
Redis篇
我看你做的项目中,都用到了redis,你在最近的项目中哪些场景使用了redis呢?
- 验证你项目场景的真实性,二是为了深入发问的切入点
- 缓存 缓存三兄弟(穿透、击穿、雪崩)、双写一致、持久化、数据过期策略、数据淘汰策略
- 分布式锁 setnx、redisson
- 消息队列、延迟队列 何种数据类型
==缓存穿透==:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查询数据库(可能原因是数据库被攻击了 发送了假的/大数据量的请求url)
解决方案一:缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存 {key:1, value:null}
优点:简单
缺点:消耗内存,可能会发生不一致的问题解决方案二:布隆过滤器 (拦截不存在的数据)
在缓存预热时,要预热布隆过滤器。根据id查询文章时查询布隆过滤器如果不存在直接返回
bitmap(位图):相当于一个以bit位为单位的数组,数组中每个单元只能存储二进制数0或1
布隆过滤器作用:可以用于检索一个元素是否在集合中
- 存储数据:id为1的数据,通过多个hash函数获取hash值,根据hash计算数组对应位置改为1
- 查询数据:使用相同hash函数获取hash值,判断对应位置是否都为1
存在误判率:数组越小 误判率越大
bloomFilter.tryInit(size, 0.05) //误判率5%
==缓存击穿==:给某一个key设置了过期时间,当key过期的时候,恰好这个时间点对这个key有大量的并发请求过来,这些并发请求可能一瞬间把DB击穿
解决方案一:互斥锁【数据强一致性 性能差 (银行)】
1.查询缓存,未命中 → 2.获取互斥锁成功 → 3.查询数据库重建缓存数据 → 4.写入缓存 → 5.释放锁
1.查询缓存,未命中 → 2.获取互斥锁失败 → 3.休眠一会再重试 → 4.写入缓存重试 → 5.缓存命中
解决方案二:逻辑过期[不设置过期时间] 【高可用 性能优 不能保证数据绝对一致 (用户体验)】
也可以搞个永不过期 具体是先在业务里写好某种情况下 某些时候不会过期 比如疫情卖口罩时期在数据库一条数据里面添加一个 “expire”: 153213455
1.查询缓存,发现逻辑时间已过期 → 2.获取互斥锁成功 → 3.开启线程 ↓→ 4.返回过期数据
【在新的线程】→ 1.查询数据库重建缓存数据 → 2.写入缓存,重置逻辑过期时间 → 3.释放锁
1.查询数据缓存,发现逻辑时间已过期 → 2.获取互斥锁失败 → 3.返回过期数据
==缓存雪崩==:在同一个时段内大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来压力
- 解决方案一:给不同的key的TTL(过期时间)添加随机值
- 解决方案二:利用Redis集群提高服务的可用性 【哨兵模式、集群模式】
- 解决方案三:给缓存业务添加降级限流策略【nginx、springcloud、gateway】
- 解决方案四:给业务添加多级缓存 【Guava(做一级缓存 然后Redis是二级缓存)或Caffeine】
《缓存三兄弟》
穿透无中生有key,布隆过滤null隔离。
缓存击穿过期key,锁与非期解难题。
雪崩大量过期key,过期时间要随机。
面试必考三兄弟,可用限流来保底。
redis作为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
✅ 二、Redis 和 MySQL 不一致会发生什么?
如果同步失败,会出现:
- 缓存中的数据是脏的(脏读)
- 缓存中没有数据,但数据库中有(缓存穿透)
- 数据库更新了,但 Redis 仍是旧值(一致性问题)
- 并发写操作丢失最新值(写丢失)
写先插入数据库
更新先更新数据库 更新数据库成功但redis不成功 影响不大 因为后面会有过期删除 最终会一致,更新mysql后缓存可以删除也可以修改
更新完数据库直接删除缓存了 有过期时间兜底 最终会保持一致 我们项目中对数据敏感性一致性不高 我们追求实时性
如果是最终保持一致性的就MQ 我们对实时性不高 对数据敏感性 一致性高
删除问题不大 哪里都行!
读多写少的可以上缓存
mysql保存购物车表 但是再页面操作的时候 只操作redis 用mq给到消费者修改或定时任务 更新数据到mysql,MQ问题:我们对数据实时性要求不高 只需要保存最终一致性就行
你如果只写redis 万一丢了数据怎么办?
购物车丢点订单无影响 数据安全性要求不太高 mysql尽量不要搞购物车的表 都在redis的表 丢就丢了呗。
或者异步同步/定时任务
实时性要求 安全性要求 → MySQL
电商一般数据库和mysql都要存 → 读多写少
一定、一定、一定要设置前提,介绍自己的业务背景 (一致性要求高?允许延迟一致?)
① 介绍自己简历上的业务,我们当时是把文章的热点数据存入到了缓存中,虽然是热点数据,但是实时要求性并没有那么高,所以我们采用的是异步的方案同步的数据
② 我们当时是把抢卷的库存存入到了缓存中,这个需要实时的进行数据同步,为了保证数据的强一致性,我们当时采用的是redission提供的读写锁来保证数据的同步
双写一致性:当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致
读操作:缓存命中,直接返回;缓存未命中查询数据库,写入缓存,设定超时时间
写操作:延迟双删 [因为无论先删除缓存还是先删除数据库都可能会出数据不一致问题 有脏数据]
==基于redisson互斥锁:==[放入缓存中的数据 读多写少] 【强一致性业务 性能低】
- 共享锁:读锁readLock,加锁之后,其他线程可以共享读操作,但**不允许写操作**
- 排他锁:独占锁writeLock也叫,加锁之后,阻塞其他线程读写操作(只允许一个用户或进程独占地对数据进行读取和写入操作)
排他锁确保了写操作的原子性和一致性 - 读数据的时候添加共享锁(读不互斥、写互斥)
- 写数据的时候添加排他锁(阻塞其他线程的读写 因为读多写少)
redissionClient.getReadWriteLock(“xxxx”);
==异步通知==: 异步通知保证数据的最终一致性(需要保证MQ的可靠性)
需要在Redis中更新数据的同时,通知另一个服务进行某些操作。- 使用场景:
- 缓存与数据库双写: 当应用需要同时更新Redis缓存和数据库时,可以先将数据写入Redis,然后通过异步通知机制触发数据库的更新操作。
- 跨地域数据复制: 在跨地域部署的服务中,为了实现数据的最终一致性,可以在一个地域写入数据后,通过异步通知机制在另一个地域进行数据复制。
- 系统间数据同步: 在微服务架构中,不同的服务可能有自己的数据存储。当一个服务更新了数据后,可以通过异步通知机制告知其他相关服务进行数据同步。
- 使用场景:
==基于Canal的异步通知==:监听mysql的binlog
- 使用MQ中间件,更新数据之后,通知缓存删除
- 利用canal中间件,不需要修改业务代码,伪装为mysqls的一个从节点,canal通过读取binlog数据更新缓存
✅ 为什么会出现 Redis 和 MySQL 数据不一致?
Redis 是缓存,MySQL 是数据库,它们的数据生命周期不同,导致在更新时会出现以下几种情况:
💥 情况1:先更新数据库,再删除缓存(常见写法)
update DB delete cache
- 假设刚执行完
update DB,还没来得及delete cache,此时某个高并发请求进来:
- 它先查缓存,发现是旧数据;
- 然后返回了错误的数据;
- 后续即使删了缓存,已经晚了。
这就是:缓存未及时失效,读取到了脏数据。
💥 情况2:先删除缓存,再更新数据库
delete cache update DB
- 这个时候如果并发查询线程来得很快:
- 缓存刚被删,查询请求就查不到;
- 就会穿透查数据库,查到旧数据;
- 然后又把旧数据写入了 Redis,覆盖了更新后的数据!
💥 情况3:缓存过期后查询数据库,正好遇到更新未完成
Redis key 过期 查询数据库返回旧数据 写入 Redis(错的数据被缓存)这就是缓存击穿 + 数据同步延迟的问题。
✅ 数据为什么会“丢”?需要同步吗?
Redis 是内存数据库,不具备强一致性保障,以下情况会导致“看起来丢数据”:
- 更新了数据库,但缓存没更新/没删除
- 缓存提前过期,重新加载了旧数据
- Redis 重启,缓存丢失
- 并发穿透,旧数据反复写入缓存
- 程序异常,缓存更新/删除逻辑没执行
✅ 怎么保证 Redis 和 MySQL 的一致性?
这就是我们说的:缓存与数据库双写一致性问题,常见策略如下:
1️⃣ 读写操作采用延迟双删策略(推荐)
update DB delete Redis sleep 500ms delete Redis again
- 延迟双删可以尽可能避免并发查询旧缓存的情况。
2️⃣ 加分布式锁
- 给关键资源加锁,串行化更新操作,避免并发穿透。
3️⃣ 异步更新缓存(利用消息队列)
- 变更数据后,发送消息通知缓存异步刷新。
4️⃣ 设置合理的缓存 TTL + 定时刷新
- 防止长期过期数据驻留,降低不一致几率。
5️⃣ 不缓存非热点数据
- 某些冷门数据没必要缓存,避免无谓一致性维护。
Redis作为缓存,数据的持久化是怎么做的?
Redis持久化:RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照,简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,数据恢复。
[root@localhost ~]# redis-cli
127.0.0.1:6379> save #由Redis主进程来执行RDB,会阻塞所有命令
ok
127.0.0.1:6379> bgsave #开 启子进程执行RDB,避免主进程受到影响
Background saving started
Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:
// 900秒内,如果至少有1个key被修改,则执行bgsave
save 900 1
save 300 10
save 60 10000
==RDB的执行原理?==数据完整性高用RDBsave就是直接让主线程去执行
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据,完成fork后读取内存数据并写入RDB文件
在LInux中主进程并无法直接读取物理内存,它只能通过虚拟内存去读。因此有页表(记录虚拟地址与物理地址的映射关系)去执行操作 同时 主进程也会fork(复制页表) 成为一个新的子进程(携带页表) → 写新RDB文件替换旧的RDB文件 → 磁盘
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作
优点:二进制数据重启后 Redis无需过多解析 直接恢复
==AOF==对数据不敏感要求不高
AOF全称为Append Only File(追加文件)底层硬盘顺序读写。Redis处理的每个写命令都会记录在AOF,可以看作是命令日志文件
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
AOF的命令记录的频率也可以通过redis.conf文件来配
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完毕先放入AOF缓冲区,然后表示每隔一秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
| 配置项 | 刷盘时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步刷盘 | 可靠性高,几乎不丢数据 | 性能影响大 |
| everysec | 每秒刷盘 | 性能适中 | 最多丢失1秒数据 |
| no | 操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量数据 |
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重读功能,用最少的命令达到相同效果这是AOF文件越来越大的处理方式
Redis会在出发阈值时自动重写AOF文件。阈值也可以在redis.conf中配置
# AOF文件比上次文件 增多超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
★★★★★★★★ RDB与AOF对比 ★★★★★★★★
RDB和AOF各有优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用
RDB是二进制文件,在保存时体积较小恢复较快,但也有可能丢失数据,我们通常在项目中使用AOF来恢复数据,虽然慢但丢失数据风险小,在AOF文件中可以设置刷盘策略(每秒批量写入一次命令)
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源 但AOF重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高常见 |
假如Redis的key过期之后,会立即删除吗
Redis对数据设置数据的有效时间,数据过期以后就需要将数据从内存中删除掉。可以按照不同的规则进行删除,这种删除规则就被称之为数据的删除策略(数据过期策略)
==Redis数据删除策略-惰性删除==
惰性删除:设置该key过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key
set name zhangsan 10
get name # 发现name过期了,直接删除key
优点:对CPU友好,只会在使用该key时才会进行过期检查,对于很多用不到的key不会浪费时间进行过期检查
缺点:对内存不友好,如果一个key已经过期,但是一直没有使用,那么该key就会一直存在内存中,内存永远不会释放
==Redis数据删除策略-定期删除==
定期删除:每隔一段时间,我们就会对一些key进行检查,删除里面过期的key (从一定数量的数据库中取出一定数量的随机key进行检查,并删除其中的过期key)
定期清理的两种模式:
- SLOW模式是定时模式,执行频率默认为10hz,每次不超过25ms,以通过修改配置文件
redis.conf的hz选项来调整这个次数 - FAST模式执行频率不固定,但两次间隔不低于2ms,每次耗时不超过1ms
优点:可以通过限制删除操作执行的时长和频率来减少删除操作对CPU的影响。另外定期删除,也能有效释放过期键占用的内存
难点:难以确定删除操作执行的时长和频率
Redis过期删除策略: 惰性删除 + 定期删除 两种策略进行配合使用
假如缓存过多,内存是有限的,内存被占满了怎么办?
==数据淘汰策略==
当Redis中的内存不够用时,此时在向Redis中添加新的key,那么Redis就会按照某一种规则将内存中的数据制除掉,这种数据的制除规则被称之为内存的淘汰策略
Redis支持8种不同策略来选择要删除的key:
noeviction:不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略
maxmemory-policy noeviction
volatile-ttl:对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰 (TTL:过期时间的key)
allkeys-random:对全体key,随机进行淘汰
volatile-random:对设置了TTL的key,随机进行淘汰
allkeys-lru:对全体key,基于LRU算法进行淘汰
LRU(Least Recently Used):最近最少使用,用当前时间减去最后一次访问时间,这个值越大测淘汰优先级越高 [逐出访问时间最少的]
LFU(Least Frequently Used):最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。[逐出频率最低的] 【电商会应用】allkeys-lfu:对全体key,基于LFU算法进行淘汰
volatile-lfu:对设置了TTL的key,基于LFU算法进行淘汰
淘汰策略 - 使用建议
1.优先使用 allkeys-lru 策略。充分利用LRU算法的优势,把最近最常访问的数据留在缓存中,如果业务有明显的冷热数据区分,建议使用。
2.如果业务中数据访问频率差别不大,没有明显冷热数据区分,建议使用allkeys-random,随机选择淘汰
3.如果业务中有置顶的需求,可以使用volatile-lru策略,同时置顶数据不设置过期时间,这些数据就一直不会被删除,会淘汰其他设置过期时间的数据
4.如果业务中有短时高频访问的数据,可以使用allkeys-lfu或volatile-lfu策略
数据库有1000万数据,Redis只能缓存20w数据,如何保证Redis中的数据都是热点数据?
- 使用
allkeys-lru(挑选最近最少使用的数据淘汰) 淘汰策略,留下来的都是经常访问的热点数据
Redis的内存用完了会发生什么?
- 主要看数据淘汰策略是什么?如果是默认的配置(noeviction),会直接报错
redis分布式锁,是如何实现的?
需要结合项目中的业务进行回答,通常情况下,分布式锁的使用场景:
集群情况下的定时任务、抢单、幂等性场景
如果使用互斥锁的话 那么在集群项目有多个服务器就会出现问题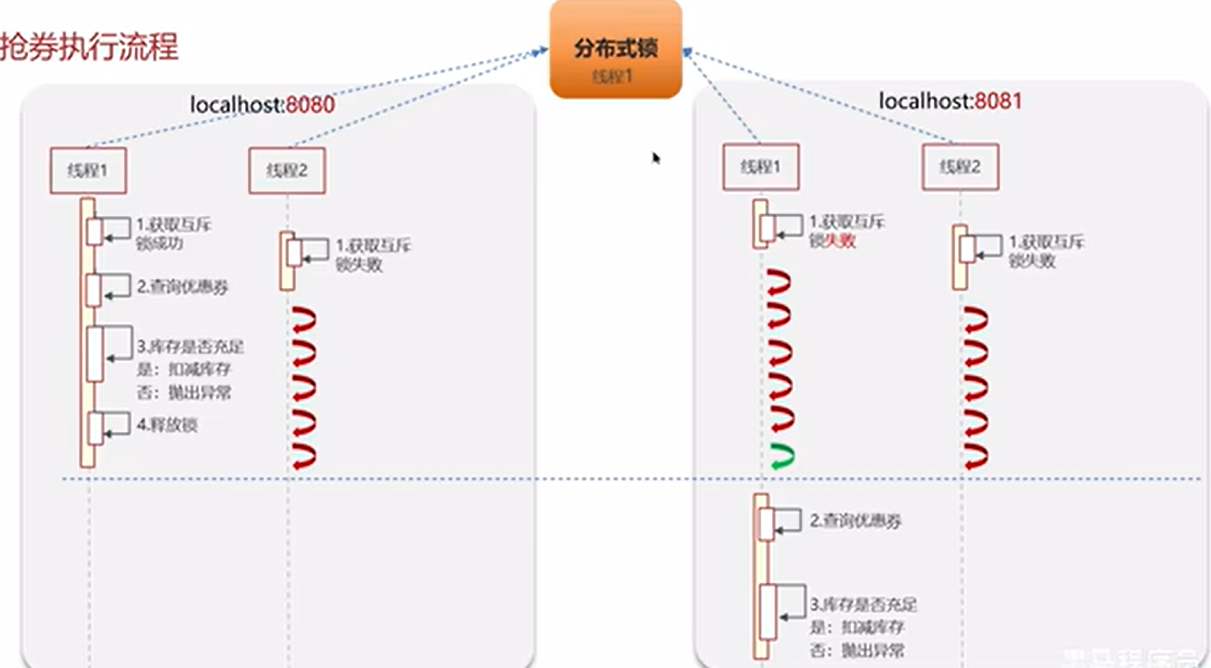
==Redis分布式锁==
Redis实现分布式锁主要利用Redis的setnx命令,setnx是**SET if not exists**(如果不存在,则SET)的简写
在同一时刻,只有一个线程/进程/服务节点能拿到锁,执行关键代码。其他的只能等或者失败退出。
获取锁
添加锁,NX是互斥、PX是设置超时时间
SET lock value NX PX 10释放锁
释放锁,删除即可
DEL key
Redis实现分布式锁如何合理的控制锁的有效时长?
- 根据业务执行时间预估
- 给锁续期
你“自己用 Redis 实现分布式锁” vs 用 Redisson 实现锁 —— 有哪些区别?
| 对比点 | 手动实现(自己用 Redis 命令) | ✅ Redisson 实现 |
|---|---|---|
| 🛠 实现方式 | 使用 SET key value NX PX、GET + DEL |
内部封装好,直接调用 .lock()、.unlock() |
| 🔐 安全性 | 容易写错,不易保证“只有加锁者能解锁” | Redisson 自动做到了“加锁者才能解锁” |
| 💣 死锁处理 | 自己必须手动加过期时间(PX),否则会死锁 | 自动设置超时时间,支持 watchdog 自动续命 |
| 🧵 可重入锁 | 不支持,需要自己实现复杂逻辑 | ✅ 内建支持可重入锁(ReentrantLock) |
| ⚠ 主从不一致 | Redis 主从复制延迟下可能“锁丢失” | Redisson 有 RedLock 模式,可用多个实例容错 |
| 🚦 阻塞等待 | 需要自己写轮询逻辑(比如 while循环) | ✅ Redisson 支持阻塞、等待、超时等参数 |
| ⏱ 自动续租 | 没有,需要自己定时续约 | ✅ 有“看门狗机制”自动续租防止业务太长释放锁 |
| 🔁 分布式支持 | 支持有限,自己写 RedLock 非常麻烦 | ✅ 内置 RedLock、联锁、多锁等高级功能 |
| ✅ 使用体验 | 复杂,代码易错 | ✅ 简单、线程安全、功能全面 |
==redisson实现分布式锁 - 执行流程==
✅ 只有在 你没指定超时时间 时,Watchdog 才会自动开启
加锁 ↓→ 加锁成功 → Watch dog(看门狗)
每隔(releaseTime/3的时间做一次续期)→ Redis
↓ 操作redis → Redis
↓→→ 释放锁↑ → 通知看门狗无需继续监听 → Redis
加锁 → → → 是否加锁成功?→→→ ↓
↑←←while循环不断尝试获取锁←←←↓
public void redisLock() throws InterruptedException{
RLock lock = redissonClient.getLock("heimalock");
// boolean isLock = lock.tryLock(10, 30, TimeUnit.SECONDS);
// 如果不设置中间的过期时间30 才会触发看门狗
// 加锁,设置过期时间等操作都是基于lua脚本完成的[调用redis命令来保证多条命令的原子性]
boolean isLock = lock.tryLock(10, TimeUnit.SECONDS);
if(isLock){
try{
sout("执行业务");
} finally{
lock.unlock();
}
}
}
要加依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
❌ 如果你这样写:
lock.lock(10, TimeUnit.SECONDS);
就不会有自动续命,看门狗不会工作。这种锁就是严格 10 秒后自动释放,不管你业务是否完成。
🔄 Watchdog 自动续命流程图
lock.lock() 被调用
↓
Redisson 设置锁为30秒过期
↓
启动看门狗线程,每10秒刷新一次锁 TTL
↓
如果线程还持有锁 → Redis.expire(lockKey, 30秒)
↓
直到 unlock() 调用 → 结束看门狗 + 删除锁
==redisson实现分布式锁 - 可重入==
redis实现分布式锁是不可重入的 但是 redisson实现分布式锁是可以重入的
可重入原理:它俩是同一个线程 每个线程都有唯一的线程id 根据线程id唯一标识做判断 判断之前获取锁是不是同一个线程
利用hash结构记录线程id和重入次数
KEY VALUE VALUE field value heimalock thread1 0
public void add1(){
RLock lock = redissonClient.getLock("heimalock");
boolean isLock = lock.tryLock();
// 执行业务
add2();
// 释放锁
lock.unlock();
}
public void add2(){
RLock lock = redissonClient.getLock("heimalock");
boolean isLock = lock.tryLock();
// 执行业务
// 释放锁 锁次数-1不完全释放
lock.unlock();
}
==redisson实现分布式锁 - 主从一致性==
Redis Master主节点:主要负责 写操作(增删改) 只能写
Redis Slave从节点:主要负责读操作只能读
当RedisMaster主节点突然宕机后 Java应用会去格外获取锁 这时两个线程就同时持有一把锁 容易出现脏数据
怎么解决呢?
- RedLock(红锁):不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁(n/2+1),避免在一个redis实例【实现复杂、性能差、运维繁琐】怎么解决?→ CP思想:zookeeper
Redis集群有哪些方案?
==主从复制==
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离
主节点写操作→增删改 从节点读操作→查介绍一下redis的主从同步
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就要搭建主从集群,实现读写分离。一般都是一主多从,主节点负责写数据,从节点负责读数据
主从数据同步原理:
- 主从全量同步:
slave从节点执行
replicaof命令建立链接 → 请求master主节点数据同步(replid+offset) → master判断是否是第一次同步(判断replid是否一致) → 是第一次, 返回master的数据版本信息(replid+offset) → slave保存版本信息 → master执行bgsave, 生成RDB → 发送RDB文件给slave → slave清空本地数据加载RDB数据 → 此时master记录RDB期间所有命令repl_balklog→ 发送repl_backlog中的命令 → slave执行接收到的命令Replication ld: 简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
offset: 偏移量,随着记录在repl baklog中的数据增多而逐渐增大。save完成同步时也会记录当前同步的offset,如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。简述全量同步的流程?
• slave节点请求增量同步
• master节点判断replid,发现不一致,拒绝增量同步
• master将完整内存数据生成RDB,发送RDB到slave
• slave清空本地数据,加载master的RDB
• master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
• slave执行接收到的命令,保持与master之间的同步
能说一下,主从同步数据的流程吗?
全量同步
1.从节点请求主节点同步数据(replication id、offset)
2.主节点判断是否为第一次请求,是第一次就与从节点同步版本信息(replication id和offset)
3.主节点执行bgsave, 生成RDB文件后, 发送给从节点去执行
4.在RDB生成执行期间, 主节点会从命令的方式记录到缓冲区(日志文件)- 主从增量同步
主从增量同步(slave重启或后期数据变化)
① slave重启后 → 携带(replid+offset)找master → master判断请求replid是否一致 → 是第一次, 返回主节点replid和offset → 保存版本信息
② slave重启后 → 携带(replid+offset)找master → master判断请求replid是否一致 → 不是第一次, 回复continue向slave → master 去repl_baklog中获取offset后的数据 → 发送offset后的命令给slave → 执行命令增量同步
1.从节点请求主节点同步数据,主节点判断不是第一次请求,不是第一次就获取从节点的offset值
2.主节点从命令日志中获取offset值后的数据,发送给节点进行数据同步
简述全量同步和增量同步区别?
•全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
•增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?
•slave节点第一次连接master节点时
•slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
•slave节点断开又恢复,并且在repl_baklog中能找到offset时
==哨兵模式==
搭过集群,具体多少个节点是组长那边,不太清楚[并发量不是太多 搭哨兵可以节省一点资源]~
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复- 监控:Sentinel会不断检查您的master和slave是否按预期工作
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为一个master。当故障实例恢复后也以新的master为主
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
服务状态监控
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令期待回复pong- 主观下线:如果某sentinel节点发现或某实例未在规定时间相应,则认为该实例主观下线
- 客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线,quorum值最好超过Sentinel实例数量的一半
哨兵选主规则
- 首先判断主与从节点断开时间长短,如超过指定值就排该从节点
- 然后判断从节点的slave-priority值,越小优先级越高
- 如果slave-priority值一样,则判断slave节点的offset值,越大优先级越高 (数据是最全的)
- 最后是判断slave节点的运行id大小,越小优先级越高
redis集群(哨兵模式) 脑裂
因网络问题 主节点和从节点分别在不同的网络分区 这样sentinel只会监控到一部分从节点网络分区 导致RedisClient继续写主节点的数据,这时网络恢复了,哨兵会将老的master强制降级到slave(携带着脑裂前的最新数据),这个时候slave就会把自己数据清空去同步master数据,这时就存在真正的数据丢失了怎么解决?
redis中有两个配置参数:【若不能达成就拒绝客户端请求 这样就会避免大量数据丢失】
min-replicas-to-write 1 表示最少的salve节点为1
min-replicas-max-lag 5 表示数据复制和同步的延迟不能超过5秒
达不到这两个条件就拒绝写入,从而避免数据丢失。怎么保证Redis的高并发高可用呢?
哨兵模式:实现主从集群的自动故障恢复(监控、自动故障恢复、通知)
你们使用redis是单点还是集群,哪种集群?
主从(1主1从) + 哨兵就可以了。单节点不超过10G内存,如果Redis内存不足则可以给不同服务分配独立的Redis主从节点
redis集群脑裂,该怎么解决?
集群脑裂是由于主节点和从节点和sentinel处于不同网络分区,使得sentinel没有能够心跳感知到主节点,所以通过选举的方式提升了一个从节点为主,这样就存在了两个master,就像大脑分裂了一样,这样会导致客户端还在老的主节点那里写入数据,新节点无法同步数据,当为网络恢复后,sentinel会将老的主节点降为从节点,此时再从新master同步数据,就会导致数据丢失
解决:我们可以修改redis的配置,可以设置最少的从节点数量以及缩短主从数据同步的延迟时间,达不到要求就拒绝请求,这样就会避免大量数据丢失。==分片集群==
主从和哨兵可以解决高可用、高并发读的问题,但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
使用分片集群可用解决上述问题,分片集群特征:
- 集群中有多个master,每个master保存不同数据
- 每个master都可用有多个slave节点
- master之间通过ping监测彼此健康状态
- 客户端请求可用访问集群任意节点,最终都会被转发到正确节点
分片集群结果 - 数据读写
Redis分片集群引入了哈希槽的概念,Redis集群有16384个哈希值,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽
存数据流程:
set name itheima → CRC16计算name的hash值(666666) → 666666%16384=11306 → 根据11306找寻所对应哈希槽的范围 并且插入数据redis的分片集群有什么用?
- 集群中有多个master,每个master保存不同数据。(解决高并发写的问题)
- 每个master都可以有多个slave节点。(解决高并发读的问题)
- master之间通过ping监测彼此健康状态
- 客户端请求可用访问集群任意节点,最终都会被转发到正确节点
redis的分片集群中数据是怎么存储和读取的?
- Redis 分片集群引入了哈希槽的概念,Redis 集群有16384个哈槽
- 将16384个插槽分配到不同的实例
- 读写数据:根据key的**有效部分**计算哈希值,对16384取余(有效部分,如果key前面有大括号,大括号的内容就是有效部分,如果没有,则以key本身做为有效部分)余数做为播槽,寻找插所在的实例
🚀 Redis 集群常见三种方式(解决不同问题)
| 模式 | 主要解决问题 | 特点 |
|---|---|---|
| ① 主从复制(+读写分离) | 读写压力分担 | 一主多从,主写从读,不能自动故障转移 |
| ② 哨兵模式(Sentinel) | 高可用(自动故障转移) | 在主从基础上,Sentinel 实现监控、自动选主、通知客户端 |
| ③ 分片集群(Cluster) | 海量数据、高写吞吐 | 数据分片+多主多从,每个主分管部分槽位(16384 slots) |
Redis是单线程的,但是为什么还那么快
- Redis是纯内存操作,执行速度非常快
- 采用单线程,避免不必要的上下文切换可竞争条件,多线程还要考虑线程安全问题
- 使用I/O多路复用模型,非阻塞IO
解释一下I/O多路复用模型?
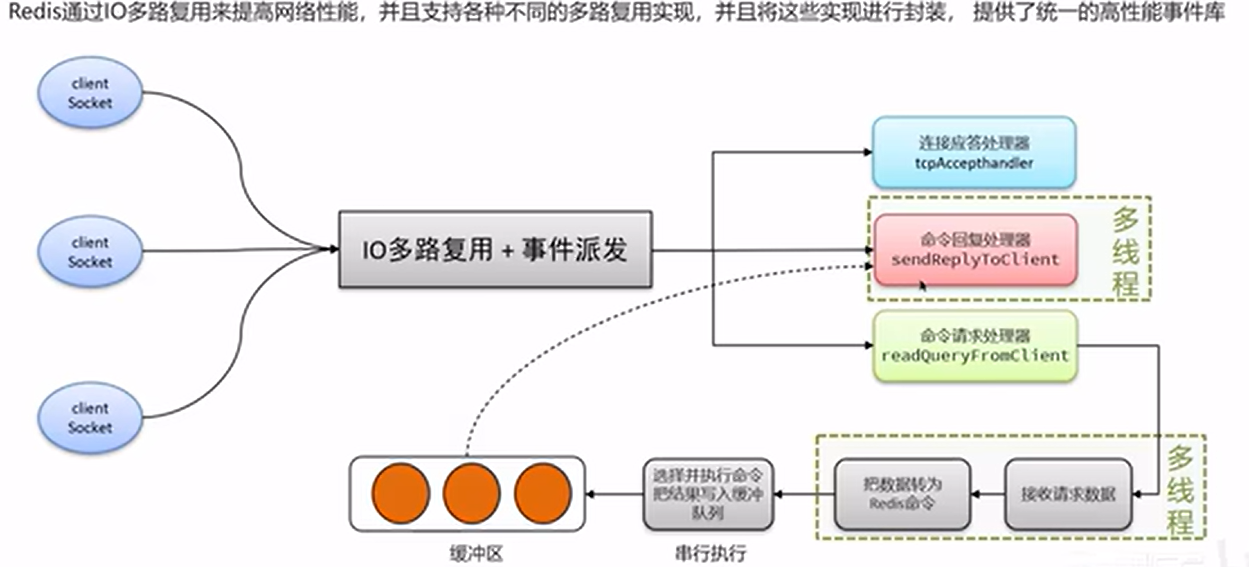
Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,I/O多路复用模型主要就是实现了高效的网络请求
是指利用单个线程来同时监听多个Socket ,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源,目前的I/O多路复用都是采用的epol模式实现,它会在通知用户进程Socket就绪的同时,把已就绪的Socket写入用户空间,不需要换个Socket来判断是否就绪,提升了性能
Redis网络模型:
就是使用I/O多路复用结合事件的处理器来应对多个Socket请求
连接应答处理器
命令回复处理器,在Redis6.0之后,为了提升更好的性能,使用了多线程来处理回复事件
命令请求处理器,在Redis6.0之后,将命令的转换使用了多线程,增加命令转换速度,在命令执行的时候,依然是单线程
==用户空间和内核空间==
- Linux系统中一个进程使用的内存情况划分两部分:内核空间、用户空间
- 用户空间只能执行受限的命令Ring3,而且不能直接调用系统资源必须通过内核提供的接口来访问
- 内核空间可以执行特权命令Ring0,调用一切系统资源
Linux系统为了提高IO效率,会在用户空间和内核空间都加入缓冲区
- 写数据时,要把用户缓冲数据拷贝到内核缓冲区,然后写入设备
- 读数据时,要从设备读取数据到内核缓冲区,然后拷贝到用户缓冲区
常见的IO模型
==阻塞IO==
阻塞IO就是两个阶段都必须阻塞等待:
阶段一:- 用户进程尝试读取数据(网卡数据等)
- 此时数据尚未到达,内核需要等待数据
- 此时用户进程也处于阻塞状态
阶段二:
- 数据到达并拷贝到内核缓冲区,代表已就绪
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程解除阻塞,处理数据
==非阻塞IO==
阶段一:
- 用户进程尝试读取数据(比如网卡数据)
- 此时数据尚未到达,内核需要等待数据
- 返回异常给用户进程
- 用户进程拿到error后,再次尝试读取
- 循环往复,直到数据就绪
阶段二:
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程解除阻塞,处理数据
==IO多路复用==
是利用单个线程来同时监听多个Socket,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源
IO多路复用是利用单个线程来同步监听多个Socket,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。不过监听Socket的方式、通知的方式又有多种实现
- select
- poll
- epoll
差异:
★ select和polI只会通知用户进程有Socket就绪,但不确定具体是哪个Socket,需要用户进程逐个历Socket来确认
★ epoll则会在通知用户进程Socket就绪的同时,把已就绪的Socket写入用户空间,阶段一:
- 用户进程调用select,指定要监听的Socket集合
- 内核监听对应的多个socket
- 任意一个或多个sacket数据就绪则返回readable
- 此过程中用户进程阻塞
阶段二:
- 用户进程找别就格的socket
- 依次调用recvfrom读取数据
- 内核将数据拷贝到用户空间
- 用户进程处理数据
Redis网络模型
MySQL篇
在MySQL中,如何定位慢查询?
1.介绍一下当时产生问题的场景(我们当时的一个接口测试的时候非常的慢,压测的结果大概5秒钟)
2.我们系统中当时采用了运维工具(Skywalking),可以监测出哪个接口,最终因为是sql的问题
3.在mysql中开启了慢日志查询,我们设置的值就是2秒,一旦sql执行超过2秒就会记录到日志中(调试阶段)
产生原因:
- 聚合查询
- 多表查询
- 表数据量过大查询
- 深度分页查询
方案一:==开源工具==[调试阶段才会开启 生产阶段不会开启]
- 调试工具Arthas
- 运维工具:Prometheus、Skywalking(接口访问时间)
方案二:==MySQL自带慢日志==
慢查询日志记录了所有执行时间超过指定参数(long_query_time, 单位:秒,默认10秒)的所有SQL语句的日志,如果要开启慢查询日志,需要在MySQL的配置文件(/etc/my.cnf)中配置信息:
# 开启MySQL慢日志查询开关
slow_query_log = 1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会被视为慢查询,记录慢查询日志
long_query_time = 2
那这个SQL语句执行很慢,如何分析呢?
可以采用MySQL自带的分析工具
explain
- 通过key和key_len检查是否命中了索引(索引本身存在是否有失效的情况)
- 通过type字段查看sql是否有进一步的优化空间,是否存在全索引扫描或全盘扫描
- 通过extra建议判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或修改返回字段来修复
产生原因:
- 聚合查询 → 新增临时表的数据
- 多表查询 → 优化SQL语句结构
- 表数据量过大查询 → 添加索引
- 深度分页查询
一个SQL语句执行很慢,如何分析?
可以采用EXPLAIN或者DESC命令获取MySQL如何执行SELECT语句的信息
# 直接在select语句之前加上关键字 explain/desc
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件;
mysql > explain select * from t_user where id = ‘1’
id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE t_user NULL const PRIMARY PRIMARY 98 const 1 100.00 NULL
- possible_key:当前sql可能会使用到的索引
- key:当前sql实际命中的索引 通过它俩查看是否可能会命中索引
- key_len:索引占用的大小 通过它俩查看是否可能会命中索引
- Extra:额外的优化建议 看是否走过覆盖索引或回表查询
Extra 含义 Using where; Using Index 查找使用了索引,需要的数据都在索引列中能找到,不需要回表查询数据 Using index condition 查找使用了索引,但是需要回表查询数据
- type:这条sql的连接的类型,性能由好到差为
- NULL
- system:查询系统中的表
- const:根据主键查询
- eq_ref:主键索引查询或唯一索引查询
- ref:索引查询
- range:范围查询
- index:索引树扫描
- all:全盘扫描
了解过索引吗?(什么是索引)
索引(index)是帮助MySQL高效获取数据的数据结构(有序),在数据之外,数据库系统还维护着满足特定查找算法的数据结构**(B+树)**,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引
- 索引(index)是帮助MySQL高效获取数据的数据结构(有序)
- 提高数据检索的效率,降低数据库的IO成本(不需要全表扫描)
- 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗
索引的底层数据结构了解过吗?
MySQL的InnoDB引擎采用的B+树的数据结构来存储索引
- 阶数更多,路径更短
- 磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据
- B+树便于扫库和区间查询,叶子节点是一个双向链表
**MySQL默认使用的索引底层数据结构是B+树**。再聊B+树之前,先来聊聊二叉树和B树
==B Tree(矮胖树)== B树是一种多叉路衡查找树,相对于二叉树,B树每个节点可以有多个分支,即多叉。以一颗最大度数(max-degree)为5(5阶)的b-tree为例,那这个B树每个节点最多存储4个key
==B+Tree== 是再BTree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是B+Tree实现其索引结构
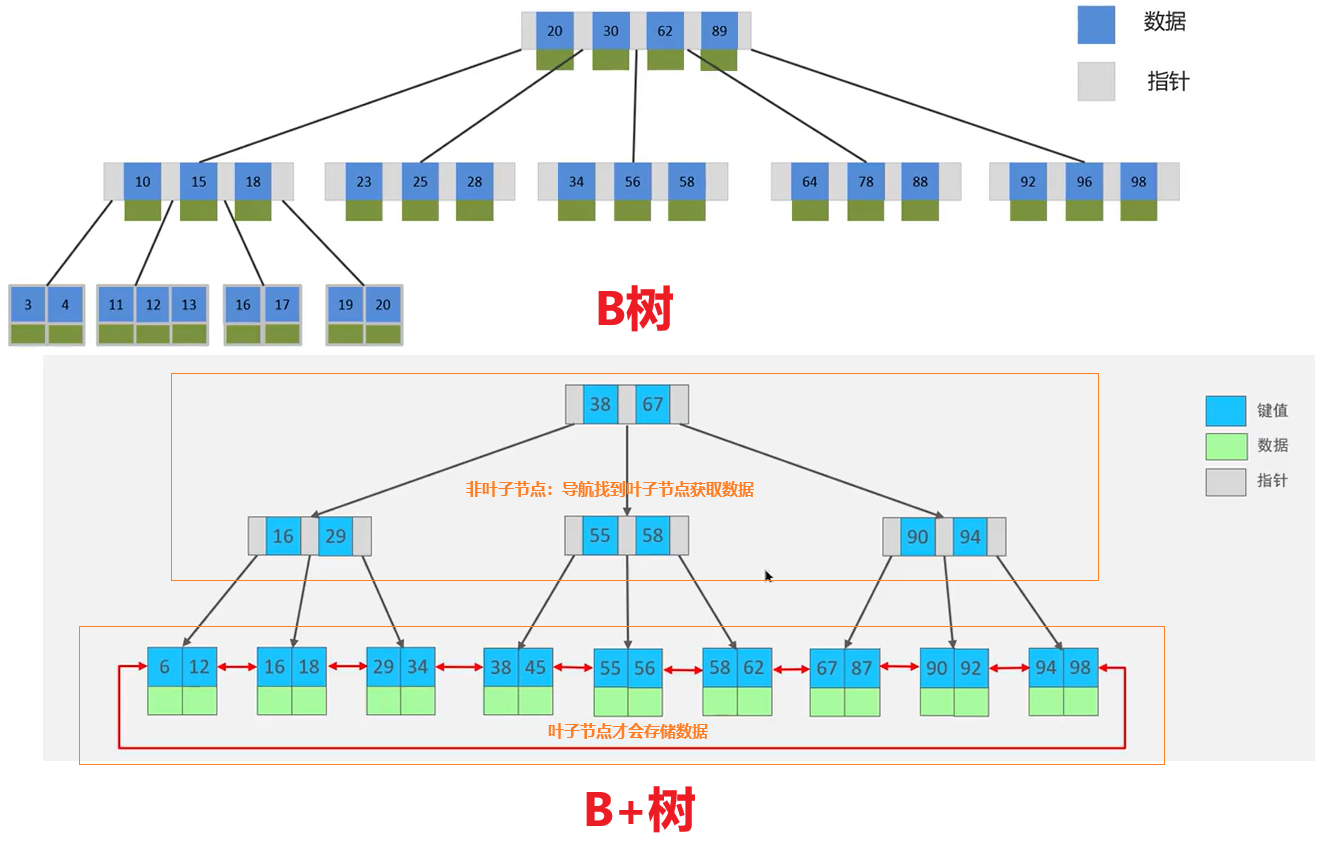
B树与B+树对比:
- 磁盘读写代价B+树更低
- 查询效率B+树更加稳定
- B+树便于扫库和区间查询
B树要找12 首先找38 左面小 再去缩小范围16和29 找到12 → 但是我们只想要12的数据 B树会额外的把38,16,29的数据全查一遍最后才到12的数据
B+树是在叶子节点才会存储数据,在非叶子节点全是指针,这样就没有其他乱七八糟的数据影响 。且查找路径是差不多的,效率较稳定
便于扫库:比如我们要查询6-34区间的数据,先去根节点扫描一次38 → 16-29 → 由于叶子节点之间有双向指针,就可以一次性把所有数据都给拿到[无需再去根节点找一次]
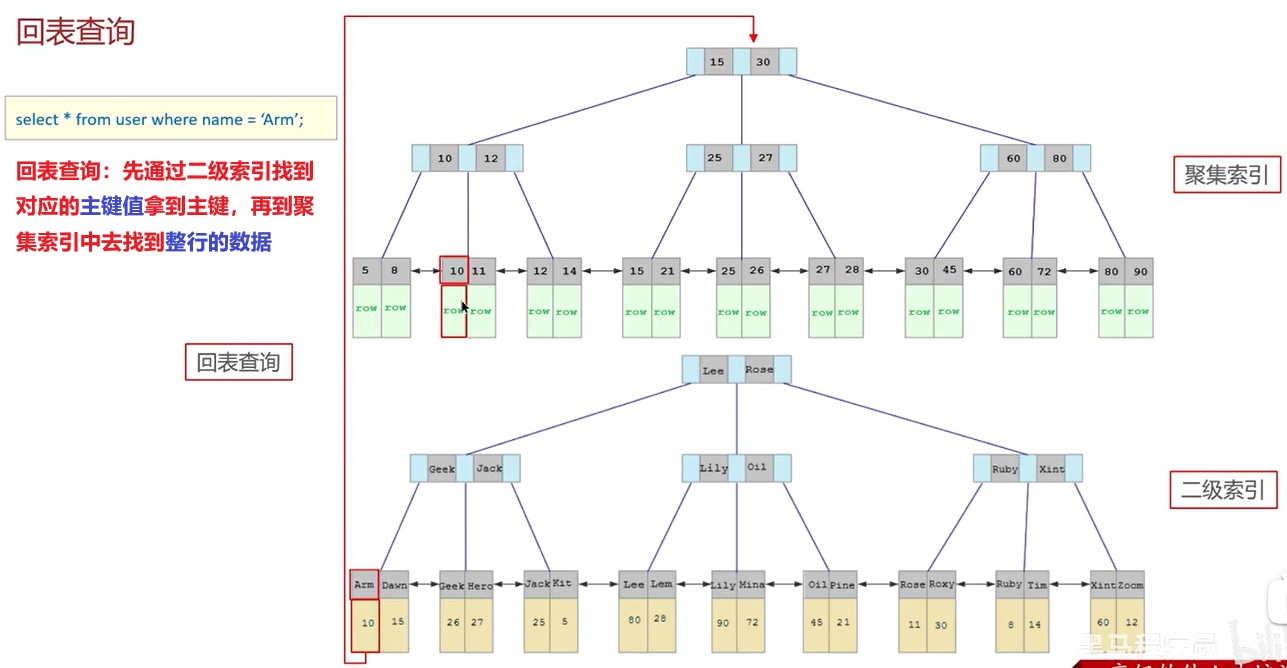
什么是聚簇索引?什么是非聚簇索引(二级索引)?什么是回表?
- 聚簇索引(聚集索引):数据与索引放到一块,B+树的叶子节点保存了整行数据,有且只有一个
- 非聚簇索引(二级索引):数据与索引分开存储,B+树的叶子节点保存对应的主键,可以有多个
- 回表查询:通过二级索引找到对应的主键值,到聚集索引中查找正行数据,这个过程就是回表
| 分类 | 含义 | 特点 |
|---|---|---|
| ==聚集索引(Clustered Index)== | 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有, 而且只有一个 |
| ==二级索引(Secondary Index)== | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一 (UNIQUE) 索引作为聚集索引
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引
聚集索引和非聚集索引的具体区别
| 特点 | 聚集索引 | 非聚集索引 |
|---|---|---|
| 数据存储方式 | 数据与索引存储在一起,叶子节点存储整行数据。 | 数据与索引分开存储,叶子节点存储指针或主键值。 |
| 物理排序 | 数据按索引键的顺序物理排序。 | 数据的物理顺序与索引无关。 |
| 索引数量 | 一个表只能有一个聚集索引。 | 一个表可以有多个非聚集索引。 |
| 查询性能 | 查询效率高,尤其是范围查询和排序操作。 | 查询效率相对较低,可能需要“回表”操作。 |
| 更新操作影响 | 插入、删除或更新数据可能需要重新排序。 | 更新操作影响较小,仅修改索引和指针。 |
| 适用场景 | 范围查询、排序、分组等操作频繁的列。 | 查询条件筛选、快速定位数据的列。 |

==回表查询==
select * from user where name = 'Arm';
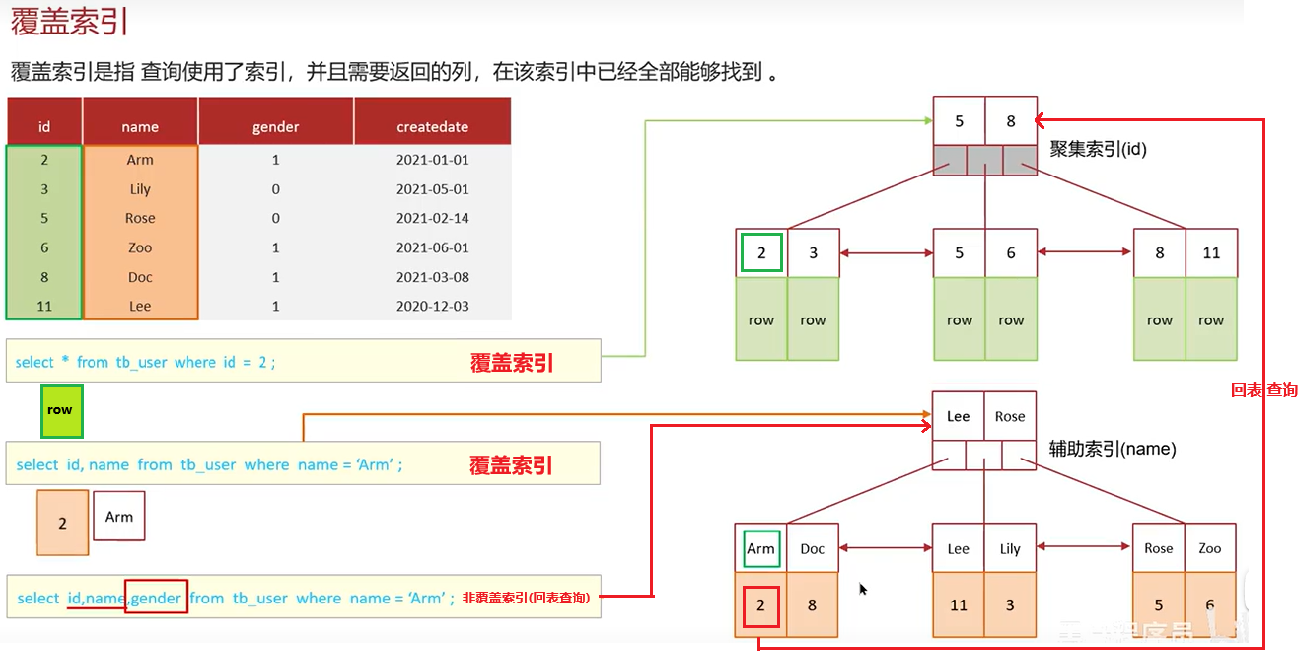
知道什么叫覆盖索引吗?
覆盖索引是指查询使用了索引,返回的列,必须在索引中全部能够找到
- 使用id查询,直接走聚集索引查询,一次索引描述,直接返回数据,性能高
- 如果返回的列中没有创建索引,有可能会触发回表查询,尽量避免使用 **select ***
[除非用的聚簇索引(主键)]
==覆盖索引==是指查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到
| id | name | gender | createdate |
|---|---|---|---|
| 2 | Arm | 1 | 2021-01-01 |
| 3 | Lily | 0 | 2021-05-04 |
| 5 | Rose | 0 | 2021-04-21 |
| 6 | Zoo | 1 | 2021-07-31 |
| 8 | Doc | 1 | 2021-02-26 |
| 11 | Lee | 1 | 2021-09-11 |
- id为主键,默认是主键索引
- name字段为普通索引
select * from tb_user where id = 1; 【覆盖索引】
select id, name from tb_user where name = 'Arm' 【覆盖索引】
select id, name, gender from tb_user where name = 'Arm' 【非覆盖索引】(需要回表查询)
MySQL超大分页怎么处理?
问题:再数据量比较大时,limit分页查询,需要对数据进行排序,效率低
解决方案:可以用覆盖索引 + 子查询处理
[我们先分页查询获取表中的id 并且对表的id进行排序 就能筛选出分页后的id集合(因为id是覆盖索引效率高) 最后再根据id集合到原来的表中做关联查询就可以得到提升了]
在数据量比较大时,如果用limit分页查询,在查询时,越往后,分页查询效率越低
mysql > select * from tb_sku limit 0,10;
10 rows in set (0.00 sec)
mysql > select * from tb_sku limit 9000000,10;
10 rows in set (11.05 sec)
因为,当在进行分页查询时,如果执行 limit 9000000,10,此时需要MySQL排序前9000010记录,仅仅返回9000000 - 9000010 的记录,其他记录丢失,查询排序的代价非常大。
==MySQL超大分页查询优化思路==:一般分页查询时,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化
# 超大分页处理:先通过覆盖索引找到符合条件的id,再通过这个id的覆盖索引查询到所有的列
select *
from tb_sku t,
(select id from tb_sku order by id limit 9000000,10) a
where t.id = a.id
# 10 rows in set (7.15 sec)
索引创建原则有哪些?
① 数据量较大,且查询比较频繁的表
② 常作为查询条件、排序、分组的字段
③ 字段内容区分度高
④ 内容较长,使用前缀索引
⑤ 尽量联合索引
⑥ 要控制索引的数量
⑦ 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它
- 先陈述自己再实际工作中是怎么用的
- 主键索引
- 唯一索引
- 根据业务创建的索引(复合索引)
创建索引的方式1
① SQL的方式
ALTER TABLE user_innodb ADD INDEX idx_name(name)
② 在建表的时候 去指定索引
...
PRIMARY KEY('id'),
KEY 'idx_name' ('name') USING HASH
③ 通过界面化工具去指定索引
字段旁边有个`索引` 可以去添加
=============================================
单个字段的索引 → 单列索引
多个字段的索引 → 联合索引
索引的类型
索引可以增加查询速度 同时也增加了更新/修改速度因为更新的第一步就是查询
① 普通索引 经过特殊设计的数据结构
② 唯一索引 唯一约束
[索引必须是唯一的 比如name就不行 因为名字可以很多建立普通索引]
③ 主键索引 在主键索引上添加了非空约束
④ 全文索引 一般使用搜索引擎,因为对中文的搜索不太友好美国英文开发的
[特殊的sql:select * from 表名 where match(字段名) against(‘马士兵教育’ IN NATURAL LANGUAGE MODE);]AVL树 右右型左旋 左子树与右子树的深度差绝对值不超过1
树的节点里应该放:键值+Value值+左右子树的地址left+right
Innodb一次会加载16k(16384字节=Redis的槽位) 内存到内存
不选红黑树是因为它是二叉的,我们需要多叉树
要用==B+树==全盘扫描能力更强 叶子节点是双向链表
因为稳定性比较好 B树非所见所得 B+树是稳定几层的查找数据因为数据都在最后一层叶子节点上
Innodb的索引方法是BTREE 不能改成HASH
**数据结构可视化网**:Data Structure Visualization
- 针对数据量较大,且查询比较频繁的表建立索引。单表超过10万数据(增加用户体验)
- 针对常作为查询条件(where)、排序(order by)、分组(group by) 操作的字段建立索引
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高 (比如address都在北京市)
- 如果是字符串类型的字段,字段的长度越长(描述信息…),可以针对于字段的特点,建立前缀索引
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引(避免回表),节省存储空间,提高查询效率
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
什么情况下索引会失效?
- 违反最左前缀法则
- 范围查询右边的列,不能使用索引
- 不要在索引列上进行运算操作,索引将失效
- 字符串不加单引号,造成索引失效。(类型转换)
- 以**%开头的Like模糊查询**,索引失效
[不影响正常查询业务 但未运用超大分页查询优化 会导致索引失效]
怎么哪块读判断索引是否失效了呢?
# 执行计划explain
【2024最新版MySQL索引讲解!一个视频带你彻底搞懂MySQL索引!!【马士兵】】https://www.bilibili.com/video/BV17z421i7Kb?vd_source=5966d6c3cf3709c10b3c53b278b0f4d3
什么情况下索引会失效?
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始,并且不跳过索引中的列。匹配最左前缀法则,走索引:
谈谈你对sql的优化经验?
- 表的设计优化,数据类型的选择
- 索引优化,索引创建原则
- sql语句优化,避免索引失效,避免使用select
- 主从复制、读写分离,不让数据的写入,影响读操作
- 分库分表
表的设计优化(参考阿里开发手册《嵩山版》)
- 比如设置合适的数值(tinyint、int、bigint) ,要根据实际情况选择
- 比如设置合适的字符串类型(char和varchar) char定长效率高,varchar可变长度,效率低
候选人: 这个我们主要参考的阿里出的那个开发手册《嵩山版》,就比如,在定义字段的时候需要结合字段的内容来选择合适的类型,如果是数值的话,像tinyint、int、bigint这些类型,要根据实际情况选择。如果是字符串类型,也是结合存储的内容来选择char和varchar或者text类型
索引优化(参考优化创建原则和索引失效)
SQL语句优化
SELECT语句务必指明字段名称 (避免直使用select *)
回表SQL语句要避免造成索引失效的写法
尽量使用union all代替union,union(不会重复)会多一次过滤, 效率低
select * from t_user where id > 2 union all | union select * from t_user where id < 5避免在where子句中对字段进行表达式操作
join优化 能用inner join 就不用left join, right 如必须使用 一定要以小表为驱动;内链接会对两个表进行优化,优先把小表放到外边,把大表放到里边。left join 或 right join,不会重新调整顺序
for(int i = 0; i < 3; i++){ //只链接查询3次 for(int j = 0; j < 1000; j++){ } }
主从复制、读写分离(在生产环境下一般会搭建主库和从库 分开读操作和写操作)
如果数据库的使用场景读的操作比较多的时候,为了避免写的操作所造成的性能影响 可以采用读写分离的架构。读写分离解决的是,数据库的写入,影响了查询的效率。[Master(写) 和 Slave(读)]
分库分表(后面有介绍)
事务的特性是什么?可以详细的说一下吗?【ACID】
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
候选人:嗯,这个比较清楚,ACID,分别指的是:原子性、一致性、隔离性、持久性;
我举个例子:A向B转账500,转账成功,A扣除500元,B增加500元。
原子性操作体现在要么都成功,要么都失败。
在转账的过程中,数据要一致性,A扣除了500,B必须增加500
在转账的过程中,隔离性体现在A像B转账,不能受其他事务干扰
在转账的过程中,持久性体现在事务提交后,要把数据持久化(可以说是落盘操作)
- **原子性(**Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(lsolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境运行
- 持久性(Durabiity):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
并发事务带来哪些问题?怎么解决这些问题?MySQL默认隔离级别是?
- ==并发事务问题==:脏读、不可重复读、幻读
- ==隔离级别==:读未提交、读已提交、可重复读、串行化
| 问题 | 描述 |
|---|---|
| 脏读 | 一个事务读到另外一个事务还没有提交的数据 |
| 不可重复读 | 一个事务先后读取同一条事务,但两次读取的数据不同,称之为不可重复读 |
| 幻读 | 一个事务按照条件查询数据时,没有对应的数据行,这同时另一个事务B(insert且commit)了事务,此时事务A在插入数据时候,又发现这行数据已经存在了,好像出现了”幻影“ |
怎么解决并发事务的问题呢??
对事务进行隔离 (× 是代表可以解决此问题)
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted 未提交读 | √ | √ | √ |
| Read committed 读已提交 | × | √ | √ |
| ==Repeatable Read(默认) 可重复读== | × | × | √ |
| Serializable 串行化 | × | × | × |
注意:**事务隔离级别越高,数据越安全,但是性能越低**
数据库的undo log 和 redo log的区别?
redo log:记录的是数据页的物理变化,服务宕机可用来同步数据
undo log:记录的是逻辑日志,当事务回滚时,通过逆操作恢复原来的数据
redo log 保证了事务的持久性,undolog保证了事务的原子性和一致性
redo log 和 undo log 是 InnoDB 为了实现事务的 原子性 和 持久性 而设计的两种日志机制:
| 日志类型 | 作用 | 类比 |
|---|---|---|
| redo log | 崩溃恢复,重做操作(实现持久性)【恢复】 | 保存键 Ctrl+S |
| undo log | 回滚事务,撤销操作(实现原子性)【撤销】 | 撤销键 Ctrl+Z |
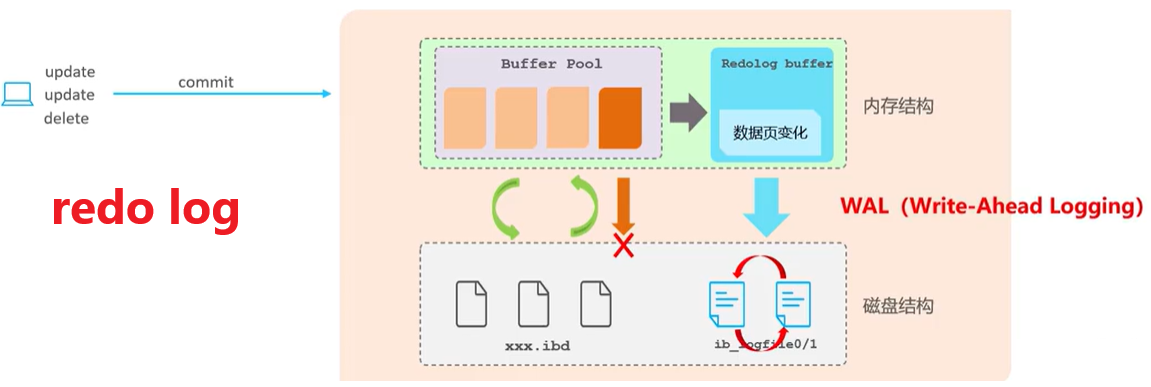
- 缓冲池(buffer pool):主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改査操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度
- 数据页(page):是InnoD8 存储引擎磁盘管理的最小单元,每个页的大小默认为 16KB。页中存储的是行数据
假设你执行一条 SQL:
UPDATE account SET balance = balance - 100 WHERE id = 1;
InnoDB 的执行顺序是:
- 写入 undo log(记录原值,便于回滚) ✅
- 修改内存中的数据(Buffer Pool)✅
- 写入 redo log(记录新的值,崩溃后可重做)✅
- 提交事务时将 redo log 落盘(刷到磁盘)
🔄 崩溃恢复时如何用它们?
- 💥 宕机恢复(crash recovery)时,MySQL 会用
redo log把“已提交但还没写到磁盘的数据”重做一遍,确保数据不丢失(持久性)。 - ❌ 事务失败或回滚时,MySQL 用
undo log把数据恢复到修改之前的样子,确保事务“要么全做,要么全不做”(原子性)。
==redo log==
重做日志,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性
该日志文件由两部分组冲:重做日志缓冲(redo log buffer) 以及 **重做日志文件(redo log file)**,前者是在内存中,后者是在磁盘中。当事务提交之后会把所有修改信息都保存到该日志文件中,用于在刷新脏页到磁盘,发生错误时,进行数据恢复使用。
==undo log==
回滚日志,用于记录数据被修改前的信息,作用包含两个:提供回滚和 MVCC(多版本并发控制)。undolog 和 redolog记录物理日志不一样,它是逻辑日志
- **可以认为当delete一条记录时,undo log中会记录一条对应的insert记录**,反之亦然
- 当update一条记录时,它记录一条对应相反的update记录。当执行rolback时,就可以从undolog中的逻辑记录读取到相应的内容并进行回滚。
undo log可以实现事务的一致性和原子性
事务中的隔离性是如何保证的呢?
事务的隔离性主要是通过锁机制和 MVCC(多版本并发控制) 来实现的。
对于更新操作 (写),MySQL 会使用加锁机制,比如行级锁中的排他锁(X锁)来避免并发写冲突;
对于查询操作 (读),MySQL 使用 MVCC 来避免加锁带来的性能开销,从而支持高并发读操作。
MVCC 的核心思想是:为同一条数据维护多个版本,从而实现 “读写不冲突、并发更高效”。
排他锁 (如果一个事务获取到了一个数据行的排他锁,其他事务就不能再获取该行的其他锁)
mvcc: 多版本并发控制 让MySQL中的多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突
隐藏字段:
每一行数据都会有两个隐藏字段
① trx _id(事务id),记录每一次操作的事务id,是自增的 [当前这条记录是由哪个事务创建的(事务ID)]
② roll_pointer(回滚指针),指向上一个版本的事务版本记录地址(形成一个版本链)undo log:
① 回滚日志,存储老版本数据
② 版本链:多个事务并行操作某一行记录,记录不同事务修改数据的版本,通过rollpointer指针形成一个链表readView:解决的是一个事务查询选择版本的问题
根据readView的匹配规则和当前的一些事务id判断该访问那个版本的数据》不同的隔离级别快照读是不一样的,最终的访问的结果不一样RC:每一次执行快照读时生成ReadView
RR:仅在事务中第一次执行快照读时生成ReadView,后续复用
面试官: 事务中的隔离性是如何保证的呢?(你解释一下MVCC)
候选人: 事务的隔离性是由锁和mvcc实现的。
其中mvcc的意思是多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突,它的底层实现主要是分为了三个部分,第一个是隐藏字段,第二个是undolog日志,第三个是readView读视图
隐藏字段是指:在mysq!中给每个表都设置了隐藏字段,有一个是x_id(事务id),记录每一次操作的事务id,是自增的;另一个字段是roll-pointer(回滚指针),指向上一个版本的事务版本记录地址
undolog主要的作用是记录回滚日志,存储老版本数据,在内部会形成一个版本链,在多个事务并行探作某一行记录,记录不同事务修改数据的版本,通过roll_pointer指针形成一个链表
readview解决的是一个事务查询选择版本的问题,在内部定义了一些匹配规则和当前的一些事务id判断该访问那个版本的数据,不同的隔离级别快照读是不一样的,最终的访问的结果不一样。如果是rc隔离级别,每一次执行快照读时生成ReadView,如果是r隔离级别仅在事务中第一次执行快照读时生成ReadView,后续复用MVCC底层的三个关键机制
🔹 1. 隐藏字段
每一行数据都会有两个隐藏字段:
trx_id:当前这条记录是由哪个事务创建的(事务ID)roll_pointer:回滚指针,指向这条记录的上一个版本(形成一个版本链)
🔹 2. undo log(回滚日志)
- 当事务对数据进行修改时,会记录修改前的旧数据到
undo log- 所有旧版本数据通过
roll_pointer串成一个“版本链”- 查询时可以根据版本选择合适的数据版本,从而“读老数据”
🔹 3. ReadView(读视图)
- 在执行快照读时,InnoDB 会生成一个 ReadView
- 它记录了当前活跃的事务ID列表,以及当前事务的ID
- 查询时,会根据 ReadView 判断:这条记录版本是否“可见”
总的来说,写操作靠加锁,读操作靠 MVCC。MVCC 通过维护多个版本的数据 + ReadView 机制,让不同事务之间在查询时互不干扰,从而保证隔离性,同时提升并发性能。
🔐 写用锁、📚 读用 MVCC,🔁 多版本 + 🔍 读视图 + 🧾 回滚日志,性能高,隔离强!
解释一下MVCC?
全程 Multi-Version Concurrency Control,多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突
问题的来源:(橙色的)查询的是哪个事务版本的记录?
| 事务2 | 事务3 | 事务4 | 事务5 |
|---|---|---|---|
| 开始事务 | 开始事务 | 开始事务 | 开始事务 |
| 修改id为30记录, age改为3 | 查询id为30的记录 | ||
| 提交事务 | |||
| 修改id为30记录, name改为A3 | |||
| 查询id为30的记录 | |||
| 提交文件 | 修改id为30的记录, age改为10 | ||
| 查询id为30的记录 | 查询id为30的记录 | ||
| 提交事务 |
MVCC-实现原理
- 记录中的隐藏字段
| id | age | name | DB_TRX_ID | DB_ROLL_PTR | DB_ROW_ID |
|---|
- DB_TRX_ID:最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID
- DB_ROLL_PTR:回滚指针,指向这条记录的上一个版本,用于配合undo log, 指向上一个版本
- DB_ROW_ID:隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段
undo log
- 回滚日志,在insert、update、delete的时候产生的便于数据回滚的日志
相反的语句。 - 当insert的时候,产生的undolog日志只在回滚时需要,在事务提交后,可被立即删除。
- 而update、delete的时候,产生的undo log日志不仅在回滚时需要,mvcc版本访问也需要,不会立即被删除。
undo log版本链
不同事务或相同事务对同一条记录进行修改,会导致该记录的undolog生成一条记录版本链表,链表的头部是最新的旧记录,链表尾部是最早的旧记录
- readview
ReadView(读视图) 是 快照读 SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id
ReadView中包含了四个核心字段
| 字段 | 含义 |
|---|---|
| m_ids | 当前活跃的事务ID集合 |
| min_trx_id | 最小活跃事务ID |
| max_trx_id | 预分配事务ID, 当前最大事务ID+1 (事务ID是自增的) |
| creator_trx_id | ReadView创建者的事务ID |
- 当前读
读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。对于我们日常的操作,如:select .. lock in share mode(共享锁),select .. for update、update、insert、delete(排他锁)都是一种当前读。
- 快照读
简单的select(不加锁)就是快照读,快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。
Read Committed:每次select,都生成一个快照读。
Repeatable Read:开启事务后第一个select语句才是快照读的地方。
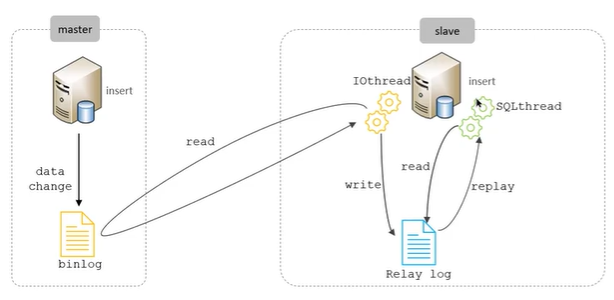
MySQL主从同步原理?
主从同步就是主库把所有数据修改写到日志文件(Binlog)里,从库再去“抄作业”——读日志,写自己,中继日志相当于中转站,最终把主库的修改同步过来。
MySQL主从复制的核心就是二进制日志binlog[DDL(数据定义语言)语句 和 DML(数据操纵语言)语句]
主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
从库读取主库的二进制日志文件 Binlog,写入到从库的中继日志 Relay Log。
从库重做中继日志中的事件,将改变反映它自己的数据。
MySQL 主从同步分三步:
- 写日志:主库提交事务 → 写 Binlog
- 拉日志:从库 I/O 线程拉取 Binlog → 写 Relay Log
- 执行日志:从库 SQL 线程执行 Relay Log → 同步数据
整个过程就是:主库写 → 从库拉 → 从库执行
MySQL主从复制的核心就是二进制日志
二进制文件(BINLOG) 记录了所有的DDL(数据定义语言)语句 和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句
+---------------------+
| Master 主库 |
| 写 Binlog(记录变更) |
+---------------------+
↓
[ I/O 线程拉取 Binlog ]
↓
+---------------------+
| Slave 从库 |
| 写 Relay Log(中继) |
| 执行日志 → 同步数据 |
+---------------------+
复制分成三步:
- Master主库在事务提交时,会把数据变更记录在二进制日志文件Binlog中
- 从库读取主库的二进制日志文件Binlog,写入到从库的中继日志Relay Log
- slave重做中继日志中的事件,将改变反应他自己的数据
你们项目用过分库分表吗?
是的,我们项目在业务数据达到一定规模后使用了分库分表策略。
具体来说,我们在做【举个真实业务:比如订单系统、日志存储系统、会员行为分析系统】时,由于单表数据量突破了 1000W+,单表容量超过 20GB,查询响应变慢,索引命中率降低,磁盘和网络 I/O 成为瓶颈。
一开始我们尝试通过主从读写分离、加索引、缓存优化等方式缓解,但效果有限,最终采用了分库分表来从根本上解决性能问题。
业务介绍
1,根据自己简历上的项目,想一个数据量较大业务(请求数多或业务累积大)
2,达到了什么样的量级(单表1000万或超过20G)具体拆分策略
1,水平分库,将一个库的数据拆分到多个库中,解决海量数据存储和高并发的问题
2,水平分表,解决单表存储和性能的问题
3,垂直分库,根据业务进行拆分,高并发下提高磁盘I0和网络连接数
4,垂直分表,冷热数据分离,多表互不影响
分担了访问压力、解决存储压力
分库分表的时机:
① 前提:项目业务数据逐渐增多,业务发展比较迅速【单表数据量达1000W或20G以后】
② 优化解决不了性能问题(主从读写分离、查询索引)
③ IO瓶颈(磁盘IO、网络IO)、CPU瓶颈(聚合查询、连接数太多)
拆分策略【垂直 ≈ 微服务、水平 ≈ 分配数值】
- ==垂直拆分==
- 垂直分库:以表为依据,根据业务将不同表拆分到不同库中
(特点:按业务对数据分级管理、维护、监控、扩展;在高并发下,提高磁盘IO和数据量连接数)- tb_user → 用户微服务
- tb_order → 订单微服务
- tb_sku → 商品微服务
- 垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中
(把不常用的字段单独放在一张表;把text, blob等大字段[描述]拆分出来放在附表中)
(特点:冷热数据分离、减少IO过渡争抢,两表互不影响)
- 垂直分库:以表为依据,根据业务将不同表拆分到不同库中
- ==水平拆分==
- 水平分库:将一个库的数据拆分到多个库中
(解决了单库大数量,高并发的性能瓶颈问题;提高了系统的稳定性和可用性)
路由规则- 根据id节点取模
- 按id也就是范围路由,节点1(1-100万),节点2(100万-200万)
- 水平分表:将一个库的数据拆分到多个表中(可以在同一个库内)
(优化单一表数据量过大而产生的性能问题;避免IO争抢并减少锁表的几率)
- 水平分库:将一个库的数据拆分到多个库中
分库后的问题:↓↓
- 分布式事务一致性问题
- 跨节点关联查询
- 跨节点分页、排序函数
- 主键避重
使用分库分表中间件
- sharding-sphere
- mycat
Spring框架中的单例bean是线程安全的吗?
不是线程安全的,是这样的
当多用户同时请求一个服务时,容器会给每一个请求分配一个线程,这是多个线程会并发执行该请求对应的业务逻辑(成员方法),如果该处理逻辑中有对该单列状态的修改(体现为该单例的成员属性),则必须考虑线程同步问题。
Spring框架并没有对单例bean进行任何多线程的封装处理。关于单例bean的线程安全和并发问题需要开发者自行去搞定。
比如:我们通常在项目中使用的Springbean都是不可可变的状态(比如Service类和DAO类),所以在某种程度上说Spring的单例bean是线程安全的。如果你的bean有多种状态的话(比如 View Model对象),就需要自行保证线程安全。最浅显的解决办法就是将多态bean的作用由“singleton”变更为“prototype”。
Spring框架中的bean是单例的
@Service @Scope("singleton") public class UserServiceImpl implements UserService{ }
- singleton:bean在每个Spring IOC容器中只有一个实例
- prototype:一个bean的定义可以有多个实例
Spring bean并没有可变的状态(比如Service类和DAO类), 所以在某种程度上说Spring的单例bean是线程安全的。但要尽可能的少创造可变参数比如count
@Controller @RequeestMapping("/user") public class UserController{ private int count; //成员方法需要考虑线程安全问题 @Autowired private UserService userService; @GetMapping("/getById/{id}") public User getById(@PathVariable("id") Integer id){ count++; sout(count); return userService.getById(id); } }
- 单例Bean就像共享单车:
- 整个小区(Spring容器)只有一辆共享单车(单例Bean),所有居民(线程)都要轮流骑这辆车。
- 如果只是骑车(调用无状态方法),不会出问题。
- 但如果有人在车筐里放东西(修改成员变量),下个人可能就会看到/改动这些东西。
- 什么时候安全?
- 比如Service、DAO这类Bean,它们通常只干活不记账(没有成员变量),就像只提供骑行服务的单车,很安全。
- 这也是为什么我们平时用@Autowired注入的Service不会出问题。
- 什么时候危险?
- 如果Bean里有个计数器count(就像你代码里的例子),多个线程同时”+1”就会乱套。
- 就像多个人同时往单车筐里放苹果,最后苹果数量肯定对不上。
- 怎么解决?
- 方法一:不记账 → 永远不在Bean里放成员变量(推荐)
- 方法二:用锁 → 像公共厕所那样,一个人用的时候锁门(加synchronized)
- 方法三:每人发一辆车 → 改用@Scope(“prototype”),每次请求都新建Bean(但浪费资源)
- 实际开发建议:
- 大多数情况下,Service/Dao写成单例完全没问题
- 遇到要记录状态的场景(比如计数器),要么改成prototype,要么把变量存在ThreadLocal里
- 绝对不要在Controller里定义成员变量!你代码里的count就是个典型反例
简单说:单例Bean本身不是线程安全的,但只要我们遵守”不用成员变量记事情”的原则,就能安全使用。就像共享单车,只要大家都不往车筐里放私人物品,就不会有问题。
什么是AOP,你们项目中有没有用到AOP?
AOP称为面向切面编程,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect),减少系统中的重复代码,降低了模块间的耦合度,同时提高了系统的可维护性。
常见AOP使用场景:
拒绝策略记录操作日志
nginx → 新增用户 → @Around(“pointcut()”) 环绕通知
缓存处理
Spring中内置的事务处理
Spring中的事务是如何实现的
Spring支持 编程式事务管理 和 声明式事务 管理两种方式。
- 编程式事务控制:需使用TransactionTemplate来进行实现,对业务代码有侵入性,项目中很少使用
- 声明式事务管理:声明式事务管理建立在AOP之上的。其本质是通过AOP功能,对方法前后进行拦截,将事务处理的功能编织到拦截的方法中,也就是在目标方法开始之前加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。
AOP(面向切面编程)可以理解为 “在不修改原有代码的情况下,给程序动态添加功能”。
生活中的例子:
- 假设你开了一家咖啡店,主要业务是 做咖啡(核心业务)。
- 但除了做咖啡,你还要 记录销售日志、检查权限、处理异常(如咖啡机坏了)等(横切关注点)。
- 如果用传统OOP(面向对象编程),你需要在每个做咖啡的方法里都写日志、权限检查代码,这样代码会变得臃肿且难以维护。
- 而AOP的做法是:把这些公共逻辑(如日志、权限)抽出来,做成一个“切面”,然后“织入”到需要的地方,不影响原有业务代码。
AOP的核心概念
- 切面(Aspect):封装横切逻辑的模块(比如日志、事务)。
- 连接点(Join Point):程序执行的点(如方法调用、异常抛出)。
- 通知(Advice):切面在连接点执行的动作(如方法执行前、后、异常时做什么)。
- 切点(Pointcut):定义哪些连接点会被切面影响(如“所有Service层的方法”)。
- 织入(Weaving):把切面应用到目标对象的过程(编译期、类加载期、运行时)。
Spring中事务失效的场景有哪些?
异常捕获处理,自己处理了异常,没有抛出,解决:手动抛出
抛出检查异常,配置rollbackFor属性为Exception
非public方法导致的事务失效,改为public
考察对spring框架的深入理解、复杂业务的编码经验
==异常捕获处理==【异常被try-catch吃掉】
原因:事务通知只有捉到了目标抛出的异常,才能进行后续的回滚处理,如果目标自己处理掉异常,事务通知无法知悉【Spring 的事务是基于 AOP 的,只有方法抛出异常,事务管理器才能感知并触发回滚;你在方法内部
try-catch了异常,但没有再往外抛,就会导致事务不能回滚】解决:在catch块添加throw new RuntimeException(“转账失败”) 抛出
==抛出检查异常==
原因:Spring 默认只对 非检查异常(RuntimeException 及其子类)、 进行回滚
@Transactional public void update(...) throw FileNotFoundException{ ... new FileInputStream("dddd") ... }解决:配置
rollbackFor属性@Transcational(rollbackFor=Exception.class)==非public方法==
Spring 的事务本质是基于 AOP 代理实现的,而 AOP 默认只对public方法生效。@Transcational(rollbackFor=Exception.class) void update(...) throw FileNotFoundException{ ... new FileInputStream("dddd") ... }原因:Spring为方法创建代理、添加事务通知、前提条件都是该方法是public的
解决:把方法改为public==同类内部调用,导致代理失效==
原因:Spring AOP 基于代理机制。如果类内部方法调用类内的另一个
@Transactional方法,实际上不会经过代理,事务不会生效。// ❌ 会失效 public void methodA() { methodB(); // 不经过代理 } @Transactional public void methodB() { // 无效 }
- 解决:
- 将方法调用抽出到另一个 bean 中;
- 或使用
AopContext.currentProxy()获取当前代理对象执行调用。
Spring的bean的生命周期?
Spring容器是如何管理和创建bean实例
方便调试和解决问题① 通过BeanDefinition获取bean的定义信息 [Spring 会将 XML 或注解配置的 Bean 信息封装成
BeanDefinition对象,用于描述 Bean 的元数据信息,如 class 类型、作用域、是否懒加载等]
② 调用构造函数实例化bean [通过构造函数或工厂方法创建 Bean 对象,还没进行依赖注入]
③ bean的依赖注入 [Spring 根据 BeanDefinition 中的配置信息,进行依赖注入,例如通过@Autowired、@Resource等注解注入其它 Bean]
④ 处理Aware接囗回调(BeanNameAware、BeanFactoryAware、ApplicationContextAware)
⑤ Bean的后置处理器BeanPostProcessor-前置
⑥ 初始化方法(InitializingBean、init-method)
⑦ Bean的后置处理器BeanPostProcessor-后置
⑧ 销毁bean
BeanDefinition
Spring容器在进行实例化时,会将xml配置的< bean >的信息封装成一个BeanDefinition对象,Spring根据BeanDefinition来创建Bean对象,里面有很多的属性来描述Bean
<bean id="userDao" class="com.itheima.dao.impl.UserDaolmpl" lazy-init="true"/><bean id="userService" class="com.itheima.service.UserServicelmpl" scope="singleton">
<property name="userDao" ref="userDao"></property>
</bean>

