
Java面试 —— 准备
給职场新人的建议
- 不要有为老板工作的心态
- 永远不要敷衍工作
- 事情做完马上汇报
- 管理好自己的情绪,做一个可爱的人
- 接受任务有确认机制
- 注意工作汇报方式
- 注重细节
- 提建议要有数据支撑
- 給主管选择题 而不是判断题
- 要提升自己的价值 [人脉网]
- 认真对待工作汇报3
介绍面试环节中常见问题
自我介绍
张总你好,我叫潘春尧,今年23岁,来自河北唐山人,来应聘贵公司的Java软件工程师职位,26年毕业于南昌工学院软件工程专业,从事Java开发有2年的工作时间了,我对编程有着浓厚的兴趣,擅长基于HTML5的互联网应用开发,擅长使用Mysql数据库对大数据量方面的调优有经验,同时具备完整的项目开发能力,具备一定的分布式架构经验,之前我做过两个项目,都是独立完成的,第一个是XX 在2024年开发,这是一个电商网站,已经运用了一年的时间,我负责底层的架构搭建与前后端开发,技术方面采用了XXXX。架构方面底层使用了XXX,我负责的模块设计XXX,这些都是由我完整开发的,而第二个项目是由我开发的xxx,这是一个xxx平台,基于阿里云搭建,技术方面与上一个相似,工作原因产品需要增加XXX,我负责的网站模块主要负责xxx,这也是由我负责开发的,以上是我的个人介绍,有不足的请您多保函。
现场面对面 [要面试官知道我有闪光的价值]
- 容貌要求 [注意形象(刮胡子,短发,指甲)]
- 着装要求 [品牌+面料+皮鞋(商务休闲)]
- 面试礼仪 [提前15分钟到达面试场地填写表格、敬语(您好,感谢,再见)、善意的微笑] [和前台了解面试官的称呼和职位 主动握手 张总… ] [跟着面试官进去后 注意关门 进去前注意敲门] [沟通时眼神不要游离] [提交简历调转180°双手呈递] [不要抖腿翘腿] [手放腿上 十指交叉放桌子上 不许靠着椅子靠背]
- 一对多面试 [一男一女 男: 技术主管[考察技术能力] 女: HR[根据动作分析本人能力]] [面试紧张的时候要降低语速]
面试必知必会
我从小对软件技术有着很浓厚的兴趣,在未来我五年内我希望从事于与技术相关的岗位,我给自己定位了一个小目标,在五年的时间内我希望拿下系统架构师的认证,同时在分布式、微服务的领域有自己独道的见识。希望在未来的一段时间里公司能给我提供成长的机会。
[不诋毁任何人 不传达任何负面情绪 以大局为重]
我很少与别人产生正面的冲突,面对别人对我个人的职责批评,我通常先会反思我是不是真的做错了,如果是我会虚心接受,尽快改正。如果是别人对我无端的诽谤,在公共场合也会保持沉默,我会在私下跟他心平气和的沟通看看之间是不是有什么误会。如果是在工作中就某些问题产生了分歧。在会议时直接打开天窗说亮话,阐述自己的观点,这种是典型的对事不对人,这也是点到为止,如果双方意见僵持不下,这可能需要项目经理在中间做出定夺,他看到的问题可能比我们的更加全面而且更有建设性,总之我处事的原则是对事不对人,做事必须认真,做人还是要谦虚一些
[考察你对待工作 生活 家庭是什么态度] [强调以事业为重]
我一个人来到XX打拼,目前是单身,对于我现在而言,事业就是我的全部,我会珍惜每一天,让自己尽快的成长起来
[不能太过实在 避重就轻 强调自己的特性]
我对咱们公司的业务不太了解,经验很少,进入公司以后我会听取领导的指示和要求,尽快的熟悉公司的业务和技能,并且制定一份近期的工作计划并报告給领导批准,最后按照计划展开工作,其实针对这个问题,明眼人都看得出来,都说了一堆套话,废话,但是对于面试官来说,你正面的回答了这些问题。而这些问题肯定是现实中存在的,这样既无伤大雅又巧妙的表达了自己对这份工作的期望
[考察情商]
作为刚步入社会的新人,我应该要求自己多熟悉工作环境适应环境,而不是对环境提出要求,对于我的工作只要能发挥我的专长就可以了,如果工作中有做的不对的地方还请领导多批评指正
[面试通过几率已经很大了]
每天我会提高工作效率,完成公司交付的工作任务,任务未完成绝不下班,根据领导的指示和工作安排制定好工作计划,提前预备并按照计划完成,多请示领导及时汇报,如果有遇到不明白的地方要向前辈们请教,抓住缝隙时间多学习多提升,尽快的提高自己的专业能力与业务水平
[面试官喜欢有冲劲的小伙子 给出明确的时间规划 不要说我是来公司学习的]
我当然有想过创业,但我觉得不是现在,我计划在30岁前后选择创业,软件行业需要大量的技术积累才能有竞争力,同时呢创业对我来说也需要很多的资金,我是一名刚走出校园的新人,在这两方面都不成熟,所以在未来的5年时间内,我会努力的工作,在经验和资金方面做好准备,同时之所以来贵公司,是因为贵公司在XXX行业是一个知名的企业,我想在为公司创造价值的同时,也能进一步的掌握咱们行业最新的动向,希望您能给我一次证明自己的机会,我肯定不会让公司失望的。
[千万不能说海投 也不能说hr打了电话才来 最好不要跨行业]
做一些准备了
[很难回答 送命题 学历非常重要的 话术把劣势转换优势]
实话实说上高中的时候我并不是一个好学生,在那时候爱玩电脑,确实也耽误了不少学业。但我认为学历的高低并不代表能力的好坏,在我上了专科以后我更加意识到因为学历比别人落后,自己就更需要努力了,从小对编程感兴趣,上了大学后就更有时间朝着自己喜欢的领域努力。在大学几年的时间里面我没有醉生梦死,自己呢也连续学习了XXX技术内容,我知道有朝一日,这些知识一定能给我带来用处,我一定能成为所向往的软件工程师,我能用实际行动来证明专科不比本科差
[测试你是否能为公司奉献 要强调上班提高效率 强调加班并不是我的工作效率低下]
上班时间我会提高效率,做到当日事当日毕,但是如果当天的事没有按时完成,我会义不容辞的加班,现在我是单身,没有家庭的负担,可以全身心的工作
[提前有明确主张 自己能赚多少钱 给出hr谈薪资的余地期待8k 可以报价8.5k 千万不要说区间6-8k]
我期望的薪资是8.5k,每一个公司都有自己的薪资结构,咱们公司是xxx行业中是非常有实力的企业,相对于薪资来说我更看重技术和行业本身,如果您觉得薪资水平超出了公司的预期的话,这个咱们可以谈
[千万不要说负面话语 也不能说工资太低、福利太差、没有晋升空间]
我这个人稳定性很好,本身反对频繁跳槽,但是有一种情况我会选择跳槽,就是公司的发展对于我的事业规划不符,我之前在进入xxx公司的时候,公司主要从事金融行业的项目开发,后来该行业金融不理想改作了电信行业了,当我的长期规划是想成为长期的金融软件工程师与架构师,如果遇到这种情况我会好不容易的选择离开。
Java面试——Java基础面试技巧
JDK、JRE、JVM有什么区别
- JDK:Java Development Kit 针对Java程序员的产品
- JRE:Java Runtime Environment是运行Java的环境集合
- JVM:Java虚拟机用于运行Java字节码文件[class],跨平台的核心。通过JVM隐藏了操作系统最底层的API,对于我们java工程师只需要面对jvm层面进行开发,再转移到其他就可以了
为什么可以跨平台?
因为JVM可以跨平台,JVM只认识字节码,能够解释到系统的API调用,对于不同的系统有不同的JVM实现。Windows和Linux有不同的JVM实现,但是编成字节码后都是一样的。
常用数字类型的区别
| 名次 | 取值范围 | 存储空间 |
|---|---|---|
| 字节(byte) | -$2^7$ ~ $2^7$-1 -128 ~ 127 |
1个字节 |
| 短整数(short) | -$2^{15}$ ~ $2^{15}$-1 -32768 ~ 32767 |
2个字节 |
| 整数(int) | -$2^{31}$ ~ $2^{31}$-1 -2147483648 ~ 2147483647 |
4个字节 |
| 长整数(long) | -$2^{63}$ ~ $2^{63}$-1 | 8个字节 |
| 单精度(float) | $2^{-149}$ ~ $2^{128}$-1 | 4个字节 |
| 双精度(double) | $2^{-1074}$ ~ $2^{1024}$-1 | 8个字节 |
Float在JVM的表达方式及使用陷阱
float d1 = 423432423f;
float d2 = d1 + 1;
if(d1 == d2){
System.out.println("d1==d2");
}else{
System.out.println("d1!=d2");
}
答案:d1 == d2
对于单精度浮点型float d1在内存中是采用科学计数法表示
表达为:4.2343242E7 保留小数点后七位 [如果更高精度的用double]
d1是八位数
无论是d1还是d2不考虑最后一位
d2用科学计数法表示同样为4.2343242E7
因此 d1 == d2
银行业务数值精确计算要用BigDecimal类进行加减乘除的计算
随机数的使用
编程题:随机生成30~100之间的整数
==========================================================
package com.example.demo12;
import java.util.Random;
public class RandomSample {
public Integer randomInt1(){
int min = 30;
int max = 100;
//生成正整数范围0-70的随机数 => 30~100
int result = new Random().nextInt(max - min) + min;
return result;
}
public Integer randomInt2(){
int min = 30;
int max = 100;
int result = (int)(Math.random() * (max-min)) + min;
return result;
}
public static void main(String[] args) {
System.out.println(new RandomSample().randomInt1());
System.out.println(new RandomSample().randomInt2());
}
}
编程题:列出1-1000的质数[大于1的情况下 只能被1和自身整除的数]
==========================================================
package com.example.demo12;
public class PrimeNumber {
public static void main(String[] args) {
for (int i = 2; i <= 1000; i++){
boolean flag = true;
for (int j = 2; j < i; j++){
if(i % j == 0){
flag = false;
break;
}
}
if (flag){
System.out.println(i);
}
}
}
}
面向对象的三大特征是什么
封装
对同一类事务的特征和功能包装到一起,只对外暴露需要调用接口而已
[我想让你看到的你能看到 不想让你看到的不能看到]。作用:对接口进行实现的过程中每一个接口的实现类对接口进行了实现,但是在调用的时候通常是面对接口的,对于使用者来说只需要知道接口对应的哪些方法做什么用的就可以了,对内部的什么是不需要理解的。接口是体现封装的常见方法
封装的好处:- 实现专业的分工
- 减少代码耦合
- 可以自由修改类的内部结构
继承
是Java中面向对象最显著的特征,继承是从已有的类中派生出新的类,新的类能够吸收原有属性的属性和行为并扩展新的类,Java中类是不支持多继承的,接口可以,一个接口可以继承多个其他接口 父类是子类的抽象化,子类是父类的具体化。
接口与抽象类有那些异同?相同点 不同点 都是上层的抽象 抽象类可包含方法的实现
接口则只能包含方法的声明不能被实例化 [不可new] 继承类只能继承一个抽象类
实现类可以实现多个接口都可以包含抽象发发 抽象级别:接口>抽象类>实现类 作用不同:接口用于约束程序行为。继承则用于代码复用
注意:JDK8以上版本,接口可以有default方法,包含方法实现多态
最重要的特性 前面是为多态服务的
多态是三大特性中最重要的操作
多态是同一个行为具有多个不同表现形式或形态的能力
多态是同一个接口,使用不同的实例而执行不同操作
静态和实例变量(方法)的区别
- 语法区别:静态变量前要加static关键字,实例则不用
- 隶属区别:实例变量属于某个对象的属性,而静态属于类
- 运行区别:静态变量在JVM加载类字节码创建,实例变量在实例化对象时创建
静态变量
在类中定义,使用static关键字修饰
静态方法:可以通过类名直接访问,也可以通过对象访问
调用上下文:不依赖于类的实例,不能访问实例变量和实例方法
生命周期:从类加载到类卸载,生命周期与类相同
实例变量
在类中定义,不适用static关键字修饰
实例方法:只能通过对象访问
调用上下文:依赖于类的实例,可以访问实例变量和实例方法
生命周期:从对象创建到对象被垃圾回收,生命周期与对象相同
类的执行顺序
package com.example.text;
//请写出程序输出结果
//1. 静态优先
//2. 父类优先
//3. 非静态块优先于构造函数
public class ExecutionSequence {
public static void main(String[] args) {
new GeneralClass();
}
}
class ParentClass{
static {
System.out.println("①我是父类静态块");
}
{
System.out.println("②我是父类非静态块");
}
public ParentClass(){
System.out.println("③我是父类构造函数");
}
}
class GeneralClass extends ParentClass{
static{
System.out.println("④我是子类静态块");
}
{
System.out.println("⑤我是子类非静态块");
}
public GeneralClass(){
System.out.println("⑥我是子类构造函数");
}
}
/*
①我是父类静态块
④我是子类静态块
②我是父类非静态块
③我是父类构造函数
⑤我是子类非静态块
⑥我是子类构造函数
*/
总结
静态块:静态块在类加载时执行,且父类静态块先于子类静态块执行。
非静态块和构造函数:在对象创建时,先执行父类的非静态块和构造函数,再执行子类的非静态块和构造函数。
请说明java的异常体系
Error → Throwable
RuntimeException → Exception → Throwable
运行时产生的异常不要求对其强制try catch…
Error和Exception的区别和联系
| Exception | Error |
|---|---|
| 可以是可被控制或不可控制的 | 总是不可控制的 |
| 表示一个由程序员导致的错误 | 经常用来用于表示系统错误或低层资源的错误 |
| 表示在应用程序级被处理 | 如果可能的话,应该在系统级被捕捉 |
String与字符串常量池 [比较内存地址]
String s1 = "abc";
String s2 = "abc";
String s3 = "abc"+"def";
String s4 = "abcdef";
String s5 = s2 + "def";
String s6 = new String("abc");
System.ouut.println(s1==s2); //true
System.ouut.println(s3==s4); //true 相等的都保存到常量池
System.ouut.println(s4==s5); //false
//s5中的s2属于引用类型 在java编译期间无法确定其类型 只有在运行时才能确定具体的值 会产生一个新的内存地址给s5 所以不相等
System.ouut.println(s4.equals(s5));//true equals比较的是内容
System.ouut.println(s1==s6); //false
//s1是在常量池的常量 new String("abc");创建的东西不在常量池 存储的地方是完全不同的
String、StringBuilder、StringBuffer的区别
| String | StringBuffer | StringBuilder | |
|---|---|---|---|
| 执行速度 | 最差 | 其次 | 最高 |
| 线程安全 | 线程安全 | 线程安全 | 线程不安全 |
| 使用场景 | 少量字符串操作 | 多线程环境下的大量操作 | 单线程环境下的大量操作 |
优先使用哪个?
单线程环境:优先使用 StringBuilder。因为 StringBuilder 没有线程同步开销,性能更高。
多线程环境:优先使用 StringBuffer。因为 StringBuffer 提供了线程安全的保证,避免了多线程环境下的并发问题
List与Set的区别
| List | Set | |
|---|---|---|
| 允许重复 | 是 | 否 |
| 是否允许null | 是 | 否 |
| 是否有序 | 是 | 否 |
| 常用类 | ArrayList LinkedList |
HashSet LinkedHashSet TreeSet |
ArrayList与LinkedList的区别
| ArrayList | LinkedList | |
|---|---|---|
| 存储结构 | 基于动态数组 | 基于链表 |
| 遍历方式 | 连续读取 | 基于指针 |
| 使用场景 | 大数据量读取 | 频繁新增、插入[写入类型] |
HashSet和TreeSet的区别
| HashSet | TreeSet | |
|---|---|---|
| 排序方式 | 不能保证顺序 | 按预置规则顺序 |
| 底层存储 | 基于HashMap | 基于TreeMap |
| 底层实现 | 基于Hash表实现 | 基于二叉树实现 |
List排序的编码实现
编程题:List排序
Employee.java
package com.example.text;
public class Employee {
private String ename;
private Integer age;
private Float salary;
@Override
public String toString() {
return "Employee{" +
"ename='" + ename + '\'' +
", age=" + age +
", salary=" + salary +
'}';
}
public Employee() {}
public Employee(String ename, Integer age, Float salary) {
this.ename = ename;
this.age = age;
this.salary = salary;
}
public String getEname() { return ename;}
public void setEname(String ename) {this.ename = ename;}
public Integer getAge() { return age;}
public void setAge(Integer age) {this.age = age;}
public Float getSalary() {return salary;}
public void setSalary(Float salary) {this.salary = salary;}
}
ListSorter.java
package com.example.text;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class ListSorter {
public static void main(String[] args) {
List<Employee> emps = new ArrayList<>();
emps.add(new Employee("张三", 33, 1800f));
emps.add(new Employee("李四", 55, 3800f));
emps.add(new Employee("王五", 40, 2300f));
Collections.sort(emps, new Comparator<Employee>() {
@Override
public int compare(Employee o1, Employee o2) {
//以薪资排序 如果是以年龄的话o1.getAge() - o2.getAge();
return (int) (o1.getSalary() - o2.getSalary());
//返回正数 第一个大于第二个
}
});
System.out.println(emps);
}
}
TreeSet排序的编码实现
编程题:TreeSet排序
Employee.java 同上
[自定义排序]
SetSorter.java
package com.example.text.TreeSet;
import java.util.*;
//自定义排序
public class SetSorter {
public static void main(String[] args) {
TreeSet<Employee> emps = new TreeSet<Employee>(new Comparator<Employee>() {
@Override
public int compare(Employee o1, Employee o2) {
return (int)(o2.getSalary() - o1.getSalary());
}
});
emps.add(new Employee("张三", 33, 1800f));
emps.add(new Employee("李四", 55, 3800f));
emps.add(new Employee("王五", 40, 2300f));
}
}
[自然排序]
package com.example.text;
public class Employee implements Comparable<Employee>{
private String ename;
private Integer age;
private Float salary;
@Override
public String toString() {
return "Employee{" +
"ename='" + ename + '\'' +
", age=" + age +
", salary=" + salary +
'}';
}
@Override
public int compareTo(Employee o){
//如果返回-1 Employee对象返回到红黑树的左边 采用降序排列
//如果返回1
return this.getAge().compareTo(o.getAge());
// return o.getAge().compareTo(this.getAge()); 输出降序
//如果前面比后面大 返回1 反之返回-1 如果两者相等返回0
}
public Employee() {}
public Employee(String ename, Integer age, Float salary) {
this.ename = ename;
this.age = age;
this.salary = salary;
}
public String getEname() { return ename;}
public void setEname(String ename) {this.ename = ename;}
public Integer getAge() { return age;}
public void setAge(Integer age) {this.age = age;}
public Float getSalary() {return salary;}
public void setSalary(Float salary) {this.salary = salary;}
}
=============================================================
SetSorter.java
package com.example.text.TreeSet;
import java.util.*;
//自定义排序
public class SetSorter {
public static void main(String[] args) {
TreeSet<Employee> emps = new TreeSet<Employee>
emps.add(new Employee("张三", 33, 1800f));
emps.add(new Employee("李四", 55, 3800f));
emps.add(new Employee("王五", 40, 2300f));
System.out.println(emps);
}
}
hashCode与equals的联系与区别
Object类hashCode()和equals()的区别
equals()方法用来判断两个对象是否”相同”
hashCode()返回一个int,代表”将该对象的内部地址” [如果不相等肯定不是同一个对象] [小概率情况下不同的对象也产生相同的hashCode(), 之后再用equals()去比较]
序号 描述 1 两个对象如果equals()成立, hashcode()一定成立 2 如果equals()不成立, hashcode()可能成立 3 如果hashcode()成立, equals()不一定成立 4 hashcode()不相等, equals()一定不成立
hashCode 方法用于快速定位哈希表中的桶(bucket),而 equals 方法用于确认桶中的具体对象。通过 hashCode 快速过滤掉大部分不相等的对象,可以显著提高查找效率。
通常是先调用 hashCode 方法来定位桶,然后再调用 equals 方法来确认具体对象。equals 方法不会直接调用 hashCode 方法,而是依赖于 hashCode 方法的一致性。
Java IO中有集中类型的流
| 输入流 | 输出流 | |
|---|---|---|
| 字节流 | InputStream[父类] FileInputStream BufferedInputStream[缓存] |
OutputStream[父类] FileOutputStream BufferedOutputStream[缓存] |
| 字符流 | Reader FileReader InputStreamReader BufferedReader |
Writer FileWeiter OutputStreamWriter BufferedWeiter |
★ 利用IO实现文件复制 ★ [笔试]
编程题:复制文件到指定文件夹
package com.example.text.FileCopy;
import java.io.*;
public class FileCopy {
public static void main(String[] args) {
//1. 利用JavaIo
File source = new File("D:/application.rar");
File target = new File("D:/target/application.rar");
InputStream input = null;
OutputStream output = null;
try {
input = new FileInputStream(source);
output = new FileOutputStream(target);
byte[] buf = new byte[1024];
int byteRead;
while((byteRead = input.read(buf)) != -1){
output.write(buf,0,byteRead);
}
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
} catch (IOException e) {
throw new RuntimeException(e);
}finally {
try {
input.close();
output.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//2. 利用FileChannel实现文件复制
//3. Commons Io组件实现文件复制
//FileUtils.copyFile(Source,Target);
}
}
请介绍JVM的内存组成
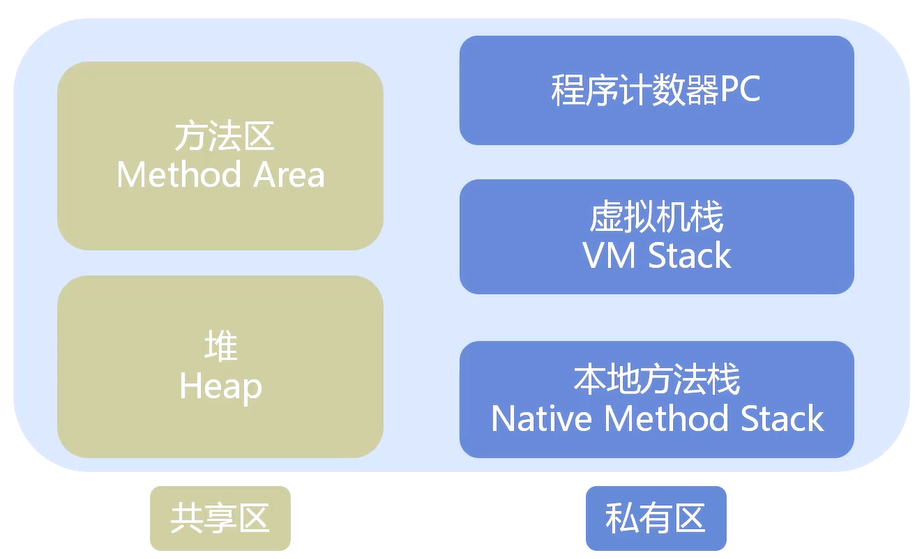
[共享区:供所有对象共享 所有线程都访问到的地方]
堆:垃圾回收销毁处理区
方法区:虚拟机加载的类的信息、常量、静态变量等信息[私有区:所有对象都是私有的]
程序计数器PC: 当前线程所执行的字节码指令的行号指示器[分值、跳转、循环、异常处理、线程恢复] 每个线程都有单独的程序计数器 [私有的]
虚拟机栈VM Stack:为Java的方法服务 当线程创建的时候虚拟机栈会为线程分配一个虚拟机栈,在线程执行的时候创建的每个方法都会创建一个栈针,用于存放局部变量、操作方法等 [入栈+出栈]
本地方法栈:类似于虚拟机栈,本地方法栈是执行本地方法使用的
请简述Java的垃圾回收(GC)
- GC(Garbage Collection)用于回收不再使用的内存
- GC负责3项任务:分配内存、确保引用、回收内存
- GC回收的依据某对象没有任何引用、则可以被回收
垃圾回收(GC)算法
- 引用计数算法 [计数器 引用到这个对象的时候+1 被释放或断开计数器-1 当计数器变成0就可以被垃圾回收]
若两个对象相互引用就会产生循环计数器 这个对于引用计数算法是无效的 - 跟踪回收算法 [利用JVM维护的对象引用图 每个对象彼此依赖和引用 从根节点标记对象引用图和可以被标记的对象 遍历结束以后未被标记的对象是不能够使用的对象可以被回收]
- 压缩回收算法 [将JVM堆中活动的对象放到一个集中的区域中 另外一大块留出一个活动的区域 对堆中的碎片进行集中的处理]
- 复制回收算法 [把堆分成两个相同大小的区域 只有其中的一个区域被使用 直到这个区域被消耗完 垃圾回收器就会中断这个程序的运行 以遍历的方式把活动的对象移动到另一个区域 移动的过程中对象是紧密挨在一起的 可以消除其中的碎片 【在复制的同时也对对象进行重新复制和安排 一次性解决了内存碎片的问题】【需要两倍大小的内存空间 降低了效率】]
- 按代回收算法 [把堆分成多个子堆,每个堆命名成一代,算法优先收集年幼年轻的对象,在这其中对象仍然存活的就把它移动到高级堆中 【减少扫描次数和范围 提高回收效益】]
Java的内存泄露的场景
请列举Java中内存泄漏的场景
一个不需要使用的对象还在内存中占用并使用其内存空间,忘记释放就会存在内存泄露
- 静态集合类 static描述对象 存储在方法区 垃圾回收器不会对其扫描回收
- 各种连接 JVM一直可达不会被回收
- 监听器 全局存在的
- 不合理的作用域 能用在方法中public 不要用在方法外private
- 没有把对象及时设置为null【极少发生】
请实现对象的浅复制与深复制
- 浅复制:只对对象及变量值进行复制,引用对象地址不变
- 深复制[序列化方式]:创建一个新的对象,并且复制所有引用类型字段的对象。修改新对象的引用类型字段不会影响原对象。[彼此互不干扰]
com/example/text/clone/Dancer.java
package com.example.text.clone;
import java.io.*;
public class Dancer implements Cloneable,Serializable{
private String name;
private Dancer partner;
public Dancer() {
}
public Dancer(String name, Dancer partner) {
this.name = name;
this.partner = partner;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Dancer getPartner() {
return partner;
}
public void setPartner(Dancer partner) {
this.partner = partner;
}
public Dancer deepClone() throws IOException, ClassNotFoundException {
//序列化, 将内存中的对象序列化为字节数组
//序列化要注意加Serializable接口
ByteArrayOutputStream bos = new ByteArrayOutputStream();//字节数组
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
//反序列化, 将字节数组转回到对象, 同时完成深复制的任务
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis); //字节数组还原成对象
return (Dancer) ois.readObject();
}
//初始化一下
public static void main(String[] args) throws CloneNotSupportedException, IOException, ClassNotFoundException {
Dancer d1 = new Dancer();
d1.setName("小明");
Dancer d2 = new Dancer();
d2.setName("小红");
d1.setPartner(d2);
//hashCode()是内存地址转化后的一个整数
System.out.println("Partner:" + d2.hashCode());
//浅复制
Dancer shallow = (Dancer)d1.clone();
System.out.println("浅复制:" + shallow.getPartner().hashCode());
//深复制
Dancer deep = (Dancer) d1.deepClone();
System.out.println("深复制:" + deep.getPartner().hashCode());
}
}
简述一下equalsIgnoreCase和equals的区别
equalsIgnoreCase:比较两个字符串的内容是否相等, 忽略大小写
equals:比较两个字符的内容是否完全相等, 包括大小写
equalsIgnoreCase 和 equals 都是 String 类的方法,用于比较两个字符串是否相等(返回值都是Boolean)。它们的主要区别在于对大小写的处理方式。
Java面试——Web基础与数据处理
请说明Servlet执行流程
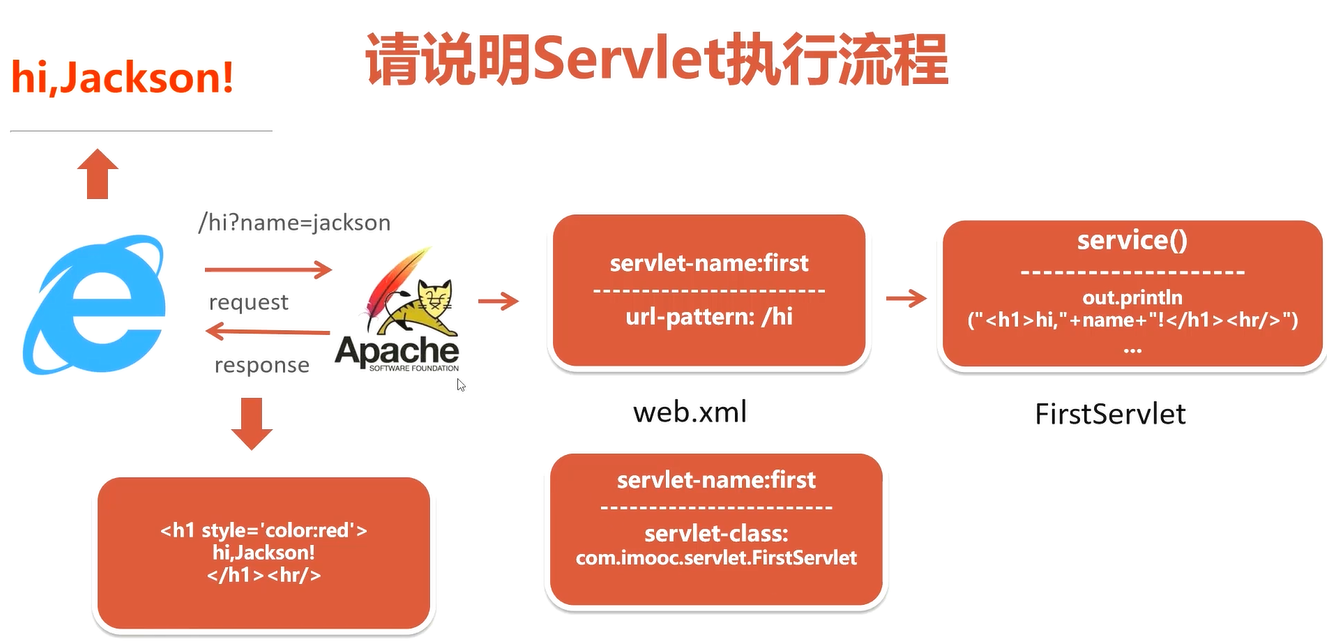
问:Servlet什么时候被实例化的呢?
