
线程池的执行流程大致如下:
线程池:ThreadPoolExecutor
一开始new的时候没有 是空的。先当一个任务提交给线程池时,线程池首先检查当前运行的线程数是否达到核心线程数。如果没有达到核心线程数,线程池会创建一个新的线程来执行任务。如果已经达到核心线程数,线程池会将任务放入工作队列中等待执行。如果工作队列满了,并且当前运行的线程数小于最大线程数,线程池会创建新的线程来执行任务。如果工作队列满了,并且当前运行的线程数等于最大线程数,线程池会根据拒绝策略
- 丢弃任务抛出异常
- 丢弃任务不抛弃异常
- 丢弃队列最前面的任务,然后重新提交被拒绝的任务、
- 由主线程处理该任务来处理无法执行的任务。【线程池无法起到异步问题】
- 问题:想继续异步且不丢弃任务怎么办?
- 把这个业务先存到别的地方 ↓↓↓
- 自定义拒绝策略 自己写实现类实现拒绝策略 可以先存到mysql到时候再慢慢搞
怎么确定核心线程数和最大线程数?
核心线程数
- CPU密集型任务:如果任务是CPU密集型的,即任务主要是进行计算而不是等待I/O操作,核心线程数通常设置为CPU核心数加1。这样可以确保CPU在忙于计算的同时,还有额外的线程来处理可能出现的临时高峰。【纯内存计算 不涉及到网络计算和io计算】【N+1】
- 八个核 创建十个cpu 没意义 因为最多并发只是8,建议保持一致或者+1,减少加入队列和创建队列的开销
- 先把其当成io密集 因为层级不一样 不断压测去逼近最理想值
- I/O密集型任务:对于I/O密集型任务,由于线程在等待I/O操作时会阻塞,因此可以设置更多的核心线程数。一个常用的经验法则是核心线程数设置为CPU核心数的两倍。【线程数越多越好】【压测无限逼近取最合适的线程数】【2N+1】
最大线程数
需要一开始创建好线程等着访问来,如果 核心=最大,此时没有临时线程
创建线程有几种方式(必会)
1.继承 Thread类并重写 run 方法创建线程,实现简单但不可以继承其他类
2.实现 Runnable接口并重写 run 方法。避免了单继承局限性,编程更加灵活,实现解耦。 [无返回值]
3.实现 Callable接口并重写 call 方法,创建线程。可以获取线程执行结果的返回值,并且可以抛出异常。[有返回值]
4.使用线程池创建(使用java.util.concurrent.Executor接口)
- 想获得线程池里的返回结果用什么?execute + submit
- 线程有哪些状态? java线程有哪些状态?
- 线程池有哪些状态?
// 1. 继承Thread类并重写run方法
class MyThread extends Thread {
@Override
public void run() {
System.out.println("线程运行中 - 继承Thread类");
}
}
// 2. 实现Runnable接口并重写run方法
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("线程运行中 - 实现Runnable接口");
}
}
// 3. 实现Callable接口并重写call方法
import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask;
class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("线程运行中 - 实现Callable接口");
return "Callable线程返回结果";
}
}
// 4. 使用线程池创建线程
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadCreationExamples {
public static void main(String[] args) {
// 继承Thread类创建线程
Thread thread1 = new MyThread();
thread1.start();
// 实现Runnable接口创建线程
Thread thread2 = new Thread(new MyRunnable());
thread2.start();
// 实现Callable接口创建线程
MyCallable callable = new MyCallable();
FutureTask<String> futureTask = new FutureTask<>(callable);
Thread thread3 = new Thread(futureTask);
thread3.start();
try {
// 获取线程执行结果的返回值
String result = futureTask.get();
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
// 使用线程池创建线程
ExecutorService executor = Executors.newFixedThreadPool(2);
executor.execute(new MyRunnable()); // 提交Runnable任务
executor.submit(new MyCallable()); // 提交Callable任务
executor.shutdown(); // 关闭线程池
}
}
线程池哪些类型?通过JUC[包]的executes可以创建这四个类型的线程池
问题:为什么阿里巴巴不推荐JUC?有可能会出现OOM、资源浪费
- 单线程线程池
- 可缓存线程池/定长
- 变长的线程池
- 定时任务的线程池
java 线程池创建时核心参数(高薪常问)
七大核心参数解释
参数名 说明 corePoolSize核心线程数,线程池常驻的线程数量,即使空闲也不会被销毁(除非 allowCoreThreadTimeOut = true)maximumPoolSize最大线程数,线程池能容纳的最大线程数量(包括核心线程) keepAliveTime非核心(临时)线程的存活时间,超过这个时间,空闲的线程会被回收 unit时间单位, keepAliveTime的时间单位,如:秒(TimeUnit.SECONDS)workQueue任务(阻塞)队列,用于缓存提交但尚未执行的任务(如: ArrayBlockingQueue、LinkedBlockingQueue)threadFactory线程工厂,用于自定义线程创建(可以设置线程名称、是否为守护线程等) handler拒绝策略,当任务队列已满且线程数量达到最大线程数时的处理方式;(抛不抛异常…)
核心线程池大小、线程池创建线程的最大个数(核心+非核心[临时线程])、临时线程存活时间、时间单位、阻塞队列、线程工厂(指定线程池创建线程的命名)、拒绝策略
线程工厂可以设置创建的属性:
守护线程:主线程(main)一天不死 守护线程不死 [同生共死]
非守护线程:new一个就是 [不是同生共死]
阻塞队列常用的队列:
- ArrayBlockingQueue: 基于数组结构的有界阻塞队列,此队列按照先进先出(FIFO)的原则对元素进行排序。创建时需要指定容量。【底层是数组 随机读写的 **时间复杂度O(1)**】
- 开辟新空间创建新数组 把旧数组的数据迁移过去 new ArrayList为空 需要add才可以 扩容是+10 取1.5倍
- 高并发不会超过某个值 数组不会涉及到扩容 性能会好一些【比较稳定能预估】
- new的时候不用指定长度
- LinkedBlockingQueue: 基于链表结构的有界阻塞队列(如果不指定容量,则默认为
Integer.MAX_VALUE,即视为无界)。按照先进先出的原则排序元素。【随机读写的 时间复杂度O(n) 随机读写快 查询慢 是通过二分查找定位到下标元素(通过下标访问数组和链表) 只会走一次二分查找】- 读中间的慢 读头尾快
- 新增元素不涉及到数组的迁移
- 一般情况下高并发推荐使用,因为队列
高级数据结构(可以用数组和链表的实现 由于底层数据结构不同)的特性是先进先出,链表不涉及到数组的扩容 末尾的最快是O(1)【不稳定】 - new的时候可指定长度是最大链表的长度
- 不可指定长度 [有界队列&无界队列] → 可能产生JVM的OOM
线程池的应用要有实际的业务场景
- 异步任务处理:将任务提交到线程池异步执行,而不阻塞主线程
假设我们有一个电商平台,其中一个核心业务是处理用户订单。在订单处理过程中,我们需要执行以下任务:
由于这些任务相对独立,并且处理时间可能较长,我们希望在不影响用户操作的前提下异步执行它们。以下是使用线程池处理这些异步任务的模拟代码:
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.TimeUnit; class Order { // 订单信息 private String orderId; private String userId; private double amount; // 构造函数、getter和setter省略 } class OrderService { private ExecutorService executorService = Executors.newFixedThreadPool(10); // 假设线程池大小为10 // 处理订单 public void processOrder(Order order) { // 1. 验证订单信息 executorService.submit(() -> { System.out.println("验证订单信息: " + order.getOrderId()); // 假设验证成功 }); // 2. 计算订单金额 executorService.submit(() -> { System.out.println("计算订单金额: " + order.getOrderId()); // 假设计算成功,设置订单金额 order.setAmount(100.0); // 示例金额 }); // 3. 生成订单并保存到数据库 executorService.submit(() -> { System.out.println("生成订单并保存到数据库: " + order.getOrderId()); // 假设保存成功 }); // 4. 发送订单确认邮件 executorService.submit(() -> { System.out.println("发送订单确认邮件: " + order.getOrderId()); // 假设邮件发送成功 }); } // 关闭线程池 public void shutdown() { try { executorService.shutdown(); if (!executorService.awaitTermination(60, TimeUnit.SECONDS)) { executorService.shutdownNow(); } } catch (InterruptedException e) { executorService.shutdownNow(); } } } public class ThreadPoolApplication { public static void main(String[] args) { OrderService orderService = new OrderService(); Order order = new Order(); order.setOrderId("ORDER12345"); order.setUserId("USER12345"); // 处理订单 orderService.processOrder(order); // 假设主线程还有其他任务,这里模拟等待其他任务完成 try { Thread.sleep(5000); // 等待5秒 } catch (InterruptedException e) { e.printStackTrace(); } // 关闭线程池 orderService.shutdown(); } }在这个模拟场景中,我们创建了一个
OrderService类,它包含一个线程池用于异步处理订单的各个步骤。当用户创建订单时,processOrder方法会将订单处理的各个任务提交到线程池中异步执行。这样,主线程不会被阻塞,可以继续处理其他用户请求或执行其他任务。在所有任务都提交到线程池后,主线程可能会执行其他逻辑,最后调用shutdown方法来优雅地关闭线程池。
线程池执行流程图解
当你调用:
executorService.submit(() -> { // 任务逻辑 });实际上背后会触发
ThreadPoolExecutor的如下处理逻辑:线程池内部执行流程
- 核心线程数未满:
- 立即创建新线程来处理该任务。
- 核心线程数已满,进入下一步:
- 将任务放入任务队列(如
LinkedBlockingQueue)。- 任务队列已满,进入下一步:
- 判断当前线程数是否小于最大线程数:
- 如果小于,创建非核心线程来执行任务;
- 如果等于最大线程数,触发 拒绝策略。
- 执行完毕的线程会回到池中等待下一个任务(如果有),非核心线程在空闲超时后会被销毁。
结合你的业务场景做解析
你这个订单场景中,共有 四个异步任务:
步骤 任务名称 是否必须顺序 是否耗时 ① 验证订单 否 是 ② 计算金额 否 是 ③ 写入数据库 否(有依赖) 是 ④ 发送确认邮件 否 是 “不一定必须顺序”,是基于“线程池异步任务” 的并发角度而言的 —— 如果某些任务之间没有直接依赖关系,那就可以并发异步执行,提高效率。
但是你指出了一个关键点:这个场景中每个步骤其实是有依赖关系的,这种顺序性是业务逻辑所要求的,不是线程池可以随意打乱的!
✅ 这正是线程池最适用的场景:任务独立 / 可并行处理 / 需要节省响应时间
🧠 所以在这个场景中,线程池的正确使用方式应该是:
我们不能把所有任务都直接丢进线程池 并发执行,而应该是:
主线程: 1. 验证订单(同步执行) 2. 计算金额(同步执行或异步计算后 get() 等待结果) 3. 写入数据库(依赖前面两个成功) 4. 发送确认邮件(可异步执行)✅ 其中 步骤 ④ 发送邮件 是唯一适合异步执行的 —— 它不影响主流程,可以交给线程池异步去发。
订单处理是有严格先后顺序依赖的:
- 验证 → 金额 → 入库 → 邮件 是一条主流程链;
- 线程池 不是用来打乱这个顺序的,而是用来 并发执行不影响主流程的附属任务(如邮件通知、日志、异步推送等);
使用线程池的好处:
- 🚀 提升响应速度:主线程快速返回(如 UI/接口响应),耗时任务交给线程池异步完成。
- ✅ 防止线程资源滥用:相比每个任务都
new Thread(),线程池能重用线程,避免频繁创建/销毁造成资源浪费。- 🔒 线程复用 + 并发控制:通过设置
corePoolSize和queueCapacity控制系统负载。ExecutorService executorService = new ThreadPoolExecutor( 5, // 核心线程数 10, // 最大线程数 60, // 非核心线程的空闲存活时间 TimeUnit.SECONDS, new LinkedBlockingQueue<>(100), // 队列长度 Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy() // 拒绝策略 );🎯 参数如何选择:
参数 选型建议 corePoolSize 可设为CPU核心数或稍高,如 Runtime.getRuntime().availableProcessors()maximumPoolSize 视任务复杂度、响应时间等决定,通常为核心数的 2~3 倍 2N+1 queueCapacity 适合使用有限队列(如100),避免OOM keepAliveTime 一般设置 30~60 秒 拒绝策略 建议使用 CallerRunsPolicy或自定义策略什么时候不该用线程池?
虽然线程池非常好,但在这些情况下应该慎用:
场景 建议方式 任务轻量、低频 可直接 new Thread 任务耗时严重、不确定性高 可用异步消息队列或限流机制替代 并发极高,超出系统承载能力 应加熔断、降级、防抖等保护机制 总结线程池应用场景
应用场景 是否推荐 理由说明 ✅ 异步任务 推荐 提升响应速度,释放主线程 ✅ 数据汇总 推荐 多接口并行调用、加速结果收敛 ✅ 定时批处理任务 推荐 比如定时拉取、导入数据、分段分页并发处理等 ❌ 高频IO长耗时任务 慎用 应考虑消息队列+异步消费,避免线程被长时间占用
你单独部署过项目吗?
前端打包ng配置文件
git所有人都用 需要拉分支 maven打包后端 包放到远程服务器 java -jar 启动!【不应该有人去做】
有专门工具去流水线制作 → Jenkins是一个开源的自动化服务器,它可以帮助您实现自动化构建、测试和部署项目 JenKins + docker 做自动化部署
部署是建立本地的项目再推到服务器
安装 Docker:确保你的部署服务器上安装了 Docker。
安装 Jenkins:可以通过 Docker 安装 Jenkins,或者直接在服务器上安装。步骤 1:安装 Jenkins 和 Docker
确保 Jenkins 和 Docker 在服务器上都已经安装并运行。
步骤 2:配置 Jenkins
启动 Jenkins:
使用 Docker 启动 Jenkins:
docker run -d --name jenkins -p 8080:8080 -p 50000:50000 jenkins/jenkins:lts访问 Jenkins:在浏览器中访问
http://<服务器地址>:8080,并按照指示完成 Jenkins 的初始设置。安装必要的插件:安装 Docker、Git 等相关插件。
步骤 3:创建 Jenkins 任务
新建任务:在 Jenkins 主页上,点击“新建任务”。
配置源码管理:配置 Git 仓库地址。
配置构建触发器:选择合适的触发器。
配置构建环境:勾选“Build inside a Docker container”。
添加构建步骤:
执行 Shell:
docker build -t myapp .添加构建后操作:
Push built image:如果需要将镜像推送到 Docker 仓库,填写仓库信息。
执行 Shell:
docker stop myapp || true docker rm myapp || true docker run -d --name myapp -p 8080:8080 myapp步骤 4:执行构建
保存配置后,可以手动触发构建或者等待触发器自动执行构建。
步骤 5:验证部署
构建完成后,访问服务器的指定端口(例如
http://<服务器地址>:8080),验证应用是否成功部署。
你的期望薪资?
我目前的薪资是8000,考虑到我即将承担的职责和我的职业发展,我期望的薪资是在现有基础上有所提升,大约在8000到10000之间。当然,我对整体的薪酬包[包括福利、奖金和职业发展机会]也很感兴趣。薪资是如何构成的,包括固定工资、奖金、股权、福利等。
线程池场景题
核心线程数5个,最大线程数设置了10个,队列也设置了10个,现在有并发6个任务来,线程池中有多少个任务?
在您描述的线程池配置下,当有6个并发任务到来时,这些任务的处理情况如下:
- 核心线程数是5,意味着线程池会首先创建5个线程来处理任务。
- 当第6个任务到来时,由于核心线程都在忙,线程池会将这个任务放入队列中,因为队列的大小也是10。
所以,在这种情况下,线程池中会有6个任务:5个任务正在被5个核心线程处理,另外1个任务在队列中等待。线程池并没有达到最大线程数10个,因为当前的任务数量和队列容量还未超过核心线程数和队列的总和。
在您提供的线程池配置下(核心线程数5个,最大线程数10个,队列容量10个),当6个并发任务到来时,线程池不会立即创建10个线程,原因如下:
- 核心线程数优先:线程池首先会使用核心线程来处理任务。核心线程数是5,所以前5个任务会分别由5个核心线程来处理。
- 队列缓冲:当核心线程都在忙碌时,额外的任务会被放入队列中等待,而不是立即创建新的线程。您的队列容量是10,足以容纳当前的第6个任务。
- 按需创建线程:线程池会根据任务的处理速度和队列的饱和度来决定是否需要创建超出核心线程数的线程。在您的例子中,尽管有6个并发任务,但队列还未满,因此没有必要创建额外的线程。
- 最大线程数限制:最大线程数是线程池可以创建的线程数量的上限,但这并不意味着线程池会一开始就创建到这个上限。只有当队列满了,且还有新的任务到来时,线程池才会创建额外的线程(最多达到最大线程数)来处理这些任务。
因此,在您的场景中,当6个并发任务到来时,线程池的操作是:
- 5个核心线程各自处理一个任务。
- 第6个任务被放入队列中等待。
此时,线程池中只有5个线程在运行,队列中有1个任务,总共6个任务。线程池不会创建额外的线程,因为当前的任务数量还未超过核心线程数和队列的总容量。只有当队列满了(即有10个任务在队列中),且还有新的任务到来时,线程池才会考虑创建额外的线程,直到达到最大线程数10个。
get请求和post请求的区别
get请求
- 请求指定的资源。使用GET的目的是获取数据,
- 数据在URL中传输,通过将数据附在URL之后,以查询字符串的形式出现
- 由于数据在URL中可见,因此安全性较低,敏感数据不应通过过GET请求发送
- URL长度限制通常在2000个字符左右,这意味着GET请求能够传输的数据有限
- 可以被缓存,也会被浏览器保存在历史记录中
- 常用于信息查询、数据检索等操作.
post请求
- 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。
- 数据存储在请求体(HTTP消息主体)中,不会密在URL上
- 数据不会出现在URL中,相对更安全,适合传输敏感信息。
- 理论上没有大小限制,适用于传输大量数据.
- 不会被缓存,且不会保存在浏觉器历史记录中
- 常用于数据提交、表单提交等操作
请求行:请求类型 请求方法 url http版本1.1 老式1.0不支持长连接
请求头:key value
常见请求头: 请求数据类型,restful基于json
Content-Type:上传文件不用application 要用 multipart/form-data”
Host:指定请求的服务器的域名和端口号。
User-Agent:包含发出请求的用户代理软件信息,通常包括浏览器类型和版本
请求体:get请求可以有请求体
响应:响应行 响应体 状态码 描述
常见响应头:Content-Type:返回数据的格式 Content-Length:响应体的长度,以字节为单位
post请求也可以用问号的形式拼接到浏览器 也可以用路径参数
很大区别:get一般放在url后面 会展示url和后面参数 会暴露传参隐私 登录接口用post来做 有密码敏感信息
表单、密码、长数据用post 不过怕黑客抓包 相对来说安全
get请求后面传参的大小限制 理论上没有限制 只是浏览器厂商会有限制
get用来查询 post新增提交表单
“GET 和 POST 都是 HTTP 协议中最常用的请求方式,最本质的区别在于数据传输的位置与幂等性,不仅影响安全性和缓存行为,也关系到实际应用场景选择。”
✅ GET 与 POST 请求的对比总结表
项目 GET 请求 POST 请求 作用 查询资源(获取数据) 提交资源(发送数据) 数据位置 URL 参数:拼接在 ?后面,如/user?id=1请求体:放在 HTTP 请求体中 是否显示参数 ✅ 显示(暴露在 URL 中,用户可见) ❌ 不显示(隐藏在 Body 中) 是否安全 ❌ 不安全(敏感信息容易泄露,如明文密码) ✅ 相对安全(但也要注意防止抓包等问题) 参数长度限制 有限制(由浏览器和服务器限制,一般不超过 2KB) 理论上无限制(受服务器配置影响) 是否可缓存 ✅ 可以被缓存 ❌ 默认不可缓存 是否保留历史记录 ✅ 会被浏览器记录 ❌ 不会记录 是否能被收藏为书签 ✅ 可以(URL完整) ❌ 不建议(没有完整 URL 参数) 应用场景 查询、检索、列表展示 提交表单、上传文件、登录、注册 请求幂等性 ✅ 幂等(多次请求结果一样) ❌ 不一定幂等(多次提交可能创建多条数据) 常用请求头 Accept、User-Agent、Host、Authorization等额外使用: Content-Type(如:application/json、multipart/form-data)是否可附带请求体 ✅ 理论支持,但不推荐使用,很多服务端框架默认忽略(如 Spring MVC) ✅ 正常使用请求体(Body)传参 是否支持路径参数 ✅ 支持,如 /user/1✅ 同样支持路径参数和 query 参数(但参数多用 Body 传) 是否可以拼接 ? 参数 ✅ 常用,如 /api?key=123✅ 也可以 /api?token=abc,但数据主体依然建议放在请求体中对缓存友好程度 ✅ 友好,可被浏览器缓存,也可用于 CDN 缓存 ❌ 默认不可缓存(除非通过响应头指定) 在 RESTful 中常用场景 获取资源,如 GET /api/users创建资源,如 POST /api/users,或提交登录等敏感操作冷门但常考 & 实战必备考点
冷门知识点 / 实战经验 说明 GET 请求也可以有请求体 ✅ HTTP 协议允许,但很多框架(如 Spring)不解析,默认忽略 POST 请求也可以拼接 URL 参数 ✅ URL 参数与请求体可同时存在,如: POST /api?type=1+ body 传参浏览器最大 URL 长度限制 ❗ 通常为 2KB~8KB,IE 最小,Chrome 支持更长 POST 也可以被缓存 ❌ 默认不会缓存,但可通过 Cache-Control或自定义缓存策略强制缓存GET 请求一般不能上传文件(除非用 Base64 等特殊形式) 文件上传推荐用 POST + multipart/form-data登录操作必须用 POST 因为 GET 暴露用户名/密码容易被记录,敏感数据必须走 POST + HTTPS 加密传输 GET 请求参数对顺序敏感 某些框架(如部分网关、签名认证)会对 URL 参数顺序敏感,应注意参数顺序一致 Content-Type 区别 - GET 请求常省略或默认 - POST 常设定为: ① application/json ② application/x-www-form-urlencoded ③ multipart/form-data GET 请求会被预检(preflight)吗? ❌ 不会,只有跨域的非简单请求(如 PUT、带自定义头的 POST)才会有 OPTIONS 预检
是否上传过图片
阿里云是最后存储的
完整的上传图片应该:
前端要配合(表单 post提交) Content-Type:上传文件不用application 要用 multipart/form-data” 同一个请求能边上传图片和文本数据
后端的操作:传到后端controller接收,有一个类multipart 专门接收二进制数据 图片视频等,有很多api → get input stream封装util 调用upload上传。中小型企业都用阿里云oss 因为要考虑容灾 地震 容易数据丢失,要考虑备份→集群,服务器有物理硬件上限(要有运维成本),文件维护很专业交给专业的人。阿里云的机房在深圳,广州的人访问会比哈尔滨的更快。光纤受物理限制 越长越有损耗。大型运营商在全国各地都有机房,可以智能判断比如哈尔滨的就去访问黑龙江服务器。CSDN内容分发(收费)
🔧 完整的上传流程
环节 说明 前端 使用 form表单或 Ajax 上传,Content-Type设置为multipart/form-data,支持同时传文本+文件控制器 Spring Boot 使用 MultipartFile类型接收上传文件,可使用.getInputStream()获取内容流上传工具类 将文件流封装上传到第三方云存储,如阿里云 OSS、七牛云、腾讯云等 云存储 云厂商拥有备份、容灾、集群、分发等能力,确保数据安全和访问速度 返回前端 返回上传后的图片 URL 或文件 ID 等信息
前端传过来的图片怎么设置图片大小 有没有什么办法?
思考:为什么后端要限制前端图片传的大小?
大图片 + 多人上传,首先后端要读到jvm内存再二进制流给到阿里云,同时并发有可能超出OM的java内存大小
springboot yml加文件上传大小配置
spring:
servlet:
multipart:
max-file-size: 10MB # 单个文件的最大大小
max-request-size: 20MB # 整个请求的最大大小,包括多个文件的总和
- 读取到 JVM 内存:
- 当前端发送图片文件到后端时,后端服务器需要接收这个文件的数据。
- 在 Java 应用程序中,接收到的文件数据首先会被加载到 JVM(Java 虚拟机)的内存中。这是因为在 Java 应用程序中处理任何数据之前,数据必须先被加载到内存中。
- 二进制流给到阿里云:
- 一旦文件数据被加载到 JVM 内存中,后端服务通常会将这些数据以二进制流的形式上传到云存储服务,比如阿里云的对象存储服务(OSS)。
- 这个过程涉及到数据的读取和写入操作,即从 JVM 内存读取数据,然后写入到云存储服务。
- 并发可能导致内存溢出:
- 如果有多个用户同时上传大图片,后端服务器可能会同时处理多个上传请求。
- 每个上传请求都会占用一部分 JVM 内存。如果上传的图片非常大,且并发请求的数量很多,那么所有请求加起来的内存使用量可能会迅速增加。
- 如果内存使用量超过了 JVM 分配给应用程序的内存大小(即 OutOfMemory,简称 OOM),就会发生内存溢出错误。这种错误会导致应用程序崩溃或者变得不稳定。
- 限制上传大小的重要性:
- 为了防止内存溢出错误,后端通常会限制上传文件的大小。
- 通过限制单个文件的最大大小(
max-file-size)和整个请求的最大大小(max-request-size),可以有效地控制内存的使用,避免因大量并发上传大文件而耗尽服务器内存。前端图片大小如何限制?
✅ 原因:避免后端 OOM(内存溢出)
步骤 原因 上传前 浏览器本地可限制图片大小或压缩(前端 UI 限制) 上传中 设置 multipart/form-data协议后端接收 文件先被加载到 JVM 内存,再传给云服务,大图 + 并发上传 = 高内存占用 限制大小 避免 OOM,保障服务稳定性 ✅ Spring Boot 限制配置
spring: servlet: multipart: max-file-size: 10MB # 单个文件最大10MB max-request-size: 20MB # 整体请求最大20MB(多个文件+字段)控制器代码示例(Java)
@PostMapping("/upload") public String uploadFile(@RequestParam("file") MultipartFile file) { if (file.isEmpty()) { return "上传失败,文件为空"; } try (InputStream inputStream = file.getInputStream()) { // 上传到阿里云OSS的逻辑 String url = ossUtil.upload(inputStream, file.getOriginalFilename()); return "上传成功,访问地址:" + url; } catch (IOException e) { e.printStackTrace(); return "上传失败:" + e.getMessage(); } }冷门但常考的扩展点
知识点 说明 MultipartFile是什么?是 Spring 封装的文件上传类型,内部包含文件名、文件大小、文件流等 同一请求能传图片+文本? ✅ 支持,表单中可同时上传 file+ 文本字段,如商品名、描述阿里云的上传路径建议? 可使用时间戳+UUID组合路径,如: images/2025/07/abc.jpg,防止重复文件覆盖为什么选择 OSS? 专业、安全、弹性扩展、支持 CDN 分发、支持跨区域访问 OSS 上传是否走 JVM? 是的,文件先读入 JVM,再通过 SDK 上传,但也可以优化为直传(前端直传 OSS)减少后端压力 会不会并发导致 OOM? 是的,尤其是大文件 + 并发上传,若不限制上传大小,极易导致内存溢出
你在里面主要负责哪方面的工作?
我之前负责后端开发 也会参与一部分设计工作
开发完会协助测试 和前端进行联调
和组长一起进行测试
和前后端的逻辑基本上都是可以的
上家公司的离职原因,薪资多少,薪资结构
不要说一些面试官能挑刺的理由发展前景?表明上家公司不好太想进步?表名上家公司提供的技术不好 自己技术不好
在上家公司我学习了很多 成长了很多,个人发展原因 ,想要涨薪
// 来自AI的答案 仅供参考
我在上家公司学到了很多,但我觉得为了我的职业发展,我需要寻找一个能够提供更多成长机会和挑战的职位。我想要在[技能/领域]上进一步深耕,而贵公司的职位看起来非常符合我的职业规划;我在上家公司的年薪大约在6000到7000之间;我的薪资结构主要包括基本工资、每年两次的绩效奖金、股票期权以及一些标准福利,比如健康保险、退休金计划等。此外,公司还提供了一些额外的福利,比如灵活的工作时间和远程工作的机会
简历公司
上家公司如果问工作不好找 为什么不先找到再离职?
我在这一块想好好准备面试 但是上班的时间不好分配 我想专心去找工作
上家工作繁忙抽不出时间去准备 所以我想多多准备
若异地公司 → 万能理由:现在面的公司在哪家里人就在哪[地理位置要接近 精确到哪个城市] 异地很多都线下不方便先离职专心准备
薪资多少
现在期望12k 上家最好保证**20%-30%**区间→8-9-10k(参考城市不同)
薪资结构
基本工资(七八成)+绩效工资(20%-30%) 有公司先扣除 有的当月发
A 120% S 150%-200% C 80%
你对上家公司的看法
不能贬低 要说优点 学习成长了很多 同事和领导都很照顾我
什么时候能入职?
三个工作日 到 一周之间
你离职了 现在有多少个offer了?
