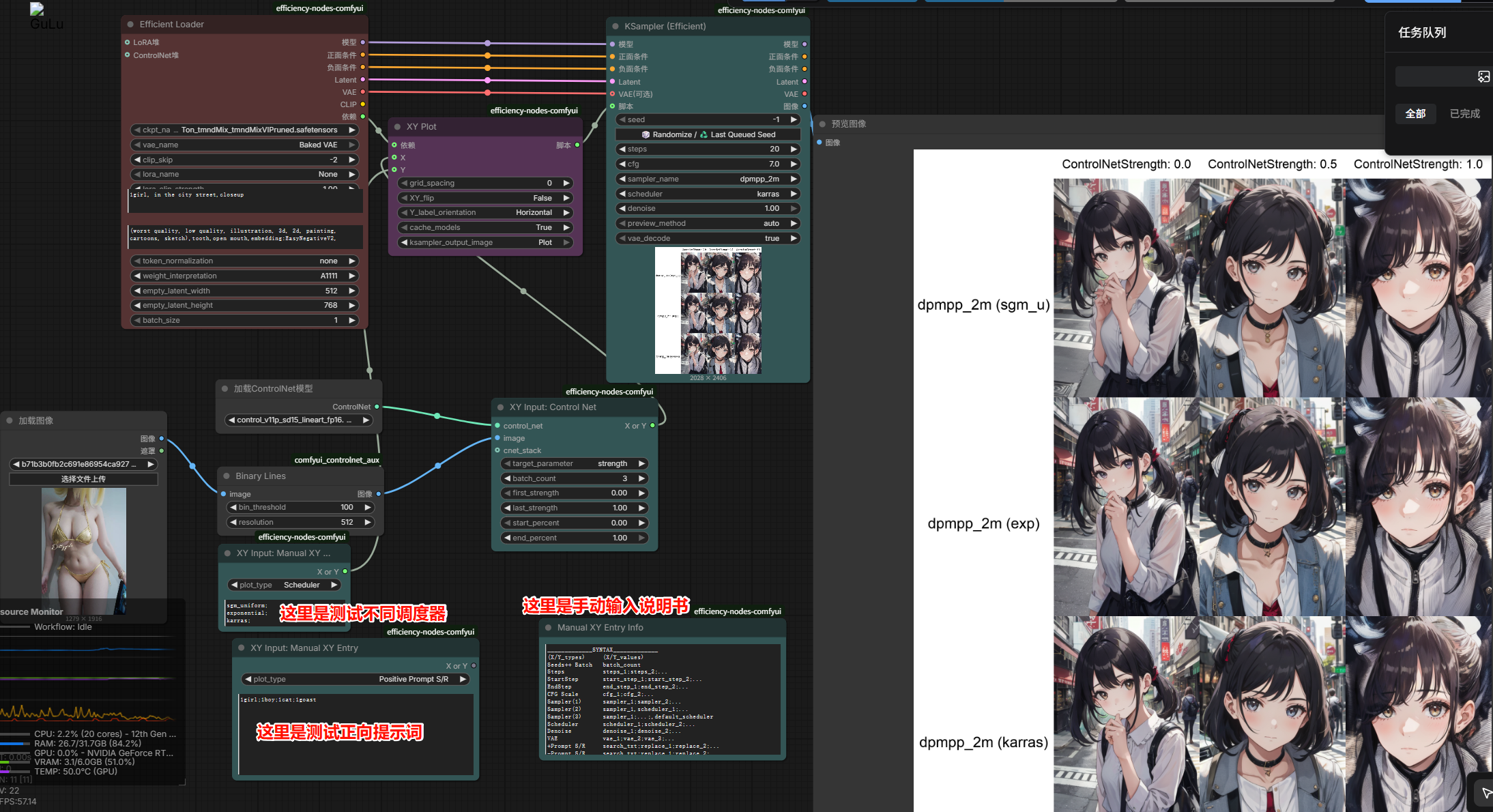
XYZ脚本参数对比测试
XY Plot:展示生成后横纵坐标的效果
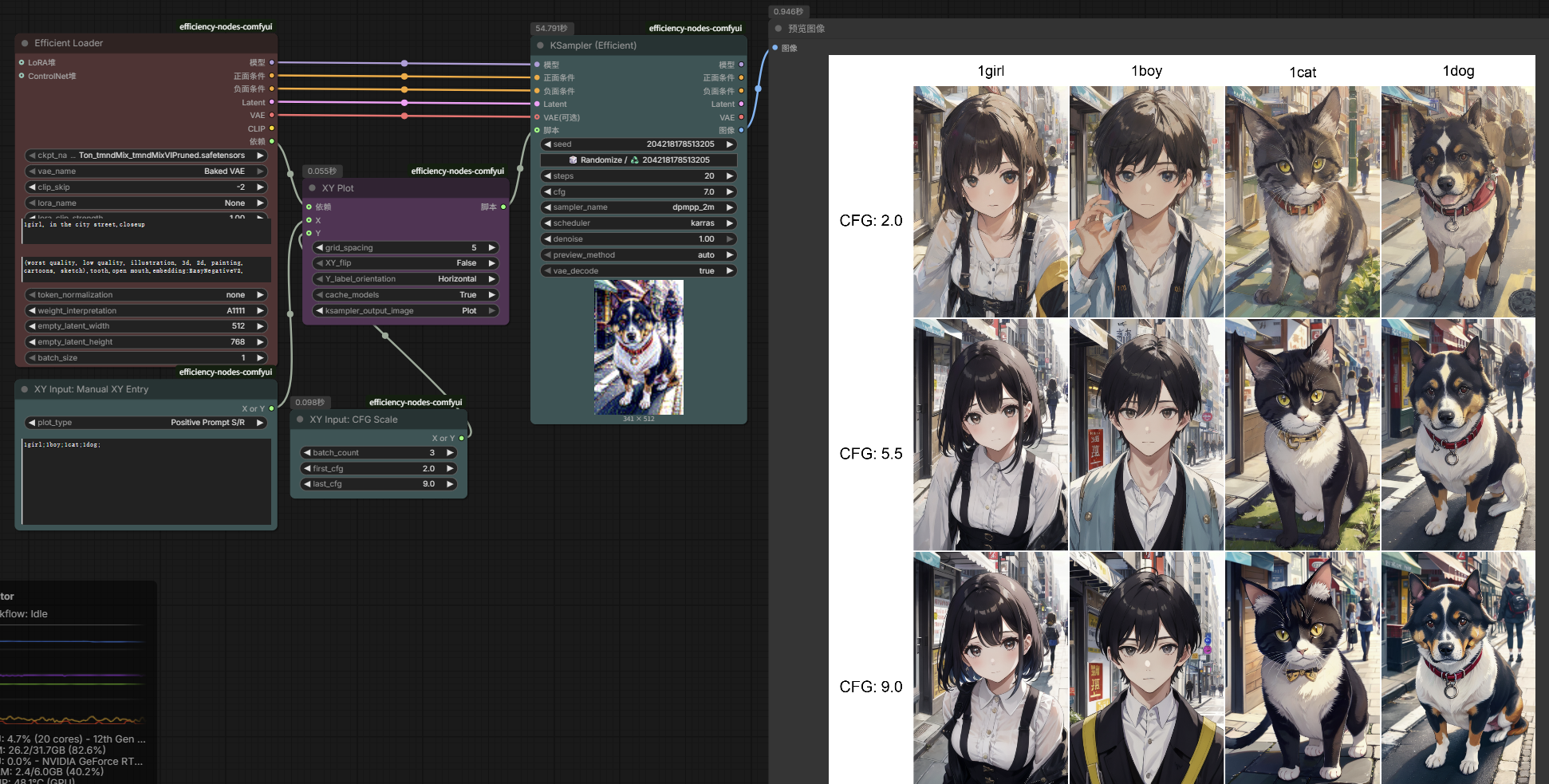
也经常成为lora脚本的测试
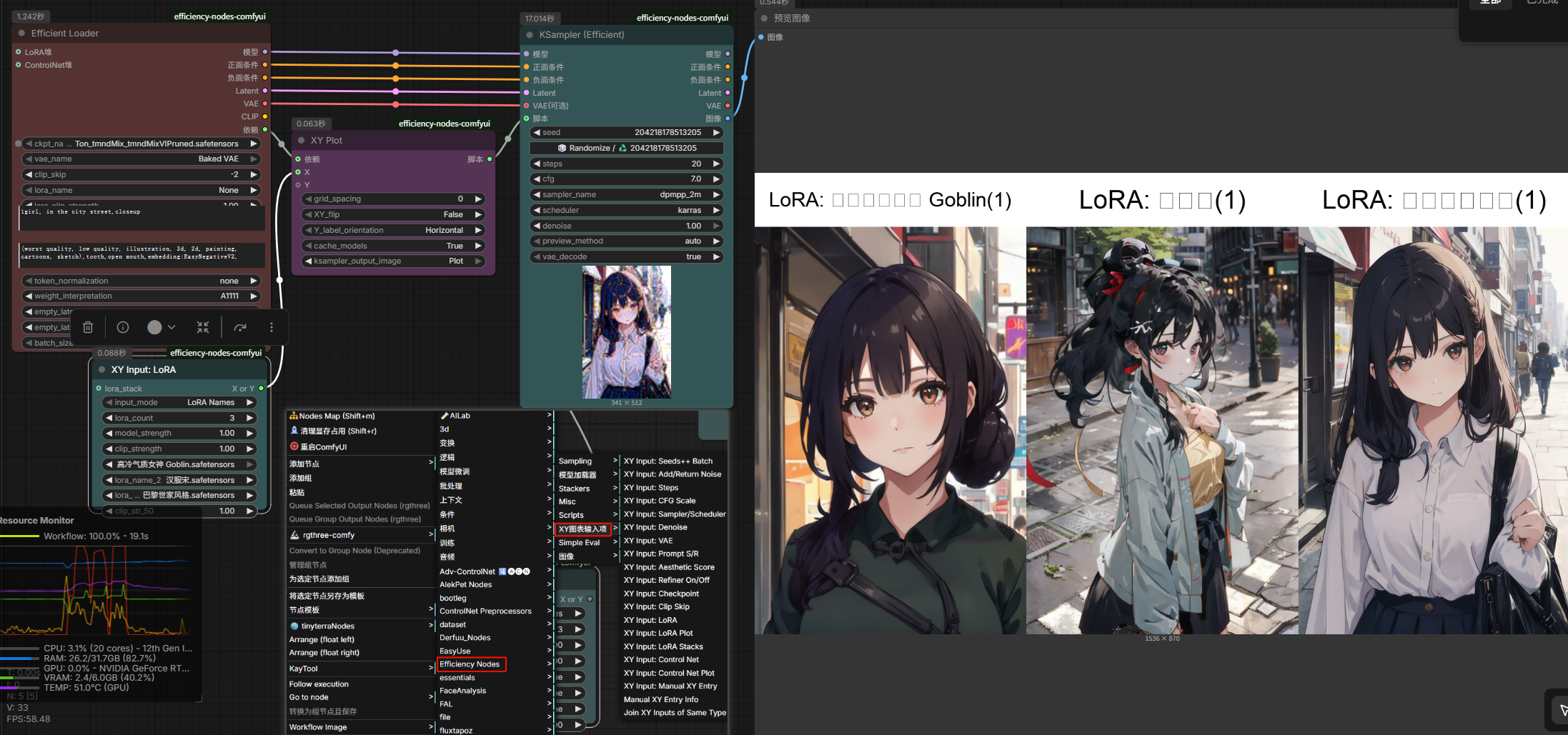
controlnet测试参数
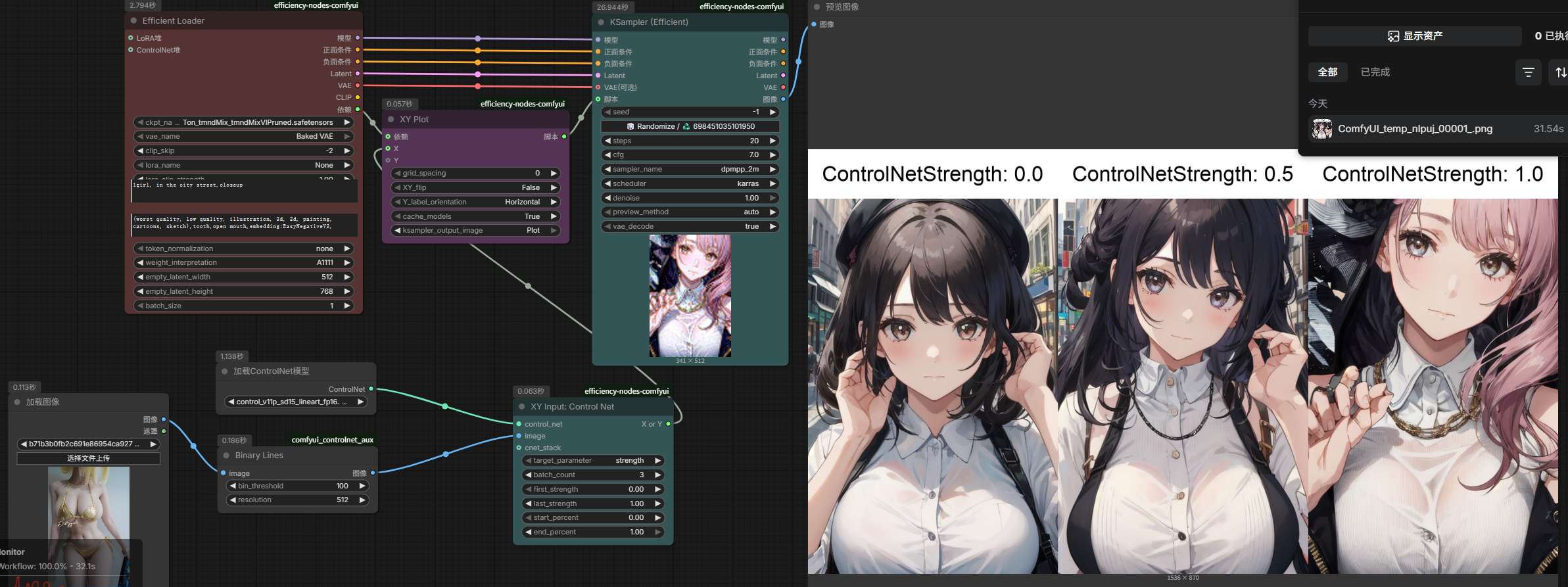
XY手动输入节点
右键 → 添加节点 → Efficiency Nodes → XY Input: Manual XY Entry
再添加一个节点说明 也是在上面的路径 → Manual XY Entry Info
这里面有详细的使用手动输入节点的说明
找到___________SCHEDULERS___________ 调度器
SCHEDULERS
simple;
sgm_uniform;
karras;
exponential;
ddim_uniform;
beta;
normal;
linear_quadratic;
kl_optimal;
AYS SD1;
AYS SDXL;
AYS SVD;
GITS
选择好后复制到手动输入节点里面
上面的plot_type(接口类型)要改成Scheduler(调度器)
此时就可以测试不同采样器和不同调度器之间的搭配生成效果了
也可以搞成正向/负向提示词 也非常好用【可以测试不同提示词的效果】
节点预设保存与重复调用必备技巧
每次不要经常拖拽 很费事
Controlnet模块;按住Ctrl框选模板节点后,在空白位置点击鼠标右键 →储存选中为模板→ 起个名右键就可以调用了- 框选中工作流,右键选择
转换为组节点且保存→ 可以把框选的节点整合成一个单独的整合节点;在整合节点中右键Manage Group Node就可以管理预设 → 右上角可以选择是想编辑哪个预设 → 可以改整合节点内部的命名 - 左上角的文件夹可以有Import进行导入工作流
在整合节点上右键 → Convert to nodes 就可以转换成普通节点了
缺点:一旦整合了节点之后,我们就不能单独进行局部修改和调整了!!!
ComfyUI批处理,批量出图技巧
Load Image Batch : 在画布上右键 → 添加节点 → WAS Suite → IO → Load Image Batch
mode里面有三种:random随机、incremental_image(递增模式)、single_image
ComfyUI基础节点详解——加载器
共计上百个节点,共5大分类,一口气了解ComfyUI各个节点的使用
五类基础节点
- 采样
- 加载器
- 条件
- Latent
- 图像
大部分的工作流都是以大模型的加载CheckPoint加载器(简易)作为起始输入源来进行展开的,一个工作流里面可以存在多个加载器
- 放大模型加载器:对生成的图片进行放大
连接controlnet的时候要用到对应的controlnet模型加载器;所以加载器是工作流中各个模块的生产力源头;随着添加插件后在右键,点击添加节点→ 加载器 → 就能看到插件的那些加载器了
节点讲解我们都将会在LiblibAI的在线版comfyui
右键添加节点 → 加载器 → ‘ 所有加载器 ‘
.png)
ComfyUI基础节点详解——条件
条件节点 => 主要作用:充当指挥官,下达命令,设定生成条件。
例如提示词要求生成什么内容,controlnet要求生成什么样的动作姿势,最终画面都需要遵循这些条件节点的要求来生成图像
StableZer123、StableZer123(批次)
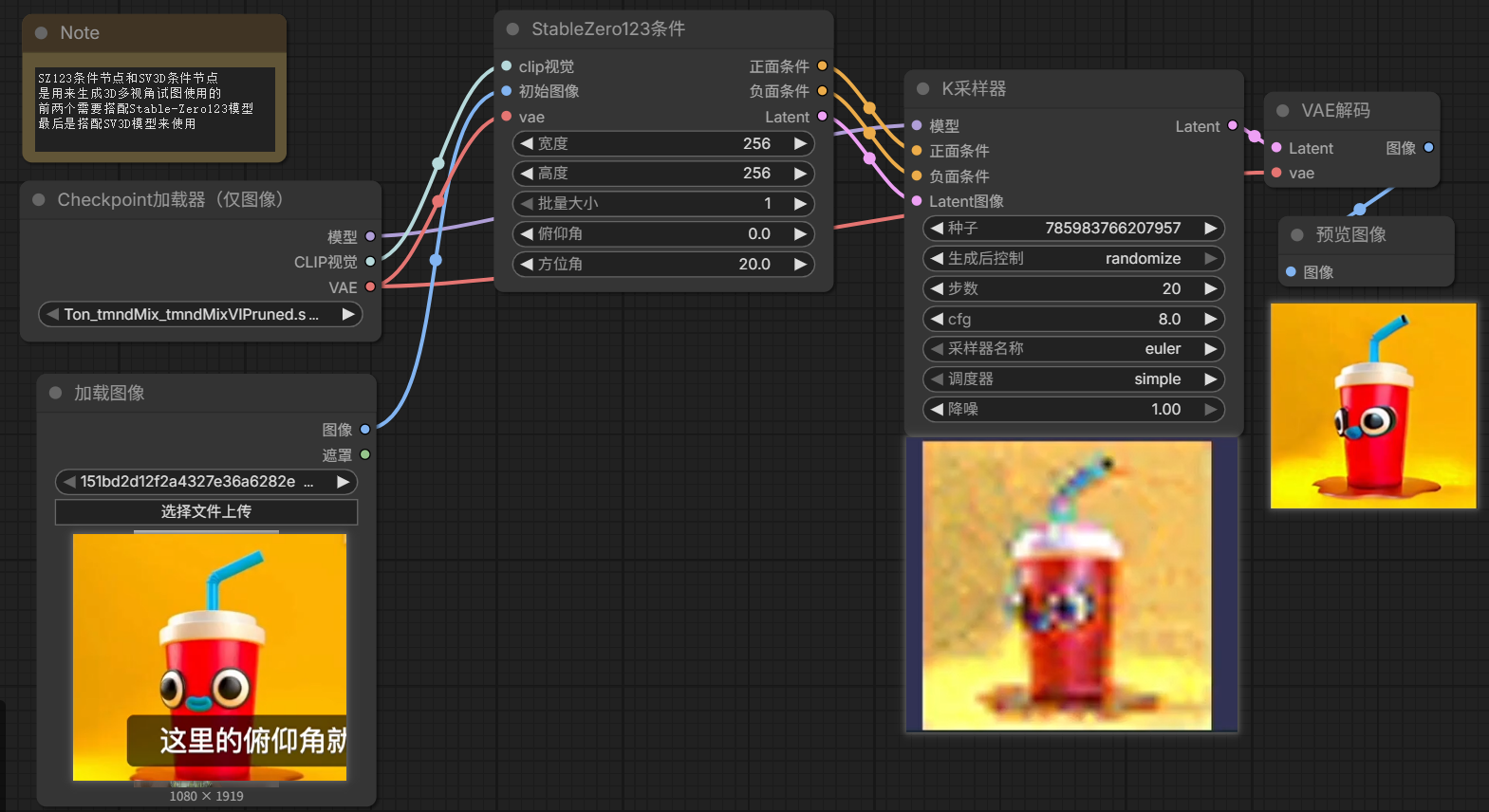
SD4X放大条件节点(SD_4X放大条件)
图片进行四倍放大后再进入潜空间进行采样降噪处理
这里要用大模型x4-upscal-ema.ckpt
Stable Cascade B阶段节点
Stable Cascade B 阶段节点(Stage B)是 Stable Cascade 三阶段生成流程里的 “高清细节上采样 + 精修” 核心节点,负责把 Stage C 生成的低分辨率小 latent 放大、补全细节,为最终出图打基础。
一、Stable Cascade 三阶段总览(先看懂流程)
Stable Cascade 分 Stage C → Stage B → Stage A 三步生成:
- Stage C(Prior / 先验):在极小 latent 空间(如 24×24)生成基础构图、语义,速度快、显存占用低。
- Stage B(Decoder / 解码器):核心上采样 + 细节精修,把 Stage C 的小 latent 放大到中高分辨率 latent,补纹理、结构、细节。
- Stage A(VAE / 最终解码):把 Stage B 的 latent 解码成像素图,输出最终高清图。
二、Stage B 节点的核心作用(你问的重点)
1. latent 上采样(最核心)
- 接收 Stage C 输出的低分辨率 latent(如 24×24),通过扩散模型将其放大到中高分辨率 latent(如 256×256、512×512)。
- 相当于 “把模糊小图放大成清晰大图的 latent 版本”,是从 “小 latent” 到 “高清图” 的关键桥梁。
2. 细节精修与语义对齐
- 基于文本提示词,对放大后的 latent 进行去噪、补细节、修正结构,让图像更贴合提示词、更真实。
- 解决 Stage C 生成的 latent 细节不足、结构粗糙的问题,是画质提升的关键环节。
3. 显存友好的高清生成
- 相比直接在高分辨率 latent 上跑扩散,Stage B 先在小 latent 跑 Stage C,再上采样,大幅降低显存占用,让普通显卡也能生成高清图。
InstructPixToPixConditioning 条件节点
通过提示词可以在我们上传图片的基础上赋予一系列新的样式风格
- 比如输入
make it file让它着火;就会在原图的基础上产生效果 - 也可以改变其他的元素,比如输入
make it old就可以让他变老
这里要用大模型cosxl_edit.safetensors
Clip停止层
参数:停止在CLIP层 (x)
真实风:-1
动漫风:-2
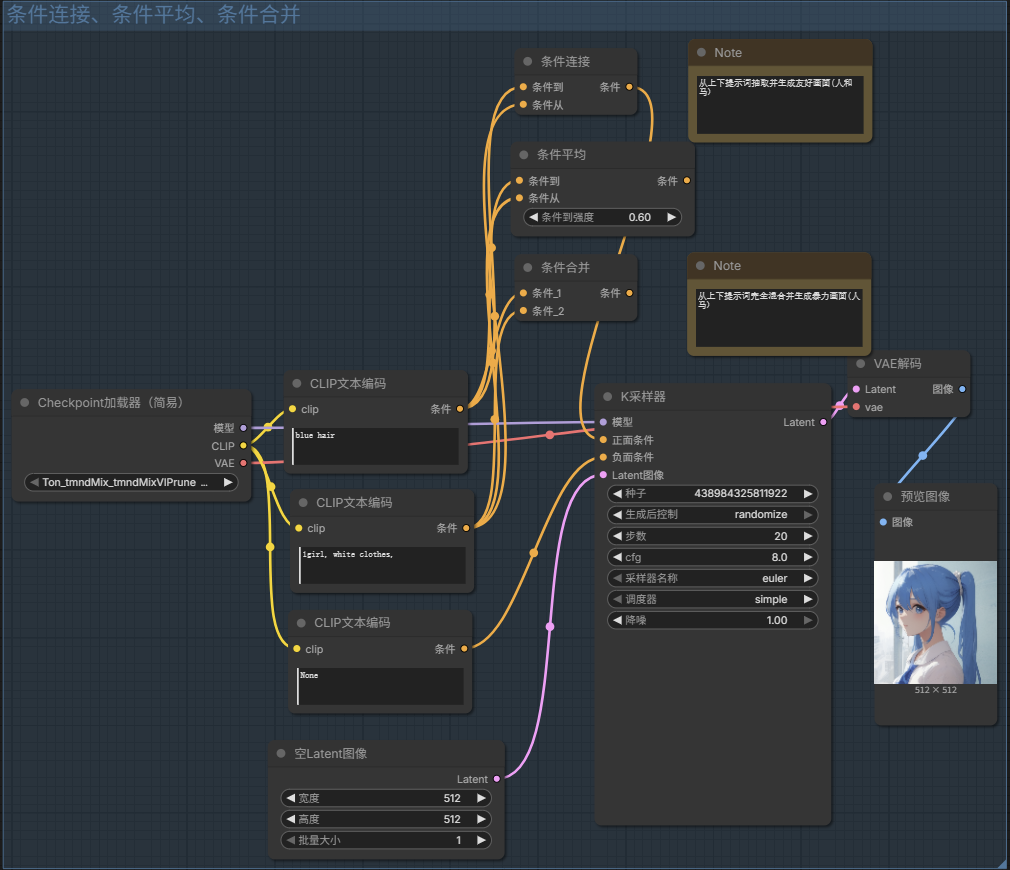
条件连接、条件平均、条件合并
条件连接(联结):可以合并两个正向提示词,因为提示词都写在一个CLIP中可能会互相干扰
条件平均:由于有两个正向提示词,可以通过其参数来调整合并之后那个提示词会起更多的作用;
- 例如默认值是1,就代表:上面的提示词起100%的作用(蓝色头发 无白色衣服)
- 如果改成0,就代表:下面的提示词起100%的作用(白色衣服 无蓝色头发)
- 所以要选择 0~1 的数值
条件合并:上下提示词进行完全混合!!!