Servlet默认情况下是第一次访问的时候实例化的
也可以通过web.xml配置load-on-startup,使其在服务启动的时候实例化
问:Servlet在并发条件下如何处理的?
基于单例多线程技术提供web服务
使用servlet时不允许使用存在状态改变的变量
补充:
单例多线程技术
单例模式:Servlet 实例在 Web 容器中通常是单例的,即一个 Servlet 类只有一个实例。这意味着所有的请求都会共享同一个 Servlet 实例。
优点:减少了对象的创建和销毁开销,提高了性能。
缺点:需要特别注意线程安全问题,因为多个请求可能会同时访问同一个 Servlet 实例。多线程:Web 容器为每个请求分配一个独立的线程来处理。当多个请求同时到达时,这些请求会被分配到不同的线程中,但这些线程都共享同一个 Servlet 实例。
线程安全:由于多个线程共享同一个 Servlet 实例,因此必须确保 Servlet 实例中的代码是线程安全的。状态改变的变量
状态改变的变量:指的是在 Servlet 实例中定义的成员变量(实例变量),这些变量在不同请求之间可能会被修改。线程安全问题:如果多个线程同时访问和修改同一个成员变量,可能会导致数据不一致、竞态条件等问题。
竞态条件(Race Condition)是指在多线程或多进程环境中,由于多个线程或进程对共享资源的访问顺序不确定,导致程序的行为依赖于这些线程或进程的执行顺序,从而产生不可预测的结果。简单来说,竞态条件发生在多个线程或进程竞争同一资源时,如果这些线程或进程的执行顺序不同,会导致不同的结果。
Servlet生命周期
启动时装载 - web.xml
创建 - 构造函数
初始化 - init() [专门的初始化资源]
提供服务 - service() [对于发来的请求无论是get post 一律使用service进行处理] [细化分出doget() dopost()]
停止时销毁 - destory() [销毁资源]
com/example/text/servlet/SampleServlet.java
package com.example.text.servlet;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
public class SampleServlet extends HttpServlet {
public SampleServlet(){
System.out.println("正在创建Servlet");
}
@Override
public void init() throws ServletException {
System.out.println("正在初始化Servlet");
}
@Override
protected void service(HttpServletRequest req, HttpServletResponse resp) throws IOException {
System.out.println(this.hashCode() + ": Service()正在提供服务");
resp.setContentType("text/html;charset=utf-8");
resp.getWriter().print(this.hashCode() + ": Service()正在提供服务");
}
@Override
public void destroy(){
System.out.println("正在销毁Servlet");
}
}
web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<servlet>
<servlet-name>SampleServlet</servlet-name>
<servlet-class>com.example.text.servlet.SampleServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>SampleServlet</servlet-name>
<url-pattern>/sample</url-pattern>
</servlet-mapping>
</web-app>
=================================================
http://localhost:8080/sample
正在创建Servlet 【启动时】
正在初始化Servlet
1025518765: Service()正在提供服务
正在销毁Servlet 【停止时】
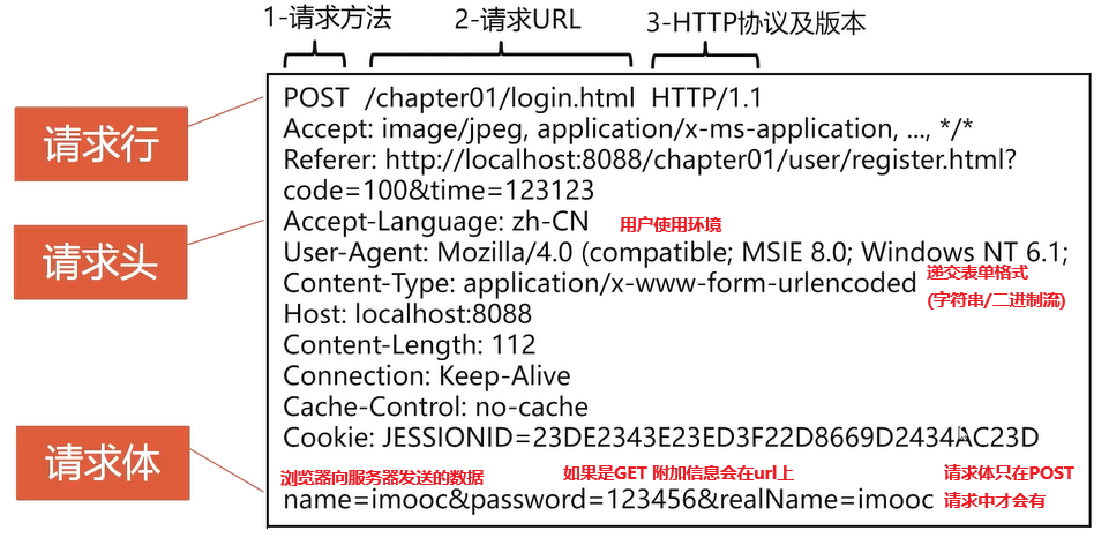
请求与响应的结构
- HTTP请求包含三部分:请求行、请求头、请求体
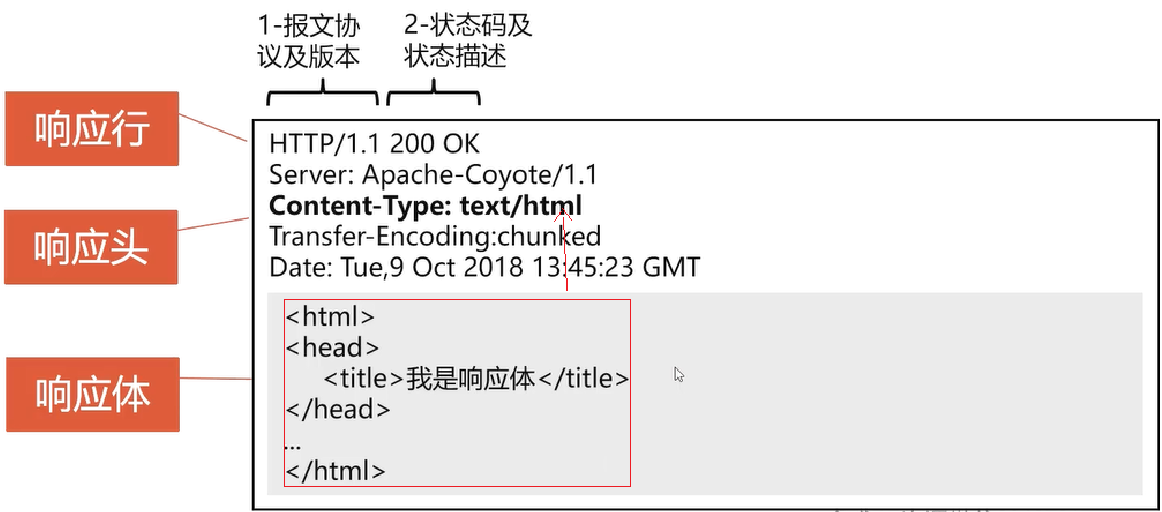
- HTTP响应包含三部分:响应行、响应头、响应体
请求转发与响应重定向的区别
请求转发 [一次请求]
- 请求转发是服务器跳转,只会产生一次请求
- 请求转发语句是:
request.getRequestDispatcher().forward()
网页请求Tomcat的Servlet1,Servlet1请求Servlet2,Servlet2响应给网页,网页收到响应
响应重定向 [两次请求]
- 重定向则是浏览器端跳转,会产生两次请求
- 响应重定向语句是:
response.sendRedirect()
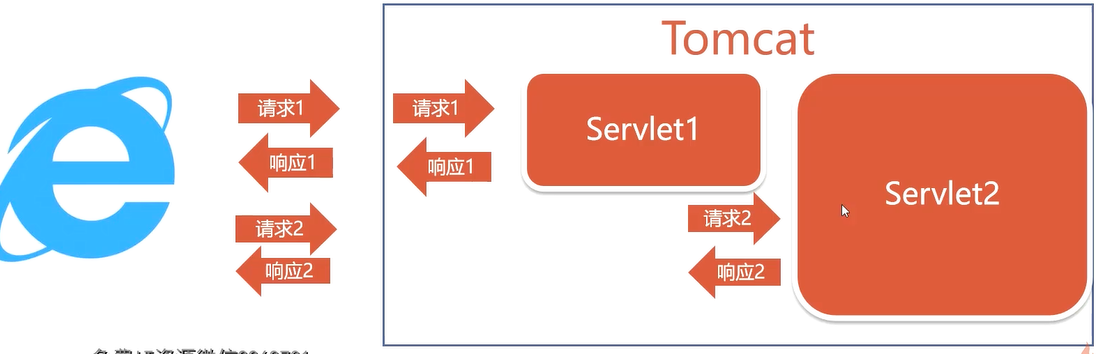
网页$请求_1$Tomcat的Servlet1,Servlet1直接$响应_1$给网页,网页收到$响应_1$[让网页创建一个新的$请求_2$]
网页新创了一个$请求_2$Tomcat的Servlet2,Servlet2只对请求进行处理返回给$响应_2$网页
请阐述Session的原理
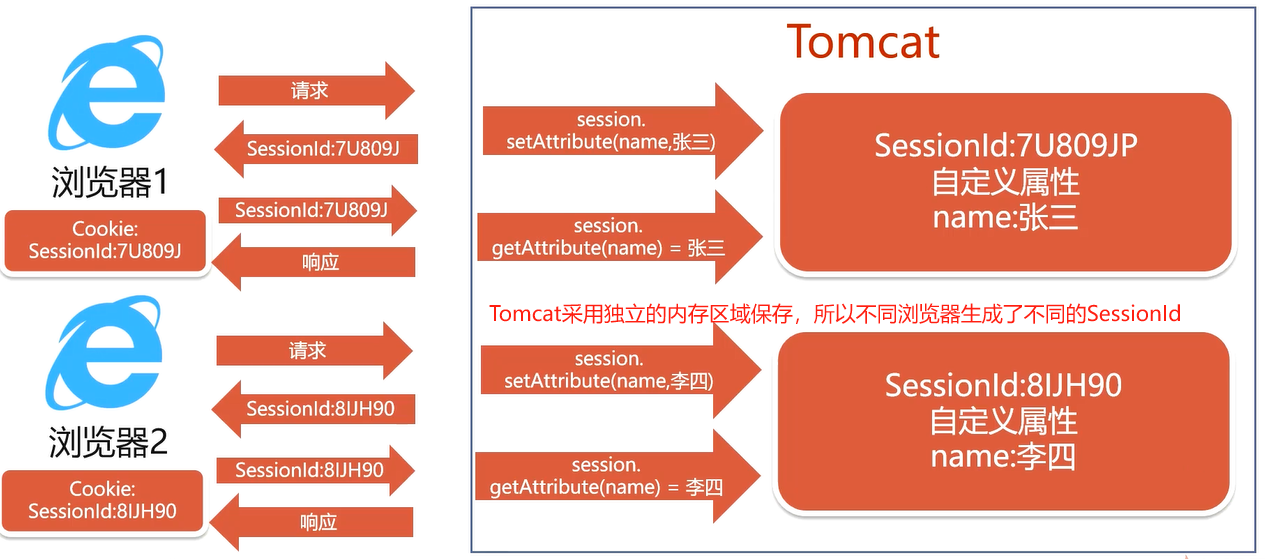
浏览器第一次向Tomcat发送请求,Tomcat收到请求自动在tomcat运行内存中生成一个存储空间并赋予一个SessionId:7U809J唯一编号,若使用了session.setAttribute(name,小潘),会在那个运行内存中存放一个小潘的内存属性[name:小潘] 当程序处理完后返回给浏览器其中包含了一个特殊信息SessionId:7U809J,浏览器收到响应后把SessionId:7U809J保存到浏览器的Cookie中SessionId:7U809J[只要当前浏览器没有被关闭的话 Cookie会一直存在 会在发送请求的时候一并发送给服务器],当第二次发送请求的时候浏览器会把SessionId:7U809J第二次发送给Tomcat,若使用了session.getAttribute(name) = 小潘,得到的结果就出现了小潘 返回浏览器响应
JSP九大内置对象是什么
| 内置对象 | 描述 |
|---|---|
| request | 请求对象 - HttpServletRequest |
| response | 响应对象 - HttpServletResponse |
| session | 用户会话 - HttpSession |
| application [全局实例] | 应用全局对象 - ServletContext |
| out | 输出对象 - PrintWriter |
| page | 当前页面对象 - this [Object实例] |
| pageContext | 页面上下文对象 - PageContext |
| config [全局参数] | 应用配置对象 - ServletConfig |
| exception | 应用异常对象 - Throwable |
Statement 和 PreparedStatement的区别
- PreparedStatement是预编译的SQL语句,效率高于Statement
- PreparedStatement支持 ‘?’ 操作符,相对于Statement更加灵活
- PreparedStatement可以防止SQL注入,安全性高于Statement
package com.example.text.jdbc;
import java.sql.*;
public class StatementSample {
//使用Statement sql语句解释N多次
//SQL注入攻击: ' or 1=1 or '
public void findByEname1(String ename) {
String driverName = "com.mysql.jdbc.Driver";
String URL = "jdbc:mysql://127.0.0.1:3306/scott";
String username = "root";
String password = "root";
Connection conn = null;
try {
Class.forName(driverName);
conn = DriverManager.getConnection(URL, username, password);
Statement ps = conn.createStatement();
//使用Statement
String sql = "SELECT * FROM emp where ename = '" + ename + "' ";
System.out.println(sql);
ResultSet rs = ps.executeQuery(sql);
while (rs.next()) {
System.out.println(rs.getString("ename") + "," +
rs.getString("job") + "," +
rs.getFloat("sal"));
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
//5.关闭连接
finally {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
package com.example.text.jdbc;
import java.sql.*;
public class StatementSample {
//使用预编译PreparedStatement sql语句解释一次
public void findByEname2(String ename) {
String driverName = "com.mysql.jdbc.Driver";
String URL = "jdbc:mysql://127.0.0.1:3306/scott";
String username = "root";
String password = "root";
Connection conn = null;
try {
Class.forName(driverName);
conn = DriverManager.getConnection(URL, username, password);
//使用预编译PreparedStatement
String sql = "SELECT * FROM emp where ename = ?";
System.out.println(sql);
PreparedStatement ps = conn.prepareStatement(sql);
ps.setString(1, ename);
ResultSet rs = ps.executeQuery();
while (rs.next()) {
System.out.println(rs.getString("ename") + "," +
rs.getString("job") + "," +
rs.getFloat("sal"));
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
//5.关闭连接
finally {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
StatementSample sample = new StatementSample();
sample.findByEname1("SMITH' or 1=1 or '"); //SQL注入攻击
sample.findByEname2("SMITH");
}
}
请说明JDBC的使用步骤
- 加载JDBC驱动
- 创建数据库连接(Connection)
- 创建命令(Statement)
- 处理结果(ResultSet)
- 关闭连接
package com.example.text.jdbc;
import java.sql.*;
public class MysqlJDBC {
public static void main(String[] args) {
//连接需要提前下载好包 mysql-connector-java-5.1.47.jar
String driverName = "com.mysql.jdbc.Driver";
String URL = "jdbc:mysql://127.0.0.1:3306/scott";
String sql = "SELECT * FROM emp";
String username = "root";
String password = "root";
Connection conn = null;
try {
//1.加载JDBC驱动
Class.forName(driverName);
//2.建立连接
conn = DriverManager.getConnection(URL, username, password);
//3.创建命令(Statement)
Statement ps = conn.createStatement();
//4.处理结果
ResultSet rs = ps.executeQuery(sql);
while (rs.next()) {
System.out.println(rs.getString("ename") + "," +
rs.getString("job") + "," +
rs.getFloat("sal"));
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
//5.关闭连接
finally {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
SQL编程训练

scott.sql文件已准备好
★按部门编号升序、工资倒序的排列员工信息
SELECT * FROM emp ORDER BY deptno ASC, sal DESC
★列出deptno=30的部门名称及员工[关联查询]
SELECT dept.dname, emp.* FROM emp,dept
WHERE emp.deptno = dept.deptno
AND dept.deptno = 30
★列出每个部门最高、最低、平均工资 #若再列出人数只需要再SELECT后面加 COUNT(*)
SELECT deptno, max(sal), min(sal), avg(sal)
FROM emp
GROUP BY deptno
★列出市场部(SALES)及研发部(RESEARCH)的员工
SELECT * FROM dept d, emp e
WHERE d.deptno = e.deptno
AND (d.dname = 'SALES' or d.dname = 'RESEARCH')
★列出人数超过3人的部门 #按照部门分组
# WHERE对原始数据进行筛选[在GROUP BY之前进行的]
# HAVING对分组后的进行二次筛选[在GROUP BY之后进行的]
SELECT d.dname, count(*)
FROM dept d, emp e
WHERE d.deptno = e.deptno
GROUP BY d.dname
HAVING count(*)>3
★计算MILLER年薪比SMITH高多少
SELECT a.a_sal, b.b_sal, a.a_sal - b.b_sal FROM
(SELECT sal * 12 a_sal FROM emp WHERE ename = 'MILLER') a,
(SELECT sal * 12 b_sal FROM emp WHERE ename = 'SMITH') b
★★列出直接向King汇报的员工
SELECT * FROM emp
WHERE mgr = (SELECT empno FROM emp WHERE ename = 'KING')
#或
SELECT e.* FROM emp e, (SELECT empno FROM emp WHERE ename = 'KING') k
WHERE e.mgr = k.empno
★★列出公司所有员工的工龄,并倒序排列
# NOW获取当前时间
# SELECT DATE_FORMAT(date,format) DATE_FORMAT只对日期形式的数据生效
SELECT * FROM(
SELECT emp.*, DATE_FORMAT(NOW(),"%Y") - DATE_FORMAT(hiredate,"%Y") yg
FROM emp
)d
ORDER BY d.yg DESC
★★计算管理者与基层员工平均薪资差额
SELECT a_avg - b_avg
FROM
(SELECT avg(sal) a_avg
FROM emp
WHERE job = 'MANAGER' OR job = 'PRESIDENT') a,
(SELECT avg(sal) b_avg
FROM emp
WHERE job IN ('CLERK','SALESMAN','ANALYST'))b
Java面试 —— 主流框架
谈谈你对IOC和DI的理解
[DI是一种具体的技术实现,是对宏观IOC里面的一种技术上的形式,在Spring中使用了反射+工厂模式来实现DI]
IDAO dao = new UserDao(); //原始版本 原本的容器控制器
运行时Spring动态进行创建 对程序进行有效的解耦 //将控制权交给第三方控制容器 IOC容器
// applicationContext最底层是类工厂模式
IDAO dao = (IDAO)applicationContext.getBean("userDAO"); //ICO容器 动态实例化DAO
<bean id = "userDAO" class = "com.imooc.dao.UserDAO"/>
<bean id = "userDAO" class = "com.imooc.dao.UserExtDAO"/> //方便随时更改
Spring中Bean实例化有几种方式
- 使用类构造器实例化
- 使用静态工厂方法实例化
- 使用实例工厂方法实例化
com/example/text/spring/Person.java
package com.example.text.spring;
public class Person {
private String name;
private Integer age;
public Person() {
System.out.println("Person默认构造函数");
}
public Person(String name, Integer age) {
this.name = name;
this.age = age;
System.out.println("Person{" +
"name='" + name + '\'' +
", age=" + age +
'}');
}
}
com/example/text/spring/PersonStaticFactory.java
package com.example.text.spring;
/**
* Person静态工厂
*/
public class PersonStaticFactory {
public static Person createPerson(String name,int age){
return new Person(name,age);
}
}
com/example/text/spring/PersonFactory.java
package com.example.text.spring;
/**
* Person实例工厂 实例化以后才可以调用
*/
public class PersonFactory {
public Person createPerson(String name,int age){
return new Person(name,age);
}
}
C:\Users\Pluminary\Desktop\text\src\main\resources\applicationContext.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<!--构造函数实例化-->
<!-- 1.调用无参构造函数 -->
<bean id="person1" class="com.imooc.spring.instance.Person"></bean>
<!-- 2.调用有参构造函数 -->
<bean id="person2" class="com.imooc.spring.instance.Person">
<constructor-arg name="name" value="枫叶(构造函数)"/>
<constructor-arg name="age" value="23"/>
</bean>
<!-- 通过静态工厂创建对象-->
<bean id="person3" class="com.imooc.spring.instance.PersonStaticFactory" factory-method="createPerson">
<constructor-arg name="name" value="蓝天(静态工厂)"/>
<constructor-arg name="age" value="27"/>
</bean>
<!-- 通过实例工厂创建对象-->
<!-- 实例化PersonFactory-->
<bean id="instanceFactory" class="com.imooc.spring.instance.PersonFactory"></bean>
<bean id="person4" factory-bean="instanceFactory" factory-method="createPerson">
<constructor-arg name="name" value="绿地(实例工厂)"/>
<constructor-arg name="age" value="29"/>
</bean>
</beans>
com/example/text/Application.java
package com.example.text;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Application {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("classpath:applicationContext.xml");
}
}
===================================================================
Person默认构造函数
Person{name='枫叶(构造函数)',age=23}
Person{name='蓝天(静态工厂)',age=27}
Person{name='绿地(实例工厂)',age=29}
Bean注入属性有哪几种方式
setter注入
在UserService使用的时候依赖于UserDao,目前UserDao是空的,要想运行时通过setter方法注入的话,我们需要在injection.xml中
<context:component-scan base-package=”com.imooc.spring”/>
前面的name=”userDAO”对应着UserService.java中的userDAO属性private UserDAO userDAO
后面的ref=”userDAO”对应着当前文件中的bean id = “userDAO”
com/example/text/injection/UserDAO.java
package com.example.text.injection;
public interface UserDAO {
public void insert();
}
com/example/text/injection/UserDAOImpl.java
package com.example.text.injection;
import org.springframework.stereotype.Repository;
//@Repository("userDAO") ★注解方式注入
public class UserDAOImpl implements UserDAO{
public UserDAOImpl(){
System.out.println(this + "已创建");
}
public void insert() {
System.out.println(this + ":正在调用UserDAOImpl.insert()");
}
}
com/example/text/injection/UserService.java
package com.example.text.injection;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
//@Service("userService") ★注解方式注入
//spring需要动态将userDao注入到UserService上
public class UserService {
// @Resource(name="userDAO") 注解方式注入 可以把原始的bean都注释掉
private UserDAO userDAO;
public UserService() {
System.out.println(this + "已创建");
}
/* 注解方式这些可以抛弃 并且摒弃了xml的那些bean 只需要增加个扫描的注解方式注入
//通过构造函数注入
public UserService(UserDAO userDAO) {
this.userDAO = userDAO;
System.out.println(this + ":正在调用构造函数注入,UserService(" + userDAO + ")");
}
//通过Setter方法注入
public void setUserDAO(UserDAO userDAO) {
this.userDAO = userDAO;
System.out.println(this + ":正在调用Setter方法注入,setUserDAO(" + userDAO + ")");
}
*/
public void createUser(){
System.out.println(this + ":正在调用UserService.createUser()");
userDAO.insert();
}
}
com/example/text/InjectionRunner.java
package com.example.text;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class InjectionRunner {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("classpath:injection.xml");
UserService userService = (UserService)ctx.getBean("userService");
userService.createUser();
}
}
==============================================================
UserDAOImpl@531be3c5对象已创建
UserService@5034c75a对象已创建
UserService@5034c75a:正在调用Setter方法注入,setUserDAO
UserService@5034c75a:正在调用UserService.createUser()
UserDAOImpl@531be3c5:正在调用UserDAOImpl.insert()
C:\Users\Pluminary\Desktop\text\src\main\resources\injection.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="com.imooc.spring"/> //★扫描注解方式注入
<bean id="userDAO" class="com.imooc.spring.injection.UserDAOImpl"/>
<bean id="userService" class="com.imooc.spring.injection.UserService">
<property name="userDAO" ref="userDAO"/> //★这个是setter注入
<constructor-arg name="userDAO" ref="userDAO"/> //★这个是构造函数注入
</bean>
</beans>
Java config注入
Appconfig.java
[配置文件 在原有代码之外的东西 优点:不用破坏原始代码去达到效果 比xml优点在于java可以及时检查]
package com.imooc.spring.injection;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class AppConfig { //类似创建对象的方法
@Bean(name="userDAO")
public UserDAO userDAO(){
return new UserDAOImpl();
}
@Bean(name="userService")
public UserService userService(){
UserService userService = new UserService();
userService.setUserDAO(this.userDAO());
return userService;
}
}
Spring常见面试问题
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="userDAO" class="com.imooc.spring.scope.UserDAOImpl"/>