不能说一个都没有
- 我已经有2个offer 但是一定要表达对当前公司的期待 经过我的了解 我更喜欢贵公司的发展和文化
- 我也是刚刚开始找工作…
你可以接受加班吗
(必须完全接受全部加班 先拿到offer再说)
Controller和RestController的区别
@RestController = @Controller + @ResponseBody
@Controller如果要返回JSON/XML等格式的数据给客户端,必须显式的使用@ResponseBody注解将返回的对象转换为HTTP响应体内容。
@RestController 专门为构建RESTful Web服务设计的控制器。它简化了创建API的过程,因为所有方法默认都会将返回值直接写入HTTP响应体中作为JSON或XML格式的数据。
@Controller可以声明一个类为一个bean 控制器用
@ResponseBody 具体方法和类都可以 不是包装类和字符 都可以自动转成json数据格式 更符合restful风格
“
@RestController是 Spring 为了简化 RESTful 接口开发而推出的复合注解,等价于@Controller + @ResponseBody。它让我们开发 API 接口时无需再为每个方法添加@ResponseBody,所有返回值会自动转换为 JSON 或 XML 格式写入响应体,非常适合前后端分离项目。”
在yaml文件中定义了一些参数,该怎么调用
- 使用 @Value 注解,这是最直接的方式,适用于简单的属性注入。是bean的注解 用${key}还可以用#
${}:用于注入外部配置文件的值。它告诉Spring需要从环境变量、属性文件、系统属性等地方查找相应的值。#{}:用于执行SpEL(Spring Expression Language,Spring表达式语言)表达式。它允许你在注入值时执行一些简单的计算或逻辑。- 如果在多个类里引用 配置多 杂乱 可以写个配置类写一堆的属性 提供get set方法 配置类.get获取到配置
# application.yml server: port: 8080 custom: property: myCustomValue number: 42 enabled: trueimport org.springframework.beans.factory.annotation.Value; import org.springframework.stereotype.Component; @Component public class CustomComponent { // 注入server.port属性 @Value("${server.port}") private String serverPort; // 注入custom.property属性 @Value("${custom.property}") private String customProperty; // 注入custom.number属性,并转换为int类型 @Value("${custom.number}") private int customNumber; // 注入custom.enabled属性,并转换为boolean类型 @Value("${custom.enabled}") private boolean customEnabled; // 使用SpEL表达式来计算值 @Value("#{${custom.number} * 2}") private int doubleCustomNumber; // 使用SpEL表达式来获取环境变量 @Value("#{systemProperties['os.name']}") private String osName; // ... 使用注入的值进行操作 // Getter和Setter方法 // ... }
- 使用 @ConfigurationProperties 注解,通常会指定一个前缀(prefix),这个前缀用于指定配置文件中哪些属性应该被绑定到这个 Bean 上。然后确保主应用程序类或某个配置类上有
@EnableConfigurationProperties(AppProperties.class)注解@ConfigurationProperties(prefix = "prefix")
IOC和DI有了解过吗,它们的好处是什么
它们的目的是为了解耦
IOC(控制反转)是Spring的两大核心之一,DI(依赖注入)
IOC把控制权交给spring容器
对象创建好之后 之间会有依赖关系 DI因此而生
实现方式:DI通常有四种实现方式
IOC 与 DI 总结对比表
概念 IOC(控制反转) DI(依赖注入) 含义 控制权从代码“主动”创建对象,反转给 Spring 容器 Spring 容器将依赖对象“注入”到目标对象中 目标 解耦合,管理对象生命周期和依赖关系 实现 IOC 的核心手段,降低模块耦合度 体现 Bean 由容器统一创建和维护 对象的依赖由容器自动提供 好处 降低耦合、统一管理对象 提高可维护性、扩展性、便于测试 关系 是一种设计思想 是实现方式(IOC 的具体实现手段) IOC & DI 经典解释
- IOC(控制反转) 是一种思想,把原来由开发者手动 new 对象的工作交给 Spring 容器来做,实现对象创建和依赖管理的统一控制。
- DI(依赖注入) 是实现 IOC 的一种方式,即通过注解、构造函数等方式,由容器注入依赖对象。
📌 举个栗子:
类似租房平台,房东提供房子(Bean),中介平台(Spring 容器)统一管理,租客(业务类)不直接找房东,而是由平台分配依赖。
属性注入
注解注入@Autowired是 Spring 提供的注解,用于自动装配 Bean。它可以用于字段、构造函数、方法或设置器上。当 Spring 容器启动时,它会自动查找并注入匹配的 Bean。- 偶尔有不影响程序运行的报错?写spring技术人员是根据jdk写,怕别人不用。
@Resource是 Java 的注解[JDK的],用于依赖注入,它也可以用于字段、方法或设置器上。与@Autowired不同的是,@Resource默认通过名称进行匹配,如果未指定名称,则尝试通过类型进行匹配。- 两者区别
- @Autowired 先根据属性类型 去容器里面找 如果找不到 再根据**属性名称[字段]**去找 如果实在找不到就会报错 [@Autowired永远不会放弃你的 尽其所能去帮你找]
- @Resource 先根据属性名称去找 要么找不到 要么找到一个 找到就去注入 如果找不到 可以再根据属性类型去找 [类型找不到 或者 找到多个 也会报错]
它俩最大的区别是什么?
@Autowired更倾向于按类型注入,如果类型不唯一,则需要指定注入的名称。
@Resource更倾向于按名称注入,如果没有指定名称,则尝试按类型注入。
两者的不同在于默认的注入策略和如何处理不唯一的 Bean 定义。@Autowired和@Resource最大的区别在于它们的默认注入策略和所依赖的注入机制:- 默认注入策略:
@Autowired:默认是按照类型(Type)进行注入的。如果容器中存在多个相同类型的 Bean,则需要通过@Qualifier注解指定具体的 Bean 名称,或者通过设置@Autowired的required属性为false来允许没有找到匹配的 Bean 时不抛出异常。@Resource:默认是按照名称(Name)进行注入的。如果未指定名称,则尝试按类型进行注入。如果容器中存在多个相同类型的 Bean,且没有指定名称,可能会抛出异常。
- 依赖的注入机制:
@Autowired:是 Spring 框架提供的注解,因此它只能用于 Spring 管理的上下文中。@Resource:是 Java 的扩展包(javax.annotation)提供的注解,它是 JSR-250 规范的一部分,因此可以在任何实现了 JSR-250 规范的容器中使用,不仅限于 Spring。
简而言之,最大的区别在于
@Autowired更侧重于类型匹配,而@Resource更侧重于名称匹配,并且@Resource是 Java 标准的一部分,具有更广泛的适用性。@Autowired vs @Resource 区别总结表
特性 @Autowired@Resource提供方 Spring JDK(JSR-250) 默认注入方式 按类型(byType) 按名称(byName) 是否支持按类型注入 ✅ 支持 ✅ 支持(次选) 是否支持按名称注入 ✅ 需搭配 @Qualifier✅ 默认 是否推荐 ✅ 推荐 ⚠️ 部分场景适用 可用位置 构造方法、字段、方法 字段、方法 是否支持多个构造方法 ❌ 不能多个都加 @Autowired ❌ 同理 ✅ 开发建议
场景 建议 只有一个依赖对象 优先使用构造器注入,语义清晰 需要注入多个依赖 使用字段注入或构造器注入 对依赖可选性较强 可考虑 setter 或普通方法注入 想确保更强约束性 使用构造器注入(+final属性) “IOC 是一种反转控制权的思想,由 Spring 容器来统一管理对象的创建和依赖;而 DI 是实现 IOC 的手段,通过构造器、属性等方式将依赖对象注入到类中。它们的最终目的是为了解耦,提高代码的可维护性和扩展性。开发中常用
@Autowired和@Resource实现属性注入,构造器注入则更具可读性和测试友好性。”构造函数注入 [默认生成空参构造方法 若写有参构造原来无参会被覆盖 参数根据类型去找和
@Autowired类型一样 可以写多个构造方法 如果去多个构造方法重载会报错 怎么办?加个@Autowired[属性,构造方法,参数]都可加不可多个方法都加@Autowired 反射会触发构造方法 @Bean => new ]public class MyService { private DependencyA dependencyA; private DependencyB dependencyB; // 构造函数注入 @Autowired public MyService(DependencyA dependencyA) { this.dependencyA = dependencyA; } // 另一个构造函数 @Autowired public MyService(DependencyB dependencyB) { this.dependencyB = dependencyB; } // ... 其他方法 ... } ///////////////////////////////////////////////////// 在上面的例子中,由于有两个构造函数都使用了 @Autowired 注解,Spring 将无法确定使用哪一个构造函数,因此会抛出异常。要解决这个问题,你应该只在一个构造函数上使用 @Autowired 注解。Set方法注入[原生spring 用xml去定义才有 SpringBoot没有这个注入 ]
public class MyService { private DependencyA dependencyA; // Set 方法注入 @Autowired public void setDependencyA(DependencyA dependencyA) { this.dependencyA = dependencyA; } // ... 其他方法 ... } ////////////////////////////////////////////////////// 在 Spring Boot 中,虽然不常用 XML 配置,但是你仍然可以通过注解来实现 Set 方法注入。普通方法注入
public class MyService { private DependencyA dependencyA; // 普通方法注入 @Autowired public void init(DependencyA dependencyA) { this.dependencyA = dependencyA; } // ... 其他方法 ... } ////////////////////////////////////////////////////// 普通方法注入指的是在类中的任意非构造函数方法上使用 @Autowired 注解
测试过程有没有出现反复的困扰?
客户需求频繁更改
测试用例没有覆盖到
开发和测试环境未协调
太复杂的改动要先报备技术经理、项目经理
测试:自测 单元测试 专业人员
公司使用哪些技术?
后端:Redis RabbitMQ 搜索引擎 微服务常用组件 远程调用 统一网关 Springboot Springcloud MybatisPlus
项目有多少个成员?
2前 8后 1测 1运维 1项目经理(小公司约13人左右) 要具体人数
自研公司?外包?
自研公司:
- 创业型自研公司:通常员工人数在10-50人之间,初期可能更少,只有几人到十几人。
- 成熟自研公司:员工人数可能从几十人到几百人甚至更多。
外包公司:
- 小型外包公司:员工人数可能在10-50人之间。
- 中型外包公司:员工人数可能在50-200人之间。
- 大型外包公司:员工人数可能超过200人。
HashMap底层原理
底层数据结构
jdk1.8之前底层结构是数组+链表(key+value) 数据结构通用的[键值对+哈希表的数据结构]
jdk1.8以后【数组+链表+红黑树】在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时且数组长度大于64时,将链表转化为红黑树,以减少搜索时间。扩容时,红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表。后期使用map获取值时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
底层的地址运算出来 如果地址不一样计算出来的hashcode不一样,hashcode一般是数字[整数(±或0)] 通过key进行hashcode运算 对数组长度取模 eg:任何整数去取模10 可以定位到value可以放在哪个桶下面
hashcode本身不同的对象算出来的hashcode值是相同的怎么办呢?
两个value不可能放在同一个桶 这就是hash冲突 如果数组长度是8 算出来一个hashcode值是8 和 16 此时取模余数相同这样的情况也是相同。所以此时应该用拉链法[小葡萄串],即使桶一样 可以用指针一个个指,此时的链表是单向链表[linkedlist才是双向链表]。
在1.8后指出如果同一个桶的葡萄串太多了,此时要拿出数据,时间复杂度就是O(n),如果没有很多就是O(1)数组的长度。红黑树的引入是解决链表过长的问题。
红黑树是树形的高级数据结构 时间复杂度O(logn)
二叉树在某些情况下会退化成链表 右子树永远比根节点大
红黑树会旋转自平衡[局部旋转达到平衡] 超过多少层会旋转 不至于退化成链表。
拉链法(Chaining)是 Java 的
HashMap在 JDK 1.8 之前以及之后都使用的一种解决哈希冲突的方法。在 JDK 1.8 之前,HashMap的实现主要是基于拉链法,即使用链表来解决哈希冲突。当不同的键通过哈希函数计算出相同的哈希码,并且映射到同一个桶(bucket)时,这些键值对将以链表的形式存储在同一个桶中。在 JDK 1.8 中,
HashMap的实现进行了改进,当链表的长度超过一定阈值(默认是 8)时,链表会被转换成红黑树。这是为了优化哈希表的性能,特别是当哈希冲突严重时,链表的查询效率会降低到 O(n),而红黑树可以将查询效率提升到 O(log n)。红黑树如何避免哈希冲突
红黑树本身并不直接解决哈希冲突,而是优化了哈希冲突发生后的数据结构。以下是红黑树在
HashMap中是如何工作的:
- 哈希冲突:当不同的键产生相同的哈希码或经过取模运算后落在同一个桶时,就会发生哈希冲突。
- 链表:在 JDK 1.8 中,如果桶中的元素少于一定数量(默认为 8),就会使用链表来存储这些元素。
- 红黑树转换:当链表的长度超过阈值(默认为 8)时,并且数组的长度超过 64,链表会被转换成红黑树。这样可以减少查找时间,因为红黑树是一种自平衡的二叉搜索树。
- 自平衡:红黑树通过旋转和重新着色操作来保持树的平衡,从而避免了二叉搜索树退化成链表的情况。
红黑树的旋转和自平衡
红黑树通过以下规则保持平衡:
- 节点颜色:每个节点要么是红色,要么是黑色。
- 根节点:根节点是黑色的。
- 红色规则:如果一个节点是红色的,则它的子节点必须是黑色的(不能有两个连续的红色节点)。
- 黑色高度:从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
当插入或删除节点时,可能会破坏这些规则,此时红黑树会通过以下操作来重新平衡:
- 左旋转:当右子节点是红色,而左子节点是黑色或不存在时,进行左旋转。
- 右旋转:当左子节点是红色,并且它的左子节点也是红色时,进行右旋转。
- 重新着色:在某些情况下,通过改变节点颜色来维持红黑树的性质。
通过这些操作,红黑树确保了即使在最坏的情况下,树的高度也不会超过 2log(n+1),从而保证了 O(log n) 的时间复杂度。
总结来说,红黑树并不直接解决哈希冲突,而是优化了哈希冲突后的数据结构,使得即使在发生大量哈希冲突的情况下,
HashMap的性能也不会显著下降。
扩容机制
new的初始化 数组为空
当第一次put的时候才不会为空 为16
扩容因子为什么是0.75?hashmap不仅仅java 其他语言也有这种数据结构 但扩容因子可能不同,是通过大量的数学概率统计出的最好最平衡的值。达到12的时候会扩容成2倍
new一个hashmap可以指定数组长度为7 此时数组长度是8【hashmap的长度永远是2的幂次方 比你传入的长度永远大 且 是2的幂次方】 为什么2的幂次方?因为1.7要数组取模 怎么打这个符号 shift+5 => %,1.8之后用了位运算,>>2 <<2 让你的取模运算更快。如果出现hash冲突会拉链 当它的数组长度大于64 并且 链表长度大于8时,当链表长度小于等于6临界值会变回来【为什么是6?避免频繁切换(离8太近) 链表 ←→ 红黑树[消耗性能]】
链表1.7之前是头插法 会产生一条首尾相接的死循环【并发情况[但是hashmap线程不安全不会用在并发,要用ConcurrentHashMap]一起put 且 同一个桶】
1.8之后是尾插法,并发情况下不会出现cpu飙高
HashSet底层数据结构
底层是包装了一个hashmap,无序 key不允许重复 value可重复
HashSet单列无序不重复的 key就是那个元素 value就是new了一个无意义的object对象
ArrayList和LinkedList不是线程安全的 用什么?
- Vector 读写都加锁。
- CopyOnWriteArrayList 读不加锁 写加锁
ConcurrentHashMap能存null吗?不允许使用 null 作为键,但是允许使用 null 作为值。
HashMap:null默认放在第一个桶下面 下标写死为0
Hashcode相同equals一定相同吗?
hashCode() 相同不一定意味着 equals() 相同,但 equals() 相同则 hashCode() 必须相同。
equals()方法用于判断两个对象是否逻辑上相等。hashCode()方法用于返回对象的哈希码,这个哈希码通常用于哈希表的快速查找。
key可以放复合对象,要注意要重写 hashcode()和equals() 如果不重写 new了的两个对象有可能会相同"重地" 和 "通话" 。计算hashcode会比equals更快,一个对象new出来后hashcode已经计算出来了。equals要比较每个对象值,所以先判断hashcode 再判断equals 重写:@Override 用属性里面的hashcode,user里面包含了复杂对象order 此时order也要重写。包装类已经重写了hashcode,要整个对象返回true才为正确的,要层层递进去判断。hashmap重写复杂对象就一定要重写那俩个 ∵ 是比较对象里的属性值
list 有序可重复单列
map 双列key不能重复value可重复 treemap是有序的
set 单列不重复无序 hashset 无序 treeset 有序
== 值 + 地址值
equals 是对象属性值是否一 一相等
hashCode()与equals()总结对比表
比较项 hashCode()equals()作用 返回对象的哈希值 判断两个对象是否“逻辑相等” 定义位置 Object类中定义,可被重写同上 默认行为 返回对象内存地址的整数表示 比较是否为同一对象(地址) 需要重写的场景 自定义对象作为集合的 key(如 HashMap、HashSet)自定义对象需要逻辑比较 是否与对象属性有关 默认无关,重写后应有关 重写时应只关心关键属性 性能 高效(整型值) 慢(逐个属性比较) 二者关系说明(核心规则)
判断 是否成立 equals()返回true→hashCode()必须相等✅ 必须成立 hashCode()相等 →equals()不一定相等⚠️ 可能不成立(哈希冲突) 👉 这就是为什么 HashMap 在比较 key 时,先比
hashCode(),再比equals(),为了提升性能,也确保正确性。String s1 = "重地"; String s2 = "通话"; System.out.println(s1.hashCode()); // 输出1179395 System.out.println(s2.hashCode()); // 输出1179395 System.out.println(s1.equals(s2)); // false⚠️ 两个字符串的
hashCode()相同,但equals()不相同,说明它们逻辑上不相等(只是哈希冲突)。✅ 为什么要重写
hashCode()和equals()?如果你将自定义对象用作集合中的 key(如放入
HashMap或HashSet),那么:
- 不重写:默认使用地址判断,相同内容的新对象视为不同
- 正确重写:按属性判断内容一致性,可识别“逻辑相同”的对象
public class User { private String name; private int age; @Override public boolean equals(Object o) { if (this == o) return true; if (!(o instanceof User)) return false; User other = (User) o; return this.age == other.age && Objects.equals(this.name, other.name); } @Override public int hashCode() { return Objects.hash(name, age); } }
equals()用于判断两个对象是否逻辑相等,hashCode()用于加快集合查找效率。在实际开发中,若你要将对象作为HashMap或HashSet的 key,必须同时重写这两个方法,保证逻辑一致性,避免出现“相等的对象进不了集合”的问题。
HashMap是线程安全的吗
不安全的,可以使用ConcurrentHashMap线程安全、Collections.synchronizedMap()、HashTable
线程安全:多线程对同一个数据进行增删改是否受到影响
怎么办?
加锁
- synchronized
- ReentrantLock
加锁为什么能解决线程安全问题?线程访问资源的先后顺序
多线程访问同一个数据 => 多个线程访问同一个数据
秒杀 =>[思想] 1w个人买 对 100个库存进行扣减,只搞100个线程 把100个库存分成10份 其中每份有10个初始化库存: 创建一个共享的库存计数器,初始值为100。 创建线程: 创建100个线程,每个线程在启动时分配到一个特定的库存分片。 扣减库存: 每个线程尝试扣减其分配到的库存分片中的一个商品。扣减操作必须是原子的,以确保线程安全。 同步机制: 使用适当的同步机制(如synchronized关键字、ReentrantLock等)来保护库存扣减操作,防止并发问题。 库存检查: 在扣减前,线程需要检查当前分片是否有剩余库存。如果没有,则线程可以终止或进行其他处理。HashTable不管读写都会用synchronized加锁,并发一起来读都加锁 没必要,所以用了ConcurrentHashMap读不加锁 写加锁。
随着时间的推移,Hashtable已经被认为是遗留代码,现代Java代码更倾向于使用HashMap(非线程安全)或ConcurrentHashMap(线程安全)。
Synchronized
public class SynchronizedExample { public synchronized void synchronizedMethod() { // 这里是同步代码块 System.out.println("进入同步方法"); // 执行一些操作 System.out.println("退出同步方法"); } } ----------------------------------------------------- public class SynchronizedBlockExample { private final Object lock = new Object(); public void synchronizedBlock() { synchronized (lock) { // 这里是同步代码块 System.out.println("进入同步代码块"); // 执行一些操作 System.out.println("退出同步代码块"); } } }ReentrantLock
import java.util.concurrent.locks.ReentrantLock; public class ReentrantLockExample { private final ReentrantLock lock = new ReentrantLock(); public void lockedMethod() { lock.lock(); // 加锁 try { // 这里是同步代码块 System.out.println("进入锁定的方法"); // 执行一些操作 System.out.println("退出锁定的方法"); } finally { lock.unlock(); // 解锁 } } }
红黑树查询效率高的原因
红黑树是一种自平衡的二叉搜索树,它通过特定的规则来保持树的平衡,这些规则确保了树的高度大约是log(n)
自平衡 局部旋转
hashMap时间复杂度
- O(1):不涉及到拉链
- O(n):拉链不是树
- O(logn):桶为红黑树
这个测试是你做的吗,还是你们团队去做的?
像自测的话是我自己去做的(测试用例、apifox),然后交给专业测试人员
团队是怎么协作的?
像我们团队的话,有使用禅道来做我们的文档管理,需求管理和需求的变更控制,和工作的一个统计报表,大部分的协作任务都可以在禅道上完成,代码这一块我们是使用git来做一个代码管理和协作的。
linux查看每个文件夹下的文件大小的命令
ls -lh
linux查看文件夹大小的命令
du -sh
du -sh –all 隐藏
du -sh ./* : 单独列出各子项占用的容量
linux查看进程的命令,动态查看一个文件的最后100行的命令
ps -ef
ps aux [查看所有用户的进程(包括其他用户的进程):]
ps -ef | grep mysql
动态:tail -n 100 -f xxx 【-f → follow】
静态:tail -n 100 xxx
常用的Linux命令
rm = romove
用于删除文件和目录
rm [-rf] name
-r(recursive递归):将目录及目录中所有文件(目录)逐一删除,即递归删除
-f(force):无需确认,直接删除
rmdir = remove directory
它用于删除空目录。如果目录不为空,即目录中包含文件或其他子目录,rmdir 命令将无法删除该目录
pwd = print working directory
打印出当前工作目录的绝对路径。当你需要知道你在文件系统中的当前位置时,这个命令非常有用
cp = copy
复制文件和目录。这个命令可以用来创建文件的副本或将文件从一个位置移动到另一个位置。
cp [-r] source dest
-r (recursive递归):如果复制的是目录需要使用此选项,此时将复制该目录下所有的子目录和文件
mv = move
为文件或目录改名、或将文件或目录移动到其他位置【移动 重命名 修改】
grep
用于搜索文本数据,特别是使用正则表达式来匹配指定的模式
查看特定进程的详细信息,例如进程名为 mysql
ps -ef | grep mysql
tar [tape archive]
用于打包多个文件和目录到一个归档文件中,或者从归档文件中提取文件
cd
切换路径
vim
编辑文件
cat
查看文件[head]
如何查日志
查看/var/log/user.log文件,并且想要跟踪用户 name:pcy 的活动
tail -f /var/log/user.log | grep “pcy”
高级专用使用:awk 可以用正则等一些逻辑操作去获取日志
内建函数
awk非常强大,可以用于执行复杂的文本分析和报告生成,awk有许多内建函数,如length()、toupper()、tolower()等。awk '{print toupper($0)}' filename # 将所有内容转换为大写条件语句
awk '{if ($1 > 100) print$1}' filename循环
awk '{for (i=1; i<=NF; i++) print $i}' filename数组
awk '{count[$1]++} END {for (word in count) print word, count[word]}' filename
你们接口是如何让前端调用的
我们会在设计阶段提前设计好给前端 并行开发 前后端联调[本地ip端口告诉前端]
接口文档怎么定下来的
根据页面原型、需求设计接口文档[后端自己写],绝大部分后端看原型的出参入参 无太大需求和前端商量。【前端组件库】[若修改返回结构的时候] [按照数据结构修改] 需要听前端意见
前端调用后端用的是什么请求方式
WebSocket【基于长连接通讯】
HTTP
前端开发中,以下是一些常见的使用场景:
- 获取数据:使用GET请求。
- 提交表单或数据:使用POST请求。
- 更新资源:使用PUT或PATCH请求。
- 删除资源:使用DELETE请求。
前端可以通过多种方式发起这些请求,例如:
- 使用HTML表单(通常用于GET和POST请求)。
- 使用JavaScript的
XMLHttpRequest对象或者更现代的fetchAPI来发起各种类型的HTTP请求。- 使用各种前端框架和库(如React, Angular, Vue.js)中提供的封装好的HTTP服务。
SpringBoot主要的一些注解?都有哪些,以及主要作用
SpringBoot:
@SpringBootApplication [见↓↓]
@ConfigurationProperties:注解用于将外部配置(如来自properties文件、YAML文件或环境变量)绑定到JavaBean上。它的作用是将配置文件中的属性映射到JavaBean的属性上,这样就可以在应用程序中使用这些配置属性。
@SpringBootTest:用于测试 Spring Boot 应用,提供测试环境的支持
@EnableConfigurationProperties:启用对配置属性的支持,允许将配置文件中的属性注入到 bean 中。
Spring:
@Component
@ComponentScan
@Conditional
@SpringBootApplication 是一个组合注解,它结合了以下三个注解的功能:
1. @SpringBootConfiguration: 表示这是一个Spring Boot配置类,它本质上是一个@Configuration注解,用于定义配置类,可以包含多个@Bean注解的方法。
2. @EnableAutoConfiguration: 告诉Spring Boot基于类路径设置、其他bean和各种属性设置来添加bean。例如,如果你添加了spring-webmvc和thymeleaf的依赖,这个注解就会自动配置你的应用程序为一个web应用程序。
3. @ComponentScan: 告诉Spring在包及其子包下扫描注解定义的组件(如@Component, @Service, @Repository等)。
aop在项目中有没有使用?aop使用的一些注解及其功能
一定要描述项目场景,web使用aop打印操作日志、使用aop做数据脱敏(150***8786)
过滤器是Servlet技术的一部分,它是Java EE规范的一部分
拦截器是Spring MVC框架的一部分,用于在处理HTTP请求时拦截控制器方法调用。
AOP底层是动态代理设计模式,在理论上效果在一定程度上相同
过滤器拦截器一般拦截某个web的前后,在controller执行前后
AOP是万物皆可拦截、甚至接口和类都可以切,可以增强controller、service、mapper……
定义一个切面类 @Aspect 声明为切面类 + @Component
定义切点 @Pointcut 声明切点表达式
eg:@AfterReturning(pointcut = “execution(public String com.example.yourpackage.Controller.*(..))”, returning = “result”)
通知
- 前置 @Before
- 后置 @After
- 返回 @AfterReturning
- 异常 @AfterThrowing
- 环绕 @Around
💬 有没有在项目中使用 AOP?用来做什么?
有使用,主要应用场景有两个:
- 一是 操作日志记录:在 Web 项目中,我们通过 AOP 拦截 Controller 层方法,在方法执行后记录操作人、操作类型、接口路径等信息,用于审计和排查问题。
- 二是 数据脱敏处理:在某些返回值中包含手机号、身份证等敏感字段,通过 AOP 拦截 Service 返回结果,在返回给前端前进行统一脱敏(如:150***8786)。
@Aspect @Component public class LogAspect { // 定义切点,拦截所有 controller 包下的方法 @Pointcut("execution(* com.example.controller..*(..))") public void controllerPointcut() {} // 环绕通知 @Around("controllerPointcut()") public Object doAround(ProceedingJoinPoint joinPoint) throws Throwable { long start = System.currentTimeMillis(); try { return joinPoint.proceed(); } finally { long end = System.currentTimeMillis(); System.out.println("接口耗时:" + (end - start) + "ms"); } } }🧠 AOP 通知类型简述(答题建议)
通知类型 注解 说明 前置通知 @Before在方法执行前执行 后置通知 @After方法执行后(无论成功或异常) 返回通知 @AfterReturning方法成功返回后执行,可获取返回值 异常通知 @AfterThrowing方法抛出异常后执行 环绕通知 @Around方法执行前后都可执行,适合统一处理(如 try…finally) 你在项目中遇到的 AOP 注意事项
- 如果你在 AOP 中使用
ThreadLocal(如存储登录用户信息),一定要在方法执行完后调用remove()释放资源,否则可能造成内存泄漏。- 推荐使用
@Around+try-finally模式,无论是否抛异常,finally 都能执行,比如清理上下文。@AfterReturning:仅在方法成功返回时执行,不会处理异常情况,这一点面试常考。- AOP 是基于 动态代理机制(JDK 或 CGLIB),本质是对方法的增强。和拦截器、过滤器最大的不同是:AOP 不是仅限于 HTTP 请求,可以增强任意 Bean 的任意方法。
你在公司里负责的内容
想在controller访问完之后,想在aop实现之后再进行操作
UserThreadLocal 在执行完之后要 remove 出去,抛异常也会执行
@After 不管有无异常都会执行
@Around 结合try…catch…finally 里也可以达到同样效果
@After:这个注解用于定义一个通知(Advice),它在目标方法执行之后执行,无论目标方法执行的结果如何(成功或异常)。
@Aspect
@Component
public class AroundFinallyAspect {
// 定义切点
@Pointcut("execution(* com.example.yourpackage.controller..*(..))")
public void controllerMethods() {
}
// 环绕通知
@Around("controllerMethods()")
public Object aroundAdvice(ProceedingJoinPoint joinPoint) throws Throwable {
Object result = null;
try {
// 在目标方法执行之前执行
result = joinPoint.proceed(); // 执行目标方法
// 在目标方法成功执行之后执行
} catch (Throwable e) {
// 在目标方法抛出异常时执行
throw e; // 可以选择处理异常或者重新抛出
} finally {
// 无论目标方法是否成功执行或者是否抛出异常,这里的代码都会执行
performFinallyAction();
}
return result;
}
private void performFinallyAction() {
// 在这里放置最终要执行的代码
}
}
--------------------------------------------------------------------------------
// 后置通知
@After("execution(* com.example.service.*.*(..))")
public void afterAdvice(JoinPoint joinPoint) {
// 在目标方法执行之后执行的逻辑
}
// 返回后通知
@AfterReturning(pointcut = "execution(* com.example.service.*.*(..))", returning = "result")
public void afterReturningAdvice(JoinPoint joinPoint, Object result) {
// 在目标方法成功执行并返回结果后执行的逻辑
}
在第一个例子中,你直接在@After注解中指定了切点表达式,因此不需要额外的pointcut属性。
对于@AfterReturning注解,它不仅需要在目标方法执行之后执行通知,还需要访问目标方法的返回值。因此,@AfterReturning注解有一个额外的pointcut属性,用于指定切点表达式。此外,@AfterReturning注解还有一个returning属性,用于指定一个参数名,该参数将接收目标方法的返回值
@AfterReturning:在方法执行后返回结果后执行通知。【如果有异常不会处理】
我来帮你通俗一点梳理这段 AOP 的使用逻辑和运行机制,你可以类比成“程序在运行到某个点的时候,会自动执行你预设的增强代码”。
✅ 举个例子你就明白了:
你写了个 Controller:
@RestController public class TestController { @GetMapping("/hello") public String hello() { System.out.println("正在执行业务逻辑"); return "Hello World"; } }⚙️ 当你访问
/hello,Spring 执行流程如下:
步骤 内容 1️⃣ 执行你的 AOP 中 @Around方法(aroundAdvice)2️⃣ joinPoint.proceed()触发目标方法(即hello())执行3️⃣ 方法返回或抛异常,finally 一定会执行 4️⃣ AOP 把最终返回值交回 Spring 继续响应前端 ✅ 补充理解:execution 表达式
你这个表达式:
execution(* com.example.yourpackage.controller..*(..))