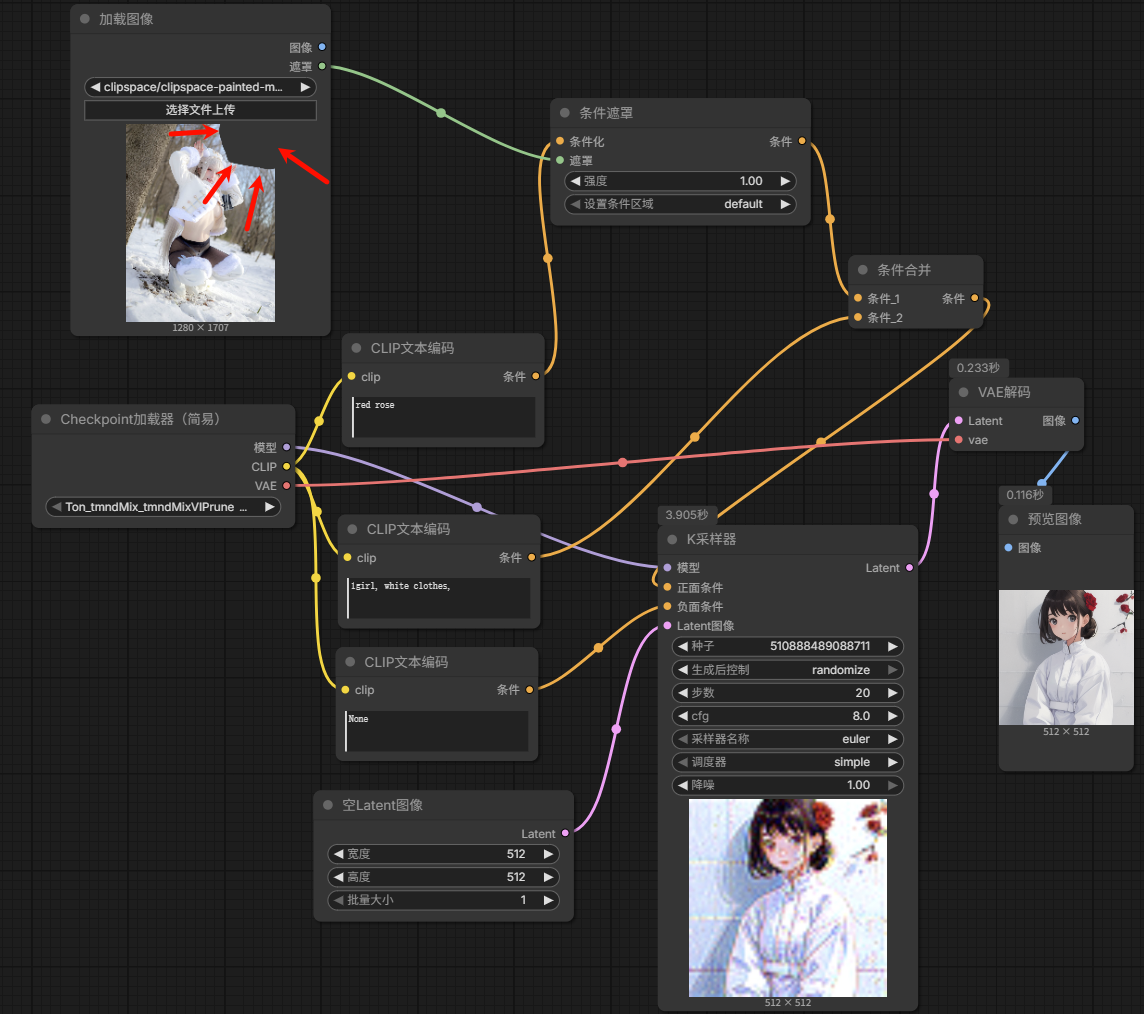
条件设置遮罩
CLIP视觉编码 + unCLIP条件
在图生图下,让comfyUI参考图片的风格去生成图片
.json.png)
ComfyUI基础节点详解——Latent(潜空间)
K采样器就是典型的潜空间模块,这个潜空间是专门AI处理图像的空间,不管是我们给它传输内容还是从潜空间里面产出的内容,都需要靠Latent节点来进行中转转化
- 空Latent(适合文生图使用):不需要传输内容进潜空间
- 加载图像→VAE编码.Latent→K.Latent(给图片参考):图片经过编码后转换成Latent,传输给K采样器;同理在K采样器里面处理完毕的图像就需要通过VAE解码节点来转换成像素,最终得到我们看得到的图片
Latent缩放,Latent按系数缩放
Latent缩放:可以手动改变我们上传图片的宽度和高度(因为不知道宽高比可能出现畸变);所以一般用Latent按系数缩放节点
Latent按系数缩放节点:会自动获取图片的宽度和高度,通过系数值来进行等比放大或缩小
- 缩放算法一般选择
nearest-exact(缩放系数最高效果最好)【如果图片生成后有锯齿状可以切换其他柔和算法】
合成Latent、合成Latent遮罩
将两个图片的画面融合,把下面的源图片覆盖在目标图片上面
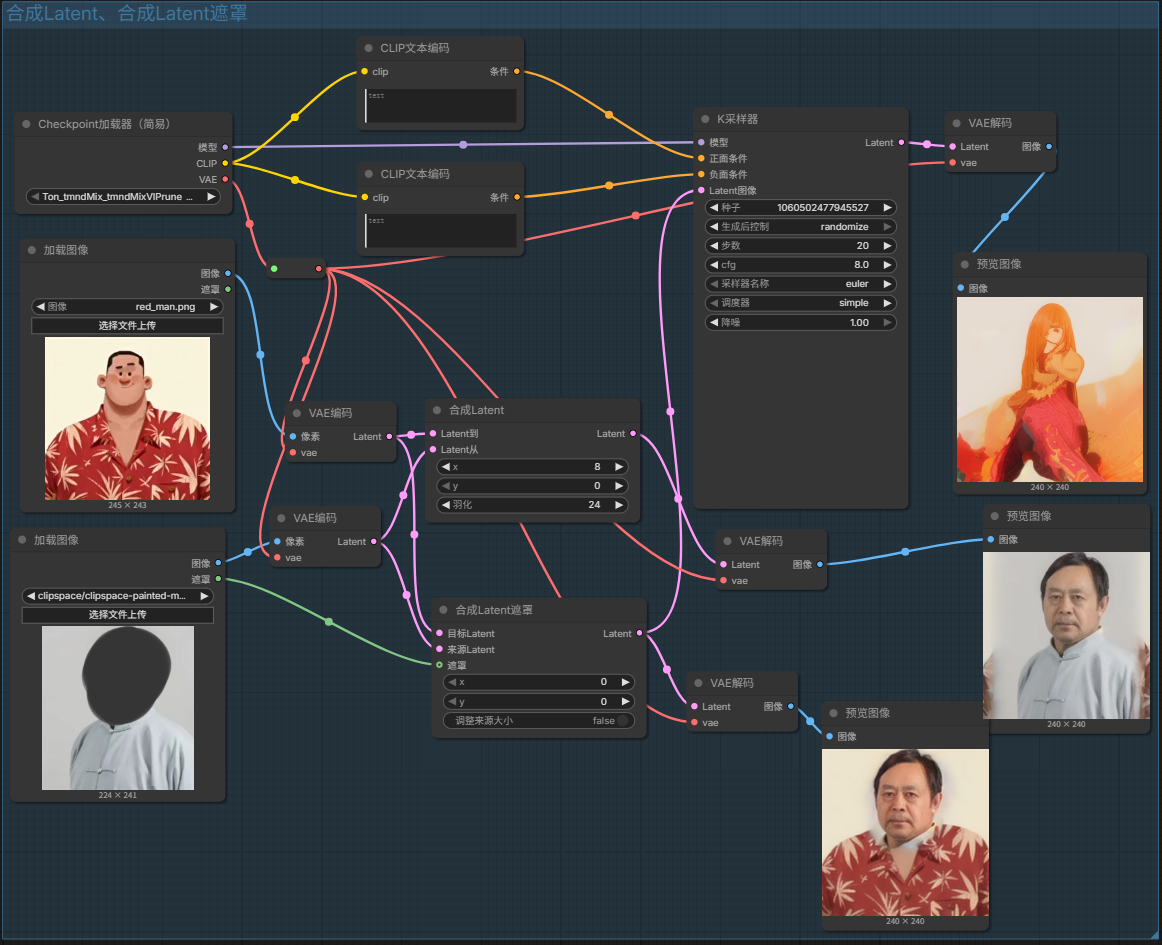
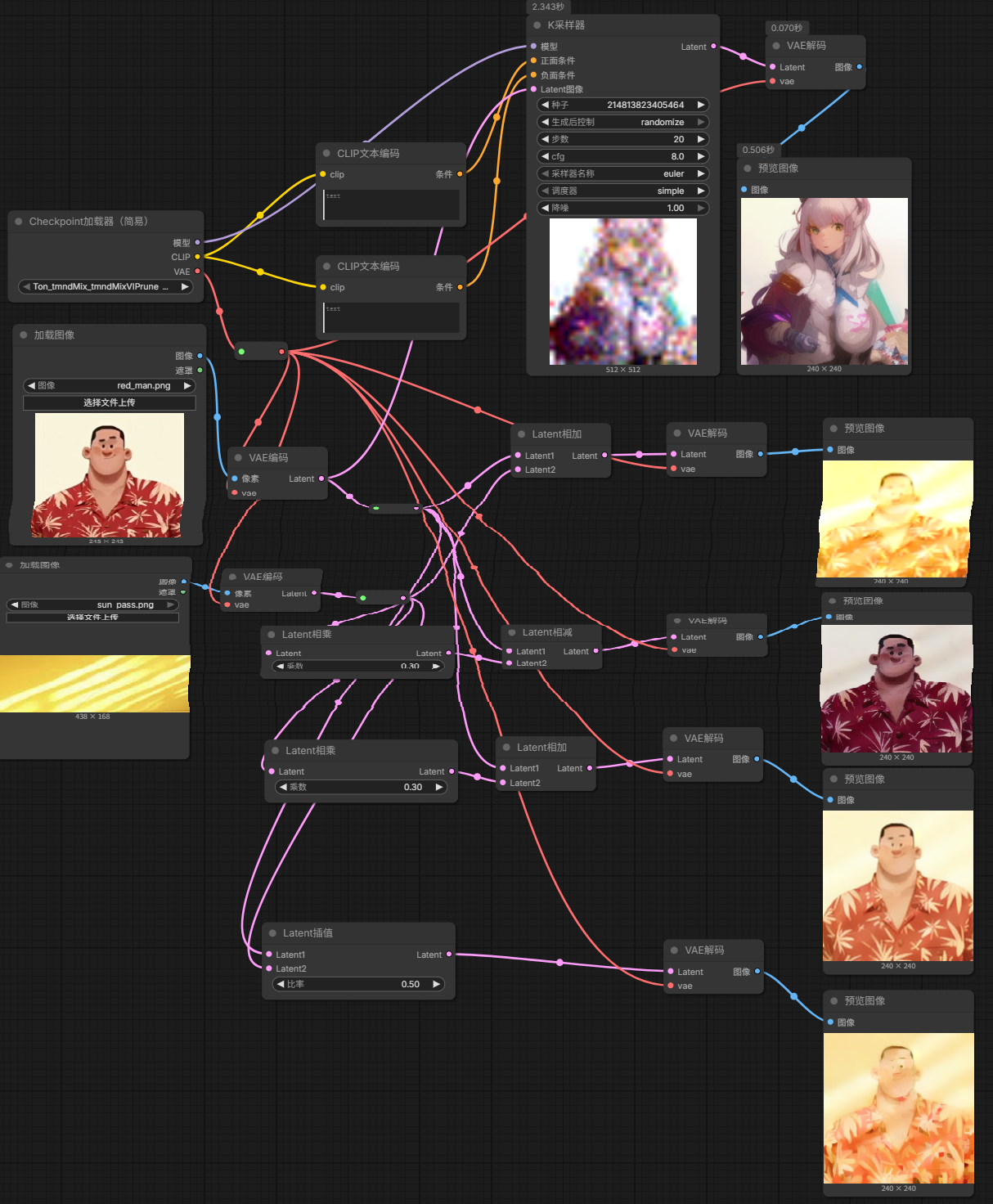
Latent相加、相减、相乘、插值
Latent插值:比率是1,只显示上面的图片;比率是0,只显示下面的图片;比率是0.5,两个图片以插值的方式相互交互在一起
Latent相加:把下面图片亮度最高的地方叠加到上面的图片来
Latent相乘(图片阳光透光) + Latent相加:通过相乘的系数来调整阳光的亮度
Latent相减:和相加相反,上面的图片减去下面阳光最亮的区域(光亮的地方变成阴影)
VAE内补编码器、设置Latent噪波遮罩
VAE内补编码器(VAE编码+设置Latent噪波遮罩):内补就是inpaint的意思是专门用来进行局部重绘的;其原理是把重绘区域涂抹成白色的潜空间进行重绘
[适合重绘一切和原图没有关系的内容]
设置Latent噪波遮罩:让上传的图片多出遮罩的输入;其原理是原图的基础上进行重绘的,重绘出来的内容会考虑到原图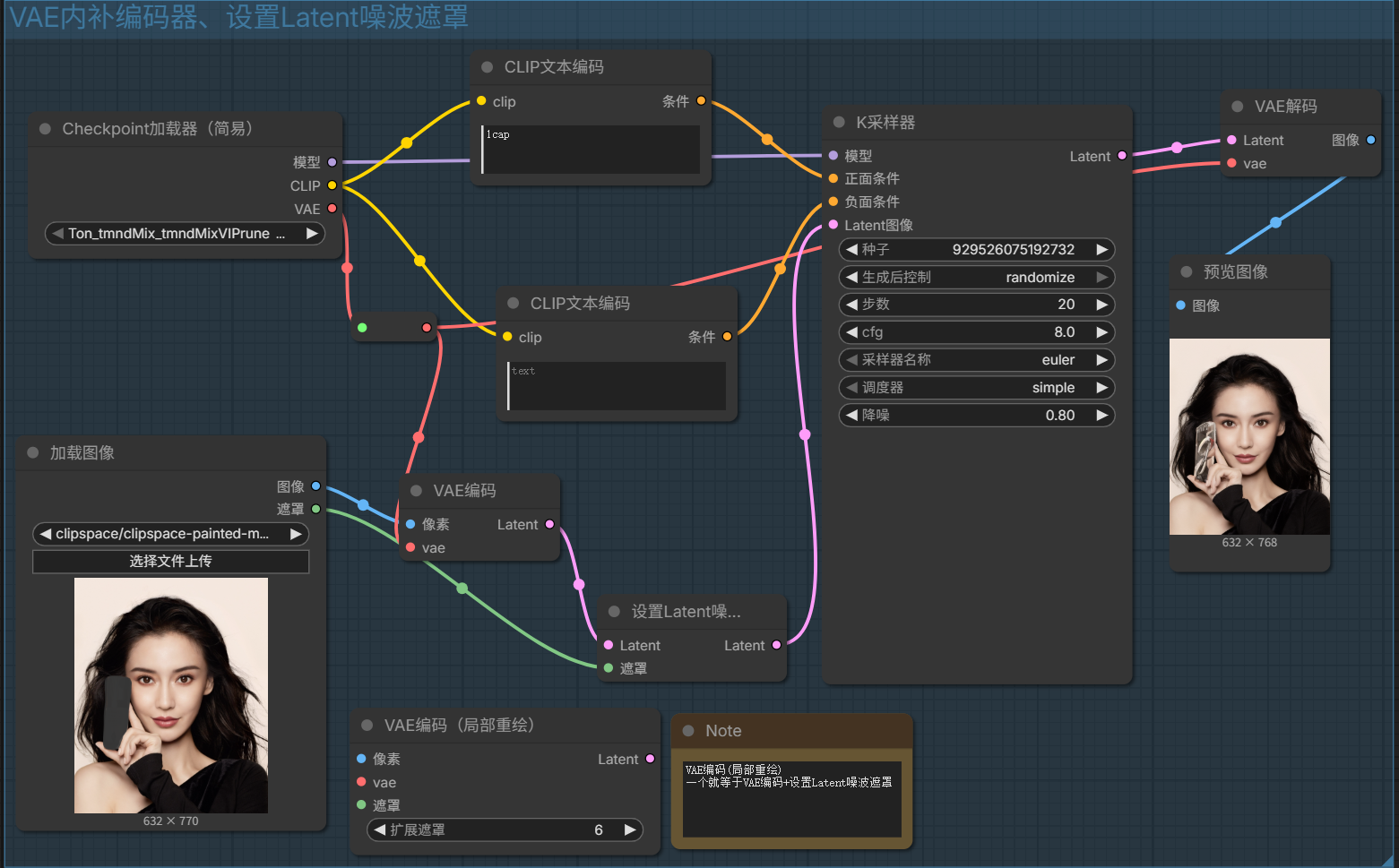
Latent旋转、翻转、裁剪
可以改变图像的位置和方位以及大小
批处理Latent节点【后续进阶批量化出图】
复制Latent批次、重设Latent批次、从批次获取Latent
背景:我们在文生图的工作流里可以通过空Latent的批次大小 来改变一次生成多张图片;但如果是图生图工作流的话没有办法一次生成多个图片;所以需要Latent组合批次
批处理:一次生成多个图片的处理流程
复制Latent批次:连接后可以设置Latent生成图片的数量
重设Latent批次:拆分重组批次节省批量出图显存占用
从批次获取Latent:我想要通过复制Latent批次中的第二个索引(第三张图)的图片,此时只需要设置从批次获取Latent的批次索引为2即可;长度默认是1,也就是可以获取到索引以后的根据长度来断定图的数量
.png)
ComfyUI基础节点详解——图像
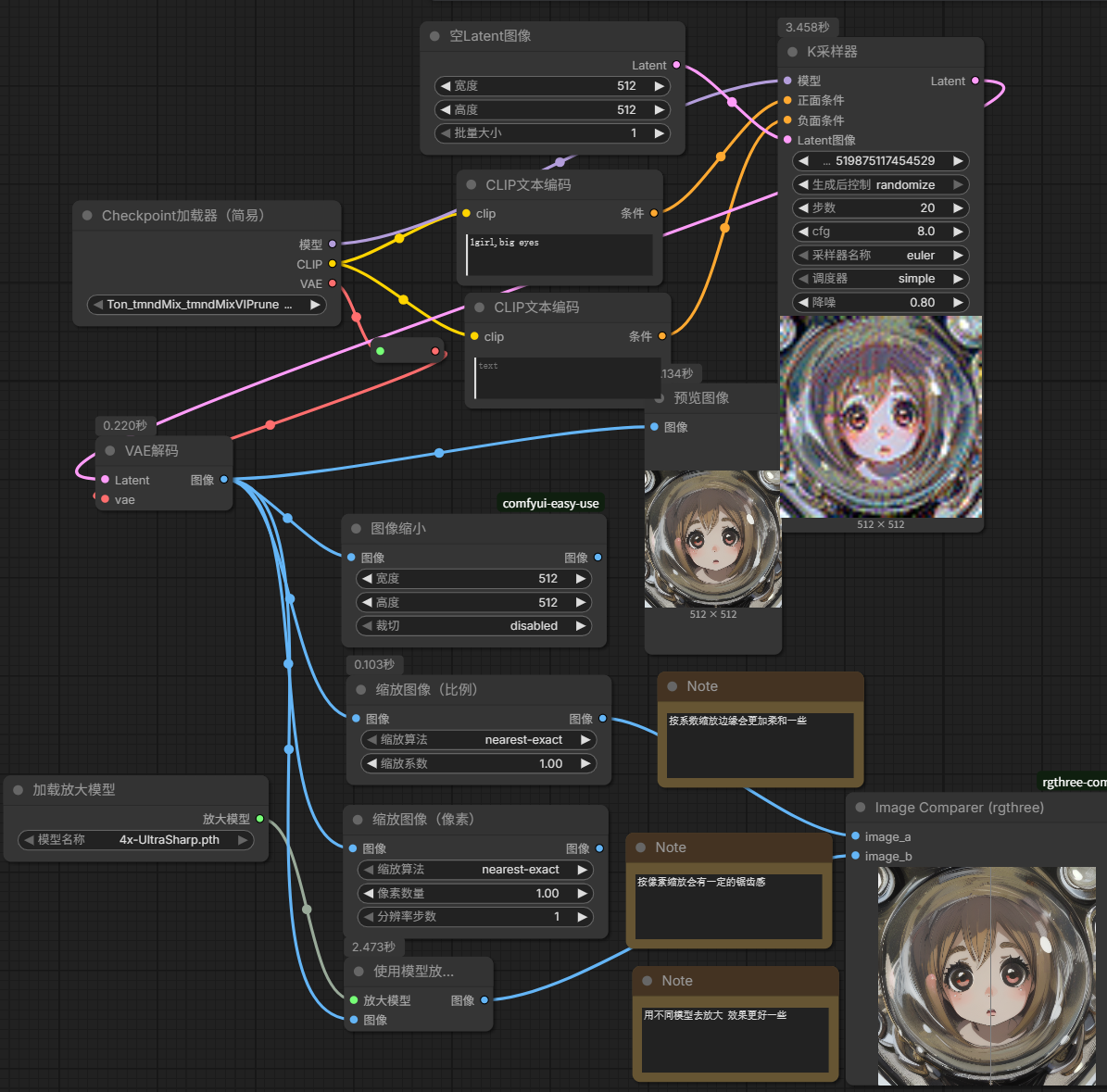
图像—放大
图像缩放:直接缩放按照宽高
图像按系数缩放按照插值的方式放大:按系数缩放边缘会更加柔和一些
图像缩放(按像素)增加像素点方式放大:按像素缩放会有一定的锯齿感
图像通过模型放大:用不同模型去放大 效果更好一些
可以新建一个Image Comparer来对比
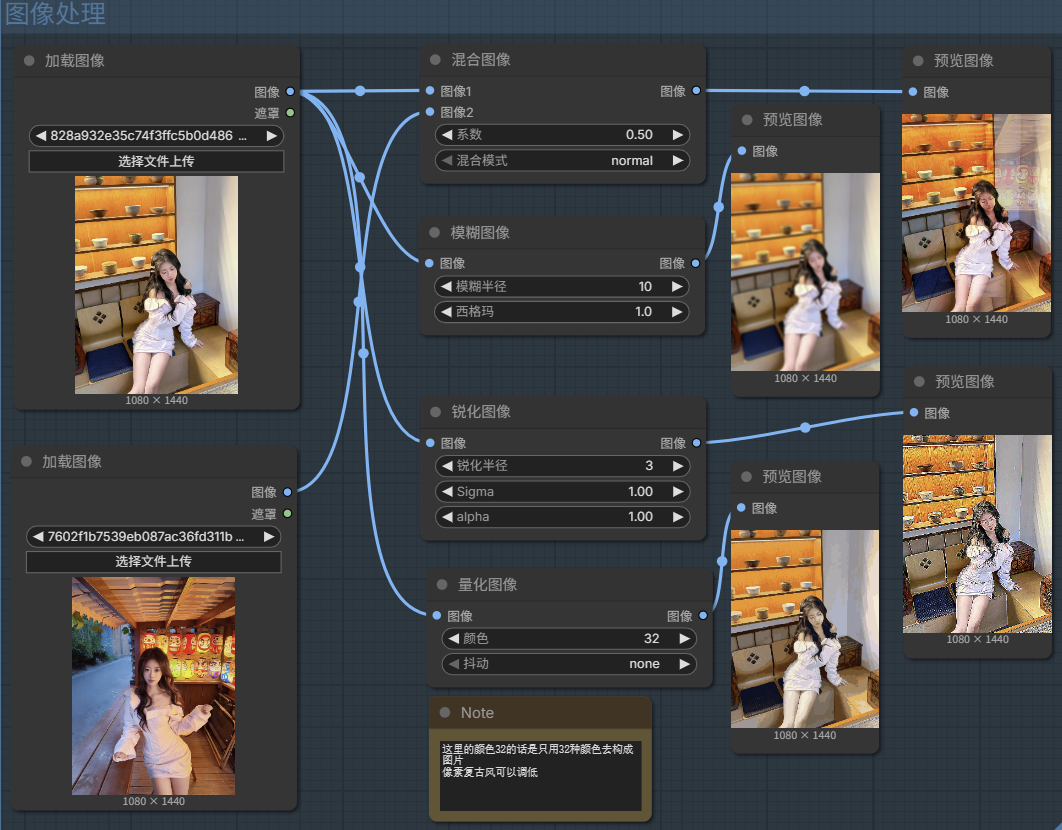
图像—处理
图像—批量
复制图像批次、重设图像批次、ImageFromBatch(这个是拿到某图像批次)
这里的原理跟上方的Latent是一样的
图像—预处理(Canny)
可以把图像变成噪点图像(捕捉图像边缘的Canny节点)!!!