<bean id="userService" class="com.imooc.spring.scope.UserService" scope="prototype" lazy-init="false">
//scope是控制对象的数量是单例(singleton)还是多例(prototype)[每一次创建getbean创建对象]
//还有两个不常见的值 request[同一个对象是同一个请求 不同对象ICO容器创建不同对象] 和
//session[调用多个getbean是同一个对象 不同session是不同对象] [SpringMVC时用]
//lazy-init="true" 延迟初始化 需要的时候才会加载 若getBean被注释则不会加载
<property name="userDAO" ref="userDAO"/>
</bean>
</beans>
ScopeRunner.java
package com.imooc.spring.scope;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class ScopeRunner {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("classpath:scope.xml");
UserService userService1 = (UserService)ctx.getBean("userService");
UserService userService2 = (UserService)ctx.getBean("userService");
}
}
UserDAO.java UserDAOImpl.java UserService.java 与上方相同
两个注解
@Autowired[第三方] 和 @Resource[官方推荐]
@Resource(name=”userDAO”) //设置了则进行精准匹配
private UserDAO userDAO;//没设置则优先将名字userDAO在beanId内查找, 再没有就按照UserDAO类型在IOC容器中查找
AOP有几种通知类型
在不修改原始程序的前提下使用通知来对程序进行扩展
SampleAspect.java
package com.imooc.spring.aop;
import java.util.Date;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
//切面类
public class SampleAspect {
//1.前置通知
public void doBefore(JoinPoint jp){
String clzName = jp.getTarget().getClass().getName();
//getTarget() 获取即将要执行的对象
String method = jp.getSignature().getName();//即将要执行的方法
Object args = jp.getArgs();
System.out.println("【前置通知】" + clzName + "." + method );
}
//2.后置通知
public void doAfter(JoinPoint jp){
String clzName = jp.getTarget().getClass().getName();
//getTarget() 获取即将要执行的对象
String method = jp.getSignature().getName();//即将要执行的方法
System.out.println("【后置通知】" + clzName + "." + method );
}
//3.返回通知
public void doAfterReturning(JoinPoint jp , Object ret){
System.out.println("【返回后通知】" + ret);
}
//4.异常通知
public void doAfterThrowing(JoinPoint jp , Throwable t){
System.out.println("【异常通知】" + t.getMessage());
}
//5.环绕通知
public Object doAround(ProceedingJoinPoint pjp) throws Throwable{
String clzName = pjp.getTarget().getClass().getName();
//getTarget() 获取即将要执行的对象
String method = pjp.getSignature().getName();//即将要执行的方法
Object args = pjp.getArgs();
System.out.println("【前置通知】" + clzName + "." + method );
Object ret = null;
try {
ret = pjp.proceed();//执行目标方法
System.out.println("【返回后通知】" + ret);
} catch (Throwable t) {
// TODO Auto-generated catch block
System.out.println("【异常通知】" + t.getMessage());
throw t;
}finally{
System.out.println("【后置通知】" + clzName + "." + method + "()");
}
return ret;
}
}
UserService.java
package com.imooc.spring.aop;
import com.imooc.spring.scope.UserDAO;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
//@Transactional(propagation = Propagation.REQUIRED , rollbackFor = Exception.class)
@Transactional(propagation = Propagation.NOT_SUPPORTED , readOnly = true )
public class UserService {
public String createUser(){
//打开事务
System.out.println(this + ":正在调用UserService.createUser()");
//提交事务
//catch块中回滚事务 - RuntimeException
return "success";
}
}
AOPRunner.java
package com.imooc.spring.aop;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class AOPRunner {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("classpath:aop.xml");
UserService userService1 = (UserService)ctx.getBean("userService");
userService1.createUser();
}
}
aop.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd">
<!-- 定义类被Spring IOC容器管理 -->
<bean name="sampleAspect" class="com.imooc.spring.aop.SampleAspect"></bean>
<bean name="userService" class="com.imooc.spring.aop.UserService"></bean>
<!-- 配置Spring AOP -->
<aop:config>
<!-- 配置过程中引用切面类 sampleAspect是切面 扩展-->
<aop:aspect ref="sampleAspect">
<!-- PointCut(切点) 限制了切面应用的范围 ↓↓aop作用了哪些方法上↓↓-->
<aop:pointcut id="samplePC" expression="execution(* com.imooc.spring.aop.*Service.create*(..))" />
<!-- 定义通知 -->
<!-- 前置通知 method=对应着SampleAspect.java中的doBefore-->
<aop:before pointcut-ref="samplePC" method="doBefore"/>
<!-- 后置通知 -->
<aop:after pointcut-ref="samplePC" method="doAfter"/>
<!-- 返回后通知,注意:返回后通知需要增加retruning属性
指向doAfterReturning的名为ret的参数,使用ret参数获取方法的返回值 -->
<aop:after-returning method="doAfterReturning" pointcut-ref="samplePC" returning="ret"/>
<!--3.ret是返回通知里面的参数 public void doAfterReturning(JoinPoint jp , Object ret)-->
<!-- 异常通知 -->
<!--public void doAfterThrowing(JoinPoint jp , Throwable t)中的Throwable的参数是目标方法所抛出的异常 throwing="t"相关噢~ -->
<aop:after-throwing method="doAfterThrowing" pointcut-ref="samplePC" throwing="t"/>
-->
<!-- ★★★★ 环绕通知 ★★★★ -->
<aop:around method="doAround" pointcut-ref="samplePC"/>
</aop:aspect>
</aop:config>
</beans>
请介绍Spring的声明式事务
Spring的声明式事务是Spring框架提供的一种管理事务的方法,它允许开发者通过声明的方式管理事务,而不是通过编写繁琐的事务管理代码。这种方式使得事务管理更加解耦,业务逻辑代码不需要直接处理事务的开启、提交、回滚等操作,从而使得代码更加简洁和易于维护。
- 在执行方法前自动开启的事务
- 声明式事务式指利用AOP自动提交、回滚数据库事务
- 声明式事务式规则进入方法打开事务,成功提交,运行时异常回滚
@Transactional是声明式事务的注解 放在类上则所有方法执行此事务 放在方法上则单独方法执行此事务- propagation = 确定方法是否启动事务[Propagation.REQUIRED]执行的方法自动使用事务
rollbackFor = Exception.class在什么时机进行回滚 readOnly = true 方法只读 - 通过程序打开或关闭事务属于编程式事务
UserService.java
package com.imooc.spring.aop;
import com.imooc.spring.scope.UserDAO;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
//@Transactional(propagation = Propagation.REQUIRED , rollbackFor = Exception.class)
@Transactional(propagation = Propagation.NOT_SUPPORTED , readOnly = true )
public class UserService {
public String createUser(){
//进入方法 → 打开事务
System.out.println(this + ":正在调用UserService.createUser()");
//方法执行成功 → 提交事务
//方法抛出运行时异常 → 回滚事务
//catch块中回滚事务 - RuntimeException[及其子类会自动回滚]
return "success";
}
}
使用SpringMVC实现REST风格
- REST(表述性状态传递)以URL表示要访问的资源
- GET/POST/PUT/DELETE对应查询、新增、更新、删除操作[浏览器不支持PUT和DELETE操作]
[用GET对应查询操作(写)、用POST对应新增、更新、删除操作(写)] - REST风格只响应的数据,通常是以JSON形式体现
以下是一些常用的HTTP方法及其在REST中的用途:
- GET:检索资源的表示。
- POST:创建新的资源或子资源。
- PUT:更新或替换资源。
- DELETE:删除资源。
REST风格的API通常被称为RESTful API,它们通过使用标准的HTTP方法、状态代码和URI来提供一种简单、一致和可预测的方式来访问和操作网络资源。RESTful API的设计通常遵循一些最佳实践,比如使用名词而不是动词来命名资源,使用HTTP状态码来传达操作的结果等。
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.imooc</groupId>
<artifactId>interview-springmvc</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.1.3.RELEASE</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.54</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
</project>
web/WEB-INF/web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<servlet>
<servlet-name>spring</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:applicationContext.xml</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>spring</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
</web-app>
interview-springmvc\src\main\resources\applicationContext.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc.xsd">
<!-- 配置扫描的包 -->
<context:component-scan base-package="com.imooc.interview"/>
<!-- 注册HandlerMapper、HandlerAdapter两个映射类 开启注解模式-->
<mvc:annotation-driven/>
<!-- 访问静态资源 -->
<mvc:default-servlet-handler/>
<mvc:interceptors>
<mvc:interceptor>
<mvc:mapping path="/**"/> //所有URL不分层级和格式
<bean class="com.imooc.interview.rest.MyInterceptor"/>
</mvc:interceptor>
</mvc:interceptors>
</beans>
Employee.java
package com.imooc.interview.rest;
public class Employee {
private String name;
private int age;
private String department;
public Employee(String name, int age, String department) {
this.name = name;
this.age = age;
this.department = department;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getDepartment() {
return department;
}
public void setDepartment(String department) {
this.department = department;
}
}
RestfulController.java
package com.imooc.interview.rest;
import com.alibaba.fastjson.JSON;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.*;
import java.util.ArrayList;
import java.util.List;
@Controller //在IOC容器初始化的情况下自动扫描这个类进行加载并且通知IOC容器 这个是一个MVC中的控制类
//@RestController
public class RestfulController { //{XXX}是路径变量 随时产生变化的 注解@PathVariable("DEPT")
@GetMapping("/emp/list/{DEPT}") //响应GET请求 前面的是响应URL输入这个的时候响应下面的方法
@ResponseBody
public String list(@PathVariable("DEPT") String department) {
List<Employee> list = new ArrayList<Employee>();
if (department.equals("RESEARCH")) {
list.add(new Employee("JAMES", 38, "RESEARCH"));
list.add(new Employee("ANDY", 23, "RESEARCH"));
list.add(new Employee("SMITH", 31, "RESEARCH"));
}
return JSON.toJSONString(list);//只返回纯粹的JSON数据 只返回页面名称
//如何只返回数据不跳转页面呢? 用 @RespondBoday 直接将返回的数据输出到客户端
//但是可以简化使用 @RestController 所有的可以直接不用写 @RespondBoday
}
}//前端使用AJAX技术接收数据
请说明SpringMVC拦截器的作用 [底层就是AOP面向切面编程技术]
- SpringMVC拦截器用于对控制器方法进行前置、后置处理
- 拦截器的底层实现技术是AOP(面向切面编程)
- 拦截器必须实现HandlerInterceptor接口
★★ 上一个代码通用 ★★
interview-springmvc\src\main\java\com\imooc\interview\rest\MyInterceptor.java
package com.imooc.interview.rest;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.logging.Logger;
public class MyInterceptor implements HandlerInterceptor {
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("进入 preHandle 方法..." + request.getRequestURL().toString());
return true;
}
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("进入 postHandle 方法..." + request.getRequestURL().toString());
}
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("进入 afterCompletion 方法..." + request.getRequestURL().toString());
}
}
====================================================================================
查看上面的applicationContext.xml
<bean>
<!-- 访问静态资源 -->
<mvc:default-servlet-handler/>
<mvc:interceptors>
<mvc:interceptor>
<mvc:mapping path="/**"/> //所有URL不分层级和格式
<bean class="com.imooc.interview.rest.MyInterceptor"/>
//对上面这个类进行处理和拦截
</mvc:interceptor>
</mvc:interceptors>
</bean>
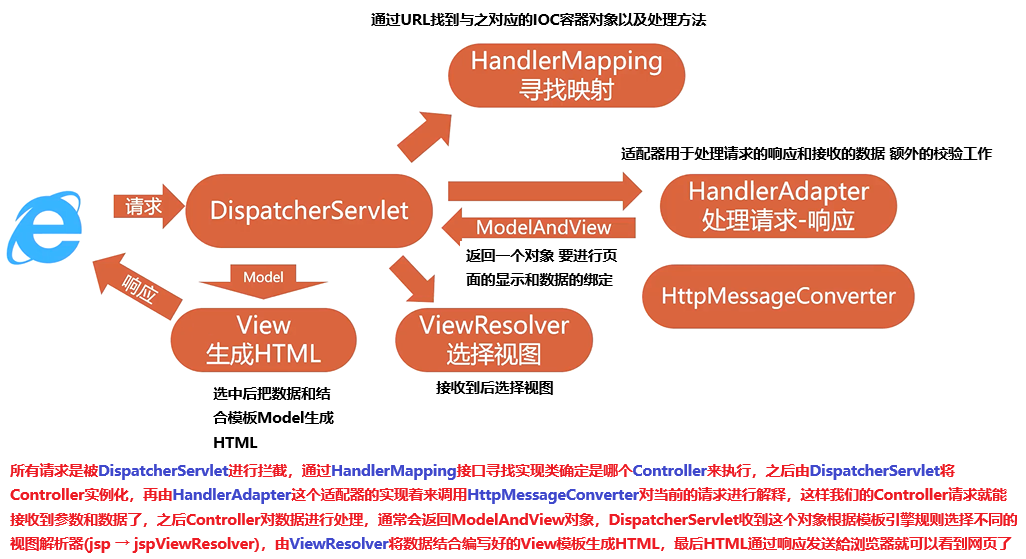
SpringMVC的执行流程
说明Mybatis的开发过程
案例沿用之前的scott.sql表
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.imooc</groupId>
<artifactId>interview-mybatis</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.6</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
</dependencies>
</project>
mybatis.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC" />
<!-- 配置数据库连接信息 -->
<dataSource type="POOLED"> <!--数据库连接池的方式-->
<property name="driver" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/scott" />
<property name="username" value="root" />
<property name="password" value="root" />
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/emp.xml"></mapper>
</mappers>
</configuration>
Employee.java
package com.imooc.interview.mybatis.entity;
import java.io.Serializable;
import java.util.Date;
public class Employee implements Serializable {
private Integer empno;
private String ename;
private String job;
private Integer mgr;
private Date hiredate;
private Float sal;
private Float comm;
private Integer deptno;
}Getter + Setter
用于查询的配置文件 emp.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- 命名空间是个虚拟的类 -->
<mapper namespace="com.imooc.interview.mybatis.mapper.EmpMapper">
<cache size="512" eviction="FIFO" flushInterval="60000" readOnly="true"/>
<select id="findAll" resultType="com.imooc.interview.mybatis.entity.Employee" useCache="false">
select * from emp
</select>
<!-- 类型是int 把传入的int代入到#{value}中 -->
<select id="findById" parameterType="int"
resultType="com.imooc.interview.mybatis.entity.Employee" useCache="true">
select * from emp where empno = #{value}
<!--查询数据 根据数据自动创建Employee对象 根据字段名把值一一的设置到属性中-->
<!--记得写完以后再mybatis.xml中注册 通知mybatis 有个<mapper resource="mapper/emp.xml">-->
<!--至此mybatis的配置全部完成 -->
</select>
</mapper>
MybatisRunner.java
package com.imooc.interview.mybatis.entity;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.InputStream;
public class MybatisRunner {
public static void main(String[] args) {
//mybatis的配置文件 核心配置文件↓
String resource = "mybatis.xml";
InputStream is = MybatisRunner.class.getClassLoader().getResourceAsStream(resource);
//构建sqlSession的工厂(对Mybatis进行解析) build(is)是初始化
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(is);
//com.imooc.interview.mybatis.mapper.EmpMapper前面是命名空间
//.findById对应着select的Id
String statement = "com.imooc.interview.mybatis.mapper.EmpMapper.findById";
SqlSession session = sessionFactory.openSession();
//selectOne获取唯一的查询结果 之前定义了要传入整数int
Employee emp1 = session.selectOne(statement, 7566);
System.out.println(emp1);
session.close();
}
}
Mybatis的缓存机制
把一些不太常变动的数据保存在内存中或高速存储器中,从而降低查询时间提高查询效率
Mybatis存在两级缓存
一级缓存与SqlSession会话绑定,默认开启 [巨大的HashMap] [默认开启]
二级缓存是应用全局缓存,所有SqlSession共享 [分布式数据库等]
//一级缓存验证结果
Employee emp1 = session.selectOne(statement, 7566);
Employee emp2 = session.selectOne(statement, 7566);
System.out.println(emp1);
System.out.println(emp2);
======================打印结果========================
com.imooc.interview.mybatis.entity.Employee@6a41eaa2
com.imooc.interview.mybatis.entity.Employee@6a41eaa2
从缓存中将这个7566提出来,所以对象是一样的
随着session的关闭 → session.close(); 一级缓存也随着消失; 输出的对象结果就不相同了
//二级缓存验证结果 让7566全局缓存 默认是不开启的 需要在mapper中开启 → emp.xml
//在缓存中最大容纳512个对象 缓存多余清除策略[FIFO先进先出算法 LRU访问最少的对象清除]
//flushInterval=>时间间隔定时清理缓存[毫秒数 每60秒]
<cache size="512" eviction="FIFO" flushInterval="60000" readOnly="true"/>
//若对全部查找 则不适合使用缓存 因为每次都变化 这样就可以设置useCache="false"
<select id="findAll" resultType="com.imooc.interview.mybatis.entity.Employee" useCache="false">
//对数据进行新增、修改、删除也会对缓存进行强制更新 上面设置 readOnly="true" 保存在缓存中的数据都是只读的
//二级缓存要对工具类Employee进行接口的实现
public class Employee implements Serializable {...}
Spring、SpringMVC与SpringBoot的区别
- Spring是所有应用的基础,提供了IOC与AOP特性实现对对象轻松的管理
- SpringMVC是Spring的子项目用于提供Web支持 替代传统的Servlet [提高兼容性和可维护性]
- SpringBoot是Spring体系的敏捷开发框架,提高了开发效率 [对Spring整个体系都有良好的支撑]
- Spring Framework是整个Spring的框架基础
- Spring Cloud对分布式架构与微服务提供了良好的支持
- Spring Data简化关系型数据库 非关系型数据库 大数据源
- Spring Batch提供高效率的批处理任务
- Spring Security超级牛逼的安全框架 登录验证之类的
- Spring Amqp消息队列进行支持 统一的接口进行适配
- Spring Mobile手机开发特性
SpringBoot面试题
Spring Initializr是创建SpringBoot Project的唯一方法吗?
否!也可以用Maven进行手动创建,也可以官网创建
SpringBoot支持几种配置文件?