*:匹配所有返回值类型com.example.yourpackage.controller..*:匹配该包及子包的所有类*:匹配所有方法(..):匹配任意参数类型和个数🧠 所以可以理解成:**”凡是 controller 包下的任何方法,AOP 都要插手”**
你就是告诉 Spring AOP:“当你运行到这些方法时,先来找我执行一些额外操作”,这就是切面增强的精髓。
你们这个项目怎么技术选型的
我进到项目中很多已经确认下来的 一般由组长确定了
那你自己怎么想的?[开放性问题]
选xxx技术 网上资料/备书 比较多可以参考[用的人多]
学习成本[框架厉害但上手复杂不好用]
社区的活跃度[官网持续更新版本 框架会不断发展]
你处于后端的什么位置
初级 中级 高级
中级 骨干开发位置[协助组长完成]
中高级 完成设计类
你对你的职业规划是什么
讲实际的话
想成为高级开发/某个领域的专家
提前了解公司领域,有备而来
java基本类型

short 可以占两个字节 可以用16位
int 可以占四个字节 -21亿 ~ 21亿
long 可以占八个字节 天文数字
float 可以占四个字节 0.2F/f
double 可以占八个字节 0.2D/d
float double尽量不要进行运算 ,在Java中进行金钱运算时,应当特别注意浮点数的精度问题,因为浮点数(如float和double)在表示某些数值时可能会丢失精度,这对于需要精确计算的金融计算来说是非常不合适的。
1.金钱转成分 向下取整
2.BigDecimal
ASCII码占1个字节 → Unicode字符占2个字节【有些汉字存不了】→ UTF-8占1-3个字节[灵活可变]
在我们性能中一般走Unicode编码性能更高一点 在网络中/存入磁盘Unicode转成ASCII码
jdk?之后 jdk开始存储大量英文和数字 String类也作了更新 不是基于基本数据类型 而是基于byte数组
在Java的早期版本中(例如JDK 1.4及之前版本),String类内部确实使用char数组来存储字符串数据。每个char在Java中占用16位(2个字节),这意味着不管存储的是英文字符还是数字,每个字符都会占用2个字节的内存空间。
从JDK 5开始,Java平台引入了一些变化,但String类的内部表示仍然基于char数组。直到JDK 6和JDK 7,String类的内部表示并没有改为基于byte数组。
真正发生变化的是在JDK 9中,String类内部表示从char数组转变为byte数组加上一个编码标识(coder),这种改变是为了更有效地存储只有ASCII字符的字符串。ASCII字符只需要一个字节来表示,因此使用byte数组可以节省内存空间。当字符串包含Unicode字符时,String类可能会使用更多的编码方式,例如LATIN1或UTF-16。
Vue的生命周期
生命周期的八个阶段:每触发一个生命周期事件,会自动执行一个生命周期方法(钩子)
- beforeCreate创建前
- created创建后
- beforeMount载入前
- mounted挂载完成
- beforeUpdate数据更新前
- updated数据更新后
- beforeUnmount组件销毁前
- unmounted组件销毁后
String是基础类型吗
不是,是java.lang下的类
String 在 Java 中并不是基础类型,而是一个引用类型。因为 String 是一个类,所以它是引用类型,意味着当我们声明一个 String 变量时,你实际上是指向一个 String 对象的引用
String 的特性
不可变性:String 对象一旦创建就不能被修改。任何改变 String 内容的操作都会创建一个新的 String 对象。
线程安全:由于 String 的不可变性,它们是线程安全的,可以自由地在多个线程之间共享。
字符串池:为了提高性能和减少内存使用,Java 为 String 提供了字符串常量池(String Pool)。当创建一个新字符串时,如果字符串池中已经存在相同内容的字符串,则会返回池中的实例,而不是创建新的对象。
java集合中list和set的区别?
都是接口 某个实现类
单链 有顺序 可重复 有索引[有下标]
单链 不可重复 无索引[无下标] 不能说是无序 因为TreeSet有序 HashSet就是无序的
做了几年开发呢? 实际几个项目?
三年[初中级] → 四~五个项目
你觉得敲代码最重要的是什么?
理解需求、前期设计工作[数据库、接口 → 流程图(思路清晰)]、编码阶段[考虑方法封装、注释、考虑代码后期和维护性(设计模式 → 可维护性+扩展性)]、编码风格[阿里巴巴规范]
你的项目有上线吗? 多少人进行开发? 你主要负责后端吗?
有,介绍一下项目组成结构,是的[再问再回答]
SpringBoot的自动装配原理[启动过程中的一部分]SpringBoot启动原理&&如何内嵌外部原件
Spring Boot的自动装配原理是基于Spring框架的IoC(控制反转)和DI(依赖注入)的核心概念,并结合了一系列的约定和条件注解来实现配置类的自动加载和Bean的自动注册
- 启动类:Spring Boot 应用通常有一个带有
@SpringBootApplication注解的启动类。这个注解是一个组合注解,它包含了@Configuration、@EnableAutoConfiguration和@ComponentScan。- @EnableAutoConfiguration:这个注解是自动装配的关键。它告诉 Spring Boot 根据类路径下的类、Bean 的定义以及各种属性设置,自动配置 Spring 应用。这个注解会导入
AutoConfigurationImportSelector类,该类会读取所有spring.factories文件中的EnableAutoConfiguration条目,并将它们作为配置类导入。- 条件化配置:Spring Boot 使用
@Conditional注解及其一系列的派生注解(如@ConditionalOnClass、@ConditionalOnMissingBean等)来确保只有在满足特定条件时,配置类或 Bean 才会被创建。- 配置类:自动装配是通过一系列的配置类来实现的,这些配置类包含了
@Bean方法,用于创建和配置 Spring 容器中的 Bean。
自定义Starter
<!-- Maven项目的依赖示例 -->
<dependency>
<groupId>com.xxx</groupId>
<artifactId>xxx-spring-boot-starter</artifactId>
<version>1.0.0</version>
</dependency>
三大优点:依赖Maven特性[依赖传递] 自动配置 内嵌Tomcat
Spring Boot的自动装配原理是
在src/main/resources/META-INF目录下创建spring.factories文件,添加自动配置类的全限定名
我们可以在-info定义spring.factories位于META-INF目录下,Spring Boot使用它来发现和加载自动配置类。
配置类扫描: 通过@SpringBootApplication注解,Spring Boot会触发对@EnableAutoConfiguration注解的处理,该注解会查找spring.factories文件中定义的自动配置类。
Maven里面写test类 用configuration声明 写很多的test类 但是我可以自己写test类然后调不同的方法 应该怎么办?@Conditional[Spring的注解] → 做成非常灵活的 如果没有就用自己写的
Spring里面的事务传播行为
在Spring框架中,事务传播行为定义了事务方法之间的调用关系,即一个事务方法被另一个事务方法调用时,事务应该如何传播。
- REQUIRED(默认值) required
- 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
- SUPPORTS supports
- 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务方式执行。
- MANDATORY mandatory
- 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
- REQUIRES_NEW requires_new
- 创建一个新的事务,如果当前存在事务,则挂起当前事务。
- NOT_SUPPORTED not_supported
- 以非事务方式执行操作,如果当前存在事务,则挂起当前事务。
- NEVER never
- 以非事务方式执行,如果当前存在事务,则抛出异常。
- NESTED nested
- 如果当前存在事务,则在嵌套事务内执行;如果当前没有事务,则行为类似于
REQUIRED。
- 如果当前存在事务,则在嵌套事务内执行;如果当前没有事务,则行为类似于
REQUIRED:通常用于方法需要在一个事务中运行,但如果已经有一个事务在运行,那么它应该加入这个事务。
SUPPORTS:用于方法不需要事务上下文,但如果已经在一个事务中,它也可以在这个事务中运行。
MANDATORY:用于方法必须在事务中运行,如果没有事务,则会抛出异常。
REQUIRES_NEW:用于方法必须在自己的新事务中运行,即使当前已经有一个事务在运行。
[一般适用于不管有没有抛出异常 都要记录某些操作日志 不能在同一个类里底层是动态代理]
[如果a()和b()方法在同一个类中,并且a()直接调用b(),那么Spring的事务代理无法拦截这个内部调用,因此b()的REQUIRES_NEW事务传播行为不会生效。这是因为内部方法调用不会通过代理,而是直接在同一个对象实例上调用。]import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import org.springframework.transaction.annotation.Transactional; import org.springframework.transaction.annotation.Propagation; @Service public class MyService { @Autowired private MyService self; // 注入自身代理实例 public void methodA() { // ... 业务逻辑 ... self.methodB(); // 通过代理实例调用,事务注解将生效 } @Transactional(propagation = Propagation.REQUIRES_NEW) public void methodB() { // ... 业务逻辑 ... } }NOT_SUPPORTED:用于方法不应该在事务中运行,如果有一个事务在运行,它将被挂起。
NEVER:用于方法绝对不应该在事务中运行,如果有一个事务在运行,将抛出异常。
NESTED:用于方法应该在嵌套事务中运行,嵌套事务可以独立于外部事务进行提交或回滚Spring 事务传播行为对比表
传播行为 是否加入当前事务 当前无事务是否新建事务 当前有事务是否挂起原事务 常见用途 / 场景举例 REQUIRED(默认) ✅加入 ✅新建 ❌不挂起 大多数业务逻辑,默认即可(如用户下单) SUPPORTS ✅加入 ❌不新建,直接运行 ❌不挂起 非核心操作,事务可有可无(如查询、打日志、非敏感接口) MANDATORY ✅加入 ❌不新建 → 报错 ❌不挂起 强依赖事务环境,如在已有事务内强制做某个操作(如审计组件) REQUIRES_NEW ❌不加入 ✅新建 ✅挂起原事务 日志记录、补偿事务等。如主逻辑回滚了,日志也必须写入数据库 NOT_SUPPORTED ❌不加入 ✅以非事务运行 ✅挂起原事务 第三方接口调用、不能用事务的场景(如读库压力大,必须立即返回) NEVER ❌不加入 ✅以非事务运行 ❌不挂起 → 如果有事务 → 报错 严禁事务场景,例如你调用了一个只能在无事务环境下工作的接口 NESTED ✅作为嵌套事务 ✅新建(嵌套) ❌不挂起 子事务失败可以单独回滚但主事务不影响(例如更新多个模块,一个失败不影响其他) 🧠 快速记忆技巧
记忆关键词 说明 REQUIRED 就像“我有就用,没有我自己建” → 默认值 REQUIRES_NEW “谁都有我不管,我自己开新号” SUPPORTS “随缘,有就上,没有就裸跑” MANDATORY “必须有事务,没有就不干” NOT_SUPPORTED “你们开会我不参与,我要单干” NEVER “你们别开会,我一开会就炸” NESTED “我是你肚子里的小事务,单独受罚,妈你别哭” 💬 示例记忆法(像讲段子一样):
老板(事务A)叫你干活(方法B):
- REQUIRED:老板已经在开会,我就进来一起开;没会议我就自己组织一个
- REQUIRES_NEW:我不管老板在不在,我自己重新开一个会(挂起老板的)
- SUPPORTS:老板开会我就进,不开我就随便干干
- MANDATORY:老板必须先开会,否则我不干活(抛异常)
- NOT_SUPPORTED:老板要是开会,我就去抽根烟;不开我才来干活(挂起事务)
- NEVER:谁开会我跟谁急,我只干没有事务的活
- NESTED:老板开了会,我在会里又开了一个子会,出了事自己担责不连累老板
✅ 重点注意(常考陷阱)
场景 考点 同一个类中 a() 直接调用 b()(b有事务) 事务注解失效!因为 Spring 是基于代理的,自己调自己不走代理!解决:注入自己 @Autowired private Self self;然后self.b()为什么要用 REQUIRES_NEW? 防止主事务回滚时影响某些必须成功的操作(如操作日志、发送消息) NESTED 与 REQUIRES_NEW 区别? NESTED 依赖原事务,提交回滚可以局部控制;REQUIRES_NEW 完全独立,互不干扰 使用 NOT_SUPPORTED/NEVER 的典型场景? 调用第三方接口不允许事务干扰,如防止长事务锁表等问题
用过Spring的事务吗
一组数据库的增删改操作
声明式事务管理:这是Spring推荐的用法,它通过使用注解(如@Transactional)或基于XML的配置来声明事务边界。底层基于AOP实现动态代理增强方法
编程式事务管理:允许你通过编程的方式直接管理事务,通常使用TransactionTemplate或者直接使用底层的PlatformTransactionManager。
声明式事务管理
(@Transactional)// 你需要在 Spring 配置中启用事务注解支持: @Configuration @EnableTransactionManagement public class SpringConfig { @Bean public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) { return new JpaTransactionManager(entityManagerFactory); } // ... 其他配置 } // 然后,你可以在服务层的方法上使用 @Transactional 注解来声明事务边界: import org.springframework.stereotype.Service; import org.springframework.transaction.annotation.Transactional; @Service public class AccountService { @Autowired private AccountRepository accountRepository; @Transactional public void transferMoney(Long fromAccountId, Long toAccountId, BigDecimal amount) { // 执行转账操作,比如: Account fromAccount = accountRepository.findById(fromAccountId).orElseThrow(...); Account toAccount = accountRepository.findById(toAccountId).orElseThrow(...); fromAccount.setBalance(fromAccount.getBalance().subtract(amount)); toAccount.setBalance(toAccount.getBalance().add(amount)); accountRepository.save(fromAccount); accountRepository.save(toAccount); // 如果这里发生异常,Spring 将回滚事务 } }编程式事务管理
import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import org.springframework.transaction.TransactionStatus; import org.springframework.transaction.support.TransactionCallbackWithoutResult; import org.springframework.transaction.support.TransactionTemplate; @Service public class AccountService { @Autowired private TransactionTemplate transactionTemplate; public void transferMoney(Long fromAccountId, Long toAccountId, BigDecimal amount) { transactionTemplate.execute(new TransactionCallbackWithoutResult() { @Override protected void doInTransactionWithoutResult(TransactionStatus status) { try { // 执行转账操作,与声明式事务管理中的操作相同 // ... } catch (Exception e) { status.setRollbackOnly(); // 如果发生异常,标记事务回滚 } } }); } }✅ 一句话理解
Spring事务 = 帮你保证一组数据库操作要么全部成功,要么全部失败(ACID)。
🌟 Spring事务使用方式
类型 特点 使用场景举例 声明式事务(@Transactional) 推荐方式,简洁,基于AOP代理增强方法 99%业务场景,转账、下单、库存扣减 编程式事务(TransactionTemplate) 自己控制事务开始、提交、回滚流程 特殊场景需要精细控制事务,如代码逻辑复杂、异常处理嵌套 🎯 实战答题模板
“在项目中我主要用的是声明式事务,通过
@Transactional注解来管理事务,通常放在service层方法上。比如用户下单时,我需要在一个事务中完成订单生成、库存扣减、用户积分变更,如果中间任何一环失败,整个事务都会自动回滚,确保数据一致性。”“我还了解过编程式事务,像使用
TransactionTemplate手动管理事务边界,适合一些流程比较复杂或需要细粒度事务控制的业务场景。”
@Transactional注解常用属性:
属性 说明 示例 propagation事务的传播行为(REQUIRED/REQUIRES_NEW等) @Transactional(propagation=...)rollbackFor哪些异常会触发回滚(默认只回滚运行时异常) @Transactional(rollbackFor=Exception.class)readOnly是否只读事务,优化性能 @Transactional(readOnly=true)timeout超时时间,单位:秒 @Transactional(timeout=5)💥 易错点提示(面试常问)
问题点 正确做法 注解加在controller层 ❌ → @Transactional应加在service层方法内自己调用自己 ❌ 事务失效!应通过注入自己调用 只抛了Exception没加rollbackFor 默认只回滚RuntimeException 数据库引擎不是InnoDB MySQL需用InnoDB才支持事务 🔧 小结:项目中事务用法模版
@Service public class OrderService { @Autowired private OrderMapper orderMapper; @Autowired private StockMapper stockMapper; @Transactional(rollbackFor = Exception.class) // 推荐加上 rollbackFor public void createOrder(Order order) { // 1. 创建订单 orderMapper.insert(order); // 2. 扣减库存 stockMapper.deduct(order.getProductId(), order.getQuantity()); // 3. 模拟异常测试事务回滚 // int i = 1 / 0; // 4. 插入日志等其他操作... } }
你熟悉的技术栈有哪些,用了哪些?
SpringBoot Vue Git Maven MyBatis……
解决难点的决策有和用户沟通的吗?
有过沟通 让他们了解一下我们的方案
万一用户听不懂怎么办?
我会用一些更加直白通俗的语言让用户理解我们的方案
用户不接受这个方案怎么办?
我们可以提供不止一个方案 或者 提供他提的方案 综合一下各种方案告诉其优缺点(站在我们的专业角度意见)和风险 让客户明知 让其选择
通常一般怎么学习的?最近在研究什么技术?
想面试的目的 要給公司带来一些好的
一般以公司的实际项目中为切入点去学习会更有效率
学习一个新的技术大概要多久?
1-2天 首先看官网 这个技术是解决哪些 看我们的项目需要哪些技术切入点能引用 然后去专门针对这个技术功能点去学习快速上手的接口文档
redis为什么这么快?
- 主数据基于内存操作
- Redis是单线程[操作数据的线程],避免上下文的频繁切换
整个redis不是就一个线程 - 底层基于C语言实现
得益于底层良好的数据结构[] - 基于非阻塞的IO
提升IO读写性能,NIO,BIO,AIO…
Java四大杀手
集合数据结构 jvm 并发编程 网络IO
非阻塞IO(Non-blocking I/O)是一种IO模型,它允许程序在执行IO操作时不会被阻塞,即程序可以在发起IO请求后继续执行其他任务,而不需要等待IO操作完成。以下是关于非阻塞IO的一些关键点:
非阻塞IO的特点:
- 异步操作:非阻塞IO操作通常是异步的,意味着程序发起IO请求后,不需要等待IO操作完成,而是可以立即返回去做其他事情。
- 事件驱动:非阻塞IO往往与事件驱动模型结合使用,程序可以通过监听器来响应IO事件(如数据可读、连接可写等)。
- 减少等待时间:由于程序在等待IO操作完成时不会阻塞,它可以继续处理其他任务,从而提高了程序的响应性和吞吐量。
非阻塞IO的实现方式:
- NIO(New I/O):在Java中,NIO提供了一种非阻塞的IO方式,使用
Selector来管理多个通道(Channel)上的IO事件。- AIO(Asynchronous I/O):AIO是另一种非阻塞IO模型,它允许程序完全异步地执行IO操作,通常是通过完成端口(Completion Ports)来实现。
- BIO(Blocking I/O):与非阻塞IO相对的是阻塞IO,其中每个IO操作都会阻塞调用线程,直到操作完成。
非阻塞IO的优势:
- 资源利用率:非阻塞IO可以更有效地利用系统资源,因为单个线程可以处理多个IO操作。
- 高并发处理:在处理大量并发连接时,非阻塞IO可以显著提高系统的并发处理能力。
非阻塞IO在Redis中的应用:
- 单线程模型:Redis是一个基于内存的键值存储数据库,它使用单线程模型来处理所有客户端请求。由于操作是基于内存的,速度非常快,而单线程避免了上下文切换的开销。
- 非阻塞IO和多路复用:尽管Redis是单线程的,但它使用非阻塞IO和多路复用技术(如epoll或kqueue)来同时处理多个IO流。这意味着Redis可以在等待IO操作(如网络响应)时不阻塞,从而可以继续处理其他请求。
- 高性能:Redis的非阻塞IO和多路复用机制使得它即使在面对大量并发请求时也能保持高性能。
redis的数据类型以及使用场景分别是什么
写入依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version> <!-- Use the latest version available -->
</dependency>
String:存储对象信息(转JSON)
将用户信息序列化为JSON字符串后存储。SET user:1000 '{"name":"Alice","age":30,"email":"alice@example.com"}' ---------------------------------------------------------------------- import redis.clients.jedis.Jedis; public class RedisStringExample { public static void main(String[] args) { Jedis jedis = new Jedis("localhost"); jedis.set("user:1000", "{\"name\":\"Alice\",\"age\":30,\"email\":\"alice@example.com\"}"); String userInfo = jedis.get("user:1000"); System.out.println(userInfo); jedis.incr("visits"); long visits = jedis.get("visits"); System.out.println("Visits: " + visits); jedis.close(); } }List:链表,查询记录的缓存、列表,朋友圈,微博,队列数据结构
可以将数据库查询结果缓存为一个列表# 查询记录的缓存 LPUSH recent:queries "SELECT * FROM users WHERE age > 30" # 消息队列 使用List作为消息队列,生产者将消息LPUSH到列表,消费者从列表中RPOP消息 LPUSH message:queue "message1" RPOP message:queue ---------------------------------------------------------------------- import redis.clients.jedis.Jedis; public class RedisListExample { public static void main(String[] args) { Jedis jedis = new Jedis("localhost"); jedis.lpush("recent:queries", "SELECT * FROM users WHERE age > 30"); String query = jedis.rpop("recent:queries"); System.out.println("Recent Query: " + query); jedis.close(); } } wHash:获取局部属性,小key不能设置过期时间
Hash是一个键值对集合,适合存储对象
Hash是一个键值对集合,适合存储对象HSET user:1000 name "Alice" age 30 email "alice@example.com" HGET user:1000 name ---------------------------------------------------------------------- import redis.clients.jedis.Jedis; public class RedisHashExample { public static void main(String[] args) { Jedis jedis = new Jedis("localhost"); jedis.hset("user:1000", "name", "Alice"); jedis.hset("user:1000", "age", "30"); jedis.hset("user:1000", "email", "alice@example.com"); String name = jedis.hget("user:1000", "name"); System.out.println("Name: " + name); jedis.close(); } }Set:无序不可重复的,收藏,点赞,社交场景,聚合计算(∩∪差集)
社交场景:使用Set来存储用户的关注列表,确保关注关系的唯一性。SADD user:1000:following 2000 3000 4000 ---------------------------------------------------------------------- import redis.clients.jedis.Jedis; public class RedisSetExample { public static void main(String[] args) { Jedis jedis = new Jedis("localhost"); jedis.sadd("user:1000:following", "2000", "3000", "4000"); Set<String> following = jedis.smembers("user:1000:following"); System.out.println("Following: " + following); jedis.close(); } }聚合计算:计算两个用户的共同关注。
SINTER user:1000:following user:2000:followingZset:排序场景,排行榜,姓名排序
排行榜:根据用户得分来存储排行榜
ZADD leaderboard 1000 Alice 950 Bob 900 Charlie ZRANGE leaderboard 0 -1 WITHSCORES ---------------------------------------------------------------------- import redis.clients.jedis.Jedis; import java.util.Set; public class RedisZsetExample { public static void main(String[] args) { Jedis jedis = new Jedis("localhost"); jedis.zadd("leaderboard", 1000, "Alice"); jedis.zadd("leaderboard", 950, "Bob"); jedis.zadd("leaderboard", 900, "Charlie"); Set<String> leaderboard = jedis.zrange("leaderboard", 0, -1); System.out.println("Leaderboard: " + leaderboard); jedis.close(); } }姓名排序:存储学生姓名和成绩,并按成绩排序。
ZADD students 92 John 85 Mary 88 Alice ZRANGE students 0 -1 WITHSCORES
分布式锁都可以用。Redisson是Redis的儿子,底层为Hash
redis数据过期策略
惰性删除:键过期时不会立即删除,当访问该键时判断是否过期,如果过期就删除
惰性删除策略是在访问键时检查键是否过期,如果过期则删除。import redis.clients.jedis.Jedis; public class LazyExpiration { private Jedis jedis; public LazyExpiration() { // 连接到Redis服务器 this.jedis = new Jedis("localhost"); } public String getKey(String key) { // 检查键是否存在 if (!jedis.exists(key)) { return null; } // 检查键是否过期 if (isExpired(key)) { // 如果键已过期,则删除它 jedis.del(key); return null; } // 如果键未过期,返回键的值 return jedis.get(key); } private boolean isExpired(String key) { // 获取键的剩余生存时间,如果返回值大于0,则键未过期 return jedis.ttl(key) == -2; } public static void main(String[] args) { LazyExpiration lazyExpiration = new LazyExpiration(); String value = lazyExpiration.getKey("myKey"); if (value != null) { System.out.println("Key value: " + value); } else { System.out.println("Key does not exist or has expired."); } } }定时删除:设置键的过期时间,当键过期时,立即删除
import redis.clients.jedis.Jedis; public class ActiveExpiration { private Jedis jedis; public ActiveExpiration() { // 连接到Redis服务器 this.jedis = new Jedis("localhost"); } public void activeExpireCycle() { // 随机检查一定数量的键 for (int i = 0; i < 10; i++) { String key = jedis.randomKey(); if (key != null && isExpired(key)) { // 如果键已过期,则删除它 jedis.del(key); } } } private boolean isExpired(String key) { // 获取键的剩余生存时间,如果返回值大于0,则键未过期 return jedis.ttl(key) == -2; } public void runPeriodicTask() { // 定时任务,按照一定的频率运行 while (true) { activeExpireCycle(); try { Thread.sleep(1000); // 每秒执行一次 } catch (InterruptedException e) { e.printStackTrace(); } } } public static void main(String[] args) { ActiveExpiration activeExpiration = new ActiveExpiration(); // 启动定时任务 activeExpiration.runPeriodicTask(); } }
高薪冲刺 → 定时删除详细策略
要扫描所有的定期任务删除 有策略可以设置阈值
啥时候离职的?半个月太长了
刚刚离职 也是刚刚开始投
主要工作职责
主要负责后端工作,协助测试,运维上线
你对前端有了解过吗?
有了解过,如HTML、CSS、JavaScript、框架[Vue、Element]等 可以很快的上手
我主要专长在于后端开发,可以学习和了解更多的前端知识。
各种淘汰策略介绍
Redis提供了8种淘汰策略,可以分成两大类:
1、针对所有键的策略:对所有键进行选择和淘汰。
2、仅针对有过期时间的键的策略:只在设置了过期时间的键中选择淘汰对象。
以下具体策略:
可以区分为两类:[有设置过期时间的key 不管你有没有设置过期时间]
1. noeviction【默认】
- 描述:达到内存限制时,不再执行删除操作,直接拒绝所有写入请求(包括插入和更新)。[可以读 但是拒绝写请求]
- 适用场景:希望数据永不丢失的场景,但需要保证内存充足,否则会导致写入操作失败。
2. allkeys-lru(最近最少使用)
- 描述:在所有的键中使用 LRU算法,删除最近最少使用的键。
- 适用场景:适合缓存场景,保留频繁访问的键,逐出很少被访问的键。
3. allkeys-lfu(最少使用频率)【电商】
- 描述:在所有键中使用 LFU 算法,删除使用频率最低的键。
- 适用场景:适用于需根据使用频率进行淘汰的场景,更关注访问次数而非访问时间。
4. volatile-lru(最近最少使用)
- 描述:仅对设置了过期时间的键使用 LRU 算法。
- 适用场景:适合缓存一些有过期时间的数据,希望根据访问频率来进行内存管理的场景。
5. volatile-lfu(最少使用频率)【电商】
- 描述:仅对设置了过期时间的键使用 LFU算法。
- 适用场景:同 volatile-lru,但更关注使用频率。
6. allkeys-random
- 描述:在所有键中随机选择删除某个键。
- 适用场景:适用于缓存数据访问频率没有明显差异的情况。
7. volatile-random
- 描述:在所有设置了过期时间的键中随机选择删除某个键。
- 适用场景:适合缓存带有过期时间的数据,删除哪个数据不重要的场景。
8. volatile-ttl
- 描述:在设置了过期时间的键中,优先删除剩余生存时间(TTL)较短的键。
- 适用场景:适合希望优先清理即将过期的数据的场景。
import redis.clients.jedis.Jedis;
public class RedisMaxMemoryPolicyExample {
private Jedis jedis;
public RedisMaxMemoryPolicyExample() {
// 连接到Redis服务器
this.jedis = new Jedis("localhost");
}
public void setMaxMemoryPolicy(String policy) {
// 设置Redis的内存淘汰策略
jedis.configSet("maxmemory-policy", policy);
}
public String getMaxMemoryPolicy() {
// 获取当前Redis的内存淘汰策略
return jedis.configGet("maxmemory-policy").get(1);
}
public static void main(String[] args) {
RedisMaxMemoryPolicyExample example = new RedisMaxMemoryPolicyExample();
// 设置不同的内存淘汰策略
example.setMaxMemoryPolicy("noeviction"); // 默认策略,拒绝写请求
example.setMaxMemoryPolicy("allkeys-lru"); // 所有键使用LRU淘汰
example.setMaxMemoryPolicy("allkeys-lfu"); // 所有键使用LFU淘汰
example.setMaxMemoryPolicy("volatile-lru"); // 仅有过期时间的键使用LRU淘汰
example.setMaxMemoryPolicy("volatile-lfu"); // 仅有过期时间的键使用LFU淘汰
example.setMaxMemoryPolicy("allkeys-random"); // 所有键随机淘汰
example.setMaxMemoryPolicy("volatile-random"); // 仅有过期时间的键随机淘汰
example.setMaxMemoryPolicy("volatile-ttl"); // 优先淘汰TTL较短的键
// 获取当前内存淘汰策略
String currentPolicy = example.getMaxMemoryPolicy();
System.out.println("Current Max Memory Policy: " + currentPolicy);
}
}
缓存三兄弟(穿透、击穿、雪崩)
一般在读缓存的时候出现的问题。思路:产生的原因 + 解决的方案
==缓存穿透==:用户或前端查询到一个在数据库中不存在的数据,先查redis再走数据库。对数据库压力会很大。关系型数据库是性能的瓶颈 希望把高数量都挡在数据库前面。查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查询数据库(可能原因是数据库被攻击了 发送了假的/大数据量的请求url)
- 解决方案一:缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存 {key:1, value:null} 【空字符串】
没有Null的数据类型下一次读取直接把空串返回
优点:简单
缺点:消耗内存,可能会发生不一致的问题
如果一直模拟一个不同的不存在的key 这时候就要用到布隆过滤器
解决方案二:布隆过滤器 (拦截不存在的数据)
[商品读多写少上缓存,要把商品数据写到布隆过滤器中,以商品的id独一无二计算hashcode,用布隆过滤器。取模数组落到桶内 会把0置为1]
有很多个二进制数组每个二进制数组用不同的hash算法进行计算此时落到的桶就不一样
作用:读的时候 前端传id 之前怎么写进去就怎么拿出来。[位运算(与)速度很快 把多个数组的数据拿出来与运算如果都是1 则这个数据可能存在再查一遍缓存若不存在直接return返回] 布隆过滤器说你不存在 一定不存在,说你存在 则可能存在[哈希冲突]★ 项目上线很久了 商品早就下架不卖了 这时候会发生什么问题?
这时候布隆过滤器还有之前的痕迹,需要把那些1设置为0。
布隆过滤器 不支持对某个的1设置0 → 因为有哈希冲突我不知道这个1曾经是誰设置的
支持将整个都置为0,之后可以搞个定时任务
布隆过滤器具体实现:Redis、Redission亲儿子、1cache、咖啡因(Caffeine提供了一种非常高效且易于使用的缓存解决方案,它支持多种缓存过期策略)、Guava谷歌★ 以前没设置过且上架过 后面加了布隆,后面要把之前所有数据重新搞进去 怎么解决?