Spring中的循环引用?
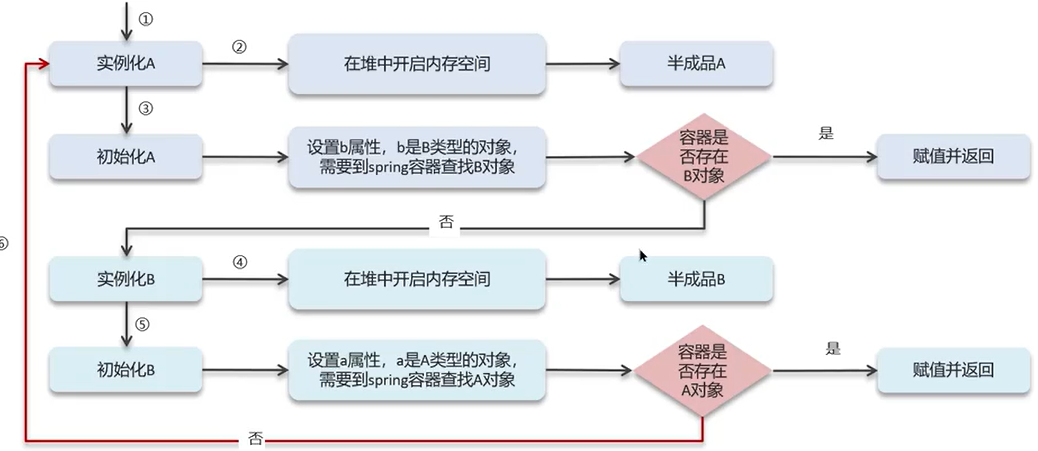
★ 循环依赖:循环依赖其实就是循环引用, 也就是两个或两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于A
★ 循环依赖在spring中是允许存在,spring框架**依据三级缓存已经解决了大部分的循环依赖**
☆ 一级缓存:单例池,缓存已经经历了完整的生命周期,已经初始化完成的bean对象
☆ 二级缓存:缓存早期的bean对象(生命周期还没走完)
☆ 三级缓存:缓存的是ObjectFactory,表示对象工厂,用来创建某个对象的✅ 处理流程简要说明:
- Spring 创建 A → A 依赖 B → 创建 B
- B 依赖 A,发现 A 还没完成创建
- Spring 把 A 的 半成品(early reference) 暴露到二级缓存,让 B 先注入用
- 最后 A 初始化完成,加入一级缓存
✅ 这样就解决了大多数基于 setter 注入 / 字段注入 的循环依赖问题。
构造方法出现了循环依赖怎么解决?
A依赖于B,B依赖于A,注入的方式是构造函数
原因:由于bean的生命周期中构造函数是第一个执行的,spring框架并不能解决构造函数的的依赖注入
解决方案:使用**@Lazy进行懒加载**,什么时候需要对象再进行bean对象的创建public A(@Lazy B b){
sout(“A的构造方法执行了”);
this.b=b;
}
@Component @Component
public class A{ → ← public class B{
@Autowired ↑ ↑ @Autowired
private B b; →↑ ↑← private A a;
} }🧠 三大缓存:
缓存级别 对应源码字段名 作用说明 一级缓存 singletonObjects已完全初始化的 Bean(生命周期完成),正式放入单例池 二级缓存 earlySingletonObjects暂时暴露的半成品 Bean 实例(未执行初始化方法) 三级缓存 singletonFactories存的是创建代理对象的 ObjectFactory,用于解决代理类循环依赖 Spring 把 A 的 半成品(early reference) 暴露到二级缓存,让 B 先注入用为啥要放到二级缓存 而不是一级呢?
✅ 答案核心:
因为此时 A 只是一个 尚未完成初始化的半成品对象,它还没有执行:
- 属性填充(依赖注入)
- Aware 接口回调
- 初始化方法(如
@PostConstruct、afterPropertiesSet())➡️ 这个 Bean 还不“完整”,不能放入正式的一级缓存!🔍 为什么不能直接放入一级缓存?
一级缓存是
singletonObjects,是 Spring 的“成品仓库”:
- 放入这个缓存意味着:
- Bean 已经完成生命周期(包括依赖注入、初始化)
- 可以被别人安全引用
但在处理循环依赖时,我们是中途打断流程,把未初始化完成的 Bean 暴露出来给另一个 Bean 注入(比如 A 注入给 B)
🔴 如果此时放入一级缓存,有两个风险:
- 状态不一致风险
其他 Bean 拿到这个未初始化完成的 Bean,会误以为它是“成品”,使用后可能报错或引发不一致。- 生命周期混乱
BeanPostProcessor、InitializingBean、@PostConstruct 等生命周期操作可能被跳过或错乱,严重破坏 Spring 的生命周期管理逻辑。✅ 二级缓存的作用正是:**”暴露早期引用”,但不当成成品!**
// 二级缓存 earlySingletonObjects:仅仅作为“抢先使用”的通道 this.earlySingletonObjects.put(beanName, earlyReference);它是 Spring 对“对象未完成但又必须提前使用”这个两难问题的妥协方案。✅ 最终完整的 Bean 放入一级缓存:
当整个 Bean 初始化完成(属性注入 + 初始化方法 + 后置处理器都执行完),才会放入一级缓存:
addSingleton(beanName, exposedObject); // 放入 singletonObjects
那按照你这样说 三级缓存又是干啥的?你问得非常到位!
✅ 我们已经知道:
- 一级缓存:成品 Bean 的正式仓库;
- 二级缓存:未初始化完成的“早期引用”,暴露给依赖它的 Bean 使用。
✅ 简明结论(先记住):
三级缓存的本质作用是:为了解决“代理对象”在循环依赖中的提前暴露问题。
🎯 三级缓存的角色是什么?
三级缓存存的是:
Map<String, ObjectFactory<?>> singletonFactories也就是说:它不是直接存 Bean 实例本身,而是存一个对象工厂 ObjectFactory,这个工厂可以在需要的时候返回一个 Bean(甚至是它的代理对象)。
🧠 为什么需要三级缓存?——解决AOP 代理对象的提前暴露
Spring 在三级缓存里放一个
ObjectFactory,用于 延迟构建代理对象等到别的 Bean(比如 B)需要注入 A 时,先从二级缓存找不到,就用三级缓存的
ObjectFactory.getObject()来构造这个 Bean,此时可以通过SmartInstantiationAwareBeanPostProcessor(比如 AOP 后置处理器)提前生成代理。
什么是Spring的循环依赖??
==一级缓存==作用:限制bean在beanFactory中只存一份,即实现singleton scope,解决不了循环依赖
如果想打破循环依赖,就需要一个中间人的参与,这个中间人就是==二级缓存==如果一个对象是代理对象(被增强了)就不行
针对如果是代理对象的话如何解决呢? → ==三级缓存==
那如果构造方法出现了循环依赖怎么解决?
@Component @Component
public class A{ → ← public class B{
private B b; ↑ ↑ private A a;
public A(B c){ →↑ ↑← public B(A c){
sout(“A的构造方法执行了”) sout(“B的构造方法执行了”)
this.b=b; this.b=b;
} }
} }报错信息:Is there an unresolvable circular reference?
解决:@Lazy延迟加载→什么时候需要对象的时候什么时候实例化对象public A(@Lazy B b){ sout("A的构造方法执行了"); this.b=b; }
Spring解决循环依赖是通过三级缓存
// 单实例对象注册器
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
private static final int SUPPRESSED EXCEPTIONS LIMIT= 100;
private final Map<String, Object>singletonObjects = new ConcurrentHashMap(256); 一级缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap(16); 三级缓存
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap(16); 二级缓存
}
| 缓存名称 | 源码名称 | 作用 |
|---|---|---|
| 一级缓存 | singletonObject | 单例池,缓存已经经历了完整的生命周期,已经初始化完成的bean对象 |
| 二级缓存 | earlySingletonObjects | 缓存早期的bean对象(生命周期还没走完) |
| 三级缓存 | singletonFactories | 缓存的是ObjectFactory,表示对象工厂,用来创建某个对象的 |
SpringMVC的执行流程知道吗?
- 视图阶段(老旧JSP等)
- 前后端分离阶段(接口开发,异步)
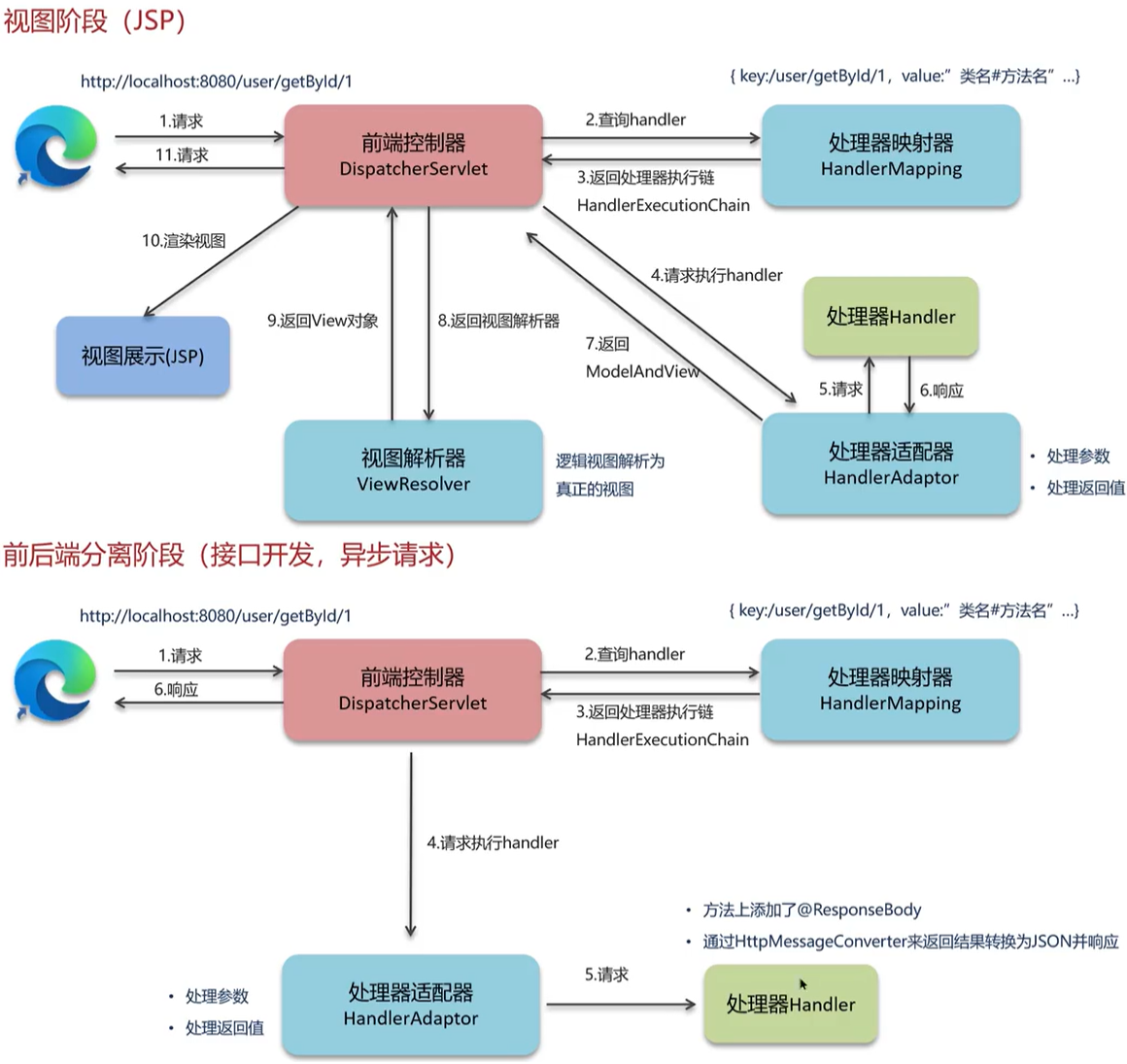
==视图阶段(jsp)==
- 用户发送出请求到前端控制器DispatcherServlet
- DispatcherServlet收到请求调用HandlerMapping(处理器映射器)
- HandlerMapping找到具体的处理器,生成处理器对象及处理器拦截器(如果有)
- DispatcherServlet调用HandlerAdapter(处理器适配器)HandlerAdapter经过适配调用具体的处理器(Handler/Controller)Controller执行完成返回
- ModelAndView对象HandlerAdapter将Controller执行结果ModelAndView返回给DispatcherServlet
- DispatcherServlet将ModelAndView传给ViewReslover(视图解析器)
- ViewReslover解析后返回具体View(视图)
- DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)
- DispatcherServlet响应用户
==前后端分离阶段(接口开发,异步请求)==
- 用户发送出请求到前端控制器DispatcherServlet
- DispatcherServlet收到请求调用HandlerMapping(处理器映射器)
- HandlerMapping找到具体的处理器,生成处理器对象及处理器拦截器(如果有),再一起返回给DispatcherServlet
- DispatcherServlet调用HandlerAdapter(处理器适配器)
- HandlerAdapter经过适配调用具体的处理器(Handler/Controller)
✅ 一、SpringMVC 是什么?
SpringMVC 是基于Servlet 的原生请求处理模型封装的一套 MVC Web 框架,它通过 DispatcherServlet 实现请求分发,解耦了控制器、视图解析器等组件之间的关系。
🚀 1. 用户发起请求
浏览器访问一个 URL,例如:
http://localhost:8080/user/list,请求会先到达 前端控制器 DispatcherServlet。
🔄 2. DispatcherServlet 接收到请求
DispatcherServlet 是 SpringMVC 的核心入口,用于请求分发和生命周期管理。
🔎 3. 查找 HandlerMapping(处理器映射器)
- DispatcherServlet 调用 HandlerMapping 来查找当前请求所匹配的 Handler(Controller 方法);
- 会封装成
HandlerExecutionChain,里面包含目标处理器和拦截器链。
⚙️ 4. 调用 HandlerAdapter(处理器适配器)
SpringMVC 不直接调用 Handler,而是交给 HandlerAdapter 来统一调用逻辑(比如支持 @RequestMapping/@RestController 方法)。
🧠 5. 执行 Handler(也就是 Controller 方法)
通过适配器调用具体的 Controller 中的业务处理方法,如:
java复制代码@GetMapping("/user/list") public List<User> list() { return userService.findAll(); }
📦 6. 返回 ModelAndView(传统视图模式)或 @ResponseBody 数据(前后端分离)
- 传统 MVC 场景下,Controller 返回一个
ModelAndView;- 如果是前后端分离,通常会返回 JSON 数据,经过
HttpMessageConverter处理后直接写入响应体。
🪞 7. 调用 ViewResolver(视图解析器)【视图模式专属】
- 如果返回的是视图名(如 “userList”),SpringMVC 会调用 ViewResolver 解析为具体的 JSP 或 Thymeleaf 模板。
🎨 8. 渲染视图 View(视图模式专属)
- 将模型数据(Model)填充进视图模板,生成 HTML 页面。
📤 9. DispatcherServlet 返回响应给浏览器
- 前后端分离下是 JSON 响应;
- 传统模式下是完整渲染后的 HTML。
[用户请求] ↓ DispatcherServlet ↓ HandlerMapping → 找到 Handler + 拦截器链 ↓ HandlerAdapter → 统一执行 Handler ↓ Controller → 执行业务逻辑 ↓ 返回 ModelAndView / JSON ↓ (传统)ViewResolver → 找视图模板 ↓ 渲染视图 / 写入 JSON 响应体 ↓ DispatcherServlet 响应浏览器✅ 四、不同开发阶段下的区别
阶段 返回值 是否走视图解析器 常见注解 JSP 阶段 ModelAndView ✅ 是 @Controller前后端分离 JSON 数据 ❌ 否 @RestController+@ResponseBody🎯 五、总结金句(可背):
SpringMVC 核心就是一个请求经过 DispatcherServlet,根据 HandlerMapping 找到处理器,由 HandlerAdapter 调用 Controller 执行逻辑,最终通过视图解析或消息转换,返回结果给客户端。
SpringBoot自动配置原理?
@SpringBootApplication =
@SpringBootConfiguration +
@EnableAutoConfiguration +
@ComponentScan
SpringBoot中最高频的一道面试题,也是框架最核心的思想
==@SpringBootConfiguration==:该注解与 @Configuration 注解作用相同,用来声明当前也是一个配置类
==@EnableAutoConfiguration==:SpringBoot实现自动化配置的核心注解,通过配置选择器导入自动配置类
==@ComponentScan==:组件扫描,默认扫描当前引导类所在包及其子包1,在Spring Boot项目中的引导类上有一个注解
@SpringBootApplication,这个注解是对三个注解进行了封装,分别是:
@SpringBootConfiquration@EnableAutoConfiquration@ComponentScan2,其中
@EnableAutoConfiguration是实现自动化配置的核心注解。该注解通过@Import注解导入对应的配置选择器。内部就是读取了该项目和该项目引用的jar包的classpath路径下META-INF/spring.factories文件中的所配置的类的全类名。在这些配置类中所定义的Bean会根据条件注解所指定的条件来决定是否需要将其导入到Spring容器中。3,条件判断会有像
@ConditionalOnClass这样的注解,判断是否有对应的class文件,如果有则加载该类,把这个配置类的所有的Bean放入spring容器中使用。
package com.itheima;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
// SpringBoot的启动类
// 注意: 我们写的代码要在启动类的包或者子包中
// @SpringBootApplication注解中包含了 @ComponentScan,没有指定扫描哪个包,默认扫描当前类所在的包和子包
@SpringBootApplication
public class Day15TliasManagement01IocDiApplication {
// 启动项目, 内嵌的Tomcat会启动, 把项目部署到这个内嵌Tomcat中
public static void main(String[] args) {
SpringApplication.run(Day15TliasManagement01IocDiApplication.class, args);
}
}
按住
ctrl+左键点击@SpringBootApplication会弹到SpringBootApplication.class界面
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(
excludeFilters = {@Filter(
type = FilterType.CUSTOM,
classes = {TypeExcludeFilter.class}
), @Filter(
type = FilterType.CUSTOM,
classes = {AutoConfigurationExcludeFilter.class}
)}
)
按住
ctrl+左键点击@EnableAutoConfiguration会弹到EnableAutoConfiguration.class界面
# @Import({AutoConfigurationImportSelector.class})
# AutoConfigurationImportSelector是自动配置的选择器
# 会加载META-INF中的spring.factories文件的自动配置类...AutoConfiguration...
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.springframework.boot.autoconfigure;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import org.springframework.context.annotation.Import;
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage
@Import({AutoConfigurationImportSelector.class})
public @interface EnableAutoConfiguration {
String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
Class<?>[] exclude() default {};
String[] excludeName() default {};
}
Spring框架常见的注解有哪些?
| 注解 | 说明 |
|---|---|
| @Component、@Controller、@Service、@Repository | 使用在类上用于实例化Bean |
| @Autowired | 使用在字段上用于根据类型依赖注入 |
| @Qualifier | 结合@Autowired一起使用用于根据名称进行依赖注入 |
| @Scope | 标注Bean的作用范围 |
| @Configuration | 指定当前类是一个Spring配置类,当创建容器时会从该类上加载注解 |
| @ComponentScan | 用于指定Spring在初始化容器时要扫描的包 |
| @Bean | 使用在方法上,标注将该方法的返回值存储到Spring容器中 |
| @Import | 使用@Import导入的类会被Spring加载到IOC容器中 |
| @Aspect、@Before、@After、@Around、@Pointcut | 用于切面编程(AOP) |
SpringMVC框架常见的注解有哪些?
| 注解 | 说明 |
|---|---|
| @RequestMapping | 用于映射请求路径,可以定义在类上和方法上。用于类上,则标识类中的所有的方法都是以该地址作为父路径 |
| @RequestBody | 注解实现接收http请求的json数据,将json转换为java对象 |
| @RequestParam | 指定请求参数的名称 |
| @PathViriable | 从请求路径中获取请求参数(/user/{id}),传递给方法的形式参数 |
| @ResponseBody | 注解实现将Controller方法返回对象转换成json对象响应给客户端 |
| @RequestHeader | 获取指定的请求头数据 |
| @RestController | @Controller + @RequestBody |
SpringBoot常见的注解有哪些?
| 注解 | 说明 |
|---|---|
| @SpringBootConfiguration | 组合了 -@Configuration注解,实现配置文件的功能 |
| @EnableAutoConfiguration | 打开自动配置的功能,也可以关闭某个自动配置的选项 |
| @ComponentScan | Spring组件扫描 |

MyBatis执行流程?
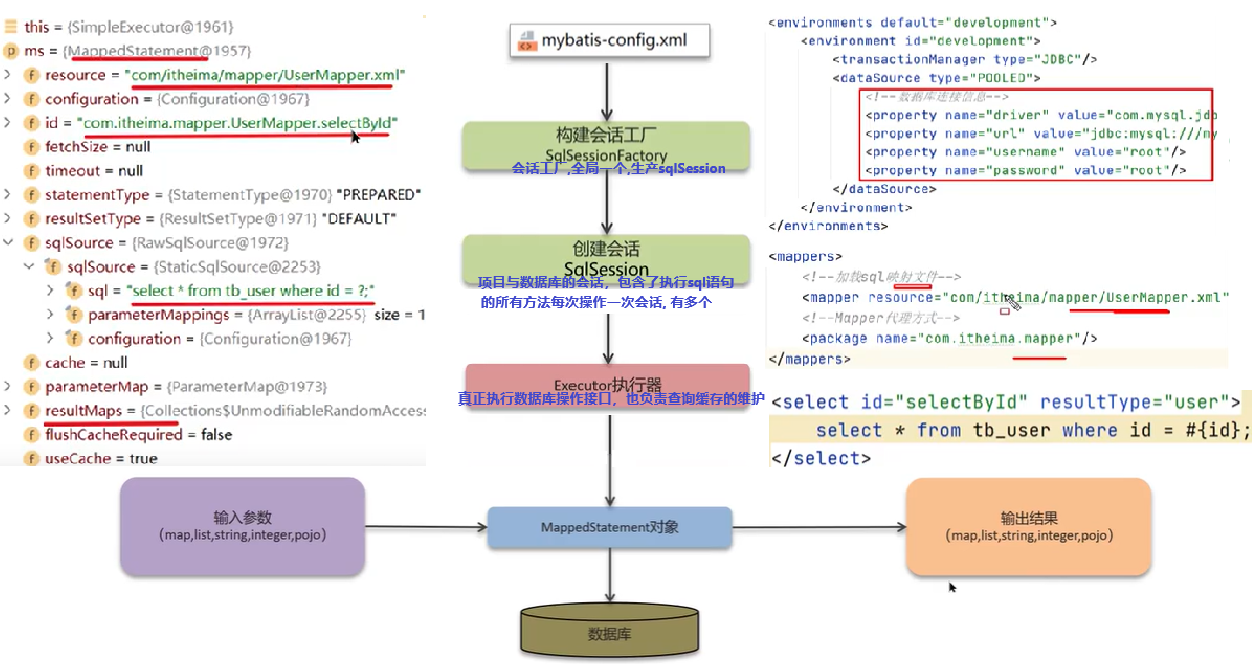
- 读取MyBatis配置文件:mybatis-config.xml加载运行环境和映射文件
- 构造会话工厂SqlSessionFactory
- 会话工厂创建SqlSession对象(包含了执行SQL语句的所有方法)
- 操作数据库的接口,Executor执行器,同时负责查询缓存的维护
- Executor接口的执行方法中有一个MappedStatement类型的参数,封装了映射信息
- 输入参数映射
- 输出结果映射
执行流程从读取配置文件、创建 SqlSession、查找 MappedStatement、参数映射、执行 SQL 到结果映射,每个环节都有对应的组件协作完成。
- 理解了各个组件的关系
- Sql的执行过程(参数映射、sql解析、执行和结果处理)
MyBatis是否支持延迟加载?
- 延迟加载的意思是:就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据。
- Mybatis支持一对一关联对象和一对多关联集合对象的延迟加载
- 在
Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true/false,默认是关闭的<settings> <setting name="lazyLoadingEnabled" value="true"/> <setting name="aggressiveLazyLoading" value="false"/> </settings>延迟加载(懒加载):查询主对象时不立即加载关联对象,而是在访问关联属性时再去执行查询语句加载数据。
查询User时不查Order,只有调用user.getOrders()时,才执行select * from order where user_id = ?
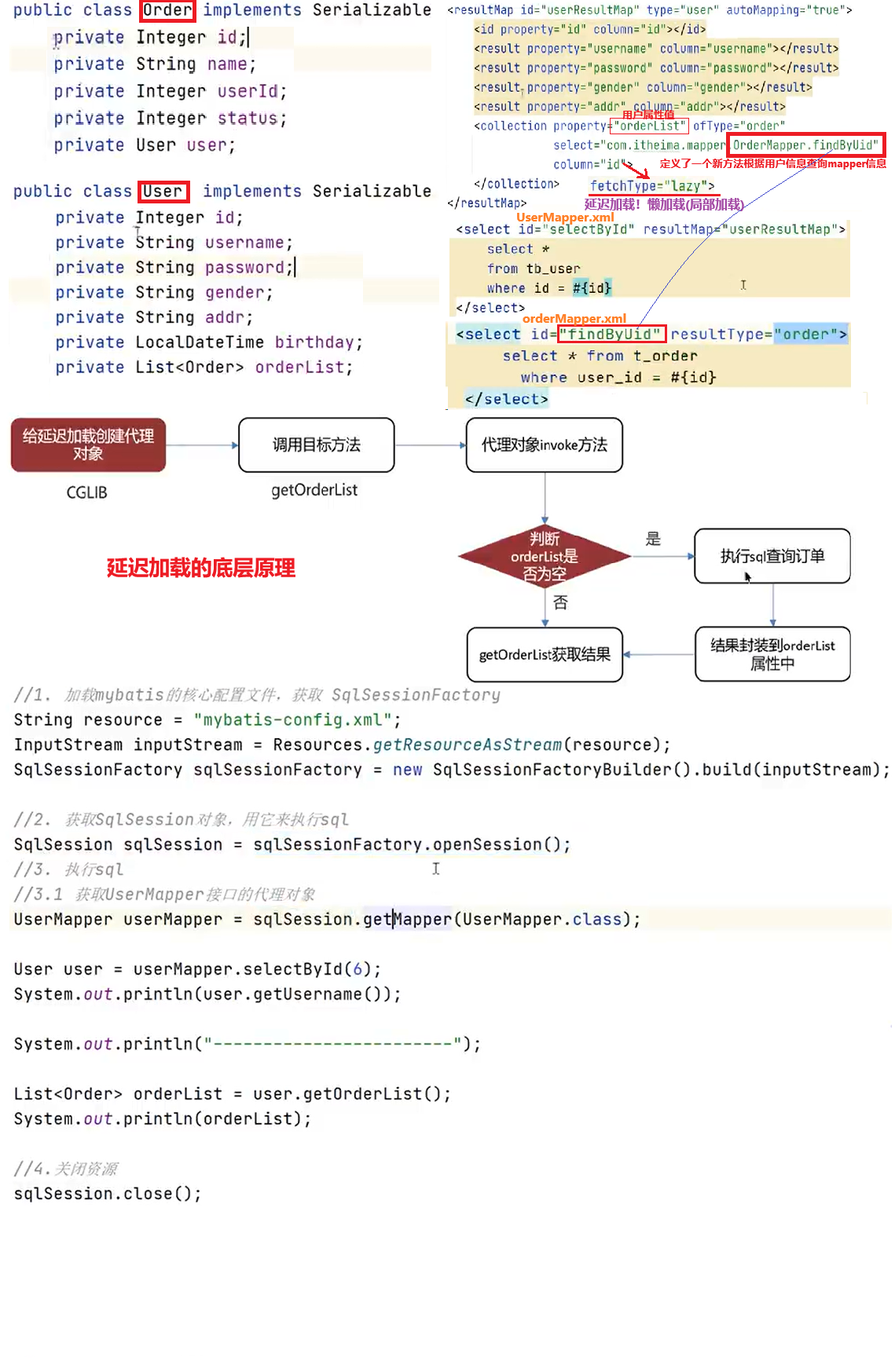
延迟加载的底层原理知道吗?
MyBatis 延迟加载的核心是代理模式 + 拦截器机制,底层主要通过 CGLIB 创建目标对象的代理对象
- 使用CGLIB创建目标对象的代理对象
- 当调用目标方法时,进入拦截器invoke方法,发现目标方法是nul值,执行sql查询
- 获取数据以后,调用set方法设置属性值,再继续查询目标方法,就有值了
查询用户的时候,把用户所属的订单数据也查询出来,这个是==立即加载==
查询**用户的(sql)时候,暂时不查询订单数据,当需要订单的时候,再查询订单(sql)**,这个就是==延迟加载==执行流程 👇
- 查询主对象时,不会立即查关联对象,而是用 CGLIB 创建一个代理对象(继承目标类)
- 当访问关联属性时,进入代理类的
intercept方法(拦截器)- 拦截器判断属性是否已加载:
- 没加载 → 执行对应的 SQL(如
selectOrdersForUser)- 查出结果后 → 通过
setXxx()方法注入属性值- 属性值设置好之后,后续访问就是直接取值,不再触发数据库查询
延迟加载的实现步骤:
- 配置开启延迟加载: 在MyBatis的配置文件中(通常是
mybatis-config.xml),需要设置两个属性:
lazyLoadingEnabled=true:开启延迟加载。aggressiveLazyLoading=false:关闭积极的延迟加载,即访问对象的时候不会立即加载其所有属性。- 映射文件配置: 在对应的Mapper映射文件中,对于需要延迟加载的关联查询,使用
select标签定义延迟加载的SQL语句,并通过fetchType="lazy"属性明确指定使用延迟加载。- 创建代理对象: 当执行查询操作时,MyBatis不会立即执行关联查询的SQL,而是返回一个代理对象。这个代理对象是使用CGLIB库创建的,它继承自目标对象。
- 拦截器方法调用: 当我们首次访问这个代理对象的某个方法(比如访问订单详情)时,实际上会调用CGLIB生成的代理对象的拦截器方法(
intercept方法)。在拦截器方法中,会判断当前要访问的属性是否已经被加载:
- 如果属性已经被加载,则直接返回属性值。
- 如果属性未被加载,则会执行之前定义好的延迟加载SQL语句,从数据库中查询数据。
- 设置属性值: 查询得到数据后,MyBatis会将这些数据设置到目标对象的相应属性上,这样下次访问该属性时,就不需要再次查询数据库了。
底层原理:
- CGLIB代理:MyBatis使用CGLIB库创建目标对象的代理,当调用目标方法时,实际上会进入拦截器(Interceptor)的
intercept方法。- 拦截器逻辑:在拦截器中,会判断当前调用的方法是否需要触发延迟加载。如果需要,则执行延迟加载的SQL查询。
- 结果处理:查询结果会被处理并设置到目标对象的属性上,这样目标对象的相关属性就持有了数据,后续访问将直接返回这些数据,而无需再次查询。
MyBatis在执行完延迟加载的SQL查询后,会获取查询结果,并将这些结果映射到目标对象的相应属性中示例说明:
假设有一个用户
User和订单Order的关系,在查询用户时,通常不会立即加载其订单信息,而是当需要时再加载。以下是简化的代码示例:<!-- UserMapper.xml --> <resultMap id="userMap" type="User"> <id property="id" column="id"/> <result property="name" column="name"/> <!-- 延迟加载订单信息 --> <collection property="orders" column="id" ofType="Order" select="selectOrdersForUser" fetchType="lazy"/> </resultMap> <select id="selectUser" resultMap="userMap"> SELECT * FROM user WHERE id = #{id} </select> <select id="selectOrdersForUser" resultType="Order"> SELECT * FROM order WHERE user_id = #{id} </select>在上述配置中,当调用
selectUser查询用户信息时,不会立即查询订单信息。只有当程序中访问User对象的orders属性时,才会执行selectOrdersForUser查询,这就是延迟加载的具体实现。
MyBatis的一级、二级缓存用过吗?
- 一级缓存:基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当Session进行flush或close之后,该Session中的所有Cache就将清空,默认打开一级缓存
- 二级缓存是基于namespace和mapper的作用域起作用的,不是依赖于SQLsession,默认也是采用PerpetualCache,HashMap 存储。需要单独开启,一个是核心配置,一个是mapper映射文件
MyBatis的二级缓存什么时候会清理缓存中的数据?
- 当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了新增、修改、删除操作后,默认该作用域下所有 select 中的缓存将被 clear。
- 本地缓存,基于PerpetualCache,本质是一个HashMap
- 一级缓存:作用域是session级别
- 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当Session进行flush或close之后,该Session中的所有Cache就将清空,默认打开一级缓存
- 二级缓存:作用域是namespace和mapper的作用域,不依赖于session
- 二级缓存是基于namespace和mapper的作用域起作用的,不是依赖于SQLsession,默认也是采用 PerpetualCache
HashMap 存储
- 二级缓存是基于namespace和mapper的作用域起作用的,不是依赖于SQLsession,默认也是采用 PerpetualCache

注意事项
- 对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了新增、修改、删除操作后,默认该作用域下所有 select 中的缓存将被 clear
- 二级缓存需要缓存的数据实现Serializable接口
- 只有会话提交或者关闭以后,一级缓存中的数据才会转移到二级缓存中
SpringCloud篇
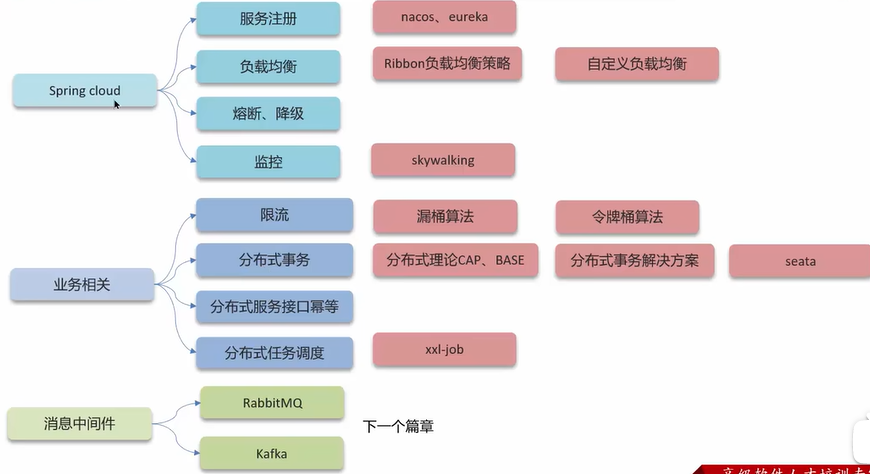
SpringCloud 5大组件有哪些?
回答原则:简单的问题不能答错
| 通常情况 | SpringCloudAlibba |
|---|---|
| Eureka:注册中心 | Nacos:注册中心/配置中心 |
| Ribbon:负载均衡 | Ribbon:负载均衡 |
| Feign:远程调用 | Feign:远程调用 |
| Hystrix:服务熔断 | sentinel:服务保护 |
| Zuul/Gateway:网关 | Gateway:服务网关 |
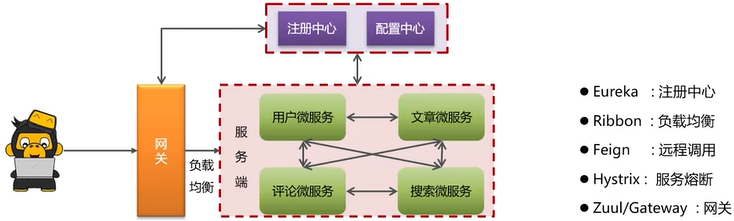
服务注册和发现是什么意思? SpringCloud 如何实现服务注册发现?
- 我们当时项目采用的
eureka作为注册中心,这个也是SpringCloud体系的一个核心组件- 服务注册:服务提供者需要把自己的信息注册到eureka来保存这些信息,比如**服务名称、ip、端口**等等
- 服务发现:消费者向eureka拉取服务列表信息,如果服务提供者有集群,则消费者利用负载均衡算法,选择一个发起调用
- 服务监控:服务提供者会每隔30秒向eureka发送心跳,报告健康状态,如果eureka服务90秒没有收到心跳,从eureka中剔除
- 微服务中必须要使用的组件,考虑我们使用微服务的程度
- 注册中心的核心作用是:服务注册和发现
- 常见的注册中心:eureka、nocas、zookeeper
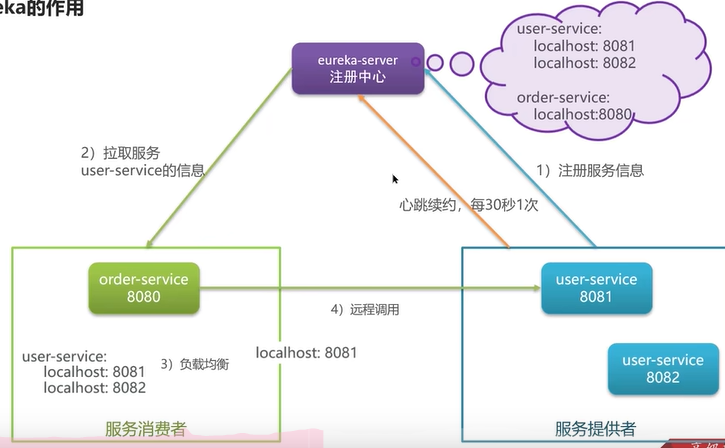
请你说一下nacos与eureka的区别?
- Nacos与Eureka的共同点 (注册中心)
- 都支持服务注册和服务拉取
- 都支持服务者心跳方式做健康检测
- Nacos与Eureka的区别 (注册中心)
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
- 临时实例心跳不正常会被剔除,非临时实例则不会被提出
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos集群默认采用AP方式
高可用模式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式- Nacos还支持了配置中心,Eureka只有注册中心,也是选择选用nacos的一个重要原因
把RestTemplate替换成OpenFeign后它们的底层还是一样的吗?OpenFeign是远程调用
OpenFeign的底层原理也是根据服务名称,首先去远程注册中心拉取服务列表,底层也会在本地缓存一份,也会根据负载均衡选出一个实例,又运用了jdk的动态代理生成代理类,也会涉及到反射机制,最终拼出完整的url,发起http远程调用
@FeignClient(name = "service-provider")
public interface ServiceProviderClient {
// 定义接口方法,映射到服务提供者的具体API
@GetMapping("/api/resource")
String getResource();
}
✅ 一、使用方式不同
RestTemplate 是显式调用(自己写 URL,拼参数)
restTemplate.getForObject("http://user-service/user/1", String.class);OpenFeign 是声明式调用(只写接口 + 注解,SpringBoot自动帮你拼URL发请求)
@FeignClient("user-service") public interface UserClient { @GetMapping("/user/{id}") String getUser(@PathVariable("id") Long id); }
✅ 二、底层原理差不多,但实现机制不同
对比点 RestTemplate OpenFeign 发起方式 手动构造 URL + 参数 注解接口 + 动态代理自动拼 URL 底层通信方式 HttpClient / OKHttp / JDK Http 同样也是基于 HttpClient 或 OKHttp 注册中心拉取服务 可搭配 Ribbon 手动实现服务发现 默认集成 Spring Cloud LoadBalancer 自动发现服务 负载均衡 手动配置 Ribbon 或 LoadBalancer 自动内置 LoadBalancer,基于服务名均衡选择 动态代理 无 有,基于 JDK 动态代理生成接口实现类 扩展能力 灵活性高,配置复杂 扩展性强,统一规范,支持熔断/重试/拦截器等 ✅ 三、OpenFeign 更高级,集成更好
OpenFeign 是对 RestTemplate 的一层封装 + 声明式远程调用:
- 内置了服务注册发现(Eureka/Nacos)
- 内置了负载均衡(Ribbon / Spring Cloud LoadBalancer)
- 可配合 Hystrix / Sentinel 实现熔断降级
- 支持拦截器、日志、重试、压缩等功能
- 统一异常处理、超时配置更方便
✅ 四、结论一句话总结:
虽然最终底层都是通过 HTTP 客户端发起请求(如 OkHttp / HttpClient),但 OpenFeign 是基于动态代理+注解的声明式封装,实现了更强大的远程调用能力和集成能力,远比 RestTemplate 更高级、更易维护。
如果面试官继续追问:“你们项目是怎么替换的?”,你可以说:
我们之前用 RestTemplate 是在业务代码里拼 URL,很冗余。后来统一封装为 OpenFeign,只保留接口定义,调用方更清晰,服务注册与发现、负载均衡也变成自动处理,配合 Sentinel 做了服务熔断与限流,提升了整体的系统健壮性。
怎么个自动处理法?
默认情况下 —— OpenFeign 自动处理
✅ 默认配置时:
- 服务注册与发现:依赖 Nacos / Eureka 等注册中心,OpenFeign 会根据服务名自动从注册中心拉取可用实例。
- 负载均衡:默认通过 Spring Cloud LoadBalancer(以前是 Ribbon)对服务列表进行轮询或权重等策略选择一个实例。
- HTTP请求:通过
HttpClient/OkHttp等客户端执行。你只写:
@FeignClient("user-service") public interface UserClient { @GetMapping("/user/{id}") User getUser(@PathVariable("id") Long id); }OpenFeign 会自动做:
- 拉取
user-service的服务列表- 选出一个实例(负载均衡)
- 拼接 URL 发起 HTTP 请求
🧠 一、什么叫“选出一个实例”?
在 微服务架构 中,一个服务往往会 部署多个实例 来应对高并发或容灾,例如:
服务名 实例地址 user-service 10.0.0.1:8080 user-service 10.0.0.2:8080 user-service 10.0.0.3:8080 当你通过 OpenFeign 发送请求:
@FeignClient("user-service") User getUser(...);你只写了一个服务名
user-service,但后台其实有多个实例,必须从这些实例中选出一个具体地址来发请求,比如选中10.0.0.2:8080。
⚖️ 二、这就是负载均衡要干的事!
✅ 负载均衡做的事:
就是 从多个可用实例中选择一个。
✅ 为什么要选?不选行不行?
如果不做选择,就不知道到底该请求哪个服务器,容易:
- 总是访问同一个实例 → 某一个实例过载
- 有的实例空闲,有的压力大 → 资源利用不均衡
- 某些实例宕机,没人检测 → 请求失败
✅ 所以负载均衡的作用是:
- 分摊压力:让不同请求打到不同实例,防止某一个服务器崩掉
- 提高可用性:某个实例挂了,下一次选择其他实例,系统还能继续用
- 自动切换:负载均衡组件还能感知服务状态变化,动态更新可用实例列表
🧮 三、OpenFeign 背后使用了什么做负载均衡?
在 Spring Cloud 中,OpenFeign 默认集成了:
✅ Spring Cloud LoadBalancer(或老版 Ribbon)
它的核心就是在每次请求前调用:
choose("user-service")然后根据你配置的策略,比如:
- 轮询(RoundRobin)👉 按顺序一个一个来
- 随机(Random)👉 随机挑一个
- 最少连接数(LeastConnections)
- 权重(Weighted)
最终得到一个实例,例如
10.0.0.2:8080,然后拼接成最终 URL:http://10.0.0.2:8080/api/user/1再发起 HTTP 请求。
🎯 总结一句话:
OpenFeign 中的“选出一个实例”就是 从多个服务实例中选择一个合适的来发送请求的过程,这个选择过程就是“负载均衡”负责的。它的目标是为了 提升性能、避免单点压力、实现高可用。
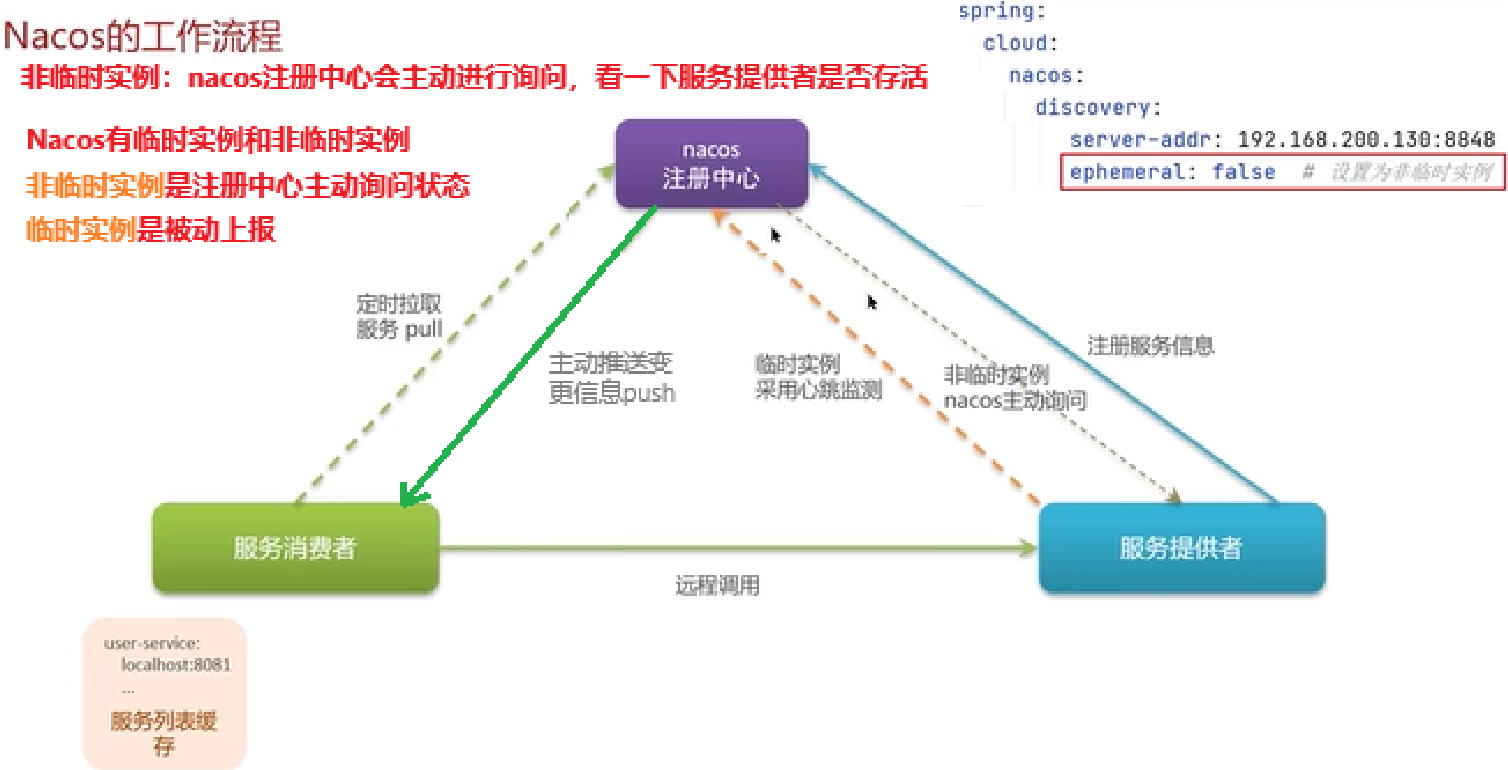
你们项目负载均衡如何实现的?图1.1
微服务的负载均衡主要使用了一个组件Ribbon,比如,我们再使用feign远程调用的过程中,底层的负载均衡就是使用了Ribbon 【与RestTemplate不同,OpenFeign默认是LoadBalancer】
- 负载均衡Ribbon,发起远程调用feign就会使用Ribbon
- Ribbon负载均衡策略有哪些?
- 如果想自定义负载均衡策略如何实现?
Ribbon已经进入维护模式,Netflix不再积极开发新功能。而Spring Cloud LoadBalancer作为替代,不仅提供了Ribbon的核心功能,还引入了一些新特性和改进
Ribbon负载均衡策略有哪些?简单、权重、随机、区域
- RoundRobinRule:简单轮询服务列表来选择服务器
- WeightedResponseTimeRule:按照权重来选择服务器,响应时间越长,权重越小
- RandomRule:随机选择一个可用的服务器
- BestAvaliableRule:忽略那些短路的服务器,并选择并发数较低的服务器
- RetryRule:重试机制的选择逻辑
- AvaliabilityFilteringRule:可用性敏感策略,先过滤非健康的,再选择连接数较小的实例
- ZoneAvoidanceRule:以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可用理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询
✅ Ribbon 常见负载均衡策略一览
策略名 简介 核心逻辑 适用场景 RoundRobinRule 轮询策略 依次选择服务列表中的每个实例,循环使用 简单、适用于服务性能相当、请求量均匀的场景 RandomRule 随机策略 随机选一个可用实例 测试环境、低并发系统或对分布无要求的场景 WeightedResponseTimeRule 权重 + 响应时间 根据服务实例响应时间动态调整权重,响应快的被选中几率高 适用于实例性能差异明显,希望高性能实例被优先选中 RetryRule 带重试机制的轮询 每次选择失败后会在一段时间内重试其他实例(默认使用 RoundRobinRule) 适用于请求容错性强、临时性网络波动频繁的情况 BestAvailableRule 最少并发策略 忽略短路(熔断)的实例,选择并发数最少的可用实例 适用于高并发下控制服务压力 AvailabilityFilteringRule 可用性过滤策略 过滤掉连接失败次数多的和并发高的实例,避免访问不健康服务 适用于系统对可用性要求高、网络波动大的场景 ZoneAvoidanceRule(默认) 区域感知策略 综合评估 zone(区域)内实例的可用性和负载(Zone可以理解为机房或机架),选出最优 zone 再轮询选择服务 适用于跨机房、跨地域部署,希望优先选择本地/低延迟实例的系统 📌 补充小Tips
- Spring Cloud 2020 后 Ribbon 官方不再维护,推荐用 Spring Cloud LoadBalancer 替代,但思想类似。
- 如果你项目还用 Ribbon,推荐配合 Hystrix 或 Sentinel 做服务熔断和限流。
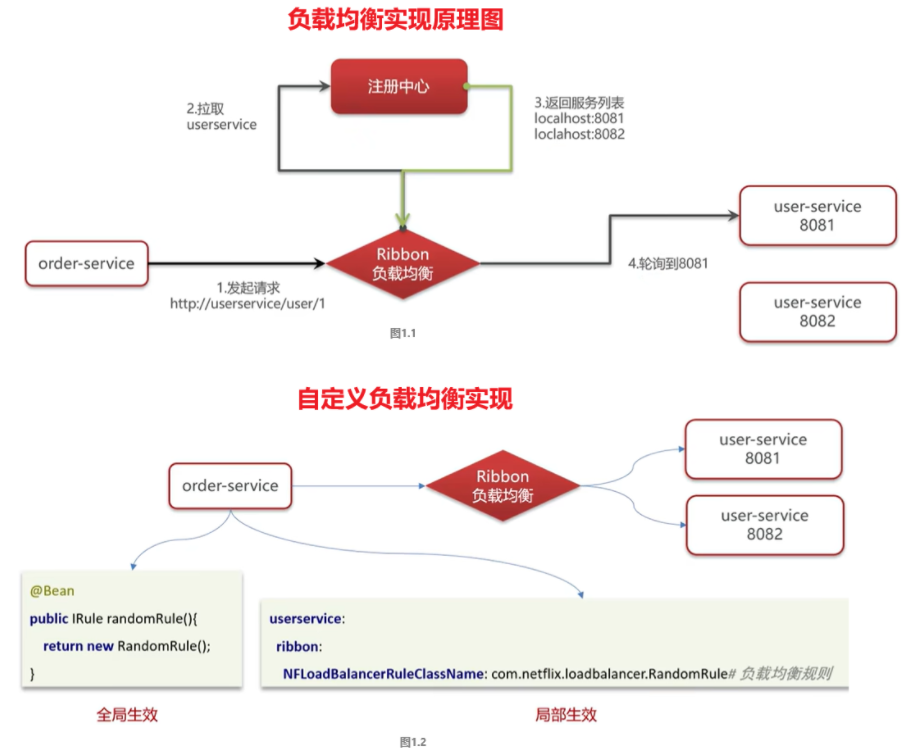
如果想自定义负载均衡策略如何实现?图1.2
- 创建类实现IRule接口,可以指定负载均衡策略(全局)
- 在客户端的配置文件中,可以配置某一个服务调用的负载均衡(局部)
首先,你需要创建一个类来实现
IRule接口,这样就能自定义负载均衡的策略。
实现 IRule 接口:import com.netflix.loadbalancer.IRule; import com.netflix.loadbalancer.Server; import com.netflix.loadbalancer.ZoneAwareLoadBalancer; import com.netflix.loadbalancer.RandomRule; import java.util.List; public class CustomLoadBalancerRule implements IRule { private IRule delegate = new RandomRule(); // 默认策略 @Override public Server choose(Object key) { // 在这里实现自己的负载均衡算法 // 比如,你可以使用 RoundRobin、Random 或者基于健康检查的策略 return delegate.choose(key); } @Override public void setLoadBalancer(ZoneAwareLoadBalancer<?> lb) { delegate.setLoadBalancer(lb); } @Override public ZoneAwareLoadBalancer<?> getLoadBalancer() { return delegate.getLoadBalancer(); } }然后,你需要在 Spring 配置类或者启动类上注入该自定义的负载均衡策略。
配置 Bean 注册到容器(全局策略):import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class RibbonConfig { @Bean public IRule customLoadBalancerRule() { return new CustomLoadBalancerRule(); } }
SpringCloud中什么是服务雪崩,怎么解决这个问题?
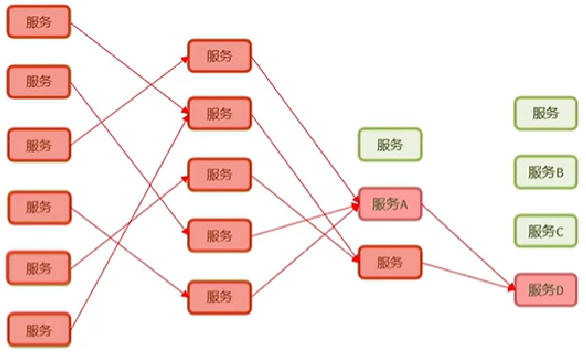
- 什么是==服务雪崩==?
一个服务失败,导致整条链路的服务都失败的情形
- 服务雪崩:当某个服务因为故障不可用,导致依赖它的上游服务纷纷失败,进而整个系统连锁崩溃的现象
- 常发生在服务调用链路较长时
- 一个服务挂了,所有调用它的服务都会超时挂起,线程资源被耗尽,最终整个系统瘫痪
📌 通俗比喻:你访问淘宝商品详情页面 → 商品服务依赖库存服务 → 库存服务挂了 → 商品服务一直卡着等 → 网页加载失败 → 淘宝崩了
- ==熔断降级== && ==服务熔断==(解决)Hystix 服务熔断降级
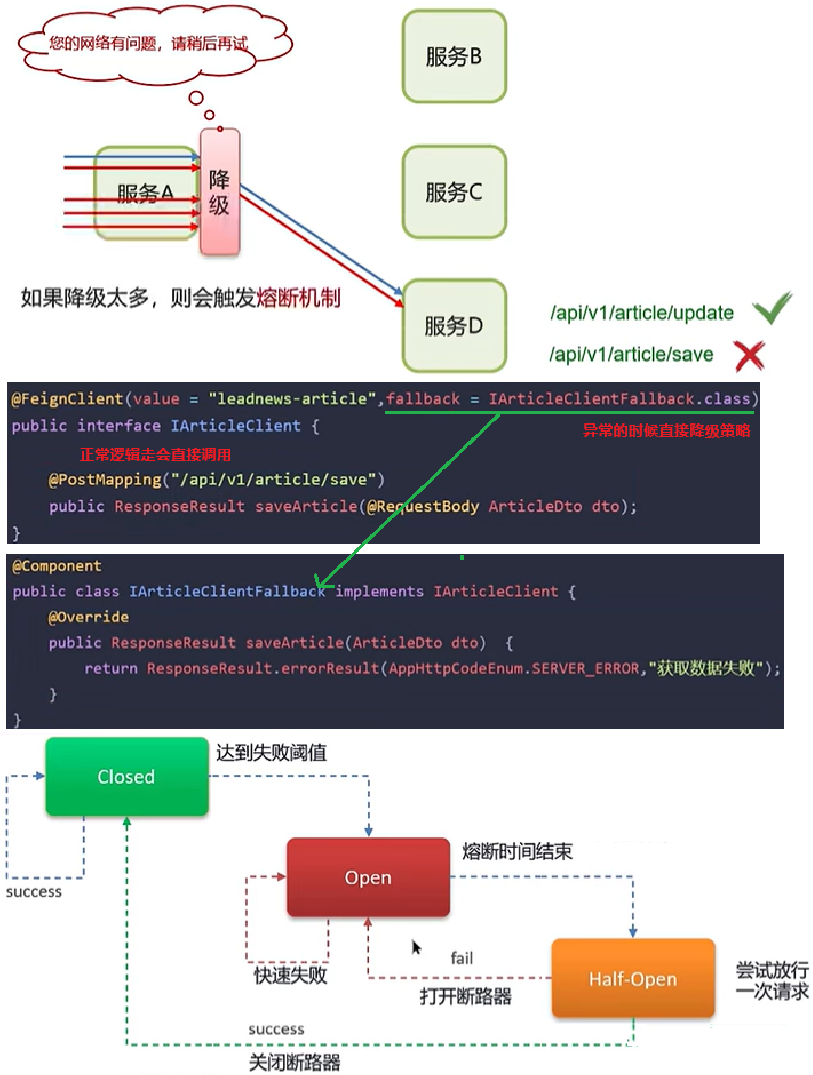
服务降级
部分服务不可用:服务自我保护的一种方式,或者保护下游服务的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不会崩溃,一般在实际开发中与Feign接口整合,编写降级逻辑 (某个服务挂了或响应慢,不让请求卡住,而是返回预设的“备胎数据”,用户体验不会很差)
服务熔断
整个服务不可用:默认关闭,需要手动打开,如果监测到10秒内请求的失败率超过50%,就触发熔断机制。之后每隔5秒重新尝试请求微服务,如果微服务不能响应,继续走熔断机制。如果微服务可达,则关闭熔断机制,恢复正常请求
限流(预防)
微服务限流(漏桶算法、令牌桶算法)限制单位时间的请求数,避免流量洪峰打垮服务
- 漏桶算法:匀速出水,适合平滑限流
- 令牌桶算法:按需取令牌,适合突发流量控制
📍 实现工具:Sentinel、Gateway限流、Bucket4j、RateLimiter
你们项目中有没有做到限流?怎么做的?&& 限流常见的算法有哪些??
① 先来介绍一下业务,什么情况下去做限流,需要说明QPS具体是多少
- 我们有一个活动,到了假期就会抢购优惠券,QPS最高可以达到2000,平时10-50之间,为了应对突发流量,需要做限流
- 常规限流,为了防止恶意攻击,保护系统正常运行,我们当时系统能够承受最大的QPS是多少(压测结果)
② nginx限流
- 控制速率(突发流量),使用的漏桶算法来实现过滤,让请求以固定的速率处理请求,可以应对突发流量
- 控制并发数,限制单个ip的连接数和并发链接的总数
③ 网关限流
- 在SpringCloudGateway中支持局部过滤器RequestRateLimiter来做限流,使用的是令牌桶算法
- 可以根据ip或路径进行限流,可以设置每秒填充平均速率,和令牌桶总容量
解释原理:
QPS(Queries Per Second,每秒查询率)是衡量一个系统处理请求能力的指标,它表示服务器在一秒钟内能够处理的查询数量。这个指标常用于数据库和web服务器等应用,以评估系统在高并发情况下的性能。
以下是对您提到的两句话的分析:
- 活动期间的高并发处理:
- 背景知识: 在电子商务等应用中,促销活动往往会引起用户的大量点击和购买行为,导致短时间内流量剧增。
- 限流原理: 为了应对这种突发的高流量,系统需要实施限流措施。限流是为了保护系统资源不被过度消耗,确保系统的稳定性和可靠性。常见的限流算法有固定窗口、滑动窗口、令牌桶和漏桶等。
固定窗口: 假设每 1 分钟允许 100 次请求,10:00:00 到 10:01:00 期间的 100 次请求被允许,超出 100 次则会被限流,10:01:00 到 10:02:00 则重新开始计算。
滑动窗口: 每 60 秒内最多允许 100 次请求,滑动窗口的时间长度为 60 秒,窗口内的请求数会随着时间滑动更新,防止请求在时间边界上积压
令牌桶:假设每秒生成 10 个令牌,令牌桶的容量为 100 个令牌。如果 1 秒内有 15 个请求到达,则前 10 个请求能获得令牌并继续执行,剩余的 5 个请求需要等到下一个时间窗口令牌生成后再执行。
漏桶:假设每秒钟流出 10 个请求,漏桶的容量为 100 个请求。如果 1 秒钟内接收了 30 个请求,系统只会处理 10 个请求,剩余的 20 个请求被丢弃,直到下一个时间点。
- 实施方式: 在您提到的情况下,可以采用以下策略:
- 预判性扩容: 根据历史数据和活动规模预测流量,提前进行服务器资源的扩容。
- 动态限流: 在活动期间,根据实时监控的QPS数据动态调整限流阈值,保证系统平稳运行。
- 排队处理: 对于超出系统处理能力的请求,可以采用队列进行缓冲,分批次处理。
- 常规限流与系统最大承受QPS:
- 背景知识: 常规限流是为了在日常运行中防止恶意攻击(如DDoS攻击)和保护系统资源不被滥用。
- 压测结果: 系统的最大承受QPS是通过压力测试得出的。压力测试(也称为负载测试)是通过模拟高并发访问来测试系统的极限性能,以确定系统在保证稳定运行的前提下能够承受的最大QPS。
- 原理分析:
- 保护系统: 通过设定一个QPS上限,可以防止系统过载,保障系统的正常运行。
- 资源分配: 了解系统的最大承受QPS有助于合理分配资源,如数据库连接、内存和CPU等。
- 用户体验: 适当的限流可以保证用户的体验,避免因系统过载导致的响应缓慢或服务不可用。
在实施限流策略时,还需要考虑以下因素:- 业务优先级: 对于不同的业务请求,可能需要有不同的限流策略,优先保证核心功能的可用性。
- 用户体验: 限流策略应尽量减少对用户体验的影响,例如通过友好的错误提示或降级方案。
- 数据监控: 实时监控系统的QPS和其他关键指标,以便快速响应并调整限流策略。
综上所述,限流是确保系统在高并发情况下稳定运行的重要措施,而了解系统的最大承受QPS是制定合理限流策略的基础。
为什么要限流?
- 并发业务量大(突发流量)
- 防止用户恶意刷接口
限流的实现方式:
==Tomcat==
单体项目可以,分布式不行:可以设置最大连接数<Connector port="8080"...maxThreads="150"...>==Nginx==:漏桶算法
固定速率露出(平滑)控制速率(突发流量)