只有两种
一种 server.port=80 debug=false server.servlet.context-path=/myspringboot logging.file=d:/logs/msb.log spring.mvc.date-format=yyyy-MM-dd二种 [按层级进行区分 yml 对程序维护有很大帮助] debug:false server: port:8000 servlet: context-path:/ spring: mvc: date-format:yyyy-MM-dd请列举至少五个SpringBoot中配置选项
配置名称 默认值 描述 server.port 8080 端口号 server.servlet.context-path / 设置应用上下文 logging.file 无 日志文件输出路径 logging.level info 最低日志输出级别 debug false 开启/关闭调试模式 spring.datasource.* 与数据库相关的设置
Maven的构建生命周期
| 命令 | 用途 |
|---|---|
| mvn archetype:generate | 创建Maven工程构建 |
| mvn validate | 验证工程结构 |
| mvn compile | 编译源代码 |
| mvn test | 执行测试用例 |
| mvn package | 项目打包 |
| mvn install | 安装至本地仓库 |
| mvn deploy | 发布至远程仓库 |
请简述一下Java反射的作用和原理
作用:
Java反射(Reflection)允许程序在运行时检查和操作类、接口、字段和方法的信息
① 动态获取类的信息:获取类的名称、父类、实现的接口等;获取类的构造方法、字段和方法的信息
② 动态创建和访问对象:创建类的实例;访问和修改对象的字段;调用对象的方法
③ 动态调用方法:调用私有方法、静态方法、实例方法等;传递参数和处理返回值
④ 动态代理:创建动态代理类,实现接口和动态代理
原理:
① 获取Class对象:
Ⅰ. 通过类名获取:Class.forName(“类的路径”);
Ⅱ. 通过类字面常量获取:类名.class;
Ⅲ. 通过对象获取:对象名.getClass();
② 获取类的信息:
Ⅰ. 获取类名:类名.getName;
Ⅱ. 获取父名:类名.getSuperclass();
Ⅲ. 获取实现的接口:类名.getInterfaces();
Ⅳ. 获取构造方法:类名.getConstructors();
Ⅴ. 获取字段:类名.getFields();
Ⅵ. 获取方法:类名.getMethods();
优点和缺点:
优点:能够运行时动态获取类的实例,提高灵活性;与动态编译结合
缺点:使用反射性能较低,需要解析字节码,将内存中的对象进行解析
解决办法→通过setAccessible(true)关闭JDK的安全检查来提升反射速度;多次创建一个类的实例时有缓存会快很多
;;;;;;;;;;;;;;;;;;;;洪哥面试题分隔符;;;;;;;;;;;;;;;;;;;;;;
线程池的执行流程大致如下:
线程池:ThreadPoolExecutor
一开始new的时候没有 是空的。先当一个任务提交给线程池时,线程池首先检查当前运行的线程数是否达到核心线程数。如果没有达到核心线程数,线程池会创建一个新的线程来执行任务。如果已经达到核心线程数,线程池会将任务放入工作队列中等待执行。如果工作队列满了,并且当前运行的线程数小于最大线程数,线程池会创建新的线程来执行任务。如果工作队列满了,并且当前运行的线程数等于最大线程数,线程池会根据拒绝策略
- 丢弃任务抛出异常
- 丢弃任务不抛弃异常
- 丢弃队列最前面的任务,然后重新提交被拒绝的任务、
- 由主线程处理该任务来处理无法执行的任务。【线程池无法起到异步问题】
- 问题:想继续异步且不丢弃任务怎么办?
- 把这个业务先存到别的地方 ↓↓↓
- 自定义拒绝策略 自己写实现类实现拒绝策略 可以先存到mysql到时候再慢慢搞
怎么确定核心线程数和最大线程数?
核心线程数
- CPU密集型任务:如果任务是CPU密集型的,即任务主要是进行计算而不是等待I/O操作,核心线程数通常设置为CPU核心数加1。这样可以确保CPU在忙于计算的同时,还有额外的线程来处理可能出现的临时高峰。【纯内存计算 不涉及到网络计算和io计算】
- 八个核 创建十个cpu 没意义 因为最多并发只是8,建议保持一致或者+1,减少加入队列和创建队列的开销
- 先把其当成io密集 因为层级不一样 不断压测去逼近最理想值
- I/O密集型任务:对于I/O密集型任务,由于线程在等待I/O操作时会阻塞,因此可以设置更多的核心线程数。一个常用的经验法则是核心线程数设置为CPU核心数的两倍。【线程数越多越好】【压测无限逼近取最合适的线程数】
最大线程数
需要一开始创建好线程等着访问来,如果 核心=最大,此时没有临时线程
创建线程有几种方式(必会)
1.继承Thread类并重写 run 方法创建线程,实现简单但不可以继承其他类
2.实现Runnable接口并重写 run 方法。避免了单继承局限性,编程更加灵活,实现解耦。
3.实现 Callable接口并重写 call 方法,创建线程。可以获取线程执行结果的返回值,并且可以抛出异常。
4.使用线程池创建(使用java.util.concurrent.Executor接口)
- 想获得线程池里的返回结果用什么?execute + submit
- 线程有哪些状态? java线程有哪些状态?
- 线程池有哪些状态?
线程池哪些类型?通过JUC[包]的executes可以创建这四个类型的线程池
问题:为什么阿里巴巴不推荐JUC?有可能会出现OOM、资源浪费
- 单线程线程池
- 可缓存线程池/定长
- 变长的线程池
- 定时任务的线程池
java 线程池创建时核心参数(高薪常问)
核心线程池大小、线程池创建线程的最大个数(核心+非核心[临时线程])、临时线程存活时间、时间单位、阻塞队列、线程工厂(指定线程池创建线程的命名)、拒绝策略
线程工厂可以设置创建的属性:
守护线程:主线程(main)一天不死 守护线程不死 [同生共死]
非守护线程:new一个就是 [不是同生共死]
阻塞队列常用的队列:
- ArrayBlockingQueue: 基于数组结构的有界阻塞队列,此队列按照先进先出(FIFO)的原则对元素进行排序。创建时需要指定容量。【底层是数组 随机读写的 **时间复杂度O(1)**】
- 开辟新空间创建新数组 把旧数组的数据迁移过去 new ArrayList为空 需要add才可以 扩容是+10 取1.5倍
- 高并发不会超过某个值 数组不会涉及到扩容 性能会好一些【比较稳定能预估】
- new的时候不用指定长度
- LinkedBlockingQueue: 基于链表结构的有界阻塞队列(如果不指定容量,则默认为
Integer.MAX_VALUE,即视为无界)。按照先进先出的原则排序元素。【随机读写的 时间复杂度O(n) 随机读写快 查询慢 是通过二分查找定位到下标元素(通过下标访问数组和链表) 只会走一次二分查找】- 读中间的慢 读头尾快
- 新增元素不涉及到数组的迁移
- 一般情况下高并发推荐使用,因为队列
高级数据结构(可以用数组和链表的实现 由于底层数据结构不同)的特性是先进先出,链表不涉及到数组的扩容 末尾的最快是O(1)【不稳定】 - new的时候可指定长度是最大链表的长度
- 不可指定长度 [有界队列&无界队列] → 可能产生JVM的OOM
线程池的应用要有实际的业务场景
- 异步任务处理:将任务提交到线程池异步执行,而不阻塞主线程
你单独部署过项目吗?
前端打包ng配置文件
git所有人都用 需要拉分支 maven打包后端 包放到远程服务器 java -jar 启动!【不应该有人去做】
有专门工具去流水线制作 → Jenkins是一个开源的自动化服务器,它可以帮助您实现自动化构建、测试和部署项目 JenKins + docker 做自动化部署
部署是建立本地的项目再推到服务器
你的期望薪资?
我目前的薪资是8000,考虑到我即将承担的职责和我的职业发展,我期望的薪资是在现有基础上有所提升,大约在8000到10000之间。当然,我对整体的薪酬包[包括福利、奖金和职业发展机会]也很感兴趣。薪资是如何构成的,包括固定工资、奖金、股权、福利等。
get请求和post请求的区别
get请求
- 请求指定的资源。使用GET的目的是获取数据,
- 数据在URL中传输,通过将数据附在URL之后,以查询字符串的形式出现
- 由于数据在URL中可见,因此安全性较低,敏感数据不应通过过GET请求发送
- URL长度限制通常在2000个字符左右,这意味着GET请求能够传输的数据有限
- 可以被缓存,也会被浏览器保存在历史记录中
- 常用于信息查询、数据检索等操作.
post请求
- 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。
- 数据存储在请求体(HTTP消息主体)中,不会密在URL上
- 数据不会出现在URL中,相对更安全,适合传输敏感信息。
- 理论上没有大小限制,适用于传输大量数据.
- 不会被缓存,且不会保存在浏觉器历史记录中
- 常用于数据提交、表单提交等操作
请求行:请求类型 请求方法 url http版本1.1 老式1.0不支持长连接
请求头:key value
常见请求头: 请求数据类型,restful基于json
Content-Type:上传文件不用application 要用 multipart/form-data”
Host:指定请求的服务器的域名和端口号。
User-Agent:包含发出请求的用户代理软件信息,通常包括浏览器类型和版本
请求体:get请求可以有请求体
响应:响应行 响应体 状态码 描述
常见响应头:Content-Type:返回数据的格式 Content-Length:响应体的长度,以字节为单位
post请求也可以用问号的形式拼接到浏览器 也可以用路径参数
很大区别:get一般放在url后面 会展示url和后面参数 会暴露传参隐私 登录接口用post来做 有密码敏感信息
表单、密码、长数据用post 不过怕黑客抓包 相对来说安全
get请求后面传参的大小限制 理论上没有限制 只是浏览器厂商会有限制
get用来查询 post新增提交表单
是否上传过图片
阿里云是最后存储的
完整的上传图片应该:
前端要配合(表单 post提交) Content-Type:上传文件不用application 要用 multipart/form-data” 同一个请求能边上传图片和文本数据
后端的操作:传到后端controller接收,有一个类multipart 专门接收二进制数据 图片视频等,有很多api → get input stream封装util 调用upload上传。中小型企业都用阿里云oss 因为要考虑容灾 地震 容易数据丢失,要考虑备份→集群,服务器有物理硬件上限(要有运维成本),文件维护很专业交给专业的人。阿里云的机房在深圳,广州的人访问会比哈尔滨的更快。光纤受物理限制 越长越有损耗。大型运营商在全国各地都有机房,可以智能判断比如哈尔滨的就去访问黑龙江服务器。CSDN内容分发(收费)
前端传过来的图片怎么设置图片大小 有没有什么办法?
思考:为什么后端要限制前端图片传的大小?
大图片 + 多人上传,首先后端要读到jvm内存再二进制流给到阿里云,同时并发有可能超出OM的java内存大小
springboot yml加文件上传大小配置
spring:
servlet:
multipart:
max-file-size: 10MB # 单个文件的最大大小
max-request-size: 20MB # 整个请求的最大大小,包括多个文件的总和
你在里面主要负责哪方面的工作?
我之前负责后端开发 也会参与一部分设计工作
开发完会协助测试 和前端进行联调
和组长一起进行测试
和前后端的逻辑基本上都是可以的
上家公司的离职原因,薪资多少,薪资结构
不要说一些面试官能挑刺的理由
发展前景?表明上家公司不好
太想进步?表名上家公司提供的技术不好 自己技术不好
在上家公司我学习了很多 成长了很多,个人发展原因 ,想要涨薪
// 来自AI的答案 仅供参考
我在上家公司学到了很多,但我觉得为了我的职业发展,我需要寻找一个能够提供更多成长机会和挑战的职位。我想要在[技能/领域]上进一步深耕,而贵公司的职位看起来非常符合我的职业规划;我在上家公司的年薪大约在6000到7000之间;我的薪资结构主要包括基本工资、每年两次的绩效奖金、股票期权以及一些标准福利,比如健康保险、退休金计划等。此外,公司还提供了一些额外的福利,比如灵活的工作时间和远程工作的机会
简历公司
上家公司如果问工作不好找 为什么不先找到再离职?
我在这一块想好好准备面试 但是上班的时间不好分配 我想专心去找工作
上家工作繁忙抽不出时间去准备 所以我想多多准备
若异地公司 → 万能理由:现在面的公司在哪家里人就在哪[地理位置要接近 精确到哪个城市] 异地很多都线下不方便先离职专心准备
薪资多少
现在期望12k 上家最好保证**20%-30%**区间→8-9-10k(参考城市不同)
薪资结构
基本工资(七八成)+绩效工资(20%-30%) 有公司先扣除 有的当月发
A 120% S 150%-200% C 80%
你对上家公司的看法
不能贬低 要说优点 学习成长了很多 同事和领导都很照顾我
什么时候能入职?
三个工作日 到 一周之间
你离职了 现在有多少个offer了?
不能说一个都没有
- 我已经有2个offer 但是一定要表达对当前公司的期待 经过我的了解 我更喜欢贵公司的发展和文化
- 我也是刚刚开始找工作…
你可以接受加班吗
(必须完全接受全部加班 先拿到offer再说)
Controller和RestController的区别
@RestController = @Controller + @ResponseBody
@Controller如果要返回JSON/XML等格式的数据给客户端,必须显式的使用@ResponseBody注解将返回的对象转换为HTTP响应体内容。
@RestController 专门为构建RESTful Web服务设计的控制器。它简化了创建API的过程,因为所有方法默认都会将返回值直接写入HTTP响应体中作为JSON或XML格式的数据。
@Controller可以声明一个类为一个bean 控制器用
@ResponseBody 具体方法和类都可以 不是包装类和字符 都可以自动转成json数据格式 更符合restful风格
在yaml文件中定义了一些参数,该怎么调用
- 使用 @Value 注解,这是最直接的方式,适用于简单的属性注入。是bean的注解 用${key}还可以用#
${}:用于注入外部配置文件的值。它告诉Spring需要从环境变量、属性文件、系统属性等地方查找相应的值。#{}:用于执行SpEL(Spring Expression Language,Spring表达式语言)表达式。它允许你在注入值时执行一些简单的计算或逻辑。- 如果在多个类里引用 配置多 杂乱 可以写个配置类写一堆的属性 提供get set方法 配置类.get获取到配置
- 使用 @ConfigurationProperties 注解,通常会指定一个前缀(prefix),这个前缀用于指定配置文件中哪些属性应该被绑定到这个 Bean 上。
@ConfigurationProperties(prefix = "prefix")
IOC和DI有了解过吗,它们的好处是什么
它们的目的是为了解耦
IOC(控制反转)是Spring的两大核心之一,DI(依赖注入)
IOC把控制权交给spring容器
对象创建好之后 之间会有依赖关系 DI因此而生
实现方式:DI通常有四种实现方式
属性注入
注解注入@Autowired是 Spring 提供的注解,用于自动装配 Bean。它可以用于字段、构造函数、方法或设置器上。当 Spring 容器启动时,它会自动查找并注入匹配的 Bean。- 偶尔有不影响程序运行的报错?写spring技术人员是根据jdk写,怕别人不用。
@Resource是 Java 的注解[JDK的],用于依赖注入,它也可以用于字段、方法或设置器上。与@Autowired不同的是,@Resource默认通过名称进行匹配,如果未指定名称,则尝试通过类型进行匹配。- 两者区别
- @Autowired 先根据属性类型 去容器里面找 如果找不到 再根据**属性名称[字段]**去找 如果实在找不到就会报错 [@Autowired永远不会放弃你的 尽其所能去帮你找]
- @Resource 先根据属性名称去找 要么找不到 要么找到一个 找到就去注入 如果找不到 可以再根据属性类型去找 [类型找不到 或者 找到多个 也会报错]
构造函数注入 [默认生成空参构造方法 若写有参构造原来无参会被覆盖 参数根据类型去找和@Autowired类型一样 可以写多个构造方法 如果去多个构造方法重载会报错 怎么办?加个
@Autowired[属性,构造方法,参数]都可加不可多个方法都加@Autowired 反射会触发构造方法 @Bean => new ]Set方法注入[原生spring 用xml去定义才有 SpringBoot没有这个注入 ]
普通方法注入
测试过程有没有出现反复的困扰?
客户需求频繁更改
测试用例没有覆盖到
开发和测试环境未协调
太复杂的改动要先报备技术经理、项目经理
测试:自测 单元测试 专业人员
公司使用哪些技术?
后端:Redis RabbitMQ 搜索引擎 微服务常用组件 远程调用 统一网关 Springboot Springcloud MybatisPlus
项目有多少个成员?
2前 8后 1测 1运维 1项目经理(小公司约13人左右) 要具体人数
自研公司?外包?
自研公司:
- 创业型自研公司:通常员工人数在10-50人之间,初期可能更少,只有几人到十几人。
- 成熟自研公司:员工人数可能从几十人到几百人甚至更多。
外包公司:
- 小型外包公司:员工人数可能在10-50人之间。
- 中型外包公司:员工人数可能在50-200人之间。
- 大型外包公司:员工人数可能超过200人。
HashMap底层原理
底层数据结构
jdk1.8之前底层结构是数组+链表(key+value) 数据结构通用的[键值对+哈希表的数据结构]
jdk1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时且数组长度大于64时,将链表转化为红黑树,以减少搜索时间。扩容 时,红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表。后期使用map获取值时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
底层的地址运算出来 如果地址不一样计算出来的hashcode不一样,hashcode一般是数字[整数(±或0)] 通过key进行hashcode运算 对数组长度取模 eg:任何整数去取模10 可以定位到value可以放在哪个桶下面
hashcode本身不同的对象算出来的hashcde值是相同的怎么办呢?
两个value不可能放在同一个桶 这就是hash冲突 如果数组长度是8 算出来一个hashcode值是8 和 16 此时取模余数相同这样的情况也是相同。所以此时应该用拉链法[小葡萄串],即使桶一样 可以用指针一个个指,此时的链表是单项链表[linkedlist才是双向链表]。拉链法的解决哈希冲突。
在1.8后指出如果同一个桶的葡萄串太多了,此时要拿出数据,时间复杂度就是O(n),如果没有很多就是O(1)数组的长度。红黑树的引入是解决链表过长的问题。
红黑树是树形的高级数据结构 时间复杂度O(logn)
二叉树在某些情况下会退化成链表 右子树永远比根节点大
红黑树会旋转自平衡[局部旋转达到平衡] 超过多少层会旋转 不至于退化成链表。
扩容机制
new的初始化 数组为空
当第一次put的时候才不会为空 为16
扩容因子为什么是0.75?hashmap不仅仅java 其他语言也有这种数据结构 但扩容因子可能不同,是通过大量的数学概率统计出的最好最平衡的值。达到12的时候会扩容成2倍
new一个hashmap可以指定数组长度为7 此时数组长度是8【hashmap的长度永远是2的幂次方 比你传入的长度永远大 且 是2的幂次方】 为什么2的幂次方?因为1.7要数组取模 怎么打这个符号 shift+5 => %,1.8之后用了位运算,>>2 <<2 让你的取模运算更快。如果出现hash冲突会拉链 当它的数组长度大于64 并且 链表长度大于8时,当链表长度小于等于6临界值会变回来【为什么是6?避免频繁切换(离8太近) 链表 ←→ 红黑树[消耗性能]】
链表1.7之前是头插法 会产生一条首尾相接的死循环【并发情况[但是hashmap线程不安全不会用在并发,要用ConcurrentHashMap]一起put 且 同一个桶】
1.8之后是尾插法,并发情况下不会出现cpu飙高,
HashSet底层数据结构
底层是包装了一个hashmap,无序 key不允许重复 value可重复
HashSet单列无序不重复的 key就是那个元素 value就是new了一个无意义的object对象
ArrayList和LinkedList不是线程安全的 用什么?
- Vector 读写都加锁。
- CopyOnWriteArrayList读不加锁 写加锁
ConcurrentHashMap能存null吗?不允许使用 null 作为键,但是允许使用 null 作为值。
HashMap:null默认放在第一个桶下面 下标写死为0
Hashcode相同equals一定相同吗?
hashCode() 相同不一定意味着 equals() 相同,但 equals() 相同则 hashCode() 必须相同。
equals()方法用于判断两个对象是否逻辑上相等。hashCode()方法用于返回对象的哈希码,这个哈希码通常用于哈希表的快速查找。
key可以放复合对象,要注意要重写 hashcode()和equals() 如果不重写 new了的两个对象有可能会相同"重地" 和 "通话" 。计算hashcode会比equals更快,一个对象new出来后hashcode已经计算出来了。equals要比较每个对象值,所以先判断hashcode 再判断equals 重写:@Override 用属性里面的hashcode,user里面包含了复杂对象order 此时order也要重写。包装类已经重写了hashcode,要整个对象返回true才为正确的,要层层递进去判断。hashmap重写复杂对象就一定要重写那俩个 ∵ 是比较对象里的属性值
list 有序可重复单列
map 双列key不能重复value可重复 treemap是有序的
set 单列不重复无序 hashset 无序 treeset 有序
== 值 + 地址值
equals 是对象属性值是否一 一相等
HashMap是线程安全的吗
不安全的,可以使用ConcurrentHashMap、Collections.synchronizedMap()、HashTable
线程安全:多线程对同一个数据进行增删改是否受到影响
怎么办?
加锁
- synchronized
- ReentrantLock
加锁为什么能解决线程安全问题?线程访问资源的先后顺序
多线程访问同一个数据 => 多个线程访问同一个数据
秒杀 =>[思想] 1w个人买 对 100个库存进行扣减,只搞100个线程 把100个库存分成10份 其中每份有10个初始化库存: 创建一个共享的库存计数器,初始值为100。 创建线程: 创建100个线程,每个线程在启动时分配到一个特定的库存分片。 扣减库存: 每个线程尝试扣减其分配到的库存分片中的一个商品。扣减操作必须是原子的,以确保线程安全。 同步机制: 使用适当的同步机制(如synchronized关键字、ReentrantLock等)来保护库存扣减操作,防止并发问题。 库存检查: 在扣减前,线程需要检查当前分片是否有剩余库存。如果没有,则线程可以终止或进行其他处理。hashtable不管读写都会用synchronized加锁,并发一起来读都加锁 没必要,所以用了ConcurrentHashMap读不加锁 写加锁。
随着时间的推移,Hashtable已经被认为是遗留代码,现代Java代码更倾向于使用HashMap(非线程安全)或ConcurrentHashMap(线程安全)。
红黑树查询效率高的原因
红黑树是一种自平衡的二叉搜索树,它通过特定的规则来保持树的平衡,这些规则确保了树的高度大约是log(n)
自平衡 局部旋转
hashMap时间复杂度
- O(1):不涉及到拉链
- O(n):拉链不是树
- O(logn):桶为红黑树
这个测试是你做的吗,还是你们团队去做的?
像自测的话是我自己去做的(测试用例、apifox),然后交给专业测试人员
团队是怎么协作的?