存量数据写一个定时任务
★ 场景:工商银行统计每天的用户日活量[上线就算] 要查询某个人连续七天签到 怎么查(用位图)
用户量太多了搞一个二进制数组,10亿长度的数组,每个数组是一个bit = 10亿个位,一个字节
1/bit=8个位,综合计算后大概消耗119MB的空间每天。用用户id去hash 如果用户登录将0置为1有单独的位图结构,统计时间就可以拿日期 往前面数 拿某个id去取模得到桶 找前七个,去进行与运算,连续为1就达到了重复连续七天前端。否则非连续七天。在缓存预热时,要预热布隆过滤器。根据id查询文章时查询布隆过滤器如果不存在直接返回
import redis.clients.jedis.Jedis; public class DailyActiveUserCounter { private Jedis jedis; public DailyActiveUserCounter() { this.jedis = new Jedis("localhost"); // 连接到Redis服务器 } // 映射用户ID到位图的键 private String getUserBitmapKey(long userId, int day) { return "user:bitmap:" + userId + ":" + day; } // 用户签到 public void userSignIn(long userId, int day) { String key = getUserBitmapKey(userId, day); jedis.setbit(key, userId % 86400, true); // 假设一天有86400秒,使用秒数作为偏移量 } // 检查用户连续七天的签到情况 public boolean checkContinuousSignIn(long userId, int day) { for (int i = 0; i < 7; i++) { String key = getUserBitmapKey(userId, day - i); if (jedis.getbit(key, userId % 86400) == false) { return false; // 如果在连续的七天内有一天没有签到,则返回false } } return true; // 连续七天都有签到 } public static void main(String[] args) { DailyActiveUserCounter counter = new DailyActiveUserCounter(); // 假设用户ID为12345,今天签到 long userId = 12345; int today = 1; // 假设今天是第1天 counter.userSignIn(userId, today); // 检查用户是否连续七天签到 boolean isContinuous = counter.checkContinuousSignIn(userId, today); System.out.println("User " + userId + " has signed in for 7 consecutive days: " + isContinuous); } }**bitmap(位图)
巨大的二进制数组**:相当于一个以bit位为单位的数组,数组中每个单元只能存储二进制数0或1布隆过滤器作用:可以用于检索一个元素是否在集合中
- 存储数据:id为1的数据,通过多个hash函数获取hash值,根据hash计算数组对应位置改为1
- 查询数据:使用相同hash函数获取hash值,判断对应位置是否都为1
存在误判率:数组越小 误判率越大 【要数组足够大 误判率就小】
bloomFilter.tryInit(size, 0.05) //误判率5%
==缓存击穿==:给某一个热点key设置了过期时间,当key过期的时候,恰好这个时间点对这个key有大量的并发请求过来,这些并发请求可能一瞬间把DB击穿微博[鹿晗+关晓彤]【并发同一时间访问】
解决方案一:互斥锁【数据强一致性 性能差 (银行)】[控制一个个来访问的次数]
AQS、ReentrantLock是进程级别的互斥锁,因为有数据在节点1或节点2,分布式锁是在不同场景都可以锁也可以控制访问顺序。以商品id作为key 先redis开始查缓存 判断是否为空 不为空直接return后解锁,空就先加锁 去数据库查完备份一份redis后解锁。被锁的其他线程在外面等待。
★ 100个人访问同一个商品,只有一个抢到锁,剩下的99个人也要查redis缓存和数据库。
方案:**双重缓存校验** 先查缓存 查不到加锁 再查缓存 查不到再去数据库 查完后看是否备份后解锁
冷代码1.查询缓存,未命中 → 2.获取互斥锁成功 → 3.查询数据库重建缓存数据 → 4.写入缓存 → 5.释放锁
1.查询缓存,未命中 → 2.获取互斥锁失败 → 3.休眠一会再重试 → 4.写入缓存重试 → 5.缓存命中
解决方案二:逻辑过期[ 不设置过期时间 ] 【高可用 性能优 不能保证数据绝对一致 (用户体验)】
在数据库一条数据里面添加一个 “expire”: 153213455
1.查询缓存,发现逻辑时间已过期 → 2.获取互斥锁成功 → 3.开启线程 ↓→ 4.返回过期数据
【在新的线程】→ 1.查询数据库重建缓存数据 → 2.写入缓存,重置逻辑过期时间 → 3.释放锁
1.查询数据缓存,发现逻辑时间已过期 → 2.获取互斥锁失败 → 3.返回过期数据
==缓存雪崩==:在同一个时段内大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来压力
- 解决方案一:给不同的key的TTL(过期时间)添加随机值
不在同一时间过期 - 解决方案二:利用Redis集群提高服务的可用性 【哨兵模式、集群模式】
- 解决方案三:给缓存业务添加降级限流策略【nginx、springcloud、gateway】
- 解决方案四:给业务添加多级缓存 【Guava(做一级缓存 然后Redis是二级缓存)或Caffeine】
★ redis宕机的时候 再RedisTemplate.set()后会报错 但是现在mysql还可以访问 应该怎么办?
try catch 在里面继续再去查mysql数据库
降级代码:对于读操作,如果Redis缓存失效,可以直接从MySQL数据库读取数据。
public boolean setData(String key, String value) {
try {
// 尝试将数据设置到Redis
redisTemplate.opsForValue().set(key, value);
return true;
} catch (Exception e) {
// 日志记录Redis错误
log.error("Redis is down, failing over to MySQL", e);
// Redis设置失败,降级到MySQL
return setDataToMySQL(key, value);
}
}
private boolean setDataToMySQL(String key, String value) {
// 这里实现将数据写入MySQL的逻辑
// 例如:
// mySqlTemplate.update("INSERT INTO cache (key, value) VALUES (?, ?)", key, value);
// 注意:这里的mySqlTemplate和SQL语句需要根据实际情况调整
return true; // 假设写入成功
}
如果公司对要求更高,需要限流降级、熔断
同一时间设置QPS为100 超过的返回友好提示[商品太火爆啦,请稍后再试]
你有自己部署过环境吗
公司里面用 Jenkins + docker 测试环境我们部署 生产环境是组长部署
未来1-3年规划
将具体一点,从业务技术上提升自己的深度和广度达到高级工程师
你平时做笔记吗
有做笔记 Xmind + Markdown
因为我觉得无论从网上的还是别人请教的不经历我的消化都不是我的东西
我还是会将这些知识点总结起来变成自己的知识
什么是动态代理?&& 动态代理有哪些,他们之间的区别?
代理是一种设计模式 用来增强目标的逻辑 与被增强的并没有太大关系装饰者模式
在程序运行期间才会产生代理类加载到我们jvm中yaml文件
JDK动态代理是 基于接口实现来实现增强
[txt文本 把目标增强类 作为接口
本身就是接口实现过来写成源码 源文件 再用jdk工具把源码编译成class字节码 再用类加载器把class加载到jvm中]CGLIB动态代理是 基于继承目标类并覆写其方法来实现
[ASN字节码机制直接生成class 直接加载到内存中]
性能较高,速度更快。因为直接生成class
要调用某个方法 CGLIB性能高 是通过反射来实现的 老版本的jdk的反射性能较低。如今在调用方法的性能上差距不大
区别:
- JDK动态代理要求目标类必须实现一个或多个接口,而CGLIB没有这个要求。
- JDK动态代理生成的代理类是接口的实现,而CGLIB生成的代理类是目标类的子类。
- 性能上,CGLIB通常比JDK动态代理更快,因为它直接操作字节码生成新的类。
什么样的代码是静态代理?
发生在我们写代码的过程中 在编译阶段产生了代理类
静态代理是指代理类在编译时就已经确定,通常由程序员手动编写
你用过Linux吗?
是的,我在工作中经常使用Linux操作系统。我熟悉Linux的基本命令
基础的命令:xxx【查看之前笔记】
你工作的时候有需求文档吗?
有的,有一些简单的需求是没有的[沟通成本太高了]
稍微复杂的需求会有需求文档,我会根据需求文档来理解项目需求,并进行系统设计和开发。
你有什么需要了解的?不要难为面试官,不问技术栈
我想了解一下贵公司的业务是什么…好的那我这块已经没有什么想了解的了 感谢面试官
HR:想了解一下贵公司的上班时间…
我没有什么想了解的,来之前有了解过贵公司
平时用注解创建的bean是单例的还是多例的?
默认情况下,通过注解(如@Component、@Service、@Repository、@Bean等)创建的Bean是单例的。如果需要创建多例Bean,可以在注解上添加@Scope(“prototype”)来指定。
// 单例Bean
import org.springframework.stereotype.Component;
@Component
public class SingletonBean {
// Bean的代码
}
----------------------------------------------------
// 多例Bean
import org.springframework.context.annotation.Scope;
import org.springframework.stereotype.Component;
@Component
@Scope("prototype")
public class PrototypeBean {
// Bean的代码
}
SQL语句的执行顺序,为什么顺序是这样排的,这样的顺序有什么优势或者好处?
FROM -> Join -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY -> limit
这样的顺序是为了优化查询性能。首先确定数据来源(FROM),然后筛选出满足条件的数据(WHERE),接着进行分组(GROUP BY),在分组的基础上进行进一步筛选(HAVING),然后选择需要的数据(SELECT),最后对结果进行排序(ORDER BY)。这样的顺序可以减少中间结果集的大小,提高查询效率。
书写顺序
select -> from -> join -> on -> where -> group by -> having -> order by -> limit
SQL的“写法顺序” vs “执行顺序”
书写顺序(你写的时候) 实际执行顺序(数据库引擎执行时) SELECT … FROM … FROM(确定数据源) [JOIN … ON …] JOIN/ON(表连接) WHERE … WHERE(行过滤) GROUP BY … GROUP BY(分组) HAVING … HAVING(组过滤) SELECT … SELECT(列筛选/表达式) ORDER BY … ORDER BY(排序) LIMIT … LIMIT(分页/截断) 为什么执行顺序是这样设计的?(核心)
🌟1. 先FROM:
确定要操作的表或视图,这是基础,后面所有步骤都基于这个“数据源”。
🌟2. JOIN/ON:
在多个表之间构建连接关系,决定你从这些表中怎样拼接出一张“临时大表”。
🌟3. WHERE:
在JOIN后对临时表做行级过滤,只保留符合条件的记录。
👉 这样可以尽早“减小数据量”,提升后续处理效率(比如分组)。🌟4. GROUP BY:
基于保留的数据按某个字段做分组聚合,如统计、求和等。
🌟5. HAVING:
对聚合后的组进行筛选(如:只保留总金额 > 1000 的组)。
🌟6. SELECT:
选择返回哪些字段,同时也可能包含聚合函数(如
COUNT(*),SUM()),此时组已经存在了。🌟7. ORDER BY:
对最终结果排序,这个阶段才有机会看到完整结果。
🌟8. LIMIT:
只取前几行,分页优化的最后一环,减少结果输出体积
SELECT u.username, SUM(o.amount) AS total_amount FROM user u JOIN `order` o ON u.id = o.user_id WHERE o.status = 'paid' GROUP BY u.id HAVING total_amount > 0 ORDER BY total_amount DESC LIMIT 5;这样的顺序有什么优势?
阶段 目的/优势 FROM+JOIN 先构建大数据源结构,作为后续处理基础 WHERE 尽早过滤不必要的数据 → 提高性能(减少后续数据量) GROUP BY 只对保留下来的数据做聚合,提高分组效率 HAVING 聚合后再过滤,避免误筛不完整组 SELECT 最后选择字段,保证表达式都合法且数据齐全 ORDER BY 排序通常开销大,放最后执行最合理 LIMIT 控制输出量,提高响应速度和用户体验 面试如何回答(建议模板)
“SQL的执行顺序设计是为了最大限度提升查询效率。先执行FROM和JOIN是因为必须先构建数据源;然后用WHERE尽早过滤行,避免无意义的数据进入分组、排序等更耗性能的阶段;GROUP BY在WHERE过滤后进行,HAVING则是对聚合结果再做筛选;SELECT最后才执行,是因为只有在前面都处理完后,才能确定哪些字段可用;ORDER BY 和 LIMIT是最终结果的加工。这种顺序是数据库执行优化的核心逻辑。”
线上项目发生死锁如何去解决? 我暂时没遇到过→分布式事务上去答
死锁:两个线程争夺两个资源的时候 1线程拿到a 想拿b 2线程拿到了b 想拿a
四个原因:互斥条件 请求保持 不可剥夺 循环等待
产生死锁的四个因素 同时满足才会死锁 想要解决死锁 需要打破其中一个原因就行
- 互斥条件(Mutual Exclusion):资源不能被多个线程同时使用。即某个资源在一段时间内只能由一个线程占用,其他线程必须等待该资源被释放后才能使用。
- 持有和等待条件(Hold and Wait):线程至少持有一个资源,并且正在等待获取额外的资源,而该资源又被其他线程持有。
- 非抢占条件(No Preemption):已经分配给某个线程的资源在该线程完成任务前不能被抢占,即只能由线程自己释放。
- 循环等待条件(Circular Wait):存在一种线程资源的循环等待链,每个线程都在等待下一个线程所持有的资源。
在实际操作中,以下是一些打破死锁的具体方法:
- 资源分配图:使用资源分配图来检测循环等待条件,并在检测到循环时采取措施。
- 锁排序:确保所有线程以相同的顺序获取锁,从而避免循环等待。
- 超时机制:线程在请求资源时设置超时时间,如果超过时间未获得资源,则放弃当前任务并释放已持有的资源。
- 死锁检测算法:运行死锁检测算法,如银行家算法,来检测系统中的死锁,并在必要时采取措施。
- 线程中断:允许系统或其他线程中断正在等待资源的线程。
- 回滚操作:如果检测到死锁,可以让某些线程回滚它们的工作,并释放资源,从而打破死锁。
MySQL是不会有死锁的 自身会检测 [让后面的超时释放回滚]
在分布式事务 线程1拿着资源a是数据库1 线程2拿着资源b是数据库2
JVM中也有死锁,jvm没有超时机制不会解决 可以查看命令打印堆栈信息可以查看哪里产生死锁
你可以使用
jstack命令来打印指定进程ID的Java堆栈跟踪信息。这个命令可以帮助你分析线程的状态
首先,找到你的Java进程ID(PID)。你可以使用
jps命令来列出所有正在运行的Java进程及其PID。jps使用
jstack命令打印出该Java进程的堆栈跟踪。jstack <PID>将
<PID>替换为实际的进程ID。查找堆栈跟踪中的”DEADLOCK”关键字。
jstack会自动检测死锁并在输出中报告。我们在生产环境中遇到接口卡住不响应的情况,会先使用
jps找到目标 Java 进程的 PID,然后用jstack <PID>导出线程堆栈日志。我们重点查看是否存在Found one Java-level deadlock的提示,并分析具体是哪几个线程锁住了彼此的资源。如果确认是死锁,我们会进一步分析代码逻辑进行解耦或调整加锁顺序。Found one Java-level deadlock:
“Thread-1”:
waiting to lock monitor 0x00000000053c3d28 (object 0x000000076b300030, a java.lang.Object),
which is held by “Thread-0”
“Thread-0”:
waiting to lock monitor 0x00000000053c3d48 (object 0x000000076b300028, a java.lang.Object),
which is held by “Thread-1”Java stack information for the threads listed above:
Thread-1:
at DeadlockDemo.lambda$main$1(DeadlockDemo.java:20)
- waiting to lock <0x000000076b300030> (a java.lang.Object)
- locked <0x000000076b300028> (a java.lang.Object)
Thread-0:
at DeadlockDemo.lambda$main$0(DeadlockDemo.java:11)
- waiting to lock <0x000000076b300028> (a java.lang.Object)
- locked <0x000000076b300030> (a java.lang.Object)
如果你遇到(新的)技术栈,怎么去解决?
【return Previous.notes(NowDay);】
如果你在实际开发中遇到问题,你怎么去解决,怎么去沟通?
首先尝试自己解决问题,通过搜索引擎、官方文档、Debug等。
尽可能不让这个问题不出现风险 实在解决不了就向上反馈 寻求帮助 请教上司领导或同事
平常和项目经理进行沟通 如果需求评审有些不理解还是会及时沟通 不清楚的一定要及时明确
对于加班情况怎么看?
为了确保项目进度和团队利益,加班是可以接受的。
多线程怎么保证线程之间的安全
加锁 不让多线程抢夺资源
互斥锁、读写锁、线程局部存储(ThreadLocal每个线程独享自己变量)
mybatis中${}和#{}的区别,哪个更好? 为什么?
${}(字符串替换):${}会将参数直接替换到SQL语句中,不进行任何转义处理。- 它适用于动态SQL中的表名或列名,或者在SQL语句中需要使用特定数据库函数的情况。
- 使用
${}时,如果参数是用户输入的,那么可能会引发SQL注入攻击,因为它不会对参数进行转义。
#{}(预处理语句参数):#{}会创建预处理语句(prepared statement)的参数占位符,并在设置参数时进行适当的转义处理。- 它适用于大部分情况,特别是当参数是用户输入时,可以有效防止SQL注入攻击。
- MyBatis会根据参数的类型自动选择
setString、setInt、setDate等预处理语句方法。
在大多数情况下,
#{}是更好的选择,因为它提供了以下优势:- 安全性:
#{}可以防止SQL注入攻击,因为它会自动转义参数。 - 类型处理:MyBatis会根据参数的实际类型来设置预处理语句的参数,这减少了类型错误的可能性。
- 可读性和维护性:使用
#{}可以使SQL语句更加清晰,因为它清楚地标识了参数的位置。
然而,在某些特定的场景下,如需要动态地指定表名或列名时,
${}是必要的,因为预处理语句MyBatis 中
#{}和${}的区别项目 #{}(占位符)${}(字符串拼接)替换方式 使用 ? 占位符 字符串直接拼接进SQL 是否转义 ✅ 自动转义,安全 ❌ 不转义,有SQL注入风险 使用底层 JDBC 的 PreparedStatement 字符串拼接,执行前已成完整SQL 场景 传入值如:用户名、ID、价格等参数 动态表名、列名、排序字段、函数等 安全性 安全,推荐使用 不安全,谨慎使用 类型处理 ✅ 自动处理类型转换 ❌ 不做类型处理,需手动拼接格式 性能(缓存) 支持 SQL 缓存 由于 SQL 变化大,缓存命中低 正确使用
#{}<select id="getUser" resultType="User"> SELECT * FROM users WHERE id = #{userId} </select>- 自动转为:
SELECT * FROM users WHERE id = ? - 安全,可防止 SQL 注入。
必须使用
${}的场景(动态表名或列)<select id="selectByColumn" resultType="User"> SELECT * FROM users WHERE ${columnName} = #{value} </select>- 用于:动态字段(如
name、email)查询。 - 注意:
${columnName}可能来自用户输入,必须白名单校验,否则容易被 SQL 注入。
- 安全性:
说一下内连接和外连接的区别
左外连接(Left Outer Join):
- 定义:左外连接返回左表中的所有行,即使在右表中没有匹配的行。对于左表中没有匹配的行,结果集中的右表部分将包含NULL。
- 如果左表是主表,或者左表中的数据是查询的主要关注点,而右表中的数据是辅助信息时,通常使用左外连接。
右外连接(Right Outer Join):
- 定义:右外连接返回右表中的所有行,即使在左表中没有匹配的行。对于右表中没有匹配的行,结果集中的左表部分将包含NULL。
- 如果右表是主表,或者右表中的数据是查询的主要关注点,而左表中的数据是辅助信息时,通常使用右外连接
全外连接(Full Outer Join):
- 定义:全外连接返回左表和右表中的所有行。当某行在另一个表中没有匹配时,结果集中的相应部分将包含NULL。
- 全外连接不常用,因为它通常会返回大量的包含NULL的数据,这可能会导致查询结果难以解释。只有在确实需要两表中的所有数据时才使用。
- 性能考虑:外连接可能会比内连接(Inner Join)更消耗资源,特别是当表很大时。如果可能,尽量使用内连接。
- 数据完整性:如果业务逻辑要求查询结果必须包含某个表的所有记录,那么应该使用相应的外连接。
内连接 vs 外连接:核心区别总结
类型 说明 是否保留非匹配行 NULL 出现在哪一边 内连接 只返回两个表中满足连接条件的交集部分 ❌ ❌ 不会有 NULL 左外连接 保留左表所有记录,右表没有匹配的填 NULL ✅(保留左表) 右表字段为 NULL 右外连接 保留右表所有记录,左表没有匹配的填 NULL ✅(保留右表) 左表字段为 NULL 全外连接 左右两表都保留,不匹配的部分填 NULL(并集) ✅(都保留) 两边都可能为 NULL ✅ 图示记忆法
A表在左边,B表在右边:INNER JOIN: A ∩ B LEFT JOIN: A ⟕ B RIGHT JOIN: A ⟖ B FULL JOIN: A ∪ B✅ 实际应用建议
场景 推荐连接方式 获取匹配数据 INNER JOIN 主表必须展示,辅表可无 LEFT JOIN 辅表必须展示,主表可无 RIGHT JOIN 数据对账/差异比对/全量汇总 FULL OUTER JOIN 内连接只返回满足条件的交集数据,外连接用于保留某一边或两边的所有记录。常用的是左外连接,适合主表为主、辅表为辅的场景。外连接比内连接更全,但性能略低,因此建议根据业务场景合理选择。
自我介绍
xxx
你觉得学习我们这些技术最重要的是什么?
首先要清楚**这个技术是解决什么领域的问题**,学习技术很多方面都是用来服务业务的,结合实际业务来学习技术融合性会更强
技术栈有些不同,有没有想过换方向发展?
没问题的 因为技术是相通的 可以去学新技术
ThreadLocal相关面试题
1.概述
ThreadLocal(定义全局静态变量 项目中共用)是Java中的一个线程局部变量工具类,它提供了一种在多线程环境下,每个线程都可以独立访问自己的变量副本的机制。ThreadLocal中存储的数据对于每个线程来说都是独立的,互不干扰。
2. 使用场景
ThreadLocal适用于以下场景:
- 在多线程环境下,需要保持线程安全性的数据访问。
- 需要在多个方法之间共享数据,但又不希望使用传递参数的方式。
- 在传递登录用户id是非常方便且适用
以后获取用户id不用再解析token了,线程拿仅仅拿当前线程的数据 每个登录的用户都有自己的threadlocal数据
ThreadLocal并不是一个Thread,而是Thread的局部变量【可以存储数据】
ThreadLocal为每个线程提供单独一份存储空间,具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问。**ThreadLocal实现一个线程内传递数据**[就不用一个个参数往后传递了]
注意:客户端发送的每次请求,后端的tomcat服务器都会分配一个单独的线程来处理请求
- 一个请求是一个线程[意义:在第一个线程里面使用ThreadLocal存储用户Id 在后面controller或service中就可以取出来用户id]
- 第二个请求就是另一个线程 线程池用完第一个放回线程池 也有可能把上一个线程接着给它用
postHandle 只有在正确调用返回才会引用 如果抛出异常则不会使用afterCompletion 无论怎样最后都要运行
ThreadLocal
3.1 创建ThreadLocal对象
首先,我们需要创建一个ThreadLocal对象来存储线程局部变量。可以使用ThreadLocal的默认构造函数创建一个新的实例。【给每个线程拷贝一份 synchn + Lock锁】
ThreadLocal<String> threadLocal = new ThreadLocal<>();
3.2 设置线程局部变量的值
使用set()方法可以设置当前线程的局部变量的值。
threadLocal.set("value");
3.3 获取线程局部变量的值
使用get()方法可以获取当前线程的局部变量的值。
String value = threadLocal.get();
3.4 清除线程局部变量的值
使用remove()方法可以清除当前线程的局部变量的值,建议在整个请求使用完一定要执行remove清除数据,不然可能会发生内存泄漏问题。
threadLocal.remove();
下面是一个简单的示例代码,演示了如何使用ThreadLocal。
public class ThreadLocalTest {
private static final ThreadLocal THREAD_LOCAL = new ThreadLocal();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
THREAD_LOCAL.set("itheima");// 写入线程本地变量
getData("t1");// 读取线程本地变量
}, "t1");
Thread t2 = new Thread(() -> {
THREAD_LOCAL.set("itcast");// 写入线程本地变量
getData("t2");// 读取线程本地变量
}, "t2");
t1.start();
t2.start();
}
private static void getData(String threadName){
Object data = THREAD_LOCAL.get();
System.out.println(threadName+"-"+data);
}
}
运行以上代码,输出结果为:
t1-itheima
t2-itcast
在任意位置都可以调用Threadlocal,线程隔离互不影响,解决了线程安全问题:[每个线程存一份 线程不共享]
用mybatis+建造者模式 一定要在类里面加 一定要具有有参和无参构造缺一不可 否则mybatis数据封装无法映射
@AllArgsConstructor
@NoArgsConstructor
@Builder
字符和字符串类型的区别
字符是基本数据类型 没有null 用单引号
字符串是引用数据类型[一个类] 用双引号

操作字符串的工具类是什么
apache的common提供的String Utils工具类,hutool也有String Utils
字符串工具类
工具类库 类名 说明与特点 Apache Commons StringUtils(org.apache.commons.lang3.StringUtils)提供了大量字符串处理方法,如 isBlank()、join()、split()、contains()等。非常稳定、功能强大。Hutool StrUtil(cn.hutool.core.util.StrUtil)轻量级工具包,功能类似,但更加面向国人开发,API 命名更简洁清晰,如 isBlank()、format()、hide()等。Java 自带 String类和StringBuilder,StringBuffer提供基础字符串操作,如 substring()、indexOf()、replace()等。推荐:开发中可以结合使用
Apache StringUtils或Hutool StrUtil,比自己写字符串判断高效且可读性好。✅ 1. 用户注册校验 — Apache Commons
StringUtils业务背景: 用户注册时,需要校验用户名和邮箱不能为 null 或空字符串。
import org.apache.commons.lang3.StringUtils; public class UserService { public boolean isValidUser(String username, String email) { return StringUtils.isNotBlank(username) && StringUtils.isNotBlank(email); } }📌 优势说明:
StringUtils.isNotBlank()能判断 null、空字符串、全是空格的字符串。- 替代了传统的
"".equals(x) || x == null || x.trim().length() == 0,简洁高效。
✅ 2. 昵称脱敏展示 — Hutool
StrUtil业务背景: 用户中心页面要展示脱敏后的昵称,如
张三丰→张*丰。import cn.hutool.core.util.StrUtil; public class UserUtil { public static String desensitizeName(String name) { return StrUtil.hide(name, 1, name.length() - 1); // 从第2位到倒数第1位隐藏 } }输出示例:
System.out.println(desensitizeName("张三丰")); // 张*丰📌 优势说明:
StrUtil.hide()非常适合做数据脱敏处理(身份证、手机号等)。- API 直观易用,无需自己写 substring 拼接逻辑。
✅ 3. SQL拼接或日志打印 — Java 原生
StringBuilder业务背景: 拼接一段复杂 SQL 或多字段日志输出。
public class LogBuilder { public static String buildLog(String userId, String action, long timestamp) { StringBuilder sb = new StringBuilder(); sb.append("用户ID: ").append(userId) .append(", 操作: ").append(action) .append(", 时间: ").append(timestamp); return sb.toString(); } }输出:
用户ID: 123456, 操作: 登录, 时间: 1721559065000📌 优势说明:
StringBuilder适合循环中或大量字符串拼接,性能比+更优。- 通常用于日志、SQL、通知信息构建等场景。
局部变量和成员变量的区别
成员变量是在jvm的堆
局部变量是在jvm的栈
基本数据类型的引用类型 类在堆
基本数据类型的成员变量在堆 非静态在堆 静态变量在方法区
引用类型 无论静态还是非静态成员变量都在堆区
局部变量是在方法或代码块内部声明的变量,其作用域仅限于声明它的方法或代码块
局部变量不能被static修饰
局部变量必须被初始化才能使用
成员变量是在类内部声明的变量,其作用域是整个类
成员变量可以被static修饰
成员变量有默认值
public class VariableDemo {
// 成员变量
int age = 18; // 非静态成员变量 -> 堆中
static String school = "北大"; // 静态成员变量 -> 方法区中
public void printInfo() {
// 局部变量
String name = "小明"; // 局部变量 -> 栈中
int age = 20; // 局部变量,和成员变量重名(就近原则)
System.out.println("局部变量 name:" + name); // 小明
System.out.println("局部变量 age:" + age); // 20
System.out.println("成员变量 age:" + this.age); // 18(用this访问成员变量)
System.out.println("静态变量 school:" + school); // 北大
}
public static void main(String[] args) {
VariableDemo v = new VariableDemo();
v.printInfo();
}
}
------------------------------------------------------------------------
JVM 内存结构:
方法区(存放类信息、静态变量等)
└── VariableDemo.class
└── static school = "北大"
堆内存(存放对象和非静态成员变量)
└── v 对象
└── age = 18
栈内存(每个线程的栈帧)
└── main() 栈帧
└── v 引用
└── printInfo() 栈帧
├── name = "小明"
├── age = 20 (局部变量)
你编写完代码,写完这个功能后,会进行什么操作呢
进行代码审查,检查代码是否符合编码规范和设计要求。
- 进行单元测试,确保代码的功能正确无误。
- 进行代码优化,提高代码的性能和可维护性。
- 与团队成员进行代码合并,确保代码的集成。
- 编写文档,记录功能实现和代码变更。
上一家公司的薪资是多少?期望薪资是多少?上一家还有什么其他的福利吗?
期望薪资:
了解过广东这边的市场 我想换工作想涨薪10~20%
节假日会发放礼品和福利
可以接受低代码平台吗?
可以接受
低代码平台:类若依
具体说说Java面向对象
Java面向对象是一种编程范式,它将现实世界的事物抽象成程序中的对象。Java面向对象的主要特征包括:
- 封装:将对象的属性和行为封装在一起,对外只暴露必要的接口,隐藏内部实现细节。
- 继承:允许子类继承父类的属性和行为,实现代码的复用。
- 多态:同一个接口可以有多个不同的实现,通过对象的类型和方法的调用,实现不同的功能。
== 和 equals 的区别
- ==:比较基本数据类型时,比较的是值;比较引用数据类型时,比较的是对象的内存地址。
- equals:是Object类的一个方法,默认比较的是对象的内存地址。但在很多类中(如String、Integer等),equals方法被重写,用于比较对象的内容是否相等。
没重写 就是 == 比较对象地址。重写过的话就比较对象的值。
有没有做过权限控制,整个系统的权限
有过 SpringSecurity
能具体说一下权限控制怎么做?
使用RBAC模型 不是把用户关联资源 而是中间利用角色间接关联
用户+角色+资源+用户角色中间表+角色资源中间表多对多
SpringSecurity 具体怎么实现
我的项目是基于JWT的前后端分离的项目,在自定义认证管理器AuthenticationManager认证成功后,生成JWT令牌并返回给前端。前端在随后的请求中携带这个JWT令牌。这时候,我们使用AccessDecisionManager来实现接口的鉴权逻辑,其中包括一个check方法,该方法会校验JWT令牌的有效性。如果校验通过,就去查询数据库以确定用户拥有哪些权限。在用户登录时,其权限信息已经被缓存到Redis中。后续的请求中,我们可以直接从Redis中检索用户的权限信息。如果请求的接口权限与用户缓存中的权限匹配,则放行;如果不匹配,则返回一个友好的错误信息。
✅ 有没有做过权限控制?
有,在项目中我用的是 Spring Security + JWT 的权限控制方案,整体基于 RBAC 模型(基于角色的访问控制)。
✅ 权限模型设计(RBAC)
核心思路:通过“角色”来间接管理用户权限
实体 关系说明 用户(User) 关联多个角色(Role) 角色(Role) 关联多个权限/菜单(Permission) 权限(Permission) 描述资源:菜单、接口等 中间表设计:
- 用户角色表(user_role)→ 多对多
- 角色权限表(role_permission)→ 多对多
✅ SpringSecurity 是如何实现的?
项目是 前后端分离,使用的是 JWT 无状态认证。
1️⃣ 用户登录认证(
AuthenticationManager)
- 用户登录提交账号密码 → 调用 SpringSecurity 的认证逻辑
- 认证通过后,生成 JWT Token 返回给前端
前端在随后的请求中携带这个JWT令牌- 同时把 用户信息 + 权限信息 缓存在 Redis 中
2️⃣ 用户请求鉴权(拦截 + 校验)
用户每次访问接口都带上 JWT:
使用AccessDecisionManager来实现接口的鉴权逻辑,其中包括一个check方法,该方法会校验JWT令牌的有效性核心流程:
请求到来 → JWT过滤器提取Token → 解析用户信息 → 加载权限 → 比对是否有权限 → 放行 or 拦截具体细节:
- 使用 自定义过滤器 替换
UsernamePasswordAuthenticationFilter- Token 中取出用户名 → 去 Redis 中拿权限信息(避免每次都查库)
- 使用
AccessDecisionManager和SecurityMetadataSource判断当前接口所需权限是否被用户拥有- 校验成功:放行;校验失败:返回 403 自定义响应(如“无权限访问”)
✅ 为什么使用 Redis 缓存权限?
- 避免每次请求都去查数据库,提升性能
- 实现单点登录、Token失效管理等操作更方便
- 权限信息改动 → Redis 也同步更新
✅ 如何定义哪些接口需要权限?