图像—裁剪(图像裁剪)
图像裁剪 X,Y是进行移动位置
图像—动画(保存WEBP、保存APNG)
保存WEBP:把视频保存为适合网页播放的动画格式
保存APNG:把视频保存成一系列的动画序列帧
图像—加载图像
可以加载出图像
图像—空图像
空图像串入VAE编码,在空图像下方再拉出一个预览图像。那么K就会根据预览图像的基准生成
图像—反转
类似于冲洗相片→得到相片底片效果
图像—图像组合批次、图像遮罩复合
这里的原理跟上方的Latent是一样的
图像—预览图像
仅生成图像结果,不会在硬盘中保存
图像—保存图像
生成预览结果的同时,还会保存图片到对应文件夹
图像—外补画板
在图片扩充工作流里经常用的到
有上,下,左,右,羽化的参数;比如可以扩展图像左侧街道的画面 → 左 100
这里注意要对原来的图像进行扩充需要用到之前讲过的VAE内补编码器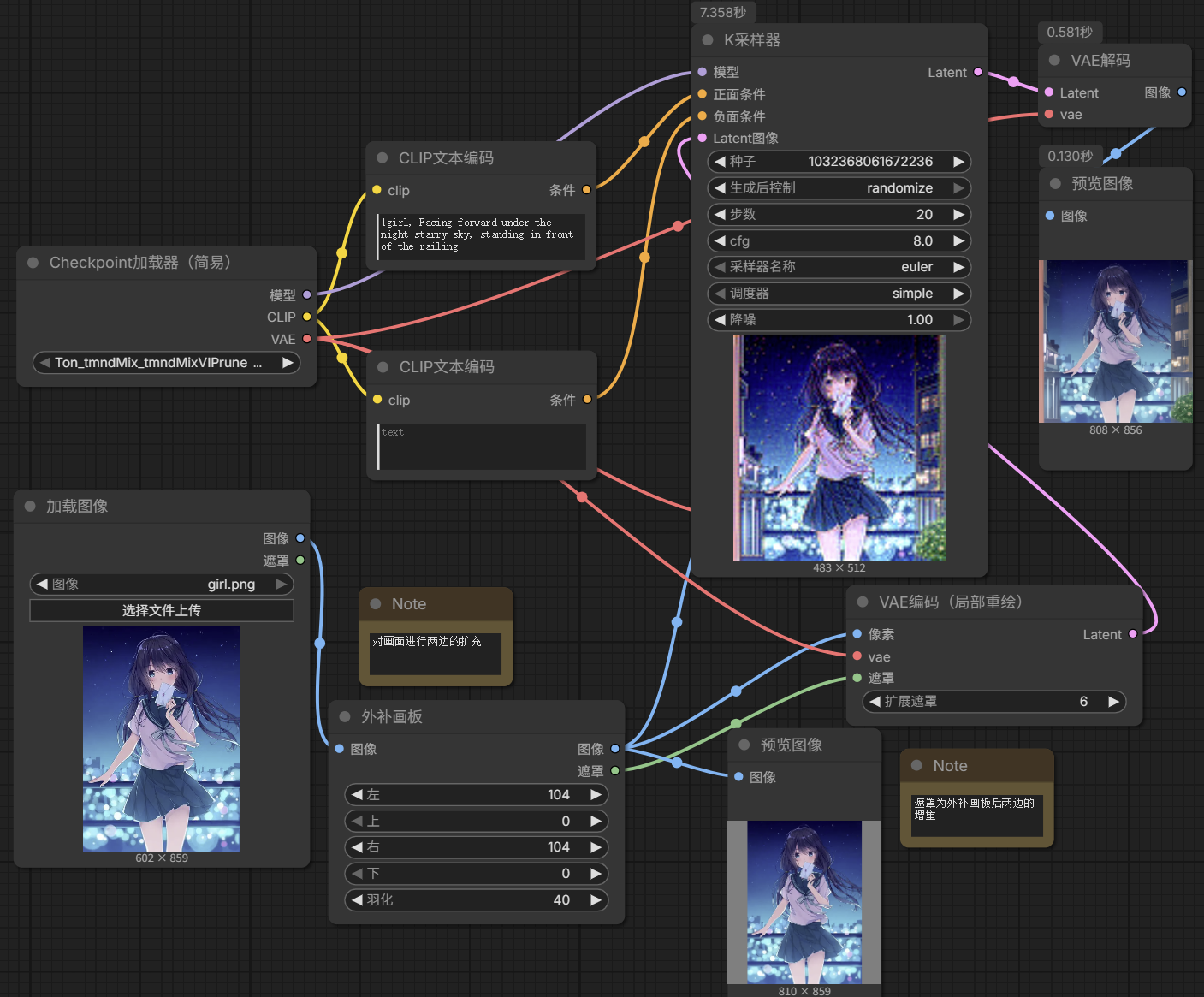
ComfyUI基础节点详解——采样器
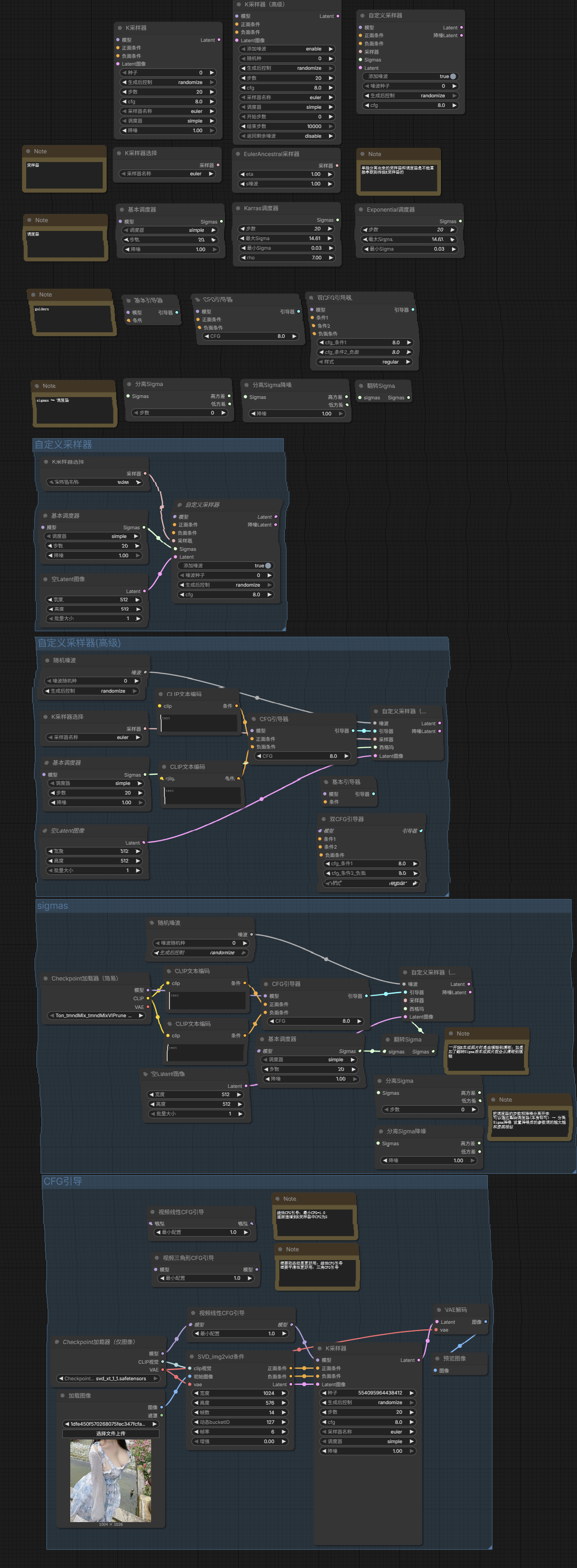
- **K采样器(高级)**:下面的开始、结束降噪步数专门是给
SDXL refiner使用的 - 自定义采样器:左边输入接口多出了采样器和Sigmas(调度器)
- K采样器选择
- 基础调度器
- 自定义采样器(高级)
- 随机噪波
- 基础引导器
- CFG引导器:CFG值越低,那么AI就会加入越多自己的想法【一般设置低一些(太低会带来画面动态闪烁)】
- 双CFG引导器
把这些参数一一单独划分出来的好处就是同样的参数,我们分配给多个采样器共用,对多个采样器进行同步控制,增加工作流的灵活性。
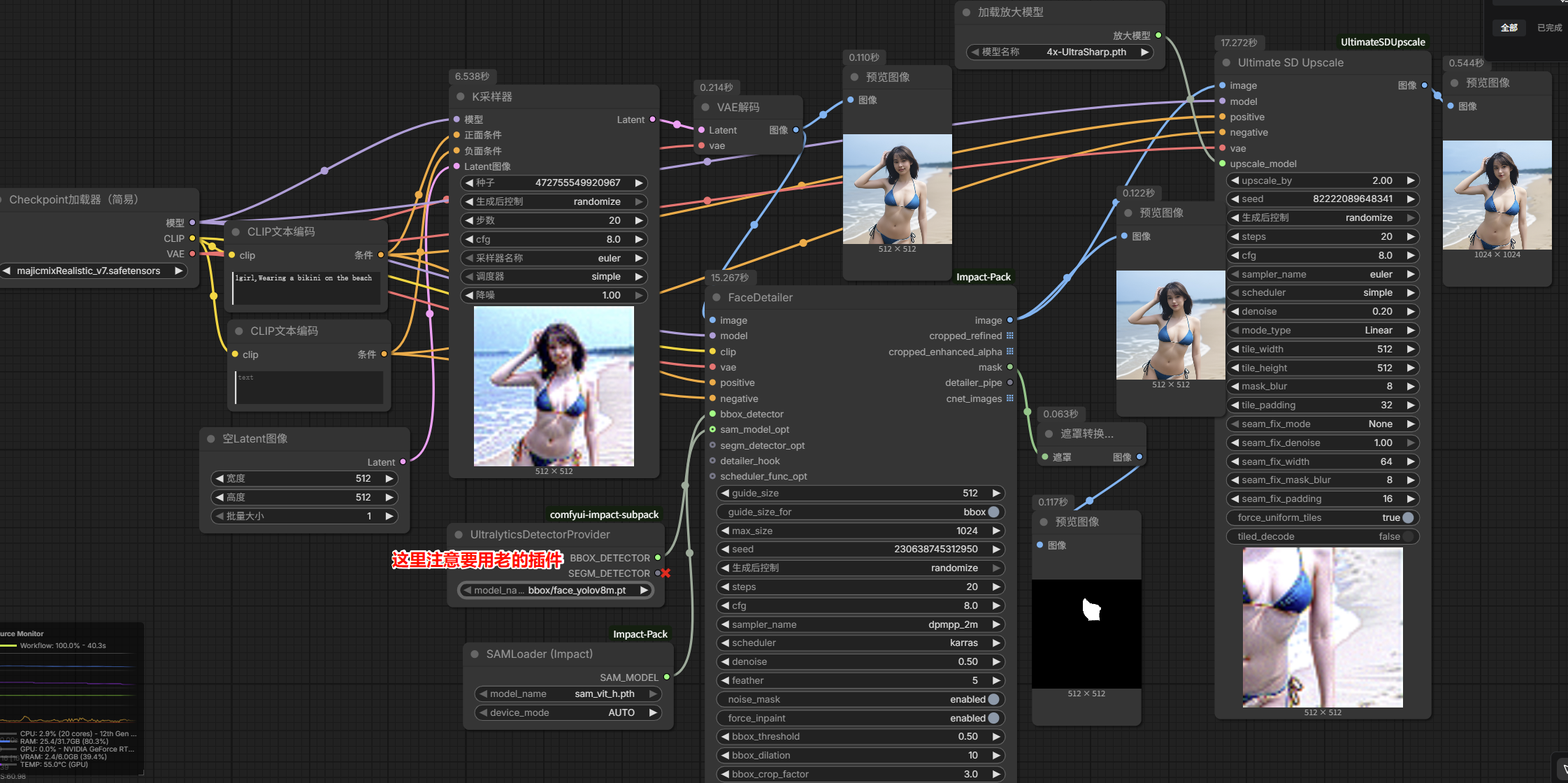
面部检测与面部修复技巧
右键 → 新建节点 → Impact节点 → 简易 → 面部细化(FaceDetailer)
这里有个大坑 新版要安装comfyui-impact-subpack插件,并用老的UltralyticsDetectorProvider
SUPIR智能修复高清放大
下载模型:SUPIR-v0Q.ckpt(适合大部分场景)、而SUPIR-v0f.ckpt(适合暗光场景) 这两个非常吃显卡资源,所以有平替SUPIR-v0Q_fp16.safetensors(容量降低一半的FP16半精度模型)
SUPIR是必须配对SDXL模型才有效果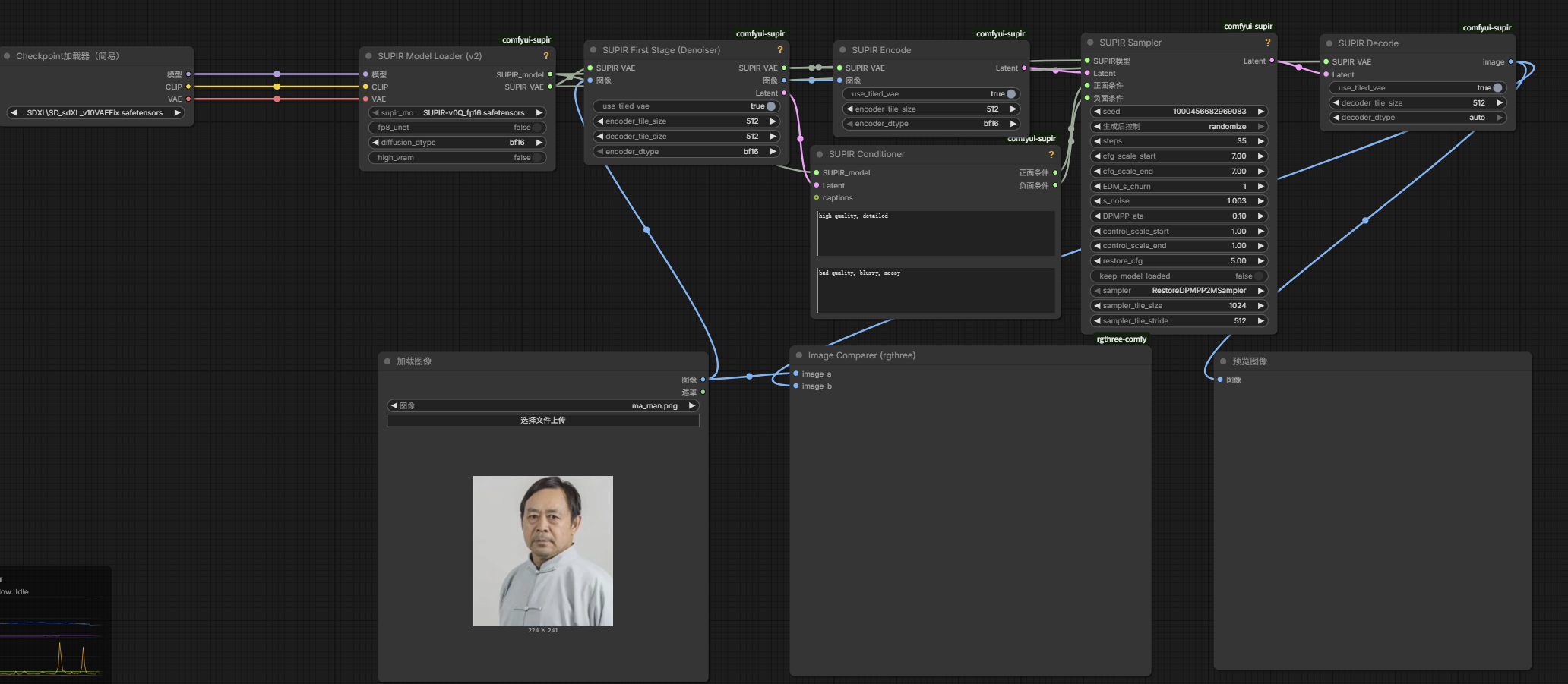
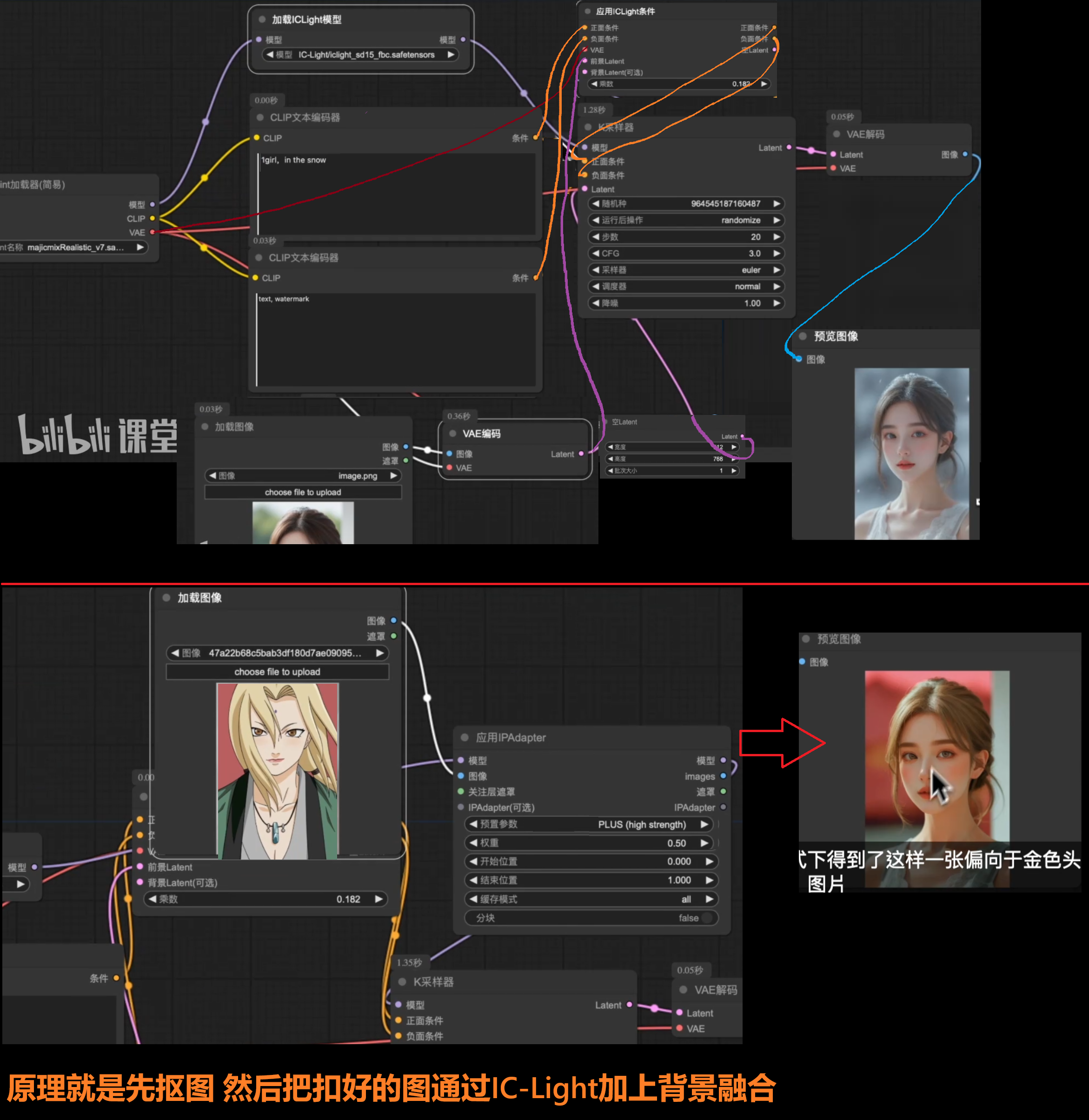
IC-Light智能自定义重打光
IC-Light + kjnode + video-Matting
下载iclight_sd15_fbc.safetensors放在xxx/models/unet/IC-Light文件夹里面
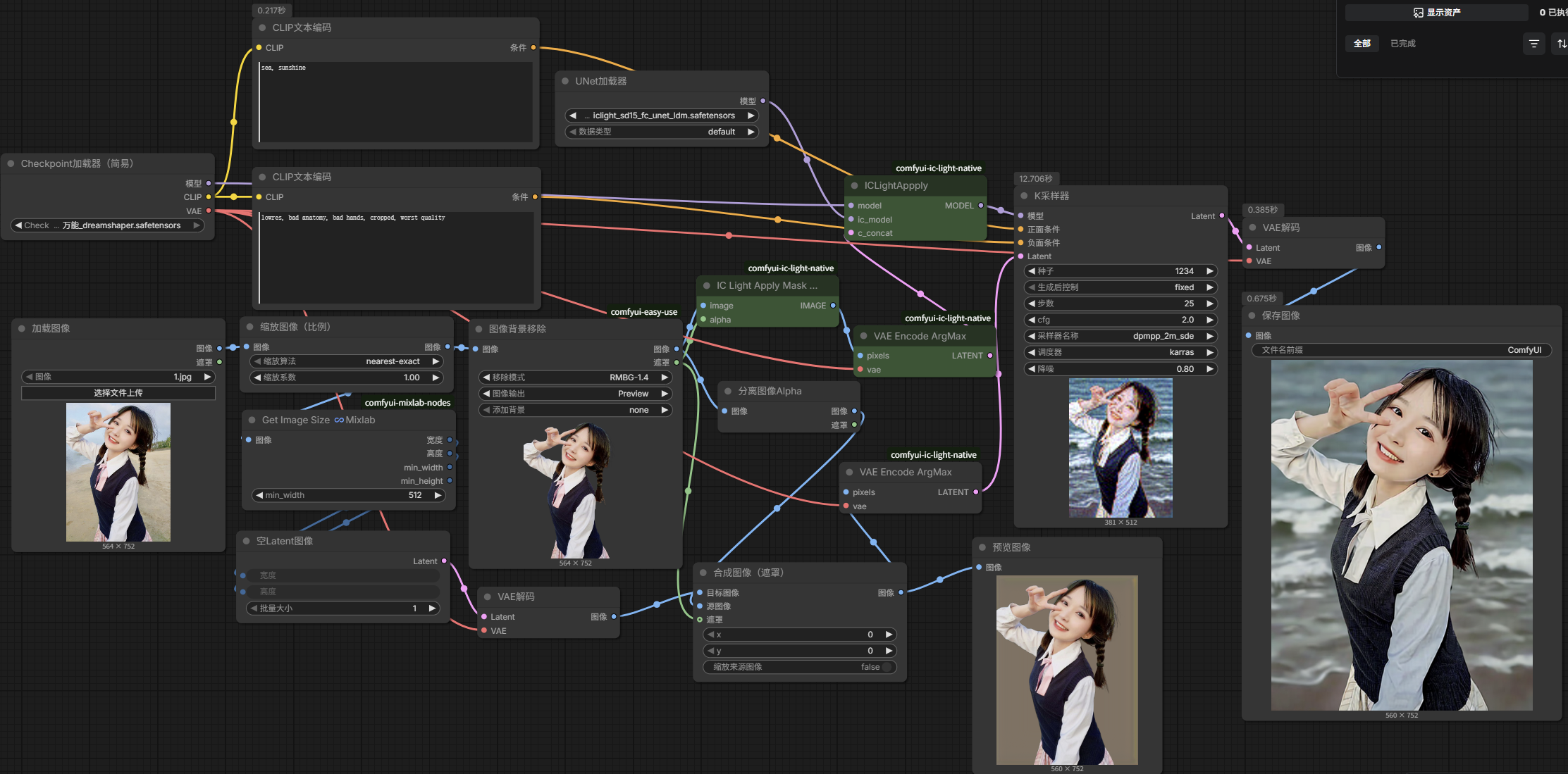
IC-Light-Native自定义背景融合打光
重映射图像范围Remap Image Range中的min 可以变小 就相相当于增加暗光的暗