像我们团队的话,有使用禅道来做我们的文档管理,需求管理和需求的变更控制,和工作的一个统计报表,大部分的协作任务都可以在禅道上完成,代码这一块我们是使用git来做一个代码管理和协作的。
linux查看每个文件夹下的文件大小的命令
ls -lh
linux查看文件夹大小的命令
du -sh
du -sh –all 隐藏
du -sh ./* : 单独列出各子项占用的容量
linux查看进程的命令,动态查看一个文件的最后100行的命令
ps -ef
ps aux [查看所有用户的进程(包括其他用户的进程):]
ps -ef | grep mysql
动态:tail -n 100 -f xxx 【-f → follow】
静态:tail -n 100 xxx
常用的Linux命令
rm = romove
用于删除文件和目录
rm [-rf] name
-r(recursive递归):将目录及目录中所有文件(目录)逐一删除,即递归删除
-f(force):无需确认,直接删除
rmdir = remove directory
它用于删除空目录。如果目录不为空,即目录中包含文件或其他子目录,rmdir 命令将无法删除该目录
pwd = print working directory
打印出当前工作目录的绝对路径。当你需要知道你在文件系统中的当前位置时,这个命令非常有用
cp = copy
复制文件和目录。这个命令可以用来创建文件的副本或将文件从一个位置移动到另一个位置。
cp [-r] source dest
-r (recursive递归):如果复制的是目录需要使用此选项,此时将复制该目录下所有的子目录和文件
mv = move
为文件或目录改名、或将文件或目录移动到其他位置【移动 重命名 修改】
grep
用于搜索文本数据,特别是使用正则表达式来匹配指定的模式
查看特定进程的详细信息,例如进程名为 mysql
ps -ef | grep mysql
tar [tape archive]
用于打包多个文件和目录到一个归档文件中,或者从归档文件中提取文件
cd
切换路径
vim
编辑文件
cat
查看文件[head]
如何查日志
查看/var/log/user.log文件,并且想要跟踪用户 name:pcy 的活动
tail -f /var/log/user.log | grep “pcy”
高级专用使用:awk 可以用正则等一些逻辑操作去获取日志
内建函数
awk非常强大,可以用于执行复杂的文本分析和报告生成,awk有许多内建函数,如length()、toupper()、tolower()等。bash
复制
awk '{print toupper($0)}' filename # 将所有内容转换为大写条件语句
bash
复制
awk '{if ($1 > 100) print$1}' filename循环
bash
复制
awk '{for (i=1; i<=NF; i++) print $i}' filename数组
bash
复制
awk '{count[$1]++} END {for (word in count) print word, count[word]}' filename
你们接口是如何让前端调用的
我们会在设计阶段提前设计好给前端 并行开发 前后端联调[本地ip端口告诉前端]
接口文档怎么定下来的
根据页面原型、需求设计接口文档[后端自己写],绝大部分后端看原型的出参入参 无太大需求和前端商量。【前端组件库】[若修改返回结构的时候] [按照数据结构修改] 需要听前端意见
前端调用后端用的是什么请求方式
WebSocket【基于长连接通讯】
HTTP
前端开发中,以下是一些常见的使用场景:
- 获取数据:使用GET请求。
- 提交表单或数据:使用POST请求。
- 更新资源:使用PUT或PATCH请求。
- 删除资源:使用DELETE请求。
前端可以通过多种方式发起这些请求,例如:
- 使用HTML表单(通常用于GET和POST请求)。
- 使用JavaScript的
XMLHttpRequest对象或者更现代的fetchAPI来发起各种类型的HTTP请求。- 使用各种前端框架和库(如React, Angular, Vue.js)中提供的封装好的HTTP服务。
SpringBoot主要的一些注解?都有哪些,以及主要作用
SpringBoot:
@SpringBootApplication [见↓↓]
@ConfigurationProperties:注解用于将外部配置(如来自properties文件、YAML文件或环境变量)绑定到JavaBean上。它的作用是将配置文件中的属性映射到JavaBean的属性上,这样就可以在应用程序中使用这些配置属性。
@SpringBootTest:用于测试 Spring Boot 应用,提供测试环境的支持
@EnableConfigurationProperties:启用对配置属性的支持,允许将配置文件中的属性注入到 bean 中。
Spring:
@Component
@ComponentScan
@Conditional
@SpringBootApplication 是一个组合注解,它结合了以下三个注解的功能:
1. @SpringBootConfiguration: 表示这是一个Spring Boot配置类,它本质上是一个@Configuration注解,用于定义配置类,可以包含多个@Bean注解的方法。
2. @EnableAutoConfiguration: 告诉Spring Boot基于类路径设置、其他bean和各种属性设置来添加bean。例如,如果你添加了spring-webmvc和thymeleaf的依赖,这个注解就会自动配置你的应用程序为一个web应用程序。
3. @ComponentScan: 告诉Spring在包及其子包下扫描注解定义的组件(如@Component, @Service, @Repository等)。
aop在项目中有没有使用?aop使用的一些注解及其功能
一定要描述项目场景,web使用aop打印操作日志、使用aop做数据脱敏(150***8786)
过滤器是Servlet技术的一部分,它是Java EE规范的一部分
拦截器是Spring MVC框架的一部分,用于在处理HTTP请求时拦截控制器方法调用。
AOP底层是动态代理设计模式,在理论上效果在一定程度上相同
过滤器拦截器一般拦截某个web的前后,在controller执行前后
AOP是万物皆可拦截、甚至接口和类都可以切,可以增强controller、service、mapper……
定义一个切面类 @Aspect 声明为切面类 + @Component
定义切点 @Pointcut 声明切点表达式
eg:@AfterReturning(pointcut = “execution(public String com.example.yourpackage.Controller.*(..))”, returning = “result”)
通知
- 前置 @Before
- 后置 @After
- 返回 @AfterReturning
- 异常 @AfterThrowing
- 环绕 @Around
你在公司里负责的内容
想在controller访问完之后,想在aop实现之后再进行操作
UserThreadLocal 在执行完之后要 remove 出去,抛异常也会执行
@After 不管有无异常都会执行
@Around 结合try…catch…finally 里也可以达到同样效果
@After:这个注解用于定义一个通知(Advice),它在目标方法执行之后执行,无论目标方法执行的结果如何(成功或异常)。
@Aspect
@Component
public class AroundFinallyAspect {
// 定义切点
@Pointcut("execution(* com.example.yourpackage.controller..*(..))")
public void controllerMethods() {
}
// 环绕通知
@Around("controllerMethods()")
public Object aroundAdvice(ProceedingJoinPoint joinPoint) throws Throwable {
Object result = null;
try {
// 在目标方法执行之前执行
result = joinPoint.proceed(); // 执行目标方法
// 在目标方法成功执行之后执行
} catch (Throwable e) {
// 在目标方法抛出异常时执行
throw e; // 可以选择处理异常或者重新抛出
} finally {
// 无论目标方法是否成功执行或者是否抛出异常,这里的代码都会执行
performFinallyAction();
}
return result;
}
private void performFinallyAction() {
// 在这里放置最终要执行的代码
}
}
--------------------------------------------------------------------------------
// 后置通知
@After("execution(* com.example.service.*.*(..))")
public void afterAdvice(JoinPoint joinPoint) {
// 在目标方法执行之后执行的逻辑
}
// 返回后通知
@AfterReturning(pointcut = "execution(* com.example.service.*.*(..))", returning = "result")
public void afterReturningAdvice(JoinPoint joinPoint, Object result) {
// 在目标方法成功执行并返回结果后执行的逻辑
}
在第一个例子中,你直接在@After注解中指定了切点表达式,因此不需要额外的pointcut属性。
对于@AfterReturning注解,它不仅需要在目标方法执行之后执行通知,还需要访问目标方法的返回值。因此,@AfterReturning注解有一个额外的pointcut属性,用于指定切点表达式。此外,@AfterReturning注解还有一个returning属性,用于指定一个参数名,该参数将接收目标方法的返回值
@AfterReturning:在方法执行后返回结果后执行通知。【如果有异常不会处理】
你们这个项目怎么技术选型的
我进到项目中很多已经确认下来的 一般由组长确定了
那你自己怎么想的?[开放性问题]
选xxx技术 网上资料/备书 比较多可以参考[用的人多]
学习成本[框架厉害但上手复杂不好用]
社区的活跃度[官网持续更新版本 框架会不断发展]
你处于后端的什么位置
初级 中级 高级
中级 骨干开发位置[协助组长完成]
中高级 完成设计类
你对你的职业规划是什么
讲实际的话
想成为高级开发/某个领域的专家
提前了解公司领域,有备而来
java基本类型

short 可以占两个字节 可以用16位
int 可以占四个字节 -21亿 ~ 21亿
long 可以占八个字节 天文数字
float 可以占四个字节 0.2F/f
double 可以占八个字节 0.2D/d
float double尽量不要进行运算 ,在Java中进行金钱运算时,应当特别注意浮点数的精度问题,因为浮点数(如float和double)在表示某些数值时可能会丢失精度,这对于需要精确计算的金融计算来说是非常不合适的。
1.金钱转成分 向下取整
2.BigDecimal
ASCII码占1个字节 → Unicode字符占2个字节【有些汉字存不了】→ UTF-8占1-3个字节[灵活可变]
在我们性能中一般走Unicode编码性能更高一点 在网络中/存入磁盘Unicode转成ASCII码
jdk?之后 jdk开始存储大量英文和数字 String类也作了更新 不是基于基本数据类型 而是基于byte数组
在Java的早期版本中(例如JDK 1.4及之前版本),String类内部确实使用char数组来存储字符串数据。每个char在Java中占用16位(2个字节),这意味着不管存储的是英文字符还是数字,每个字符都会占用2个字节的内存空间。
从JDK 5开始,Java平台引入了一些变化,但String类的内部表示仍然基于char数组。直到JDK 6和JDK 7,String类的内部表示并没有改为基于byte数组。
真正发生变化的是在JDK 9中,String类内部表示从char数组转变为byte数组加上一个编码标识(coder),这种改变是为了更有效地存储只有ASCII字符的字符串。ASCII字符只需要一个字节来表示,因此使用byte数组可以节省内存空间。当字符串包含Unicode字符时,String类可能会使用更多的编码方式,例如LATIN1或UTF-16。
String是基础类型吗
不是,是java.lang下的类
String 在 Java 中并不是基础类型,而是一个引用类型。因为 String 是一个类,所以它是引用类型,意味着当我们声明一个 String 变量时,你实际上是指向一个 String 对象的引用
String 的特性
不可变性:String 对象一旦创建就不能被修改。任何改变 String 内容的操作都会创建一个新的 String 对象。
线程安全:由于 String 的不可变性,它们是线程安全的,可以自由地在多个线程之间共享。
字符串池:为了提高性能和减少内存使用,Java 为 String 提供了字符串常量池(String Pool)。当创建一个新字符串时,如果字符串池中已经存在相同内容的字符串,则会返回池中的实例,而不是创建新的对象。
java集合中list和set的区别?
都是接口 某个实现类
单链 有顺序 可重复 有索引[有下标]
单链 不可重复 无索引[无下标] 不能说是无序 因为TreeSet有序 HashSet就是无序的
做了几年开发呢? 实际几个项目?
三年[初中级] → 四~五个项目
你觉得敲代码最重要的是什么?
理解需求、前期设计工作[数据库、接口 → 流程图(思路清晰)]、编码阶段[考虑方法封装、注释、考虑代码后期和维护性(设计模式 → 可维护性+扩展性)]、编码风格[阿里巴巴规范]
你的项目有上线吗? 多少人进行开发? 你主要负责后端吗?
有,介绍一下项目组成结构,是的[再问再回答]
SpringBoot的自动装配原理[启动过程中的一部分]SpringBoot启动原理&&如何内嵌外部原件
Spring Boot的自动装配原理是基于Spring框架的IoC(控制反转)和DI(依赖注入)的核心概念,并结合了一系列的约定和条件注解来实现配置类的自动加载和Bean的自动注册
自定义Starter
<!-- Maven项目的依赖示例 -->
<dependency>
<groupId>com.xxx</groupId>
<artifactId>xxx-spring-boot-starter</artifactId>
<version>1.0.0</version>
</dependency>
三大优点:依赖Maven特性[依赖传递] 自动配置 内嵌Tomcat
Spring Boot的自动装配原理是
在src/main/resources/META-INF目录下创建spring.factories文件,添加自动配置类的全限定名
我们可以在-info定义spring.factories位于META-INF目录下,Spring Boot使用它来发现和加载自动配置类。
配置类扫描: 通过@SpringBootApplication注解,Spring Boot会触发对@EnableAutoConfiguration注解的处理,该注解会查找spring.factories文件中定义的自动配置类。
Maven里面写test类 用configuration声明 写很多的test类 但是我可以自己写test类然后调不同的方法 应该怎么办?@Conditional[Spring的注解] → 做成非常灵活的 如果没有就用自己写的
Spring里面的事务传播行为
在Spring框架中,事务传播行为定义了事务方法之间的调用关系,即一个事务方法被另一个事务方法调用时,事务应该如何传播。
- REQUIRED(默认值) required
- 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
- SUPPORTS supports
- 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务方式执行。
- MANDATORY mandatory
- 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
- REQUIRES_NEW requires_new
- 创建一个新的事务,如果当前存在事务,则挂起当前事务。
- NOT_SUPPORTED not_supported
- 以非事务方式执行操作,如果当前存在事务,则挂起当前事务。
- NEVER never
- 以非事务方式执行,如果当前存在事务,则抛出异常。
- NESTED nested
- 如果当前存在事务,则在嵌套事务内执行;如果当前没有事务,则行为类似于
REQUIRED。
- 如果当前存在事务,则在嵌套事务内执行;如果当前没有事务,则行为类似于
REQUIRED:通常用于方法需要在一个事务中运行,但如果已经有一个事务在运行,那么它应该加入这个事务。
SUPPORTS:用于方法不需要事务上下文,但如果已经在一个事务中,它也可以在这个事务中运行。
MANDATORY:用于方法必须在事务中运行,如果没有事务,则会抛出异常。
REQUIRES_NEW:用于方法必须在自己的新事务中运行,即使当前已经有一个事务在运行。
[一般适用于不管有没有抛出异常 都要记录某些操作日志 不能在同一个类里底层是动态代理]
[如果a()和b()方法在同一个类中,并且a()直接调用b(),那么Spring的事务代理无法拦截这个内部调用,因此b()的REQUIRES_NEW事务传播行为不会生效。这是因为内部方法调用不会通过代理,而是直接在同一个对象实例上调用。]import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import org.springframework.transaction.annotation.Transactional; import org.springframework.transaction.annotation.Propagation; @Service public class MyService { @Autowired private MyService self; // 注入自身代理实例 public void methodA() { // ... 业务逻辑 ... self.methodB(); // 通过代理实例调用,事务注解将生效 } @Transactional(propagation = Propagation.REQUIRES_NEW) public void methodB() { // ... 业务逻辑 ... } }NOT_SUPPORTED:用于方法不应该在事务中运行,如果有一个事务在运行,它将被挂起。
NEVER:用于方法绝对不应该在事务中运行,如果有一个事务在运行,将抛出异常。
NESTED:用于方法应该在嵌套事务中运行,嵌套事务可以独立于外部事务进行提交或回滚
用过Spring的事务吗
一组数据库的增删改操作
声明式事务管理:这是Spring推荐的用法,它通过使用注解(如@Transactional)或基于XML的配置来声明事务边界。底层基于AOP实现动态代理增强方法
编程式事务管理:允许你通过编程的方式直接管理事务,通常使用TransactionTemplate或者直接使用底层的PlatformTransactionManager。
你熟悉的技术栈有哪些,用了哪些?
SpringBoot Vue Git Maven MyBatis……
解决难点的决策有和用户沟通的吗?
有过沟通 让他们了解一下我们的方案
万一用户听不懂怎么办?
我会用一些更加直白通俗的语言让用户理解我们的方案
用户不接受这个方案怎么办?
我们可以提供不止一个方案 或者 提供他提的方案 综合一下各种方案告诉其优缺点(站在我们的专业角度意见)和风险 让客户明知 让其选择
通常一般怎么学习的?最近在研究什么技术?
想面试的目的 要給公司带来一些好的
一般以公司的实际项目中为切入点去学习会更有效率
学习一个新的技术大概要多久?
1-2天 首先看官网 这个技术是解决哪些 看我们的项目需要哪些技术切入点能引用 然后去专门针对这个技术功能点去学习快速上手的接口文档
redis为什么这么快?
- 主数据基于内存操作
- Redis是单线程[操作数据的线程],避免上下文的频繁切换
整个redis不是就一个线程 - 底层基于C语言实现
得益于底层良好的数据结构[] - 基于非阻塞的IO
提升IO读写性能,NIO,BIO,AIO…
Java四大杀手
集合数据结构 jvm 并发编程 网络IO
redis的数据类型以及使用场景分别是什么
- String:存储对象信息(转JSON)、
- List:链表,查询记录的缓存、列表,朋友圈,微博,队列数据结构
- Hash:获取局部属性,小key不能设置过期时间
- Set:无序不可重复的,收藏,点赞,社交场景,聚合计算(∩∪差集)
- Zset:排序场景,排行榜,姓名排序
分布式锁都可以用。Redisson是Redis的儿子,底层为Hash
redis数据过期策略
- 惰性删除:键过期时不会立即删除,当访问该键时判断是否过期,如果过期就删除
- 定时删除:设置键的过期时间,当键过期时,立即删除
高薪冲刺 → 定时删除详细策略
要扫描所有的定期任务删除 有策略可以设置阈值
啥时候离职的?半个月太长了
刚刚离职 也是刚刚开始投
主要工作职责
主要负责后端工作,协助测试,运维上线
你对前端有了解过吗?
有了解过,如HTML、CSS、JavaScript、框架[Vue、Element]等 可以很快的上手
我主要专长在于后端开发,可以学习和了解更多的前端知识。
各种淘汰策略介绍
Redis提供了8种淘汰策略,可以分成两大类:
1、针对所有键的策略:对所有键进行选择和淘汰。
2、仅针对有过期时间的键的策略:只在设置了过期时间的键中选择淘汰对象。
以下具体策略:
可以区分为两类:[有设置过期时间的key 不管你有没有设置过期时间]
1. noeviction【默认】
- 描述:达到内存限制时,不再执行删除操作,直接拒绝所有写入请求(包括插入和更新)。[可以读 但是拒绝写请求]
- 适用场景:希望数据永不丢失的场景,但需要保证内存充足,否则会导致写入操作失败。
2. allkeys-lru(最近最少使用)
- 描述:在所有的键中使用 LRU算法,删除最近最少使用的键。
- 适用场景:适合缓存场景,保留频繁访问的键,逐出很少被访问的键。
3. allkeys-lfu(最少使用频率)【电商】
- 描述:在所有键中使用 LFU 算法,删除使用频率最低的键。
- 适用场景:适用于需根据使用频率进行淘汰的场景,更关注访问次数而非访问时间。
4. volatile-lru(最近最少使用)
- 描述:仅对设置了过期时间的键使用 LRU 算法。
- 适用场景:适合缓存一些有过期时间的数据,希望根据访问频率来进行内存管理的场景。
5. volatile-lfu(最少使用频率)【电商】
- 描述:仅对设置了过期时间的键使用 LFU算法。
- 适用场景:同 volatile-lru,但更关注使用频率。
6. allkeys-random
- 描述:在所有键中随机选择删除某个键。
- 适用场景:适用于缓存数据访问频率没有明显差异的情况。
7. volatile-random
- 描述:在所有设置了过期时间的键中随机选择删除某个键。
- 适用场景:适合缓存带有过期时间的数据,删除哪个数据不重要的场景。
8. volatile-ttl
- 描述:在设置了过期时间的键中,优先删除剩余生存时间(TTL)较短的键。
- 适用场景:适合希望优先清理即将过期的数据的场景。
缓存三兄弟(穿透、击穿、雪崩)
一般在读缓存的时候出现的问题。思路:产生的原因 + 解决的方案
==缓存穿透==:用户或前端查询到一个在数据库中不存在的数据,先查redis再走数据库。对数据库压力会很大。关系型数据库是性能的瓶颈 希望把高数量都挡在数据库前面。查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查询数据库(可能原因是数据库被攻击了 发送了假的/大数据量的请求url)
- 解决方案一:缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存 {key:1, value:null} 【空字符串】
没有Null的数据类型下一次读取直接把空串返回
优点:简单
缺点:消耗内存,可能会发生不一致的问题
如果一直模拟一个不同的不存在的key 这时候就要用到布隆过滤器
解决方案二:布隆过滤器 (拦截不存在的数据)
[商品读多写少上缓存,要把商品数据写到布隆过滤器中,以商品的id独一无二计算hashcode,用布隆过滤器。取模数组落到桶内 会把0置为1]
有很多个二进制数组每个二进制数组用不同的hash算法进行计算此时落到的桶就不一样
作用:读的时候 前端传id 之前怎么写进去就怎么拿出来。[位运算(与)速度很快 把多个数组的数据拿出来与运算如果都是1 则这个数据可能存在再查一遍缓存若不存在直接return返回] 布隆过滤器说你不存在 一定不存在,说你存在 则可能存在[哈希冲突]★ 项目上线很久了 商品早就下架不卖了 这时候会发生什么问题?
这时候布隆过滤器还有之前的痕迹,需要把那些1设置为0。
布隆过滤器 不支持对某个的1设置0 → 因为有哈希冲突我不知道这个1曾经是誰设置的
支持将整个都置为0,之后可以搞个定时任务
布隆过滤器具体实现:Redis、Redission亲儿子、1cache、咖啡因(Caffeine提供了一种非常高效且易于使用的缓存解决方案,它支持多种缓存过期策略)、Guava谷歌★ 以前没设置过且上架过 后面加了布隆,后面要把之前所有数据重新搞进去 怎么解决?
存量数据写一个定时任务
★ 场景:工商银行统计每天的用户日活量[上线就算] 要查询某个人连续七天签到 怎么查(用位图)
用户量太多了搞一个二进制数组,10亿长度的数组,每个数组是一个bit = 10亿个位,一个字节
1/bit=8个位,综合计算后大概消耗119MB的空间每天。用用户id去hash 如果用户登录将0置为1有单独的位图结构,统计时间就可以拿日期 往前面数 拿某个id去取模得到桶 找前七个,去进行与运算,连续为1就达到了重复连续七天前端。否则非连续七天。在缓存预热时,要预热布隆过滤器。根据id查询文章时查询布隆过滤器如果不存在直接返回
**bitmap(位图)
巨大的二进制数组**:相当于一个以bit位为单位的数组,数组中每个单元只能存储二进制数0或1布隆过滤器作用:可以用于检索一个元素是否在集合中
- 存储数据:id为1的数据,通过多个hash函数获取hash值,根据hash计算数组对应位置改为1
- 查询数据:使用相同hash函数获取hash值,判断对应位置是否都为1
存在误判率:数组越小 误判率越大 【要数组足够大 误判率就小】
bloomFilter.tryInit(size, 0.05) //误判率5%
==缓存击穿==:给某一个热点key设置了过期时间,当key过期的时候,恰好这个时间点对这个key有大量的并发请求过来,这些并发请求可能一瞬间把DB击穿微博[鹿晗+关晓彤]【并发同一时间访问】
解决方案一:互斥锁【数据强一致性 性能差 (银行)】[控制一个个来访问的次数]
AQS、ReentrantLock是进程级别的互斥锁,因为有数据在节点1或节点2,分布式锁是在不同场景都可以锁也可以控制访问顺序。以商品id作为key 先redis开始查缓存 判断是否为空 不为空直接return后解锁,空就先加锁 去数据库查完备份一份redis后解锁。被锁的其他线程在外面等待。
★ 100个人访问同一个商品,只有一个抢到锁,剩下的99个人也要查redis缓存和数据库。
方案:**双重缓存校验** 先查缓存 查不到加锁 再查缓存 查不到再去数据库 查完后看是否备份后解锁
冷代码1.查询缓存,未命中 → 2.获取互斥锁成功 → 3.查询数据库重建缓存数据 → 4.写入缓存 → 5.释放锁
1.查询缓存,未命中 → 2.获取互斥锁失败 → 3.休眠一会再重试 → 4.写入缓存重试 → 5.缓存命中
解决方案二:逻辑过期[ 不设置过期时间 ] 【高可用 性能优 不能保证数据绝对一致 (用户体验)】
在数据库一条数据里面添加一个 “expire”: 153213455
1.查询缓存,发现逻辑时间已过期 → 2.获取互斥锁成功 → 3.开启线程 ↓→ 4.返回过期数据
【在新的线程】→ 1.查询数据库重建缓存数据 → 2.写入缓存,重置逻辑过期时间 → 3.释放锁
1.查询数据缓存,发现逻辑时间已过期 → 2.获取互斥锁失败 → 3.返回过期数据
==缓存雪崩==:在同一个时段内大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来压力
- 解决方案一:给不同的key的TTL(过期时间)添加随机值
不在同一时间过期 - 解决方案二:利用Redis集群提高服务的可用性 【哨兵模式、集群模式】
- 解决方案三:给缓存业务添加降级限流策略【nginx、springcloud、gateway】
- 解决方案四:给业务添加多级缓存 【Guava(做一级缓存 然后Redis是二级缓存)或Caffeine】
★ redis宕机的时候 再RedisTemplate.set()后会报错 但是现在mysql还可以访问 应该怎么办?
try catch 在里面继续再去查mysql数据库
降级代码:对于读操作,如果Redis缓存失效,可以直接从MySQL数据库读取数据。
public boolean setData(String key, String value) {
try {
// 尝试将数据设置到Redis
redisTemplate.opsForValue().set(key, value);
return true;
} catch (Exception e) {
// 日志记录Redis错误
log.error("Redis is down, failing over to MySQL", e);
// Redis设置失败,降级到MySQL
return setDataToMySQL(key, value);
}
}
private boolean setDataToMySQL(String key, String value) {
// 这里实现将数据写入MySQL的逻辑
// 例如:
// mySqlTemplate.update("INSERT INTO cache (key, value) VALUES (?, ?)", key, value);
// 注意:这里的mySqlTemplate和SQL语句需要根据实际情况调整
return true; // 假设写入成功
}
如果公司对要求更高,需要限流降级、熔断
同一时间设置QPS为100 超过的返回友好提示[商品太火爆啦,请稍后再试]
你有自己部署过环境吗
公司里面用 Jenkins + docker 测试环境我们部署 生产环境是组长部署
未来1-3年规划
将具体一点,从业务技术上提升自己的深度和广度达到高级工程师
你平时做笔记吗
有做笔记 Xmind + Markdown
因为我觉得无论从网上的还是别人请教的不经历我的消化都不是我的东西
我还是会将这些知识点总结起来变成自己的知识
什么是动态代理?&& 动态代理有哪些,他们之间的区别?