- 使用
@PreAuthorize("hasAuthority('xxx')")- 或者用自定义权限注解 + AOP 实现
✅ 总结一句话回答
我使用的是基于 JWT + SpringSecurity 的权限控制,采用的是 RBAC 模型,通过用户角色权限的绑定来控制资源访问。权限信息登录时就缓存到 Redis,提高了性能,接口鉴权用的是自定义的
AccessDecisionManager来校验 Token 与权限是否匹配,确保接口安全。
✅ 场景描述:权限精确到按钮级别
不仅控制用户能否访问“某个菜单”,还要控制:
- 某些用户能看到“编辑”按钮
- 某些用户不能看到“删除”按钮
- 某些按钮点击后后台要鉴权(如“导出”、“审核”等)
🧩 一、数据库设计(基于 RBAC 模型)
1️⃣ 表结构设计(核心五张表)
表名 说明 user用户表 role角色表 permission权限资源表(菜单、接口、按钮) user_role用户与角色的多对多关联 role_permission角色与权限的多对多关联 2️⃣
permission权限表示例(关键)
字段 说明 id 主键 name 权限名称,例如“删除按钮” type 类型: menu、button、apiperm_code 权限标识,例如: user:delete、user:editparent_id 上级权限(菜单树结构) url / path 前端路由或接口路径 method 请求方式: GET/POST/DELETE(接口专用)🚨 重点:按钮权限是存放在
permission表里的,只是type = button,和菜单/接口共用一个表。🔁 二、后端逻辑处理流程
1️⃣ 用户登录时加载权限
@Override public UserDetails loadUserByUsername(String username) { // 1. 查询用户 User user = userMapper.selectByUsername(username); // 2. 查询权限(按钮 + 接口 + 菜单) List<String> permissionCodes = permissionMapper.getUserPerms(user.getId()); // 3. 存入 UserDetails return new LoginUser(user, permissionCodes); }✔️ 这些
permissionCodes会通过 JWT 或 Redis 存起来,后续用来鉴权和前端展示。2️⃣ 鉴权控制(精确到按钮)
你需要:
- 后端校验接口权限(如调用删除接口必须拥有
user:delete权限)- 前端展示按钮要判断是否有权限
🧷 方法一:接口权限控制(后端)
@PreAuthorize("hasAuthority('user:delete')") // ★★★★ @DeleteMapping("/user/delete/{id}") public void deleteUser(@PathVariable Long id) { // 业务逻辑 }✔️ 只有拥有
user:delete权限的用户才能调用这个接口。
🧷 方法二:按钮权限控制(前端)
<!-- Vue 示例 --> <template> <div> <el-button v-if="hasPermission('user:edit')">编辑</el-button> <el-button v-if="hasPermission('user:delete')">删除</el-button> </div> </template>// 权限判断函数 export function hasPermission(code) { const perms = JSON.parse(localStorage.getItem("userPerms")) || []; return perms.includes(code); }🛠 三、JWT + Redis 权限缓存方案(提高性能)
登录成功后:
// 登录成功后: String token = jwtUtil.generateToken(userId); // Redis缓存用户权限 redis.set("login:" + userId, JSON.stringify(LoginUser对象)) // 包括 permissionCodes // 返回token给前端鉴权过滤器:
// Token过滤器从请求头获取token → 从Redis读取用户权限 → 设置SecurityContext
📐 四、权限结构如何传给前端?
示例:
[ { "menuName": "用户管理", "path": "/user", "children": [ { "menuName": "用户列表", "path": "/user/list", "permissions": ["user:add", "user:delete", "user:edit"] } ] } ]前端根据这些
permissions控制按钮显示。
✅ 总结一句话回答:
在项目中我们实现了精确到按钮级别的权限控制。使用 RBAC 模型统一管理“菜单、接口、按钮权限”,后端统一校验权限(用 Spring Security 的
@PreAuthorize),前端根据用户权限码动态控制按钮的显示,用户权限在登录时就加载并缓存到 Redis + JWT 中,实现了性能与安全的平衡。✅ 真实项目中常见补充点(面试必问)
问题 解答 前端怎么知道自己有哪些权限? 登录后从后端返回权限码数组,如 ["user:add", "user:delete"],存在 Vuex / Pinia 或 localStorage 中权限更新了怎么办? 更新用户角色后,同时刷新 Redis 缓存或设置 token 过期时间较短 一个按钮需要多个权限怎么办? v-if="hasPermission('user:add') && hasPermission('user:export')"我想要你详细讲一下 数据库的那张权限表 帮我模拟一些字段和数据 实现达到按钮级别
我们就来详细 模拟一张完整的权限表(
permission),并:
- 定义它的字段含义
- 填入一些真实的示例数据(精确到按钮级别)
- 分析如何建立菜单树、按钮权限和接口权限之间的关系
- 说明这些数据在前后端中如何使用
🧩 一、权限表(
permission)字段设计
字段名 类型 示例值 含义说明 idBIGINT 1001权限唯一标识(长整型,通常是雪花ID) nameVARCHAR "用户管理"权限名称(菜单/按钮/接口名称) typeVARCHAR "menu"/"button"/"api"权限类型,支持菜单、按钮、接口 parent_idBIGINT 0/1001/1002上级ID(0 表示顶级) perm_codeVARCHAR "user:list"/"user:delete"权限标识,用于校验 url/pathVARCHAR "/user/list"/"/api/user/delete"前端路由或后台接口地址 methodVARCHAR "GET"/"POST"/"DELETE"请求方式(用于接口) sortINT 1/2/3排序字段 statusTINYINT 1启用状态:1启用、0禁用 visibleTINYINT 1是否前端可见(按钮用) 📌 二、模拟真实权限表数据(示例)
假设我们有一个系统模块叫“用户管理”,有一个菜单和三个按钮:
- 用户管理(菜单)
- 查询用户(按钮)
- 编辑用户(按钮)
- 删除用户(按钮)
我们再加上一个接口权限作为后台控制。【这里id和parent_id很重要】
id name type parent_id perm_code path method visible sort 1000 用户管理 menu0 user:root/usernull 1 1 1001 用户列表 menu1000 user:list/user/listnull 1 1 1002 查询按钮 button1001 user:querynull null 1 1 1003 编辑按钮 button1001 user:editnull null 1 2 1004 删除按钮 button1001 user:deletenull null 1 3 1005 删除用户API api1001 user:delete/api/user/deleteDELETE 0 4 🧠 三、说明和作用分析
1️⃣
type = menu
- 表示是页面菜单节点
- 前端构建菜单树的依据
- 有
path字段,用于前端路由匹配2️⃣
type = button
- 表示按钮级别权限
- 前端判断按钮显隐时使用:
hasPermission('user:delete') ? 显示删除按钮 : 不显示3️⃣
type = api
- 表示后台接口权限
- 由 Spring Security +
@PreAuthorize("hasAuthority('user:delete')")控制接口是否放行4️⃣
perm_code
- 每一个权限都有一个唯一
perm_code,即权限码- 按钮和API**可以共用一个
perm_code**,代表前后端权限打通🧾 附:完整表结构建表SQL
CREATE TABLE `permission` ( `id` BIGINT PRIMARY KEY, `name` VARCHAR(100) NOT NULL, `type` VARCHAR(20) NOT NULL COMMENT 'menu, button, api', `parent_id` BIGINT DEFAULT 0, `perm_code` VARCHAR(100), `path` VARCHAR(200), `method` VARCHAR(10), `visible` TINYINT DEFAULT 1, `sort` INT DEFAULT 1, `status` TINYINT DEFAULT 1 );
线程池有哪些状态,这些状态是怎么进行转换的
线程池有以下几种状态:
- RUNNING:线程池正常运行,可以接受新的任务和处理任务队列中的任务。
- SHUTDOWN:线程池不再接受新的任务,但会处理任务队列中的任务。
- STOP:线程池不再接受新的任务,也不处理任务队列中的任务,并且会中断正在执行的任务。
- TIDYING:所有任务都已终止,线程池即将关闭。
- TERMINATED:线程池已关闭。
状态转换过程如下:
- RUNNING -> SHUTDOWN:调用shutdown()方法。
- RUNNING -> STOP:调用shutdownNow()方法。
- SHUTDOWN -> TIDYING:当线程池和任务队列都为空时。
- STOP -> TIDYING:当线程池为空时。
- TIDYING -> TERMINATED:当terminated()钩子方法执行完成后。
说一下怎么使用多线程?
继承Thread类,并重写run()方法。
实现Runnable接口,并将实现类传递给Thread对象。【无返回值】
实现Callable接口,实现
call()方法【有返回值】使用Executor框架,如ExecutorService和ThreadPoolExecutor来管理线程池。
操作系统上的线程有多少种状态[5]?Java线程有多少种状态[6]?
- 新建(New):创建后尚未启动的线程处于这个状态。
new Thread - 可运行(Runnable):包括运行(Running)和就绪(Ready)状态,线程正在执行或等待CPU调度。
- 阻塞(Blocked):线程因为等待某些资源或锁而被阻塞。notify可以唤醒阻塞状态 睡眠完会自动唤醒
- 等待(Waiting):线程等待其他线程执行特定操作(如通知)。
- 计时等待(Timed Waiting):线程在一定时间内等待另一个线程的通知。
- 终止(Terminated):线程执行完成或因异常而终止。
怎么把线程杀死 终止
stop()方法[暴力方法] interrupt()方法[优雅关闭线程] 正常回收
乐观锁和悲观锁的区别
乐观锁:读多写少 线程执行时间相差较大 并发不太激烈
悲观锁:写多读少 线程执行时间相差不大 竞争激烈 并发锁多
加锁的时机不一样,
悲观锁:没改数据的时候先加锁 比较明显利用底层操作系统api实现
乐观锁:在改数据的时候才加锁 依靠底层的硬件
java层面:synchronized ReentrantLock
数据库层面:
悲观锁:select for update是mysql的的实现
乐观锁:JUC Java Util Concurrent)是Java并发工具包
SELECT ... FOR UPDATE:这个语句在读取记录时会锁定这些记录,直到事务提交或回滚。其他的事务不能更新这些锁定的记录,这是悲观锁的一个典型实现
乐观锁要读取目前旧的值再将新设置的值以及旧的值比较 如果相同 就把新的值更新 如果不相同 就把旧的值重新提取 因为在这期间有人读取了这个数据跟我之前不一样(底层api 要调用两个 一个旧的值 一个新的值)。一般乐观锁是结合自旋 类于while(true)直到读到为止 要设计次数后再报错
要更新数据库某个值 把旧的值读出来 想更新银行里的余额
这是典型的ABA问题:要用时间戳或自增版本号去做
🔒 各种锁对比表格
锁类型 适用场景 优点 缺点 乐观锁(version) 冲突少、性能优先 无阻塞、效率高 有冲突时需重试,自旋成本高 悲观锁(for update) 冲突多、安全性要求高 强一致性 并发性能差,可能导致死锁 分布式锁(Redis/Redisson) 多服务/微服务场景 支持跨节点资源锁定 实现复杂,依赖中间件 本地锁(synchronized/Lock) 单服务场景 实现简单 无法跨JVM,分布式无效
Stream流的使用及常用API
Stream是Java 8中引入的一种新特性,用于简化数据处理和操作。它可以用来解决集合循环遍历处理的问题。在此之前用循环来代替
基础Stream操作
stream(): 为集合创建串行流。parallelStream(): 为集合创建并行流。forEach: 对每个元素执行操作。map: 将每个元素映射到对应的结果。filter: 过滤出满足条件的元素。limit: 限制流的大小。skip: 跳过流中的前n个元素。sorted: 对流进行排序。终端操作
collect: 将流转换为其他形式,比如列表、集合或Map。reduce: 通过一个起始值,反复利用BinaryOperator来处理和累积元素,返回一个值。count: 返回流中元素的数量。min/max: 找到流中的最小/最大值。anyMatch: 流中是否有一个元素匹配给定的谓词。allMatch: 流中的所有元素是否都匹配给定的谓词。noneMatch: 流中没有任何元素匹配给定的谓词。findFirst: 返回第一个元素。findAny: 返回当前流中的任意元素。🧩 场景 1:筛选出余额大于1000的用户列表(
filter)List<User> richUsers = userList.stream() .filter(user -> user.getBalance().compareTo(BigDecimal.valueOf(1000)) > 0) .collect(Collectors.toList());✅ 重点理解:
filter用来“过滤”,留下满足条件的用户。
🧩 场景 2:获取所有用户名组成的新列表(
map)List<String> usernameList = userList.stream() .map(User::getUsername) .collect(Collectors.toList());✅ 重点理解:
map是映射,通常是将对象转换成某个字段或新结构。
🧩 场景 3:对订单按金额排序(
sorted)List<Order> sortedOrders = orderList.stream() .sorted(Comparator.comparing(Order::getAmount)) .collect(Collectors.toList());✅ 重点理解:
sorted用于排序,自定义排序字段。
🧩 场景 4:统计多少个订单金额大于1000(
filter + count)long highValueOrderCount = orderList.stream() .filter(order -> order.getAmount().compareTo(BigDecimal.valueOf(1000)) > 0) .count();✅ 重点理解:
count()是终止操作,直接返回数量。
🧩 场景 5:判断是否有用户未激活(
anyMatch)boolean hasInactive = userList.stream() .anyMatch(user -> !user.isActive());✅ 重点理解:
anyMatch检查是否存在一个满足条件的元素。
🧩 场景 6:求所有订单的总金额(
map + reduce)BigDecimal totalAmount = orderList.stream() .map(Order::getAmount) .reduce(BigDecimal.ZERO, BigDecimal::add);✅ 重点理解:
reduce是归约,把多个值合成一个值。
🧩 场景 7:跳过前5条,取后5条(
skip + limit)List<Order> lastFive = orderList.stream() .skip(orderList.size() - 5) .limit(5) .collect(Collectors.toList());✅ 重点理解: 用于分页、滚动加载的典型场景。
🧩 场景 8:分组统计——按用户ID分组他们的订单(
collect(Collectors.groupingBy))Map<Long, List<Order>> ordersByUser = orderList.stream() .collect(Collectors.groupingBy(Order::getUserId));✅ 重点理解:
groupingBy是分组聚合操作。
🧩 场景 9:提取用户ID组成 Set 去重(
map + collect(Collectors.toSet()))Set<Long> userIds = userList.stream() .map(User::getId) .collect(Collectors.toSet());✅ 重点理解: 利用
Set实现自动去重。
🧩 场景 10:查找第一个未发货订单(
filter + findFirst)Optional<Order> firstUnshipped = orderList.stream() .filter(order -> !order.isShipped()) .findFirst();✅ 重点理解:
findFirst()返回的是Optional<T>,避免空指针。
✅ 总结表:常用 Stream 操作一图读懂
操作方法 功能说明 示例 filter()过滤数据 filter(u -> u.age > 18)map()映射转换 map(User::getId)sorted()排序 sorted(Comparator.comparing())limit()限制返回个数 limit(10)skip()跳过前面几个 skip(5)collect()收集结果 collect(Collectors.toList())count()计数 .count()anyMatch()是否有任意一个满足 anyMatch(u -> !u.active)allMatch()所有都满足 allMatch(u -> u.age > 0)reduce()累积求和等 reduce(0, Integer::sum)findFirst()返回第一个 findFirst()
总结一下lambdaquerywrapper 和 querywrapper的区别 还有他们各自的真实场景
✅ 一句话区分:
类型 特点 使用方式 QueryWrapper通过 字段名字符串 构造条件 .eq("username", "Tom")LambdaQueryWrapper通过 方法引用(安全) 构造条件 .eq(User::getUsername, "Tom")✳️ 1.
QueryWrapper:字段名写字符串的方式✅ 特点:
- 字段名用字符串传入,如
"username"。- 使用简单、灵活、直观。
- 但容易拼写错误,且不支持字段重构(字段名变了不会报错)。
✅ 示例:
QueryWrapper<User> wrapper = new QueryWrapper<>(); wrapper.eq("username", "Tom") .ge("age", 18) .like("email", "@gmail.com"); List<User> list = userMapper.selectList(wrapper);✅ 适用场景:
- 快速写 Demo、测试。
- 字段是动态传入的(如:前端传字段名)——需要用字符串拼字段名。
- 表字段不会频繁变动。
✳️ 2.
LambdaQueryWrapper:方法引用式,更安全!✅ 特点:
- 使用 方法引用(如
User::getUsername),可以避免拼写错误。- 编译时检查字段名,重命名字段 IDE 可自动修改引用。
- 更加 类型安全、可维护。
✅ 示例:
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.eq(User::getUsername, "Tom") .ge(User::getAge, 18) .like(User::getEmail, "@gmail.com"); List<User> list = userMapper.selectList(wrapper);✅ 适用场景:
- 实际项目开发中推荐优先使用。
- 字段会变,怕忘改地方。
- 追求代码规范、可读性和安全性。
🔍 场景对比总结:
需求/场景 推荐使用 原因 字段名是前端传过来的字符串 QueryWrapper字段名只能动态拼接 普通查询(写死字段名) LambdaQueryWrapper编译器校验字段名,防止拼写错误 想快速测试或写 Demo QueryWrapper简洁方便 表结构变动频繁、重构频繁 LambdaQueryWrapper字段引用会被 IDE 识别
LambdaQueryWrapper真实场景
✅ 场景一:精确查询:查某个用户是否存在
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.eq(User::getUsername, "admin"); User user = userMapper.selectOne(wrapper);说明:判断用户名为 admin 的用户是否存在。
eq表示等于。
✅ 场景二:范围查询:查年龄在 18~30 岁之间的用户
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.between(User::getAge, 18, 30); List<User> users = userMapper.selectList(wrapper);说明:
between等价于age >= 18 AND age <= 30
✅ 场景三:模糊查询:查邮箱包含“@gmail”的用户
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.like(User::getEmail, "@gmail"); List<User> users = userMapper.selectList(wrapper);like` 相当于 SQL 中的 `LIKE '%xxx%'
✅ 场景四:多条件查询:查 username 为 tom,且状态为启用
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.eq(User::getUsername, "tom") .eq(User::getStatus, 1); // 1 代表启用 List<User> users = userMapper.selectList(wrapper);
✅ 场景五:动态查询:某些参数可为空,不传就不作为查询条件
String username = "tom"; Integer age = null; LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.eq(StringUtils.isNotBlank(username), User::getUsername, username) .eq(age != null, User::getAge, age); List<User> users = userMapper.selectList(wrapper);⭐ 动态条件拼接是 MyBatis-Plus 的一大特色:条件为 true 才拼入 SQL
✅ 场景六:排序查询:按注册时间倒序
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.orderByDesc(User::getCreateTime); List<User> users = userMapper.selectList(wrapper);
✅ 场景七:分页查询 + 条件筛选
Page<User> page = new Page<>(1, 10); // 第1页,每页10条 LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.like(User::getUsername, "张") .ge(User::getAge, 18); IPage<User> userPage = userMapper.selectPage(page, wrapper);
selectPage返回分页对象IPage,包含总条数、总页数、当前页数据。
✅ 场景八:统计某状态下的用户数量
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.eq(User::getStatus, 1); Long count = userMapper.selectCount(wrapper);
✅ 场景九:只查指定列:查所有用户名和邮箱
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.select(User::getUsername, User::getEmail); List<User> users = userMapper.selectList(wrapper);
✅ 场景十:删除某个年龄段的用户(慎用!)
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.lt(User::getAge, 10); // 年龄小于10岁 userMapper.delete(wrapper);🧠 总结你可以记住几个关键词:
方法 功能 eq/ne等于 / 不等于 like/notLike模糊匹配 gt/ge大于 / 大于等于 lt/le小于 / 小于等于 between范围查询 in/notIn集合查询 isNull/isNotNull判空 orderByAsc/orderByDesc排序 select指定返回字段 last拼接SQL片段,比如分页的 limit挑战高级复杂场景
🧩 场景设定:后台用户综合筛选
你是某后台系统开发人员,领导提出了一个用户综合查询需求:
“我要你查出所有状态正常的用户(status=1),要求他们的:
- 昵称中包含”超”
- 年龄在 20 到 30 岁之间
- 注册时间要大于某个时间点(比如 2023-01-01)
- 邮箱不能为 null
- 并且用户类型不能是 admin
- 用户ID必须在某一批导入的 id 集合中
- 最后按照注册时间降序、年龄升序排序
- 返回分页数据,每页10条,只查
id,nickname,createTime字段。”LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper .eq(User::getStatus, 1) // 状态正常 .like(User::getNickname, "超") // 昵称模糊匹配 .between(User::getAge, 20, 30) // 年龄在20~30之间 .gt(User::getCreateTime, LocalDate.of(2023, 1, 1)) // 注册时间大于2023-01-01 .isNotNull(User::getEmail) // 邮箱不为null .ne(User::getUserType, "admin") // 类型不能是admin .in(User::getId, idList) // id必须在给定集合中 .orderByDesc(User::getCreateTime) // 注册时间降序 .orderByAsc(User::getAge) // 年龄升序 .select(User::getId, User::getNickname, User::getEmail, User::getCreateTime); // 只查这几个字段✅ 配合分页使用:
Page<User> page = new Page<>(1, 10); // 第1页,每页10条 IPage<User> result = userMapper.selectPage(page, wrapper);🧩 变种考点:动态条件拼接
比如昵称可能为空,idList可能为空,我们加上动态判断:
wrapper .eq(User::getStatus, 1) .like(StringUtils.isNotBlank(nickname), User::getNickname, nickname) .between(minAge != null && maxAge != null, User::getAge, minAge, maxAge) .in(CollectionUtil.isNotEmpty(idList), User::getId, idList);LambdaQueryWrapper 是最适合在真实业务中构建动态、复杂、类型安全 SQL 的利器,配合 Stream、分页、动态参数、条件拼接,几乎能满足所有后台 CRUD 需求。
项目中具体用到哪些设计模式
单例模式:确保一个类只有一个实例,例如配置文件管理器。[Spring原本设计好的]
工厂模式:创建对象时无需指定具体的类,例如日志工厂。
观察者模式:当一个对象状态发生改变时,所有依赖于它的对象都得到通知并自动更新,例如事件监听。
**策略模式**:定义一系列算法,将每个算法封装起来,并使它们可以互换,例如支付策略。
模板方法模式:在项目中,我有一些具有相同操作步骤但具体实现不同的算法,我使用了模板方法模式来定义这些步骤的骨架,将具体的步骤实现留给子类。任链模式的目的是将请求的发送者和接收者解耦,从而使得多个对象都有机会处理请求,将这些对象连成一条链,并沿着这条链传递请求,直到有一个对象处理它为止。
责任链模式:它允许将请求沿着处理者链进行发送。收到请求后,每个处理者都有机会对请求进行处理,或者将其传递给链上的下一个处理者。这样,请求就能在一系列处理者中传递,直到有一个处理者对其进行处理为止。
1.递归方式 :在递归模式中,每个处理者内部调用下一个处理者的处理方法。如果当前处理者无法处理请求,它会直接调用下一个处理者的处理方法。这种方式通常是通过递归调用来实现的
2.迭代模式:在迭代模式中,处理者链被构建为一个线性结构,每个处理者都有一个指向下一个处理者的引用。请求从链的第一个处理者开始,依次传递给下一个处理者,直到找到能够处理该请求的处理者为止。这种方式通常是通过循环迭代来实现的
代理模式:为了控制对远程服务的访问,我使用了代理模式。代理负责处理所有与服务对象的交互,并在必要时进行延迟加载。
在我的项目中结合工厂模式和策略模式来设计登录接口时,我们可以将登录验证的逻辑抽象为一个策略接口,并为每种登录方式(如:用户名密码登录、手机验证码登录、社交账号登录等)实现具体的策略类。工厂类则负责创建并管理这些策略对象
🧠 一句话理解每个模式(先记关键词)
模式名 核心关键词 常用场景 单例模式 只创建一次,全局唯一 Spring 中的 Bean、配置类 工厂模式 创建对象不关心具体类 日志、支付、解析器、登录类型等 策略模式 多种行为自由切换,面向接口 登录方式、支付方式、算法切换 模板方法模式 公共流程固定,步骤个别实现 钩子函数、抽象类调用子类流程 责任链模式 多个处理器按顺序处理请求 参数校验链、日志链、权限校验链 观察者模式 一变多变,通知机制 事件总线、消息订阅、MQ监听 代理模式 中间人控制访问/增强 RPC远程调用、权限控制、缓存等 📦 实战分类 + 项目应用
1️⃣ 行为型模式
✅ 策略模式(Strategy)【最常考🔥】
- 特点:行为可切换
- 场景:多个登录方式(手机号 / 密码 / 第三方登录)
- 怎么用:
- 定义统一接口
LoginStrategy- 编写不同策略类
PhoneLoginStrategy、PwdLoginStrategy- 用工厂或Map封装,接收一个登录类型参数调用
.doLogin()✅ 责任链模式(Chain of Responsibility)
- 特点:多个处理器一个接一个处理
- 场景:表单参数校验、下单流程、审批流程
- 递归 or 迭代实现:
- 迭代:List + for循环
- 递归:一个 Handler 内部
next.handle(request)✅ 模板方法模式(Template Method)
- 特点:父类定义算法框架,子类实现步骤
- 场景:支付流程、通知发送(短信/微信)
- 怎么用:
- 抽象类定义
checkParams、buildRequest、send- 子类实现这些步骤
✅ 观察者模式(Observer)
- 特点:一个变化通知多个订阅者
- 场景:MQ消费后触发多个事件、发布文章后通知关注者
- 怎么用:
- Spring 的
@EventListener- Guava EventBus / Disruptor
2️⃣ 创建型模式
✅ 工厂模式(Factory)
- 特点:创建对象解耦
- 场景:创建不同类型的策略类、构建不同报文体
- 怎么用:
- 定义工厂类,根据参数 new 不同类或从 map 中 get
✅ 单例模式(Singleton)
- 特点:只创建一个对象,节省资源
- 场景:配置类、工具类、缓存类、Spring 默认就是单例
3️⃣ 结构型模式
✅ 代理模式(Proxy)
- 特点:给目标对象加一层控制
- 场景:权限控制、RPC远程调用、限流、缓存
- 怎么用:
- JDK动态代理、CGLIB
- Spring AOP就是代理模式(加日志、权限等)
行为有策略,流程靠责任;骨架定模板,通知用观察;对象建工厂,中间靠代理,唯一单实例。
思考一个问题:哪些方式创建单例模式?
1. 懒汉式,线程不安全
这种方式在类加载时不初始化。在需要的时候才创建对象,节约资源。
public class Singleton { private static Singleton instance; private Singleton() {} public static Singleton getInstance() { if (instance == null) { instance = new Singleton(); } return instance; } }2. 懒汉式,线程安全
通过同步方法确保线程安全。
public class Singleton { private static Singleton instance; private Singleton() {} public static synchronized Singleton getInstance() { if (instance == null) { instance = new Singleton(); } return instance; } }3. 饿汉式
类加载时就完成了初始化,保证了线程的安全性。容易浪费资源
public class Singleton { private static Singleton instance = new Singleton(); private Singleton() {} public static Singleton getInstance() { return instance; } }4. 双重校验锁
线程安全且在实例域需要延迟加载时提高性能。
public class Singleton { private volatile static Singleton singleton; private Singleton() {} public static Singleton getInstance() { if (singleton == null) { synchronized (Singleton.class) { if (singleton == null) { singleton = new Singleton(); } } } return singleton; } }5. 静态内部类
这种方式既实现了懒加载,又保证了线性安全。
public class Singleton { private static class SingletonHolder { private static final Singleton INSTANCE = new Singleton(); } private Singleton() {} public static final Singleton getInstance() { return SingletonHolder.INSTANCE; } }6. 枚举
实现单例的最佳方法,它不仅能避免多线程同步问题,而且还自动支持序列化机制,防止反序列化重新创建新的对象。
public enum Singleton { INSTANCE; public void whateverMethod() { } }
MySQL支持四种隔离级别
第一个是读未提交(readuncomm itted)它解决不了刚才提出的所有问题,一般项目中也不用这个。存在脏读问题 可解决不可重复读 幻读
**不可解决脏读**:读未提交允许一个事务读取另一个事务尚未提交的数据变更。如果一个事务读取了另一个事务的未提交数据,然后那个事务回滚,则第一个事务读取的数据就是无效的(脏数据)第二个是读已提交(readcomm ited)它能解决脏读的问题的,但是解决不了不可重复读和幻读。
**解决脏独**:读已提交确保一个事务只能读取已经提交的数据变更。如果一个事务正在修改某些数据,那么在它提交之前,其他事务不能读取这些数据。这样就可以避免脏读。**不可解决不可重复读**:一个事务在读取某些数据后,另一个事务修改了这些数据并提交,导致第一个事务再次读取时得到不同的结果**不可解决幻读**:一个事务在读取某个范围的数据后,另一个事务插入了一些新数据并提交,导致第一个事务在执行范围查询时看到了新插入的数据第三个是可重复读(repeatable read)它能解决脏读和不可重复读,但是解决不了幻读[解决了一部分],这个也是mysql默认的隔离级别。
第四个是串行化(serializable)它可以解决刚才提出来的所有问题,但是由于让是事务串行执行的,性能比较低。
串行化里的读也要加锁 表锁:整个表上锁 行锁:只对一行加锁串行化是最严格的事务隔离级别。它通过强制事务串行执行来避免上述所有问题。在一个事务执行时,它会锁定涉及的所有数据行或表,直到事务完成。这确保了事务完全隔离,但是会显著降低系统的并发性能
什么时候上行锁/表锁?
INSERT不带查询筛选条件 上行锁底层是索引,b+树底层叶子
- 行锁:通常情况下,插入操作会锁定插入行所在的索引项,以防止其他事务同时修改同一行。这是因为数据库通常使用B+树来维护索引,插入操作需要在B+树中找到正确的位置来插入新的索引项。如果插入操作涉及到唯一索引,数据库还会检查是否有重复的键值,这也会触发行锁。
- 注意:即使插入操作没有查询筛选条件,它仍然可能涉及到行锁,因为数据库需要保证新插入的数据不会与现有数据冲突。
UPDATE看where后面的条件 带索引加行锁构建b+树 不带索引的加表锁
表锁的速度比行锁速度快
带索引的条件:
- 行锁:如果更新操作的条件是索引列,数据库能够快速定位到需要更新的行,因此只会锁定那些特定的行。行锁可以最大程度地减少锁定的数据量,从而提高并发性能。
- 原理:数据库使用B+树索引来快速查找满足条件的行,然后对这些行加锁。
不带索引的条件:
- 表锁:如果更新操作的条件不是索引列,数据库可能需要扫描整个表来找到需要更新的行。在这种情况下,为了简化锁定逻辑并防止在扫描过程中数据被修改,数据库可能会选择锁定整个表。
- 原理:由于没有索引可以利用,数据库必须检查每一行来确定是否满足更新条件,因此使用表锁可以避免复杂的锁定管理。
MVCC底层是多版本并发控制 但底层并不怎么了解
🧩 二、锁的判断依据
操作类型 是否使用索引? 锁类型 说明 INSERT和是否冲突有关 行锁或表锁 INSERT默认加意向排他锁 + 行锁,唯一索引冲突时加锁更复杂 UPDATEWHERE使用了索引行锁(推荐) 命中索引范围 → 行锁;可并发更新不同数据行 UPDATEWHERE没用索引表锁(不推荐) 扫描全表找目标 → 表锁;阻塞性大 DELETE和 UPDATE 类似 同上 删除符合条件的行,和更新逻辑一样 SELECT普通查询 无锁(MVCC) 读不加锁,靠快照版本 SELECT ... for update使用索引? 行锁或表锁 强制加锁,依赖索引判断行锁/表锁 ABA 问题(乐观锁延申)
你前面说得对,在并发高场景中,即使数据值一样也不能认为没变,这就是ABA问题:
- A线程读了版本为1的数据,准备更新
- B线程将数据从A改为B,又改回A,版本号变了
- A线程再更新时发现版本不一致,避免了误操作!