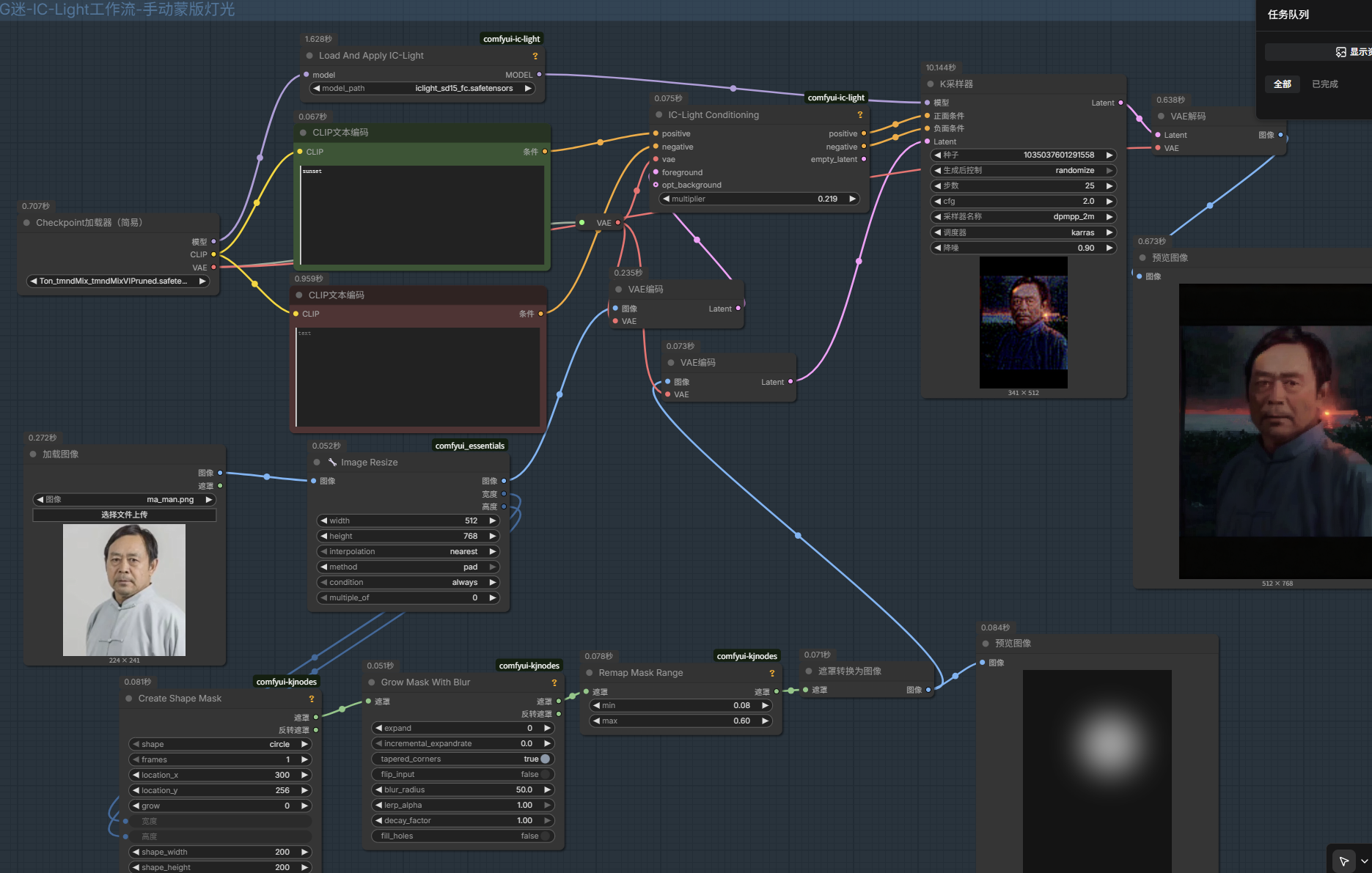
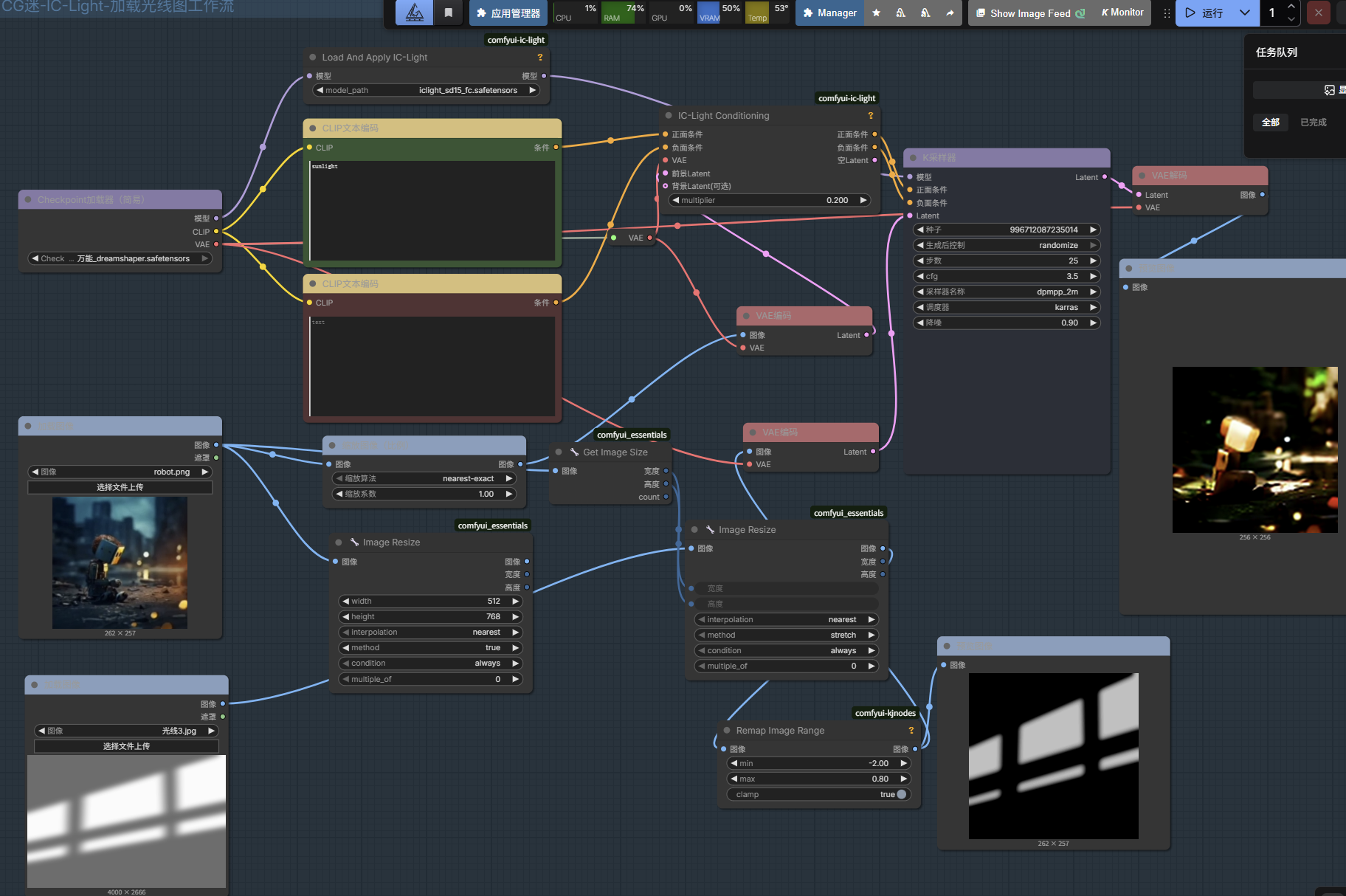
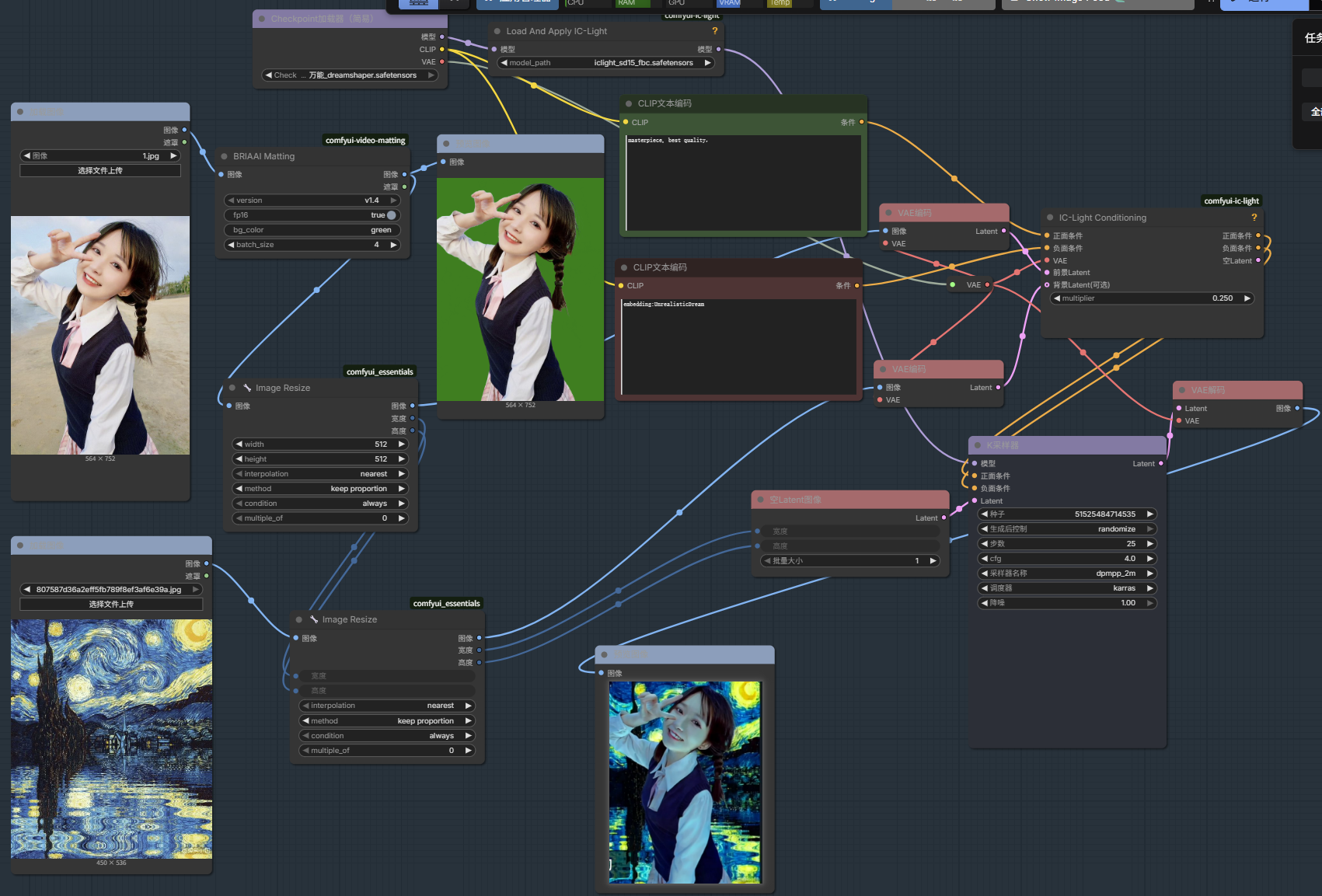
需要安装lc-light-native + layerdiffuse插件
把iclight_sd15_fbc_unet_ldm.safetensors和iclight_sd15_fc_unet_ldm.safetensors模型放到E:\ComfyUI-AI_DeskTop\ComfyUI-aki-v3\ComfyUI\models\unet中
节点自定义颜色美化与修改
下载一个组件Jovimetrix Composition Nodes 找一下旁边的调色板
新版IPadapter + FaceID使用方法
下载一个组件esay use + IPAdapter_plus
右键新建节点 → EasyUse → 模型适配器 → 有各种IPAdapter
高级一版本:
右键新建节点 → EasyUse → ipadapter → IPAdapter 创建一个Ipadapter应用
★ 初级 + 中级 + 高级 + 究极IPAdapter
.png)
新版IPadapter组合批次与嵌入组
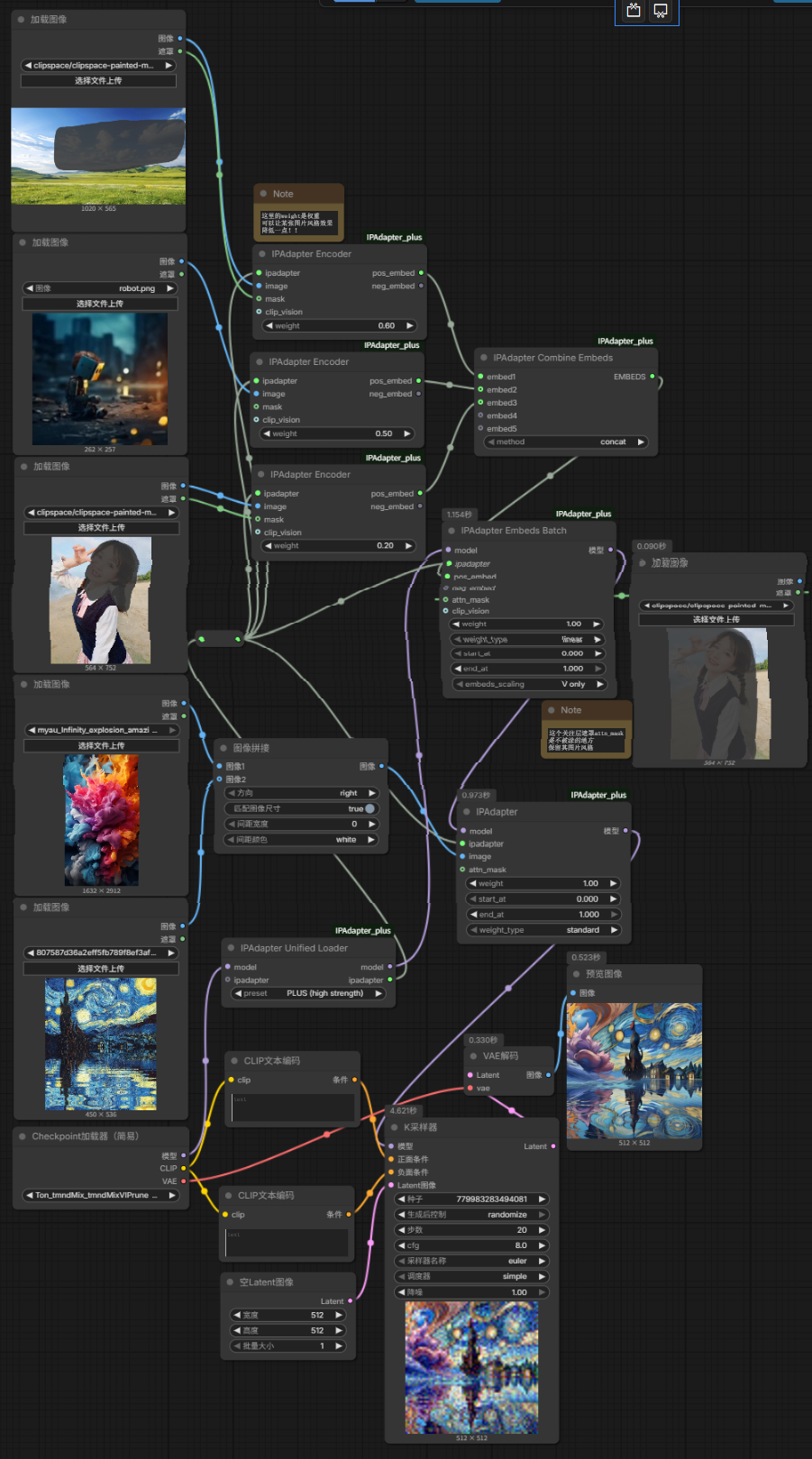
InstantID复刻人物样貌、姿势、角度
可以配合IPAdapter一起使用
专门对SDXL模型的
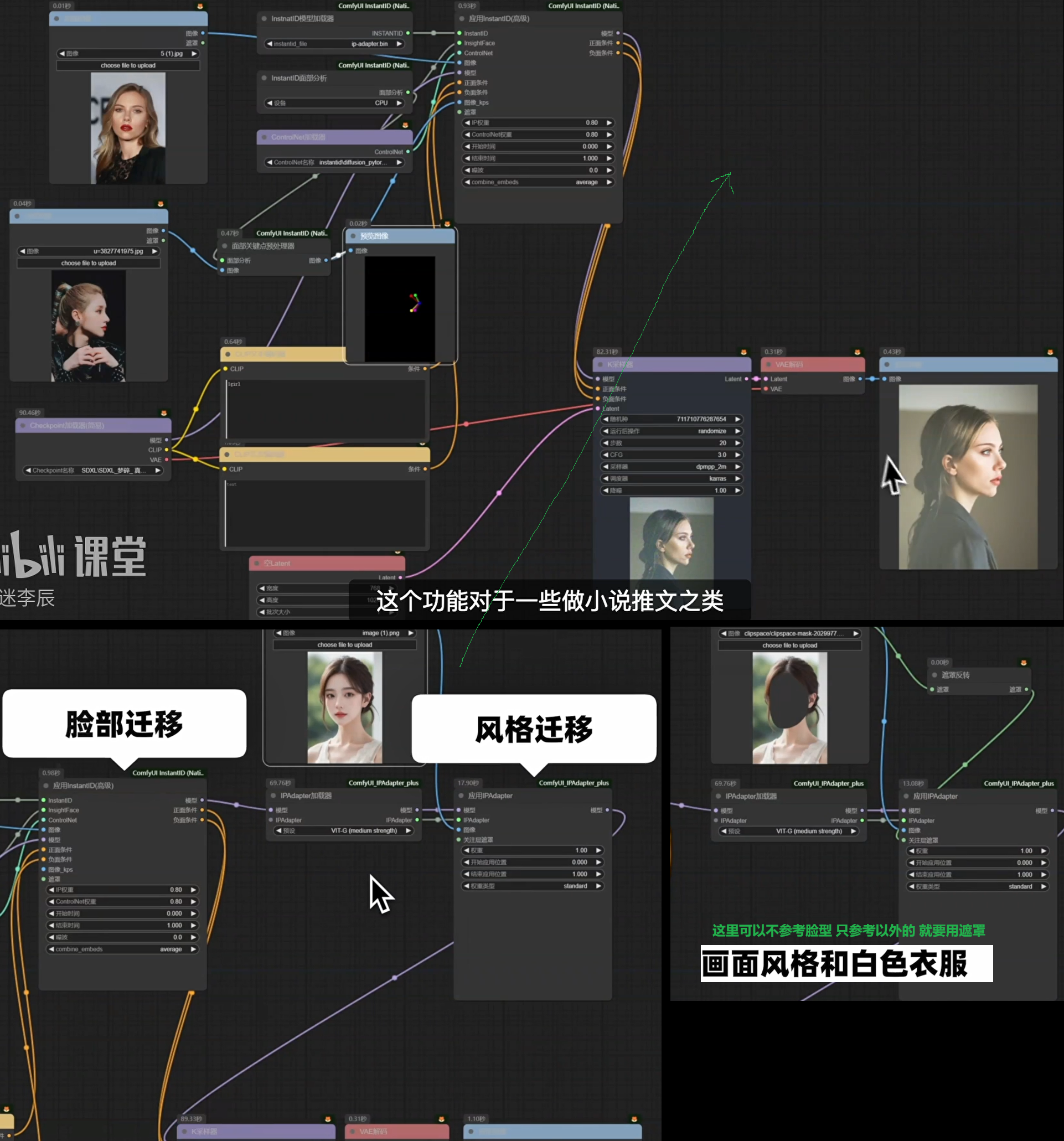
LCM lora与实时绘画
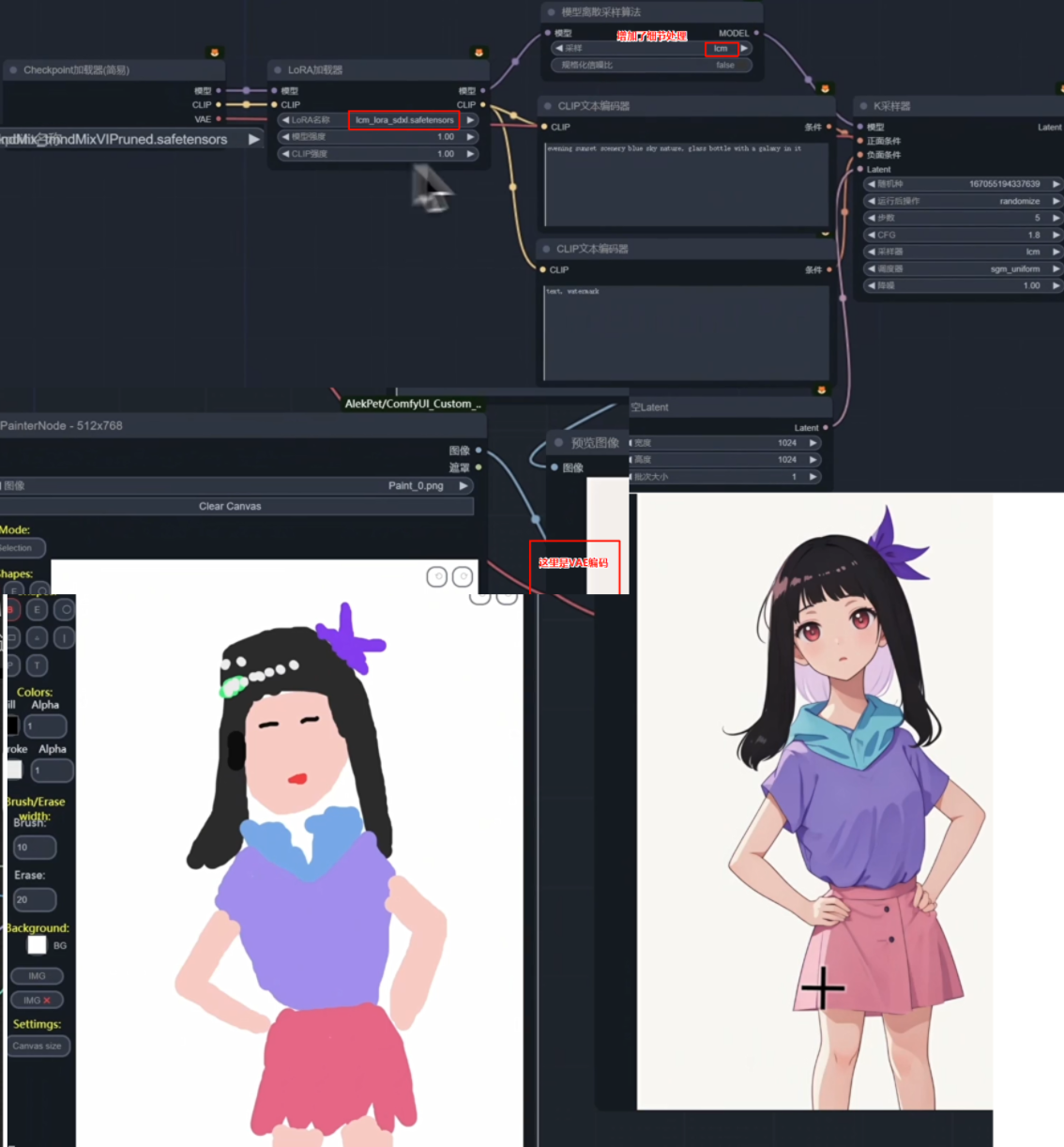
SDXL-Turbo出图速度测试
FLUX 七种模型 全方位讲解
FLUX模型优势
- 画质极佳
- 改进修手
- 字体生成与排版
- 训练参数大,风格多样
- 分辨率弹性好
- embeddings通用性好
- 不需要输入负面提示词
FLUX 7类模型
- PRO(仅API调用)
- DEV FP16(至少4090显卡)
- DEV FP8
- schnell FP6
- schnell FP8
- GGUF
需要安装插件 - NF4
需要安装插件
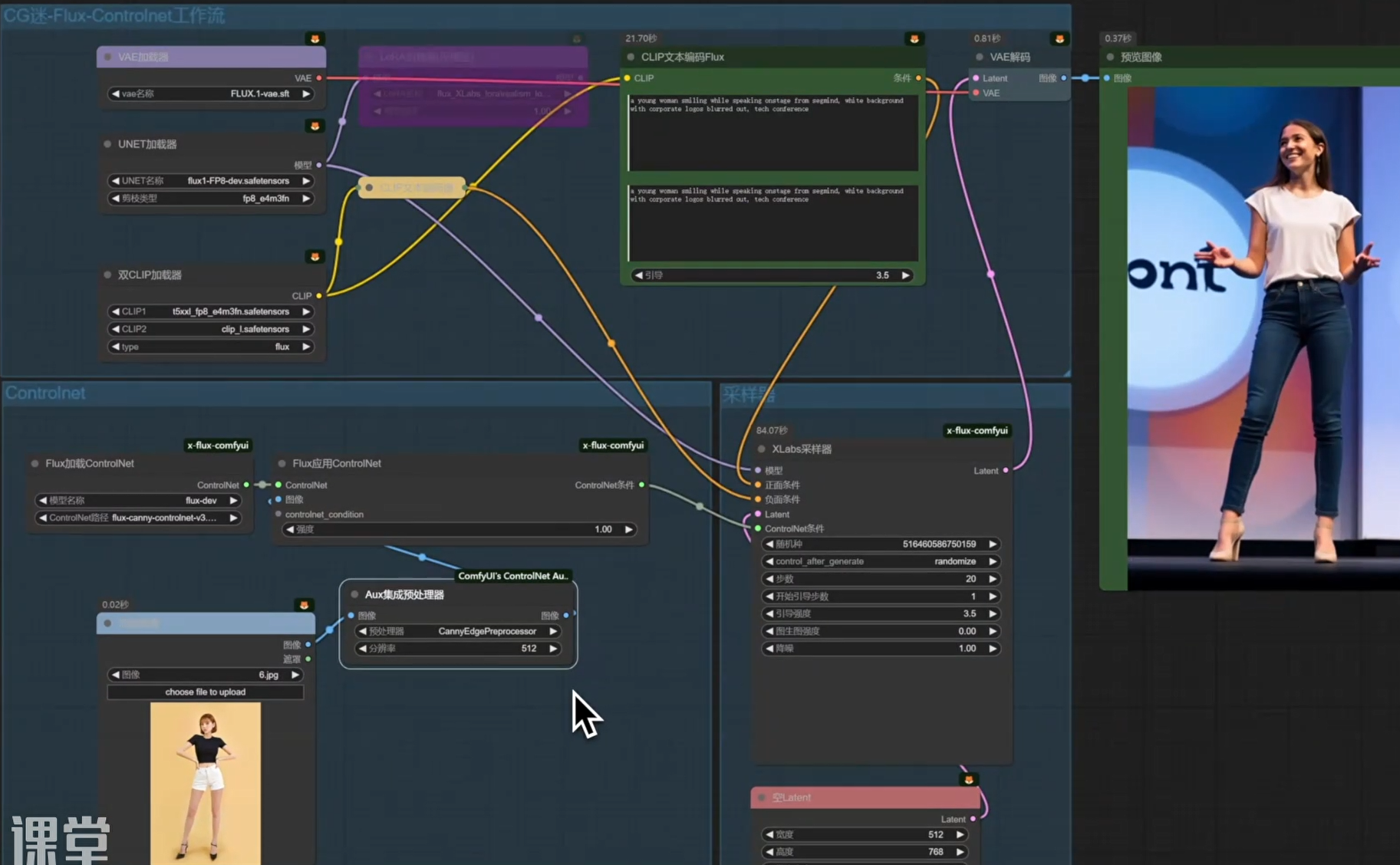
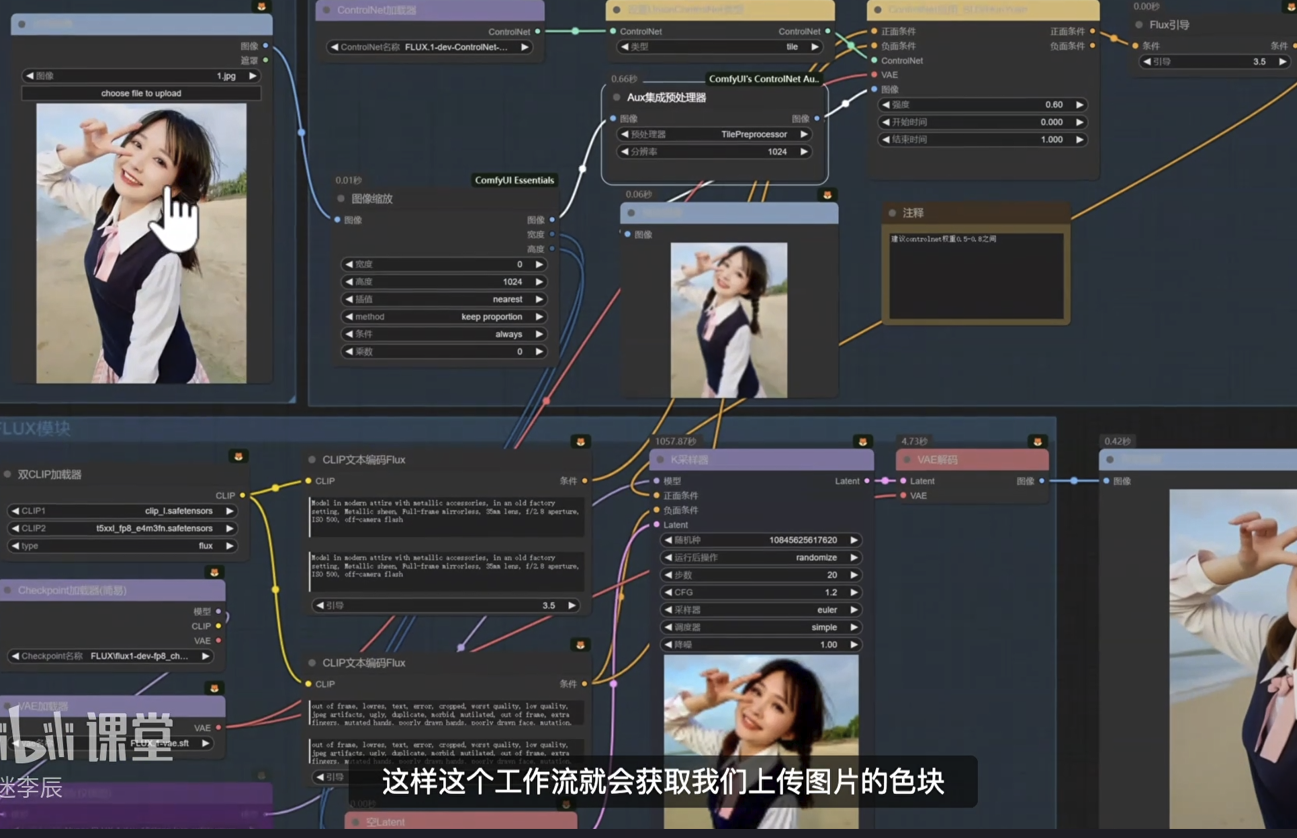
Flux全生态Controlnet工作流
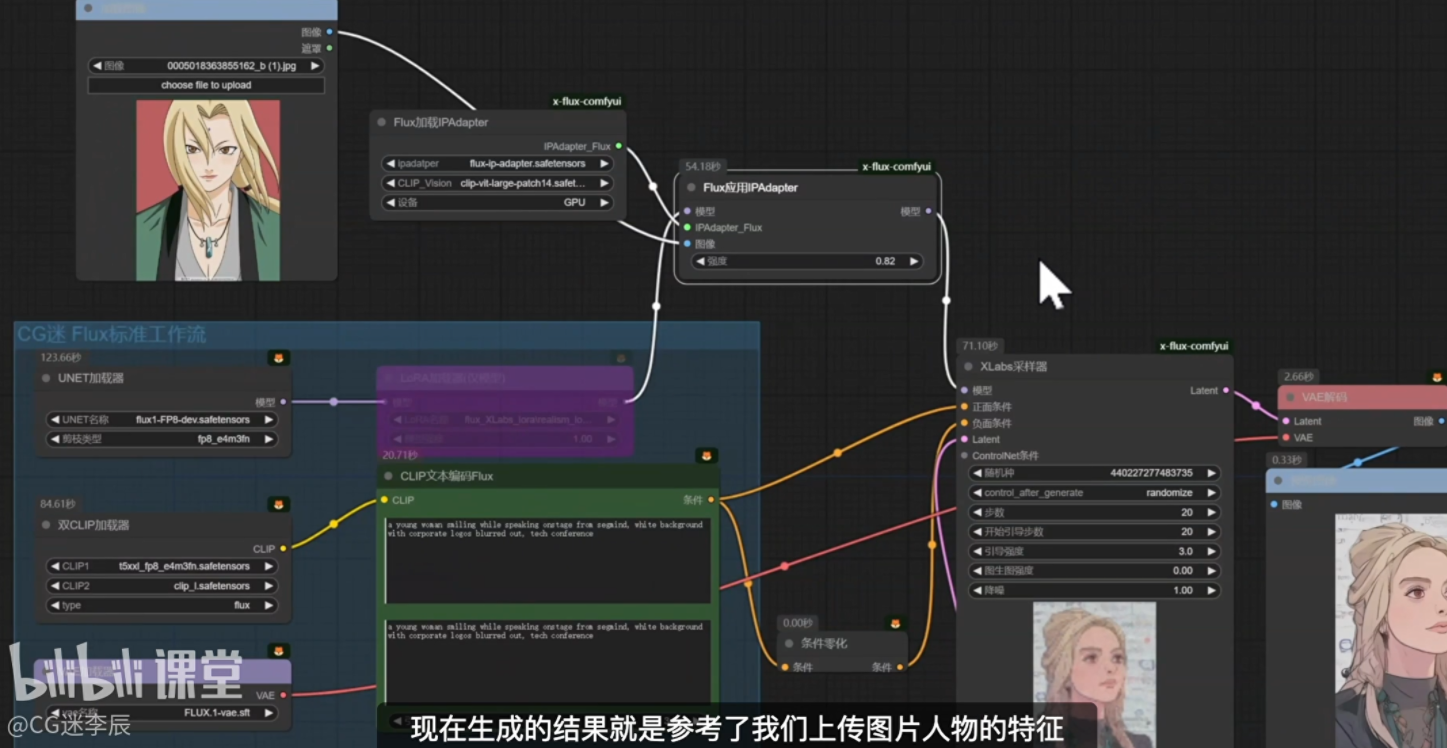
Flux模型IP-adapter工作流
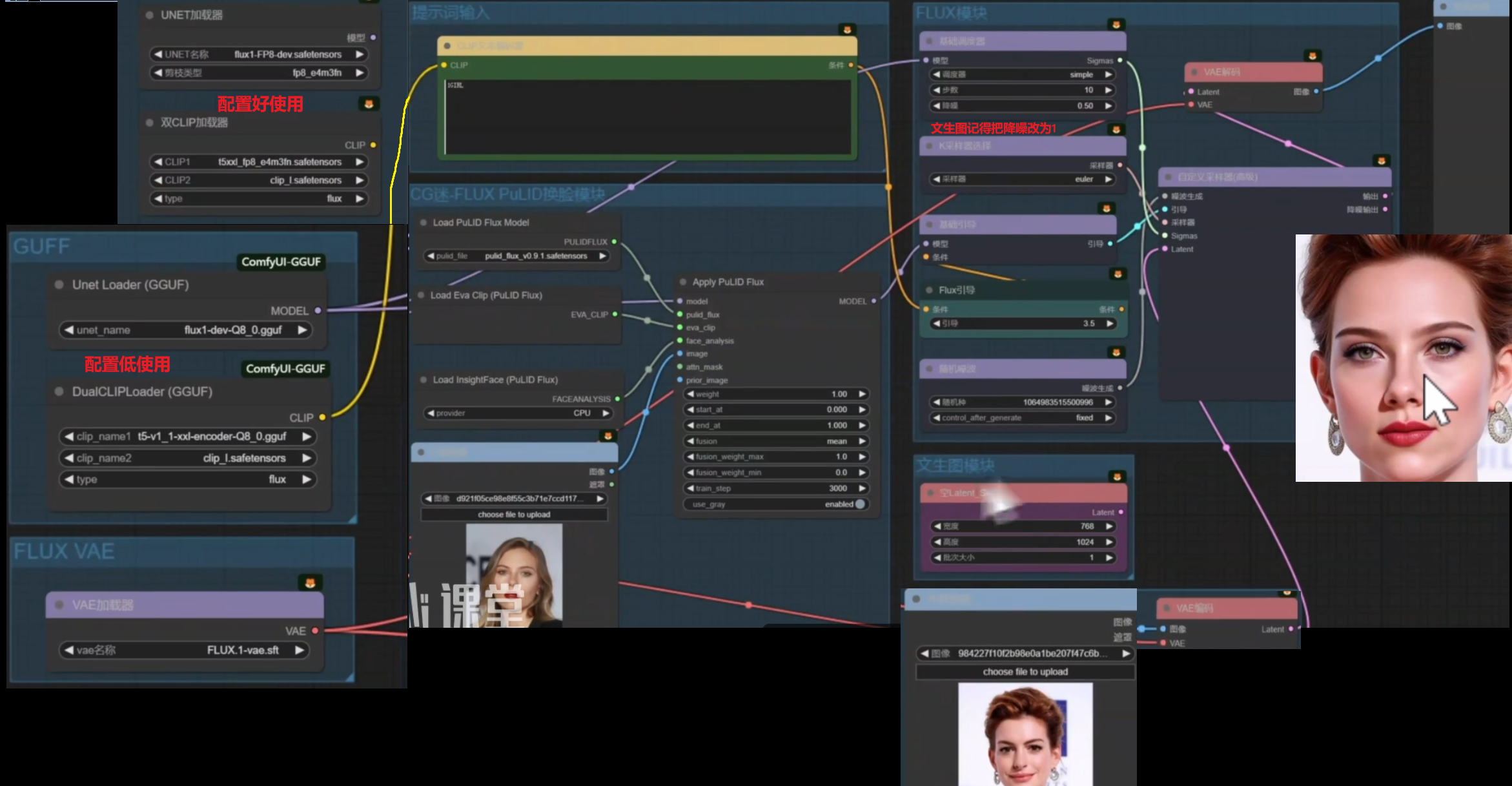
FLUX工作流要使用ip-adapter的话需要安装专门的插件x-flux-comfyui
由于FLUX不需要负面提示词 可以用条件雾化去给它的负面提示词归零
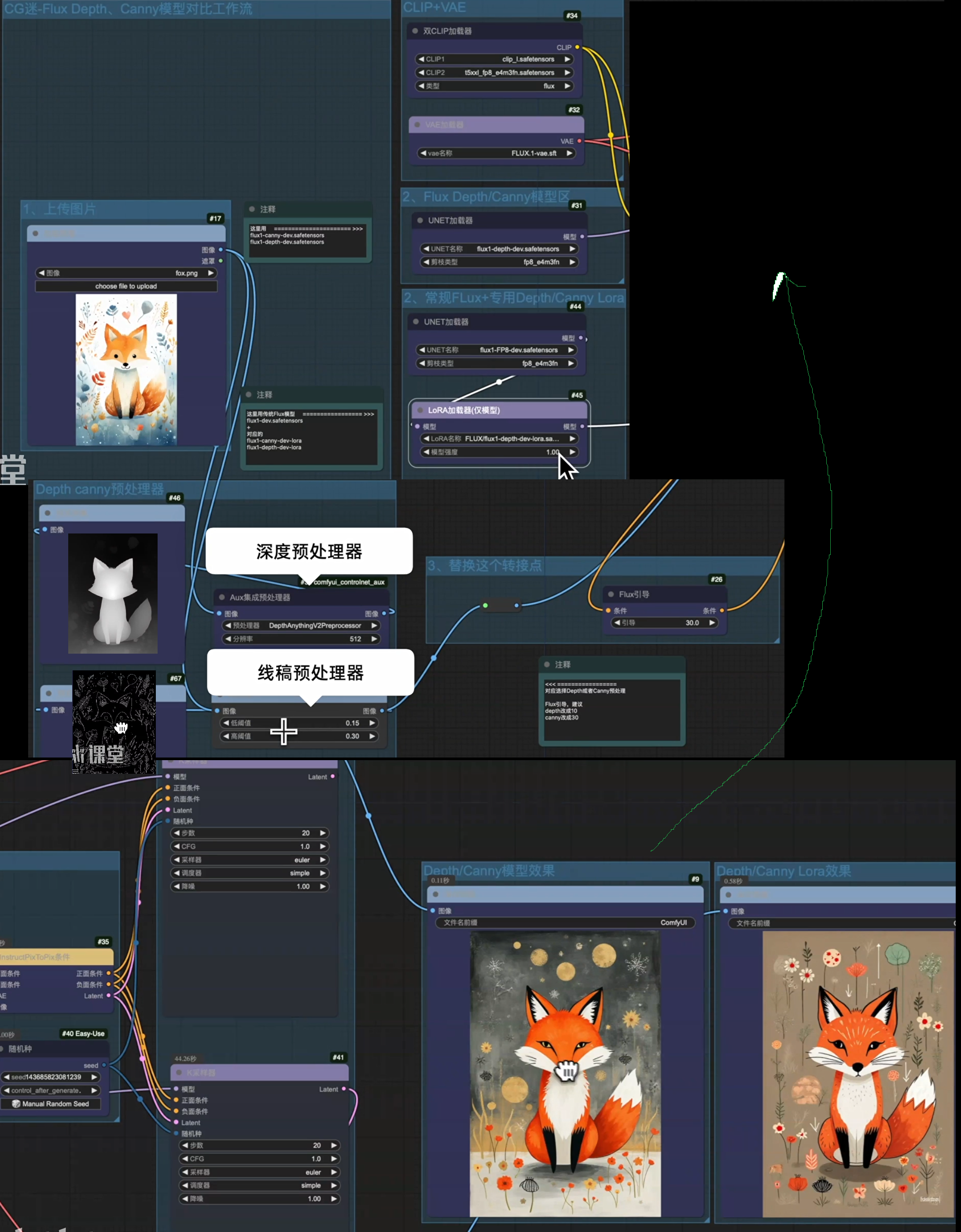
Flux Tools 4款全新模型解析24G、4090也可能爆显存
Canny
- 大模型:flux1-canny-dev(内嵌线稿)