==网关==:令牌桶算法

自定义拦截器
echos-gateway真实案例
🔷 1. 网关服务名称 + 动态发现配置
spring: application: name: ech-gateway cloud: nacos: discovery: server-addr: 192.168.188.120:8848
- 知识点:Gateway 是 Spring Cloud 架构中的 API 网关,用于请求路由、统一鉴权、日志跟踪、限流、熔断等功能。
- 动态路由注册中心配置:接入 Nacos 注册中心,自动发现服务实例。
🔷 2. Gateway 路由规则(重点)
spring: cloud: gateway: routes: - id: zk-sam-service uri: lb://ech-sam-cs predicates: - Path=/iclock/**🧠 面试要点:
id: 路由唯一标识uri: lb://xxx: 表示使用 负载均衡方式 路由到注册中心中xxx的实例(通过 Ribbon/LoadBalancer 实现)Path: 路径断言,匹配路径开头为/iclock/**的请求filters: StripPrefix=1: 去除路径中的第一级前缀(如/ech-service/a/b→/a/b)
🔷 3. 自动路由发现开启
discovery: locator: enabled: true lower-case-service-id: true🧠 面试延申:
- enabled=true:允许网关根据注册中心中注册的服务自动创建路由(简化配置)
- lower-case-service-id=true:将服务名小写化,避免大小写不一致导致路由失败
面试官可能问:
“你们项目中是手动配置路由还是用 locator 自动发现?哪种方式更推荐?”✅ 回答思路:
- 自动发现适合内部测试环境,快速接入新服务
- 生产建议手动配置,便于管理、加权限、加限流、避免误暴露
✅ 三、Feign配置部分(Gateway下游调用)
feign: client: config: default: connectTimeout: 5000 readTimeout: 5000 loggerLevel: full httpclient: enabled: false okhttp: enabled: false✅ 面试可延申:
- Feign 的连接/读取超时时间如何设置?
- loggerLevel 有哪些级别(NONE/BASIC/HEADERS/FULL)?
- Feign 支持哪几种底层 HTTP 客户端?为什么要关掉 HttpClient/OkHttp?
✅ 四、Redis连接池配置(网关限流、缓存常用)
spring: redis: database: 12 host: 192.168.188.120 port: 6379 lettuce: pool: max-active: 1000 max-idle: 10 min-idle: 5✅ 面试展开:
为什么使用 Redis?
作为 限流、缓存、黑名单过滤、Token 存储 后端,具备高性能分布式能力
你们用 Lettuce 还是 Jedis?区别在哪?
✅ 五、Actuator配置(服务监控)
management: server: port: 9090
- 暴露 Spring Boot Actuator 指标信息,常用于结合 Prometheus/Grafana 做监控
- 可暴露如
/actuator/health、/metrics、/gateway/routes等
你们的微服务是怎么监控的?
我们项目中采用的skywalking进行监控的
- skywalking主要可以监控接口、服务、物理实例的一些状态。特别是在压测的时候可以看到众多服务中哪些服务和接口比较慢,我们可以针对性的分析和优化。
- 我们还在skywalking设置了告警规则,特别是在项目上线以后,如果报错,我们分别设置了可以给相关负责人发短信和发邮件,第一时间知道项目的bug情况,第一时间修复
skywalking
一个分布式系统的应用程序性能监控工具(Application Performance Management), 提供了完善的链路追踪能力,apache的顶级项目(前华为产品经理吴晟主导开源)
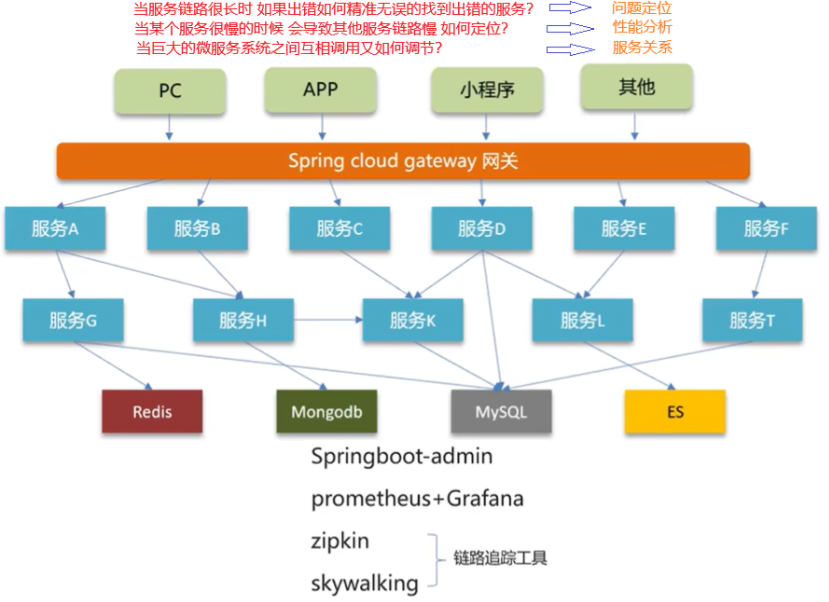

✅ 面试追问题 & 答法建议
面试官可能追问的问题 答题建议 🔸SkyWalking 是怎么接入项目的? 我们使用 Java Agent 的方式,启动时通过 -javaagent:/path/to/skywalking-agent.jar加载探针,同时在agent.config中配置服务名、采集后端等🔸和 Zipkin、Prometheus 相比有什么优劣? SkyWalking 支持 UI 更强,适合链路分析;Prometheus 更适合指标监控配合 Grafana;Zipkin 更轻量但功能少。SkyWalking 是综合性最强的一款 🔸SkyWalking 的数据存储用的什么? 默认是 ElasticSearch,也支持 H2(测试环境),生产建议搭配 ES 做查询与聚合 🔸你怎么通过 SkyWalking 优化过接口? 我们发现某个接口 RT 超过 1 秒,通过 Trace 发现是 MySQL 多表 Join 查询导致,优化了 SQL 才解决的 🔸SkyWalking 能采集哪些组件的数据? HTTP请求、Dubbo、MySQL、Redis、Kafka、RocketMQ、Elasticsearch 等主流中间件都有探针支持 ✅ 加分拓展:如何实现全链路追踪?
SkyWalking 通过在每个服务部署时挂载探针(agent),实现对请求头中 traceId 的自动传递,采集:
- 入参出参(拦截 Controller 层、Feign、RestTemplate)
- RPC调用(如Dubbo/Feign)
- 数据库执行耗时
- Redis访问
- MQ消息链路
最终统一聚合在 SkyWalking OAP 端,再通过 Web UI 展示,形成完整的 “调用链 + 指标 + 日志” 三位一体监控体系。
✅ 项目答题串联建议
你可以在项目介绍环节自然引入这段内容,例如👇:
为了保障我们微服务系统的稳定性,我们在项目中接入了 SkyWalking 作为 APM 工具。通过它我们做到了链路追踪、性能分析、异常预警等。特别在压测和上线之后,能第一时间通过短信和邮件告警通知我们,提升了系统稳定性和定位效率。
探针(Agent)本质上是一个Java 程序运行时的字节码增强器,可以在不修改源码的前提下,对目标应用的类和方法进行增强,从而实现请求数据的“埋点采集”。
✅ 简单理解:探针干了啥?
可以这样比喻👇
你写的业务代码是演员
探针就是藏在台下的摄像机
它在你表演的时候偷偷把你的一举一动都记录下来(记录你调了哪个接口,用了多久,是不是出错了)
✅ 具体工作原理:
- 运行时注入字节码
- 探针是以
-javaagent参数的形式加载到 JVM 中- JVM 启动时,探针会监听所有类的加载过程,选择特定的类(如
Controller、RestTemplate、JdbcTemplate、RedisTemplate)进行增强- 插入监控逻辑
- 在方法的前后插入监控逻辑:
- 方法开始时记录时间
- 方法执行完记录耗时、返回值
- 如果抛出异常,也能捕获异常堆栈
- traceId 传递
- 每个请求入口(比如 SpringMVC Controller)会生成一个全局
traceId- 这个 ID 会自动透传到下游服务,比如 Feign 调用、MQ 发送、数据库访问等
- 最终串成一条完整的调用链路
✅ 示例:
比如你访问这个接口:
@GetMapping("/user/{id}") public User getUser(@PathVariable Long id) { return userService.getById(id); }探针实际会在你这个方法前后偷偷插入逻辑(伪代码):
// 前置逻辑:记录 traceId、时间戳 recordTrace("traceId-xxx"); startTime = System.currentTimeMillis(); User result = userService.getById(id); // 后置逻辑:记录耗时 long cost = System.currentTimeMillis() - startTime; sendToSkywalking(traceId, methodName, cost);探针就是自动化“打点采集 + 数据上传”的代码增强器,开箱即用,不入侵业务代码。
解释一下CAP和BASE分布式系统理论
- CAP 定理(一致性、可用性、分区容错性)
- 分布式系统节点通过网络连接,一定会出现分区问题(P)
- 当分区出现时,系统的一致性(C)和可用性(A)就无法同时满足
- BASE理论
- 基本可用
- 软状态
- 最终一致
- 解决分布式事务的思想和模型
- 最终一致思想:各分支事务分别执行并提交,如果有不一致的情况,再想办法恢复数据(AP)
- 强一致思想:各分支事务执行完业务不要提交,等待彼此结果。而后统一提交或回滚(CP)
- 分布式事务方案的指导
- 分布式系统设计方向
- 根据业务指导使用正确的技术选择
==CAP定理==分布式系统无法同时满足三个指标
CAP 定理是 数学证明出来的分布式理论限制,不是人为规定的规则,而是无法回避的“物理规律”
- ==Consistency==(一致性):用户访问分布式系统中的任意节点,得到的数据必须一致。
主从一致 - ==Availability==(可用性):用户访问集群中的任意健康节点,必须能得到响应,而不是超时或拒绝
- ==Partition tolerance==(分区容错性):当出现网络分区现象后,系统能够继续运行
- Partition(分区):因为网络故障或其他原因导致分布式系统中的部分节点与其他节点失去链接,形成独立分区
- Tolerance(容错):在集群出现分区时,整个系统也要持续对外提供服务
结论:
- 分布式系统节点之间肯定是需要网络链接的,分区 (P) 必然存在
- 如果保证访问的高可用性(A)可以持续对外提供服务,但不能保证数据的强一致性 AP
- 如果保证访问的数据强一致性(C)就要放弃高可用性 CP
🎯 CAP 的结论:
在分布式系统中,由于网络问题不可避免(P必选),所以只能在 C 和 A 之间选其一:
类型 特点 场景 CP 系统 放弃可用性,保证一致性 银行/支付系统(宁可服务不可用,也不能出错) AP 系统 放弃一致性,保证可用性 电商商品浏览、社交系统(稍微不一致无所谓) 为什么 CAP 无法同时满足?
我们来看一个例子理解「一致性(C) vs 可用性(A) 在分区故障(P)下的矛盾」:
❗ 场景设定:
- 系统有两个节点:节点A 和 节点B
- 正常时,A 和 B 通过网络通信同步数据
- 现在发生了网络分区(P):A 和 B 之间断网了!
🧩 你怎么选?C 和 A 只能二选一:
✅ 如果你要保证【一致性 C】:
- 当客户端向 A 节点写数据时,为了保证一致性,A 必须等待 B 同步成功
- 但现在 A 和 B 网络断了,同步不了
- 所以 A 只能拒绝请求:不响应 —— ❌ 违反了可用性 A
✅ 如果你要保证【可用性 A】:
- A 收到写请求就立刻接受并返回成功
- 但 B 此时拿到的还是老数据
- 数据就不一致了 —— ❌ 违反了一致性 C
🎯 所以:在【网络分区 P】已发生的前提下 ——
你只能选:C+A ❌,C+P ✅,A+P ✅
这就是 CAP 定理的本质逻辑。
所以我们在设计系统时必须做权衡 —— 这正是分布式架构的难点和美感所在。
==BASE理论==
BASE理论是对CAP的一种解决思路,包含三个思想:
- ==Basically Avaliable==(基本可用):分布式系统在出现故时,允许损失部分可用性,即保证核心可用
- ==Soft State==(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态
- ==Eventually Consistent==(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致性
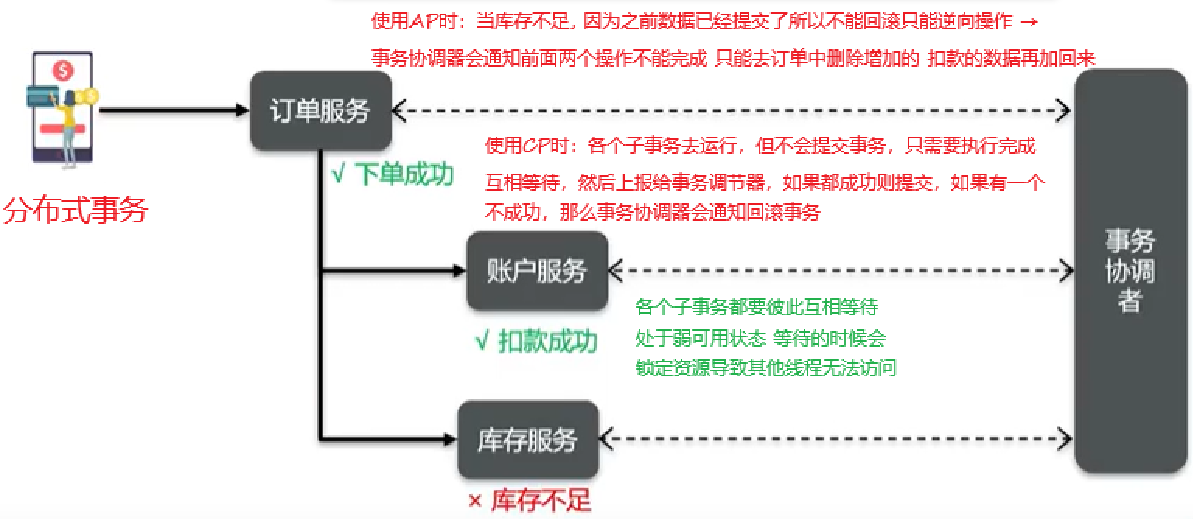
🎯 举个通俗易懂的例子:
你去银行转账,系统提示:“资金将在2小时内到账”。这就是:
- ✅ 系统可用(你能转账)
- ✅ 软状态(中间状态是“处理中”)
- ✅ 最终一致(2小时内一定到账)
这就符合 BASE 理论。
✅ BASE 与 CAP 的关系?
理论 类型 强调 CAP 理论限制 三选二原则,强调不可能同时满足一致性、可用性、分区容错 BASE 实践理念 放弃强一致性,追求最终一致,以换取系统可用性与性能
CAP如何选择?
- CP[支付宝]或者AP[超级跑跑系统维护]
- 在什么场合,可用性高于一致性?
- 网页必须要保障可用性(一定能看到最重要 是不是最新的不重要)和分区容错
- 支付的时候一定要保障一致性(我可以保证不可用 但我不允许余额不一致)和分区容错
- 合适的才是最好的

你们采用哪种分布式事务解决方案?
● 简历上写的微服务,只要是发生了多个服务之间的写操作,都需要进行分布式事务控制
● 描述项目中采用的哪种方案(seataMQ)
⚪ seata的XA模式,CP,需要互相等待各个分支事务提交,可以保证强一致性,性能差 (银行业务 )
⚪ seata的AT模式,AP,底层使用undolog 实现,性能好 (互联网业务 )
⚪ seata的TCC模式,AP,性能较好,不过需要人工编码实现 (银行业务 )
⚪ MQ模式实现分布式事务,在A服务写数据的时候,需要在同一个事务内发送消息到另外一个事务异步,性能最好 (互联网业务 )✅ 你的理解:Seata 的 XA ≈ CP,AT ≈ AP?
Seata 是实现,CAP 是原则
你这样理解有一定道理,但这两者并不是等价关系。
Seata 是一种“解决分布式事务问题的技术方案”,目的是确保多个数据库操作的一致性,属于 CAP 中的一致性实现策略之一,但不能反过来说它就是 CAP 的实现。
对比 Seata XA / AT 模式 CAP 理论中的 CP / AP 本质 一种分布式事务协议实现 一种分布式系统权衡模型 关注点 一致性、事务原子性 可用性 vs 一致性 vs 分区容忍性 使用背景 数据库操作级别的事务控制 整个分布式系统的架构设计选择 🟢 Seata 为什么要设计成 XA、AT 两种模式?
因为不同的业务场景对性能 vs 一致性 的需求不同,Seata 提供了“可插拔”式的事务解决方案:
模式 一致性 性能 特点 XA模式(两阶段提交) 强一致性 性能差、资源占用多 接近传统分布式事务,事务期间资源锁定 AT模式(自动补偿) 最终一致性 性能好 非侵入,靠 Undo Log 回滚操作,适用于大部分业务场景
- Seata框架(XA、AT、TCC)
- MQ
Seata架构
- TC(Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚
- TM(Transaction Manager) - 事务管理器:定义全局事务的范围、开启全局事务、提交或回滚全局事务
- RM(Resource Manager) - 资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚
Seata 的 XA 和 AT 确实在一致性与可用性方面体现了 CAP 的设计权衡,但它并不是 CAP 的实现,而是面向分布式事务的一种可插拔事务解决方案。Seata 架构之所以独立,是因为它提供了统一的事务协调服务,支持多种协议(XA/AT/TCC/SAGA),以满足不同业务场景对一致性和性能的需求,这在真实的微服务架构中非常关键。

分布式服务的接口幂等性如何设计?
- 幕等:多次调用方法或者接口不务状态,可以保证重复调用的结果和单次调用的结果一致;常用于支付、下单等关键业务防止重复提交。
- 如果是**新增数据**,可以使用数据库的唯一索引
- 如果是**新增或修改数据**
- 分布式锁,性能较低
- 使用token+redis来实现,性能较好
● 第一次请求,生成一个唯一token存入redis,返回给前端
● 第二次请求,业务处理,携带之前的token,到redis进行验证,如果存在,可以执行业务,删除token; 如果不存在,则直接返回,不处理业务🧠 一、什么是幂等性?
- 幂等性是指:一次和多次请求同一个接口,对资源的影响是相同的
- 幂等操作的特性是:无副作用(No Side Effect)
📌 二、幂等性为什么重要?
会出现重复调用的原因:
- 网络抖动、页面重复点击
- 分布式事务重试机制
- 网关重试、MQ重复投递
- 前端误操作(如双击支付按钮)
🎯 三、幂等性保障方案(重点)
场景 适用范围 实现方式 特点 ✅ 数据库唯一约束 新增接口 通过唯一索引防止重复插入 简单高效 ✅ Token机制 + Redis 提交类(订单、支付) 一次性Token防止重复提交 推荐,效率高 ✅ 分布式锁 修改、转账等接口 基于Redisson、ZK等实现同步控制 精准,但性能稍差 ✅ 接口幂等表 所有需幂等接口 记录请求唯一标识 + 状态 控制最强,适合高并发 ✅ 乐观锁(版本号机制) 更新操作 防止并发更新,CAS思想 要求带版本号字段 ✅ 幂等组件中间件 通用接口平台 拦截层统一幂等处理 企业封装,灵活可控 🔨 Token+Redis 实现幂等(推荐)
流程:
- 客户端请求创建订单,先调用接口获取
幂等Token- 后续提交时在请求头中携带该 Token
- 服务端收到请求:
- 判断 Redis 中是否存在该 Token
- 若存在,则处理业务并删除 Token
- 若不存在,说明已处理或重复请求,直接返回
优点:
- 轻量级,无锁高并发
- 可扩展性强,适用于 POST/PUT 等需要控制的接口
幂等:多次调用方法或者接口不会改变业务状态,可以保证重复调用的结果和单次调用的结果一致
需要幂等场景
- 用户重复点击(网络波动)
- MQ消息重复
- 应用使用失败或超时
| 请求方式 | 说明 | 是否天然幂等 |
|---|---|---|
| GET | 查询操作,天然幂等 | ✅ 是 |
| POST | 新增操作,请求一次与请求多次造成的结果不同,不是幂等的 | ❌ 否 |
| PUT | 更新操作,如果是以绝对值更新,则是幂等的。如果是通过增量的方式更新,则不是幂等的 | ✅ 是(全量)或❌ 否(增量) |
| DELETE | 删除操作,根据唯一值删除,是幂等的 | ✅ 是(按主键) |
-- 幂等更新:将余额设置为固定值
UPDATE account SET money = 500 WHERE id = 1;
-- 非幂等更新:余额加上500
UPDATE account SET money = money + 500 WHERE id = 1;
数据库唯一索引【新增】
==token + redis== 【新增+修改】**AND** ==分布式锁== 【新增+修改】
🧠 面试答题思路模板
我们项目中对于需要幂等性的接口(如支付、下单等),主要采用了Token + Redis机制:
- 请求前由前端向后端申请一次性 Token
- 后续接口请求中携带该 Token
- 后端通过 Redis 判断 Token 是否存在,从而保证接口只被处理一次
此外,对于批量创建类操作,还会结合数据库唯一索引控制幂等,对于状态更新类操作会使用乐观锁或分布式锁。
创建商品、提交订单、转账、支付等操作

你们项目中使用了什么分布式任务调度
xxl-job 是一个分布式任务调度平台,它致力于解决分布式场景下的任务调度问题,主要由调度中心和执行器两部分组成。调度中心负责统一管理任务调度,而执行器则是负责接收调度并执行任务逻辑的客户端。
🎯 一句话总结
我们项目使用的是 XXL-Job 分布式任务调度平台,用来实现定时任务管理,比如取消订单、同步库存、发送通知等,解决了分布式环境下定时任务重复、不可控的问题。
xxl-job路由策略有哪些?
xxl-job提供了很多的路由策略,我们平时用的较多的就是:轮询、故障转移、分片广播
🚦 路由策略有哪些?(面试重点)
路由策略就是调度中心选 哪个执行器节点去执行任务 的方式。
路由策略 描述 轮询(Round) ✅ 多个节点轮流执行任务,负载均衡常用 故障转移(Failover) ✅ 优先使用健康节点,失败时自动切换执行 分片广播(Broadcast) ✅ 每个节点都执行一次任务,适合大数据并行处理 随机(Random) 随机选取一个可用节点 一致性哈希 根据任务参数哈希选节点,适合状态保持 最少运行节点 选当前执行任务最少的机器 指定机器 手动指定执行器 xxl-job任务执行失败怎么解决?
- 路由策略选择故障转移,使用健康的实例来执行任务
- 设置重试次数
- 查看日志+邮件警告来通知相关负责人解决
- 配置 任务超时时间 + 告警通知(邮件、短信)
- 失败日志可在调度中心查看,有堆栈信息
如果有大数据量的任务同时都现需要执行,怎么解决?
- 让多个实例一块去执行(部署集群),路由策略分片广播
- 在任务执行的代码中可以获取分片总数和当前分片,按照取模的方式分摊到各个实例执行;通过
ShardingContext拿到当前分片信息
@JobHandler("xxxHandler") public ReturnT<String> execute(ShardingContext context) { int totalShards = context.getTotalShardCount(); int shardIndex = context.getShardIndex(); List<Data> allData = getData(); for (int i = 0; i < allData.size(); i++) { if (i % totalShards == shardIndex) { process(allData.get(i)); } } return SUCCESS; }
💡 面试高频问法总结
面试问题 回答提示 你们怎么做定时任务调度? 我们使用 XXL-Job 做分布式定时调度,支持失败重试、分片执行、失败告警 XXL-Job 怎么实现任务分片? 配置为广播策略,任务中使用 ShardingContext 获取分片信息 路由策略都有哪些?你们用哪个? 常用轮询、故障转移、分片广播;我们大任务用广播,小任务轮询 如果一个任务执行失败怎么办? 设置了最大重试次数、使用了 Failover 策略、并配置了邮件告警通知 为什么不用 @Scheduled? @Scheduled 适用于单体项目,不能解决多实例下重复执行问题;XXL-Job 支持分布式调度、管理界面、执行日志等 ✅ 详细对比分析:SpringTask vs XXL-Job
对比维度 SpringTask XXL-Job 定位 本地轻量级定时调度工具 分布式定时任务调度平台 部署方式 内嵌在应用中(@Scheduled) 独立部署调度中心 + 执行器 集群支持 不支持,单实例任务 支持分布式执行和 failover 任务失效恢复 无(如服务挂了任务丢) 支持失败重试 + 调度日志记录 任务管理 无可视化界面 Web 界面管理、动态配置任务 任务执行方式 方法注解 + 固定周期 支持 Bean 调用、Shell、HTTP、RPC 等 执行结果监控 无 有日志管理、失败报警、状态追踪 调度策略 固定时间(cron) cron、分片广播、失败重试、手动触发等 适用场景 简单、稳定的定时逻辑,如定期清理缓存 多任务调度、跨服务控制、任务分发、分片执行、手动补偿等复杂场景
xxl-job解决的问题
- 解决集群任务的重复执行问题 xxl-job路由策略有哪些?
- cron表达式定义灵活
在页面上xxl-job任务执行失败怎么解决? - 定时任务失败了,重试和统计 如果有大数据量的任务同时都需要执行,怎么解决?
- 任务量大,分片执行
场景 1: 定时处理过期订单
假设用户下单后如果订单超过了某个时间没有支付,平台需要自动取消该订单并释放库存。这个任务需要在每天的某个固定时间(比如凌晨 2 点)运行。
解决的问题:
- 定时任务调度:XXL-Job 可以轻松管理该任务的执行时间和周期,确保每天准时执行,不需要开发者手动触发。
- 任务失败重试:如果该任务因为某些原因执行失败,XXL-Job 可以自动进行重试,并设置重试次数,确保任务最终被执行。
- 分布式执行:假设电商平台是一个分布式系统,订单数据存储在多个数据库中,XXL-Job 可以通过分布式执行确保每个数据库的订单都被正确处理
假设每晚 2 点有一个任务需要取消未支付的订单:
public class OrderJob { @JobHandler("orderCancelJobHandler") public void cancelUnpaidOrders() { // 查询所有未支付的订单 List<Order> unpaidOrders = orderService.findUnpaidOrders(); for (Order order : unpaidOrders) { if (order.isExpired()) { orderService.cancelOrder(order); inventoryService.releaseStock(order.getProductId(), order.getQuantity()); // 发送订单取消通知给用户 notificationService.sendOrderCancelledNotification(order.getUserId()); } } } }场景 2: 定时更新商品库存
假设电商平台上销售的是一些有时效性的商品,商家需要定期更新商品的库存状态(例如,库存数量达到一定阈值时,自动下架商品,或者增加库存数量)。这个任务同样需要定时执行。
解决的问题:
- 任务分片:在商品很多的情况下,XXL-Job 可以通过任务分片的方式并行处理不同商品的库存更新,提升任务的执行效率。
- 任务优先级:根据不同商品的重要程度,XXL-Job 可以设置任务的优先级,确保关键商品的库存更新优先执行。
public class InventoryJob { @JobHandler("inventoryUpdateJobHandler") public void updateProductInventory() { // 获取需要更新库存的商品 List<Product> productsToUpdate = productService.findProductsForInventoryUpdate(); for (Product product : productsToUpdate) { inventoryService.updateInventory(product); if (product.getStockQuantity() <= product.getLowStockThreshold()) { productService.deactivateProduct(product); // 发送商品下架通知 notificationService.sendOutOfStockNotification(product.getId()); } } } }场景 3: 定时发送促销活动通知
假设电商平台有一个促销活动,每个活动的开始和结束时间都由后台系统控制。需要在活动开始前 1 小时、活动结束时发送通知给用户。这些通知可以是短信、邮件或 APP 推送通知。
解决的问题:
- 定时任务管理:XXL-Job 可以定时触发通知任务,确保用户在活动前后及时收到通知。
- 高并发支持:在促销活动开始或结束时,平台可能会有大量的通知需要发送,XXL-Job 支持任务的并行处理,可以帮助我们高效地分发通知,避免性能瓶颈。
- 任务状态监控:XXL-Job 提供任务的实时监控功能,平台可以随时查看任务的执行情况,确保通知任务按时执行。
public class PromotionJob { @JobHandler("promotionNotifyJobHandler") public void sendPromotionNotifications() { // 获取当前正在进行的促销活动 List<Promotion> activePromotions = promotionService.findActivePromotions(); for (Promotion promotion : activePromotions) { if (promotion.isStartingSoon()) { notificationService.sendStartNotification(promotion); } else if (promotion.isEndingSoon()) { notificationService.sendEndNotification(promotion); } } } }✅ 这段代码做了什么?
java复制编辑@JobHandler("orderCancelJobHandler") public void cancelUnpaidOrders() { ... }这是一个 XXL-Job 的定时任务处理方法,任务名叫
orderCancelJobHandler,作用是:定时扫描所有未支付订单,判断是否过期,过期则取消订单、释放库存并通知用户
🔧 XXL-Job 是怎么运行这个方法的?
🧩 步骤 1:添加依赖
在你的
pom.xml中,需要加入 XXL-Job 的执行器依赖:<dependency> <groupId>com.xuxueli</groupId> <artifactId>xxl-job-core</artifactId> <version>2.4.0</version> </dependency>
🧩 步骤 2:执行器配置(application.yml)
xxl: job: admin: addresses: http://localhost:8080/xxl-job-admin executor: appname: order-job-executor address: ip: port: 9999 logpath: /data/applogs/xxl-job/jobhandler logretentiondays: 30 accessToken:说明:
admin.addresses: 调度中心地址executor.*: 当前服务是执行器,配置端口、日志路径等
🧩 步骤 3:启动类开启执行器功能
@EnableXxlJob @SpringBootApplication public class OrderJobExecutorApplication { public static void main(String[] args) { SpringApplication.run(OrderJobExecutorApplication.class, args); } }
🧩 步骤 4:创建 JobHandler 并注册到容器
@Component public class OrderJob { @XxlJob("orderCancelJobHandler") public void cancelUnpaidOrders() { // 执行任务逻辑 } }注意:你用的是
@JobHandler,它是旧版本用法,新版本统一改为@XxlJob(推荐)
🧩 步骤 5:在调度中心页面注册该任务
登录调度中心(xxl-job-admin)
- 新建任务
- 执行器:选择
order-job-executor- JobHandler名称:
orderCancelJobHandler- 调度类型:如“CRON”
- 执行方式:BEAN 模式
- CRON 表达式:比如每天凌晨 2 点
0 0 2 * * ?- 保存并启动任务
xxl-job路由策略有哪些?
实例找任务项执行任务 这种找机器的方式就是路由策略
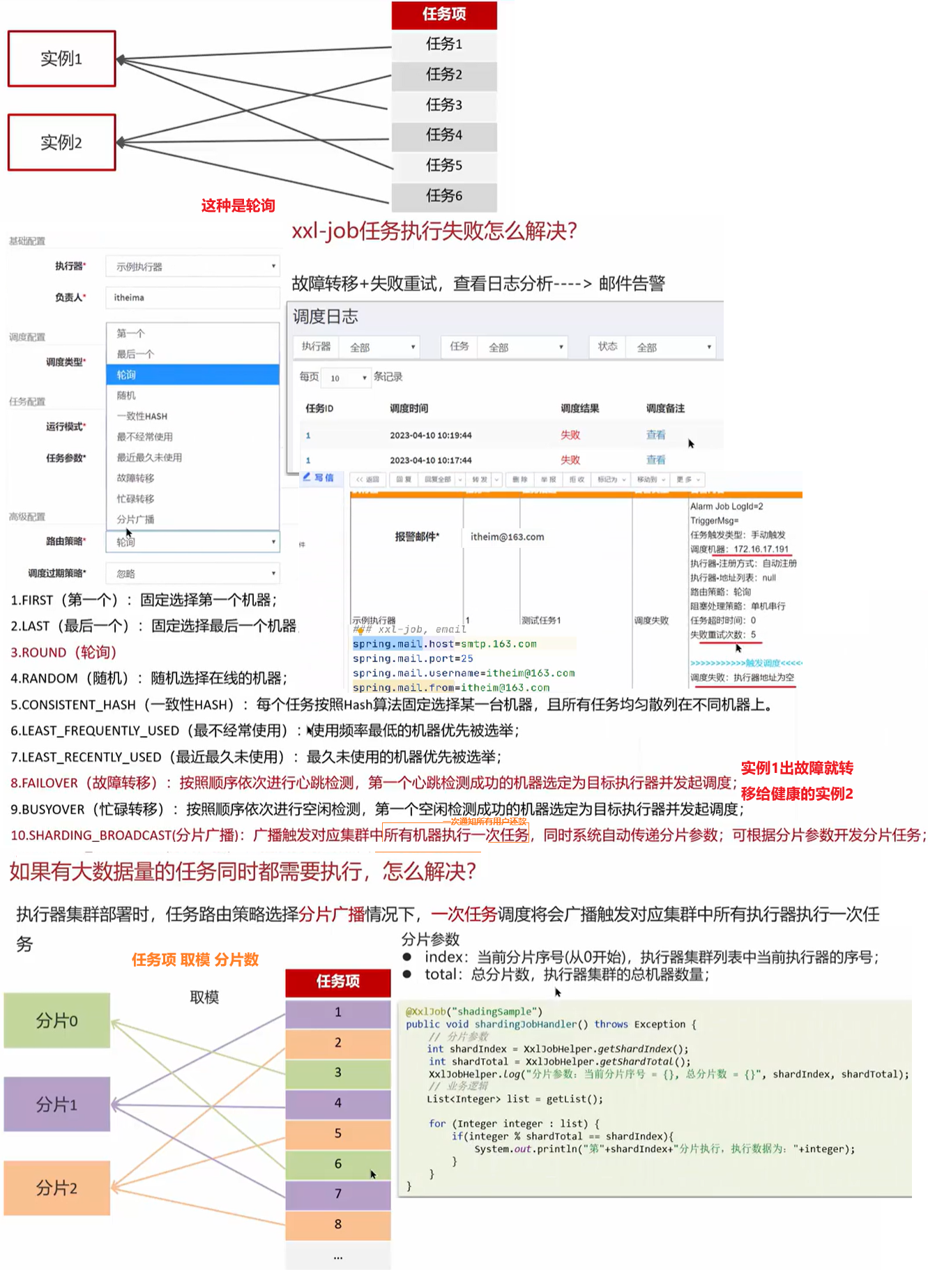
消息中间件RabbitMQ+Kafka
消息中间件提供了服务与服务之间的异步调用,还可以服务与服务之间解耦
RabbitMQ:**消息不丢失、消息重复消费、消息堆积、延迟队列、死信队列、高可用机制**
Kafka:**消息不丢失、消息重复消费、高可用机制、高性能设计吞吐量达到百万级、数据存储和清理**
RabbitMQ-如何保证消息不丢失?
开启生产者确认机制,确保生产者的消息能到达队列
confirm到交换机ack 不到nack 和 return没到返回nack机制保证生产者把消息发过去达到队列成功返回
ack,失败返回nack【negative acknowledgment】
- 生产者发送消息到交换机。
- 交换机收到消息后,根据绑定规则(是否有匹配的队列)决定消息是否被正确路由。
- 如果消息成功路由到队列,交换机会向生产者返回
ack确认。- 如果消息没有成功路由到任何队列,交换机会通过
return将消息退回给生产者。- 生产者收到
ack或nack,可以处理消息确认或重试逻辑。开启持久化功能,确保消息未消费前在队列中不会丢失
durable = True
万一broker挂掉就惨了 保证至少成功一次消费
MQ是默认内存存储信息,开启持久化功能可以确保缓存在MQ中的消息不丢失[把数据存在磁盘上]# 声明持久化交换器 channel.exchange_declare(exchange='exchange_name', durable=True) # 声明持久化队列 channel.queue_declare(queue='queue_name', durable=True) # 发送持久化消息 channel.basic_publish(exchange='exchange_name', routing_key='routing_key', body='Hello World!', properties=pika.BasicProperties( delivery_mode=2, # 使消息持久化 ))开启消费者确认机制为auto,由spring确认消息处理成功后完成ack
消费者三种机制:RabbitMQ支持消费者确认机制,即:**消费者处理消息后可以向MQ发送ack回执,MQ收到ack回执后才会删除该消息**,而Spring AMQP则允许配置三种确认模式:
manual:手动ack,需要在业务代码结束后,调用api发送ack。
auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
开启消费者失败重试机制,多次重试失败后将消息投递到异常交换机,交由人工处理
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecoverer接口来处理,它包含三种不同的实现:
RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
- 异步发送(验证码、短信、邮件)
- MySQL和Redis,ES之间的数据同步
- 分布式事务
- 削峰填谷
==生产者确认机制==
RabbitMQ提供了publisher confirm机制来避免消息发送到MQ过程中丢失。消息发送到MQ以后,会返回一个结果给发送者,表示消息是否处理成功