代理是一种设计模式 用来增强目标的逻辑 与被增强的并没有太大关系装饰者模式
在程序运行期间才会产生代理类加载到我们jvm中
JDK动态代理是基于接口实现来实现增强
[txt文本 把目标增强类 作为接口
本身就是接口实现过来写成源码 源文件 再用jdk工具把源码编译成class字节码 再用类加载器把class加载到jvm中]CGLIB动态代理是基于继承目标类并覆写其方法来实现
[ASN字节码机制直接生成class 直接加载到内存中]
性能较高,速度更快。因为直接生成class
要调用某个方法 CGLIB性能高 是通过反射来实现的 老版本的jdk的反射性能较低。如今在调用方法的性能上差距不大
区别:
- JDK动态代理要求目标类必须实现一个或多个接口,而CGLIB没有这个要求。
- JDK动态代理生成的代理类是接口的实现,而CGLIB生成的代理类是目标类的子类。
- 性能上,CGLIB通常比JDK动态代理更快,因为它直接操作字节码生成新的类。
什么样的代码是静态代理?
发生在我们写代码的过程中 在编译阶段产生了代理类
静态代理是指代理类在编译时就已经确定,通常由程序员手动编写
你用过Linux吗?
是的,我在工作中经常使用Linux操作系统。我熟悉Linux的基本命令
基础的命令:xxx【查看之前笔记】
你工作的时候有需求文档吗?
有的,有一些简单的需求是没有的[沟通成本太高了]
稍微复杂的需求会有需求文档,我会根据需求文档来理解项目需求,并进行系统设计和开发。
你有什么需要了解的?不要难为面试官,不问技术栈
我想了解一下贵公司的业务是什么…好的那我这块已经没有什么想了解的了 感谢面试官
HR:想了解一下贵公司的上班时间…
我没有什么想了解的,来之前有了解过贵公司
平时用注解创建的bean是单例的还是多例的?
默认情况下,通过注解(如@Component、@Service、@Repository、@Bean等)创建的Bean是单例的。如果需要创建多例Bean,可以在注解上添加@Scope(“prototype”)来指定。
SQL语句的执行顺序,为什么顺序是这样排的,这样的顺序有什么优势或者好处?
FROM -> Join -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY -> limit
这样的顺序是为了优化查询性能。首先确定数据来源(FROM),然后筛选出满足条件的数据(WHERE),接着进行分组(GROUP BY),在分组的基础上进行进一步筛选(HAVING),然后选择需要的数据(SELECT),最后对结果进行排序(ORDER BY)。这样的顺序可以减少中间结果集的大小,提高查询效率。
书写顺序
select -> from -> join -> on -> where -> group by -> having -> order by -> limit
线上项目发生死锁如何去解决? 我暂时没遇到过→分布式事务上去答
死锁:两个线程争夺两个资源的时候 1线程拿到a 想拿b 2线程拿到了b 想拿a
四个原因:互斥条件 请求保持 不可剥夺 循环等待
产生死锁的四个因素 同时满足才会死锁 想要解决死锁 需要打破其中一个原因就行
- 互斥条件(Mutual Exclusion):资源不能被多个线程同时使用。即某个资源在一段时间内只能由一个线程占用,其他线程必须等待该资源被释放后才能使用。
- 持有和等待条件(Hold and Wait):线程至少持有一个资源,并且正在等待获取额外的资源,而该资源又被其他线程持有。
- 非抢占条件(No Preemption):已经分配给某个线程的资源在该线程完成任务前不能被抢占,即只能由线程自己释放。
- 循环等待条件(Circular Wait):存在一种线程资源的循环等待链,每个线程都在等待下一个线程所持有的资源。
在实际操作中,以下是一些打破死锁的具体方法:
- 资源分配图:使用资源分配图来检测循环等待条件,并在检测到循环时采取措施。
- 锁排序:确保所有线程以相同的顺序获取锁,从而避免循环等待。
- 超时机制:线程在请求资源时设置超时时间,如果超过时间未获得资源,则放弃当前任务并释放已持有的资源。
- 死锁检测算法:运行死锁检测算法,如银行家算法,来检测系统中的死锁,并在必要时采取措施。
- 线程中断:允许系统或其他线程中断正在等待资源的线程。
- 回滚操作:如果检测到死锁,可以让某些线程回滚它们的工作,并释放资源,从而打破死锁。
MySQL是不会有死锁的 自身会检测 [让后面的超时释放回滚]
在分布式事务 线程1拿着资源a是数据库1 线程2拿着资源b是数据库2
JVM中也有死锁,jvm没有超时机制不会解决 可以查看命令打印堆栈信息可以查看哪里产生死锁
你可以使用
jstack命令来打印指定进程ID的Java堆栈跟踪信息。这个命令可以帮助你分析线程的状态
首先,找到你的Java进程ID(PID)。你可以使用
jps命令来列出所有正在运行的Java进程及其PID。jps使用
jstack命令打印出该Java进程的堆栈跟踪。jstack <PID>将
<PID>替换为实际的进程ID。查找堆栈跟踪中的”DEADLOCK”关键字。
jstack会自动检测死锁并在输出中报告。
如果你遇到(新的)技术栈,怎么去解决?
【return Previous.notes(NowDay);】
如果你在实际开发中遇到问题,你怎么去解决,怎么去沟通?
首先尝试自己解决问题,通过搜索引擎、官方文档、Debug等。
尽可能不让这个问题不出现风险 实在解决不了就向上反馈 寻求帮助 请教上司领导或同事
平常和项目经理进行沟通 如果需求评审有些不理解还是会及时沟通 不清楚的一定要及时明确
对于加班情况怎么看?
为了确保项目进度和团队利益,加班是可以接受的。
多线程怎么保证线程之间的安全
加锁 不让多线程抢夺资源
互斥锁、读写锁、线程局部存储(ThreadLocal每个线程独享自己变量)
mybatis中${}和#{}的区别,哪个更好? 为什么?
${}(字符串替换):${}会将参数直接替换到SQL语句中,不进行任何转义处理。- 它适用于动态SQL中的表名或列名,或者在SQL语句中需要使用特定数据库函数的情况。
- 使用
${}时,如果参数是用户输入的,那么可能会引发SQL注入攻击,因为它不会对参数进行转义。
#{}(预处理语句参数):#{}会创建预处理语句(prepared statement)的参数占位符,并在设置参数时进行适当的转义处理。- 它适用于大部分情况,特别是当参数是用户输入时,可以有效防止SQL注入攻击。
- MyBatis会根据参数的类型自动选择
setString、setInt、setDate等预处理语句方法。
在大多数情况下,
#{}是更好的选择,因为它提供了以下优势:- 安全性:
#{}可以防止SQL注入攻击,因为它会自动转义参数。 - 类型处理:MyBatis会根据参数的实际类型来设置预处理语句的参数,这减少了类型错误的可能性。
- 可读性和维护性:使用
#{}可以使SQL语句更加清晰,因为它清楚地标识了参数的位置。
然而,在某些特定的场景下,如需要动态地指定表名或列名时,
${}是必要的,因为预处理语句- 安全性:
说一下内连接和外连接的区别
左外连接(Left Outer Join):
- 定义:左外连接返回左表中的所有行,即使在右表中没有匹配的行。对于左表中没有匹配的行,结果集中的右表部分将包含NULL。
右外连接(Right Outer Join):
- 定义:右外连接返回右表中的所有行,即使在左表中没有匹配的行。对于右表中没有匹配的行,结果集中的左表部分将包含NULL。
全外连接(Full Outer Join):
- 定义:全外连接返回左表和右表中的所有行。当某行在另一个表中没有匹配时,结果集中的相应部分将包含NULL。
自我介绍
xxx
你觉得学习我们这些技术最重要的是什么?
首先要清楚这个技术是解决什么领域的问题,学习技术很多方面都是用来服务业务的,结合实际业务来学习技术融合性会更强
技术栈有些不同,有没有想过换方向发展?
没问题的 因为技术是相通的 可以去学新技术
1.概述
ThreadLocal(定义全局静态变量 项目中共用)是Java中的一个线程局部变量工具类,它提供了一种在多线程环境下,每个线程都可以独立访问自己的变量副本的机制。ThreadLocal中存储的数据对于每个线程来说都是独立的,互不干扰。
2. 使用场景
ThreadLocal适用于以下场景:
- 在多线程环境下,需要保持线程安全性的数据访问。
- 需要在多个方法之间共享数据,但又不希望使用传递参数的方式。
- 在传递登录用户id是非常方便且适用
以后获取用户id不用再解析token了,线程拿仅仅拿当前线程的数据 每个登录的用户都有自己的threadlocal数据
ThreadLocal并不是一个Thread,而是Thread的局部变量【可以存储数据】
ThreadLocal为每个线程提供单独一份存储空间,具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问。**ThreadLocal实现一个线程内传递数据**[就不用一个个参数往后传递了]
注意:客户端发送的每次请求,后端的tomcat服务器都会分配一个单独的线程来处理请求
- 一个请求是一个线程[意义:在第一个线程里面使用ThreadLocal存储用户Id 在后面controller或service中就可以取出来用户id]
- 第二个请求就是另一个线程 线程池用完第一个放回线程池 也有可能把上一个线程接着给它用
postHandle 只有在正确调用返回才会引用 如果抛出异常则不会使用afterCompletion 无论怎样最后都要运行
ThreadLocal
3.1 创建ThreadLocal对象
首先,我们需要创建一个ThreadLocal对象来存储线程局部变量。可以使用ThreadLocal的默认构造函数创建一个新的实例。【给每个线程拷贝一份 synchn + Lock锁】
ThreadLocal<String> threadLocal = new ThreadLocal<>();
3.2 设置线程局部变量的值
使用set()方法可以设置当前线程的局部变量的值。
threadLocal.set("value");
3.3 获取线程局部变量的值
使用get()方法可以获取当前线程的局部变量的值。
String value = threadLocal.get();
3.4 清除线程局部变量的值
使用remove()方法可以清除当前线程的局部变量的值,建议在整个请求使用完一定要执行remove清除数据,不然可能会发生内存泄漏问题。
threadLocal.remove();
下面是一个简单的示例代码,演示了如何使用ThreadLocal。
public class ThreadLocalTest {
private static final ThreadLocal THREAD_LOCAL = new ThreadLocal();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
THREAD_LOCAL.set("itheima");
getData("t1");
}, "t1");
Thread t2 = new Thread(() -> {
THREAD_LOCAL.set("itcast");
getData("t2");
}, "t1");
t1.start();
t2.start();
}
private static void getData(String threadName){
Object data = THREAD_LOCAL.get();
System.out.println(threadName+"-"+data);
}
}
运行以上代码,输出结果为:
t1-itheima
t2-itcast
在任意位置都可以调用Threadlocal,线程隔离互不影响,解决了线程安全问题:[每个线程存一份 线程不共享]
用mybatis+建造者模式 一定要在类里面加 一定要具有有参和无参构造缺一不可 否则mybatis数据封装无法映射
@AllArgsConstructor
@NoArgsConstructor
@Builder
字符和字符串类型的区别
字符是基本数据类型 没有null 用单引号
字符串是引用数据类型[一个类] 用双引号

操作字符串的工具类是什么
apache的common提供的String Utils工具类,hutool也有String Utils
局部变量和成员变量的区别
成员变量是在jvm的堆
局部变量是在jvm的栈
基本数据类型的引用类型 类在堆
基本数据类型的成员变量在堆 非静态在堆 静态变量在方法区
引用类型 无论静态还是非静态成员变量都在堆区
局部变量是在方法或代码块内部声明的变量,其作用域仅限于声明它的方法或代码块
局部变量不能被static修饰
局部变量必须被初始化才能使用
成员变量是在类内部声明的变量,其作用域是整个类
成员变量可以被static修饰
成员变量有默认值
你编写完代码,写完这个功能后,会进行什么操作呢
进行代码审查,检查代码是否符合编码规范和设计要求。
- 进行单元测试,确保代码的功能正确无误。
- 进行代码优化,提高代码的性能和可维护性。
- 与团队成员进行代码合并,确保代码的集成。
- 编写文档,记录功能实现和代码变更。
上一家公司的薪资是多少?期望薪资是多少?上一家还有什么其他的福利吗?
期望薪资:
了解过广东这边的市场 我想换工作想涨薪10~20%
节假日会发放礼品和福利
可以接受低代码平台吗?
可以接受
低代码平台:类若依
具体说说Java面向对象
Java面向对象是一种编程范式,它将现实世界的事物抽象成程序中的对象。Java面向对象的主要特征包括:
- 封装:将对象的属性和行为封装在一起,对外只暴露必要的接口,隐藏内部实现细节。
- 继承:允许子类继承父类的属性和行为,实现代码的复用。
- 多态:同一个接口可以有多个不同的实现,通过对象的类型和方法的调用,实现不同的功能。
== 和 equals 的区别
- ==:比较基本数据类型时,比较的是值;比较引用数据类型时,比较的是对象的内存地址。
- equals:是Object类的一个方法,默认比较的是对象的内存地址。但在很多类中(如String、Integer等),equals方法被重写,用于比较对象的内容是否相等。
没重写 就是 == 比较对象地址。重写过的话就比较对象的值。
有没有做过权限控制,整个系统的权限
有过 SpringSecurity
能具体说一下权限控制怎么做?
使用RBAC模型 不是把用户关联资源 而是中间利用角色间接关联
用户+角色+资源+用户角色中间表+角色资源中间表多对多
SpringSecurity 具体怎么实现
我的项目是基于JWT的前后端分离的项目,在自定义认证管理器AuthenticationManager认证成功后,生成JWT令牌并返回给前端。前端在随后的请求中携带这个JWT令牌。这时候,我们使用AccessDecisionManager来实现接口的鉴权逻辑,其中包括一个check方法,该方法会校验JWT令牌的有效性。如果校验通过,就去查询数据库以确定用户拥有哪些权限。在用户登录时,其权限信息已经被缓存到Redis中。后续的请求中,我们可以直接从Redis中检索用户的权限信息。如果请求的接口权限与用户缓存中的权限匹配,则放行;如果不匹配,则返回一个友好的错误信息。
线程池有哪些状态,这些状态是怎么进行转换的
线程池有以下几种状态:
- RUNNING:线程池正常运行,可以接受新的任务和处理任务队列中的任务。
- SHUTDOWN:线程池不再接受新的任务,但会处理任务队列中的任务。
- STOP:线程池不再接受新的任务,也不处理任务队列中的任务,并且会中断正在执行的任务。
- TIDYING:所有任务都已终止,线程池即将关闭。
- TERMINATED:线程池已关闭。
状态转换过程如下:
- RUNNING -> SHUTDOWN:调用shutdown()方法。
- RUNNING -> STOP:调用shutdownNow()方法。
- SHUTDOWN -> TIDYING:当线程池和任务队列都为空时。
- STOP -> TIDYING:当线程池为空时。
- TIDYING -> TERMINATED:当terminated()钩子方法执行完成后。
说一下怎么使用多线程?
继承Thread类,并重写run()方法。
实现Runnable接口,并将实现类传递给Thread对象。
实现Callable接口,实现
call()方法使用Executor框架,如ExecutorService和ThreadPoolExecutor来管理线程池。
操作系统上的线程有多少种状态[5]?Java线程有多少种状态[6]?
- 新建(New):创建后尚未启动的线程处于这个状态。
new Thread - 可运行(Runnable):包括运行(Running)和就绪(Ready)状态,线程正在执行或等待CPU调度。
- 阻塞(Blocked):线程因为等待某些资源或锁而被阻塞。notify可以唤醒阻塞状态 睡眠完会自动唤醒
- 等待(Waiting):线程等待其他线程执行特定操作(如通知)。
- 计时等待(Timed Waiting):线程在一定时间内等待另一个线程的通知。
- 终止(Terminated):线程执行完成或因异常而终止。
怎么把线程杀死 终止
stop()方法[暴力方法] interrupt()方法[优雅关闭线程] 正常回收
乐观锁和悲观锁的区别
乐观锁:读多写少 线程执行时间相差较大 并发不太激烈
悲观锁:写多读少 线程执行时间相差不大 竞争激烈 并发锁多
加锁的时机不一样,
悲观锁:没改数据的时候先加锁 比较明显利用底层操作系统api实现
乐观锁:在改数据的时候才加锁 依靠底层的硬件
java层面:synchronized ReentrantLock
数据库层面:
悲观锁:select for update是mysql的的实现
乐观锁:JUC Java Util Concurrent)是Java并发工具包
SELECT ... FOR UPDATE:这个语句在读取记录时会锁定这些记录,直到事务提交或回滚。其他的事务不能更新这些锁定的记录,这是悲观锁的一个典型实现
乐观锁要读取目前旧的值再将新设置的值以及旧的值比较 如果相同 就把新的值更新 如果不相同 就把旧的值重新提取 因为在这期间有人读取了这个数据跟我之前不一样(底层api 要调用两个 一个旧的值 一个新的值)。一般乐观锁是结合自旋 类于while(true)直到读到为止 要设计次数后再报错
要更新数据库某个值 把旧的值读出来 想更新银行里的余额
这是典型的ABA问题:要用时间戳或自增版本号去做
Stream流的使用及常用API
Stream是Java 8中引入的一种新特性,用于简化数据处理和操作。它可以用来解决集合循环遍历处理的问题。在此之前用循环来代替
基础Stream操作
stream(): 为集合创建串行流。parallelStream(): 为集合创建并行流。forEach: 对每个元素执行操作。map: 将每个元素映射到对应的结果。filter: 过滤出满足条件的元素。limit: 限制流的大小。skip: 跳过流中的前n个元素。sorted: 对流进行排序。终端操作
collect: 将流转换为其他形式,比如列表、集合或Map。reduce: 通过一个起始值,反复利用BinaryOperator来处理和累积元素,返回一个值。count: 返回流中元素的数量。min/max: 找到流中的最小/最大值。anyMatch: 流中是否有一个元素匹配给定的谓词。allMatch: 流中的所有元素是否都匹配给定的谓词。noneMatch: 流中没有任何元素匹配给定的谓词。findFirst: 返回第一个元素。findAny: 返回当前流中的任意元素。
项目中具体用到哪些设计模式
单例模式:确保一个类只有一个实例,例如配置文件管理器。[Spring原本设计好的]
**工厂模式**:创建对象时无需指定具体的类,例如日志工厂。
观察者模式:当一个对象状态发生改变时,所有依赖于它的对象都得到通知并自动更新,例如事件监听。
**策略模式**:定义一系列算法,将每个算法封装起来,并使它们可以互换,例如支付策略。
模板方法模式:在项目中,我有一些具有相同操作步骤但具体实现不同的算法,我使用了模板方法模式来定义这些步骤的骨架,将具体的步骤实现留给子类。任链模式的目的是将请求的发送者和接收者解耦,从而使得多个对象都有机会处理请求,将这些对象连成一条链,并沿着这条链传递请求,直到有一个对象处理它为止。
责任链模式:它允许将请求沿着处理者链进行发送。收到请求后,每个处理者都有机会对请求进行处理,或者将其传递给链上的下一个处理者。这样,请求就能在一系列处理者中传递,直到有一个处理者对其进行处理为止。 1.递归方式 :在递归模式中,每个处理者内部调用下一个处理者的处理方法。如果当前处理者无法处理请求,它会直接调用下一个处理者的处理方法。这种方式通常是通过递归调用来实现的
2.迭代模式:在迭代模式中,处理者链被构建为一个线性结构,每个处理者都有一个指向下一个处理者的引用。请求从链的第一个处理者开始,依次传递给下一个处理者,直到找到能够处理该请求的处理者为止。这种方式通常是通过循环迭代来实现的
代理模式:为了控制对远程服务的访问,我使用了代理模式。代理负责处理所有与服务对象的交互,并在必要时进行延迟加载。
在我的项目中结合工厂模式和策略模式来设计登录接口时,我们可以将登录验证的逻辑抽象为一个策略接口,并为每种登录方式(如:用户名密码登录、手机验证码登录、社交账号登录等)实现具体的策略类。工厂类则负责创建并管理这些策略对象
思考一个问题:哪些方式创建单例模式?
MySQL支持四种隔离级别
第一个是读未提交(readuncomm itted)它解决不了刚才提出的所有问题,一般项目中也不用这个。存在脏读问题 可解决不可重复读 幻读
第二个是读已提交(readcomm ited)它能解决脏读的问题的,但是解决不了不可重复读和幻读。
第三个是可重复读(repeatable read)它能解决脏读和不可重复读,但是解决不了幻读[解决了一部分],这个也是mysql默认的隔离级别。
第四个是串行化(serializable)它可以解决刚才提出来的所有问题,但是由于让是事务串行执行的,性能比较低。
串行化里的读也要加锁 表锁:整个表上锁 行锁:只对一行加锁
什么时候上行锁/表锁?
insert不带查询筛选条件 上行锁底层是索引,b+树底层叶子
update看where后面的条件 带索引加行锁构建b+树 不带索引的加表锁
表锁的速度比行锁速度快
MVCC底层是多版本并发控制 但底层并不怎么了解
深拷贝和浅拷贝的区别?
浅拷贝:只复制对象的基本数据类型和引用类型地址,不复制引用类型指向的对象。如果原对象和浅拷贝对象中的一个改变了引用类型,另一个也会受到影响。旧对象改变新对象也会改变。
深拷贝:复制对象的所有字段,包括基本数据类型和引用类型指向的对象。原对象和深拷贝对象之间不会相互影响。旧对象改变新对象不会改变
Java是值传递
如何实现深拷贝?数组不需要重写【体现了原型设计模式】
实现Cloneable接口并重写clone方法 会调用构造方法
这是最常见的实现深拷贝的方法。首先,你的类需要实现
Cloneable接口,然后重写clone()方法构造新对象的过程,并在该方法中调用super.clone(),同时递归地克隆所有引用类型的字段。[如果里面有多层嵌套复杂对象 在每层都要实现Cloneable接口一直重写到基本数据类型的时候才停止]
public class Person implements Cloneable {
private int age;
private Address address;
// 构造器、getter、setter 省略
@Override
protected Object clone() throws CloneNotSupportedException {
Person cloned = (Person) super.clone();
// 假设Address也实现了Cloneable接口
cloned.address = (Address) this.address.clone();
return cloned;
}
}
public class Address implements Cloneable {
private String street;
private String city;
// 构造器、getter、setter 省略
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
- 通过序列化
对象转二进制和反序列化二进制转对象。这种方式不需要实现Cloneable接口,但你的类需要实现Serializable接口。反序列化不会调用构造方法
开启线程的时候为什么用的是thread.start方法:
thread.start()方法用于启动一个新线程,并执行该线程的run()方法。调用start()方法后,线程会被放入线程调度队列,等待CPU调度执行。
直接调用run()方法,并不会启动一个新线程,而是在当前线程中执行run()方法,这不符合多线程编程的目的。使用start()方法可以确保线程并发执行,提高程序的性能和响应速度。
java没权限开启一个线程 要调用底层的操作系统 在JVM的底层实现中,会有相应的本地(C或C++)方法来处理线程的创建和管理
你在你们项目中使用过多线程吗?