- Lora:flux1-canny-Lora
Depth
- 大模型:flux1-depth-dev(内嵌深度)
- Lora:flux1-depth-Lora
Fill
- 大模型:flux1-fill-dev (内嵌inpaint)
- 局部重绘和扩展
Redux
- 风格模型:flux1-redux-dev
- ip-adapter风格迁移作用
Flux Canny、Depth、Fill模型放置到:ComfyUI\models\diffusion_models\里面
Canny、Depth lora模型放置到:ComfyU\models\loras\里面
Redux模型放置到:ComfyUl\models\style_models\里面
sigclip_vision模型放置到:ComfyUl\models\clip_vision\里面
**CFG(Classifier-Free Guidance)**:主要是控制提示词的听话程度;CFG数值越低,AI就越多自己的想法
FLUX Tools Canny和Depth
FLUX Tools Redux风格迁移与工作流优化 这个在Flux Tools 4款全新模型教程里有,将两个图片的风格场景融合到一起
训练Flux 超高效Flux Gym
ComfyUI进行打标工作流 可对图片素材进行打标,打标完毕后再导入Flux训练工作流
Kohya-ss训练脚本
秋叶训练器
FluxGym
需要代码从GitHub下载;需要先下载pinokio客户端
可以用智灵SPIRIT可以租显卡
一键裁剪素材birme.ne
SD3.5与FLUX出图效果
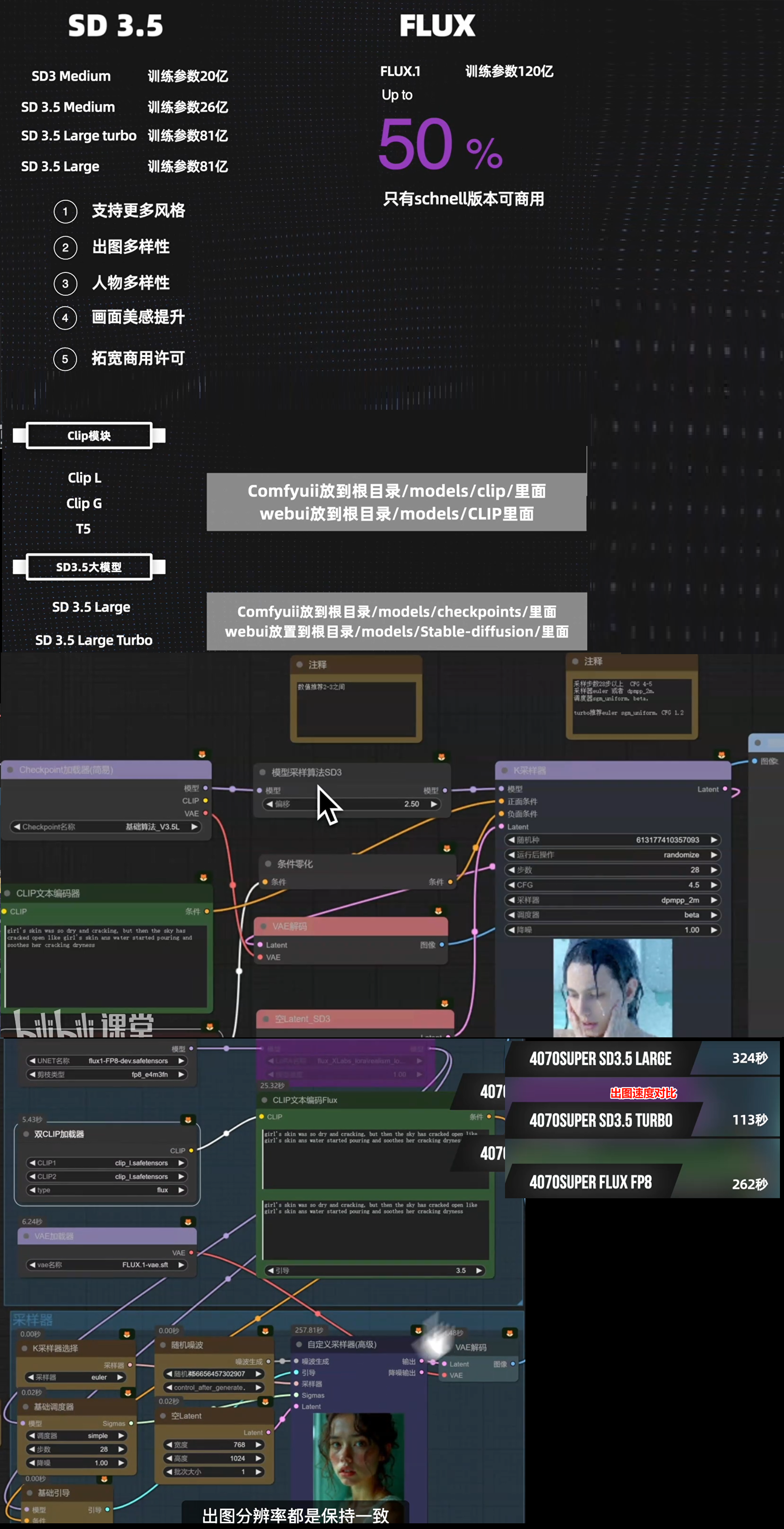
alibaba—FLUX.1-Turbo
要去这里alimama-creative/FLUX.1-Turbo-Alpha
下载模型:alimama-creative/FLUX.1-Turbo-Alpha
放置到ComfyUi\models\loras里面
指定遮罩区域控制画面内容生成
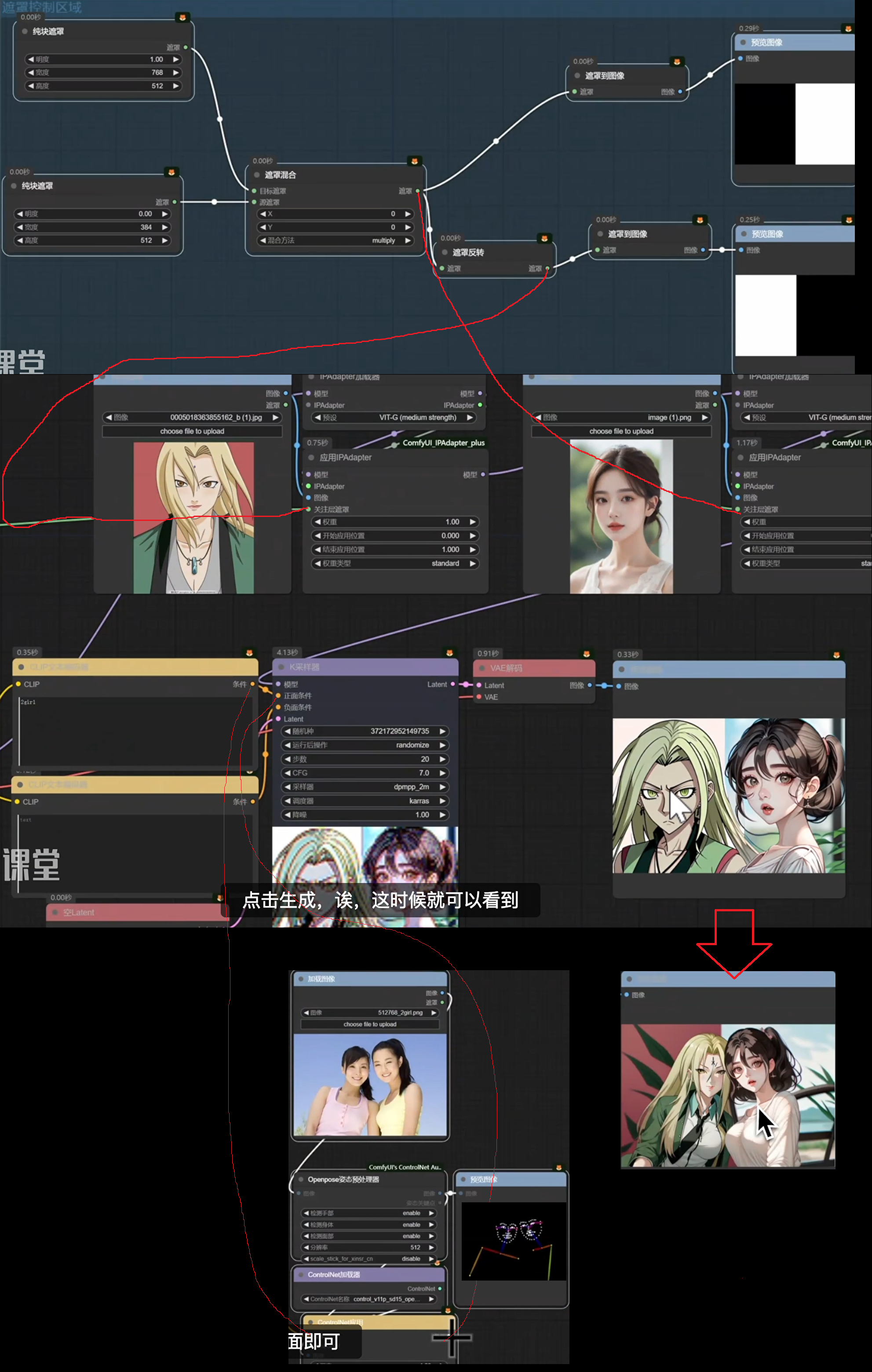
区域采样器 指定画面局部内容生成
ComfyUI Impact Pack插件
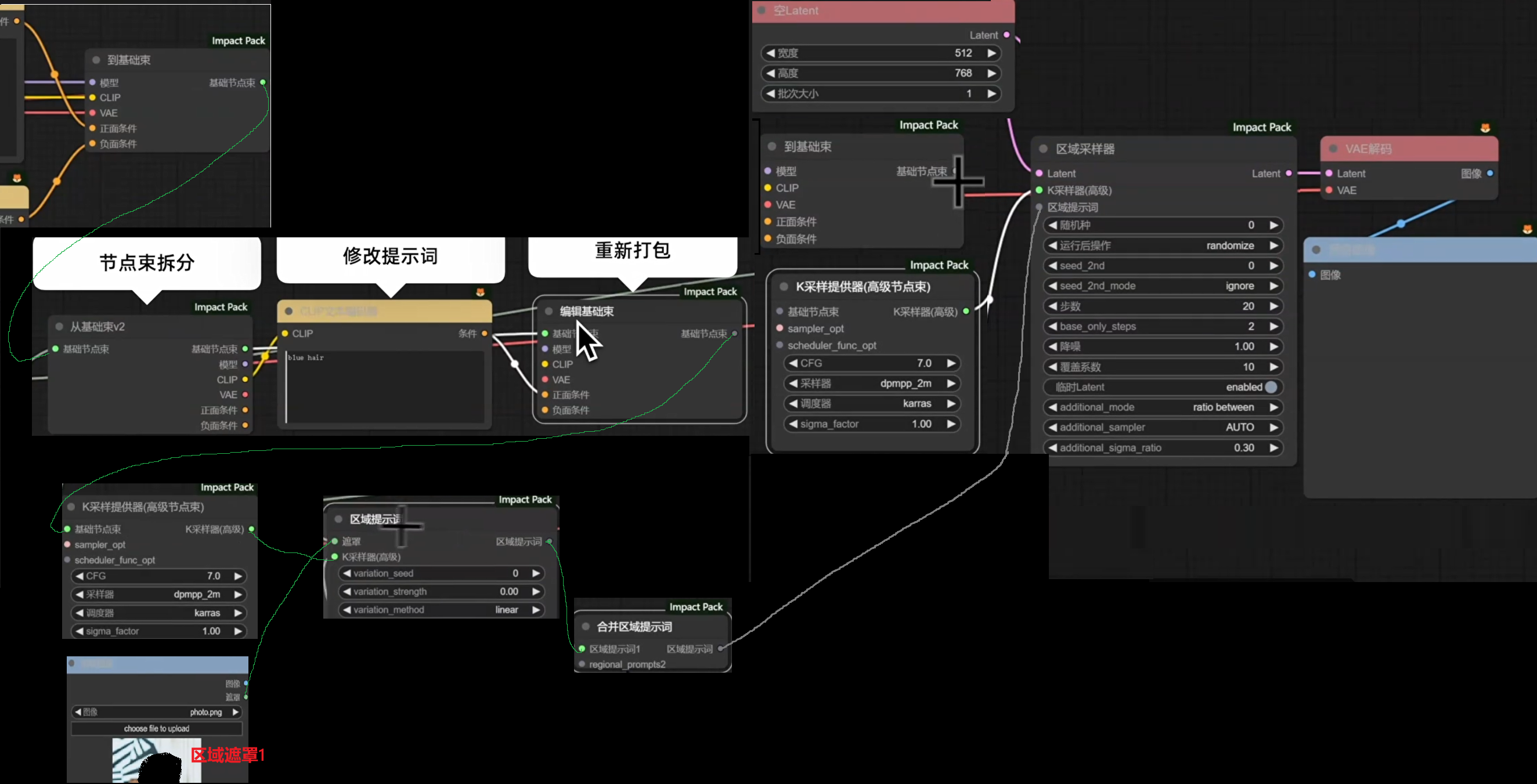
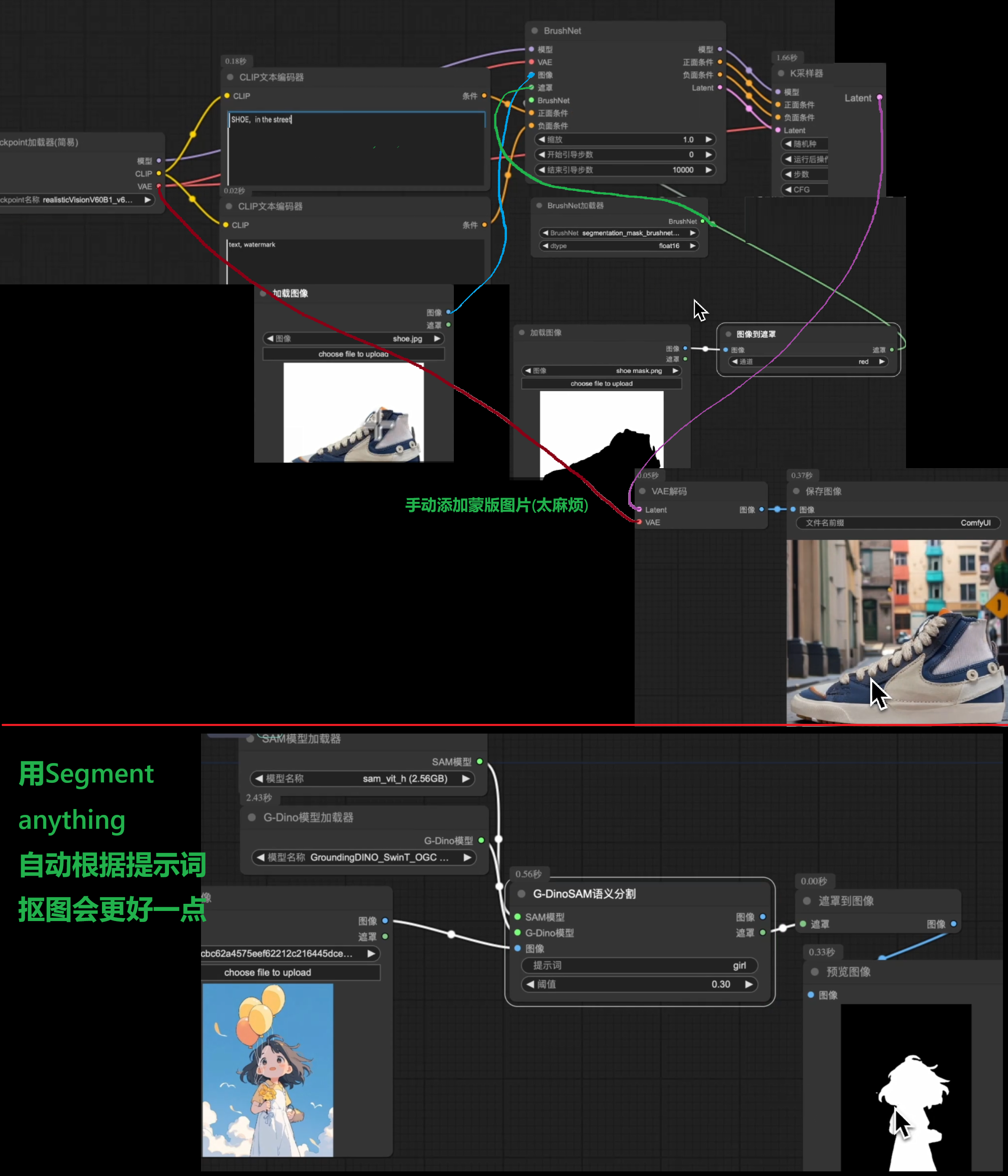
BrushNet + 语义分割局部重绘
BrushNet需要特定的模型segmentation_mask_brushnet...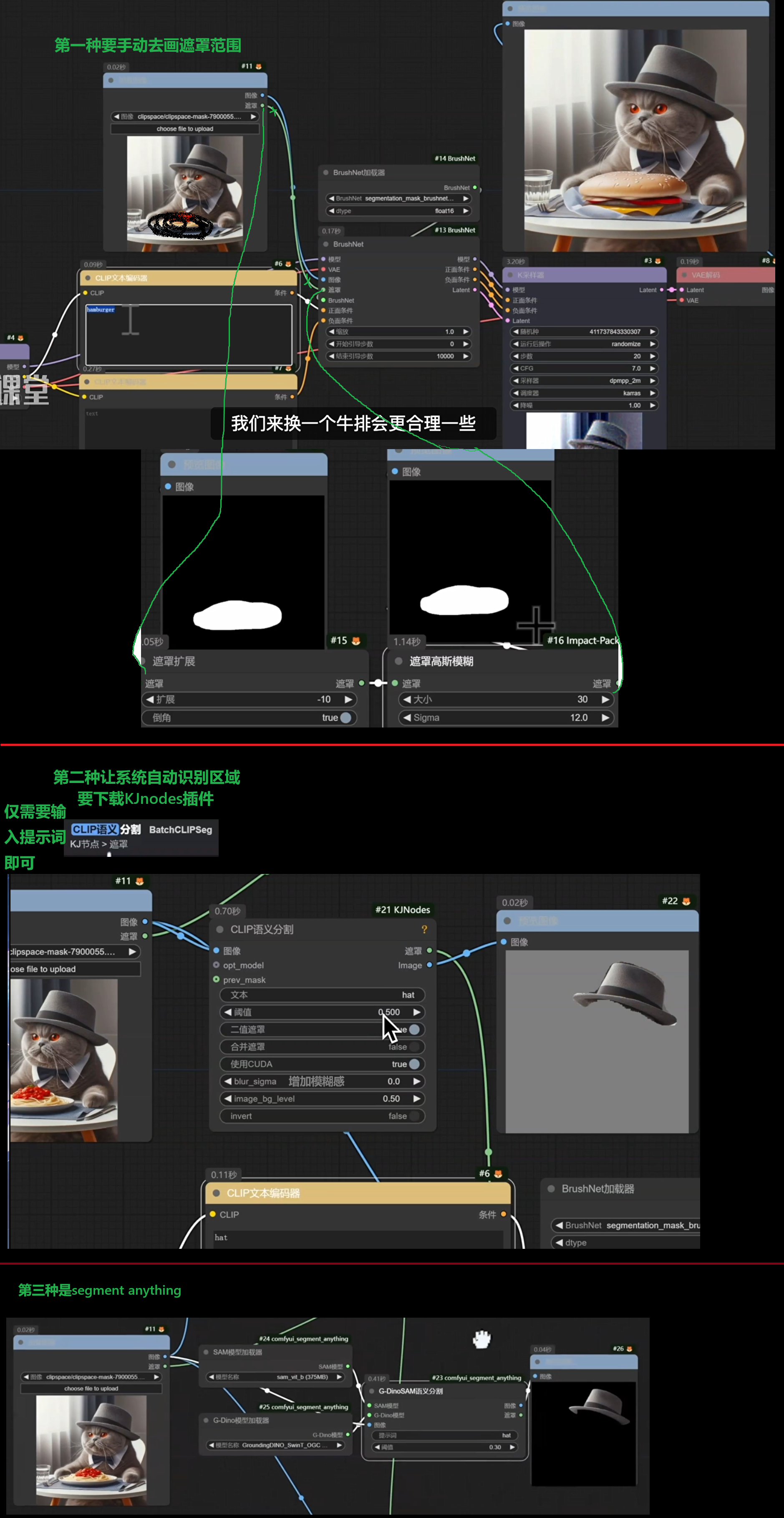
Florence 2提示词反推与区域视觉识别
主要是用到Segment-anything里面的sam模型
下载插件ComfyUI-Florence2(kijai)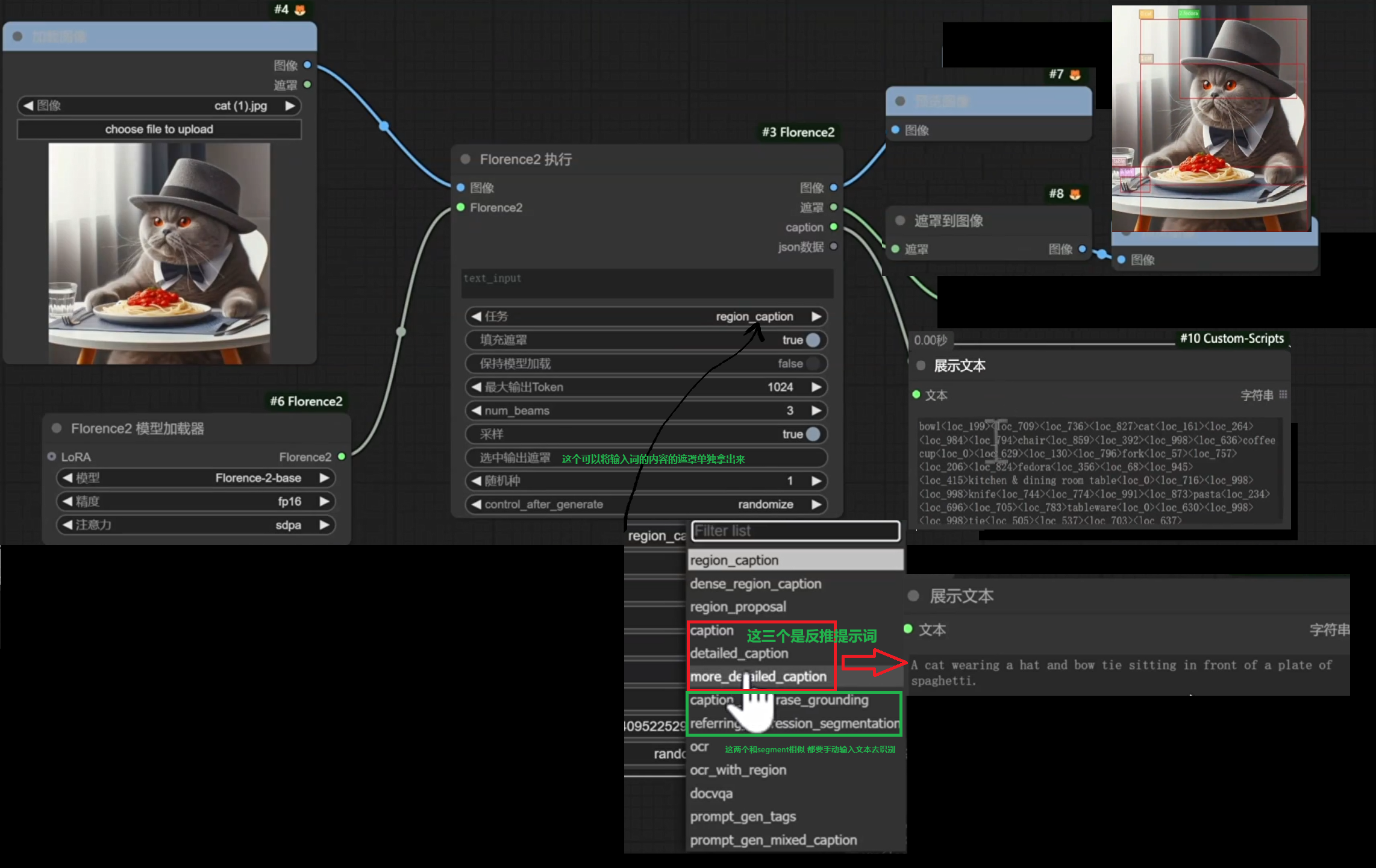
segment anything V2与曲线编辑器
背景:对于某些特定区域语义识别很难(细小物品)
下载插件segment-anything-2
★ 增加曲线节点需要按住Shift不放 再点击插入图片后的空白区域 即可新建一个节点