RabbitMQ消息的重复消费问题如何解决的?
我们当时消费者是设置了自动确认机制,当服务还没来得及给MQ确认的时候,服务宕机了,导致服务重启之后,又消费了一次消息,这样就重复消费了
因为我们当时处理的支付(订单|业务唯一标识),它有一个业务的唯一标识,我们再处理消息时,先到数据库查询一下,这个数据是否存在,如果不存在,说明没有处理过,这个时候就可以正常处理这个消息了。如果已经存在这个数据了,就说明消息重复消费了,我们就不需要再消费了。
原因
- 网络抖动
- 消费者挂了
解决方案:适用于任何MQ(Kafka,RabbitMQ,RocketMQ)
- 每条消息设置一个唯一的标识id
- 幂等方案:【分布式锁、数据库锁(悲观锁、乐观锁)】
RabbitMQ中死信交换机?(RabbitMQ延迟队列有了解过吗)
如果用原来的定时任务 也可以但是 可能会有订单空窗期 如果没人消费的时候 它内部还是回去sql查询已下单 +(now()-下单时间)?15min : true, false
- 我们当时一个什么业务使用到了延迟队列(超时订单、限时优惠、定时发布)
- 其中延迟队列就用到了死信交换机和TTL(消息存活时间)实现的
- 消息超时未消费就会变成死信(死信的其他情况:拒绝被消费,队列满了)
我们用延迟队列处理未支付订单:用户下单后 15 分钟未付款,自动取消订单+释放库存;其他场景也用到延迟队列,比如限时促销、定时发布文章、定时发通知等。
延迟队列插件实现延迟队列
DelayExchange
延迟队列的底层实现就是通过 TTL(消息存活时间)+ 死信交换机(DLX)组合完成的。
- 声明一个交换机,添加delayed属性为true
- 发送消息时,添加
x-delay头,值为超过时间什么样的消息会成为死信? ★ 消费者返回reject或者nack,且requeue参数设置为false【消息被拒绝并且不重入队列】 ★ 消息超时未消费 ★ 队列满了 如何给队列绑定死信交换机? ★ 给队列设置dead-letter-exchange属性,指定一个交换机 ★ 给队列设置dead-letter-routing-key属性,设置死信交换机与死信队列的RoutingKey ------------------------------------------------------------------------ ★ ★ ★ 使用 Spring AMQP 配置 ★ ★ ★ import org.springframework.amqp.core.Queue; import org.springframework.amqp.core.Exchange; import org.springframework.amqp.core.TopicExchange; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class RabbitMQConfig { // 定义普通队列 @Bean public Queue normalQueue() { return new Queue("normalQueue", true, false, false, Map.of("x-dead-letter-exchange", "dlx_exchange", "x-dead-letter-routing-key", "dlx_routing_key")); } // 定义死信队列 @Bean public Queue dlxQueue() { return new Queue("dlxQueue", true); } // 定义普通交换机 @Bean public Exchange normalExchange() { return new TopicExchange("normal_exchange"); } // 定义死信交换机 @Bean public Exchange dlxExchange() { return new TopicExchange("dlx_exchange"); } // 将普通队列与交换机绑定 @Bean public Binding bindNormalQueue() { return BindingBuilder.bind(normalQueue()).to(normalExchange()).with("normal.routing.key").noargs(); } // 将死信队列与死信交换机绑定 @Bean public Binding bindDLXQueue() { return BindingBuilder.bind(dlxQueue()).to(dlxExchange()).with("dlx_routing_key").noargs(); } } ------------------------------------------------------------------------ 如果你希望将死信队列配置成带有过期时间或其他特殊属性的队列,可以在定义 dlxQueue 时增加更多的设置,例如 TTL(过期时间)。 例如,设置死信队列的 TTL: @Bean public Queue dlxQueue() { return QueueBuilder.durable("dlxQueue") .withArgument("x-message-ttl", 60000) // 设置TTL为60秒 .build(); }✅ Spring AMQP 中配置延迟队列 + 死信队列(简洁版) @Bean public Queue orderQueue() { return QueueBuilder.durable("order.queue") .ttl(15 * 60 * 1000) // 15分钟TTL .deadLetterExchange("dlx.exchange") // 超时后投递到死信交换机 .deadLetterRoutingKey("order.dlx") // 指定死信路由key .build(); } @Bean public Queue orderDLXQueue() { return new Queue("order.dlx.queue"); }
延迟队列 = 死信交换机 + TTL (生存时间)
- 延迟队列:进入队列的消息会被延迟消费的队列
- 场景:超时订单、限时优惠,定时发布
死信交换机
当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter):
- 消费者使用basic.reject 或 basic.nack声明消费失败,并且信息的requeue参数设置为false
- 消息是一个过期消息,超时无人消费
- 要投递的队列消息堆积满了,最早的消息可能成为死信
如果该队列配置了dead-letter-exchange属性,指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机称为死信交换机(Dead Letter Exchange,简称DLX)
@Bean
public QUeue ttlQueue(){
return QueueBuilder.durable("simple.queue") // 指定队列名称,并持久化
.ttl(10000) // 设置队列的超时时间 10秒
.deadLetterExchange("dl.direct") // 指定死信交换机
.build();
}
✅ 死信交换机配置核心属性(面试考点)
x-dead-letter-exchange: 死信交换机名称
x-dead-letter-routing-key: 投递死信用的路由key
x-message-ttl: 消息过期时间(单位:毫秒)
TTL
TTL(Time-To-Live)。如果一个队列中的消息TTL结束仍未消费,则会变成死信,ttl超时分为两种情况:
- 消息所在的队列设置了存活时间
- 消息本身设置了存活时间
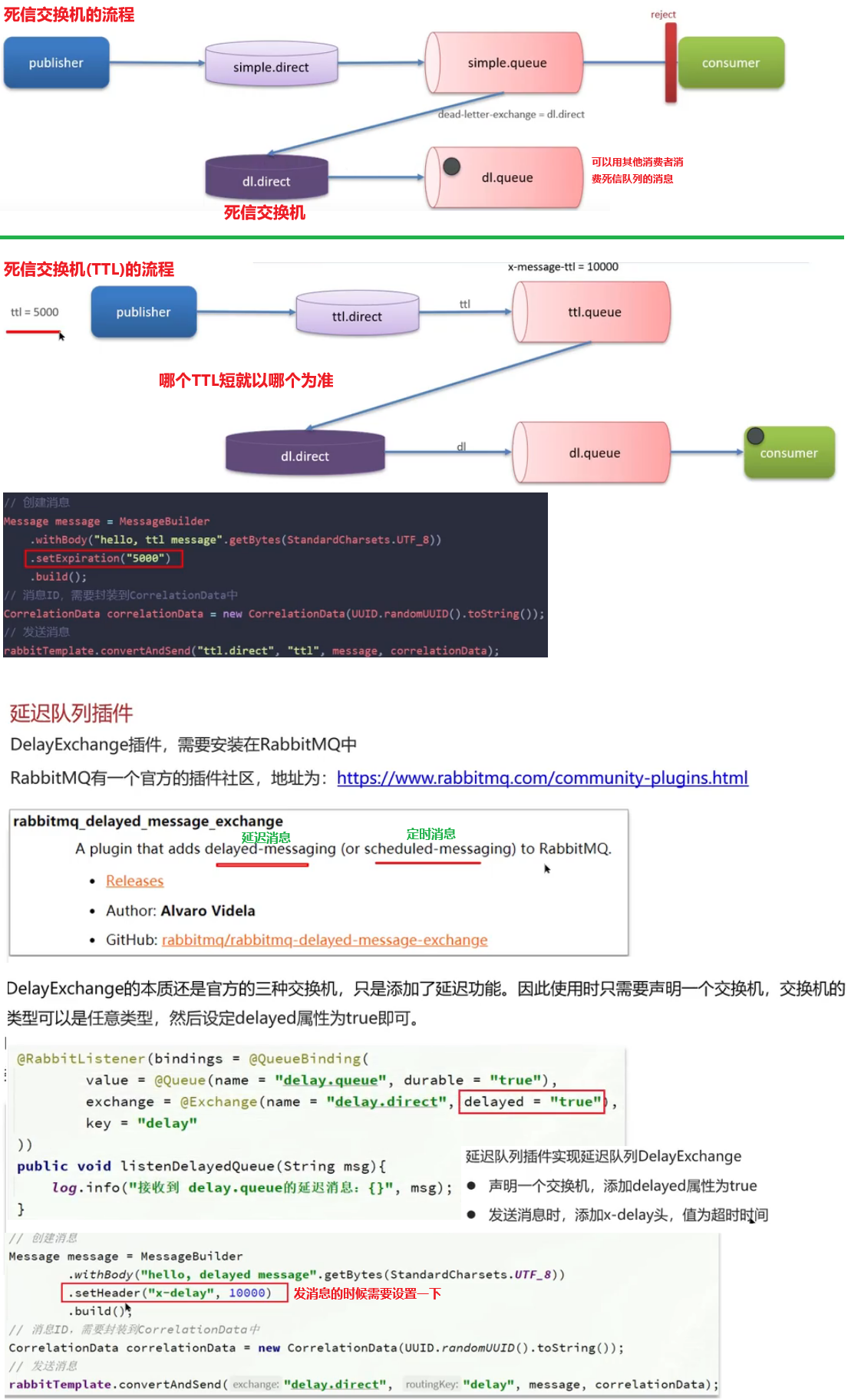
RabbitMQ如果有100万消息堆积在MQ,如何解决(消息堆积怎么解决)?
消息堆积的本质是消费能力不足,解决重点是提升消费者处理能力 + 降低系统压力。
**解决消息堆积有三种思路 **
- 增加更多消费者,提高消费速度
- 在消费者内开启线程池加快消息处理速度
- 扩大队列容积,提高堆积上限
- 在声明队列的时候可以设置
x-queue-model为lazy,即为惰性队列- 基于磁盘存储,消息上限高
- 性能比较稳定,但基于磁盘存储,受限于磁盘IO,时效性会降低
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是堆积问题
**解决消息堆积有三种思路 **
- 增加更多消费者,提高消费速度
- 在消费者内开启线程池加快消息处理速度
- 扩大队列容积,提高堆积上限
达到上限发送的消息会变成死信,那我为什么不搞个死信交换机 而是用了上面的三种思路??
使用死信交换机(DLX, Dead Letter Exchange)是另一种处理消息堆积的方式,但它的作用更偏向于“消息过期”或“处理失败”的情况下将消息转发到另一个队列。并不直接解决生产者发送消息过快或消费者处理速度过慢的问题。通过死信交换机,你可以将无法处理的消息转发到其他队列,方便你后续进行分析或处理,但它并不能提高消费者处理消息的速度。
针对消息堆积的本质问题,解决方式更多的是优化消费者处理能力,而不是仅依赖死信交换机。具体而言,死信交换机和你的三种思路的关系如下:
- 死信交换机(DLX):当消息达到队列上限或无法消费时,消息被转发到死信队列。你可以分析死信队列中的消息,了解原因,并决定是重试、丢弃还是进行其他处理。它的作用是不丢失消息,但并不能帮助消除堆积。
- 增加消费者:这是直接针对堆积的根本解决方案,通过增加消费者数量来加速消息的处理。死信交换机无法直接解决消费者处理能力不足的问题。
- 开启消费者线程池:在单个消费者上开启线程池,可以提高消费者的处理能力,减少堆积。死信交换机并不能增加消息处理速度,它只是用来应对消费失败的情况。
- 扩大队列容量并使用惰性队列:惰性队列可以将消息存储在磁盘上,而非内存中,减轻内存压力,但这也会降低时效性,并不能解决生产者生产过快或消费者消费过慢的问题。死信交换机同样无法直接解决这一点。
总结来说,死信交换机是处理消息丢失或无法消费的方式,它和通过增加消费者、线程池、队列优化这些手段并不冲突,但也无法替代这些更直接的解决方案。你可以结合这两者,使用死信交换机来保障消息不丢失,同时采取上述方法来提高消息消费速度。
死信交换机主要作用是保底机制,用于处理失败的消息,比如超时、拒绝、队列满。它不能真正解决堆积问题,只能帮我们兜底不丢消息。
所以,我们会搭配使用:前面是用多线程和惰性队列来压堆积,后面用死信队列来兜住异常消息,保障系统稳定。
惰性队列
惰性队列特征如下:
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存
- 支持数百万条的消息存储
@Bean
public Queue lazyQueue(){
return QueueBuilder
.durable("lazy.queue")
.lazy() // 设置为惰性队列,落盘存储
.build();
}
// 惰性队列是 RabbitMQ 提供的一种机制,消息直接写入磁盘,内存消耗小,堆积能力强,适合处理海量不紧急消息。但缺点是消费速度会稍慢,因为要从磁盘读。
@RabbitListener(queuesToDeclare = @Queue){
name = "lazy.queue",
durable = "true",
arguments = @Argument(name = "x-queue-mode"), value="lazy"
}
public void listenLazyQUeue(String msg){
log.info("接收到lazy.queue的消息:{}",msg);
}
提高消费能力是解决堆积的根本;惰性队列能缓解内存压力,死信机制是辅助保障不丢消息。三者应配合使用。
RabbitMQ高可用机制有了解过吗? && 请描述 RabbitMQ 镜像队列的工作原理及其在高可用性场景下的优缺点
在我们项目中,为了保障消息队列的高可用性,我们采用了 RabbitMQ 的镜像队列集群部署方案,后来也了解并测试了仲裁队列来提升一致性保障。
我们当时的项目在生产环境下,采用的是镜像模式搭建的集群,共有3个节点
镜像队列结构是一主多从(从就是镜像),所有(写)操作都是主节点完成,然后同步给镜像节点
主宕机后,镜像节点会代替成为新的主(如果在主从同步完成前,主就已经宕机,可能出现数据丢失)🔹 RabbitMQ 高可用机制对比三种:
模式 原理 是否同步消息 容灾能力 是否强一致 应用场景 普通集群 共享元数据,不同步消息内容 ❌ 弱 ❌ 测试、非关键业务 镜像队列 主节点写入,同步到镜像节点 ✅ 中 弱~中 读多写少 仲裁队列 Raft 协议选主,多节点确认写入 ✅ 强 ✅(强一致) 关键数据、支付
那出现丢数据怎么解决呢?
我们可以采用仲裁队列,与镜像队列一样,都是主从模式,支持主从数据同步,主从同步基于wwwwwwwwwwwwwwwwwwwww,强一致性,并且使用起来也非常简单,不需要格外的配置,在声明队列的时候只需要指定这个是仲裁队列即可
Raft 协议 是一种 共识算法(Consensus Algorithm);
🔴 在分布式系统中,让多个节点就某个值达成一致(即使有部分节点故障)
Raft 就是“几个节点如何选出一个 Leader,让它来统筹所有更新,然后让大多数节点都确认成功后再算真正提交成功”。
为了避免这些 “脑裂、数据冲突” 问题,就需要一种 “大家达成共识” 的机制,Raft 协议就是这种机制🏗️ Raft 核心角色和流程✅ Raft 有三种角色:
角色 说明 Leader 主节点,唯一能接收客户端写请求 Follower 跟随者,接受 Leader 同步数据 Candidate 候选人,用于选举新 Leader ✅ 正常流程:
- 所有节点刚启动时,都是 Follower。
- 一段时间内没收到 Leader 的心跳,会变成 Candidate,发起投票选举。
- 多数投票成功后,变成新的 Leader。
- 所有写请求只能由 Leader 处理,然后同步给其他节点(Follower)。
- 如果 大多数节点都确认写入成功,则这条数据才算真正提交成功。
- 在生产环境下,使用集群来保证高可用性
- 普通集群、镜像集群、仲裁队列(Raft协议)
普通集群
普通集群,或者叫标准集群(classic cluster)
- 会在集群的各个节点间共享部分数据,包括:交换机、队列元信息。不包含队列中的信息
- 当访问集群某节点时,如果队列不在该节点,会从数据所在节点传递到当前节点并返回
- 队列所在节点宕机,队列中的消息就会丢失
镜像集群
镜像集群:本质是主从模式,具备下面的特征:
- 交换机、队列、队列中的消息会在各个mq的镜像节点之间同步备份
- 创建队列的节点被称为该队列的主节点,备份到的其他节点叫做该队列的镜像节点
- 一个队列的主节点可能是另一个队列的镜像节点
- 所有操作都是主节点完成,然后同步给镜像节点
- 主宕机后,镜像节点会替代成新的主
🔹 镜像队列原理(项目中实际使用)
在我们的生产环境中,RabbitMQ 集群采用的是 镜像队列(Classic Mirrored Queue) 模式,有以下特点:
- 主从同步: 队列存在一个主节点,多个镜像节点。
- 所有写操作都落在主节点,随后同步给镜像节点。
- 如果主节点宕机,镜像节点会被选举为新主。
- 同步存在延迟,一旦主节点宕机且尚未同步完,就可能出现数据丢失。
💡 镜像队列优点:
- 数据有副本,具备一定容灾能力
- 节点可切换,保证服务不中断
⚠ 镜像队列缺点:
- 主从同步可能延迟 → 存在数据丢失风险
- 配置复杂、资源开销大,大集群下性能差
🔹 那出现丢数据怎么办?
我们后来开始测试和使用了 仲裁队列(Quorum Queue),它在 3.8+ 中推出,作为镜像队列的替代方案,支持强一致性。
仲裁队列:.quorum()
仲裁队列是3.8版本以后才有的新功能,用来替代镜像队列
- 与镜像队列一样,都是主从模式,支持主从数据同步
- 使用非常简单,没有复杂的配置
- 主从同步基于Raft协议,强一致性
仲裁队列的工作原理如下:
- 主从模式:仲裁队列也是主从模式,支持主从数据同步。
- Raft 协议:主从同步基于 Raft 协议,确保数据的一致性和可靠性。
- 强一致性:所有写操作必须得到大多数节点的确认后才能完成,避免了数据丢失。
仲裁队列通过以下机制保证数据不丢失:
- 多数派确认:每次写操作需要得到大多数节点的确认,确保数据已经成功复制到多个节点。
- 自动故障转移:如果主节点宕机,Raft 协议会自动选举新的主节点,确保服务的连续性。
- 数据一致性:Raft 协议保证了数据的强一致性,即使在网络分区或节点宕机的情况下,也不会出现数据不一致的问题。
仲裁队列的优点是配置简单、数据强一致,但需要至少 3 个节点,并且在写操作上的延迟和资源消耗可能会比镜像队列高。
@Bean
public Queue quorumQueue(){
return QueueBuilder
.durable("quorum.queue") // 持久化
.quorum() // 仲裁队列
.build();
}
Kafka是如何保证消息不丢失?
需要从三个层面去解决这个问题
生产者发送消息到Brocker丢失
- 设置异步发送,发送失败使用回调进行记录或重发
- 失败重试,参数配置,可以设置重试次数消息
在Brocker中存储丢失
发送确认acks,选择all,让所有的副本都参与保存数据后确认
消费者从Brocker接收消息丢失
- 关闭自动提交偏移量,开启手动提交偏移量
- 提交方式:最好是同步+异步提交
使用Kafka在消息的收发过程中都会出现消息丢失,Kafka分别给出了解决方案
- 生产者发送消息到Brocker丢失
- 消息在Brocker中存储丢失
- 消费者从Brocker接收消息丢失
kafka-高产出的分布式消息系统(A high-throughput distributed messaging system)。
Kafka是一个高吞吐、分布式、基于发布订阅的消息系统,利用Kafka技术可以在廉价的PC Server上搭建起大规模消息系统。
Kafka的特性:
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作;
- 可扩展性:kafka集群支持热扩展;
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败);
- 高并发:支持数千个客户端同时读写;
- 支持实时在线处理和离线处理:可以使用Storm这种实时流处理系统对消息进行实时进行处理,同时还可以使用Hadoop这种批处理系统进行离线处理;
Kafka和其他组件比较,具有消息持久化、高吞吐、分布式、多客户端支持、实时等特性,适用于离线和在线的消息消费,如常规的消息收集、网站活性跟踪、聚合统计系统运营数据(监控数据)、日志收集等大量数据的互联网服务的数据收集场景。
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如Hadoop、Hbase、Solr等;
- 消息系统:解耦和生产者和消费者、缓存消息等;
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到Hadoop、数据仓库中做离线分析和挖掘;
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
- 流式处理:比如spark streaming和storm;
- 事件源;
- kafka在FusionInsight中的位置:
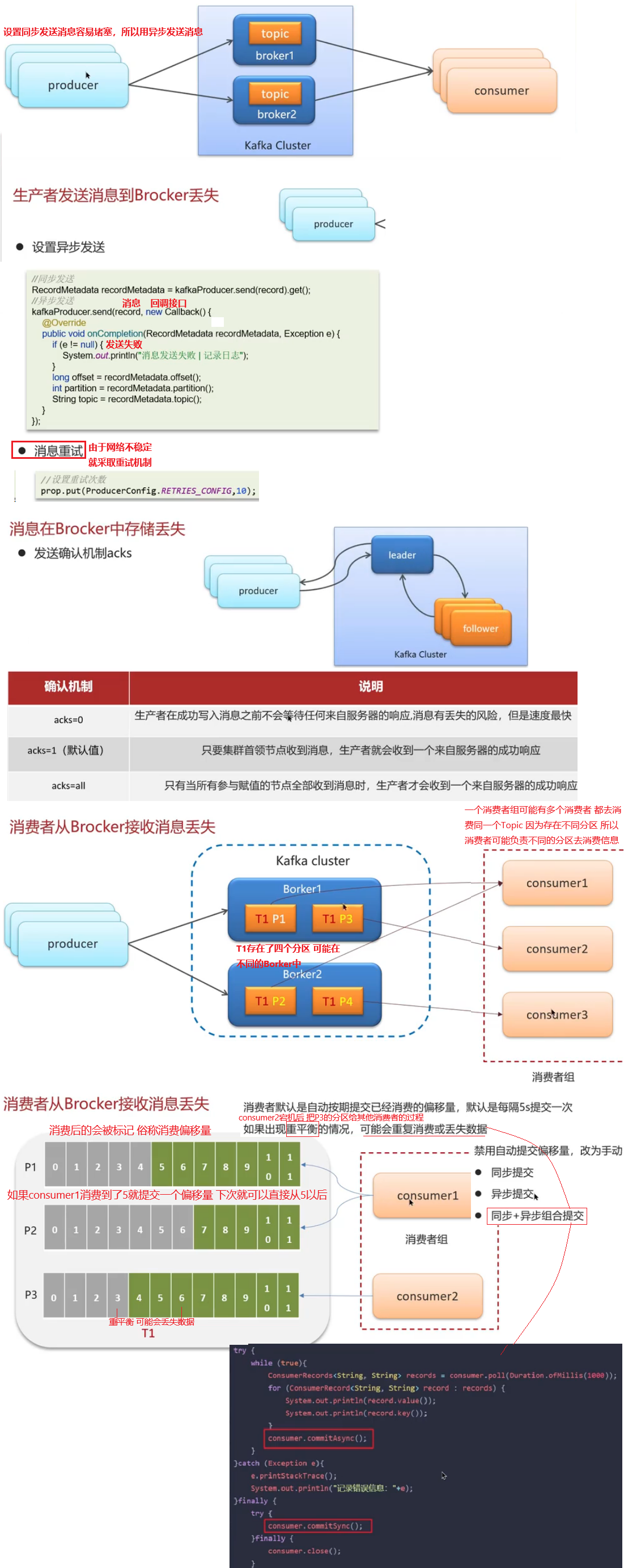
Kafka是如何保证消费的顺序性?
Kafka 保证消息不丢失需要从 生产者、Broker、消费者 三个维度考虑:
- 生产者侧:通过设置
acks=all、启用幂等性(enable.idempotence=true)、配置重试机制等,确保消息可靠送达 Kafka。- Broker 侧:通过消息持久化、
副本同步机制(ISR)、故障转移机制等,确保存储端可靠。- 消费者侧:通过
关闭自动提交 offset,使用手动同步/异步提交,并搭配幂等消费逻辑,避免消息处理丢失。多项机制结合,共同保障 Kafka 在高吞吐、高并发下仍具备良好的可靠性与稳定性。
问题原因:
一个topic的数据可能存储在不同的分区中 ,每个分区都有一个按照顺序的存储的偏移量,如果消费者关联了多个分区不能保证顺序性==解决方案:==
- 发送消息时指定分区号
- 发送消息时按照相同的业务设置相同的key
应用场景:
- 即时消息中的单对单聊天和群聊,保证发送方消息发送顺序与接收方的顺序一致
- 充值转账两个渠道在同一个时间进行金额变更,短信通知必须要有顺序
承接上图消费者从Brocker接收消息丢失:
如何做?→ topic分区中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个分区。
// 指定分区
kafkaTemplate.sent("springboot-kafka-topic",0,"key-001","value-001");
// 相同的业务key
kafkaTemplate.sent("springboot-kafka-topic","key-001","value-001");
会计算key的hashcode值推断出它在哪个分区,如果要求有顺序性 就可以设置同一个key,此时hash值都是一样的 就可以在同一个分区存储
Kafka的高可用机制有了解过吗?
==集群模式==
一个kafka集群由多个broker实例组成,即使某一台宕机,也不会耽误其他broker继续对外提供服务
==分区备份机制==
- 一个topic有多个分区,每个分区有多个副本,有一个leader,其余的是follower,副本存储在不同的broker中
- 所有的分区副本的内容都是相同的,如果leader发生故障时,会自动将其中一个follower提升为leader,保证了系统的容错性、高可用性
✅ 真实业务场景案例:订单创建消息流的高可用设计(基于 Kafka)
🟡 业务背景
你在做一个电商平台系统,其中订单创建之后,需要进行如下异步操作:
- 通知库存中心扣减库存
- 通知积分服务赠送用户积分
- 通知数据中心写入大数据平台(如 HDFS)
为了解耦服务、削峰填谷,并保障消息不丢失,我们决定使用 Kafka 进行消息中转。
🟧 Kafka 高可用设计
▶ 架构图概览(文字版)
[订单服务 OrderService] | | 生产消息 send(order_id=1001) ▼ [Kafka集群 topic=order-create partition=0,1,2] | partition-0:leader 在 broker1,follower 在 broker2,3 | partition-1:leader 在 broker2,follower 在 broker1,3 | partition-2:leader 在 broker3,follower 在 broker1,2 ▼ [消费者集群] ├── 库存服务(group=stock) ├── 积分服务(group=points) └── 数据服务(group=bigdata)🔵 Kafka 高可用机制在这里怎么体现?
✅ 1. Kafka 集群部署(Broker 多节点)
部署 3 个 Kafka Broker:
broker.id=1,2,3 分别配置在三台服务器上即便其中任意一台 Broker 宕机,剩下两台仍然可以继续服务。
✅ 2. Topic 分区 + 副本机制
创建 topic 时设定副本数:
bin/kafka-topics.sh --create \ --topic order-create \ --partitions 3 \ --replication-factor 3 \ --zookeeper zk1:2181
每个分区会有 1 个 leader + 2 个 follower
Leader 负责读写,follower 同步数据
当 Leader 所在 Broker 宕机时,Kafka 会自动从 ISR 列表中选一个 follower 升级为 leader
🔁 例如:原来 partition-0 的 leader 是 broker1
broker1 崩了 → Kafka Controller 会选 broker2 或 broker3 提升为新 leader
✅ 3. 生产者配置 acks=all + 幂等性
为了保障消息可靠写入 Kafka:
props.put("acks", "all"); // 所有副本都确认才算成功 props.put("enable.idempotence", "true"); // 避免重复投递📝 所以生产者即便 retry 了,也不会生成重复消息。
✅ 4. 消费者使用手动提交 offset
为了保证消费者处理完消息再提交 offset,避免消息处理失败却误提交偏移量:
props.put("enable.auto.commit", "false"); while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, String> record : records) { // 处理消息 process(record); } consumer.commitSync(); // 处理完手动提交 }🔻 模拟突发事件:Kafka Broker 宕机,系统是否正常?
❓ 假设 Broker1 宕机,会发生什么?
- partition-0 的 leader 在 broker1 → Kafka Controller 自动将 broker2 提升为新的 leader
- 生产者发送消息依然正常(因为 follower 已同步数据)
- 消费者照常消费 partition-0 的数据
✅ 总结一波这个真实案例带来的知识点
组件 高可用机制 关键作用 Kafka 集群 多 Broker + Controller 任一节点挂掉不影响整体服务 Topic 分区副本 leader + follower 保证消息副本安全、自动故障转移 Producer acks=all + 幂等性 防止生产过程中消息丢失或重复 Consumer 手动提交 offset 避免处理失败误提交偏移量 ❓面试模拟追问
面试官:你们 Kafka 的 leader 挂了会不会影响消费者?
你可以回答:
Kafka 的消费者是从分区的 leader 拉取消息的,如果 leader 节点挂了,Kafka 会自动从 ISR 列表中挑选新的 follower 作为 leader,整个过程对消费者来说是无感知的,消费过程会自动恢复。
解释一下复制机制中的ISR?
ISR (in-sync replica) 需要同步复制保存的follower;跟 Leader 保持同步 的副本集合
分区副本分为了两类,一个是ISR,与leader副本同步保存数据,另外一个普通的副本,是异步同步数据,当leader挂掉后,会优先从ISR副本列表中选取一个作为leaderKafka 每个分区(Partition)都会有多个副本(Replicas):
- 一个 Leader
- 若干个 Follower
这些副本被分成两类:
类型 描述 ISR 副本 与 Leader 保持数据同步的副本(最健康的副本集) OSR(Out-of-Sync Replicas) 落后太多,未能及时同步 Leader 数据的副本 🧠 工作机制详解
1️⃣ 消息写入
- Producer 只写 Leader
- Leader 负责将数据同步到 ISR 中的所有 Follower
- 所有 ISR 成员都成功写入后,才向 Producer 发送
ack如果 Leader 挂了:
- Kafka 只会从 ISR 列表中挑选一个副本晋升为新的 Leader
- 这样可以确保新 Leader 中的数据是完整的
🟩 举个例子助记
假设 topic 有 3 个副本:
Partition-0: - broker1 (Leader) - broker2 (Follower) - broker3 (Follower)此时,**ISR = [broker1, broker2]**(broker3 落后太多,暂不在 ISR 中)
如果 broker1 挂掉了 → Kafka 会从 broker2 中选一个当 Leader(因为它是同步副本)
📌 broker3 不在 ISR 中,就算数据多,也不会被选为 leader(因为可能数据不一致)
Kafka 中每个分区都会有多个副本,其中 ISR(In-Sync Replicas)表示与 Leader 保持同步的副本集合。
ISR 是 Kafka 高可用的重要保障,Kafka 只会从 ISR 中选 leader,避免使用落后副本导致数据丢失。
可以通过配置
min.insync.replicas来控制 ISR 最小数量,从而配合acks=all确保数据写入可靠性。
// 一个topic默认分区的replication个数,不能大于集群中broker的个数。默认为1
default.replication.factor=3
// 最小的ISR副本个数
min.insync.replicas=2
.png)
Kafka数据清理机制了解过吗?
- kafka文件存储机制
- Kafka中topic的数据存储在分区上,分区如果文件过大会分段存储segment
- 每个分段都在磁盘上以索引(xxxx.index)和日志文件(xxx.log)的形式存储
- 分段的好处是,第一能够减少单个文件内容的大小,查找数据方便,第二方便kafka进行日志清理
- 数据清理机制
- 根据消息的保留时间,当消息保存的时间超过了指定的时间,就会触发清理,默认168小时(7天)
- 根据topic存储的数据大小,当topic所占的日志文件大小大于一定的阈值,则开始删除最久的消息(默认关闭)
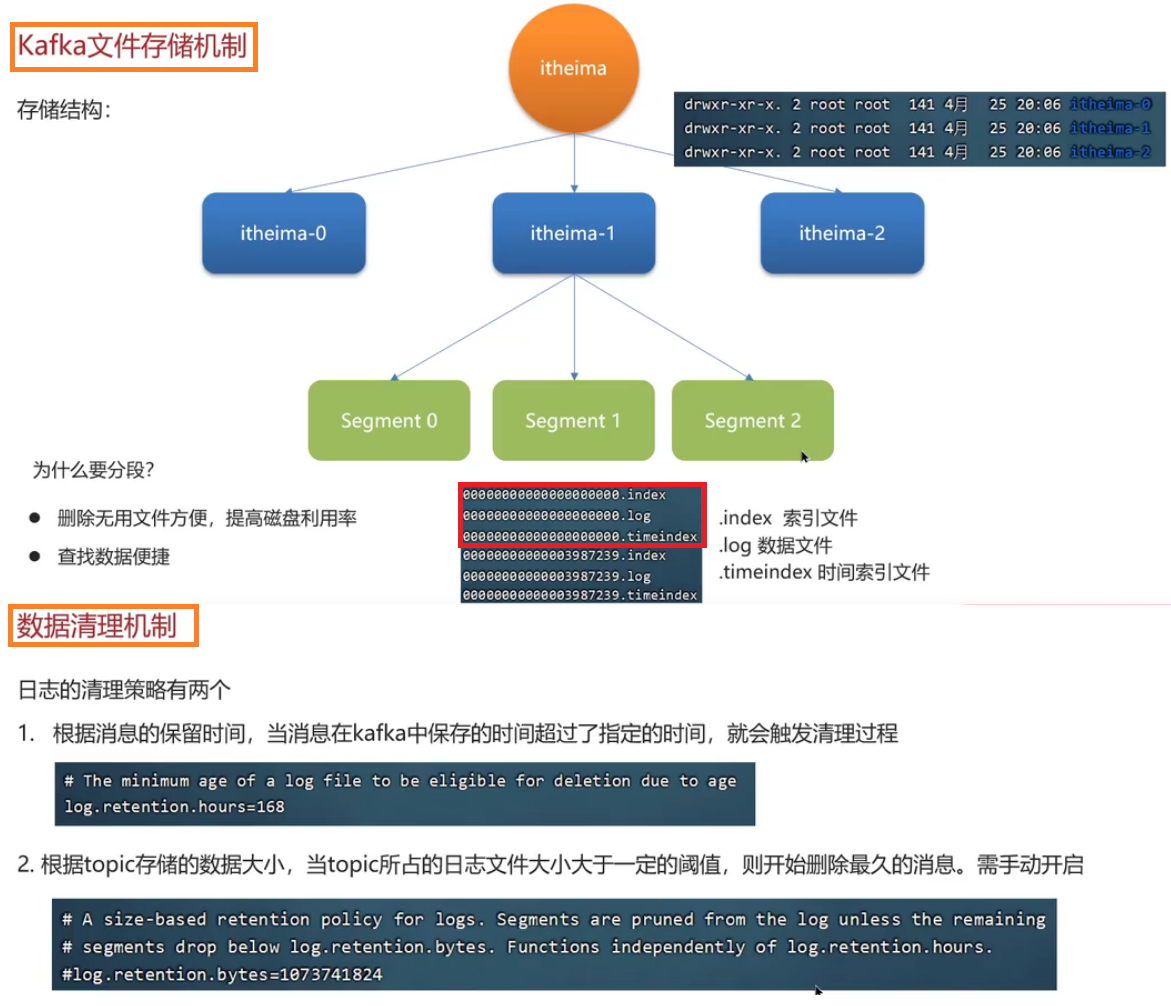
✅ Kafka 和 RabbitMQ 对比
| 对比维度 | Kafka | RabbitMQ |
|---|---|---|
| 核心模型 | 发布-订阅模型(Pub-Sub) | 基于消息队列(Queue) |
| 架构设计 | 分布式、高吞吐、日志存储 | 面向消息、消息中间人 |
| 消息存储 | 持久化日志,磁盘为主,保留时间可配 | 内存为主,结合磁盘,可配置 TTL |
| 性能吞吐量 | 非常高(百万级) | 相对较低(万级) |
| 消息顺序性 | 同一个分区内有序 | 默认无序(队列先进先出 FIFO) |
| 消息重复消费 | 可能(需要幂等性) | 通过消息确认机制避免 |
| 消息确认机制 | Offset 手动提交或自动提交(可恢复) | Ack 机制、可配置手动/自动确认 |
| 可靠性机制 | 副本机制 + ISR 保证 | 持久化、确认机制、死信队列、重试机制 |
| 高可用性 | 分区副本机制 + Leader选举(Raft) | 镜像队列或仲裁队列 |
| 消息丢失保护 | acks=all + min.insync.replicas |
confirm机制 + durable队列 + ack |
| 延迟队列支持 | 原生不支持(需要定时调度或借助外部插件) | 原生支持延迟队列(TTL + 死信队列) |
| 使用场景 | 日志采集、行为跟踪、数据管道、实时流处理 | 任务异步处理、延迟任务、订单超时处理等 |
| 管理界面 | UI界面较弱,需要依赖第三方 | 自带 Web 管理后台,功能强大 |
| 学习曲线 | 略陡峭,需要理解 partition、offset、consumer group 等 | 简单易上手,文档丰富 |
| 协议支持 | Kafka 自有协议 | 支持 AMQP、MQTT、STOMP 等多种协议 |
| 成熟度 | 大数据生态首选,社区活跃,企业常用 | 轻量级场景常用,灵活扩展,适合中小型应用 |
🧠 总结一句话对比
- 🔥 Kafka 更适合:高吞吐、日志/流式处理、大数据实时系统
- 🔧 RabbitMQ 更适合:业务系统间的解耦、任务异步处理、延迟消息机制
Kafka 和 RabbitMQ 都是消息中间件,但定位不同:
- Kafka 是高吞吐、分布式日志系统,更适合大数据场景和实时流式处理,使用 Partition 和 Offset 保证扩展性。
- RabbitMQ 是传统的消息队列中间件,支持 AMQP 协议,适合轻量级业务异步解耦,原生支持延迟队列和消息确认机制。
我们项目中如果要处理高并发日志或用户行为采集就选 Kafka,如果是下单通知、订单超时等场景就更适合 RabbitMQ。
Kafka中实现高性能的设计有了解过吗?
- 消息分区:不受单台服务器的限制,可以不受限的处理更多的数据
- 顺序读写:磁盘顺序读写,提升读写效率
- 页缓存:把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问
- 零拷贝:减少上下文切换及数据拷贝
- 消息压缩:减少磁盘IO和网络IO
- 分批发送:将消息打包批量发送,减少网络开销
零拷贝
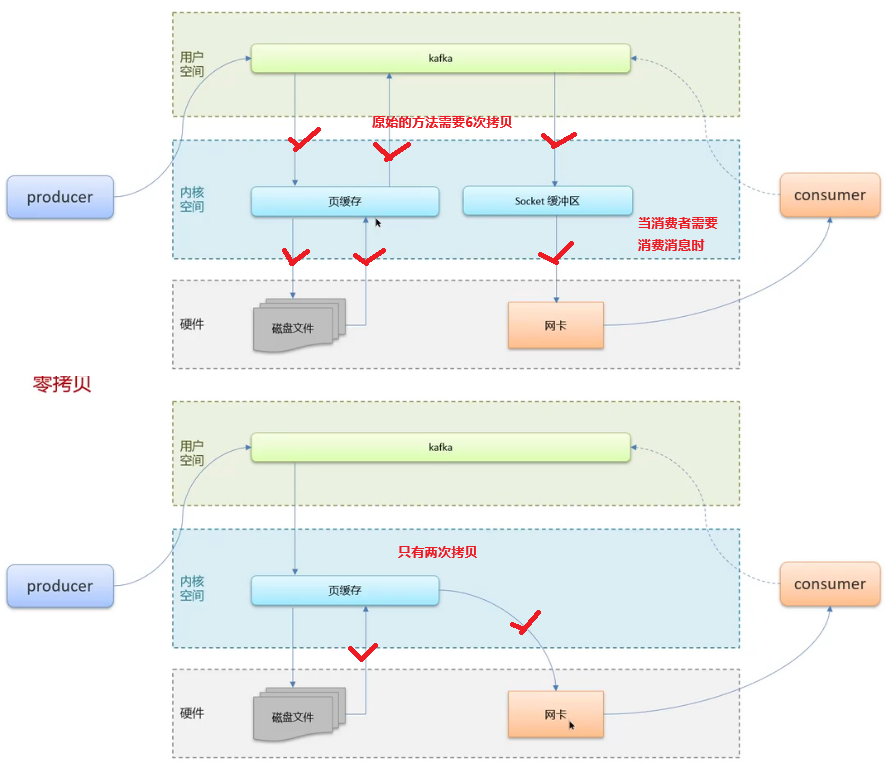
集合面试篇
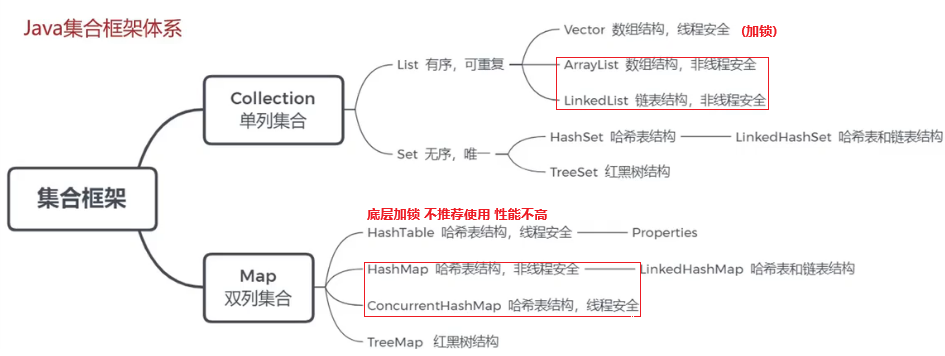
算法复杂度分析
什么是算法时间复杂度?
- 时间复杂度表示了算法的执行时间与数据规模之间的增长关系
常见的时间复杂度有哪些?
口诀:常对幂指阶
- O(1)、O(n)、O(n^2)、O(logn)
什么是算法的空间复杂度?
- 表示算法占用的额外
存储空间和数据规模之间的增长关系
常见的空间复杂度:O(1)、O(n)、O(n^2)
为什么要进行复杂度分析?
- 指导你编写出性能更优的代码
- 评判别人写的代码的好坏
时间复杂度分析:来评估代码的执行耗时的
大O表示法:不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势
只要代码的执行时间**不随着n的增大而增大,这样的代码复杂度都是O(1)**
复杂度分析就是要弄清楚代码的执行次数和数据规模n之间的关系
时间复杂度:全称是渐进空间复杂度,表示算法占用的额外存储空间和数据规模之间的增长关系

List相关面试题
数组是一种用连续的内存空间存储相同数据类型数组的线性数据结构
数组下标为什么从0开始
寻址公式是:
baseAddress + i * data TypeSize计算下标的内存地址效率较高查找的时间复杂度
- 随机(通过下标)查询的时间复杂度是O(1)
- 查找元素(未知下标)的时间复杂度是O(n)
- 查找元素(未知下标但排序)通过二分查找的时间复杂度是O(logn)
插入和删除时间复杂度
插入和删除的时候,为了保证数组的内存连续性,需要挪动数组元素,平均复杂度为O(n)
底层实现
- 数据结构—数组
- ArrayList源码分析
面试问题
- ArrayList底层的实现原理是什么
- ArrayList list = new ArrayList(10)中的list扩容几次
- 如何实现数组和List之间的转换
- ArrayList和LinkedList的区别是什么

ArrayList源码分析
List< Integer > list = new ArrayList< Integer >();
list.add(1)
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
private static final long serialVersionUID = 8683452581122892189L;
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 用于空实例的共享空数组实例
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* 用于默认大小的空实例的共享空数组实例
* 与上面的区分开,以了解添加第一个元素时要膨胀多少
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/* 存储ArrayList元素的数组缓冲区,ArrayList的容量就是这个数组缓冲区的长度 */
transient Object[] elementData; // non-private to simplify nested class access
/**
* ArrayList的大小(包含的元素数量)
* @serial
*/
private int size;
...
}
--------------------------------------------------------------------------------
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
// 创建一个真正存储集合位置的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
// 如果容量是0则创建一个新的数组给elementData
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
// 无参构造函数,默认创建空集合
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
-------------------------------------------------------------------------------
// Collection是所有单列集合的父接口
// 将 Collection 对象转换成数组,然后将数组的地址赋给 elementData
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// 判断集合类型是否为不为object[]
// 在其他jdk此处是 ?? == ArrayList.class
if (elementData.getClass() != Object[].class)
// 不是的话就拷贝到数组elementData中
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
ArrayList源码分析-添加和扩容操作(第1次添加数据)

ArrayList底层的实现原理是什么
- ArrayList底层是用动态数组实现的
- ArrayList初始容量为0,当第一次添加数据的时候才会初始化容量为10
- ArrayList在进行扩容的时候是原来容量的1.5倍,每次扩容都需要拷贝数组
- ArrayList在添加数据的时候
- 确保数组已使用长度(size)加1之后足够存下下一个数据
- 计算数组的容量,如果当前数组已使用长度+1后的大于当前的数组长度,则调用
grow方法扩容(原来的1.5倍) - 确保新增的数据有地方存储之后,则将新元素添加到位于size的位置上
- 返回添加成功布尔值
ArrayList list = new ArrayList(10)中的list扩容几次
- 该语句只是声明和实例了一个
ArrayList,指定了容量为10,未扩容
如何实现数组和List之间的转换
- 数组转List,使用JDK中
java.util.Arrays工具类的asList方法 - List转数组,使用List的
toArray方法,无参toArray方法返回Object数组,传入初始化长度的数组对象,返回该对象数组
使用 Hutool 工具库可以非常方便地实现数组和
List之间的转换。Hutool 提供了ArrayUtil和CollUtil工具类来处理数组和集合之间的转换。问:我不能用BeanUtil吗?
答:BeanUtil是 Hutool 工具库中用于 Java Bean 操作的工具类,主要用于 对象属性拷贝、Bean 转 Map、Map 转 Bean 等操作。它并不适用于 数组和 List 之间的转换。如果你误以为
BeanUtil可以用于数组和 List 的转换,可能是因为它的名字容易让人误解。实际上,数组和 List 的转换应该使用ArrayUtil或CollUtil。正确的工具类选择
- 数组转 List:使用
ArrayUtil.toList。- List 转数组:使用
CollUtil.toArray。- Bean 属性拷贝:使用
BeanUtil.copyProperties。- Bean 转 Map:使用
BeanUtil.beanToMap。- Map 转 Bean:使用
BeanUtil.fillBeanWithMap。更多的Hutool工具使用
高能预警1. 字符串工具类:
StrUtil
- 功能:字符串操作,如判空、格式化、截取、替换等。
- 常用方法:
StrUtil.isEmpty():判断字符串是否为空。StrUtil.format():格式化字符串。StrUtil.split():拆分字符串。StrUtil.join():连接字符串。
2. 日期时间工具类:
DateUtil
- 功能:日期和时间的格式化、解析、计算等。
- 常用方法:
DateUtil.now():获取当前时间。DateUtil.format():格式化日期。DateUtil.parse():解析字符串为日期。DateUtil.offsetDay():日期加减。
3. 文件工具类:
FileUtil
- 功能:文件和目录的操作,如读写、复制、删除等。
- 常用方法:
FileUtil.readUtf8String():读取文件内容为字符串。FileUtil.writeUtf8String():将字符串写入文件。FileUtil.copy():复制文件或目录。FileUtil.del():删除文件或目录。
4. JSON 工具类:
JSONUtil
- 功能:JSON 的解析和生成。
- 常用方法:
JSONUtil.parseObj():将 JSON 字符串解析为 JSON 对象。JSONUtil.parseArray():将 JSON 字符串解析为 JSON 数组。JSONUtil.toJsonStr():将对象转换为 JSON 字符串。
5. 集合工具类:
CollUtil
- 功能:集合操作,如创建集合、判空、过滤、分组等。
- 常用方法:
CollUtil.newArrayList():快速创建 ArrayList。CollUtil.isEmpty():判断集合是否为空。CollUtil.filter():过滤集合。CollUtil.group():对集合进行分组。
6. 反射工具类:
ReflectUtil
- 功能:反射操作,如调用方法、获取字段、创建对象等。
- 常用方法:
ReflectUtil.invoke():调用方法。ReflectUtil.getFieldValue():获取字段值。ReflectUtil.newInstance():创建对象实例。
7. HTTP 工具类:
HttpUtil
- 功能:HTTP 请求的发送和响应处理。
- 常用方法:
HttpUtil.get():发送 GET 请求。HttpUtil.post():发送 POST 请求。HttpUtil.downloadFile():下载文件。
8. 加密解密工具类:
SecureUtil
- 功能:常见的加密解密操作,如 MD5、SHA、AES 等。
- 常用方法:
SecureUtil.md5():计算 MD5 值。SecureUtil.sha256():计算 SHA-256 值。SecureUtil.aes():AES 加密解密。
9. IO 工具类:
IoUtil
- 功能:IO 流操作,如读写、关闭流等。
- 常用方法:
IoUtil.read():读取流内容。IoUtil.write():写入流内容。IoUtil.close():关闭流。
10. 随机工具类:
RandomUtil
- 功能:生成随机数、随机字符串等。
- 常用方法:
RandomUtil.randomInt():生成随机整数。RandomUtil.randomString():生成随机字符串。RandomUtil.randomEle():从集合中随机选择一个元素。
11. 验证工具类:
Validator
- 功能:数据验证,如邮箱、手机号、身份证等。
- 常用方法:
Validator.isEmail():验证是否为邮箱。Validator.isMobile():验证是否为手机号。Validator.isCitizenId():验证是否为身份证号。
12. 缓存工具类:
CacheUtil
- 功能:简单的缓存操作。
- 常用方法:
CacheUtil.newTimedCache():创建定时缓存。CacheUtil.put():添加缓存。CacheUtil.get():获取缓存。
13. 线程工具类:
ThreadUtil
- 功能:线程操作,如睡眠、创建线程池等。
- 常用方法:
ThreadUtil.sleep():线程睡眠。ThreadUtil.newExecutor():创建线程池。
14. Excel 工具类:
ExcelUtil
- 功能:Excel 文件的读写操作。
- 常用方法:
ExcelUtil.getReader():读取 Excel 文件。ExcelUtil.getWriter():写入 Excel 文件。
15. 压缩工具类:
ZipUtil
- 功能:文件或目录的压缩和解压缩。
- 常用方法:
ZipUtil.zip():压缩文件或目录。ZipUtil.unzip():解压缩文件。
16. 日志工具类:
Log
- 功能:简化日志操作。
- 常用方法:
Log.get():获取日志对象。Log.info():输出日志信息。
17. 数学工具类:
MathUtil
- 功能:数学计算,如四舍五入、最大值、最小值等。
- 常用方法:
MathUtil.round():四舍五入。MathUtil.max():获取最大值。MathUtil.min():获取最小值。
18. 网络工具类:
NetUtil
- 功能:网络相关操作,如获取本机 IP、Ping 等。
- 常用方法:
NetUtil.getLocalhost():获取本机 IP。NetUtil.ping():Ping 测试。
- 用
Arrays.asList转List后,如果修改了数组内容,list受影响吗 - List用
toArray转数组后,如果修改了List内容,数组受影响吗
再答:
- Arrays.asList转换list之后,如果修改了数组的内容,list会受影响,因为它的底层使用的Arrays类中的一个内部类ArrayList来构造的集合,在这个集合的构造器中,把我们传入的这个集合进行了包装而已,最终指向的都是同一个内存地址
- list用了toArray转数组后,如果修改了list内容,数组不会受影响,当调用了toArray以后,在底层是它进行了数组拷贝,跟原来的元素就没啥关系了,所以即使list修改了以后,数组也不受影响

LinkedList的数据结构—链表
单向链表
- 链表中的每一个元素称之为结点(Node)
- 物理存储单元上,非连续、非顺序的存储结构
- 单向链表:每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。记录下个结点地址的指针叫作后继指针 next
1.单向链表和双向链表的区别是什么
- 单向链表只有一个方向,结点只有一个后继指针 next。
- 双向链表它支持两个方向,每个结点不止有一个后继指针next指向后面的结点,还有一个前驱指针prev指向前面的结点
2.链表操作数据的时间复杂度是多少
| 查询 | 新增删除 | |
|---|---|---|
| 单向链表 | 头O(1), 其他O(n) | 头O(1), 其他O(n) |
| 双向链表 | 头尾O(1), 其他O(n), 给定节点O(1) | 头尾O(1), 其他O(n), 给定节点O(1) |
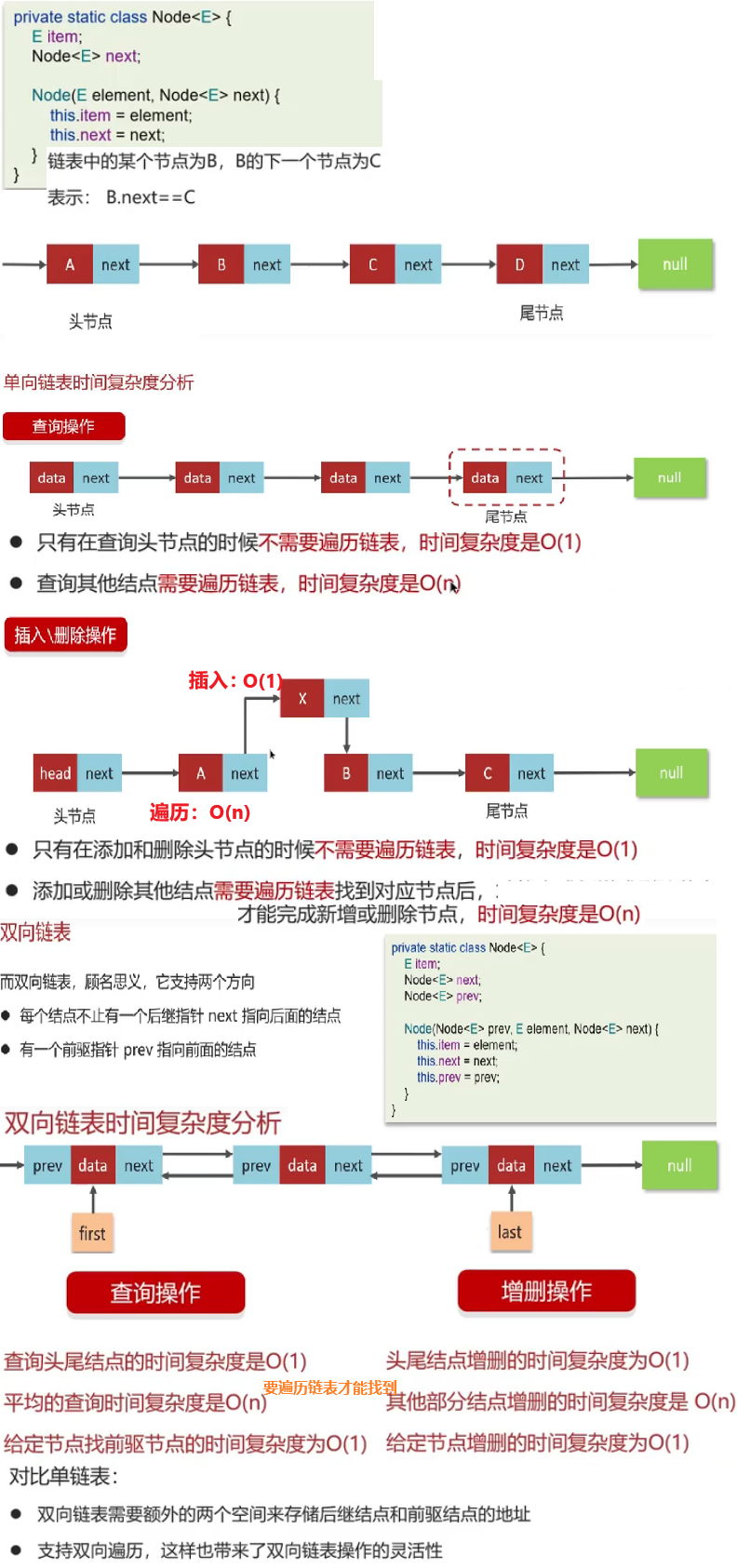
ArrayList和LinkedList的区别
底层数据结构
- ArrayList 是动态数组的数据结构实现
- LinkedList 是双向链表的数据结构实现
操作数组效率
ArrayList 按照下标查询的时间复杂度O(1);【内存是连续的,根据寻址公式】,LinkedList不支持下标查询
查找(未知索引):ArrayList需要遍历,链表也需要遍历,时间复杂度都是O(n)
新增和删除【查询多用
ArrayList;插入/删除多用Linked】- ArrayList 尾部插入和删除,时间复杂度是O(1);其他部分增删需要挪动数组,时间复杂度是O(n)
- LinkedList 头尾节点增删时间复杂度是O(1),其他都需要遍历链表,时间复杂度是O(n)
内存空间占用
- ArrayList 底层是数组,内存连续,节省内存
- LinkedList 是双向链表需要存储数据,和两个指针,更占用内存
线程安全
ArrayList和LinkedList都不是线程安全的
如果要保证线程安全,有两种方法
在方法内使用,局部变量则是线程安全的
使用线程安全的ArrayList和LinkedList
List<Object> syncArrayList = Collections.synchronizedList(new ArrayList<>()); List<Object> syncLinkedList = Collections.synchronizedList(new LinkedList<>());
HashMap相关面试题
二叉树
满二叉树
完全二叉树
二叉搜索树
二叉搜索树又名二叉查找树,有序二叉树或者排序二叉树,是二叉树中比较常用的一种类型二叉查找树要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值
红黑树
红黑树
散列表
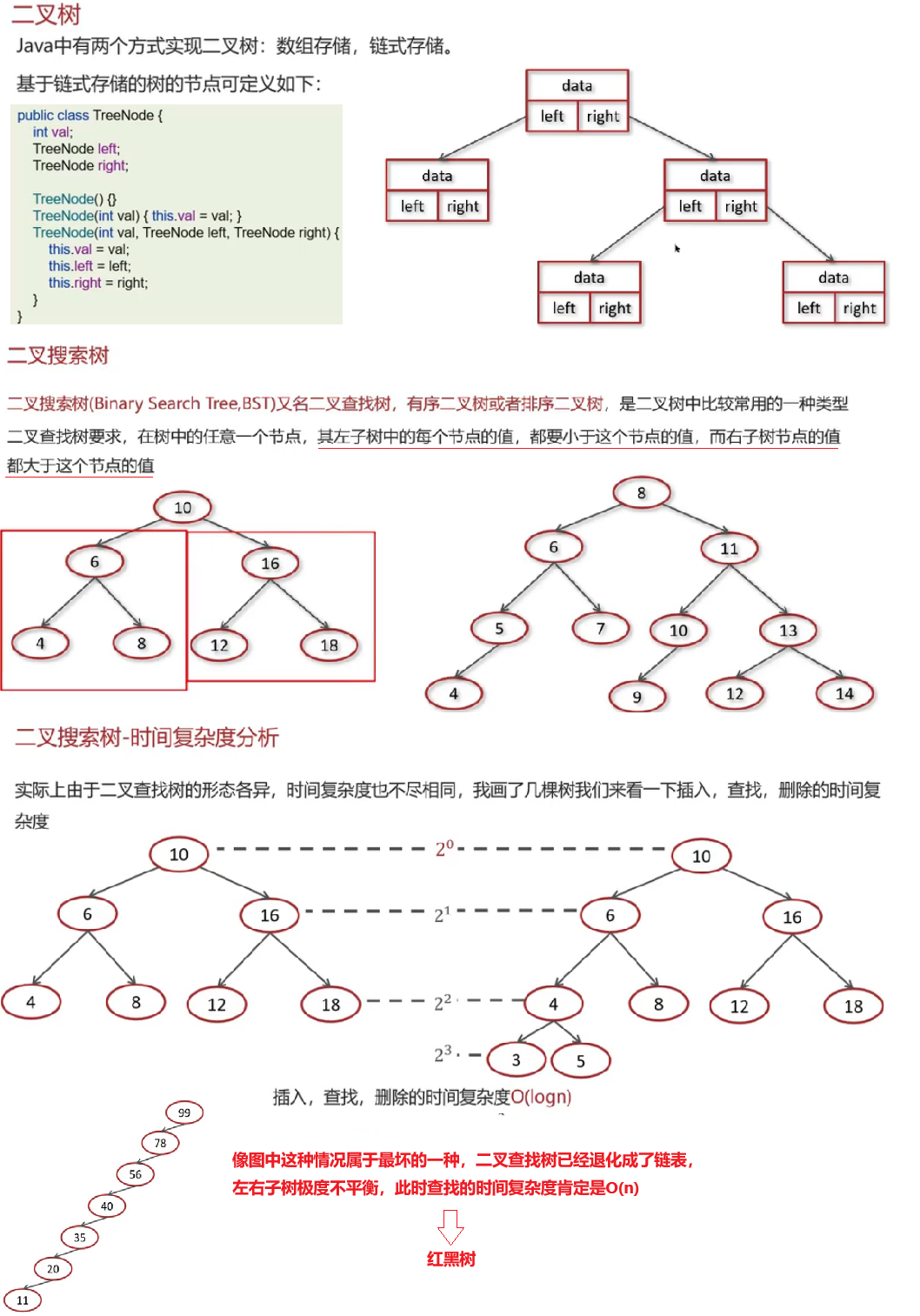
✅ 1. 二叉树(Binary Tree)
每个节点最多有两个子节点,称为左子节点和右子节点。
✅ 2. 满二叉树(Full Binary Tree)
每个节点要么是叶子节点,要么恰好有两个子节点,且所有叶子都在同一层。
✅ 3. 完全二叉树(Complete Binary Tree)
除了最后一层,其他每一层的节点数都达到最大值,且最后一层节点集中在左侧。
✅ 4. 二叉搜索树(Binary Search Tree,BST)
又叫:二叉查找树、有序二叉树
特点:
- 对于任意一个节点
node:
- 左子树中所有节点值 <
node值- 右子树中所有节点值 >
node值- 中序遍历是升序排列
用途:
- 用于快速查找、插入、删除(时间复杂度平均为 O(log n),最坏为 O(n))
✅ 5. 红黑树(Red-Black Tree)
红黑树是自平衡的二叉搜索树,在多种语言的底层集合结构(如 Java 的
TreeMap、TreeSet,C++ 的map、set)都有使用。特点:
- 每个节点是红或黑
- 根节点是黑色
- 每个叶子节点(NIL)是黑色
- 红色节点不能有红色子节点(即不能连续两个红)
- 任意一节点到其所有后代叶子节点的路径上,黑色节点数量相同
目的:
- 保证在最坏情况下,查找、插入、删除的时间复杂度是 O(log n)
✅ 6. 散列表(Hash Table)
与树不同,散列表是通过哈希函数(Hash Function)将键映射到数组下标进行查找。
特点:
- 查找时间接近 O(1)
- 冲突处理方式如链地址法、开放定址法等
- 用于实现如 Java 的
HashMap、HashSet、Python 的dict、set等结构
数据结构—红黑树 什么是红黑树?
- 红黑树:也是一种自平衡的二叉搜索树(BST)
- 所有的红黑规则都是希望红黑树能够保证平衡
- 红黑树的时间复杂度:查找、添加、删除都是O(logn)
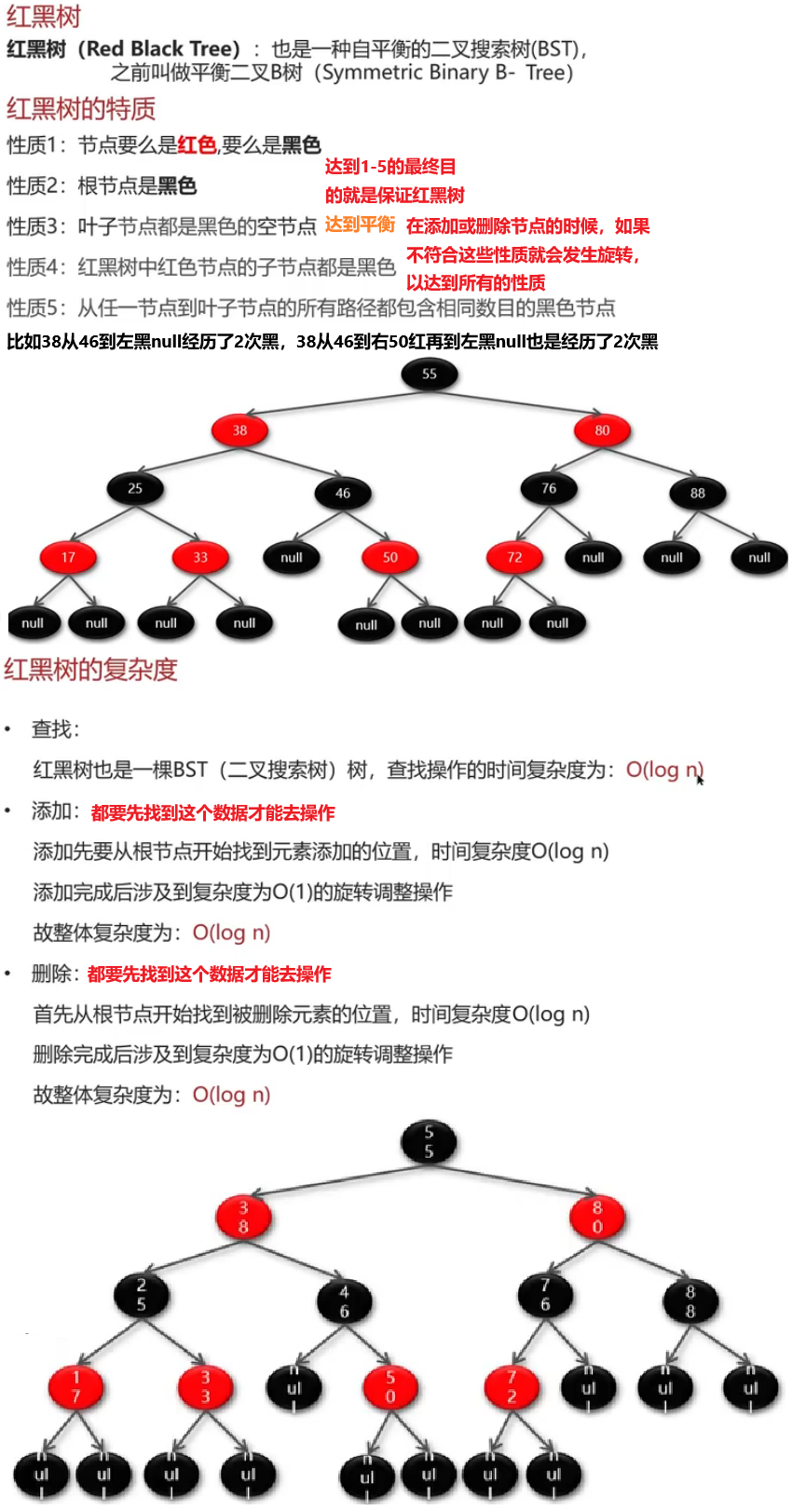
散列表
什么是散列表?
- 散列表(Hash Table)又叫哈希表/Hash表
- 根据键(Key)直接访问再内存存储位置值(Value)的数据结构
- 由数组演化而来的,利用了数组支持按照下标进行随机访问数据
散列冲突
- 散列冲突又成为哈希冲突,哈希碰撞
- 指多个key映射到同一个数组下标位置
散列冲突—链表法(拉链)
- 数组的每个下标位置称之为桶(bucket) 或者 槽(slot)
- 每个桶(槽)会对应一条链表
- hash冲突后的元素都放到相同槽位对应的链表中或红黑树中
在HashMap中的最重要的一个数据结构就是散列表,在散列表中又用到了红黑树和链表
散列表(Hash Table)又名为哈希表/Hash表,是根据键(Key)直接访问在内存存储位置值(value)的数据结构,它是由数组演化而来的,利用了数组支持按照下标进行随机访问数据的特性[根据寻址公式,时间复杂度O(1)]
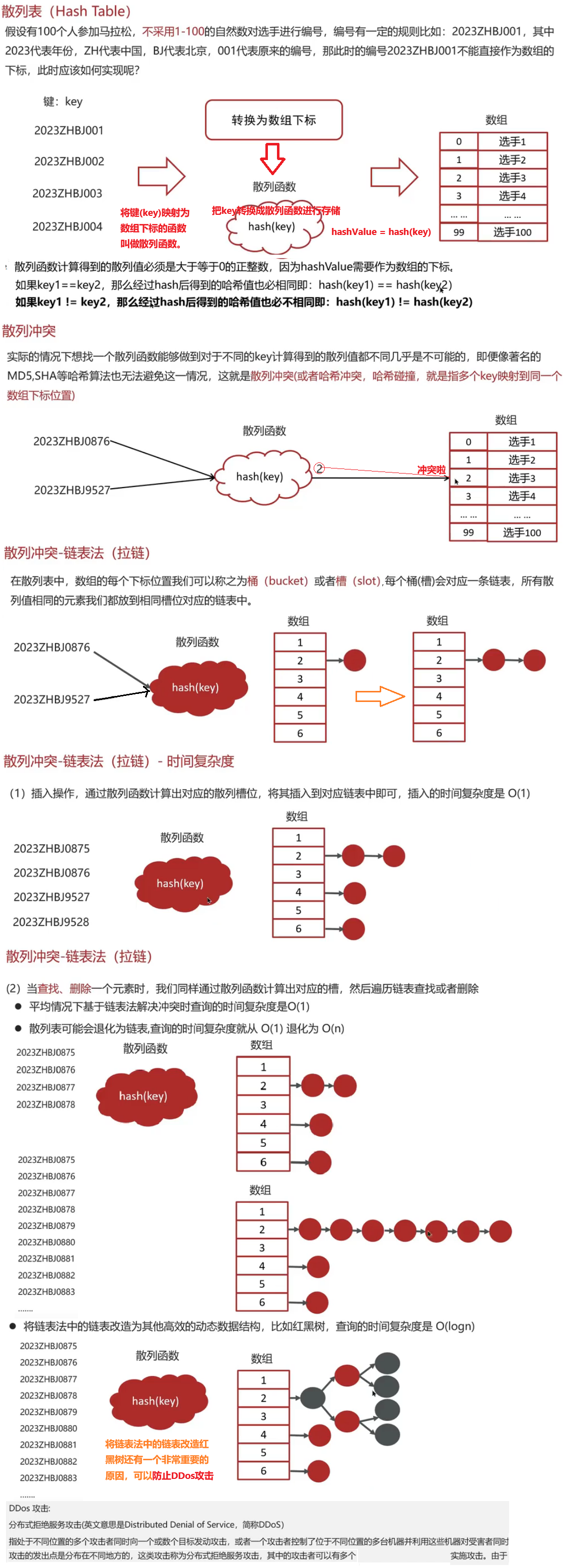
说一下HashMap的实现原理
1.说一下HashMap的实现原理
HashMap的数据结构:底层使用hash表数据结构,即数组和链表或红黑树
添加数据时,计算key的值确定元素在数组中的下标
- key相同则替换
- 不同则存入链表或红黑树中
获取数据通过key的hash计算数组下标获取元素
2.HashMap的jdk1.7和jdk1.8有什么区别
- JDK1.8之前采用的拉链法,数组+链表
- JDK1.8之后采用数组+链表+红黑树
链表长度大于8且数组长度大于64则会从链表转化为红黑树
当我们往HashMap中put元素时(扰动函数),利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
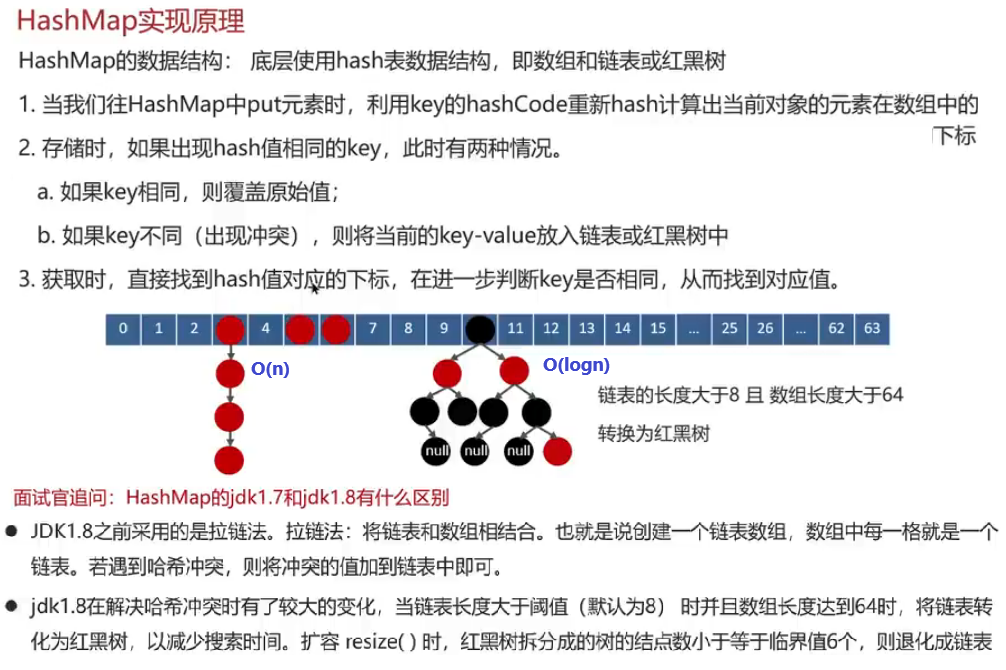
HashMap的put方法的具体流程
1.判断键值对数组table是否为空或为null,否则执行resize()进行扩容 [初始化]
2.根据键值key计算hash值得到数组索引
3.判断table[i] == null,条件成立,直接新建节点添加
4.如果table[i] == null,不成立
4.1 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
4.2 判断table[i]是否为treeNode,即table[i]是否是红黑树,如果是红黑树,则直接在树中插入键值对
4.3 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,遍历过程中若发现key已经存在直接覆盖value
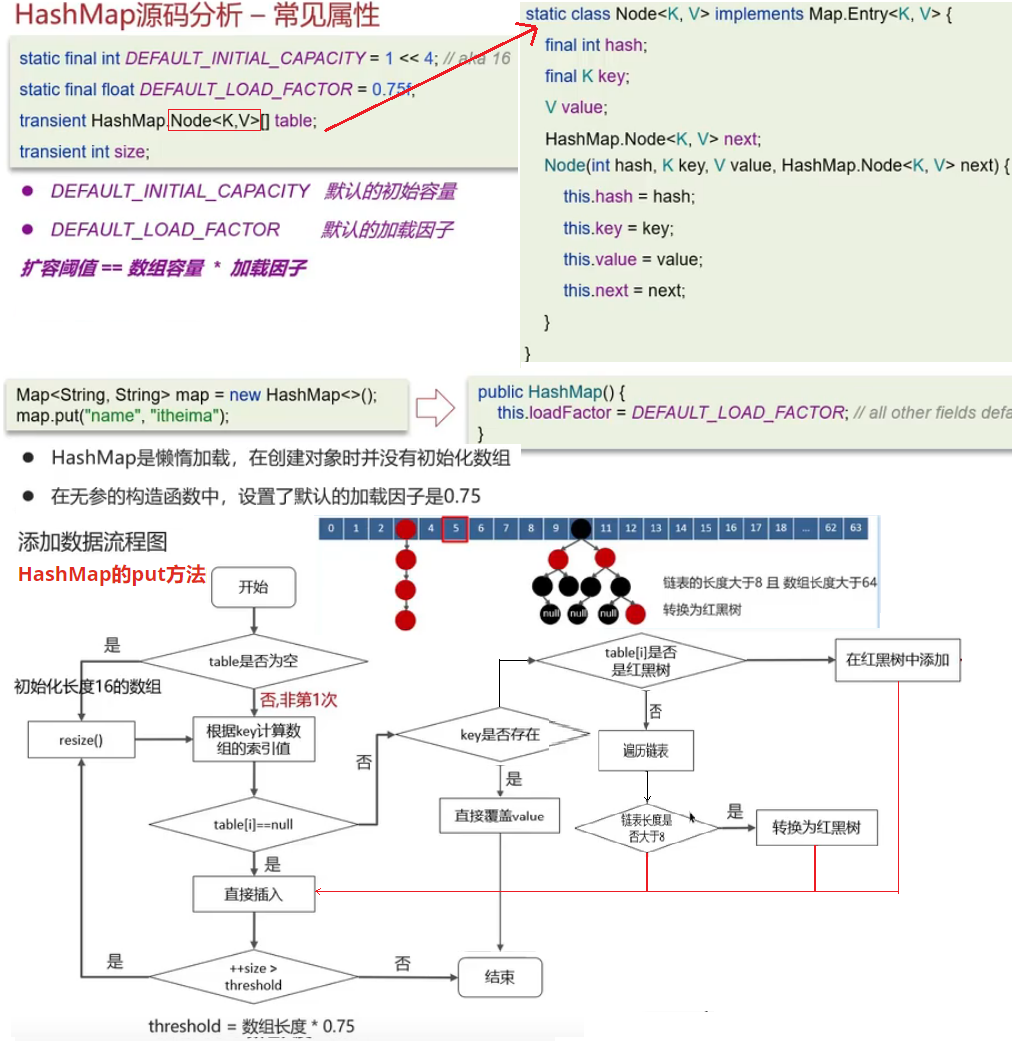
讲一下HashMap的扩容机制
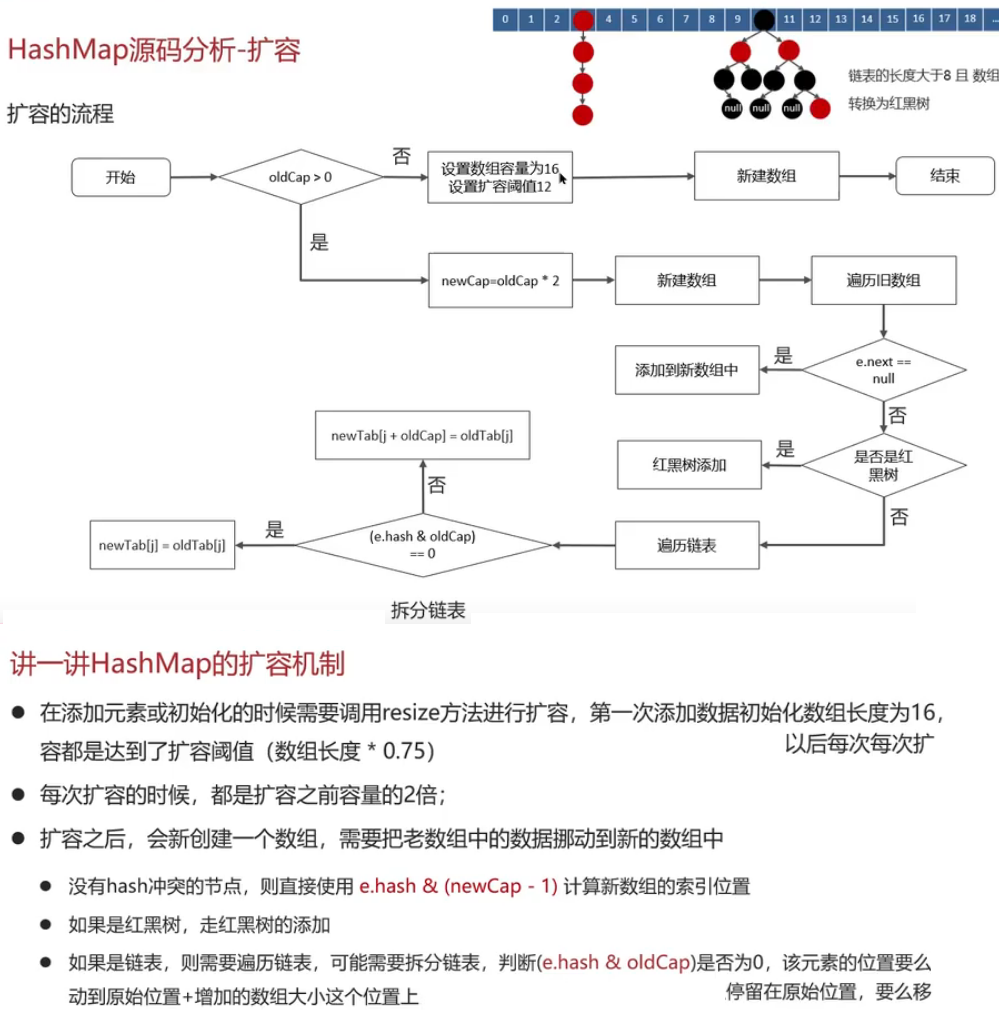
HashMap源码分析
桶下标是hash值取模数组(长度)下标 capacity
HashMap的寻址算法
Hash值右移16位后与原来的hash值进行异或运算【扰动算法hash值更加均匀,减少hash冲突】
数组长度必须是2的n次幂 按位与运算的效果才能代替取模
int hash = h ^ (h >>> 16); // hashCode 的扰动处理
index = hash & (table.length - 1); // 更快的取模运算
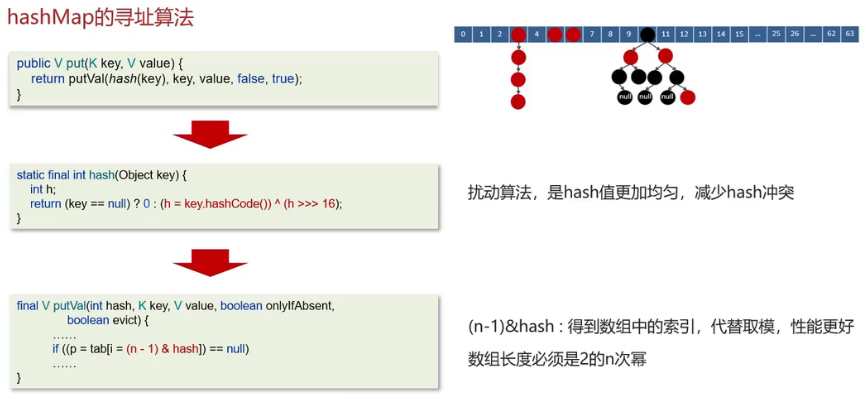
HashMap在1.7情况下的多线程死循环问题
jdk7的数据结构是:数组+链表
在数组进行扩容的时候,因为链表是头插法(在并发情况下可能出现链表反转成环形结构),在进行数据迁移的过程中,有可能导致死循环
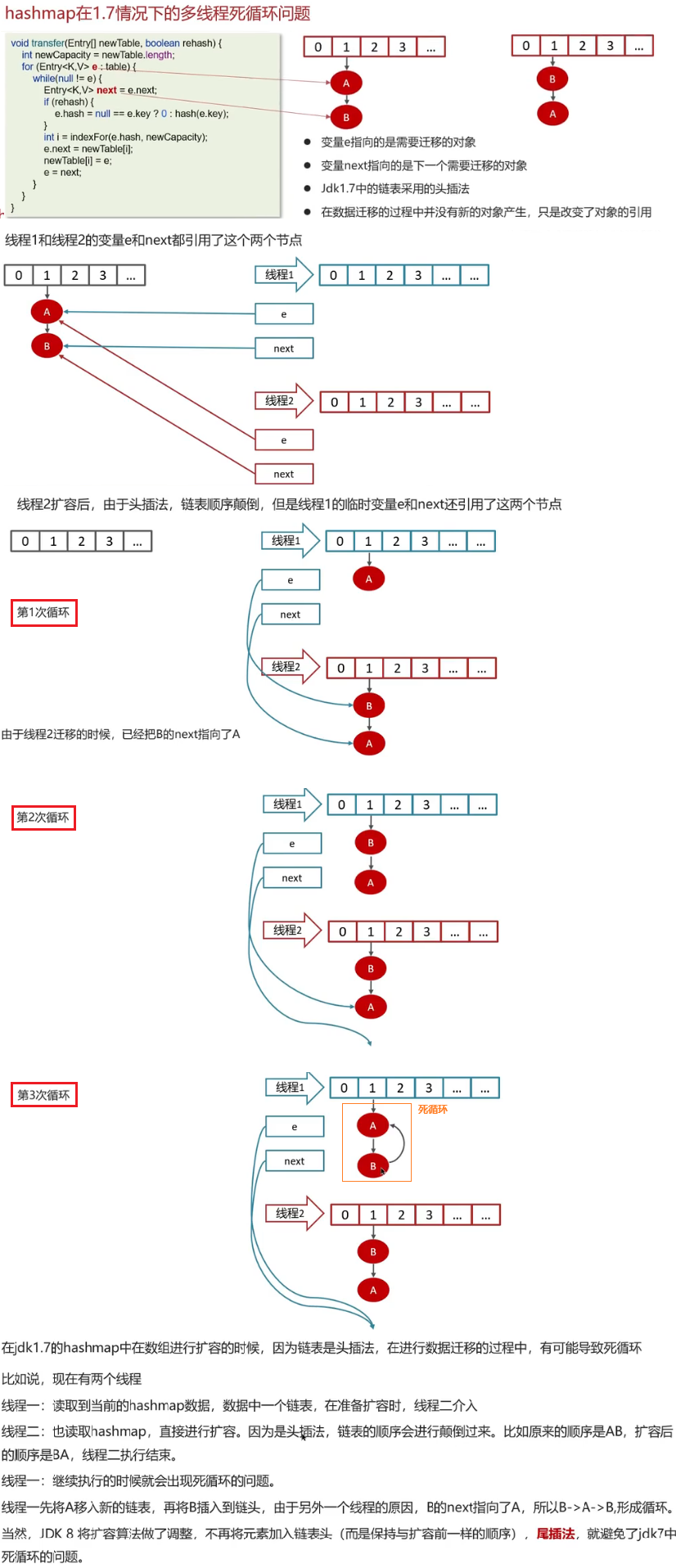
进程和线程的区别?
两者对比:
- 进程是整个在运行程序的实例,进程中包含了线程,每个线程执行不同的任务
- 不同的进程使用不同的内存空间,在当前进程下的所有线程可以共享内存空间
- 线程更轻量,线程上下文切换成本一般上要比进程上下文切换低(上下文切换指的是从一个线程切换到另一个线程)
类型 简要定义 进程 程序的执行实例,资源分配的最小单位 线程 进程内的执行单元,cpu调度的最小单位
项目 进程 线程 概念 正在运行的程序实例 进程中的执行单元 所属关系 进程可包含多个线程 线程依附于进程存在 内存空间 拥有独立地址空间 共享所属进程的内存空间 创建开销 创建/销毁成本高(需要资源分配) 创建/销毁成本低(共享资源) 通信方式 进程间通信较复杂(如管道/套接字) 线程通信简单(共享变量) 崩溃影响 一个进程崩溃不会影响其他进程 一个线程崩溃可能影响整个进程 切换开销 上下文切换开销大 上下文切换开销小 资源隔离 资源独立,安全性高 资源共享,效率高但易出错 [ 进程A ] ├── 线程1:负责计算 ├── 线程2:负责文件IO └── 线程3:负责网络通信 [ 进程B ] └── 线程1:完全独立
程序由指令和数据组成,但这些指令要运行,数据要读写,就必须将指令加载至CPU,数据加载至内存。在指令运行过程中还需要用到磁盘、网络等设备,进程就是用来加载指令、管理内存、管理IO的。
当一个程序被运行,从磁盘加载这个程序的代码至内存,这时就开启了一个**进程**
一个线程就是一个指令流,将指令流中的一条条指令以一定的顺序交给CPU执行。一个进程之内可以分为一到多个线程
core → 线程1[指令1,指令2,指令3…] 线程2[指令1,指令2,指令3…]
并行和并发的区别?
现在都是多核CPU,在多核CPU下
- 并发是同一时间应对多件事情的能力,多个线程轮流使用一个或多个CPU
- 并行是同一时间动手做多件事的能力,4核CPU同时执行4个线程
概念 定义 并发 同一时间段处理多个任务的能力(任务轮流切片执行) 并行 同一时刻真正同时执行多个任务(多个核同时执行)
==单核CPU== → 单核CPU下线程实际还是串行执行的
- 操作系统中有一个组件叫做任务调度器,将cpu的时间片(windows下时间片最小约为15ms)分给不同的程序使用,只是由于cpu在线程间(时间片很短)的切换非常快,人类感觉是同时运行的
- 每个时间片只能用有一个线程被执行
- 总结一句话:**微观串行,宏观并行**
- 一般会将这种线程轮流使用CPU的做法称为并发(concurrent)
| CPU | 时间片1 | 时间片2 | 时间片3 |
|---|---|---|---|
| core | 线程1 | 线程2 | 线程3 |
==多核CPU== → 每个核(core)都可以调度运行线程,这个时候线程是可以并行的
| CPU | 时间片1 | 时间片2 | 时间片3 | 时间片4 |
|---|---|---|---|---|
| core1 | 线程1 | 线程2 | 线程3 | 线程3 |
| core2 | 线程2 | 线程4 | 线程2 | 线程4 |
并发 (concurrent) 是同一时间应对 (dealing with) 多件事情的能力
并行 (parallel) 是同一时间动手做 (doing) 多件事情的能力
- 家庭主妇做饭、打扫卫生、给孩子喂奶,她一个人轮流交替做这么多件事,这就是并发【单核CPU】
- 家庭主妇雇了个保姆,她们一起做这些事,这时既有并发,也有并行【会产生竞争,例如锅只有一个,一个人用锅时,另一个人就要等待】
- 雇了3个保姆,一个专门做饭,一个专门打扫卫生,一个专门喂奶,互不干扰,这就是并行
创建线程的方式有哪些?
public class MyThread extends Thread{
@Override
public void run(){
sout("MyThread...run...");
}
public static void main(String[] args){
// 创建MyThread对象
MyThread t1 = new MyThread();
MyThread t2 = new MyThread();
// 调用start方法启动线程
t1.start();
t2.start();
}
}
public class MyRunnable implements Runnable {
@Override
public void run() {
// 在这里编写要执行的任务
System.out.println("线程正在执行任务...");
}
public static void main(String[] args) {
// 创建MyRunnable实例
MyRunnable myRunnable = new MyRunnable();
// 创建线程并启动
Thread t1 = new Thread(myRunnable);
Thread t2 = new Thread(myRunnable);
// 调用start方法启动线程
t1.start();
t2.start();
}
}
public class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
sout(Thread.currentThread().getName());
return "ok";
}
public static void main(String[] args) {
// 创建MyCallable实例
MyCallable myCallable = new MyCallable();
// 使用FutureTask来包装Callable对象
FutureTask<String> ft = new FutureTask<String>(myCallable);
// 创建并启动线程
Thread t1 = new Thread(ft);
t1.start();
// 调用ft的get方法获取执行结果
String result = ft.get();
sout(result)
}
}
public class MyExecutors implements Runnable{
@Override
public void run(){
sout("MyRunnable...run...");
}
public static void main(String[] args){
// 创建线程池对象
ExecutorService threadPool = Executors.newFixedThreadPool(3);
threadPool.submit(new MyExecutors());
//submit用来提交线程
// 关闭线程池
threadPool.shutdown();
}
}
刚刚你说过,使用runnable和callable都可以创建线程,它们有什么区别呢?
- Runnable接口run方法没有返回值
- Callable接口call方法有返回值,要结合FutureTask配合可以用来获取异步执行的结果
FutureTask是Future的实现类,它可以包装一个Callable或Runnable对象,并允许我们在任务执行完毕后获取执行结果或取消任务。
FutureTask可以在子线程中异步执行任务,而主线程可以通过调用FutureTask.get()方法获取任务执行的结果。
- Callable接口的call()方法允许抛出异常;而Runnabble接口的run()方法的异常只能在内部消化,不能继续上抛
import java.util.concurrent.Callable; import java.util.concurrent.FutureTask; public class CallableExample { public static void main(String[] args) throws Exception { // 创建一个Callable任务 Callable<Integer> task = new Callable<Integer>() { @Override public Integer call() throws Exception { System.out.println("Task is running in the background..."); // 模拟耗时操作 Thread.sleep(2000); return 42; // 返回计算结果 } }; // 创建FutureTask对象,包装Callable任务 FutureTask<Integer> futureTask = new FutureTask<>(task); // 启动线程执行FutureTask Thread thread = new Thread(futureTask); thread.start(); // 主线程可以做一些其他工作 System.out.println("Main thread is doing something else..."); // 获取异步执行结果,阻塞直到任务完成 Integer result = futureTask.get(); // 这会阻塞主线程直到获取到结果 System.out.println("Task result: " + result); // 打印任务执行结果 } }
在启动线程的时候,可以使用run方法吗?run()和start()有什么区别?
start()是开启一个线程 run()跟开启普通方法一样
start():用来启动线程,通过该线程调用run方法执行run方法中所定义的逻辑代码。start方法只能被调用一次
run():封装了要被线程执行的代码,可以被调用多次
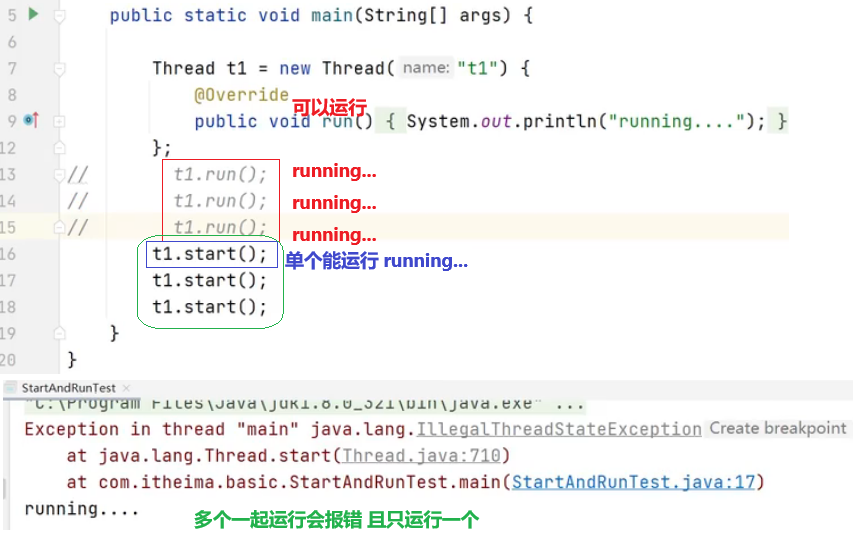
线程包括哪些状态,状态之间是如何变化的?
状态:
新建New、可运行Runnable、阻塞Blocked、等待Waiting、时间等待Timed_waiting、终止Terminated线程状态之间如何变化:
- 创建线程对象是新建状态
- 调用了start()方法转变为可执行状态
- 线程获取到了CPU的执行权,执行结束是终止状态
- 在可执行状态的过程中,如果没有获取CPU的执行权,可能会切换其他状态
- 如果没有获取锁(synchronized或lock) 进入阻塞状态,获得锁再切换为可执行状态
- 如果线程调用了wait()方法进入等待状态,其他线程调用notify()唤醒后可转换为可执行状态
- 如果线程调用了sleep(50)方法,进入计时等待状态,到时间后可切换为可执行状态
Thread.java
public enum State {
/**
* 新建状态。线程已经被创建,但尚未启动。
*/
NEW,
/**
* 可运行状态。线程在JVM中是可运行的,这并不意味着它一定在运行,它可能在等待其他线程或操作系统的资源。
*/
RUNNABLE,
/**
* 阻塞状态。线程正在等待监视器锁,以进入一个同步块/方法,或者在调用Object.wait后等待重新进入同步块/方法。
*/
BLOCKED,
/**
* 等待状态。线程在等待另一个线程执行特定操作。例如,一个线程调用了Thread.join,它在等待指定的线程终止。
*/
WAITING,
/**
* 超时等待状态。线程在等待另一个线程执行特定操作,但它设置了超时时间。如果线程在指定时间内没有等待到所需条件,它将自动返回。
*/
TIMED_WAITING,
/**
* 终止状态。线程已经完成了执行。
*/
TERMINATED;
}
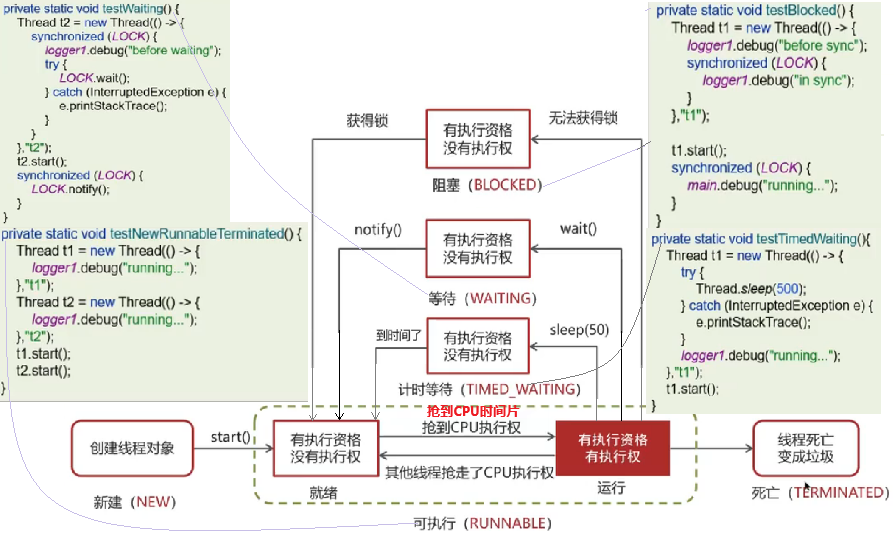
新建T1、T2、T3三个线程,如何保证它们按顺序执行?
可以使用线程中的join方法解决join() 等待线程运行结束
t.join() 阻塞调用此方法的线程进入timed_waiting 直到线程t执行完毕后,此线程再继续执行
Thread t1 = new Thread(()->{
sout("t1");
});
Thread t2 = new Thread(()->{
try{
t1.join();
}catch(InterruptedException e){
e.printStackTrance();
}
sout("t2");
})
Thread t3 = new Thread(()->{
try{
t2.join();
}catch(InterruptedException e){
e.printStackTrance();
}
sout("t3");
});
// 启动线程
t1.start();
t2.start();
t3.start();
notify() 和 notifyAll() 有什么区别?
- notifyAll:唤醒所有wait的线程
- notify:只随机唤醒一个wait线程
java中wait和sleep方法有什么区别?wait要和synchronized一起使用
| 方法 | 归属类 | 是否释放锁 | 唤醒方式 | 使用前提 |
|---|---|---|---|---|
sleep() |
Thread |
❌ 不释放锁 | 时间到、被打断 | 直接调用即可 |
wait() |
Object |
✅ 释放锁 | notify()/时间到/被打断 |
必须配合 synchronized 使用 |
共同点
wait(),wait(long)和sleep(long)的效果都是让当前线程暂时放弃CPU的使用权,进入阻塞状态
不同点
- 方法归属不同
- sleep(long)是Thread的静态方法
- 而wait(),wait(long)都是Object的成员方法,每个对象都有
- 醒来时机不同
- 执行sleep(long)和wait(long)的线程都会在等待相应毫秒后醒来
- wait(long)和wait()还可以被notify唤醒,wait()如果不唤醒就一直等下去
wait要和synchronized一起使用 - 它们都可以被打断唤醒
- 锁特性不同【重点】
- wait方法的调用必须先获取wait对象的锁,而sleep则无此限制
- wait方法执行后会释放锁对象,允许其他线程获得该锁对象 (我放弃cpu,但你们还可以用)
- 而sleep如果在synchronized代码块中执行,并不会释放锁对象 (我放弃cpu,你们也用不了)
✅ 核心区别(面试高频)
维度 sleep()wait()所属类 Thread静态方法Object实例方法是否释放锁 ❌ 不释放锁 ✅ 释放当前对象锁 是否需要锁 ❌ 不需要任何锁 ✅ 必须持有该对象的锁( synchronized)唤醒方式 到时间/中断 到时间/中断/ notify/notifyAll使用目的 让线程暂停执行,但持有锁不让别人进 让线程等待并释放锁,协调多线程通信 ✅ 场景对比
场景 使用方法 原因 想暂停线程几秒钟(不释放锁) Thread.sleep(ms)常用于模拟网络延迟/定时任务 多线程协作(生产者-消费者模型) wait()/notify()用于线程间通信,让出锁资源 ✅ 通俗类比 🌰
sleep():你在厕所里睡觉,门上锁了(别人不能进),你虽然休息了,但别人也进不来。wait():你说“我出去抽根烟(释放锁)”,别人可以进去用厕所(释放资源),抽完烟再回来(被唤醒)继续工作。