是的,在我们的项目中,我确实使用过多线程。 【结合项目去说】
在处理大量数据计算或执行耗时的IO操作时,我会使用Java的线程池(如ExecutorService)来并行处理任务,以提高系统的响应速度和吞吐量
sleep和wait的区别
sleep是Thread类的一个静态方法,它使当前线程暂停执行指定的时间,但不会释放锁资源。
wait是Object类的一个方法,它使当前线程暂停执行并释放当前对象上的锁,直到另一个线程调用同一个对象的notify()或notifyAll()方法,或者过了指定的等待时间。
sleep是线程内的静态方法 需要指定睡眠的时间 或者自动自己唤醒 不会释放锁
wait是Object类的一个方法 可以指定睡眠时间 不指定就等于无限期 要释放锁
wait一定要搭配synchronized,且都为同一个对象 synchronized锁住了wait万物对象皆为锁
可以被唤醒notify()或notifyAll()方法 区别:notify是唤醒一个 notifyall会唤醒全部
普通方法上 锁的是this
静态方法上 锁的是当前类的class对象
ConcurrentHashMap 和 HashTable的区别
是否支持传入NULL
HashMap可以支持为null
若尝试将 null 作为键或值放入 ConcurrentHashMap 将会抛出 NullPointerException
ConcurrentHashMap 不能支持存null
底层实现
ConcurrentHashMap 1.8之前是分段锁来实现 默认是16个HashTable
1.8之后无限接近单个的HashMap 底层用CAS+synchronized
HashTable通过加synchronized锁来控制线程安全
ConcurrentHashMap 读不要加锁 [读写的读也不会加锁] 会走最终一致性
HashTable 读要加锁 [读读都加锁]
为什么要用Redis
高性能:Redis是基于内存的数据结构存储,可以提供高速的数据读写操作。
数据结构丰富:Redis支持多种数据结构,如字符串、列表、集合、散列表、有序集合等,非常适合各种场景。
持久化:Redis支持数据持久化,可以将内存中的数据保存到磁盘中,防止数据丢失。
分布式:Redis支持主从复制、哨兵和集群模式,可以轻松实现分布式缓存。
Redis中缓存了哪些数据
若放登录的信息到Redis的时候 不再用JWT了
Session在集群里面不能用了
替代方案:用Redis 不用JWT
JWT是无状态 无需集中存储
在我们的项目中,Redis中缓存了以下类型的数据:
会话信息:如用户登录信息、购物车内容等。
热点数据:如热门商品信息、推荐内容等。
计数器:如用户访问次数、点赞数、评论数等。
缓存数据库查询结果:减少数据库访问次数,提高系统响应速度。
检测数据存在Redis中,有过期时间吗? 过期时间是多少?仅参考
是的,我们在Redis中缓存的数据通常会设置过期时间,以避免过时的数据占用内存。具体的过期时间取决于数据的类型和业务需求。对于会话信息,我们可能会设置较短的过期时间,如30分钟或1小时;而对于热点数据,可能会设置较长的过期时间,如几小时或一天。具体的过期时间需要根据实际业务场景和数据访问模式来决定。
微服务之间如何调用?
通过注册中心去协调的
首先是有三个重要的概念,服务消费者,注册中心,服务提供者提供者在第一次会把自己的信息注册到注册中心中,比如ip端口,服务功能等消费者需要到注册中心来寻找服务进行消费,在服务消费者第一次请求的时候会拉取服务提供者的信息,注册中心会把提供者的实例列表给到消费者供消费者选择,使用负载均衡来选择服务,默认为轮询,还有加权轮询,随机。同时服务消费者还会定时去注册中心拉取服务提供者的信息如果我们的服务挂掉了怎么办?
服务提供者会每隔一段时间去向注册中心报告自己的状态,如果没有向注册中心报告状态,那么这个时候注册中心会认为服务提供者已经宕机,同时会推送到我们的服务消费者,这个服务提供者已经宕机
微服务的五大组件
- 服务注册与发现:如Eureka
已过时、Nacos、Consul,用于服务的注册和发现。 - 配置管理:如Spring Cloud Config、OpenFeign 用于集中管理服务的配置。
- 服务网关:如Zuul、Spring Cloud Gateway,作为系统的唯一入口,处理外部请求的路由和过滤。
- 负载均衡:如Ribbon,用于在多个服务实例之间分配请求。
- 断路器:如Hystrix,用于服务熔断,防止系统雪崩
对于服务注册这块有什么了解?
- 服务注册中心:服务实例在启动时向服务注册中心注册自己的地址和端口信息。检查 心跳 如果未查询就剔除,同时也有注册中心主动发起请求。
- 健康检查:服务注册中心通常会定期对已注册的服务进行健康检查,以确保服务的可用性。
- 服务发现:服务消费者通过服务注册中心查找可用的服务实例,以进行服务调用。
- 服务去注册:当服务实例关闭或出现故障时,它需要从服务注册中心注销,以避免调用不可用的服务。
你能说一下小程序的登录流程吗?
调用微信api,根据code获取openid;根据openid查询用户为空就新增;调用微信api WechatService + WechatServiceImpl(openId+phoneCode) 获取用户绑定的手机号;保存或修改该用户;将用户id存入token返回(JWT生成token)
有哪些方式可以创建单例?
- 饿汉式:在类加载时就立即初始化并创建单例对象。
- 懒汉式:在第一次调用时初始化单例对象,通常需要考虑线程安全问题。
- 双重校验锁:在懒汉式的基础上,通过双重校验锁确保线程安全。
- 静态内部类:利用静态内部类的加载机制来确保单例对象的唯一性。
- 枚举:利用枚举的特性,保证单例对象的唯一性和线程安全【不可用反射】
并发情况下严格控制单例?volatile→禁止进行指令重排序
双重校验锁:在懒汉式的基础上,通过双重校验锁确保线程安全。
公平锁和非公平锁的区别?
- 公平锁:多个线程按照它们请求锁的顺序来获取锁,先来先得。这种方式不会产生饥饿现象,但可能会降低吞吐量,因为需要额外的开销来维护等待队列的顺序。【僵尸线程】对资源顺序有严格要求
- 非公平锁:线程获取锁的顺序不一定是按照请求锁的顺序,允许线程“插队”。这种方式可能会提高吞吐量,但可能导致某些线程长时间无法获取锁,产生饥饿现象。【为什么性能高?不用沉睡和阻塞 避免来回切换】对性能要求高
ReentrantLock 看传参 公平/非公平都支持
Synchronized 公平锁
SpringMVC的工作原理
前端的HTTP请求到达时首先被DispatcherServlet接收
DispatcherServlet根据请求信息
路径查找合适的HandlerMapping来确定哪个Controller应该处理该请求。找到合适的Controller后,DispatcherServlet将请求转发给它处理。
Controller处理完请求后返回一个ModelAndView对象给DispatcherServlet。
DispatcherServlet再通过ViewResolver解析ModelAndView中的视图逻辑名,找到对应的视图。
最后,DispatcherServlet将模型数据渲染到视图上并响应给客户端。
OpenFeign的底层原理
OpenFeign 实现了简洁、声明式的 HTTP 请求调用,并且与 Spring Cloud 集成后能提供更多的功能如负载均衡等
动态代理: OpenFeign 使用 Java 动态代理技术,基于接口创建代理类,代理类会自动发起 HTTP 请求。你定义的接口方法会映射到 HTTP 请求上,OpenFeign 会根据注解(如 @RequestMapping, @GetMapping 等)来构建请求。
注解解析: OpenFeign 会解析接口方法上的注解,构造 HTTP 请求的 URL、请求方法类型(GET、POST 等),以及请求体和请求头等信息。
请求拦截和处理: 在请求发起之前,OpenFeign 允许通过拦截器(RequestInterceptor)来修改请求,比如设置请求头、参数等。
负载均衡与容错: 如果与 Spring Cloud 一起使用,OpenFeign 会集成 Ribbon(负载均衡)和 Hystrix(容错),使得服务调用更加健壮和可靠。
序列化与反序列化: OpenFeign 会利用 Jackson 等库进行请求和响应的序列化和反序列化,将 Java 对象与 HTTP 请求/响应内容相互转换
在使用OpenFeign时,开发者只需要定义接口并添加相应的注解,OpenFeign会在运行时动态生成实现类来执行HTTP请求。
对Volatile的理解
确保了不同线程对这个变量进行读写操作时的可见性。
是java的关键字是修饰共享的变量,不能修饰局部变量。
修饰普通或静态成员变量,主要用来保证可见性和有序性。
Spring Security的实现
我的项目是基于JWT的前后端分离的项目,在自定义认证管理器AuthenticationManager认证成功后,生成JWT令牌并返回给前端。前端在随后的请求中携带这个JWT令牌。这时候,我们使用AccessDecisionManager来实现接口的鉴权逻辑,其中包括一个check方法,该方法会校验JWT令牌的有效性。如果校验通过,就去查询数据库以确定用户拥有哪些权限。在用户登录时,其权限信息已经被缓存到Redis中。后续的请求中,我们可以直接从Redis中检索用户的权限信息。如果请求的接口权限与用户缓存中的权限匹配,则放行;如果不匹配,则返回一个友好的错误信息
什么是AQS
是多线程中的抽象队列同步器。是一种锁机制,它是做为一个基础框架使用的,是一个抽象类。
像ReentrantLock都是基于AQS实现的
定义了一个并发情况下一些抽象的资源 资源能否共享/独享 定义了公平和非公平
如果是非公平锁如果来了个新的线程来抢线程 也是会去抢一次
AQS成为了JUC很多类都去继承的 它抽象了很多并发的属性和行为,让子类去继承它扩展自己
Synchronized的锁升级
- Monitor实现的锁属于重量级锁,里面涉及到了用户态
权限低和内核态权限高的切换、进程的上下文切换,成本较高,性能比较低 - 在JDK1.6引入了两种新型锁机制:偏向锁和轻量级锁,它们的引入是为了解决在没有多线程竞争或基本没有竞争的场景下使用传统锁机制带来的性能开销问题
一段很长的时间内都只被一个线程使用锁 偏向锁
有线程交替或线程加锁的时间是错开的 轻量级锁
有很多线程来抢 重量级锁
java语言是高级语言如果想调用底层的操作系统和硬件要通过操作系统的API去操作。以前老的JDK版本 数据是在操作系统找的数据锁,Monitor的标志0 和 1,底层使用的Monitor实现,里面涉及到了用户态和内核态的切换、进程的上下文切换,成本较高,性能比较低 。
引入新型锁后,java里是用对象头找个地方存一把锁,这样就不涉及到调用操作系统底层。一开始new了个对象 此时是无锁状态。接下来来人拿锁,长期一个人拿到那个锁 此时是偏向锁竞争不激烈。后面多线程一起来 交替抢锁 此时是轻量级锁。随着并发越来越高 此时在一个线程拿到锁后很多线程来抢锁 线程先尝试自己先获取几次(自旋锁64次未拿到锁就会升级为重量级锁) 这时就涉及到操作系统的底层对象涉及到了用户态权限低和内核态权限高的切换、进程的上下文切换,成本较高,性能比较低。锁不可逆可能新版本可以降级
Dockerfile 常用命令
FROM: 指定基础镜像。ENV: 设置环境变量。RUN: 执行命令并创建新的镜像层。COPY: 将文件从宿主机复制到容器中。EXPOSE: 声明容器运行时将监听的端口。ENTRYPOINT: 配置容器启动时运行的命令。
常用的 Docker 命令
docker run: 创建一个新的容器并运行一个命令。docker pull: 从仓库中拉取或者更新一个镜像。docker push:推送镜像到服务docker build: 从 Dockerfile 构建一个镜像。docker images: 列出本地镜像。docker ps: 列出运行中的容器。docker stop: 停止一个运行中的容器。docker start: 启动一个停止的容器。docker rm: 删除一个容器。docker rmi: 删除一个镜像。docker exec: 在运行中的容器内执行命令。docker logs: 获取容器的日志。
- docker volume create:创建数据卷
- docker volume ls:查看所有数据卷
- docker volume inspect:查看数据卷详细信息,包括关联的宿主机目录位置
- docker volume rm:删除指定数据卷
Docker Compose 常用命令
docker-compose up: 启动所有服务的容器。docker-compose down: 停止并删除容器、网络、卷和镜像。docker-compose ps: 列出项目中所有的容器。docker-compose exec: 进入指定的容器。docker-compose build: 构建或重建服务。docker-compose logs: 查看服务的日志输出。docker-compose stop: 停止运行的容器。
synchronized 和 ReentrantLock 的区别
synchronized是Java的一个关键字用于方法和代码块中,而ReentrantLock是JUC包的一个类。synchronized可以自动加锁和解锁,而ReentrantLock需要手动加锁和解锁。synchronized的锁是非公平的,而ReentrantLock默认也是非公平的,但可以设置为公平锁。
你们公司是怎么部署项目的
是通过docker + jenkins
测试环境我们参与 生产环境组长部署
varchar 与 char 区别
varchar是可变长度的字符串,而char是固定长度的字符串。varchar的性能通常比char差,因为需要处理额外的长度信息。- 当数据长度变化很大时,推荐使用
varchar;当数据长度几乎固定时,使用char可能更合适。
Redis的持久化有哪几种? 它们的区别是什么?
完整性 大小 数据恢复速度 建议
Redis持久化:RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照,简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,数据恢复。
[root@localhost ~]# redis-cli
127.0.0.1:6379> save #由Redis主进程来执行RDB,会阻塞所有命令
ok
127.0.0.1:6379> bgsave #开启子进程执行RDB,避免主进程受到影响
Background saving started
Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:
// 900秒内,如果至少有1个key被修改,则执行bgsave
save 900 1
save 300 10
save 60 10000
==RDB的执行原理?==数据完整性高用RDB
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据,完成fork后读取内存数据并写入RDB文件
在LInux中主进程并无法直接读取物理内存,它只能通过虚拟内存去读。因此有页表(记录虚拟地址与物理地址的映射关系)去执行操作 同时 主进程也会fork(复制页表) 成为一个新的子进程(携带页表) → 写新RDB文件替换旧的RDB文件 → 磁盘
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作
优点:二进制数据重启后 Redis无需过多解析 直接恢复
==AOF==对数据不敏感要求不高
AOF全称为Append Only File(追加文件)底层硬盘顺序读写。Redis处理的每个写命令都会记录在AOF,可以看作是命令日志文件
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
AOF的命令记录的频率也可以通过redis.conf文件来配
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完毕先放入AOF缓冲区,然后表示每隔一秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
| 配置项 | 刷盘时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步刷盘 | 可靠性高,几乎不丢数据 | 性能影响大 |
| everysec | 每秒刷盘 | 性能适中 | 最多丢失1秒数据 |
| no | 操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量数据 |
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重读功能,用最少的命令达到相同效果
Redis会在出发阈值时自动重写AOF文件。阈值也可以在redis.conf中配置
# AOF文件比上次文件 增多超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
★★★★★★★★ RDB与AOF对比 ★★★★★★★★
RDB和AOF各有优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用
RDB是二进制文件,在保存时体积较小恢复较快,但也有可能丢失数据,我们通常在项目中使用AOF来恢复数据,虽然慢但丢失数据风险小,在AOF文件中可以设置刷盘策略(每秒批量写入一次命令)
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照哦 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源 但AOF重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高常见 |
项目中是怎么使用redis的
需要结合项目中的业务进行回答,通常情况下,分布式锁的使用场景:
集群情况下的定时任务、抢单、幂等性场景
如果使用互斥锁的话 那么在集群项目有多个服务器就会出现问题
用Hash类型 大Key是Id 小key是商品id value是商品数量
数据量点击量 用String类型
用Set类型 Zset做排行榜
你的项目中哪里使用到分布式锁?
==Redis分布式锁==
Redis实现分布式锁主要利用Redis的setnx命令,setnx是**SET if not exists**(如果不存在,则SET)的简写
获取锁
添加锁,NX是互斥、EX是设置超时时间
SET lock value NX EX 10释放锁
释放锁,删除即可
DEL key
你可以说一下redis的分布式锁的原理吗
我在项目中是集成了redisson(底层基于Lua脚本[具有原子性])
==redisson实现分布式锁 - 执行流程==
加锁 ↓→ 加锁成功 → Watch dog(看门狗)
每隔(releaseTime/3的时间做一次续期)→ Redis
↓ 操作redis → Redis
↓→→ 释放锁↑ → 通知看门狗无需继续监听 → Redis
加锁 → → → 是否加锁成功?→→→ ↓
↑←←while循环不断尝试获取锁←←←↓
public void redisLock() throws InterruptedException{
RLock lock = redissonClient.getLock("heimalock");
// boolean isLock = lock.tryLock(10, 30, TimeUnit.SECONDS);
// 如果不设置中间的过期时间30 才会触发看门狗
// 加锁,设置过期时间等操作都是基于lua脚本完成的[调用redis命令来保证多条命令的原子性]
boolean isLock = lock.tryLock(10, TimeUnit.SECONDS);
if(isLock){
try{
sout("执行业务");
} finally{
lock.unlock();
}
}
}
==redisson实现分布式锁 - 可重入==
redis实现分布式锁是不可重入的 但是 redisson实现分布式锁是可以重入的
可重入原理:它俩是同一个线程 每个线程都有唯一的线程id 根据线程id唯一标识做判断 判断之前获取锁是不是同一个线程
利用hash结构记录线程id和重入次数
KEY VALUE VALUE field value heimalock thread1 0
public void add1(){
RLock lock = redissonClient.getLock("heimalock");
boolean isLock = lock.tryLock();
// 执行业务
add2();
// 释放锁
lock.unlock();
}
public void add2(){
RLock lock = redissonClient.getLock("heimalock");
boolean isLock = lock.tryLock();
// 执行业务
// 释放锁 锁次数-1不完全释放
lock.unlock();
}
==redisson实现分布式锁 - 主从一致性==
Redis Master主节点:主要负责写操作(增删改) 只能写
Redis Slave从节点:主要负责读操作只能读
当RedisMaster主节点突然宕机后 Java应用会去格外获取锁 这时两个线程就同时持有一把锁 容易出现脏数据
怎么解决呢?
- RedLock(红锁):不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁(n/2+1),避免在一个redis实例【实现复杂、性能差、运维繁琐】怎么解决?→ CP思想:zookeeper
redis和mysql怎么保证数据一致性
写先插入数据库
更新先更新数据库 更新数据库成功但redis不成功 影响不大 因为后面会有过期删除 最终会一致,更新mysql后缓存可以删除也可以修改
更新完数据库直接删除缓存了 有过期时间兜底 最终会保持一致 我们项目中对数据敏感性一致性不高 我们追求实时性
如果是最终保持一致性的就MQ 我们对实时性不高 对数据敏感性 一致性高
删除问题不大 哪里都行!
读多写少的可以上缓存
mysql保存购物车表 但是再页面操作的时候 只操作redis 用mq给到消费者修改或定时任务 更新数据到mysql,MQ问题:我们对数据实时性要求不高 只需要保存最终一致性就行
你如果只写redis 万一丢了数据怎么办?
购物车丢点订单无影响 数据安全性要求不太高 mysql尽量不要搞购物车的表 都在redis的表 丢就丢了呗。或者异步同步/定时任务
实时性要求 安全性要求 → MySQL
电商一般数据库和mysql都要存 → 读多写少
一定、一定、一定要设置前提,介绍自己的业务背景 (一致性要求高?允许延迟一致?)
① 介绍自己简历上的业务,我们当时是把文章的热点数据存入到了缓存中,虽然是热点数据,但是实时要求性并没有那么高,所以我们采用的是异步的方案同步的数据
② 我们当时是把抢卷的库存存入到了缓存中,这个需要实时的进行数据同步,为了保证数据的强一致性,我们当时采用的是redission提供的读写锁来保证数据的同步
双写一致性:当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致
读操作:缓存命中,直接返回;缓存未命中查询数据库,写入缓存,设定超时时间
写操作:延迟双删 [因为无论先删除缓存还是先删除数据库都可能会出数据不一致问题 有脏数据]
==基于redisson互斥锁:==[放入缓存中的数据 读多写少] 【强一致性业务 性能低】
有过期时间兜底- 共享锁:读锁readLock,加锁之后,其他线程可以共享读操作,但**不允许写操作**
- 排他锁:独占锁writeLock也叫,加锁之后,阻塞其他线程读写操作(只允许一个用户或进程独占地对数据进行读取和写入操作)
排他锁确保了写操作的原子性和一致性 - 读数据的时候添加共享锁(读不互斥、写互斥)
- 写数据的时候添加排他锁(阻塞其他线程的读写 因为读多写少)
redissionClient.getReadWriteLock(“xxxx”);
==异步通知:==异步通知保证数据的最终一致性(需要保证MQ的可靠性)
需要在Redis中更新数据的同时,通知另一个服务进行某些操作。- 使用场景:
- 缓存与数据库双写: 当应用需要同时更新Redis缓存和数据库时,可以先将数据写入Redis,然后通过异步通知机制触发数据库的更新操作。
- 跨地域数据复制: 在跨地域部署的服务中,为了实现数据的最终一致性,可以在一个地域写入数据后,通过异步通知机制在另一个地域进行数据复制。
- 系统间数据同步: 在微服务架构中,不同的服务可能有自己的数据存储。当一个服务更新了数据后,可以通过异步通知机制告知其他相关服务进行数据同步。
- 使用场景:
==基于Canal的异步通知==:监听mysql的binlog
可以解析binlog文件 可以存放mysql里面的数据 看最近有无增删改查 转换成redis命令 再给redis里面- 使用MQ中间件,更新数据之后,通知缓存删除
- 利用canal中间件,不需要修改业务代码,伪装为mysqls的一个从节点,canal通过读取binlog数据更新缓存
synchronized可以作用在哪些地方,分别锁的是什么
在Java中,synchronized关键字可以用来实现线程同步,它可以作用在不同的地方,并且锁定的对象也不同:
实例方法:
- 作用在实例方法上时,锁的是调用该方法的对象实例(即**this对象**)。
- 任何线程想要执行这个方法,都必须获得该对象实例的锁。
public synchronized void synchronizedMethod() { // 方法体 }静态方法:
- 作用在静态方法上时,锁的是类的Class对象。
- 由于静态方法是属于类的,而不是属于任何特定实例,所以所有线程要想执行这个静态同步方法,都必须获得该类的Class对象的锁。
public static synchronized void synchronizedStaticMethod() { // 方法体 }代码块:
- 作用在代码块上时,可以指定一个锁对象
括号里的对象,可以是任何对象。 - 当进入这个代码块时,线程必须获得指定锁对象的锁。
public void synchronizedBlock() { synchronized(this) { // 锁定当前对象实例 // 代码块 } } public void synchronizedBlockWithObject() { Object lock = new Object(); synchronized(lock) { // 锁定指定的对象 // 代码块 } }- 作用在代码块上时,可以指定一个锁对象
什么情况下索引会失效?
- 违反最左前缀法则
- 范围查询右边的列,不能使用索引
- 不要在索引列上进行运算操作,索引将失效
- 字符串不加单引号,造成索引失效。(类型转换)
- 以%开头的Like模糊查询,索引失效
[不影响正常查询业务 但未运用超大分页查询优化 会导致索引失效]
索引创建原则有哪些?索引很多就会有很多B+树
① 数据量较大,且查询比较频繁的表
② 常作为查询条件、排序、分组的字段 [where、group by、order by]
③ 字段内容区分度高
④ 内容较长,使用前缀索引
⑤ 尽量联合索引对存储节省空间如果我们经常根据客户ID和订单日期来查询订单,那么可以在 customer_id 和 order_date 上创建一个联合索引。 CREATE INDEX idx_customer_date ON orders (customer_id, order_date); 这个联合索引 idx_customer_date 有以下几个特点: 索引顺序:首先根据 customer_id 排序,然后在每个 customer_id 的基础上根据 order_date 排序。 查询优化:以下查询可以利用这个联合索引: SELECT * FROM orders WHERE customer_id = ? AND order_date = ?; SELECT * FROM orders WHERE customer_id = ?;⑥ 要控制索引的数量
⑦ 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它
大字段不建议建立索引是因为B+树一个叶子节点/一个非叶子节点 差不多16k 一个节点对应一个[页] 多的话会更多层
尽量不用性别去创建索引
- 先陈述自己再实际工作中是怎么用的
- 主键索引
- 唯一索引
- 根据业务创建的索引(复合索引)
索引的底层数据结构了解过吗?
MySQL的InnoDB引擎采用的B+树的数据结构来存储索引
- 阶数更多,路径更短
- 磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据
- B+树便于扫库和区间查询,叶子节点是一个双向链表
**MySQL默认使用的索引底层数据结构是B+树**。再聊B+树之前,先来聊聊二叉树和B树
==B Tree(矮胖树)==,B树是一种多叉路衡查找树,相对于二叉树,B树每个节点可以有多个分支,即多叉。以一颗最大度数(max-degree)为5(5阶)的b-tree为例,那这个B树每个节点最多存储4个key
==B+Tree== 是再BTree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是B+Tree实现其索引结构
B树与B+树对比:
- 磁盘读写代价B+树更低
- 查询效率B+树更加稳定
- B+树便于扫库和区间查询
B树要找12 首先找38 左面小 再去缩小范围16和29 找到12 → 但是我们只想要12的数据 B树会额外的把38,16,29的数据全查一遍最后才到12的数据
B+树是在叶子节点才会存储数据,在非叶子节点全是指针,这样就没有其他乱七八糟的数据影响 。且查找路径是差不多的,效率较稳定
便于扫库:比如我们要查询6-34区间的数据,先去根节点扫描一次38 → 16-29 → 由于叶子节点之间有双向指针,就可以一次性把所有数据都给拿到[无需再去根节点找一次]
mysql底层为什么用B+树利用二分查找,树越矮经过磁盘IO次数越少,它是稳定的每次都查到最底层
二叉树 O(logn) 容易退化成链表 所以不用它平衡二叉树 全部倾斜红黑树 一个节点只能存一个数据
B树能不能除了叶子节点其他不存数据呢?