★ 点击鼠标右键即可删除某个节点!!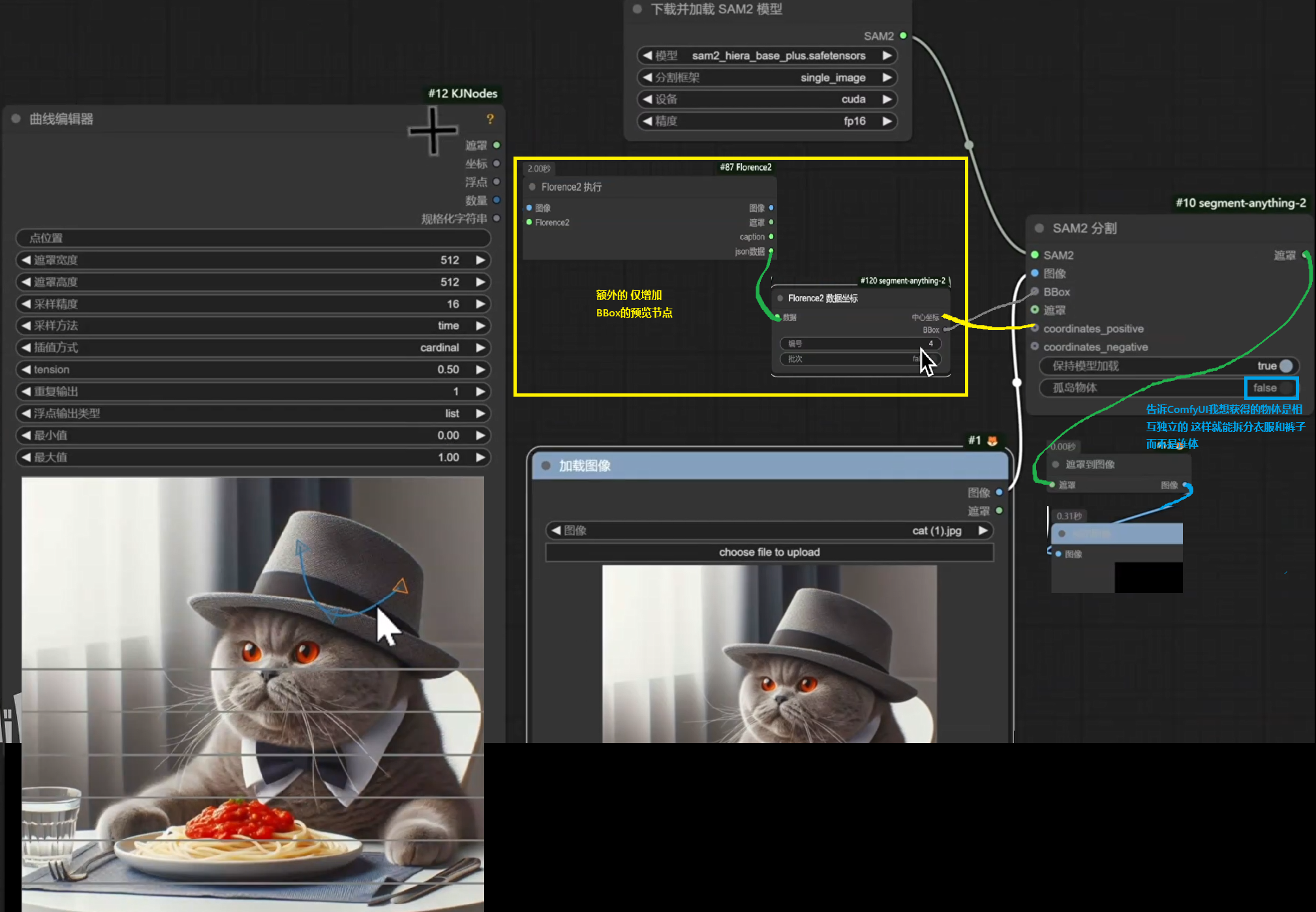
SVD视频工作流(Stable Video Diffusion)
安装ComfyUl-VideoHelperSuite插件 就可以选择很多保存视频的格式了.png)
LTX-Video高效快速生成视频模型
文生视频
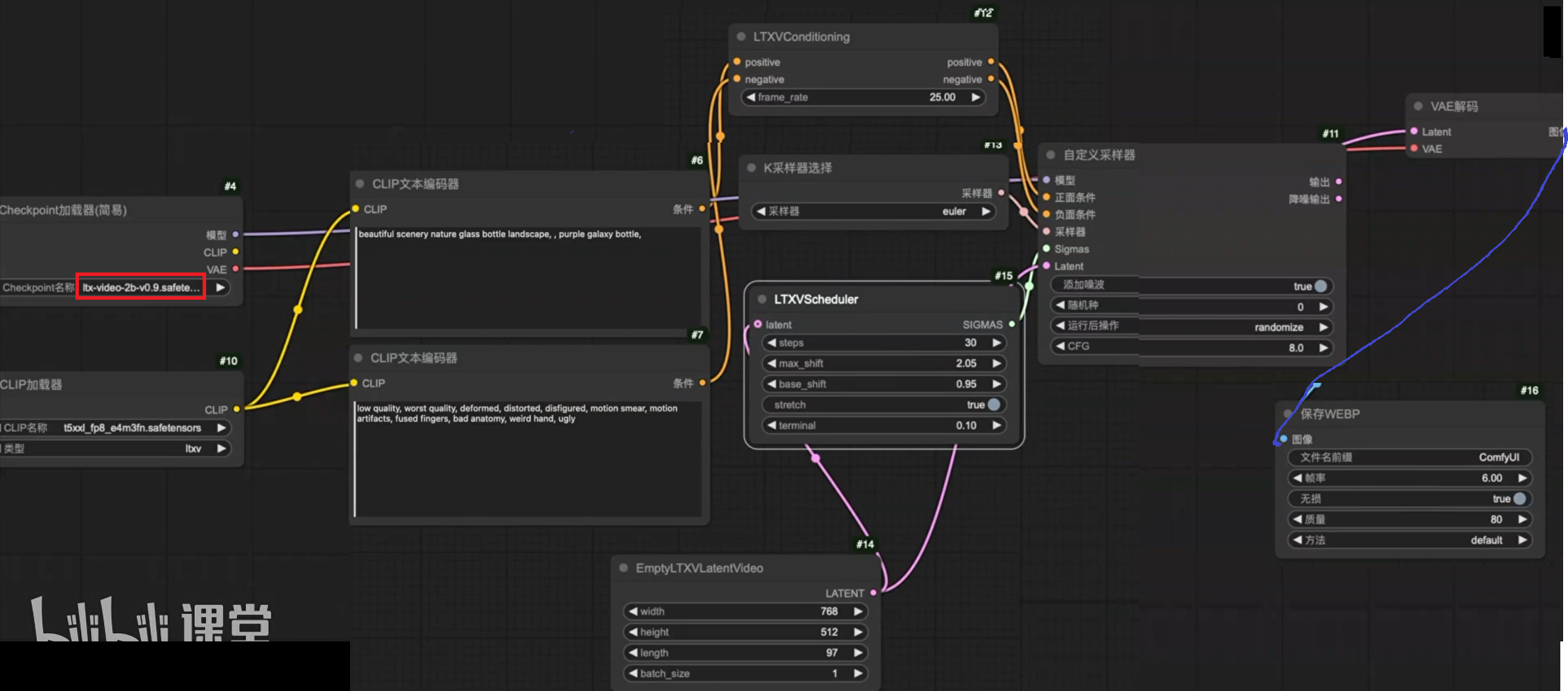
如果想保存视频,下载插件VideoHelperSuite → 合并为视频
图生视频
.png)
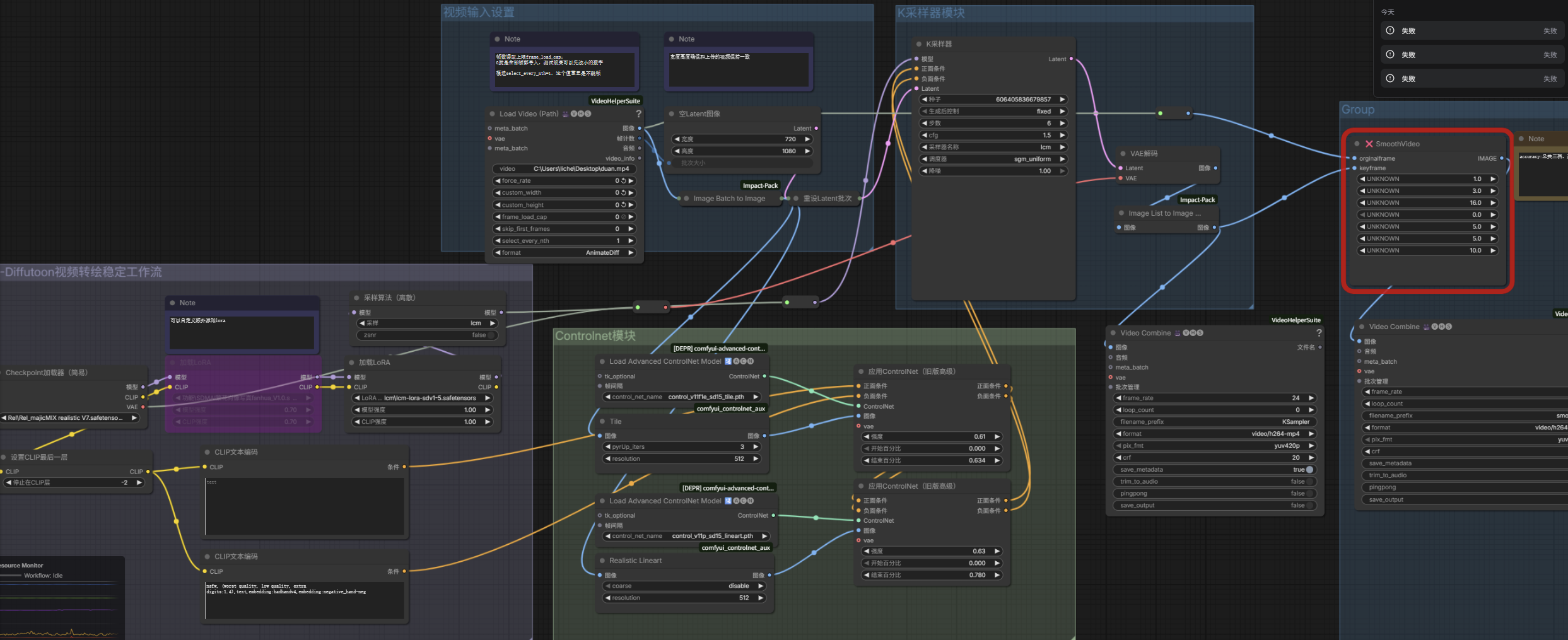
丝滑动画转绘 Diffutoon视频工作流
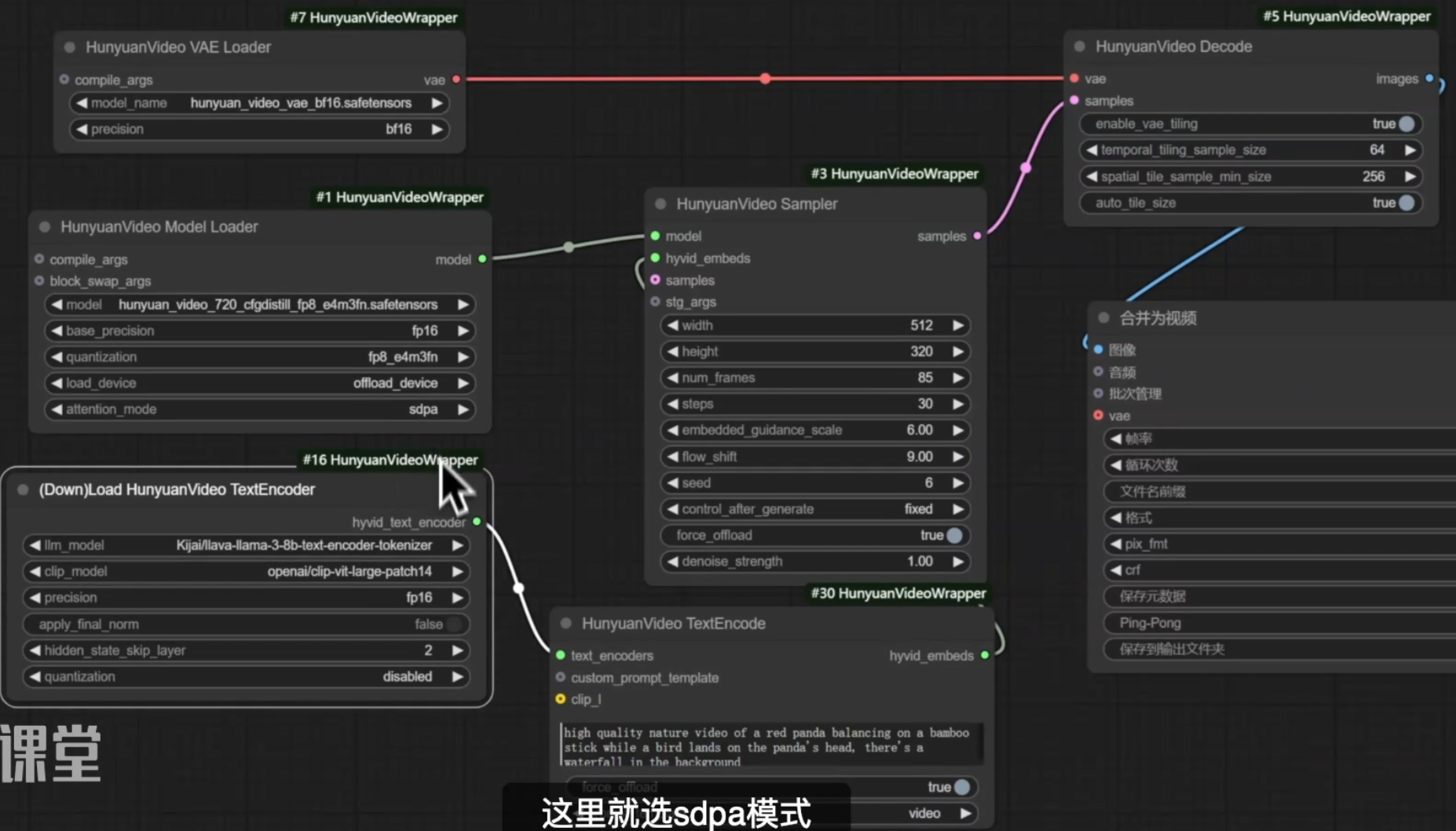
腾讯混元HumyuanVideo开源视频模型
[腾讯混元] (https://hunyuan.tencent.com/)
ComfyUI需要安装HunyuanVideoWrapper插件
提前需要环境要求:(4090+)
1、腾讯混元视频Python环境要求3.11或以上的版本(秋叶的启动器comfyui是3.10),所以推荐用comfyui官方版本,不然整个过程会破坏原本秋叶整合包的环境,切记!
2、需要安装torch+cuda
3、需要安装visual studio
4、配置win环境
5、配置模型
- hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors放置到comfyui目录models的diffusion_models里面
- clip-vit-large-patch14整个文件夹放置到comfyui目录models的clip里面
- llava-llama-3-8b-text-encoder-tokenizer整个文件夹放置到comfyui目录models的LLM面
- hunyuan_video_vae_bf16.safetensors放置到comfyui目录models的vae里面
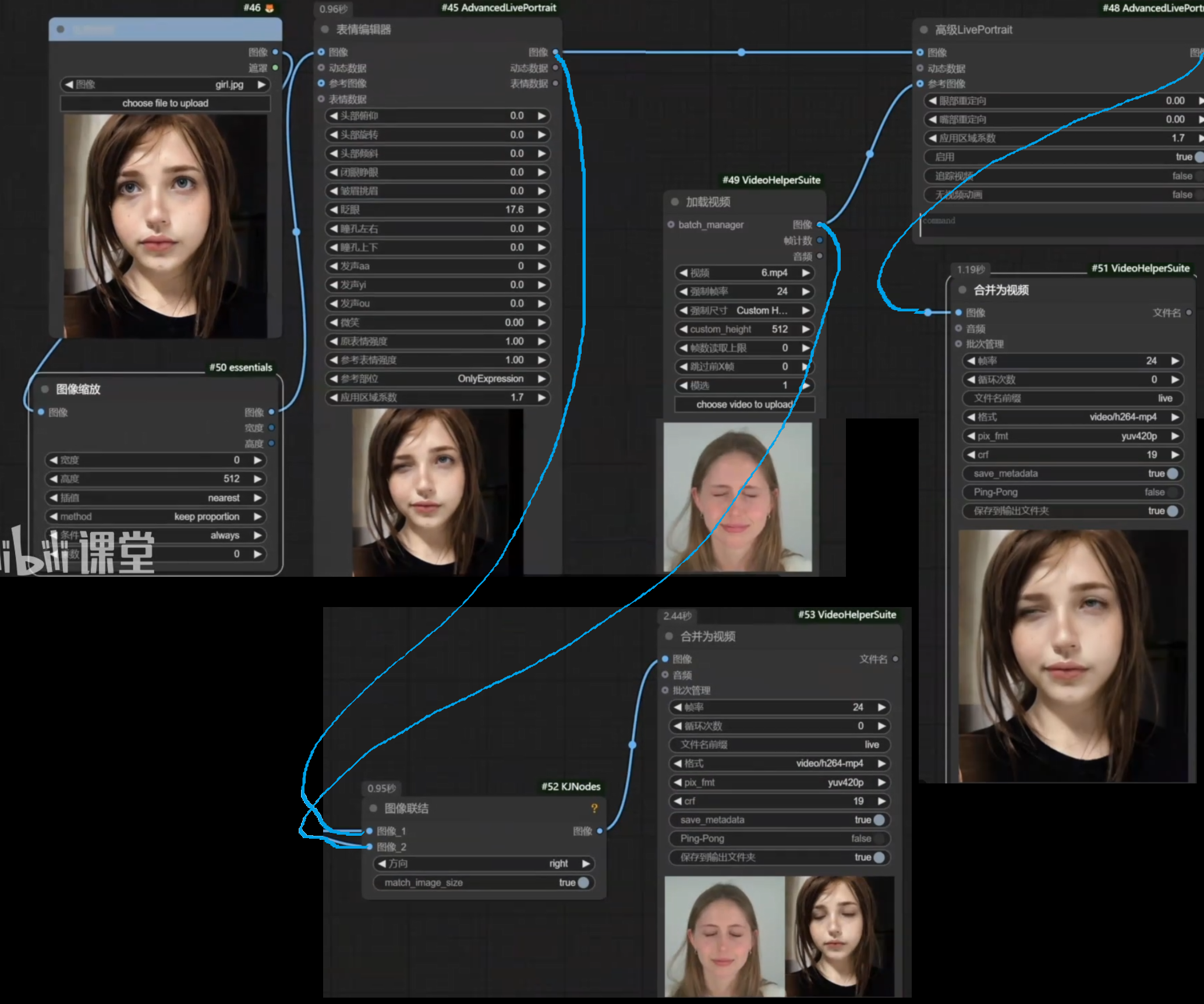
LivePortrait脸部表情改变与脸部驱动
需要下载ComfyUI-AdvancedLivePortrait插件
Segment anything + BrushNet产品背景更换
IC-Light + IP-Adapter光效配合匹配工作流
easy-use + segment anything
无惧放大,电商产品海报最终工作流产品有精细化刻度(手表)
was node suite(调色) + pythongosssss/ComfyUI-Custom-Script(缩放) + Impact Pack(高斯模糊)
E:\ComfyUI\全面掌握Comfyui系统教程\75 无惧放大,电商产品海报终极工作流.mp4
① 反转图层;② 新建模糊图层;③ 50%ADD叠加CG迷—高清产品工作流
百度网盘里没有工作流.json,看看端脑云里面有没有!!!!!!!!!
瑕疵完美消除 进阶局部重绘和擦除工作流
放大!!