如何停止一个正在运行的线程?
有三种方式可以停止线程
- 使用退出标志位,使线程正常退出,也就是当run方法完成后线程终止
- 使用stop方法强行终止(不推荐,方法已作废)
- 使用interrupt方法中断线程
- 打断阻塞的线程(sleep, wait, join)的线程,线程会抛出InterruptedException异常
- 打断正常的线程,可以根据打断状态来标记是否退出线程
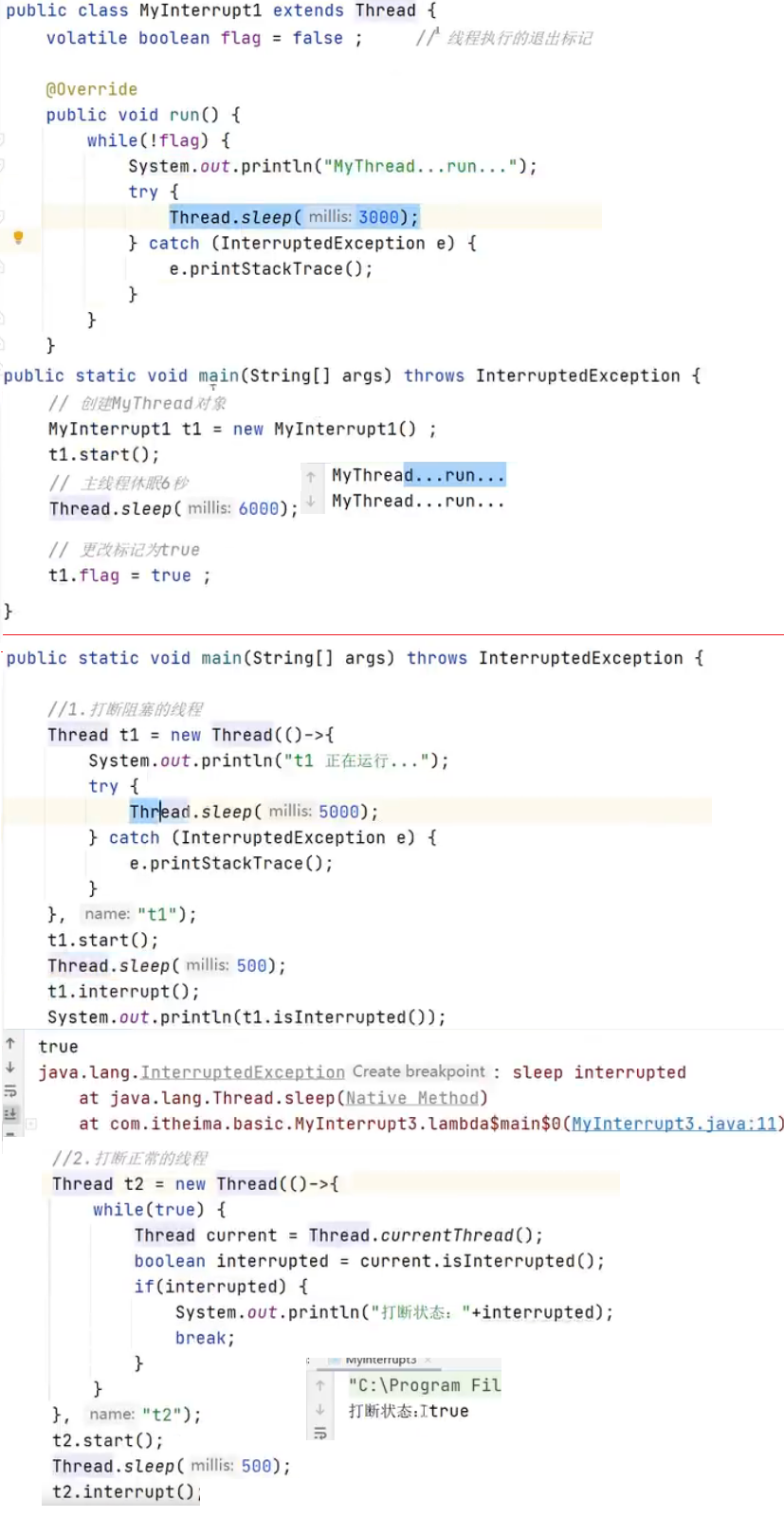
synchronized关键字的底层原理?底层:Monitor
- synchronized【对象锁】采用互斥的方式让同一时刻至多只有一个线程能持有【对象锁】
- 它的底层由monitor实现的,monitor**是jvm级别的现象(C++实现)**,线程获得锁需要使用对象(锁)关联monitor
- 在monitor内部有三个属性,分别是
owner、entrylist、waitset
- owner是关联的获得锁的线程,并且只能关联一个线程;
- entrylist关联的是处于阻塞状态的线程;
- waitset关联的是处于Waiting状态的线程;
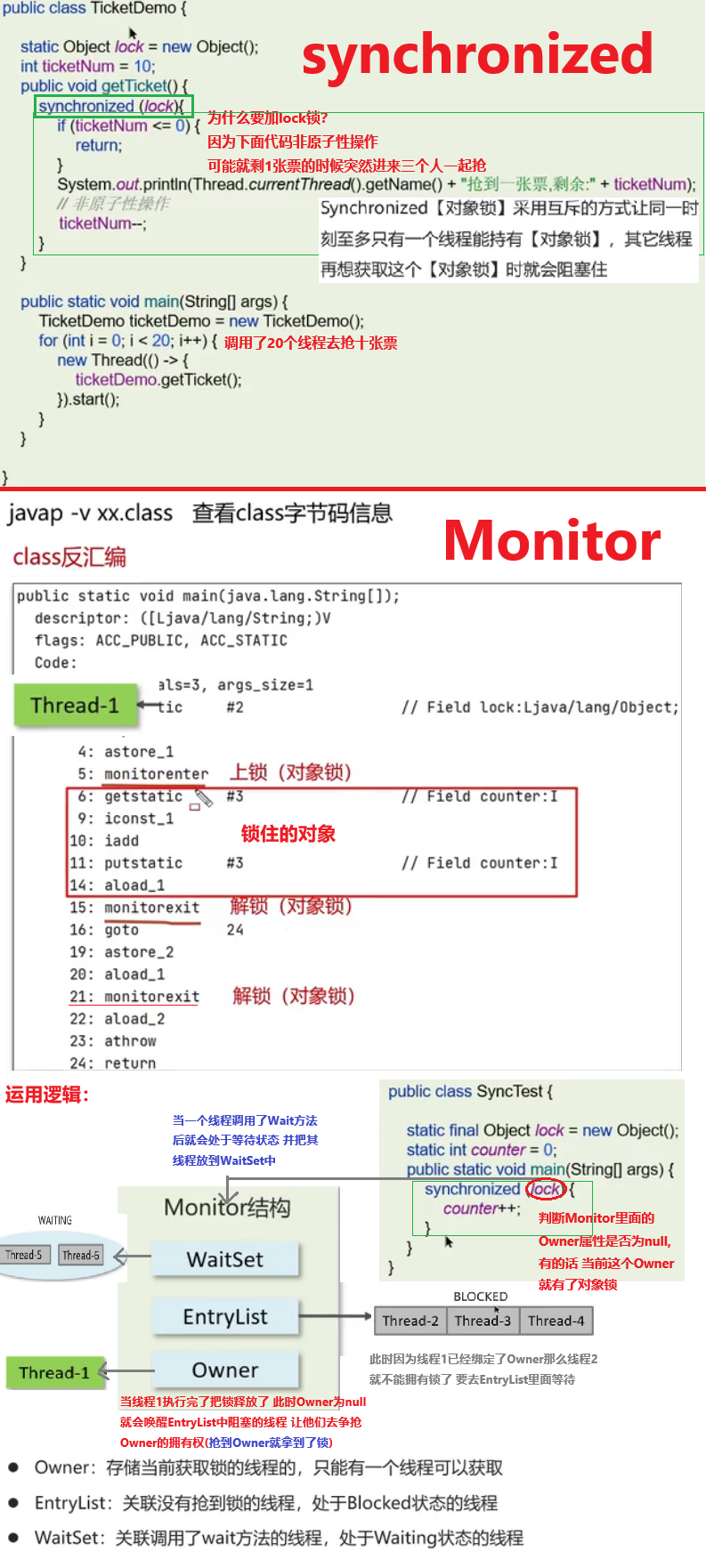
synchronized关键字的底层原理—进阶
Monitor实现的锁属于重量级锁,你了解过锁升级吗?
一旦锁发生了竞争,都会升级为重量级锁
Java中的synchronized有偏向锁、轻量级锁、重量级锁三种形式,分别对应了锁只被一个线程持有、不同线程交替持有锁、多线程竞争锁三种情况。
描述 重量级锁 底层使用的Monitor实现,里面涉及到了用户态和内核态的切换、进程的上下文切换,成本较高,性能比较低 【有多个线程来抢】 轻量级锁 线程加锁的时间是错开的(也就是没有竞争)可以使用轻量级锁来优化。轻量级修改了对象头的锁标志,相对重量级锁性能提升很多。每次修改都是CAS操作,保证原子性 偏向锁 一段很长的时间内都只被一个线程使用锁,可以使用了偏向锁,在第一次获得锁时,会有一个CAS操作,之后该线程再获取锁,只需要判断mark word中是否是自己的线程id即可,而不是开销相对较大的CAS命令
- Monitor实现的锁属于重量级锁,里面涉及到了用户态
权限低和内核态权限高的切换、进程的上下文切换,成本较高,性能比较低 - 在JDK1.6引入了两种新型锁机制:偏向锁和轻量级锁,它们的引入是为了解决在没有多线程竞争或基本没有竞争的场景下使用传统锁机制带来的性能开销问题
每一个 Java 对象在 JVM 中都有一个对象头,其中包含 MarkWord,用于存储锁信息。
当线程访问synchronized方法或代码块时,会尝试获取对象关联的 Monitor,进入临界区:Monitor 中包含:
字段 作用说明 owner 当前持有锁的线程 entryList 等待获取锁(阻塞)的线程队列 waitSet 调用 wait()被挂起的线程队列获取锁流程(简化):
- 检查对象头中的 MarkWord;
- 如果未被锁,尝试通过 CAS 设置为当前线程(偏向或轻量级);
- 如果竞争失败 → 升级为重量级锁(Monitor);
- 等待唤醒或抢占锁。
锁升级过程(从偏向锁 → 轻量级锁 → 重量级锁)
锁类型 触发条件 优点 场景 偏向锁 只有一个线程访问(无竞争) 几乎无开销,不用 CAS 单线程长时间持有的锁 轻量级锁 多线程访问,但加锁时间错开 使用 CAS,无阻塞,性能较高 少量线程短时间交替访问 重量级锁 多线程同时竞争同一把锁 线程阻塞 + 唤醒,开销大 并发激烈,必须互斥的场景 偏向锁 / 轻量级锁 / 重量级锁细节图解(简述)
🚀 偏向锁原理:
- 第一次访问:CAS 记录当前线程 ID 到对象头
- 再次访问时:只判断对象头的线程 ID 是否是自己
- 如果有竞争,偏向锁就会被撤销,升级为轻量级锁
🚀 轻量级锁原理:
- 在 线程栈中创建 LockRecord;
- 尝试 CAS 将 LockRecord 指针复制到对象头;
- 成功 → 获取锁;失败 → 说明竞争,升级为重量级锁
🚀 重量级锁原理(Monitor):
- Monitor 的实现是基于 操作系统的互斥量(mutex)
- 涉及线程的挂起、唤醒(用户态 → 内核态切换,开销大)
Monitor重量级锁
每个Java对象都可以关联一个Monitor对象,如果使用 synchronized 给对象上锁(重量级)之后,该对象头的Mark Word中就被设置指向Monitor对象的指针
加锁流程
- 在线程栈中创建一个Lock Record,将其obj字段指向锁对象。
- 通过CAS指令将Lock Record的地址存储在对象头的mark word中,如果对象处于无锁状态则修改成功,代表该线程获得了轻量级锁。
- 如果是当前线程已经持有该锁了,代表这是一次锁重入。设置Lock Record第一部分为nul,起到了一个重入计数器的作用。
- 如果CAS修改失败,说明发生了竞争,需要膨胀为重量级锁。
解锁过程
- 遍历线程栈,找到所有obj字段等于当前锁对象的Lock Record.
- 如果Lock Record的Mark Word为null,代表这是一次重入,将obj设置为null后continue。
- 如果Lock Record的 Mark Word不为nul,则利用CAS指令将对象头的mark word恢复成为无锁状态。如果失败则膨胀为重量级锁。
偏向锁性能比轻量级锁好
- 轻量级锁在没有竞争时(就自己这个线程)每次重入仍然需要执行 CAS 操作。
- Java6 中引入了偏向锁来做进一步优化:只有第一次使用 CAS 将线程 ID 设置到对象的 Mark Word 头,之后发现这个线程 ID 是自己的就表示没有竞争,不用重新 CAS。以后只要不发生竞争,这个对象就归该线程所有

你谈谈JMM (Java内存模型)
Java内存模型
- JMM(Java Memory Model)Java内存模型,定义了共享内存中多线程程序读写操作的行为规范,通过这些规则来规范对内存的读写操作从而保证指令的正确性
- JMM把内存分为两块,一块是私有线程的工作区域(工作内存),一块是所有线程的共享区域(主内存)
- 线程跟线程之间是相互隔离,线程跟线程相互需要通过主内存
CAS你知道吗?乐观锁
- CAS全称是:Compare And Swap(比较再交换),它体现的一种无锁(乐观锁)的思想,在无锁情况下保证线程操作共享数据的原子性。
- CAS使用到的地方很多:AQS框架、AtomicXXX类
- 在操作共享变量的时候使用自旋锁,效率上更高一些
- CAS的底层是调用的Unsafe类中的方法,都是操作系统提供的,其他语言实现
比较内存值是否与预期值相等,如果相等则更新为新值;否则不做操作,重新尝试(一般配合自旋)
// 伪代码 if (value == expectedValue) { value = newValue; }💡 应用场景:
java.util.concurrent.atomic包下的AtomicInteger等ReentrantLock的底层 AQSConcurrentHashMap局部并发控制
在JUC(java.util.concurrent)包下实现的很多类都用到了CAS操作
- AbstractQueuedSynchronizer (AQS框架)
- AtomicXXX类
乐观锁和悲观锁的区别?
+CAS.png)
乐观锁 vs 悲观锁(对比表)
| 特性 | 乐观锁(CAS) | 悲观锁(synchronized/Lock) |
|---|---|---|
| 思想 | 默认不会冲突,失败后重试 | 默认可能冲突,先加锁 |
| 开销 | CPU 开销高(自旋) | 上下文切换成本高 |
| 性能 | 高并发下优于悲观锁 | 并发低时更稳定 |
| 实现方式 | CAS,自旋锁,版本号控制 | synchronized, ReentrantLock等 |
谈一谈你对volatile的理解?轻量级的同步机制
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
保证线程间的可见性
用volatile修饰共享变量,能够防止编译器等优化发生,让一个线程对共享变量的修改对另一个线程可见
当一个线程修改了被
volatile修饰的变量,新值会立即同步到主内存中,其他线程读取这个变量时也会立即从主内存中刷新,而不是使用线程工作内存中的旧副本。- ✅ 保证多个线程看到的是同一个值
- ❌ 但是 不能保证原子性
禁止进行指令重排序
用volatile修饰共享变量会在读、写共享变量时加入不同的屏障,阻止其他读写操作越过屏障,从而达到阻止重排序的效果
Java 编译器 & CPU 为了提高性能可能会对指令进行优化,造成代码执行顺序与书写顺序不一致。
volatile能在变量读写操作前插入内存屏障(Memory Barrier):写屏障:防止写操作后面的指令重排到前面
读屏障:防止读操作前面的指令被排到后面
JMM 是理论模型,
volatile是其具体体现。🔄
volatile是 JMM(Java内存模型)在语义上的一个重要实现。JMM 内容 volatile实现作用主内存 & 工作内存 强制将值立即刷新到主内存 可见性保证 ✅ volatile 提供 原子性保证 ❌ volatile 不提供 禁止指令重排 ✅ volatile 提供(内存屏障) 这几个进行一下比较
特性 volatilesynchronized/LockCAS ( AtomicXXX)可见性 ✅ ✅ ✅ 原子性 ❌ ✅ ✅(通过硬件指令) 重排序控制 ✅(内存屏障) ✅(通过锁的语义) ✅(内存屏障) 是否加锁 否,轻量,性能高 是,重量级,性能相对低 否,自旋CAS 适用场景 状态标志、单例双检锁等 临界区互斥、大块同步场景 高并发下原子计数/计量等操作
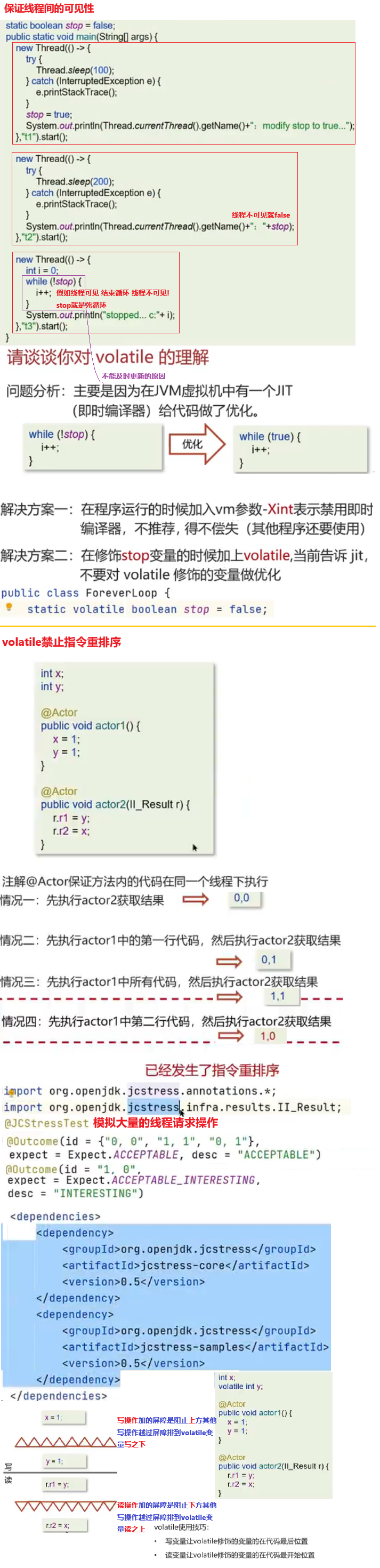
什么是AQS?
- 是多线程中的队列同步器。是一种锁机制,它是做为一个基础框架使用的,像ReentrantLock、Semaphore都是基于AQS实现的
- AQS内部维护了一个**先进先出的双向队列**,队列中存储的排队的线程
- 在AQS内部还有一个属性state,这个state就相当于是一个资源,默认是0(无所状态),如果队列中有一个线程修改成功了state为1,则当前线程就相当于获取了资源。
- 在对state修改的时候使用CAS(compare and swap)操作,保证多个线程修改的情况下原子性
AQS(AbstractQueuedSynchronizer),即抽象队列同步器。它是构建锁或者其他同步组件的基础框架
AQS与Synchronized的区别
| AQS | synchronized |
|---|---|
| java语言实现 | 关键字,C++语言实现 |
| 悲观锁,手动开启和关闭 | 悲观锁,自动释放锁 |
| 锁竞争激烈的情况下,提供了多种解决方案 | 锁竞争激励都会升级为重量级锁,性能差 |
CAS和AQS的区别
CAS(Compare And Swap)
乐观锁:一种无锁的原子操作机制,用于实现数据层面的原子性,是底层原语。AQS(AbstractQueuedSynchronizer)
悲观锁:一种同步器框架,用于构建锁和同步器(如 ReentrantLock、Semaphore 等),是结构设计。表格对比:CAS vs AQS
对比点 CAS AQS 全称 Compare And Swap AbstractQueuedSynchronizer 概念类型 原子操作机制(CPU指令级别) 同步器框架(Java并发包核心) 功能目的 保证共享变量原子性更新 实现线程同步控制(排队、阻塞、唤醒等) 属于哪一层 底层原子操作 高层并发框架 是否加锁 否(无锁) 是(加锁或排队等待) 底层依赖 CPU的 CAS 指令(如 cmpxchg)CAS、LockSupport、队列、模板方法 应用场景 AtomicXXX、线程安全计数器、乐观锁等 ReentrantLock、Semaphore、CountDownLatch、FutureTask 等 是否自带阻塞/唤醒 ❌ 不具备阻塞机制 ✅ 自带阻塞/唤醒机制(如 condition.await/signal) 实现原理 通过比较内存值 + 原子更新 模板方法 + 状态位 state + FIFO 等待队列 失败机制 自旋重试(乐观锁) 阻塞挂起,进入等待队列 各自常见应用场景
场景 用的是谁? 举例 实现原子操作 CAS AtomicInteger.incrementAndGet()实现线程排队获取锁 AQS ReentrantLock.lock()信号量控制 AQS Semaphore.acquire()倒计时器 AQS CountDownLatch.await()实现 Future 机制 AQS FutureTask.run()高并发无锁计数器 CAS LongAdder.add()(改进版CAS 是 AQS 的底层基础之一:AQS 内部更新同步状态(
state)时就用的是 CAS。
AQS 是基于 CAS + FIFO 队列实现的线程同步框架,比 CAS 更复杂、能力更强。// AQS 内部设置状态的关键方法 protected final boolean compareAndSetState(int expect, int update) { return unsafe.compareAndSwapInt(this, stateOffset, expect, update); // 使用CAS }举个例子:ReentrantLock
lock.lock();
- 内部结构:
- 使用 AQS 实现公平/非公平锁的排队机制
- 使用 CAS 来设置 state = 1(加锁)
CAS 是一种基于硬件的原子操作指令,用于在无锁环境下保证共享变量的线程安全,常用于
AtomicInteger等类。而 AQS 是 Java 并发包中用于构建同步器(如锁、信号量等)的框架,它通过 CAS 操作来维护内部状态state,并通过一个基于 FIFO 的等待队列来实现线程的阻塞与唤醒。因此,CAS 是底层原语,而 AQS 是上层的并发框架,AQS 内部正是基于 CAS 实现的。
AQS常见的实现类
- ReentrantLock 阻塞式锁
- Semaphore 信号量
- CountDownLatch 倒计时锁
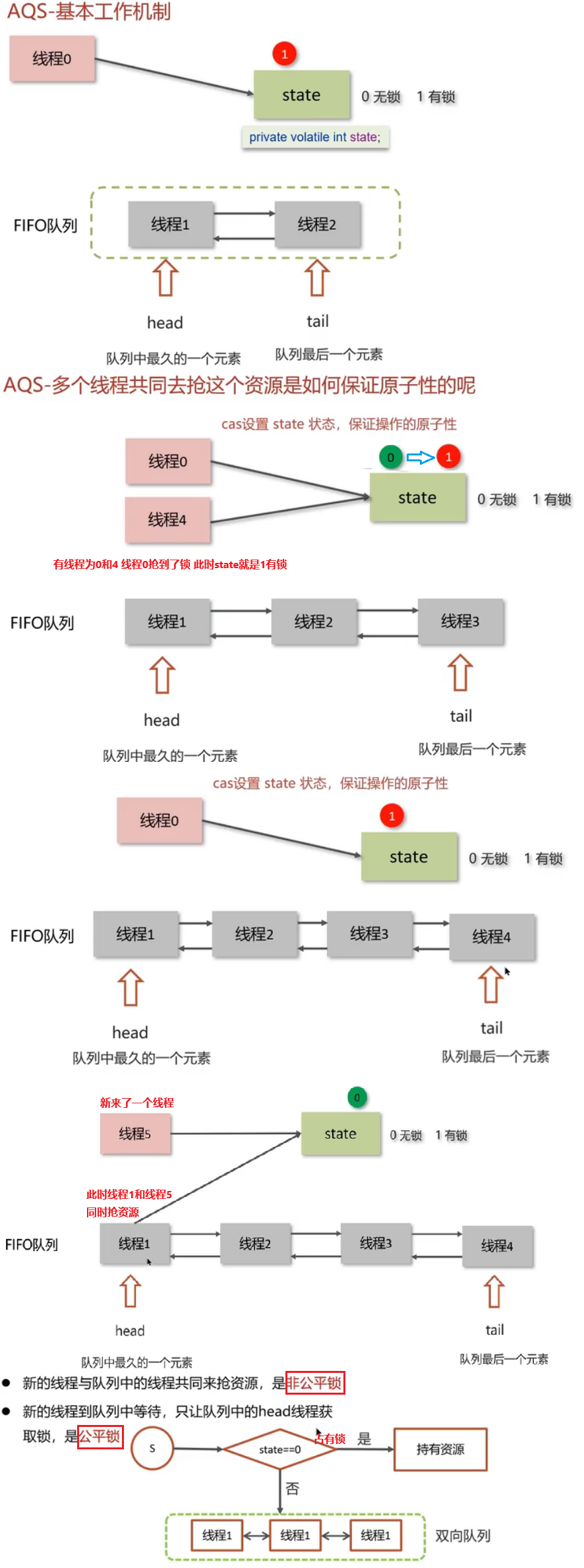
ReentrantLock [rɪ’entrənt]lock 的实现原理?[关联HashMap线程不安全需加锁(synchronized或ReentrantLock)]
ReentrantLock主要利用CAS+AQS队列
CompareAndSwap+AbstractQueuedSynchronized来实现。**它支持公平锁和非公平锁,两者的实现类似构造方法接受一个可选的公平参数(默认非公平锁),当设置为true时,表示公平锁,否则为非公平锁**。公平锁的效率往往没有非公平锁的效率高,在许多线程访问的情况下,公平锁表现出较低的吞吐量。
ReentrantLock翻译过来是可重入锁,相对于synchronized它具备以下特点:
- 可中断
synchronized不可中断 - 可设置超时时间
没有获得锁时只能进入等待[没有获取锁可以放弃锁] - 可以设置公平锁
synchronized只有非公平锁[也支持非公平锁] - 支持多个条件变量
- 与synchronized一样,都支持重入
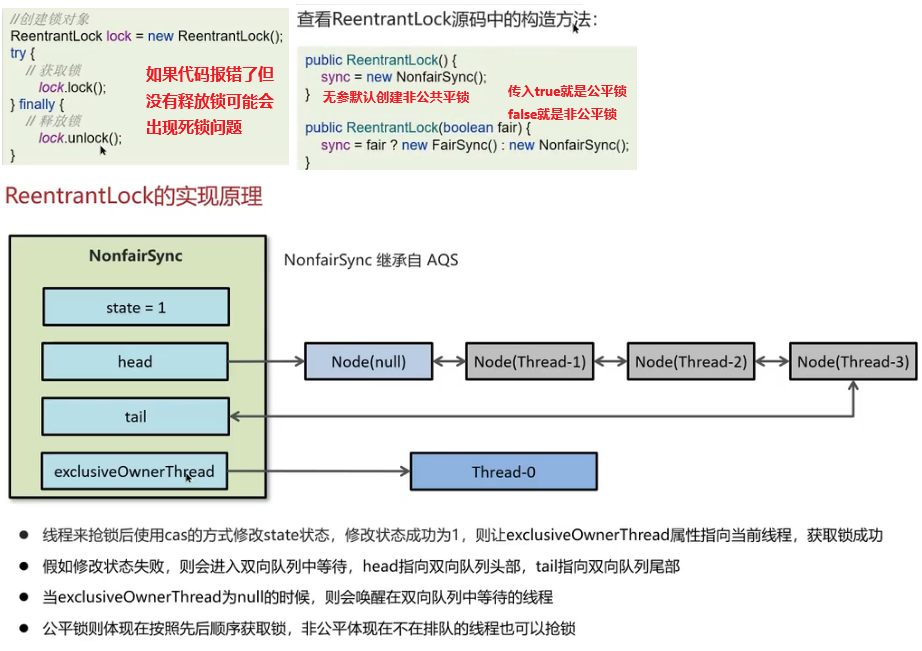
synchronized和Lock有什么区别?
- 语法层面
synchronized是关键字,源码在jvm中,用c++语言实现
Lock是接口,源码由jdk提供,用java语言实现
使用synchronized时,退出同步代码块锁会自动释放,而使用Lock时,需要手动调用unlock方法释放锁
- 功能层面
二者均属于悲观锁、都具备基本的互斥、同步、锁重入功能
Lock提供了许多synchronized不具备的功能,例如公平锁、可打断、可超时、多条件变量
Lock有适合不同场景的实现,如ReentrantLock、ReentrantReadWeiteLock(读写锁)
死锁产生的条件是什么
死锁:一个线程需要同时获取多把锁,这时就容易发生死锁
如何进行死锁诊断 ?
当程序出现了死锁现象,我们可以使用jdk自带的工具:jps和jstack
- jps:输出JVM中运行的进程状态信息
- jstack:查看java进程内线程的堆栈信息
JVM中也有死锁,jvm没有超时机制不会解决 可以查看命令打印堆栈信息可以查看哪里产生死锁
你可以使用
jstack命令来打印指定进程ID的Java堆栈跟踪信息。这个命令可以帮助你分析线程的状态
首先,找到你的Java进程ID(PID)。你可以使用
jps命令来列出所有正在运行的Java进程及其PID。jps使用
jstack命令打印出该Java进程的堆栈跟踪。jstack -l <PID>将
<PID>替换为实际的进程ID。查找堆栈跟踪中的”DEADLOCK”关键字。
jstack会自动检测死锁并在输出中报告。
其他解决工具,可视化工具
- jconsole
用于对jvm的 内存,线程,类 的监控,是一个基于jmx的GUI性能监控工具
打开方式:java安装目录 bin目录下 直接启动 jconsole.exe就行
- VisualVM:故障处理工具
能够监控线程,内存情况,查看方法的cpu时间和内存中的对象,已被GC的对象,反向查看分配的堆栈
打开方式:java安装目录 bin目录下 直接启动 jvisualvm.exe就行
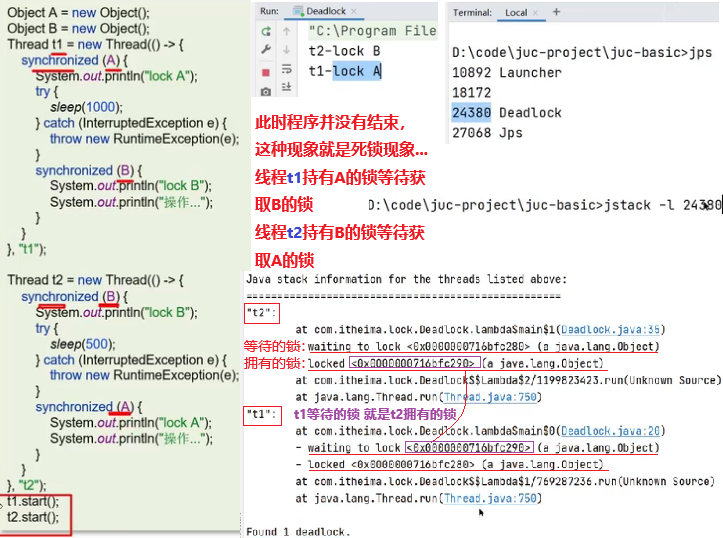
死锁:两个线程争夺两个资源的时候 1线程拿到a 想拿b 2线程拿到了b 想拿a
四个原因:互斥条件 请求保持 不可剥夺 循环等待
产生死锁的四个因素 同时满足才会死锁 想要解决死锁 需要打破其中一个原因就行
- 互斥条件(Mutual Exclusion):资源不能被多个线程同时使用。即某个资源在一段时间内只能由一个线程占用,其他线程必须等待该资源被释放后才能使用。
- 持有和等待条件(Hold and Wait):线程至少持有一个资源,并且正在等待获取额外的资源,而该资源又被其他线程持有。
- 非抢占条件(No Preemption):已经分配给某个线程的资源在该线程完成任务前不能被抢占,即只能由线程自己释放。
- 循环等待条件(Circular Wait):存在一种线程资源的循环等待链,每个线程都在等待下一个线程所持有的资源。
在实际操作中,以下是一些打破死锁的具体方法:
银行家算法可以避免死锁
- 资源分配图:使用资源分配图来检测循环等待条件,并在检测到循环时采取措施。
- 锁排序:确保所有线程以相同的顺序获取锁,从而避免循环等待。
- 超时机制:线程在请求资源时设置超时时间,如果超过时间未获得资源,则放弃当前任务并释放已持有的资源。
- 死锁检测算法:运行死锁检测算法,如银行家算法,来检测系统中的死锁,并在必要时采取措施。
- 线程中断:允许系统或其他线程中断正在等待资源的线程。
- 回滚操作:如果检测到死锁,可以让某些线程回滚它们的工作,并释放资源,从而打破死锁。
MySQL是不会有死锁的 自身会检测 [让后面的超时释放回滚]
在分布式事务 线程1拿着资源a是数据库1 线程2拿着资源b是数据库2
JVM中也有死锁,jvm没有超时机制不会解决 可以查看命令打印堆栈信息可以查看哪里产生死锁
你可以使用
jstack命令来打印指定进程ID的Java堆栈跟踪信息。这个命令可以帮助你分析线程的状态
首先,找到你的Java进程ID(PID)。你可以使用
jps命令来列出所有正在运行的Java进程及其PID。jps使用
jstack命令打印出该Java进程的堆栈跟踪。jstack <PID>将
<PID>替换为实际的进程ID。查找堆栈跟踪中的”DEADLOCK”关键字。
jstack会自动检测死锁并在输出中报告。
聊一下ConcurrentHashMap
ConcurrentHashMap是一种线程安全的高效Map集合
底层数据结构:
JDK1.7底层采用分段的数组+链表实现
JDK1.8采用的数数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树
在JDK1.8中,放弃了Segment臃肿的设计,数据结构跟HashMap的数据结构是一样的:
数组+红黑树+链表,采用CAS + Synchronized来保证并发安全进行实现- CAS控制数组节点的添加
- synchronized只锁定当前链表或红黑二叉树的首节点,只要hash不冲突,就不会产生并发的问题,效率得到提升
加锁的方式:
- JDK1.7采用
Segment分段锁,底层使用的是ReentrantLock - JDK1.8采用
CAS自旋锁添加新节点,采用synchronized锁定链表或红黑二叉树的首节点,相对Segment分段锁粒度更细,性能更好
在 JDK1.7 的
ConcurrentHashMap实现中:
ConcurrentHashMap底层被分成了多个 Segment(段)。- 每个 Segment 本质上就是一个小型的 HashMap + 一把锁(
ReentrantLock)。- 整个 Map 是由多个 Segment 组成的数组:
Segment<K, V>[] segments;- 每个 Segment 管理自己那部分的数据,互不干扰,从而实现高并发。
提高并发性,减小锁竞争:
- 将一个大的 HashMap 拆成多个 Segment(默认16个),每个 Segment 单独加锁。
- 这样多个线程并发访问不同 Segment 的数据时,就不会互相阻塞,从而提升性能。
- 线程只会锁定自己需要访问的那个 Segment,不会锁全表。
【下列图中针对于整体和put的解释】
📌 1. 整体结构
- 外部是一个 Segment 数组:每个 Segment 是独立加锁的。
- 每个 Segment 内部又是一个 HashEntry 数组(就像 HashMap 的结构)。
📌 2. put 操作流程(以 JDK1.7 为例):
- 根据 key 的 hash 计算出 Segment 的下标(如 Segment[5])。
- 进入对应的 Segment,获取其锁(
ReentrantLock.lock())。- 再在该 Segment 中,查找对应的桶位(HashEntry 数组)。
- 找到位置后:
- 如果该位置已有数据,做链表遍历、替换或追加。
- 如果链表过长,在 JDK1.7 仍然是链表(没有红黑树)。
- 插入完成后释放锁。
✅ JDK1.8 为什么放弃 Segment?
JDK1.8 里,取消了 Segment 分段锁结构,改为节点粒度的同步控制:
- 使用 CAS + synchronized 替代了 Segment + ReentrantLock。
- 好处:
- 不再有 Segment 的内存占用与操作复杂度。
- 粒度更细,性能更好。
- 数据结构与 HashMap 接轨,统一维护。
在 JDK1.7 中,
ConcurrentHashMap使用 Segment 分段锁机制 提高并发性能,将 Map 拆成多个小的 Segment,每个 Segment 内部结构类似 HashMap,通过加锁控制并发。而在 JDK1.8 中,放弃 Segment,采用 CAS + synchronized 锁节点的方式,结构变为数组 + 链表 + 红黑树,性能与简洁性双双提升。
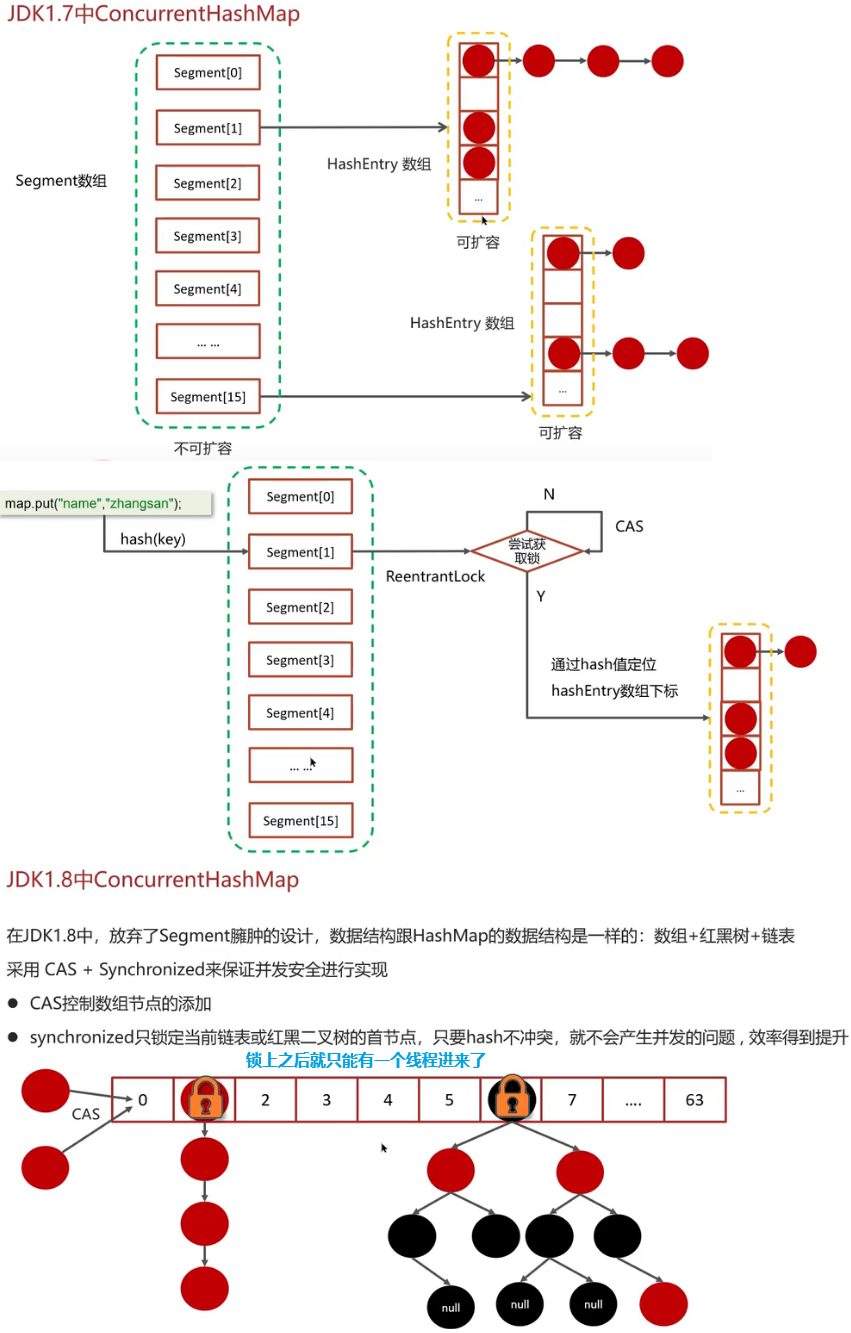
导致并发程序出现问题的根本原因是什么 (Java程序中怎么保证多线程的执行安全)
Java并发编程三大特性
- 原子性
synchronized、lock:一个线程在CPU中操作不可暂停,也不可中断,要么执行完成,要么不执行
int ticketNum = 10;
public void getTicket(){
if(ticketNum <= 0){
return;
}
sout(Thread.currentThread().getName() + "抢到一张票,剩余:" + ticketNum);
// 非原子性操作
ticketNum--;
}
main{
TicketDemo demo = new TicketDemo();
for(int i = 0; i < 20; i++){
new Thread(demo::getTicket).start();
}
}
不是原子操作,怎么保证原子操作呢?
- synchronized:同步加锁
- JUC里面的lock:加锁
- 可见性
volatile、synchronized、lock
内存可见性:让一个线程对共享变量的修改对另一个线程可见
public class VolatileDemo{
private static boolean flag = false;
public static void main(String[] args) throws InterruptedException{
new Thread(()->{
while(!flag){
sout("第一个线程执行完毕...");
}
}).start();
Thread.sleep(100);
new Thread(()->{
flag = true;
sout("第二个线程执行完毕...");
}).start();
}
}
解决方案:synchronized、volatile、LOCK
volatile:加在共享变量上面即可 → private static volatile boolean flag = false;
- 有序性
volatile
指令重排:处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的
int x;
int y;
@Actor
public void actor1(){
x = 1;
y = 1;
}
@Actor
public void actor2(II_Result r){
r.r1 = y;
r.r2 = x;
}
解决办法:在前面加上volatile
说一下线程池的核心参数
为什么要创建线程池 因为每次创建线程的时候就要占用一定的内存空间 无限创建线程会浪费内存严重会导致内存溢出
CPU有限的同一时刻只能同时处理一个线程 大量线程来的话就没有线程权 会造成线程等待 造成大量线程在之间切换也会导致性能变慢
在这个例子中,我们创建了一个线程池,核心线程数为5,最大线程数为10,如果线程池中的线程数大于核心线程数,则空闲线程在60秒后会被终止。工作队列使用ArrayBlockingQueue,其容量为100。
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExample {
public static void main(String[] args) {
// 核心线程数
int corePoolSize = 5;
// 最大线程数 = (核心线程 + 救急线程的最大数目)
int maximumPoolSize = 10;
// 线程池中超过 corePoolSize 数量的空闲线程最大存活时间
long keepAliveTime = 60L;
// 时间单位 - 救急线程的生存时间单位,如秒、毫秒等
TimeUnit unit = TimeUnit.SECONDS;
// 工作队列,用于存放提交的任务 当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务
ArrayBlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(100);
// 线程工厂 - 可以定制线程对象的创建,例如设置线程名字、是否是守护线程等
ThreadFactory threadFactory = new ThreadFactory;
// 拒绝策略 - 当所有线程都繁忙,workQueue也繁忙时,会触发拒绝策略
RejectedExecutionHandler handler = new RejectedExecutionHandler;
// 创建线程池
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
corePoolSize,
maximumPoolSize,
keepAliveTime,
unit,
workQueue
);
// 示例:向线程池提交任务 threadPoolExecutor.submit()/.execute()
for (int i = 0; i < 20; i++) {
int taskNumber = i;
threadPoolExecutor.execute(() -> {
System.out.println("Executing task " + taskNumber);
// 模拟任务执行时间
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
// 关闭线程池
threadPoolExecutor.shutdown();
}
}
一开始new的时候没有是空的。先当一个任务提交给线程池时,线程池首先检查当前运行的线程数是否达到核心线程数。如果没有达到核心线程数,线程池会创建一个新的线程来执行任务。如果已经达到核心线程数,线程池会将任务放入工作队列中等待执行。如果工作队列满了,并且当前运行的线程数小于最大线程数,线程池会创建新的线程来执行任务。如果工作队列满了,并且当前运行的线程数等于最大线程数,线程池会根据拒绝策略
拒绝策略:
- 丢弃任务抛出异常
- 丢弃任务不抛弃异常
- 丢弃队列最前面的任务,然后重新提交被拒绝的任务、
- 由主线程处理该任务来处理无法执行的任务。【线程池无法起到异步问题】
- 问题:想继续异步且不丢弃任务怎么办?
- 把这个业务先存到别的地方 ↓↓↓
- 自定义拒绝策略 自己写实现类实现拒绝策略 可以先存到mysql到时候再慢慢搞
线程池中有哪些常见的阻塞队列
线程工厂可以设置创建的属性:
守护线程:主线程(main)一天不死 守护线程不死 [同生共死]
非守护线程:new一个就是 [不是同生共死]
workQueue - 阻塞队列常用的队列:当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务
- ArrayBlockingQueue: 基于数组结构的有界阻塞队列,此队列按照先进先出(FIFO)的原则对元素进行排序。创建时需要指定容量。【底层是数组 随机读写的 **时间复杂度O(1)**】
- 开辟新空间创建新数组 把旧数组的数据迁移过去 new ArrayList为空 需要add才可以 扩容是+10 取1.5倍
- 高并发不会超过某个值 数组不会涉及到扩容 性能会好一些【比较稳定能预估】
- new的时候不用指定长度
- LinkedBlockingQueue: 基于链表结构的有界阻塞队列(如果不指定容量,则默认为
Integer.MAX_VALUE,即视为无界)。按照先进先出的原则排序元素。【随机读写的 时间复杂度O(n) 随机读写快 查询慢 是通过二分查找定位到下标元素(通过下标访问数组和链表) 只会走一次二分查找】- 读中间的慢 读头尾快
- 新增元素不涉及到数组的迁移
- 一般情况下高并发推荐使用,因为队列
高级数据结构(可以用数组和链表的实现 由于底层数据结构不同)的特性是先进先出,链表不涉及到数组的扩容 末尾的最快是O(1)【不稳定】 - new的时候可指定长度是最大链表的长度
- 不可指定长度 [有界队列&无界队列] → 可能产生JVM的OOM
- DelayedWorkQueue:是一个优先级队列,它可以保证每次出队的任务都是当前队列中时间最靠前的
- SynchronousQueue:不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作
| ArrayBlockingQueue | LinkedBlockingQueue |
|---|---|
| 强制有界 | 默认无界,支持有界 |
| 底层是数组 | 底层是链表 |
| 提前初始化Node数组 | 是懒惰的,创建节点的时候添加数据 |
| Node需要是提前创建好的 | 入队会生成新Node |
| 一把锁 | 两把锁(头尾) |
ArrayBlockingQueue(数组有界队列)
特性 描述 类型 有界队列(必须指定容量) 底层结构 数组(先进先出 FIFO) 线程安全 内部使用一把锁(ReentrantLock)实现 性能 读写快,结构稳定 应用场景 可以准确预估任务数量的场景,推荐用于生产环境保障系统稳定 特点 不支持扩容,满了会阻塞或抛异常 ✅ 适用于:生产环境中任务量可控,保证内存稳定,不希望触发OOM。
LinkedBlockingQueue(链表无界队列)
特性 描述 类型 默认无界队列(最大为 Integer.MAX_VALUE,可设置为有界) 底层结构 链表(FIFO) 线程安全 使用两把锁(put锁 + take锁),可以同时入队出队 性能 插入删除性能好,随机访问性能差(O(n)) 应用场景 任务流量大、不可预估任务量的场景 特点 不容易触发拒绝策略,但容易造成内存溢出(OOM) ✅ 适用于:高并发日志、事件处理等消费速度快但生产不确定的情况。
队列类型 有界性 底层结构 锁机制 特点描述 ArrayBlockingQueue有界 数组 一把锁 性能稳定,适合任务量可控场景 LinkedBlockingQueue默认无界 链表 两把锁(头尾) 插入删除效率高,容易堆积任务造成内存压力 线程池中选择哪个阻塞队列?
使用场景 推荐队列类型 说明 普通后台异步任务 ArrayBlockingQueue稳定、安全,可预估任务量 高并发任务,消费快但产量不可控 LinkedBlockingQueue适合吞吐量大场景,注意内存风险 守护线程补充
你提到的这段也非常好,总结如下:
- 守护线程(daemon):依附主线程存在,主线程结束,守护线程也自动终止。如:GC线程。
- 非守护线程(user thread):默认类型,主线程结束后仍会继续运行。
可通过:
Thread thread = new Thread(...); thread.setDaemon(true); // 设置为守护线程
如何确定核心线程数
① 高并发、任务执行时间短 → (CPU核数 + 1),减少线程上下文的切换
② 并发不高、任务执行时间长
- IO密集型任务 → (CPU核数 * 2 + 1)
- 计算密集型任务 → (CPU核数 + 1)
③ 并发高、业务执行时间长,解决这种类型任务的关键不在于线程池而在于整体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,增加服务器是第二步,至于线程池的设置参考②
- IO密集型任务:文件读写、DB读写、网络请求等 核心线程数大小设置为2N+1
- CPU密集型任务:计算型代码、Bitmap转换、Gson转换等 核心线程数大小设置为N+1
// 查看机器的CPU核数
public static void main(String[] args){
// 查看机器的CPU核数
System.out.println(Runtime.getRuntime().avaliableProcessors());
}
线程池的种类有哪些
在java.util.concurrent.Executors类中提供了大量创建线程池的静态方法,常见的有四种
① 创建使用固定线程数的线程池
适用于任务已知,相对耗时的任务
public static ExecutorService newFixedThreadPool(int nThreads){
return new ThreadPoolExecutor(nThreads, nThreads,0L,TimeUnit.MILLISECONDS.new LinkedBlockingQueue<Runnable>)
}
- 核心线程数与最大线程数一样,没有
救急线程 = 最大线程数 - 核心线程数 - 阻塞队列是LinkedBlockingQueue,最大容量为Integer.MAX_VALUE
② 单线程化的线程池它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO)执行→[先进先出]
适用于按照顺序执行的任务
public static ExecutorService newSingleThreadExecutor(){
return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1,1,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));
}
- 核心线程数和最大线程数都是1
- 阻塞队列是
LinkedBlockingQueue,最大容量为Integer.MAX_VALUE
③ 可缓存线程池
public static ExecutorService newCachedThreadPool(){
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L,TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
}
- 核心线程数为0
- 最大线程数是
Integer.MAX_VALUE - 阻塞队列是
SynchronousQueue: 不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作
④ 提供了 延迟 和 周期执行 功能的ThreadPoolExecutor
public ScheduledThreadPoolExecutor(int corePoolSize){
super(corePoolSize, Integer.MAX_VALUE,0,NANOSECONDS,new DelayedWorkQueue());
}
为什么不建议使用Executors创建线程池?
参考阿里开发手册
【强制】 线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors返回的线程池对象的弊端如下:
1. FixedThreadPool 和 SingleThreadPool:
允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM
2. CachedThreadPool:
允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM
在实际开发中,不建议使用 Executors 创建线程池,因为其底层默认参数具有潜在的 OOM 风险。例如 FixedThreadPool 使用无界队列、CachedThreadPool 最大线程数为 Integer.MAX_VALUE,容易在高并发场景下造成内存溢出。因此建议通过 ThreadPoolExecutor 显式指定核心参数,做到资源可控,避免系统风险。
线程池的使用场景①:ES数据批量导入
CountDownLatch
CountDownLatch(闭锁/倒计时锁)用来进行线程同步协作,等待所有线程完成倒计时时(一个或多个线程,等待其他多个线程完成某件事情之后才能执行)
- 其中构造参数用来初始化等待计数值
await()用来等待计数归零countDown()用来让计数减一
多线程使用场景一 (es数据批量导入)
在我们项目上线之前,我们需要把数据库中的数据一次性的同步到es索引库中,但是当时的数据好像是1000万左右一次性读取数据肯定不行(oom异常),当时我就想到可以使用线程池的方式导入,利用CountDownLatch来控制就能避免一次性加载过多,防止内存溢出
在我们项目中,曾有一次需要把MySQL中的一千万条历史文章同步到ES。为了避免一次性加载引发OOM,我将数据分页为每页2000条,使用线程池批量提交导入任务,同时使用
CountDownLatch控制主线程阻塞等待所有子任务完成,再统一执行收尾逻辑。这样做极大优化了内存占用和同步效率。
DB(一千万) → 线程池(CountDownLatch) → Elasticearch
批量导入 → 查询总条数 → DB
↓ ↑ 批量导入到ES中 → ES
(固定每页2000条) 计算总页数 ↑ (countDownLatch.countDown())
↓ ↑ ↑
(总页数) CountDownLatch ↑ ↑
↓ ↑ ↑
分页查询文章数据 → [查询当前页的文章 → 创建任务批量导入ES → 提交到线程池执行]循环
(文章列表, countDownLatch)
↓
countDownLatch.await()