你可以设计一种变体的B树,其中只有叶子节点存储数据,而所有其他非叶子节点仅作为导航节点,不存储实际的数据。这种结构在概念上类似于B树的一个特例,通常被称为B树索引结构的一部分,其中非叶子节点存储的是键值,而叶子节点存储的是实际的数据记录或者是指向数据记录的指针
B+树第三层2000多万条数据,尽量不要把数据达到2000多万
B+树叶子节点加了双向链表 让我们查询更加稳定 范围查询会更快
mysql索引底层不一定只有B+树,也可能是Hash 在精准查询性能比它高
R—Tree:地理位置搜索
联合索引
where b= AND c= AND a= 这样走索引都能走 底层自己排序
为什么联合索引要遵循最左匹配原则【里面的b+树 先按照a排序 再b 因为要二分查找 不排序怎么找?】
在MySQL中,如何定位慢查询?查询前用explain查询是否走了索引等问题
explain查询后的列:
id:查询中SELECT语句的序列号,如果该行引用其他行的并集结果,则该值可以为空。
select_type:表示查询的类型,常见的类型有:
SIMPLE:简单的SELECT查询,不使用UNION或子查询。
PRIMARY:最外层的SELECT查询。
UNION:在UNION中的第二个或随后的SELECT查询。
DEPENDENT UNION:在UNION中的第二个或随后的SELECT查询,取决于外层查询。
UNION RESULT:UNION的结果。
SUBQUERY:子查询中的第一个SELECT。
DEPENDENT SUBQUERY:子查询中的第一个SELECT,取决于外层查询。
table:查询的是哪个表。
type:这是你提到的一个非常重要的列,它表示MySQL在表中找到所需行的方式,也称为“访问类型”。以下是一些常见的访问类型,从最好到最差排序:
system:表只有一行(系统表)。
const:表最多有一个匹配行,它将在查询开始时被读取。因为仅有一行,所以优化器的其余部分可以将这一行视为常量。
eq_ref:对于每个来自于前面的表的行组合,从该表中读取一行。这通常是最好的联接类型,除了const类型。
ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。
fulltext:使用全文索引执行查询。
ref_or_null:与ref类似,但是MySQL会额外搜索包含NULL值的行。
index_merge:表示查询使用了两个或更多的索引。
unique_subquery:用于IN子查询,子查询返回不重复的值集。
index_subquery:用于IN子查询,子查询返回不重复的值集,可以使用索引。
range:使用索引来检索给定范围的行。
index:全索引扫描(比ALL快,因为索引通常比数据行小)。
ALL:全表扫描,这是最差的一种类型,因为MySQL必须检查每一行以找到匹配的行。
possible_keys:指出MySQL能使用哪些索引来优化查询。
key:MySQL实际决定使用的索引。
key_len:使用的索引的长度。越短越好。
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数。
rows:MySQL认为必须检查的用来返回请求数据的行数。
filtered:显示了通过条件过滤出的行数的百分比估计。
Extra:包含MySQL解析查询的额外信息,例如是否使用了索引,是否排序了结果,是否使用了临时表等
1.介绍一下当时产生问题的场景(我们当时的一个接口测试的时候非常的慢,压测的结果大概5秒钟)
2.我们系统中当时采用了运维工具(Skywalking),可以监测出哪个接口,最终因为是sql的问题
3.在mysql中开启了慢日志查询,我们设置的值就是2秒,一旦sql执行超过2秒就会记录到日志中(调试阶段)
产生原因:
- 聚合查询
- 多表查询
- 表数据量过大查询
- 深度分页查询
方案一:==开源工具==[调试阶段才会开启 生产阶段不会开启]
- 调试工具Arthas
- 运维工具:Prometheus、SKywalking(接口访问时间)
方案二:==MySQL自带慢日志==
慢查询日志记录了所有执行时间超过指定参数(long_query_time, 单位:秒,默认10秒)的所有SQL语句的日志,如果要开启慢查询日志,需要在MySQL的配置文件(/etc/my.cnf)中配置信息:
# 开启MySQL慢日志查询开关
slow_query_log = 1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会被视为慢查询,记录慢查询日志
long_query_time = 2
什么是聚簇索引?什么是非聚簇索引(二级索引)?什么是回表?
- 聚簇索引(聚集索引):数据与索引放到一块,B+树的叶子节点保存了整行数据,有且只有一个【id存放的b+树】
- **非聚簇索引(二级索引)**:数据与索引分开存储,B+树的叶子节点保存对应的主键,可以有多个【叶子就是id的字段】
- 回表查询:通过二级索引找到对应的主键值,到聚集索引中查找正行数据,这个过程就是回表
怎么避免回表 → 使用覆盖索引!
需要name 直接 select name 而不用 select *
要按需来查找
除了InnoDB,MySQL数据库还支持多种其他存储引擎,其中最著名的是MyISAM。以下是InnoDB和MyISAM两个存储引擎的主要区别:
事务支持:
InnoDB:支持事务,它遵循ACID原则(原子性、一致性、隔离性和持久性)。如果事务中的某个操作失败,整个事务可以回滚到开始状态。
MyISAM:不支持事务,这意味着你无法回滚操作,这对于数据完整性和恢复可能是一个问题。
锁定机制:
InnoDB:使用行级锁定,只锁定需要的特定行,这可以大大减少数据库操作的冲突。
MyISAM:使用表级锁定,每次操作都会锁定整个表,这在并发操作较多时可能导致性能问题。
崩溃恢复:
InnoDB:具有自动崩溃恢复功能,即使数据库崩溃,也不会丢失数据,因为它将事务日志写入磁盘。
MyISAM:在崩溃后恢复较为困难,可能会丢失数据,因为它不记录事务日志。
全文搜索:
InnoDB(MySQL 5.6及以后版本):支持全文索引,但功能上不如MyISAM的全文搜索强大。
MyISAM:提供了更强大的全文搜索功能,但在MySQL 5.6之前,这是MyISAM相对于InnoDB的主要优势。
存储限制:
InnoDB:表的大小理论上受限于操作系统的文件大小限制,通常可以处理更大的数据量。
MyISAM:表的大小受限于最大文件大小,通常是2GB到4GB,这取决于文件系统的限制。
外键支持:
InnoDB:支持外键约束,这有助于保持数据的引用完整性。
MyISAM:不支持外键约束。
存储空间:
InnoDB:通常需要更多的存储空间,因为它存储了额外的信息来支持事务和行级锁定。
MyISAM:通常占用更少的存储空间,因为它不需要存储这些额外的信息
| 分类 | 含义 | 特点 |
|---|---|---|
| ==聚集索引(Clustered Index)== | 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有, 而且只有一个 |
| ==二级索引(Secondary Index)== | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一 (UNIQUE) 索引作为聚集索引
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引

==回表查询==
select * from user where name = 'Arm';
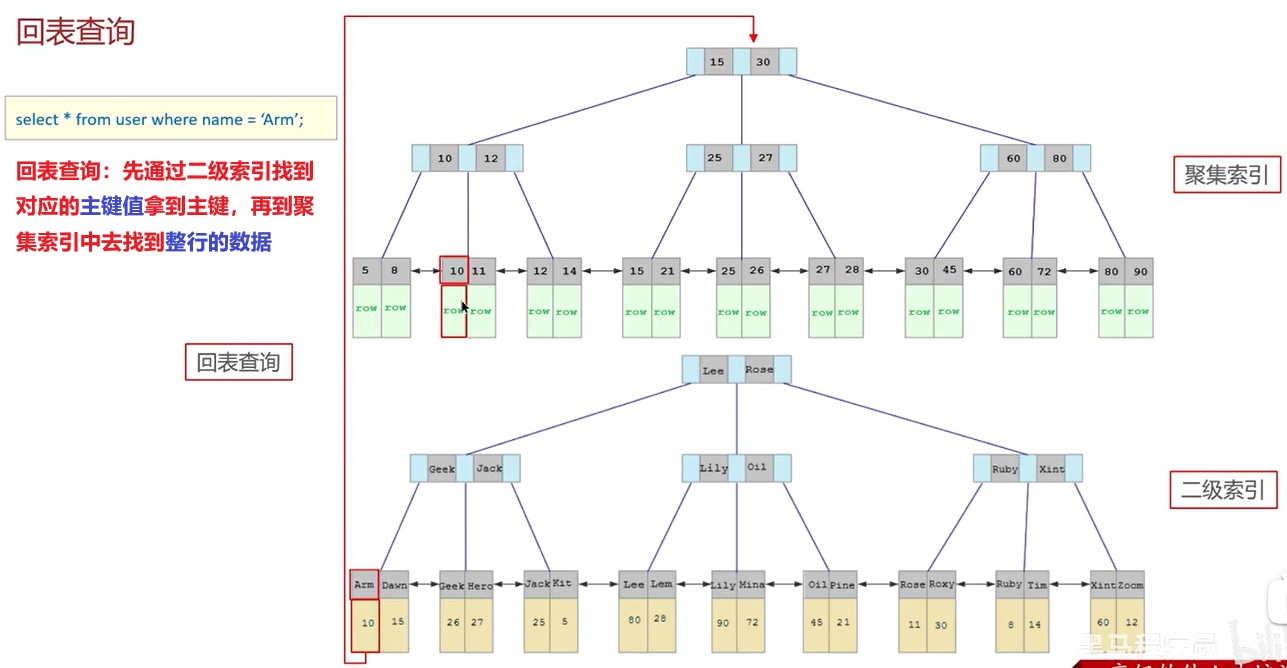
MySQL的日志文件有哪些,它们的作用是什么
MySQL的日志文件有哪些,它们的作用是什么?
MySQL主要有以下几种日志文件:
- 错误日志(Error Log):记录MySQL服务的启动、运行或停止过程中的错误信息。
- 查询日志(General Query Log):记录所有MySQL执行的SQL命令,无论这些命令是否正确执行。
- 慢查询日志(Slow Query Log):记录执行时间超过指定阈值的查询语句。
- 二进制日志(Binary Log):记录所有更改数据的SQL语句,用于主从复制和数据恢复。事务的提交 和 主从复制
- 事务日志/重做日志(InnoDB Redo Log):记录InnoDB存储引擎的事务操作,用于崩溃恢复。
- 回滚日志/撤销日志(InnoDB Undo Log):用于事务回滚,保证事务的原子性。
undo log 和 redo log的区别?
redo log:记录的是数据页的物理变化,服务宕机可用来同步数据
undo log:记录的是逻辑日志,当事务回滚时,通过逆操作恢复原来的数据
redo log 保证了事务的持久性,undo log保证了事务的原子性和一致性
- 缓冲池(buffer pool):主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改査操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度
- 数据页(page):是InnoD8 存储引擎磁盘管理的最小单元,每个页的大小默认为 16KB。页中存储的是行数据
==redo log==
重做日志,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性
该日志文件由两部分组冲:重做日志缓冲(redo log buffer) 以及 **重做日志文件(redo log file)**,前者是在内存中,后者是在磁盘中。当事务提交之后会把所有修改信息都保存到该日志文件中,用于在刷新脏页到磁盘,发生错误时,进行数据恢复使用。
==undo log==
回滚日志,用于记录数据被修改前的信息,作用包含两个:提供回滚和 MVCC(多版本并发控制)。undolog 和 redolog记录物理日志不一样,它是逻辑日志
- 可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然
- 当update一条记录时,它记录一条对应相反的update记录。当执行rolback时,就可以从undolog中的逻辑记录读取到相应的内容并进行回滚。
undo log可以实现事务的一致性和原子性
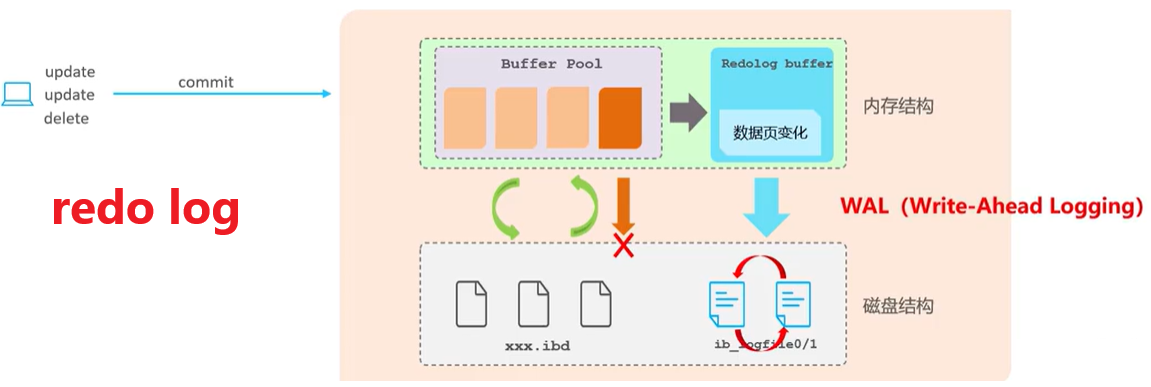
MySQL主从同步原理?
MySQL主从复制的核心就是二进制日志binlog[DDL(数据定义语言)语句 和 DML(数据操纵语言)语句]
主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
从库读取主库的二进制日志文件 Binlog,写入到从库的中继日志 Relay Log。
从库重做中继日志中的事件,将改变反映它自己的数据。主服务器(Master)上的数据更改(如INSERT、UPDATE、DELETE操作)会被记录到二进制日志中。 从服务器(Slave)上的I/O线程连接到主服务器,请求主服务器上的二进制日志。 主服务器将二进制日志发送给从服务器,从服务器将这些日志事件写入到本地的中继日志(Relay Log)。 从服务器上的SQL线程读取中继日志中的事件,并在本地执行这些事件,从而实现数据的复制。
MySQL主从复制的核心就是二进制日志
二进制文件(BINLOG) 记录了所有的DDL(数据定义语言)语句 和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句
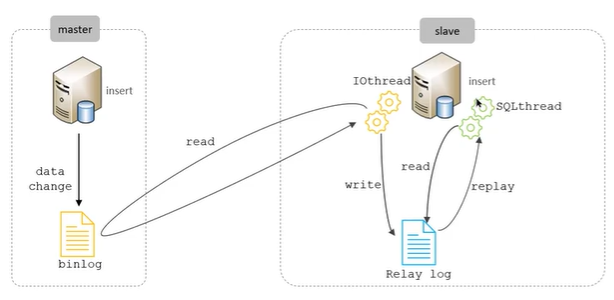
复制分成三步:
- Master主库在事务提交时,会把数据变更记录在二进制日志文件Binlog中
- 从库读取主库的二进制日志文件Binlog,写入到从库的中继日志Relay Log
- slave重做中继日志中的事件,将改变反应他自己的数据
项目中哪里涉及到分布式事务问题? 你是怎么解决的? 能说一下
分布式事务问题可能出现在跨多个服务或数据库的操作中,例如在订单服务中同时更新订单状态和扣减库存。秒杀案例:是先扣库存提前缓存到redis里,判断够不够,用RabbitMQ异步下来
解决方案:可以使用分布式事务框架,如Seata,其中AT模式是一种常见的解决方案。
AT模式原理:
- AT模式基于两阶段提交,分为两个阶段:一阶段 prepare 和二阶段 commit/rollback。
- 在业务方法开始时,Seata会拦截业务SQL,记录业务数据在执行前后的镜像,生成行锁。
- 如果一阶段 prepare 成功,则二阶段进行 commit,直接提交事务;如果 prepare 失败,则执行 rollback,利用之前保存的数据镜像回滚到执行前的状态。
项目中哪里用到MQ,用来干什么?
异步发优惠卷 + 积分 [用户对于实时性要求不是很高]
使用MQ的场景:订单处理
具体场景
当用户在电子商务平台上成功下单后,订单服务需要执行以下操作:
- 更新订单状态为“已支付”。
- 扣减商品库存。
- 通知支付服务处理支付。
- 通知物流服务准备发货。
使用MQ的原因
在这些操作中,更新订单状态和扣减库存是实时且同步的操作,但通知支付服务和物流服务则可以异步进行。使用MQ可以帮助我们实现以下目标:
- 解耦服务:订单服务不需要直接调用支付服务和物流服务,降低了服务间的耦合度。
- 异步处理:订单服务可以立即响应客户端,不必等待支付和物流服务的处理结果。
- 流量削峰:在高峰期,MQ可以缓冲大量的订单处理请求,避免服务被压垮。
订单服务生产消息: 当订单服务完成订单状态更新和库存扣减后,它将以下消息发送到
{
"orderId": "123456789",
"status": "paid",
"userId": "user123",
"items": [
{"productId": "prod123", "quantity": 1},
{"productId": "prod456", "quantity": 2}
]
}
这个消息将被发送到不同的主题或队列,例如payment_topic和logistics_topic。
2. 支付服务和物流服务消费消息:
- 支付服务订阅
payment_topic,当接收到订单支付消息后,它会处理支付逻辑,如验证支付状态、记录交易日志等。 - 物流服务订阅
logistics_topic,当接收到订单消息后,它会准备发货,更新物流信息,并通知用户。
通过这种方式,订单服务可以快速响应用户请求,而支付和物流服务可以按照自己的节奏处理订单相关的操作,整个系统因此变得更加灵活和可扩展。
如何保证消息不丢失?
保证生产者能够成功发送到交换机和队列(存储消息),生产者提供了消息确认机制
到队列后消息要有持久化机制
消费者要有一个消息确认机制 保证消费者至少消费成功消息一次
开启生产者确认机制,确保生产者的消息能到达队列
confirm到交换机ack 不到nack 和 return没到返回nack机制保证生产者把消息发过去开启持久化功能,确保消息未消费前在队列中不会丢失
万一broker挂掉就惨了 保证至少成功一次消费开启消费者确认机制为auto,由spring确认消息处理成功后完成ack
消费者三种机制:RabbitMQ支持消费者确认机制,即:消费者处理消息后可以向MQ发送ack回执,MQ收到ack回执后才会删除该消息,而SpringAMQP则允许配置三种确认模式:
manual:手动ack,需要在业务代码结束后,调用api发送ack。
auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
开启消费者失败重试机制,多次重试失败后将消息投递到异常交换机,交由人工处理
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecoverer接口来处理,它包含三种不同的实现:
RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
- 异步发送(验证码、短信、邮件)
- MySQL和Redis,ES之间的数据同步
- 分布式事务
- 削峰填谷
如何解决消息积压?
产生原因:当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是堆积问题
**解决消息堆积有三种思路 **
- 增加更多消费者,提高消费速度
- 在消费者内开启线程池加快消息处理速度
- 扩大队列容积,提高堆积上限
如何保证消费幂等性【MQ】
幂等性是指同一个操作执行多次和执行一次的效果相同。在消息消费的场景中,保证幂等性通常有以下几种方法:
利用数据库的唯一约束:
在数据库中为消息设置唯一标识(如消息ID),在处理消息前先检查该标识是否已存在。
导致重复消费 返回ack,blocker未收到。一定要在生产者投递的时候生成全局唯一的id,消费者就会去判断。异步生成 拿订单号去数据库查 如果查得到就直接return
精髓就是全局唯一
UUID不行 因为每次发送的消息都不是同一个UUID 要用业务上的
哪些地方还会有幂等问题?
提供者的openfegin、xxl-job、被别人调用且涉及到增删改
状态记录:
在消费消息前,记录消息的状态(如已处理),处理完毕后再更新状态。要根据订单ID+状态 来保证消费幂等性。订单存在且未支付 → 更新锁订单ID
并发情况幂等性:
完美的幂等要加上分布式锁对敏感性要求高,且要控制好锁的力度
如何保证消费有序性
队列中可以指定消息的消费顺序
RabbitMQ → 多个生产者并发投,所以生产者不能保证有序性,只考虑消费有序性。以消息进入的MQ的消息去回答。
怎么保证?
单线程消费:
在消费者端使用单个线程处理消息,确保消息按顺序处理。
分区有序:
在如Kafka这样的消息队列中,可以保证同一个分区内的消息是有序的。
如何既要又要【有序 + 速度快】
既要又要”通常指的是在保证消息的幂等性和有序性的同时,还需要考虑其他特性(如高性能、高可用等)
在一些场景下,可能需要在性能和一致性之间做权衡。例如,可以选择最终一致性来换取更高的性能。
Kafka 和 RocketMQ可以天生实现【底层Hash取模】
若非要用RabbitMQ实现呢?
不同订单之间是否要求一定顺序??
镜像集群,先搭3个节点的镜像集群,建立三个队列分为不同的镜像节点 各占一个队列,需要自己去实现
对订单号进行hash取模看到落到哪个节点
三个队列至少三个消费者 分别去消费它们
此时就可以并行有三个消费者去执行
把业务数据没关系的放在不同的队列去管理
万一挂掉了呢?
队列有持久化不用担心
能说一下如何使用死信交换机吗支付
死信交换机(DLX)用于处理无法正常消费的消息
创建一个正常的交换机和队列,以及一个死信交换机和死信队列。
- 定义死信交换机:创建一个用于处理死信的交换机。
- 定义死信队列:创建一个队列用于接收死信,并将其绑定到死信交换机。
- 配置主队列的死信交换机属性:在主队列上设置参数,指定当消息无法正常处理时应该发送到哪个死信交换机。
- 发送消息到主队列:生产者将消息发送到主交换机,进而路由到主队列。
- 消费主队列消息:消费者从主队列中获取消息并进行处理。如果消息处理失败,它将被路由到死信交换机。
- 消费死信队列消息:设置消费者来处理死信队列中的消息,进行错误处理或记录日志等操作。
mysql如何提升深分页查询效率子查询+索引
使用索引:
- 确保查询中使用的列上有适当的索引,这样可以加快查找速度。
**避免使用OFFSET和LIMIT**:
- 使用
OFFSET进行深分页时,MySQL需要遍历所有OFFSET之前的行。可以通过记住上一次查询的最大ID来避免使用OFFSET。
使用条件过滤:
- 如果可能,使用WHERE子句来减少需要扫描的数据量。
增加LIMIT的大小:
- 如果业务允许,可以增加每次查询返回的结果集大小,减少分页次数。
缓存:
- 对于不经常变更的数据,可以使用缓存来存储已经查询过的页。
使用EXPLAIN分析查询:
- 使用
EXPLAIN来分析查询计划,找出性能瓶颈并进行优化。
能说一下常用的存储引擎以及它们的差异吗
InnoDB:
支持事务、行级锁和外键。
适合处理大量短期事务。
为了维护数据的完整性,写操作相对较慢
MyISAM:
不支持事务、不支持行锁只支持表锁
并发没那么大 事务要求没那么高可以用
能说一下倒排索引的原理吗?
根据参与文档中的字段 要构建倒排就会去分词
根据用户索引也会分词 就会去查文档id 再去查文档
中文词库为IK (Ikun 你干嘛 哎哟~)
es的text和keyword的区别
text
用于全文搜索,会分词,字符串类型
keywod
用于精确搜索字段,不会被分词,字符串类型
es在你的项目中是用来做什么的
快速搜索商品(C端)、订单(后台) + 日志查询 + 地理位置搜索经纬度定位附近的事物
mysql和ElasticSearch如何做数据同步
mysql进行增删改的时候
对数据敏感性实时性要求没那么高 只看可靠性[MQ异步 + 定时任务 = 没有那么强一致性]
如果数据量没那么大 有没有必要上ES?
没有必要,正排索引不走全表扫描也蛮快
组长进行技术选型 考虑到以后的业务增长
项目已经上线了 但是中途想换成ES 怎么办
mysql是全量数据 mq只能同步增量数据 怎么办呢?
新上架的只能到ES 那应该如何?
此时涉及到全量和增量的同步与Redis不一样
加定时任务每周/每天 会定期重构一次索引库晚上跑→兜底模式,全量同步,后期再增量同步
能说一下分词的原理吗
底层是大数据量的内容 树的结构来构建分词 IK,字符分割、词汇识别、过滤停用词
不好意思面试官 具体底层原理不是很了解
使用ES有遇到什么问题吗
类似于深分页!
测试环境数据量不会很大 等到上线后才会有这种问题