插件放大
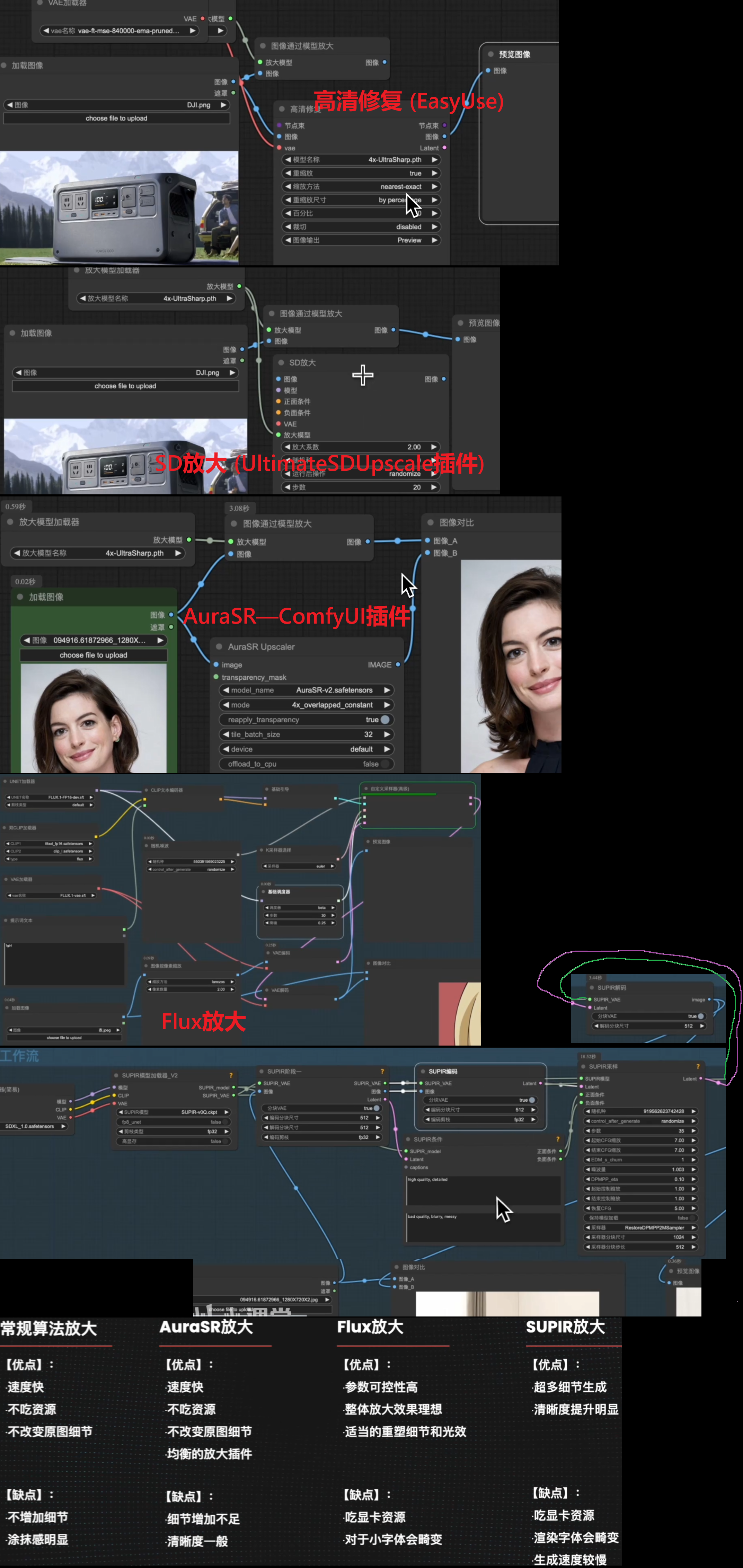
SD放大 (UltimateSDUpscale插件) + 高清修复 (EasyUse)
AuraSR—ComfyUI插件
AuraSR-v2模型和config.json文件
放到ComfyUI目录\models\Aura-SR里面
Flux放大
爆炸细节SUPIR放大 需要SUPIR插件 模型放入 models\checkpoints里面
不过任何带有字体文字的都不适合用SUPIR放大!!
手把手模块化搭建Flux模型产品摄影工作流

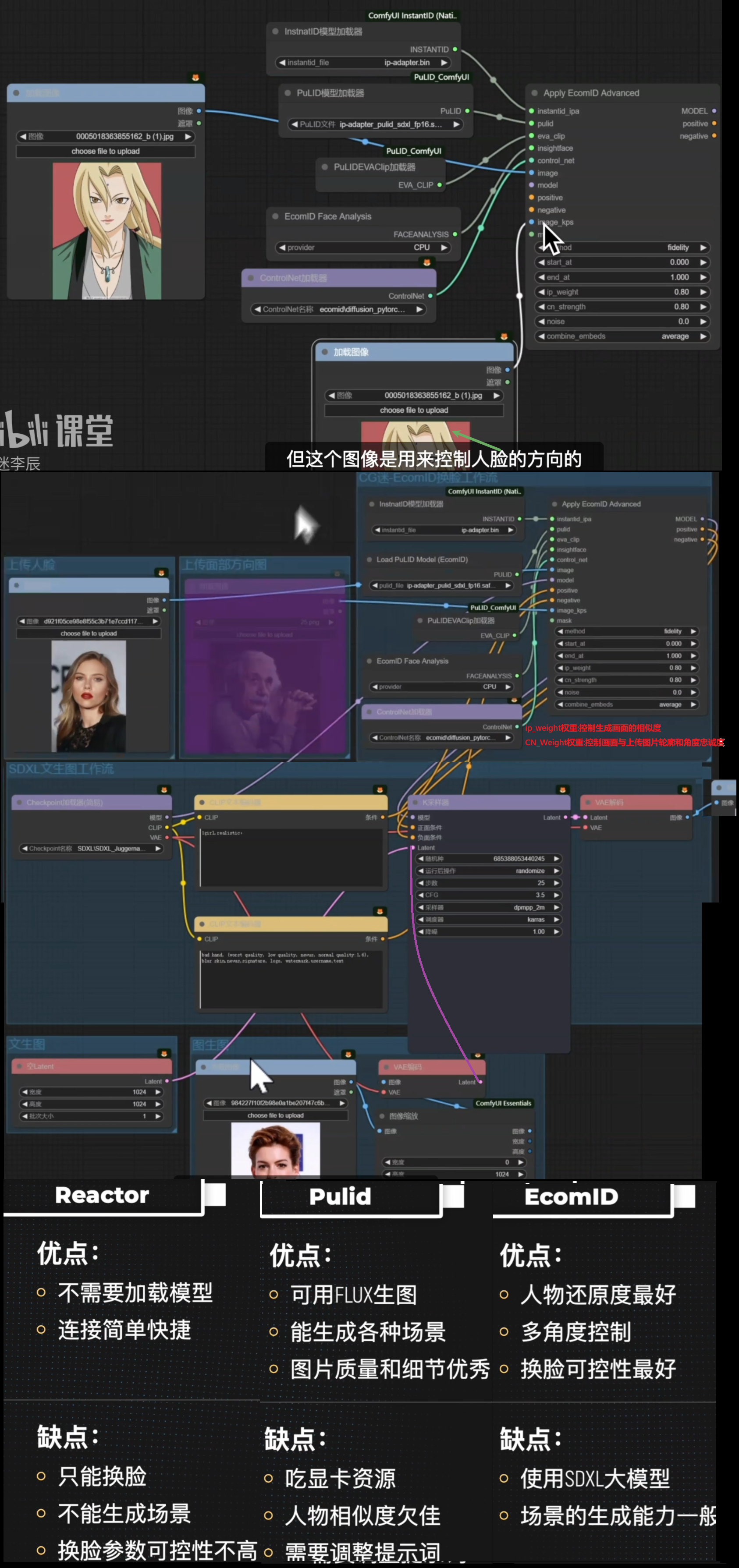
Reactor、Pulid、EcomID换脸插件对比
Reactor
ReActor Node for ComfyUI下载此插件
1、face_yolov8m.pt,放到ComfyUImodels\ultralytics\bbox里面
2、codeformer、GFPGAN脸部修复模型,放到comfyui目录的models\facerestore_models里面
3、inswapper_128.onnx換脸模型,放置到ComfyUNmodels\insightface里面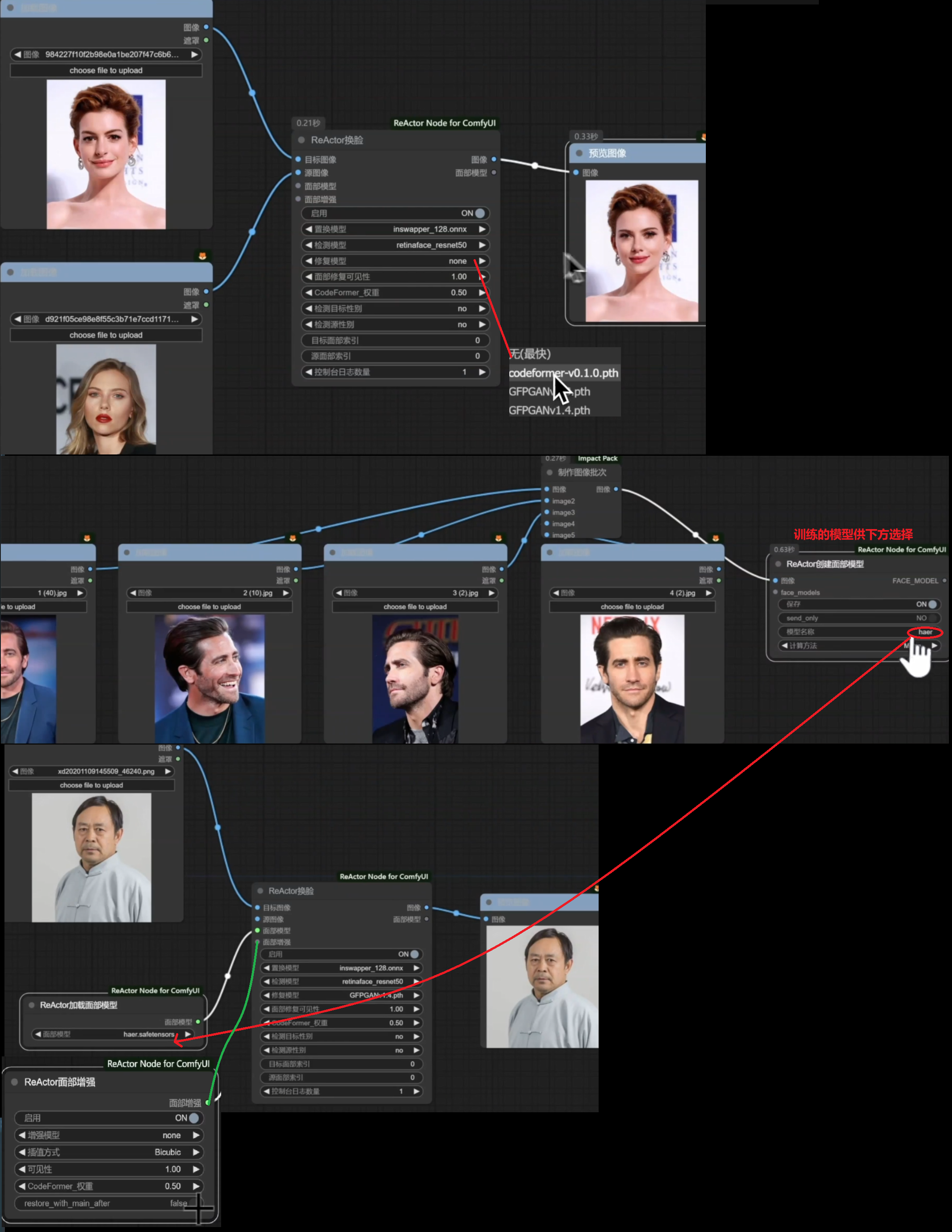
FLUX Pulid搭配人物指定动作和场景
Alibaba-EcomID
由于需要搭配instantID使用。不能使用FLUX 只能使用SDXL大模型
https://github.com/adityacaturputra/SDXL_EcomlD_ComfyUl下载插件
EcomID同样要调用Pulid节点
1、pulid_sdxl_fp16.safetensors模型,放到ComfyUl/models/pulid/里面
(没有的话手动新建一个文件夹)
2、AntelopeV2系列5个模型,放到ComfyUl/models/insightface/models/antelopev2里面
3、EVA02-CLIP-L-14-336,放到ComfyUI/models/clip里面
(放置未必有效,首次运行开启魔法网络)
4、ip-adapter.bin放置到ComfyUI/models/instantid里面
5、diffusion_pytorch_model.safetensors模型放到ComfyUl/models/controlnet/里面
真人照片卡通风格化转绘
普通
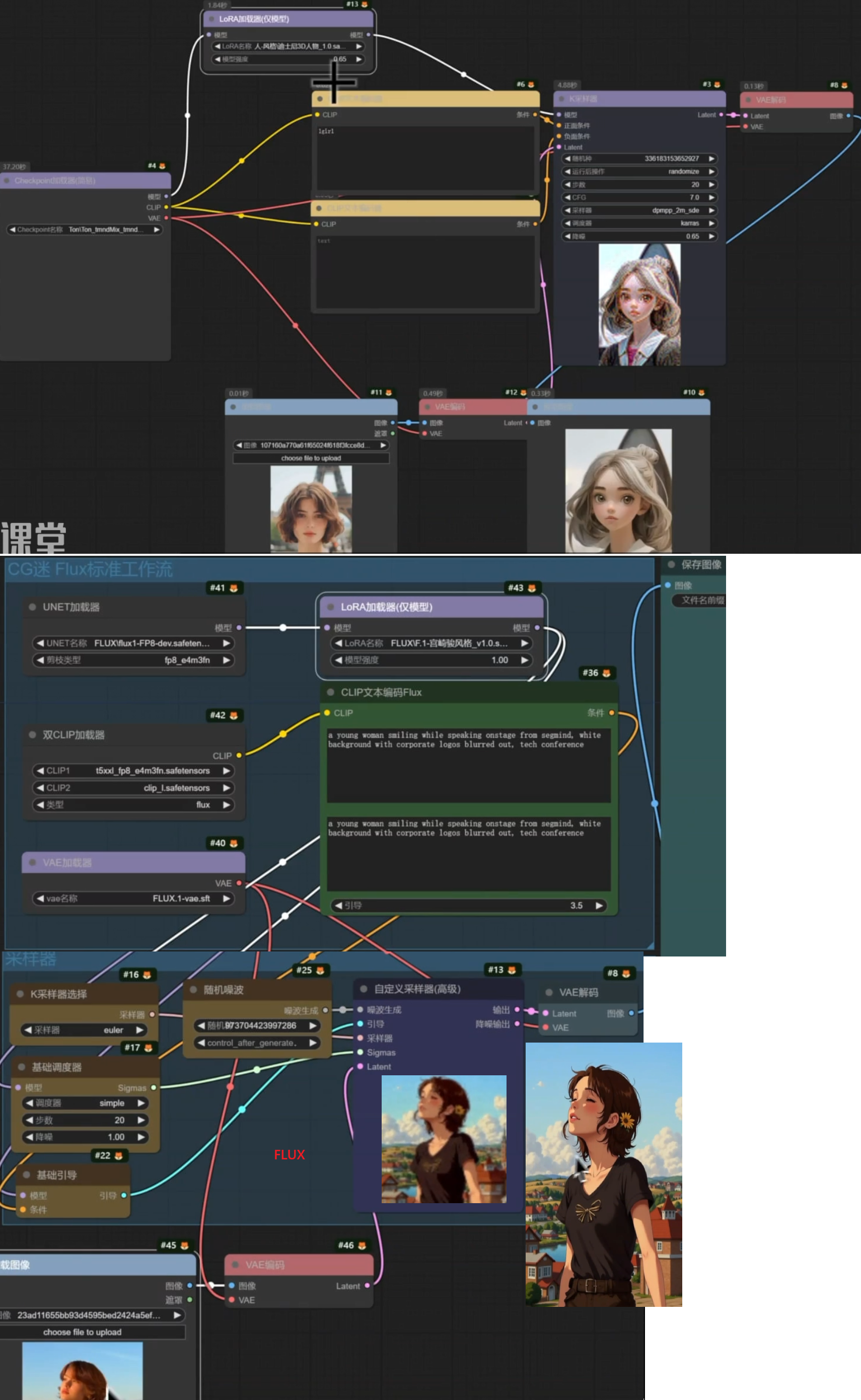
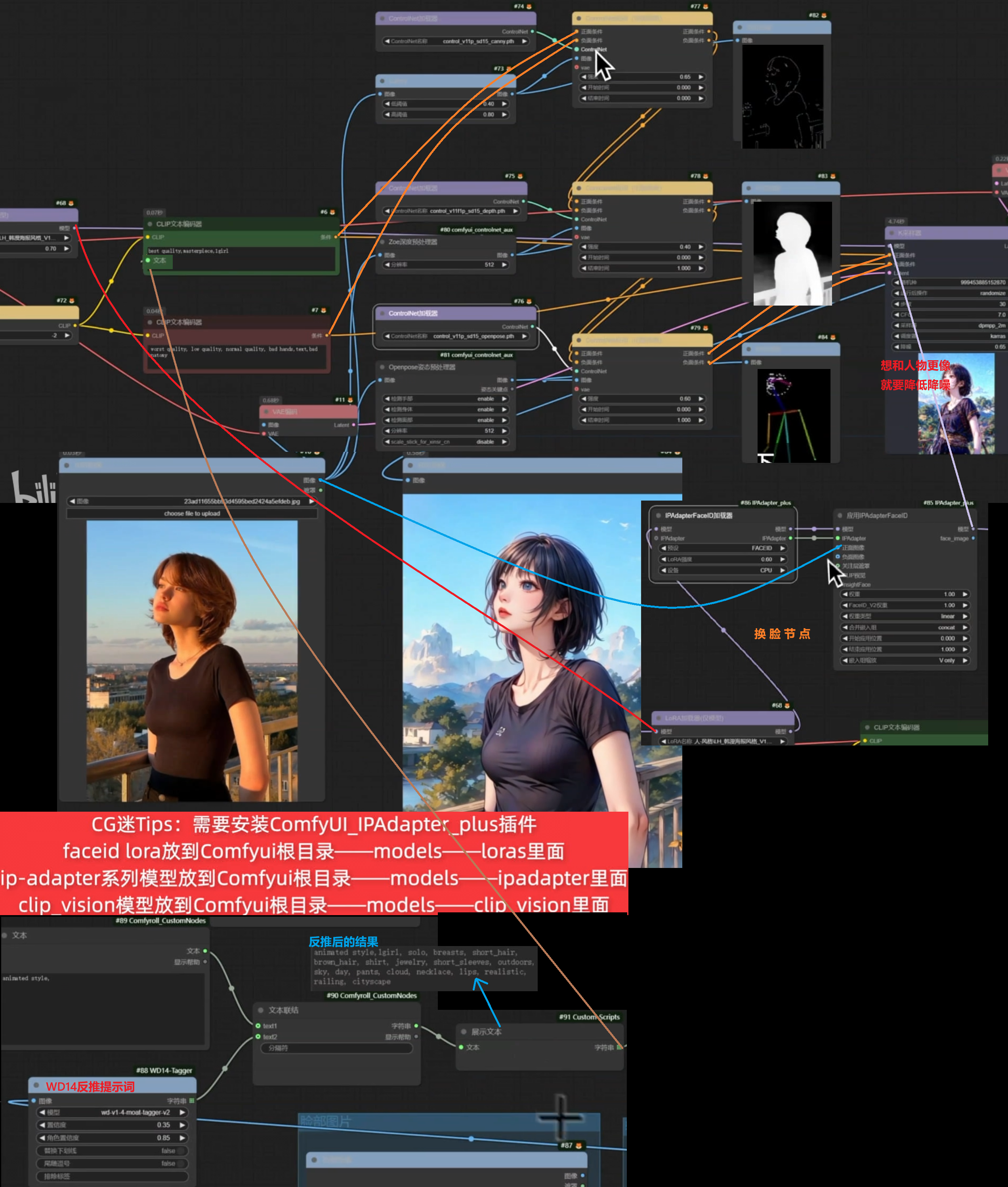
Controlnet + FaceID + 提示词反推 转绘
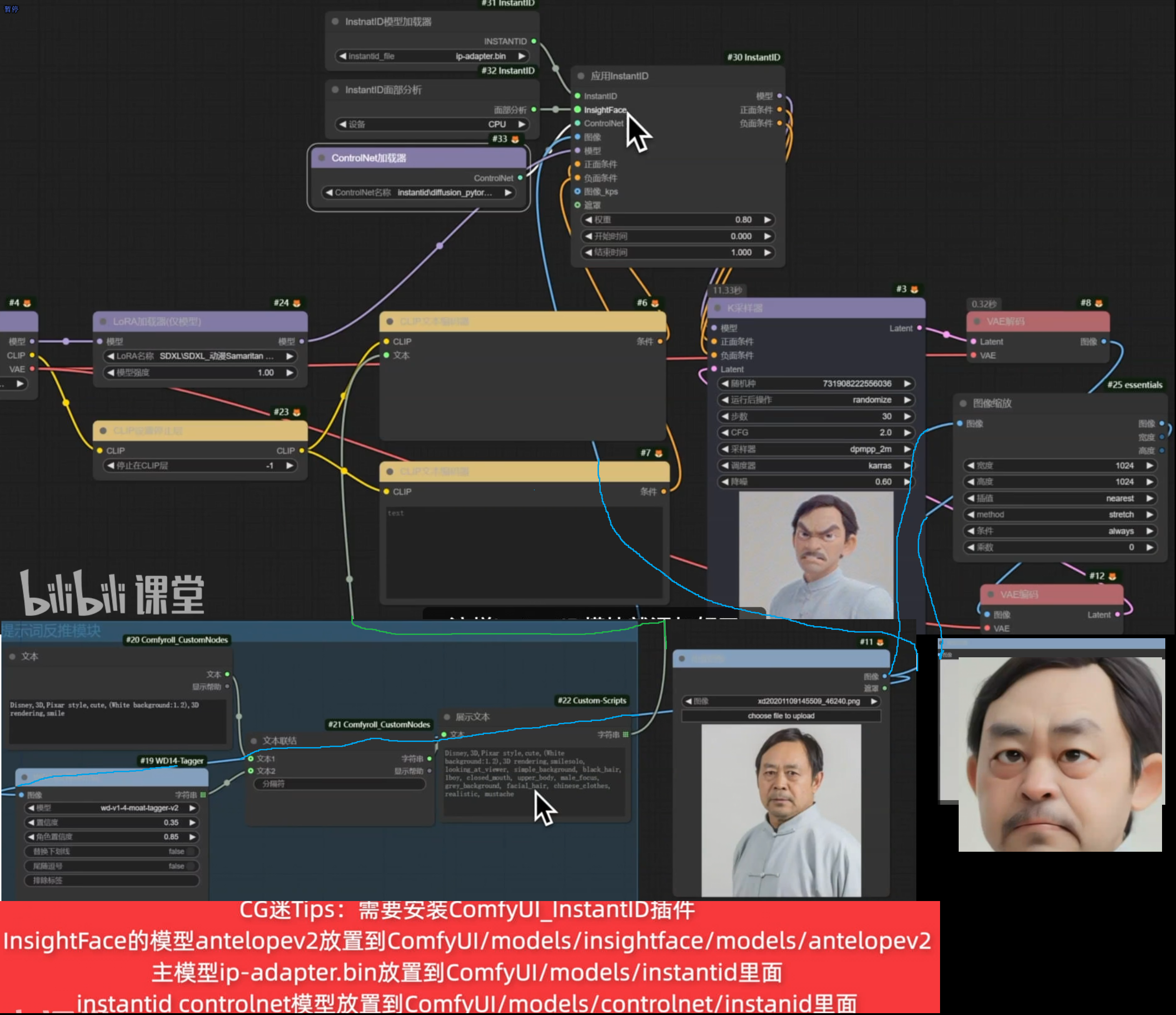
SDXL + instantID
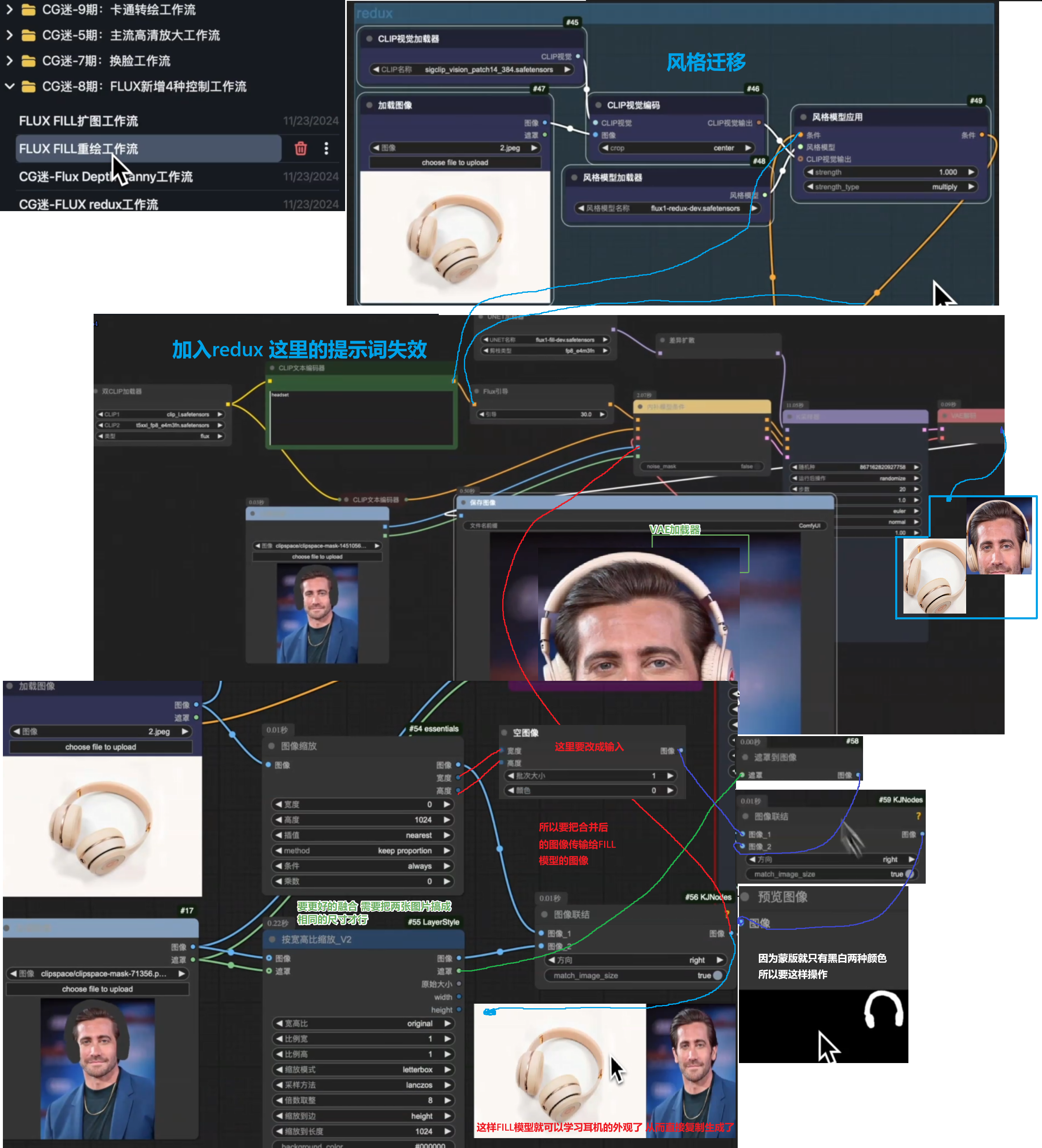
FLUX超强万物迁移工作流
安装Layer Style类似于ps有图层、滤镜、颜色等节点
FLUX超强重绘万物 修手神器(阿里妈妈)
这里需要下载alimama-creative/FLUX.1-dev-Controlnet-Inpainting-Bata中的diffusion_pytorch_model.safetensors 下完记得改名成:FLUX.1-dev-Controlnet-Inpainting-Bata
.png)
AnimateDiff首尾帧丝滑可控动画工作流
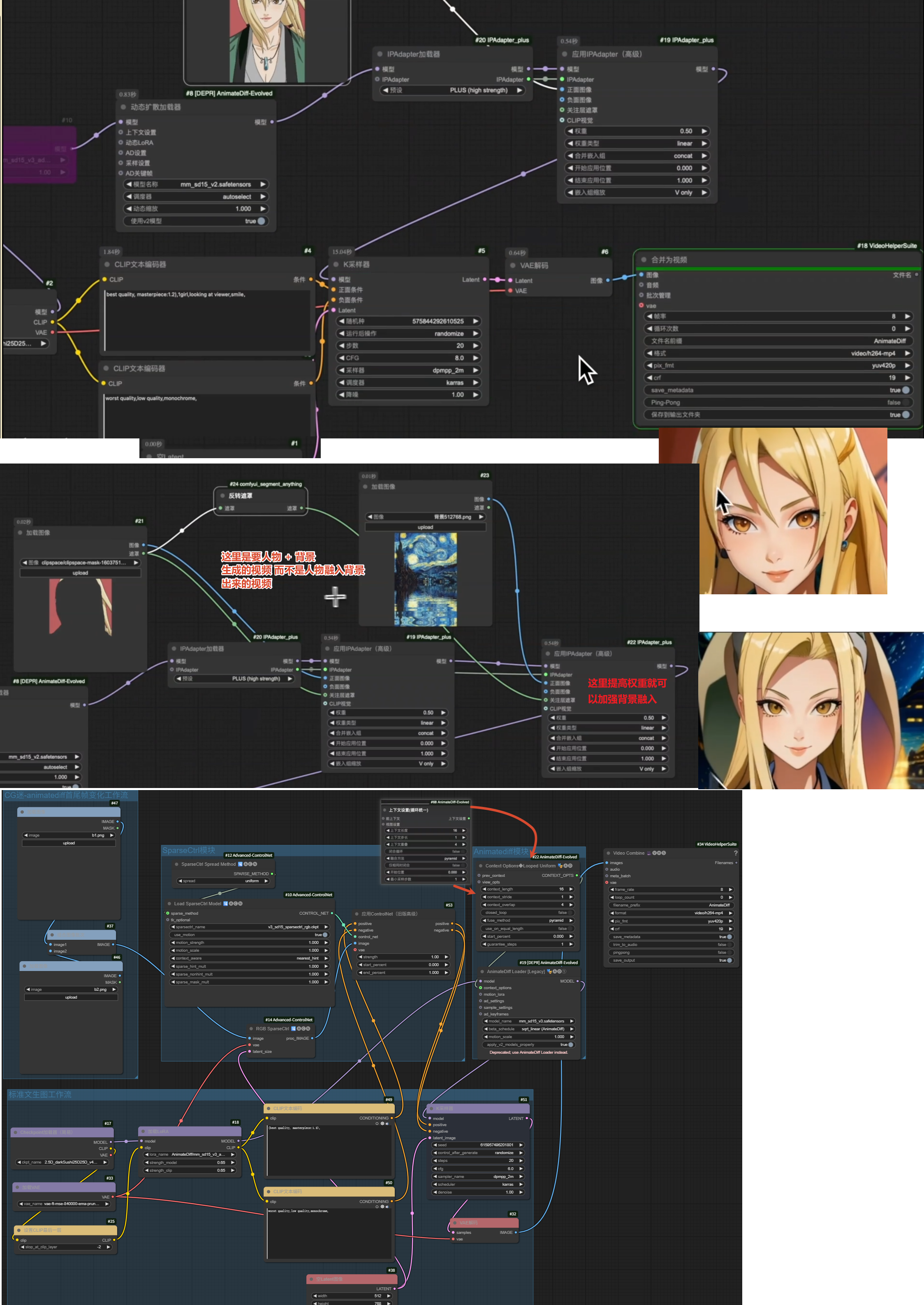
AnimateDiff长视频生成与LCM加速
下载FizzNodes插件 → 提示词调度(批次)
要应用长视频首先要明确指出 第几帧要生成怎么样的画面
LCM是对渲染加速的!!