解决方式就是:
- 使用
version字段 + 乐观锁更新WHERE version = ?- 如果更新失败,重试或提示失败(可加重试次数)
在MySQL中是否加行锁还是表锁,取决于是否命中了索引。
- 对于
UPDATE/DELETE等 DML 语句,如果WHERE条件命中索引,InnoDB 会加行锁;- 如果未命中索引,则会加表锁,以保证操作的原子性和一致性。
插入INSERT一般是对 B+ 树页加意向锁和插入位置加锁,如果涉及唯一索引校验也会加锁。
对于并发控制,MySQL采用MVCC机制来实现非阻塞读写,在读时不加锁而是使用快照版本。
如果业务涉及乐观锁防止并发更新错误,还可以通过版本号控制来避免ABA问题。
深拷贝和浅拷贝的区别?
浅拷贝:只复制对象的基本数据类型和引用类型地址,不复制引用类型指向的对象。如果原对象和浅拷贝对象中的一个改变了引用类型,另一个也会受到影响。旧对象改变新对象也会改变。
深拷贝:创建一个新的对象,并复制对象的所有字段,包括基本数据类型和引用类型指向的对象。原对象和深拷贝对象之间不会相互影响。旧对象改变新对象不会改变
Java是值传递
如何实现深拷贝?数组不需要重写【体现了原型设计模式】
实现Cloneable接口并重写clone方法 会调用构造方法
这是最常见的实现深拷贝的方法。首先,你的类需要实现
Cloneable接口,然后重写clone()方法构造新对象的过程,并在该方法中调用super.clone(),同时递归地克隆所有引用类型的字段。[如果里面有多层嵌套复杂对象 在每层都要实现Cloneable接口一直重写到基本数据类型的时候才停止]
public class Person implements Cloneable {
private int age;
private Address address;
// 构造器、getter、setter 省略
@Override
protected Object clone() throws CloneNotSupportedException {
Person cloned = (Person) super.clone();
// 假设Address也实现了Cloneable接口
cloned.address = (Address) this.address.clone();
return cloned;
}
}
public class Address implements Cloneable {
private String street;
private String city;
// 构造器、getter、setter 省略
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
- 通过序列化
对象转二进制和反序列化二进制转对象。这种方式不需要实现Cloneable接口,但你的类需要实现Serializable接口。反序列化不会调用构造方法
维度 浅拷贝 深拷贝 基本数据类型 复制值 复制值 引用类型 复制引用地址,指向同一对象 复制引用所指向的对象,开辟新内存空间 是否影响原对象 会影响(共享引用) 不会影响(各自独立) 性能 快,开销小 慢,递归复制所有对象 使用场景 数据不变或只读场景 数据完全隔离、需要独立副本场景 在Java中,浅拷贝仅复制对象的基本类型值和引用类型地址,因此多个对象可能共享同一引用,一方修改会影响另一方;而深拷贝则会递归复制所有引用对象,完全隔离副本。
通常浅拷贝使用
super.clone()即可,而深拷贝需要实现Cloneable接口 + 手动对每一个引用类型递归克隆,或使用序列化方案更为简洁。深拷贝体现了原型设计模式的思想,适合于需要保留对象快照、撤销功能、缓存隔离等场景。
开启线程的时候为什么用的是thread.start方法:
thread.start()方法用于启动一个新线程,并执行该线程的run()方法。调用start()方法后,线程会被放入线程调度队列,等待CPU调度执行。
直接调用run()方法,并不会启动一个新线程,而是在当前线程中执行run()方法,这不符合多线程编程的目的。使用start()方法可以确保线程并发执行,提高程序的性能和响应速度。
java没权限开启一个线程 要调用底层的操作系统 在JVM的底层实现中,会有相应的本地(C或C++)方法来处理线程的创建和管理
你在你们项目中使用过多线程吗?
是的,在我们的项目中,我确实使用过多线程。 【结合项目去说】
在处理大量数据计算或执行耗时的IO操作时,我会使用Java的线程池(如ExecutorService)来并行处理任务,以提高系统的响应速度和吞吐量
我们将使用多线程来处理一个在线电子商务平台的后台订单处理系统
项目需求
该系统需要处理大量的订单,包括订单验证、库存检查、支付处理和订单状态更新。为了提高处理效率,我们决定使用多线程来并行处理订单。
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.TimeUnit; import java.util.Random; public class OrderProcessingSystem { public static void main(String[] args) { // 创建一个固定大小的线程池 int numberOfProcessors = Runtime.getRuntime().availableProcessors(); ExecutorService executor = Executors.newFixedThreadPool(numberOfProcessors); // 模拟订单队列 Random random = new Random(); for (int orderId = 1; orderId <= 100; orderId++) { int finalOrderId = orderId; executor.submit(() -> { processOrder(finalOrderId, random.nextInt(1000)); }); } // 关闭线程池 executor.shutdown(); try { if (!executor.awaitTermination(60, TimeUnit.SECONDS)) { executor.shutdownNow(); } } catch (InterruptedException e) { executor.shutdownNow(); Thread.currentThread().interrupt(); } } private static void processOrder(int orderId, int orderAmount) { System.out.println("Processing order ID: " + orderId + " - Thread: " + Thread.currentThread().getName()); // 模拟订单验证 validateOrder(orderId); // 模拟库存检查 checkInventory(orderId); // 模拟支付处理 processPayment(orderId, orderAmount); // 更新订单状态 updateOrderStatus(orderId, "Completed"); } private static void validateOrder(int orderId) { // 模拟订单验证逻辑 try { Thread.sleep(100); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } System.out.println("Order ID " + orderId + " validated."); } private static void checkInventory(int orderId) { // 模拟库存检查逻辑 try { Thread.sleep(200); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } System.out.println("Inventory checked for Order ID " + orderId + "."); } private static void processPayment(int orderId, int orderAmount) { // 模拟支付处理逻辑 try { Thread.sleep(300); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } System.out.println("Payment processed for Order ID " + orderId + " - Amount: " + orderAmount); } private static void updateOrderStatus(int orderId, String status) { // 模拟订单状态更新逻辑 System.out.println("Order ID " + orderId + " status updated to " + status + "."); } }在这个示例中,我们创建了一个固定大小的线程池,其大小等于可用处理器的数量。然后,我们模拟了一个包含100个订单的队列,并为每个订单提交了一个任务到线程池中。每个任务代表订单处理的整个流程,包括验证、库存检查、支付处理和状态更新。每个步骤都通过休眠来模拟耗时操作。最后,我们关闭线程池并等待所有任务完成。
sleep和wait的区别
sleep是Thread类的一个静态方法,它使当前线程暂停执行指定的时间,但不会释放锁资源。
wait是Object类的一个方法,它使当前线程暂停执行并释放当前对象上的锁,直到另一个线程调用同一个对象的notify()或notifyAll()方法,或者过了指定的等待时间。
sleep是线程内的静态方法 需要指定睡眠的时间 或者自动自己唤醒 不会释放锁
wait是Object类的一个方法 可以指定睡眠时间 不指定就等于无限期 要释放锁
wait一定要搭配synchronized,且都为同一个对象 synchronized锁住了wait万物对象皆为锁
可以被唤醒notify()或notifyAll()方法 区别:notify是随机唤醒一个 notifyall会唤醒全部
普通方法上 锁的是this
静态方法上 锁的是当前类的class对象
ConcurrentHashMap 和 HashTable的区别
是否支持传入NULL
HashMap可以支持为null
若尝试将 null 作为键或值放入 ConcurrentHashMap 将会抛出 NullPointerException
ConcurrentHashMap 不能支持存null
底层实现
ConcurrentHashMap 1.8之前是分段锁来实现 默认是16个HashTable
1.8之后无限接近单个的HashMap 底层用CAS+synchronized
HashTable通过加synchronized锁来控制线程安全
ConcurrentHashMap 读不要加锁 [读写的读也不会加锁] 会走最终一致性
HashTable 读要加锁 [读读都加锁]
为什么要用Redis
高性能:Redis是基于内存的数据结构存储,可以提供高速的数据读写操作。
数据结构丰富:Redis支持多种数据结构,如字符串、列表、集合、散列表、有序集合等,非常适合各种场景。
持久化:Redis支持数据持久化,可以将内存中的数据保存到磁盘中,防止数据丢失。
分布式:Redis支持主从复制、哨兵和集群模式,可以轻松实现分布式缓存。
Redis中缓存了哪些数据
可以存储一下类型的数据
- 会话缓存(Session Store):用户会话信息,如用户登录状态、用户偏好设置等。
- 页面缓存:动态生成的网页内容,以减少数据库的读取次数。
- 对象缓存:例如,用户信息、商品详情等,减少数据库访问。
- 消息队列:用作消息队列,处理异步任务。
- 排行榜或计数器:如用户点赞数、视频播放次数等。
- 地理空间数据:用于实现基于地理位置的查询。
- 分布式锁:在分布式系统中协调不同服务或节点的操作
关于您提到的替代JWT的方案,即使用Redis来管理登录状态而不是使用JWT,这里有一些详细说明:
若放登录的信息到Redis的时候 不再用JWT了
Session在集群里面不能用了
替代方案:用Redis 不用JWT
JWT是无状态 无需集中存储
在我们的项目中,Redis中缓存了以下类型的数据:
会话信息:如用户登录信息、购物车内容等。
热点数据:如热门商品信息、推荐内容等。
计数器:如用户访问次数、点赞数、评论数等。
缓存数据库查询结果:减少数据库访问次数,提高系统响应速度。
JWT(JSON Web Tokens)
JWT是一种在各方之间传递安全可靠信息的简洁的、URL安全的表达方式。其特点包括:
- 无状态:服务器不存储任何会话信息,每个请求都携带包含所有必要信息的JWT。
- 自包含:JWT中包含了用户的所有声明,减少了服务器的数据库查询。
- 跨域认证:特别适用于单点登录(SSO)。
JWT的局限性
- 无法失效:一旦签发了JWT,在它过期之前,它在任何地方都是有效的,无法提前失效。
- 续签问题:JWT过期后需要重新签发,处理起来相对复杂。
- 携带信息量大:每个请求都携带JWT,如果JWT中包含的信息较多,会增加请求的大小。
使用Redis替代JWT
使用Redis作为会话存储,可以解决JWT的一些问题:
- 中心化控制:通过Redis,服务器可以集中管理会话信息,可以随时使会话失效。
- 灵活的过期策略:可以设置更细粒度的过期时间,并在需要时刷新会话。
- 状态管理:对于需要频繁更改用户状态的应用,使用Redis可以更方便地管理。
- 安全性:虽然Redis存储会话信息,但可以结合HTTPS和合适的加密策略来保证传输过程的安全
实现方案
- 用户登录:用户登录成功后,生成一个唯一的会话标识(如UUID),并将其作为key存储在Redis中,value可以是用户ID或者其他必要信息,并设置适当的过期时间。
- 请求验证:用户每次请求时,需要在请求头中携带会话标识,服务器端通过这个标识在Redis中查找会话信息,进行验证。
- 会话过期或失效:当用户登出或会话过期时,从Redis中删除对应的会话信息。
注意事项
- 数据持久性:Redis的数据是存储在内存中的,需要考虑持久化策略以防止数据丢失。
- 高可用性:在集群环境下,需要配置Redis的高可用方案,如哨兵(Sentinel)或集群模式。
- 安全性:确保Redis的安全性,防止未授权访问。
检测数据存在Redis中,有过期时间吗? 过期时间是多少?仅参考
是的,我们在Redis中缓存的数据通常会设置过期时间,以避免过时的数据占用内存。具体的过期时间取决于数据的类型和业务需求。对于会话信息,我们可能会设置较短的过期时间,如30分钟或1小时;而对于热点数据,可能会设置较长的过期时间,如几小时或一天。具体的过期时间需要根据实际业务场景和数据访问模式来决定。
// 用户登录,创建会话
public String loginUser(String userId) {
String sessionId = UUID.randomUUID().toString();
String sessionData = createSessionData(userId);
jedis.setex(sessionId, 1800, sessionData); // 设置会话过期时间为30分钟
return sessionId;
}
微服务之间如何调用?
通过注册中心去协调的
首先是有三个重要的概念,服务消费者,注册中心,服务提供者在第一次会把自己的信息注册到注册中心中,比如ip端口,服务功能等消费者需要到注册中心来寻找服务进行消费,在服务消费者第一次请求的时候会拉取服务提供者的信息,注册中心会把提供者的实例列表给到消费者供消费者选择,使用负载均衡来选择服务,默认为轮询,还有加权轮询,随机。同时服务消费者还会定时去注册中心拉取服务提供者的信息
如果我们的服务挂掉了怎么办?
服务提供者会每隔一段时间去向注册中心报告自己的状态[发送心跳ping 30s/次 共90s],如果没有向注册中心报告状态,那么这个时候注册中心会认为服务提供者已经宕机,同时会推送到我们的服务消费者,这个服务提供者已经宕机
微服务的五大组件
- 服务注册与发现:如Eureka
已过时、Nacos、Consul,用于服务的注册和发现。 - 配置管理:如Spring Cloud Config、OpenFeign 用于集中管理服务的配置。
Feign是一个声明式的Web服务客户端(Web服务客户端就是Http客户端),让编写Web服务客户端变得非常容易,只需创建一个接口并在接口上添加注解即可。
OpenFeign是Spring Cloud 在Feign的基础上支持了SpringMVC的注解,如@RequesMapping等等。OpenFeign的@FeignClient可以解析SpringMVC的@RequestMapping注解下的接口,并通过【动态代理】的方式产生实现类,实现类中做负载均衡并调用其他服务。
@FeignClient(name = "feignTestService", url = "http://localhost/8001")
public interface FeignTestService {
}
@Component
@FeignClient(url = "http://localhost/8001")
public interface PaymentFeignService{
}
二、OpenFeign使用 2.1.OpenFeign 常规远程调用 所谓常规远程调用,指的是对接第三方接口,和第三方并不是微服务模块关系,所以肯定不可能通过注册中心来调用服务。 第一步:导入OpenFeign的依赖 第二步:启动类需要添加 【@EnableFeignClients】 第三步:提供者的接口 @RestController @RequestMapping("/test") public class FeignTestController { @GetMapping("/selectPaymentList") public CommonResult<Payment> selectPaymentList(@RequestParam int pageIndex, @RequestParam int pageSize) { System.out.println(pageIndex); System.out.println(pageSize); Payment payment = new Payment(); payment.setSerial("222222222"); return new CommonResult(200, "查询成功, 服务端口:" + payment); } @GetMapping(value = "/selectPaymentListByQuery") public CommonResult<Payment> selectPaymentListByQuery(Payment payment) { System.out.println(payment); return new CommonResult(200, "查询成功, 服务端口:" + null); } @PostMapping(value = "/create", consumes = "application/json") public CommonResult<Payment> create(@RequestBody Payment payment) { System.out.println(payment); return new CommonResult(200, "查询成功, 服务端口:" + null); } @GetMapping("/getPaymentById/{id}") public CommonResult<Payment> getPaymentById(@PathVariable("id") String id) { System.out.println(id); return new CommonResult(200, "查询成功, 服务端口:" + null); } 第四步:消费者调用提供者接口 @FeignClient(name = "feignTestService", url = "http://localhost/8001") public interface FeignTestService { @GetMapping(value = "/payment/selectPaymentList") CommonResult<Payment> selectPaymentList(@RequestParam int pageIndex, @RequestParam int pageSize); @GetMapping(value = "/payment/selectPaymentListByQuery") CommonResult<Payment> selectPaymentListByQuery(@SpringQueryMap Payment payment); @PostMapping(value = "/payment/create", consumes = "application/json") CommonResult<Payment> create(@RequestBody Payment payment); @GetMapping("/payment/getPaymentById/{id}") CommonResult<Payment> getPaymentById(@PathVariable("id") String id); }
- 服务网关:如Zuul、Spring Cloud Gateway,作为系统的唯一入口,处理外部请求的路由和过滤。
- 负载均衡:如Ribbon,用于在多个服务实例之间分配请求。
- 断路器:如Hystrix,用于服务熔断,防止系统雪崩
对于服务注册这块有什么了解?
- 服务注册中心:服务实例在启动时向服务注册中心注册自己的地址和端口信息。检查 心跳 如果未查询就剔除,同时也有注册中心主动发起请求。
- 健康检查:服务注册中心通常会定期对已注册的服务进行健康检查,以确保服务的可用性。
- 服务发现:服务消费者通过服务注册中心查找可用的服务实例,以进行服务调用。
- 服务去注册:当服务实例关闭或出现故障时,它需要从服务注册中心注销,以避免调用不可用的服务。
你能说一下小程序的登录流程吗?
调用微信api,根据code获取openid;根据openid查询用户为空就新增;调用微信api WechatService + WechatServiceImpl(openId+phoneCode) 获取用户绑定的手机号;保存或修改该用户;将用户id存入token返回(JWT生成token)
有哪些方式可以创建单例?
- 饿汉式:在类加载时就立即初始化并创建单例对象。
- 懒汉式:在第一次调用时初始化单例对象,通常需要考虑线程安全问题。
- 双重校验锁:在懒汉式的基础上,通过双重校验锁确保线程安全。
- 静态内部类:利用静态内部类的加载机制来确保单例对象的唯一性。
- 枚举:利用枚举的特性,保证单例对象的唯一性和线程安全【不可用反射】
并发情况下严格控制单例?volatile→禁止进行指令重排序
双重校验锁:在懒汉式的基础上,通过双重校验锁确保线程安全。
思考一个问题:哪些方式创建单例模式?
1. 懒汉式,线程不安全
这种方式在类加载时不初始化。在需要的时候才创建对象,节约资源。
public class Singleton { private static Singleton instance; private Singleton() {} public static Singleton getInstance() { if (instance == null) { instance = new Singleton(); } return instance; } }2. 懒汉式,线程安全
通过同步方法确保线程安全。
public class Singleton { private static Singleton instance; private Singleton() {} public static synchronized Singleton getInstance() { if (instance == null) { instance = new Singleton(); } return instance; } }3. 饿汉式
类加载时就完成了初始化,保证了线程的安全性。
public class Singleton { private static Singleton instance = new Singleton(); private Singleton() {} public static Singleton getInstance() { return instance; } }4. 双重校验锁
线程安全且在实例域需要延迟加载时提高性能。
public class Singleton { private volatile static Singleton singleton; private Singleton() {} public static Singleton getInstance() { if (singleton == null) { synchronized (Singleton.class) { if (singleton == null) { singleton = new Singleton(); } } } return singleton; } }5. 静态内部类
这种方式既实现了懒加载,又保证了线性安全。
public class Singleton { private static class SingletonHolder { private static final Singleton INSTANCE = new Singleton(); } private Singleton() {} public static final Singleton getInstance() { return SingletonHolder.INSTANCE; } }6. 枚举
实现单例的最佳方法,它不仅能避免多线程同步问题,而且还自动支持序列化机制,防止反序列化重新创建新的对象。
public enum Singleton { INSTANCE; public void whateverMethod() { } }
公平锁和非公平锁的区别?
公平锁:多个线程按照它们请求锁的顺序来获取锁,先来先得。这种方式不会产生饥饿现象,但可能会降低吞吐量,因为需要额外的开销来维护等待队列的顺序。【僵尸线程】对资源顺序有严格要求
为什么会降低吞吐量?
- 维护等待队列:公平锁为了保证按照请求锁的顺序来获取锁,必须维护一个有序的等待队列。这意味着每次有线程请求锁或者释放锁时,都需要进行额外的操作来管理这个队列,这会增加开销。
- 上下文切换开销:当锁被释放时,公平锁需要唤醒等待队列中的第一个线程。这个过程涉及到线程的上下文切换,上下文切换是有成本的,因为它涉及到保存和恢复线程的状态。
- 减少并发机会:由于公平锁要求先来先得,即使锁被释放后请求锁的线程即使处于可运行状态,也必须等待前面的线程先执行。这可能会减少并发执行的机会,从而降低吞吐量。
- 增加延迟:公平锁可能会增加线程获取锁的平均等待时间,因为每个线程都必须等待前一个线程完成。这种延迟可能会导致系统整体性能下降。
非公平锁:线程获取锁的顺序不一定是按照请求锁的顺序,允许线程“插队”。这种方式可能会提高吞吐量,但可能导致某些线程长时间无法获取锁,产生饥饿现象。【为什么性能高?不用沉睡和阻塞 避免来回切换】对性能要求高
ReentrantLock 看传参 公平/非公平都支持
ReentrantLock 是Java提供的显式锁,它允许你通过构造函数参数来选择是使用公平锁还是非公平锁:
公平锁(Fair Lock):通过传递true给ReentrantLock的构造函数来创建。这确保了锁的获取是按照线程请求锁的顺序进行的,防止饥饿现象。
ReentrantLock fairLock = new ReentrantLock(true);
非公平锁(Non-Fair Lock):通过传递false或者不传递参数(默认值)给ReentrantLock的构造函数来创建。这种方式允许线程“插队”,可能会提高吞吐量,但也可能导致某些线程长时间无法获取锁。
ReentrantLock nonFairLock = new ReentrantLock(false); // 或者
ReentrantLock nonFairLock = new ReentrantLock(); // 默认是非公平锁
Synchronized 公平锁
从Java 6开始,synchronized的实现得到了改进,它试图实现一种偏向锁和轻量级锁的策略,以提高性能。
以下是关于synchronized的一些关键点:
偏向性:synchronized在锁竞争不激烈的情况下,会尝试偏向第一个获取锁的线程,这有助于减少不必要的同步开销。
轻量级锁:当没有竞争时,synchronized会使用轻量级锁,这比使用操作系统提供的重量级锁要快得多。
重量级锁:当存在竞争时,synchronized会升级为重量级锁,这涉及到操作系统的线程调度。
synchronized不会严格地保证公平性,因为它允许锁的“重入”和偏向性,这意味着它更倾向于非公平锁的行为。然而,在锁竞争激烈的情况下,synchronized会尽量保持一定的公平性,因为它会按照线程在监视器队列中的顺序来获取锁。
总的来说,synchronized不是严格意义上的公平锁,但它的实现细节和调度策略可能会在一定程度上表现出公平锁的特性。与ReentrantLock相比,synchronized的锁获取机制更为复杂,并且它是由JVM内部实现的,因此具体的调度细节对开发者来说是透明的。
SpringMVC的工作原理
前端的HTTP请求到达时首先被DispatcherServlet接收
DispatcherServlet根据请求信息
路径查找合适的HandlerMapping来确定哪个Controller应该处理该请求。找到合适的Controller后,DispatcherServlet将请求转发给它处理。
Controller处理完请求后返回一个ModelAndView对象给DispatcherServlet。
DispatcherServlet再通过ViewResolver解析ModelAndView中的视图逻辑名,找到对应的视图。
最后,DispatcherServlet将模型数据渲染到视图上并响应给客户端。

OpenFeign的底层原理
OpenFeign 实现了简洁、声明式的 HTTP 请求调用,并且与 Spring Cloud 集成后能提供更多的功能如负载均衡等
动态代理: OpenFeign 使用 Java **动态代理技术**,基于接口创建代理类,代理类会自动发起 HTTP 请求。你定义的接口方法会映射到 HTTP 请求上,OpenFeign 会根据注解(如 @RequestMapping, @GetMapping 等)来构建请求。
注解解析: OpenFeign 会解析接口方法上的注解,构造 HTTP 请求的 URL、请求方法类型(GET、POST 等),以及请求体和请求头等信息。
请求拦截和处理: 在请求发起之前,OpenFeign 允许通过拦截器(RequestInterceptor)来修改请求,比如设置请求头、参数等。
负载均衡与容错: 如果与 Spring Cloud 一起使用,OpenFeign 会集成 Ribbon(负载均衡)和 Hystrix(容错),使得服务调用更加健壮和可靠。
序列化与反序列化: OpenFeign 会利用 Jackson 等库进行请求和响应的序列化和反序列化,将 Java 对象与 HTTP 请求/响应内容相互转换
在使用OpenFeign时,开发者只需要定义接口并添加相应的注解,OpenFeign会在运行时动态生成实现类来执行HTTP请求。
对Volatile的理解
volatile 是Java语言中的一个关键字,用于修饰变量,以确保该变量的读写操作对所有线程立即可见,并且防止指令重排序优化。
确保了不同线程对这个变量进行读写操作时的可见性。
是java的关键字是修饰共享的变量,不能修饰局部变量。
修饰普通或静态成员变量,主要用来保证可见性和有序性。
可见性(Visibility)
在一个多线程程序中,为了提高性能,每个线程可能会将共享变量缓存到自己的CPU缓存中。如果一个线程修改了这个变量的值,而这个新值没有及时写回主内存,那么其他线程可能会读取到旧值。使用
volatile关键字可以确保:
- 每次读写变量都是直接操作主内存。
- 当一个线程修改了一个
volatile变量时,新值会立即被写入主内存。- 其他线程读取
volatile变量时,会从主内存中读取最新值。这样,
volatile就保证了不同线程之间共享变量的可见性。有序性(Ordering)
在没有
volatile修饰的变量上,Java编译器和处理器可能会进行指令重排序,以提高程序运行的效率。指令重排序可能会导致程序的执行顺序与代码的编写顺序不一致。使用volatile可以防止以下两种类型的重排序:
- 写操作的重排序:
volatile变量的写操作不允许与它之前的操作重排序。- 读操作的重排序:
volatile变量的读操作不允许与它之后的操作重排序。这样,
volatile就提供了一定的有序性保证。
Spring Security的实现
我的项目是基于JWT的前后端分离的项目,在自定义认证管理器AuthenticationManager认证成功后,生成JWT令牌并返回给前端。前端在随后的请求中携带这个JWT令牌。这时候,我们使用AccessDecisionManager来实现接口的鉴权逻辑,其中包括一个check方法,该方法会校验JWT令牌的有效性。如果校验通过,就去查询数据库以确定用户拥有哪些权限。在用户登录时,其权限信息已经被缓存到Redis中。后续的请求中,我们可以直接从Redis中检索用户的权限信息。如果请求的接口权限与用户缓存中的权限匹配,则放行;如果不匹配,则返回一个友好的错误信息
什么是AQS
是多线程中的抽象队列同步器。是一种锁机制,它是做为一个基础框架使用的,是一个抽象类。
像ReentrantLock都是基于AQS实现的
在Java的并发编程中,
AbstractQueuedSynchronizer(简称AQS)是一个非常重要的类,它提供了一个框架,用于实现依赖于先进先出(FIFO)等待队列的阻塞锁和其他同步器(例如信号量、事件等)。AQS 本身是一个抽象类,它内部定义了获取资源(锁)和释放资源(锁)的基本方法,以及管理同步状态和队列的机制。当说“ReentrantLock是基于AQS实现的”,意味着
ReentrantLock这个具体锁的实现类,是继承并利用了AQS提供的模板方法来构建其功能的。具体来说:
- 继承:
ReentrantLock内部有一个内部类叫做Sync,这个Sync类直接继承自AbstractQueuedSynchronizer。- 实现:
Sync类(及其子类)会根据需要重写AQS的一些方法,如tryAcquire和tryRelease,这些方法用于定义获取锁和释放锁的具体行为。- 利用模板方法:AQS提供了一系列的模板方法(如
acquire、release等),这些方法内部会调用前面提到的可重写方法(如tryAcquire、tryRelease),从而允许ReentrantLock按照特定的逻辑来管理锁的状态。因此,“基于AQS实现”的表述强调了
ReentrantLock并不是从头开始构建锁的所有细节,而是站在AQS这个强大的基础框架之上,通过实现特定的策略来完成锁的具体功能。这样做的好处是减少了代码量,提高了代码的可维护性和可重用性,并且由于AQS经过了严格的测试,基于它实现的锁也更加可靠。
定义了一个并发情况下一些抽象的资源 资源能否共享/独享 定义了公平/非公平
如果是非公平锁如果来了个新的线程来抢线程 也是会去抢一次
AQS成为了JUC很多类都去继承的 它抽象了很多并发的属性和行为,让子类去继承它扩展自己
Synchronized的锁升级
- Monitor实现的锁属于重量级锁,里面涉及到了用户态
权限低和内核态权限高的切换、进程的上下文切换,成本较高,性能比较低 - 在JDK1.6引入了两种新型锁机制:偏向锁和轻量级锁,它们的引入是为了解决在没有多线程竞争或基本没有竞争的场景下使用传统锁机制带来的性能开销问题
一段很长的时间内都只被一个线程使用锁 偏向锁
有线程交替或线程加锁的时间是错开的 轻量级锁
有很多线程来抢 重量级锁
偏向锁
偏向锁是一种优化锁的机制,它的设计初衷是:如果一个锁在大多数时间里只被一个线程访问,那么就没有必要进行线程间的同步操作,因为不存在锁竞争。在这种情况下,JVM会为这个锁赋予一个“偏向”,即偏向于第一个获取它的线程。在后续的锁操作中,如果该线程再次请求这个锁,就不需要进行同步操作,从而提高性能。偏向锁适用于只有一个线程访问同步块的场景。
轻量级锁
轻量级锁是另一种锁的优化,它适用于锁竞争不是很激烈,且锁持有的时间短的场景。当线程交替访问同步块时,使用轻量级锁可以减少传统的重量级锁带来的性能开销。轻量级锁是通过在对象头中的一些标记位来实现的,当锁处于轻量级锁状态时,线程通过CAS操作来尝试获取锁,如果成功,则直接进入同步块执行,从而避免了使用操作系统级别的重量级锁机制。
重量级锁
重量级锁是JVM中最传统的锁实现,也是性能开销最大的锁。当有很多线程同时竞争同一个锁时,JVM会使用重量级锁来确保线程安全。重量级锁依赖于操作系统的互斥量(mutex),会导致线程状态在用户态和核心态之间转换,这种转换是非常耗时的。因此,当锁竞争非常激烈时,使用重量级锁可以保证公平性和线程安全,但会带来较大的性能开销。
在处理多线程同时竞争同一个锁的情况时,并不一定总是需要使用重量级锁。以下是一些优化和策略,可以帮助您更好地处理并发场景:
- 最小化同步范围:
- 仅对必要的代码块进行同步,减少锁的竞争。
- 使用细粒度锁,比如对不同的数据结构使用不同的锁,而不是对整个对象加锁。
- 使用并发工具类:
- Java提供了许多并发工具类,如
java.util.concurrent包中的ReentrantLock、ReadWriteLock、Semaphore、CountDownLatch、ConcurrentHashMap等,它们提供了比synchronized更丰富的功能。- 锁分离:
- 对于读多写少的场景,可以使用读写锁(
ReadWriteLock),它允许多个读线程同时访问,而写线程则互斥。- 锁优化:
- 在锁竞争不是很激烈的情况下,可以使用轻量级锁或偏向锁,这些锁的开销比重量级锁小。
- 无锁编程:
- 使用原子类(如
AtomicInteger、AtomicReference)和线程安全的数据结构,这些类通过CAS操作实现了无锁的线程安全。- 线程池:
- 使用线程池来管理线程,避免频繁创建和销毁线程带来的开销。
- 避免死锁:
- 设计代码时注意锁的顺序,避免循环等待条件,减少死锁的发生。
- 性能测试:
- 对并发代码进行性能测试,了解不同锁策略对性能的影响,并根据测试结果选择合适的锁。
java语言是高级语言如果想调用底层的操作系统和硬件要通过操作系统的API去操作。以前老的JDK版本 数据是在操作系统找的数据锁,Monitor的标志0 和 1,底层使用的Monitor实现,里面涉及到了用户态和内核态的切换、进程的上下文切换,成本较高,性能比较低 。
引入新型锁后,java里是用对象头找个地方存一把锁,这样就不涉及到调用操作系统底层。一开始new了个对象 此时是无锁状态。接下来来人拿锁,长期一个人拿到那个锁 此时是偏向锁竞争不激烈。后面多线程一起来 交替抢锁 此时是轻量级锁。随着并发越来越高 此时在一个线程拿到锁后很多线程来抢锁 线程先尝试自己先获取几次(自旋锁64次未拿到锁就会升级为重量级锁) 这时就涉及到操作系统的底层对象涉及到了用户态权限低和内核态权限高的切换、进程的上下文切换,成本较高,性能比较低。锁不可逆可能新版本可以降级
Dockerfile 常用命令
FROM: 指定基础镜像。ENV: 设置环境变量。RUN: 执行命令并创建新的镜像层。COPY: 将文件从宿主机复制到容器中。EXPOSE: 声明容器运行时将监听的端口。ENTRYPOINT: 配置容器启动时运行的命令。
常用的 Docker 命令
docker run: 创建一个新的容器并运行一个命令。docker pull: 从仓库中拉取或者更新一个镜像。docker push:推送镜像到服务docker build: 从 Dockerfile 构建一个镜像。docker images: 列出本地镜像。docker ps: 列出运行中的容器。docker stop: 停止一个运行中的容器。docker start: 启动一个停止的容器。docker rm: 删除一个容器。docker rmi: 删除一个镜像。docker exec: 在运行中的容器内执行命令。docker logs: 获取容器的日志。
- docker volume create:创建数据卷
- docker volume ls:查看所有数据卷
- docker volume inspect:查看数据卷详细信息,包括关联的宿主机目录位置
- docker volume rm:删除指定数据卷
Docker Compose 常用命令
docker-compose up: 启动所有服务的容器。docker-compose down: 停止并删除容器、网络、卷和镜像。docker-compose ps: 列出项目中所有的容器。docker-compose exec: 进入指定的容器。docker-compose build: 构建或重建服务。docker-compose logs: 查看服务的日志输出。docker-compose stop: 停止运行的容器。
synchronized 和 ReentrantLock 的区别
synchronized是Java的一个关键字用于方法和代码块中,而ReentrantLock是JUC包的一个类。synchronized可以自动加锁和解锁,而ReentrantLock需要手动加锁和解锁。synchronized的锁是非公平的,而ReentrantLock默认也是非公平的,但可以设置为公平锁。
你们公司是怎么部署项目的
是通过docker + jenkins
测试环境我们参与 生产环境组长部署
varchar 与 char 区别
varchar是可变长度的字符串,而char是固定长度的字符串。varchar的性能通常比char差,因为需要处理额外的长度信息。- 当数据长度变化很大时,推荐使用
varchar;当数据长度几乎固定时,使用char可能更合适。
Redis的持久化有哪几种? 它们的区别是什么?