线程池的使用场景②:数据汇总
- 在一个电商网站中,用户下单之后,需要查询数据,数据包含了三部分:订单信息、包含的商品、物流信息;这三块信息都在不同的微服务中进行实现的,我们如何完成这个业务呢?
- 在实际开发的过程中,难免需要调用多个接口来汇总数据,如果所有接口(或部分接口)的没有依赖关系,就可以使用线程池+future来提升性能
[统计的图文发布量、点赞数量、收藏数量、评论数量若不在同一台微服务下 或者 部分没有依赖关系]
- 在实际开发的过程中,难免需要调用多个接口来汇总数据,如果所有接口(或部分接口)的没有依赖关系,就可以使用线程池+future来提升性能
并发数据汇总(如订单数据聚合)
关键词:接口无依赖、加速响应、Future并发调用
📌 适用场景
- 一个接口需要聚合多个来源服务(如订单服务、商品服务、物流服务)
- 服务之间无强依赖,可并发发起请求提升响应速度
✅ 技术点
线程池 + Future + Callable- 三个子任务并发发起 →
.get()阻塞获取返回值- 总响应时间 ≈ 最慢的那个接口,而不是三个之和
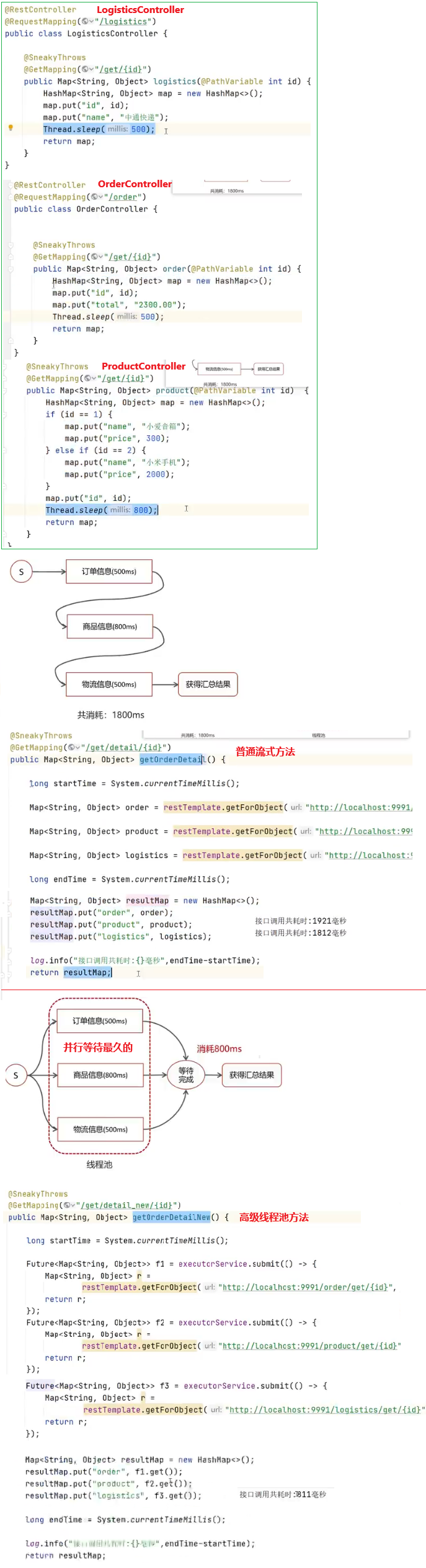
线程池的使用场景③:异步调用
为了避免下一级方法影响上一级方法(性能考虑),可使用异步线程调用下一个方法(不需要下一级方法返回值),可以提升方法相应时间

如何控制某个方法允许并发访问线程的数量
Semaphore信号量,是JUC包下的一个工具类,底层是AQS,我们可以通过其限制执行的线程数量
适用场景:
通常用于那些资源有明确访问数量限制的场景,常用于限流
Semaphore使用步骤
- 创建Semaphore对象,可以给一个容器
- semaphore.acquire():请求一个信号量,这时候的信号量个数 -1 (一旦没有可使用的信号量,也即信号量个数变为负数时,再次请求的时候就会阻塞,直到其他线程释放了信号量)
- semaphore.release():释放一个信号量,此时信号量个数 +1
使用
Semaphore信号量
Semaphore是 JUC 包下的并发工具类,用于控制同时访问某个资源的线程数量- 底层基于 AQS(AbstractQueuedSynchronizer)实现
- 常用于限流、并发资源控制、连接池管理、接口控制等场景
Semaphore 就像操作系统中的“通行证/信号灯”,只有拿到令牌(acquire)才能进入方法执行,执行完后必须释放令牌(release),否则其他线程会一直阻塞在那等令牌释放。
new Semaphore(n):设置可同时访问的线程数量为 nsemaphore.acquire():申请令牌,获取不到则阻塞semaphore.release():释放令牌,通知其他线程Semaphore 可以限制方法的并发访问线程数,常用于限流或控制资源并发度。通过
acquire()获取访问许可、release()释放许可,从而确保同时最多只有固定数量的线程能访问目标方法或资源。
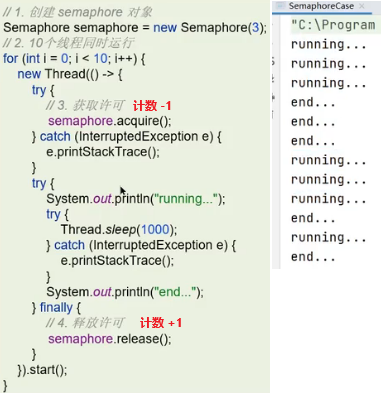
谈一谈你对ThreadLocal的理解
ThreadLocal 是 Java 提供的线程本地变量工具类,用于实现线程间的数据隔离,也可理解为线程级别的“共享变量”。
🌟 一句话总结(记住这个)
ThreadLocal 实现线程间变量隔离,让每个线程拥有一份自己的变量副本,常用于解决共享变量的线程安全问题。
📌 附加:ThreadLocal ≠ 线程安全
ThreadLocal 并不是让对象变“线程安全”,只是让每个线程用自己那份数据,避免共享导致的问题。
🚀 作用与优势
- 线程隔离:每个线程持有一份独立变量,互不干扰,解决并发线程对共享资源读写冲突的问题。
- 线程内共享:同一线程中可以在不同方法、组件间共享数据(如事务控制、用户上下文等)。
🧠 原理说明(核心)
每个线程内部都维护一个
ThreadLocalMap(它是 Thread 类的成员变量):
- 当调用
threadLocal.set(value)时:
- 当前线程的
ThreadLocalMap中以threadLocal实例作为 key,value作为值进行存储。- 当调用
threadLocal.get()时:
- 会从当前线程中以
threadLocal为 key 查找对应的值。remove()用于手动移除,防止内存泄漏。✅ 本质上:ThreadLocal 并不是把值保存在自己内部,而是保存在当前线程的
ThreadLocalMap中。☢️ 内存泄漏问题
ThreadLocalMap中的 key 是ThreadLocal的弱引用,但 value 是强引用- 当 ThreadLocal 实例被 GC 回收后,key 变成 null,**value 仍存在,若不手动 remove,就会造成内存泄漏**
- 最佳实践:用完一定要调用
remove()方法清除数据
- ThreadLocal 可以实现【资源对象】的线程隔离,让每个线程各用各的【资源对象】避免争用引发的线程安全问题
- ThreadLocal 同时实现了线程内的资源共享
- 每个线程内有一个 ThreadLocalMap 类型的成员变量,用来存储资源对象
- 调用 set 方法,就是以 ThreadLocal 自己作为 key,资源对象作为 value,放入当前线
程的 ThreadLocalMap 集合中- 调用 get 方法,就是以 ThreadLocal 自己作为 key,到当前线程中査找关联的资源值
- 调用remove 方法,就是以 ThreadLocal 自己作为 key,移除当前线程关联的资源值
- ThreadLocal内存泄漏问题ThreadLocalMap 中的key是弱引用,值为强引用; key会被Gc释放内存,关联 value的内存并不会释放。建议主动remove 释放 key,value
ThreadLocal概述
ThreadLocal是多线程中对于解决线程安全的一个操作类,它会为每个线程都分配一个独立的线程副本从而解决了变量并发访问冲突的问题。ThreadLocal同时实现了线程内的资源共享
案例:使用JDBC操作数据库时,会将每一个线程的Connection放入各自的ThreadLocal中,从而保证每个线程都在各自的 Connection 上进行数据库的操作,避免A线程关闭了B线程的连接。
ThreadLocal基本使用
- set(value) 设置值
- get() 获取值
- remove() 清除值
ThreadLocal的实现原理 & 源码解析
ThreadLocal本质来说就是一个线程内部存储类,从而让多个线程只操作自己内部的值,从而实现线程数据隔离
JVM相关面试题
什么是JVM?
JVM = Java Virtual Machine 是java程序的运行环境
JVM是运行在操作系统中的 屏蔽了操作系统的差异
好处:
- 一次编码,到处运行
- 自动内存管理,垃圾回收机制
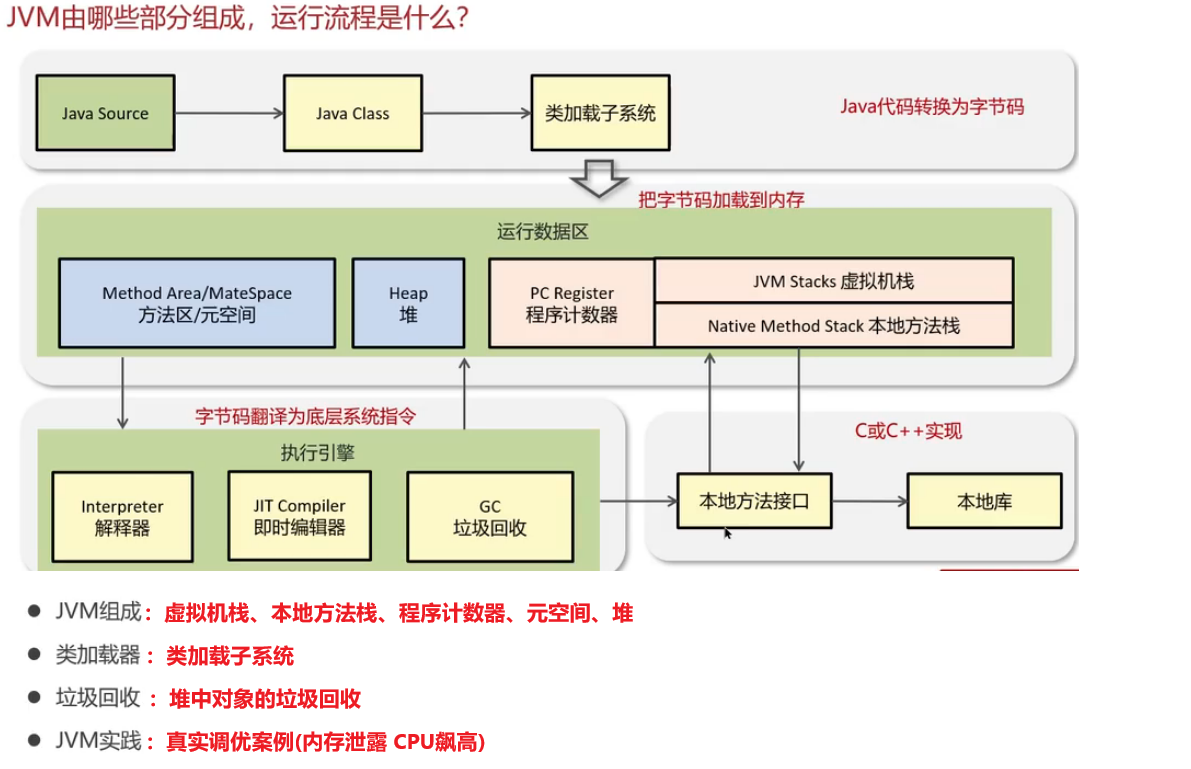
什么是程序计数器?
程序计数器:线程私有的,内部保存的字节码的行号。用于记录正在执行的字节码指令的地址
javap -v xx.class:打印堆栈大小,局部变量的数量和方法的参数
找到Application的class文件后 → Build → Rebuild Project
编译一下→ 找到该Application的class文件黄色的→ Open in → Terminal → javap -v Application.class

你能给我详细介绍Java堆吗?
线程共享的区域:主要用来保存对象实例、数组等,当堆中没有内存空间可分配给实例,也无法再扩展,则抛出OutOfMemoryError异常
- 组成:年轻代 + 老年代
- 年轻代被划分为三部分,Eden区和两个大小严格相同的Survivor区
幸存者区 - 老年代主要保存生命周期长的对象,一般是一些老的对象
- 年轻代被划分为三部分,Eden区和两个大小严格相同的Survivor区
- jdk1.7和1.8的区别
- 1.7中有一个永久代,存储的是类信息、静态变量、常量、编译后的代码
- 1.8移除了永久代,把数据存储到了本地内存的元空间中,防止内存溢出
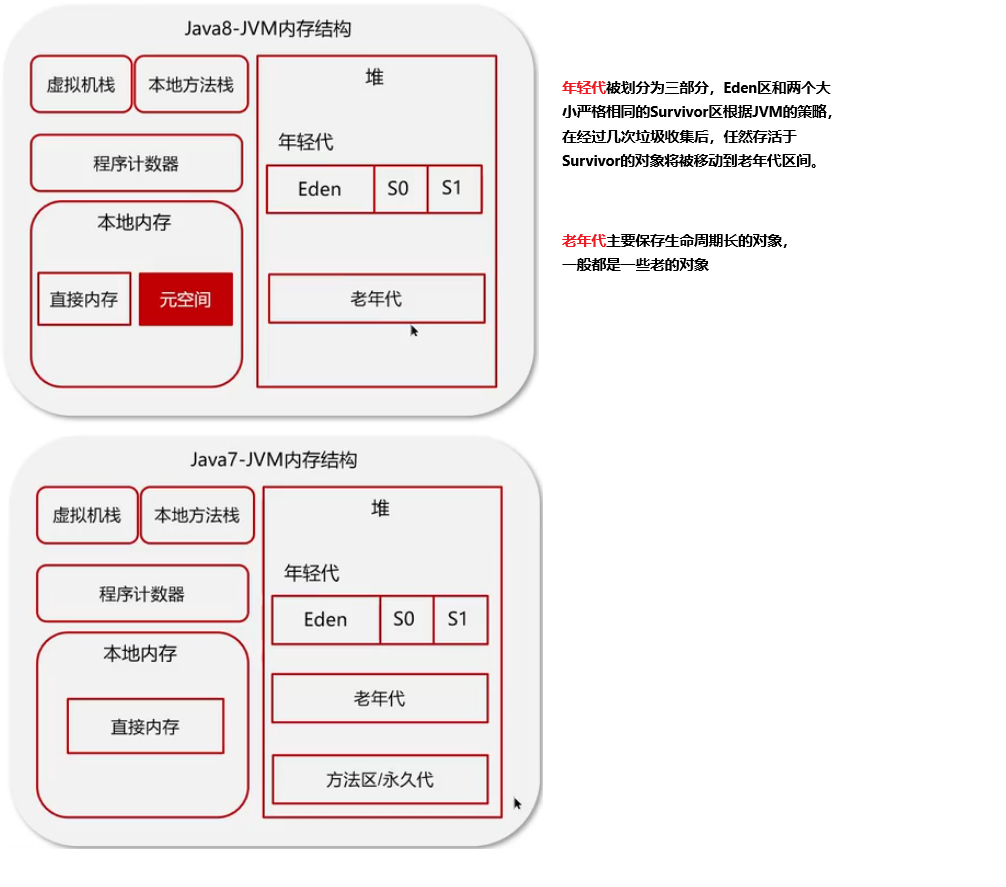
什么是虚拟机栈?
Java Virtual machine Stacks(Java虚拟机栈)
- 每个线程运行时所需要的内存,称为虚拟机栈,先进后出
- 每个栈由多个栈帧(frame)组成,对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
垃圾回收是否涉及栈内存?
不涉及,因为垃圾回收主要指的是堆内存。
这里当栈帧弹栈后,内存就会释放
栈内存分配越大越好吗?
未必,默认的栈内存通常为1024k
栈帧过大会导致线程数变少,例如,机器总内存为512m,目前能活动的线程数则为512个,如果把栈内存改为2048k,那么能活动的栈帧就会减半
方法内的局部变量是否线程安全?
如果方法内局部变量没有逃离方法的作用范围,它是线程安全的
如果是局部变量引用了对象,并逃离方法的作用范围,需要考虑线程安全
什么情况下会导致栈内存溢出?
栈帧过多导致栈内存溢出,经典问题:递归调用
栈帧过大导致栈内存溢出
堆栈的区别是什么?
栈内存一般会用来存储局部变量和方法调用,但堆内存是用来存储Java对象和数组的的。堆会GC垃圾回收,而栈不会
栈内存是线程私有的,而堆内存是线程共有的。
两者异常错误不同,但如果栈内存或者堆内存不足都会抛出异常
栈空间不足:java.lang.StackOverFlowError。
堆空间不足:java.ang.OutOfMemoryError。

能不能解释一下方法区
- 方法区(Method Area)是各个线程 共享的内存区域
- 主要存储类的信息、运行时常量池
- 虚拟机启动的时候创建,关闭虚拟机时释放
- 如果方法区域中的内存无法满足分配请求,则会抛出
OutOfMemoryError: Metaspace
常量池
可以看作是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息
在Terminal中执行:javap -v Application.class
可以查看字节码结构 (类的基本信息、常量池、方法定义)
当类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
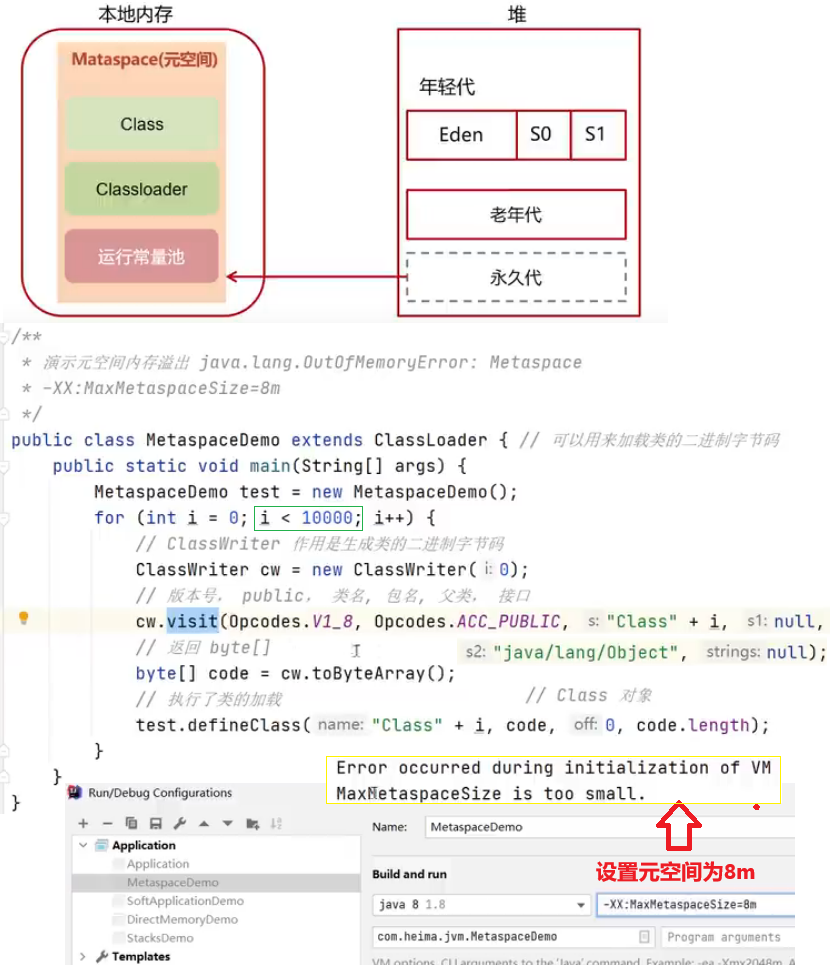
你听过直接内存吗?
直接内存:并不属于JVM中的内存结构,不由JVM进行管理。是虚拟机的系统内存,常见于NIO操作时,用于数据缓冲区,它分配回收成本较高,但读写能力高。[平时的是BIO]
直接内存并不属于JVM中的内存结构,不由VM进行管理。是虚拟机的系统内存常见于 NIO 操作时,用于数据缓冲区,分配回收成本较高,但读写性能高,不受 JVM 内存回收管理
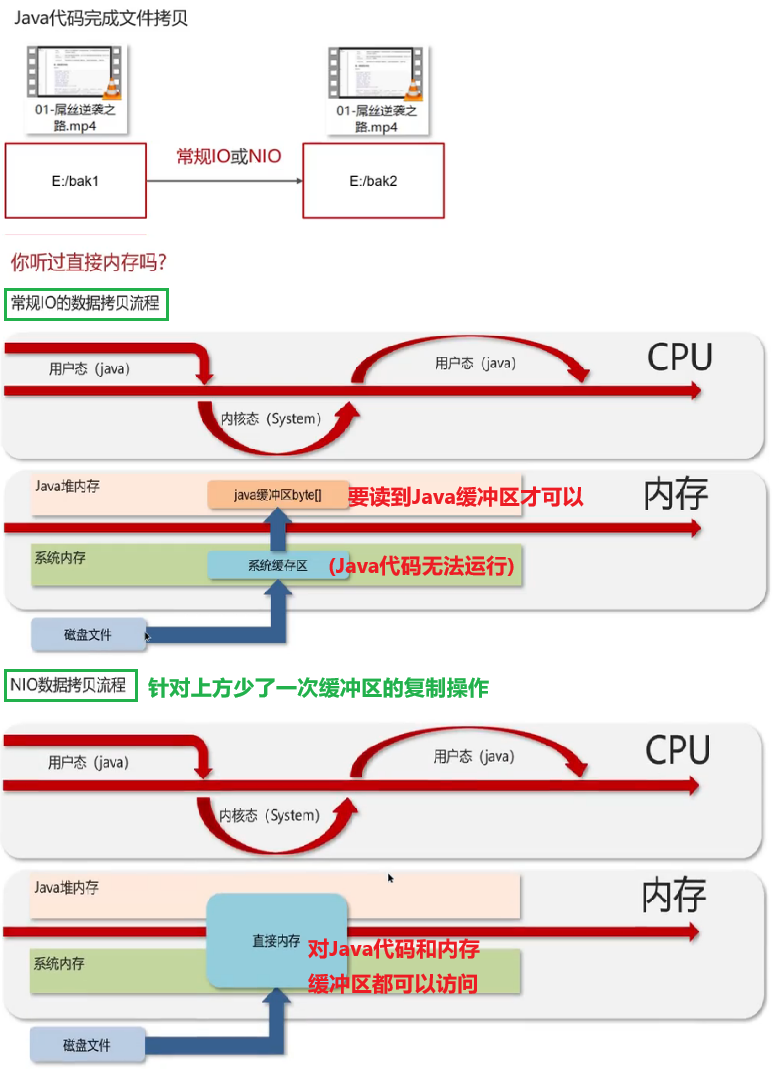
什么是类加载器,类加载器有哪些?
类加载器
JVM只会运行二进制文件,类加载器的作用就是将字节码文件加载到JVM中,从而让Java程序能够启动起来
- 引导类加载器(Bootstrap ClassLoader):
加载JAVA_HOME/jre/lib目录下的库- 这是最顶层的类加载器,它用于加载Java的核心库,这些库位于
<JAVA_HOME>/jre/lib目录(比如rt.jar、resources.jar等),或者被-Xbootclasspath参数指定的路径中。 - 引导类加载器是用原生代码(如C/C++)实现的,它属于JVM的一部分。
- 它并不继承自
java.lang.ClassLoader,而是由JVM自身实现。
- 这是最顶层的类加载器,它用于加载Java的核心库,这些库位于
- 扩展类加载器(Extension ClassLoader):
加载JAVA_HOME/jre/lib/ext目录中的类- 它负责加载
<JAVA_HOME>/lib/ext目录中,或者由系统属性java.ext.dirs指定的路径中的类库。 - 它是
sun.misc.Launcher$ExtClassLoader类的实例。
- 它负责加载
- 系统类加载器(System ClassLoader):
用于加载classPath下的类- 也称为应用类加载器(Application ClassLoader),它负责加载用户类路径(Classpath)上的所有类库。
- 系统类加载器是
sun.misc.Launcher$AppClassLoader类的实例。 - 它是程序中默认的类加载器,可以通过
ClassLoader.getSystemClassLoader()方法获取。
- 自定义加载器(CustomizeClassLoader)
自定义继承ClassLoader,实现自定义类加载规则- 用户还可以自定义类加载器。自定义类加载器通过继承
java.lang.ClassLoader类并重写相应的方法来实现。自定义类加载器可以用于特定的需求,例如在Web容器中加载类,或者在运行时从网络或其他地方动态加载类。
- 用户还可以自定义类加载器。自定义类加载器通过继承
什么是双亲委派模型?
加载某一个类,先委托上一级的加载器进行加载,如果上级加载器也有上级,则会继续向上委托,如果该类委托上级没有被加载,子加载器尝试加载该类
JVM为什么采用双亲委派机制?
- 通过双亲委派机制可以避免某一个类被重复加载,当父类已经加载后则无需重复加载,保证唯一性
- 为了安全,保证类库API不会被修改

说一下类装载的执行过程?
加载:查找和导入class文件
验证:保证加载类的准确性
准备:为类变量分配内存并设置类变量初始值
解析:把类中的符号引用转换为直接引用
初始化:对类的静态变量,静态代码块执行初始化操作
使用:JVM 开始从入口方法开始执行用户的程序代码
卸载:当用户程序代码执行完毕后,JVM便开始销毁创建的Class对象
类从加载到虚拟机中开始,直到卸载为止,它的整个生命周期包括了:加载、验证、准备、解析、初始化、使用和卸载这7个阶段。其中,验证、准备和解析这三个部分统称为连接(linking)
- 通过类的全名,获得类的二进制数据流
- 解析类的二进制数据流为方法区内的数据结构(Java类模型)
- 创建
java.lang.Class类的实例,表示该类型。作为方法区这个类的各种数据的访问入口
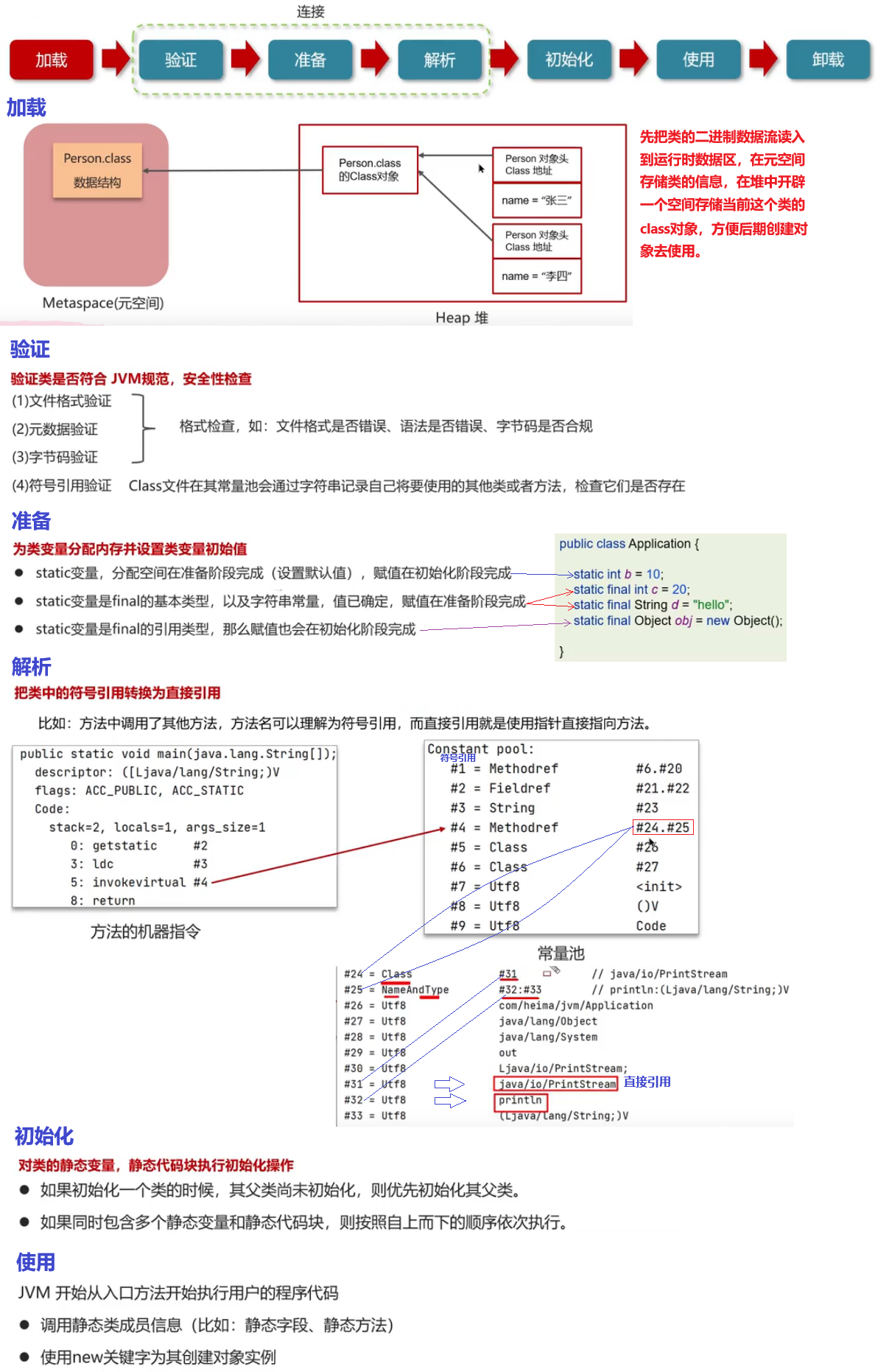
对象什么时候可以被垃圾器回收
如果一个或多个对象没有任何的引用指向它了,那么这个对象现在就是垃圾,如果定位了垃圾,则有可能会被垃圾回收器回收
怎么确定什么是垃圾?
引用计数法
一个对象被引用了一次,在当前的对象头上递增一次引用次数,如果这个对象的引用次数为0,代表这个对象可回收
可达性分析算法
采用的都是通过可达性分析算法来确定哪些内容是垃圾
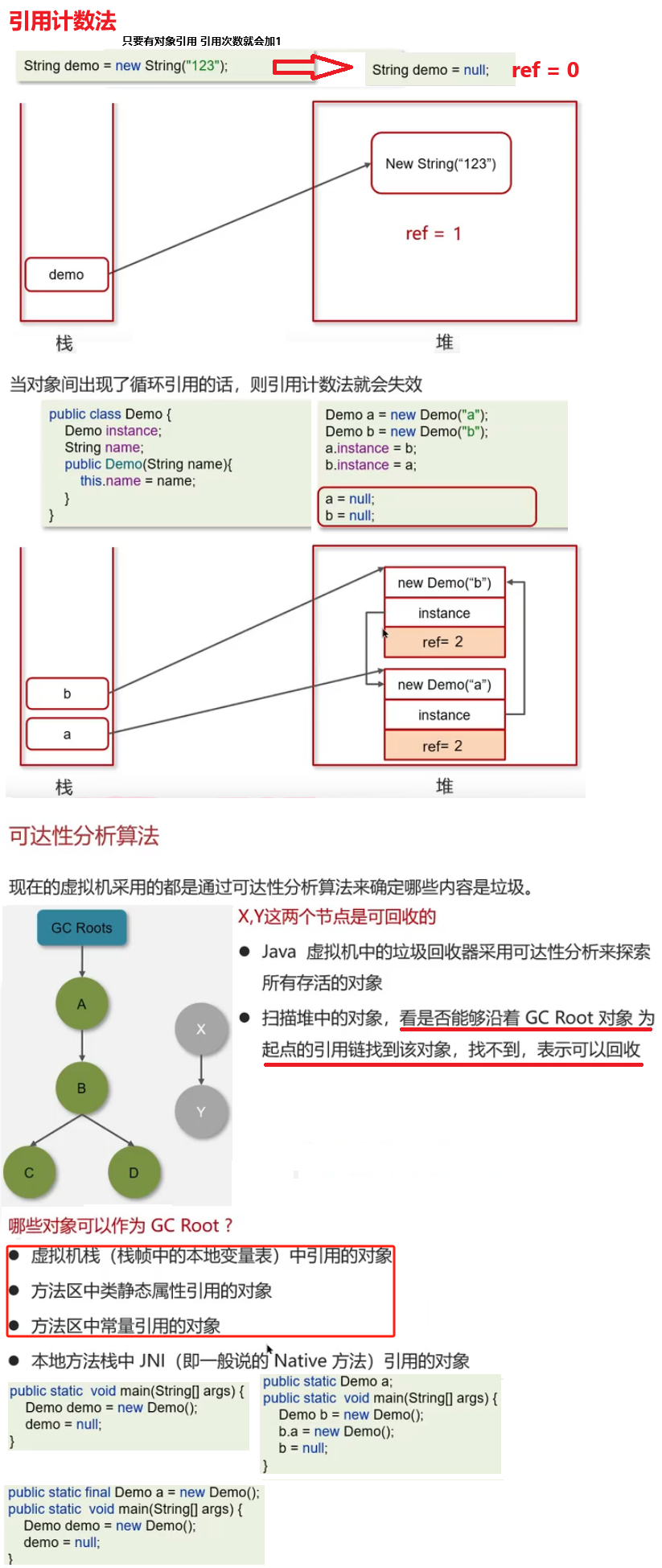
JVM垃圾回收算法有哪些?
标记清除算法
是将垃圾回收分为2个阶段,分别为标记和清除
- 根据可达性分析算法得出的垃圾进行标记
- 对这些标记为可回收的内容进行垃圾回收
复制算法
将原有的内存空间一分为二,每次只用其中的一块,正在使用的对象复制到另一个内存空间中,然后将该内存空间清空,交换两个内存的角色,完成垃圾的回收;无碎片,内存使用率低
标记清理算法
一般用于老年代标记清除算法一样,将存活对象都向内存另一端移动,然后清理边界以外的垃圾,无碎片,对象需要移动,效率低
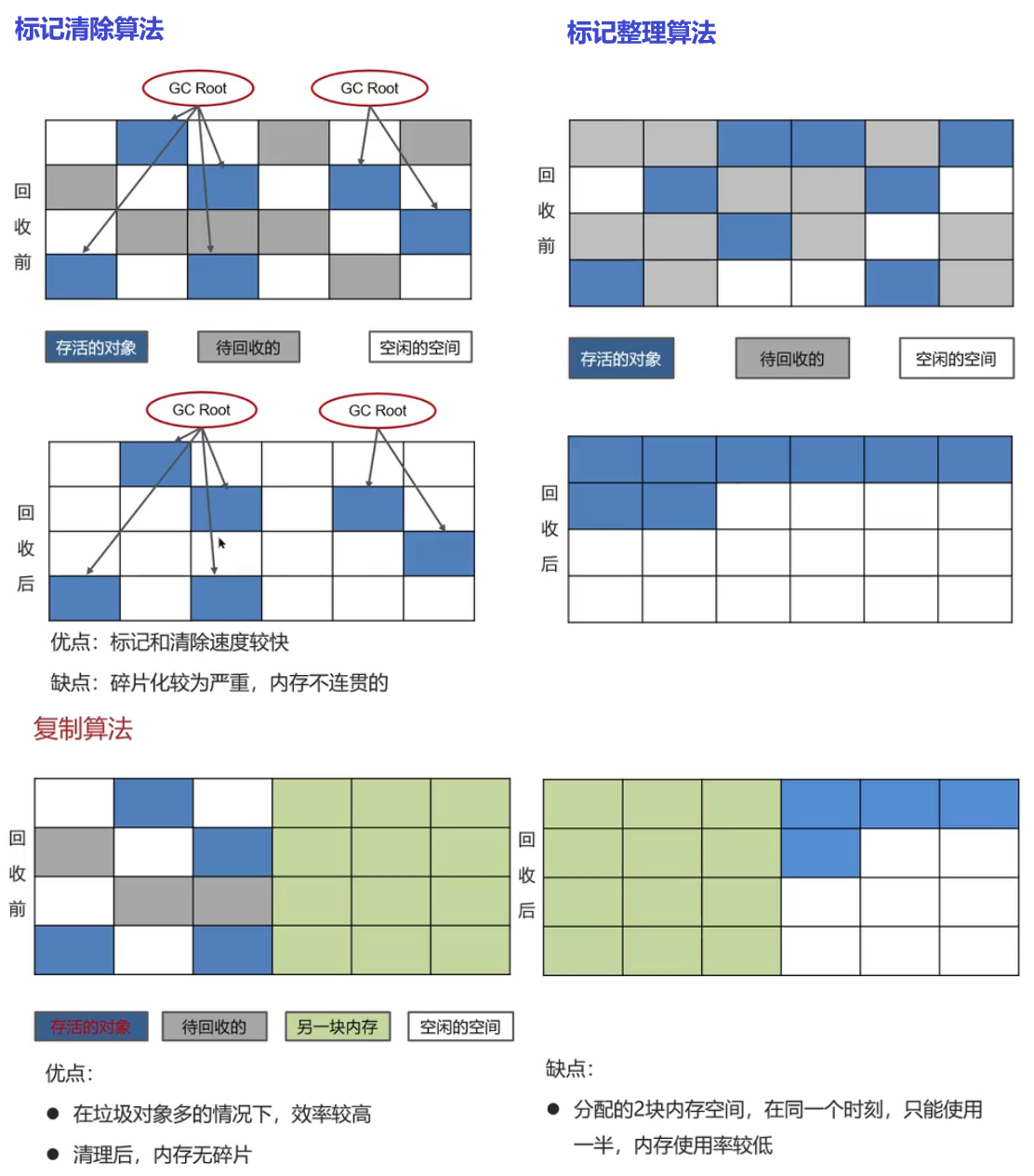
JVM的分代回收是什么?
分代收集算法
在java8时,堆被分为了两份:新生代和老年代[1:2]
对于新生代,内部又分为了三个区域,Eden区,幸存者区survivor(分成from和to)【8:1:1】
MinorGC、MixedGC、FullGC的区别是什么
- MinorGC
(youngGC)发生在新生代的垃圾回收,暂停时间短(STW) - MixedGC:新生代 + 老年代 部分区域的垃圾回收,G1收集器特有
- FullGC:新生代 + 老年代 完整垃圾回收,暂停时间长(STW),应尽力避免
STW(Stop-The-World):暂停所有应用程序线程,等待垃圾回收的完成
JVM有哪些垃圾回收器?
在jvm中,实现了多种垃圾收集器,包括:
串行垃圾收集器
Serial和Serial Old串行垃圾收集器,是指使用单线程进行垃圾回收,堆内存较小,适合个人电脑
- Serial 作用于新生代,采用复制算法
- Serial Old 作用于老年代,采用标记-整理算法垃圾回收时,只有一个线程在工作,并且java应用中的所有线程都要暂停(STW),等待垃圾回收的完成
并行垃圾收集器
Parallel New和Parallel Old是一个并行垃圾回收器,JDK8默认使用此垃圾回收器
Parallel New作用于新生代,采用复制算法
Parallel Old作用于老年代,采用标记-整理算法
垃圾回收时,多个线程在工作,并且java应用中的所有线程都要暂停(STW),等待垃圾回收的完成。
CMS(并发)垃圾收集器
CMS全称 Concurrent Mark Sweep,是一款并发的、使用标记-清除算法的垃圾回收器,该回收器是针对老年代垃圾回收的,是一款以获取最短回收停顿时间为目标的收集器,停顿时间短,用户体验就好。其最大特点是在进行垃圾回收时,应用仍然能正常运行
G1垃圾收集器
作用在新生代和老年代
详细聊一下G1垃圾回收器
- 应用于新生代和老年代,在JDK9之后默认使用G1
- 划分成多个区域,每个区域都可以充当eden,survivor,old,humongous,其中
humongous专为大对象准备 - 采用复制算法
- 响应时间与吞吐量兼顾
- 分成三个阶段:新生代回收(STW)、并发标记(重新标记STW)、混合收集
- 如果并发失败(即回收速度赶不上创建新对象速度),就会触发
Full GC
强引用、软引用、弱引用、虚引用的区别
强引用:只要所有 GC Roots 能找到,就不会被回收
软引用:需要配合SoftReference使用,当垃圾多次回收,内存依然不够时候会回收软引用对象
弱引用:需要配合WeakReference使用,只要进行了垃圾回收,就会把引用对象回收
虚引用:必须配合引用队列使用,被引用对象回收时,会将虚引用入队由Reference Handler线程调用虚引用相关方法释放直接内存
- 强引用:只有所有
GCRoots对象都不通过【强引用】 引用该对象,该对象才能被垃圾回收
User user = new User();
GC Root → User对象
- 软引用:仅有软引用引用该对象时,在垃圾回收后,内存仍不足时会再次触发垃圾回收
User user = new User();
SoftReference softReference = new SoftReference(user);
GC Root → SoftReference对象 →→虚线 User对象
一开始并不会对User对象进行回收 此时User对象就是软引用 如果内存还是不够 马上又再次进行了垃 圾回收 此时软引用的User就会被回收
- 弱引用:仅有弱引用引用该对象时,在垃圾回收时,无论内存是否充足,都会回收弱引用对象
User user = new User();
WeakReference weakReference = new WeakReference(user)
GC Root → WeakReference对象 →→虚线 User对象
延申话题:ThreadLocal内存泄露问题
static class Entry extends WeakReference<ThreadLocal<?>>{ Object value; Entry(ThreadLocal<?>k, Object v){ super(k); // k是弱引用 value = v; // 强引用,不会被回收 } }
- 虚引用:必须配合引用队列使用,被引用对象回收时,会将虚引用入队,由
Reference Handler线程调用虚引用相关方法释放直接内存
User user = new User();
ReferenceQueue referenceQueue = new ReferenceQueue();
PhantomReference phantomReference = new PhantomReference(user, queue);
JVM调优的参数可以在哪里设置?
war包部署在tomcat中设置修改
TOMCAT_HOME/bin/catalina.sh文件D:\apache-tomcat-8.5.93\bin\catalina.sh【卡特琳娜】# OS specific support. $var _must_ be set to either true or false. JAVA_OPTS="-Xms512m -Xmx1024m" cygwin=false darwin=false os400=false hpux=falsejar包部署在启动参数设置通常在linux系统下直接加参数启动SpringBoot项目
—VMnohup java -Xms512m -Xmx1024n -jar xxxx.jar --spring.profiles.active=prod &
nohup:用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行
**参数&**:让命令在后台执行,终端退出后命令仍然执行
JVM调优的参数都有哪些?
对于JVM调优,主要就是调整 年轻代、老年代、元空间 的内存大小及使用的垃圾回收器类型
设置堆空间大小
设置堆的初始大小和最大大小,为了防止垃圾收集器在初始大小、最大大小之间收缩堆而产生额外的时间,通常把最大、初始大小设置为相同的值
-Xms: 设置堆的初始化大小 -Xmx: 设置堆的最大大小 // 不指定单位默认为字节 -Xms:1024 -Xms:1024k堆内存设置多少合适?
- 最大大小的默认值是物理内存的1/4,初始大小是物理内存的1/64
【不设置的情况下】 - 堆太小,可能会频繁的导致年轻代和老年代的垃圾回收,会产生STW,暂停用户线程
- 堆内存大肯定是好的,存在风险,假如发生了fullgc,它会扫描整个堆空间,暂停用户线程的时间长
- 最大大小的默认值是物理内存的1/4,初始大小是物理内存的1/64
虚拟机栈的设置
虚拟机栈的设置:每个线程默认会开启1M的内存,用于存放栈帧、调用参数、局部变量等,但一般256K就够用。通常减少每个线程的堆栈,可以产生更多的线程,但这实际上还受限于操作系统。
-Xss 对每个线程stack大小的调整,-Xss128k年轻代中Eden区和两个Survivor区的大小比例
设置年轻代中Eden区和两个Survivor区的大小比例。该值如果不设置,则默认比例为8:1:1。通过增大Eden区的大小来减少YGC发生的次数,但有时我们发现,虽然次数减少了,但Eden区满的时候,由于占用的空间较大,导致释放缓慢,此时STW的时间较长,因此需要按照程序情况去调优。
-XXSurvivorRatio=8,表示年轻代中的分配比率:survivor:eden = 2:8年前代晋升老年代阈值【默认值为15,取值范围0-15】
-XX:MaxTenuringThreshold=threshold设置垃圾回收收集器
通过增大吞吐量提高系统性能,可以通过设置并行垃圾回收收集器
-XX:+UseParallelGC-XX:+UseParallelOldGC-XX:+UserG1GC
JVM调优的参数都有哪些?
命令工具
jps 进程状态信息
jstack 查看进程内线程的堆栈信息
产生死锁可以查看jmap 查看堆栈信息[生成堆转内存快照,内存使用信息]
jmap -head pid 显示Java堆的信息 jmap -dump:format=b,file=heap.hprof pidformat=b 表示以hprof二进制格式存储Java堆的内存
file=< filename > 用于指定快照dump文件的文件名
dump:它是我们都可以通过工个进程或系统在某一给定的时间的快照。比如在进程崩溃时,甚至是任何时候,具将系统或某进程的内存备份出来供调试分析用,dump文件中包含了程序运行的模块信息、线程信息、堆调用信息、异常信息等数据,方便系统技术人品进行错误排查
jhat 堆转储快照分析工具
jstat JVM统计监测工具[可以用来显示垃圾回收信息、类加载信息、新生代统计信息等]
- 总结垃圾回收统计:
jstat -gcutil pid - 垃圾回收统计:
jstat -gc pid
- 总结垃圾回收统计:
可视化工具
- jconsole 用于对jvm的内存,线程,类的监控, 是一个可视化工具
D:\java\jdk-11.0.20\bin\jconsole.exe - VisualVM 能够监控线程,内存情况
只有jdk1.8有D:\java\jdk1.8.0_181\bin\jvisualvm.exe
- jconsole 用于对jvm的内存,线程,类的监控, 是一个可视化工具
Java内存泄露的排查思路?
内存泄漏通常是指堆内存,通常是指一些大对象不被回收的情况
1、通过jmap或设置jvm参数获取堆内存快照dump
2、通过工具,VisualVM去分析dump文件,VisualVM可以加载离线的dump文件
3、通过查看堆信息的情况,可以大概定位内存溢出是哪行代码出了问题
4、找到对应的代码,通过阅读上下文的情况,进行修复即可
JVM Stacks 虚拟机栈 → StackOverFlowError
Heap 堆 → OutOfMemoryError:java heap space
Method Are/ MateSpace 方法区/元空间 → OutOfMemoryError: Metaspace
模拟堆空间溢出场景:-VM设置参数 → -Xmx10m
List<String> list = new ArrayList<>();
while(true){
list.add("北京");
}
-------------------------------------------
// OutOfMemoryError:java heap space
如何排查启动闪退、运行一段时间宕机
获取堆内存快照dump
- 使用jmap命令获取运行中程序的dump文件
【只有在项目运行时候才可以用】
jmap -head pid 显示Java堆的信息 jmap -dump:format=b,file=heap.hprof pid 【只有在项目运行时候才可以用】使用vm参数获取dump文件
有的情况是内存溢出之后程序则会直接中断,而jmap只能打印在运行中的程序,所以建议通过参数的方式生成dump文件
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/app/dumps/- 使用jmap命令获取运行中程序的dump文件
VisualVM区分析dump文件
通过查看堆内存的信息,定位内存溢出问题
CPU飙高排查方案与思路?
1.使用top命令查看占用cpu的情况
2.通过top命令查看后,可以查看是哪一个进程占用cpu较高
3.使用ps命令查看进程中的线程信息
4.使用jstack命令查看进程中哪些线程出现了问题,最终定位问题
使用top命令查看占用cpu的情况
哪个进程占用的cpu最高finalShell中输入
top查看进程中的线程信息
ps H -eo pid,tid,%cpu | gerp pidjstack 查看进程内线程的堆栈信息
产生死锁可以查看因为是十六进程所以要十进程转换十六进程
直接linux输入printf "%x\n" Pid
然后就可以根据十六进制的去找哪个线程cpu占用
之后查看文件是cat xxx
设计模式
框架中的设计模式 + 项目中的设计模式
简单工厂模式
简单工厂包含如下角色
- 抽象产品:定义了产品的规范,描述了产品的主要特性和功能。
- 具体产品 :实现或者继承抽象产品的子类
- 具体工厂:提供了创建产品的方法,调用者通过该方法来获取产品。
需求:设计一个咖啡店点餐系统。
设计一个咖啡类(Coffee),并定义其两个子类(美式咖啡【AmericanCofee】和拿铁咖啡【LatteCoffee】); 再设计一个咖啡店类(CoffeeStore),咖啡店具有点咖啡的功能。
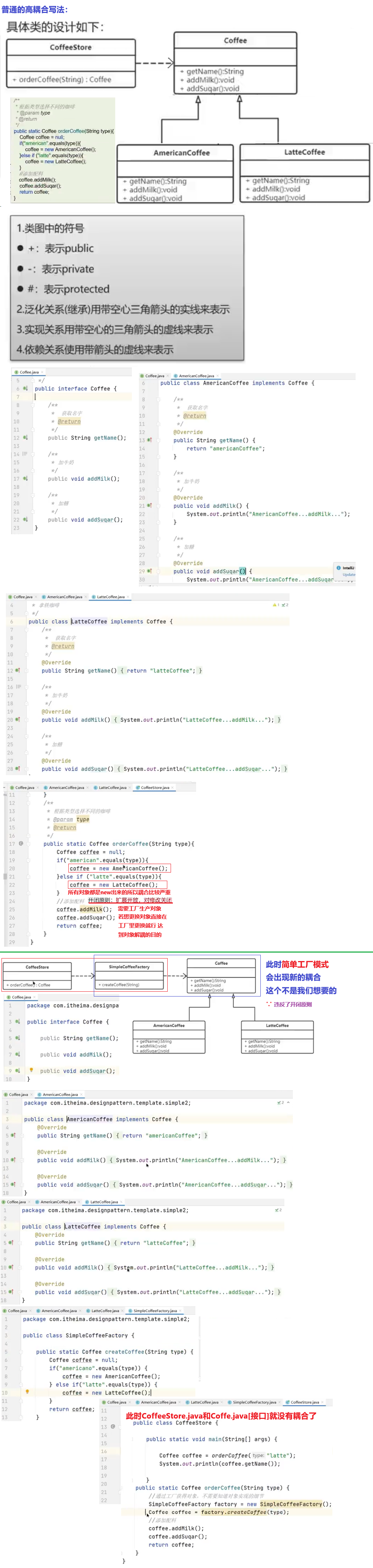
工厂方法模式完全遵循开闭原则
方法模式的主要角色:
抽象工厂(Abstract Factory):提供了创建产品的接口,调用者通过它访问具体工厂的工厂方法来创建产品。
具体工厂(ConcreteFactory):主要是实现抽象工厂中的抽象方法,完成具体产品的创建。
抽象产品(Product):定义了产品的规范,描述了产品的主要特性和功能。
具体产品(ConcreteProduct):实现了抽象产品角色所定义的接口,由具体工厂来创建,它同具体工厂之间一 一对应。
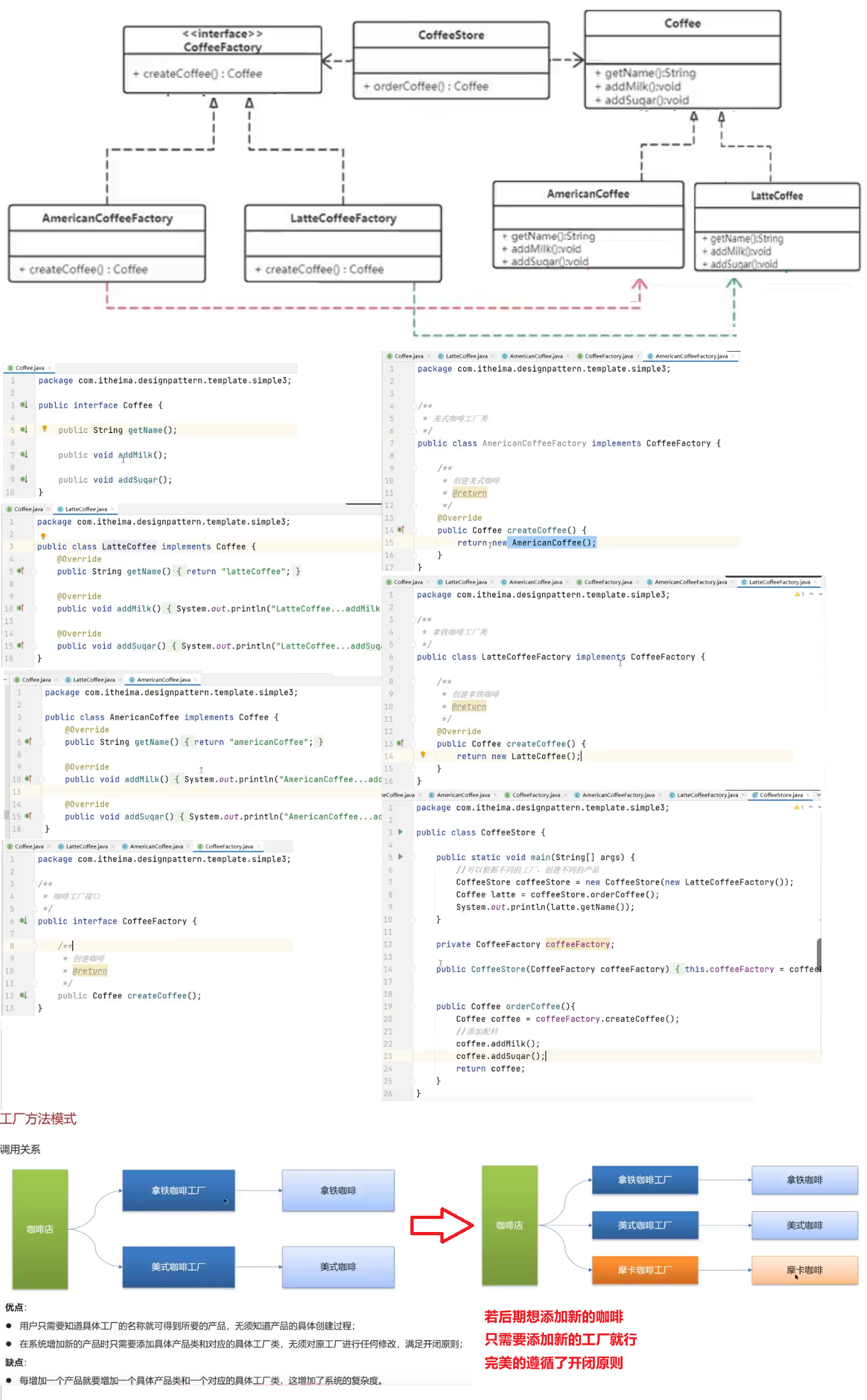
抽象工厂模式
工厂方法模式只考虑生产同等级的产品,抽象工厂可以处理等级产品的生产
抽象工厂模式是工厂方法模式的升级版本,工厂方法模式只生产–个等级的产品,而抽象工厂模式可生产多个等级的产品。一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂
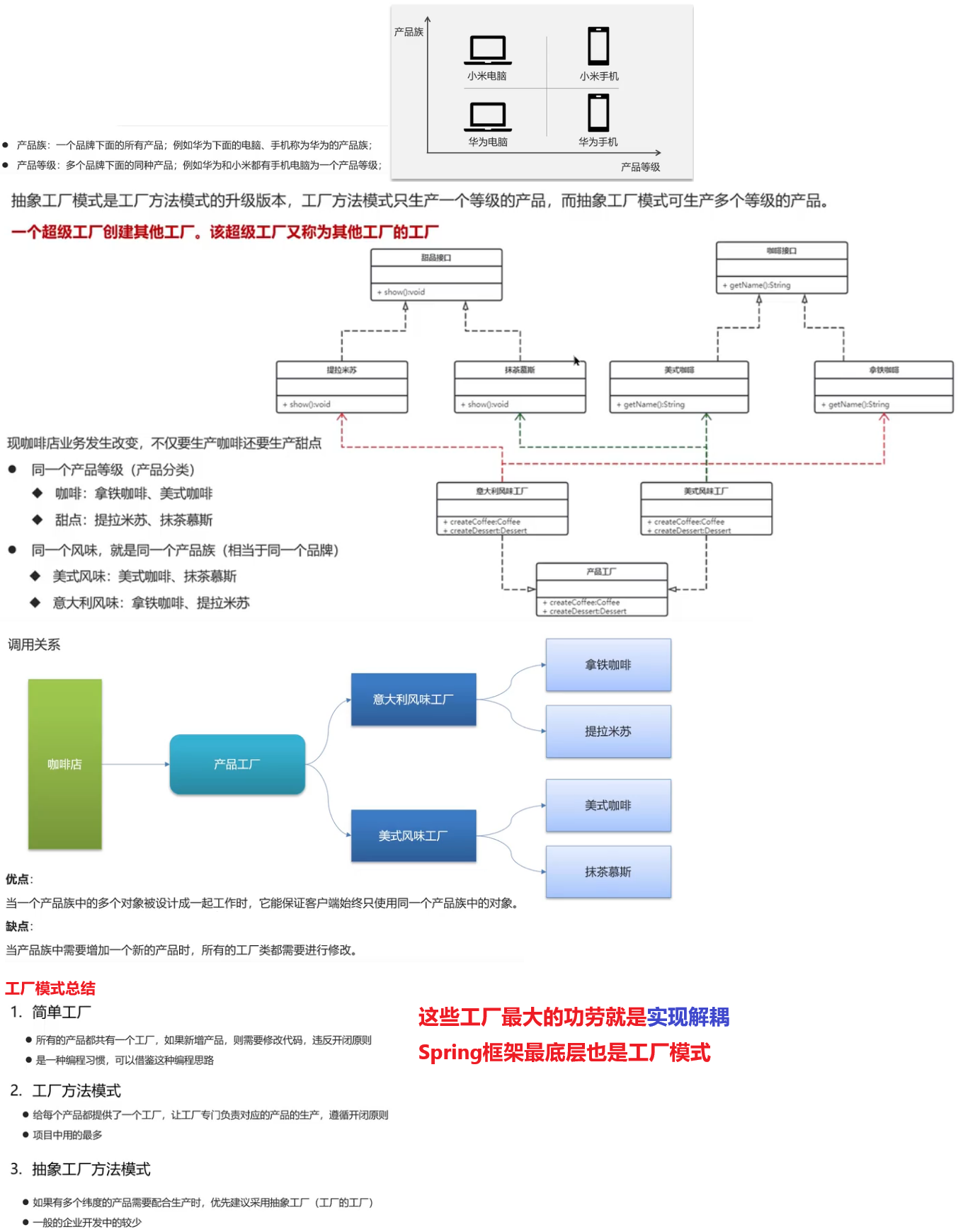
策略模式
- 该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户
- 它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理
策略模式的主要角色如下:
抽象策略(Strategy)类:这是一个抽象角色,通常由一个接口或抽象类实现。此角色给出所有的具体策略类所需的接口
具体策略(Concrete Strategy)类:实现了抽象策略定义的接口,提供具体的算法实现或行为。
环境(Context)类:持有一个策略类的引用,最终给客户端调用。