AnimateLCM_sd15_t2v.ckpt放到comfyui\custom_nodes\ComfyUI-AnimateDiff-Evolved\models里面AnimateLCM_sd15_t2v_lora.safetensors放到comfyui\models\loras里面
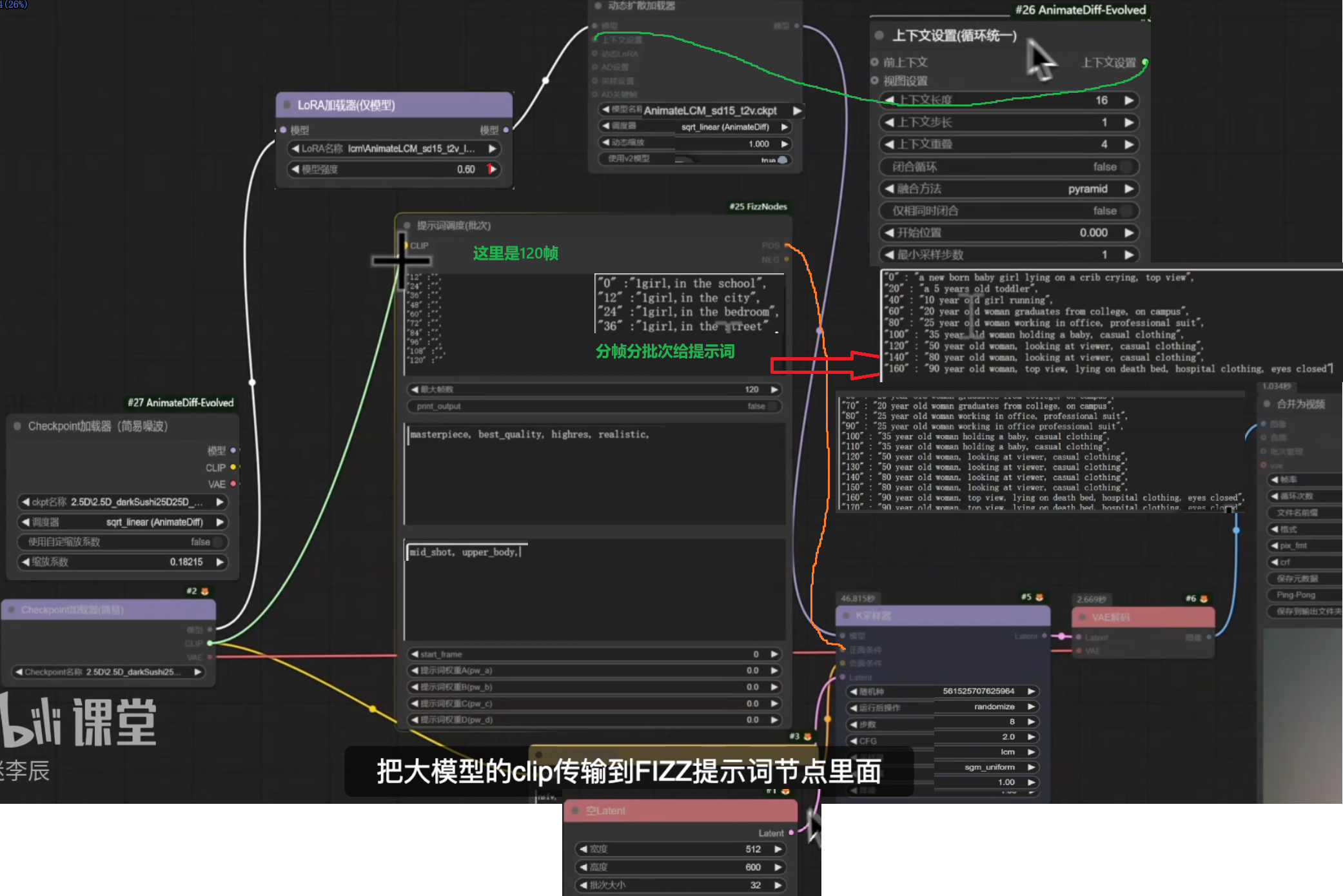
AnimateDiff高级采样与补帧输出优化
增加视频分辨率:用二次放大
增加视频清晰度:用ComfyUI Frame Interpolation → RIFE VFI节点
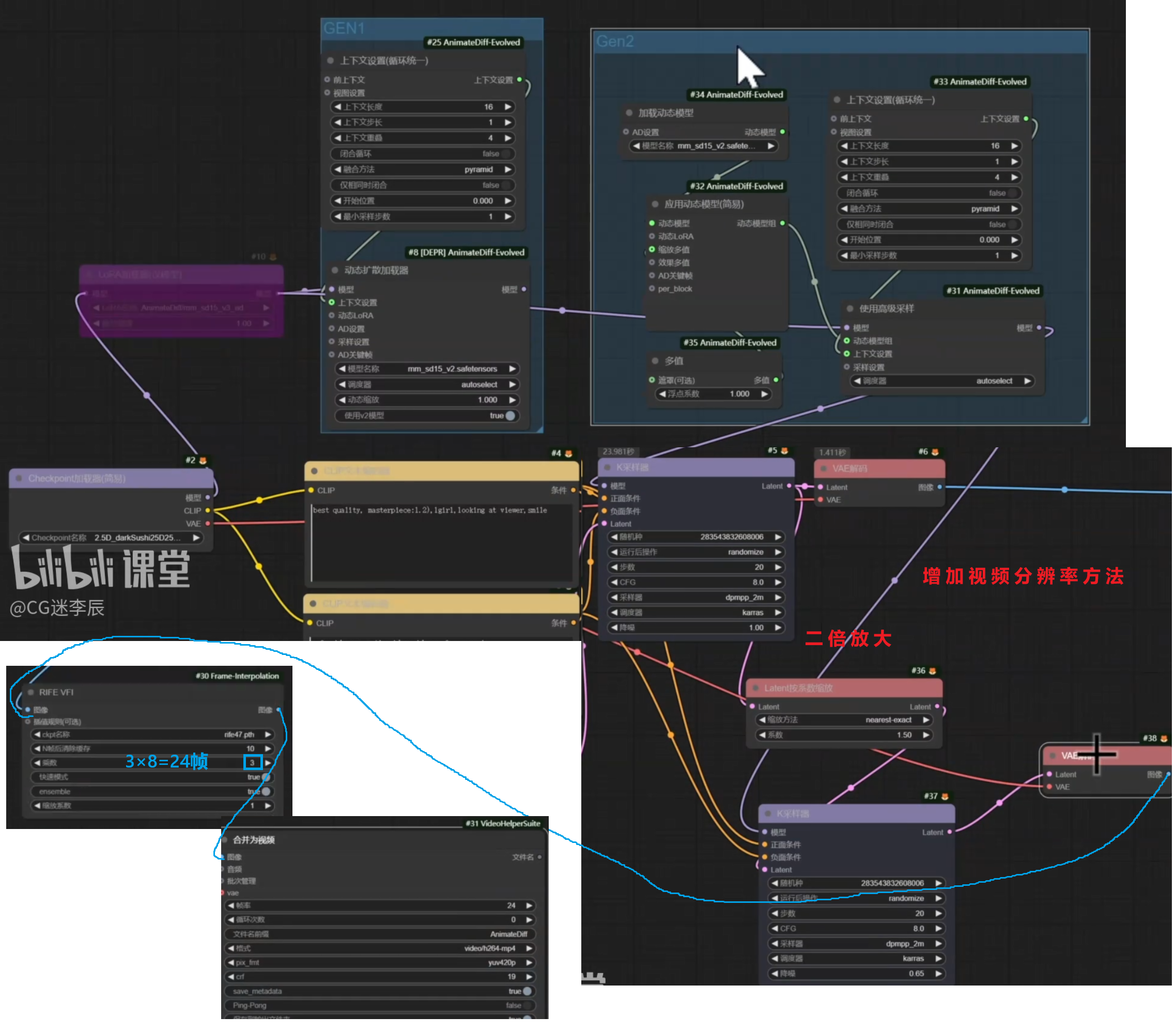
AnimateDiff局部控制指定区域动效
重点是:局部重绘
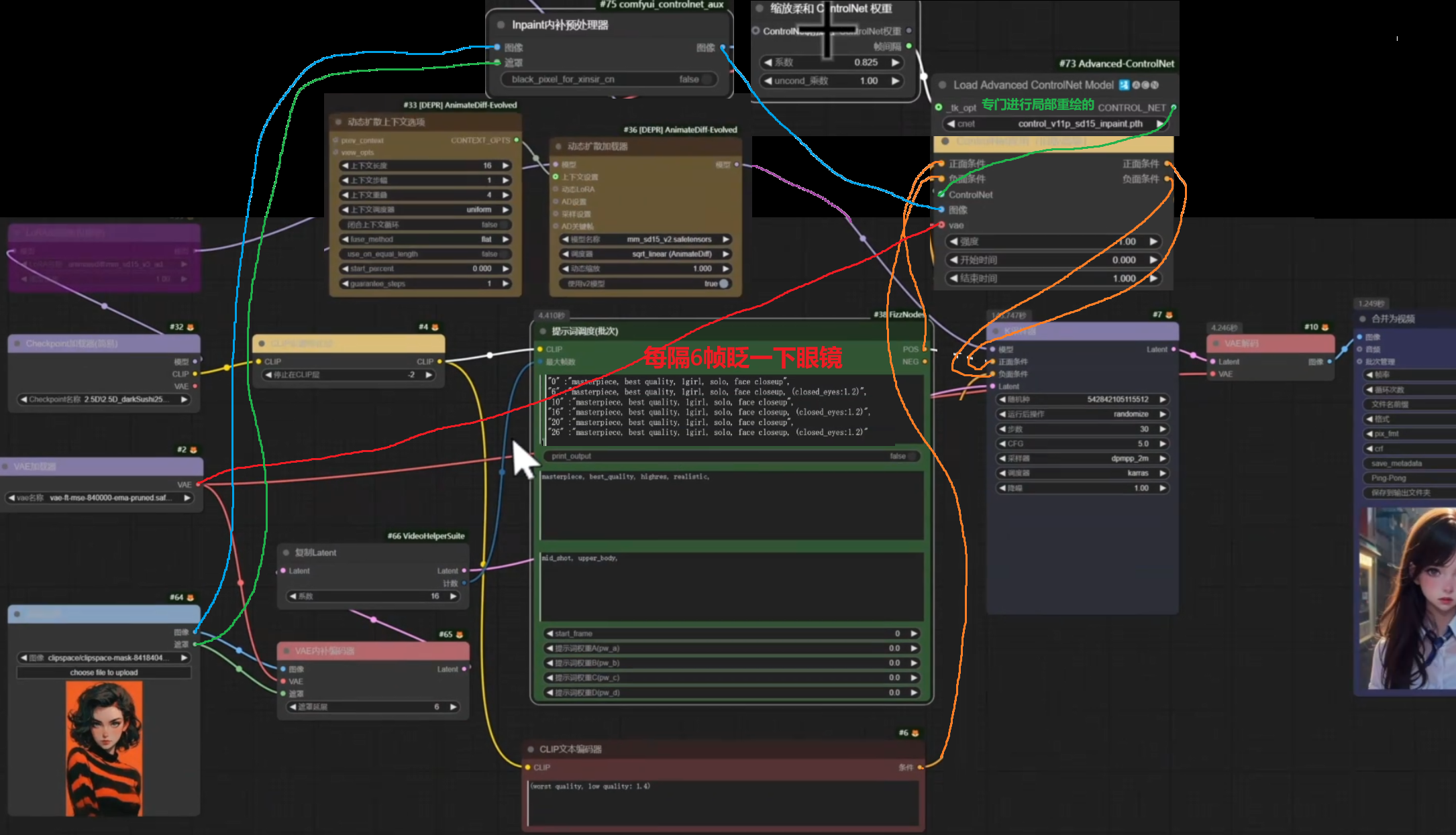
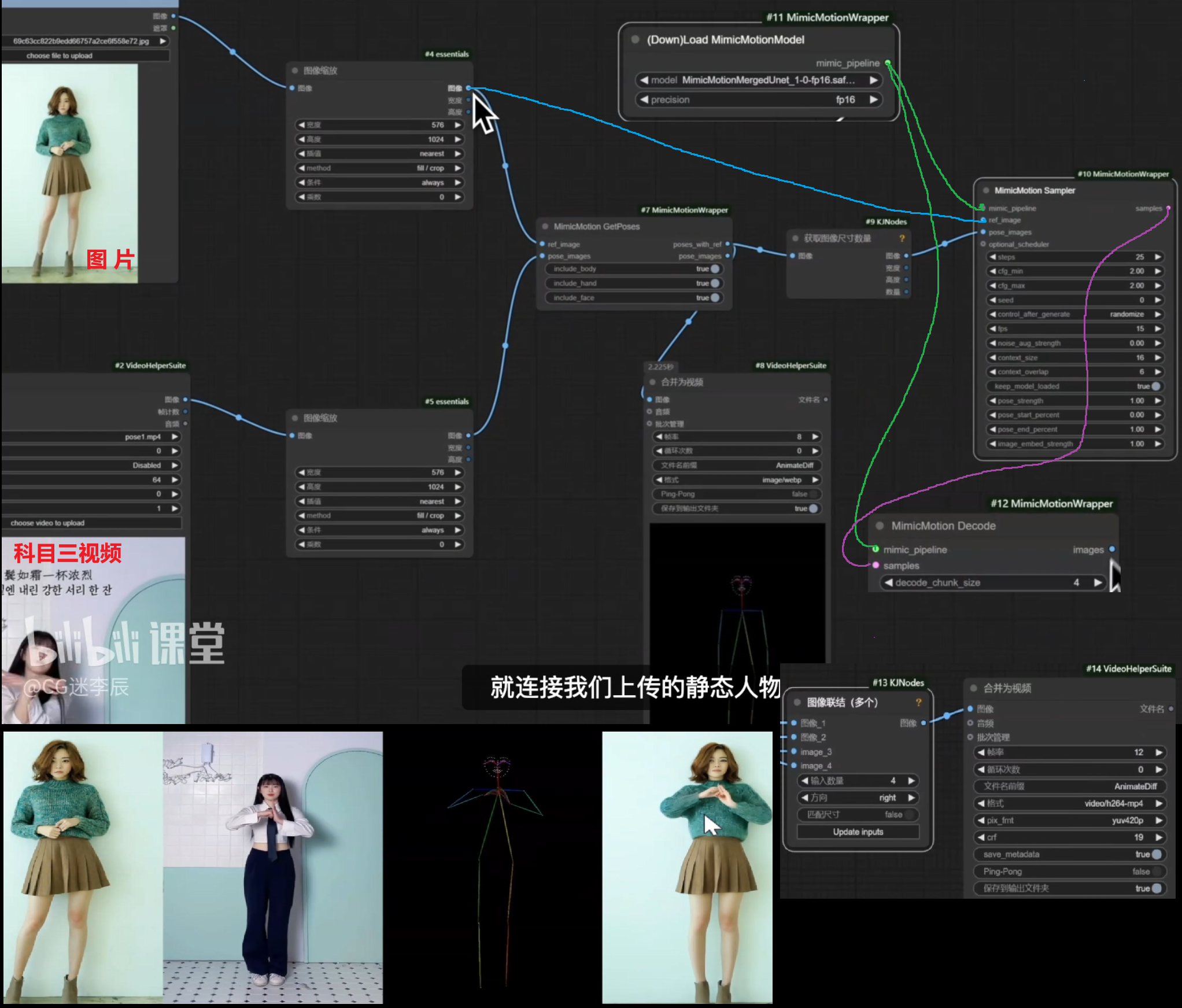
指定动作,视频捕捉,骨骼动画复刻图片模仿视频跳舞
尽量手指背景清晰 手指分叉的
下载插件MimicMotionWrapper + KJNodes
1、MimicMotionMergedUnet大模型,放到ComfyU\models\mimicmotion里面
2、DWPose姿态文件夹,整个文件夹放到ComfyUl\custom_nodes\ComfyUl-MimicMotionWrapper\models里面
3、stable-video-diffusion-img2vid-xt-1-1整个文件夹放到ComfyUl\models\diffusers里面
EchoMimic V2打造自己的数字人
把CG迷文件里的echo_mimic所有文件都放到ComfyUI/models/echo_mimic里面即可【42G】
尽量不要上传带手部的照片 半身照即可 干净一点的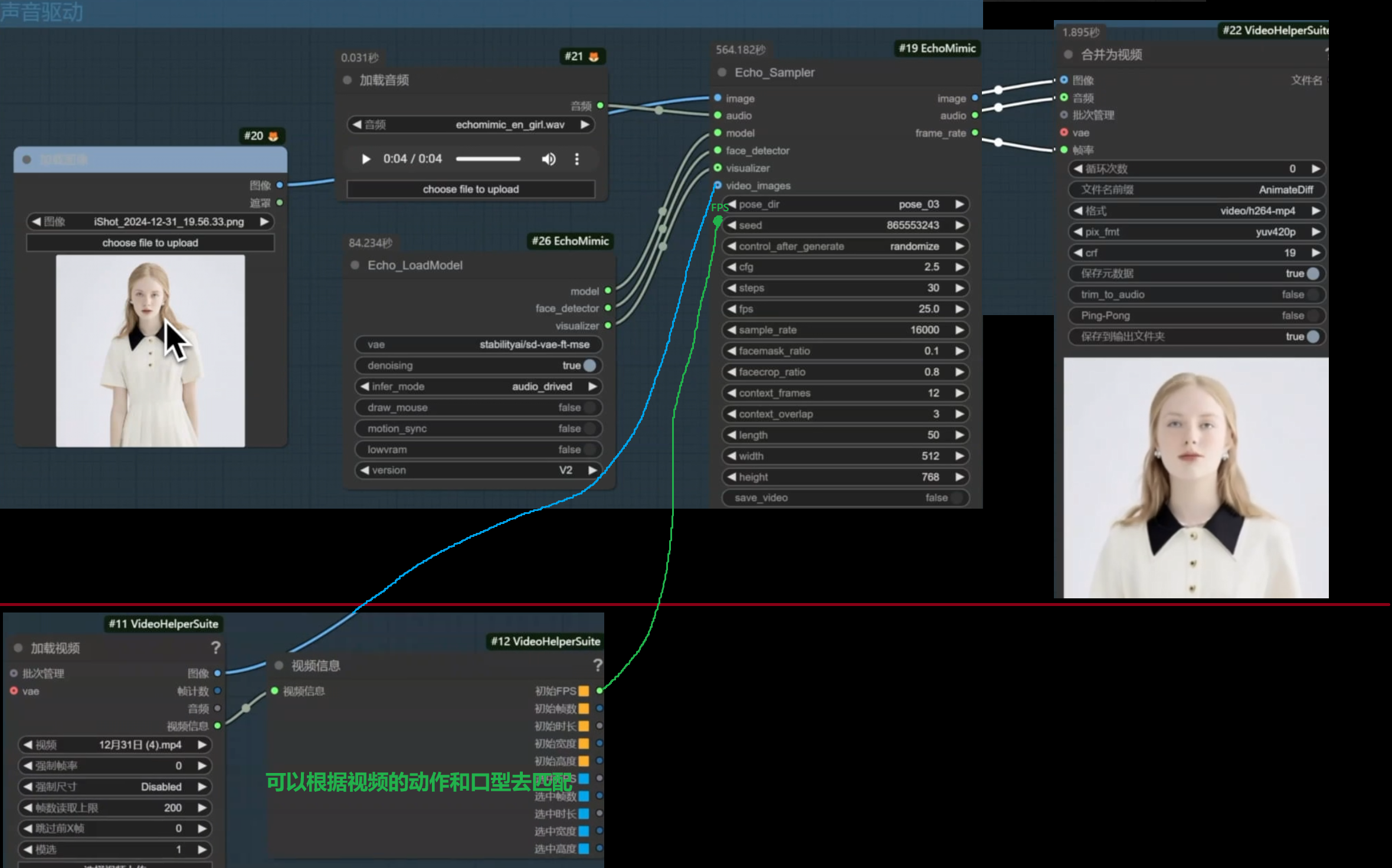
IF—else逻辑节点,让工作流配备双方案
on_true、on_false → true
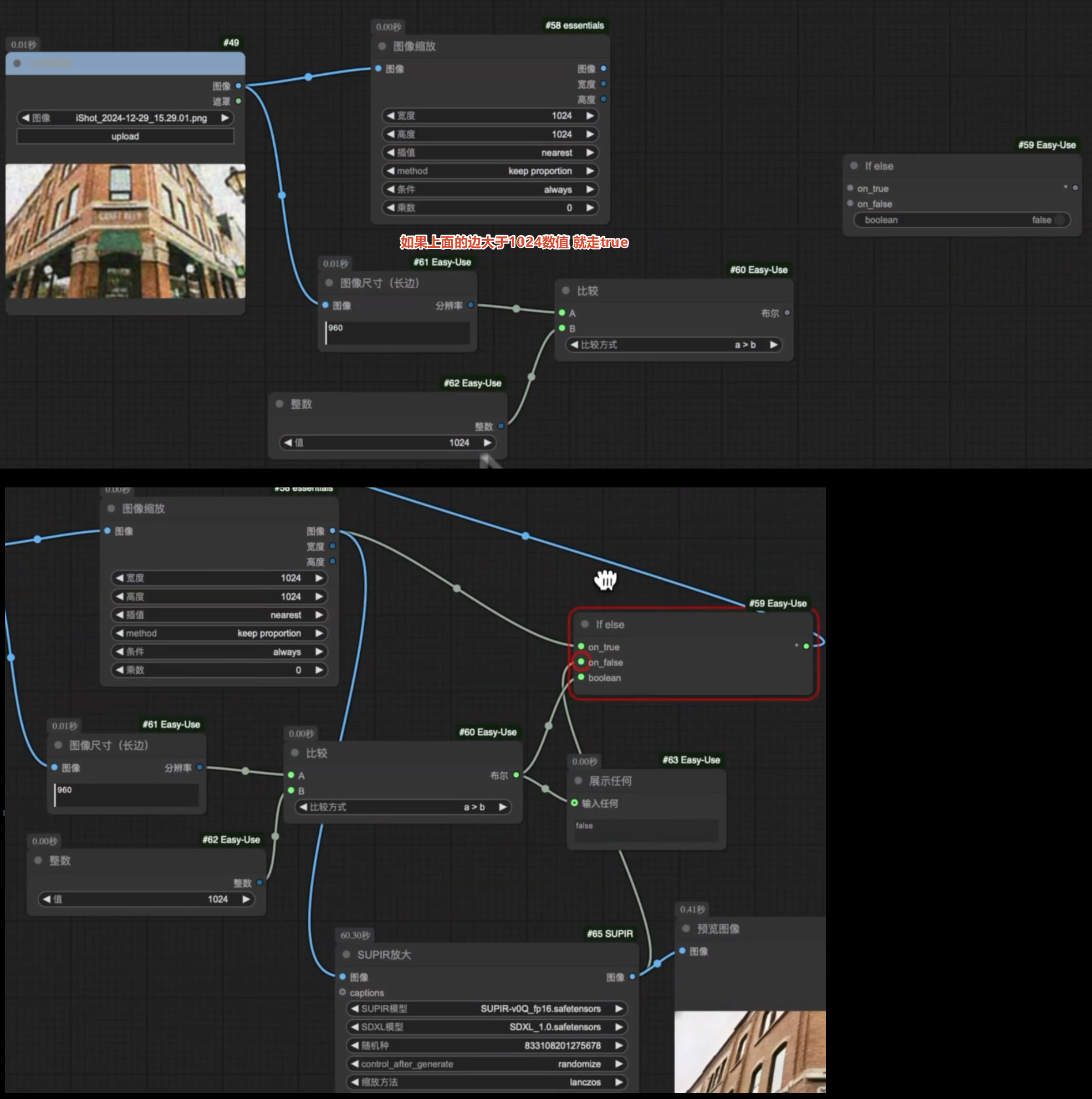
Flux Upscaler高清放大洗图工作流
找jasperai/Flux.1-dev-Controlnet-Upscaler;下载diffusion_pytorch_model.safetensors后改名
Flux.1-dev-Controlnet-Upscaler 模型放到 ComfyUl/models/controlnet目录下
搞个ControlNet + 加载器,加载器里选择下载的模型即可