完整性 大小 数据恢复速度 建议
Redis持久化:RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照,简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,数据恢复。
[root@localhost ~]# redis-cli
127.0.0.1:6379> save #由Redis主进程来执行RDB,会阻塞所有命令
ok
127.0.0.1:6379> bgsave #开启子进程执行RDB,避免主进程受到影响
Background saving started
Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:
// 900秒内,如果至少有1个key被修改,则执行bgsave
save 900 1
save 300 10
save 60 10000
==RDB的执行原理?==数据完整性高用RDB
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据,完成fork后读取内存数据并写入RDB文件
在LInux中主进程并无法直接读取物理内存,它只能通过虚拟内存去读。因此有页表(记录虚拟地址与物理地址的映射关系)去执行操作 同时 主进程也会fork(复制页表) 成为一个新的子进程(携带页表) → 写新RDB文件替换旧的RDB文件 → 磁盘
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作
优点:二进制数据重启后 Redis无需过多解析 直接恢复
==AOF==对数据不敏感要求不高
AOF全称为Append Only File(追加文件)底层硬盘顺序读写。Redis处理的每个写命令都会记录在AOF,可以看作是命令日志文件
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
AOF的命令记录的频率也可以通过redis.conf文件来配
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完毕先放入AOF缓冲区,然后表示每隔一秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
| 配置项 | 刷盘时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步刷盘 | 可靠性高,几乎不丢数据 | 性能影响大 |
| everysec | 每秒刷盘 | 性能适中 | 最多丢失1秒数据 |
| no | 操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量数据 |
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重读功能,用最少的命令达到相同效果
Redis会在出发阈值时自动重写AOF文件。阈值也可以在redis.conf中配置
# AOF文件比上次文件 增多超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
★★★★★★★★ RDB与AOF对比 ★★★★★★★★
RDB和AOF各有优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用
RDB是二进制文件,在保存时体积较小恢复较快,但也有可能丢失数据,我们通常在项目中使用AOF来恢复数据,虽然慢但丢失数据风险小,在AOF文件中可以设置刷盘策略(每秒批量写入一次命令)
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照哦 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源 但AOF重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高常见 |
项目中是怎么使用redis的
需要结合项目中的业务进行回答,通常情况下,分布式锁的使用场景:
集群情况下的定时任务、抢单、幂等性场景
如果使用互斥锁的话 那么在集群项目有多个服务器就会出现问题
用Hash类型 大Key是Id 小key是商品id value是商品数量
数据量点击量 用String类型
用Set类型 Zset做排行榜
你的项目中哪里使用到分布式锁?
==Redis分布式锁==
Redis实现分布式锁主要利用Redis的setnx命令,setnx是**SET if not exists**(如果不存在,则SET)的简写
获取锁
添加锁,NX是互斥、EX是设置超时时间
SET lock value NX EX 10释放锁
释放锁,删除即可
DEL key
你可以说一下redis的分布式锁的原理吗
我在项目中是集成了redisson(底层基于Lua脚本[具有原子性])
==redisson实现分布式锁 - 执行流程==
加锁 ↓→ 加锁成功 → Watch dog(看门狗)
每隔(releaseTime/3的时间做一次续期)→ Redis
↓ 操作redis → Redis
↓→→ 释放锁↑ → 通知看门狗无需继续监听 → Redis
加锁 → → → 是否加锁成功?→→→ ↓
↑←←while循环不断尝试获取锁←←←↓
public void redisLock() throws InterruptedException{
RLock lock = redissonClient.getLock("heimalock");
// boolean isLock = lock.tryLock(10, 30, TimeUnit.SECONDS);
// 如果不设置中间的过期时间30 才会触发看门狗
// 加锁,设置过期时间等操作都是基于lua脚本完成的[调用redis命令来保证多条命令的原子性]
boolean isLock = lock.tryLock(10, TimeUnit.SECONDS);
if(isLock){
try{
sout("执行业务");
} finally{
lock.unlock();
}
}
}
==redisson实现分布式锁 - 可重入==
redis实现分布式锁是不可重入的 但是 redisson实现分布式锁是可以重入的
可重入原理:它俩是同一个线程 每个线程都有唯一的线程id 根据线程id唯一标识做判断 判断之前获取锁是不是同一个线程
利用hash结构记录线程id和重入次数
KEY VALUE VALUE field value heimalock thread1 0
public void add1(){
RLock lock = redissonClient.getLock("heimalock");
boolean isLock = lock.tryLock();
// 执行业务
add2();
// 释放锁
lock.unlock();
}
public void add2(){
RLock lock = redissonClient.getLock("heimalock");
boolean isLock = lock.tryLock();
// 执行业务
// 释放锁 锁次数-1不完全释放
lock.unlock();
}
==redisson实现分布式锁 - 主从一致性==
Redis Master主节点:主要负责写操作(增删改) 只能写
Redis Slave从节点:主要负责读操作只能读
当RedisMaster主节点突然宕机后 Java应用会去格外获取锁 这时两个线程就同时持有一把锁 容易出现脏数据
怎么解决呢?
- RedLock(红锁):不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁(n/2+1),避免在一个redis实例【实现复杂、性能差、运维繁琐】怎么解决?→ CP思想:zookeeper
redis和mysql怎么保证数据一致性
写先插入数据库
更新先更新数据库 更新数据库成功但redis不成功 影响不大 因为后面会有过期删除 最终会一致,更新mysql后缓存可以删除也可以修改
更新完数据库直接删除缓存了 有过期时间兜底 最终会保持一致 我们项目中对数据敏感性一致性不高 我们追求实时性
如果是最终保持一致性的就MQ 我们对实时性不高 对数据敏感性 一致性高
删除问题不大 哪里都行!
读多写少的可以上缓存
mysql保存购物车表 但是再页面操作的时候 只操作redis 用mq给到消费者修改或定时任务 更新数据到mysql,MQ问题:我们对数据实时性要求不高 只需要保存最终一致性就行
你如果只写redis 万一丢了数据怎么办?
购物车丢点订单无影响 数据安全性要求不太高 mysql尽量不要搞购物车的表 都在redis的表 丢就丢了呗。或者异步同步/定时任务
实时性要求 安全性要求 → MySQL
电商一般数据库和mysql都要存 → 读多写少
一定、一定、一定要设置前提,介绍自己的业务背景 (一致性要求高?允许延迟一致?)
① 介绍自己简历上的业务,我们当时是把文章的热点数据存入到了缓存中,虽然是热点数据,但是实时要求性并没有那么高,所以我们采用的是异步的方案同步的数据
② 我们当时是把抢卷的库存存入到了缓存中,这个需要实时的进行数据同步,为了保证数据的强一致性,我们当时采用的是redission提供的读写锁来保证数据的同步
双写一致性:当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致
读操作:缓存命中,直接返回;缓存未命中查询数据库,写入缓存,设定超时时间
写操作:延迟双删 [因为无论先删除缓存还是先删除数据库都可能会出数据不一致问题 有脏数据]
==基于redisson互斥锁:==[放入缓存中的数据 读多写少] 【强一致性业务 性能低】
有过期时间兜底- 共享锁:读锁readLock,加锁之后,其他线程可以共享读操作,但**不允许写操作**
- 排他锁:独占锁writeLock也叫,加锁之后,阻塞其他线程读写操作(只允许一个用户或进程独占地对数据进行读取和写入操作)
排他锁确保了写操作的原子性和一致性 - 读数据的时候添加共享锁(读不互斥、写互斥)
- 写数据的时候添加排他锁(阻塞其他线程的读写 因为读多写少)
redissionClient.getReadWriteLock(“xxxx”);
==异步通知:==异步通知保证数据的最终一致性(需要保证MQ的可靠性)
需要在Redis中更新数据的同时,通知另一个服务进行某些操作。- 使用场景:
- 缓存与数据库双写: 当应用需要同时更新Redis缓存和数据库时,可以先将数据写入Redis,然后通过异步通知机制触发数据库的更新操作。
- 跨地域数据复制: 在跨地域部署的服务中,为了实现数据的最终一致性,可以在一个地域写入数据后,通过异步通知机制在另一个地域进行数据复制。
- 系统间数据同步: 在微服务架构中,不同的服务可能有自己的数据存储。当一个服务更新了数据后,可以通过异步通知机制告知其他相关服务进行数据同步。
- 使用场景:
==基于Canal的异步通知==:监听mysql的binlog
可以解析binlog文件 可以存放mysql里面的数据 看最近有无增删改查 转换成redis命令 再给redis里面- 使用MQ中间件,更新数据之后,通知缓存删除
- 利用canal中间件,不需要修改业务代码,伪装为mysqls的一个从节点,canal通过读取binlog数据更新缓存
synchronized可以作用在哪些地方(作用域),分别锁的是什么
在Java中,synchronized关键字可以用来实现线程同步,它可以作用在不同的地方,并且锁定的对象也不同:
实例方法:
- 作用在实例方法上时,锁的是调用该方法的对象实例(即**this对象**)。
- 任何线程想要执行这个方法,都必须获得该对象实例的锁。
public synchronized void synchronizedMethod() { // 方法体 }静态方法:
- 作用在静态方法上时,锁的是类的Class对象。
- 由于静态方法是属于类的,而不是属于任何特定实例,所以所有线程要想执行这个静态同步方法,都必须获得该类的Class对象的锁。
public static synchronized void synchronizedStaticMethod() { // 方法体 }代码块:
- 作用在代码块上时,可以指定一个锁对象
括号里的对象,可以是任何对象。 - 当进入这个代码块时,线程必须获得指定锁对象的锁。
public void synchronizedBlock() { synchronized(this) { // 锁定当前对象实例 // 代码块 } } public void synchronizedBlockWithObject() { Object lock = new Object(); synchronized(lock) { // 锁定指定的对象 // 代码块 } }- 作用在代码块上时,可以指定一个锁对象
什么情况下索引会失效?
- 违反最左前缀法则
- 范围查询右边的列,不能使用索引
- 不要在索引列上进行运算操作,索引将失效
- 字符串不加单引号,造成索引失效。(类型转换)
- 以%开头的Like模糊查询,索引失效
[不影响正常查询业务 但未运用超大分页查询优化 会导致索引失效]
索引创建原则有哪些?索引很多就会有很多B+树
① 数据量较大,且查询比较频繁的表
② 常作为查询条件、排序、分组的字段 [where、group by、order by]
③ 字段内容区分度高
④ 内容较长,使用前缀索引
⑤ 尽量联合索引对存储节省空间如果我们经常根据客户ID和订单日期来查询订单,那么可以在 customer_id 和 order_date 上创建一个联合索引。 CREATE INDEX idx_customer_date ON orders (customer_id, order_date); 这个联合索引 idx_customer_date 有以下几个特点: 索引顺序:首先根据 customer_id 排序,然后在每个 customer_id 的基础上根据 order_date 排序。 查询优化:以下查询可以利用这个联合索引: SELECT * FROM orders WHERE customer_id = ? AND order_date = ?; SELECT * FROM orders WHERE customer_id = ?;⑥ 要控制索引的数量
⑦ 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它
大字段不建议建立索引是因为B+树一个叶子节点/一个非叶子节点 差不多16k 一个节点对应一个[页] 多的话会更多层
尽量不用性别去创建索引
- 先陈述自己再实际工作中是怎么用的
- 主键索引
- 唯一索引
- 根据业务创建的索引(复合索引)
索引的底层数据结构了解过吗?
MySQL的InnoDB引擎采用的B+树的数据结构来存储索引
- 阶数更多,路径更短
- 磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据
- B+树便于扫库和区间查询,叶子节点是一个双向链表
**MySQL默认使用的索引底层数据结构是B+树**。再聊B+树之前,先来聊聊二叉树和B树
==B Tree(矮胖树)==,B树是一种多叉路衡查找树,相对于二叉树,B树每个节点可以有多个分支,即多叉。以一颗最大度数(max-degree)为5(5阶)的b-tree为例,那这个B树每个节点最多存储4个key
==B+Tree== 是再BTree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是B+Tree实现其索引结构
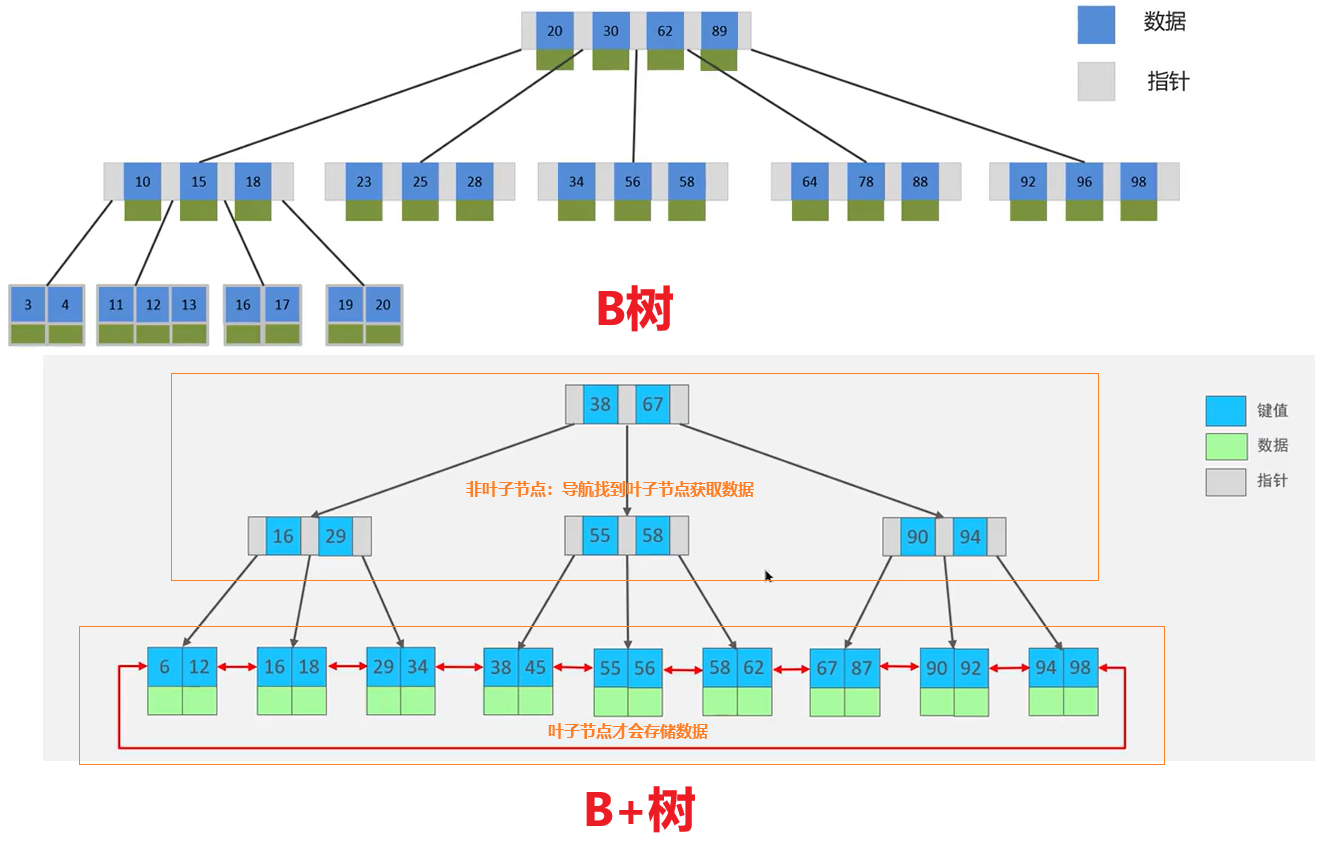
B树与B+树对比:
- 磁盘读写代价B+树更低
- 查询效率B+树更加稳定
- B+树便于扫库和区间查询
B树要找12 首先找38 左面小 再去缩小范围16和29 找到12 → 但是我们只想要12的数据 B树会额外的把38,16,29的数据全查一遍最后才到12的数据
B+树是在叶子节点才会存储数据,在非叶子节点全是指针,这样就没有其他乱七八糟的数据影响 。且查找路径是差不多的,效率较稳定
便于扫库:比如我们要查询6-34区间的数据,先去根节点扫描一次38 → 16-29 → 由于叶子节点之间有双向指针,就可以一次性把所有数据都给拿到[无需再去根节点找一次]
mysql底层为什么用B+树利用二分查找,树越矮经过磁盘IO次数越少,它是稳定的每次都查到最底层
二叉树 O(logn) 容易退化成链表 所以不用它平衡二叉树 全部倾斜红黑树 一个节点只能存一个数据
B树能不能除了叶子节点其他不存数据呢?
你可以设计一种变体的B树,其中只有叶子节点存储数据,而所有其他非叶子节点仅作为导航节点,不存储实际的数据。这种结构在概念上类似于B树的一个特例,通常被称为B树索引结构的一部分,其中非叶子节点存储的是键值,而叶子节点存储的是实际的数据记录或者是指向数据记录的指针
B+树第三层2000多万条数据,尽量不要把数据达到2000多万
B+树叶子节点加了双向链表 让我们查询更加稳定 范围查询会更快
mysql索引底层不一定只有B+树,也可能是Hash 在精准查询性能比它高
R—Tree:地理位置搜索
联合索引
where b= AND c= AND a= 这样走索引都能走 底层自己排序
为什么联合索引要遵循最左匹配原则【里面的b+树 先按照a排序 再b 因为要二分查找 不排序怎么找?】
在MySQL中,如何定位慢查询?查询前用explain查询是否走了索引等问题
explain查询后的列:
id:查询中SELECT语句的序列号,如果该行引用其他行的并集结果,则该值可以为空。
select_type:表示查询的类型,常见的类型有:
SIMPLE:简单的SELECT查询,不使用UNION或子查询。
PRIMARY:最外层的SELECT查询。
UNION:在UNION中的第二个或随后的SELECT查询。
DEPENDENT UNION:在UNION中的第二个或随后的SELECT查询,取决于外层查询。
UNION RESULT:UNION的结果。
SUBQUERY:子查询中的第一个SELECT。
DEPENDENT SUBQUERY:子查询中的第一个SELECT,取决于外层查询。
table:查询的是哪个表。
type:这是你提到的一个非常重要的列,它表示MySQL在表中找到所需行的方式,也称为“访问类型”。以下是一些常见的访问类型,从最好到最差排序:
system:表只有一行(系统表)。
const:表最多有一个匹配行,它将在查询开始时被读取。因为仅有一行,所以优化器的其余部分可以将这一行视为常量。
eq_ref:对于每个来自于前面的表的行组合,从该表中读取一行。这通常是最好的联接类型,除了const类型。
ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。
fulltext:使用全文索引执行查询。
ref_or_null:与ref类似,但是MySQL会额外搜索包含NULL值的行。
index_merge:表示查询使用了两个或更多的索引。
unique_subquery:用于IN子查询,子查询返回不重复的值集。
index_subquery:用于IN子查询,子查询返回不重复的值集,可以使用索引。
range:使用索引来检索给定范围的行。
index:全索引扫描(比ALL快,因为索引通常比数据行小)。
ALL:全表扫描,这是最差的一种类型,因为MySQL必须检查每一行以找到匹配的行。
possible_keys:指出MySQL能使用哪些索引来优化查询。
key:MySQL实际决定使用的索引。
key_len:使用的索引的长度。越短越好。
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数。
rows:MySQL认为必须检查的用来返回请求数据的行数。
filtered:显示了通过条件过滤出的行数的百分比估计。
Extra:包含MySQL解析查询的额外信息,例如是否使用了索引,是否排序了结果,是否使用了临时表等
1.介绍一下当时产生问题的场景(我们当时的一个接口测试的时候非常的慢,压测的结果大概5秒钟)
2.我们系统中当时采用了运维工具(Skywalking),可以监测出哪个接口,最终因为是sql的问题
3.在mysql中开启了慢日志查询,我们设置的值就是2秒,一旦sql执行超过2秒就会记录到日志中(调试阶段)
产生原因:
- 聚合查询
- 多表查询
- 表数据量过大查询
- 深度分页查询
方案一:==开源工具==[调试阶段才会开启 生产阶段不会开启]
- 调试工具Arthas
- 运维工具:Prometheus、SKywalking(接口访问时间)
方案二:==MySQL自带慢日志==
慢查询日志记录了所有执行时间超过指定参数(long_query_time, 单位:秒,默认10秒)的所有SQL语句的日志,如果要开启慢查询日志,需要在MySQL的配置文件(/etc/my.cnf)中配置信息:
# 开启MySQL慢日志查询开关
slow_query_log = 1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会被视为慢查询,记录慢查询日志
long_query_time = 2
什么是聚簇索引?什么是非聚簇索引(二级索引)?什么是回表?
- 聚簇索引(聚集索引):数据与索引放到一块,B+树的叶子节点保存了整行数据,有且只有一个【id存放的b+树】
- **非聚簇索引(二级索引)**:数据与索引分开存储,B+树的叶子节点保存对应的主键,可以有多个【叶子就是id的字段】
- 回表查询:通过二级索引找到对应的主键值,到聚集索引中查找正行数据,这个过程就是回表
怎么避免回表 → 使用覆盖索引!
需要name 直接 select name 而不用 select *
要按需来查找
除了InnoDB,MySQL数据库还支持多种其他存储引擎,其中最著名的是MyISAM。以下是InnoDB和MyISAM两个存储引擎的主要区别:
事务支持:
InnoDB:支持事务,它遵循ACID原则(原子性、一致性、隔离性和持久性)。如果事务中的某个操作失败,整个事务可以回滚到开始状态。
MyISAM:不支持事务,这意味着你无法回滚操作,这对于数据完整性和恢复可能是一个问题。
锁定机制:
InnoDB:使用行级锁定,只锁定需要的特定行,这可以大大减少数据库操作的冲突。
MyISAM:使用表级锁定,每次操作都会锁定整个表,这在并发操作较多时可能导致性能问题。
崩溃恢复:
InnoDB:具有自动崩溃恢复功能,即使数据库崩溃,也不会丢失数据,因为它将事务日志写入磁盘。
MyISAM:在崩溃后恢复较为困难,可能会丢失数据,因为它不记录事务日志。
全文搜索:
InnoDB(MySQL 5.6及以后版本):支持全文索引,但功能上不如MyISAM的全文搜索强大。
MyISAM:提供了更强大的全文搜索功能,但在MySQL 5.6之前,这是MyISAM相对于InnoDB的主要优势。
存储限制:
InnoDB:表的大小理论上受限于操作系统的文件大小限制,通常可以处理更大的数据量。
MyISAM:表的大小受限于最大文件大小,通常是2GB到4GB,这取决于文件系统的限制。
外键支持:
InnoDB:支持外键约束,这有助于保持数据的引用完整性。
MyISAM:不支持外键约束。
存储空间:
InnoDB:通常需要更多的存储空间,因为它存储了额外的信息来支持事务和行级锁定。
MyISAM:通常占用更少的存储空间,因为它不需要存储这些额外的信息
| 分类 | 含义 | 特点 |
|---|---|---|
| ==聚集索引(Clustered Index)== | 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有, 而且只有一个 |
| ==二级索引(Secondary Index)== | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一 (UNIQUE) 索引作为聚集索引
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引

==回表查询==
select * from user where name = 'Arm';
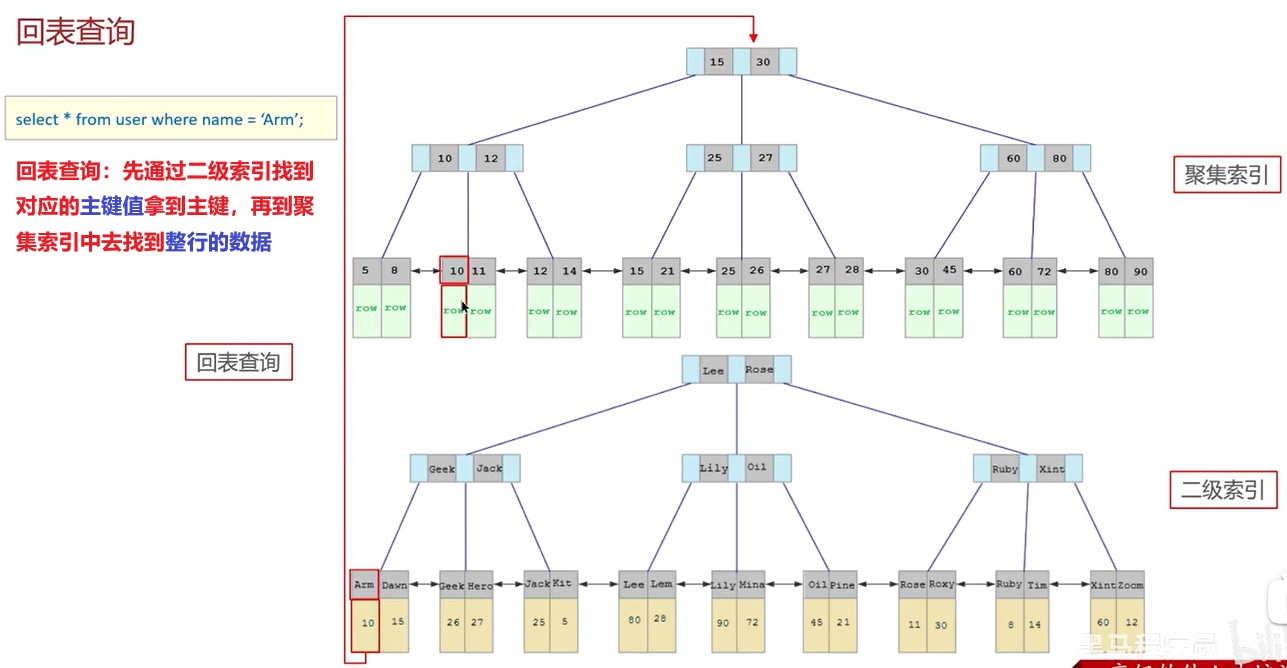
MySQL的日志文件有哪些,它们的作用是什么
MySQL的日志文件有哪些,它们的作用是什么?
MySQL主要有以下几种日志文件:
- 错误日志(Error Log):记录MySQL服务的启动、运行或停止过程中的错误信息。
- 查询日志(General Query Log):记录所有MySQL执行的SQL命令,无论这些命令是否正确执行。
- 慢查询日志(Slow Query Log):记录执行时间超过指定阈值的查询语句。
- 二进制日志(Binary Log):记录所有更改数据的SQL语句,用于主从复制和数据恢复。事务的提交 和 主从复制
- 事务日志/重做日志(InnoDB Redo Log):记录InnoDB存储引擎的事务操作,用于崩溃恢复。
- 回滚日志/撤销日志(InnoDB Undo Log):用于事务回滚,保证事务的原子性。
undo log 和 redo log的区别?
redo log:记录的是数据页的物理变化,服务宕机可用来同步数据
undo log:记录的是逻辑日志,当事务回滚时,通过逆操作恢复原来的数据
redo log 保证了事务的持久性,undo log保证了事务的原子性和一致性
- 缓冲池(buffer pool):主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改査操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度
- 数据页(page):是InnoD8 存储引擎磁盘管理的最小单元,每个页的大小默认为 16KB。页中存储的是行数据
==redo log==
重做日志,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性
该日志文件由两部分组冲:重做日志缓冲(redo log buffer) 以及 **重做日志文件(redo log file)**,前者是在内存中,后者是在磁盘中。当事务提交之后会把所有修改信息都保存到该日志文件中,用于在刷新脏页到磁盘,发生错误时,进行数据恢复使用。
==undo log==
回滚日志,用于记录数据被修改前的信息,作用包含两个:提供回滚和 MVCC(多版本并发控制)。undolog 和 redolog记录物理日志不一样,它是逻辑日志
- 可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然
- 当update一条记录时,它记录一条对应相反的update记录。当执行rolback时,就可以从undolog中的逻辑记录读取到相应的内容并进行回滚。
undo log可以实现事务的一致性和原子性
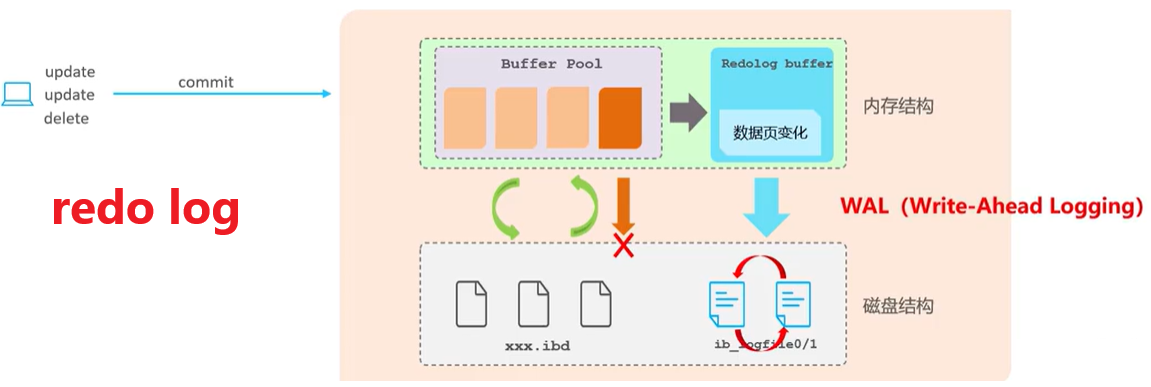
MySQL主从同步原理?