策略模式—登录案例 (工厂模式 + 策略模式)
什么是策略模式
策略模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户
一个系统需要动态地在几种算法中选择一种时,可将每个算法封装到策略类中
案例(工厂方法+策略)
- 介绍业务(登录、支付、解析excel、优惠等级…)
- 提供了很多种策略,都让spring容器管理
- 提供一个工厂:准备策略对象,根据参数提供对象
一句话总结:只要代码中有冗长的if-else 或switch 分支判断都可以采用策略模式优化
举一反三
- 订单的支付策略(支付宝、微信、银行卡..)
- 解析不同类型excel(xls格式、xlsx格式)
- 打折促销(满300元9折、满500元8折、满1000元7折..)
- 物流运费阶梯计算(5kg以下、5-10kg、10-20kg、20kg以上)
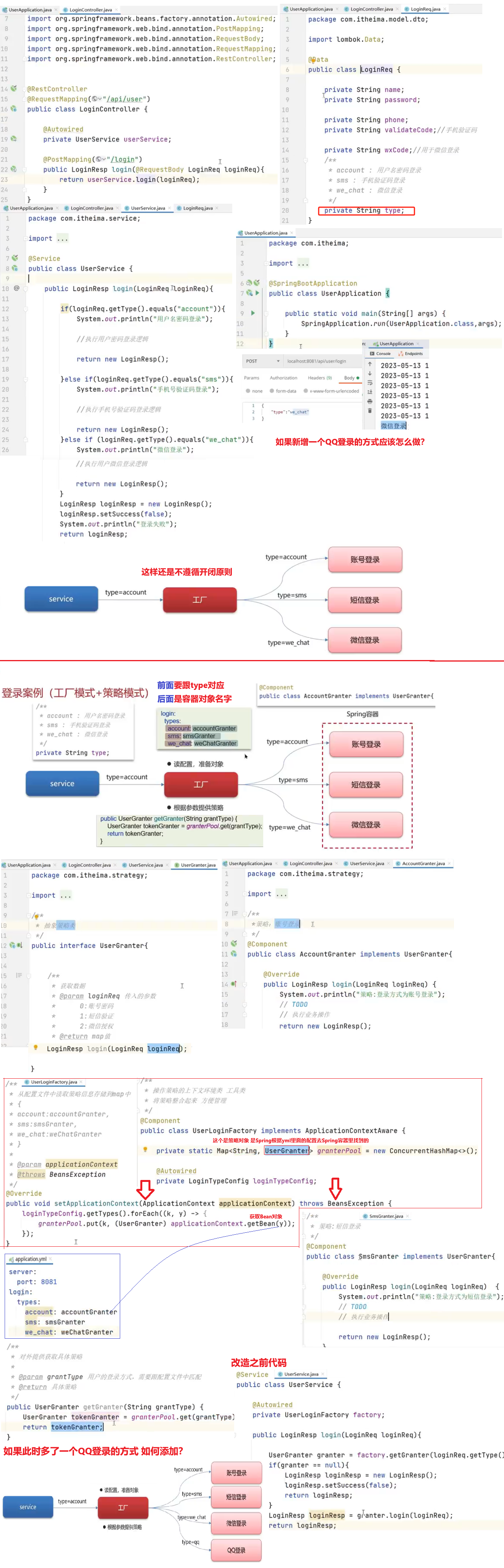
责任链模式—概述及案例
责任链模式:为了避免请求发送者与多个请求处理者耦合在一起,将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。
- 抽象处理者(Handler)角色:定义一个处理请求的接口,包含抽象处理方法和一个后继连接。
- 具体处理者(Concreate Handler)角色:实现抽象处理者的处理方法,判断能否处理本次请求,如果可以处理请求则处理,否则将该请求转给它的后继者。
- 客户类(Cient)角色:创建处理链,并向链头的具体处理者对象提交请求,它不关心处理细节和请求的传递过程。
举一反三
- 内容审核(视频、文章、课程)
- 订单创建
- 简易流程审批
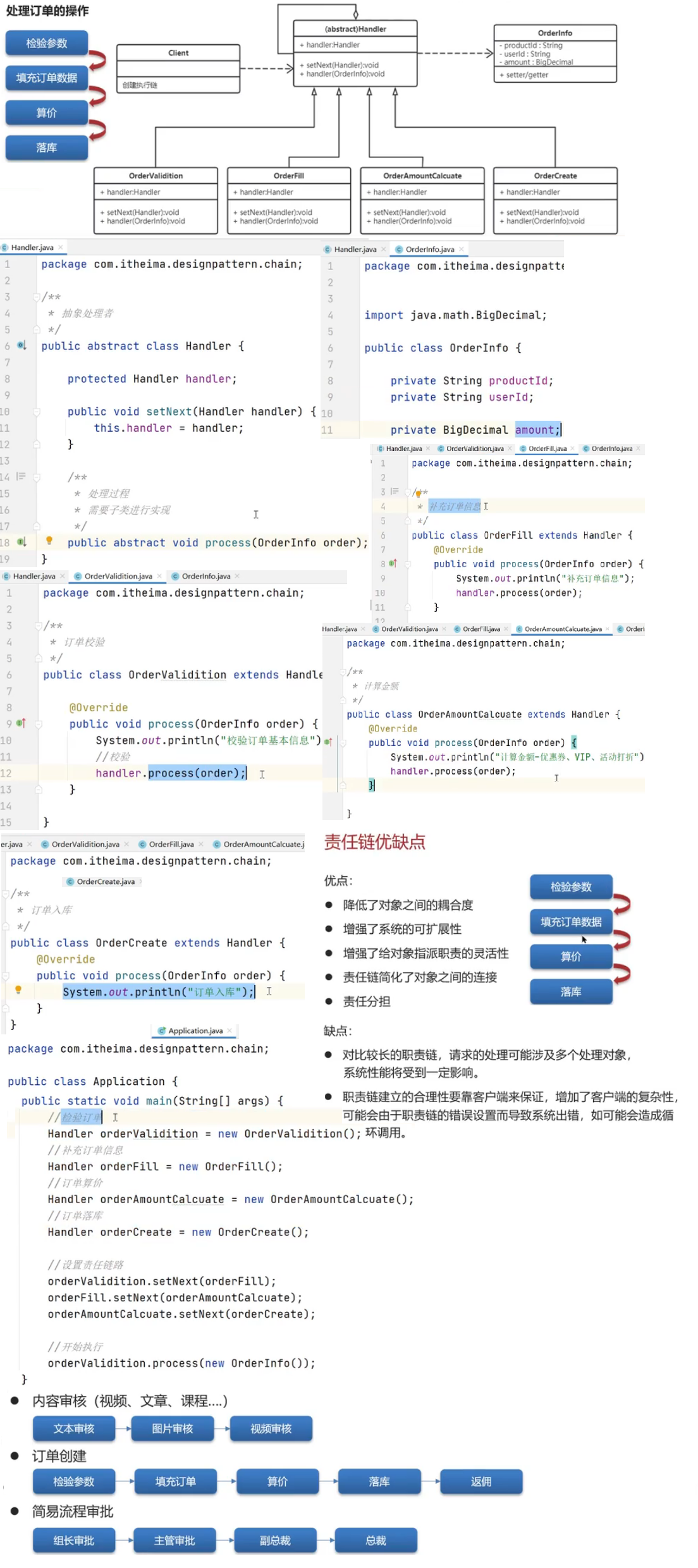
区分责任链模式和策略模式 在if的情况下
✅ 一句话区分
模式 一句话理解 策略模式 多种方案中选一个执行(if 就是“选择谁”) 责任链模式 多个处理器依次尝试处理(if 是“要不要接着传下去”)
👀 从 if 角度看
模式 if 的含义 结果 策略模式 选择哪个处理逻辑(只执行一个) 一旦匹配执行完毕,不再走其他 责任链模式 是否要处理或继续传递(可能多个都执行) 可以处理多个,也可以提前终止 🎯 场景类比(超级形象)
📦 策略模式:
像点菜:你从多个菜中选择一个最合适的吃
🔁 选择一个策略就完事if (type == "微信") { payWithWeChat(); } else if (type == "支付宝") { payWithAliPay(); }
- 策略模式核心:同一个接口,不同实现类,运行时选择哪个
🛠️ 责任链模式:
像审批流程:你写了个请假单,先经理签字 → 主管签字 → HR签字
🔁 每个人看一下自己要不要处理,处理完能不能往下传if (金额 <= 1000) { 主管处理 return } if (金额 <= 5000) { 经理处理 return } HR处理
- 责任链核心:链式传递,一个接一个处理(可中断)
✅ 示例代码对比
🧪 策略模式(支付选择)
public interface PayStrategy { void pay(); } public class WeChatPay implements PayStrategy { public void pay() { System.out.println("微信支付"); } } public class AliPay implements PayStrategy { public void pay() { System.out.println("支付宝支付"); } } // 使用 PayStrategy strategy; if ("wechat".equals(type)) { strategy = new WeChatPay(); } else { strategy = new AliPay(); } strategy.pay();✔️ 选择一个策略类并执行,
if只是为了选哪一个
🧪 责任链模式(审批流程)
public abstract class Approver { protected Approver next; public void setNext(Approver next) { this.next = next; } public abstract void process(int amount); } public class Manager extends Approver { public void process(int amount) { if (amount <= 1000) { System.out.println("Manager approved"); } else if (next != null) { next.process(amount); } } } public class Director extends Approver { public void process(int amount) { if (amount <= 5000) { System.out.println("Director approved"); } else if (next != null) { next.process(amount); } } } // 链式构建 Manager m = new Manager(); Director d = new Director(); m.setNext(d); // 发起请求 m.process(3000);✔️ 多个处理器按顺序尝试,
if是为了决定自己是否处理,并可能往下传递if 语句长得一样,但目的不同:
- 策略 if 是“选哪一个”
- 责任链 if 是“要不要传下去”
常见技术场景题
单点登录这块怎么实现的?
单点登录的英文名:Single Sign On (SSO),只需要登录一次,就可以访问所有信任的应用系统
① 先解释什么是单点登录:单点登录的英文名叫做:Single SignOn(简称SSO)
② 介绍自己项目中涉及到的单点登录(即使没涉及过,也可以说实现的思路)
③ 介绍单点登录的解决方案,以JWT为例
用户访问其他系统,会在网关判断token是否有效
如果token无效则会返回401(认证失败)前端跳转到登录页面
用户发送登录请求,返回浏览器一个token,浏览器把token保存到cookie
再去访问其他服务的时候,都需要携带token,由网关统一验证后路由到目标服务
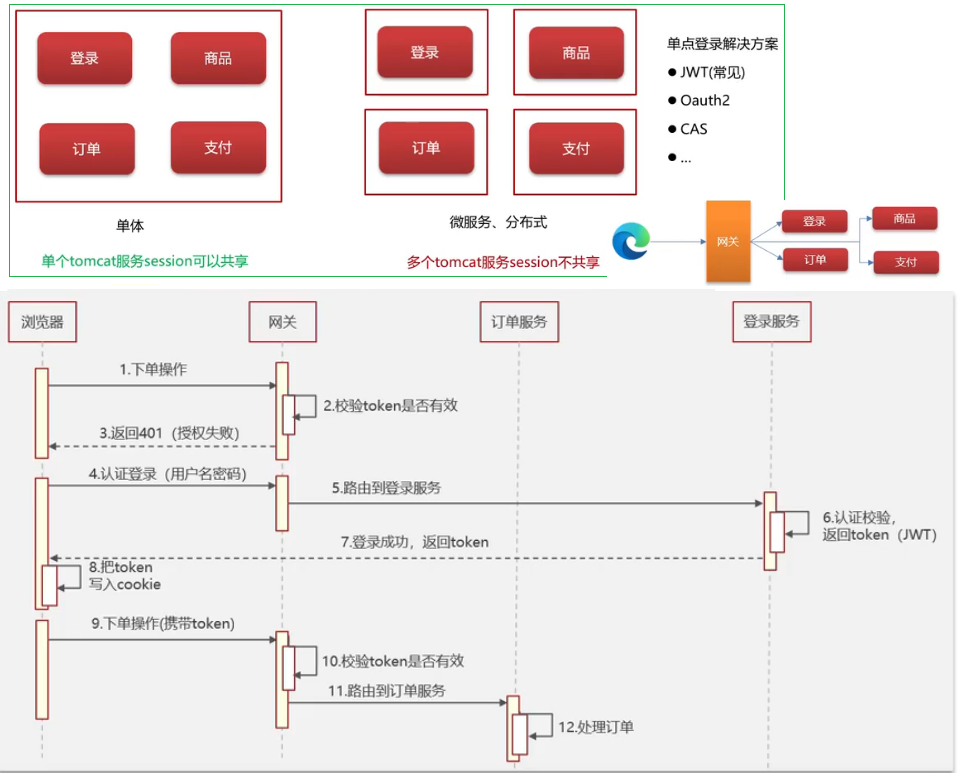
权限认证是如何实现的?
后台的管理系统,更注重权限控制,最常见的就是RBAC模型来指导实现权限
RBAC(Role-Based Access Control)基于角色的访问控制
- 3个基础部分组成:用户、角色、权限
- 具体实现:
- 5张表:用户表、角色表、权限表、用户角色中间表、角色权限中间表
- 7张表:用户表、角色表、权限表、菜单表、用户角色中间表、角色权限中间表、权限菜单中间表
张三具有什么权限呢?
流程:张三登录系统 → 查询张三拥有的角色列表 → 再根据角色查询拥有的权限
权限框架:Apache shiro、Spring Security(推荐)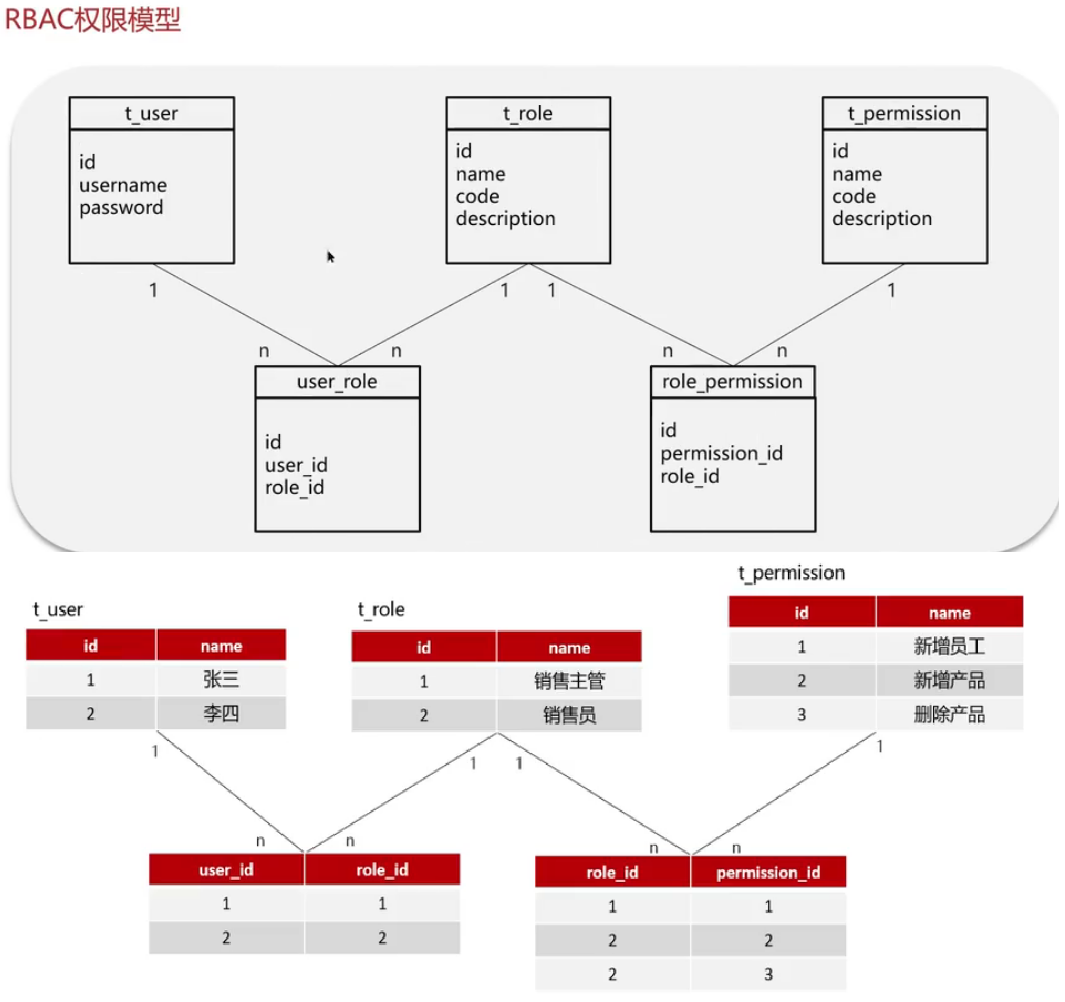
上传数据的安全性你们怎么控制?
主要说的是数据在网络上传输如何保证安全
使用**非对称加密(或对称加密)**,给前端一个公钥让他把数据加密后传到后台,后台负责解密后处理数据
对称加密
文件加密和解密使用相同的密钥,即加密密钥也可以用作解密密钥
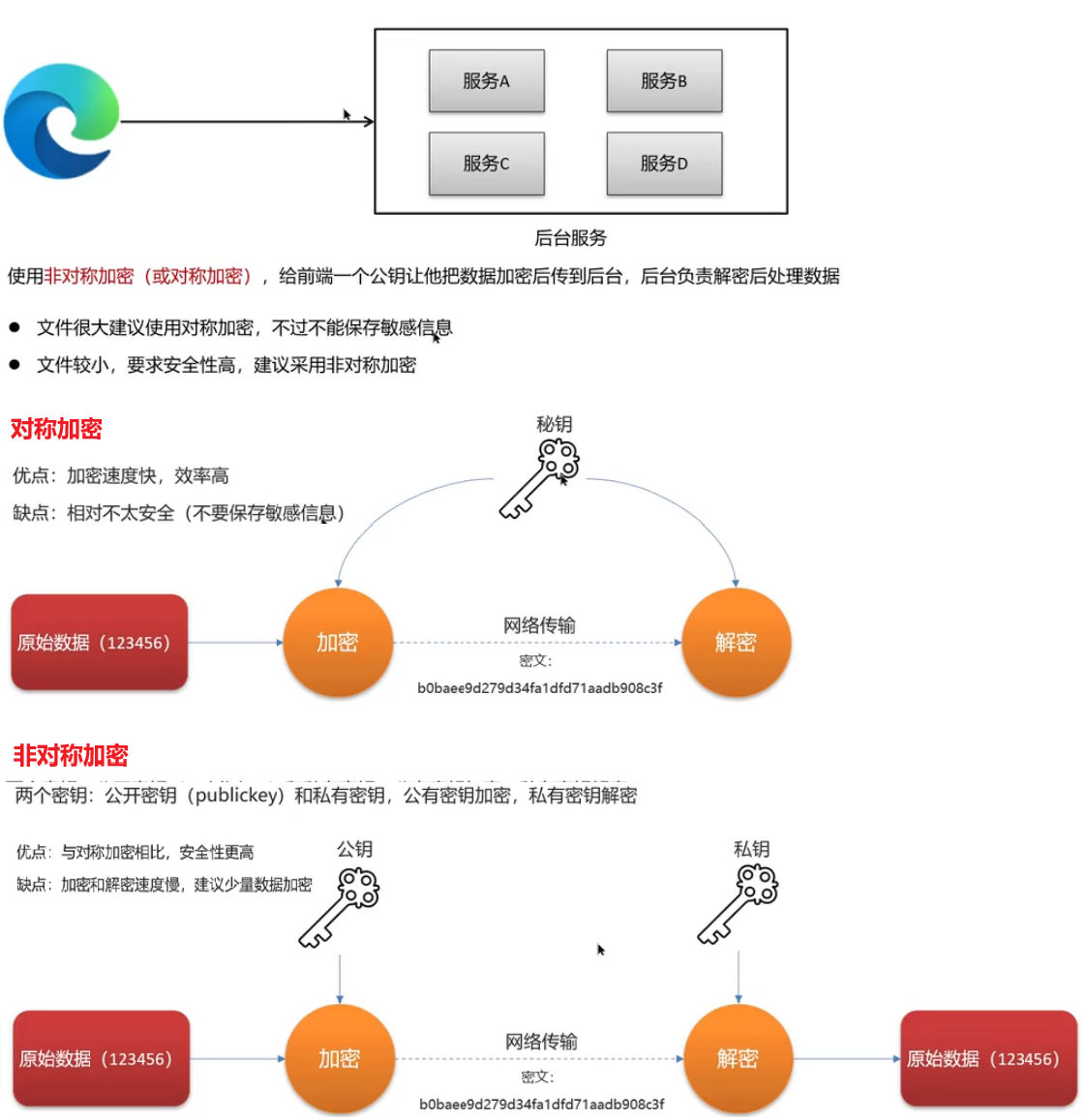
你负责项目的时候遇到了哪些比较棘手的问题?怎么解决的?1+3
其次你也可以说说aop的实现,比如你们操作日志记录等,利用aop切面思想,通过环绕通知等但需封装出出个切面工具类。建议你们说说sql调优,比如商品列表页需要分页查询,但是几百万商品导致查询慢,如何优化的,这是一个
① 设计模式在项目中的应用
是为了遵循一系列的开发原则【工厂、策略、责任链】
- 什么背景[技术问题] → 登录的例子
- 过程[解决问题的过程]
- 最终落地方案
② 线上BUGJVM+多线程
- CPU飙高
- 内存泄露
- 线程死锁
③ 调优
- 慢接口
- 慢SQL
- 缓存方案
④ 组件封装
- 分布式锁
- 接口幂等
- 分布式事务
- 支付通用
你们项目中日志怎么采集的?
我们搭建了ELK日志采集系统
介绍**ELK**的三个组件:
Elasticsearch是全文搜索分析引擎,可以对数据存储、搜索、分析
Logstash是一个数据收集引擎,可以动态收集数据,可以对数据进行过滤、分析,将数据存储到指定的位置
Kibana是一个数据分析和可视化平台,配合Elasticsearch对数据进行搜索,分析,图表化展示
- 为什么要采集日志?
日志是定位系统问题的重要手段,可以根据日志信息快速定位系统中的问题
- 采集日志的方式有哪些
- ELK:即
ElasticSearch、LogStash、Kibanna三个软件的首字母 - 常规采集:按天保存到一个日志文件
- ELK:即
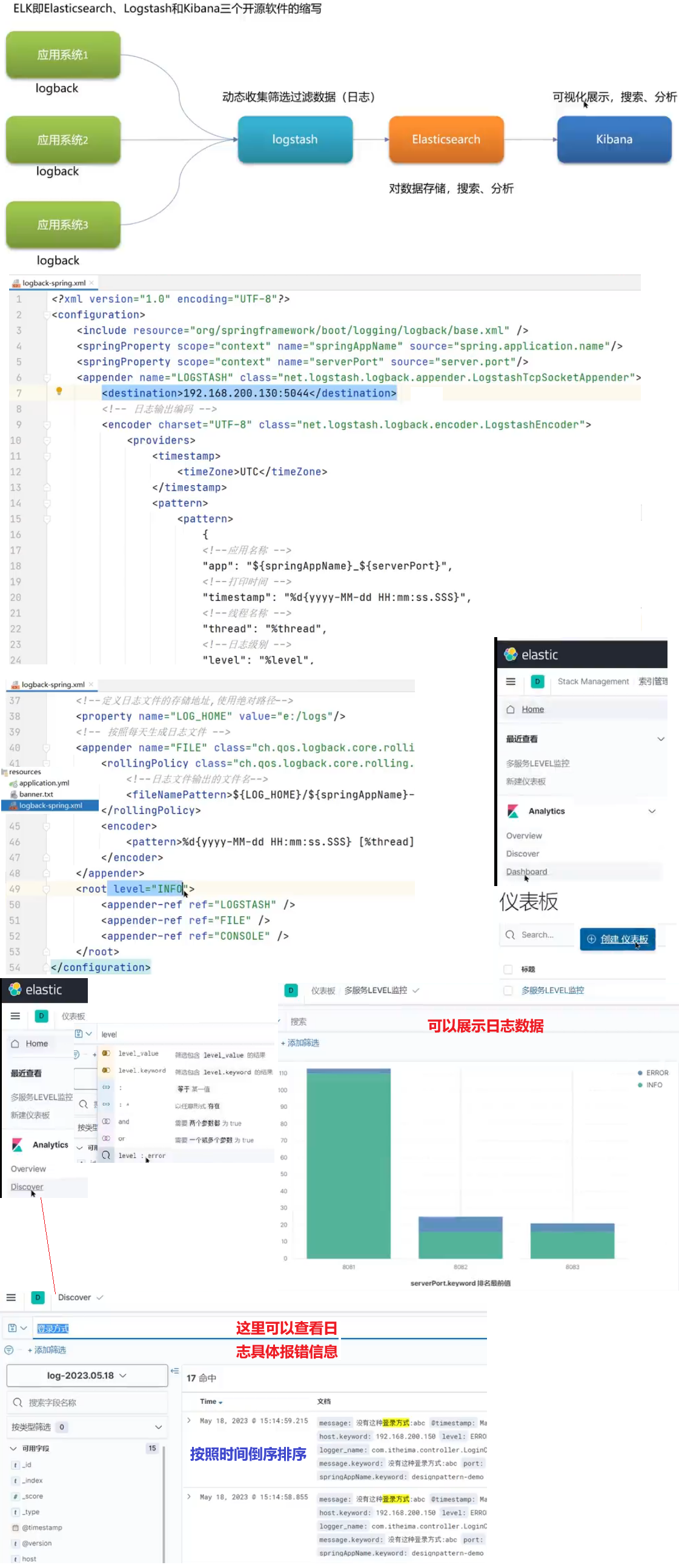
查看日志的命令?查看是否在线查看过日志
实时监控日志的变化
实时监控某一个日志文件的变化:tail -f xx.log
实时监控日志文件最后100行的变化:tail -n 100 -f xx.log按照行号查询
查询日志尾部最后100行日志:tail -n 100 xx.log
查询日志头部开始100行日志:head -n 100 xx.log
查询某一个日志行号区间:cat -n xx.log | tail -n +100 | head -n 100(查询100行至200行的日志)按照关键字找日志的信息
查询日志文件中包含debug的日志行号:cat -n xx.log | grep "debug"按照日期查询
日期必须在日志中出现过sed -n '/2025-01-14 14:22:31.070/,/ 2025-01-14 14:27:18.158/p' xx.log日志太多,处理方式
- 分页查询日志信息:
cat -n xx.log | grep "debug" | more - 筛选过滤后,输出到一个文件:
cat -n xx.log | grep "debug" > debug.txt
- 分页查询日志信息:

上线的项目远程Debug —— 生产问题怎么排查?本地调试远程代码
已经上线的bug排查的思路:
- 先分析日志,通常在业务中都会有日志的记录,或者查看系统日志,或者查看日志文件,然后定位问题
- 远程debug(通常公司的正式环境(生产环境)是不允许远程debug的。一般远程debug都是公司的测试环
境,方便调试代码)
远程debug
前提条件:远程的代码和本地的代码要保持一致
① 远程代码需要配置启动参数,把项目打包放到服务器后启动项目的参数:
java -jar -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005 project-1.0-SNAPSHOT.jar
② idea中设置远程debug,找到idea中的Edit Configurations... → 添加一个Remote JVM debug → 右侧要配置Configuration的Host → 添加上面的代码…
③ 在项目中点debug(绿色小虫子)
④ 访问远程服务器,在本地代码中打断点即可调试远程
怎么快速定位系统的瓶颈?
压测(性能测试),项目上线之前测评系统的压力
- 压测目的:给出系统当前的性能状况;定位系统性能瓶颈或潜在性能瓶颈
- 指标:响应时间、QPS、并发数、吞吐量、CPU利用率、内存使用率、磁盘IO、错误率
- 压测工具:LoadRunner、Apache Jmeter …
- 后端工程师:根据压测的结果进行解决或调优(接口、代码报错、并发达不到要求.)
监控工具、链路追踪工具,项目上线之后监控
- 监控工具:Prometheus+Grafana
- 链路追踪工具:skywalking、Zipkin
线上诊断工具Arthas(阿尔萨斯),项目上线之后监控、排查
核心功能:Arthas 是 Alibaba 开源的 Java 诊断工具,深受开发者喜爱。
当你遇到以下类似问题而束手无策时,Arthas 可以帮助你解决:这个类从哪个jar 包加载的?为什么会报各种类相关的 Exception?
我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
是否有一个全局视角来查看系统的运行状况?
有什么办法可以监控到 JVM 的实时运行状态?
怎么快速定位应用的热点,生成火焰图?
怎样直接从 JVM 内查找某个类的实例?
怎么解决cpu飙高?
使用top命令查看占用cpu的情况
通过top命令查看后,可以查看是哪一个进程占用cpu较高
使用ps命令查看进程中的线程信息 使用top -H -p 进程Id [找线程哪个使用多]
记住要打印%X十六进制的
使用jstack命令查看进程中哪些线程出现了问题,最终定位问题jstack 进程PID | grep 16进制线程PID -A 20
使用top命令查看占用cpu的情况
哪个进程占用的cpu最高finalShell中输入
top查看进程中的线程信息
ps H -eo pid,tid,%cpu | gerp pidjstack 查看进程内线程的堆栈信息
产生死锁可以查看因为是十六进程所以要十进程转换十六进程
直接linux输入printf "%x\n" Pid
然后就可以根据十六进制的去找哪个线程cpu占用
之后查看文件是cat xxx
2025/1/14 20:35 地点广州 完结撒花
项目难点?四方保险——day11-数据中心:时序数据库、看板展示【实战】
技术上的难点:时序数据库、看板展示
12306技术难点
这份是12306 真实 / 同源技术栈 + 你能直接学、直接用的替代方案,按「从前端到库存核心」整理好,照着学就能吃透高并发。
12306 核心技术栈(官方 + 业界对标)
1. 接入层 / 网关 / 限流
- 核心作用:抗流量、防刷、路由
- 12306 在用:
- Nginx + 自研网关
- 自研限流、排队、防刷系统
- 你可学 / 可用:
- Nginx、OpenResty
- Spring Cloud Gateway / Zuul
- Sentinel、Hystrix(限流、熔断、降级)
2. 高并发读:多级缓存(最关键)
- 12306 70%+ 流量都是查票,全靠缓存顶住
- 技术栈:
- 本地缓存:Caffeine、Guava Cache
- 分布式缓存:Redis 集群(主从 + 哨兵)
- 缓存策略:
- 余票查询:缓存 1~5 秒
- 读多写少:先缓存后 DB
3. 消息队列:削峰填谷
- 作用:下单、支付、退票、通知异步化
- 12306 类方案:
- Kafka(高吞吐)
- RocketMQ(金融级可靠,阿里系)
- 你必学:
- 异步削峰
- 最终一致性
- 幂等性(防重复下单)
4. 微服务 & 业务层
- 拆分:用户、票务、订单、支付、风控
- 技术:
- Java(12306 主体语言)
- Spring Boot / Spring Cloud
- Dubbo(国内高并发主流)
- 思想:服务隔离、独立扩容、故障不扩散
- 读多写少、并发极高
- 技术栈:
- MySQL / Oracle(12306 核心用 Oracle)
- 读写分离
- 分库分表:ShardingSphere、MyCat
- 关键点:
- 订单按用户 ID / 日期分片
- 库存绝对不能随便分片
6. 世界级难点:席位库存 & 内存计算
12306 最牛、最难、最值得学的部分。
- 核心问题:一段座位可以卖多段行程(北京→济南→上海)
- 12306 方案:
- 内存分布式数据库:GemFire / 国产类产品
- 位图(BitMap) 表示座位
- 位运算判断余票(毫秒级)
- 你能学的替代:
- Redis Bitmap
- 自定义内存网格
- 席位分段算法(核心业务模型)
7. 风控 & 反黄牛(12306 第二硬核)
- 设备指纹、IP 画像、行为风控
- 技术:
- Lua + Nginx 拦截
- 机器学习异常识别
- 你可学:
- 滑动窗口限流
- 接口防刷
- 黑名单、频控、人机验证
8. 云原生 & 高可用
- Docker + Kubernetes
- 两地三中心、异地多活
- 监控:Prometheus + Grafana(你刚记住那个)
你按这个路线学,就能吃透 12306 级高并发
- 先学:Redis + 缓存设计
- 再学:消息队列削峰
- 再学:分库分表 + 读写分离
- 攻坚:位图、库存算法、高一致性
- 最后:网关、限流、风控、监控
秒杀系统如何优化?
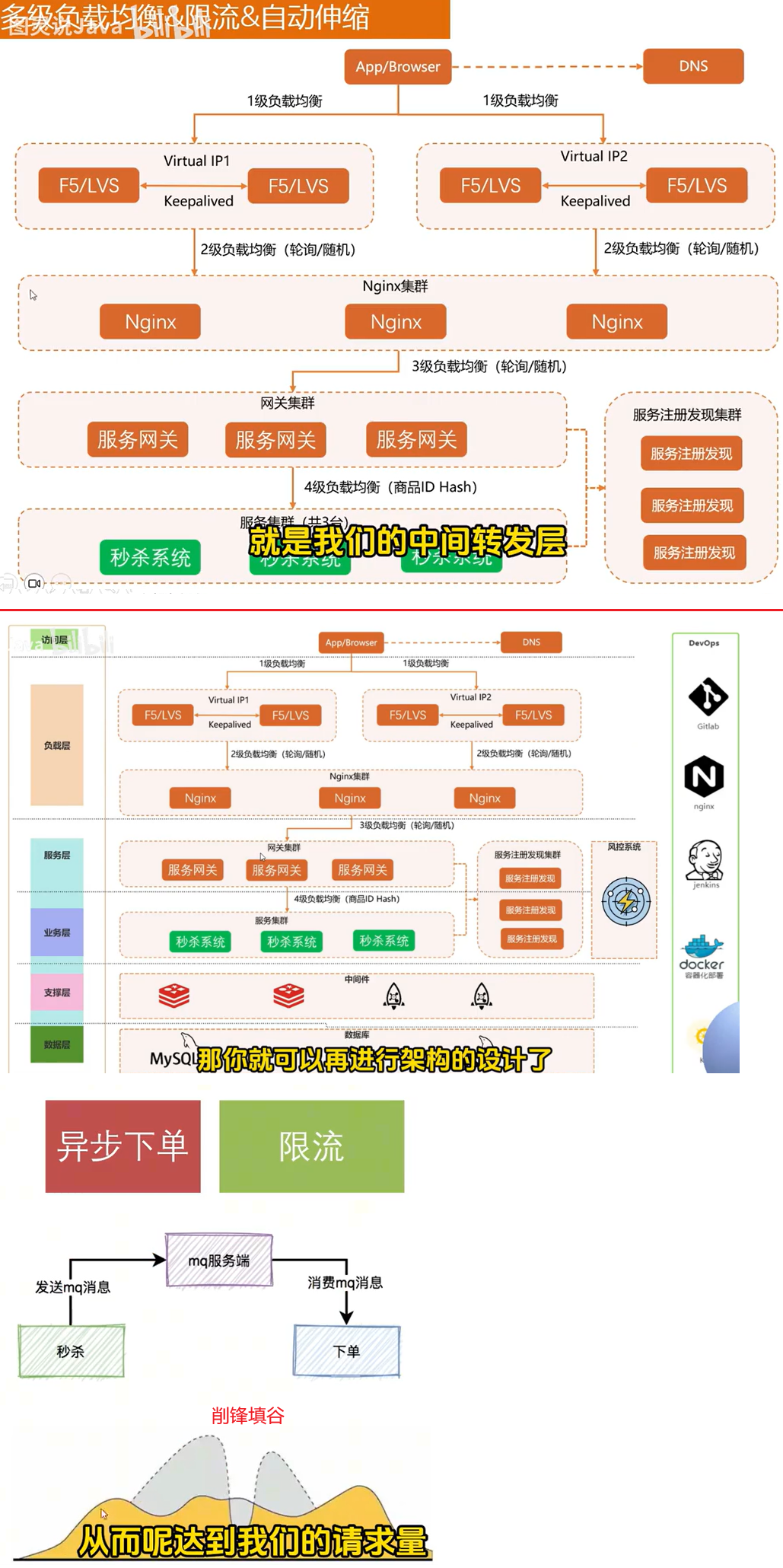
痛点描述:
- 瞬时并发量大
- 大量用户会在同一时间进行抢购
- 网站瞬时访问流量激增
- 库存少
- 访问请求数量远远大于库存数量
- 只有少部分用户能够秒杀成功
Ⅰ. 访问层 — 商品页
- 可以将静态秒杀页面放在cdn上[用户访问速度↑ 减轻服务器压力++]
Ⅱ. 访问层 — 秒杀按钮
- 活动前禁用按钮、点击后禁用按钮、滑动验证码[防羊毛党]、排队体验[提升用户体验]
Ⅲ. 中间转换层 — 多级负载均衡 & 限流 & 自动伸缩
- 通常会通过Nginx来进行负载均衡【单台Ng处理的并发量是两三万左右】
- 在它上层要做到硬件级别的隔离器 【F5/LVS】
- 通过Ng负载均衡到网关之后 通过客户端的负载均衡器Ribbon
- 4级的负载均衡 可以处理每秒上10W以上的QPS并发量
- 通过Docker或K8S来进行云服务器的动态伸缩的部署[秒杀开始自动扩容 秒杀结束自动缩减]
- 注意要在Ng上做好限流 防止一些绕过了我们前端的DDOS攻击 还需要在网关层通过
Sentinel对不同的服务节点去设置限流以及熔断的机制 - 可以在秒杀中通过MQ做削锋填股 通过MQ可以减轻下游的压力 防止激增流量打垮下游数据库
Ⅳ. 服务端 — 用Redis做缓存减轻数据库压力
- 秒杀商品信息预热到Redis中 防止Redis被击穿我们的数据库
- 通过Redis的Lua脚本[保证多个操作的原子性]操作库存
- 防重 可以通过 redis的SETNX → 用 Token + 商品URL // IP + 商品URL 只能有一个有效
- 分布式锁保证请求的原子性 → Redisson的分布式锁
**Ⅴ. 数据库 — 读写分离 **
- 数据量很大就分库分表
✅ 一张图理清:秒杀系统全链路优化流程
[用户点击秒杀按钮] ↓ 【前端防刷】 - 限制频繁点击 - 滑动验证码 - 倒计时、按钮控制 ↓ 【网关 & Nginx】 - 黑名单拦截(IP、UA) - Sentinel 限流 + 降级 + 熔断 ↓ 【秒杀服务】 - 判断秒杀状态、时间、库存是否存在 - 生成秒杀Token(防重) - Redis 原子性扣减库存(Lua脚本) - 发送下单消息至 MQ 异步处理 ↓ 【MQ异步削峰】 - 持久化队列(RocketMQ / Kafka) - 消费者异步落库 ↓ 【数据库层】 - MySQL最终扣减库存 + 创建订单(事务) - 数据库读写分离 / 分库分表Sentiel
Sentinel = 阿里开源的”流量防卫兵”,像小区门口的保安,控制多少人能同时进。
核心作用
// 没有限流时: 10000人同时抢10个商品 → 服务器瞬间被打爆 → 所有人都抢不到 // 有限流时: Sentinel:每秒只放行1000个请求 多余的请求直接返回"人多拥挤,请稍后" 服务器稳稳的,1000个人公平抢10个商品三种核心能力
1. 限流(控制流量)
// 规则:/seckill 接口每秒最多1000个请求 if 当前QPS > 1000 { return "当前人数过多,请重试" }2. 降级(有损服务)
// 监控接口响应时间 if 接口P95 > 500ms { // 95%的请求变慢了 // 自动降级:返回缓存数据或友好提示 return "活动太火爆,稍后再试" }3. 熔断(自动断电)
// 像保险丝:发现后端数据库出问题了 if 错误率 > 50% { // 熔断器打开,10秒内不再请求 return "服务维护中" // 10秒后尝试恢复 }秒杀场景示例
# Sentinel配置 限流规则: - 资源名: /seckill/buy 阈值: 1000 # 每秒最多1000请求 限流效果: 直接拒绝 熔断规则: - 资源名: /seckill/buy 阈值: 20% # 错误率超过20%熔断 熔断时长: 10秒 降级规则: - 资源名: /seckill/query 阈值: 500ms # 响应时间超过500ms降级一句话:Sentinel就是给系统装了个”智能限流阀”,防止秒杀时系统被冲垮。
🧩 各模块详细优化方案
① 前端层(第一道防线)
✅ 活动页静态化:部署在 CDN,秒开页面,减少服务器并发压力。
CDN域名是指通过内容分发网络(CDN)技术加速访问的域名。CDN的全称是Content Delivery Network,即内容分发网络。它通过将源站内容分发到分布在全球各地的加速节点,使用户可以从离自己最近的节点获取内容,从而提升访问速度和体验。【可以提前把一些静态资源 图片视频等放入,但不可以放接口那种】
CDN域名的工作原理是将用户的访问请求通过DNS解析,指向最优的CDN节点。如果节点上已有缓存内容,则直接返回给用户;如果没有缓存,则从源站拉取内容并缓存到节点,供后续用户访问。
✅ JS 控制按钮状态:倒计时期间按钮禁用;点击后立即禁用防止重复提交。
✅ 防刷机制:
- 滑动验证码(极验、腾讯滑动等)
- 限制频繁请求(客户端节流 + 后端拦截)
- 秒杀路径动态化(通过接口获取临时随机URL)
② 网关层(第二道防线)
- ✅ Nginx限流 + F5/LVS 硬件负载均衡
- ✅ Sentinel限流:
- QPS限流、线程数限制
- 降级策略(服务不稳定时快速失败)
- ✅ 灰度发布 + 金丝雀策略防雪崩
③ 服务层(核心逻辑)
- ✅ Redis预热商品库存:
key: seckill:stock:123 => 10- ✅ Lua脚本保证扣减原子性
if redis.call("get", KEYS[1]) >= tonumber(ARGV[1]) then return redis.call("decrby", KEYS[1], ARGV[1]) else return -1 end
- ✅ Token校验防重(防止同一用户多次提交)
- 用户下发秒杀Token
- 下单时校验 token 是否存在
- ✅ 幂等性处理:幂等令牌、Redis标记等手段防止重复下单
- ✅ Redisson分布式锁(用于控制某些全局状态,如每秒限量)
④ MQ 消息队列层(削峰填谷)
- ✅ 典型架构:RocketMQ / RabbitMQ / Kafka
- ✅ 一进一出,异步下单逻辑
- 消息格式:包含
userId,productId,token- ✅ 消息失败怎么办?
- 死信队列 + 重试机制 + 日志报警
⑤ 数据库层(最终一致性)
- ✅ 分库分表:
- 订单表按用户ID或时间范围分表
- 库存表按商品类型分表
- ✅ 读写分离:
- MySQL主从复制
- 下单写入主库,查询走从库
- ✅ 事务处理:
- 扣库存 + 创建订单需要事务包裹
- ✅ 补偿机制:
- MQ失败回滚机制 + 自动重试 or 人工介入
🎯 秒杀系统关键点总结(重点记忆)
优化维度 关键点 防刷防作弊 滑动验证码、动态路径、限流、IP黑名单 限流削峰 Sentinel、MQ异步下单、排队 高性能扣减 Redis + Lua 脚本,原子扣减库存 数据一致性 MQ消息可靠投递、事务补偿机制 分布式扩展 分库分表、读写分离、动态扩容 安全性 Token校验、防重、防止超卖 我将为你详细讲解和设计一个真实的秒杀系统完整优化方案,从 Redis 预热、限流、库存扣减、异步下单、订单状态回写等关键步骤一一展开说明,并配上示意代码。
🔧 一、整体秒杀流程概览图
用户请求 → 接入层限流 → Redis预扣库存(Lua脚本) → 发送MQ消息 → 异步下单 → 数据库落库 → 回写订单状态
🧱 二、Redis缓存预热(秒杀前的准备工作)
提前将商品库存加载到 Redis,避免高并发时频繁访问数据库。
// Redis结构设计 // key: seckill:stock:<skuId> // val: 商品库存数量 public void preloadSeckillStock(Long skuId, Integer stock) { String key = "seckill:stock:" + skuId; redisTemplate.opsForValue().set(key, stock); }
🛡 三、限流 + 防刷 + 验签(接入层)
使用网关 Sentinel 限流,前端限制点击频率,后端防刷接口做风控。
@GetMapping("/doSeckill") public ResponseEntity<?> doSeckill(@RequestParam Long skuId) { // 判断是否登录 Long userId = getLoginUserId(); // 判断是否重复请求(防重) String repeatKey = "seckill:user:" + userId + ":sku:" + skuId; Boolean hasBought = redisTemplate.opsForValue().setIfAbsent(repeatKey, "1", 5, TimeUnit.MINUTES); if (!hasBought) return ResponseEntity.status(429).body("请勿重复抢购"); // 执行扣库存的 Lua 脚本 Long result = redisTemplate.execute(luaScript, Collections.singletonList("seckill:stock:" + skuId), "1"); if (result == 0L) return ResponseEntity.status(410).body("库存不足"); // 发送消息至 MQ 进行异步处理 SeckillMessage msg = new SeckillMessage(userId, skuId); mqTemplate.convertAndSend("seckill.queue", msg); return ResponseEntity.ok("下单请求已提交"); }
📜 四、Lua脚本操作 Redis(保证原子性)
-- KEYS[1]: 库存key -- ARGV[1]: 扣减数量 local stock = redis.call("get", KEYS[1]) if tonumber(stock) >= tonumber(ARGV[1]) then return redis.call("decrby", KEYS[1], ARGV[1]) end return 0
📦 五、MQ异步消费 + 创建订单(核心业务)
用 RabbitMQ、RocketMQ、Kafka 等异步落库下单,减轻主线程压力。
@RabbitListener(queues = "seckill.queue") public void handleSeckill(SeckillMessage msg) { Long userId = msg.getUserId(); Long skuId = msg.getSkuId(); // 检查数据库是否已下单(防止重复下单) boolean exists = orderMapper.existsByUserAndSku(userId, skuId); if (exists) return; // 创建订单 Order order = new Order(); order.setUserId(userId); order.setSkuId(skuId); order.setStatus("WAIT_PAY"); orderMapper.insert(order); }
🧨 六、下单后定时关闭未支付订单(延迟消息)
利用 RabbitMQ 的延迟队列(或用 Redis 的 ZSet+定时任务轮询)。
// 下单后发送延迟消息 rabbitTemplate.convertAndSend("order.ttl.exchange", "order.ttl", orderId); // 死信队列处理超时未支付订单 @RabbitListener(queues = "order.dlx.queue") public void closeOrder(String orderId) { Order order = orderMapper.selectById(orderId); if ("WAIT_PAY".equals(order.getStatus())) { order.setStatus("CLOSED"); orderMapper.updateById(order); // 回滚库存 redisTemplate.opsForValue().increment("seckill:stock:" + order.getSkuId()); } }
📊 七、数据一致性考虑
场景 解决方案 Redis库存扣减成功但消息发送失败 使用本地事务 + MQ事务消息机制 订单超时未支付但库存没回滚 MQ死信队列 + 回滚库存 秒杀重复下单 Redis防重 + DB唯一约束
✅ 八、技术选型建议
模块 技术 缓存 Redis 消息队列 RabbitMQ/RocketMQ 限流防刷 Sentinel、滑动窗口 延迟任务 MQ延迟队列、定时任务轮询 锁 Redisson 分布式锁 脚本原子性 Lua脚本
你说的很好 我想更进一步了解一下 你说的 Nginx限流+F5/LVS硬件负载均衡;网关&nginx黑名单拦截(IP、UA);生成秒杀Token;灰度发布+金丝雀策略
✅ 一、Nginx 限流 + F5/LVS 硬件负载均衡
1. Nginx 限流
✨目的:
- 限制单位时间的请求数,防止恶意刷接口、瞬间高并发导致服务崩溃。
✨配置方式:
http { limit_req_zone $binary_remote_addr zone=req_limit_per_ip:10m rate=1r/s; ... server { location /seckill { limit_req zone=req_limit_per_ip burst=5 nodelay; proxy_pass http://seckill-server; } } }参数解释:
rate=1r/s:每秒允许一个请求。burst=5:允许瞬间突发5个请求。nodelay:立即处理突发请求,不排队。✅应用场景:
- 秒杀接口、登录接口、验证码接口等敏感接口的访问频控。
2. F5 / LVS 硬件负载均衡
✨作用:
- F5/LVS 作为物理网络设备层面的高性能负载均衡系统,位于企业最外层(防火墙之后,Nginx之前),进行四层(TCP/UDP)转发,性能远高于 Nginx。
✅典型架构:
用户请求 ↓ ┌────────────────┐ │ F5 / LVS (L4)│ └────────────────┘ ↓ ┌────────────────┐ │ Nginx (L7) │ └────────────────┘ ↓ 应用服务层✅优势:
- 性能高、吞吐量大(每秒几十万 QPS)。
- 更稳定,更适合企业级大并发业务。
- 通常和 Nginx 搭配使用,分别处理 L4 / L7 流量调度。
✅ 二、网关 & Nginx 黑名单拦截(IP/UA)
✅ 目标:
防止恶意攻击、秒杀脚本、爬虫工具参与秒杀。
1. 拦截策略
- IP 黑白名单:将恶意访问源加入黑名单。
- UA 校验:不允许 curl、httpclient、python 等工具模拟请求。
- 访问频率统计:单位时间内访问频率超过阈值即封禁。
2. 网关层实现(如 SpringCloud Gateway)
// 伪代码:过滤器中处理 if (blackList.contains(ip) || suspiciousUA(ua)) { return 403 Forbidden; }
✅ 三、生成秒杀Token(防黄牛、刷请求)
✅ 核心思想:
用户先请求一个随机 Token,再带着这个 Token 才能参与秒杀,且只能用一次。
✅ 实现流程:
🔁 第一步:获取秒杀Token
GET /seckill/token?productId=123 Header: Authorization: Bearer 用户登录Token返回:
{ "token": "a8729f03-6a22-4cdb-8ad4-e19932cf" }Redis 存储 token →
seckill:token:uid:productId -> token🏃 第二步:用户秒杀请求带上Token
POST /seckill/submit Body: { productId: 123, token: "a8729f03-6a22-4cdb-8ad4-e19932cf" }✅ 服务端校验:
- token是否存在;
- token是否属于当前用户;
- 校验通过后删除 token(一次性);
- 进入库存扣减逻辑。
✅ 四、灰度发布 + 金丝雀策略(保障系统稳定性)
✅ 区别:
策略 说明 灰度发布 指在小范围(如某些用户/机器)上逐步发布新功能 金丝雀发布 类似灰度,但更强调监控与回滚能力
✅ 示例:
1. 灰度规则:
- 仅对北京地区、特定用户ID段、Android设备开放新功能;
- 灰度用户看到的是新接口,其他人访问旧接口。
2. 实现方式:
- 在网关中增加灰度判断逻辑,如基于用户ID、设备类型、地理位置等维度;
- 配合 Nacos / Apollo 实现灰度配置动态下发。
if (grayUser(userId)) { routeTo(newServiceV2); } else { routeTo(oldServiceV1); }3. 金丝雀监控:
- 接入 Prometheus + Grafana;
- 实时监控新版本的接口成功率、响应时间、异常率;
- 若指标异常,立即自动或手动回滚。
🧠 总结:秒杀防护层层递进
层级 技术 / 策略 目的 网络层 F5/LVS、Nginx限流 硬抗高并发 网关层 黑名单拦截、UA过滤、灰度/金丝雀 防刷 + 风控 应用层 秒杀Token、验证码、人机校验 精准控制用户行为 缓存层 Redis库存控制、Lua原子操作、布隆过滤器 高性能、数据一致 后端层 MQ异步削峰、数据库分库分表 解耦 + 弹性架构
订单超时自动取消是怎么实现的?
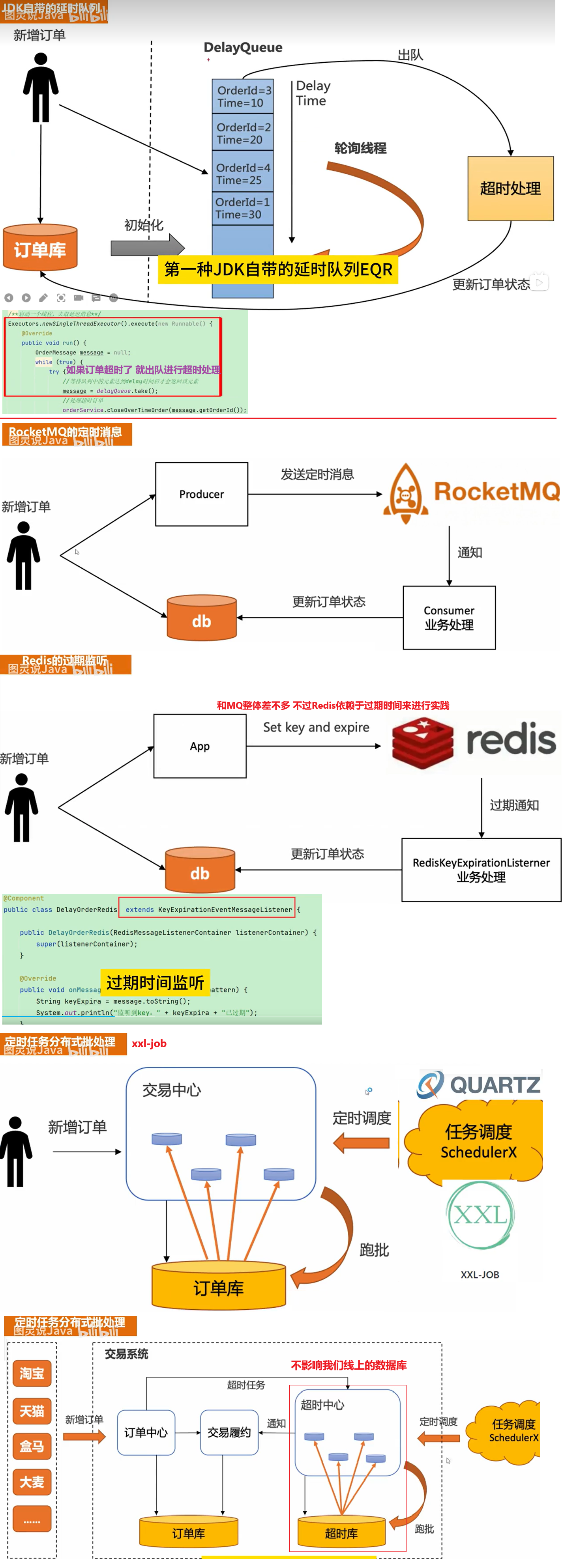
① JDK自带的延时队列
优点:简单,不需要借助其他第三方组件,成本低。
缺点:所有超时处理订单都要加入到DelayQueue中,占用内存大,没办法做到分布式处理,之恶能在集群中挑选一台leader专门处理,效率低
不适合订单量比较大的
② 基于RocketMQ的定时消息 — 延时消息
优点:使用简单,和使用普通消息一样,支持分布式。精度高,支持任意时刻
缺点:使用限制:定时时长最大值24小时。
成本高:每个订单需要新增一个定时消息,且不会马上消费,给MQ带来很大的存储成本。
同一个时刻大量消息会导致消息延迟:定时消息的实现逻辑需要先经过定时存储等待触发,定时时间到达后才会被投递给消费者。因此,如果将大量定时消息的定时时间设置为同一时刻,则到达该时刻后会有大量消息同时需要被处理,会造成系统压力过大,导致消息分发延迟,影响定时精度。
③ 基于Redis的过期监听
设置过期时间:24小时内没有支付就会自动取消
缺点:(也是所有中间件的缺点)
- 不可靠 Redis在过期通知的时候,如果应用正好重启了,那么就有可能通知事件就丢了,会导致订单一直无法关闭,有稳定性问题。如果一定要使用Redis过期监听方案,建议再通过定时任务做补偿机制。
- 如果订单量大需要占用中间件大量的存储空间,需要额外维护成本。
④ 定时任务分布式处理【要按照成本思维的思考方式】
通过定时任务(任务调度)的批量处理 → 一次性把所有超时的订单全部捞出来 处理完再全部执行更新
如果使用中间件都要单独存储那些数据,如果存储压力大就要涉及到集群
如果对于超时精度比较高,超时时间在24小时内,且不会有峰值压力的场景下,推荐使用RocketMQ的定时消息解决方案
在电商业务下,许多订单超时场景都在24小时以上,对于超时精度没那么敏感,并且有海量订单需要批处理,推荐使用基于定时任务的跑批解决方案。
✅ 最佳实践对比表
方案 分布式支持 精度 可靠性 适用场景 优缺点总结 DelayQueue ❌ 否 秒级 ❌ 低 单体项目/小订单量 简单、无需中间件,但不支持分布式和高可用 RocketMQ延时消息 ✅ 是 秒级 ✅ 高 秒杀、限时抢购、延迟关闭等 精度高、支持分布式,但时长限制 & 消息堆积 Redis过期监听 ✅ 是 秒级 ❌ 较低 轻量业务、有兜底机制的场景 实时、方便,但事件容易丢失,不适合重要任务 定时任务跑批 ✅ 是 分钟级 ✅ 高 电商订单系统、大量订单处理 稳定、灵活、适合大业务,容忍分钟级延迟 🔄 常见混合策略推荐
- 秒杀业务 / 限时订单:RocketMQ 延时消息为主 + 补偿机制(定时任务兜底)
- 电商平台:定时任务跑批为主 + MQ 异步通知用户(取消成功推送)
- 轻量小应用:Redis 过期监听 + 手动补偿兜底
- 单体项目或demo:DelayQueue 简单可用
🧠 思考:为什么不用 cron 来做?
cron 固定执行时间点,而订单创建是动态的,无法精确知道每个订单的30分钟是哪一刻。
举例:
- cron表达式只能写
每隔5分钟扫描或每天0点执行- 订单创建时间是不确定的 → 用cron不能实时取消30分钟后的每个订单
所以,动态调度任务(MQ/DelayQueue)或带参数处理(定时扫描数据库)更合适。
如何防止重复下单?
方案一:提交订单按钮置灰 [防止用户无意点击多次]
方案二:后端采用redis的setnx 来保证它的唯一幂等性
同一个用户、同一个请求,在极短时间内只能成功创建 1 次订单。
利用 Redis SETNX(SET if Not Exists)的原子性,同一时间只有一个请求能加锁成功,其他请求直接拒绝。
用户点击提交 ↓ 生成唯一锁key ↓ Redis SETNX 尝试加锁 ↓ 成功?→ 是 → 创建订单 ↓ 订单完成 → 释放锁 失败?→ 直接返回:请勿重复提交
setnx:当我们调用setnx来去保存一个key和value的时候,如果这个value没有值的话,那么就会返回true保存成功;如果有值就会返回false → 保证多次存储只能存储一个值