MySQL主从复制的核心就是二进制日志binlog[DDL(数据定义语言)语句 和 DML(数据操纵语言)语句]
主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
从库读取主库的二进制日志文件 Binlog,写入到从库的中继日志 Relay Log。
从库重做中继日志中的事件,将改变反映它自己的数据。主服务器(Master)上的数据更改(如INSERT、UPDATE、DELETE操作)会被记录到二进制日志中。 从服务器(Slave)上的I/O线程连接到主服务器,请求主服务器上的二进制日志。 主服务器将二进制日志发送给从服务器,从服务器将这些日志事件写入到本地的中继日志(Relay Log)。 从服务器上的SQL线程读取中继日志中的事件,并在本地执行这些事件,从而实现数据的复制。
MySQL主从复制的核心就是二进制日志
二进制文件(BINLOG) 记录了所有的DDL(数据定义语言)语句 和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句
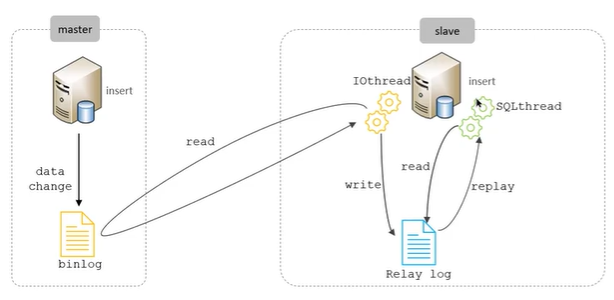
复制分成三步:
- Master主库在事务提交时,会把数据变更记录在二进制日志文件Binlog中
- 从库读取主库的二进制日志文件Binlog,写入到从库的中继日志Relay Log
- slave重做中继日志中的事件,将改变反应他自己的数据
项目中哪里涉及到分布式事务问题? 你是怎么解决的? 能说一下
分布式事务问题可能出现在跨多个服务或数据库的操作中,例如在订单服务中同时更新订单状态和扣减库存。秒杀案例:是先扣库存提前缓存到redis里,判断够不够,用RabbitMQ异步下来
解决方案:可以使用分布式事务框架,如Seata,其中AT模式是一种常见的解决方案。
AT模式原理:
- AT模式基于两阶段提交,分为两个阶段:一阶段 prepare 和二阶段 commit/rollback。
- 在业务方法开始时,Seata会拦截业务SQL,记录业务数据在执行前后的镜像,生成行锁。
- 如果一阶段 prepare 成功,则二阶段进行 commit,直接提交事务;如果 prepare 失败,则执行 rollback,利用之前保存的数据镜像回滚到执行前的状态。
面试答题模板:项目中如何解决分布式事务问题
1. 在哪些地方遇到分布式事务?
在项目中,当一个操作需要同时修改多个服务或数据库中的数据时,就涉及到分布式事务。
举个例子,比如:
- 用户下单时,同时需要更新订单服务、库存服务、账户服务
- 秒杀系统中,用户提交订单 → 扣减库存 → 支付 → 发货,这些服务彼此独立,不能直接使用本地事务
- 使用了微服务架构(Spring Cloud 或 Dubbo),服务之间通过 RPC 或 MQ 通信
2. 为什么不能用本地事务?
因为每个服务有独立的数据源和事务管理器,Spring 或数据库事务不能跨 JVM、不能跨库。使用
@Transactional只对一个服务内部有效。
3. 怎么解决的?你项目中用的什么方式?
我们使用了 Seata 分布式事务框架,配合 MySQL + Nacos 注册中心 + Spring Cloud Alibaba。
✅ 主要使用的是 AT 模式:
- 一阶段(try):执行业务逻辑(如插入订单、扣库存),Seata 会自动代理数据源,记录前镜像和后镜像,并生成全局锁,挂起全局事务。
- 二阶段 commit:如果所有子事务都执行成功,Seata 释放资源,数据自动提交。
- 二阶段 rollback:如果其中一个失败,Seata 会根据前镜像自动回滚其他操作。
项目中哪里用到MQ,用来干什么?
使用 MQ 的主要场景
我们项目中使用了 MQ 来实现一些异步解耦、流量削峰、延迟处理的需求,典型场景包括:
- 下单成功后异步发放优惠券和积分
- 订单支付成功后通知物流发货
- 延迟关闭未支付订单(延迟队列)
具体业务流程(订单 + 积分 + 优惠券)
📦 用户下单 → 支付成功 → MQ 异步通知:
用户提交订单,订单服务创建订单。
用户完成支付,订单服务更新订单状态为“已支付”。
然后将订单信息封装成消息,发送到多个 Topic:
{ "orderId": "123456789", "userId": "user123", "status": "PAID" }
- 发给
coupon_topic:异步发放优惠券- 发给
point_topic:异步发放积分- 发给
logistics_topic:异步准备发货为什么使用 MQ?
目的 说明 解耦服务 各个服务(积分/优惠券/物流)独立开发部署,订单服务只需发送消息,不关心接收者 异步处理 订单服务快速响应用户请求,提升用户体验 流量削峰 高并发秒杀场景中,通过 MQ 缓冲请求,避免库存服务被直接打爆 延迟处理 通过延迟消息机制实现“30分钟未支付自动关闭订单”等功能 示例:异步发放积分与优惠券
🛠 技术栈
- 消息中间件:RocketMQ / RabbitMQ / Kafka(我使用的是 RocketMQ)
- 消息格式:JSON
- 发送方式:异步发送
sendAsync或可靠发送sendSync👇 示例代码:
订单服务 - 发送消息
OrderMessage message = new OrderMessage(orderId, userId, "PAID"); rocketMQTemplate.syncSend("point_topic", message); rocketMQTemplate.syncSend("coupon_topic", message);积分服务 - 监听消息
@RocketMQMessageListener(topic = "point_topic", consumerGroup = "point_group") public class PointConsumer implements RocketMQListener<OrderMessage> { public void onMessage(OrderMessage msg) { pointService.addPoint(msg.getUserId(), 100); } }延迟队列:关闭未支付订单
- 下单成功但未支付时,发送一条延迟消息到
order_timeout_topic,延迟30分钟。- 消费时判断订单状态是否已支付,未支付则关闭订单并恢复库存。
Message message = MessageBuilder.withPayload(orderId) .setHeader(MessageConst.PROPERTY_DELAY_TIME_LEVEL, 16) // 延迟30分钟 .build(); rocketMQTemplate.syncSend("order_timeout_topic", message);
问:mq发送的消息 那怎么样才是对接到了真正的业务代码 比如我30分钟没付款 那就给我关闭未支付订单 我这里是mq不只是发送消息的吗 又怎么能触碰到真实的调用关闭未支付订单的那个业务逻辑代码呢?
✅ 所以完整流程如下:
场景:30分钟内未支付 → 自动关闭订单(延迟队列)
✅ 1. 下单成功 → 发一条延迟消息 到 MQ
这一步由订单服务完成,它只是把订单ID封装成消息,发到某个延迟Topic,比如
order_timeout_topic。Message<String> message = MessageBuilder.withPayload(orderId) .setHeader(MessageConst.PROPERTY_DELAY_TIME_LEVEL, 16) // 延迟30分钟 .build(); rocketMQTemplate.syncSend("order_timeout_topic", message);✅ 2. 等待30分钟,消息达到时间被投递 → 触发消费者
这一步由你自己写的消费者类完成。
@RocketMQMessageListener( topic = "order_timeout_topic", consumerGroup = "order_timeout_group" ) @Component public class OrderTimeoutConsumer implements RocketMQListener<String> { @Autowired private OrderService orderService; @Override public void onMessage(String orderId) { // ✅ 真正的业务逻辑调用就在这里 orderService.closeUnpaidOrder(orderId); } }✅ 3. 消费者接收到消息,调用你的真实业务代码:
public void closeUnpaidOrder(String orderId) { Order order = orderMapper.selectById(orderId); // ✅ 校验状态:只有未支付才关闭 if ("UNPAID".equals(order.getStatus())) { // 更新订单状态为“已关闭” order.setStatus("CLOSED"); orderMapper.updateById(order); // 回滚库存(如果之前预扣了库存) stockService.rollbackStock(order.getItems()); log.info("订单 {} 已超时未支付,自动关闭", orderId); } }✅ 总结一句话:
MQ 只是“消息的搬运工”,但你要写消费者类(
RocketMQListener/@RabbitListener/KafkaListener),在onMessage()方法中调用你的业务代码,才算真正“对接了业务逻辑”。
📌 这样你就能实现:
- 下单时发送一条“30分钟后的提醒消息”
- 30分钟后,消息被自动投递
- 消费者接收消息
- 消费者去执行你写好的“关闭订单”逻辑
✅ 你写的业务代码只是“收到通知之后”执行
❗是 MQ 延迟队列在背后帮你等待 30 分钟
🔁 两种“定时任务”的方式对比
实现方式 谁来等待30分钟? 缺点 优点 定时任务 Cron 你写一个 @Scheduled每隔1分钟轮询数据库数据多了会导致 扫描性能差,且 不精确 简单、直观 MQ 延迟队列 MQ自动等待30分钟后投递消息 要配合消息系统、消费者写法略复杂 精准、性能高、无感知、无需数据库轮询 🧩 真实执行流程再解释一遍
🔵 用户下单成功
业务代码执行完后做两件事:
- 把订单状态写入数据库:
UNPAID- 向 MQ 发一条“延迟30分钟”的消息,内容是订单ID
🟡 MQ 延迟队列(如 RocketMQ)
你设置了:
.setHeader(MessageConst.PROPERTY_DELAY_TIME_LEVEL, 16); // 表示延迟30分钟MQ 会帮你缓存这条消息,不会立即投递!
🔴 等到 30 分钟后,MQ 才把这条消息交给你写的消费者类(比如
OrderTimeoutConsumer)你的消费者代码才会被执行:
public void onMessage(String orderId) { orderService.closeUnpaidOrder(orderId); }此时才会调用你写的业务逻辑代码,检查订单是否已支付,如果没支付,就自动关闭
✅ 为什么不用
@Scheduled?你当然可以用定时任务,比如:
@Scheduled(cron = "0 */1 * * * ?") public void scanUnpaidOrders() { // 每1分钟检查一次数据库里状态为 UNPAID 且超过30分钟的订单 }❗但是问题是:
- 每次都要 扫整个表 或者一部分数据,性能差
- 不能做到秒级准确执行(可能要等1分钟才触发)
- 高并发系统(像电商、秒杀)根本扛不住频繁轮询
✅ 为什么用 MQ 延迟消息是最佳选择?
- MQ自己维护延时,精确到秒级
- 不依赖数据库定时轮询
- 一条消息就是一笔订单,到时间再投递,性能高
- 和核心业务逻辑完全解耦
异步发优惠卷 + 积分 [用户对于实时性要求不是很高]
使用MQ的场景:订单处理
具体场景
当用户在电子商务平台上成功下单后,订单服务需要执行以下操作:
- 更新订单状态为“已支付”。
- 扣减商品库存。
- 通知支付服务处理支付。
- 通知物流服务准备发货。
使用MQ的原因
在这些操作中,更新订单状态和扣减库存是实时且同步的操作,但通知支付服务和物流服务则可以异步进行。使用MQ可以帮助我们实现以下目标:
- 解耦服务:订单服务不需要直接调用支付服务和物流服务,降低了服务间的耦合度。
- 异步处理:订单服务可以立即响应客户端,不必等待支付和物流服务的处理结果。
- 流量削峰:在高峰期,MQ可以缓冲大量的订单处理请求,避免服务被压垮。
订单服务生产消息: 当订单服务完成订单状态更新和库存扣减后,它将以下消息发送到
{
"orderId": "123456789",
"status": "paid",
"userId": "user123",
"items": [
{"productId": "prod123", "quantity": 1},
{"productId": "prod456", "quantity": 2}
]
}
这个消息将被发送到不同的主题或队列,例如payment_topic和logistics_topic。
2. 支付服务和物流服务消费消息:
- 支付服务订阅
payment_topic,当接收到订单支付消息后,它会处理支付逻辑,如验证支付状态、记录交易日志等。 - 物流服务订阅
logistics_topic,当接收到订单消息后,它会准备发货,更新物流信息,并通知用户。
通过这种方式,订单服务可以快速响应用户请求,而支付和物流服务可以按照自己的节奏处理订单相关的操作,整个系统因此变得更加灵活和可扩展。
如何保证消息不丢失?
保证生产者能够成功发送到交换机和队列(存储消息),生产者提供了消息确认机制
到队列后消息要有持久化机制
消费者要有一个消息确认机制 保证消费者至少消费成功消息一次
开启生产者确认机制,确保生产者的消息能到达队列
confirm到交换机ack 不到nack 和 return没到返回nack机制保证生产者把消息发过去开启持久化功能,确保消息未消费前在队列中不会丢失
万一broker挂掉就惨了 保证至少成功一次消费开启消费者确认机制为auto,由spring确认消息处理成功后完成ack
消费者三种机制:RabbitMQ支持消费者确认机制,即:消费者处理消息后可以向MQ发送ack回执,MQ收到ack回执后才会删除该消息,而SpringAMQP则允许配置三种确认模式:
manual:手动ack,需要在业务代码结束后,调用api发送ack。
auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
开启消费者失败重试机制,多次重试失败后将消息投递到异常交换机,交由人工处理
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecoverer接口来处理,它包含三种不同的实现:
RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
- 异步发送(验证码、短信、邮件)
- MySQL和Redis,ES之间的数据同步
- 分布式事务
- 削峰填谷
如何解决消息积压?
产生原因:当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是堆积问题
**解决消息堆积有三种思路 **
- 增加更多消费者,提高消费速度
- 在消费者内开启线程池加快消息处理速度
- 扩大队列容积,提高堆积上限
如何保证消费幂等性【MQ】
幂等性是指同一个操作执行多次和执行一次的效果相同。在消息消费的场景中,保证幂等性通常有以下几种方法:
利用数据库的唯一约束:
在数据库中为消息设置唯一标识(如消息ID),在处理消息前先检查该标识是否已存在。
导致重复消费 返回ack,blocker未收到。一定要在生产者投递的时候生成全局唯一的id,消费者就会去判断。异步生成 拿订单号去数据库查 如果查得到就直接return
精髓就是全局唯一
UUID不行 因为每次发送的消息都不是同一个UUID 要用业务上的
哪些地方还会有幂等问题?
提供者的openfegin、xxl-job、被别人调用且涉及到增删改
状态记录:
在消费消息前,记录消息的状态(如已处理),处理完毕后再更新状态。要根据订单ID+状态 来保证消费幂等性。订单存在且未支付 → 更新锁订单ID
并发情况幂等性:
完美的幂等要加上分布式锁对敏感性要求高,且要控制好锁的力度
如何保证消费有序性
队列中可以指定消息的消费顺序
RabbitMQ → 多个生产者并发投,所以生产者不能保证有序性,只考虑消费有序性。以消息进入的MQ的消息去回答。
怎么保证?
单线程消费:
在消费者端使用单个线程处理消息,确保消息按顺序处理。
分区有序:
在如Kafka这样的消息队列中,可以保证同一个分区内的消息是有序的。
如何既要又要【有序 + 速度快】
既要又要”通常指的是在保证消息的幂等性和有序性的同时,还需要考虑其他特性(如高性能、高可用等)
在一些场景下,可能需要在性能和一致性之间做权衡。例如,可以选择最终一致性来换取更高的性能。
Kafka 和 RocketMQ可以天生实现【底层Hash取模】
若非要用RabbitMQ实现呢?
不同订单之间是否要求一定顺序??
镜像集群,先搭3个节点的镜像集群,建立三个队列分为不同的镜像节点 各占一个队列,需要自己去实现
对订单号进行hash取模看到落到哪个节点
三个队列至少三个消费者 分别去消费它们
此时就可以并行有三个消费者去执行
把业务数据没关系的放在不同的队列去管理
万一挂掉了呢?
队列有持久化不用担心
能说一下如何使用死信交换机吗支付
死信交换机(DLX)用于处理无法正常消费的消息
创建一个正常的交换机和队列,以及一个死信交换机和死信队列。
- 定义死信交换机:创建一个用于处理死信的交换机。
- 定义死信队列:创建一个队列用于接收死信,并将其绑定到死信交换机。
- 配置主队列的死信交换机属性:在主队列上设置参数,指定当消息无法正常处理时应该发送到哪个死信交换机。
- 发送消息到主队列:生产者将消息发送到主交换机,进而路由到主队列。
- 消费主队列消息:消费者从主队列中获取消息并进行处理。如果消息处理失败,它将被路由到死信交换机。
- 消费死信队列消息:设置消费者来处理死信队列中的消息,进行错误处理或记录日志等操作。
mysql如何提升深分页查询效率子查询+索引
使用索引:
- 确保查询中使用的列上有适当的索引,这样可以加快查找速度。
**避免使用OFFSET和LIMIT**:
- 使用
OFFSET进行深分页时,MySQL需要遍历所有OFFSET之前的行。可以通过记住上一次查询的最大ID来避免使用OFFSET。
使用条件过滤:
- 如果可能,使用WHERE子句来减少需要扫描的数据量。
增加LIMIT的大小:
- 如果业务允许,可以增加每次查询返回的结果集大小,减少分页次数。
缓存:
- 对于不经常变更的数据,可以使用缓存来存储已经查询过的页。
使用EXPLAIN分析查询:
- 使用
EXPLAIN来分析查询计划,找出性能瓶颈并进行优化。
能说一下常用的存储引擎以及它们的差异吗
InnoDB:
支持事务、行级锁和外键。
适合处理大量短期事务。
为了维护数据的完整性,写操作相对较慢
MyISAM:
不支持事务、不支持行锁只支持表锁
并发没那么大 事务要求没那么高可以用
能说一下倒排索引的原理吗?
根据参与文档中的字段 要构建倒排就会去分词
根据用户索引也会分词 就会去查文档id 再去查文档
中文词库为IK (Ikun 你干嘛 哎哟~)
es的text和keyword的区别
text
用于全文搜索,会分词,字符串类型
keywod
用于精确搜索字段,不会被分词,字符串类型
es在你的项目中是用来做什么的
快速搜索商品(C端)、订单(后台) + 日志查询 + 地理位置搜索经纬度定位附近的事物
mysql和ElasticSearch如何做数据同步
mysql进行增删改的时候
对数据敏感性实时性要求没那么高 只看可靠性[MQ异步 + 定时任务 = 没有那么强一致性]
如果数据量没那么大 有没有必要上ES?
没有必要,正排索引不走全表扫描也蛮快
组长进行技术选型 考虑到以后的业务增长
项目已经上线了 但是中途想换成ES 怎么办
mysql是全量数据 mq只能同步增量数据 怎么办呢?
新上架的只能到ES 那应该如何?
此时涉及到全量和增量的同步与Redis不一样
加定时任务每周/每天 会定期重构一次索引库晚上跑→兜底模式,全量同步,后期再增量同步
能说一下分词的原理吗
底层是大数据量的内容 树的结构来构建分词 IK,字符分割、词汇识别、过滤停用词
不好意思面试官 具体底层原理不是很了解
使用ES有遇到什么问题吗
类似于深分页!
测试环境数据量不会很大 等到上线后才会有这种问题
说一下jvm的内存区域,以及每个区域是干什么的
虚拟机栈、本地方法栈、程序计数器、元空间、堆
运行时数据区
虚拟机栈:每个线程运行时所需要的内存(先进后出)
方法调用过程。每个栈由多个栈帧组成,对应着每次方法调用所占用的内存。每个线程只能有一个活动栈帧,对应着当前执行的那个方法本地方法栈:与虚拟机栈类似,区别→虚拟机栈执行java方法,本地方法栈执行native方法【被封装的方法 没有具体实现的 都封装在java虚拟机中】专门存储java写的局部方法的局部变量
程序计数器:是当前线程所执行的字节码指令的行号指示器 同一个核是错峰出行 会上下文切换,要用程序计数器记录下当前执行到哪里的代码
元空间:元空间的本质和永久代类似,都是对JVM规范中方法区的实现。最大区别是元空间在本地内存中而不是虚拟机中。1.8以前叫永久代 1.8后叫方法区或元空间 一般存储类元信息。还会存有运行时常量池。在里面还会存有静态变量
堆内存:是JVM所有线程共享的部分,唯一用途是来保存对象实例、数组;由年轻代和老年代组成。new一个都会开启一个空间
类加载器:类加载器(Class Loader)负责将类的字节码文件(.class文件)加载到JVM中,并转化为对应的java.lang.Class对象,以供Java程序使用。
执行引擎:执行引擎(Execution Engine)是负责执行字节码的核心组件。执行引擎的作用是读取字节码指令,对它们进行解析并执行,从而实现Java程序的功能
本地库接口:是Java虚拟机的一部分,它允许Java程序调用其他语言编写的本地应用程序和库(通常是C或C++)。这是因为Java本身设计为平台无关的语言,但它有时需要与特定平台的底层系统或硬件进行交互,而这通常是通过本地代码实现的。
直接内存(Direct Memory):直接内存并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域。但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError异常出现。在JDK 1.4中新加入了NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O方式,可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆中的DirectByteBuffer对象作为这块内存的引用进行操作。
说一下常见的垃圾回收算法 他们的特点是什么?
标记清除算法:将垃圾回收分为2个阶段,标记和清除。内存碎片高,效率高,清除快
标记整理算法:一般用于老年代,将存活的对象都向另一端移动,然后清理边界以外的垃圾。[对象要移动,效率低],效率慢一些 需要把内存碎片移动,内存碎片没有 但是效率低一点
复制算法:将原有的内存空间一分为二,每次只用其中一块,正在使用的对象复制到另一个内存中,然后将该内存空间清空,交换两个内存的角色,完成垃圾回收。
被标记的是没有被回收的
说一下常见的垃圾回收器以及他们的特点垃圾收集器是垃圾收集算法的具体实现
串行垃圾收集器[新生代区]:指使用单线程进行垃圾回收(用户请求不能访问STW),堆内存较小适合个人电脑。底层用的复制算法
并行垃圾收集器:JDK8默认使用此垃圾回收器,在垃圾回收时,多个线程在工作(用户请求不能访问STW),并且java应用中所有线程都要暂停,等待垃圾回收的完成。底层用的复制算法
CMS(并发[Concurrent Mark Sweep])垃圾收集器:是一款并发的、使用标记—清除算法的垃圾回收器(针对老年代) 初始标记 → 并发标记 → 并发预清理 → 最终标记 → 并发清除 → 并发重置 小于8G内存用CMS 一般用并发垃圾收集器配合收集年轻小内存
G1垃圾收集器[复制算法]:Eden(2M)、最大回收停顿时间、大内存适合用G1、大于8G内存用G1
说一下cms的各个阶段过程以及特点CMS一般都清理老年代
过程:初始标记 → 并发标记 → 并发预清理 → 最终标记 → 并发清除 → 并发重置
是一款以获取最短回收停顿时间为目标的收集器,停顿时间短,用户体验就好。
其最大特点是在进行垃圾回收时,应用仍然能正常运行
初始标记:找GCRoot根去的第一层对象[STW] 速度是非常快的。为什么STW?如果找的时候同时也要标记 那么若这时候有的未被标记那就有大BUG。
并发标记:从第一层找到后的之后那些对象不能被回收(CMS回收器会遍历老年代,标记出所有活动的对象),在这个阶段,应用程序线程与垃圾回收线程并发运行[能接收用户请求],会产生新的对象。
并发预清理:这个阶段也是并发执行的,目的是处理在并发标记阶段应用程序线程产生的新垃圾,CMS回收器会清理那些在并发标记阶段被修改的对象,并执行一些预清理工作,以减少下一个STW阶段的暂停时间。
最终标记:这个阶段是STW的,它是为了处理在并发标记和并发预清理阶段未被处理的对象。CMS回收器会完成所有剩余的标记工作,确保所有存活的对象都被正确标记
并发清除:在这个阶段,应用程序线程与垃圾回收线程再次并发运行。CMS回收器会清除未被标记的对象,释放内存空间。清除过程中不会移动存活对象,因此可能会产生内存碎片。
并发重置:这个阶段是并发执行的,目的是重置CMS数据结构,为下一次垃圾回收做准备。
说一下g1的各个阶段过程以及特点,
划分成多个区域,每个区域都可以充当eden,survivor,old,humongous,其中humongous专为大对象准备
分成三个阶段:新生代回收(STW)、并发标记(重新标记STW)、混合收集。如果并发失败(即回收速度赶不上创建新对象速度),就会触发Full GC
你们项目是用哪一个垃圾收集器,为什么用这个?
每个服务两个节点 8G4核 用CMS 太大就用G1
什么样的对象会被成为垃圾对象?
如果一个或多个对象没有任何的引用指向它了,那么这个对象现在就是垃圾,如果定位了垃圾,则有可能会被垃圾回收器回收
怎么确定什么是垃圾?
引用计数法
一个对象被引用了一次,在当前的对象头上递增一次引用次数,如果这个对象的引用次数为0,代表这个对象可回收可达性分析算法
- 标记阶段:从GCRoots开始,标记所有可达的对象。
- 回收阶段:遍历堆中的所有对象,回收那些未被标记的对象所占用的空间。
采用的都是通过可达性分析算法来确定哪些内容是垃圾
通过可达性分析算法,那些从任何GCRoots都无法到达的对象被认为是不可达的,因此可以被垃圾回收器回收。这种方法能够处理循环引用的情况,这是引用计数法所无法解决的
静态的成员变量[元空间 基本不会被回收] 局部变量 成员属性
说一下双亲委派机制以及优点
加载某一个类,先委托上一级的加载器进行加载,如果上级加载器也有上级,则会继续向上委托,如果该类委托上级没有被加载,子加载器尝试加载该类
优点:
- 通过双亲委派机制可以避免某一个类被重复加载,当父类已经加载后则无需重复加载,保证唯一性
- 为了安全,保证类库API不会被修改
用相同的加载器在同一个路径下只能用同一个路径的类 用不同的加载器就可以加载
如何打破双亲委派模型?
自定义类加载器:
通过自定义类加载器,并重写
loadClass方法,可以实现在加载类时不遵循双亲委派模型。在自定义类加载器中,你可以直接尝试加载类,而不是先委派给父类加载器。public class CustomClassLoader extends ClassLoader { @Override public Class<?> loadClass(String name) throws ClassNotFoundException { // 直接加载,不委派给父类加载器 return findClass(name); } }
jvm常用的参数有哪些?代表什么意思
jps 进程状态信息
jstack 查看进程内线程的堆栈信息(产生死锁也可以查看)
jmap 查看堆栈信息(生成堆栈内存快照,内存使用信息)
jhat 堆转存快照分析工具
jstat JVM统计监测工具
-Xms和-Xmx:-Xms:设置JVM堆内存的初始大小(最小值)。-Xmx:设置JVM堆内存的最大大小。
-Xss:- 设置每个线程的堆栈大小。
-XX:NewSize和-XX:MaxNewSize:-XX:NewSize:设置新生代内存的初始大小。-XX:MaxNewSize:设置新生代内存的最大大小。
-XX:SurvivorRatio:- 设置新生代中Eden区与Survivor区的容量比例。
-XX:PermSize和-XX:MaxPermSize(Java 8及之前版本):-XX:PermSize:设置永久代(方法区)的初始大小。-XX:MaxPermSize:设置永久代的最大大小。
- 设置元空间大小
-XX:MetaspaceSize:- 设置元空间的初始大小。当元空间耗尽时,JVM会尝试扩展元空间的大小,直到达到最大值(如果设置了的话)。
-XX:MaxMetaspaceSize:- 设置元空间的最大大小。如果没有设置这个参数,元空间的大小只受本地内存限制。
四大引用分别是什么,代表什么意思?
强引用:只要所有 GC Roots 能找到,就不会被回收。
软引用:需要配合SoftReference使用,当垃圾多次回收,内存依然不够时候会回收软引用对象
弱引用:需要配合WeakReference使用,只要进行了垃圾回收,就会把引用对象回收
虚引用:必须配合引用队列使用,被引用对象回收时,会将虚引用入队由 Reference Handler 线程调用虚引用相关方法释放直接内存
● 强引用指的就是代码中普遍存在的赋值方式,比如A 但是不a = new A()这种。强引用关联的对象,永远不会被GC回收。
● 软引用可以用SoftReference来描述,指的是那些有用是必须要的对象。系统在发生内存溢出前会对这类引用的对象进行回收。
● 弱引用可以用WeakReference来描述,他的强度比软引用更低一点,只要进行了垃圾回收,就会把引用对象回收。
● 虚引用他必须和ReferenceQueue一起使用,必须配合引用队列使用,被引用对象回收时,
会将虚引用入队由 Reference Handler 线程调用虚引用相关方法释放直接内存。
什么是内存溢出?什么是内存泄露?
内存溢出:内存溢出是指程序在申请内存时,没有足够的内存空间供其使用,导致所需要的内存超出了系统所能提供的最大内存。【会先进行一次GC实在不够就OOM 堆\栈(递归过多,局部变量过多)\方法区都有可能发生内存溢出】
内存泄露ThreadLocal会导致(未及时释放):内存泄露是指程序中已分配的内存由于某种原因未能释放,即使在不再需要这些内存的情况下,它们仍然保持分配状态,导致可用内存逐渐减少
你的项目中出现过内存泄漏吗?你是怎么排查并且解决的?
有的,内存泄漏通常是指堆内存,通常是指一些大对象不被回收的情况
1、通过jmap或设置jvm参数获取堆内存快照dump
2、通过工具,VisualVM去分析dump文件,VisualVM可以加载离线的dump文件
3、通过查看堆信息的情况,可以大概定位内存溢出是哪行代码出了问题
4、找到对应的代码,通过阅读上下文的情况,进行修复即可
异常的祖先是:Throwable
怎么解决cpu飙高
使用top命令查看占用cpu的情况
通过top命令查看后,可以查看是哪一个进程占用cpu较高
使用ps命令查看进程中的线程信息
使用jstack命令查看进程中哪些线程出现了问题,最终定位问题
使用top命令查看占用cpu的情况
哪个进程占用的cpu最高finalShell中输入
top查看进程中的线程信息
ps H -eo pid,tid,%cpu | gerp pidjstack 查看进程内线程的堆栈信息
产生死锁可以查看因为是十六进程所以要十进程转换十六进程
直接linux输入printf "%x\n" Pid
然后就可以根据十六进制的去找哪个线程cpu占用
之后查看文件是cat xxx
项目中遇到的难点
1.从业务角度 曾经做过保险项目 金融保险领域 行外人需要花很多时间了解需求还有同事的帮助才懂得需求知道如何去写