业务幂等号(如唯一Token机制)
- 用户点击下单前,后端下发一个
token(存 Redis),用户下单时带上这个 token。- 后端验证 token 是否存在,使用后即删除。
// 伪代码 if (redisToken == null || !redisToken.equals(requestToken)) { throw new RuntimeException("重复请求或非法请求"); } redisTemplate.delete(redisToken);✅ 优点:
- 通用幂等机制,不局限订单;
- 可防止表单重复提交、支付回调重复通知等场景;
✅ 使用场景:
- 秒杀下单、提交表单、支付回调。
🔐 方案四:消息队列去重(异步场景)
- 使用 RocketMQ 的幂等机制,确保同一消息只消费一次(消费端做去重处理),适用于下单流程是异步的情况。
✅ 三、多手段组合更安全
层级 技术手段 是否强制 前端 按钮置灰/节流 否 应用层 Redis + setnx 或 Token 是 数据层 唯一约束字段 是 异步处理 MQ消费幂等处理 是
📌 典型实践示意图:
- 用户点击下单 ➜ 获取唯一Token/Redis锁 ➜ 请求成功后释放 ➜ 写入订单表时校验唯一性。
💡 小贴士:
- 并发高推荐:Redis方案(+Redisson分布式锁)
- 最后兜底:数据库唯一索引
- 支付类、接口幂等推荐:Token机制
怎么防止刷单?【人肉机刷单!!】
业务风控
提高羊毛门槛:实名认证、消费门槛、随机优惠
限制用户参与、中奖、奖励次数
根据用户的历史行为和忠诚度,提供不同层次的优惠,优待忠实用户
奖池(优惠券数量)限制上限
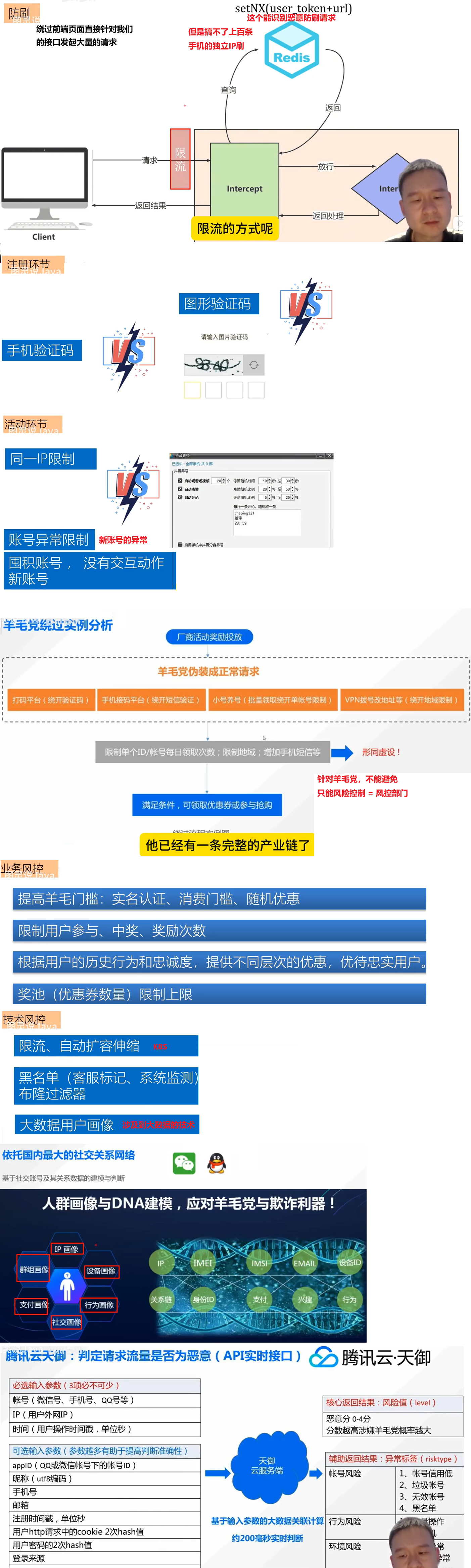
分布式集群架构下怎么保证并发安全?
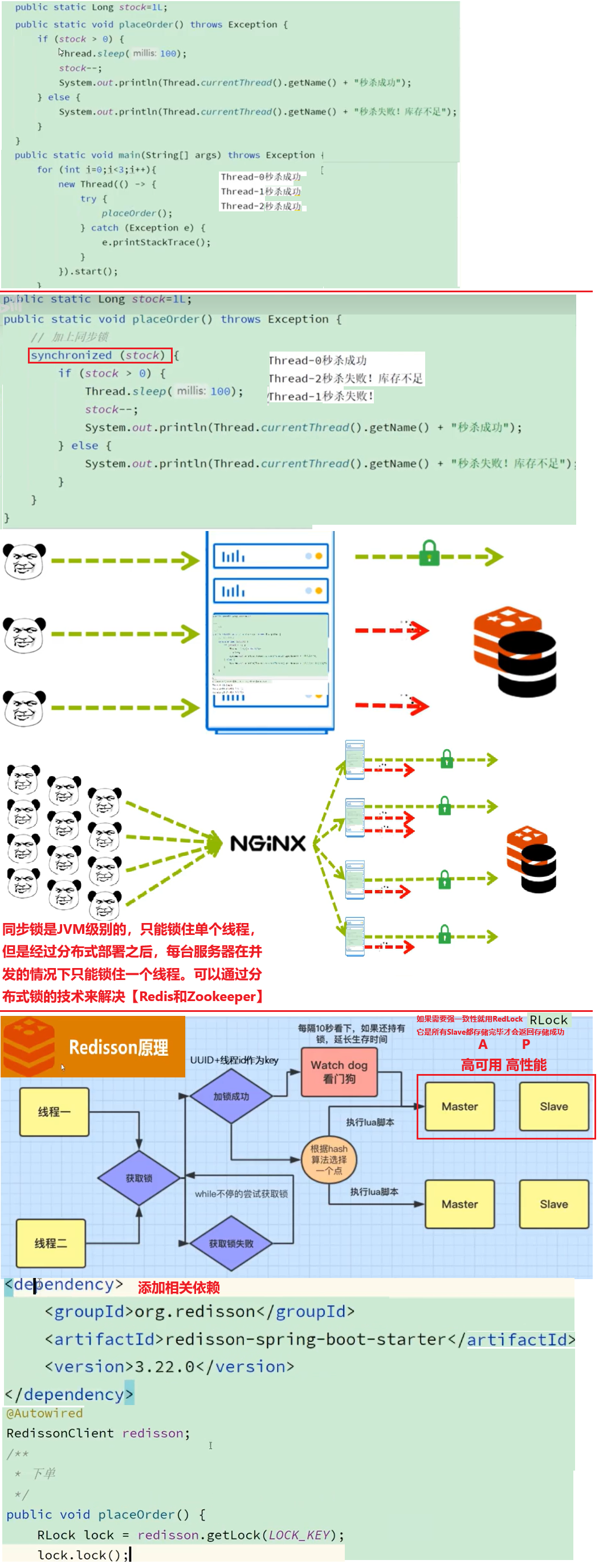
✅ 一、为什么分布式架构下更容易出现并发问题?
在单体应用中,所有请求在同一个进程内处理,天然可以用
synchronized等方式控制并发。而在分布式集群架构中:
- 请求会打到多个节点 → 本地锁失效
- 数据可能分库分表 → 数据不在一个数据库
- 多线程 + 多机器 + 多服务 → 并发成倍放大
所以需要一整套分布式并发安全解决方案。
✅ 二、并发安全常见场景
- 秒杀/抢购:多个用户同时抢一件商品
- 下单:防止重复下单、超卖
- 支付:防止重复支付
- 分布式调度:防止定时任务重复执行
- 分布式ID生成:避免重复ID
✅ 三、总结:解决并发的“组合拳”
组件/策略 主要作用 Redis分布式锁 跨节点并发控制,控制共享资源 乐观锁(version) 控制数据库并发更新冲突 消息队列MQ 异步削峰,提高系统吞吐 唯一Token机制 防止重复提交 限流 & 黑名单机制 拦截恶意请求,保护系统 本地 + 分布式缓存 缓解数据库压力,提高响应速度 灰度发布 降低风险,平稳上线 一、先看背景:为什么要用 Redisson?
同步锁(比如 Java 的
synchronized、ReentrantLock)是 JVM 级别 的,只能锁住同一个进程里的线程。在分布式部署(多台服务器)场景下,不同服务器的线程之间完全感知不到彼此的锁,会出现并发安全问题(比如超卖、重复下单)。
所以需要 分布式锁 来跨机器、跨进程保证原子性,Redisson 就是基于 Redis 实现的成熟分布式锁框架。
二、Redisson 核心流程拆解
生成唯一锁 Key
锁的 Key 由
UUID + 线程ID组成,用来精确标识:谁(哪个线程 + 哪个客户端)持有这把锁,避免误删别人的锁。尝试获取锁
- 多个线程(甚至跨服务器)同时尝试获取同一把锁。
- Redisson 会通过 hash 算法 选择一个 Redis 节点,执行 Lua 脚本 完成加锁操作(Lua 脚本保证原子性)。
- 加锁成功:进入下一步;加锁失败:进入
while循环,不断重试获取锁(自旋等待)。看门狗(Watch Dog)自动续期
- 加锁成功后,Redisson 会启动一个后台线程(看门狗),每隔 10 秒 检查锁是否还被当前线程持有。
- 如果业务还没执行完,看门狗会自动延长锁的过期时间(默认 30 秒),防止锁提前过期导致并发问题。
- 这解决了 “业务执行时间过长,锁过期释放后被其他线程抢到” 的经典问题。
Redis 主从架构保证高可用
- 锁数据会写入 Redis Master 节点,并同步到 Slave 节点,实现数据冗余。
- 如果 Master 宕机,Slave 会自动提升为新 Master,保证锁服务不中断,实现 高可用 + 高性能。
- 若需要更强一致性,可使用 RedLock(RLock):要求所有 Slave 都存储完成后才返回成功,牺牲部分性能换取更高一致性。
释放锁
- 业务执行完毕后,Redisson 会通过 Lua 脚本原子性地删除锁 Key。
- 只有持有锁的线程(匹配 UUID + 线程 ID)才能释放锁,避免误删其他线程的锁。
- 看门狗也会在锁释放后自动停止。
三、核心优势 ✨
- 自动续期:看门狗机制避免锁过期导致的并发问题。
- 原子操作:基于 Lua 脚本保证加锁 / 解锁的原子性。
- 可重入:同一个线程可以多次获取同一把锁,不会自己阻塞自己。
- 高可用:依托 Redis 主从 / 集群架构,锁服务不会单点故障。
- 防误删:用
UUID+线程ID做锁值,只有持有者才能释放锁。
四、和原生
setnx的区别
特性 原生 Redis setnxRedisson 分布式锁 自动续期 无,需手动处理 看门狗自动续期 可重入 不支持 天然支持 主从一致性 依赖 Redis 主从同步 支持 RedLock 强一致模式 易用性 需自己写代码处理各种边界 封装完善,开箱即用
五、一句话总结
Redisson 是在 Redis 基础上封装的企业级分布式锁,通过 Lua 原子脚本 + 看门狗续期 + 主从高可用,解决了分布式环境下多线程 / 多服务的并发安全问题,比原生
setnx更可靠、更易用。
让你设计一个扫码登录怎么实现?
生成二维码
请求登录页生成二维码,PC端请求后端生成一个二维码,此时在后端就会生成一个全局唯一的二维码ID,主要保存二维码的状态[二维码ID, NEW],状态设置到Redis设置过期时间,然后把当前的二维码ID返回给前端,然后生成二维码 【前后端都可以生成 → 返回Base64的编码给前端】此时的二维码就绑定了用户的ID让用户扫描。
扫码
PC端和后端会建立一个轮询的请求,不断的根据二维码ID去查询二维码状态,一旦状态改变页面也会改变。也可以通过长连接WebSocket获取状态 淘宝用的轮询、抖音用的长连接,此时就可以扫码。
扫码前保证手机是登录状态 没有登录肯定是不能扫码的,登录后进行扫码就会携带手机端的用户token以及二维码的ID在后端去校验请求Token,如果校验成功就代表手机可以登录,此时可以变更二维码状态为扫描。前端就可以根据这个把页面变为待确认状态
✅ 一、整体流程概述
目标: 用户在 PC 端扫码并登录系统,安全、高效、用户体验好。
参与者:
- PC 浏览器(Web)
- 手机 App(用户已登录)
- 后端服务(Web + API)
- Redis(状态存储)
- 前端轮询/长连接
🧩 二、关键技术点拆解
1️⃣ 二维码生成(PC端发起)
- 用户打开 PC 登录页面,请求后端接口
/api/qr/generate- 后端逻辑:
- 生成唯一的二维码ID(一般用 UUID、Snowflake 或 Redis Incr)
- 创建二维码状态:
[qrCodeId: {status: NEW, userId: null}]存入 Redis,设置过期时间(如:3分钟)- 把
qrCodeId返回给前端(前端将其转成二维码图像)二维码状态定义:
状态值 含义 NEW 二维码已生成,待扫码 SCANNED 手机已扫码,待确认 CONFIRMED 用户已确认登录 EXPIRED 二维码过期
2️⃣ 轮询 or WebSocket 监听状态(PC端)
- 前端定时调用
/api/qr/status?qrCodeId=xxx或使用 WebSocket 长连接订阅状态变更。- 后端通过 Redis 获取二维码状态,响应当前状态值给前端;
- 前端根据状态更新 UI:
NEW:显示二维码提示扫码SCANNED:显示“请确认登录”CONFIRMED:跳转系统首页EXPIRED:提示“二维码已失效”
3️⃣ 手机扫码(App 端发起)
- 用户打开手机 App,扫码得到
qrCodeId- App 发起请求
/api/qr/scan,携带:
qrCodeId- 当前用户登录 Token(说明谁在扫码)
- 后端校验 Token 合法性 + 校验二维码状态是否是
NEW- 如果校验通过:
- 更新 Redis 状态为
SCANNED- 保存扫码用户ID(用于确认登录)
4️⃣ 手机端确认登录(App 端)
- 用户点击“确认登录”按钮,App 发起请求
/api/qr/confirm- 后端再次校验 Token、状态、qrCodeId
- 如果合法:
- 更新 Redis 状态为
CONFIRMED- 后端为 PC 端生成登录凭证(JWT 或 Session ID)
- 可以将 token 写入 Redis,让 PC 端后续使用
5️⃣ PC端轮询到 CONFIRMED 状态后
- 前端收到 CONFIRMED 状态
- 发起请求
/api/qr/login?qrCodeId=xxx- 后端从 Redis 中取出对应用户信息
- 为 PC 创建 Session 或返回 JWT Token
- 登录成功,跳转首页
🔐 三、安全要点
- 二维码应设置过期时间,防止被反复使用
- Token 校验要严谨,确保扫码者是本人
- Redis 里状态更新使用 Lua 脚本或事务 CAS 保证一致性
- 后端二维码状态需加密传输或限制频繁请求(防刷)
🚀 四、技术选型小结
功能 技术 说明 二维码生成 UUID + Redis 可快速唯一生成并记录状态 状态存储 Redis(带 TTL) 快速响应,高并发,易过期处理 实时通知 轮询 / WebSocket 淘宝用轮询、抖音用 WS 登录授权 JWT / Session 生成 PC 端登录凭证 防刷限流 接口限流 + 签名校验 避免恶意轮询/伪造请求 ✅ 五、流程图(配合讲解)
text复制编辑[PC端] [后端] [App端] | | | |--> 请求生成二维码 -->| | | |-- 生成qrCodeId + Redis存储 |<-- 返回二维码Base64--| | | | | |==轮询/WS监听状态====>| | | | | | |<--扫码携带Token + qrCodeId | |--校验后标记为SCANNED | |<==收到SCANNED状态== | | | |<--确认登录 | | |--更新为CONFIRMED +登录信息 |<==收到CONFIRMED== | | |-- 请求登录状态凭证 -->| | |<-- 返回JWT/Session--| |
如何设计分布式日志存储架构?
使用redis出现缓存三兄弟如何解决?减轻数据库的压力
你在项目中用到了Redis对吧 介绍一下有没有遇到关于redis的什么问题?
暂时还没看!
12.使用redis出现缓存击穿雪崩穿透怎么解决_哔哩哔哩_bilibili
如何使用Redis记录用户连续登录了多少天?放在数据库里不合适
放在数据库不合适因为你要创建一个表 记录用户哪一天进行了签到 如果用户量很多就会很大的量

这个问题其实就是一个连续签到/登录统计问题,数据库不适合是因为:
- 每签到一天就插一行 → 数据量巨大,I/O压力大。
- 查询连续签到天数复杂,SQL不好写,效率低。
所以使用 Redis 的 位图(bitmap) 来解决,是一种低存储+高性能的方案。
🎯 场景目标
统计用户连续登录天数、本月第几天登录过,实现类似:
复制编辑用户A 7月签到状态 = 01111100010001000(1表示登录,0表示没登录) 查询当前用户是否今天登录过? 查询用户本月连续登录天数?
🧠 技术选型:使用 Redis Bitmap
什么是 Bitmap?
Redis 的 Bitmap 本质上是字符串(
String类型),但你可以对它的每一位 bit 操作:# 设置偏移量为 5 的位置为 1(签到) SETBIT user:sign:1001:202507 5 1 # 查询偏移量为 5 的位置是否为 1(是否登录) GETBIT user:sign:1001:202507 5
✅ 实现思路
1. 登录/签到时
int offset = today - 1; // 7月19日 → offset = 18,从0开始 String key = "user:sign:" + userId + ":" + yyyyMM; redisTemplate.opsForValue().setBit(key, offset, true);2. 查询某天是否登录
Boolean isLogin = redisTemplate.opsForValue().getBit(key, offset);3. 查询本月累计登录多少天
BitCountOptions options = BitCountOptions.defaults(); Long total = redisTemplate.execute((RedisCallback<Long>) conn -> conn.bitCount(key.getBytes(), options) );4. 查询连续登录天数(重点)
假设今天是第19天,从 offset = 18 开始向前看:
int count = 0; for (int i = offset; i >= 0; i--) { if (redisTemplate.opsForValue().getBit(key, i)) { count++; } else { break; // 一旦中断,退出循环 } }
🚀 优势
- Redis Bitmap 单月只占用 31 bit,超省空间(一个用户一年只用 372 bit ≈ 47 字节)
- 查询效率高,O(1)
- 写入也快,支持并发
🔐 注意点
设置过期时间:避免内存占用过大
redisTemplate.expire(key, Duration.ofDays(60));如果需要“补签”功能,操作相应的 bit 位即可
📌 示例 Redis 数据结构(7月)
Key: user:sign:1001:202507 Value (bit位):0111110000000000000000000000000 日期:1 2 3 4 5 6 7 ... 31 含义:从左往右,第i位是第i+1天12306 用BitMap
所以 12306 用 Bitmap:
- 极省内存:一列火车 2000 座 = 2000 bit = 250 字节
- 极快:扣减座位 1 毫秒内完成
- 原子操作:高并发下绝对不超卖
二、12306 怎么用 Bitmap 存座位?
核心规则
- 一列火车 = 一个 Redis Bitmap
- 一个座位 = 一个 bit 位
0 = 空座(可卖)1 = 已售(不可卖)例子
一列火车有 5 个座位:
座位号: 01A 01B 01C 02A 02B bit 位: 0 1 0 0 1含义:
- 01B、02B 已卖掉(1)
- 其他是空座(0)
三、最难的地方:区间票怎么存?
这是 12306 独有的世界级难题。
比如:
- 北京 → 济南 → 南京 → 上海
- 你买 北京→南京
- 会占用:北京 - 济南、济南 - 南京 两段区间
普通系统根本算不明白,但 Bitmap 可以轻松搞定。
12306 的超级方案:
一趟车,每两个站之间,都做一个独立 Bitmap
比如 4 个站,会产生 6 个区间:
- 北京→济南
- 北京→南京
- 北京→上海
- 济南→南京
- 济南→上海
- 南京→上海
每个区间 = 一个 Bitmap,存这个区间的座位占用情况
北京→南京 会经过两段:
- 北京→济南
- 济南→南京
所以系统会同时把 3 个 Bitmap 的第 3 位设为 1:
北京→济南bit3 = 1济南→南京bit3 = 1北京→南京bit3 = 1比如你买 北京→上海
系统要保证:
- 北京→济南 有座
- 济南→南京 有座
- 南京→上海 有座
怎么快速判断?
用位运算:AND 运算
把三个小段的 Bitmap 做 AND
结果中 = 0 的位置,就是全程都空的座位
bj-jn: 0 0 1 0 0 jn-nj: 0 0 1 0 0 nj-sh: 0 0 1 0 0 AND 后: 0 0 1 0 0只有 bit=0 的位置,全程都有座!
四、用户买票时,怎么毫秒级判断?
流程(超级关键)
用户选:北京→南京
后端找到对应的区间 Bitmap
用
BITOP 或 位运算
计算:
- 哪些座位在 整个区间都是 0(空座)
找到一个空座,把所有经过的区间 bit 都设为 1
下单成功
一句话总结
用多个 Bitmap 叠加运算,毫秒级算出 “全程都有空” 的座位。
五、为什么这是世界最难?
因为要同时满足:
- 不超卖(绝对不能卖重座位)
- 速度极快(百万并发不卡)
- 区间计算极复杂(一站一卖,交叉占用)
- 空间极小(存得下全国几万辆车)
只有 Bitmap 能同时做到。
和你刚才学的 “签到” 对比
你会瞬间彻底懂:
功能 Bitmap 含义 用户签到 1 = 签到,0 = 未签 12306 座位 1 = 已售,0 = 空座 签到统计 数有多少个 1 查余票 找连续为 0 的位置 原理一模一样,只是业务场景换了!
给你一亿个Redis keys统计双方的共同好友?
🧩 题目解析
假设:
- 每个用户的好友列表存储在 Redis 的 Set 结构中,例如:
SADD friends:user1 A B C D
SADD friends:user2 B C E F目标:
- 快速统计两个人共同的好友,即集合交集数量。
✅ 常规解法:Redis
SINTER命令Redis 支持对多个集合求交集:
SINTER friends:user1 friends:user2返回结果即为双方的共同好友。
如果只要交集数量,可以使用:
SINTERCARD 2 friends:user1 friends:user2这是 Redis 7.0 新增的命令,效率更高。
🧠 问题难点:一亿个 keys 怎么办?
一亿个 keys 说明用户量巨大或好友数量极多,可能涉及以下挑战:
问题 描述 Redis 内存压力 如果所有好友关系都存在 Redis Set 中,消耗大量内存 网络 IO 开销 获取或计算时大量命令交互 集合元素巨大 每个 Set 元素多(例如几千好友),单次 SINTER代价大频繁交集操作 如果这是一个高频功能(如社交推荐),需要高效方案 🧠 实战建议
场景 推荐方案 精确共同好友、数量不大 SINTER/SINTERCARD只需估算交集数量 PFCOUNT(HyperLogLog)只需交集数量 + 数据量很大 Bitmap + BITOP+BITCOUNT数据量超大,追求压缩极致 Roaring Bitmap、Redis Module
如何做一亿用户实时积分排行榜?
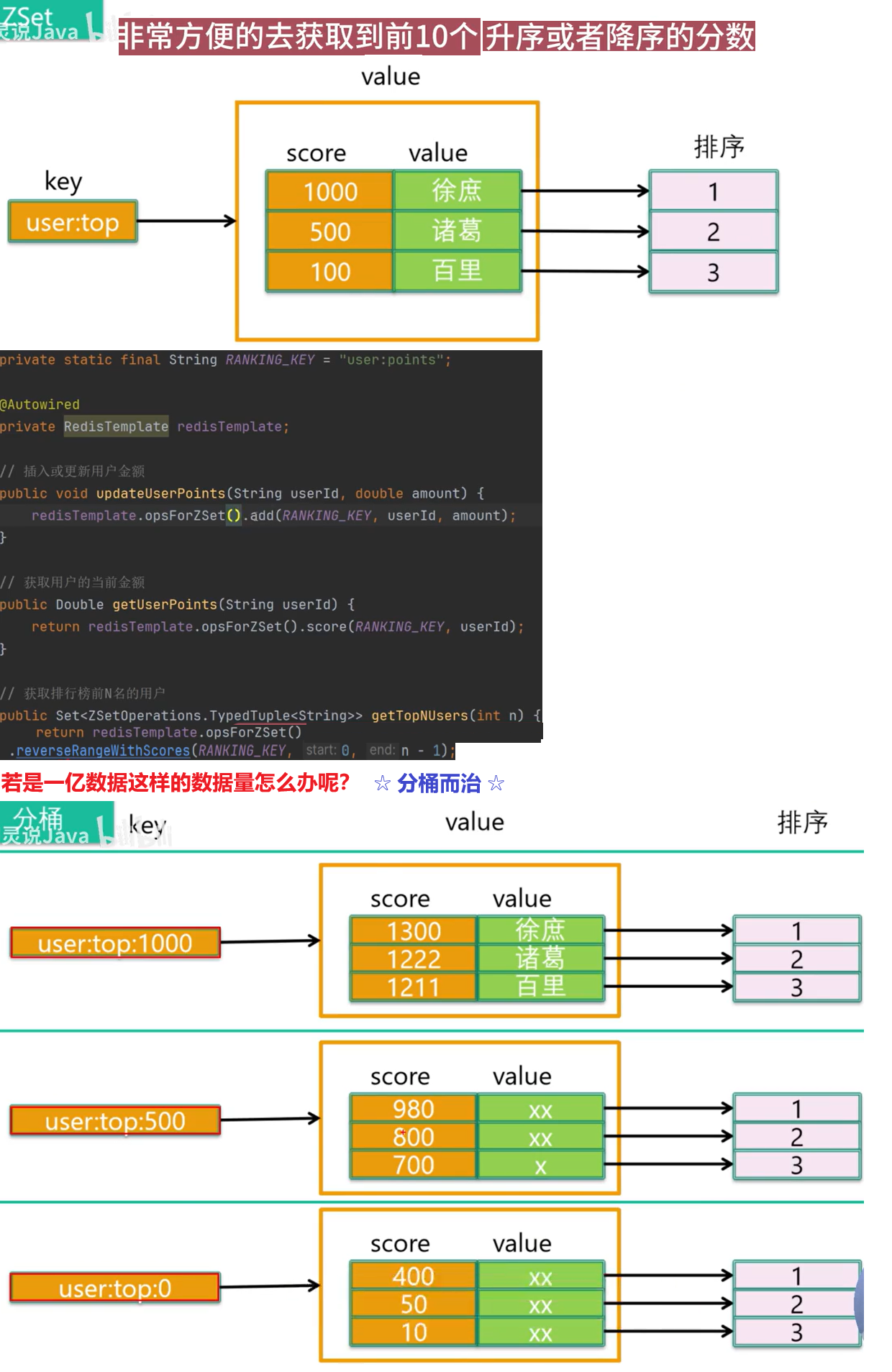
一亿用户真的放得下吗?
放得下,而且非常小!
- 一个用户在 ZSet 中占 约 30 字节
- 1 亿用户 = 300MB 左右内存
一台普通 Redis 就能轻松扛住!
做“一亿用户实时积分排行榜”时,面临的挑战是:高并发写入、高频读、排序性能、排行榜分页、内存管理等。使用传统数据库难以胜任,我们通常结合 Redis 的 ZSet(有序集合)结构 + 分布式架构 来高效实现。
💡 核心思路
- 使用 Redis 的
ZSet存储用户积分(ZSet天然支持有序集合)。- 使用 用户ID为 member,积分为 score,自动排序。
- 按业务场景设置多个排行榜(总榜、日榜、周榜等)。
- 使用分片/分区 + 多 Redis 实例缓解内存压力。
🚀 性能优化方案
场景 方案 高并发写入 异步批处理写入积分变化(Kafka / MQ) 高并发读榜 热榜分页结果缓存(Redis 二级缓存) 大数据量 分片存储排行榜(按地域/业务线) 数据持久化 后台定期将 ZSet 持久化至 MySQL(定时备份) 用户查自己排名 排名反查缓存 + 异步修正(定时刷新) ⚙️ 分布式架构下的挑战与解决
问题 解决方案 单机内存不足 Redis 分布式集群 + 按 key 做水平分区 网络波动 Redis 哨兵或主从架构容灾 跨机房 使用 Kafka MQ 异步同步数据 并发冲突 ZINCRBY 原子操作,确保并发安全
内存200M读取1G文件并统计内容重复次数?内存受限时
一次性读取肯定会OOM
可以根据缓冲区分块读取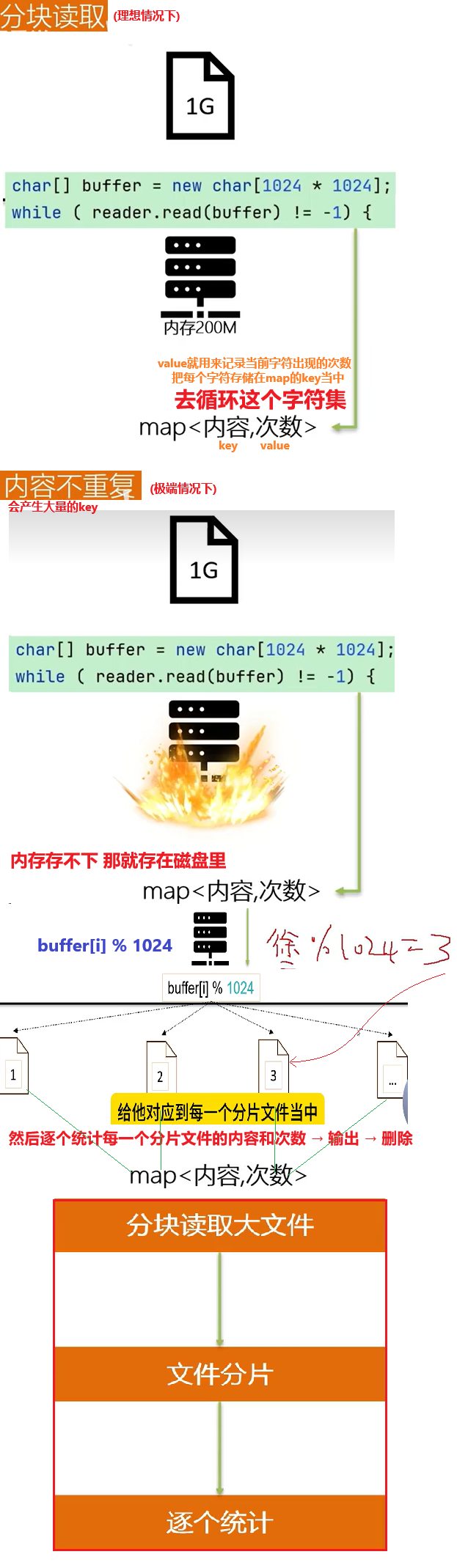
📌 方案核心:“分治 + 磁盘中间结果 + 再归并统计”
📍第一步:分片预处理(Hash 分桶)
遍历文件,每条记录用 hash 函数映射到 N 个临时小文件中(如 100 个文件)。
例如:
hash(line) % 100 -> 选择第 i 个 bucket_i.txt 写入每个桶的数据量 << 1GB,避免某一个桶数据过大(可以动态调节桶数)。
📝 实现要点:
- 不能直接把 key 存在内存中,而是用
BufferedWriter把行写入不同的中间文件。- 临时文件名如
bucket_0.txt,bucket_1.txt, …,bucket_99.txt。
📍第二步:小文件内统计(Map 阶段)
每个小文件都可以用内存加载(一般几十 MB),然后用
Map<String, Integer>来做频次统计。统计完毕后,结果写入新的临时文件,如:
result_bucket_0.txt: word1 -> 5 word2 -> 3 ...
📍第三步:归并所有桶(Reduce 阶段)
- 如果需要所有数据的总频率(跨桶汇总),则可以:
- 对所有结果文件做归并统计(Map 合并)。
- 比如
word1在result_bucket_0.txt是 5,result_bucket_1.txt是 2,总共就是 7。- 这一步可再次用 hashmap 缓存 + 写磁盘防止内存爆掉。
📘 总结一句话
“把大象装进冰箱,需要分步来——分桶写临时文件 → 每桶局部统计 → 全局归并或提取 Top-N。”
查询200条数据耗时200ms,怎么在500ms内查询1000条数据?
SpringBoot如果有百万数据插入怎么优化?
SpringBoot 百万数据插入优化:
使用 MyBatis-Plus 批量插入 + 每 1000 条一批 + 手动事务 + MySQL rewriteBatchedStatements=true 开启真正批处理,避免循环单条插入,将性能提升 50~100 倍。
SpringBoot可以同时处理多少请求?

volatile的应用场景?
为了保证我们并发编程的可见性和有序性
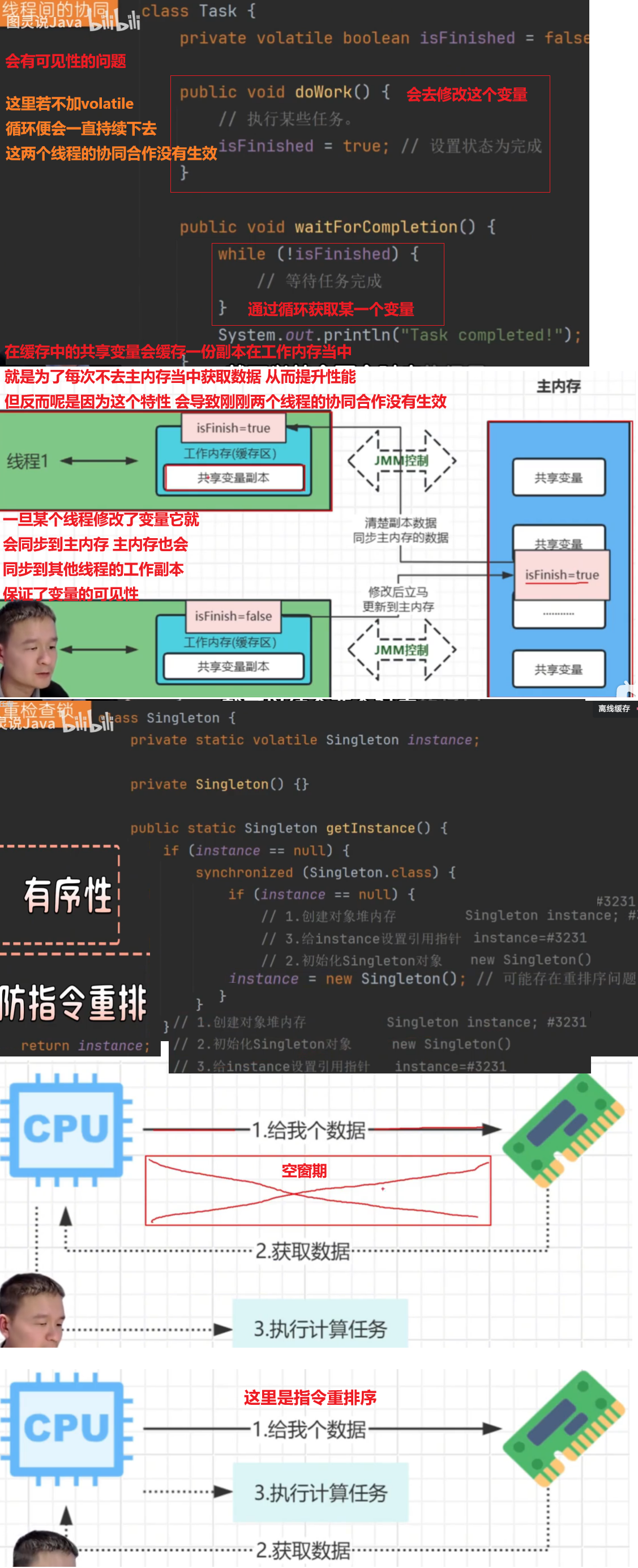
SQL的执行流程
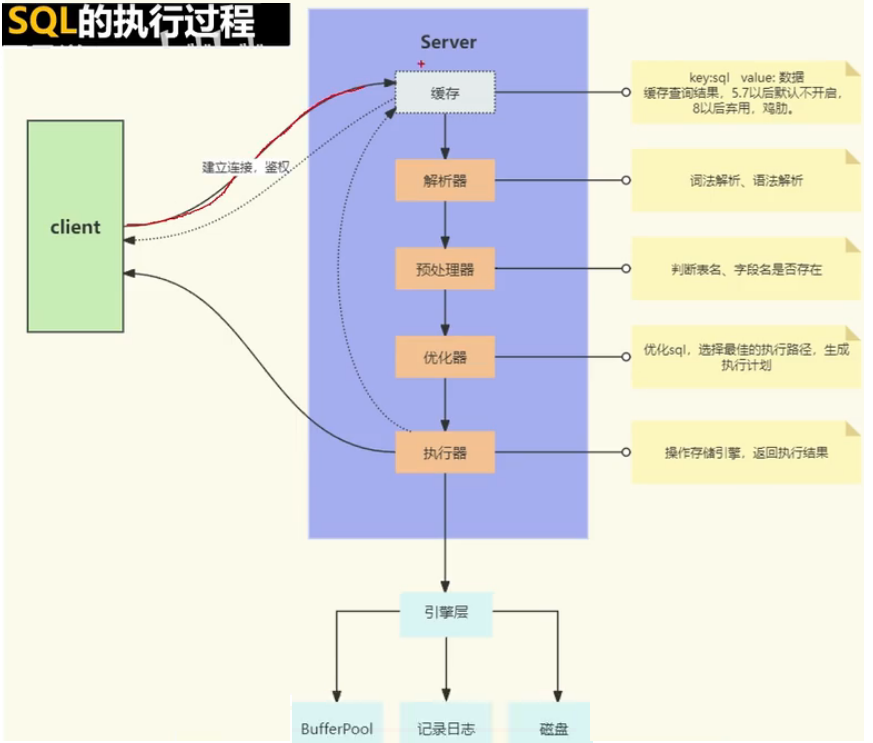
单表最多数据量需要多大才涉及到分表?

Mysql引擎层BufferPool工作过程原理?
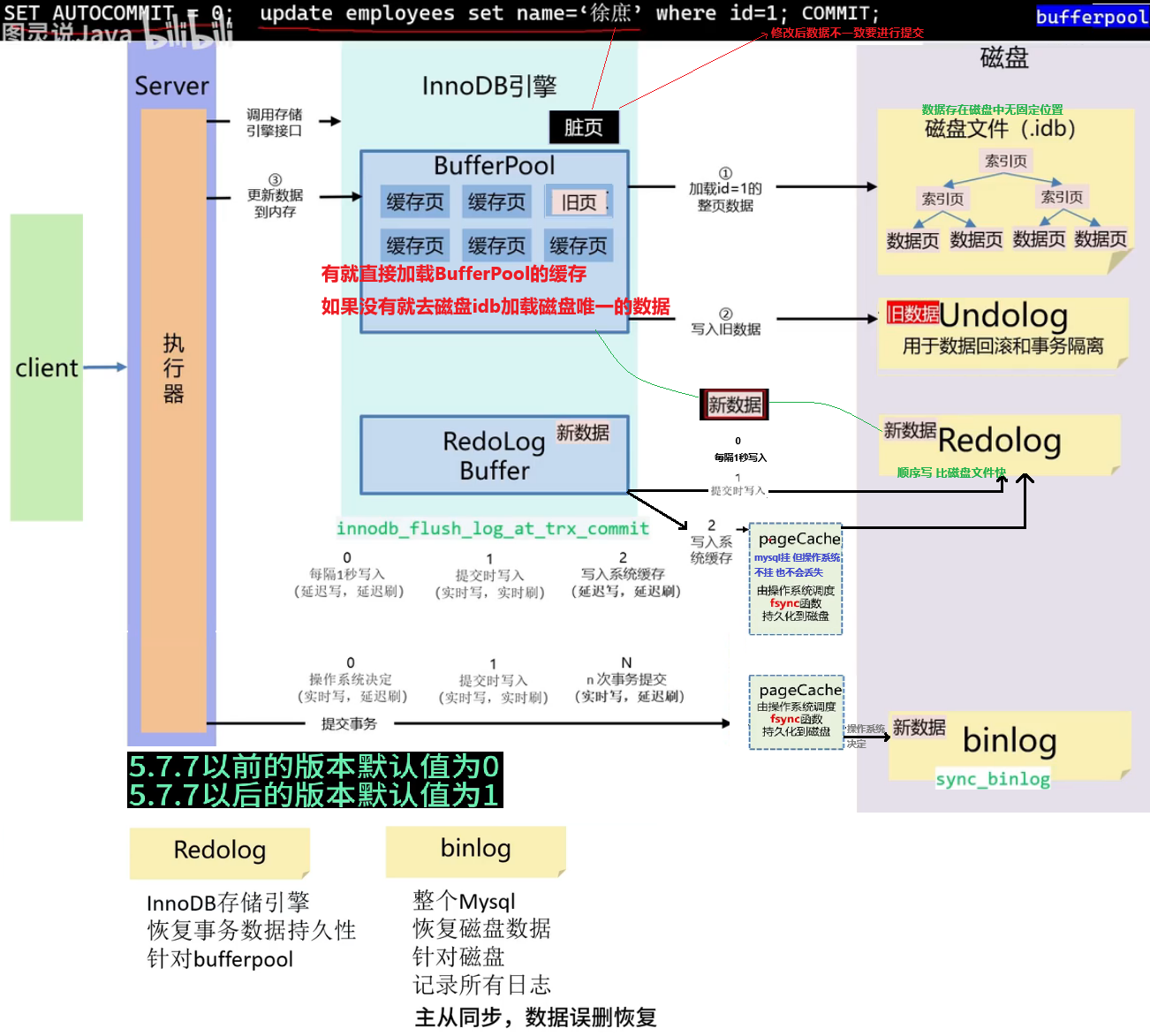
什么是聚集索引和非聚集索引?
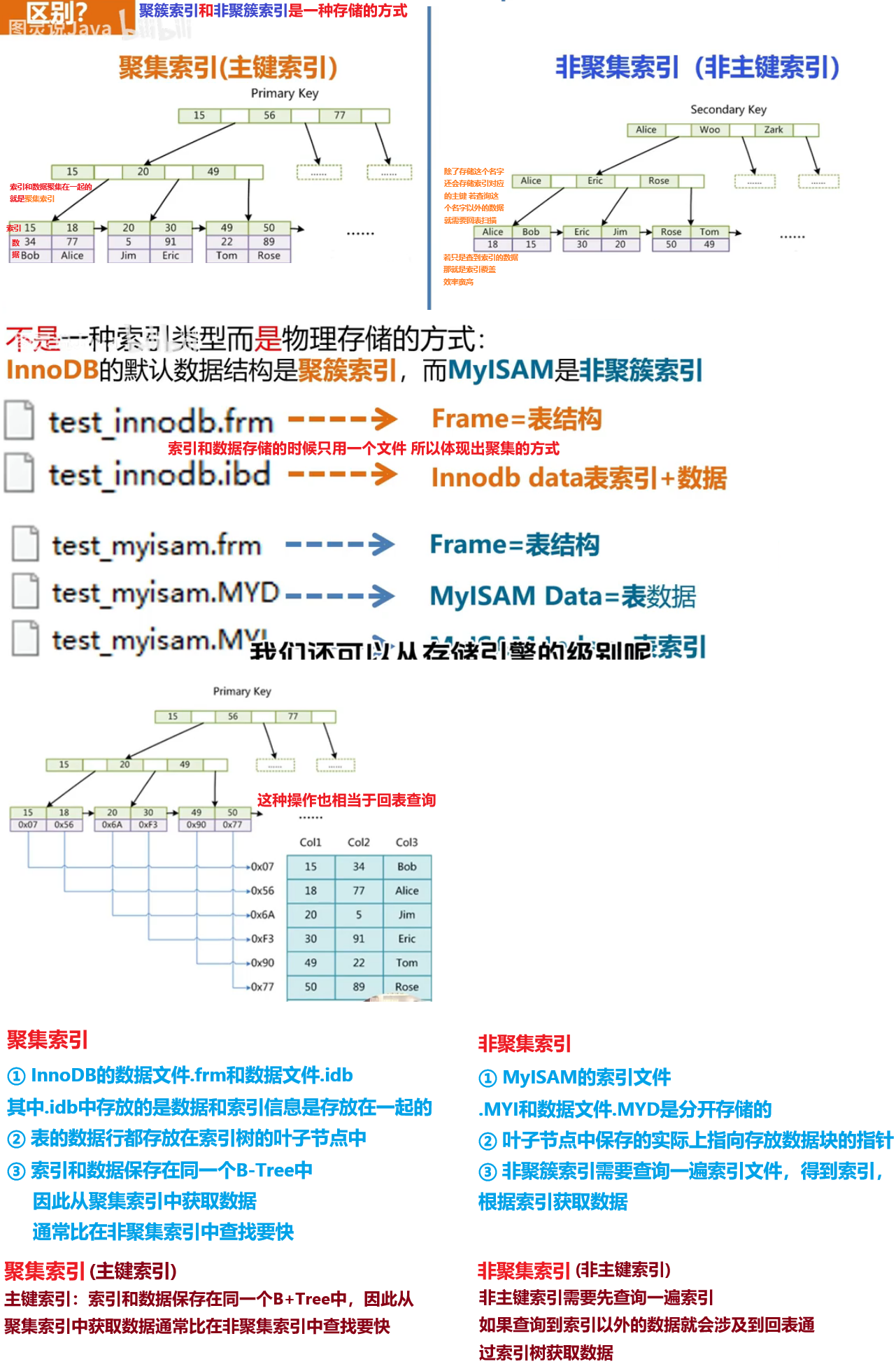
count(*)、count(1)、count(字段) 谁更快?有什么区别?
tb_user
| id | name |
|---|---|
| 1 | 潘春尧 |
| 2 | NULL |
| 3 | 张三 |
Ⅰ. SELECT count(*) FROM tb_user; → 3
Ⅱ. SELECT count(1) FROM tb_user; → 3
Ⅲ. SELECT count(name) FROM tb_user; → 2
在功能上没有区别 Ⅲ.如果你统计的数据需要排除NULL 就可以用count(指定字段)
在性能上没有任何区别 非要比较就是count(1)更胜一筹 因为不需要mysql在底层做任何的sql优化
SQL语句中使用了前模糊会导致索引失效?
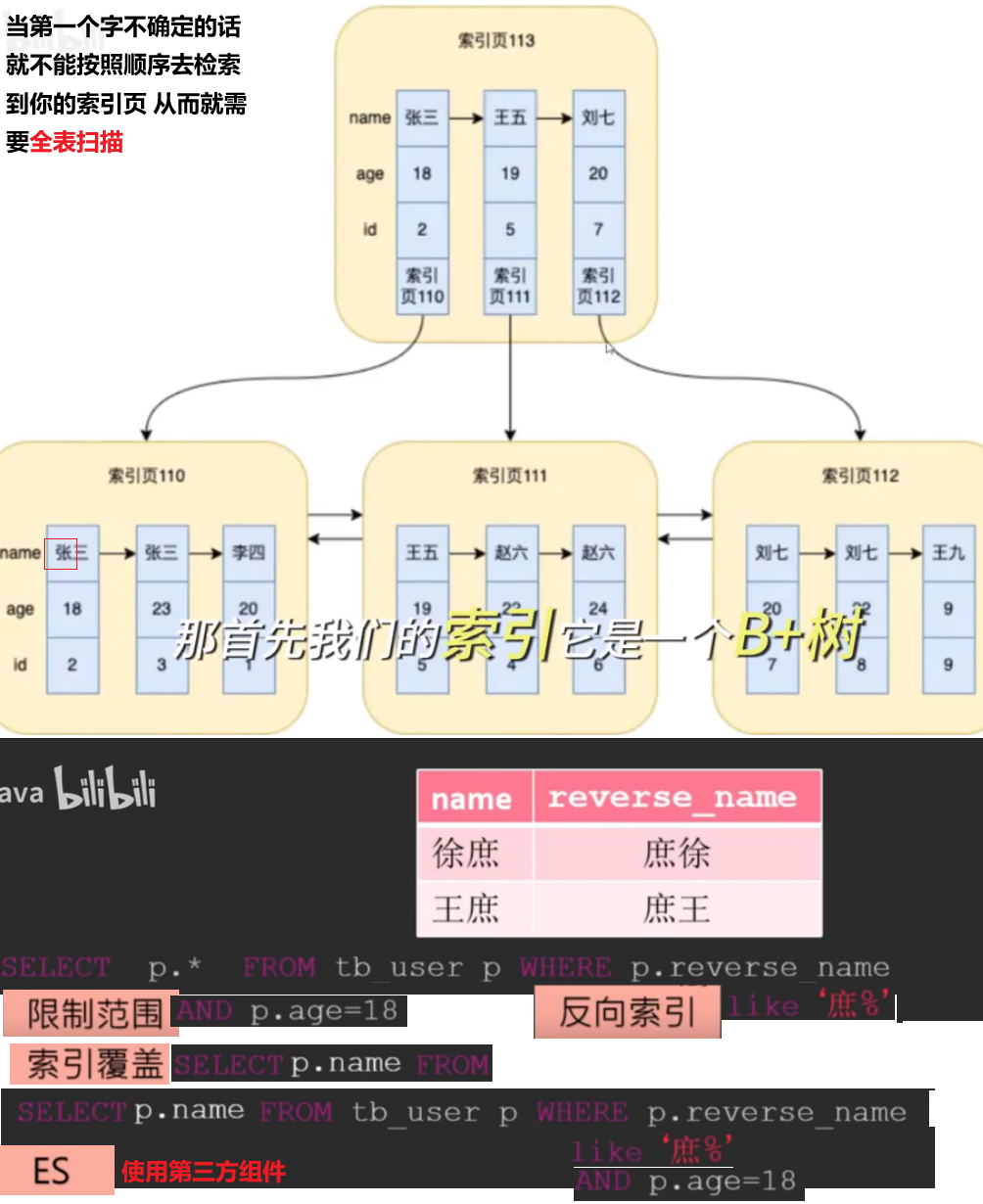
分库分表id冲突解决方案?
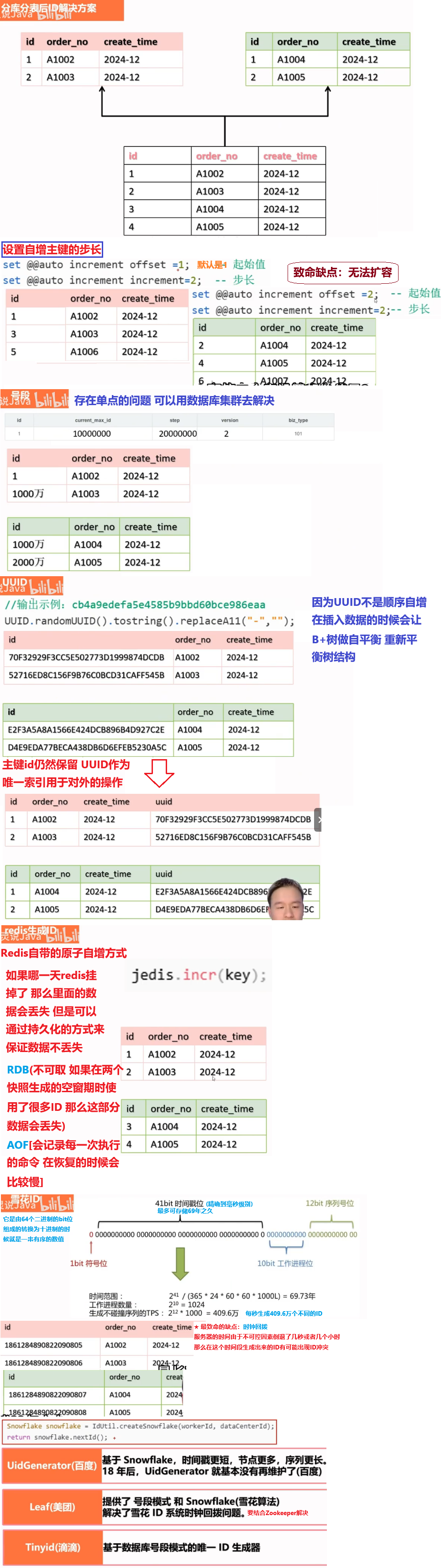
✅ 解决方案详解
1. 数据库主键自增(不推荐)
- 每个分库或分表自己用数据库的自增主键生成 ID。
- 缺点:跨库表合并数据时会重复,不具备全局唯一性。
2. UUID 作为主键
- 使用 Java 的
UUID.randomUUID().toString()等方式。- 优点:天然全局唯一。
- 缺点:
- 不适合做主键(无序、冗长,影响数据库索引性能)。
- 可读性差,调试困难。
3. 数据库主键段(Segment)模式(推荐)
- 思路:中心服务维护一张 ID 号段表,为每个业务系统分配一个号段。
- 实现:
- 表中记录:
biz_tag, max_id, step, version- 应用请求号段:
SELECT max_id, step FROM id_segment WHERE biz_tag = 'order'- 然后更新 max_id 为
max_id + step- 优点:
- 性能高(本地生成,无需每次访问数据库)
- 避免重复(由号段控制)
- 缺点:需要一个中心服务(如美团 Leaf)
4. 雪花算法(Snowflake)
Twitter 出品,用于生成 64 位整数 ID。
格式如下:
0 - 41位时间戳 - 10位机器ID - 12位自增序列优点:
- 单机高性能、趋势递增、可分布式部署
缺点:
- 依赖机器时钟,系统时间回拨可能导致重复 ID 或服务挂掉
- 需要保证机器 ID 唯一(通常通过配置或 ZooKeeper 分配)
5. Redis 生成自增 ID
利用 Redis 的
INCR命令,生成全局递增 ID:INCR order:id可配合时间戳、业务前缀等拼接成全局唯一 ID。
优点:
- 简单、轻量、分布式支持
缺点:
- Redis 挂掉或主从切换期间可能丢失或重复
🏁 总结推荐
方案 唯一性 性能 实现复杂度 推荐使用场景 UUID ✅ 高 简单 临时标识、测试用途 自增主键 ❌ 高 简单 单库表内可用 Segment ✅ ✅ 中等 企业级 ID 服务(如 Leaf) 雪花算法 ✅ ✅ 中等 分布式高并发业务 Redis INCR ✅ 高 简单 轻量级全局 ID 需求 如果你是在高并发、微服务、分布式环境下,强烈推荐使用:
- 雪花算法 + Redis 搭配
- 或引入一个中心 ID 生成服务(如 Leaf、TinyId、美团 UID Generator)
超直白对比(不用记术语)
1. Eureka(最简单、最纯粹)
定位:只做服务注册发现
- 就像一个简单电话本
- 只干一件事:服务注册、服务发现
- 不做主从选举、不做分布式锁
- 适合:Spring Cloud 微服务
- 特点:可用性优先,集群挂一部分还能跑
缺点:功能少,现在慢慢被淘汰了
2. ZooKeeper(老大哥、全能但重)
定位:分布式协调工具(元老级)
- 什么都能干:配置、注册、锁、选主
- 像一个全能管家
- 很多中间件(Kafka、HBase)依赖它
- 特点:强一致性,数据绝对准确
- 缺点:重、难维护、不专门给微服务设计
3. Nacos(现在的主流、最香)
定位:专为微服务而生的一站式平台
- 对标:Eureka + ZooKeeper 的简化版
- 像一个现代化管理平台
- 能做:服务注册发现 + 配置中心
- 开箱即用、简单、轻量、性能强
- 现在国内微服务首选 Nacos
最关键区别(面试必问)
产品 主要功能 特点 现在地位 Eureka 服务注册发现 简单、AP、老技术 慢慢淘汰 ZooKeeper 协调服务(配置、锁、选主) 全能、CP、重、老架构 中间件用得多,微服务少用 Nacos 服务发现 + 配置中心 简单、好用、主流 现在最火,企业首选 你可以这么理解
- Eureka:老式电话本
- ZooKeeper:老式全能管家
- Nacos:现代化智能管理平台
它们都是让服务之间能互相找到、配置能统一管理的工具。Nacos 是现在的王者,最简单最好用;ZooKeeper 是老大哥,功能多但笨重;Eureka 是前任,快退休了。
深分页为什么慢,怎么优化?
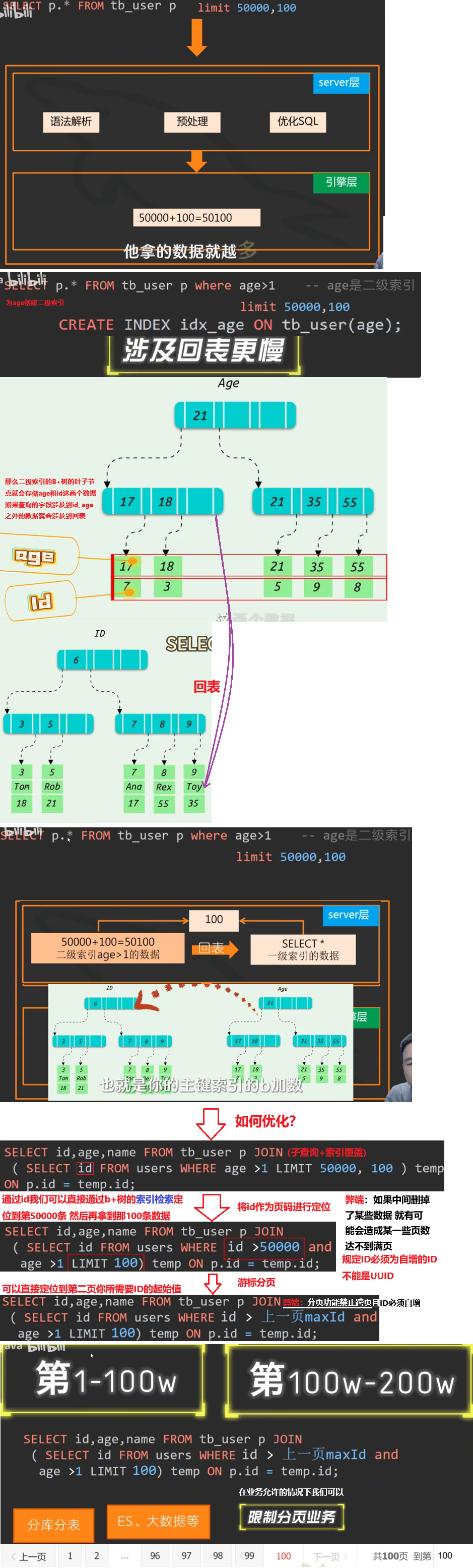
❓ 问题背景:什么是深分页?
深分页 = 当前页数很大,比如
page=100000 & size=10
对应 SQL:SELECT * FROM table LIMIT 1000000, 10;
LIMIT offset, size这种分页方式,在 offset 特别大时非常慢。- 根因:数据库在处理时,仍然会扫描前面 offset 条记录,然后丢弃它们,仅返回后面的 size 条。
🐌 为什么慢?
数据库执行过程(如MySQL):
LIMIT 1000000, 10数据库内部会:
- 先从磁盘/缓冲中 取出前 1000000 条记录;
- 然后只返回第 1000001 ~ 1000010 条;
- 前面的全丢了,但依然耗费 CPU、IO 和内存资源。
当数据量大时:
- IO开销大(全表扫描)
- CPU开销大(排序、过滤)
- 数据库响应延迟高
🚀 如何优化深分页?
✅ 方案一:使用 覆盖索引
SELECT id FROM table ORDER BY id LIMIT 1000000, 10;如果
id是索引字段,数据库可以直接从索引树上读取,无需回表。但这个优化能力有限,适合某些查询字段很少、又刚好有索引的情况。
✅ 方案二:记录上次的游标(Keyset Pagination)
又叫 基于条件的分页,避免使用 offset。
例如:
SELECT * FROM table WHERE id > 上一页最后一条记录id ORDER BY id LIMIT 10;优点:
- 快!数据库利用索引跳过前面的数据
- 没有 offset,性能非常稳定
适用场景:
- id 或时间戳等字段是自增或顺序的
- 不要求用户可以跳到任意页,只支持“向前/向后翻页”
✅ 方案三:缓存 + 异步预处理
对于排行榜、热点数据等:
- 查询结果提前生成并缓存(Redis 等)
- 用户点页数 → 直接读缓存,避免实时查询
✅ 方案四:使用临时表或中间结果表
- 查询结果太大 → 先异步存入临时表
- 分页从临时表中读取数据(配合游标分页)
适用于复杂 SQL 查询 + 多表连接
✅ 总结对比
方案 优点 缺点 适用场景 offset 分页 简单 深分页慢 小数据量 覆盖索引 快 限制大 查询字段少 游标分页 性能高 不支持跳页 流式阅读/时间线 缓存分页 快 一致性差 热点排行榜等 临时表分页 灵活 复杂 大查询分页导出
MySQL的隔离级别实现原理MVCC ?
核心:隐藏字段 + Undo Log + ReadView
🔸 1. 每行记录都有两个隐藏字段:
字段 含义 trx_id(创建事务ID)表示创建该版本的事务 ID roll_pointer(回滚指针)指向 Undo Log(历史版本)的位置
🔸 2. Undo Log(回滚日志)
- 用于记录数据修改前的旧版本数据
- 当有读请求(快照读)时,就通过
roll_pointer访问历史版本- 写操作失败或回滚,也依赖 Undo Log 恢复数据
🔸 3. ReadView(读视图)
- 当事务开启时,会创建一个 ReadView(可见性判断工具)
- 包含当前活跃事务 ID 列表、最小事务ID、最大事务ID
- 判断规则:
- 如果行的创建事务ID < ReadView 中最小事务ID → 可见
- 如果在活跃事务列表中 → 不可见
- 如果创建事务ID > 当前事务ID → 不可见(未来数据)
**MVCC ** (Multiversion Concurrency Control) 多版本并发控制器
它是事务隔离级别的无锁的实现方式,用于提高事务的并发性能
事务隔离级别 (isolation)
用来解决并发事务所产生一些问题:
并发:同一个时间,多个线程同时进行请求。
什么时候会发生并发问题:在并发情况下,对同一个数据(变量、对象)进行读写操作才会产生并发问题
并发会产生什么问题?
1.脏读一读已提交(行锁,读不会加锁)
2.不可重复度–重复读(行锁,读和写都会上锁)
3.幻影读–串行化(表锁)概念: 通过设置隔离级别可解决在并发过程中产生的那些问题

用户忘记密码,系统为什么不直接提供原密码,而让改密码
因为系统它也不知道我们的原密码是什么
服务端在保存密码的时候绝不会明文存到数据库,怕有数据库权限的人或者黑客恶意利用
必须用不可逆的加密算法
MD5
- 只能加密不可解密 但是它是hash算法 可能会有哈希冲突 至少加密2^128次方才有可能发生哈希碰撞
- 每次生成的密文都一样,不管加密多少次生成的密文都是一样的 可以通过暴力破解
- 解决暴力破解 就要在里面加盐 每次加密 解密 都要加入盐
HS256
- 增加加密字符长度 目前没有碰撞性
- 最好加入随机盐
BCrypt → 加入spring-security-core依赖
- 盐是随机的
- 无法通过暴力破解
Git怎么修复线上的突发BUG线上突发Bug要修复,本地正在开发新需求
在git里我们通常会用一个单独的分支来进行管理
本地开发也会有一个单独的分支
可以将线上代码的分支签出来单独进行修复
- 正在开发的代码 → 暂存dev分支
- 严重故障:回滚上一个版本
非严重故障:在fix分支修复紧急Bug - 非常紧急:直接合并master分支上线
- 一般急:合并release分支,走测试、上线流程
- 非紧急:合并dev分支,走测试、线上流程
RestTemplate如何优化连接池
默认是没有连接池的
要用框架HTTPClient、OKHTTP
RestTemplate 是Spring框架中用于简化HTTP请求的一个类,它提供了多种方法来处理HTTP请求和响应。RestTemplate可以用于发送GET、POST、PUT、DELETE等HTTP请求,并且可以处理请求头、请求体、URL参数等。
Synchronized怎么提升性能
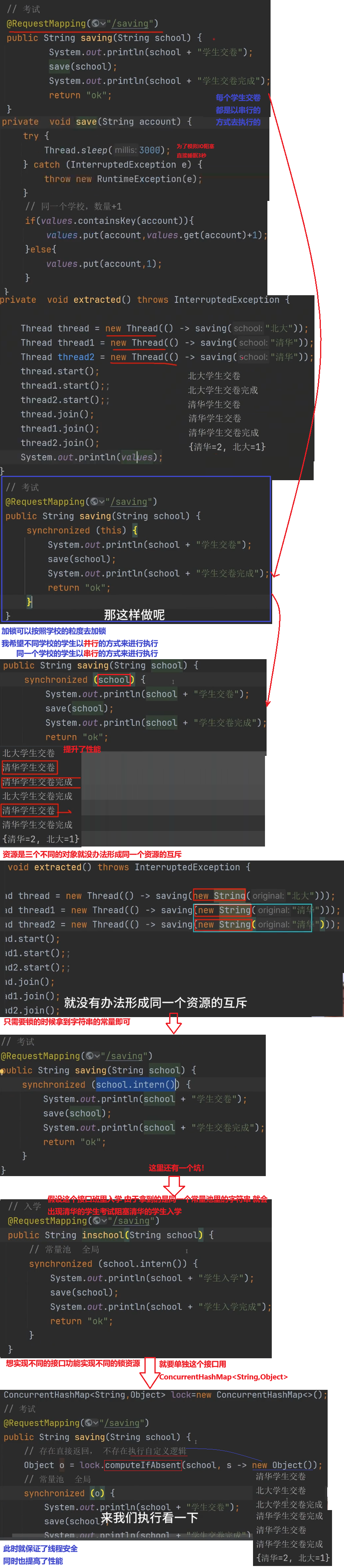
🧠 实际开发中如何用好 synchronized?
✅ 尽量减少锁的粒度
// ❌ 锁了整个方法 public synchronized void update() { ... } // ✅ 只锁关键代码段 public void update() { // 非关键代码 synchronized (this) { // 只锁关键部分 } }
✅ 使用局部锁对象代替类锁
private final Object lock = new Object(); public void doTask() { synchronized (lock) { // 更细粒度的锁,避免不必要的争用 } }
✅ 使用并发类替代锁(性能更高)
ConcurrentHashMapReadWriteLockReentrantLockAtomicInteger等
开发中有没有用到设计模式?怎么用的
策略模式 + 简单工厂 + 模板方法

SpringBoot如何防止反编译
有没有出现过Spring正常SpringBoot报错的情况?
SpringBoot配置文件敏感信息如何加密?
一个需求来了怎么办!
首先看这个需求 进行一个分析 分析这个需求跟哪些功能有关联 比如说在我做过的xxx里面 和什么关联 要思考怎么去做这个关联 数据库 代码层面 思考好之后 再去ER画图 写接口文档 再去开始写代码